部署架构图
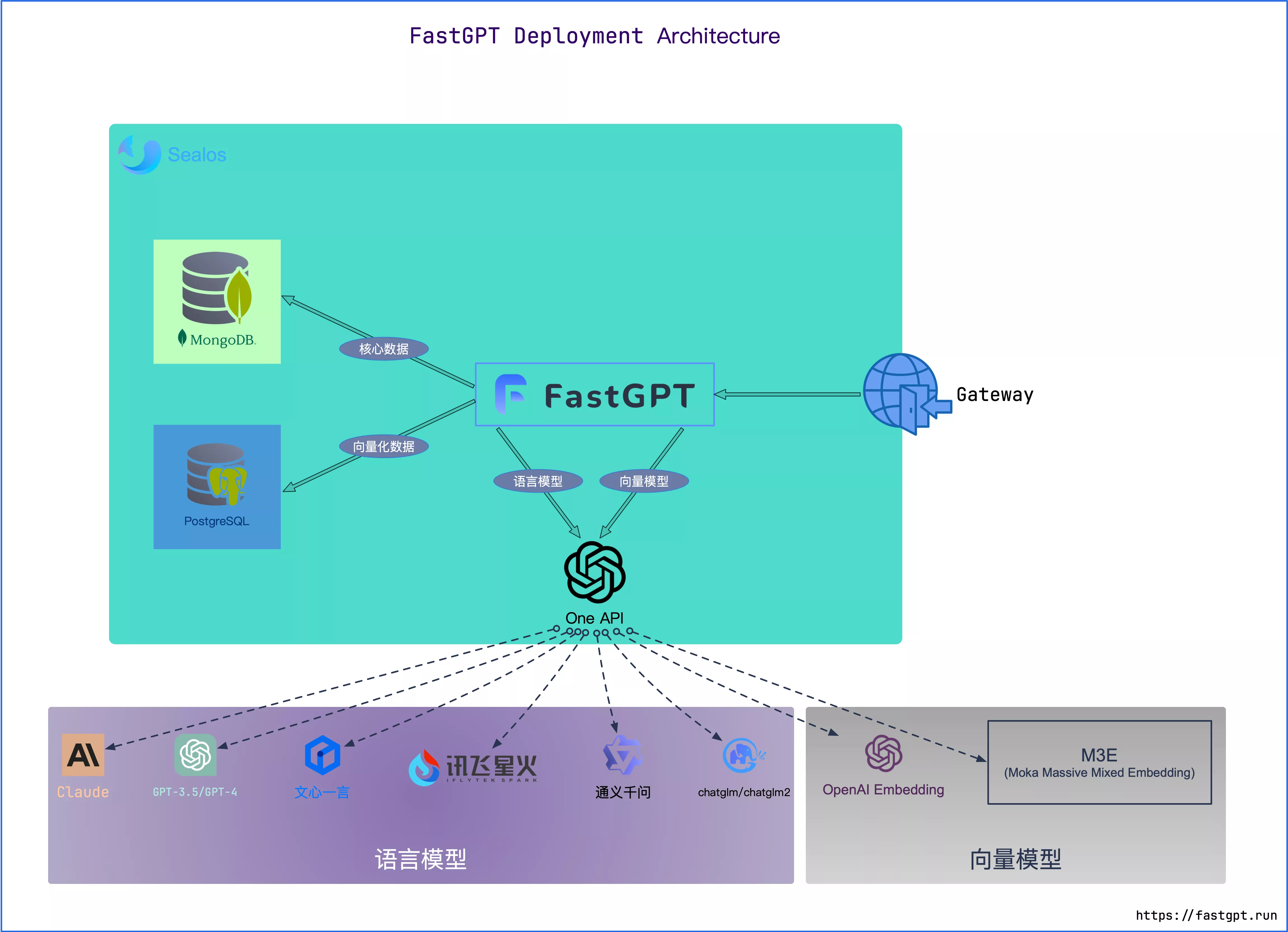
MongoDB:用于存储除了向量外的各类数据
PostgreSQL/Milvus:存储向量数据
OneAPI: 聚合各类 AI API,支持多模型调用 (任何模型问题,先自行通过 OneAPI 测试校验)
推荐配置
PgVector版本
体验测试首选
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试 | 2c2g | 2c4g |
| 100w 组向量 | 4c8g 50GB | 4c16g 50GB |
| 500w 组向量 | 8c32g 200GB | 16c64g 200GB |
Milvus版本
生产部署首选,对于千万级以上向量性能更优秀。
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试 | 2c8g | 4c16g |
| 100w 组向量 | 未测试 | |
| 500w 组向量 |
zilliz cloud版本
Milvus 的全托管服务,性能优于 Milvus 并提供 SLA,点击使用 Zilliz Cloud。
由于向量库使用了 Cloud,无需占用本地资源,无需太关注。
前置工作
1. 确保网络环境
如果使用OpenAI等国外模型接口,请确保可以正常访问,否则会报错:Connection error 等。 方案可以参考:代理方案
2. 准备 Docker 环境
+Table of Contents
Docker Compose 快速部署
使用 Docker Compose 快速部署 FastGPT
部署架构图
MongoDB:用于存储除了向量外的各类数据
PostgreSQL/Milvus:存储向量数据
OneAPI: 聚合各类 AI API,支持多模型调用 (任何模型问题,先自行通过 OneAPI 测试校验)
推荐配置
PgVector版本
体验测试首选
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试 | 2c2g | 2c4g |
| 100w 组向量 | 4c8g 50GB | 4c16g 50GB |
| 500w 组向量 | 8c32g 200GB | 16c64g 200GB |
Milvus版本
生产部署首选,对于千万级以上向量性能更优秀。
| 环境 | 最低配置(单节点) | 推荐配置 |
|---|---|---|
| 测试 | 2c8g | 4c16g |
| 100w 组向量 | 未测试 | |
| 500w 组向量 |
zilliz cloud版本
Milvus 的全托管服务,性能优于 Milvus 并提供 SLA,点击使用 Zilliz Cloud。
由于向量库使用了 Cloud,无需占用本地资源,无需太关注。
前置工作
1. 确保网络环境
如果使用OpenAI等国外模型接口,请确保可以正常访问,否则会报错:Connection error 等。 方案可以参考:代理方案
2. 准备 Docker 环境
开始部署
1. 下载 docker-compose.yml
非 Linux 环境或无法访问外网环境,可手动创建一个目录,并下载配置文件和对应版本的docker-compose.yml,在这个文件夹中依据下载的配置文件运行docker,若作为本地开发使用推荐docker-compose-pgvector版本,并且自行拉取并运行sandbox和fastgpt,并在docker配置文件中注释掉sandbox和fastgpt的部分
- config.json
- docker-compose.yml (注意,不同向量库版本的文件不一样)
所有 docker-compose.yml 配置文件中 MongoDB 为 5.x,需要用到AVX指令集,部分 CPU 不支持,需手动更改其镜像版本为 4.4.24**(需要自己在docker hub下载,阿里云镜像没做备份)
Linux 快速脚本
+
或者直接下载安装包进行安装。
我们建议将源代码和其他数据绑定到 Linux 容器中时,将其存储在 Linux 文件系统中,而不是 Windows 文件系统中。
可以选择直接使用 WSL 2 后端在 Windows 中安装 Docker Desktop。
