by Javier Ferrando
The Transformer was presented in "Attention is All You Need" and introduced a new architecture for many NLP tasks. In this post we exhibit an explanation of the Transformer architecture on Neural Machine Translation focusing on the fairseq implementation. We believe this could be useful for researchers and developers starting out on this framework.
The blog is inspired by The annotated Transformer, The Illustrated Transformer and Fairseq Transformer, BART blogs.
The Transformer is based on a stack of encoders and another stack of decoders. The encoder maps an input sequence of tokens to a sequence of continuous vector representations
. Given
, the decoder then generates an output sequence
of symbols one element at a time. At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next token.
![]()
To see the general structure of the code in fairseq implementation I recommend reading Fairseq Transformer, BART.
This model is implemented in fairseq as TransformerModel in fairseq/models/transformer.py.
class TransformerModel(FairseqEncoderDecoderModel):
...
def forward(
self,
src_tokens,
src_lengths,
prev_output_tokens,
return_all_hiddens: bool = True,
features_only: bool = False,
alignment_layer: Optional[int] = None,
alignment_heads: Optional[int] = None,
):
encoder_out = self.encoder(
src_tokens, src_lengths=src_lengths, return_all_hiddens=return_all_hiddens
)
decoder_out = self.decoder(
prev_output_tokens,
encoder_out=encoder_out,
features_only=features_only,
alignment_layer=alignment_layer,
alignment_heads=alignment_heads,
src_lengths=src_lengths,
return_all_hiddens=return_all_hiddens,
)
return decoder_outThe encoder (TransformerEncoder) is composed of a stack of identical layers.
The encoder recieves a list of tokens src_tokens which are then converted to continuous vector representions
x = self.forward_embedding(src_tokens, token_embeddings), which is made of the sum of the (scaled) embedding lookup and the positional embedding: x = self.embed_scale * self.embed_tokens(src_tokens) + self.embed_positions(src_tokens).
From now on, let's consider as the
encoder layer input sequence.
refers then to the vectors representation of the input sequence tokens of the first layer, after computing
self.forward_embedding on src_tokens.
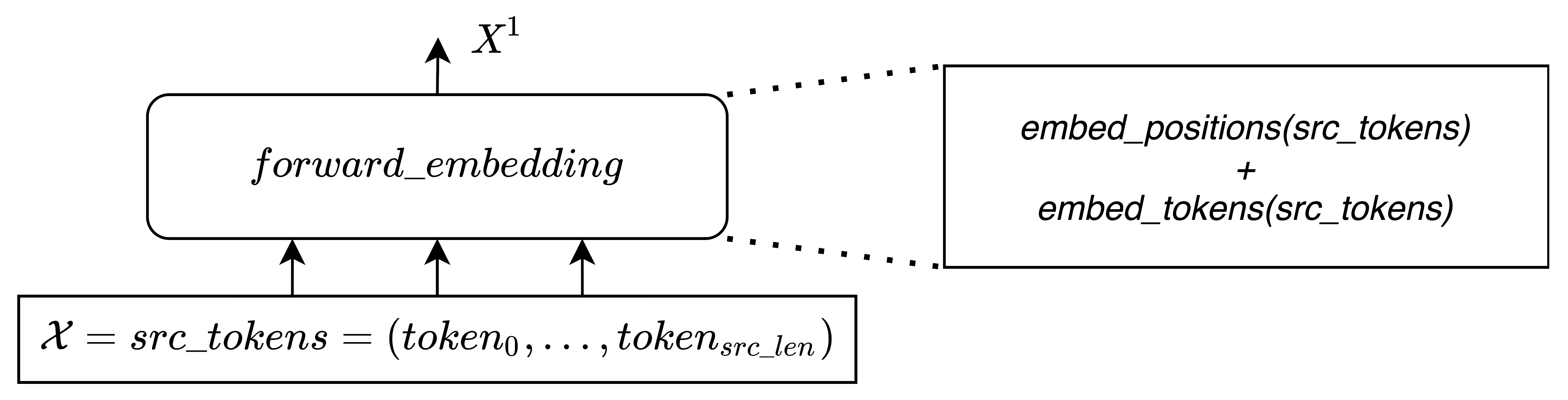
Note that although is represented in fairseq as a tensor of shape
src_len x batch x encoder_embed_dim, for the sake of simplicity, we take batch=1 in the upcoming mathematical notation and just consider it as a src_len x encoder_embed_dim matrix.
