by Gerard I. Gállego
The initial motivation behind speech-to-text translation was to obtain a written form for those languages that lack a writing system (Besacier et al., 2006). Nowadays, the primary motivation has shifted, and we perceive speech translation as an extraordinary opportunity for breaking language barriers in spoken communication. Especially during these days, in which most of the meetings are taking place virtually. Furthermore, we are experiencing an unprecedented democratization of audiovisual content production and broadcasting; hence, translating speech is more crucial than ever.

The classical way to face the task was to transcribe the speech utterance with an automatic speech recognition (ASR) module and then translate it with a machine translation (MT) system, which is known as "cascade" or "pipeline" ST. However, in the last years, the community has proposed a new paradigm in which speech is not transcripted but directly translated into the target language, using a single sequence-to-sequence model. This approach, known as "end-to-end" or "direct" ST, supposes many advantages over the former, such as avoiding the concatenation of errors, the direct use of prosodic from speech and a lower inference time. Nevertheless, direct ST systems struggle to achieve cascade performance due to data scarcity. There is a tradeoff between error propagation from the pipeline approach and the data inefficiency of end-to-end systems (Sperber et al., 2019).
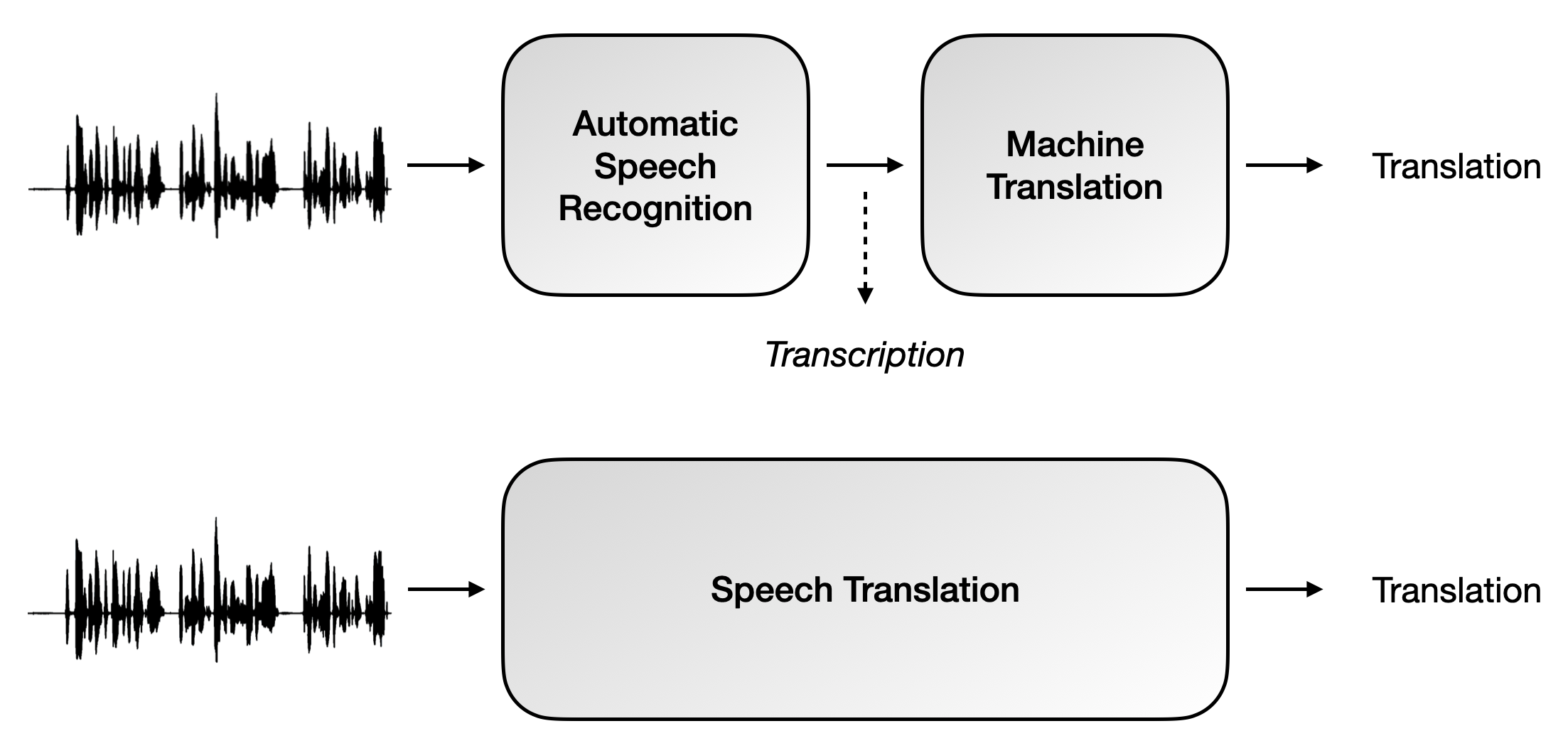
The International Conference on Spoken Language Translation (IWSLT) evaluation campaign, which has separate categories for cascade and end-to-end systems, allows tracking both approaches' evolution. In the 2020 edition, an end-to-end system achieved the best result in the challenge for the first time (Ansari et al., 2020).
