An ongoing attempt at tying together various ML techniques for trending topic and sentiment analysis, coupled with some experimental Python async coding, a distributed architecture, EventSource and lots of Docker goodness.
I needed a readily available corpus for doing text analytics and sentiment analysis, so I decided to make one from my RSS feeds.
Things escalated quickly from there on several fronts:
- I decided I wanted this to be fully distributed, so I split the logic into several worker processes who coordinate via Redis queues, orchestrated (and deployed) using
docker-compose - I decided to take a ride on the bleeding edge and refactored everything to use
asyncio/uvloop(as well as Sanic for the web front-end) - Rather than just consuming cognitive APIs, I also decided to implement a few NLP processing techniques (I started with a RAKE keyword extractor, and am now looking at NLTK-based tagging)
- Instead of using React, I went with RiotJS, largely because I wanted to be able to deploy new visual components without a build step.
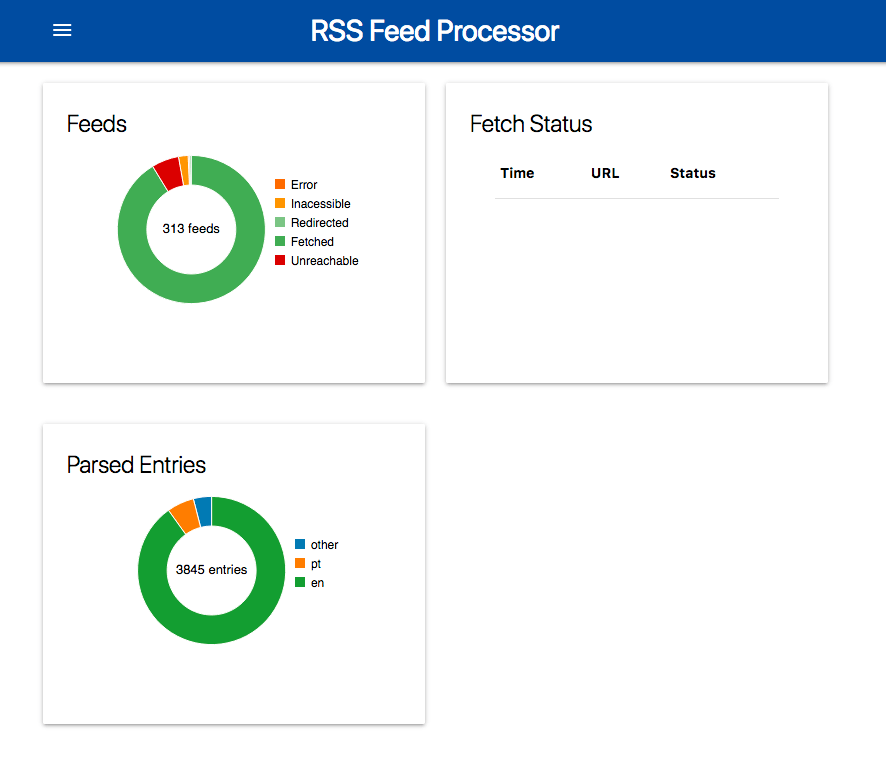
- I also started using this as a "complex" Docker/Kubernetes demo, which meant some flashy features (like a graphical dashboard) started taking precedence.
This was originally the "dumb" part of the pipeline -- the corpus was fed into Azure ML and the Cognitive Services APIs for the nice stuff, so this started out mostly focusing fetching, parsing and filing away feeds.
It's now a rather more complex beast than I originally bargained for. Besides acting as a technology demonstrator for a number of things (including odds and ends like how to bundle NLTK datasets inside Docker) it is currently pushing the envelope on my Python Docker containers, which now feature Python 3.6.3 atop Ubuntu LTS.
- move to billboard.js
- Add
auth0support - Move to Cosmos DB
-
import.pyis a one-shot OPML importer (you should place your ownfeeds.opmlin the root directory) -
metrics.pykeeps tabs on various stats and pushes them out every few seconds -
scheduler.pyiterates through the database and queues feeds for fetching -
fetcher.pyfetches feeds and stores them on DocumentDB/MongoDB -
parser.pyparses updated feeds into separate items and performs: [x] language detection [x] keyword extraction (usinglangkit.py) [ ] basic sentiment analysis -
cortana.py(WIP) will do topic detection and sentiment analysis -
web.pyprovides a simple web front-end for live status updates via SSE.
Processes are written to leverage asyncio/uvloop and interact via Redis (previously they interacted via ZeroMQ, but I'm already playing around with deploying this on Swarm and an Azure VM scaleset).
A Docker compose file is supplied for running the entire stack locally - you can tweak it up to version 3 and get things running on Swarm if you manually push the images to a private registry first, but I'll automate that once things are a little more stable.