每当我解雇一个语言学家,语音识别的性能就会提升。
开始之前,咱们先来回顾一下语音识别常用的建模单元都有哪些,Kaldi 时代,或者说前端到端时代,一般使用 phone 来建模,mono-phone,bi-phone,tri-phone 各种粒度都有。使用 phone 建模一般会有一个 lexicon,里面记录着每一个词对应的 phone 序列,表示当前这个词的发音。随着端到端模型的流行,sub-word 也开始流行起来,在 sub-word 建模中,sub-word 不是像 phone 一样人为定义的单元,而是通过统计模型从语料中提取的,单个的 sub-word 并没有物理意义,就是一个符号而已。对于 sub-word 建模,这里要提一下 CJK (中日韩)文字跟英文的区别,英文的词是字母序列,CJK的词是字序列,所以 sub-word 对于字母文字可以拆到字母级别,比如最极端的 wav2vec 只需要 28 个 token (26 个字母加空格和 ' ),但 CJK 文字只能拆到字级别,建模单元数量受限于单字的数量。
上面提到对于英文 sub-word 模型其实已经就是 byte level 的序列,因为英文用 Latin 字符就可以表达,所以今天咱们讨论的 byte level BPE 主要就是针对 CJK 文字的。CJK 文字的 sub-word 建模由于只能拆到字符级别,所以哪怕最极端的情况,也只能拆成单字(实际情况大家也是这么做的),所以 CJK 的建模单元数量取决于单字数量,而不幸的是单字数量总是很大。
众所周知,为了计算损失函数需要将神经网络的输出转换到 vocab-size 的维度,对于 CTC 是 (N, T, V), 对于 k2 现在主推的 Pruned Transducer 模型,则是 (N, T, s_range, V)。V 如果太大,则最后一层线性变换的参数量就会加大,计算损失函数所需的内存也会增大,不但计算量增大了,而且也没法使用大的 batch size 训练。举个例子,Aishell 的 recipe 如果使用 char 建模,建模单元为 4337,用 V100 训练,max-duratioin 只能到 300s, 而如果使用 byte level BPE 建模,建模单元设置为 500, max-duration 能到 800s,训练速度提升了一倍多。
之所以能取得这么大的速度提升,跟 k2 中的 pruned rnnt 实现有关系,k2 中 pruned rnnt 跟序列长度 S 关系不大,但对 V 比较敏感,具体可以参考:https://mp.weixin.qq.com/s/M7Oz5b0LbtIxm0PfVb5iww
所以,我们使用 byte level BPE 建模的第一目的是提升 CJK 语言的训练速度。
无论出于何种目的,想把中文进一步拆分的尝试一直在进行,经过不完全的调研,大概了解了有以下几种拆字的方法,总体上都是转换成 int8 能表达的 ascii 字符或者 byte。
-
先转换成拼音再拆。
我爱你中国 -> wo ai ni zhong guo -
转成音素再拆
我爱你中国 -> uu uo3 aa ai4 n i3 zh ong1 g uo2 -
转换成五笔输入字符再拆
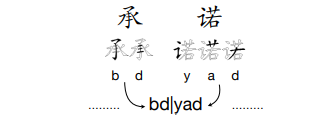
根据五笔输入法,将中文转换为键盘的输入序列,比如下面的承诺 -> bd|yad。 -
转换成 byte 序列再拆
本文将要介绍的方法,下面将详细阐述。 -
直接 用 byte 建模
上面的四种方法,大概都是转成 Latin 字符后再使用它们训练 sub-word,得到建模单元。而此种方法则直接使用 byte 建模,省去了训练 sub-word 的过程。
起初干这活并没有做太多调研,后来跟群里的小伙伴讨论,从各位大佬哪里学(tao)到好多论文,所以,交流有益,希望大家多多在群里交流,扫描文末二维码添加工作人员微信,加入 k2 讨论群!
既然有那么多拆中文的方法,我们为啥选择了 byte level BPE 呢?我们认为主要有以下几点(其实主要是简单效果又好)。
- 使用 byte 建模可以打破语言的限制,所有的语言都可以共用建模单元,便于训练多语言的模型。
- 解码方便,这里说的解码是指从拼音/音素/五笔/byte 恢复成中文,拼音、音素和五笔都有一对多的情况,而 byte 只需要直接合并就行。
- 使用 byte level BPE 相比于 byte 直接建模可以有效利用 sub-word (比如 byte pair encoding)带来的提升。
