


[
目次(クリックして展開)
ドキュメンテーション documentation
PyPIで最新版が利用可能 PyPI
解説スライドは こちら
SCOPE-RL は,データ収集からオフ方策学習,オフ方策性能評価,方策選択をend-to-endで実装するためのオープンソースのPythonソフトウェアです.私たちのソフトウェアには,人工データ生成,データの前処理,オフ方策評価 (off-policy evaluation; OPE) の推定量,オフ方策選択 (off-policy selection; OPS) 手法を実装するための一連のモジュールが含まれています.
このソフトウェアは,オンラインおよびオフラインの強化学習 (reinforment learning; RL) 手法を実装するd3rlpyとも互換性があります.また,SCOPE-RLは OpenAI Gym や Gymnasium のインターフェースに基づく環境であればどのような設定の環境でも使用できます.さらに,様々なカスタマイズされたデータや実データに対して,オフライン強化学習の実践的な実装や,透明性や信頼性の高い実験を容易にします.
特に,SCOPE-RLは以下の研究トピックに関連する評価とアルゴリズム比較を簡単に行えます:
-
オフライン強化学習:オフライン強化学習は,データ収集方策によって収集されたオフラインのログデータのみから新しい方策を学習することを目的としています.SCOPE-RLは,様々なデータ収集と環境によって収集されたデータによる柔軟な実験を可能にします.
-
オフ方策評価(OPE):オフ方策評価は,データ収集方策により集められたオフラインのログデータのみを使用して(データ収集方策とは異なる)新たな方策の性能を評価することを目的とします.SCOPE-RLは多くのオフ方策推定量の実装可能にする抽象クラスや、推定量を評価し比較するための実験手順を実装しています.また、SCOPE-RLが実装し公開している発展的なオフ方策評価手法には、状態-行動密度推定や累積分布推定に基づく推定量なども含まれます.
-
オフ方策選択(OPS):オフ方策選択は,オフラインのログデータを使用して,いくつかの候補方策の中から最も性能の良い方策を特定することを目的とします.SCOPE-RLは様々な方策選択の基準を実装するだけでなく,方策選択の結果を評価するためのいくつかの指標を提供します.
このソフトウェアは,文脈付きバンディットにおけるオフ方策評価のためのライブラリであるOpen Bandit Pipelineを参考にしています.SCOPE-RLはオフ方策評価の実験を容易にするための一連のオフ方策推定量と手法を実装しており,より強化学習の設定に適したものになっています.
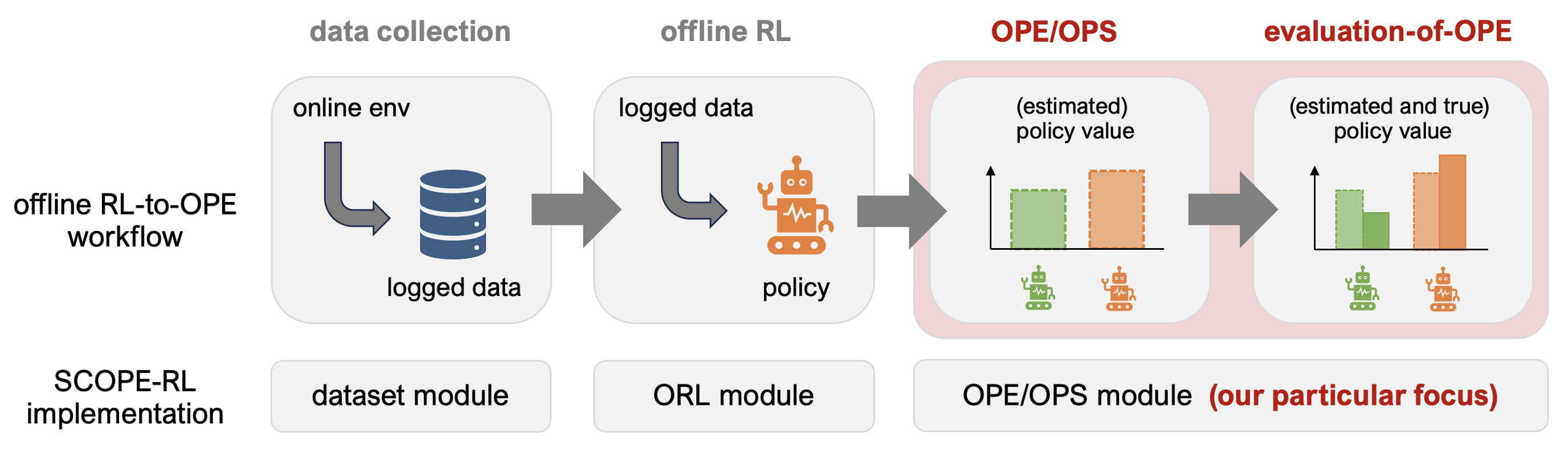
SCOPE-RL上で行えるオフライン強化学習とオフ方策評価の一貫した実装手順
SCOPE-RL は主に以下の3つのモジュールから構成されています.
