Releases: openzipkin/zipkin
Zipkin 2.16
Zipkin 2.16 includes revamps of two components, our Lens UI and our Elasticsearch storage implementation. Thanks in particular to @tacigar and @anuraaga who championed these two important improvements. Thanks also to all the community members who gave time to guide, help with and test this work! Finally, thanks to the Armeria project whose work much of this layers on.
If you are interested in joining us, or have any questions about Zipkin, join our chat channel!
Lens UI Revamp
As so much has improved in the Zipkin Lens UI since 2.15, let's look at the top 5, in order of top of screen to bottom. The lion's share of effort below is with thanks to @tacigar who has put hundreds of hours effort into this release.
To understand these, you can refer to the following images which annotate the number discussed. The first image in each section refers to 2.15 and the latter 2.16.2 (latest patch at the time)






1. Default search to 15minutes, not 1 hour, and pre-can 5 minute search
Before, we had an hour search default which unnecessarily hammers the backend. Interviewing folks, we realized that more often it is 5-15minutes window of interest when searching for traces. By changing this, we give back a lot of performance with zero tuning on the back end. Thanks @zeagord for the help implementing this.
2. Global search parameters apply to the dependency diagram
One feature of Expedia Haystack we really enjoy is the global search. This is where you can re-use context added by the user for trace queries, for other screens such as network diagrams. Zipkin 2.16 is the first version to share this, as before the feature was stubbed out with different controls.
3. Single-click into a trace
Before, we had a feature to preview traces by clicking on them. The presumed use case was to compare multiple traces. However, this didn't really work as you can't guarantee traces will be near eachother in a list. Moreover, large traces are not comparable this way. We dumped the feature for a simpler single-click into the trace similar to what we had before Lens. This is notably better when combined with network improvements described in 5. below.
4. So much better naming
Before, in both the trace list and also detail, names focused on the trace ID as opposed to what most are interested in (the top-level span name). By switching this out, and generally polishing the display, we think the user interface is a lot more intuitive than before.
5. Fast switching between Trace search and detail screen.
You cannot see 5 unless you are recording, because the 5th is about network performance. Lens now shares data between the trace search and the trace detail screen, allowing you to quickly move back and forth with no network requests and reduced rendering overhead.


Elasticsearch client refactor
Our first Elasticsearch implementation allowed requests to multiple HTTP endpoints to failover on error. However, it did not support multiple HTTPS endpoints, nor any load balancing features such round-robin or health checked pools.
For over two years, Zipkin sites have asked us to support sending data to an Elasticsearch cluster of multiple https endpoints. While folks have been patient, workarounds such as "setup a load balancer", or change your hostnames and certificates, have not been received well. It was beyond clear we needed to do the work client-side. Now, ES_HOSTS can take a list of https endpoints.
Under the scenes, any endpoints listed receive periodic requests to /_cluster/health. Endpoints that pass this check receive traffic in a round-robin fashion, while those that don't are marked bad. You can see detailed status from the Prometheus endpoint:
$ curl -sSL localhost:9411/prometheus|grep ^armeria_client_endpointGroup_healthy
armeria_client_endpointGroup_healthy{authority="search-zipkin-2rlyh66ibw43ftlk4342ceeewu.ap-southeast-1.es.amazonaws.com:443",ip="52.76.120.49",name="elasticsearch",} 1.0
armeria_client_endpointGroup_healthy{authority="search-zipkin-2rlyh66ibw43ftlk4342ceeewu.ap-southeast-1.es.amazonaws.com:443",ip="13.228.185.43",name="elasticsearch",} 1.0Note: If you wish to disable health checks for any reason, set zipkin.storage.elasticsearch.health-check.enabled=false using any mechanism supported by Spring Boot.