我们使用的是 google 的 sentencepiece 工具来训练 BPE,那么怎么让 sentencepiece 从 byte level 来训练 BPE 而不是 char level 呢,这就需要对中文先做一个编码操作。一般的中文由3个 byte 编码,一个 byte 用 int8 表示,所以我们需要用 256 个可打印字符来表示这些 byte,具体的编码方法可以参考 icefall 中 icefall/byte_utils.py 的实现。 举个例子,我爱你中国将会被编码成下面这个"乱码" (5个字变成了15个字符)。
我爱你中国 -> ƍĩĴƎĩŗƋţŅƋŞœƌľţ
注:sentencepiece 会对输入文本做 NFKC 规范化,所以在选择这 256 个可打印字符时切记选择那些经过 NFKC 规范化后不变的字符。(NFKC 规范化这里就不介绍了,各位自己 google 吧)。
既然都使用 byte 了,为什么又还会有切分中文的问题呢,这里主要是 sub-word 工具(或者说 sentencepiece)的原因。因为 sentencepiece 是为 latin 语言开发的,所以以空格为词的边界,那么中文是否需要边界呢?需要边界的话是以字为边界还是以词为边界?
- 没有边界:No space between chars (NS)
- 以字为边界:Space between single chars (SIC)
- 以词为边界:Space between words (SIW)
三种的区别是在上述编码之前中文句子里哪里有空格:
NS: 我爱你中国
SIC:我 爱 你 中 国
SIW:我 爱 你 中国
由于 sentencepiece 不会跨边界拆词,可以这么理解三者的区别,NS 有可能把“爱”的最后一个 byte 和“你”的第一个 byte 组成 BPE,而 SIC 和 SIW 不会;NS 和 SIW 有可能把 “中” 的最后一个 byte 和 “国”的第一个 byte 组成 BPE,而 SIC 不会。
训练 byte level BPE 的方法跟训练正常 BPE 无异,只不过 sentencepiece 的输入并非中文,而是编码过的字符序列。具体实现参考 Aishell recipe 下面的 local/train_bbpe_model.py。
解码过程是把编码后的序列还原为中文的过程,比如:ƍĩĴƎĩŗƋţŅƋŞœƌľţ -> 我爱你中国。显而易见,并不是所有的字符序列都可以还原为中文,识别的结果可能会有一些无效的组合,所以我们引入了基于动态规划的最佳解码方法(其实是抄的 fairseq 的代码)。举个例子,假设我们把 ƍĩĴƎĩŗƋţŅƋŞœƌľţ 第四个字符删掉变成 ƍĩĴĩŗƋţŅƋŞœƌľţ,那么它就无法解码成 我爱你中国 了,因为 爱 少了一个 byte,使用 smart decode 之后,ƍĩĴĩŗƋţŅƋŞœƌľţ 会解码成 我你中国,即,跳过了非法的字符。
目前我们在 Aishell 和中英混合数据集 TALCS 数据集上进行了实验,代码实现参考:k2-fsa/icefall#986
后续还会加入 wenetspeech 的实验结果,有兴趣的同学也可以帮忙做实验(画外音:我们还没开始搞)。
这是使用不同 vocab size 和不同切分方法的结果(greedy search),可以看出 vocab-size 不宜太大,这可能是 Aishell 数据太少的原因,等有了 wenetspeech 的结果再来分析 vocab-size 的问题,此处只是说明,500 就能取得很好的效果,并不需要用几千个字来建模。 关于中文拆分方法,实验结果显示 SIC (按单字拆)的效果最好,这里我们认为,中文的字可以和英文的词对应,英文不希望跨词组合 BPE,中文也对应的不希望跨字来组合 BPE,当然,这个结论从一个 Aishell 数据集就下有些鲁莽,我们可以从后续的大数据集中继续探讨。

上面的结果是可比的(相同训练设置),目前 Aishell 上我们得到的最好效果如下(上面PR的结果):

我们也尝试在好未来中英文数据集 TALCS 上做了中英文共享建模单元的实验,结果如下:

第一行是 icefall 中目前的结果,英文使用 BPE 中文使用 char 建模,vocab-size 为 7000+,后面两行是不同 vocab-size byte level BPE 的结果,可以看到 byte level BPE 的结果还是有些提升的(当然,也可能是 zipformer 带来的提升)。下面是 TALCS 论文里的结果,可以看到,k2 的结果还是要稍微好一些的。

本文详细介绍了怎么使用 byte level BPE 来建模的全流程,同时给出了实验结果,可以看出使用 byte level BPE 来建模中文可以使用更小得多的 vocab-size,极大提升训练速度,并且并不会降低性能。 开展工作之前并没有做太多调研,只是根据 Dan 的一个建议并参考了 fairseq 的实现,后来群里交流后发现苹果也做过此类工作,有兴趣的同学可以参考:https://arxiv.org/pdf/2205.00485.pdf