- dataset module: このモジュールは,OpenAI Gym やGymnasiumのようなインターフェイスに基づく任意の環境から人工データを生成するためのツールを提供します.また,ログデータの前処理を行うためのツールも提供します.
- policy module: このモジュールはd3rlpyのwrapperクラスを提供し,様々なデータ収集方策による柔軟なデータ収集を可能にします.
- ope module: このモジュールは,オフ方策推定量を実装するための汎用的な抽象クラスを提供します.また,オフ方策選択を実行するために便利ないくつかのツールも提供します.
データ収集方策(クリックして展開)
- Discrete
- Epsilon Greedy
- Softmax
- Continuous
- Gaussian
- Truncated Gaussian
OPE推定量(クリックして展開)
- 性能期待値の推定
- 基礎的な推定量
- Direct Method (Fitted Q Evaluation)
- Trajectory-wise Importance Sampling
- Per-Decision Importance Sampling
- Doubly Robust
- Self-Normalized Trajectory-wise Importance Sampling
- Self-Normalized Per-Decision Importance Sampling
- Self-Normalized Doubly Robust
- State Marginal Estimators (状態分布を用いた推定量)
- State-Action Marginal Estimators (状態行動分布を用いた推定量)
- Double Reinforcement Learning
- 重みと状態 (行動) 価値の推定手法
- Augmented Lagrangian Method (BestDICE, DualDICE, GradientDICE, GenDICE, MQL/MWL)
- Minimax Q-Learning and Weight Learning (MQL/MWL)
- 基礎的な推定量
- 性能の信頼区間推定
- Bootstrap
- Hoeffding
- (Empirical) Bernstein
- Student T-test
- 性能の累積分布推定
- Direct Method (Fitted Q Evaluation)
- Trajectory-wise Importance Sampling
- Trajectory-wise Doubly Robust
- Self-Normalized Trajectory-wise Importance Sampling
- Self-Normalized Trajectory-wise Doubly Robust
オフ方策選択に用いる指標(クリックして展開)
- Policy Value
- Policy Value Lower Bound
- Lower Quartile
- Conditional Value at Risk (CVaR)
オフ方策選択の評価指標(クリックして展開)
- Mean Squared Error
- Spearman's Rank Correlation Coefficient
- Regret
- Type I and Type II Error Rates
- 上位k個の方策の{Best/Worst/Mean/Std}
- 上位k個の方策のsafety violation rate
- SharpeRatio@k
研究上でのSCOPE-RLの利点は,抽象クラスを用いることで既に実装されているオフ方策評価およびオフ方策選択手法に加えて,研究者が自分の推定量を簡単に実装し,比較することができることです.さらに実践上では,様々なオフ方策推定量を実データに適用し,自身の実際の状況に合った方策を評価し,選択することができることです.
さらにSCOPE-RLでは既存のパッケージの機能に留まらず,以下の図の通りより実用に即したオフ方策評価の実装が可能です.
