unification of extensions apis #71
Comments
|
These are all interesting ideas - I'll need to think about them!
I use Adobe Illustrator CS5, which has been my favourite drawing program for some time. |
Dang it. I was hoping you used some special program that takes a cons list and produces an output -- e.g. takes |
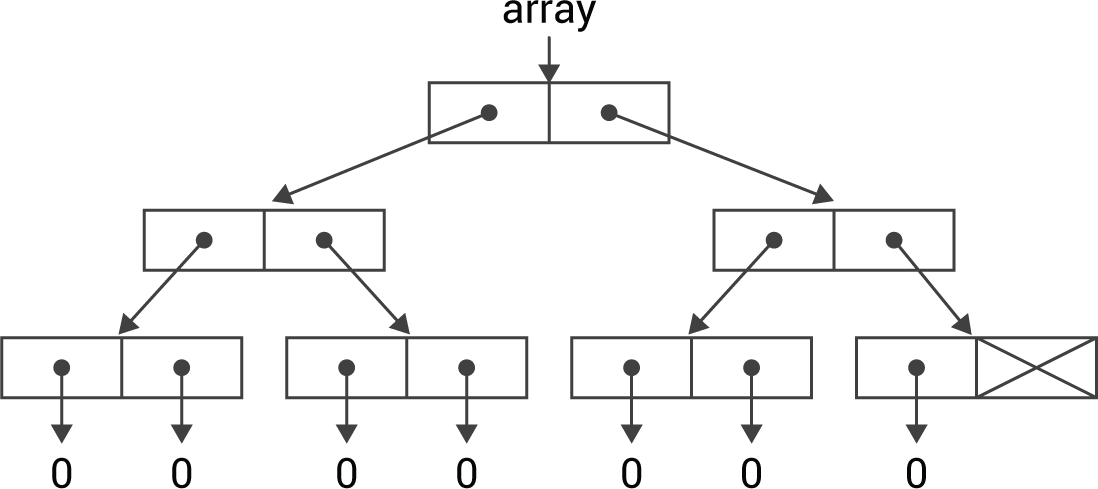
|
No, but that's a great idea! Perhaps a Lisp program that generates SVG? |
|
If I'm going to write it I would write it in Python and use Hy as a Lisp reader. But the biggest issue I can see with some sort of program like this is that there's no way to specify the layout (side-by-side? tree? etc?) without supplying additional parameters. Although there are plenty of Javascript diagram libraries that allow you to draw something like this and there are Scheme interpreters in Javascript too, so maybe a Web-based GUI program would be appropriate. But that's not your responsibility. I also have some ideas for how to make uLisp object-oriented like Janet (https://janet-lang.org/docs/object_oriented.html) using keywords and something like the opaque objects idea, but I'll hold off on that for now because I don't want to overload you with ideas. |
Have you seen this? |
I don't yet quite understand opaque types, but this suggestion is a great idea for tidying up the currently messy code for dealing with streams. I'll have a go at implementing a rough version. |
|
By the way, I'll probably try to sort out the problems with LastChar at the same time, since that involves streams too. |
I was alos thinking along the same lines -- streams could be representad as some sort of opaque-pointer structure, perhaps pointing to an entry in an array of Arduino |
status update? no rush. |
|
I've been thinking about how it might work. No one else is complaining, so it's not a high priority for me - more like a fun project! |
|
any more progress? Just wondering the current state of this proposal. Once it is implemented the graphics and wifi extensions could ostensibly be both moved to separate extensions rather than being built-in. Also, if you're willing to tell, what is the next "big feature" you're working on for uLisp? |
|
Hi - good questions! Although I enjoy writing code for uLisp I'm actually trying to resist the temptation to keep extending it further. I think it has reached an ideal point: it meets my original objective, which is an interpreted, interactive language that's a more user-friendly alternative to C for programming microcontroller boards. It also still supports my original target board, the Arduino Uno. I think there are benefits in keeping the specification relatively compact so, for example, the language reference fits in a single web page. There are some exceptions to this: I still want to make bug fixes, and make improvements that don't extend the specification, but make uLisp more reliable, or run faster, or are just more elegant. But my main concern at the moment is to make uLisp more accessible to the target audience. Currently, judging by the feedback I get by email and on the forum, uLisp has quite a small number of users, mainly among people who are already fans of Lisp. I think other users are put off by the brackets and unfamiliar syntax of Lisp, and so stick to C, or choose MicroPython rather than uLisp. I believe that one thing that would help is an easier way to edit and upload uLisp programs to a microcontroller board, like a simple stand-alone IDE, and this is what I'm currently thinking about. This is not to say that I don't welcome extensions by other users, such as your macros, etc. But although they will be welcomed by Lisp users, I don't think they will widen to appeal of uLisp to general users. I like your idea of a streams API that would make it possible to implement the graphics and wi-fi extensions as separate extension files. However, I'm not sure how easy it would be to do this, and another problem is that the extension file mechanism I've implemented currently only supports one extension file. I had an initial version working with unlimited extension files, but there was a performance penalty, so I decided to go with a single extension file for the first release. Look forward to your feedback on this. |
I wrote one in Python in my repository that runs in the terminal. It probably doesn't help you that it's written in Python 😉 but it might be a good starting point. It's still pretty basic.
