\n",
@@ -713,23 +712,24 @@
"
If you created a new database in your Standard or Premium Workspace, you can drop the database by running the cell below. Note: this will not drop your database for Free Starter Workspaces. To drop a Free Starter Workspace, terminate the Workspace using the UI.
\n",
"
\n",
@@ -584,23 +583,24 @@
"
If you created a new database in your Standard or Premium Workspace, you can drop the database by running the cell below. Note: this will not drop your database for Free Starter Workspaces. To drop a Free Starter Workspace, terminate the Workspace using the UI.
\n",
"
If you created a new database in your Standard or Premium Workspace, you can drop the database by running the cell below. Note: this will not drop your database for Free Starter Workspaces. To drop a Free Starter Workspace, terminate the Workspace using the UI.
\n",
" \n",
""
- ]
+ ],
+ "id": "fc8b28e8"
},
{
"cell_type": "code",
"execution_count": 10,
- "id": "0e91592f-4856-4cab-b15e-23585f551ab3",
"metadata": {},
"outputs": [],
"source": [
"shared_tier_check = %sql show variables like 'is_shared_tier'\n",
"if not shared_tier_check or shared_tier_check[0][1] == 'OFF':\n",
" %sql DROP DATABASE IF EXISTS semantic_search;"
- ]
+ ],
+ "id": "10aae5a1"
},
{
+ "id": "60d17a89",
"cell_type": "markdown",
- "id": "a6829f66-b37e-493d-9631-6da519140485",
"metadata": {},
"source": [
"\n",
diff --git a/notebooks/semantic-search-with-openai-embedding-creation/notebook.ipynb b/notebooks/semantic-search-with-openai-embedding-creation/notebook.ipynb
index 0fd6c313..28a6d830 100644
--- a/notebooks/semantic-search-with-openai-embedding-creation/notebook.ipynb
+++ b/notebooks/semantic-search-with-openai-embedding-creation/notebook.ipynb
@@ -1,8 +1,8 @@
{
"cells": [
{
+ "id": "abecce4f",
"cell_type": "markdown",
- "id": "8e19358e-22e8-406c-ae17-d916db889313",
"metadata": {},
"source": [
""
- ]
+ ],
+ "id": "c636f590"
},
{
"cell_type": "markdown",
- "id": "8124ab1c-7f17-47bc-9f8a-c7bd5a33a426",
"metadata": {},
"source": [
"## 3. Install and import required libraries\n",
"\n",
"We will use the OpenAI embeddings API and will need to import the relevant dependencies accordingly."
- ]
+ ],
+ "id": "7c480439"
},
{
"cell_type": "code",
"execution_count": 2,
- "id": "af6146b2-a044-4dd8-b020-e3d8c1f91aba",
"metadata": {},
"outputs": [],
"source": [
@@ -115,21 +114,21 @@
"\n",
"from openai import OpenAI\n",
"import requests"
- ]
+ ],
+ "id": "48c7b3d1"
},
{
"cell_type": "markdown",
- "id": "f80d23bc-7e98-4ac8-b2a0-7a737e4010e5",
"metadata": {},
"source": [
"## 4. Create an OpenAI account and get API connection details\n",
"\n",
"To vectorize and embed the employee reviews and query strings, we leverage OpenAI's embeddings API. To use this API, you will need an API key, which you can get [here](https://platform.openai.com/account/api-keys). You'll need to add a payment method to actually get vector embeddings using the API, though the charges are minimal for a small example like we present here."
- ]
+ ],
+ "id": "6d2c11f1"
},
{
"cell_type": "markdown",
- "id": "22de8d4c-6b79-4496-8812-37e0b82e980b",
"metadata": {},
"source": [
"\n",
@@ -139,12 +138,12 @@
"
You will have to update your notebook's firewall settings to include *.*.openai.com in order to get embedddings from OpenAI APIS.
\n",
"
\n",
@@ -302,23 +301,24 @@
"
If you created a new database in your Standard or Premium Workspace, you can drop the database by running the cell below. Note: this will not drop your database for Free Starter Workspaces. To drop a Free Starter Workspace, terminate the Workspace using the UI.
\n",
"
\n",
@@ -549,23 +548,24 @@
"
If you created a new database in your Standard or Premium Workspace, you can drop the database by running the cell below. Note: this will not drop your database for Free Starter Workspaces. To drop a Free Starter Workspace, terminate the Workspace using the UI.
\n",
"
3. Drop the blob column.
\n",
" 4. Rename the new vector column to the old blob column name. This will ensure any previous queries will still work, or at least require fewer changes.\n",
"
"
- ]
+ ],
+ "id": "ca8ad8bd"
},
{
"cell_type": "code",
"execution_count": 19,
- "id": "233bfe2c-e99c-4dd3-bf56-eafa923ba4d8",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT VECTOR_NUM_ELEMENTS(word_embeddings) FROM words_table LIMIT 1;"
- ]
+ ],
+ "id": "f6e449f9"
},
{
"cell_type": "code",
"execution_count": 20,
- "id": "b467da39-b9c4-4576-828e-135520713907",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"ALTER TABLE words_table ADD COLUMN emb2 vector(384) AFTER word_embeddings;\n",
"UPDATE words_table SET emb2=word_embeddings;"
- ]
+ ],
+ "id": "d58eefb6"
},
{
"cell_type": "code",
"execution_count": 21,
- "id": "4288cee5-3dc0-4108-a272-287a1ffbbb01",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT word, emb2, JSON_ARRAY_UNPACK(word_embeddings) FROM words_table LIMIT 1;"
- ]
+ ],
+ "id": "d40fe9ce"
},
{
"cell_type": "code",
"execution_count": 22,
- "id": "bf42a048-0a42-496d-8925-fbc6125316b4",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"ALTER TABLE words_table DROP COLUMN word_embeddings;\n",
"ALTER TABLE words_table CHANGE emb2 word_embeddings;"
- ]
+ ],
+ "id": "5bffb8aa"
},
{
"cell_type": "code",
"execution_count": 23,
- "id": "fef19d53-3f4e-4e75-a1ca-8328a5ae29a2",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"DESC words_table;"
- ]
+ ],
+ "id": "60a3d4bd"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "d906c5e5-bd11-4c4f-ba13-8b4a2a09c9d7",
"metadata": {},
"source": [
"## 11. Semantic Search of the word -sunshine 🌞 using Infix Operator\n",
@@ -608,12 +607,12 @@
"Performing a semantic search for the word 'sunshine' to find contextually similar or related words and phrases based on their semantic meanings rather than exact lexical matches.\n",
"\n",
"The infix operators `<*>` and `<->` can be used to facilitate DOT_PRODUCT and EUCLIDEAN_DISTANCE operations, respectively, providing a more concise query syntax compared to using the existing built-in functions such as DOT_PRODUCT(a, b) and EUCLIDEAN_DISTANCE(a, b)."
- ]
+ ],
+ "id": "02364df2"
},
{
"cell_type": "code",
"execution_count": 24,
- "id": "77bb3be5-83c0-4413-87fa-36fc245856d7",
"metadata": {},
"outputs": [],
"source": [
@@ -623,21 +622,21 @@
" FROM words_table\n",
" ORDER BY score desc\n",
" LIMIT 3;"
- ]
+ ],
+ "id": "98a39ef5"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "9bd7668c-a84d-42ff-962b-ead151d81b9a",
"metadata": {},
"source": [
"## Clean up"
- ]
+ ],
+ "id": "99b34b0a"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "72e79695-e9a0-4e09-817e-8963a9dcd340",
"metadata": {},
"source": [
"\n",
@@ -647,23 +646,24 @@
"
If you created a new database in your Standard or Premium Workspace, you can drop the database by running the cell below. Note: this will not drop your database for Free Starter Workspaces. To drop a Free Starter Workspace, terminate the Workspace using the UI.
\n",
"
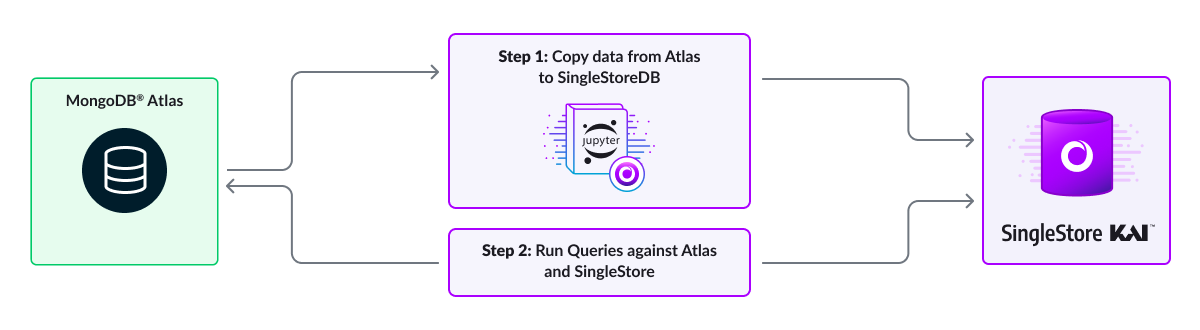 "
- ]
+ ],
+ "id": "ed84f878"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "5353b6a2-006f-4a71-834f-045d3e054640",
"metadata": {},
"source": [
"# No code change required! 100% MongoDB notebook!\n",
@@ -63,51 +62,51 @@
"7. Average satisfaction per product\n",
"8. Number of transactions by Location and membership\n",
"9. Top 10 product sales"
- ]
+ ],
+ "id": "8bf8f031"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "a5f3d92f-5721-4f28-a91a-b04def563dfb",
"metadata": {},
"source": [
"## 1. Install libraries and import modules"
- ]
+ ],
+ "id": "38e1f148"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "856860b6-c6ac-4f72-8d64-5d405dbb7acc",
"metadata": {},
"source": [
"**Make sure that you have a created MongoDB enabled workspace.**\n",
"\n",
"This must be done when creating a workspace (for Standard/Premium Workspaces) For Starter Workspaces, the KAI API will be on by default."
- ]
+ ],
+ "id": "c845fbec"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "33506e25-c044-4f6f-9d62-df61783076e1",
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "ed84f878"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "5353b6a2-006f-4a71-834f-045d3e054640",
"metadata": {},
"source": [
"# No code change required! 100% MongoDB notebook!\n",
@@ -63,51 +62,51 @@
"7. Average satisfaction per product\n",
"8. Number of transactions by Location and membership\n",
"9. Top 10 product sales"
- ]
+ ],
+ "id": "8bf8f031"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "a5f3d92f-5721-4f28-a91a-b04def563dfb",
"metadata": {},
"source": [
"## 1. Install libraries and import modules"
- ]
+ ],
+ "id": "38e1f148"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "856860b6-c6ac-4f72-8d64-5d405dbb7acc",
"metadata": {},
"source": [
"**Make sure that you have a created MongoDB enabled workspace.**\n",
"\n",
"This must be done when creating a workspace (for Standard/Premium Workspaces) For Starter Workspaces, the KAI API will be on by default."