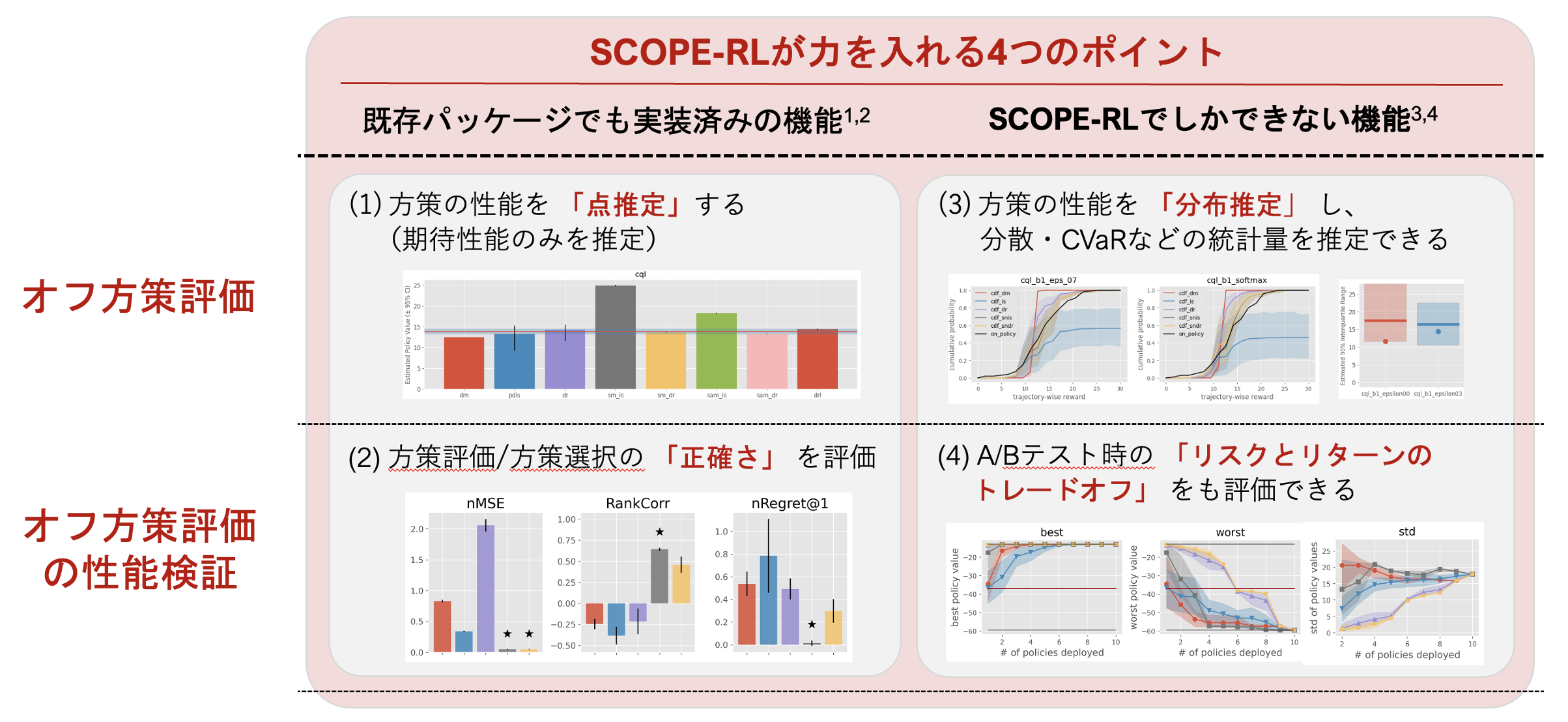
SCOPE-RLのオフ方策評価モジュールが力を入れる4つの機能
またSCOPE-RLはサブパッケージとして、シンプルな設定のBasicGym実用的な環境をシミュレーションした広告入札 (real-time bidding; RTB) と推薦システム用の強化学習環境であるRTBGymとRecGymも提供しています。
pythonのpipを利用してSCOPE-RLをインストールできます.
pip install scope-rl
またコードからSCOPE-RLをインストールすることもできます.
git clone https://github.com/hakuhodo-technologies/scope-rl
cd scope-rl
python setup.py installSCOPE-RLはPython 3.9以降をサポートしています.その他の要件についてはrequirements.txtを参照してください.依存関係の競合が発生した場合は,#17も参照してください.
ここでは,RTBGymを使用してSCOPE-RLでオフライン強化学習,オフ方策評価,オフ方策選択を実行するための例を紹介します.
まず,オフライン強化学習を実行するためにいくつかの (人工) ログデータを生成します.