Our group has been working on end-to-end systems for a while and, in this post, we will cover the most influential papers in this speech translation subfield.
After many years in which the only way to face the speech translation task was the cascade approach, Duong et al. (2016) proposed for the first time a sequence-to-sequence model for directly pairing speech with its translation. However, they did not create an end-to-end translation system per se, but instead, they focused on the alignment between source speech and text translation.
Later that year, Bérard et al. (2016) proposed the first end-to-end speech-to-text translation system, which could translate speech directly, without using any transcription during training or inference. The system's main limitation was that the authors trained it exclusively with artificial data, extending a very simple MT parallel corpus with synthetic speech.
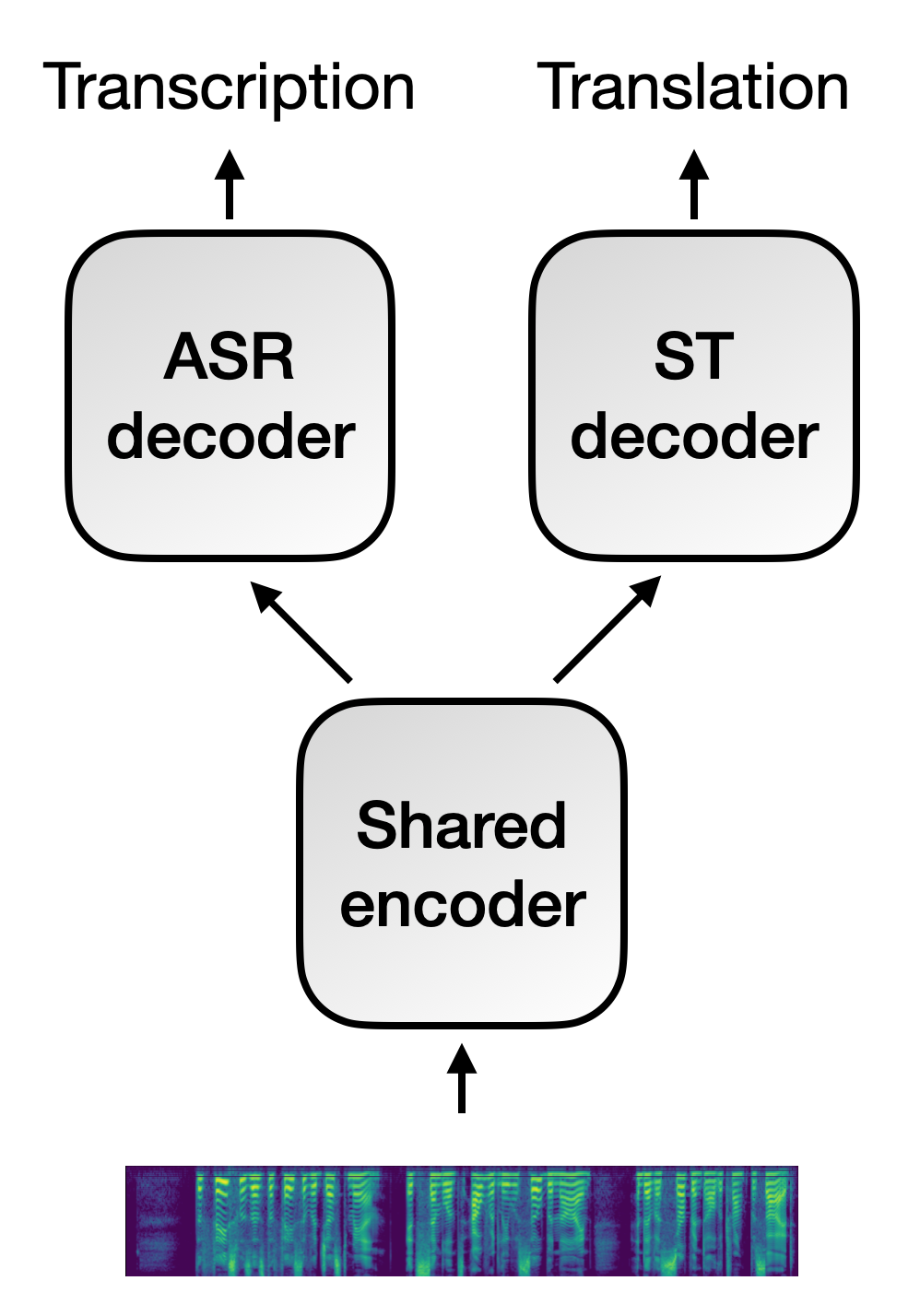
The work by Weiss et al. (2017) supposed the consolidation of the end-to-end approach as a plausible alternative to the classical pipeline ST systems. It used an encoder-decoder architecture inspired by a sequence-to-sequence ASR system (Chan et al., 2016), and they used a real speech corpus for training.

Furthermore, the authors introduced a training strategy where the system can benefit from available transcriptions. They proposed a multi-task training in which the encoder updates its parameters based on both ST and ASR tasks. It is important to remark that, during inference, they could use the ST system without the ASR-specific decoder, so it did not need transcriptions during this phase.
