notebook中链接Hadoop生态
| 组件名称 | 组件版本 | 备注 |
|---|---|---|
| Hadoop | 3.2.2 | hadoop-3.2.2 |
| Spark | 3.1.3 | spark-3.1.3-bin-hadoop3.2 |
| Hive | 3.1.2 | apache-hive-3.1.2-bin |
| Flink | 1.15.1 | pyFlink |
| Python | 3.8.12 | notebook:jupyter-ubuntu-cpu-base 自带版本 |
本教程提供两种方法,分别是第二章节的"基于已有镜像手动安装Hadoop生态"和第三章节的"基于Dockerfile实现"。 读者可按照顺序进行操作,也可直接基于已有镜像去快速体验自带的examples。
基于ccr.ccs.tencentyun.com/cube-studio/notebook:jupyter-ubuntu-cpu-base镜像启动JupyterLab。
docker run --name jupyter -p 3000:3000 -p 32788-32888:32788-32888 \
-d ccr.ccs.tencentyun.com/cube-studio/notebook:jupyter-ubuntu-cpu-base \
jupyter lab \
--notebook-dir=/ --ip=0.0.0.0 --no-browser --allow-root \
--port=3000 --NotebookApp.token='' --NotebookApp.password='' \
--NotebookApp.allow_origin='*'注意: 增加映射端口范围32788-32888,用于下文提交spark作业到yarn运行。
提交spark作业到yarn上运行需要用到Hadoop集群的配置文件,分别是core-site.xml、hdfs-site.xml、yarn-site.xml。 如果没有Hadoop集群,可参考第3.2和3.3小节来搭建一个单机伪分布式的集群来测试。 因此在JupyterLab中新建Terminal执行命令:
# 新建HADOOP_CONF_DIR目录
mkdir -p /opt/third/hadoop/etc/hadoop/在Web界面中上传3个xml到/opt/third/hadoop/etc/hadoop/目录下。
注意检查yarn-site.xml一定要有yarn.resourcemanager.address 配置项,否则默认值是0.0.0.0:8032会导致JupyterLab中的作业无法提交到yarn上运行。示例配置如下:
<property>
<name>yarn.resourcemanager.address</name>
<value>xxx.xxx.xxx.xxx:8032</value>
</property>参考Spark官网 安装方式本质上有两种: 一是通过 pip install pyspark,二是手动下载spark安装包安装。第一种方式针对Apache Spark的安装比较快速简单,但是不支持其他大数据厂商的Spark安装,例如华为FusionInsight 、星环TDH 、Cloudera CDH 的Spark安装。 因此,本教程采用第二种方式,其扩展性好,针对各种厂商都是通用的。
- 下载安装包
cd /opt/third
# 下载安装包
wget http://dlcdn.apache.org/spark/spark-3.1.3/spark-3.1.3-bin-hadoop3.2.tgz
# 解压,建立软连接
tar -xvzf spark-3.1.3-bin-hadoop3.2.tgz
ln -s spark-3.1.3-bin-hadoop3.2 spark- 设置环境变量
vi ~/.bashrc
# hadoop
export HADOOP_CONF_DIR=/opt/third/hadoop/etc/hadoop
# spark
export SPARK_HOME=/opt/third/spark
export PATH=$PATH:$SPARK_HOME/bin
export PYTHONPATH=$(ZIPS=("$SPARK_HOME"/python/lib/*.zip); IFS=:; echo "${ZIPS[*]}"):$PYTHONPATH
source ~/.bashrc - 配置spark-defaults.conf
cd /opt/third/spark/conf
mv spark-defaults.conf.template spark-defaults.conf
# 增加spark作业配置项
vi spark-defaults.conf输入以下内容:
spark.ui.enabled=false
spark.driver.port=32788
spark.blockManager.port=32789
spark.driver.bindAddress=0.0.0.0
spark.driver.host=xxx.xxx.xxx.xxx其中spark.driver.host是宿主机的IP地址,spark.driver.port和spark.blockManager.port的两种端口32788、32789是启动容器时增加的映射端口。两个参数解释如下: spark.driver.port 是driver监听来自executor请求的端口,executor启动时要跟driver进行通信和获取任务信息。 spark.blockManager.port 是driver和executor进行数据传输的端口。
参考pyspark开发环境搭建,运行pyspark关于依赖包共有三种解决方案,分别如下:
- 使用findspark库自动识别spark依赖包。
import findspark
findspark.init()- 动态加载依赖文件。
os.environ['SPARK_HOME'] = "/opt/third/spark"
sys.path.append("/opt/third/spark/python")
sys.path.append("/opt/third/spark/python/lib/py4j-0.10.9-src.zip")- 设置环境变量
环境变量SPARK_HOME和PYTHONPATH,其实上文已设置,但由于在notebook不生效,因此放弃此方法。
第二种方法比较对用户成本过高,因此本文采用findspark的方法。
pip install findspark当前是python3 -> python3.6*,要把python3连接到python3.8*上。
cd /usr/bin
rm -rf python3
