来简单认识一下:
如便于向量、矩阵和复杂科学计算的 NumPy 与 SciPy;仿 Matlab 样式绘图的 Matplotlib;包含大量经典机器学习模型的 Scikit-learn;对数据进行快捷分析和处理的 Pandas;以及集成了上述所有第三方程序库的综合实践平台 Anaconda。 <摘自《Python机器学习及实践:从零开始通往Kaggle竞赛之路》 >
小结:matplob 是画图工具,numpy 是矩阵运算库,scipy 是数学运算工具,pandas 是数据处理的工具。
来认识几个常见第三方库:
-
NumPy:
<摘自知乎回答>:
来存储和处理大型矩阵,比 Python 自身的嵌套列表(nested list structure)结构要高效的多,本身是由 C 语言开发。这个是很基础的扩展,其余的扩展都是以此为基础。数据结构为 ndarray,一般有三种方式来创建。
- Python 对象的转换
- 通过类似工厂函数 numpy 内置函数生成:np.arange、np.linspace.....
- 从硬盘读取,loadtxt
<摘自《Python机器学习及实践:从零开始通往Kaggle竞赛之路》>:
NumPy 是最为基础的 Python 编程库,NumPy 除了提供一些高级的数学运算机制以外,还具备非常高效的向量和矩阵运算功能,这些功能对于机器学习的计算任务是尤为重要的,因为不论是数据的特征表示也好,还是参数的批量计算也好,都离不开更加方便的矩阵和向量计算。而 NumPy 更为突出的是它内部独到的设计,是的处理这些矩阵和向量比起一般的程序员自行编写,甚至是 Python 自带程序库的运行效率都高很多。
<参考北风教育某PPT>
Numerical Python,即数值 Python 包,是 Python 进行科学计算的一个基础包,因此要更好理解和掌握 Python 科学计算包,尤其是 Pandas,需要先行掌握 NumPy 库的用法。
-
SciPy:
<摘自知乎回答>:
方便、易于使用、专为科学和工程设计的 Python 工具包。它包括统计,优化,整合,线性代数模块,傅里叶变换,信号和图像处理,常微分方程求解器等等。基本可以代替 Matlab,但是使用的话和数据处理的关系不大,数学系,或者工程系相对用的多一些。
<摘自《Python机器学习及实践:从零开始通往Kaggle竞赛之路》>:
SciPy 是在 NumPy 的基础上构建的更为强大,应用领域也更为广泛的科学计算包。正是出于这个原因,SciPy 需要依赖 NumPy 的支持进行安装和运行。
-
Pandas:
<摘自知乎回答>:
基于 NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。最具有统计意味的工具包,某些方面优于 R 软件。数据结构有一维的 Series,二维的 DataFrame(类似于 Excel 或者 SQL 中的表,如果深入学习,会发现 Pandas 和 SQL 相似的地方很多,例如merge函数),三维的 Panel(Pan(el) + da(ta) + s,知道名字的由来了吧)。学习 Pandas 你要掌握的是:
- 汇总和计算描述统计,处理缺失数据 ,层次化索引
- 清理、转换、合并、重塑、GroupBy技术
- 日期和时间数据类型及工具(日期处理方便地飞起)
-
Matplotlib:
<摘自知乎回答>:
Python 中最著名的绘图系统,很多其他的绘图例如 seaborn(针对 pandas 绘图而来)也是由其封装而成。创世人 John Hunter 于2012年离世。这个绘图系统操作起来很复杂,和 R 的 ggplot,lattice 绘图相比显得望而却步,这也是为什么我个人不丢弃 R 的原因,虽然调用
plt.style.use("ggplot")绘制的图形可以大致按照 ggplot 的颜色显示,但是还是感觉很鸡肋。但是 matplotlib 的复杂给其带来了很强的定制性。其具有面向对象的方式及 Pyplot 的经典高层封装。
需要掌握的是:
- 散点图,折线图,条形图,直方图,饼状图,箱形图的绘制。
- 绘图的三大系统:pyplot,pylab(不推荐),面向对象
- 坐标轴的调整,添加文字注释,区域填充,及特殊图形patches的使用
- 金融的同学注意的是:可以直接调用 Yahoo财经数据绘图(真。。。)
-
Scikit-learn:
<摘自《Python机器学习及实践:从零开始通往Kaggle竞赛之路》>:
Scikit-learn 依托于上述几种工具包,封装了大量经典以及最新的机器学习模型。该项目最早由 David Cournapeau 在2007 年 Google 夏季代码节中提出并启动。后来作为 Matthieu Brucher 博士工作的一部分得以延续和完善。现在已经是相对成熟的机器学习开源项目。近十年来,有超过 20 位计算机专家参与其代码的更新和维护工作。作为一款用于机器学习和实践的 Python 第三方开源程序库,Scikit-learn 无疑是成功的。
参考和学习资料:
- 知乎:如何系统地学习Python 中 matplotlib, numpy, scipy, pandas?