Although (Weiss et al., 2017) supposed a significant milestone for the ST community, there was still much room for improvement. For instance, the training dataset used was too small to train a powerful enough system, with only 38 hours of speech. The increasing interest in ST induced researchers to put more efforts into producing larger datasets. The first parallel speech-to-text corpus with a considerable size was Augmented Librispeech, with 236 hours of English speech coming from audiobooks, and translated into French (Kocabiyikoglu et al., 2018).
After the release of such an extensive corpus, Bérard et al. (2018) developed an end-to-end model trained with the new dataset. It was the first ST system trained with a significant amount of data, and thus, it became a benchmark. Even more important is that they proposed an alternative to the multi-task strategy: using an encoder pre-trained in the ASR task as a starting point of the ST training.


Both multi-task and pre-training strategies caused a significant impact on the field. They opened the door to consider transcriptions as a valuable resource during the training of end-to-end ST systems, in an attempt to reduce the performance gap with the cascade systems. These new strategies used transcriptions as targets for auxiliary ASR systems, but also as inputs for auxiliary MT models. For instance, Liu et al. (2019) proposed to use Knowledge Distillation to train the ST model with an MT system as the teacher, Indurthi et al. (2020) suggested using meta-learning to transfer knowledge from ASR and MT tasks to the ST task, and Kano et al. (2017) and Wang et al. (2020) trained their systems with a curriculum learning strategy that considers ASR and MT as elementary courses. Furthermore, a current trend proposes to divide the encoder into two parts, that process the acoustic and the semantic information independently, and train them by different multi-task learning strategies (Dong et al., 2020a)(Dong et al., 2020b)(Liu et al., 2020b).
