Practice 3 ‐ Graph Modeling
The goal of this laboratory session is to gain practical experience with domain-specific modeling and the Refinery generator technology. In this syllabus the demonstrating scenario is simple dataflow (activity) modeling, from which workflow implementation code is generated.
The notation of Data-flow diagrams (DFDs, basically the same as activity diagrams) are widely used for designing parallel, concurrent or asynchronous systems. It served as the inspiration for more advanced modeling notions such as UML Activity Diagrams. An example DFD specification of the Document Similarity Estimation algorithm is visible below.
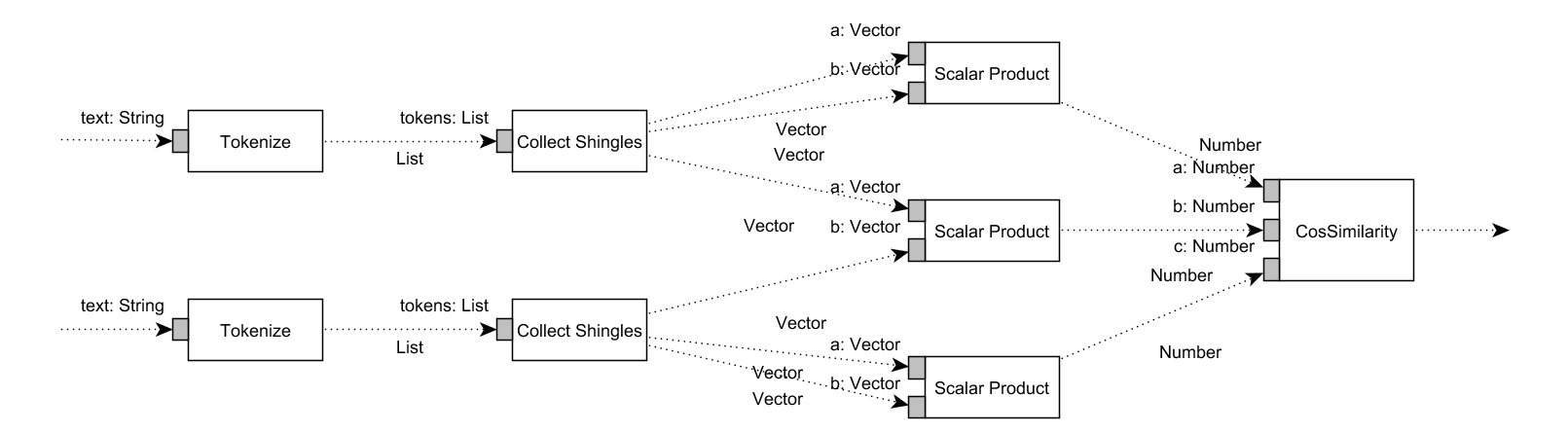
A DFD consists of the following elements:
-
Data transformation nodes (Workers), which transform inputs to output. For example, the Tokenize process transforms Strings to Lists of Strings. It is important to note that a Worker type may have multiple instances in a diagram, for example there are two
Tokenizernode instances in the process. - Each node may have one or more unique input pins, which consume input values of a specific type. For example, the Scalar Product node has two input pins "1" and "2", each accepting Vectors.
- The input pins and the outputs are connected by dedicated channels, which forward the output of a node to the input of another node. The output of a node can be used by multiple input pins, in this case each input pin gets the output. For example, the shingles of a document are processed by two different Scalar product nodes.
For the whole task, we will use the online version of the Refinery framework, which can be accessed here: Refinery.services.
- Open the online editors.
- Create a metamodel for the task. An example implementation can be the following:
// Metamodel
class Process {
contains Worker[0..*] workers
}
abstract class Worker{
}
class Tokenizer extends Worker{
Shingler[1] shingler
}
class Shingler extends Worker{
ScalarProductInput[1..*] scalarProduct
}
class ScalarProduct extends Worker{
contains ScalarProductInput[2] inputs
}
class ScalarProductInput.- This state of the task can be accessed in ▷Refinery via this link.
- By setting the scope of the problem to a limited size (by adding setting
scope node = 10.), example instance models can be generated.
- Developers would like to use this metamodel to develop different text processing frameworks. To start with that, let set in refinery that we use close world semantics. Close wolrd semantics can be achieved by stating no additional
newobjectsexists, and bydefault, everything isfalse. - For that purpose, add the following lines to the problem:
// Close world assumption
!exists(Process::new).
!exists(Tokenizer::new).
!exists(Shingler::new).
!exists(Shingler::new).
!exists(ScalarProduct::new).
