![]()


Indexiere und archiviere alle deine eingescannten Papierdokumente
Ich hasse Papier. Abgesehen von Umweltproblemen, ist es der Albtraum einer technisch-interessierten Person:
- Es gibt keine Suchfunktion
- Es braucht physischen Platz
- Sicherungen bedeuten mehr Papier
In den vergangenen Monaten hatte ich mehrmals das Problem, das richtige Dokument nicht zur Hand zu haben. Manchmal warf ich Dokumente weg, die ich noch gebraucht hätte (wer behält schon Wasserrechnungen für zwei Jahre?), andere verlor ich einfach... weil PAPIER. Ich schrieb dies, um mein Leben einfacher zu machen.
Paperless steuert nicht deinen Scanner, es hilft nur damit umzugehen, was der Scanner herausspuckt
- Kaufe einen Dokumentenscanner, der an einen Ort in deinem Netzwerk schreiben kann. Wenn du Inspirationen brauchst, schau in die Scannerempfehlungen.
- Stelle "Scanne zu FTP" oder ähnliches ein. Es sollte möglich sein, eingescannte Bilder ohne etwas tun zu müssen an einen Server hochzuladen. Natürlich kannst du auch die einscannte Datei händisch hochladen, wenn der Scanner automatisches Hochladen nicht unterstützt. Paperless ist es egal, wie die Dokumente in seinen lokalen Konsumordner gelangen.
- Besitze einen Zielserver, lasse das Paperless-Konsumskript laufen, um die Datei mit OCR zu versehen und sie in einer lokalen Datenbank zu indexieren.
- Benutze die Weboberfläche, um die Datenbank zu durchforsten und zu finden, was du suchst.
- Lade die PDF-Datei, die du brauchst/möchtest über die Weboberfläche herunter und mach was auch immer du willst damit. Du kannst es auch drucken und versenden, so als wäre es das Original. In den meisten Fällen wird das niemanden interessieren oder bemerken.
Hier das, was du bekommt:
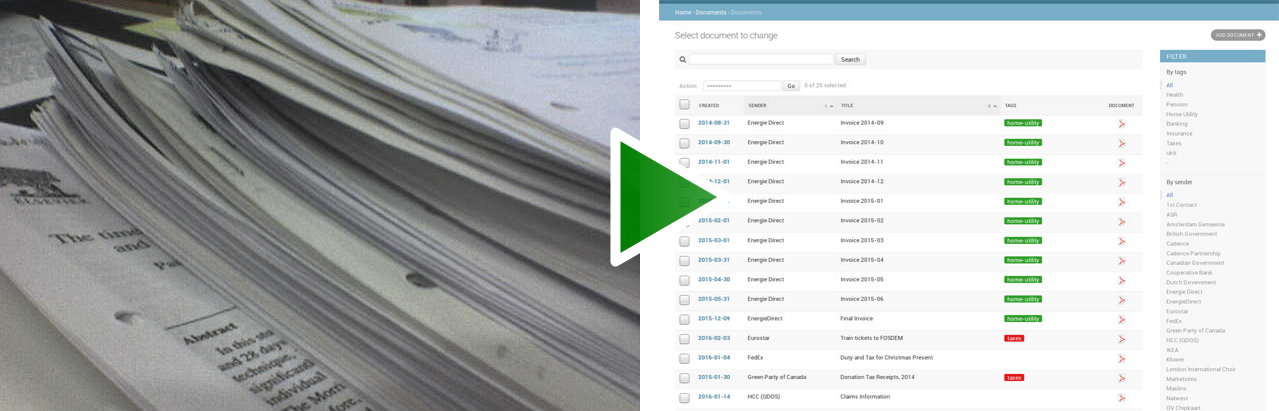
Diese ist komplett verfügbar auf ReadTheDocs.
Dies alles ist eine wirklich ziemlich einfache, glänzende und benutzerfreundliche Hülle rund um einige sehr mächtige Werkzeuge.
- ImageMagick wandelt Bilder zwischen Farbe und Graustufen um.
- Tesseract erledigt die Buchstabenerkennung.
- Unpaper bereinigt und begradigt das eingescannte Bild.