While the ST field was growing, larger datasets also appeared. After Augmented Librispeech, the community experienced a huge step forward with the release of MuST-C, which contains up to 500 hours of speech in some language pairs (Di Gangi et al., 2019a). However, the amount of data available for the ST task was still much less than for MT or ASR, while being a more complex task.
Hence, a new idea emerged within the community, seeking to benefit from those larger datasets to train the ST systems. The strategy consisted of performing data augmentation with synthetic ST corpora, obtained using a high-quality MT model on an ASR dataset, or a text-to-speech system on an MT corpus.
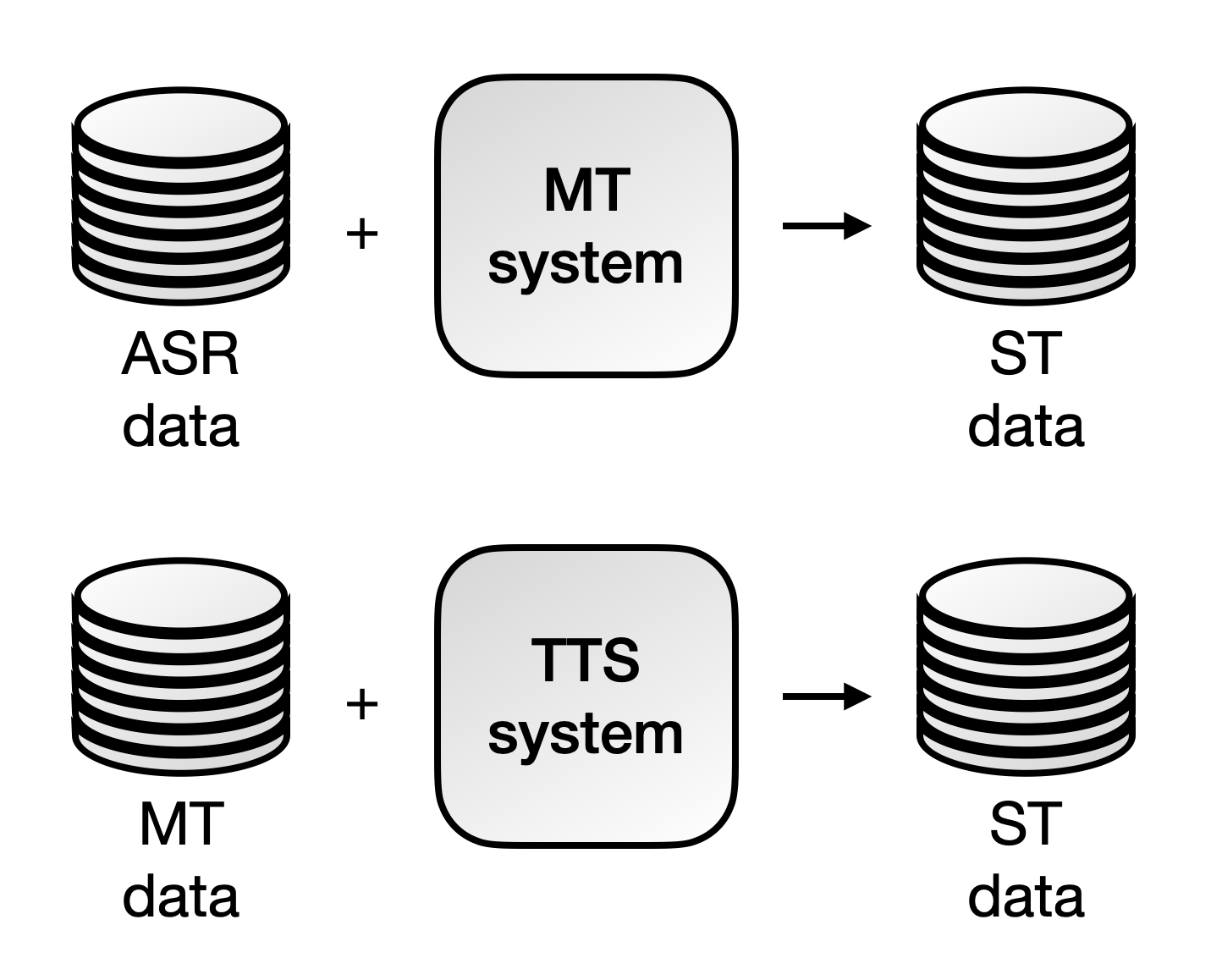
Finetuning an ST model with synthetic data was the approach followed by Jia et al. (2019) to boost their system's performance. Furthermore, they provided insights into avoiding overfitting when working with TTS-generated data, like using a high-quality multispeaker TTS model and freezing the pre-trained encoder.