# RTBGym環境でのデータ収集手順を実装する
# SCOPE-RLモジュールをインポートする
from scope_rl.dataset import SyntheticDataset
from scope_rl.policy import EpsilonGreedyHead
# d3rlpyのアルゴリズムをインポートする
from d3rlpy.algos import DoubleDQNConfig
from d3rlpy.dataset import create_fifo_replay_buffer
from d3rlpy.algos import ConstantEpsilonGreedy
# rtbgymとgymをインポートする
import rtbgym
import gym
import torch
random_state = 12345
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# (0) 環境のセットアップ
env = gym.make("RTBEnv-discrete-v0")
# (1) オンライン環境で基本方策を学習する(d3rlpyを使用)
# アルゴリズムを初期化する
ddqn = DoubleDQNConfig().create(device=device)
# オンラインデータ収集方策を訓練する
# 約5分かかる
ddqn.fit_online(
env,
buffer=create_fifo_replay_buffer(limit=10000, env=env),
explorer=ConstantEpsilonGreedy(epsilon=0.3),
n_steps=100000,
n_steps_per_epoch=1000,
update_start_step=1000,
)
# (2) ログデータを生成する
# ddqn方策を確率的なデータ収集方策に変換する
behavior_policy = EpsilonGreedyHead(
ddqn,
n_actions=env.action_space.n,
epsilon=0.3,
name="ddqn_epsilon_0.3",
random_state=random_state,
)
# データクラスを初期化する
dataset = SyntheticDataset(
env=env,
max_episode_steps=env.step_per_episode,
)
# データ収集方策がいくつかのログデータを収集する
train_logged_dataset = dataset.obtain_episodes(
behavior_policies=behavior_policy,
n_trajectories=10000,
random_state=random_state,
)
test_logged_dataset = dataset.obtain_episodes(
behavior_policies=behavior_policy,
n_trajectories=10000,
random_state=random_state + 1,
)ログデータを生成したことで,新しい方策 (評価方策) を学習する準備が整いました.次は d3rlpyを使用し,オフライン強化学習を行います.
# SCOPE-RLとd3rlpyを使用してオフラインRL手順を実装する
# d3rlpyのアルゴリズムをインポートする
from d3rlpy.dataset import MDPDataset
from d3rlpy.algos import DiscreteCQLConfig
# (3) オフラインログデータから新しい方策を学習する(d3rlpyを使用)
# ログデータをd3rlpyのデータ形式に変換する
offlinerl_dataset = MDPDataset(
observations=train_logged_dataset["state"],
actions=train_logged_dataset["action"],
rewards=train_logged_dataset["reward"],
terminals=train_logged_dataset["done"],
)
# アルゴリズムを初期化する
cql = DiscreteCQLConfig().create(device=device)
# オフライン方策を学習する
cql.fit(
offlinerl_dataset,
n_steps=10000,
)次に,データ収集方策によって収集されたオフラインのログデータを使用して,いくつかの評価方策 (ddqn,cql,random) のパフォーマンスを評価します.具体的には,Direct Method (DM),Trajectory-wise Importance Sampling (TIS),Per-Decision Importance Sampling (PDIS),Doubly Robust (DR) を含む様々なオフ方策推定量の推定結果を比較します.
# SCOPE-RLを使用して基本的なOPE手順を実装する
# SCOPE-RLモジュールをインポート
from scope_rl.ope import CreateOPEInput
from scope_rl.ope import OffPolicyEvaluation as OPE
from scope_rl.ope.discrete import DirectMethod as DM
from scope_rl.ope.discrete import TrajectoryWiseImportanceSampling as TIS
from scope_rl.ope.discrete import PerDecisionImportanceSampling as PDIS
from scope_rl.ope.discrete import DoublyRobust as DR
# (4) 学習した方策をオフラインで評価する
# ここではddqn,cql,randomを比較する
cql_ = EpsilonGreedyHead(
base_policy=cql,
n_actions=env.action_space.n,
name="cql",
epsilon=0.0,
random_state=random_state,
)
ddqn_ = EpsilonGreedyHead(
base_policy=ddqn,
n_actions=env.action_space.n,
name="ddqn",
epsilon=0.0,
random_state=random_state,
)
random_ = EpsilonGreedyHead(
base_policy=ddqn,
n_actions=env.action_space.n,
name="random",
epsilon=1.0,
random_state=random_state,
)
evaluation_policies = [cql_, ddqn_, random_]
# オフ方策評価クラスに入力するデータを作成する
prep = CreateOPEInput(
env=env,
)
input_dict = prep.obtain_whole_inputs(
logged_dataset=test_logged_dataset,
evaluation_policies=evaluation_policies,
require_value_prediction=True,
n_trajectories_on_policy_evaluation=100,
random_state=random_state,
)
# オフ方策評価クラスを初期化する
ope = OPE(
logged_dataset=test_logged_dataset,
ope_estimators=[DM(), TIS(), PDIS(), DR()],
)
# オフ方策評価を実行し,結果を可視化する
ope.visualize_off_policy_estimates(
input_dict,
random_state=random_state,
sharey=True,
)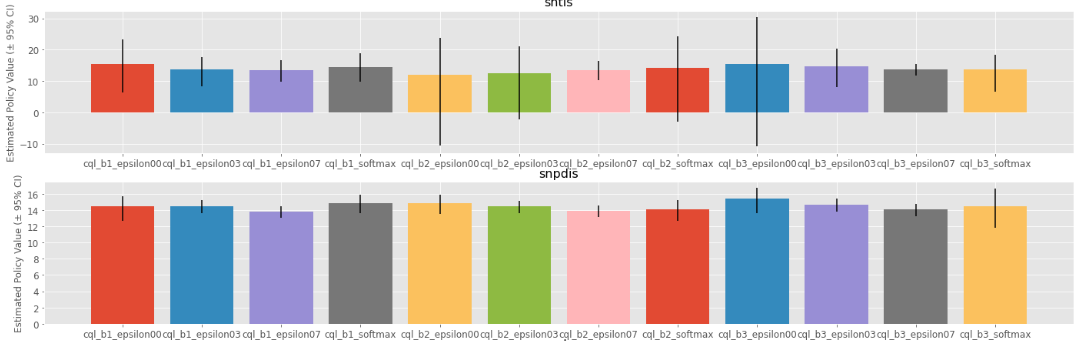
様々なオフ方策推定量により推定した方策の期待性能
RTBGymを使用したより詳細の実装の例は,./examples/quickstart_ja/rtb/で確認できます.RecGymを使用した例も./examples/quickstart_ja/rec/で公開しています.