I'm not really sure why there was a performance hit, as I implemented unlimited extensions (using malloc) on my fork and I don't see any performance issues. Perhaps that may be more apparent on slower processors (I'm still using an esp32) or maybe you implemented it differently than I did. The key function for multi-extension support in mine is the function Anyway, in terms of making uLisp more accessible, one thing you could do is have a global variable for the reading meachanism As for a well-defined streams and multi-extension API, I think something like having a "metatable" holding pointers to extension structs; the first one could be core uLisp. show big codetypedef struct {
tbl_entry_t* table;
size_t table_size;
stream_type_t* streams_table;
size_t streams_size;
void (*gc_hook)(); // called after each GC
const char* extension_name; // could be used for initializing *features* list etc.
// add more pointers for opaque object management, etc.
} extension_t;
#ifdef ULISP_USE_DMA
extension_t** Extensions;
size_t num_extensions = 0;
void add_extension (extension_t* ext) {
Extensions = realloc(Extensions, ++num_extensions);
Extensions[num_extensions-1] = ext;
}
#else
#define MAX_EXTENSIONS 16
extension_t* Extensions[MAX_EXTENSIONS]
size_t num_extensions = 0;
void add_extension (extension_t* ext) {
num_extensions++;
if (num_extensions >= 16) {
Serial.println("too many extensions");
while (1); // Halt
}
Extensions[num_extensions-1] = ext;
}
#endifAs for the streams, each stream needs 6 functions (open/close, read/write, and seek/tell if applicable), plus a buffer to hold the last few characters (to eliminate LastChar mix-ups). This might be a starting point. show big codetypedef struct {
stream_t* (*open)(object* args);
char (*read)(stream_t*, bool*); // bool parameter is to indicate failure
bool (*write)(stream_t*, char); // False == failed to write
bool (*seek)(stream_t*, ssize_t, bool); // like fseeko()
size_t (*tell)(stream_t*);
bool (*close)(stream_t*);
const char* type;
} stream_type_t;
#define STREAM_BUFFER_SIZE 8
typedef struct {
bool open;
stream_type_t* type; // POINTER to statically allocated one, saves RAM
uint8_t num_buffered;
char buffer[STREAM_BUFFER_SIZE];
void* context; // pointer to cons pair of head & tail for stringstream, not used on gfxstream, File* for sd-stream, Wire or Wire1, Serial, Serial1, Serial2, Serial3, current wifi-client, etc.
} stream_t;
#ifndef ULISP_USE_DMA
#define MAX_STREAMS 16
stream_t Streams[MAX_STREAMS];
#endif
// Replacement for isstream() and gstreamfun()
char stream_getchar (object* stream) {
if (!streamp(stream)) error(notastream, stream);
stream_t* str = stream->stream;
if (str->num_buffered > 0) {
str->num_buffered--;
return str->buffer[str->num_buffered];
}
bool ok = true;
char c = str->type->read(str, &ok);
if (!ok) error(PSTR("failed to read"), stream);
return c;
}Also, one other thing that I think might make uLisp more accessible to the wider Arduino community is making uLisp a file/library to be included, not its own sketch. You don't have to split it up into separate files, but having everything uLisp be in one file that is not the .ino would probably help. All that you really need to do there is rename it to ulisp.hpp, move setup() and loop() back to the .ino, and and add I hope I'm not overwhelming you with code or ideas. |
No, I welcome code and ideas. It might take me a couple of days to digest them though!
I think that's pretty much what I did in uLisp 4.4. If you can see a way of improving what I did I'd welcome suggestions. For example, here's lookupfn(): |
Sorry, I don't get this at all. Why does it help to have uLisp a file/library? Can you describe how someone might use it? |
The performance hit comes from getminmax(), which has to do table lookups at runtime; the other functions only get called when a Lisp function is read in, which isn't a problem. It's only a few percent, but I didn't think that was a price worth paying. My design aims for the extension file mechanism were:
I didn't quite achieve (3) but got it down to one #define. If you can see how to eliminate this I'd be interested. One initial problem I had was how to avoid having to define forward references in the main uLisp file to the additional lookup table(s) in the extension file(s), but you'll see how I solved this. |
The problem wit this is that it hard-codes 2 tables -- if you pass a builtin that would appear in table 3, it would look and say OK, name >= tablesize(0), so it's in table 2 and then read an out-of-bounds pointer. Also in one place you explicitly add tablesize(0)+tablesize(1), this will have to be replaced by a loop sum if you do an arbitrary number of extensions. Same sort of problem will occur if this gets missed.