Similarly, Pino et al. (2019) analyzed different pre-training, finetuning, and data augmentation strategies. Their model showed competitive performance compared to robust cascade systems, but they realized that using too much TTS-generated data could be harmful to the system performance.
In 2017, the introduction of the Transformer (Vaswani et al., 2017) supposed a revolution for neural machine translation. It also triggered a chain reaction that had a massive impact on sequence-to-sequence models and natural language processing in general. Hence, it was a matter of time that the Transformer landed in the ST field too. It did not take very long, and Cros Vila et al. (2018) were the first to propose using the Transformer for end-to-end speech translation.
Speech representations (e.g. spectrograms) are much longer sequences than text representations, which can cause some problems. Hence, it is common to reduce the input sequence length when using sequence-to-sequence architectures for ST. Considering this, Di Gangi et al. (2019b) proposed an adaptation of the Transformer for ST, which adds some layers before the Transformer encoder with that purpose. Concretely, it combines two 2D convolutional layers, that capture local patterns and reduce the sequence length, and two 2D self-attention layers, that model the long-range dependencies. Furthermore, the Transformer encoder has a logarithmic distance penalty that biases its self-attention layers towards the local context.
![]()
![]()
Nowadays, there is an increasing interest in developing multilingual ST systems. As demonstrated in machine translation, it can provide positive transfer to low-resourced languages, and it might even enable zero-shot translation (see our previous post). Therefore, this is an exciting approach because it could bring ST to languages that do not have enough resources to train a bilingual ST system from scratch.
Inaguma et al. (2019) proposed the first multilingual ST system. Following a similar approach to machine translation systems, it uses a shared encoder and decoder for all the languages. They explored both the one-to-many and the many-to-many scenario, using target forcing to choose the output language. To do so, they added a language token at the beginning of the target sentence.

Simultaneously, Di Gangi et al. (2019c) proposed a very similar approach which, instead of prepending a language token to the output sentence, merges a language embedding to the speech representations. However, in this case, they only explored the one-to-many scenario.
More recently, Escolano et al. (2020) extended a multilingual NMT architecture, based on language-specific encoders-decoders, with speech encoders. It allowed exploiting the prior multilingual MT knowledge of the model and enabled zero-shot translation.
The most recent proposal to bypass the lack of enough parallel ST corpora is to use self-supervised pre-trained components. Self-supervision is a type of learning that exploits unlabeled data, which is much easier to collect. For instance, in ST, it consists of pre-training some system modules using only speech utterances, without any transcription or translation, and later finetuning the model with parallel ST data.
One of the most notable self-supervised models for speech applications is Wav2Vec (Schneider et al., 2019), which improves ASR performance. Similarly, Nguyen et al. (2020) and Wu et al. (2020) found that using the speech representations from Wav2Vec, instead of classical speech features, improved their ST systems.