The mammoth of effort here is with thanks to @anuraaga. Even though he doesn't use Elasticsearch anymore, he volunteered a massive amount of time to ensure everything works end-to-end all the way to prometheus metrics and client-side health checks. A fun fact is Rag also wrote the first Elasticsearch implementation! Thanks also to the brave who tried early versions of this work, including @jorgheymans, @jcarres-mdsol and stanltam
If you have any feedback on this feature, or more questions about us, please reach out on gitter
Test refactoring
Keeping the project going is not automatic. Over time, things take longer because we are doing more, testing more, testing more dimensions. We ran into a timeout problem in our CI server. Basically, Travis has an absolute time of 45 minutes for any task. When running certain integration tests, and publishing at the same time, we were hitting near that routinely, especially if the build cache was purged. @anuraaga did a couple things to fix this. First, he ported the test runtime from classic junit to jupiter, which allows more flexibility in how things are wired. Then, he scrutinized some expensive cleanup code, which was unnecessary when consider containers were throwaway. At the end of the day, this bought back 15 minutes for us to.. later fill up again 😄 Thanks, Rag!
Small changes
- We now document instructions for custom certificates in Elasticsearch.
- We now document the behaviour of in-memory storage thanks @jorgheymans
- We now have consistent COLLECTOR_X_ENABLED variables to turn off collectors explicitly thanks @jeqo
Background on Elasticsearch client migration
The OkHttp java library is everywhere in Zipkin.. first HTTP instrumentation in Brave, the encouraged way to report spans, and relevant to this topic, even how we send data to Elasticsearch!
For years, the reason we didn't support multiple HTTPS endpoints was the feature we needed was on OkHttp backlog. This is no criticism of OkHttp as it is both an edge case feature, and there are ways including layering a client-side load balancer on top. This stalled out for lack of volunteers to implement the OkHttp side or an alternative. Yet, people kept asking for the feature!
We recently moved our server to Armeria, resulting in increasing stake, experience and hands to do work. Even though its client side code is much newer than OkHttp, it was designed for advanced features such as client-side load balancing. The idea of re-using Armeria as an Elasticsearch client was interesting to @anuraaga, who volunteered both ideas and time to implement them. The result was a working implementation complete with client-side health checking, supported by over a month of Rag's time.
The process of switching off OkHttp taught us more about its elegance, and directly influenced improvements in Armeria. For example, Armeria's test package now includes utilities inspired by OkHttp's MockWebServer.
What we want to say is.. thanks OkHttp! Thanks for the formative years of our Elasticsearch client and years ahead as we use OkHttp in other places in Zipkin. Keep up the great work!
Zipkin 2.15
ActiveMQ 5.x span transport
Due to popular demand, we've added support for ActiveMQ 5.x. Zipkin server will connect to ActiveMQ when the env variable ACTIVEMQ_URL is set to a valid broker. Thanks very much to @IAMTJW for work on this feature and @thanhct for testing it against AWS MQ.
Ex. simple usage against a local broker
ACTIVEMQ_URL=tcp://localhost:61616 java -jar zipkin.jarEx. usage with docker against a remote AWS MQ failover group
docker run -d -p 9411:9411 -e ACTIVEMQ_URL='failover:(ssl://b-da18ebe4-54ff-4dfc-835f-3862a6c144b1-1.mq.ap-southeast-1.amazonaws.com:61617,ssl://b-da18ebe4-54ff-4dfc-835f-3862a6c144b1-2.mq.ap-southeast-1.amazonaws.com:61617)' -e ACTIVEMQ_USERNAME=zipkin -e ACTIVEMQ_PASSWORD=zipkin12345678 -e ACTIVEMQ_CONCURRENCY=8 openzipkin/zipkinRewrite of Zipkin Lens global search component
One of the most important roles in open source is making sure the project is maintainable. As features were added in our new UI, maintainability started to degrade. Thanks to an immense amount of effort by @tacigar, we now have new, easier to maintain search component. Under the covers, it is implemented in Material-UI and React Hooks.

Behind the crisp new look is clean code that really helps the sustainability of our project. Thanks very much to @tacigar for his relentless attention.