ln -s python3.8* python3新建Python3 Notebook来测试。
import os
from random import random
from operator import add
import findspark
os.environ['SPARK_HOME']='/opt/third/spark'
findspark.init()
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("PythonPi-Local")\
.master("local")\
.getOrCreate()
n = 100000 * 2
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), 2).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()import os
import findspark
os.environ['SPARK_HOME']='/opt/third/spark'
findspark.init()
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder \
.appName('spark-hive-demo') \
.config("hive.metastore.uris", "thrift://xxx.xxx.xxx.xxx:9083") \
.enableHiveSupport() \
.getOrCreate()
spark.sql("create table if not exists demo(id bigint,name String)")
spark.sql("insert overwrite demo values (1,'hamawhite'),(2,'song.bs')")
spark.sql("select * from demo").show()其中 xxx.xxx.xxx.xxx:9083是Hive MetaStore的地址。
命令行模式测试spark jar作业,确保容器、spark、yarn的配置都是正确的。
cd /opt/third/spark
# 运行作业
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
--queue default \
examples/jars/spark-examples*.jar \
10可以在Yarn Web界面上看到提交过去的作业。
import os
import sys
from random import random
from operator import add
import findspark
os.environ['SPARK_HOME']='/opt/third/spark'
os.environ['HADOOP_CONF_DIR']='/opt/third/hadoop/etc/hadoop'
findspark.init()
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("PythonPi-Yarn-Client")\
.master("yarn")\
.config("spark.submit.deployMode", "client")\
.getOrCreate()
n = 100000 * 2
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), 2).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()可以在Yarn Web界面上看到提交过去的作业,如下图所示。

pip install apache-flink==1.15.1如果不需要用到HiveCatalog,可直接进入到1.5.1节进行测试。
镜像里自带的是JDK11,但由于Hive3是基于Java8编译的,基于JDK11运行时 PyFlink连接HiveCatalog会报错。 因此修改JDK版本为8。
# 删除已有的JDK11
rm -rf /usr/lib/jvm/
# 安装JDK8
apt-get update
apt-get install -y openjdk-8-jdk
# 设置下环境变量
vi ~/.bashrc
#java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
source ~/.bashrc
# 测试下java命令
java -version由于下面pyflink连接Hive Catalog时要配置一些依赖jar包,可以通过maven来批量一次性安装。
cd /opt/third
wget http://dlcdn.apache.org/maven/maven-3/3.8.6/binaries/apache-maven-3.8.6-bin.tar.gz
tar -xvzf apache-maven-3.8.6-bin.tar.gz
ln -s apache-maven-3.8.6 maven
# 配置maven镜像
$ vi maven/conf/settings.xml
# <mirrors>内添加如下内容 <!-- 华为云镜像 -->
<mirror>
<id>huaweimaven</id>
<name>huawei maven</name>
<url>https://mirrors.huaweicloud.com/repository/maven/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<!-- 阿里云镜像 -->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror># 设置环境变量
$ vi ~/.bashrc
# maven
export M2_HOME=/opt/third/maven
export PATH=$PATH:$M2_HOME/bin
$ source ~/.bashrc
$ mvn -vmkdir -p /opt/third/flink
cd /opt/third/flink
mkdir lib
# 新建下面的flink-dep.xml文件来定义依赖的jar(后续可以直接扩展的)
vi flink-dep.xml<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.flink.dep</groupId>
<artifactId>flink-dep</artifactId>
<version>1.0.0</version>
<properties>
<flink.version>1.15.1</flink.version>