More recently, Li et al. (2020) have shown even more encouraging results using Wav2Vec as the encoder and another pre-trained module, mBART (Liu et al., 2020a), as the decoder. They finetune the model following a particular training strategy with many frozen layers. Furthermore, they train it with multilingual data, and it is even capable of performing zero-shot translation. Probably, this paper will be one of the most influential ones in the ST field.

End-to-end ST has still a long way ahead, but, as we have seen throughout this post, it has experienced considerable improvements in very few years. We look forward to the upcoming innovations, and we will do our best to contribute favourably to the growth of this field.
-
Ansari, E., Axelrod, A., Bach, N., Bojar, O., Cattoni, R., Dalvi, F., Durrani, N., ... & Wang, C. (2020). FINDINGS OF THE IWSLT 2020 EVALUATION CAMPAIGN. In Proceedings of the 17th International Conference on Spoken Language Translation (pp. 1–34). Association for Computational Linguistics.
-
Besacier, L., Zhou, B., & Gao, Y. (2006). Towards speech translation of non written languages. In 2006 IEEE Spoken Language Technology Workshop (pp. 222-225).
-
Bérard, A., Pietquin, O., Besacier, L., & Servan, C. (2016). Listen and Translate: A Proof of Concept for End-to-End Speech-to-Text Translation. In NIPS Workshop on end-to-end learning for speech and audio processing.
-
Bérard, A., Besacier, L., Kocabiyikoglu, A. C., & Pietquin, O. (2018). End-to-end automatic speech translation of audiobooks. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6224-6228). IEEE.
-
Chan, W., Jaitly, N., Le, Q., & Vinyals, O. (2016). Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 4960-4964).
-
Cros Vila, L., Escolano, C., Fonollosa, J. A., & Costa-Jussa, M. R. (2018). End-to-End Speech Translation with the Transformer. In IberSPEECH (pp. 60-63).
-
Di Gangi, M., Cattoni, R., Bentivogli, L., Negri, M., & Turchi, M. (2019a). MuST-C: a Multilingual Speech Translation Corpus. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (pp. 2012–2017). Association for Computational Linguistics.
-
Di Gangi, M. A., Negri, M., & Turchi, M. (2019b). Adapting transformer to end-to-end spoken language translation. In INTERSPEECH 2019 (pp. 1133-1137). International Speech Communication Association (ISCA).
-
Di Gangi, M. A., Negri, M., & Turchi, M. (2019c). One-to-many multilingual end-to-end speech translation. In 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) (pp. 585-592). IEEE.
-
Dong, Q., Wang, M., Zhou, H., Xu, S., Xu, B., & Li, L. (2020a). Consecutive Decoding for Speech-to-text Translation. arXiv preprint arXiv:2009.09737.
-
Dong, D., Ye, R., Wang, M., Zhou, H., Xu, S., Xu, B., Li, L. (2020b). "Listen, Understand and Translate": Triple Supervision Decouples End-to-end Speech-to-text Translation. arXiv preprint arXiv:2009.09704.
-
Duong, L., Anastasopoulos, A., Chiang, D., Bird, S., & Cohn, T. (2016). An Attentional Model for Speech Translation Without Transcription. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 949–959). Association for Computational Linguistics.
-
Escolano, C., Costa-jussà, M., Fonollosa, J. A., & Segura, C. (2020). Enabling Zero-shot Multilingual Spoken Language Translation with Language-Specific Encoders and Decoders. arXiv preprint arXiv:2011.01097.
-
Inaguma, H., Duh, K., Kawahara, T., & Watanabe, S. (2019). Multilingual end-to-end speech translation. In 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) (pp. 570-577). IEEE.
-
Indurthi, S., Han, H., Lakumarapu, N. K., Lee, B., Chung, I., Kim, S., & Kim, C. (2020). End-end Speech-to-Text Translation with Modality Agnostic Meta-Learning. In ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 7904-7908).