- 《Python机器学习及实践:从零开始通往Kaggle竞赛之路》
- GitHub:notes-python
- ......
ndarry:N-dimensional array, N维数组
ndarray 是一个N维齐次同构数组对象,每个数组都有一个shape和dtype属性,shape描述的是ndarray的形状,而dtype则描述ndarray里面元素的数据类型。
- 一种由相同类型的元素组成的多维数组,元素数量是事先指定好的。
- 元素的数据类型由dtype(data-type)对象来指定,每个ndarray只有一种dtype 类型
- 大小固定,创建好数组时一旦指定好大小,就不会再发生改变
- ndim 维度数量
- shape是一个表示各维度大小的元组,即数组的形状
- dtype,一个用于说明数组元素数据类型的对象
- size,元素总个数,即shape中各数组相乘
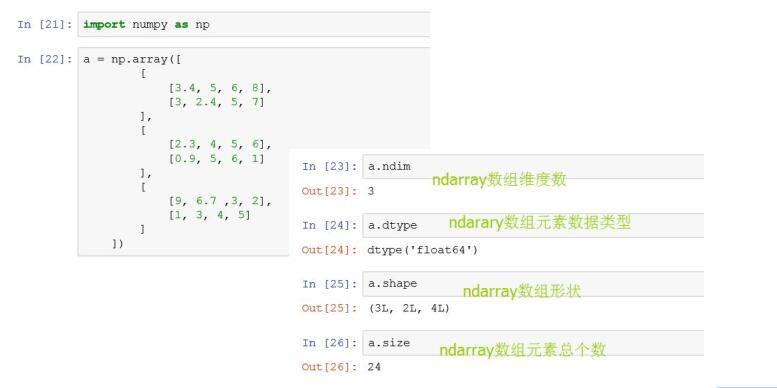
ndarry的shape属性巧算:



小总结:
- 先规范显示出数组
- 层层去中括号对,直到无中括号对,每去一层,一个维度,去掉一层 [ ],后的元素个数(逗号隔开)即该维度的元素个数
- array函数:接收一个普通的Python序列,转成ndarray
- zeros函数:创建指定长度或形状的全零数组
- ones函数:创建指定长度或形状的全1数组
- empty函数:创建一个没有任何具体值的数组(准确地说是一些未初始化的垃圾值)
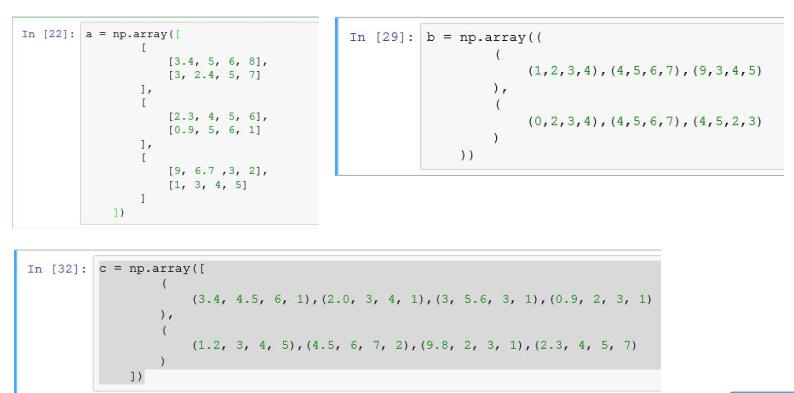
-
arrange函数:类似于python的range函数,通过指定开始值、终值和步长来创建一维数组,注意数组不包括终值
-
linspace函数:通过指定开始值、终值和元素个数来创建一维数组,可以通过endpoint关键字指定是否包括终值,缺省设置是包括终值
-
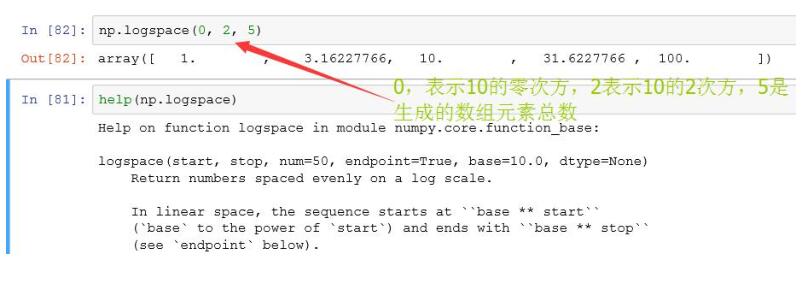
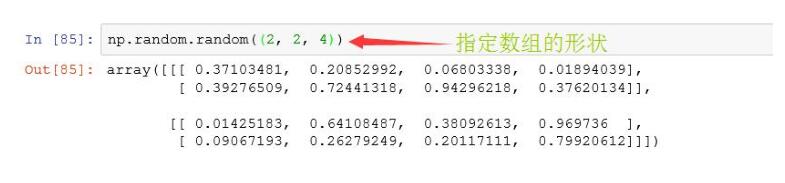
logspace函数:和linspace类似,不过它创建等比数列使用随机数填充数组,即使用numpy.random模块的
-
random()函数,数组所包含的的元素数量由参数决定
arrange 函数:

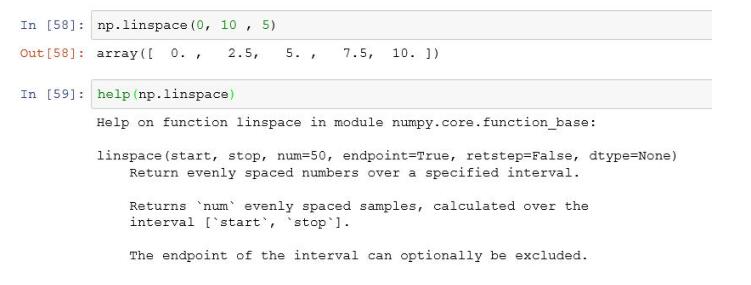
-
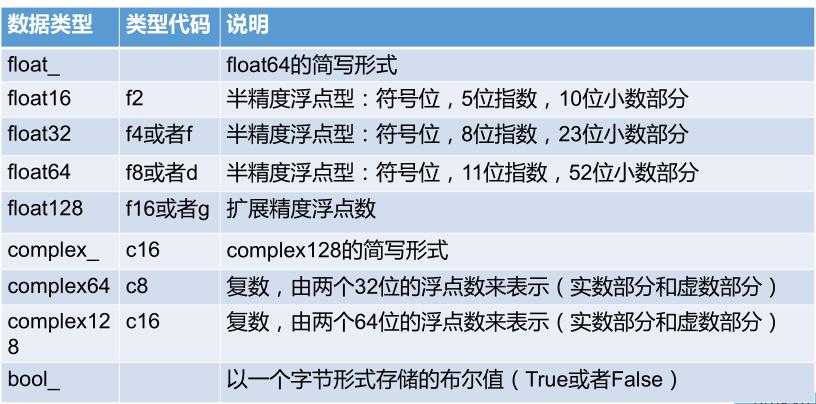
数值型dtype的命名方式:一个类型名(比如int、float),后面接着一个用于表示各元素位长的数字
- 比如表中的双精度浮点值,即Python中的float对象,需要占用8个字节(即64位),因此该类型在NumPy中就记为float64
-
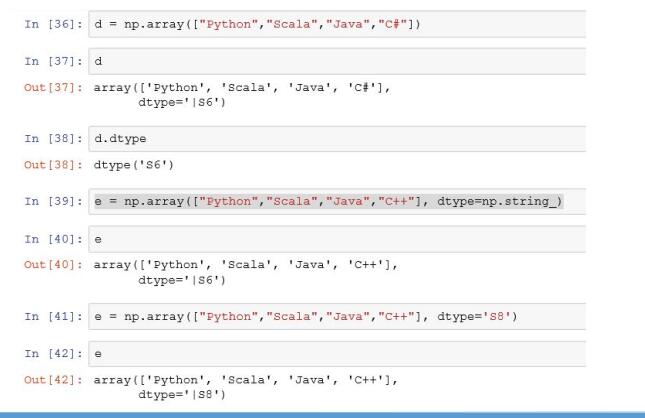
每种类型有一个相对应的类型代码,即简写方式,参照下面的表


NumPy 中所支持的数据类型:
改变 ndarray 的形状:
-
直接修改 ndarray 的shape值
-
使用 reshape 函数,可以创建一个改变了尺寸的新数组,原数组的 shape 保持不变,但注意他们共享内存空间,因此修改任何一个也对另一个产生影响,因此注意新数组的元素个数必须与原数组一样
-
当指定新数组某个轴的元素为-1时,将根据数组元素的个数自动计算此轴的长度

- 数组与标量、数组之间的运算
- 数组的矩阵积(matrix product)
- 数组的索引与切片
- 数组转置与轴对换
- 通用函数:快速的元素级数组函数
