srpc是sogou内部自研的基于Workflow项目做的RPC生态项目,通过解析部分IDL(接口描述文件)和进行代码生成,实现了与workflow底层通信框架的对接和非常简洁的用户接口。
srpc整体代码量大约1万行,内部使用多种泛型编程的方式,实现纵向解耦合、横向可扩展,核心使用同一套代码,架构十分精巧美丽。以下是架构设计思路详解。
一、整体介绍
二、接口描述、协议和通信层次介绍
- 接口描述文件层
- RPC协议层
- 网络通信层
- 协议+网络通信结合
三、架构层次介绍
四、代码生成
- IDL原生接口
- srpc代码生成的接口
- srpc内部各网络协议
- service与server的n对m关系
五、同步、异步、半同步接口,及打通workflow任务流
- 异步接口
- 同步接口
- 半同步接口
- task接口
- 利用Context打通workflow任务流,以及异步server的做法
六、其他可以借用workflow做的事情
七、写在最后
作为一个RPC,srpc的定位很明确,是做多个层级的纵向拆解和横向解耦。层次包括:
- 用户代码(client的发送函数/server的函数实现)
- IDL序列化(protobuf/thrift serialization)
- 数据组织 (protobuf/thrift/json)
- 压缩(none/gzip/zlib/snappy/lz4)
- 协议 (SRPC-std/BRPC-std/Thrift-framed/TRPC)
- 通信 (TCP/HTTP)
以上各层级可以相互拼装,利用函数重载、派生子类实现父类接口和模版特化等多种多态方式,来实现内部使用同一套代码的高度复用,以后如果想架构升级,无论是中间再加一层、还是某层内横向添加一种内容都非常方便,整体设计比较精巧。
且得益于workflow的性能,srpc本身的性能也很优异。srpc系统除了SRPC-std协议以外,同时实现了BRPC-std协议、Thrift-framed协议、腾讯的TRPC协议,同协议下与brpc系统和apache thrift系统进行了性能对比,吞吐性能领先,长尾性能与brpc各有优势但都比thrift强。
srpc目前在搜狗公司内部和开源后业界一些开发者的团队中已经稳定使用一段时间,并以其简单的接口让小伙伴们可以快速开发,且协助业务性能带来好几倍的提升。
本篇主要是对srpc架构设计思路的阐述,建议开发者结合主页readme等文档一起参考。
一般来说用户使用任何一种RPC,需要关心的是:method,request,response,以下会结合这三项来讲述如何和各层级打交道。
刚才整体介绍里看到的层级很多,但是作为srpc的开发,需要知道的层级是以下三种:
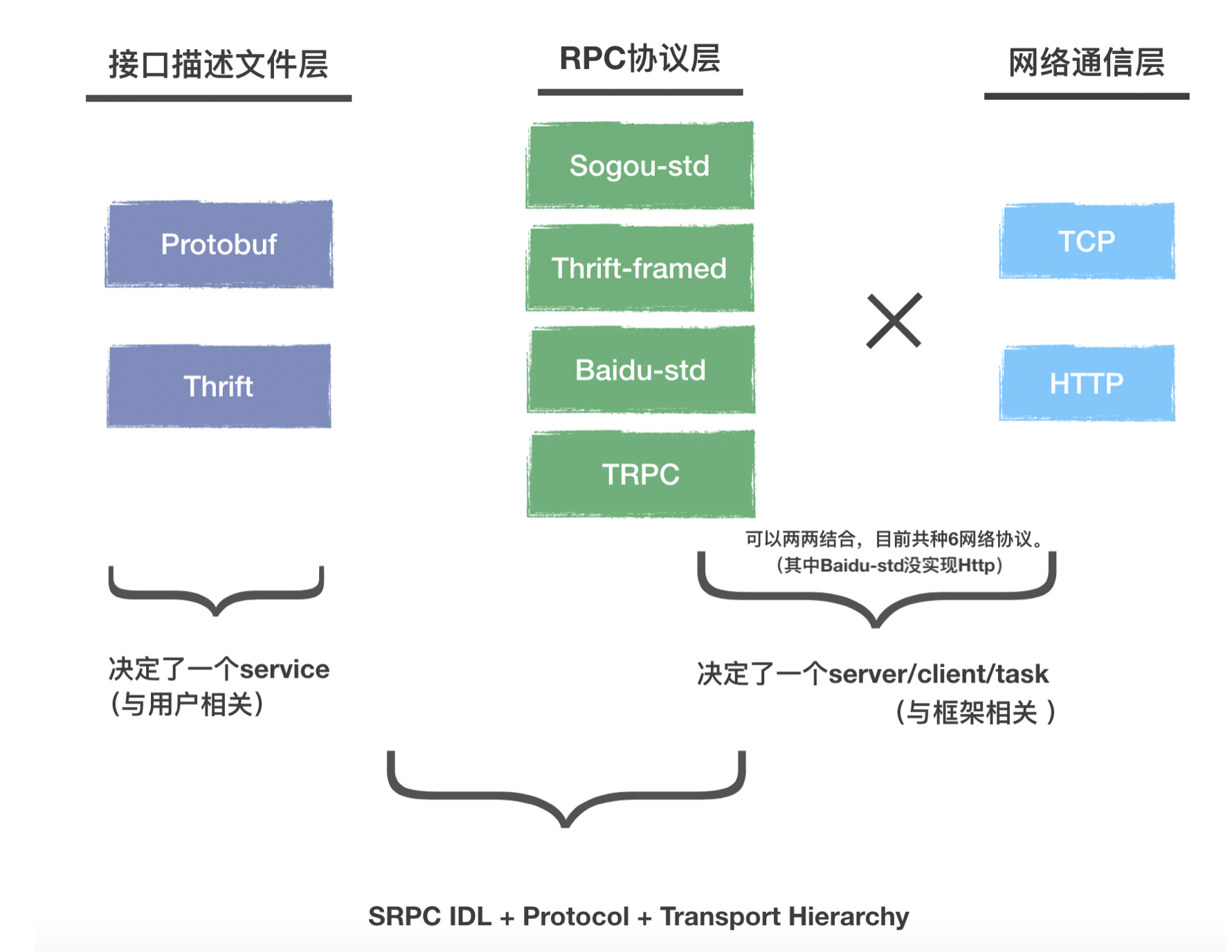