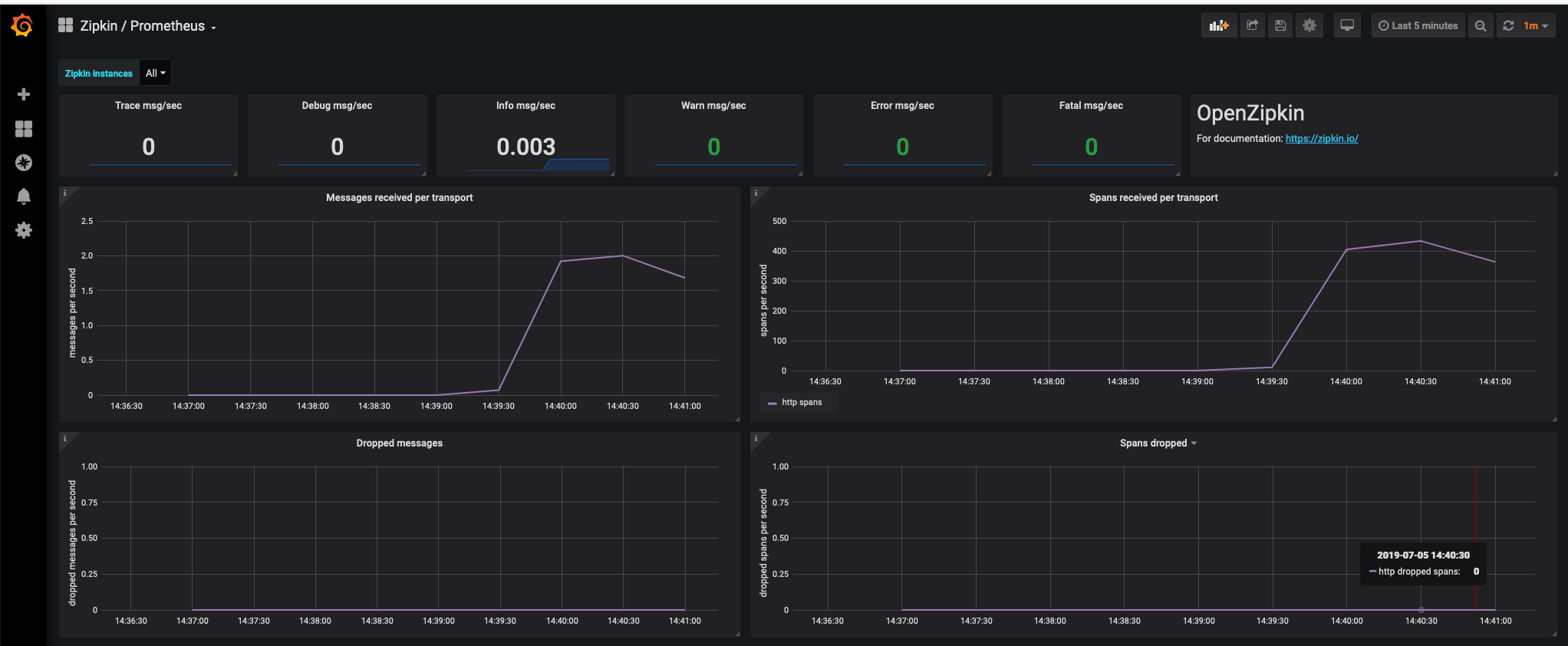
Refreshed Grafana Dashboard
While many have tried our Grafana dashboard either directly or via our docker setup, @mstaalesen really dug deep. He noticed some things drifted or were in less than ideal places. Through a couple weeks of revision, we now have a tighter dashboard. If you have suggestions, please bring them to Gitter as well!
Small, but appreciated fixes
- Fixes a bug where a Java 8 class could be accidentally loaded when in Java 1.7
- Ensures special characters are not used in RabbitMQ consumer tags (thx @bianxiaojin)
- Shows connect exceptions when using RabbitMQ (thx @thanhct)
- Fixes glitch where health check wasn't reported properly when throttled (thx @lambcode)
Zipkin 2.14
Zipkin 2.14 adds storage throttling and Elasticsearch 7 support. We've also improved efficiency around span collection and enhanced the UI. As mentioned last time, this release drops support for Elasticsearch v2.x and Kafka v0.8.x. Here's a run-down of what's new.
Storage Throttling (Experimental)
How to manage surge problems in collector architecture is non-trivial. While we've collected resources for years about this, only recently we had a champion to take on some mechanics in practical ways. @Logic-32 fleshed out concerns in collector surge handling and did an excellent job evaluating options for those running pure http sites.
Towards that end, @Logic-32 created an experimental storage throttling feature (bundled for your convenience). When STORAGE_THROTTLE_ENABLED=true calls to store spans pay attention to storage errors and adjust backlog accordingly. Under the hood, this uses Netfix concurrency limits.