- 聚合函数
- np.where函数
- np.unique函数
1、数组与标量、数组之间的运算:
- 数组不用循环即可对每个元素执行批量运算,这通常就叫做矢量化,即用数组表达式代替循环的做法
- 矢量化数组运算性能要比纯Python方式快上一两个数量级
- 大小相等的数组之间的任何算术运算都会将运算应用到元素级
import numpy as np
arr1 = np.array([1, 2, 3, 4, 5])
arr1 +2 # 结果:array([3, 4, 5, 6, 7])
arr1 ** 2 # 结果:array([ 1, 4, 9, 16, 25])大小相等的数组之间的运算:
import numpy as np
arr1 = np.array([[1, 2.0], [1.9, 3.4]])
arr2 = np.array([[3.6, 1.2], [2.0, 1.2]])
arr1 + arr2
arr1 * arr2# 结果:
array([[4.6, 3.2],
[3.9, 4.6]])
array([[3.6 , 2.4 ],
[3.8 , 4.08]])像上面例子展现出来的,加、减、乘、除、幂运算等,可以用于数组与标量、大小相等数组之间。在 NumPy 中,大小相等的数组之间运算,为元素级运算,即只用于位置相同的元素之间,所得到的运算结果组成一个新的数组,运算结果的位置跟操作数位置相同。
2、数组的矩阵积(matrix product):
- 两个二维矩阵(多维数组即矩阵)满足第一个矩阵的列数与第二个矩阵的行数相同,那么可以进行矩阵乘法,即矩阵积,矩阵积不是元素级的运算
- 两个矩阵相乘结果所得到的的数组中每个元素为,第一个矩阵中与该元素行号相同的元素与第二个矩阵中与该元素列号相同的元素,两两相乘后求和
import numpy as np
arr = np.array([
[120, 60, 220],
[115, 23, 201],
[132, 48, 230]
])
arr2 = np.array([
[12.34, 0.04],
[204.56, 2.34],
[9.89, 0.45]
])
arr.dot(arr2) # 或者 np.dot(arr, arr2)结果:
array([[15930.2 , 244.2 ],
[ 8111.87, 148.87],
[13722.46, 221.1 ]])3、数组的索引与切片
多维数组的索引:

NumPy 中数组的切片:

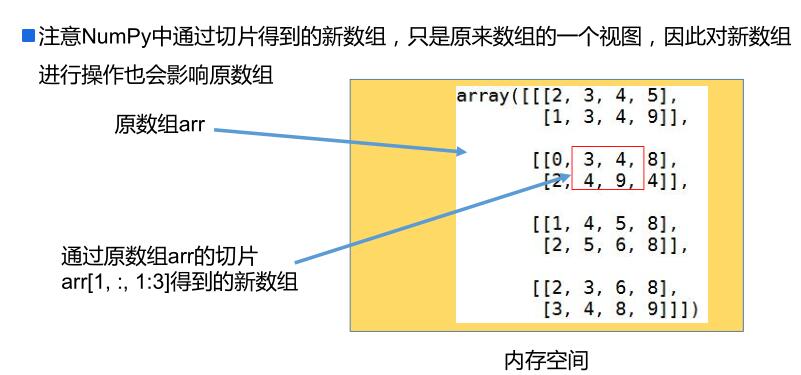
布尔型索引:

花式索引:

关于花式索引这里补充些内容,详细参考:
这里提下这个。新建一个数组 arr2:
>>> arr2 = np.arange(32).reshape((8,4))
>>> arr2
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])按坐标选取每一个数:
>>> arr2[[1,5,7,2],[0,3,1,2]]
# 意思就是,取坐标所对应的数(1,0)——4,(5,3)——23,(7,1)——29,(2,2)——10,然后返回一个数组
array([ 4, 23, 29, 10])希望先按我们要求选取行,再按顺序将列排序,获得一个矩形:
>>> arr2[[1,5,7,2]][:,[0,3,1,2]]
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])先按先选取第 1、5、2、7 行,每一行再按第 0 个、第 3 个、第 1 个、第 2 个排序。