如图从左到右,是用户接触得最多到最少的层次。我们作为一个已经使用了某种RPC的用户,一般会选择一种现有的IDL,目前小伙伴们用得比较多的是protobuf和thrift,这两种srpc都支持了。其中:
- thrift:IDL纯手工解析,用户使用srpc是不需要链thrift的库的 !!!
- protobuf:service的定义部分纯手工解析
用户在写开发代码的时候,必定是请求一个method,拿着某种IDL填request,拿回同种IDL定义的response。
一种IDL决定了一种service。
中间那列是具体的协议,我们实现了SRPC-std,BRPC-std,Thrift-framed和TRPC,其中SRPC-std的协议如下:
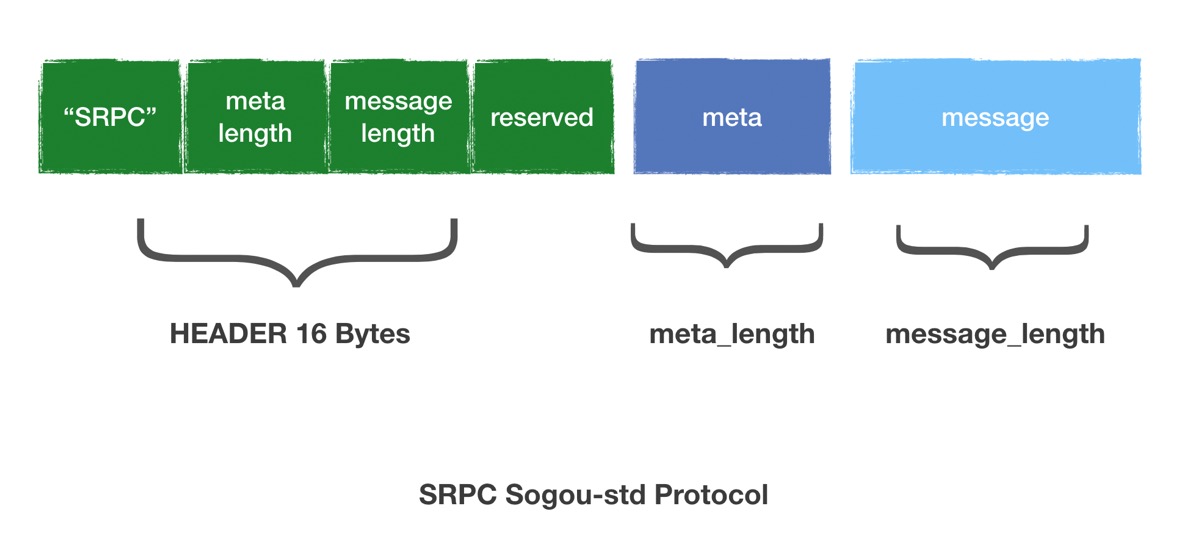
其中RPC的service名字和method名字等信息会的填到meta中,第三部分是完完整整的用户的IDL:具体的request/response的内容。
以上一片内容,如果直接二进制走TCP发出去,那么肯定要求对方要是相同协议的server/client才能解析。但是,如果我们希望跨语言,最简单的方式是借用HTTP协议,于是乎,我们的第三列网络通信,和TCP二进制内容并列的,是HTTP协议。
第二列和第三列理论上是可以两两结合的,只需要第二列的具体RPC协议在发送时,把HTTP相关的内容进行特化,不要按照自己的协议去发,而按照HTTP需要的形式去发。HTTP需要什么?URL,header和body。
我们把service/method拼到URL的host后面,接下来把具体协议的meta的内容按照HTTP可以识别的header key一项一项填进header里。 最后把具体request/response作为HTTP的body填好,发送出去。
我们除了BRPC + Http没有实现,其他两两结合一共实现出了7种网络通信协议:
- SRPCStd
- SRPCHttp
- BRPCStd
- TRPCStd
- TRPCHttp
- ThriftBinaryFramed
- ThriftBinaryHttp
另外,为了更好地兼容HTTP用户,我们的body除了protobuf/thrift之外,还可以支持json,也就是说,client可以是任何语言,只要发一个带json的HTTP请求给server,server收到的依然是一个IDL结构体。
一种网络通信协议决定了一种server/client/task。
我们先看一下,把request通过method发送出去并处理response再回来的整件事情是怎么做的:
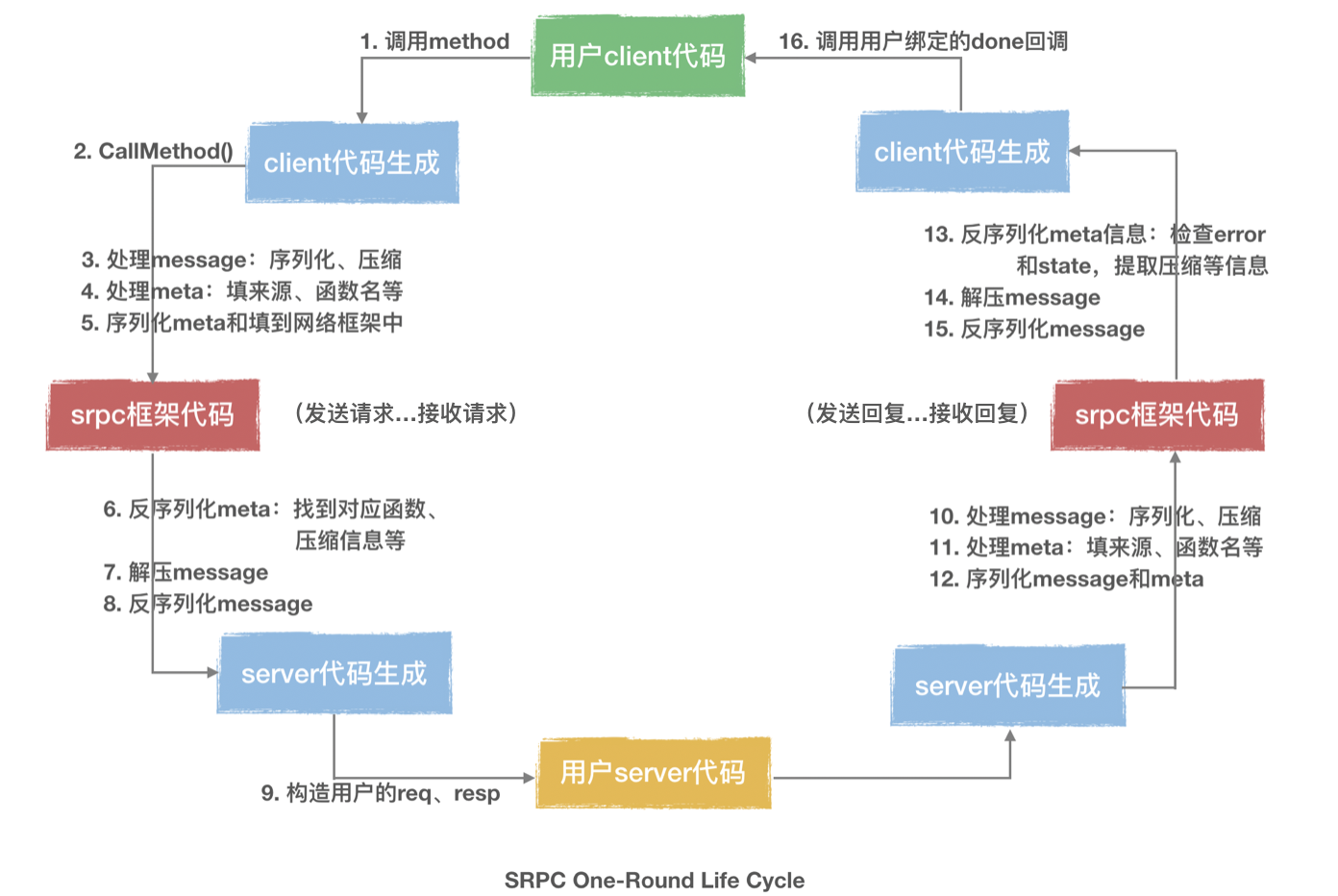
根据上图,
可以更清楚地看到文章开头提到的各个层级,其中压缩层、序列化层、协议层是互相解耦打通的,代码实现上非常统一,横向增加任何一种压缩算法或IDL或协议都不需要改动现有的代码~
