This repository contains pre-trained models and demo code for the project 'Visual Dynamics: Probabilistic Future Frame Synthesis via Cross Convolutional Networks', published at the Conferece of Neural Information Processing Systems (NIPS) 2016.
http://visualdynamics.csail.mit.edu/
We use Torch 7 (http://torch.ch) for our implementation.
We use the convert toolbox in 'Imagemagick' to generate gif images for visualization. See demo.lua about how to disable it.
Our current release has been tested on Ubuntu 14.04.
git clone [email protected]:tfxue/visual-dynamics.git cd visual-dynamics
./download_models.shcd src
th demo.luaThere are a few options in demo.lua:
useCuda: Set to false if not using Cuda
gpuId: GPU device ID
demo: Set it to 'all' to run all demos. Set it to 'demo?' to run a specific demo
modeldir, datadir, outputdirRoot: Directories that store models, input files, and output files
createGIF: Generate gif visualizations. This requires Imagemagick. Set it to false if Imagemagick is not installed.
Demo 1: sample future frames from a single image
 |
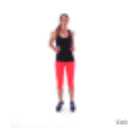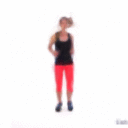 |
 |
 |
| Input image | Sample 1 | Sample 2 | Sample 3 |
Demo 2: transfer motion from a source pair to a target image
 |
 |
 |
 |
 |
| Source motion | Target image 1 | Transfered motion | Target image 2 | Transfered motion |
Demo 3: visualize selected dimensions of the latent representation
 |
 |
 |
| Dimension 0752 | Dimension 1746 | Dimension 2195 |
- Exercise dataset: zip, 1.1GB
@inproceedings{visualdynamics16,
author = {Xue, Tianfan and Wu, Jiajun and Bouman, Katherine L and Freeman, William T},
title = {Visual Dynamics: Probabilistic Future Frame Synthesis via Cross Convolutional Networks},
booktitle = {NIPS},
year = {2016}
}
For any questions, please contact Tianfan Xue ([email protected]) and Jiajun Wu ([email protected]).