注:关于这里的理解,举个例子如 arr2[:, [2,1] ] 表示取出第二列、第一列数据。
arr2 = np.arange(9).reshape((3,3)) print(arr2) print(arr2[:,[2,1]])结果:
[[0 1 2] [3 4 5] [6 7 8]] [[2 1] [5 4] [8 7]]
np.ix_函数,能把两个一维数组转换为一个用于选取方形区域的索引器
实际意思就是,直接往np.ix_()里扔进两个一维数组[1,5,7,2],[0,3,1,2],就能先按我们要求选取行,再按顺序将列排序,跟上面得到的结果一样,而不用写“[ : , [0,3,1,2] ]”
**原理:**np.ix_函数就是输入两个数组,产生笛卡尔积的映射关系。
>>> arr2[np.ix_([1,5,7,2],[0,3,1,2])]
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])例如就这个例子,np.ix_函数,将数组[1,5,7,2]和数组[0,3,1,2]产生笛卡尔积,就是得到(1,0),(1,3),(1,1),(1,2);(5,0),(5,3),(5,1),(5,2);(7,0),(7,3),(7,1),(7,2);(2,0),(2,3),(2,1),(2,2)的数值。
4、数组转置与轴对换
- transpose 函数用于数组转置,对于二维数组来说就是行列互换:
arr.transpose()- 数组的 T 属性,也是转置:
arr.T
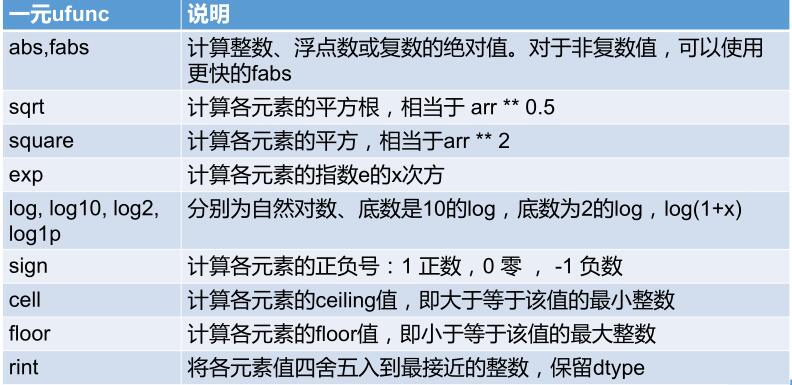
5、通用函数:快速的元素级数组函数
ufunc:一种对 ndarray 中的数据执行元素级运算的函数,也可以看做是简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。
import numpy as np
arr = np.arange(10).reshape(2, -1)
arr
arr.sqrt(arr)结果:
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
array([[0. , 1. , 1.41421356, 1.73205081, 2. ],
[2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ]])常见的一元通用函数:

常见的二元通用函数:

6、聚合函数

7、np.where函数


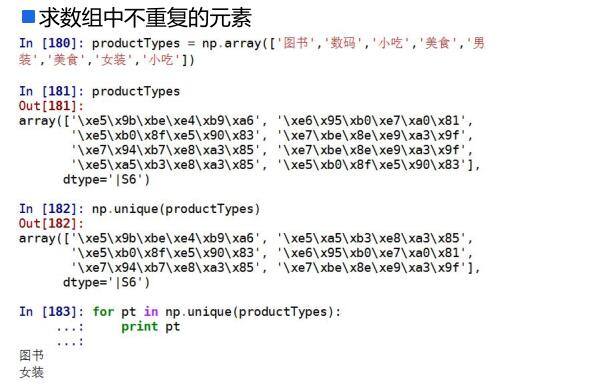
8、np.unique函数
将数组以二进制格式保存到磁盘:np.save('data', data)、np.;oad('data.npy')
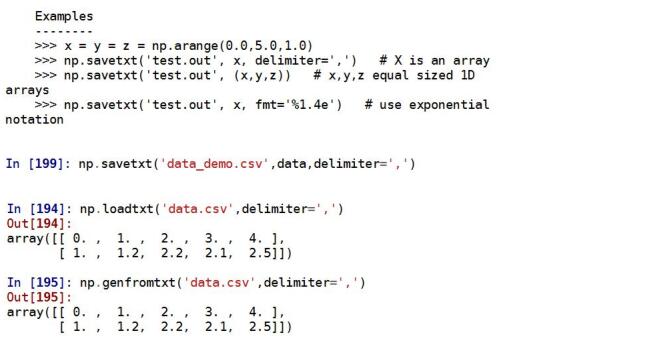
获取文本文件:
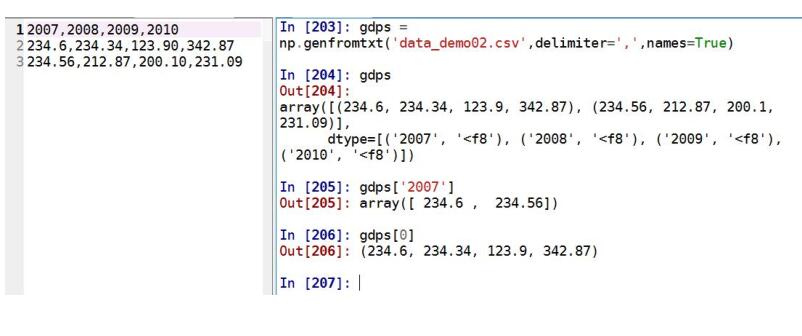
pandas 是 python 的一个数据分析包,最初由 AQR Capital Management 于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于 PyData 项目的一部分。Pandas 最初被作为金融数据分析工具而开发出来,因此,pandas 为时间序列分析提供了很好的支持。 Pandas 的名称来自于面板数据(panel data)和 python 数据分析(data analysis)。panel data 是经济学中关于多维数据集的一个术语,在 Pandas 中也提供了 panel 的数据类型。