在做srpc的架构设计期间的工作基本可以总结为:不停地解耦。
另外,作为一个通信框架,srpc为了支持外部服务的调用和可扩展的控制逻辑,对各个切面进行了模块化插件的设计。以server收消息到回复的一条线展开,模块化插件的架构图如下:
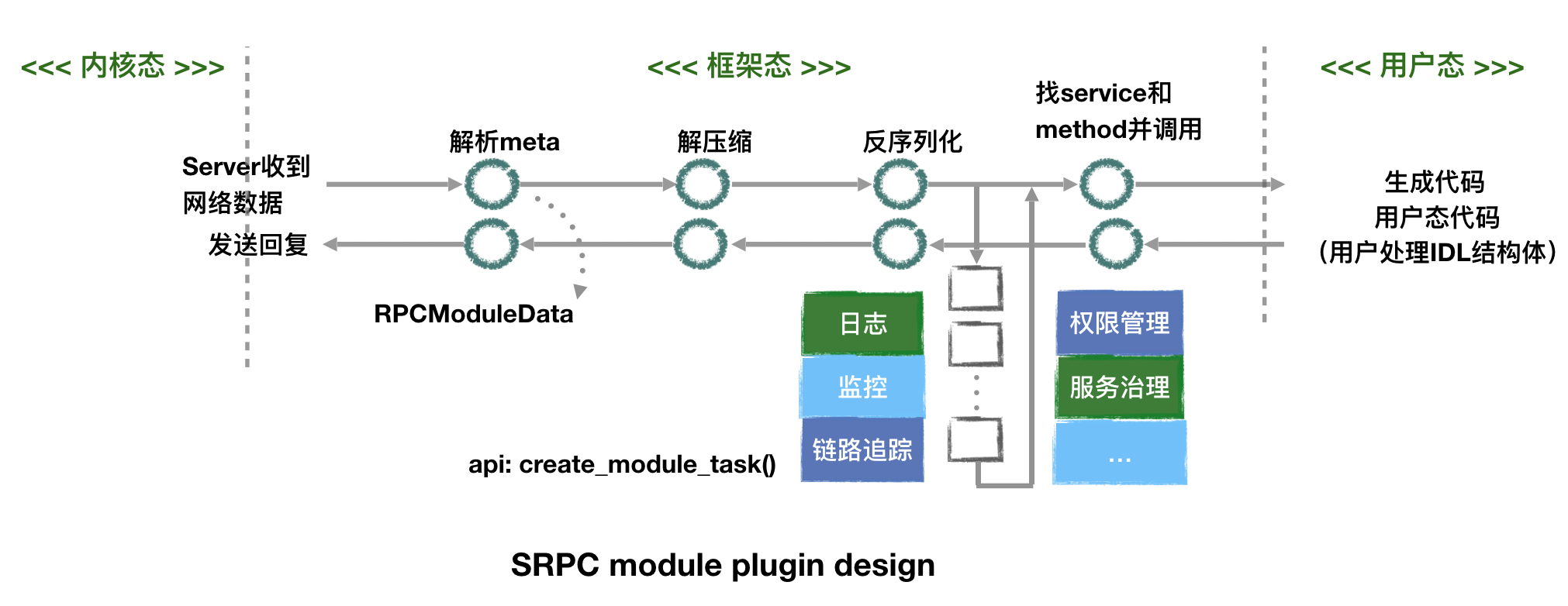
插件如果需要使用,都提前需要注册,以做到不使用的模块无任何额外消耗。每个模块的内部实现都会把具体执行方式封装成一个任务,这是遵循workflow内部任务流的编程范式思想。
可以看到上图中,有许多步骤是通过代码生成完成的。做rpc框架,因为用户要自定义自己的IDL结构体,对于网络上收到一片内存如何按照结构体定义的内容反射出来,并且为用户提供自定义结构体作为参数的接口,这些对于C++来说都是需要生成一部分代码来做的。理论上,如果依赖了protobuf和thrift,确实可以不用纯手工代码生成。
因此这里给大家介绍一下我们为什么要代码生成。
我们说过,对于一个protobuf的service定义,或者thrift的全部内容,我们都选择了代码生成。这里以protobuf为例:
message EchoRequest
{
optional string message = 1;
};
message EchoResponse
{
optional string message = 1;
};
service ExamplePB
{
rpc Echo(EchoRequest) returns (EchoResponse);
};其实pb本身只需要配上:
option cc_generic_services = true;就可以帮你生成具体service/method的接口了,但是protobuf本身不带网络通信功能,你需要基于这个接口做开发,但是我们可以看看pb这个原生接口,非常的复杂:
// SERVER代码
class ExamplePB : public ::PROTOBUF_NAMESPACE_ID::Service {
public:
// 这里是接口层,用户需要派生这个类,实现同名函数,在函数里写server的业务逻辑
virtual void Echo(::PROTOBUF_NAMESPACE_ID::RpcController* controller,
const ::example::EchoRequest* request,
::example::EchoResponse* response,
::google::protobuf::Closure* done);
};
// CLIENT代码
class ExamplePB_Stub : public ExamplePB {
public:
// 发起RPC调用也需要知道controller和Closure done