評価方策の期待性能だけでなく,その分散や下位試行平均性能 (conditional value at risk; CVaR) など,様々な統計を推定することもできます.これは,評価方策のもとでの報酬の累積分布関数 (cumulative distribution function; CDF) を推定することで行います.
# SCOPE-RLを使用して累積分布推定手順を実装する
# SCOPE-RLモジュールをインポートする
from scope_rl.ope import CumulativeDistributionOPE
from scope_rl.ope.discrete import CumulativeDistributionDM as CD_DM
from scope_rl.ope.discrete import CumulativeDistributionTIS as CD_IS
from scope_rl.ope.discrete import CumulativeDistributionTDR as CD_DR
from scope_rl.ope.discrete import CumulativeDistributionSNTIS as CD_SNIS
from scope_rl.ope.discrete import CumulativeDistributionSNTDR as CD_SNDR
# (4) 評価方策の下での報酬の累積分布関数をオフラインで評価する
# 前のセクションで定義されたddqn,cql,randomを比較する(基本的なOPE手順の(3))
# OPEクラスを初期化する
cd_ope = CumulativeDistributionOPE(
logged_dataset=test_logged_dataset,
ope_estimators=[
CD_DM(estimator_name="cd_dm"),
CD_IS(estimator_name="cd_is"),
CD_DR(estimator_name="cd_dr"),
CD_SNIS(estimator_name="cd_snis"),
CD_SNDR(estimator_name="cd_sndr"),
],
)
# 分散を推定する
variance_dict = cd_ope.estimate_variance(input_dict)
# CVaRを推定する
cvar_dict = cd_ope.estimate_conditional_value_at_risk(input_dict, alphas=0.3)
# 方策性能の累積分布関数を推定し,可視化する
cd_ope.visualize_cumulative_distribution_function(input_dict, n_cols=4)
様々なオフ推定量による累積分布関数の推定
より詳細な実装例についてはexamples/quickstart_ja/rtb/rtb_synthetic_discrete_advanced_ja.ipynbを参照してください.
オフ方策選択クラスを用いると,オフ方策評価の結果に基づき,候補方策の中から最も性能の高い方策を選択することができます.mean squared error,rank correlation,regret,type I & type II error rates など,様々な指標を使用してオフ方策評価やオフ方策選択の信頼性を評価することも可能です.