- ]
+ ],
+ "id": "c845fbec"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "33506e25-c044-4f6f-9d62-df61783076e1",
"metadata": {},
"source": [
" "
- ]
+ ],
+ "id": "31dd9660"
},
{
"cell_type": "code",
"execution_count": 1,
- "id": "26ec8d2d-25b1-4b8f-a62f-098192b8d45f",
"metadata": {},
"outputs": [],
"source": [
"!pip install pymongo pandas matplotlib plotly ipywidgets --quiet"
- ]
+ ],
+ "id": "812aabaf"
},
{
"cell_type": "code",
"execution_count": 2,
- "id": "6087e187-ab0b-4df6-8c9e-ee9fc7153a6b",
"metadata": {},
"outputs": [],
"source": [
@@ -119,12 +118,12 @@
"else:\n",
" database_to_use = \"new_transactions\"\n",
" %sql CREATE DATABASE {{database_to_use}}"
- ]
+ ],
+ "id": "09fe48fc"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "27a6f491",
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "31dd9660"
},
{
"cell_type": "code",
"execution_count": 1,
- "id": "26ec8d2d-25b1-4b8f-a62f-098192b8d45f",
"metadata": {},
"outputs": [],
"source": [
"!pip install pymongo pandas matplotlib plotly ipywidgets --quiet"
- ]
+ ],
+ "id": "812aabaf"
},
{
"cell_type": "code",
"execution_count": 2,
- "id": "6087e187-ab0b-4df6-8c9e-ee9fc7153a6b",
"metadata": {},
"outputs": [],
"source": [
@@ -119,12 +118,12 @@
"else:\n",
" database_to_use = \"new_transactions\"\n",
" %sql CREATE DATABASE {{database_to_use}}"
- ]
+ ],
+ "id": "09fe48fc"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "27a6f491",
"metadata": {},
"source": [
" "
- ]
+ ],
+ "id": "9ce6f065"
},
{
"cell_type": "code",
"execution_count": 5,
- "id": "e53b6983-8c62-4b45-85d5-fb29fb655936",
"metadata": {},
"outputs": [],
"source": [
@@ -203,21 +202,21 @@
"s2mongoitems = s2dbmongodb[\"items\"]\n",
"s2mongocusts = s2dbmongodb[\"custs\"]\n",
"s2mongotxs = s2dbmongodb[\"txs\"]"
- ]
+ ],
+ "id": "f11f98cf"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "a6f36725-4b74-4460-b1c9-a0144159a7b4",
"metadata": {},
"source": [
"## 3. Copy Atlas collections into SingleStore Kai"
- ]
+ ],
+ "id": "6921e8c9"
},
{
"cell_type": "code",
"execution_count": 6,
- "id": "5cb978bc-03cc-4477-853d-577fc856ca94",
"metadata": {},
"outputs": [],
"source": [
@@ -228,61 +227,61 @@
" data_dict = df.to_dict(orient='records')\n",
" s2mongo_collection = s2dbmongodb[mongo_collection.name]\n",
" s2mongo_collection.insert_many(data_dict)"
- ]
+ ],
+ "id": "71cf4b5c"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "5b3928f8-2487-4553-962f-eb5bc2d83096",
"metadata": {},
"source": [
"Count documents in SingleStore"
- ]
+ ],
+ "id": "b0ea4a7f"
},
{
"cell_type": "code",
"execution_count": 7,
- "id": "91ce2d6e-3d02-4c57-88f7-365d7449d84c",
"metadata": {},
"outputs": [],
"source": [
"mg_count = s2mongoitems.count_documents({})\n",
"mg_count"
- ]
+ ],
+ "id": "62cf7161"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "48841366-41fb-45f6-81d7-323cda1b1df7",
"metadata": {},
"source": [
"# Compare Queries and Performance"
- ]
+ ],
+ "id": "b9aa35b7"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "2069ac4e-13a0-425a-b063-7434b339dd8e",
"metadata": {},
"source": [
"**In-app analytics is everywhere.**\n",
"\n",
"
"
- ]
+ ],
+ "id": "9ce6f065"
},
{
"cell_type": "code",
"execution_count": 5,
- "id": "e53b6983-8c62-4b45-85d5-fb29fb655936",
"metadata": {},
"outputs": [],
"source": [
@@ -203,21 +202,21 @@
"s2mongoitems = s2dbmongodb[\"items\"]\n",
"s2mongocusts = s2dbmongodb[\"custs\"]\n",
"s2mongotxs = s2dbmongodb[\"txs\"]"
- ]
+ ],
+ "id": "f11f98cf"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "a6f36725-4b74-4460-b1c9-a0144159a7b4",
"metadata": {},
"source": [
"## 3. Copy Atlas collections into SingleStore Kai"
- ]
+ ],
+ "id": "6921e8c9"
},
{
"cell_type": "code",
"execution_count": 6,
- "id": "5cb978bc-03cc-4477-853d-577fc856ca94",
"metadata": {},
"outputs": [],
"source": [
@@ -228,61 +227,61 @@
" data_dict = df.to_dict(orient='records')\n",
" s2mongo_collection = s2dbmongodb[mongo_collection.name]\n",
" s2mongo_collection.insert_many(data_dict)"
- ]
+ ],
+ "id": "71cf4b5c"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "5b3928f8-2487-4553-962f-eb5bc2d83096",
"metadata": {},
"source": [
"Count documents in SingleStore"
- ]
+ ],
+ "id": "b0ea4a7f"
},
{
"cell_type": "code",
"execution_count": 7,
- "id": "91ce2d6e-3d02-4c57-88f7-365d7449d84c",
"metadata": {},
"outputs": [],
"source": [
"mg_count = s2mongoitems.count_documents({})\n",
"mg_count"
- ]
+ ],
+ "id": "62cf7161"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "48841366-41fb-45f6-81d7-323cda1b1df7",
"metadata": {},
"source": [
"# Compare Queries and Performance"
- ]
+ ],
+ "id": "b9aa35b7"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "2069ac4e-13a0-425a-b063-7434b339dd8e",
"metadata": {},
"source": [
"**In-app analytics is everywhere.**\n",
"\n",
" "
- ]
+ ],
+ "id": "7458c39a"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "01f555e2-b809-4261-a8df-0669be80377c",
"metadata": {},
"source": [
"## 4. Document counts"
- ]
+ ],
+ "id": "6e758302"
},
{
"cell_type": "code",
"execution_count": 8,
- "id": "f1c54716-a4e9-49ae-9035-75a4c3761c90",
"metadata": {},
"outputs": [],
"source": [
@@ -329,21 +328,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5,6,7,8,9,10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "6e89408d"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "94d4c502-fb66-45cb-a520-6ee39ae35476",
"metadata": {},
"source": [
"## 5. Product Quantity Sold"
- ]
+ ],
+ "id": "f530c080"
},
{
"cell_type": "code",
"execution_count": 9,
- "id": "6de02fc3-fe7b-4dd4-a495-d0e785f4c58f",
"metadata": {},
"outputs": [],
"source": [
@@ -399,21 +398,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "4c5569fc"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "9f11b18f-d414-4107-83a9-5d9d10172d6a",
"metadata": {},
"source": [
"## 6. Average Customer Satisfaction"
- ]
+ ],
+ "id": "fc9813d0"
},
{
"cell_type": "code",
"execution_count": 10,
- "id": "c4bfc8e2-3f72-47be-b789-8f44a547ef60",
"metadata": {},
"outputs": [],
"source": [
@@ -473,21 +472,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "82b870c7"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "e6657ab9-551b-4d09-a1be-50a1b9091558",
"metadata": {},
"source": [
"## 7. Average Satisfaction per Product"
- ]
+ ],
+ "id": "31535113"
},
{
"cell_type": "code",
"execution_count": 11,
- "id": "8015fdd4-c6eb-437a-9d60-ee937817caf3",
"metadata": {},
"outputs": [],
"source": [
@@ -556,21 +555,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "16041e02"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "b14eb709-b58b-461e-b415-a4ca3461b1a6",
"metadata": {},
"source": [
"## 8. Number of transactions by location and membership"
- ]
+ ],
+ "id": "98090bfe"
},
{
"cell_type": "code",
"execution_count": 12,
- "id": "78abd324-cace-4ad6-abe7-d1b5d166a7e7",
"metadata": {},
"outputs": [],
"source": [
@@ -642,21 +641,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "48b8c84b"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "83fa3e5c-975e-410c-a25e-4db2b8389952",
"metadata": {},
"source": [
"## 9. Top 10 Product Sales"
- ]
+ ],
+ "id": "2c7f8d4c"
},
{
"cell_type": "code",
"execution_count": 13,
- "id": "57a5a473-e840-4310-8f31-c53d9420a4cc",
"metadata": {},
"outputs": [],
"source": [
@@ -724,21 +723,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "2022a7d1"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "f162caba-a871-4b95-a5f5-0014901f12ff",
"metadata": {},
"source": [
"## Clean up"
- ]
+ ],
+ "id": "599cc583"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "15754544",
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "7458c39a"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "01f555e2-b809-4261-a8df-0669be80377c",
"metadata": {},
"source": [
"## 4. Document counts"
- ]
+ ],
+ "id": "6e758302"
},
{
"cell_type": "code",
"execution_count": 8,
- "id": "f1c54716-a4e9-49ae-9035-75a4c3761c90",
"metadata": {},
"outputs": [],
"source": [
@@ -329,21 +328,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5,6,7,8,9,10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "6e89408d"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "94d4c502-fb66-45cb-a520-6ee39ae35476",
"metadata": {},
"source": [
"## 5. Product Quantity Sold"
- ]
+ ],
+ "id": "f530c080"
},
{
"cell_type": "code",
"execution_count": 9,
- "id": "6de02fc3-fe7b-4dd4-a495-d0e785f4c58f",
"metadata": {},
"outputs": [],
"source": [
@@ -399,21 +398,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "4c5569fc"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "9f11b18f-d414-4107-83a9-5d9d10172d6a",
"metadata": {},
"source": [
"## 6. Average Customer Satisfaction"
- ]
+ ],
+ "id": "fc9813d0"
},
{
"cell_type": "code",
"execution_count": 10,
- "id": "c4bfc8e2-3f72-47be-b789-8f44a547ef60",
"metadata": {},
"outputs": [],
"source": [
@@ -473,21 +472,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "82b870c7"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "e6657ab9-551b-4d09-a1be-50a1b9091558",
"metadata": {},
"source": [
"## 7. Average Satisfaction per Product"
- ]
+ ],
+ "id": "31535113"
},
{
"cell_type": "code",
"execution_count": 11,
- "id": "8015fdd4-c6eb-437a-9d60-ee937817caf3",
"metadata": {},
"outputs": [],
"source": [
@@ -556,21 +555,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "16041e02"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "b14eb709-b58b-461e-b415-a4ca3461b1a6",
"metadata": {},
"source": [
"## 8. Number of transactions by location and membership"
- ]
+ ],
+ "id": "98090bfe"
},
{
"cell_type": "code",
"execution_count": 12,
- "id": "78abd324-cace-4ad6-abe7-d1b5d166a7e7",
"metadata": {},
"outputs": [],
"source": [
@@ -642,21 +641,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "48b8c84b"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "83fa3e5c-975e-410c-a25e-4db2b8389952",
"metadata": {},
"source": [
"## 9. Top 10 Product Sales"
- ]
+ ],
+ "id": "2c7f8d4c"
},
{
"cell_type": "code",
"execution_count": 13,
- "id": "57a5a473-e840-4310-8f31-c53d9420a4cc",
"metadata": {},
"outputs": [],
"source": [
@@ -724,21 +723,21 @@
"fig.update_xaxes(tickmode='array', tickvals=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], row=1, col=1)\n",
"\n",
"fig"
- ]
+ ],
+ "id": "2022a7d1"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "f162caba-a871-4b95-a5f5-0014901f12ff",
"metadata": {},
"source": [
"## Clean up"
- ]
+ ],
+ "id": "599cc583"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "15754544",
"metadata": {},
"source": [
"

 "
- ]
+ ],
+ "id": "0a6f9edd"
},
{
"cell_type": "markdown",
@@ -34,28 +35,32 @@
"Once the cluster is created, perform the following tasks:\n",
"\n",
"- Create a topic, for example 's2-topic'. On the topic overview page, select Schema > Set a schema > Avro, and add a new Avro schema. In this guide, the default schema is used."
- ]
+ ],
+ "id": "5fd6e4ba"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "0a6f9edd"
},
{
"cell_type": "markdown",
@@ -34,28 +35,32 @@
"Once the cluster is created, perform the following tasks:\n",
"\n",
"- Create a topic, for example 's2-topic'. On the topic overview page, select Schema > Set a schema > Avro, and add a new Avro schema. In this guide, the default schema is used."
- ]
+ ],
+ "id": "5fd6e4ba"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"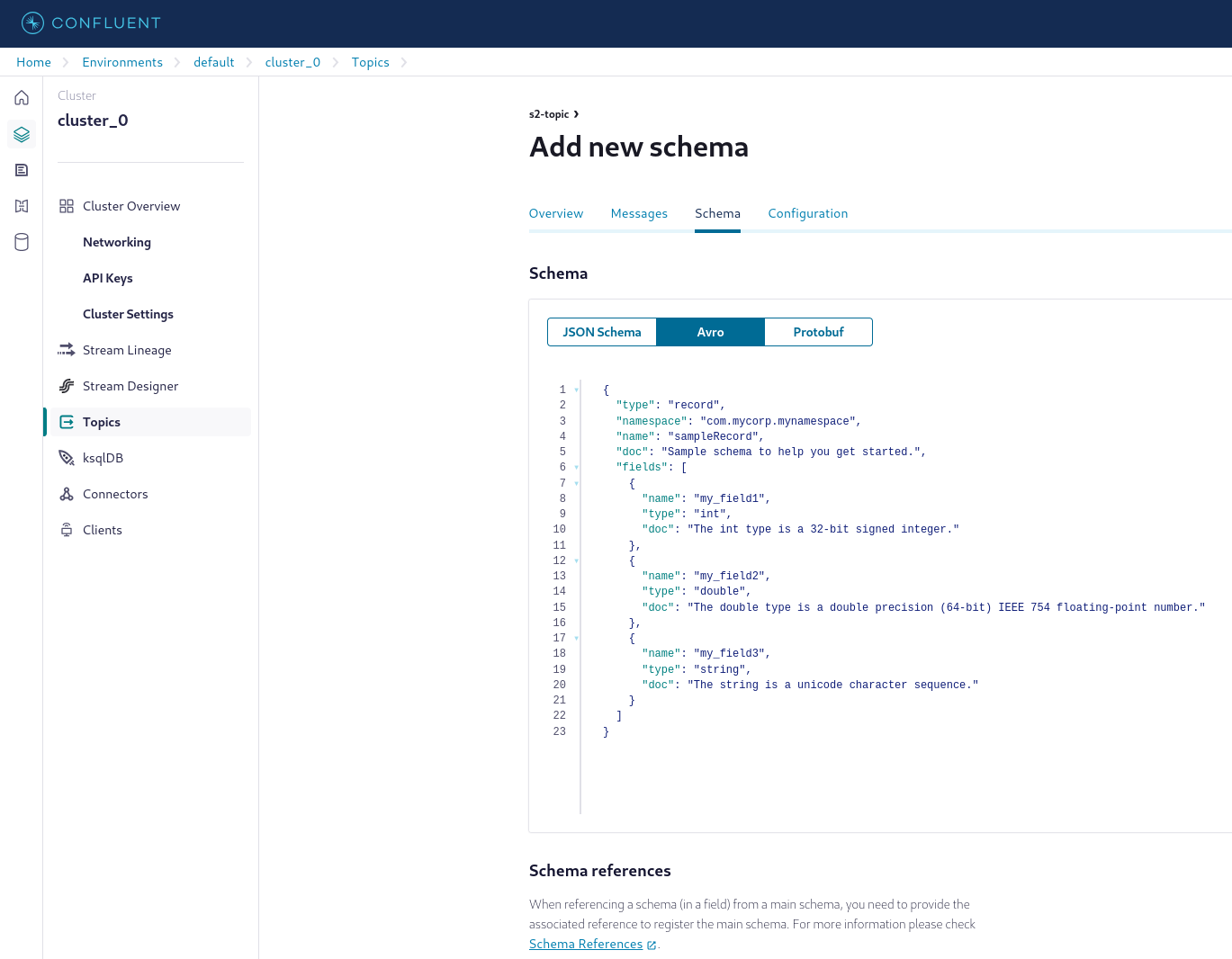 "
- ]
+ ],
+ "id": "d56193e9"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- Create API keys. The API key is displayed only once. Be sure to copy and securely store the API key."
- ]
+ ],
+ "id": "ede3b8d7"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "d56193e9"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- Create API keys. The API key is displayed only once. Be sure to copy and securely store the API key."
