-
|
I am wondering why the code for training only the last layer works, because it only passes the code: for param in model.parameters():
param.requires_grad = False
...
if args.trainable_layers == "last_layer":
pass
...I have set it more specifically, with the same results: for param in model.parameters():
param.requires_grad = False
...
if args.trainable_layers == "last_layer":
# Get the last layer
last_layer = list(model.children())[-1]
# Make the last layer trainable
for param in last_layer.parameters():
param.requires_grad = True
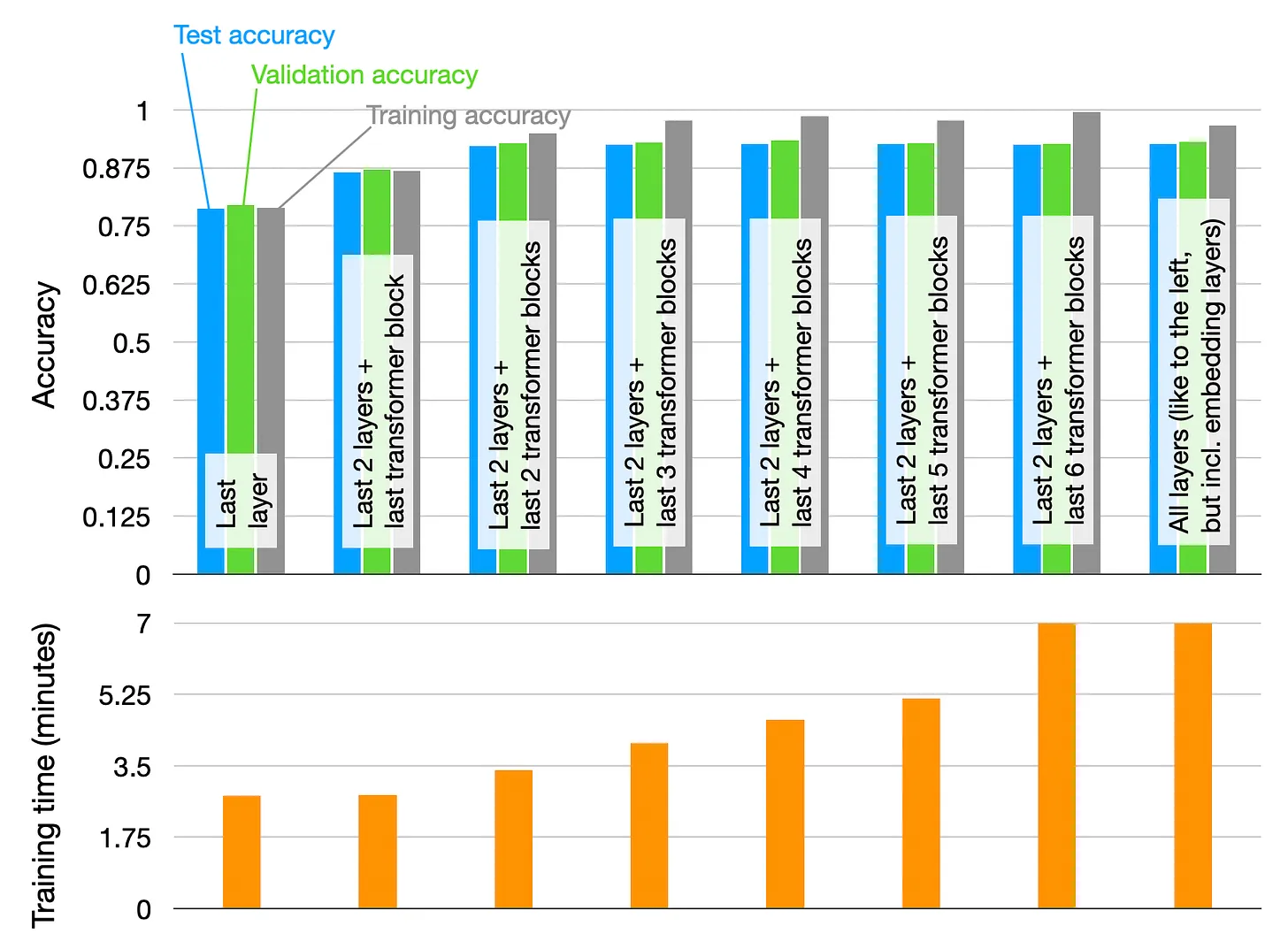
...What do you also think about adding test for the two last layers + two last transformer blocks, like from your article about finetuning LLMs: |
Beta Was this translation helpful? Give feedback.
Replies: 2 comments 13 replies
-
Oh that's simply because we first make all layers untrainable, and then we replace the last layer with |
Beta Was this translation helpful? Give feedback.
-
|
That's not a bad idea. I will put that on my list ... Right now, I need to finish chapter 7 (the deadline in 2.5 weeks 😅) |
Beta Was this translation helpful? Give feedback.
-
|
After the last chapter is done and submitted, I plan to add way more things here and there to the repo |
Beta Was this translation helpful? Give feedback.
-
|
Alright, thanks! 👍🏻 |
Beta Was this translation helpful? Give feedback.
-
|
And no worries, I am planning to add bonus material to the repo for a long time to come. Have such a long list of interesting things :). Big thanks to you by the way for all the invaluable feedback! I'll make sure you get a big shoutout in the Acknowledgements section! |
Beta Was this translation helpful? Give feedback.
-
|
Sounds great, and thanks for the shoutout! Looking forward to it! 🙂 |
Beta Was this translation helpful? Give feedback.
-
|
That was a good suggestion, the performance of the last two blocks is quite good! |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the implementation - yeah, the performance is a little better! 👍🏻 🙂 |
Beta Was this translation helpful? Give feedback.
Oh that's simply because we first make all layers untrainable, and then we replace the last layer with
nn.Linear, andnn.Linearis trainable by default. And that's becausenn.Linearusesnn.Parameter, which hasrequires_grad=Trueby default.