<hadoop.version>3.2.2</hadoop.version>
<hive.version>3.1.2</hive.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
</project># 运行命令下载依赖
mvn -f flink-dep.xml dependency:copy-dependencies -DoutputDirectory=/opt/third/flink/lib因此在JupyterLab中新建Terminal执行命令:
# 新建目录
mkdir -p /opt/third/hive/conf在Web界面中上传hive-site.xml到/opt/third/hive/conf目录下。
新建Python3 Notebook来测试。
pyflink_sql.ipynb
from pyflink.table import EnvironmentSettings, TableEnvironment
env_settings = EnvironmentSettings.in_streaming_mode()
t_env = TableEnvironment.create(env_settings)
t_env.execute_sql("""
CREATE TABLE random_source(
id BIGINT,
data TINYINT
) WITH (
'connector' = 'datagen',
'fields.id.kind'='sequence',
'fields.id.start'='1',
'fields.id.end'='8',
'fields.data.kind'='sequence',
'fields.data.start'='4',
'fields.data.end'='11'
)
""")
t_env.execute_sql("""
CREATE TABLE print_sink (
id BIGINT,
data_sum TINYINT
) WITH (
'connector' = 'print'
)
""")
t_env.execute_sql("""
INSERT INTO print_sink
SELECT id, sum(data) as data_sum FROM
(SELECT id / 2 as id, data FROM random_source )
WHERE id > 1
GROUP BY id
""").wait()元数据会存储到Hive MetaStore中, pyflink_sql_hivecatalog.ipynb
import os
from pyflink.table import EnvironmentSettings, TableEnvironment
env_settings = EnvironmentSettings.in_streaming_mode()
t_env = TableEnvironment.create(env_settings)
flink_lib_path="/opt/third/flink/lib"
jars = []
for file in os.listdir(flink_lib_path):
if file.endswith('.jar'):
jars.append(os.path.basename(file))
str_jars = ';'.join(['file://'+flink_lib_path +'/'+ jar for jar in jars])
t_env.get_config().get_configuration().set_string("pipeline.jars", str_jars)
from pyflink.table.catalog import HiveCatalog
# Create a HiveCatalog
catalog_name = "hive"
default_database = "default"
catalog = HiveCatalog(catalog_name, default_database, "/opt/third/hive/conf")
t_env.register_catalog(catalog_name, catalog)
t_env.use_catalog(catalog_name)
t_env.execute_sql("DROP TABLE IF EXISTS random_source_pyflink")
t_env.execute_sql("""
CREATE TABLE IF NOT EXISTS random_source_pyflink (
id BIGINT,
data TINYINT
) WITH (
'connector' = 'datagen',
'fields.id.kind'='sequence',
'fields.id.start'='1',
'fields.id.end'='8',
'fields.data.kind'='sequence',
'fields.data.start'='4',
'fields.data.end'='11'
)
""")
t_env.execute_sql("DROP TABLE IF EXISTS print_sink_pyflink")
t_env.execute_sql("""
CREATE TABLE IF NOT EXISTS print_sink_pyflink (
id BIGINT,
data_sum TINYINT
) WITH (
'connector' = 'print'
)
""")
t_env.execute_sql("""
INSERT INTO print_sink_pyflink
SELECT id, sum(data) as data_sum FROM
(SELECT id / 2 as id, data FROM random_source_pyflink )
WHERE id > 1
GROUP BY id
""").wait()上述操作完成后,可通过pyspark作业查看到上述新建的表random_source_pyflink和random_source_pyflink。
import os
import findspark
os.environ['SPARK_HOME']='/opt/third/spark'
findspark.init()
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder \
.appName('spark-hive-demo') \
.config("hive.metastore.uris", "thrift://192.168.90.150:9083") \