- ]
+ ],
+ "id": "ede3b8d7"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"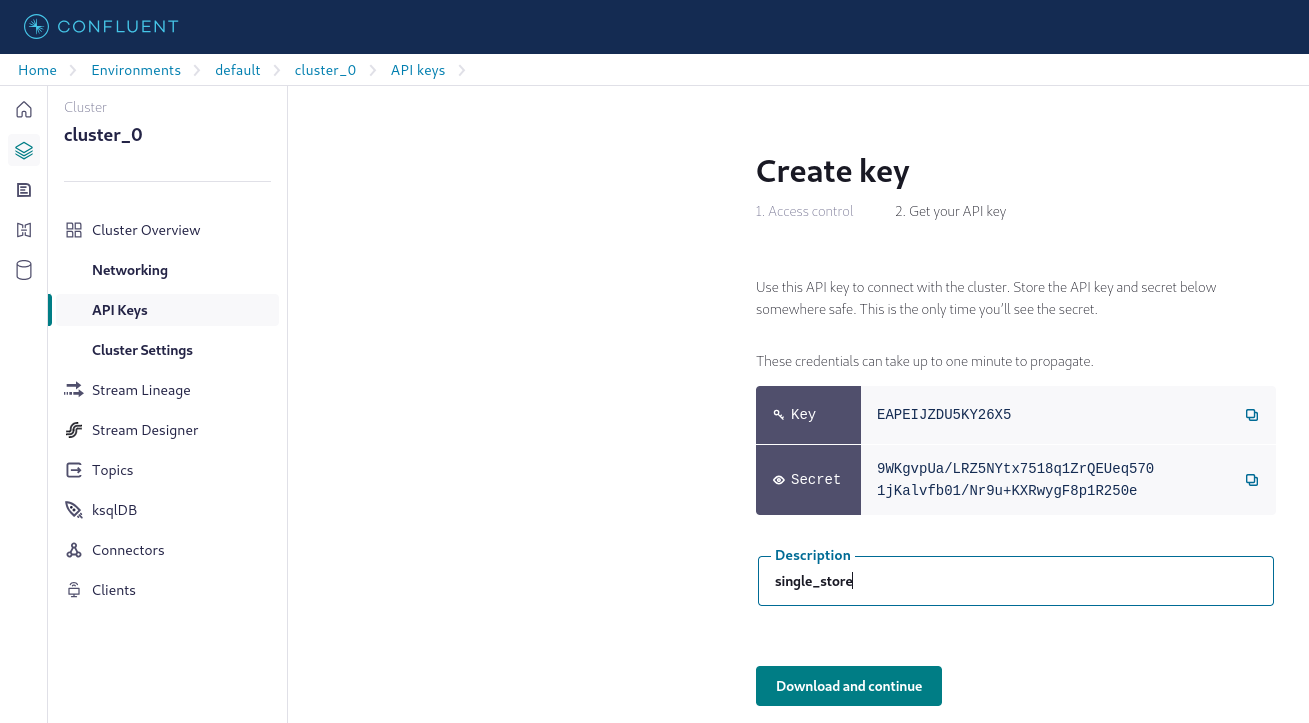 "
- ]
+ ],
+ "id": "9ed4b165"
},
{
"cell_type": "markdown",
@@ -63,7 +68,8 @@
"source": [
"- On the left navigation pane, select Connectors and create a sample producer named 'datagen' using the Datagen Source connector. In the Topic selection pane, select the 's2-topic' created earlier. In the Kafka credentials pane, select the Use an existing API key option. Configure the producer to use the same schema as the one in the created topic. Refer to
"
- ]
+ ],
+ "id": "9ed4b165"
},
{
"cell_type": "markdown",
@@ -63,7 +68,8 @@
"source": [
"- On the left navigation pane, select Connectors and create a sample producer named 'datagen' using the Datagen Source connector. In the Topic selection pane, select the 's2-topic' created earlier. In the Kafka credentials pane, select the Use an existing API key option. Configure the producer to use the same schema as the one in the created topic. Refer to  "
- ]
+ ],
+ "id": "3d29edea"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Running Experiments using UpTrain**: Let's also see how UpTrain can be used to conduct data-driven experimentation. We will increase the chunk_size from 200 to 1000 and see how that impacts the context retrieval quality."
- ]
+ ],
+ "id": "117dcc41"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Generate new embeddings**: We will again use SingleStoreDB to store new document embeddings"
- ]
+ ],
+ "id": "2f0a47a6"
},
{
"cell_type": "code",
@@ -354,14 +383,16 @@
"vectorstore_new = SingleStoreDB.from_documents(documents=all_splits,\n",
" embedding=OpenAIEmbeddings(),\n",
" table_name='vertex_ai_docs_chunk_size_1000')"
- ]
+ ],
+ "id": "4ba8654d"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Generate responses with new vectorstore**: Let's generate new responses for the same set of questions."
- ]
+ ],
+ "id": "9d307a78"
},
{
"cell_type": "code",
@@ -372,14 +403,16 @@
"results_larger_chunk = []\n",
"for question in questions:\n",
" results_larger_chunk.extend(generate_llm_response(question, vectorstore_new))"
- ]
+ ],
+ "id": "8a6a4085"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Append chunk size information**: Let's add the corresponding chunk size information for both sets of results. We will pass this column name to UpTrain to compare the two experiments"
- ]
+ ],
+ "id": "70a6b0bb"
},
{
"cell_type": "code",
@@ -392,14 +425,16 @@
"\n",
"for x in results_larger_chunk:\n",
" x.update({'chunk_size': 1000})"
- ]
+ ],
+ "id": "9dc6313c"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Evaluating Experiments using UpTrain**: UpTrain's APIClient also provides a \"evaluate_experiments\" method which takes the input data to be evaluated along with the list of checks to be run and the name of the columns associated with the experiment."
- ]
+ ],
+ "id": "0e08fb98"
},
{
"cell_type": "code",
@@ -413,7 +448,8 @@
" checks=[Evals.CONTEXT_RELEVANCE],\n",
" exp_columns=['chunk_size']\n",
");"
- ]
+ ],
+ "id": "15241a0d"
},
{
"attachments": {
@@ -425,11 +461,12 @@
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "3d29edea"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Running Experiments using UpTrain**: Let's also see how UpTrain can be used to conduct data-driven experimentation. We will increase the chunk_size from 200 to 1000 and see how that impacts the context retrieval quality."
- ]
+ ],
+ "id": "117dcc41"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Generate new embeddings**: We will again use SingleStoreDB to store new document embeddings"
- ]
+ ],
+ "id": "2f0a47a6"
},
{
"cell_type": "code",
@@ -354,14 +383,16 @@
"vectorstore_new = SingleStoreDB.from_documents(documents=all_splits,\n",
" embedding=OpenAIEmbeddings(),\n",
" table_name='vertex_ai_docs_chunk_size_1000')"
- ]
+ ],
+ "id": "4ba8654d"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Generate responses with new vectorstore**: Let's generate new responses for the same set of questions."
- ]
+ ],
+ "id": "9d307a78"
},
{
"cell_type": "code",
@@ -372,14 +403,16 @@
"results_larger_chunk = []\n",
"for question in questions:\n",
" results_larger_chunk.extend(generate_llm_response(question, vectorstore_new))"
- ]
+ ],
+ "id": "8a6a4085"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Append chunk size information**: Let's add the corresponding chunk size information for both sets of results. We will pass this column name to UpTrain to compare the two experiments"
- ]
+ ],
+ "id": "70a6b0bb"
},
{
"cell_type": "code",
@@ -392,14 +425,16 @@
"\n",
"for x in results_larger_chunk:\n",
" x.update({'chunk_size': 1000})"
- ]
+ ],
+ "id": "9dc6313c"
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Evaluating Experiments using UpTrain**: UpTrain's APIClient also provides a \"evaluate_experiments\" method which takes the input data to be evaluated along with the list of checks to be run and the name of the columns associated with the experiment."
- ]
+ ],
+ "id": "0e08fb98"
},
{
"cell_type": "code",
@@ -413,7 +448,8 @@
" checks=[Evals.CONTEXT_RELEVANCE],\n",
" exp_columns=['chunk_size']\n",
");"
- ]
+ ],
+ "id": "15241a0d"
},
{
"attachments": {
@@ -425,11 +461,12 @@
"metadata": {},
"source": [
" "
- ]
+ ],
+ "id": "9bb1175a"
},
{
+ "id": "ee02b325",
"cell_type": "markdown",
- "id": "62f5d31e-637c-4e97-8eee-34c529d21e8a",
"metadata": {},
"source": [
"\n",
@@ -457,5 +494,5 @@
}
},
"nbformat": 4,
- "nbformat_minor": 4
+ "nbformat_minor": 5
}
diff --git a/notebooks/getting-started-with-dataframes/notebook.ipynb b/notebooks/getting-started-with-dataframes/notebook.ipynb
index e6e7de49..953fcd4c 100644
--- a/notebooks/getting-started-with-dataframes/notebook.ipynb
+++ b/notebooks/getting-started-with-dataframes/notebook.ipynb
@@ -1,8 +1,8 @@
{
"cells": [
{
+ "id": "9b385acd",
"cell_type": "markdown",
- "id": "caa4ce39-2f84-48b7-92b5-dccf6bede32b",
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "9bb1175a"
},
{
+ "id": "ee02b325",
"cell_type": "markdown",
- "id": "62f5d31e-637c-4e97-8eee-34c529d21e8a",
"metadata": {},
"source": [
"\n",
@@ -457,5 +494,5 @@
}
},
"nbformat": 4,
- "nbformat_minor": 4
+ "nbformat_minor": 5
}
diff --git a/notebooks/getting-started-with-dataframes/notebook.ipynb b/notebooks/getting-started-with-dataframes/notebook.ipynb
index e6e7de49..953fcd4c 100644
--- a/notebooks/getting-started-with-dataframes/notebook.ipynb
+++ b/notebooks/getting-started-with-dataframes/notebook.ipynb
@@ -1,8 +1,8 @@
{
"cells": [
{
+ "id": "9b385acd",
"cell_type": "markdown",
- "id": "caa4ce39-2f84-48b7-92b5-dccf6bede32b",
"metadata": {},
"source": [
"
 \n",
"
\n",
" \n",
"
\n",
" "
- ]
+ ],
+ "id": "ef90c6c9"
},
{
"attachments": {},
@@ -62,7 +65,8 @@
"## Sample Table in SingleStore\n",
"\n",
"Start by creating a table that will hold the data imported from S3."
- ]
+ ],
+ "id": "8a85c544"
},
{
"cell_type": "code",
@@ -78,7 +82,8 @@
" address TEXT,\n",
" created_at TIMESTAMP\n",
");"
- ]
+ ],
+ "id": "2ca9281c"
},
{
"attachments": {},
@@ -93,23 +98,23 @@
"You have access to the S3 bucket.\n",
"Proper IAM roles or access keys are configured in SingleStore.\n",
"The CSV file has a structure that matches the table schema."
- ]
+ ],
+ "id": "a88192c9"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "a9c60e86-a548-4257-9130-5120e850aad0",
"metadata": {},
"source": [
"## Set Up Variables\n",
"\n",
"Define the URL, REGION, ACCESS_KEY, and SECRET_ACCESS_KEY variables for integration, replacing the placeholder values with your own."
- ]
+ ],
+ "id": "87d2c776"
},
{
"cell_type": "code",
"execution_count": 2,
- "id": "69c573a1-316c-49c2-9ac7-16327a302199",
"metadata": {},
"outputs": [],
"source": [
@@ -117,16 +122,17 @@
"REGION = 'your-region'\n",
"ACCESS_KEY = 'access_key_id'\n",
"SECRET_ACCESS_KEY = 'access_secret_key'"
- ]
+ ],
+ "id": "78c44e19"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "d8927379-38ca-427f-9de3-dcc76b5ba05e",
"metadata": {},
"source": [
"Using these identifiers and keys, execute the following statement."
- ]
+ ],
+ "id": "eb0c3643"
},
{
"cell_type": "code",
@@ -145,7 +151,8 @@
"FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\\\"'\n",
"LINES TERMINATED BY '\\n'\n",
"IGNORE 1 lines;"
- ]
+ ],
+ "id": "6efe3112"
},
{
"attachments": {},
@@ -155,40 +162,41 @@
"## Start the Pipeline\n",
"\n",
"To start the pipeline and begin importing the data from the S3 bucket:"
- ]
+ ],
+ "id": "5902a86a"
},
{
"cell_type": "code",
"execution_count": 4,
- "id": "24aba272-a594-4971-8d7c-640b31dcf216",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"START PIPELINE s3_import_pipeline;"
- ]
+ ],
+ "id": "bb436fc2"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "bea9d53a-45cc-4dd9-87d6-bdabd2ae6370",
"metadata": {},
"source": [
"## Select Data from the Table\n",
"\n",
"Once the data has been imported, you can run a query to select it:"
- ]
+ ],
+ "id": "c82c8439"
},
{
"cell_type": "code",
"execution_count": 5,
- "id": "3924e9fb-094a-467c-bdac-8f7826e63501",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM sample_table LIMIT 10;"
- ]
+ ],
+ "id": "bb740975"
},
{
"attachments": {},
@@ -196,7 +204,8 @@
"metadata": {},
"source": [
"### Check if all data of the data is loaded"
- ]
+ ],
+ "id": "df1cdb14"
},
{
"cell_type": "code",
@@ -206,7 +215,8 @@
"source": [
"%%sql\n",
"SELECT count(*) FROM sample_table"
- ]
+ ],
+ "id": "dd98c9a3"
},
{
"attachments": {},
@@ -217,7 +227,8 @@
"\n",
"We have shown how to insert data from a Amazon S3 using `Pipelines` to SingleStoreDB. These techniques should enable you to\n",
"integrate your Amazon S3 with SingleStoreDB."
- ]
+ ],
+ "id": "892e7f8d"
},
{
"attachments": {},
@@ -227,7 +238,8 @@
"## Clean up\n",
"\n",
"Remove the '#' to uncomment and execute the queries below to clean up the pipeline and table created."