Where .
class TransformerEncoder(FairseqEncoder):
...
def forward(
self,
src_tokens,
src_lengths,
return_all_hiddens: bool = False,
token_embeddings: Optional[torch.Tensor] = None,
):
x, encoder_embedding = self.forward_embedding(src_tokens, token_embeddings)
# batch x src_lengths x encoder_embed_dim
# -> src_lengths x batch x encoder_embed_dim
x = x.transpose(0, 1)
# compute padding mask
encoder_padding_mask = src_tokens.eq(self.padding_idx)
encoder_states = [] if return_all_hiddens else None
# encoder layers
for layer in self.layers:
x = layer(x, encoder_padding_mask)
if return_all_hiddens:
assert encoder_states is not None
encoder_states.append(x)
if self.layer_norm is not None:
x = self.layer_norm(x)
return EncoderOut(
encoder_out=x, # src_lengths x batch x encoder_embed_dim
encoder_padding_mask=encoder_padding_mask,
encoder_embedding=encoder_embedding,
encoder_states=encoder_states, # List[src_lengths x batch x encoder_embed_dim]
src_tokens=None,
src_lengths=None,
)This returns a NamedTuple object encoder_out.
- encoder_out: of shape
src_len x batch x encoder_embed_dim, the last layer encoder's embedding which, as we will see, is used by the Decoder. Note that is the same aswhen
batch=1. - encoder_padding_mask: of shape
batch x src_len. Binary ByteTensor where padding elements are indicated by 1. - encoder_embedding: of shape
src_len x batch x encoder_embed_dim, the words (scaled) embedding lookup. - encoder_states: of shape
list[src_len x batch x encoder_embed_dim], intermediate enocoder layer's output.
The previous snippet of code shows a loop over the layers of the Encoder block, for layer in self.layers. This layer is implemented in fairseq in class TransformerEncoderLayer(nn.Module) inside fairseq/modules/transformer_layer.py and computes the following operations:
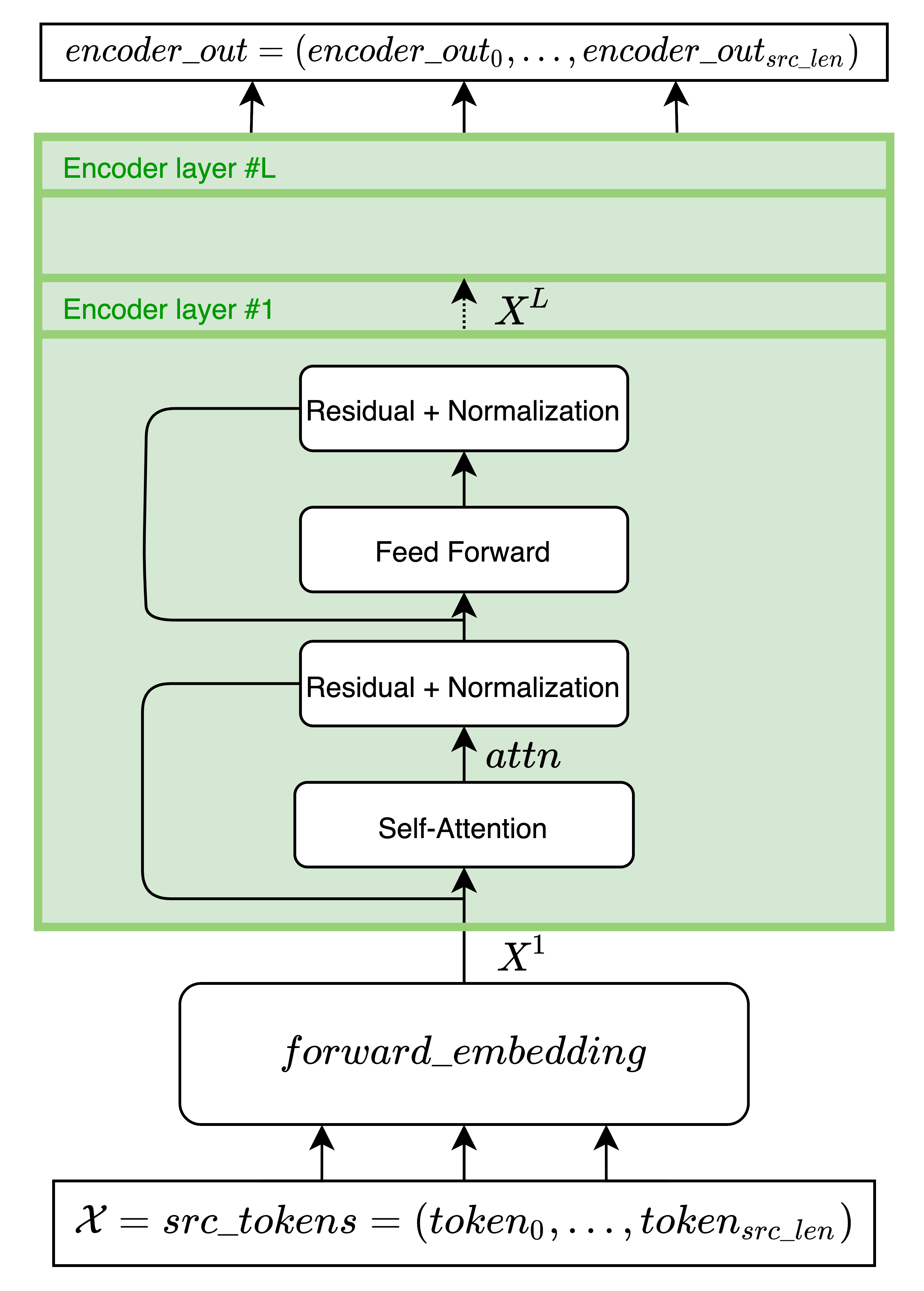
The input of the encoder layer is passed through the self-attention module self.self_attn, dropout (self.dropout_module(x)) is then applied before getting to the Residual & Normalization module (made of a residual connection self.residual_connection(x, residual) and a layer normalization (LayerNorm) self.self_attn_layer_norm(x)
class TransformerEncoderLayer(nn.Module):
...