- GNU Privacy Guard wird als Verschlüsselungsbackend genutzt.
- Python 3 ist die Sprache des Projekts.
- Pillow lädt die Bilddaten als Python-Objekt, um sie mit PyOCR zu verwenden.
- PyOCR ist ein glatter, programmatischer Wrapper um Tesseract.
- Django ist das Framework, auf das dieses Projekt aufbaut.
- Python-GNUPG entschlüsselt die PDFs auf Abruf, um das Herunterladen unverschlüsselter Dateien zu ermöglichen, während die verschlüsselten Dateien auf der Festplatte bleiben.
Dieses Projekt wurde um 2015 gestartet und es gibt viele Leute, die es verwenden. Warum auch immer ist es ziemlich beliebt in Deutschland -- vielleicht kann jemand dort drüben mich über das Warum aufklären.
Ich entwickle keine neuen Funktionen mehr für Paperless, weil es genau das tut, was ich brauche und meine Aufmerksamkeit meinem neuesten Projekt Aletheia gewidmet ist. Ich verlasse jedoch nicht das Projekt. Ich bin glücklich damit, Pull Requests zu begutachten und Fragen im Issue-Bereich zu beantworten. Wenn du ein Entwickler bist und eine neue Funktion willst, reihe sie in den Issues ein und/oder sende einen PR! Ich bin glücklich damit, neue Sachen hinzuzufügen, habe aber einfach nicht die Zeit, sie selbst zu erarbeiten.
Paperless gibt es bereits seit einer Weile und Leute haben damit angefangen, Sachen rund um Paperless zu entwickeln. Wenn du einer dieser Menschen bist, kannst du dein Projekt zu dieser Liste hinzufügen:
- Paperless App: Eine Android/iOS-App für Paperless.
- Paperless Desktop: Eine Desktop-Oberfläche für deine Paperless-Installation. Läuft auf Mac, Linux und Windows.
- ansible-role-paperless: Eine einfache Möglichkeit, Paperless via Ansible laufen zu lassen.
- paperless-cli: Ein golang Kommandozeilenprogramm, welches mit Paperless interagiert.
Es gibt da draußen auch das Projekt Mayan EDMS, welches überraschenderweise sehr große überschneidende Techniken hat wie Paperless. Mayan EDMS ist viel funktionsreicher und kommt ebenso mit einer glatten UI, aber kommt noch mit Python2; basiert jedoch auch auf Django und verwendet ein Konsummodell mit Tesseract und Unpaper. Es kann sein, dass Paperless weniger Ressourcen verbraucht, aber um ehrlich zu sein, hab ich das noch nicht selbst getestet. Eine Sache jedoch ist klar, Paperless ist ein viel besserer Name.
Dokumentenscanner werden typischerweise verwendet, um sensible Dokumente zu scannen. Dinge wie die Sozialversicherungsnummer, Steueraufzeichnungen, Rechnungen, etc. Während Paperless die Originaldateien über das Konsumskript verschlüsselt, sind die OCR-Texte nicht verschlüsselt und demnach in Klartext gespeichert (es muss durchsuchbar sein, also wenn jemand eine Idee hat, wie man das mit verschlüsselten Daten tun kann: Ich bin ganz Ohr). Das bedeutet, dass Paperless niemals auf einem nicht vertrauten Host laufen sollte. Stattdessen empfehle ich, wenn du es verwenden willst, es lokal auf einem Server in deinem Zuhause laufen zu lassen.
Wie mit aller Freier Software, liegt die Macht weniger in den Finanzen als mehr in den gemeinsamen Bemühungen. Ich schätze wirklich jeden Pull Request und Bugreport, der von Benutzern von Paperless getätigt wird, also bitte macht damit weiter. Wenn du jedoch nicht einer für Programmieren/Design/Dokumentation bist und mich wirklich finanziell unterstützen willst, sage ich nicht nein dazu ;-)
Das Ding ist, mir geht es finanziell OK, also würde ich dich darum bitten, an den Hochkommissar der Vereinten Nationen für Flüchtlinge zu spenden. Diese machen wichtige Arbeit und brauchen das Geld viel dringender als ich.