# オフ方策評価の結果に基づきオフ方策選択を行う
# SCOPE-RLモジュールをインポートする
from scope_rl.ope import OffPolicySelection
# (5) オフ方策選択を実施する
# オフ方策選択クラスを初期化する
ops = OffPolicySelection(
ope=ope,
cumulative_distribution_ope=cd_ope,
)
# (標準的な,期待性能を推定する) オフ方策評価によって推定された方策価値に基づき候補方策をランク付けする
ranking_dict = ops.select_by_policy_value(input_dict)
# 累積分布オフ方策評価によって推定された方策価値に基づき候補方策をランク付けする
ranking_dict_ = ops.select_by_policy_value_via_cumulative_distribution_ope(input_dict)
# オフ方策選択で選ばれた上位k個の方策のデプロイ結果を可視化する
ops.visualize_topk_policy_value_selected_by_standard_ope(
input_dict=input_dict,
compared_estimators=["dm", "tis", "pdis", "dr"],
relative_safety_criteria=1.0,
)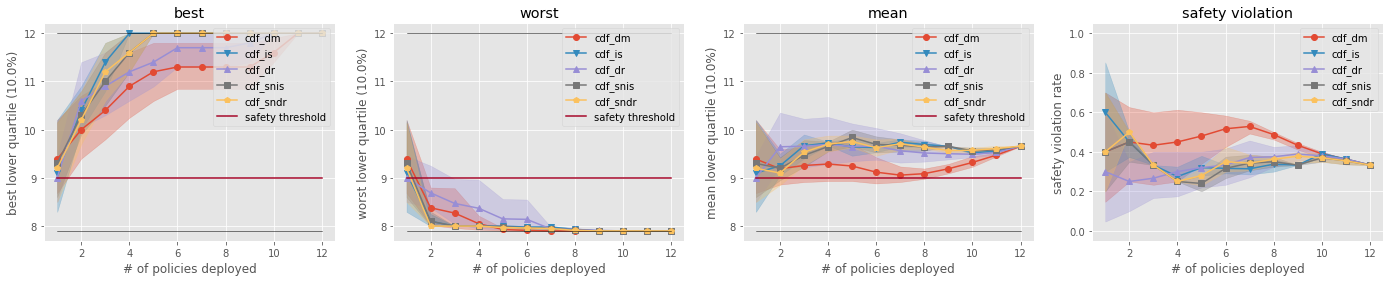
オフ方策選択で選ばれた上位k個の統計量の比較 (下位10%での方策性能)
# (6) オフ方策評価やオフ方策選択の結果を評価・検証する
# 推定された下位試行性能によって候補方策をランク付けし,選択結果を評価する
ranking_df, metric_df = ops.select_by_lower_quartile(
input_dict,
alpha=0.3,
return_metrics=True,
return_by_dataframe=True,
)
# 真の性能に基づき,オフ方策選択結果を可視化する
ops.visualize_conditional_value_at_risk_for_validation(
input_dict,
alpha=0.3,
share_axes=True,
)
方策価値の推定した分散と真の分散
より詳細の実装は,離散行動空間はquickstart_ja/rtb/rtb_synthetic_discrete_advanced_ja.ipynb,連続行動空間は quickstart_ja/rtb/rtb_synthetic_continuous_advanced_ja.ipynb を参照してください.
ソフトウェアを使用する場合は,以下の論文を引用をお願いします.
Haruka Kiyohara, Ren Kishimoto, Kosuke Kawakami, Ken Kobayashi, Kazuhide Nakata, Yuta Saito.
SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation
[arXiv] [日本語スライド]
Bibtex:
@article{kiyohara2023scope,
author = {Kiyohara, Haruka and Kishimoto, Ren and Kawakami, Kosuke and Kobayashi, Ken and Nataka, Kazuhide and Saito, Yuta},
title = {SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation},
journal={arXiv preprint arXiv:2311.18206},
year={2023},
}
オフ方策選択の評価指標である SharpeRatio@k を使用する場合は,以下の論文の引用をお願いします.
Haruka Kiyohara, Ren Kishimoto, Kosuke Kawakami, Ken Kobayashi, Kazuhide Nakata, Yuta Saito.
Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation
[arXiv] [日本語スライド]
Bibtex:
@article{kiyohara2023towards,
author = {Kiyohara, Haruka and Kishimoto, Ren and Kawakami, Kosuke and Kobayashi, Ken and Nataka, Kazuhide and Saito, Yuta},
title = {Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation},
journal={arXiv preprint arXiv:2311.18207},
year={2023},
}
SCOPE-RLのアップデートに興味がある場合は,Googleグループを通じて更新情報を受け取ることができます. https://groups.google.com/g/scope-rl
SCOPE-RLへの貢献も歓迎しています! プロジェクトへの貢献方法については, CONTRIBUTING.mdを参照してください.
このプロジェクトはApache 2.0ライセンスのもとでライセンスされています - 詳細についてはLICENSEファイルをご覧ください.
- 清原 明加 (Haruka Kiyohara) (コーネル大学,Main Contributor)
- 岸本 廉 (Ren Kishimoto) (東京工業大学)
- 川上 孝介 (Kosuke Kawakami) (博報堂テクノロジーズ)
- 小林 健 (Ken Kobayashi) (東京工業大学)
- 中田 和秀 (Kazuhide Nakata) (東京工業大学)
- 齋藤 優太 (Yuta Saito) (コーネル大学)
論文やソフトウェアに関する質問がある場合は,[email protected]までお気軽にお問い合わせください.