也可以直接在 WSL 2 中安装命令行版本的 Docker。
开始部署
1. 下载 docker-compose.yml
非 Linux 环境或无法访问外网环境,可手动创建一个目录,并下载配置文件和对应版本的docker-compose.yml,在这个文件夹中依据下载的配置文件运行docker,若作为本地开发使用推荐docker-compose-pgvector版本,并且自行拉取并运行sandbox和fastgpt,并在docker配置文件中注释掉sandbox和fastgpt的部分
- config.json
- docker-compose.yml (注意,不同向量库版本的文件不一样)
所有 docker-compose.yml 配置文件中 MongoDB 为 5.x,需要用到AVX指令集,部分 CPU 不支持,需手动更改其镜像版本为 4.4.24**(需要自己在docker hub下载,阿里云镜像没做备份)
Linux 快速脚本
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
@@ -57,13 +57,13 @@
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-milvus.yml
# zilliz 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-zilliz.yml
- 2. 修改环境变量
找到 yml 文件中,fastgpt 容器的环境变量进行下面操作:
+
2. 修改环境变量
找到 yml 文件中,fastgpt 容器的环境变量进行下面操作:
FE_DOMAIN=你的前端你访问地址,例如 http://192.168.0.1:3000;https://cloud.fastgpt.cn
- +
FE_DOMAIN=你的前端你访问地址,例如 http://192.168.0.1:3000;https://cloud.fastgpt.cn
- 打开 Zilliz Cloud, 创建实例并获取相关秘钥。
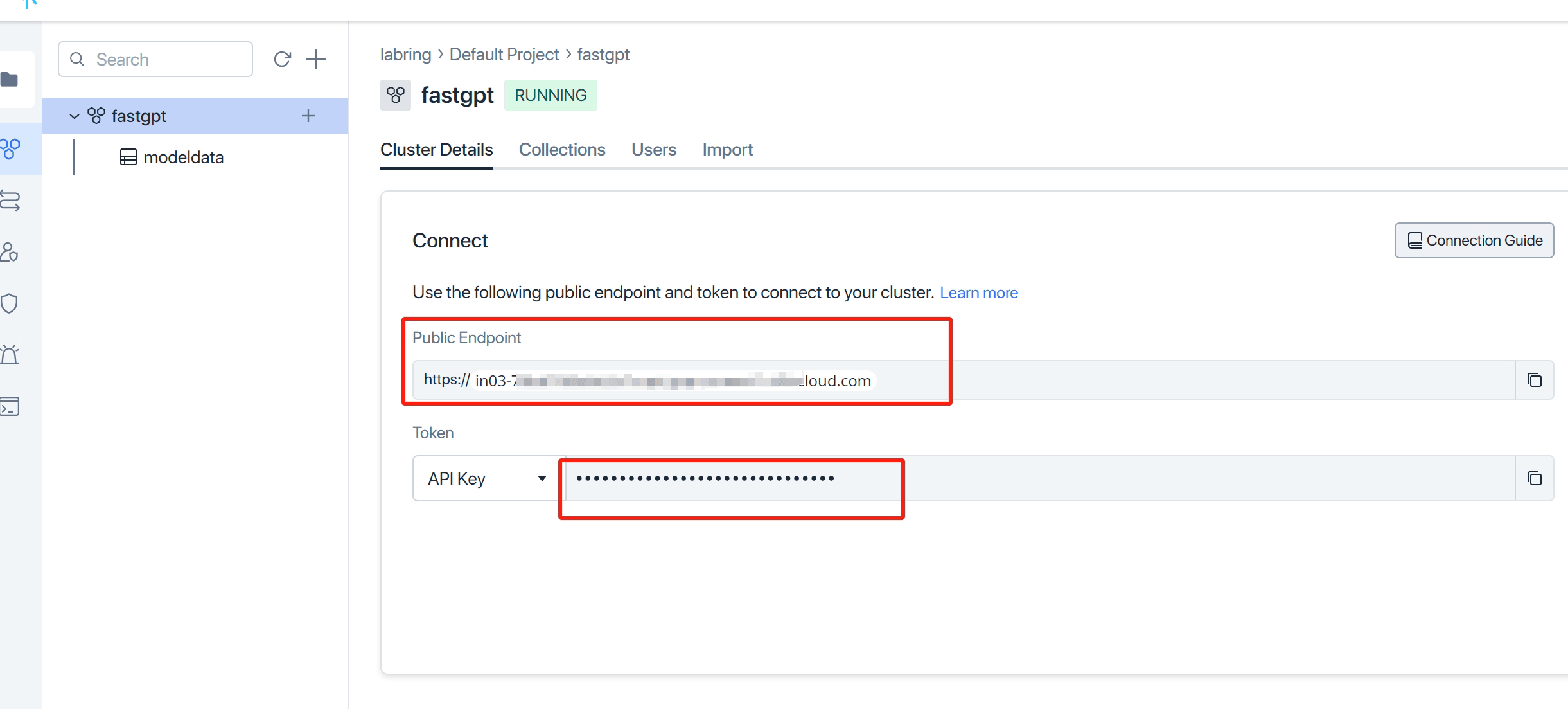
- 修改
MILVUS_ADDRESS和MILVUS_TOKEN链接参数,分别对应zilliz的Public Endpoint和Api key,记得把自己ip加入白名单。 - 修改FE_DOMAIN=你的前端你访问地址,例如 http://192.168.0.1:3000;https://cloud.fastgpt.cn
3. 启动容器
在 docker-compose.yml 同级目录下执行。请确保docker-compose版本最好在2.17以上,否则可能无法执行自动化命令。
+
打开 Zilliz Cloud, 创建实例并获取相关秘钥。
- 修改
MILVUS_ADDRESS和MILVUS_TOKEN链接参数,分别对应zilliz的Public Endpoint和Api key,记得把自己ip加入白名单。 - 修改FE_DOMAIN=你的前端你访问地址,例如 http://192.168.0.1:3000;https://cloud.fastgpt.cn
3. 启动容器
在 docker-compose.yml 同级目录下执行。请确保docker-compose版本最好在2.17以上,否则可能无法执行自动化命令。
# 启动容器
docker-compose up -d
# 等待10s,OneAPI第一次总是要重启几次才能连上Mysql
diff --git a/docs/development/openapi/chat/index.html b/docs/development/openapi/chat/index.html
index ece774e65ec..c7920b0b300 100644
--- a/docs/development/openapi/chat/index.html
+++ b/docs/development/openapi/chat/index.html
@@ -31,9 +31,9 @@
对话接口
FastGPT OpenAPI 对话接口
发起对话