- ]
+ ],
+ "id": "3c053a57"
},
{
"attachments": {},
@@ -235,7 +247,8 @@
"metadata": {},
"source": [
"#### Drop Pipeline"
- ]
+ ],
+ "id": "8874a110"
},
{
"cell_type": "code",
@@ -247,7 +260,8 @@
"#STOP PIPELINE s3_import_pipeline;\n",
"\n",
"#DROP PIPELINE s3_import_pipeline;"
- ]
+ ],
+ "id": "043861f7"
},
{
"attachments": {},
@@ -255,7 +269,8 @@
"metadata": {},
"source": [
"#### Drop Data"
- ]
+ ],
+ "id": "445c6369"
},
{
"cell_type": "code",
@@ -265,11 +280,12 @@
"source": [
"%%sql\n",
"#DROP TABLE sample_table;"
- ]
+ ],
+ "id": "f8b697e5"
},
{
+ "id": "39231766",
"cell_type": "markdown",
- "id": "b47799b9-36b3-42c5-8434-4091a38f966a",
"metadata": {},
"source": [
"\n",
diff --git a/notebooks/load-csv-data-s3/notebook.ipynb b/notebooks/load-csv-data-s3/notebook.ipynb
index 08c53921..42728409 100644
--- a/notebooks/load-csv-data-s3/notebook.ipynb
+++ b/notebooks/load-csv-data-s3/notebook.ipynb
@@ -1,8 +1,8 @@
{
"cells": [
{
+ "id": "24eeda62",
"cell_type": "markdown",
- "id": "b447e717-ea59-49fd-8092-36ece56072ae",
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "ef90c6c9"
},
{
"attachments": {},
@@ -62,7 +65,8 @@
"## Sample Table in SingleStore\n",
"\n",
"Start by creating a table that will hold the data imported from S3."
- ]
+ ],
+ "id": "8a85c544"
},
{
"cell_type": "code",
@@ -78,7 +82,8 @@
" address TEXT,\n",
" created_at TIMESTAMP\n",
");"
- ]
+ ],
+ "id": "2ca9281c"
},
{
"attachments": {},
@@ -93,23 +98,23 @@
"You have access to the S3 bucket.\n",
"Proper IAM roles or access keys are configured in SingleStore.\n",
"The CSV file has a structure that matches the table schema."
- ]
+ ],
+ "id": "a88192c9"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "a9c60e86-a548-4257-9130-5120e850aad0",
"metadata": {},
"source": [
"## Set Up Variables\n",
"\n",
"Define the URL, REGION, ACCESS_KEY, and SECRET_ACCESS_KEY variables for integration, replacing the placeholder values with your own."
- ]
+ ],
+ "id": "87d2c776"
},
{
"cell_type": "code",
"execution_count": 2,
- "id": "69c573a1-316c-49c2-9ac7-16327a302199",
"metadata": {},
"outputs": [],
"source": [
@@ -117,16 +122,17 @@
"REGION = 'your-region'\n",
"ACCESS_KEY = 'access_key_id'\n",
"SECRET_ACCESS_KEY = 'access_secret_key'"
- ]
+ ],
+ "id": "78c44e19"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "d8927379-38ca-427f-9de3-dcc76b5ba05e",
"metadata": {},
"source": [
"Using these identifiers and keys, execute the following statement."
- ]
+ ],
+ "id": "eb0c3643"
},
{
"cell_type": "code",
@@ -145,7 +151,8 @@
"FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\\\"'\n",
"LINES TERMINATED BY '\\n'\n",
"IGNORE 1 lines;"
- ]
+ ],
+ "id": "6efe3112"
},
{
"attachments": {},
@@ -155,40 +162,41 @@
"## Start the Pipeline\n",
"\n",
"To start the pipeline and begin importing the data from the S3 bucket:"
- ]
+ ],
+ "id": "5902a86a"
},
{
"cell_type": "code",
"execution_count": 4,
- "id": "24aba272-a594-4971-8d7c-640b31dcf216",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"START PIPELINE s3_import_pipeline;"
- ]
+ ],
+ "id": "bb436fc2"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "bea9d53a-45cc-4dd9-87d6-bdabd2ae6370",
"metadata": {},
"source": [
"## Select Data from the Table\n",
"\n",
"Once the data has been imported, you can run a query to select it:"
- ]
+ ],
+ "id": "c82c8439"
},
{
"cell_type": "code",
"execution_count": 5,
- "id": "3924e9fb-094a-467c-bdac-8f7826e63501",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM sample_table LIMIT 10;"
- ]
+ ],
+ "id": "bb740975"
},
{
"attachments": {},
@@ -196,7 +204,8 @@
"metadata": {},
"source": [
"### Check if all data of the data is loaded"
- ]
+ ],
+ "id": "df1cdb14"
},
{
"cell_type": "code",
@@ -206,7 +215,8 @@
"source": [
"%%sql\n",
"SELECT count(*) FROM sample_table"
- ]
+ ],
+ "id": "dd98c9a3"
},
{
"attachments": {},
@@ -217,7 +227,8 @@
"\n",
"We have shown how to insert data from a Amazon S3 using `Pipelines` to SingleStoreDB. These techniques should enable you to\n",
"integrate your Amazon S3 with SingleStoreDB."
- ]
+ ],
+ "id": "892e7f8d"
},
{
"attachments": {},
@@ -227,7 +238,8 @@
"## Clean up\n",
"\n",
"Remove the '#' to uncomment and execute the queries below to clean up the pipeline and table created."
- ]
+ ],
+ "id": "3c053a57"
},
{
"attachments": {},
@@ -235,7 +247,8 @@
"metadata": {},
"source": [
"#### Drop Pipeline"
- ]
+ ],
+ "id": "8874a110"
},
{
"cell_type": "code",
@@ -247,7 +260,8 @@
"#STOP PIPELINE s3_import_pipeline;\n",
"\n",
"#DROP PIPELINE s3_import_pipeline;"
- ]
+ ],
+ "id": "043861f7"
},
{
"attachments": {},
@@ -255,7 +269,8 @@
"metadata": {},
"source": [
"#### Drop Data"
- ]
+ ],
+ "id": "445c6369"
},
{
"cell_type": "code",
@@ -265,11 +280,12 @@
"source": [
"%%sql\n",
"#DROP TABLE sample_table;"
- ]
+ ],
+ "id": "f8b697e5"
},
{
+ "id": "39231766",
"cell_type": "markdown",
- "id": "b47799b9-36b3-42c5-8434-4091a38f966a",
"metadata": {},
"source": [
"\n",
diff --git a/notebooks/load-csv-data-s3/notebook.ipynb b/notebooks/load-csv-data-s3/notebook.ipynb
index 08c53921..42728409 100644
--- a/notebooks/load-csv-data-s3/notebook.ipynb
+++ b/notebooks/load-csv-data-s3/notebook.ipynb
@@ -1,8 +1,8 @@
{
"cells": [
{
+ "id": "24eeda62",
"cell_type": "markdown",
- "id": "b447e717-ea59-49fd-8092-36ece56072ae",
"metadata": {},
"source": [
" "
- ]
+ ],
+ "id": "08afb8bd"
},
{
"attachments": {},
@@ -102,7 +108,8 @@
"## Create a database (You can skip this Step if you are using Free Starter Tier)\n",
"\n",
"We need to create a database to work with in the following examples."
- ]
+ ],
+ "id": "4a00fe35"
},
{
"cell_type": "code",
@@ -114,7 +121,8 @@
"if not shared_tier_check or shared_tier_check[0][1] == 'OFF':\n",
" %sql DROP DATABASE IF EXISTS SalesAnalysis;\n",
" %sql CREATE DATABASE SalesAnalysis;"
- ]
+ ],
+ "id": "0b8a66cf"
},
{
"attachments": {},
@@ -122,7 +130,8 @@
"metadata": {},
"source": [
"### Create Table"
- ]
+ ],
+ "id": "3afd127b"
},
{
"cell_type": "code",
@@ -142,7 +151,8 @@
" `Price` float DEFAULT NULL,\n",
" `Total_Sales` float DEFAULT NULL\n",
")"
- ]
+ ],
+ "id": "a139fe30"
},
{
"attachments": {},
@@ -150,7 +160,8 @@
"metadata": {},
"source": [
"### Load Data Using Pipelines"
- ]
+ ],
+ "id": "85e8fdc0"
},
{
"cell_type": "code",
@@ -173,7 +184,8 @@
"\n",
"\n",
"START PIPELINE SalesData_Pipeline;"
- ]
+ ],
+ "id": "d25aa2e2"
},
{
"attachments": {},
@@ -181,7 +193,8 @@
"metadata": {},
"source": [
"### Data may take couple of seconds to load after pipeline is started, rerun cell to verify"
- ]
+ ],
+ "id": "23ba5df8"
},
{
"cell_type": "code",
@@ -191,7 +204,8 @@
"source": [
"%%sql\n",
"SELECT count(*) FROM SalesData"
- ]
+ ],
+ "id": "8208c7dc"
},
{
"attachments": {},
@@ -201,7 +215,8 @@
"
"
- ]
+ ],
+ "id": "08afb8bd"
},
{
"attachments": {},
@@ -102,7 +108,8 @@
"## Create a database (You can skip this Step if you are using Free Starter Tier)\n",
"\n",
"We need to create a database to work with in the following examples."
- ]
+ ],
+ "id": "4a00fe35"
},
{
"cell_type": "code",
@@ -114,7 +121,8 @@
"if not shared_tier_check or shared_tier_check[0][1] == 'OFF':\n",
" %sql DROP DATABASE IF EXISTS SalesAnalysis;\n",
" %sql CREATE DATABASE SalesAnalysis;"
- ]
+ ],
+ "id": "0b8a66cf"
},
{
"attachments": {},
@@ -122,7 +130,8 @@
"metadata": {},
"source": [
"### Create Table"
- ]
+ ],
+ "id": "3afd127b"
},
{
"cell_type": "code",
@@ -142,7 +151,8 @@
" `Price` float DEFAULT NULL,\n",
" `Total_Sales` float DEFAULT NULL\n",
")"
- ]
+ ],
+ "id": "a139fe30"
},
{
"attachments": {},
@@ -150,7 +160,8 @@
"metadata": {},
"source": [
"### Load Data Using Pipelines"
- ]
+ ],
+ "id": "85e8fdc0"
},
{
"cell_type": "code",
@@ -173,7 +184,8 @@
"\n",
"\n",
"START PIPELINE SalesData_Pipeline;"
- ]
+ ],
+ "id": "d25aa2e2"
},
{
"attachments": {},
@@ -181,7 +193,8 @@
"metadata": {},
"source": [
"### Data may take couple of seconds to load after pipeline is started, rerun cell to verify"
- ]
+ ],
+ "id": "23ba5df8"
},
{
"cell_type": "code",
@@ -191,7 +204,8 @@
"source": [
"%%sql\n",
"SELECT count(*) FROM SalesData"
- ]
+ ],
+ "id": "8208c7dc"
},
{
"attachments": {},
@@ -201,7 +215,8 @@
" "
- ]
+ ],
+ "id": "5799ccba"
},
{
"attachments": {},
@@ -91,7 +95,8 @@
"metadata": {},
"source": [
"## How to use this notebook"
- ]
+ ],
+ "id": "2d280222"
},
{
"attachments": {},
@@ -99,7 +104,8 @@
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "5799ccba"
},
{
"attachments": {},
@@ -91,7 +95,8 @@
"metadata": {},
"source": [
"## How to use this notebook"
- ]
+ ],
+ "id": "2d280222"
},
{
"attachments": {},
@@ -99,7 +104,8 @@
"metadata": {},
"source": [
" "
- ]
+ ],
+ "id": "1a480b1e"
},
{
"attachments": {},
@@ -60,7 +63,8 @@
"metadata": {},
"source": [
"## How to use this notebook"
- ]
+ ],
+ "id": "06f4bfee"
},
{
"attachments": {},
@@ -68,7 +72,8 @@
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "1a480b1e"
},
{
"attachments": {},
@@ -60,7 +63,8 @@
"metadata": {},
"source": [
"## How to use this notebook"
- ]
+ ],
+ "id": "06f4bfee"
},
{
"attachments": {},
@@ -68,7 +72,8 @@
"metadata": {},
"source": [
" "
- ]
+ ],
+ "id": "9039eecb"
},
{
"cell_type": "markdown",
- "id": "f940c981-b378-40cf-bb24-53b6015e486d",
"metadata": {},
"source": [
"## 1. Install required libraries\n",
"\n",
"Install the library for vectorizing the data (up to 2 minutes)."
- ]
+ ],
+ "id": "eee7cef6"
},
{
"cell_type": "code",
"execution_count": 1,
- "id": "4fc72c97-8ba9-462b-b241-ae2ff4e7531c",
"metadata": {},
"outputs": [],
"source": [
"!pip install sentence-transformers --quiet"
- ]
+ ],
+ "id": "039f0b97"
},
{
"cell_type": "markdown",
- "id": "5c9049cb-88b8-411a-b926-2517bd44859e",
"metadata": {},
"source": [
"## 2. Create database and ingest data"
- ]
+ ],
+ "id": "82ddb890"
},
{
"cell_type": "markdown",
- "id": "2642c910-72a8-433b-b5fe-e5654f93f239",
"metadata": {},
"source": [
"Create the `movie_recommender` database."
- ]
+ ],
+ "id": "d3181151"
},
{
"cell_type": "code",
"execution_count": 2,
- "id": "fd83f672-5ef5-4a8e-9e7a-267dd19815f7",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"DROP DATABASE IF EXISTS movie_recommender;\n",
"CREATE DATABASE IF NOT EXISTS movie_recommender;"
- ]
+ ],
+ "id": "3e763118"
},
{
"cell_type": "markdown",
- "id": "d6c75b9a-7a1f-44fe-9e25-f67f75c0d11f",
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "9039eecb"
},
{
"cell_type": "markdown",
- "id": "f940c981-b378-40cf-bb24-53b6015e486d",
"metadata": {},
"source": [
"## 1. Install required libraries\n",
"\n",
"Install the library for vectorizing the data (up to 2 minutes)."
- ]
+ ],
+ "id": "eee7cef6"
},
{
"cell_type": "code",
"execution_count": 1,
- "id": "4fc72c97-8ba9-462b-b241-ae2ff4e7531c",
"metadata": {},
"outputs": [],
"source": [
"!pip install sentence-transformers --quiet"
- ]
+ ],
+ "id": "039f0b97"
},
{
"cell_type": "markdown",
- "id": "5c9049cb-88b8-411a-b926-2517bd44859e",
"metadata": {},
"source": [
"## 2. Create database and ingest data"
- ]
+ ],
+ "id": "82ddb890"
},
{
"cell_type": "markdown",
- "id": "2642c910-72a8-433b-b5fe-e5654f93f239",
"metadata": {},
"source": [
"Create the `movie_recommender` database."