.enableHiveSupport() \
.getOrCreate()
spark.sql("show tables").show()此步骤仅作参考,已集成到cube-studio源码中。
FROM ccr.ccs.tencentyun.com/cube-studio/notebook:jupyter-ubuntu-cpu-base
MAINTAINER hamawhite
COPY hadoop/run-jupyter.sh /root/run-jupyter.sh
# 拷贝examples
COPY hadoop/examples/spark/* /examples/spark/
COPY hadoop/examples/flink/* /examples/flink/
# 拷贝示例的hadoop和hive配置文件
COPY hadoop/conf/hive/* /opt/third/hive/conf/
COPY hadoop/conf/hadoop/* /opt/third/hadoop/etc/hadoop/
# 新增flink-dep.xml
COPY hadoop/conf/flink/flink-dep.xml /opt/third/flink/
RUN apt-get update && apt install -y lsof
# 修改python3的软链接
RUN cd /usr/bin \
&& rm -rf python3 \
&& ln -s python3.8* python3
# 下载apache spark安装包
RUN cd /opt/third \
&& wget http://dlcdn.apache.org/spark/spark-3.1.3/spark-3.1.3-bin-hadoop3.2.tgz \
&& tar -xvzf spark-3.1.3-bin-hadoop3.2.tgz \
&& ln -s spark-3.1.3-bin-hadoop3.2 spark \
&& rm -rf spark-3.1.3-bin-hadoop3.2.tgz \
# 创建spark-defaults.conf
&& cd /opt/third/spark/conf \
&& mv spark-defaults.conf.template spark-defaults.conf \
# 安装pyflink
&& pip install apache-flink==1.15.1 \
# 安装JDK8
&& rm -rf /usr/lib/jvm/ \
&& apt-get install -y openjdk-8-jdk \
# 安装maven
&& cd /opt/third \
&& wget http://dlcdn.apache.org/maven/maven-3/3.8.6/binaries/apache-maven-3.8.6-bin.tar.gz \
&& tar -xvzf apache-maven-3.8.6-bin.tar.gz \
&& ln -s apache-maven-3.8.6 maven \
&& rm -rf apache-maven-3.8.6-bin.tar.gz
# 修改maven镜像
COPY hadoop/maven/conf/settings.xml /opt/third/maven/conf/settings.xml
ENV M2_HOME /opt/third/maven
ENV PATH $M2_HOME/bin:$PATH
# 下载pyflink hivecatalog的依赖
RUN cd /opt/third/flink \
&& mkdir lib \
&& mvn -f flink-dep.xml dependency:copy-dependencies -DoutputDirectory=lib
ENTRYPOINT ["bash","/root/run-jupyter.sh"]run-jupyter.sh内容如下:
#!/bin/bash
HOST_IP=$1
# Hadoop生态集群的环境变量统一设置在/opt/third/hadoop-env文件中。
# 设置Hadoop环境变量
echo "export HADOOP_CONF_DIR=/opt/third/hadoop/etc/hadoop" >> /opt/third/hadoop-env
SPARK_HOME="/opt/third/spark"
# 设置Spark环境变量
echo "export SPARK_HOME=${SPARK_HOME}" >> /opt/third/hadoop-env
echo 'export PATH=$PATH:$SPARK_HOME/bin' >> /opt/third/hadoop-env
echo 'export PYTHONPATH=${SPARK_HOME}/python:$(ZIPS=("$SPARK_HOME"/python/lib/*.zip); IFS=:; echo "${ZIPS[*]}"):$PYTHONPATH' >> /opt/third/hadoop-env
# 配置spark-defaults.conf
echo "spark.ui.enabled=false" >> ${SPARK_HOME}/conf/spark-defaults.conf
echo "spark.driver.port=32788" >> ${SPARK_HOME}/conf/spark-defaults.conf
echo "spark.blockManager.port=32789" >> ${SPARK_HOME}/conf/spark-defaults.conf
echo "spark.driver.bindAddress=0.0.0.0" >> ${SPARK_HOME}/conf/spark-defaults.conf
echo "spark.driver.host=${HOST_IP}" >>${SPARK_HOME}/conf/spark-defaults.conf
# 设置环境变量到全局/etc/profile
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
echo 'export M2_HOME=/opt/third/maven' >> /etc/profile
echo 'export PATH=$PATH:$M2_HOME/bin' >> /etc/profile
source /etc/profile
source /opt/third/hadoop-env