该接口的 API Key 需使用
应用特定的 key,否则会报错。有些包调用时,
BaseUrl需要添加v1路径,有些不需要,如果出现404情况,可补充v1重试。
请求简易应用和工作流
对话接口兼容GPT的接口!如果你的项目使用的是标准的GPT官方接口,可以直接通过修改BaseUrl和 Authorization来访问 FastGpt 应用,不过需要注意下面几个规则:
传入的
model,temperature等参数字段均无效,这些字段由编排决定,不会根据 API 参数改变。不会返回实际消耗
Token值,如果需要,可以设置detail=true,并手动计算responseData里的tokens值。
请求
+Table of Contents
对话接口
FastGPT OpenAPI 对话接口
发起对话
该接口的 API Key 需使用
应用特定的 key,否则会报错。有些包调用时,
BaseUrl需要添加v1路径,有些不需要,如果出现404情况,可补充v1重试。
请求简易应用和工作流
对话接口兼容GPT的接口!如果你的项目使用的是标准的GPT官方接口,可以直接通过修改BaseUrl和 Authorization来访问 FastGpt 应用,不过需要注意下面几个规则:
传入的
model,temperature等参数字段均无效,这些字段由编排决定,不会根据 API 参数改变。不会返回实际消耗
Token值,如果需要,可以设置detail=true,并手动计算responseData里的tokens值。
请求
响应
响应
交互节点响应
如果工作流中包含交互节点,依然是调用该 API 接口,需要设置detail=true,并可以从event=interactive的数据中获取交互节点的配置信息。如果是stream=false,则可以从 choice 中获取type=interactive的元素,获取交互节点的选择信息。
当你调用一个带交互节点的工作流时,如果工作流遇到了交互节点,那么会直接返回,你可以得到下面的信息:
交互节点响应
如果工作流中包含交互节点,依然是调用该 API 接口,需要设置detail=true,并可以从event=interactive的数据中获取交互节点的配置信息。如果是stream=false,则可以从 choice 中获取type=interactive的元素,获取交互节点的选择信息。
当你调用一个带交互节点的工作流时,如果工作流遇到了交互节点,那么会直接返回,你可以得到下面的信息:
交互节点继续运行
紧接着上一节,当你接收到交互节点信息后,可以根据这些数据进行 UI 渲染,引导用户输入或选择相关信息。然后需要再次发起对话,来继续工作流。调用的接口与仍是该接口,你需要按以下格式来发起请求:
交互节点继续运行
紧接着上一节,当你接收到交互节点信息后,可以根据这些数据进行 UI 渲染,引导用户输入或选择相关信息。然后需要再次发起对话,来继续工作流。调用的接口与仍是该接口,你需要按以下格式来发起请求:
对于用户选择,你只需要直接传递一个选择的结果给 messages 即可。
curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \
--header 'Authorization: Bearer fastgpt-xxx' \
--header 'Content-Type: application/json' \
@@ -308,7 +308,7 @@
}
]
}'
- 表单输入稍微麻烦一点,需要将输入的内容,以对象形式并序列化成字符串,作为messages的值。对象的 key 对应表单的 key,value 为用户输入的值。务必确保chatId是一致的。
+
表单输入稍微麻烦一点,需要将输入的内容,以对象形式并序列化成字符串,作为messages的值。对象的 key 对应表单的 key,value 为用户输入的值。务必确保chatId是一致的。
curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \
--header 'Authorization: Bearer fastgpt-xxxx' \
--header 'Content-Type: application/json' \