Craig tested this at his Elasticsearch site, and it resulted in far less dropped spans than before. If you are interested in helping test this feature, please see the configuration notes and join gitter to let us know how it works for you.
Elasticsearch 7.x
Our server now supports Elasticsearch 6-7.x formally (and 5.x as best efforts). Most notably, you'll no longer see colons in your index patterns if using Elasticsearch 7.x. Thank to @making and @chefky for the early testing of this feature as quite a lot changed under the hood!
Lens UI improvements
@tacigar continues to improve Lens so that it can become the default user interface. He's helped tune the trace detail screen, notably displaying the minimap more intuitively based on how many spans are in the trace. You'll also notice the minimap has a slider now, which can help stabilize the area of the trace you are investigating.

Significant efficiency improvements
Our Armeria collectors (http and grpc) now work natively using pooled buffers as opposed to byte arrays with renovated protobuf parsers. The sum this is more efficient trace collection when using protobuf encoding. Thanks very much to @anuraaga for leading and closely reviewing the most important parts of this work.
No more support for Elasticsearch 2.x and Kafka 0.8.x
We no longer support Elasticsearch 2.x or Kafka 0.8.x. Please see advice mentioned in our last release if you are still on these products.
Scribe is now bundled (again)
We used to bundle Scribe (Thrift RPC span collector), but eventually moved it to a separate module due to it being archived technology with library conflicts. Our server is now powered by Armeria, which natively supports thrift. Thanks to help from @anuraaga, the server has built-in scribe support for those running legacy applications. set SCRIBE_ENABLED=true to use this.
Other notable updates
- Elasticsearch span documents are written with ID
${traceID}-${MD5(json)}to allow for server-side deduplication - Zipkin Server is now using the latest Spring Boot 2.1.5 and Armeria 0.85.0
Zipkin 2.13.0
Zipkin 2.13 includes several new features, notably a gRPC collection endpoint and remote service name indexing. Lens, our new UI, is fast approaching feature parity, which means it will soon be default. End users should note this is the last release to support Elasticsearch v2.x and Kafka v0.8.x. Finally, this our first Apache Incubating release, and we are thankful to the community's support and patience towards this.
Lens UI Improvements
Led by @tacigar, Lens has been fast improving. Let's look at a couple recent improvements: Given a trace ID or json, the page will load what you want.
Open trace json

Go to trace ID

Right now, you can opt-in to Lens by clicking a button. The next step is when Lens is default and finally when the classic UI is deleted. Follow the appropriate projects for status on this.
gRPC Collection endpoint
Due to popular demand, we now publish a gRPC endpoint /zipkin.proto3.SpanService/Report which accepts the same protocol buffers ListOfSpans message as our POST /api/v2/spans endpoint. This listens on the same port as normal http traffic when COLLECTOR_GRPC_ENABLED=true. We will enable this by default after the feature gains more experience.
We chose to publish a unary gRPC endpoint first, as that is most portable with limited clients such as grpc-web. Our interop tests use the popular Android and Java client Square Wire. Special thanks to @ewhauser for leading this effort and @anuraaga who championed much of the work in Armeria.
Remote Service Name indexing
One rather important change in v2.13 is remote service name indexing. This means that the UI no longer confuses local and remote service name in the same drop-down. The impact is that some sites will have much shorter and more relevant drop-downs, and more efficient indexing. Here are some screen shots from Lens and Classic UIs:


Schema impact
We have tests to ensure the server can be upgraded ahead of schema change. Also, most storage types have the ability to automatically upgrade the schema. Here are relevant info if you are manually upgrading:
STORAGE_TYPE=cassandra
If you set CASSANDRA_ENSURE_SCHEMA=false, you are opting out of automatic schema management. This means you need to execute these CQL commands manually to update your keyspace
STORAGE_TYPE=cassandra3
If you set CASSANDRA_ENSURE_SCHEMA=false, you are opting out of automatic schema management. This means you need to execute these CQL commands manually to update your keyspace
STORAGE_TYPE=elasticsearch
No index changes were needed
STORAGE_TYPE=mysql
Logs include the following message until instructions are followed:
zipkin_spans.remote_service_name doesn't exist, so queries for remote service names will return empty.