def forward(self, x, encoder_padding_mask, attn_mask: Optional[Tensor] = None):
if attn_mask is not None:
attn_mask = attn_mask.masked_fill(attn_mask.to(torch.bool), -1e8)
residual = x
if self.normalize_before:
x = self.self_attn_layer_norm(x)
x, _ = self.self_attn(
query=x,
key=x,
value=x,
key_padding_mask=encoder_padding_mask,
attn_mask=attn_mask,
)
x = self.dropout_module(x)
x = self.residual_connection(x, residual)
if not self.normalize_before:
x = self.self_attn_layer_norm(x)Then, the result is passed through a position-wise feed-forward network composed by two fully connected layers, fc1 and fc2 with a ReLU activation in between (self.activation_fn(self.fc1(x))) and dropout self.dropout_module(x).
residual = x
if self.normalize_before:
x = self.final_layer_norm(x)
x = self.activation_fn(self.fc1(x))
x = self.activation_dropout_module(x)
x = self.fc2(x)
x = self.dropout_module(x)
Finally, a residual connection is made before another layer normalization layer.
x = self.residual_connection(x, residual)
if not self.normalize_before:
x = self.final_layer_norm(x)
return xAs we have seen, the input of each encoder layer is firstly passed through a self-attention layer (fairseq/modules/multihead_attention.py)
class MultiheadAttention(nn.Module):
...
def forward(
self,
query,
key: Optional[Tensor],
value: Optional[Tensor],
key_padding_mask: Optional[Tensor] = None,
incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
need_weights: bool = True,
static_kv: bool = False,
attn_mask: Optional[Tensor] = None,
before_softmax: bool = False,
need_head_weights: bool = False,
) -> Tuple[Tensor, Optional[Tensor]]:Each encoder layer input , shown as
query below since three identical copies are passed to the self-attention module, is multiplied by three weight matrices learned during the training process: and
, obtaining
and
. Each row of this output matrices represents the query, key and value vectors of each token in the sequence, represented as
and
in the formulas that follow.
if self.self_attention:
q = self.q_proj(query) # Q
k = self.k_proj(query) # K
v = self.v_proj(query) # V
q *= self.scalingThe self-attention module does the following operation:
attn_weights = torch.bmm(q, k.transpose(1, 2)) # QK^T multiplicationGiven a token in the input, , it is passed to the self-attention function. Then, by means of dot products, scalar values (scores) are obtained between the query vector
and every key vector of the input sequence
. The intuition is that this performs a similarity operation, similar queries and keys vectors will yield higher scores.
These scores represent how much attention is paid by the self-attention layer to other parts of the sequence when encoding . By multiplying
by the matrix
, a list of
src_len scores is output. The scores are then passed through a softmax function giving bounded values:
attn_weights_float = utils.softmax(
attn_weights, dim=-1, onnx_trace=self.onnx_trace
)
attn_weights = attn_weights_float.type_as(attn_weights)The division by the square root of the dimension of the key vectors (for getting more stable gradients) is done previously
q *= self.scaling instead in fairseq.