@@ -334,9 +334,9 @@
"query":"你好" # 我的插件输入有一个参数,变量名叫 query
}
}'
- 响应示例
- 插件的输出可以通过查找
responseData中,moduleType=pluginOutput的元素,其pluginOutput是插件的输出。 - 流输出,仍可以通过
choices进行获取。
+
响应示例
对话 CRUD
以下接口可使用任意
API Key调用。4.8.12 以上版本才能使用
重要字段
- chatId - 指一个应用下,某一个对话窗口的 ID
- dataId - 指一个对话窗口下,某一个对话记录的 ID
历史记录
获取某个应用历史记录
对话 CRUD
以下接口可使用任意
API Key调用。4.8.12 以上版本才能使用
重要字段
- chatId - 指一个应用下,某一个对话窗口的 ID
- dataId - 指一个对话窗口下,某一个对话记录的 ID
历史记录
获取某个应用历史记录
修改某个对话的标题
修改某个对话的标题
置顶 / 取消置顶
置顶 / 取消置顶
删除某个历史记录
删除某个历史记录
清空所有历史记录
清空所有历史记录
对话记录
指的是某个 chatId 下的对话记录操作。
获取单个对话初始化信息
对话记录
指的是某个 chatId 下的对话记录操作。
获取单个对话初始化信息
获取对话记录列表
获取对话记录列表
获取单个对话记录运行详情
获取单个对话记录运行详情
删除对话记录
删除对话记录
点赞 / 取消点赞
点赞 / 取消点赞
点踩 / 取消点踩
点踩 / 取消点踩
猜你想问
猜你想问
知识库接口
FastGPT OpenAPI 知识库接口
| 如何获取知识库ID(datasetId) | 如何获取文件集合ID(collection_id) |
|---|---|
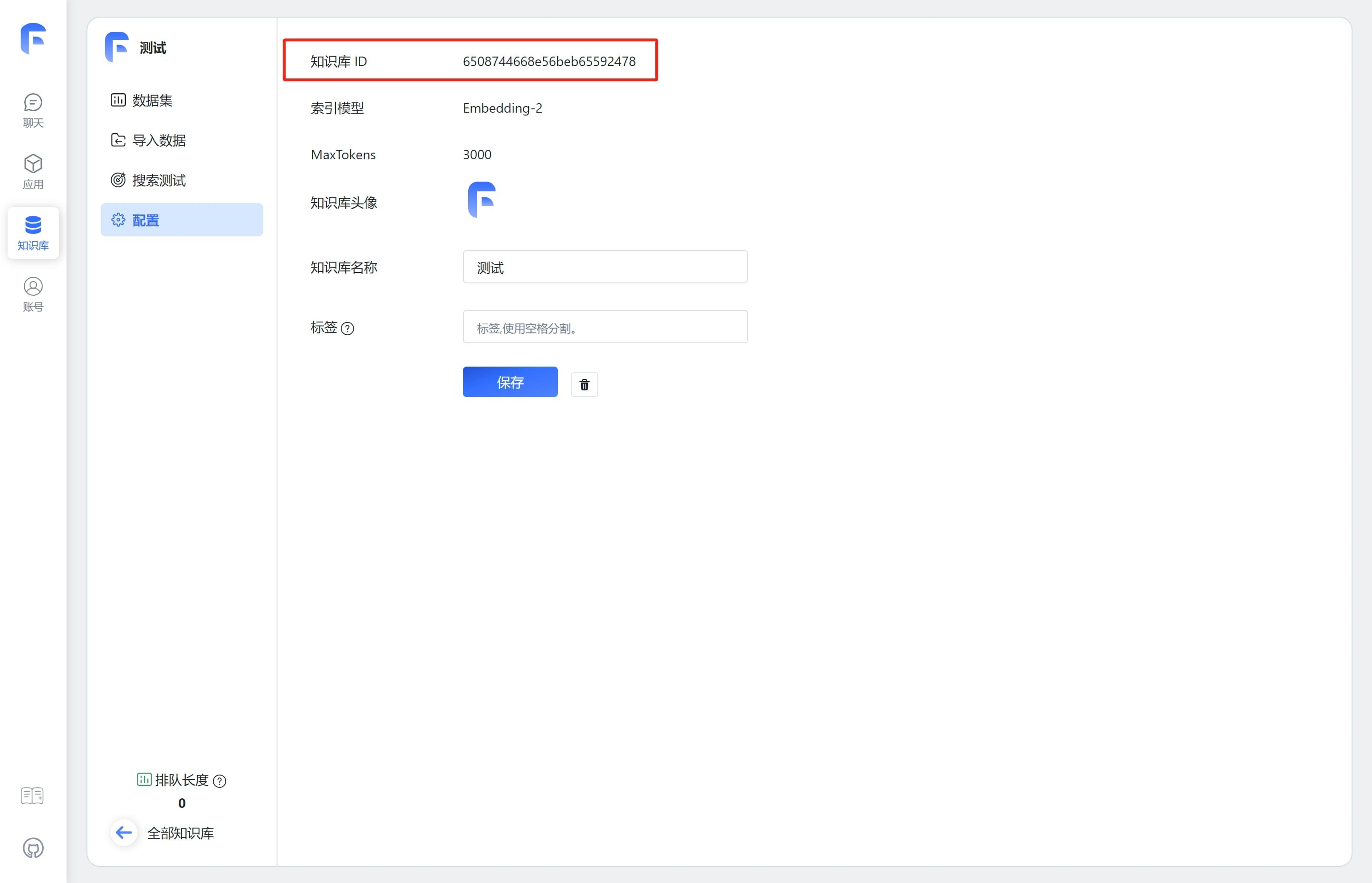 | 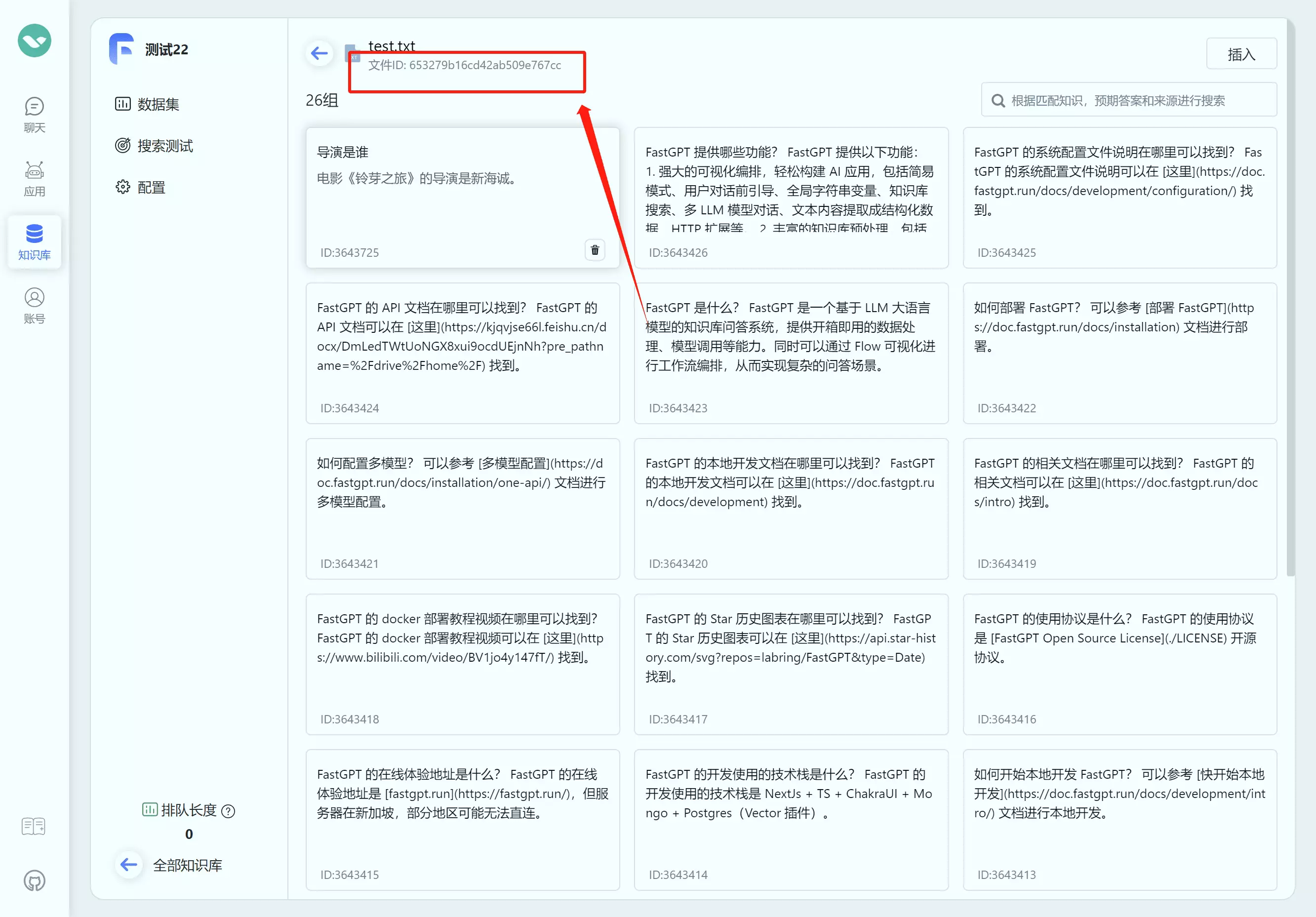 |
创建训练订单
新例子
+Table of Contents
知识库接口
FastGPT OpenAPI 知识库接口
| 如何获取知识库ID(datasetId) | 如何获取文件集合ID(collection_id) |
|---|---|
| |
创建训练订单
知识库
创建一个知识库
知识库
创建一个知识库
获取知识库列表
获取知识库列表
获取知识库详情
获取知识库详情
删除一个知识库
删除一个知识库
集合
通用创建参数说明
入参
| 参数 | 说明 | 必填 |
|---|---|---|
| datasetId | 知识库ID | ✅ |
| parentId: | 父级ID,不填则默认为根目录 | |
| trainingType | 训练模式。chunk: 按文本长度进行分割;qa: QA拆分;auto: 增强训练 | ✅ |
| chunkSize | 预估块大小 | |
| chunkSplitter | 自定义最高优先分割符号 | |
| qaPrompt | qa拆分提示词 | |
| tags | 集合标签(字符串数组) | |
| createTime | 文件创建时间(Date / String) |
出参
- collectionId - 新建的集合ID
- insertLen:插入的块数量
创建一个空的集合
集合
通用创建参数说明
入参
| 参数 | 说明 | 必填 |
|---|---|---|
| datasetId | 知识库ID | ✅ |
| parentId: | 父级ID,不填则默认为根目录 | |
| trainingType | 训练模式。chunk: 按文本长度进行分割;qa: QA拆分;auto: 增强训练 | ✅ |
| chunkSize | 预估块大小 | |
| chunkSplitter | 自定义最高优先分割符号 | |
| qaPrompt | qa拆分提示词 | |
| tags | 集合标签(字符串数组) | |
| createTime | 文件创建时间(Date / String) |
出参
- collectionId - 新建的集合ID
- insertLen:插入的块数量
创建一个空的集合
创建一个纯文本集合