- ]
+ ],
+ "id": "d3181151"
},
{
"cell_type": "code",
"execution_count": 2,
- "id": "fd83f672-5ef5-4a8e-9e7a-267dd19815f7",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"DROP DATABASE IF EXISTS movie_recommender;\n",
"CREATE DATABASE IF NOT EXISTS movie_recommender;"
- ]
+ ],
+ "id": "3e763118"
},
{
"cell_type": "markdown",
- "id": "d6c75b9a-7a1f-44fe-9e25-f67f75c0d11f",
"metadata": {},
"source": [
" "
- ]
+ ],
+ "id": "c6c8e0cc"
},
{
"cell_type": "markdown",
- "id": "886169b5-d60f-4669-9d34-20c14e9aba40",
"metadata": {},
"source": [
"With the database selected, the `connection_url` variable in the Python enviroment is now updated with that information\n",
"and we can use the `%%sql` magic command to query the selected database."
- ]
+ ],
+ "id": "58c80276"
},
{
"cell_type": "code",
"execution_count": 1,
- "id": "146c9641-23ec-4570-8466-14d2880c66f0",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM users\n",
" LIMIT 3;"
- ]
+ ],
+ "id": "8e3ec961"
},
{
"cell_type": "markdown",
- "id": "8cb9cb0f-c301-4cef-9f19-e86db0e52f73",
"metadata": {},
"source": [
"When running SQL commands against a different database explicitly, you can specify the database in your\n",
"SQL code with the `USE` command:"
- ]
+ ],
+ "id": "48a4bc93"
},
{
"cell_type": "code",
"execution_count": 2,
- "id": "22b88c07-c956-4a77-944d-4aac485c1514",
"metadata": {},
"outputs": [],
"source": [
@@ -110,70 +109,70 @@
"\n",
"SELECT * FROM users\n",
" LIMIT 3;"
- ]
+ ],
+ "id": "8963691b"
},
{
"cell_type": "markdown",
- "id": "e8b06918-25d2-40e6-9ad9-3e8c558e89e9",
"metadata": {},
"source": [
"Alternatively, you can specify the database prefix on the table in the query itself."
- ]
+ ],
+ "id": "7ef362b7"
},
{
"cell_type": "code",
"execution_count": 3,
- "id": "8ab697a9-3b41-4f92-8b88-65717d7a4202",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM information_schema.users\n",
" LIMIT 3;"
- ]
+ ],
+ "id": "9ed182ae"
},
{
"cell_type": "markdown",
- "id": "3aff8361-669b-474d-a45a-6345de985757",
"metadata": {},
"source": [
"## Connecting with SQLAlchemy"
- ]
+ ],
+ "id": "55dace8c"
},
{
"cell_type": "markdown",
- "id": "c21cdbb8-c77e-4e31-a584-ff922620fb58",
"metadata": {},
"source": [
"You can also connect to your SingleStoreDB datasource using Python and SQLAlchemy. As mentioned above,\n",
"the `connection_url` variable is automatically populated by the notebook environment when selecting a\n",
"database in the drop-down menu at the top of the notebook."
- ]
+ ],
+ "id": "aa8da56d"
},
{
"cell_type": "code",
"execution_count": 4,
- "id": "3e2781f6-626d-4f0d-a5bb-828537c9e6e1",
"metadata": {},
"outputs": [],
"source": [
"import sqlalchemy as sa\n",
"\n",
"sa_conn = sa.create_engine(connection_url).connect()"
- ]
+ ],
+ "id": "fe56aaa8"
},
{
"cell_type": "markdown",
- "id": "1cae1a31-08c6-44b4-99c8-0d0a1b8b5ff8",
"metadata": {},
"source": [
"You can also explicitly define a URL using the individual connection components."
- ]
+ ],
+ "id": "c19e3f2a"
},
{
"cell_type": "code",
"execution_count": 5,
- "id": "93f26bcd-d07d-48a9-9f7a-edc2f9431c09",
"metadata": {},
"outputs": [],
"source": [
@@ -182,41 +181,41 @@
"connection_url2 = f\"singlestoredb://{connection_user}:{connection_password}@{connection_host}:{connection_port}/{database_name}\"\n",
"\n",
"url_conn = sa.create_engine(connection_url2).connect()"
- ]
+ ],
+ "id": "d47acc43"
},
{
"cell_type": "markdown",
- "id": "082e240d-9480-46a2-a7da-33508423b8e9",
"metadata": {},
"source": [
"In addition, the SingleStoreDB Python package includes a wrapper `create_engine` function that\n",
"uses the `SINGLESTOREDB_URL` without having to specify `connection_url`."
- ]
+ ],
+ "id": "7d6b11a3"
},
{
"cell_type": "code",
"execution_count": 6,
- "id": "4ec8e9a0-b45a-4f6f-b3a5-7b51a5a89ed0",
"metadata": {},
"outputs": [],
"source": [
"import singlestoredb as s2\n",
"\n",
"conn = s2.create_engine().connect()"
- ]
+ ],
+ "id": "66cd56df"
},
{
"cell_type": "markdown",
- "id": "2dbc2854-2396-49e0-ae9f-5e68cc1e316c",
"metadata": {},
"source": [
"Using `conn`, we can run our queries much like the `%%sql` command."
- ]
+ ],
+ "id": "ddb8077e"
},
{
"cell_type": "code",
"execution_count": 7,
- "id": "cb22f3b0-547a-471b-80d3-213b38f41121",
"metadata": {},
"outputs": [],
"source": [
@@ -224,11 +223,11 @@
"\n",
"for row in conn.execute(query1):\n",
" print(row)"
- ]
+ ],
+ "id": "e73dcf45"
},
{
"cell_type": "markdown",
- "id": "1a15dcbc-4a03-49c2-ae18-130d97fb03e9",
"metadata": {},
"source": [
"# 2. Connecting to an external datasource\n",
@@ -247,64 +246,64 @@
"4. Select Save.\n",
"\n",
"
"
- ]
+ ],
+ "id": "c6c8e0cc"
},
{
"cell_type": "markdown",
- "id": "886169b5-d60f-4669-9d34-20c14e9aba40",
"metadata": {},
"source": [
"With the database selected, the `connection_url` variable in the Python enviroment is now updated with that information\n",
"and we can use the `%%sql` magic command to query the selected database."
- ]
+ ],
+ "id": "58c80276"
},
{
"cell_type": "code",
"execution_count": 1,
- "id": "146c9641-23ec-4570-8466-14d2880c66f0",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM users\n",
" LIMIT 3;"
- ]
+ ],
+ "id": "8e3ec961"
},
{
"cell_type": "markdown",
- "id": "8cb9cb0f-c301-4cef-9f19-e86db0e52f73",
"metadata": {},
"source": [
"When running SQL commands against a different database explicitly, you can specify the database in your\n",
"SQL code with the `USE` command:"
- ]
+ ],
+ "id": "48a4bc93"
},
{
"cell_type": "code",
"execution_count": 2,
- "id": "22b88c07-c956-4a77-944d-4aac485c1514",
"metadata": {},
"outputs": [],
"source": [
@@ -110,70 +109,70 @@
"\n",
"SELECT * FROM users\n",
" LIMIT 3;"
- ]
+ ],
+ "id": "8963691b"
},
{
"cell_type": "markdown",
- "id": "e8b06918-25d2-40e6-9ad9-3e8c558e89e9",
"metadata": {},
"source": [
"Alternatively, you can specify the database prefix on the table in the query itself."
- ]
+ ],
+ "id": "7ef362b7"
},
{
"cell_type": "code",
"execution_count": 3,
- "id": "8ab697a9-3b41-4f92-8b88-65717d7a4202",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM information_schema.users\n",
" LIMIT 3;"
- ]
+ ],
+ "id": "9ed182ae"
},
{
"cell_type": "markdown",
- "id": "3aff8361-669b-474d-a45a-6345de985757",
"metadata": {},
"source": [
"## Connecting with SQLAlchemy"
- ]
+ ],
+ "id": "55dace8c"
},
{
"cell_type": "markdown",
- "id": "c21cdbb8-c77e-4e31-a584-ff922620fb58",
"metadata": {},
"source": [
"You can also connect to your SingleStoreDB datasource using Python and SQLAlchemy. As mentioned above,\n",
"the `connection_url` variable is automatically populated by the notebook environment when selecting a\n",
"database in the drop-down menu at the top of the notebook."
- ]
+ ],
+ "id": "aa8da56d"
},
{
"cell_type": "code",
"execution_count": 4,
- "id": "3e2781f6-626d-4f0d-a5bb-828537c9e6e1",
"metadata": {},
"outputs": [],
"source": [
"import sqlalchemy as sa\n",
"\n",
"sa_conn = sa.create_engine(connection_url).connect()"
- ]
+ ],
+ "id": "fe56aaa8"
},
{
"cell_type": "markdown",
- "id": "1cae1a31-08c6-44b4-99c8-0d0a1b8b5ff8",
"metadata": {},
"source": [
"You can also explicitly define a URL using the individual connection components."
- ]
+ ],
+ "id": "c19e3f2a"
},
{
"cell_type": "code",
"execution_count": 5,
- "id": "93f26bcd-d07d-48a9-9f7a-edc2f9431c09",
"metadata": {},
"outputs": [],
"source": [
@@ -182,41 +181,41 @@
"connection_url2 = f\"singlestoredb://{connection_user}:{connection_password}@{connection_host}:{connection_port}/{database_name}\"\n",
"\n",
"url_conn = sa.create_engine(connection_url2).connect()"
- ]
+ ],
+ "id": "d47acc43"
},
{
"cell_type": "markdown",
- "id": "082e240d-9480-46a2-a7da-33508423b8e9",
"metadata": {},
"source": [
"In addition, the SingleStoreDB Python package includes a wrapper `create_engine` function that\n",
"uses the `SINGLESTOREDB_URL` without having to specify `connection_url`."
- ]
+ ],
+ "id": "7d6b11a3"
},
{
"cell_type": "code",
"execution_count": 6,
- "id": "4ec8e9a0-b45a-4f6f-b3a5-7b51a5a89ed0",
"metadata": {},
"outputs": [],
"source": [
"import singlestoredb as s2\n",
"\n",
"conn = s2.create_engine().connect()"
- ]
+ ],
+ "id": "66cd56df"
},
{
"cell_type": "markdown",
- "id": "2dbc2854-2396-49e0-ae9f-5e68cc1e316c",
"metadata": {},
"source": [
"Using `conn`, we can run our queries much like the `%%sql` command."
- ]
+ ],
+ "id": "ddb8077e"
},
{
"cell_type": "code",
"execution_count": 7,
- "id": "cb22f3b0-547a-471b-80d3-213b38f41121",
"metadata": {},
"outputs": [],
"source": [
@@ -224,11 +223,11 @@
"\n",
"for row in conn.execute(query1):\n",
" print(row)"
- ]
+ ],
+ "id": "e73dcf45"
},
{
"cell_type": "markdown",
- "id": "1a15dcbc-4a03-49c2-ae18-130d97fb03e9",
"metadata": {},
"source": [
"# 2. Connecting to an external datasource\n",
@@ -247,64 +246,64 @@
"4. Select Save.\n",
"\n",
" "
- ]
+ ],
+ "id": "275448eb"
},
{
"cell_type": "markdown",
- "id": "3eed3310-621f-4c37-9db4-a992980a4f46",
"metadata": {},
"source": [
"# 3. Using SQL\n",
"The default language for SingleStoreDB Cloud notebooks is Python. However, the `%%sql` magic command can be used to\n",
"submit SQL code for an entire cell."
- ]
+ ],
+ "id": "6bdc2d33"
},
{
"cell_type": "code",
"execution_count": 8,
- "id": "d82fc6bf-b786-4956-a056-851e746f97b8",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM users\n",
" LIMIT 3;"
- ]
+ ],
+ "id": "2da087fa"
},
{
"cell_type": "markdown",
- "id": "eb91c21c-1ce6-4e31-95d1-a981dea630c7",
"metadata": {},
"source": [
"By default, the results are displayed as a table. We can also store the result in a variable for use later in the\n",
"notebook. The following code includes the `result1 <<` syntax which indicates that the output of the SQL code\n",
"should be stored in the `result` variable in the Python environment."
- ]
+ ],
+ "id": "7288ccc8"
},
{
"cell_type": "code",
"execution_count": 9,
- "id": "0a6341cd-0328-4d8a-8158-72aff97b77de",
"metadata": {},
"outputs": [],
"source": [
"%%sql result1 <<\n",
"SELECT * FROM users\n",
" LIMIT 3;"
- ]
+ ],
+ "id": "4cc6a000"
},
{
"cell_type": "markdown",
- "id": "91cf2054-d223-4013-8867-2f4a9494978a",
"metadata": {},
"source": [
"We now have access to the `result` variable and can convert it to a DataFrame!"
- ]
+ ],
+ "id": "903cf8ba"
},
{
"cell_type": "code",
"execution_count": 10,
- "id": "5e436bc0-4843-4d0c-b64c-3470d963f29a",
"metadata": {},
"outputs": [],
"source": [
@@ -312,11 +311,11 @@
"\n",
"df = pd.DataFrame(result1)\n",
"df"
- ]
+ ],
+ "id": "1db6bdc7"
},
{
"cell_type": "markdown",
- "id": "360b2dc0-038e-4311-a5c3-b497b8feaf57",
"metadata": {},
"source": [
"## 4. Using Python in a code cell\n",
@@ -324,12 +323,12 @@
"By default, Python is the language for code cells. In the cell below, we are using a SQLAlchemy connection to execute\n",
"the same query as the previous example. The result of this query can be converted into a DataFrame in the same manner\n",
"as above"
- ]
+ ],
+ "id": "490f1e09"
},
{
"cell_type": "code",
"execution_count": 11,
- "id": "e0085cca-2278-4904-94aa-4e46da840b66",
"metadata": {},
"outputs": [],
"source": [
@@ -337,11 +336,11 @@
"\n",
"df = pd.DataFrame(result)\n",
"df"
- ]
+ ],
+ "id": "81e5c76f"
},
{
"cell_type": "markdown",
- "id": "afb80434-583d-4171-a95b-694ed14bbd98",
"metadata": {},
"source": [
"## 5. Using both SQL & Python in a code cell\n",
@@ -349,12 +348,12 @@
"We can use a single line of SQL within a Python cell using a single `%sql` call. Below we combine SQL and\n",
"Python in the same cell to capture the output in the `result` variable. We then convert it to a DataFrame\n",
"as in previous examples."