void Echo(::PROTOBUF_NAMESPACE_ID::RpcController* controller,
const ::example::EchoRequest* request,
::example::EchoResponse* response,
::google::protobuf::Closure* done);
};google的风格就是喜欢把接口层和实现层区分开来,想要走protobuf默认的代码生成,就需要让用户也这样写controller和closure,这两者都是可以再做具体实现的,一般来说支持protobuf的RPC都是这样做的。但是,用户要看到这么多复杂的东西会很头疼,尤其是controller,明明有了client还要多学习一个结构,不太符合架构的审美。
另外一点,response和controller的生命周期也是一个很confusing的东西,pb这种接口是需要让用户传入,用户来保证生命周期必须保持到异步请求结束,显然不太友好。
thrift的话就更不用说了,请求与连接本身结合太紧密,不利于我们自己做网络通信层。
为了支持两种不同的IDL都可以顺利请求workflow,我们进行了代码生成,包括基本的generator->parser->printer,这部分风格代码比较C。需要编译完之后对IDL文件进行如下调用:
srpc_generator [protobuf|thrift] [proto_file|thrift_file] out_dir具体文件生成到xxx.srpc.h中,还是拿刚才protobuf的例子,srpc生成出来的代码如下:
// SERVER代码
class Service : public srpc::RPCService
{
public:
// 用户需要自行派生实现这个函数,与刚才pb生成的是对应的
virtual void Echo(EchoRequest *request, EchoResponse *response,
srpc::RPCContext *ctx) = 0;
};
// CLIENT代码
using EchoDone = std::function<void (EchoResponse *, srpc::RPCContext *)>;
class SRPCClient : public srpc::SRPCClient
{
public:
void Echo(const EchoRequest *req, EchoDone done);
};用户的接口使用起来就会非常简单,尤其是client的接口,其中done是我们的回调函数,而类似于controller这种会话上下文信息的东西,用户不想用的话可以选择性忽略。
