Define the URL, REGION, ACCESS_KEY, and SECRET_ACCESS_KEY variables below for integration, replacing the placeholder values with your own.
\n", "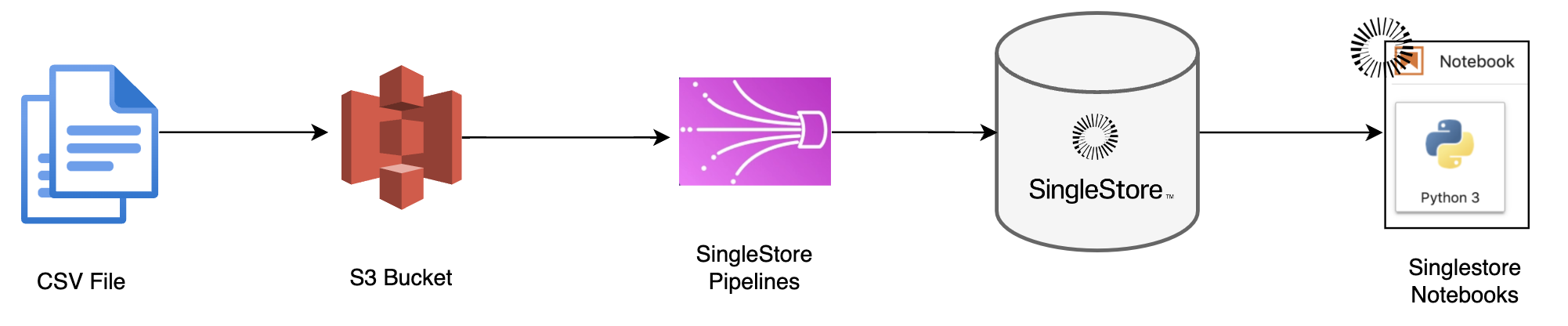 "
- ],
- "id": "7b97f983"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "d1ea9458",
"metadata": {},
"source": [
"## Creating Table in SingleStore\n",
"\n",
"Start by creating a table that will hold the data imported from S3."
- ],
- "id": "d1ea9458"
+ ]
},
{
"cell_type": "code",
"execution_count": 2,
+ "id": "66eb1b49",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"/* Feel free to change table name and schema */\n",
"\n",
@@ -112,12 +112,12 @@
" address TEXT,\n",
" created_at TIMESTAMP\n",
");"
- ],
- "id": "66eb1b49"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "3704a19a",
"metadata": {},
"source": [
"## Create a Pipeline to Import Data from S3\n",
@@ -128,25 +128,24 @@
"You have access to the S3 bucket.\n",
"Proper IAM roles or access keys are configured in SingleStore.\n",
"The CSV file has a structure that matches the table schema."
- ],
- "id": "3704a19a"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "83a75641",
"metadata": {},
"source": [
"Using these identifiers and keys, execute the following statement."
- ],
- "id": "83a75641"
+ ]
},
{
"cell_type": "code",
"execution_count": 3,
+ "id": "e88495e2",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"CREATE PIPELINE s3_import_pipeline\n",
"AS LOAD DATA S3 '{{URL}}'\n",
@@ -157,142 +156,136 @@
"FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\\\"'\n",
"LINES TERMINATED BY '\\n'\n",
"IGNORE 1 lines;"
- ],
- "id": "e88495e2"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "08781117",
"metadata": {},
"source": [
"## Start the Pipeline\n",
"\n",
"To start the pipeline and begin importing the data from the S3 bucket:"
- ],
- "id": "08781117"
+ ]
},
{
"cell_type": "code",
"execution_count": 4,
+ "id": "adb89dc1",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"START PIPELINE s3_import_pipeline;"
- ],
- "id": "adb89dc1"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "15275805",
"metadata": {},
"source": [
"## Select Data from the Table\n",
"\n",
"Once the data has been imported, you can run a query to select it:"
- ],
- "id": "15275805"
+ ]
},
{
"cell_type": "code",
"execution_count": 5,
+ "id": "f2855248",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"SELECT * FROM my_table LIMIT 10;"
- ],
- "id": "f2855248"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "ea34b089",
"metadata": {},
"source": [
"### Check if all data of the data is loaded"
- ],
- "id": "ea34b089"
+ ]
},
{
"cell_type": "code",
"execution_count": 6,
+ "id": "4e9023e8",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"SELECT count(*) FROM my_table"
- ],
- "id": "4e9023e8"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "236cb111",
"metadata": {},
"source": [
"## Conclusion\n",
"\n",
"We have shown how to insert data from a Amazon S3 using `Pipelines` to SingleStoreDB. These techniques should enable you to\n",
"integrate your Amazon S3 with SingleStoreDB."
- ],
- "id": "236cb111"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "6d195418",
"metadata": {},
"source": [
"## Clean up\n",
"\n",
"Remove the '#' to uncomment and execute the queries below to clean up the pipeline and table created."