传入一段文字,创建一个集合,会根据传入的文字进行分割。
创建一个纯文本集合
传入一段文字,创建一个集合,会根据传入的文字进行分割。
创建一个链接集合
传入一个网络链接,创建一个集合,会先去对应网页抓取内容,再抓取的文字进行分割。
创建一个链接集合
传入一个网络链接,创建一个集合,会先去对应网页抓取内容,再抓取的文字进行分割。
创建一个文件集合
传入一个文件,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
创建一个文件集合
传入一个文件,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
创建一个外部文件库集合(商业版)
创建一个外部文件库集合(商业版)
获取集合列表
获取集合列表
获取集合详情
获取集合详情
修改集合信息
修改集合信息
删除一个集合
删除一个集合
数据
数据的结构
Data结构
| 字段 | 类型 | 说明 | 必填 |
|---|---|---|---|
| teamId | String | 团队ID | ✅ |
| tmbId | String | 成员ID | ✅ |
| datasetId | String | 知识库ID | ✅ |
| collectionId | String | 集合ID | ✅ |
| q | String | 主要数据 | ✅ |
| a | String | 辅助数据 | ✖ |
| fullTextToken | String | 分词 | ✖ |
| indexes | Index[] | 向量索引 | ✅ |
| updateTime | Date | 更新时间 | ✅ |
| chunkIndex | Number | 分块下表 | ✖ |
Index结构
每组数据的自定义索引最多5个
| 字段 | 类型 | 说明 | 必填 |
|---|---|---|---|
| defaultIndex | Boolean | 是否为默认索引 | ✅ |
| dataId | String | 关联的向量ID | ✅ |
| text | String | 文本内容 | ✅ |
为集合批量添加添加数据
注意,每次最多推送 200 组数据。
数据
数据的结构
Data结构
| 字段 | 类型 | 说明 | 必填 |
|---|---|---|---|
| teamId | String | 团队ID | ✅ |
| tmbId | String | 成员ID | ✅ |
| datasetId | String | 知识库ID | ✅ |
| collectionId | String | 集合ID | ✅ |
| q | String | 主要数据 | ✅ |
| a | String | 辅助数据 | ✖ |
| fullTextToken | String | 分词 | ✖ |
| indexes | Index[] | 向量索引 | ✅ |
| updateTime | Date | 更新时间 | ✅ |
| chunkIndex | Number | 分块下表 | ✖ |
Index结构
每组数据的自定义索引最多5个
| 字段 | 类型 | 说明 | 必填 |
|---|---|---|---|
| defaultIndex | Boolean | 是否为默认索引 | ✅ |
| dataId | String | 关联的向量ID | ✅ |
| text | String | 文本内容 | ✅ |
为集合批量添加添加数据
注意,每次最多推送 200 组数据。
获取集合的数据列表
获取集合的数据列表
获取单条数据详情
获取单条数据详情
修改单条数据
修改单条数据
删除单条数据
删除单条数据
搜索测试
搜索测试
curl --location --request POST 'https://api.fastgpt.in/api/core/dataset/searchTest' \
--header 'Authorization: Bearer fastgpt-xxxxx' \
--header 'Content-Type: application/json' \
@@ -654,7 +654,7 @@