我们还模仿了thrift给生成了skeleton示例: server.xx_skeleton.cc和client.xx_skeleton.cc,帮忙在main函数里构造了client和server以及service的派生,妈妈再也不用担心我连创建的步骤都搞错了。
//以下是自动生成的代码server.pb_skeleton.cc
#include "xxxx.srpc.h"
class ExamplePBServiceImpl : public ::example::ExamplePB::Service
{
public:
void Echo(::example::EchoRequest *request, ::example::EchoResponse *response,
srpc::RPCContext *ctx) override
{ /* 收到请求后要做的事情,并填好回复;*/ }
};
int main()
{
// 1. 定义一个server
SRPCServer server;
// 2. 定义一个service,并加到server中
ExamplePBServiceImpl examplepb_impl;
server.add_service(&examplepb_impl);
// 3. 把server启动起来
server.start(PORT);
// 4. server启动是异步的,需要暂时卡住主线程
getchar();
server.stop();
return 0;
}这里可以顺理成章地给梳理通信层和协议层的配合了。我们继续看看xxxx.srpc.h这个文件,里边定义了好几种协议:
// 由protobuf生成的代码
class Service : public srpc::RPCService;
class SRPCClient : public srpc::SRPCClient;
class SRPCHttpClient : public srpc::SRPCHttpClient;
class BRPCClient : public srpc::BRPCClient;
class TRPCClient : public srpc::TRPCClient;如果我们的IDL是thrift,那么会生成的xxxx.srpc.h就会有这些:
// 由thrift生成的代码
class Service : public srpc::RPCService;
class SRPCClient : public srpc::SRPCClient;
class SRPCHttpClient : public srpc::SRPCHttpClient;
class ThriftClient : public srpc::ThriftClient;
class ThriftHttpClient : public srpc::ThriftHttpClient;可以看到,大家都是只有一个service,因为service只与IDL相关。