Execute: ALTER TABLE zipkin_spans ADD `remote_service_name` VARCHAR(255);
ALTER TABLE zipkin_spans ADD INDEX `remote_service_name`;
Dependency group ID change
For those using Maven to download, note that the group ID for libraries changed from "io.zipkin.zipkin2" to "org.apache.zipkin.zipkin2". Our server components group ID changed from "io.zipkin.java" to "org.apache.zipkin"
This is the last version to support Elasticsearch 2.x
Elastic's current support policy is latest major version (currently 7) and last minor (currently 6.7). This limits our ability to support you. For example, Elasticsearch's hadoop library is currently broken for versions 2.x and 5.x making our dependencies job unable to work on that range and also work on version 7.x.
Our next release will support Elasticsearch 7.x, but we have to drop Elasticsearch 2.x support. Elasticsearch 5.x will be best efforts. We advise users to be current with Elastic's supported version policy, to avoid being unable to upgrade Zipkin.
This is the last version to support Kafka 0.8x
This is the last release of Zipkin to support connecting to a Kafka 0.8 broker (last release almost 4 years ago). Notably, this means those using KAFKA_ZOOKEEPER to configure their broker need to switch to KAFKA_BOOTSTRAP_SERVERS instead.
Other notable updates
- Zipkin Server is now using the latest Spring boot 2.1.4
Zipkin 2.12.6
Zipkin 2.12.6 migrates to the Armeria http engine. We also move to Distroless to use JRE 11 in our docker images.
Interest in Armeria 3 years ago originated at LINE, a long time supporter of Zipkin. This was around its competency in http/2 and asynchronous i/o. Back then, we were shifting towards a more modular server so that they could create their own. Over time, interest and our use case for Armeria grown. Notably, @ewhauser has led an interest in a gRPC endpoint for zipkin. Typically, people present different listen ports for gRPC, but Armeria allows the same engine to be used for both usual web requests and also gRPC. Moreover, now more than ever LINE, the team behind Armeria are involved deeply in our community, as are former LINE engineers like @anuraaga. So, we had a match of both supply and demand for the technology.
End users will see no difference in Zipkin after we replaced the http engine. Observant administrators will notice some of the console lines being a bit different. The whole experience has been drop-in thanks to spring boot integration efforts led by @anuraaga @trustin and @hyangtack. For those interested in the technology for their own apps, please check out Armeria's example repository.
There's more to making things like http/2 work well than the server framework code. For example, there is nuance around OpenSSL which isn't solved well until newer runtimes. For a long time, we used alpine JRE 1.8 because some users were, justifiably or not, very concerned about the size of our docker image. As years passed, we kept hitting fragile setup concerns around OpenSSL. This would play out as bad releases of stackdriver integration, as that used gRPC. As we owe more service to users than perceptions around dist sizes, we decided it appropriate to move a larger, but still slim distroless JRE 11 image.
The MVP of all of this is @anuraaga, the same person who made an armeria zipkin server at LINE 3 years ago, who today backfilled functionality where needed, and addressed the docker side of things. Now, you can use this more advanced technology without thinking. Thank you, Rag!
2.12.4 DO NOT USE
This version returned corrupt data under /prometheus (/actuator/prometheus). Do not use it
Zipkin 2.12.3
Zipkin 2.12.3 provides an easy way to preview Lens, our new user interface.
Introduction to Zipkin Lens
Zipkin was open sourced by Twitter in 2012. Zipkin was the first OSS distributed tracing system shipped complete with instrumentation and a UI. This "classic" UI persisted in various forms for over six years before Lens was developed. We owe a lot of thanks to the people who maintained this, as it is deployed in countless sites. We also appreciate alternate Zipkin UIs attempts, and the work that went into them. Here are milestones in the classic UI, leading to Lens.
- Mid 2012-2015 - Twitter designed and maintained Zipkin UI
- Early 2016 - Eirik and Zoltan team up to change UI code and packaging from scala to pure javascript
- Late 2016 - Roger Leads Experimental Angular UI
- Late 2017 to Early 2018 - Mayank Leads Experimental React UI
- Mid to Late 2018 - Raja renovates classic UI while we investigate options for a standard React UI
- December 7, 2018 - LINE contributes their React UI as Zipkin Lens
- Early 2019 - Igarashi and Raja complete Zipkin Lens with lots of usage feedback from Daniele
Lens took inspiration from other UIs, such as Haystack, and cited that influence. You'll notice using it that it has a feel of its own. Many thanks to the design lead Igarashi, who's attention to detail makes Lens a joy to use. Some design goals were to make more usable space, as well be able to assign site-specific details, such as tags. Lens is not complete in its vision. However, it has feature parity to the point where broad testing should occur.

