- Understanding virtual memory
- Detour - a process memory layout
- Understanding stack allocation
- Understanding heap allocation
- When to bother with a custom allocator
- Fun with 'flags' memory mapping
http://marek.vavrusa.com/c/memory/2015/02/20/memory/
- 你的程序将会在保护模式下工作
- 除非你正在处理一些嵌入式系统或内核空间代码
- 实模式下,cpu指令访问的地址就是物理地址,形式为:段寄存器:偏移
- 在保护模式下,cpu可以使用分段机制和分页机制。
- 分段机制下使用的地址就是逻辑地址,形式为:段选择子:偏移
- 分页机制下使用的地址就是线性地址,形式为:0xXXXXXXXX
- 无论是逻辑地址还是线性地址,都要被cpu映射成物理地址。
- 保护模式下必须采用分段机制。在此基础上可采用分页机制。
- 逻辑地址被转化为线性地址
- 如果采用分页机制,则该线性地址通过分页机制被映射成物理地址
- 如果不采用分页机制,则该线性地址就是物理地址
- 你的程序保证有自己的 [virtual] address space
- “virtual” 很重要
- 这意味着你不受可用内存限制,但也无权 使用所有任意区域的内存
- 为了使用这个空间,你必须要求操作系统用真实的东西来支持它,这就是所谓的 mapping 。
- 这个支持可以是 可以是物理内存(不一定是RAM),也可以是持久性存储。
- 前者也被称为 anonymous mapping
- 虚拟内存分配器(VMA)可能会给你一个它没有的内存,希望你最好不要使用它。
- 就像今天的银行一样。 这被称为overcommiting
- 而它有合法的应用程序(稀疏数组),这也意味着内存分配不会简单地说“No”。
char *block = malloc(1024 * sizeof(char));
if (block == NULL) {
return -ENOMEM; /* Sad :( */
}- NULL返回值检查是一种很好的做法,但并不像曾经那么强大。
- with the overcommit,操作系统可能会给你的内存分配器一个有效的指针内存,但如果你要访问它 -- Dang!
- Dang 在这种情况下结果,是 platform-specific 的,但通常是一个OOM 杀死你的进程
- 关于进程的内存布局,这片文章有很好的介绍 Anatomy of a Program in Memory
- 它只介绍了 x86-32内存布局,幸运的是x86-64没有什么改变。
- 除了一个进程可以使用更多的空间 - Linux上的高达 2⁴⁸。
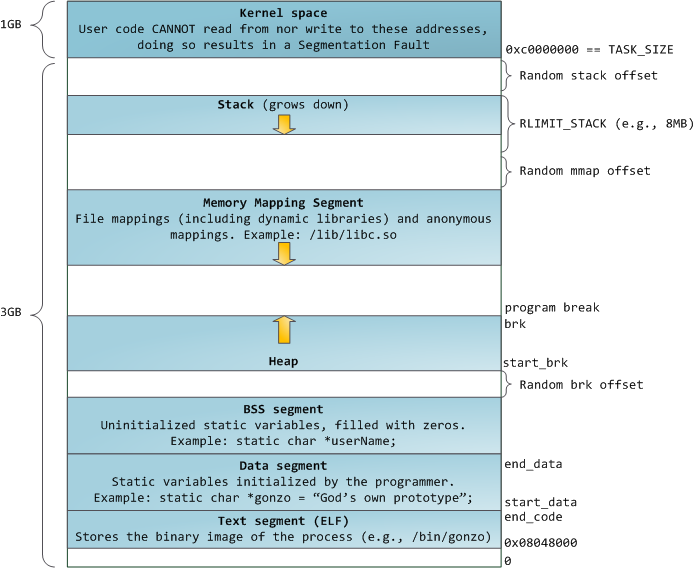
-
图上显示了内存映射段(MMS)向下增长,但并不总是如此。
-
MMS通常从低于 stack最低地址的随机地址开始。
- stack 有大小限制, 所以可以确定 最低地址
-
仅在 stack 没有限制/非常大,或启用了 compatibility layout 的情况下,MMS 可能在stack上方开始,并向上增长
-
这些并不是很重要,但可以帮助你理解 free address ranges.