論文 (クリックして展開)
-
Alina Beygelzimer and John Langford. The Offset Tree for Learning with Partial Labels. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 129-138, 2009.
-
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. OpenAI Gym. arXiv preprint arXiv:1606.01540, 2016.
-
Yash Chandak, Scott Niekum, Bruno Castro da Silva, Erik Learned-Miller, Emma Brunskill, and Philip S. Thomas. Universal Off-Policy Evaluation. In Advances in Neural Information Processing Systems, 2021.
-
Miroslav Dudík, Dumitru Erhan, John Langford, and Lihong Li. Doubly Robust Policy Evaluation and Optimization. In Statistical Science, 485-511, 2014.
-
Justin Fu, Mohammad Norouzi, Ofir Nachum, George Tucker, Ziyu Wang, Alexander Novikov, Mengjiao Yang, Michael R. Zhang, Yutian Chen, Aviral Kumar, Cosmin Paduraru, Sergey Levine, and Tom Le Paine. Benchmarks for Deep Off-Policy Evaluation. In International Conference on Learning Representations, 2021.
-
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Proceedings of the 35th International Conference on Machine Learning, 1861-1870, 2018.
-
Josiah P. Hanna, Peter Stone, and Scott Niekum. Bootstrapping with Models: Confidence Intervals for Off-Policy Evaluation. In Proceedings of the 31th AAAI Conference on Artificial Intelligence, 2017.
-
Hado van Hasselt, Arthur Guez, and David Silver. Deep Reinforcement Learning with Double Q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, 2094-2100, 2015.
-
Audrey Huang, Liu Leqi, Zachary C. Lipton, and Kamyar Azizzadenesheli. Off-Policy Risk Assessment in Contextual Bandits. In Advances in Neural Information Processing Systems, 2021.
-
Audrey Huang, Liu Leqi, Zachary C. Lipton, and Kamyar Azizzadenesheli. Off-Policy Risk Assessment for Markov Decision Processes. In Proceedings of the 25th International Conference on Artificial Intelligence and Statistics, 5022-5050, 2022.
-
Nan Jiang and Lihong Li. Doubly Robust Off-policy Value Evaluation for Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, 652-661, 2016.
-
Nathan Kallus and Masatoshi Uehara. Intrinsically Efficient, Stable, and Bounded Off-Policy Evaluation for Reinforcement Learning. In Advances in Neural Information Processing Systems, 3325-3334, 2019.
-
Nathan Kallus and Masatoshi Uehara. Double Reinforcement Learning for Efficient Off-Policy Evaluation in Markov Decision Processes. In Journal of Machine Learning Research, 167, 2020.
-
Nathan Kallus and Angela Zhou. Policy Evaluation and Optimization with Continuous Treatments. In Proceedings of the 21st International Conference on Artificial Intelligence and Statistics, 1243-1251, 2019.
-
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative Q-Learning for Offline Reinforcement Learning. In Advances in Neural Information Processing Systems, 1179-1191, 2020.
-
Vladislav Kurenkov and Sergey Kolesnikov. Showing Your Offline Reinforcement Learning Work: Online Evaluation Budget Matters. In Proceedings of the 39th International Conference on Machine Learning, 11729--11752, 2022.
-
Hoang Le, Cameron Voloshin, and Yisong Yue. Batch Policy Learning under Constraints. In Proceedings of the 36th International Conference on Machine Learning, 3703-3712, 2019.
-
Haanvid Lee, Jongmin Lee, Yunseon Choi, Wonseok Jeon, Byung-Jun Lee, Yung-Kyun Noh, and Kee-Eung Kim. Local Metric Learning for Off-Policy Evaluation in Contextual Bandits with Continuous Actions. In Advances in Neural Information Processing Systems, xxxx-xxxx, 2022.
-
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems. arXiv preprint arXiv:2005.01643, 2020.
-
Qiang Liu, Lihong Li, Ziyang Tang, and Dengyong Zhou. Breaking the Curse of Horizon: Infinite-Horizon Off-Policy Estimation. In Advances in Neural Information Processing Systems, 2018.
-
Ofir Nachum, Yinlam Chow, Bo Dai, and Lihong Li. DualDICE: Behavior-Agnostic Estimation of Discounted Stationary Distribution Corrections. In Advances in Neural Information Processing Systems, 2019.