For example, given the sentence "the nice cat walks away from us" for the token , its corresponding attention weights
for every other token
in the input sequence could be:
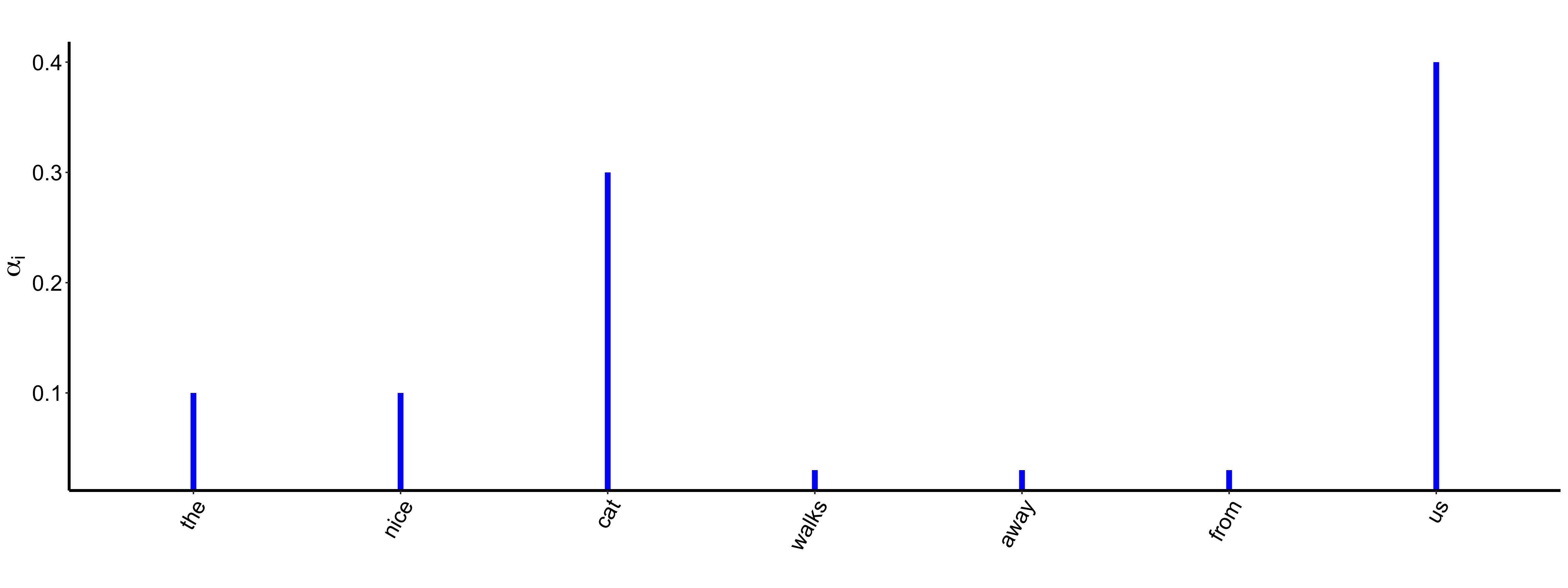
Once we have normalized scores for every pair of tokens , we multiply these weights by the value vector
(each row in matrix
) and finally sum up those vectors:
Where represents row
of
. By doing the matrix multiplication of the attention weight matrix
attn_weights and ,
, we directly get matrix
.
attn_probs = self.dropout_module(attn_weights)
assert v is not None
attn = torch.bmm(attn_probs, v)This process is done in parallel in each of the self-attention heads. So, in total encoder_attention_heads matrices are output. Each head has its own and
weight matrices which are randomly initialized, so the result leads to different representation subspaces in each of the self-attention heads.
The output matrices of every self-attention head are concatenated into a single one to which a linear transformation
(
self.out_proj) is applied:
#concatenating each head representation before W^o projection
attn = attn.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
#W^o projection
attn = self.out_proj(attn)
attn_weights: Optional[Tensor] = None
if need_weights:
attn_weights = attn_weights_float.view(
bsz, self.num_heads, tgt_len, src_len
).transpose(1, 0)
if not need_head_weights:
# average attention weights over heads
attn_weights = attn_weights.mean(dim=0)
return attn, attn_weightsNotice that attn_probs has dimensions (bsz * self.num_heads, tgt_len, src_len)
To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension encoder_embed_dim.
The decoder is composed of a stack of identical layers.
The goal of the decoder is to generate a sequence in the target language. The
TransformerDecoder inherits from FairseqIncrementalDecoder. It differs from the encoder in that it performs incremental decoding. This means that at each time step a forward pass is done through the decoder, generating
, which is then fed as input to the next time step decoding process.
The encoder output encoder_out.encoder_out is used by the decoder (in each layer) together with (
prev_output_tokens) to generate one feature vector per target token at each time step (tgt_len = 1 in each forward pass). This feature vector is then transformed by a linear layer and passed through a softmax layer self.output_layer(x) to get a probability distribution over the target language vocabulary.
Following the beam search algorithm, top beam hypotheses are chosen and inserted in the batch dimension input of the decoder (prev_output_tokens) for the next time step.
