- Description
- Demo
- How did I carry out the project?
- Implementation of project
- Dataset
- Objectives
- Acknowledgements
- Authors

Sign language is a project in which a Machine Learning model recognizes hand gestures and predicts the letters of the sign language alphabet in real time. It uses Python, Mediapipe, SKlearn, OpenCV and Streamlit.
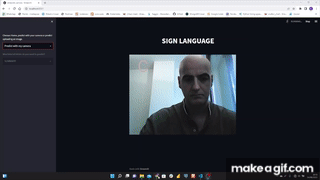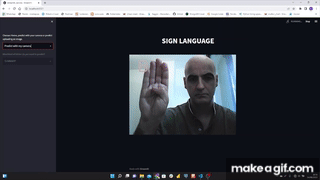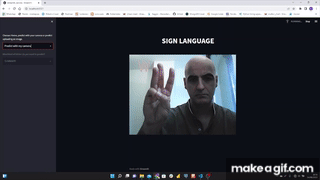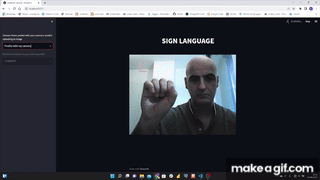
I used MediaPipe Hands that is a high-fidelity hand and finger tracking solution. It employs machine learning (ML) to infer 21 3D landmarks of a hand from just a single frame.


After downloading the dataset from Kaggle (https://www.kaggle.com/datasets/grassknoted/asl-alphabet) I extracted the 21 landmarks of each image. I also created my own dataset to have another alternative dataset in order to be able to work and train the ML models with both datasets. After training different ML models; KNN, Random forest, SVC,... and after testing with the camera, the model that best predicts was Random forest.
It is important to note that there are several letters, namely A, L, T, Z, that none of the models read them well or predict them. In the case of the Random Forest model, there were also other letters such as U, V and the letters N and M that are very similar and it is difficult for them to predict correctly.
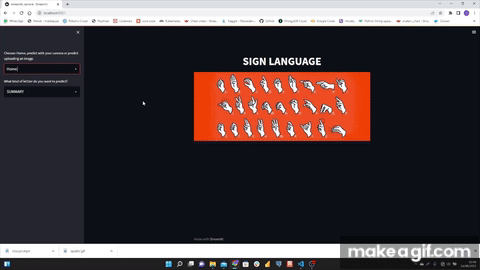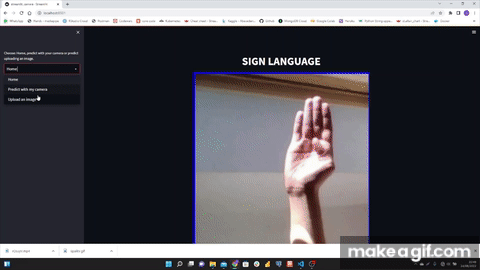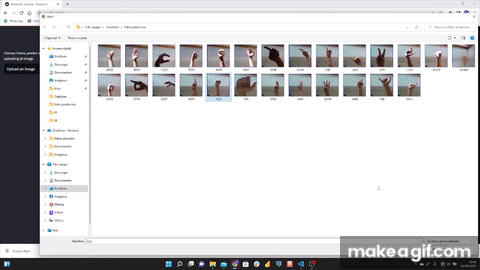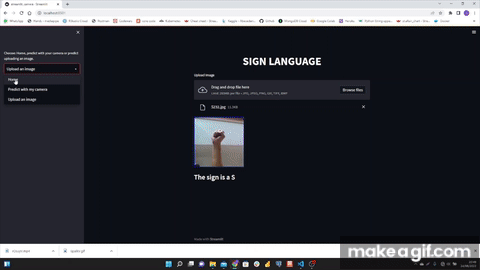
After saving the model, I created the file where I load the model and implement the camera so that streamlit can be restarted so that through streamlit a user can have the option to open the camera and be able to predict.
First of all, you have to clone the repository;
git clone [email protected]:iremirezdeganuza72/sign_language.gitSecondly, it is necessary to install the different libraries includes in "requirements" file;
pip install -r requirements.pyAfterwards, you can download the dataset from Kaggle, with 78000 images (https://www.kaggle.com/datasets/grassknoted/asl-alphabet). In case you want to create your own dataset, you should run "data_creation" file, executing the following command;
pip run data_creation.pyThe next step would be to train and predict the different models and observing the metrics obtained, choosing the one that offers the best results against the prediction in front of the camera. In our case the best model is Random Forest, that has to be saved. It is saved as "RF_model.pkl".
Finally, to run streamlit, you must execute the following command
streamlit run streamlit_camera.pyIn case it does not open browser, it should appear a local address like this one;

I worked with a Kaggle dataset where are included 78000 images (https://www.kaggle.com/datasets/grassknoted/asl-alphabet). Apart from this dataset, I worked with my own dataset created through the frames obtained from a video, with which I achieved 100 images per letter, making a total of 2600 images in ttotal.
Main objectives achieved:
- Trained model with a high level of prediction.
- Real-time forecasting.
- Possibility of uploading an image to achieve the prediction.
Next objectives:
- Uploading it to production through an api and with the Heroku cloud platform.
- Writtenn transcription of the different predicted letters, so that complete sentences can be realized.
Core Code School core-school
Alvaro Lucas Alvaro-Lucas
Daniel Alejandro Alvarado DanielDls-exe
Santino Lede Luxor5k
Marc Pomarboyander
This project was made by Iñigo Remirez de Ganuza;