This paper investigates the legal question-answering (QA) task in Vietnamese. Different from prior studies that only report results on the task of machine reading comprehension (MRC), we compare the strong QA models in two scenarios: MRC (span extraction) and answer generation (AG) (text generation). To do that, we first created a new dataset, namely ViBidLQA, using the bidding law. The dataset is synthesized by using a large language model (LLM) and corrected by two domain experts. After that, we train a set of robust MRC and AG models on the ViBidLQA dataset and predict on both ALQAC and the test set of ViBidLQA. Experimental results show that for the MRC scenario, vi-mrc-large achieves the best scores while for the AG scenario, ViT5 obtains good performance. The results also indicate that the new ViBidLQA dataset contributes to improving the performance of MRC models for domain adaptation on ALQAC

Fig.1: An example of Question Answering
QA is formulated as an MRC problem. Given a context
Then the model predicts answer span positions as:
Answer generation models produce a suitable answer
The training process uses the contextual vector
where
where
For more details, access the repo: https://github.com/Shaun-le/ViQAG. In this repo, I'll dive deeply into the Machine Reading Comprehension (MRC) approach.
git clone https://github.com/ntphuc149/ViLQA.git
cd ViLQApython3 -m venv venv
source venv/bin/activatepip install -r requirements.txtUpdate the parameters in config.py to suit your dataset and requirements.
Run the following command to start fine-tuning and evaluate the model:
python train.pyWe welcome contributions to this project. Please create a pull request or open an issue to discuss your ideas for improvement.
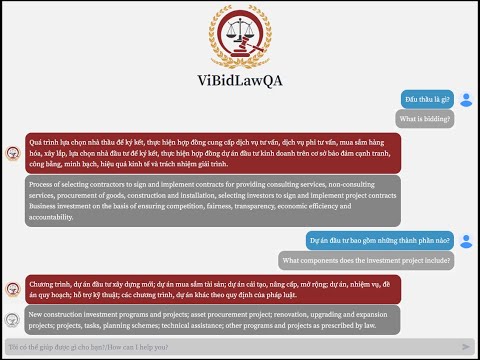
We introduce a demo application system ViBidLawQA at here. The brief introduction of the system was also shown in a video ↓↓↓
This project is licensed under the MIT License. See the LICENSE file for details.
To access our data, please take the survey at: https://forms.gle/Ti4d31xKoa78Hud69
Coming soon