-
Jia, Y., Johnson, M., Macherey, W., Weiss, R. J., Cao, Y., Chiu, C. C., ... & Wu, Y. (2019). Leveraging weakly supervised data to improve end-to-end speech-to-text translation. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 7180-7184). IEEE.
-
Kano, T., Sakti, S., & Nakamura, S. (2017). Structured-Based Curriculum Learning for End-to-End English-Japanese Speech Translation. Proc. Interspeech 2017, 2630-2634.
-
Kocabiyikoglu, A., Besacier, L., & Kraif, O. (2018). Augmenting Librispeech with French Translations: A Multimodal Corpus for Direct Speech Translation Evaluation. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). European Language Resources Association (ELRA).
-
Li, X., Wang, C., Tang, Y., Tran, C., Tang, Y., Pino, J., ... & Auli, M. (2020). Multilingual Speech Translation with Efficient Finetuning of Pretrained Models. arXiv e-prints, arXiv-2010.
-
Liu, Y., Xiong, H., Zhang, J., He, Z., Wu, H., Wang, H., & Zong, C. (2019). End-to-End Speech Translation with Knowledge Distillation. In Proc. Interspeech 2019 (pp. 1128–1132).
-
Liu, Y., Gu, J., Goyal, N., Li, X., Edunov, S., Ghazvininejad, M., Lewis, M., & Zettlemoyer, L. (2020a). Multilingual Denoising Pre-training for Neural Machine Translation. Transactions of the Association for Computational Linguistics, 8, 726-742.
-
Liu, Y., Zhu, J., Zhang, J., & Zong, C. (2020b). Bridging the Modality Gap for Speech-to-Text Translation. arXiv preprint arXiv:2010.14920.
-
Nguyen, H., Bougares, F., Tomashenko, N., Estève, Y., & Besacier, L. (2020, October). Investigating Self-supervised Pre-training for End-to-end Speech Translation. In Interspeech 2020.
-
Pino, J., Puzon, L., Gu, J., Ma, X., McCarthy, A. D., & Gopinath, D. (2019) Harnessing Indirect Training Data for End-to-End Automatic Speech Translation: Tricks of the Trade. 16th International Workshop on Spoken Language Translation (IWSLT 2019).
-
Schneider, S., Baevski, A., Collobert, R., & Auli, M. (2019). wav2vec: Unsupervised Pre-Training for Speech Recognition. In Proc. Interspeech 2019 (pp. 3465–3469).
-
Sperber, M., Neubig, G., Niehues, J., & Waibel, A. (2019). Attention-passing models for robust and data-efficient end-to-end speech translation. Transactions of the Association for Computational Linguistics, 7, 313-325.
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A., Kaiser, L., & Polosukhin, I. (2017). Attention is All you Need. In Advances in Neural Information Processing Systems. Curran Associates, Inc.
-
Wang, C., Wu, Y., Liu, S., Zhou, M., & Yang, Z. (2020). Curriculum Pre-training for End-to-End Speech Translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (pp. 3728-3738).
-
Weiss, R. J., Chorowski, J., Jaitly, N., Wu, Y., & Chen, Z. (2017). Sequence-to-Sequence Models Can Directly Translate Foreign Speech. Proc. Interspeech 2017, 2625-2629.
-
Wu, A., Wang, C., Pino, J., & Gu, J. (2020). Self-Supervised Representations Improve End-to-End Speech Translation. In Proc. Interspeech 2020 (pp. 1491–1495).
@misc{gallego-major-breakthroughs-st,
author = {Gállego, Gerard I.},
title = {Major Breakthroughs in... End-to-end Speech Translation (III)},
year = {2021},
howpublished = {\url{https://mt.cs.upc.edu/2021/02/15/major-breakthroughs-in-end-to-end-speech-translation-iii/}},
}