-
从图上我们可以看到, 有3个变量可能存放的位置
- the process data segment (static storage or heap allocation)
- the memory mapping segment
- the stack
- Utility belt:
- alloca() - allocate memory in the stack frame of the caller
- getrlimit() - get/set resource limits
- sigaltstack() - set and/or get signal stack context
- 由于我们在栈顶,我们可以使用剩余的内存,直到栈大小的限制。
- alloca() 在栈上非配的内存有一点不一样, 它并不受 scope 的约束( In C, that means this:
{})- 一般的栈上分配的变量内存,出了 scope就会被释放
- alloca() 分配的内存,只有 函数返回时 才会释放
void laugh(void) {
for (unsigned i = 0; i < megatron; ++i) {
char *res = alloca(2);
memcpy(res, "ha", 2);
char vla[2] = {'h','a'}
} /* vla dies, res lives */
} /* all allocas die */- 这会导致 stack overflow. 有两种方法,但都没有实践性。
- The first idea is to use a sigaltstack() to catch and handle the SIGSEGV
- 但是,这只是让你抓住堆栈溢出。
- 另一种方法是使用拆分堆栈进行编译。
- 实际上将整体堆栈分割成一个较小堆栈的链表。
- GCC and clang support it with the -fsplit-stack option
- 从理论上讲,这也提高了内存消耗,并降低了创建线程的成本
- 因为堆栈可以 从很小开始,并按需增长。
- 现实中,有兼容性问题 和 性能问题
- The first idea is to use a sigaltstack() to catch and handle the SIGSEGV
- Utility belt:
- brk(), sbrk() - manipulate the data segment size
- malloc() family - portable libc memory allocator
- 堆的分配可以非常简单:
- start_brk 开始
- 移动
program_brk新的位置,并要求(claim) 新位置和就位置的之间的内存
- 到目前为止,堆分配和堆栈分配一样快(如果没有分页,并 假设堆栈已经被锁定在内存中). 但是...
char *block = sbrk(1024 * sizeof(char)); // increase 1024 byte- problem
- 我们不能回收(reclaim)未使用的内存块
- is not thread-safe since the heap is shared between threads
- the interface is hardly portable, libraries must not touch the break
man 3 sbrk — Various systems use various types for the argument of
sbrk(). Common are int, ssizet, ptrdifft, intptr_t.
- 由于这些原因,libc实现了内存分配的集中式接口。
- 实现有所不同,但它为您提供了一个线程安全的内存分配任何大小... 但有成本。
- 成本是延迟,因为现在涉及锁定,数据结构保留有关使用/空闲块的信息和额外的内存开销。
- 堆也不是唯一被使用的, memory mapping segment 也经常用于 分配大块内存 ?
man 3 malloc — Normally, malloc() allocates memory from the heap,
… when allocating blocks of memory larger than MMAP_THRESHOLD, the
glibc malloc() implementation allocates the memory as a private
anonymous mapping.
- 由于堆始终是从start_brk到brk连续的, 你无法通过打洞 来减少它占用的大小
- 想象以下场景: heap [allocator] 移动 brk 给 trunk 声请了一块内存, 然后又为 bike 申请了一块内存
- 但是 trunk 被释放后, brk 没法移下来, 因为 bike 占据了 最高地址
- 你的进程 可以 复用之前 trunk的内存,但无法把 trunk 还给系统, 直到 bike 被释放.
- 但是 如果 trunk 是 mmaped , 它不会驻留在 heap segment, 并且不会影响 program_brk.