- ],
- "id": "6d195418"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "8eafa43e",
"metadata": {},
"source": [
"#### Drop Pipeline"
- ],
- "id": "8eafa43e"
+ ]
},
{
"cell_type": "code",
"execution_count": 7,
+ "id": "451e80c9",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"#STOP PIPELINE s3_import_pipeline;\n",
"\n",
"#DROP PIPELINE s3_import_pipeline;"
- ],
- "id": "451e80c9"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "ae825668",
"metadata": {},
"source": [
"#### Drop Data"
- ],
- "id": "ae825668"
+ ]
},
{
"cell_type": "code",
"execution_count": 8,
+ "id": "3c4b631d",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"#DROP TABLE my_table;"
- ],
- "id": "3c4b631d"
+ ]
},
{
"id": "89365517",
"
- ],
- "id": "7b97f983"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "d1ea9458",
"metadata": {},
"source": [
"## Creating Table in SingleStore\n",
"\n",
"Start by creating a table that will hold the data imported from S3."
- ],
- "id": "d1ea9458"
+ ]
},
{
"cell_type": "code",
"execution_count": 2,
+ "id": "66eb1b49",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"/* Feel free to change table name and schema */\n",
"\n",
@@ -112,12 +112,12 @@
" address TEXT,\n",
" created_at TIMESTAMP\n",
");"
- ],
- "id": "66eb1b49"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "3704a19a",
"metadata": {},
"source": [
"## Create a Pipeline to Import Data from S3\n",
@@ -128,25 +128,24 @@
"You have access to the S3 bucket.\n",
"Proper IAM roles or access keys are configured in SingleStore.\n",
"The CSV file has a structure that matches the table schema."
- ],
- "id": "3704a19a"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "83a75641",
"metadata": {},
"source": [
"Using these identifiers and keys, execute the following statement."
- ],
- "id": "83a75641"
+ ]
},
{
"cell_type": "code",
"execution_count": 3,
+ "id": "e88495e2",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"CREATE PIPELINE s3_import_pipeline\n",
"AS LOAD DATA S3 '{{URL}}'\n",
@@ -157,142 +156,136 @@
"FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\\\"'\n",
"LINES TERMINATED BY '\\n'\n",
"IGNORE 1 lines;"
- ],
- "id": "e88495e2"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "08781117",
"metadata": {},
"source": [
"## Start the Pipeline\n",
"\n",
"To start the pipeline and begin importing the data from the S3 bucket:"
- ],
- "id": "08781117"
+ ]
},
{
"cell_type": "code",
"execution_count": 4,
+ "id": "adb89dc1",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"START PIPELINE s3_import_pipeline;"
- ],
- "id": "adb89dc1"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "15275805",
"metadata": {},
"source": [
"## Select Data from the Table\n",
"\n",
"Once the data has been imported, you can run a query to select it:"
- ],
- "id": "15275805"
+ ]
},
{
"cell_type": "code",
"execution_count": 5,
+ "id": "f2855248",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"SELECT * FROM my_table LIMIT 10;"
- ],
- "id": "f2855248"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "ea34b089",
"metadata": {},
"source": [
"### Check if all data of the data is loaded"
- ],
- "id": "ea34b089"
+ ]
},
{
"cell_type": "code",
"execution_count": 6,
+ "id": "4e9023e8",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"SELECT count(*) FROM my_table"
- ],
- "id": "4e9023e8"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "236cb111",
"metadata": {},
"source": [
"## Conclusion\n",
"\n",
"We have shown how to insert data from a Amazon S3 using `Pipelines` to SingleStoreDB. These techniques should enable you to\n",
"integrate your Amazon S3 with SingleStoreDB."
- ],
- "id": "236cb111"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "6d195418",
"metadata": {},
"source": [
"## Clean up\n",
"\n",
"Remove the '#' to uncomment and execute the queries below to clean up the pipeline and table created."
- ],
- "id": "6d195418"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "8eafa43e",
"metadata": {},
"source": [
"#### Drop Pipeline"
- ],
- "id": "8eafa43e"
+ ]
},
{
"cell_type": "code",
"execution_count": 7,
+ "id": "451e80c9",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"#STOP PIPELINE s3_import_pipeline;\n",
"\n",
"#DROP PIPELINE s3_import_pipeline;"
- ],
- "id": "451e80c9"
+ ]
},
{
"attachments": {},
"cell_type": "markdown",
+ "id": "ae825668",
"metadata": {},
"source": [
"#### Drop Data"
- ],
- "id": "ae825668"
+ ]
},
{
"cell_type": "code",
"execution_count": 8,
+ "id": "3c4b631d",
"metadata": {},
"outputs": [],
"source": [
- "%%sql\n",
"%%sql\n",
"#DROP TABLE my_table;"
- ],
- "id": "3c4b631d"
+ ]
},
{
"id": "89365517",