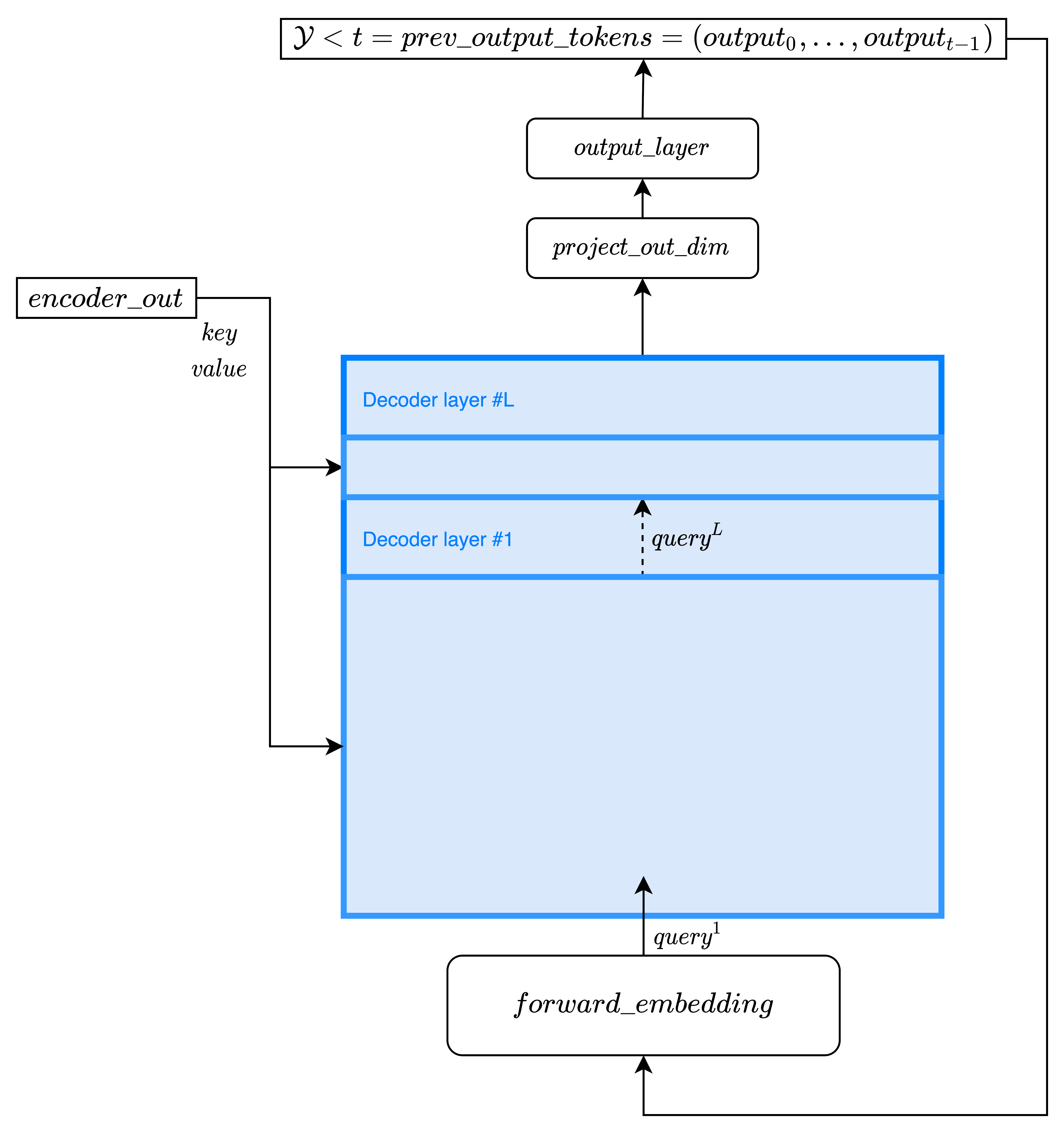
We consider as the
decoder layer input sequence.
refers then to the vector representation of the input sequence tokens of the first layer, after computing
self.forward_embedding on prev_output_tokens. Note that here self.forward_embedding is not defined, but we refer to self.embed_tokens(prev_output_tokens) and self.embed_positions(prev_output_tokens).
class TransformerDecoder(FairseqIncrementalDecoder):
...
def forward(
self,
prev_output_tokens,
encoder_out: Optional[EncoderOut] = None,
incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
features_only: bool = False,
full_context_alignment: bool = False,
alignment_layer: Optional[int] = None,
alignment_heads: Optional[int] = None,
src_lengths: Optional[Any] = None,
return_all_hiddens: bool = False,
):
x, extra = self.extract_features(
prev_output_tokens,
encoder_out=encoder_out,
incremental_state=incremental_state,
full_context_alignment=full_context_alignment,
alignment_layer=alignment_layer,
alignment_heads=alignment_heads,
)
if not features_only:
x = self.output_layer(x)
return x, extradef extract_features(
self,
prev_output_tokens,
encoder_out: Optional[EncoderOut] = None,
incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
full_context_alignment: bool = False,
alignment_layer: Optional[int] = None,
alignment_heads: Optional[int] = None,
):
return self.extract_features_scriptable(
prev_output_tokens,
encoder_out,
incremental_state,
full_context_alignment,
alignment_layer,
alignment_heads,
)In the first time step, prev_output_tokens represents the beginning of sentence (BOS) token index. Its embedding enters the decoder as a tensor beam*batch x tgt_len x encoder_embed_dim.
def extract_features_scriptable(
self,
prev_output_tokens,
encoder_out: Optional[EncoderOut] = None,
incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
full_context_alignment: bool = False,
alignment_layer: Optional[int] = None,
alignment_heads: Optional[int] = None,
):
..