"searchMode": "embedding",
"usingReRank": false
}'
- - datasetId - 知识库ID
- text - 需要测试的文本
- limit - 最大 tokens 数量
- similarity - 最低相关度(0~1,可选)
- searchMode - 搜索模式:embedding | fullTextRecall | mixedRecall
- usingReRank - 使用重排
返回 top k 结果, limit 为最大 Tokens 数量,最多 20000 tokens。
+
- datasetId - 知识库ID
- text - 需要测试的文本
- limit - 最大 tokens 数量
- similarity - 最低相关度(0~1,可选)
- searchMode - 搜索模式:embedding | fullTextRecall | mixedRecall
- usingReRank - 使用重排
返回 top k 结果, limit 为最大 Tokens 数量,最多 20000 tokens。
{
"code": 200,
"statusText": "",
diff --git a/docs/development/openapi/share/index.html b/docs/development/openapi/share/index.html
index 4b71e727cf9..78c815116e2 100644
--- a/docs/development/openapi/share/index.html
+++ b/docs/development/openapi/share/index.html
@@ -40,43 +40,43 @@
"uid": "用户唯一凭证"
}
}
- FastGPT 将会判断success是否为true决定是允许用户继续操作。message与msg是等同的,你可以选择返回其中一个,当success不为true时,将会提示这个错误。
uid是用户的唯一凭证,将会用于拉取对话记录以及保存对话记录。可参考下方实践案例。
触发流程

配置教程
1. 配置身份校验地址
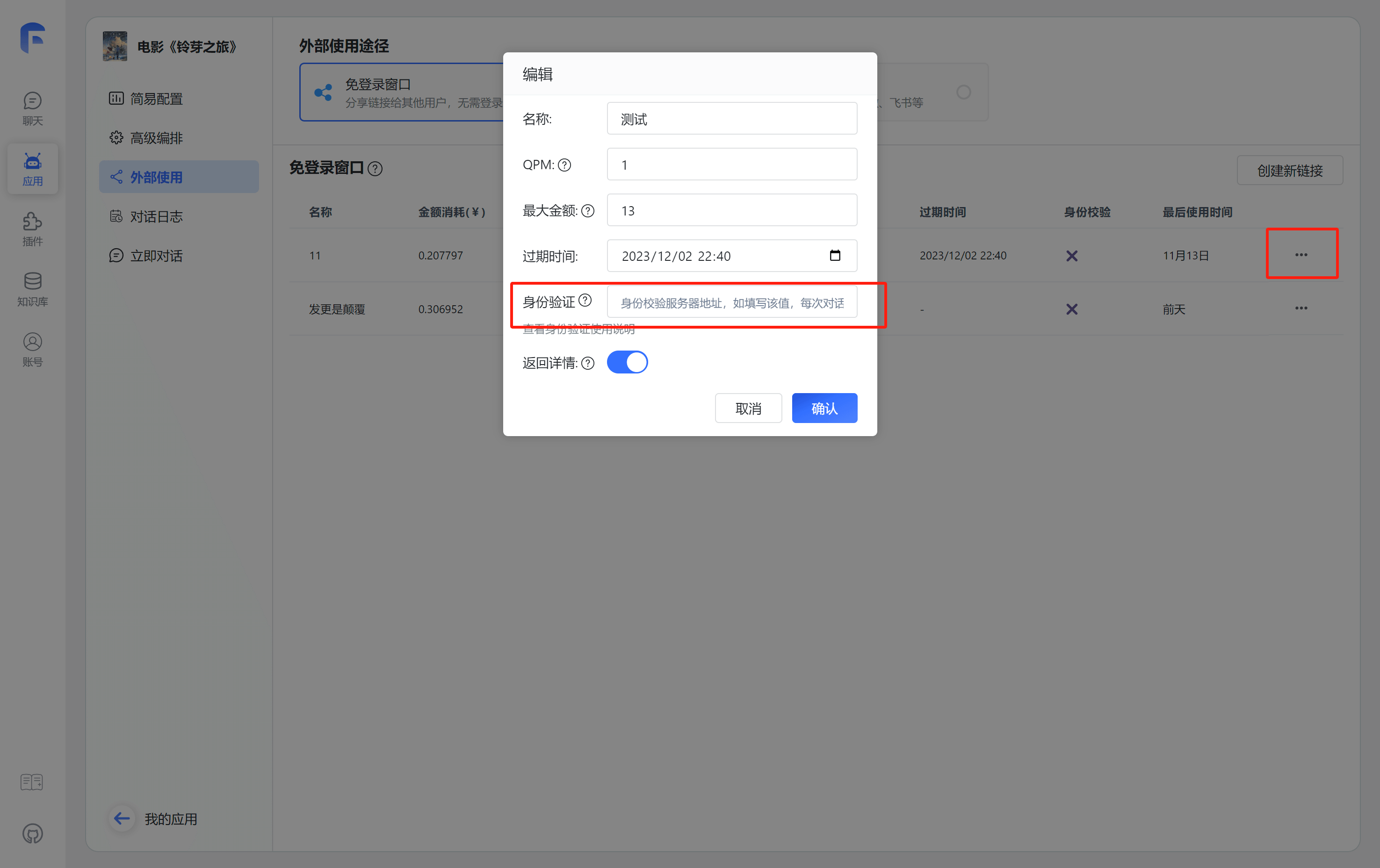
配置校验地址后,在每次分享链接使用时,都会向对应的地址发起校验和上报请求。
这里仅需配置根地址,无需具体到完整请求路径。
2. 分享链接中增加额外 query
在分享链接的地址中,增加一个额外的参数: authToken。例如:
原始的链接:https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192
完整链接: https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192&authToken=userid12345
这个authToken通常是你系统生成的用户唯一凭证(Token之类的)。FastGPT 会在鉴权接口的body中携带 token={{authToken}} 的参数。
3. 编写聊天初始化校验接口
+
FastGPT 将会判断success是否为true决定是允许用户继续操作。message与msg是等同的,你可以选择返回其中一个,当success不为true时,将会提示这个错误。
uid是用户的唯一凭证,将会用于拉取对话记录以及保存对话记录。可参考下方实践案例。
触发流程
配置教程
1. 配置身份校验地址
配置校验地址后,在每次分享链接使用时,都会向对应的地址发起校验和上报请求。
这里仅需配置根地址,无需具体到完整请求路径。
2. 分享链接中增加额外 query
在分享链接的地址中,增加一个额外的参数: authToken。例如:
原始的链接:https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192
完整链接: https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192&authToken=userid12345