Pandas数据结构:
- Series:一种类似于一维数组的对象,它是由一组数据(各种 NumPy 数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生简单的 Series。
- DataFrame:一个表格型的数据结构,含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等),DataFrame 既有行索引也有列索引,可以被看做是由 Series 组成的字典。
1、Series:
通过一维数组创建 Series:
例1:
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
arr = np.array([1, 2, 3, 4])
series01 = Series(arr)
series01
----------------结果:----------------------
0 1
1 2
2 3
3 4
dtype: int32
series01.index 结果:RangeIndex(start=0, stop=4, step=1)
series01.values 结果:array([1, 2, 3, 4])
series01.dtype 结果:dtype('int32')例2:
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
series02 = Series([34.5, 56.78, 45.67])
series02结果:
0 34.50
1 56.78
2 45.67
dtype: float64通过数组创建时,如果没有为数据指定索引,则会自动创建一个从0到N-1(N为数据的长度)的整数索引,默认索引可通过赋值方式进行修改。
series02.index = ['product01', 'product02', 'product03']
series02
结果:
product01 34.50
product02 56.78
product03 45.67
dtype: float64例3:
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
series03 = Series([98, 56, 77], index= ['语文', '数学', '英语'])
series03
-------------结果:---------------
语文 98
数学 56
英语 77
dtype: int64通过字典的方式创建 Series:
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
a_dict = {'语文':88, '数学':99, '英语':56}
series04 = Series(a_dict)
series04
---------------结果:------------------
数学 99
英语 56
语文 88
dtype: int64通过字典创建 Series 时,字典中的 key 组成 Series 的索引,字典中的 value 组成 Series 中的 values。
Series 应用 NumPy 数组运算:
NumPy 中的数组运算,在 Series 中都保留使用,并且 Series 进行数组运算时,索引与值之间的映射关系不会改变。
series04
------结果:-------
数学 99
英语 56
语文 88
dtype: int64