positions = (
self.embed_positions(
prev_output_tokens, incremental_state=incremental_state
)
x = self.embed_scale * self.embed_tokens(prev_output_tokens)
if positions is not None:
x += positions
attn: Optional[Tensor] = None
inner_states: List[Optional[Tensor]] = [x]
for idx, layer in enumerate(self.layers):
if incremental_state is None and not full_context_alignment:
self_attn_mask = self.buffered_future_mask(x)
else:
self_attn_mask = None
x, layer_attn, _ = layer(
x,
encoder_out.encoder_out if encoder_out is not None else None,
encoder_out.encoder_padding_mask if encoder_out is not None else None,
incremental_state,
self_attn_mask=self_attn_mask,
self_attn_padding_mask=self_attn_padding_mask,
need_attn=bool((idx == alignment_layer)),
need_head_weights=bool((idx == alignment_layer)),
)
inner_states.append(x)
if layer_attn is not None and idx == alignment_layer:
attn = layer_attn.float().to(x)
if attn is not None:
if alignment_heads is not None:
attn = attn[:alignment_heads]
# average probabilities over heads
attn = attn.mean(dim=0)
if self.layer_norm is not None:
x = self.layer_norm(x)
# T x B x C -> B x T x C
x = x.transpose(0, 1)
if self.project_out_dim is not None:
x = self.project_out_dim(x)
return x, {"attn": [attn], "inner_states": inner_states}The previous snippet of code shows a loop over the layers of the Decoder block for idx, layer in enumerate(self.layers):. This layer is implemented in fairseq in class TransformerDecoderLayer(nn.Module) inside fairseq/modules/transformer_layer.py and computes the following operations:
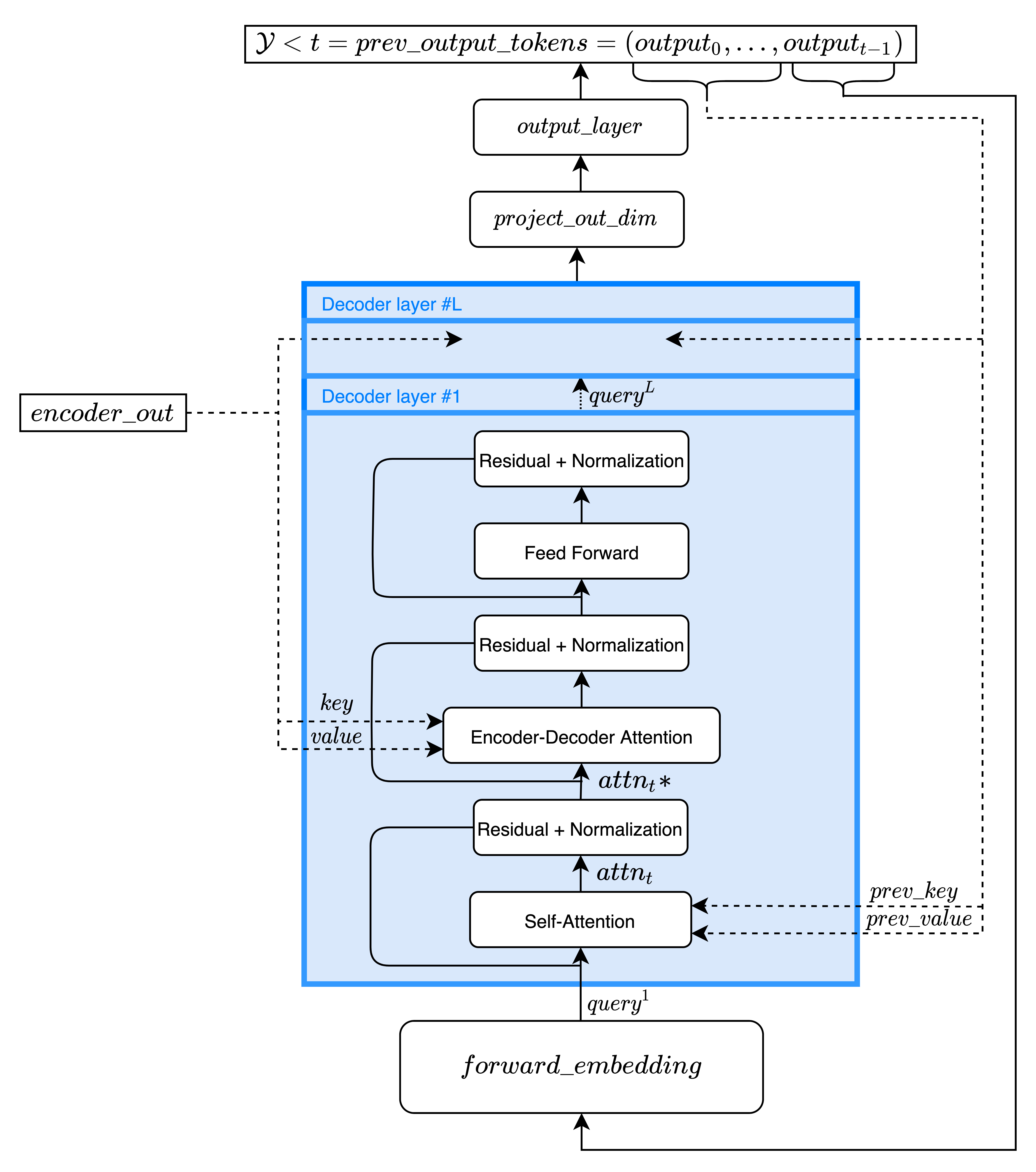
In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer (Encoder-Decoder Attention), which performs multi-head attention over the output of the encoder stack as input for and
and the ouput of the previous module
. Similar to the encoder, it employs residual connections around each of the sub-layers, followed by layer normalization.