Trying out Lens
We spend a lot of time and effort in attempts to de-risk trying new things. Notably, the Zipkin server ships with both the classic and the Lens UI, until the latter is complete. With design help from @kaiyzen and @bsideup, starting with Zipkin 2.12.3, end users can select the UI they prefer at runtime. All that's needed is to press the button "Try Lens UI", which reloads into the new codebase. There's then a button to revert: "Go back to classic Zipkin".
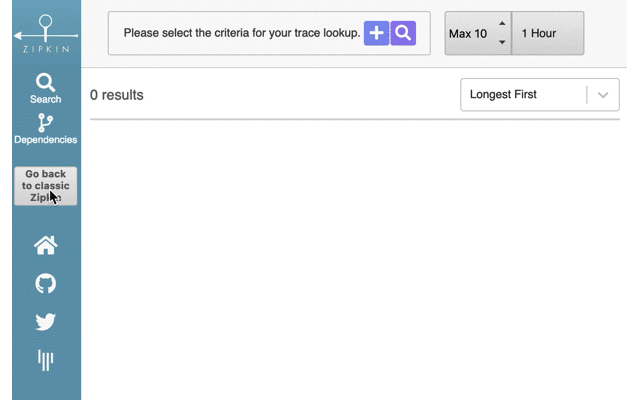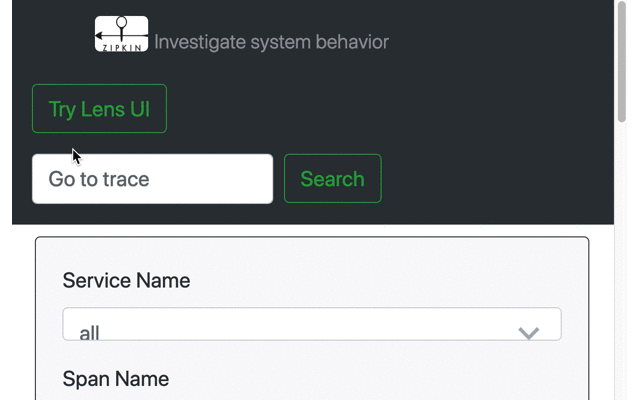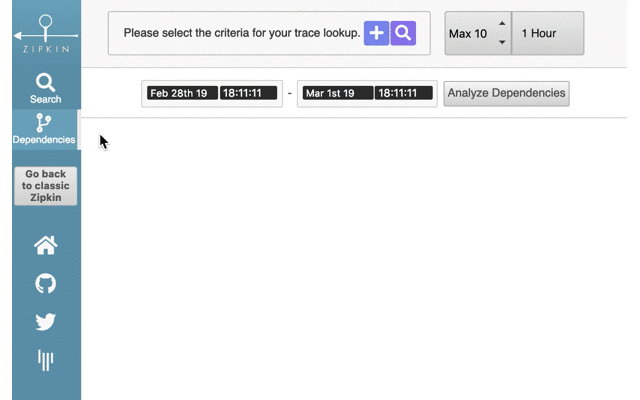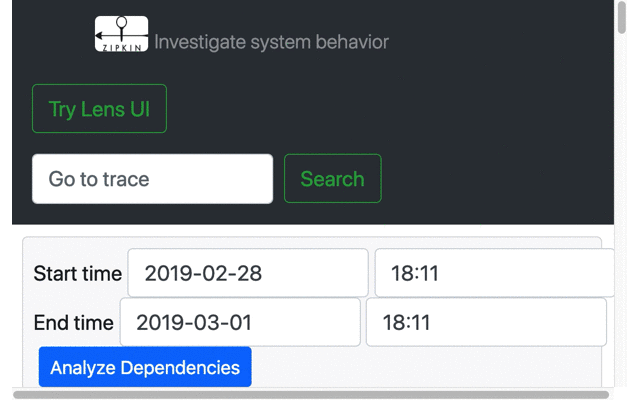
Specifically the revert rigor was thanks to Tommy and Daniele who insisted on your behalf that giving a way out is as important as the way in. We hope you feel comfortable letting users try Lens now. If you want to prevent that, you can: set the variable ZIPKIN_UI_SUGGEST_LENS=false.