- ]
+ ],
+ "id": "916e3660"
},
{
"cell_type": "code",
"execution_count": 12,
- "id": "d79f9268-7c76-47cf-bee7-577ce07ae85d",
"metadata": {},
"outputs": [],
"source": [
@@ -362,67 +361,67 @@
"\n",
"df = pd.DataFrame(result)\n",
"df"
- ]
+ ],
+ "id": "b62d2cf7"
},
{
"cell_type": "markdown",
- "id": "2b9a3995-32df-4931-8aff-44bcd2db5908",
"metadata": {},
"source": [
"## 6. Preinstalled libraries\n",
"\n",
"By default, a SingleStoreDB notebook has a large number of preinstalled libraries. Run the cell below to see what libraries are already installed!"
- ]
+ ],
+ "id": "40b48421"
},
{
"cell_type": "code",
"execution_count": 13,
- "id": "abee048d-f18a-4a35-8eae-c8f92939230a",
"metadata": {},
"outputs": [],
"source": [
"!pip list"
- ]
+ ],
+ "id": "b67782b8"
},
{
"cell_type": "markdown",
- "id": "bbc061e3-acb3-40cc-be84-ada979aaa1a5",
"metadata": {},
"source": [
"Our notebooks support libraries available from https://pypi.org/. For example, run the cell below to install the [Kaggle open dataset library](https://pypi.org/project/opendatasets/) to install the `opendatasets` package."
- ]
+ ],
+ "id": "c91a8510"
},
{
"cell_type": "code",
"execution_count": 14,
- "id": "e17e1322-33df-4e2f-97fe-9815df235b40",
"metadata": {},
"outputs": [],
"source": [
"!pip3 install opendatasets"
- ]
+ ],
+ "id": "8e6f739e"
},
{
"cell_type": "markdown",
- "id": "9c6684da-af62-42bc-9481-b53c75f64b5e",
"metadata": {},
"source": [
"You can even upgrade versions of a preinstalled library. Run the cell below to get the new version of Plotly."
- ]
+ ],
+ "id": "cae98979"
},
{
"cell_type": "code",
"execution_count": 15,
- "id": "5a989a0f-6334-42d9-a75e-a04d09bccbec",
"metadata": {},
"outputs": [],
"source": [
"!pip3 install plotly --upgrade"
- ]
+ ],
+ "id": "2c3430fc"
},
{
"cell_type": "markdown",
- "id": "8d69cb4d-58ea-40ae-83db-03ff489d8676",
"metadata": {},
"source": [
"## 7. Magic commands\n",
@@ -432,29 +431,30 @@
"\n",
"There are many other magic commands as well for everything from file system access to debugging your Python code.\n",
"For information about teh full list of magic commands available, run the code cell below."
- ]
+ ],
+ "id": "81bc2f91"
},
{
"cell_type": "code",
"execution_count": 16,
- "id": "b413bb30-0e9f-4484-8d3e-e7bc724a0c13",
"metadata": {},
"outputs": [],
"source": [
"%quickref"
- ]
+ ],
+ "id": "eb96981b"
},
{
"cell_type": "markdown",
- "id": "0ea02e78-b1e2-4cb4-a6d7-d813fdcb2759",
"metadata": {},
"source": [
"**Learn more about SingleStoreDB notebooks [here](https://docs.singlestore.com/managed-service/en/developer-resources/notebooks.html) and get started with your first notebook!**"
- ]
+ ],
+ "id": "02550a95"
},
{
+ "id": "b71125bc",
"cell_type": "markdown",
- "id": "df3c9ee9-ac57-4e84-9201-df635ac7bd36",
"metadata": {},
"source": [
"\n",
diff --git a/notebooks/optimize-performance-with-tpch-100/notebook.ipynb b/notebooks/optimize-performance-with-tpch-100/notebook.ipynb
index 18c8d9d7..a9a77c02 100644
--- a/notebooks/optimize-performance-with-tpch-100/notebook.ipynb
+++ b/notebooks/optimize-performance-with-tpch-100/notebook.ipynb
@@ -1,8 +1,8 @@
{
"cells": [
{
+ "id": "fa1acf27",
"cell_type": "markdown",
- "id": "8e67bcbe-6ace-4ca9-b28c-927b4b5a85b2",
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "275448eb"
},
{
"cell_type": "markdown",
- "id": "3eed3310-621f-4c37-9db4-a992980a4f46",
"metadata": {},
"source": [
"# 3. Using SQL\n",
"The default language for SingleStoreDB Cloud notebooks is Python. However, the `%%sql` magic command can be used to\n",
"submit SQL code for an entire cell."
- ]
+ ],
+ "id": "6bdc2d33"
},
{
"cell_type": "code",
"execution_count": 8,
- "id": "d82fc6bf-b786-4956-a056-851e746f97b8",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM users\n",
" LIMIT 3;"
- ]
+ ],
+ "id": "2da087fa"
},
{
"cell_type": "markdown",
- "id": "eb91c21c-1ce6-4e31-95d1-a981dea630c7",
"metadata": {},
"source": [
"By default, the results are displayed as a table. We can also store the result in a variable for use later in the\n",
"notebook. The following code includes the `result1 <<` syntax which indicates that the output of the SQL code\n",
"should be stored in the `result` variable in the Python environment."
- ]
+ ],
+ "id": "7288ccc8"
},
{
"cell_type": "code",
"execution_count": 9,
- "id": "0a6341cd-0328-4d8a-8158-72aff97b77de",
"metadata": {},
"outputs": [],
"source": [
"%%sql result1 <<\n",
"SELECT * FROM users\n",
" LIMIT 3;"
- ]
+ ],
+ "id": "4cc6a000"
},
{
"cell_type": "markdown",
- "id": "91cf2054-d223-4013-8867-2f4a9494978a",
"metadata": {},
"source": [
"We now have access to the `result` variable and can convert it to a DataFrame!"
- ]
+ ],
+ "id": "903cf8ba"
},
{
"cell_type": "code",
"execution_count": 10,
- "id": "5e436bc0-4843-4d0c-b64c-3470d963f29a",
"metadata": {},
"outputs": [],
"source": [
@@ -312,11 +311,11 @@
"\n",
"df = pd.DataFrame(result1)\n",
"df"
- ]
+ ],
+ "id": "1db6bdc7"
},
{
"cell_type": "markdown",
- "id": "360b2dc0-038e-4311-a5c3-b497b8feaf57",
"metadata": {},
"source": [
"## 4. Using Python in a code cell\n",
@@ -324,12 +323,12 @@
"By default, Python is the language for code cells. In the cell below, we are using a SQLAlchemy connection to execute\n",
"the same query as the previous example. The result of this query can be converted into a DataFrame in the same manner\n",
"as above"
- ]
+ ],
+ "id": "490f1e09"
},
{
"cell_type": "code",
"execution_count": 11,
- "id": "e0085cca-2278-4904-94aa-4e46da840b66",
"metadata": {},
"outputs": [],
"source": [
@@ -337,11 +336,11 @@
"\n",
"df = pd.DataFrame(result)\n",
"df"
- ]
+ ],
+ "id": "81e5c76f"
},
{
"cell_type": "markdown",
- "id": "afb80434-583d-4171-a95b-694ed14bbd98",
"metadata": {},
"source": [
"## 5. Using both SQL & Python in a code cell\n",
@@ -349,12 +348,12 @@
"We can use a single line of SQL within a Python cell using a single `%sql` call. Below we combine SQL and\n",
"Python in the same cell to capture the output in the `result` variable. We then convert it to a DataFrame\n",
"as in previous examples."
- ]
+ ],
+ "id": "916e3660"
},
{
"cell_type": "code",
"execution_count": 12,
- "id": "d79f9268-7c76-47cf-bee7-577ce07ae85d",
"metadata": {},
"outputs": [],
"source": [
@@ -362,67 +361,67 @@
"\n",
"df = pd.DataFrame(result)\n",
"df"
- ]
+ ],
+ "id": "b62d2cf7"
},
{
"cell_type": "markdown",
- "id": "2b9a3995-32df-4931-8aff-44bcd2db5908",
"metadata": {},
"source": [
"## 6. Preinstalled libraries\n",
"\n",
"By default, a SingleStoreDB notebook has a large number of preinstalled libraries. Run the cell below to see what libraries are already installed!"
- ]
+ ],
+ "id": "40b48421"
},
{
"cell_type": "code",
"execution_count": 13,
- "id": "abee048d-f18a-4a35-8eae-c8f92939230a",
"metadata": {},
"outputs": [],
"source": [
"!pip list"
- ]
+ ],
+ "id": "b67782b8"
},
{
"cell_type": "markdown",
- "id": "bbc061e3-acb3-40cc-be84-ada979aaa1a5",
"metadata": {},
"source": [
"Our notebooks support libraries available from https://pypi.org/. For example, run the cell below to install the [Kaggle open dataset library](https://pypi.org/project/opendatasets/) to install the `opendatasets` package."
- ]
+ ],
+ "id": "c91a8510"
},
{
"cell_type": "code",
"execution_count": 14,
- "id": "e17e1322-33df-4e2f-97fe-9815df235b40",
"metadata": {},
"outputs": [],
"source": [
"!pip3 install opendatasets"
- ]
+ ],
+ "id": "8e6f739e"
},
{
"cell_type": "markdown",
- "id": "9c6684da-af62-42bc-9481-b53c75f64b5e",
"metadata": {},
"source": [
"You can even upgrade versions of a preinstalled library. Run the cell below to get the new version of Plotly."
- ]
+ ],
+ "id": "cae98979"
},
{
"cell_type": "code",
"execution_count": 15,
- "id": "5a989a0f-6334-42d9-a75e-a04d09bccbec",
"metadata": {},
"outputs": [],
"source": [
"!pip3 install plotly --upgrade"
- ]
+ ],
+ "id": "2c3430fc"
},
{
"cell_type": "markdown",
- "id": "8d69cb4d-58ea-40ae-83db-03ff489d8676",
"metadata": {},
"source": [
"## 7. Magic commands\n",
@@ -432,29 +431,30 @@
"\n",
"There are many other magic commands as well for everything from file system access to debugging your Python code.\n",
"For information about teh full list of magic commands available, run the code cell below."
- ]
+ ],
+ "id": "81bc2f91"
},
{
"cell_type": "code",
"execution_count": 16,
- "id": "b413bb30-0e9f-4484-8d3e-e7bc724a0c13",
"metadata": {},
"outputs": [],
"source": [
"%quickref"
- ]
+ ],
+ "id": "eb96981b"
},
{
"cell_type": "markdown",
- "id": "0ea02e78-b1e2-4cb4-a6d7-d813fdcb2759",
"metadata": {},
"source": [
"**Learn more about SingleStoreDB notebooks [here](https://docs.singlestore.com/managed-service/en/developer-resources/notebooks.html) and get started with your first notebook!**"
- ]
+ ],
+ "id": "02550a95"
},
{
+ "id": "b71125bc",
"cell_type": "markdown",
- "id": "df3c9ee9-ac57-4e84-9201-df635ac7bd36",
"metadata": {},
"source": [
"\n",
diff --git a/notebooks/optimize-performance-with-tpch-100/notebook.ipynb b/notebooks/optimize-performance-with-tpch-100/notebook.ipynb
index 18c8d9d7..a9a77c02 100644
--- a/notebooks/optimize-performance-with-tpch-100/notebook.ipynb
+++ b/notebooks/optimize-performance-with-tpch-100/notebook.ipynb
@@ -1,8 +1,8 @@
{
"cells": [
{
+ "id": "fa1acf27",
"cell_type": "markdown",
- "id": "8e67bcbe-6ace-4ca9-b28c-927b4b5a85b2",
"metadata": {},
"source": [
"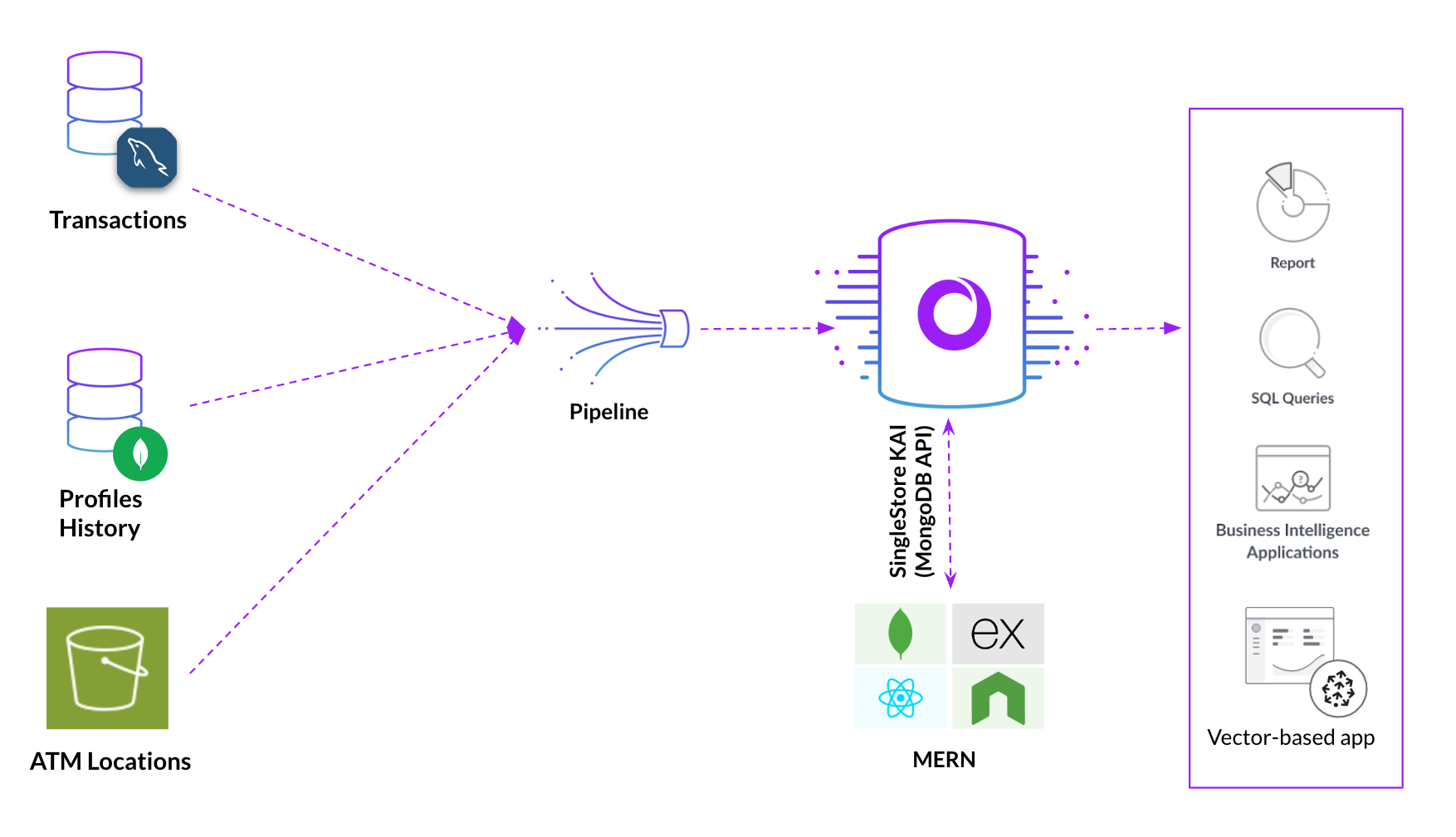 "
- ]
+ ],
+ "id": "ced3b94d"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "cacc9529-3715-4854-8d7f-05543df12c15",
"metadata": {},
"source": [
"### What you will learn in this notebook:\n",
@@ -50,45 +49,45 @@
"2. Analyze data using both NoSQL and relational approaches, depending on your specific needs. Developers and data analytics who are familiar with different programming approaches like MongoDB query language and SQL can work together on the same database. Perform familiar SQL queries on your NoSQL data!\n",
"\n",
"Ready to unlock real-time analytics and unified data access? Let's start!"