class TransformerDecoderLayer(nn.Module):
..
def forward(
self,
x,
encoder_out: Optional[torch.Tensor] = None,
encoder_padding_mask: Optional[torch.Tensor] = None,
incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
prev_self_attn_state: Optional[List[torch.Tensor]] = None,
prev_attn_state: Optional[List[torch.Tensor]] = None,
self_attn_mask: Optional[torch.Tensor] = None,
self_attn_padding_mask: Optional[torch.Tensor] = None,
need_attn: bool = False,
need_head_weights: bool = False,
):
...
residual = x
if self.normalize_before:
x = self.self_attn_layer_norm(x)
...
y = x
x, attn = self.self_attn(
query=x,
key=y,
value=y,
key_padding_mask=self_attn_padding_mask,
incremental_state=incremental_state, # previous keys and values stored here
need_weights=False,
attn_mask=self_attn_mask,
)
x = self.dropout_module(x)
x = self.residual_connection(x, residual)
if not self.normalize_before:
x = self.self_attn_layer_norm(x)During incremental decoding, enter the self-attention module as
prev_key and prev_value vectors that are stored in incremental_state. Since there is no need to recompute and
every time, incremental decoding caches these values and concatenates with keys an values from
. Then, updated
and
are stored in
prev_key and passed again to incremental_state.
The last time step output token in each decoding step, , enters as a query after been embedded. So, queries here have one element in the second dimension, that is, there is no need to use matrix
notation.
As before, scalar values (scores)
are obtained between the query vector
and every key vector of the whole previous tokens sequence.
Flashing back to (fairseq/modules/multihead_attention.py) we can see how key and values are obtained inside the Multihead attention module and how these udates in saved_state and incremental_state are done:
class MultiheadAttention(nn.Module):
...
def forward(
...
):
...
if incremental_state is not None:
saved_state = self._get_input_buffer(incremental_state) # getting saved_state
...
if saved_state is not None:
if "prev_key" in saved_state:
_prev_key = saved_state["prev_key"]
assert _prev_key is not None
prev_key = _prev_key.view(bsz * self.num_heads, -1, self.head_dim)
if static_kv: # in encoder-endoder attention
k = prev_key
else:
assert k is not None
k = torch.cat([prev_key, k], dim=1) # concatenation of K
if "prev_value" in saved_state:
_prev_value = saved_state["prev_value"]
assert _prev_value is not None
prev_value = _prev_value.view(bsz * self.num_heads, -1, self.head_dim)
if static_kv: # in encoder-endoder attention
v = prev_value
else:
assert v is not None
v = torch.cat([prev_value, v], dim=1) # concatenation of V
prev_key_padding_mask: Optional[Tensor] = None
if "prev_key_padding_mask" in saved_state:
prev_key_padding_mask = saved_state["prev_key_padding_mask"]
assert k is not None and v is not None
key_padding_mask = MultiheadAttention._append_prev_key_padding_mask(
key_padding_mask=key_padding_mask,
prev_key_padding_mask=prev_key_padding_mask,
batch_size=bsz,
src_len=k.size(1),
static_kv=static_kv,
)
saved_state["prev_key"] = k.view(bsz, self.num_heads, -1, self.head_dim)
saved_state["prev_value"] = v.view(bsz, self.num_heads, -1, self.head_dim)
saved_state["prev_key_padding_mask"] = key_padding_mask
# In this branch incremental_state is never None
assert incremental_state is not None
incremental_state = self._set_input_buffer(incremental_state, saved_state) # updateThe Encoder-Decoder attention receives key and values from the encoder output encoder_out.encoder_out and the query from the previous module . Here,
is compared against every key vector received from the encoder (and transformed by
).
As before, and
don't need to be recomputed every time step since they are constant for the whole decoding process. Encoder-Decoder attention uses
static_kv=True so that there is no need to update the incremental_state (see previous code snippet).
Now, just one vector is generated at each time step by each head as a weighted average of the
vectors.