Auto-complete Keys
One design goal of Lens was to have it better reflect the priority of sites. The first work towards that is custom search criteria via auto-completion keys defined by your site. This was inspired by an alternative to Lens, Haystack UI, which has a similar "universal search" feature. Many thanks to Raja who put in ground work on the autocomplete api and storage integration needed by this feature. Thanks to Igarashi for developing the user interface in Lens for it.
To search by site-specific tags, such as environment names, you first need to tell Zipkin which keys you want. Start your zipkin servers with an environment variable like below that includes keys whitelisted from Span.tags. Note that keys you list should have a fixed set of values. In other words, do not use keys that have thousands of values.
AUTOCOMPLETE_KEYS=client_asg_name,client_cluster_name,service_asg_name,service_cluster_name java -jar zipkin.jarHere's a screen shot of custom auto-completion, using an example trace from Netflix.

Feedback
Maintaining two UIs is a lot of burden on Zipkin volunteers. We want to transition to Lens as soon as it is ready. Please upgrade and give feedback on Gitter as you use the tool. With luck, in a month or two we will be able to complete the migration, and divert the extra energy towards new features you desire, maybe with your help implementing them! Thanks for the attention, and as always star our repo, if you think we are doing a good job for open source tracing!
Zipkin 2.11.1
Zipkin 2.11
Zipkin 2.11 dramatically improves Cassandra 3 indexing and fixes some UI glitches
Cassandra 3 indexing
We've had cassandra3 storage type for a while, which uses SASI indexing. One thing @Mobel123 noticed was particular high disk usage for indexing tags. This resulted in upstream work in cassandra to introduce a new indexing option which results in 20x performance for the type of indexing we use.
See #1948 for details, but here are the notes:
- You must upgrade to Cassandra 3.11.3 or higher first
- Choose a path for dealing with the old indexes
- easiest is re-create your keyspace (which will drop trace data)
- advanced users can run zipkin2-schema-indexes.cql, which will leave the data alone but recreate the index
- Update your zipkin servers to latest patch (2.11.1+)
Any questions, find us on gitter!
Thanks very much @michaelsembwever for championing this, and @llinder for review and testing this before release. Thanks also to the Apache Cassandra project for accepting this feature as it is of dramatic help!
UI fixes
@zeagord fixed bugs relating to custom time queries. @drolando helped make messages a little less scary when search is disabled. Zipkin's UI is a bit smaller as we've updated some javascript infra which minimizes better. This should reduce initial load times. Thanks tons for all the volunteering here!
Zipkin 2.10 completes our v2 migration
Zipkin 2.10 drops v1 library dependency and http read endpoints. Those using the io.zipkin.java:zipkin (v1) java library should transition to io.zipkin.zipkin2:zipkin as the next release of Zipkin will stop publishing updates to the former. Don't worry: Zipkin server will continue accepting all formats, even v1 thrift, for the foreseeable future.
Below is a story of our year long transition to a v2 data format, ending with what we've done in version 2.10 of our server (UI in nature). This is mostly a story of how you address an big upgrade in a big ecosystem when almost all are volunteers.
Before a year ago, the OpenZipkin team endured (and asked ourselves) many confused questions about our thrift data format. Why do service endpoints repeat all the time? What are binary annotations? What do we do if we have multiple similar events or binary annotations? Let's dig into the "binary annotation" as probably many reading still have no idea!