- 不过, 这个小技巧 并不能防止 小分配 造成的漏洞,这个就是 内存碎片
- 注意, free() 并不总是 试图收缩数据段( program_brk ? ) ,因为这是一个 潜在的昂贵操作
- 对于长时间运行的程序,如守护进程,这是个问题。
- GNU有个扩展 malloc_trim() ,用于从堆顶部释放内存,但是可能会非常缓慢。
- 大多数时候,我们分配的内存不是连续的
- 在这种情况下,不仅碎片是问题,而且数据的位置也会是问题
- cache-efficient 数据结构 需要放置在一起,最好在同一 page
- 使用默认的分配器,不能保证随后分配的块的位置。 更糟糕的是分配小单位的内存浪费。
- Utility belt:
- posix_memalign() - allocate aligned memory
- 你向分配器请求一块内存,比如 整个页面,然后把它切成许多固定大小的块。
- 假定每个片段至少可以容纳一个指针或一个整数
- 你可以将它们链接到一个列表中,列表头指向第一个空闲的元素。
/* Super-simple slab. */
struct slab {
void **head;
};
/* Create page-aligned slab */
struct slab *slab = NULL;
posix_memalign(&slab, page_size, page_size);
/* Q: why jump off a size of struct ? */
slab->head = (void **)((char*)slab + sizeof(struct slab));
/* Create a NULL-terminated slab freelist */
/* me: not understand the item iteration */
char* item = (char*)slab->head;
for(unsigned i = 0; i < item_count; ++i) {
*((void**)item) = item + item_size;
item += item_size;
}
*((void**)item) = NULL;/* Free an element */
struct slab *slab = (void *)((size_t)ptr & PAGESIZE_BITS);
*((void**)ptr) = (void*)slab->head;
slab->head = (void**)ptr;
/* Allocate an element */
if((item = slab->head)) {
slab->head = (void**)*item;
} else {
/* No elements left. */
}- 分配就像 popup list head , 释放 就是 push a new list head
- 太好了,如何装箱,可变大小的存储,缓存别名和咖啡因,怎么办?
- Utility belt:
- obstack_alloc() - allocate memory from object stack
- 你把slab切片,直到它用完,然后请求一个新的。
- 该模式令人惊讶地适用于 从 short-lived repetitive( i.e. “网络请求处理”)到 long-lived immutable data (i.e. “frozen set”)等许多任务。
- 而你在这里很幸运,因为GNU libc提供了
*whoa*,这是一个真正的API。- 它被称为obstacks,就像“堆栈对象”一样。
- 它可以让你进行池分配,也可以完全或部分地展开。
/* Define block allocator. */
#define obstack_chunk_alloc malloc
#define obstack_chunk_free free
/* Initialize obstack and allocate a bunch of animals. */
struct obstack animal_stack;
obstack_init (&animal_stack);
char *bob = obstack_alloc(&animal_stack, sizeof(animal));
char *fred = obstack_alloc(&animal_stack, sizeof(animal));
char *roger = obstack_alloc(&animal_stack, sizeof(animal));
/* Free everything after fred (i.e. fred and roger). */
obstack_free(&animal_stack, fred);
/* Free everything. */
obstack_free(&animal_stack, NULL);- Utility belt:
- mlock() - lock/unlock memory
- madvise() - give advice about use of memory
- 把内存还给系统是有代价的. 系统需要做两件事
- establish the mapping of a virtual page to real page
- give you a blanked real page
- The real page is called frame
- 每个框架都必须进行清理,因为您不希望操作系统将您的秘密泄漏到另一个进程中,对吗?
- 但是 The virtual memory allocator 并没有给你一个真的 page,而是 a special page 0
- 每次尝试访问特殊页面时,都会发生页面错误
- 这意味着:内核暂停进程执行并获取一个实际页面,然后更新页面表,然后继续执行任何事情。
- This is also called “demand paging” or “lazy loading”.
- 您可以将连续内存块 锁定 在物理内存中,避免进一步的页面错误:
char *block = malloc(1024 * sizeof(char));
mlock(block, 1024 * sizeof(char));- Utility belt:
- sysconf() - get configuration information at run time
- mmap() - map virtual memory
- mincore() - determine whether pages are resident in memory
- shmat() - shared memory operations
- There are several things that the memory allocator just can’t do, memory maps to to rescue!
- 比如,你不能选择分配的内存的地址范围
- 我们将从现在开始处理整个页面。
- 一个页面通常是一个4K块,但是你不应该依赖它, 使用sysconf()来发现它。
long page_size = sysconf(_SC_PAGESIZE); /* Slice and dice. */- 但是 当物理内存被分割时,巨大的连续块变得稀少。
- 页面错误的成本也随着页面大小的增加而增加,
- 但是有一个特定于Linux的mmap选项MAP_HUGETLB允许你明确地使用它