------------------------
series04[series04>88]
-------结果:-------
数学 99
dtype: int64
-----------------------
series04/100
--------结果:----------
数学 0.99
英语 0.56
语文 0.88
dtype: float64
-----------------------
series01 = Series([1, 2, 3, 4])
np.exp(series01)
-----结果:
0 2.718282
1 7.389056
2 20.085537
3 54.598150
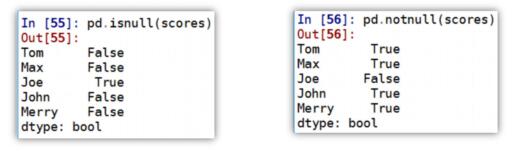
dtype: float64Series 缺失值检测:
- pandas 中的 isnull 和 notnull 函数可用于 Series 缺失值检测
- isnull 和 notnull 都返回一个布尔类型的 Series

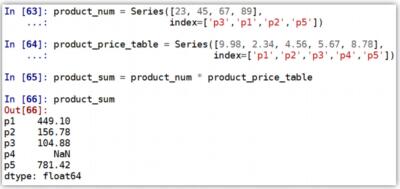
Series 自动对齐:
不同Series之间进行算术运算,会自动对齐不同索引的数据
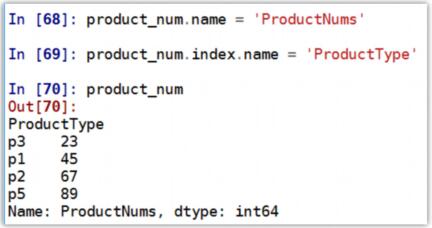
Series 及其索引的 name 属性:
Series 对象本身及其索引都有一个 name 属性,可赋值设置
2、DataFrame:
通过二维数组创建DataFrame:
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
df01 = DataFrame([['Tom', 'Mike', 'John'], [76, 98, 100]])
df01结果:
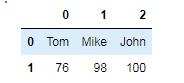
最左列为行索引 index,最上行为列索引 columns,中间为数据。
df02 = DataFrame([['Tom', 76], ['Mike', 98], ['John', 100]])结果:
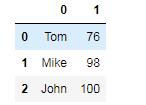
自定义行、列索引:
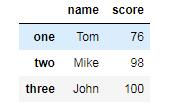
arr = np.array([['Tom', 76], ['Mike', 98], ['John', 100]])
df04 = DataFrame(arr, index=['one', 'two', 'three'], columns=['name', 'score'])
df04结果:
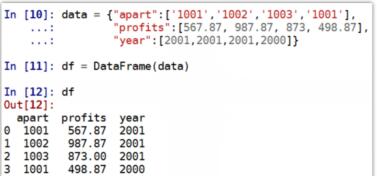
通过字典方式创建 DataFrame:
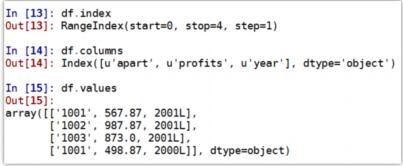
索引对象:
- 不管是 Series 对象还是 DataFrame 对象,都有索引对象
- 索引对象负责管理轴标签和其他元数据(比如轴名称等)
- 通过索引可以从 Series、DataFrame 中取值或对某个位置的值重新赋值
- Series 或者 DataFrame 自动化对齐功能就是通过索引进行的

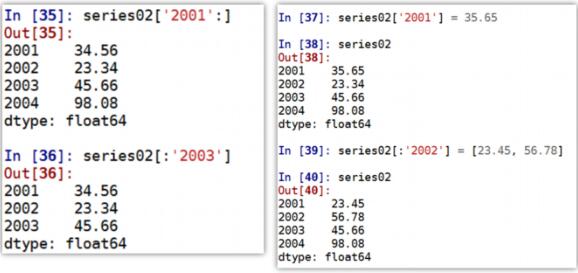
通过索引从 DataFrame 中取值:
- 可以直接通过列索引获取指定列的数据
- 要通过行索引获取指定行数据需要ix方法
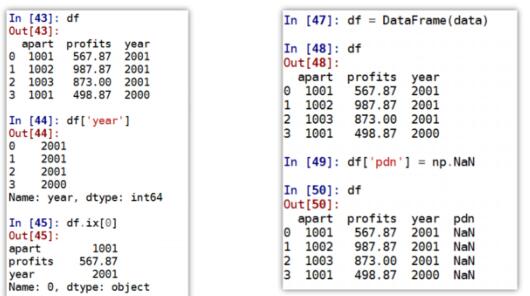