!exists(ScalarProductInput::new).
default !workers(*,*).
default !shingler(*,*).
default !scalarProduct(*,*).
default !inputs(*,*).-
As a result, the problem should look like this ▷Refinery, and the model visualization should show and empty model.
-
Then let us define a self-similarity checking framework, that calculates the degree of diversity for a text. Add the following assertions line-by-line, and observe the visualization in the web-based framework:
// Simple instance model
Process(selfSimilarity).
Tokenizer(tokenizer).
workers(selfSimilarity,tokenizer).
shingler(tokenizer,shingler).
workers(selfSimilarity,shingler).
ScalarProduct(selfProduct).
workers(selfSimilarity,selfProduct).
inputs(selfProduct,selfProductInput1).
inputs(selfProduct,selfProductInput2).
scalarProduct(shingler,selfProductInput1).
scalarProduct(shingler,selfProductInput2).-
The current state of the project should look like this: ▷Refinery.
-
The cosine similarity calculation framework could be added like this:
// Instance model
// Objects with types.
Process(cosineSimilarity).
Tokenizer(tokenizerA).
Tokenizer(tokenizerB).
Shingler(shinglerA).
Shingler(shinglerB).
ScalarProduct(scalarAA).
ScalarProductInput(scalarAAinput1).
ScalarProductInput(scalarAAinput2).
ScalarProduct(scalarAB).
ScalarProductInput(scalarABinput1).
ScalarProductInput(scalarABinput2).
ScalarProduct(scalarBB).
ScalarProductInput(scalarBBinput1).
ScalarProductInput(scalarBBinput2).
// Links
workers(cosineSimilarity,tokenizerA).
workers(cosineSimilarity,tokenizerB).
workers(cosineSimilarity,shinglerA).
workers(cosineSimilarity,shinglerB).
workers(cosineSimilarity,scalarAA).
workers(cosineSimilarity,scalarAB).
workers(cosineSimilarity,scalarBB).
inputs(scalarAA,scalarAAinput1).
inputs(scalarAA,scalarAAinput2).
inputs(scalarAB,scalarABinput1).
inputs(scalarAB,scalarABinput2).
inputs(scalarBB,scalarBBinput1).
inputs(scalarBB,scalarBBinput2).
shingler(tokenizerA,shinglerA).
shingler(tokenizerB,shinglerB).
scalarProduct(shinglerA, scalarAAinput1).
scalarProduct(shinglerA, scalarAAinput2).
scalarProduct(shinglerA, scalarABinput1).
scalarProduct(shinglerB, scalarBBinput1).
scalarProduct(shinglerB, scalarBBinput2).
scalarProduct(shinglerB, scalarABinput2).- With the complete model, the problem will look like this: ▷Refinery.
In this task, we would like to automate a software allocation problem. We should allocate each worker to different computers.
- First, let us introduce a new class:
class Machine.- Then extend the
Workerclass so each worker is allocated to a machine:
abstract class Worker{
Machine[1] allocatedTo
}- And set the scope for the number of machines:
scope Machine = 1..3.- Observe the partiality expressed in the initial model, and generate different allocations.
- This state of the laboratory can be observed here: ▷Refinery
- Let us extend the problem with some logic predicates.
- The following predicate selects all pairs of
Workernodes that communicates via some kind of dataflow:
pred dataflow(x,y) <->
shingler(x,y)
;
scalarProduct(x,i),
inputs(y,i).- Similarly, dataflow can be defined between machines as well, which requires costly network communication.
pred machineCommunication(m1,m2) <->
dataflow(x,y),
allocatedTo(x,m1),
allocatedTo(y,m2),
m1 != m2.- Generate a model, and in the visualization tab, disable all basic symbol visualization, and enable the visualization for the predicates.
- The current state of the problem can be observed here: ▷Refinery.
- For some constraints, let us ban circular communication between machines with the following constraint. This will disable all models during generation where a this predicate would match.
// Constraint
error pred loopCommunication(m1,m2) <->
machineCommunication(m1,m2),
machineCommunication(m2,m1).- At the level of instances, constraints can be expressed as additional assertions. Insert the following assertions, and set the scope for
Machinesto 2:
Machine(machine1).
Machine(machine2).
!machineCommunication(machine1, machine2).
!machineCommunication(machine2,machine1).
scope Machine = 2.- Observe the generated models.
- The final state of this lab can be accessed via the following link: ▷Refinery.
- Refinery language reference. https://refinery.tools/learn/language/
- Refinery file system tutorial. https://refinery.tools/learn/tutorials/file-system/