Binary annotations were a sophisticated tag, for example an http status. While the name is confusing, most problems were in being too flexible and this led to bugs. Specifically it was a list of elements with more type diversity than proved useful. While a noble aim, and made sense at the time, binary annotations could be a string, binary, various bit lengths of integer or floating point numbers. Even things that seem obvious could be thwarted. For example, some would accidentally choose the type binary for string, effectively disabling search. Things seemingly simple like numbers were bug factories. For example, folks would add random numbers as an i64, not thinking that you can't fit one in a json number without quoting or losing precision. Things that seemed low-hanging fruit were not. Let's take http status for example. Clearly, this is a number, but which? Is it a 16bit (technically correct) or is it a 32 bit (to avoid signed misinterpretation)? Could you search on it the way you want to (<200 || >299 && !404)? Tricky right? Let's say someone sent it as a different type by accident.. would it mess up your indexing if sent as a string (definitely some will!)? Even if all of this was solved, Zipkin is an open ecosystem including private sites with their private code. How much time does it cost volunteers to help others troubleshoot code that can't be shared? How can we reduce support burden while remaining open to 3rd party instrumentation?
This is a long winded story of how our version 2 data format came along. We cleaned up our data model, simplifying as an attempt to optimize reliability and support over precision. For example, we scrapped "binary annotation" for "tags". We don't let them repeat or use numeric types. There are disadvantages to these choices, but explaining them is cheap and the consequences are well understood. Last July, we started accepting a version 2 json format. Later, we added a protobuf representation.
Now, why are we talking about a data format supported a year ago? Because we just finished! It takes a lot of effort to carefully roll something out into an ecosystem as large as Zipkin's and being respectful of the time impact to our volunteers and site owners.
At first, we ingested our simplified format on the server side. This would "unlock" libraries, regardless of how they are written, and who wrote them, into simpler data.. data that much resembles tracing operations themselves. We next focused on libraries to facilitate sending and receiving data, notably brown field changes (options) so as to neither disrupt folks, nor scare them off. We wanted the pipes that send data to become "v2 ready" so owners can simultaneously use new and old formats, rather than expect an unrealistic synchronous switch of data format. After this, we started migrating our storage and collector code, so that internal functionality resemble v2 constructs even while reading or writing old data in old schemas. Finally, in version 2.10, we changed the UI to consume only v2 data.
So, what did the UI change include? What's interesting about that? Isn't the UI old? Let's start with the last question. While true the UI has only had facelifts and smaller visible features, there certainly has been work involved keeping it going. For example, backporting of tests, restructuring its internal routing, adding configuration hooks or integration patterns. When you don't have UI staff, keeping things running is what you end up spending most time on! More to the point, before 2.10, all the interesting data conversion and processing logic happened in Java, on the api server. For example, merging of data, correcting clock shifts etc. This setup a hard job for those emulating zipkin.. at least those who emulated the read side. Custom read api servers or proxies can be useful in practice. Maybe you need to stitch in authorization or data filtering logic.. maybe your data is segmented.. In short, while most read scenarios are supported out-of-box, some advanced proxies exist for good reason.
Here's a real life example: Yelp saves money by not sending trace data across paid links. For example, in Amazon's cloud (and most others), if you send data from one availability zone to another, you will pay for that. To reduce this type of cost, Yelp uses an island + aggregator pattern to save trace data locally, but materialize traces across zones when needed. In their site, this works particularly well as search doesn't use Zipkin anyway: they use a log based tool to find trace IDs. Once they find a trace ID, they use Zipkin to view it.. but still.. doing so requires data from all zones. To solve this, they made an aggregating read proxy. Before 2.10, it was more than simple json re-bundling. They found that our server did things like merging rules and clock skew correction. This code is complex and also high maintenance, but was needed for the UI to work correctly. Since v2.10 moves this to UI javascript, Yelp's read proxy becomes much simpler and easier to maintain. In summary, having more logic in the UI means less work for those with DIY api servers.
Another advantage of having processing logic in the UI is better answering "what's wrong with this trace?" For example, we know data can be missing or incorrect. When processing is done server-side, there is friction in deciding how to present errors. Do you decorate the trace with synthetic data, or use headers, or some enveloping? If instead that code was in the UI, such decisions are more flexible and don't impact the compatibility of others. While we've not done anything here yet, you can imagine it is easier to show, like color or otherwise, that you are viewing "a bad trace". Things like this are extremely exciting, given our primary goals are usually to reduce the cost of support!
In conclusion, we hope that by sharing our story, you have better insight into the OpenZipkin way of doing things, how we prioritize tasks, and how seriously we take support. If you are a happy user of Zipkin, find a volunteer who's helped you and thank them, star our repository, or get involved if you can. You can always find us on Gitter.