然后对于不同的RPC协议(SRPC/BRPC/Thrift/TRPC),如果有配套的通信协议(TCP/HTTP)实现,那么就会有一个对应的client。
我们刚才介绍过,一个IDL定义一个servcie,一个网络通信协议定义一个server。然后srpc内部各层是可以互相组合的,这意味着:
- 一个协议的server内可以添加多个service(这个不新鲜,除了部分rpc不可以,大部份人都是可以的)
- 用户实现一个service的函数,可以加到多个不同协议的server中,都可以run起来;
- 一个service的函数也可以同时支持服务TCP和HTTP了,业务逻辑复用非常方便~
int main()
{
SRPCServer server_srpc;
SRPCHttpServer server_srpc_http;
BRPCServer server_brpc;
ThriftServer server_thrift;
TRPCServer server_trpc;
TRPCHttpServer server_trpc_http;
ExampleServiceImpl impl_pb; // 使用pb作为接口的service
AnotherThriftServiceImpl impl_thrift; // 使用thrift作为接口的service
server_srpc.add_service(&impl_pb); // 只要协议本身支持这种IDL,就可以把这类service往里加
server_srpc.add_service(&impl_thrift);
server_srpc_http.add_service(&impl_pb); // 还可以同时提供二进制协议和Http服务
server_srpc_http.add_service(&impl_thrift);
server_brpc.add_service(&impl_pb); // brpc-std协议只支持了protobuf
server_thrift.add_service(&impl_thrift); // thrift-binary协议只支持了thrift
server_trpc.add_service(&impl_pb); // 只需要改一个字母,就可以方便兼容不同协议
server_trpc_http.add_service(&impl_pb); // 目前也是唯一开源的trpc协议实现
server_srpc.start(1412);
server_srpc_http.start(8811);
server_brpc.start(2020);
server_trpc.start(2021);
server_thrift.start(9090);
server_trpc_http.start(8822);
....