# 绑定到/data目录下
jupyter lab --notebook-dir=/ --ip=0.0.0.0 --no-browser --allow-root --port=3000 --NotebookApp.token='' --NotebookApp.password='' --NotebookApp.allow_origin='*' 2>&1构建命令:
cd cube-studio/images/jupyter-notebook
docker build -t ccr.ccs.tencentyun.com/cube-studio/notebook:jupyter-ubuntu-cpu-hadoop -f hadoop/Dockerfile-ubuntu-hadoop .docker run --name jupyter -p 3000:3000 -p 32788-32888:32788-32888 -d ccr.ccs.tencentyun.com/cube-studio/notebook:jupyter-ubuntu-cpu-hadoop xxx.xxx.xxx.xxx注意: 增加映射端口范围32788-32888,最后一个参数xxx.xxx.xxx.xxx是宿主机IP,均是用于下文提交spark作业到yarn运行。 打开http://xxx.xxx.xxx.xxx:3000/lab 来访问JupyterLab Web页面。
目录/opt/third/hadoop/etc/hadoop和/opt/third/hive/conf已自带默认配置文件,可以修改配置文件里面的参数,或者按照下面的步骤进行上传均可。
在Web界面中上传core-site.xml、hdfs-site.xml、yarn-site.xml到/opt/third/hadoop/etc/hadoop目录下。 注意检查yarn-site.xml一定要有yarn.resourcemanager.address 配置项,否则默认值是0.0.0.0:8032会导致JupyterLab中的作业无法提交到yarn上运行。示例配置如下:
<property>
<name>yarn.resourcemanager.address</name>
<value>xxx.xxx.xxx.xxx:8032</value>
</property>在Web界面中上传hive-site.xml到/opt/third/hive/conf目录下。
因为在镜像启动jupyter的时候已经设置相关环境,因此在代码中无需再额外设置环境变量或者使用findspark。 在/examples目录下已内置自带,可直接运行。
pyspark_local.ipynb
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("PythonPi-Local")\
.master("local")\
.getOrCreate()
n = 100000 * 2
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), 2).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()pyspark_local_hive.ipynb
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder \
.appName('spark-hive-demo') \
.config("hive.metastore.uris", "thrift://xxx.xxx.xxx.xxx:9083") \
.enableHiveSupport() \
.getOrCreate()
spark.sql("create table if not exists demo(id bigint,name String)")
spark.sql("insert overwrite demo values (1,'hamawhite'),(2,'song.bs')")
spark.sql("select * from demo").show()其中 xxx.xxx.xxx.xxx:9083是Hive MetaStore的地址。
pyspark_yarn.ipynb
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("PythonPi-Yarn-Client-Dockerfile")\
.master("yarn")\
.config("spark.submit.deployMode", "client")\
.getOrCreate()
n = 100000 * 2
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), 2).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()可以在Yarn Web界面上看到提交过去的作业,如下图所示。
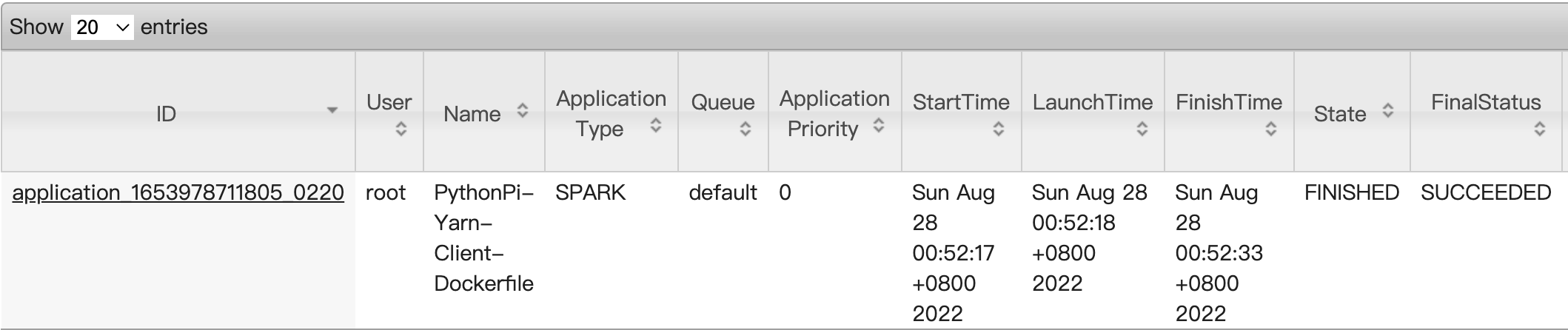
此部分跟1.5小节类似,不再阐述。在/examples目录下已内置自带,可直接运行。
由于本文用到的Hadoop集群是基于Centos7搭建的,默认的python版本是2.7,跟镜像中的Python3.8版本不一致,会导致Yarn作业运行失败。因此此处补充安装Python3.8的教程。
# 安装基础依赖
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make libffi-devel
# 下载Python安装包
wget https://www.python.org/ftp/python/3.8.12/Python-3.8.12.tgz
tar -zxvf Python-3.8.12.tgz
cd Python-3.8.12
./configure prefix=/usr/local/python3
# 安装
make && make install
# 最终在/usr/local/目录下会有python3目录
# 添加python3的软链接
ln -s /usr/local/python3/bin/python3.8 /usr/bin/python3
# 添加pip3的软链接
ln -s /usr/local/python3/bin/pip3.8 /usr/bin/pip3然后把默认python软链接到python3上。
rm -rf /bin/python
ln -s /usr/local/python3/bin/python3.8 /bin/python参考官网 https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
参考官网 https://cwiki.apache.org/confluence/display/Hive/AdminManual+Installation