Pandas 基本功能:
- 重新索引
- 丢弃指定轴上的项
- 索引、选取和过滤
- 算术运算和数据对齐
- 函数应用和映射
- 排序和排名
- 带有重复值的轴索引
汇总和计算描述统计:
- 常用的数学和统计方法
- 相关系数与协方差
- 唯一值、值计数以及成员资格
常用的数学和统计方法:
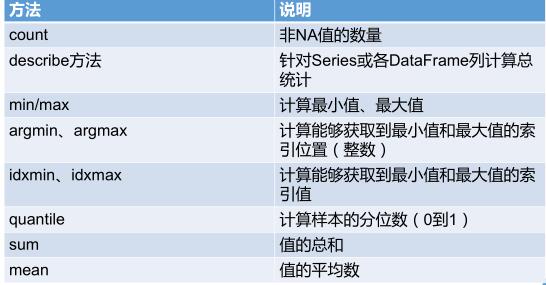
更多内容的学习参考网上教程,如:
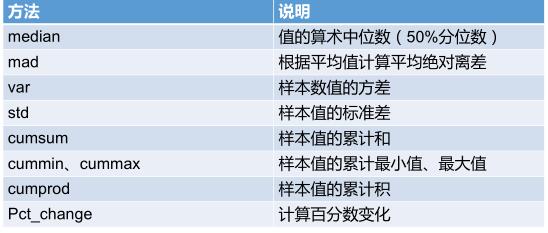
画一个简单的图形:
首先我们要画一条在 [0, 2pi] 上的正弦曲线。读者应该会注意到我们在这里使用了 Numpy 库,但是即便你没有使用过这个库也不用担心,在后面的文章中我们也会介绍到 Numpy 库。
import matplotlib.pyplot as plt
import numpy as np
# 简单的绘图
x = np.linspace(0, 2 * np.pi, 50)
plt.plot(x, np.sin(x)) # 如果没有第一个参数 x,图形的 x 坐标默认为数组的索引
plt.show() # 显示图形上面的代码将画出一个简单的正弦曲线。np.linspace(0, 2 * np.pi, 50) 这段代码将会生成一个包含 50 个元素的数组,这 50 个元素均匀的分布在 [0, 2pi] 的区间上。
plot 命令以一种简洁优雅的方式创建了图形。提醒一下,如果没有第一个参数 x,图形的 x 轴坐标将不再是 0 到 2pi,而应该是数组的索引范围。
最后一行代码 ``plt.show()` 将图形显示出来,如果没有这行代码图像就不会显示。
运行代码后应该会类似得到下面的图形:
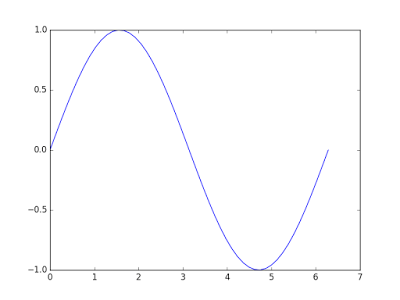
在一张图上绘制两个数据集:
大多数时候读者可能更想在一张图上绘制多个数据集。用 Matplotlib 也可以轻松实现这一点。
x = np.linspace(0, 2 * np.pi, 50)
plt.plot(x, np.sin(x),
x, np.sin(2 * x))
plt.show()上面的代码同时绘制了表示函数 sin(x) 和 sin(2x) 的图形。这段代码和前面绘制一个数据集的代码几乎完全相同,只有一点例外,这段代码在调用 plt.plot() 的时候多传入了一个数据集,并用逗号与第一个数据集分隔开。
最后你会得到类似于下面包含两条曲线的图形:
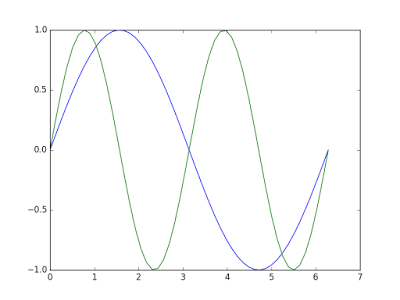
自定义图形的外观:
当在同一个图形上展示多个数据集时,通过改变线条的外观来区分不同的数据集变得非常必要。
# 自定义曲线的外观
x = np.linspace(0, 2 * np.pi, 50)
plt.plot(x, np.sin(x), 'r-o',
x, np.cos(x), 'g--')
plt.show()上述代码展示了两种不同的曲线样式:'r-o' 和 'g--'。字母 'r' 和 'g' 代表线条的颜色,后面的符号代表线和点标记的类型。例如 '-o' 代表包含实心点标记的实线,'--' 代表虚线。其他的参数需要读者自己去尝试,这也是学习 Matplotlib 最好的方式。
- 颜色: 蓝色 - 'b' 绿色 - 'g' 红色 - 'r' 青色 - 'c' 品红 - 'm' 黄色 - 'y' 黑色 - 'k'('b'代表蓝色,所以这里用黑色的最后一个字母) 白色 - 'w'
- 线: 直线 - '-' 虚线 - '--' 点线 - ':' 点划线 - '-.'