这个authToken通常是你系统生成的用户唯一凭证(Token之类的)。FastGPT 会在鉴权接口的body中携带 token={{authToken}} 的参数。
3. 编写聊天初始化校验接口
4. 编写对话前校验接口
4. 编写对话前校验接口
curl --location --request POST '{{host}}/shareAuth/start' \
--header 'Content-Type: application/json' \
--data-raw '{
"token": "{{authToken}}",
"question": "用户问题",
}'
- +
{
"success": true,
"data": {
"uid": "用户唯一凭证"
}
}
- +
{
"success": false,
"message": "身份验证失败",
@@ -199,9 +199,9 @@
isElseResult?: boolean; // 判断器结果
}
- 实践案例
我们以Laf作为服务器为例,简单展示这 3 个接口的使用方式。
1. 创建3个Laf接口
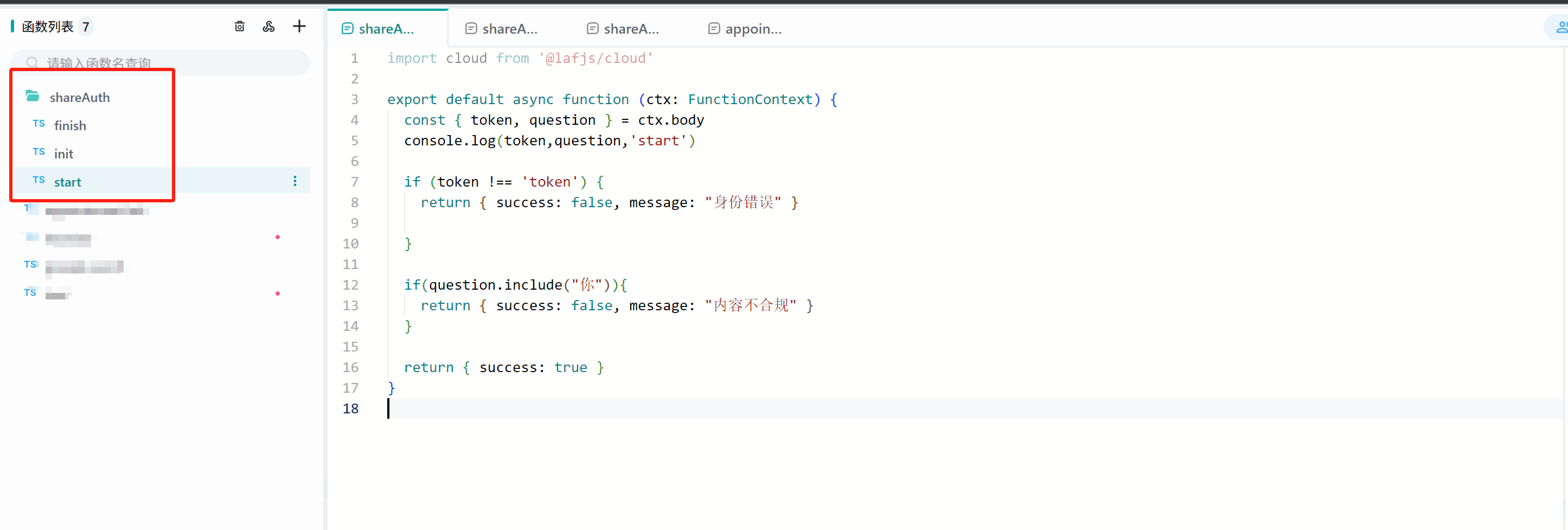
这个接口中,我们设置了token必须等于fastgpt才能通过校验。(实际生产中不建议固定写死)
+
实践案例
我们以Laf作为服务器为例,简单展示这 3 个接口的使用方式。
1. 创建3个Laf接口
HTTP 请求
FastGPT HTTP 模块介绍
特点
- 可重复添加
- 手动配置
- 触发执行
- 核中核模块
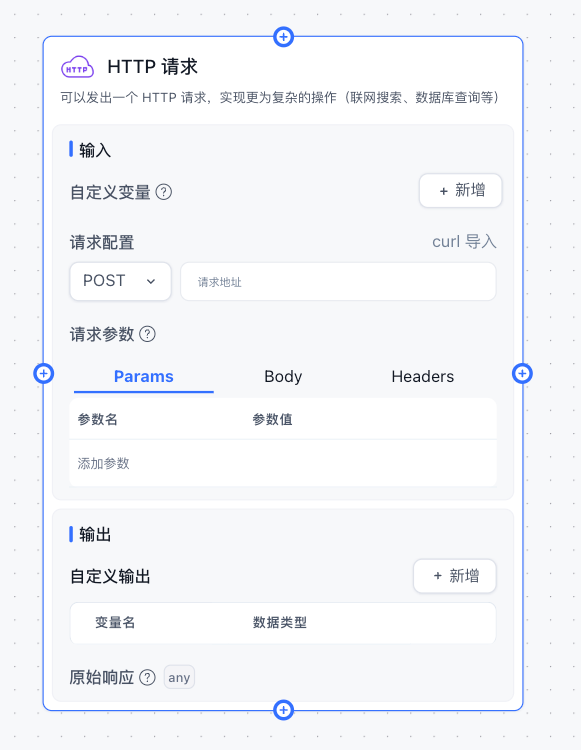
介绍
HTTP 模块会向对应的地址发送一个 HTTP 请求,实际操作与 Postman 和 ApiFox 这类直流工具使用差不多。
- Params 为路径请求参数,GET请求中用的居多。
- Body 为请求体,POST/PUT请求中用的居多。
- Headers 为请求头,用于传递一些特殊的信息。
- 自定义变量中可以接收前方节点的输出作为变量
- 3 种数据中均可以通过
{{}}来引用变量。 - url 也可以通过
{{}}来引用变量。 - 变量来自于
全局变量、系统变量、前方节点输出
参数结构
系统变量说明
你可以将鼠标放置在请求参数旁边的问号中,里面会提示你可用的变量。
- appId: 应用的ID
- chatId: 当前对话的ID,测试模式下不存在。
- responseChatItemId: 当前对话中,响应的消息ID,测试模式下不存在。
- variables: 当前对话的全局变量。
- cTime: 当前时间。
- histories: 历史记录(默认最多取10条,无法修改长度)
Params, Headers
不多描述,使用方法和Postman, ApiFox 基本一致。
可通过 {{key}} 来引入变量。例如:
| key | value |
|---|---|
| appId | {{appId}} |
| Authorization | Bearer {{token}} |
Body
只有特定请求类型下会生效。
可以写一个自定义的 Json,并通过 {{key}} 来引入变量。例如:
+Table of Contents
HTTP 请求
FastGPT HTTP 模块介绍
特点
- 可重复添加
- 手动配置
- 触发执行
- 核中核模块
介绍
HTTP 模块会向对应的地址发送一个 HTTP 请求,实际操作与 Postman 和 ApiFox 这类直流工具使用差不多。
- Params 为路径请求参数,GET请求中用的居多。
- Body 为请求体,POST/PUT请求中用的居多。
- Headers 为请求头,用于传递一些特殊的信息。
- 自定义变量中可以接收前方节点的输出作为变量
- 3 种数据中均可以通过
{{}}来引用变量。 - url 也可以通过
{{}}来引用变量。 - 变量来自于
全局变量、系统变量、前方节点输出
参数结构
系统变量说明
你可以将鼠标放置在请求参数旁边的问号中,里面会提示你可用的变量。
- appId: 应用的ID
- chatId: 当前对话的ID,测试模式下不存在。
- responseChatItemId: 当前对话中,响应的消息ID,测试模式下不存在。