return 0;
}srpc提供了同步、半同步、异步的接口,其中异步接口是用来打通workflow任务流的关键。
如果我们继续看生成代码,其中一个client为例,一个具体协议所定义出来的client所有的接口是这样的:
class SRPCClient : public srpc::SRPCClient
{
public:
// 异步接口
void Echo(const EchoRequest *req, EchoDone done);
// 同步接口
void Echo(const EchoRequest *req, EchoResponse *resp, srpc::RPCSyncContext *sync_ctx);
// 半同步接口
WFFuture<std::pair<EchoResponse, srpc::RPCSyncContext>> async_Echo(const EchoRequest *req);
public:
SRPCClient(const char *host, unsigned short port);
SRPCClient(const struct srpc::RPCClientParams *params);
public:
// 异步接口,用法与workflow其他task一致
srpc::SRPCClientTask *create_Echo_task(EchoDone done);
};这几种接口,相当于是变着花样地使用这四种东西:request,response,context和done。
异步接口本身比较好理解,而且用户发请求时不用带着response的指针,也不用自己去保证它的生命周期了~刚才已经看过我们的回调函数done,是一个std::function,框架会在调用done的生成代码中创建一个response供用户使用。在skeleton代码中例子是这样的:
static void echo_done(::example::EchoResponse *response, srpc::RPCContext *context)
{
// 这个RPCContext可以拿到请求期间框架可以提供的状态
}同步接口没有生命周期的问题,直接让用户操作response和context。
半同步接口会返回一个future,这是Workflow内部封装的WFFuture,用法与std::future类似,需要等待的时候可以通过get()接口拿到结果,结果就是response和context。
其实异步接口,内部也是通过task接口实现的。这里可以看到,我们通过一个client创建task的方式:
srpc::SRPCClientTask * task = SRPCClient::create_Echo_task(done);
task->serialize_input(req);
task->start();这个方式,充分体现了workflow的二级工厂概念。srpc对于workflow来说就是几种特定的协议和一些额外的功能(比如用户IDL的序列化和压缩),所以在workflow实现一个带复杂功能的协议其实就是实现一个二级工厂。
拿到task之后,需要填request并且start起来,这部分也是和workflow的做法一模一样的。
这个接口最重要的意义是在于: 我们通过client二级工厂创建出来的rpc,可以串到任何workflow的任务流图中,自动随流图执行被调起。
我们在两个地方可以拿到RPCContext:
- server实现service中的函数参数
- client的done的参数
这个RPCContext的功能非常多,主要是以下三种:
- server想要给当前这个response设置一些会话级(或者说task级)的信息的接口,比如压缩类型等;
- client拿到回复时,查看请求的状态和其他信息;
- 拿到series;
拿series的接口如下:
SeriesWork *get_series() const;因此,我们在server的函数实现中,就可以往这个series后串别的task从而实现异步server了(server的reply时机为此series上所有任务跑完),也可以在我作为client的回调函数里继续往任务流后面串其他workflow任务。这应该是和现有的其他RPC相比最简单的异步server实现方式了。
再以刚才的service为例做异步server:
class ExampleServiceImpl : public Example::Service
{
public:
void Echo(EchoRequest *request, EchoResponse *response, RPCContext *ctx) override
{
auto *task = WFTaskFactory::create_timer_task(10, nullptr);
ctx->get_series()->push_back(task); // 此RPC的回复时机是这个task执行完,与workflow一致
}
};以上可以看到,我们顺利地打通workflow,把rpc请求本身也都按照workflow的任务概念划分好了:协议、请求、回复。
那么workflow还有什么功能我们可以用得到的呢?
首先是服务治理。workflow的upstream是本进程内把一批机器绑定到一个域名下的upstream管理,自带多种方式的负载均衡和熔断恢复等机制,srpc的client都可以直接拿来用,一个client创建出来对应的是一个ip,或者一个带本地服务治理的集群。
Client和task其他层级的配置。比如workflow的各种超时都可以用上,workflow的网络请求本身有重试次数,rpc默认配为0,有需要的话用户可以自行配置。
其他系统资源。rpc只是网络相关,而workflow包含了如计算和异步文件IO等资源,这些在打通了任务流之后,都可以为srpc所用。
随着srpc架构演进,使用到的泛型编程的方式有如下多种:

架构设计中有些其他细节比如离散内存的管理、内存反射、模块化插件的具体做法暂时还不在本篇wiki中。srpc项目目前在服务层面上做一些拓展和调研,也在研究相关的生态项目。从用户使用和落地情况的良好反馈来看,我们非常有信心继续推进workflow与srpc的生态,建立起和大家一起学习一起进步的合作方式。