- ]
+ ],
+ "id": "3eae9c76"
},
{
"cell_type": "code",
"execution_count": 1,
- "id": "e87ac44e-ff79-466f-9c17-9f9667ad8089",
"metadata": {},
"outputs": [],
"source": [
"!pip install pymongo prettytable matplotlib --quiet"
- ]
+ ],
+ "id": "33a2b51c"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "10a03a4a-2cfa-4ecd-b2ef-97c6bfa6f755",
"metadata": {},
"source": [
"### Create database for importing data from different sources\n",
"\n",
"This example gets banking data from three different sources: ATM locations from S3, transaction data from MySQL and user profile details from MongoDB databases. Joins data from different sources to generate rich insights about the transactional activity across user profile and locations across the globe"
- ]
+ ],
+ "id": "18e3e006"
},
{
"cell_type": "code",
"execution_count": 2,
- "id": "d0463f3f-419a-4a4b-be77-ef02a027f8aa",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"DROP DATABASE IF EXISTS BankingAnalytics;\n",
"CREATE DATABASE BankingAnalytics;"
- ]
+ ],
+ "id": "a77b82b3"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "a3335e3a-1fad-4857-975d-81d4a5205f08",
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "ced3b94d"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "cacc9529-3715-4854-8d7f-05543df12c15",
"metadata": {},
"source": [
"### What you will learn in this notebook:\n",
@@ -50,45 +49,45 @@
"2. Analyze data using both NoSQL and relational approaches, depending on your specific needs. Developers and data analytics who are familiar with different programming approaches like MongoDB query language and SQL can work together on the same database. Perform familiar SQL queries on your NoSQL data!\n",
"\n",
"Ready to unlock real-time analytics and unified data access? Let's start!"
- ]
+ ],
+ "id": "3eae9c76"
},
{
"cell_type": "code",
"execution_count": 1,
- "id": "e87ac44e-ff79-466f-9c17-9f9667ad8089",
"metadata": {},
"outputs": [],
"source": [
"!pip install pymongo prettytable matplotlib --quiet"
- ]
+ ],
+ "id": "33a2b51c"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "10a03a4a-2cfa-4ecd-b2ef-97c6bfa6f755",
"metadata": {},
"source": [
"### Create database for importing data from different sources\n",
"\n",
"This example gets banking data from three different sources: ATM locations from S3, transaction data from MySQL and user profile details from MongoDB databases. Joins data from different sources to generate rich insights about the transactional activity across user profile and locations across the globe"
- ]
+ ],
+ "id": "18e3e006"
},
{
"cell_type": "code",
"execution_count": 2,
- "id": "d0463f3f-419a-4a4b-be77-ef02a027f8aa",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"DROP DATABASE IF EXISTS BankingAnalytics;\n",
"CREATE DATABASE BankingAnalytics;"
- ]
+ ],
+ "id": "a77b82b3"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "a3335e3a-1fad-4857-975d-81d4a5205f08",
"metadata": {},
"source": [
" "
- ]
+ ],
+ "id": "047ed31a"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "629241ce-8464-4834-bad3-3f88af675e59",
"metadata": {},
"source": [
"## Setup CDC from MySQL"
- ]
+ ],
+ "id": "aa69ee29"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "e99f3b06-82d3-47d0-a3f9-d93d08f3e9a2",
"metadata": {},
"source": [
"### SingleStore allows you to ingest the data from mysql using pipelines"
- ]
+ ],
+ "id": "cab7be5d"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "1807cb20-ddc8-4f8c-97c0-c473e8049768",
"metadata": {},
"source": [
"In this step, we create a link from MySQL instance and start the pipelines for the CDC"
- ]
+ ],
+ "id": "d37b87da"
},
{
"cell_type": "code",
"execution_count": 3,
- "id": "37cf747a-286b-4f37-8d8a-7b191fec1366",
"metadata": {},
"outputs": [],
"source": [
@@ -156,52 +155,52 @@
" \"database.password\": \"Password@123\",\n",
" \"database.user\": \"repl_user\"\n",
" }';"
- ]
+ ],
+ "id": "fa97ca56"
},
{
"cell_type": "code",
"execution_count": 4,
- "id": "da44f747-85c0-400b-b155-be55c860f076",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"CREATE TABLES AS INFER PIPELINE AS LOAD DATA LINK mysqllink \"*\" FORMAT AVRO;"
- ]
+ ],
+ "id": "d1025983"
},
{
"cell_type": "code",
"execution_count": 5,
- "id": "4b230ff8-913a-4f67-83d7-778a514f8136",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"START ALL PIPELINES;"
- ]
+ ],
+ "id": "e9d91511"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "af22186a-9989-4a73-8adc-6d8532c70cd6",
"metadata": {},
"source": [
"### Migrate the data from S3 storage to SingleStore using Pipelines"
- ]
+ ],
+ "id": "dd0bcb77"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "4d51519a-9e5e-43cd-95bd-07f4b59f80c7",
"metadata": {},
"source": [
"This steps loads data from S3, this requires the tables to be defined beforehand"
- ]
+ ],
+ "id": "802e47d1"
},
{
"cell_type": "code",
"execution_count": 6,
- "id": "82260c10-9482-4997-8208-5a8d6bff48d2",
"metadata": {},
"outputs": [],
"source": [
@@ -215,12 +214,12 @@
" latitude DECIMAL(9, 6),\n",
" longitude DECIMAL(9, 6)\n",
");"
- ]
+ ],
+ "id": "dd05a31c"
},
{
"cell_type": "code",
"execution_count": 7,
- "id": "689ec731-2a2a-4035-9dc3-fead074240cc",
"metadata": {},
"outputs": [],
"source": [
@@ -230,43 +229,43 @@
"CONFIG '{\"region\":\"ap-southeast-1\"}'\n",
"SKIP DUPLICATE KEY ERRORS\n",
"INTO TABLE atm_locations;"
- ]
+ ],
+ "id": "5ba219df"
},
{
"cell_type": "code",
"execution_count": 8,
- "id": "5c482f6a-c053-438e-a671-a3a7894052a7",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"START PIPELINE atmlocations"
- ]
+ ],
+ "id": "94eebb51"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "806952a2-090c-48aa-a1e4-8c71cd66143d",
"metadata": {},
"source": [
"### Setup CDC from MongoDB to SingleStore"
- ]
+ ],
+ "id": "56a58831"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "1c2d83fa-6a94-4a2b-a657-0e3f8ea0bf8b",
"metadata": {},
"source": [
"Now we setup CDC from MongoDB to replicate the data SingleStore\n",
"\n",
"The collections to be replicated are specified as a comma separated or in a wildcard format in \"collection.include.list\""
- ]
+ ],
+ "id": "87444b9b"
},
{
"cell_type": "code",
"execution_count": 9,
- "id": "fb852b9c-51a6-4d8c-a4a2-f0cb6e78dc60",
"metadata": {},
"outputs": [],
"source": [
@@ -283,166 +282,166 @@
" \"mongodb.user\":\"mongo_sample_reader\",\n",
" \"mongodb.password\":\"SingleStoreRocks27017\"\n",
" }';"
- ]
+ ],
+ "id": "b84d21a8"
},
{
"cell_type": "code",
"execution_count": 10,
- "id": "ae958c77-2e84-4434-9dcd-205837bd5f02",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"CREATE TABLES AS INFER PIPELINE AS LOAD DATA LINK mongo '*' FORMAT AVRO;"
- ]
+ ],
+ "id": "4e58d374"
},
{
"cell_type": "code",
"execution_count": 11,
- "id": "32b32f1e-072b-4273-952b-6772b4a8e380",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SHOW PIPELINES"
- ]
+ ],
+ "id": "1f3b9fe9"
},
{
"cell_type": "code",
"execution_count": 12,
- "id": "3a91eefe-6d82-453b-8d3d-10344baae466",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"START ALL PIPELINES"
- ]
+ ],
+ "id": "2c088673"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "c0d54948-e440-43f7-963b-8d6b2c1b6129",
"metadata": {},
"source": [
"### Check for records in tables"
- ]
+ ],
+ "id": "8b6caff3"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "e45a1cb9-d884-4ac5-91dd-c8ded628bcb0",
"metadata": {},
"source": [
"Data from MySQL"
- ]
+ ],
+ "id": "3e469dab"
},
{
"cell_type": "code",
"execution_count": 13,
- "id": "c288f83a-9495-4baa-940f-9fe8400ab93b",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT COUNT(*) FROM transactions"
- ]
+ ],
+ "id": "44688a3d"
},
{
"cell_type": "code",
"execution_count": 14,
- "id": "f8604704-9324-4630-9eec-2c3f6be3c853",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM transactions WHERE transaction_type LIKE '%Deposit%' LIMIT 1;"
- ]
+ ],
+ "id": "d3fc1c14"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "0a39438a-a537-490e-9191-77c9b224bbb4",
"metadata": {},
"source": [
"Data from S3"
- ]
+ ],
+ "id": "37088621"
},
{
"cell_type": "code",
"execution_count": 15,
- "id": "5d26d20e-ef26-4d73-8a6a-060716e5f5ae",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT COUNT(*) FROM atm_locations"
- ]
+ ],
+ "id": "ed1670ee"
},
{
"cell_type": "code",
"execution_count": 16,
- "id": "62eced11-86b7-4c66-a7a8-ad197460e99d",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM atm_locations LIMIT 1;"
- ]
+ ],
+ "id": "367930d2"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "a06fc97a-59ec-4134-a3cf-016b39108374",
"metadata": {},
"source": [
"Data from MongoDB"
- ]
+ ],
+ "id": "2f11225d"
},
{
"cell_type": "code",
"execution_count": 17,
- "id": "40c77598-464b-4d91-b36e-89569e1ecb12",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT _id:>JSON, _more:>JSON FROM profile LIMIT 1;"
- ]
+ ],
+ "id": "0150f6bc"
},
{
"cell_type": "code",
"execution_count": 18,
- "id": "a4694186-b064-465f-9e4f-9a33b1d6ae76",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"\n",
"SELECT _id:>JSON, _more:>JSON FROM history LIMIT 1;"
- ]
+ ],
+ "id": "21fbf852"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "40ec6ef2-dd95-43b7-947a-16c80efc359a",
"metadata": {},
"source": [
"### Join tables from different sources using SQL queries"
- ]
+ ],
+ "id": "3f3dd776"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "3bfb62de-ae36-4824-881f-c858cb852c01",
"metadata": {},
"source": [
"SQL Query 1: View Users details, their associated ATMs"
- ]
+ ],
+ "id": "1e1ade40"
},
{
"cell_type": "code",
"execution_count": 19,
- "id": "9efacacd-b36e-4208-a360-3ca239d1fad3",
"metadata": {},
"outputs": [],
"source": [
@@ -460,21 +459,21 @@
"WHERE\n",
" p._more::$account_id = a.id\n",
"LIMIT 10;"
- ]
+ ],
+ "id": "9eb6e86c"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "2cce1897-681f-4136-807e-711ed78ed80b",
"metadata": {},
"source": [
"SQL Query 2: View Users details, their associated ATMs and transaction details"
- ]
+ ],
+ "id": "c8147f4a"
},
{
"cell_type": "code",
"execution_count": 20,
- "id": "82d52f1a-35e8-4f59-99ed-cbd65842f699",
"metadata": {},
"outputs": [],
"source": [
@@ -497,21 +496,21 @@
"LEFT JOIN\n",
" transactions t ON p._more::$account_id = t.account_id\n",
"LIMIT 10;"
- ]
+ ],
+ "id": "9baa53de"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "2fb24ac0-1579-4ddb-8009-efb36aaff2d6",
"metadata": {},
"source": [
"### Run queries in Mongo Query Language using Kai"
- ]
+ ],
+ "id": "ed30b745"
},
{
"cell_type": "code",
"execution_count": 21,
- "id": "d7f5fa93-473e-4e0b-96ca-e743cb75684d",
"metadata": {},
"outputs": [],
"source": [
@@ -527,12 +526,12 @@
"\n",
"for profile in profile_coll.find().limit(1):\n",
" pprint.pprint(profile)"
- ]
+ ],
+ "id": "42e097e7"
},