- variables: 当前对话的全局变量。
- cTime: 当前时间。
- histories: 历史记录(默认最多取10条,无法修改长度)
Params, Headers
不多描述,使用方法和Postman, ApiFox 基本一致。
可通过 {{key}} 来引入变量。例如:
| key | value |
|---|---|
| appId | {{appId}} |
| Authorization | Bearer {{token}} |
Body
只有特定请求类型下会生效。
可以写一个自定义的 Json,并通过 {{key}} 来引入变量。例如:
如何获取返回值
从图中可以看出,FastGPT可以添加多个返回值,这个返回值并不代表接口的返回值,而是代表如何解析接口返回值,可以通过 JSON path 的语法,来提取接口响应的值。
语法可以参考: https://github.com/JSONPath-Plus/JSONPath?tab=readme-ov-file
如何获取返回值
从图中可以看出,FastGPT可以添加多个返回值,这个返回值并不代表接口的返回值,而是代表如何解析接口返回值,可以通过 JSON path 的语法,来提取接口响应的值。
语法可以参考: https://github.com/JSONPath-Plus/JSONPath?tab=readme-ov-file
{
"message": "测试",
"data":{
@@ -86,7 +86,7 @@
"psw": "xxx"
}
}
- +
{
"$.message": "测试",
"$.data.user": { "name": "xxx", "age": 12 },
diff --git a/docs/use-cases/external-integration/official_account/index.html b/docs/use-cases/external-integration/official_account/index.html
index bf6390f699b..733217b29c7 100644
--- a/docs/use-cases/external-integration/official_account/index.html
+++ b/docs/use-cases/external-integration/official_account/index.html
@@ -52,7 +52,7 @@
34.87.152.33
35.197.149.75
35.247.161.35
- 国内版用户(fastgpt.cn)可以填写下面的 IP 白名单:
+
国内版用户(fastgpt.cn)可以填写下面的 IP 白名单:
47.97.1.240
121.43.105.217
121.41.178.7
@@ -66,7 +66,15 @@
112.124.41.79
121.196.235.183
121.41.75.88
-121.43.108.48
+121.43.108.48
+112.124.12.6
+121.43.52.222
+121.199.162.43
+121.199.162.102
+120.55.94.163
+47.99.59.223
+112.124.46.5
+121.40.46.247
4. 获取AES Key,选择加密方式
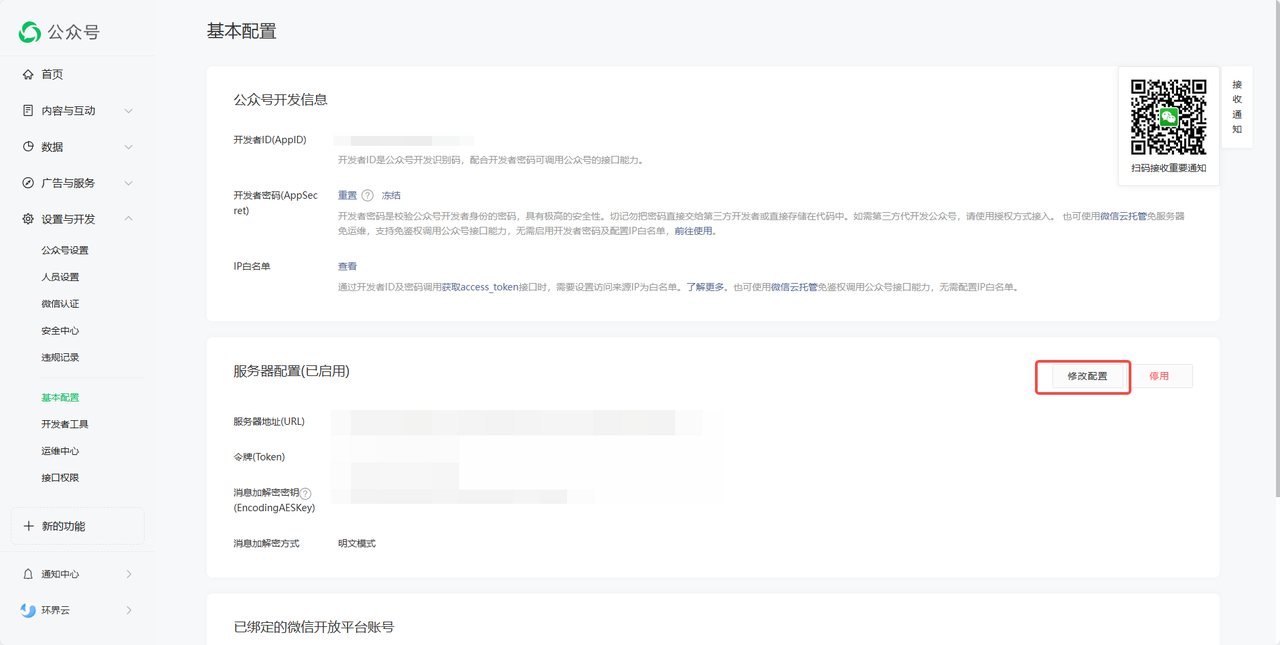
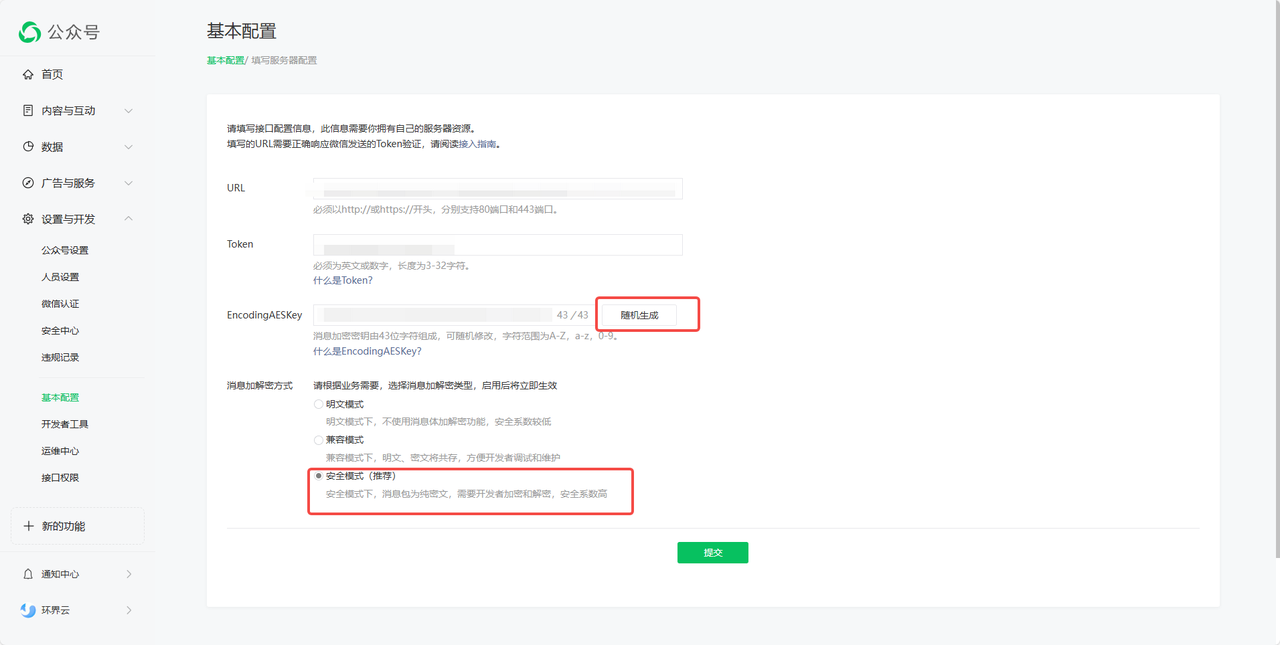
随机生成AESKey,填入 FastGPT 配置弹窗中。
选择加密方式为安全模式。
5. 获取 URL
- 在FastGPT确认创建,获取URL。
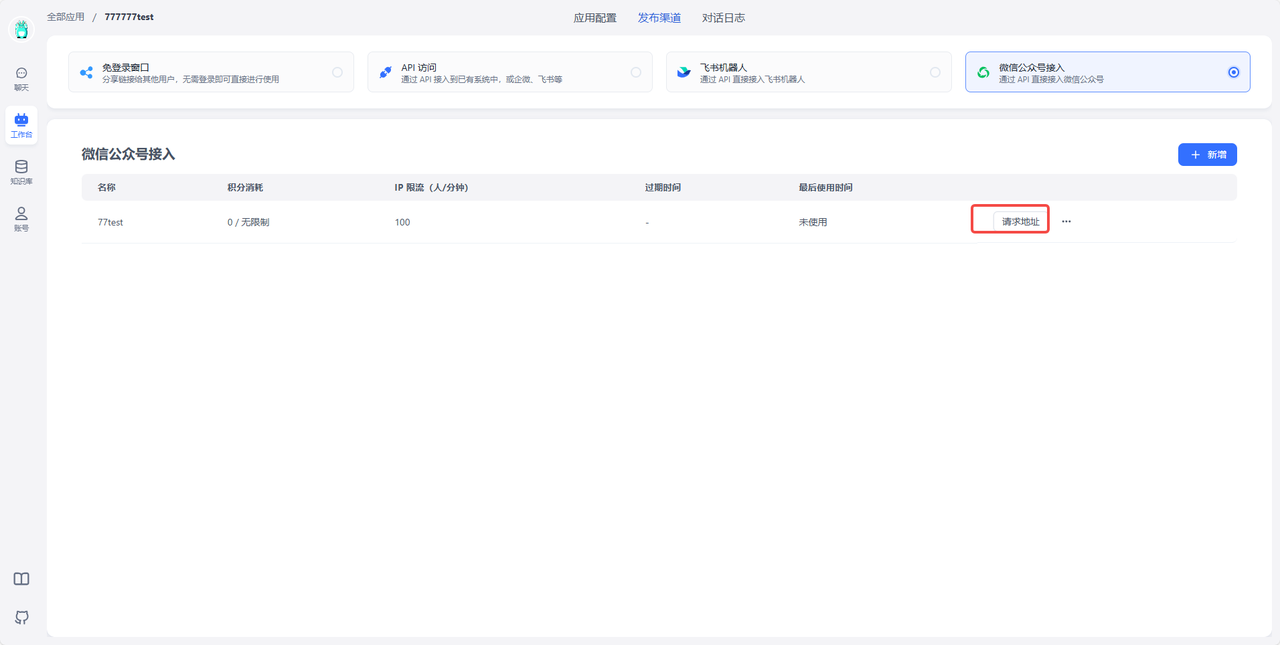
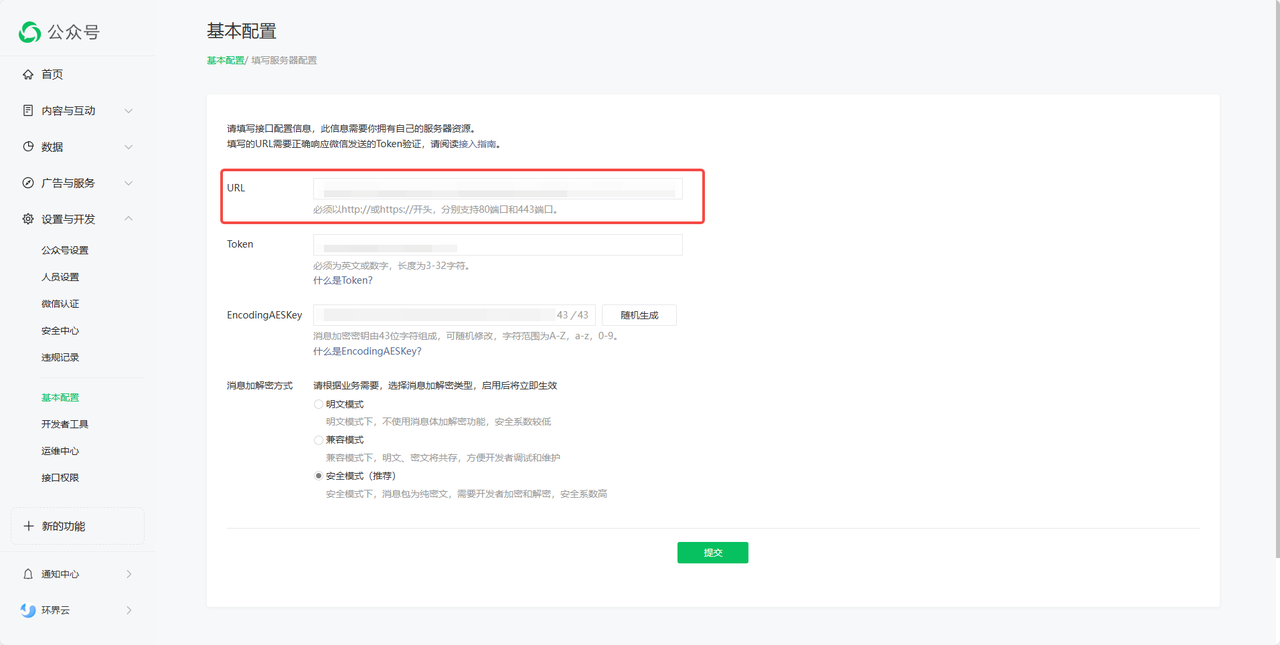
- 填入微信公众平台的 URL 处,然后提交保存
6. 启用服务器配置(如已自动启用,请忽略)
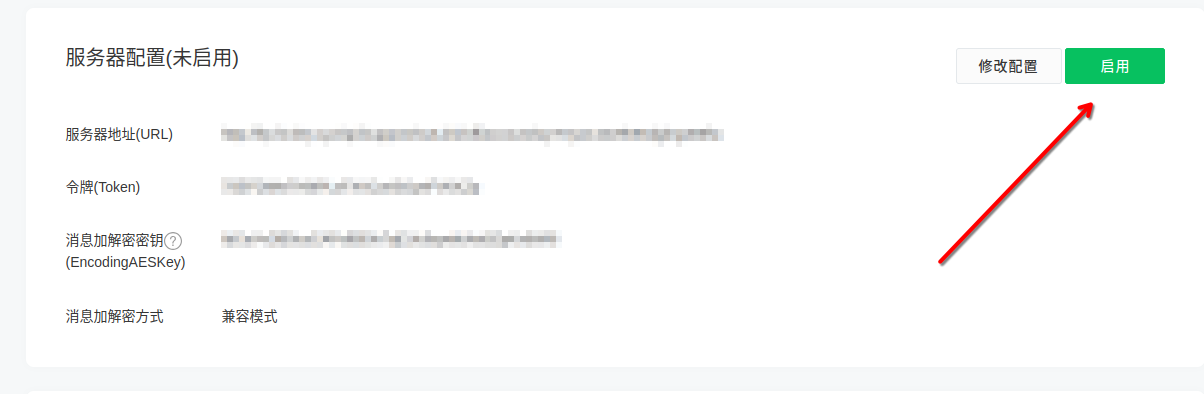
7. 开始使用
现在用户向公众号发消息,消息则会被转发到 FastGPT,通过公众号返回对话结果。