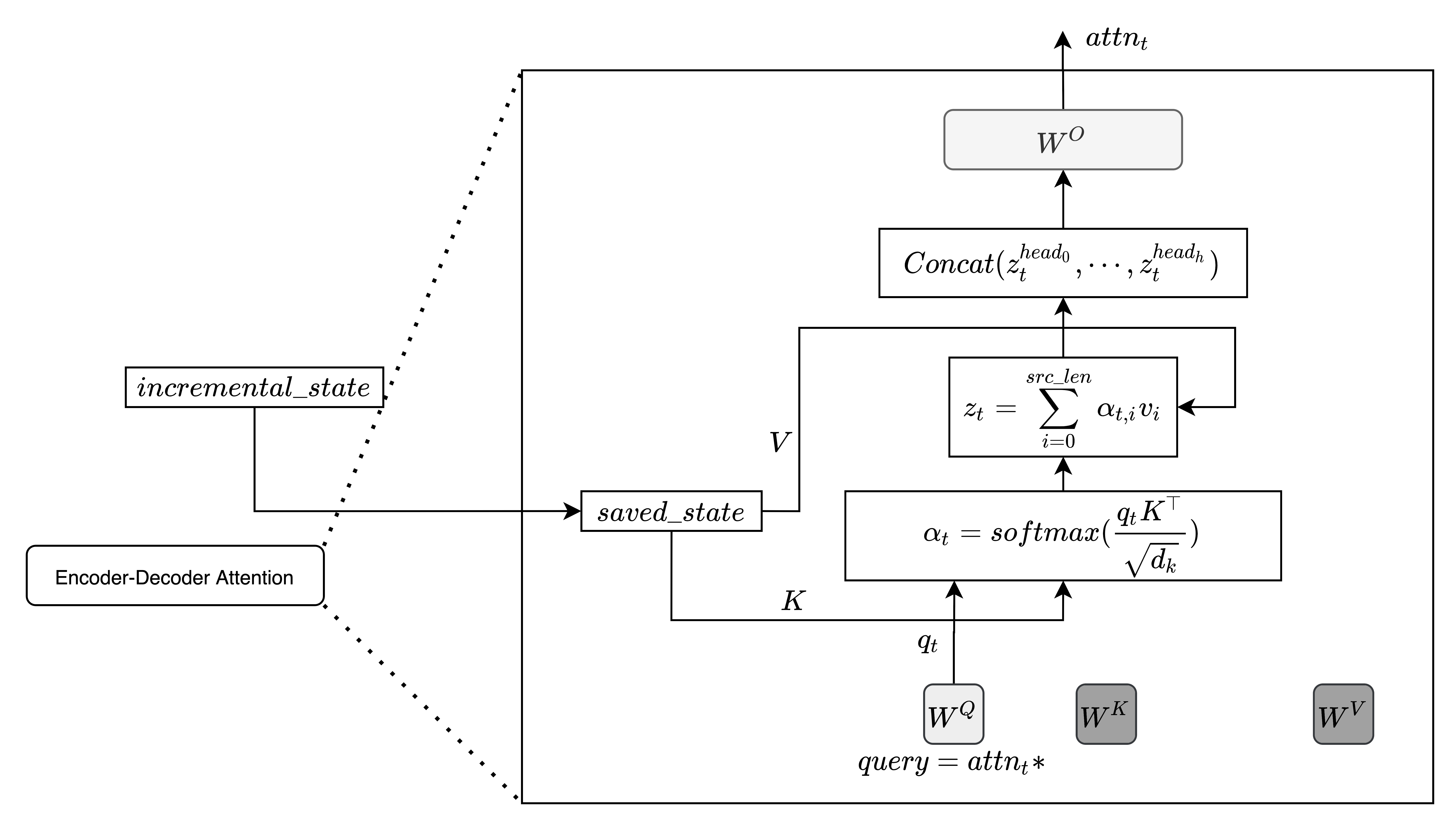
if self.encoder_attn is not None and encoder_out is not None:
residual = x
if self.normalize_before:
x = self.encoder_attn_layer_norm(x)
...
x, attn = self.encoder_attn(
query=x,
key=encoder_out,
value=encoder_out,
key_padding_mask=encoder_padding_mask,
incremental_state=incremental_state,
static_kv=True,
need_weights=need_attn or (not self.training and self.need_attn),
need_head_weights=need_head_weights,
)
x = self.dropout_module(x)
x = self.residual_connection(x, residual)
if not self.normalize_before:
x = self.encoder_attn_layer_norm(x)As in the case of the encoder, the result is passed through a position-wise feed-forward network composed by two fully connected layers:
residual = x
if self.normalize_before:
x = self.final_layer_norm(x)
x = self.activation_fn(self.fc1(x))
x = self.activation_dropout_module(x)
x = self.fc2(x)
x = self.dropout_module(x)
Finally, a residual connection is made before another layer normalization layer.
x = self.residual_connection(x, residual)
if not self.normalize_before:
x = self.final_layer_norm(x)
...
return x, attn, None@misc{ferrando-transformer,
author = {Ferrando, Javier},
title = {The Transformer: fairseq edition},
year = {2020},
howpublished = {\url{https://mt.cs.upc.edu/2020/12/21/the-transformer-fairseq-edition/}},
}