-
Ofir Nachum, Bo Dai, Ilya Kostrikov, Yinlam Chow, Lihong Li, and Dale Schuurmans. AlgaeDICE: Policy Gradient from Arbitrary Experience. arXiv preprint arXiv:1912.02074, 2019.
-
Tom Le Paine, Cosmin Paduraru, Andrea Michi, Caglar Gulcehre, Konrad Zolna, Alexander Novikov, Ziyu Wang, and Nando de Freitas. Hyperparameter Selection for Offline Reinforcement Learning. arXiv preprint arXiv:2007.09055, 2020.
-
Doina Precup, Richard S. Sutton, and Satinder P. Singh. Eligibility Traces for Off-Policy Policy Evaluation. In Proceedings of the 17th International Conference on Machine Learning, 759–766, 2000.
-
Rafael Figueiredo Prudencio, Marcos R. O. A. Maximo, and Esther Luna Colombini. A Survey on Offline Reinforcement Learning: Taxonomy, Review, and Open Problems. arXiv preprint arXiv:2203.01387, 2022.
-
Yuta Saito, Shunsuke Aihara, Megumi Matsutani, and Yusuke Narita. Open Bandit Dataset and Pipeline: Towards Realistic and Reproducible Off-Policy Evaluation. In Advances in Neural Information Processing Systems, 2021.
-
Takuma Seno and Michita Imai. d3rlpy: An Offline Deep Reinforcement Library, arXiv preprint arXiv:2111.03788, 2021.
-
Alex Strehl, John Langford, Sham Kakade, and Lihong Li. Learning from Logged Implicit Exploration Data. In Advances in Neural Information Processing Systems, 2217-2225, 2010.
-
Adith Swaminathan and Thorsten Joachims. The Self-Normalized Estimator for Counterfactual Learning. In Advances in Neural Information Processing Systems, 3231-3239, 2015.
-
Shengpu Tang and Jenna Wiens. Model Selection for Offline Reinforcement Learning: Practical Considerations for Healthcare Settings. In,Proceedings of the 6th Machine Learning for Healthcare Conference, 2-35, 2021.
-
Philip S. Thomas and Emma Brunskill. Data-Efficient Off-Policy Policy Evaluation for Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, 2139-2148, 2016.
-
Philip S. Thomas, Georgios Theocharous, and Mohammad Ghavamzadeh. High Confidence Off-Policy Evaluation. In Proceedings of the 9th AAAI Conference on Artificial Intelligence, 2015.
-
Philip S. Thomas, Georgios Theocharous, and Mohammad Ghavamzadeh. High Confidence Policy Improvement. In Proceedings of the 32nd International Conference on Machine Learning, 2380-2388, 2015.
-
Masatoshi Uehara, Jiawei Huang, and Nan Jiang. Minimax Weight and Q-Function Learning for Off-Policy Evaluation. In Proceedings of the 37th International Conference on Machine Learning, 9659--9668, 2020.
-
Masatoshi Uehara, Chengchun Shi, and Nathan Kallus. A Review of Off-Policy Evaluation in Reinforcement Learning. arXiv preprint arXiv:2212.06355, 2022.
-
Mengjiao Yang, Ofir Nachum, Bo Dai, Lihong Li, and Dale Schuurmans. Off-Policy Evaluation via the Regularized Lagrangian. In Advances in Neural Information Processing Systems, 6551--6561, 2020.
-
Christina J. Yuan, Yash Chandak, Stephen Giguere, Philip S. Thomas, and Scott Niekum. SOPE: Spectrum of Off-Policy Estimators. In Advances in Neural Information Processing Systems, 18958--18969, 2022.
-
Shangtong Zhang, Bo Liu, and Shimon Whiteson. GradientDICE: Rethinking Generalized Offline Estimation of Stationary Values. In Proceedings of the 37th International Conference on Machine Learning, 11194--11203, 2020.
-
Ruiyi Zhang, Bo Dai, Lihong Li, and Dale Schuurmans. GenDICE: Generalized Offline Estimation of Stationary Values. In International Conference on Learning Representations, 2020.
プロジェクト (クリックして展開)
このプロジェクトは,以下の3つのパッケージを参考にしています.
- Open Bandit Pipeline -- 文脈つきバンディットのためのオフ方策評価のパイプライン実装: [github] [documentation] [論文]
- d3rlpy -- オフライン強化学習のアルゴリズム実装: [github] [documentation] [論文]
- Spinning Up -- 深層強化学習の学習教材: [github] [documentation]