- 常用点标记 点 - '.' 像素 - ',' 圆 - 'o' 方形 - 's' 三角形 - '^' 更多点标记样式点击这里
最后你会得到类似下面的图形:
使用子图:
使用子图可以在一个窗口绘制多张图。
# 使用子图
x = np.linspace(0, 2 * np.pi, 50)
plt.subplot(2, 1, 1) # (行,列,活跃区)
plt.plot(x, np.sin(x), 'r')
plt.subplot(2, 1, 2)
plt.plot(x, np.cos(x), 'g')
plt.show()使用子图只需要一个额外的步骤,就可以像前面的例子一样绘制数据集。即在调用 plot() 函数之前需要先调用 subplot() 函数。该函数的第一个参数代表子图的总行数,第二个参数代表子图的总列数,第三个参数代表活跃区域。
活跃区域代表当前子图所在绘图区域,绘图区域是按从左至右,从上至下的顺序编号。例如在 4×4 的方格上,活跃区域 6 在方格上的坐标为 (2, 2)。
最终你会得到类似下面的图形:
简单的散点图:
散点图是一堆离散点的集合。用 Matplotlib 画散点图也同样非常简单。
# 简单的散点图
x = np.linspace(0, 2 * np.pi, 50)
y = np.sin(x)
plt.scatter(x,y)
plt.show()正如上面代码所示,你只需要调用 scatter() 函数并传入两个分别代表 x 坐标和 y 坐标的数组。注意,我们通过 plot 命令并将线的样式设置为 'bo' 也可以实现同样的效果。
最后你会得到类似下面的无线图形:
彩色映射散点图:
另一种你可能用到的图形是彩色映射散点图。这里我们会根据数据的大小给每个点赋予不同的颜色和大小,并在图中添加一个颜色栏。
# 彩色映射散点图
x = np.random.rand(1000)
y = np.random.rand(1000)
size = np.random.rand(1000) * 50
colour = np.random.rand(1000)
plt.scatter(x, y, size, colour)
plt.colorbar()
plt.show()上面的代码大量的用到了 np.random.rand(1000),原因是我们绘图的数据都是随机产生的。
同前面一样我们用到了 scatter() 函数,但是这次我们传入了另外的两个参数,分别为所绘点的大小和颜色。通过这种方式使得图上点的大小和颜色根据数据的大小产生变化。
然后我们用 colorbar() 函数添加了一个颜色栏。
最后你会得到类似于下面的彩色散点图:
直方图:
直方图是另一种常见的图形,也可以通过几行代码创建出来。
# 直方图
x = np.random.randn(1000)
plt.hist(x, 50)
plt.show()直方图是 Matplotlib 中最简单的图形之一。你只需要给 hist() 函数传入一个包含数据的数组。第二个参数代表数据容器的个数。数据容器代表不同的值的间隔,并用来包含我们的数据。数据容器越多,图形上的数据条就越多。
最终你会得到类似下面的直方图:
标题,标签和图例:
当需要快速创建图形时,你可能不需要为图形添加标签。但是当构建需要展示的图形时,你就需要添加标题,标签和图例。
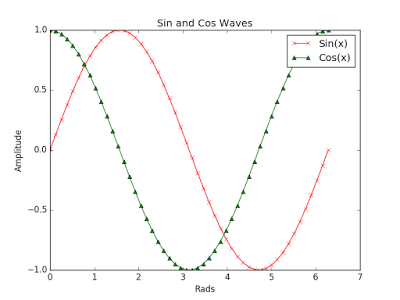
# 添加标题,坐标轴标记和图例
x = np.linspace(0, 2 * np.pi, 50)
plt.plot(x, np.sin(x), 'r-x', label='Sin(x)')
plt.plot(x, np.cos(x), 'g-^', label='Cos(x)')
plt.legend() # 展示图例
plt.xlabel('Rads') # 给 x 轴添加标签
plt.ylabel('Amplitude') # 给 y 轴添加标签
plt.title('Sin and Cos Waves') # 添加图形标题
plt.show()为了给图形添加图例,我们需要在 plot() 函数中添加命名参数 'label' 并赋予该参数相应的标签。然后调用 legend() 函数就会在我们的图形中添加图例。
接下来我们只需要调用函数 title(),xlabel() 和 ylabel() 就可以为图形添加标题和标签。
你会得到类似于下面这张拥有标题、标签和图例的图形:
更多内容参考网上教程学习。