{
"cell_type": "code",
"execution_count": 22,
- "id": "dd303812-2ec2-4e84-b436-617591099a06",
"metadata": {},
"outputs": [],
"source": [
@@ -585,12 +584,12 @@
" ])\n",
"\n",
"print(table)"
- ]
+ ],
+ "id": "a3441786"
},
{
"cell_type": "code",
"execution_count": 23,
- "id": "00e2c386-2ae5-478d-be0a-c9c07005745e",
"metadata": {},
"outputs": [],
"source": [
@@ -604,12 +603,12 @@
"]\n",
"\n",
"pprint.pprint(list(profile_coll.aggregate(pipeline)))"
- ]
+ ],
+ "id": "fe24435f"
},
{
"cell_type": "code",
"execution_count": 24,
- "id": "a0e0be36-0605-426b-a84a-1c47bab2f7cb",
"metadata": {},
"outputs": [],
"source": [
@@ -623,19 +622,20 @@
"\n",
"plt.bar(country,count)\n",
"plt.plot()"
- ]
+ ],
+ "id": "1e919cbe"
},
{
"cell_type": "markdown",
- "id": "3636037e",
"metadata": {},
"source": [
"With SingleStore Kai you can power analytics on SQL and NoSQL data using the API of your choice"
- ]
+ ],
+ "id": "f05705e2"
},
{
+ "id": "2abf5b5f",
"cell_type": "markdown",
- "id": "32756572-0488-4ac0-bf10-1a47d84bc79f",
"metadata": {},
"source": [
"\n",
diff --git a/notebooks/vector-database-basics/notebook.ipynb b/notebooks/vector-database-basics/notebook.ipynb
index 519c81f3..960852c8 100644
--- a/notebooks/vector-database-basics/notebook.ipynb
+++ b/notebooks/vector-database-basics/notebook.ipynb
@@ -1,8 +1,8 @@
{
"cells": [
{
+ "id": "76ae2947",
"cell_type": "markdown",
- "id": "1794de89-5ae3-44d3-bfa6-3d41c4f4deba",
"metadata": {},
"source": [
"
"
- ]
+ ],
+ "id": "047ed31a"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "629241ce-8464-4834-bad3-3f88af675e59",
"metadata": {},
"source": [
"## Setup CDC from MySQL"
- ]
+ ],
+ "id": "aa69ee29"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "e99f3b06-82d3-47d0-a3f9-d93d08f3e9a2",
"metadata": {},
"source": [
"### SingleStore allows you to ingest the data from mysql using pipelines"
- ]
+ ],
+ "id": "cab7be5d"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "1807cb20-ddc8-4f8c-97c0-c473e8049768",
"metadata": {},
"source": [
"In this step, we create a link from MySQL instance and start the pipelines for the CDC"
- ]
+ ],
+ "id": "d37b87da"
},
{
"cell_type": "code",
"execution_count": 3,
- "id": "37cf747a-286b-4f37-8d8a-7b191fec1366",
"metadata": {},
"outputs": [],
"source": [
@@ -156,52 +155,52 @@
" \"database.password\": \"Password@123\",\n",
" \"database.user\": \"repl_user\"\n",
" }';"
- ]
+ ],
+ "id": "fa97ca56"
},
{
"cell_type": "code",
"execution_count": 4,
- "id": "da44f747-85c0-400b-b155-be55c860f076",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"CREATE TABLES AS INFER PIPELINE AS LOAD DATA LINK mysqllink \"*\" FORMAT AVRO;"
- ]
+ ],
+ "id": "d1025983"
},
{
"cell_type": "code",
"execution_count": 5,
- "id": "4b230ff8-913a-4f67-83d7-778a514f8136",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"START ALL PIPELINES;"
- ]
+ ],
+ "id": "e9d91511"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "af22186a-9989-4a73-8adc-6d8532c70cd6",
"metadata": {},
"source": [
"### Migrate the data from S3 storage to SingleStore using Pipelines"
- ]
+ ],
+ "id": "dd0bcb77"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "4d51519a-9e5e-43cd-95bd-07f4b59f80c7",
"metadata": {},
"source": [
"This steps loads data from S3, this requires the tables to be defined beforehand"
- ]
+ ],
+ "id": "802e47d1"
},
{
"cell_type": "code",
"execution_count": 6,
- "id": "82260c10-9482-4997-8208-5a8d6bff48d2",
"metadata": {},
"outputs": [],
"source": [
@@ -215,12 +214,12 @@
" latitude DECIMAL(9, 6),\n",
" longitude DECIMAL(9, 6)\n",
");"
- ]
+ ],
+ "id": "dd05a31c"
},
{
"cell_type": "code",
"execution_count": 7,
- "id": "689ec731-2a2a-4035-9dc3-fead074240cc",
"metadata": {},
"outputs": [],
"source": [
@@ -230,43 +229,43 @@
"CONFIG '{\"region\":\"ap-southeast-1\"}'\n",
"SKIP DUPLICATE KEY ERRORS\n",
"INTO TABLE atm_locations;"
- ]
+ ],
+ "id": "5ba219df"
},
{
"cell_type": "code",
"execution_count": 8,
- "id": "5c482f6a-c053-438e-a671-a3a7894052a7",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"START PIPELINE atmlocations"
- ]
+ ],
+ "id": "94eebb51"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "806952a2-090c-48aa-a1e4-8c71cd66143d",
"metadata": {},
"source": [
"### Setup CDC from MongoDB to SingleStore"
- ]
+ ],
+ "id": "56a58831"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "1c2d83fa-6a94-4a2b-a657-0e3f8ea0bf8b",
"metadata": {},
"source": [
"Now we setup CDC from MongoDB to replicate the data SingleStore\n",
"\n",
"The collections to be replicated are specified as a comma separated or in a wildcard format in \"collection.include.list\""
- ]
+ ],
+ "id": "87444b9b"
},
{
"cell_type": "code",
"execution_count": 9,
- "id": "fb852b9c-51a6-4d8c-a4a2-f0cb6e78dc60",
"metadata": {},
"outputs": [],
"source": [
@@ -283,166 +282,166 @@
" \"mongodb.user\":\"mongo_sample_reader\",\n",
" \"mongodb.password\":\"SingleStoreRocks27017\"\n",
" }';"
- ]
+ ],
+ "id": "b84d21a8"
},
{
"cell_type": "code",
"execution_count": 10,
- "id": "ae958c77-2e84-4434-9dcd-205837bd5f02",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"CREATE TABLES AS INFER PIPELINE AS LOAD DATA LINK mongo '*' FORMAT AVRO;"
- ]
+ ],
+ "id": "4e58d374"
},
{
"cell_type": "code",
"execution_count": 11,
- "id": "32b32f1e-072b-4273-952b-6772b4a8e380",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SHOW PIPELINES"
- ]
+ ],
+ "id": "1f3b9fe9"
},
{
"cell_type": "code",
"execution_count": 12,
- "id": "3a91eefe-6d82-453b-8d3d-10344baae466",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"START ALL PIPELINES"
- ]
+ ],
+ "id": "2c088673"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "c0d54948-e440-43f7-963b-8d6b2c1b6129",
"metadata": {},
"source": [
"### Check for records in tables"
- ]
+ ],
+ "id": "8b6caff3"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "e45a1cb9-d884-4ac5-91dd-c8ded628bcb0",
"metadata": {},
"source": [
"Data from MySQL"
- ]
+ ],
+ "id": "3e469dab"
},
{
"cell_type": "code",
"execution_count": 13,
- "id": "c288f83a-9495-4baa-940f-9fe8400ab93b",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT COUNT(*) FROM transactions"
- ]
+ ],
+ "id": "44688a3d"
},
{
"cell_type": "code",
"execution_count": 14,
- "id": "f8604704-9324-4630-9eec-2c3f6be3c853",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM transactions WHERE transaction_type LIKE '%Deposit%' LIMIT 1;"
- ]
+ ],
+ "id": "d3fc1c14"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "0a39438a-a537-490e-9191-77c9b224bbb4",
"metadata": {},
"source": [
"Data from S3"
- ]
+ ],
+ "id": "37088621"
},
{
"cell_type": "code",
"execution_count": 15,
- "id": "5d26d20e-ef26-4d73-8a6a-060716e5f5ae",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT COUNT(*) FROM atm_locations"
- ]
+ ],
+ "id": "ed1670ee"
},
{
"cell_type": "code",
"execution_count": 16,
- "id": "62eced11-86b7-4c66-a7a8-ad197460e99d",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT * FROM atm_locations LIMIT 1;"
- ]
+ ],
+ "id": "367930d2"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "a06fc97a-59ec-4134-a3cf-016b39108374",
"metadata": {},
"source": [
"Data from MongoDB"
- ]
+ ],
+ "id": "2f11225d"
},
{
"cell_type": "code",
"execution_count": 17,
- "id": "40c77598-464b-4d91-b36e-89569e1ecb12",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"SELECT _id:>JSON, _more:>JSON FROM profile LIMIT 1;"
- ]
+ ],
+ "id": "0150f6bc"
},
{
"cell_type": "code",
"execution_count": 18,
- "id": "a4694186-b064-465f-9e4f-9a33b1d6ae76",
"metadata": {},
"outputs": [],
"source": [
"%%sql\n",
"\n",
"SELECT _id:>JSON, _more:>JSON FROM history LIMIT 1;"
- ]
+ ],
+ "id": "21fbf852"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "40ec6ef2-dd95-43b7-947a-16c80efc359a",
"metadata": {},
"source": [
"### Join tables from different sources using SQL queries"
- ]
+ ],
+ "id": "3f3dd776"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "3bfb62de-ae36-4824-881f-c858cb852c01",
"metadata": {},
"source": [
"SQL Query 1: View Users details, their associated ATMs"
- ]
+ ],
+ "id": "1e1ade40"
},
{
"cell_type": "code",
"execution_count": 19,
- "id": "9efacacd-b36e-4208-a360-3ca239d1fad3",
"metadata": {},
"outputs": [],
"source": [
@@ -460,21 +459,21 @@
"WHERE\n",
" p._more::$account_id = a.id\n",
"LIMIT 10;"
- ]
+ ],
+ "id": "9eb6e86c"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "2cce1897-681f-4136-807e-711ed78ed80b",
"metadata": {},
"source": [
"SQL Query 2: View Users details, their associated ATMs and transaction details"
- ]
+ ],
+ "id": "c8147f4a"
},
{
"cell_type": "code",
"execution_count": 20,
- "id": "82d52f1a-35e8-4f59-99ed-cbd65842f699",
"metadata": {},
"outputs": [],
"source": [
@@ -497,21 +496,21 @@
"LEFT JOIN\n",
" transactions t ON p._more::$account_id = t.account_id\n",
"LIMIT 10;"
- ]
+ ],
+ "id": "9baa53de"
},
{
"attachments": {},
"cell_type": "markdown",
- "id": "2fb24ac0-1579-4ddb-8009-efb36aaff2d6",
"metadata": {},
"source": [
"### Run queries in Mongo Query Language using Kai"
- ]
+ ],
+ "id": "ed30b745"
},
{
"cell_type": "code",
"execution_count": 21,
- "id": "d7f5fa93-473e-4e0b-96ca-e743cb75684d",
"metadata": {},
"outputs": [],
"source": [
@@ -527,12 +526,12 @@
"\n",
"for profile in profile_coll.find().limit(1):\n",
" pprint.pprint(profile)"
- ]
+ ],
+ "id": "42e097e7"
},
{
"cell_type": "code",
"execution_count": 22,
- "id": "dd303812-2ec2-4e84-b436-617591099a06",
"metadata": {},
"outputs": [],
"source": [
@@ -585,12 +584,12 @@
" ])\n",
"\n",
"print(table)"
- ]
+ ],
+ "id": "a3441786"
},
{
"cell_type": "code",
"execution_count": 23,
- "id": "00e2c386-2ae5-478d-be0a-c9c07005745e",
"metadata": {},
"outputs": [],
"source": [
@@ -604,12 +603,12 @@
"]\n",
"\n",
"pprint.pprint(list(profile_coll.aggregate(pipeline)))"
- ]
+ ],
+ "id": "fe24435f"
},
{
"cell_type": "code",
"execution_count": 24,
- "id": "a0e0be36-0605-426b-a84a-1c47bab2f7cb",
"metadata": {},
"outputs": [],
"source": [
@@ -623,19 +622,20 @@
"\n",
"plt.bar(country,count)\n",
"plt.plot()"
- ]
+ ],
+ "id": "1e919cbe"
},
{
"cell_type": "markdown",
- "id": "3636037e",
"metadata": {},
"source": [
"With SingleStore Kai you can power analytics on SQL and NoSQL data using the API of your choice"
- ]
+ ],
+ "id": "f05705e2"
},
{
+ "id": "2abf5b5f",
"cell_type": "markdown",
- "id": "32756572-0488-4ac0-bf10-1a47d84bc79f",
"metadata": {},
"source": [
"\n",
diff --git a/notebooks/vector-database-basics/notebook.ipynb b/notebooks/vector-database-basics/notebook.ipynb
index 519c81f3..960852c8 100644
--- a/notebooks/vector-database-basics/notebook.ipynb
+++ b/notebooks/vector-database-basics/notebook.ipynb
@@ -1,8 +1,8 @@
{
"cells": [
{
+ "id": "76ae2947",
"cell_type": "markdown",
- "id": "1794de89-5ae3-44d3-bfa6-3d41c4f4deba",
"metadata": {},
"source": [
"