The idea I was thinking of, and probably how I am going to use it, is as a part of a larger project. There is one file for uLisp, another file for another part, etc. and the .ino is the glue file that starts everything up.
On second thought with the getentry() function, you could cache the table entry pointer and use it to look up the ->minmax field as well as the ->fptr, which would make it one getentry() function instead of two. That would help, but probably not enough. There could probably be some sort of caching scheme where it caches the pointers to the table entries of the last recently used 8 builtins or so, but the performance hit from that would probably be greater than looking up a builtin in <5 tables with a loop, so I'm not going to bother. |
Yes, this is the version in uLisp 4.4 that's optimised for only one extension file (ie two tables). As I said in an earlier comment I had an initial version working with unlimited extension files which did what you're suggesting, but there was a performance penalty, so I decided to go with a single extension file for the first release.
Yes, I hadn't considered caching, and that might certainly help performance at the cost of added complexity. |
|
Had another idea: it takes advantage of the fact that if a pointer is a pointer to the workspace, Instead of just using a type enum and using special low values as the car pointer you could statically allocate structs for the types and point to them. Since the things would be allocated outside of the Workspace, it would know that it isn't a cons. The structs could then be used to hold useful information about the type - like how to mark it in the garbage collector, how to print it, and what to do when it is freed -- like I mentioned here but specific for each type. Also, to make lookup faster you could define another symbol type that functions the same, but it is used for built-in symbols. Instead of holding a base40 symbol, holding an index in the builtins table, or pointing to a long symbol, it simply points directly to its table entry. That might make it significantly faster. I don't know how much impact this would have on flash usage, but I'm not the one who's trying to run Lisp on a ATmega328. Take what you want, leave the rest. |
|
Interesting ideas.
I can't quite get my head around this. Could you give a couple of examples?
So have something like: and for a built-in symbol the car would hold BUILTIN and the cdr would hold the address of the table entry? |
Something like this: const some_struct_t INTEGER = { &other, &stuff, &about, &integers };Instead of NUMBER just being an enum entry. And then the struct could be used to hold info about the type -- e.g. its name, a function to print it (which would
That is exactly what I was thinking. Except BUILTIN in this case would not be 4, it would be a pointer to a type struct. |
|
I just thought of another reason that pointing the symbol objects directly to the builtin_t would be helpful: it would eliminate the builtins enum because you're going to have to declare all of the builtin_t's anyway and the enum was just a "hack" to "name" some of the table entries. Do you agree? |
|
I came up with some thoughts on how to make this new type struct method work smoothly with streams. It's quite large so I put it in a gist. https://gist.github.com/dragoncoder047/38aef7e4145f1dbb241547e9c7cec058 I hope the diagram helps you understand what I've been thinking -- feel free to ask me questions. |
|
Thanks! I'll have a look. |
|
After some thought and consultation of the symbol implementation I realized that making the built-in symbols point to something versus just being a number, would make the checks in longsymbolp() not work. So that would have to be revised. My best idea is to also add a check to longsymbolp() to also check if the pointer points to something inside the workspace. (Naturally the external structs a builtin would point to would not be within the workspace.) |
|
Yes, good point, thanks. |
|
I can't think of a simple solution to allow both the type struct pointing for symbols, long symbols, and base-40 compressed symbols, but maybe you could take advantage of the fact that N-bit processors rarely use all N bits for pointers, so maybe the high bit could be used to mark base-40 compressed symbols. The only problem is it shortens the max length of a compressed symbol (by 1 character on both 16- and 32-bit, I did the math) before it is turned into a long symbol. Do you think this would work? |
My thinking about a better streams api (#64), opaque objects (#70), and also more than 1 extension support using metatables, I was thinking that these different aspects could all be stored in lookup tables in flash just like the core uLisp function lookup table. Something like this for streams (like in this comment of mine but with static lookup tables):
And then
gstreamfun()andpstreamfun()could use the lookup table in the same way as the main function lookup routines. This might even reduce the code size in the long run compared to two functions with if-statment pseudo-lookup-table things.Additionally, the opaque types for the extension could also be put in a table, or at least the count of them or something.
And the metatable entries could be put in a statically allocated array (in RAM!), too, to avoid DMA on platforms that don't support it like AVR. Something like 8 or 16 slots for extensions seems appropriate.
p.s. what program do you use to draw the box-and-pointer diagrams on the uLisp website?
The text was updated successfully, but these errors were encountered: