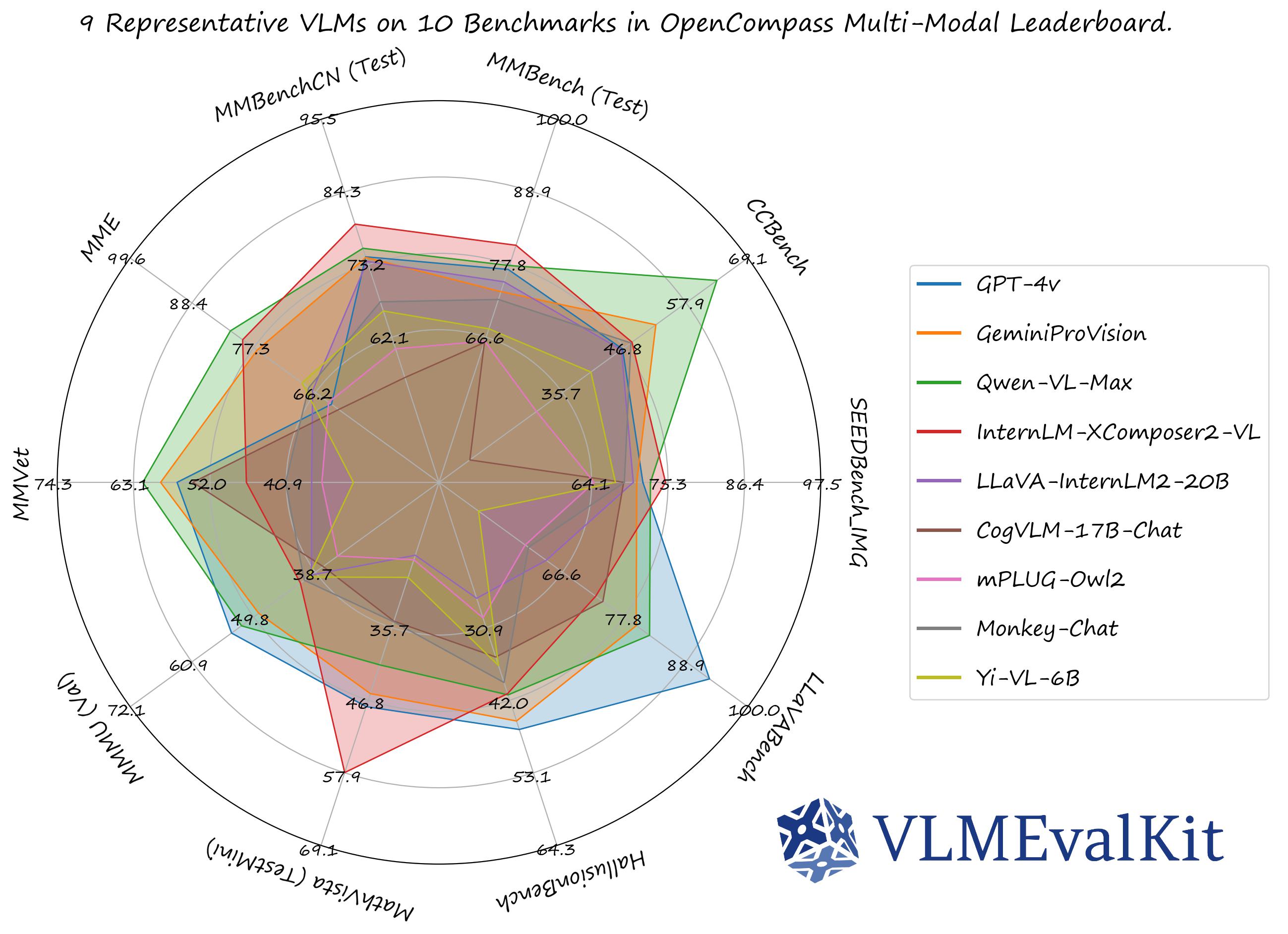





VLMEvalKit (python 包名为 vlmeval) 是一款专为大型视觉语言模型 (Large Vision-Language Models, LVLMs) 评测而设计的开源工具包。该工具支持在各种基准测试上对大型视觉语言模型进行一键评估,无需进行繁重的数据准备工作,让评估过程更加简便。在 VLMEvalKit 中,我们对所有大型视觉语言模型生成的结果进行评测,并提供基于精确匹配与基于 LLM 的答案提取两种评测结果。
- [2024-11-21] 集成了一个新的配置系统,以实现更灵活的评估设置。查看文档或运行
python run.py --help了解更多详情 🔥🔥🔥 - [2024-11-21] 支持 QSpatial,一个用于定量空间推理的多模态基准(例如,确定大小/距离),感谢 andrewliao11 提供官方支持 🔥🔥🔥
- [2024-11-21] 支持 MM-Math,一个包含约6K初中多模态推理数学问题的新多模态数学基准。GPT-4o-20240806在该基准上达到了22.5%的准确率 🔥🔥🔥
- [2024-11-16] 支持 OlympiadBench,一个多模态基准,包含奥林匹克级别的数学和物理问题 🔥🔥🔥
- [2024-11-16] 支持 WildVision,一个基于多模态竞技场数据的主观多模态基准 🔥🔥🔥
- [2024-11-13] 支持 MIA-Bench,一个多模态指令跟随基准 🔥🔥🔥
- [2024-11-08] 支持 Aria,一个多模态原生 MoE 模型,感谢 teowu 🔥🔥🔥
- [2024-11-04] 支持 WorldMedQA-V,该基准包含 1000 多个医学 VQA 问题,涵盖巴西、以色列、日本、西班牙等四个国家的语言,以及它们的英文翻译 🔥🔥🔥
- [2024-11-01] 支持
AUTO_SPLIT标志 (https://github.com/open-compass/VLMEvalKit/pull/566),用于在低配置 GPU 上进行评估。设置后,模型将自动拆分到多个 GPU(流水线并行)以减少 GPU 内存使用(目前仅支持部分 VLMs:Qwen2-VL、Llama-3.2、LLaVA-OneVision 等) 🔥🔥🔥 - [2024-10-30] 支持评估 MLVU 和 TempCompass。这两个基准将很快被纳入 OpenVLM 视频排行榜 🔥🔥🔥
请参阅快速开始获取入门指南。
OpenVLM Leaderboard: 下载全部细粒度测试结果.
- 默认情况下,我们在 OpenVLM Leaderboard 提供全部测试结果
- 使用的缩写:
MCQ: 单项选择题;Y/N: 正误判断题;MTT: 多轮对话评测;MTI: 多图输入评测 -
Dataset Dataset Names (for run.py) Task Dataset Dataset Names (for run.py) Task MMBench Series:
MMBench, MMBench-CN, CCBenchMMBench_DEV_[EN/CN]
MMBench_TEST_[EN/CN]
MMBench_DEV_[EN/CN]_V11
MMBench_TEST_[EN/CN]_V11
CCBenchMCQ MMStar MMStar MCQ MME MME Y/N SEEDBench Series SEEDBench_IMG
SEEDBench2
SEEDBench2_PlusMCQ MM-Vet MMVet VQA MMMU MMMU_[DEV_VAL/TEST] MCQ MathVista MathVista_MINI VQA ScienceQA_IMG ScienceQA_[VAL/TEST] MCQ COCO Caption COCO_VAL Caption HallusionBench HallusionBench Y/N OCRVQA* OCRVQA_[TESTCORE/TEST] VQA TextVQA* TextVQA_VAL VQA ChartQA* ChartQA_TEST VQA AI2D AI2D_[TEST/TEST_NO_MASK] MCQ LLaVABench LLaVABench VQA DocVQA+ DocVQA_[VAL/TEST] VQA InfoVQA+ InfoVQA_[VAL/TEST] VQA OCRBench OCRBench VQA RealWorldQA RealWorldQA MCQ POPE POPE Y/N Core-MM- CORE_MM (MTI) VQA MMT-Bench MMT-Bench_[VAL/ALL]
MMT-Bench_[VAL/ALL]_MIMCQ (MTI) MLLMGuard - MLLMGuard_DS VQA AesBench+ AesBench_[VAL/TEST] MCQ VCR-wiki + VCR_[EN/ZH]_[EASY/HARD]_[ALL/500/100] VQA MMLongBench-Doc+ MMLongBench_DOC VQA (MTI) BLINK BLINK MCQ (MTI) MathVision+ MathVision
MathVision_MINIVQA MT-VQA MTVQA_TEST VQA MMDU+ MMDU VQA (MTT, MTI) Q-Bench1 Q-Bench1_[VAL/TEST] MCQ A-Bench A-Bench_[VAL/TEST] MCQ DUDE+ DUDE VQA (MTI) SlideVQA+ SLIDEVQA
SLIDEVQA_MINIVQA (MTI) TaskMeAnything ImageQA Random+ TaskMeAnything_v1_imageqa_random MCQ MMMB and Multilingual MMBench+ MMMB_[ar/cn/en/pt/ru/tr]
MMBench_dev_[ar/cn/en/pt/ru/tr]
MMMB
MTL_MMBench_DEV
PS: MMMB & MTL_MMBench_DEV
are all-in-one names for 6 langsMCQ A-OKVQA+ A-OKVQA MCQ MuirBench+ MUIRBench MCQ GMAI-MMBench+ GMAI-MMBench_VAL MCQ TableVQABench+ TableVQABench VQA MME-RealWorld+ MME-RealWorld[-CN] MCQ HRBench+ HRBench[4K/8K] MCQ MathVerse+ MathVerse_MINI
MathVerse_MINI_Vision_Only
MathVerse_MINI_Vision_Dominant
MathVerse_MINI_Vision_Intensive
MathVerse_MINI_Text_Lite
MathVerse_MINI_Text_DominantVQA AMBER+ AMBER Y/N CRPE+ CRPE_[EXIST/RELATION] VQA MMSearch $$^1$$ - - R-Bench+ R-Bench-[Dis/Ref] MCQ WorldMedQA-V+ WorldMedQA-V MCQ GQA+ GQA_TestDev_Balanced VQA MIA-Bench+ MIA-Bench VQA WildVision+ WildVision VQA OlympiadBench OlympiadBench VQA
* 我们只提供了部分模型上的测试结果,剩余模型无法在 zero-shot 设定下测试出合理的精度
+ 我们尚未提供这个评测集的测试结果
- VLMEvalKit 仅支持这个评测集的推理,无法输出最终精度
如果您设置了 API KEY,VLMEvalKit 将使用一个 LLM 从输出中提取答案进行匹配判断,否则它将使用精确匹配模式 (直接在输出字符串中查找“yes”,“no”,“A”,“B”,“C”等)。精确匹配只能应用于是或否任务和多选择任务
| Dataset | Dataset Names (for run.py) | Task | Dataset | Dataset Names (for run.py) | Task |
|---|---|---|---|---|---|
| MMBench-Video | MMBench-Video | VQA | Video-MME | Video-MME | MCQ |
| MVBench | MVBench/MVBench_MP4 | MCQ | MLVU | MLVU | MCQ & VQA |
| TempCompass | TempCompass | MCQ & Y/N & Caption |
API 模型
| GPT-4v (20231106, 20240409) 🎞️🚅 | GPT-4o 🎞️🚅 | Gemini-1.0-Pro 🎞️🚅 | Gemini-1.5-Pro 🎞️🚅 | Step-1V 🎞️🚅 |
|---|---|---|---|---|
| Reka-[Edge / Flash / Core]🚅 | Qwen-VL-[Plus / Max] 🎞️🚅 Qwen-VL-[Plus / Max]-0809 🎞️🚅 |
Claude3-[Haiku / Sonnet / Opus] 🎞️🚅 | GLM-4v 🚅 | CongRong 🎞️🚅 |
| Claude3.5-Sonnet (20240620, 20241022) 🎞️🚅 | GPT-4o-Mini 🎞️🚅 | Yi-Vision🎞️🚅 | Hunyuan-Vision🎞️🚅 | BlueLM-V 🎞️🚅 |
基于 PyTorch / HF 的开源模型
🎞️ 表示支持多图片输入。
🚅 表示模型可以被直接使用,不需任何额外的配置。
🎬 表示支持视频输入。
Transformers 的版本推荐:
请注意,某些 VLM 可能无法在某些特定的 transformers 版本下运行,我们建议使用以下设置来评估对应的VLM:
- 请用
transformers==4.33.0来运行:Qwen series,Monkey series,InternLM-XComposer Series,mPLUG-Owl2,OpenFlamingo v2,IDEFICS series,VisualGLM,MMAlaya,ShareCaptioner,MiniGPT-4 series,InstructBLIP series,PandaGPT,VXVERSE. - 请用
transformers==4.37.0来运行:LLaVA series,ShareGPT4V series,TransCore-M,LLaVA (XTuner),CogVLM Series,EMU2 Series,Yi-VL Series,MiniCPM-[V1/V2],OmniLMM-12B,DeepSeek-VL series,InternVL series,Cambrian Series,VILA Series,Llama-3-MixSenseV1_1,Parrot-7B,PLLaVA Series. - 请用
transformers==4.40.0来运行:IDEFICS2,Bunny-Llama3,MiniCPM-Llama3-V2.5,360VL-70B,Phi-3-Vision,WeMM. - 请用
transformers==latest来运行:LLaVA-Next series,PaliGemma-3B,Chameleon series,Video-LLaVA-7B-HF,Ovis series,Mantis series,MiniCPM-V2.6,OmChat-v2.0-13B-sinlge-beta,Idefics-3,GLM-4v-9B,VideoChat2-HD.
如何测试一个 VLM 是否可以正常运行:
from vlmeval.config import supported_VLM
model = supported_VLM['idefics_9b_instruct']()
# 前向单张图片
ret = model.generate(['assets/apple.jpg', 'What is in this image?'])
print(ret) # 这张图片上有一个带叶子的红苹果
# 前向多张图片
ret = model.generate(['assets/apple.jpg', 'assets/apple.jpg', 'How many apples are there in the provided images? '])
print(ret) # 提供的图片中有两个苹果要开发自定义评测数据集,支持其他 VLMs,或为 VLMEvalKit 贡献代码,请参阅开发指南。
为激励来自社区的共享并分享相应的 credit,在下一次 report 更新中,我们将:
- 致谢所有的 contribution
- 具备三个或以上主要贡献 (支持新模型、评测集、或是主要特性) 的贡献者将可以加入技术报告的作者列表 。合条件的贡献者可以创建 issue 或是在 VLMEvalKit Discord Channel 私信 kennyutc,我们将进行跟进
该代码库的设计目标是:
- 提供一个易于使用的开源评估工具包,方便研究人员和开发人员评测现有的多模态大模型,并使评测结果易于复现。
- 使 VLM 开发人员能够轻松地评测自己的模型。在多个支持的基准测试上评估 VLM,只需实现一个
generate_inner()函数,所有其他工作负载(数据下载、数据预处理、预测推理、度量计算)都由代码库处理。
该代码库的设计目标不是:
复现所有第三方基准测试原始论文中报告的准确数字。有两个相关的原因:
- VLMEvalKit 对所有 VLMs 使用基于生成的评估(可选使用基于 LLM 的答案提取)。同时,一些基准测试可能官方使用不同的方法(例如,SEEDBench 使用基于 PPL 的评估)。对于这些基准测试,我们在相应的结果中比较两个得分。我们鼓励开发人员在代码库中支持其他评估范式。
- 默认情况下,我们对所有多模态模型使用相同的提示模板来评估基准测试。同时,一些多模态模型可能有他们特定的提示模板(目前可能未在代码库中涵盖)。我们鼓励 VLM 的开发人员在 VLMEvalKit 中实现自己的提示模板,如果目前未覆盖。这将有助于提高可复现性。
如果我们的工作对您有所帮助,请考虑 star🌟 VLMEvalKit。感谢支持!
如果您在研究中使用了 VLMEvalKit,或希望参考已发布的开源评估结果,请使用以下 BibTeX 条目以及与您使用的特定 VLM / 基准测试相对应的 BibTex 条目。
@misc{duan2024vlmevalkit,
title={VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models},
author={Haodong Duan and Junming Yang and Yuxuan Qiao and Xinyu Fang and Lin Chen and Yuan Liu and Xiaoyi Dong and Yuhang Zang and Pan Zhang and Jiaqi Wang and Dahua Lin and Kai Chen},
year={2024},
eprint={2407.11691},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.11691},
}