This is a short tutorial of the different things that can be done with bigcode-tools.
We will do the following
- Setup a workspace for the data
- Download a small dataset of Java repositories
- Preprocess the source code to extract ASTs
- Extract a vocabulary and learn embeddings
NOTE: most commands are documented properly, so if you do not understand one of the
command in the tutorial, try adding the -h option.
To make things easier, only Docker is needed to run the examples, and nothing else needs to be downloaded or installed locally, but each tool can be installed separately without the need for Docker.
The Docker image is available as tuvistavie/bigcode-tools
To install it, you can run
docker run tuvistavie/bigcode-tools ls
If this succeed, everything is ready. Note that download might take a while.
We will first create a directory to store downloaded code and generated
data. We will use $HOME/bigcode-workspace here, but feel free to use any directory.
export BIGCODE_WORKSPACE=$HOME/bigcode-workspace
mkdir -p $BIGCODE_WORKSPACE
To reduce Docker command boilerplate, we will alias the run command as follow
alias docker-bigcode='docker run -p 6006:6006 -v $BIGCODE_WORKSPACE:/bigcode-tools/workspace tuvistavie/bigcode-tools'
This will map the container /bigcode-tools/workspace directory to the host $BIGCODE_WORKSPACE
directory, and expose the container port 6006 to the same port on the host (for tensorboard).
We will use a subset of Apache commons. First, we need to search using the GitHub API:
docker-bigcode bigcode-fetcher search --language=java --user=apache --keyword=commons --stars='>20' -o workspace/apache-commons-projects.json
This should create a list of project in $BIGCODE_WORKSPACE/apache-commons-projects.json
where a project looks like this:
cat $BIGCODE_WORKSPACE/apache-commons-projects.json | jq '.[0]'
{
"id": 206378,
"full_name": "apache/commons-lang",
"name": "commons-lang",
"html_url": "https://github.com/apache/commons-lang",
"clone_url": "https://github.com/apache/commons-lang.git",
"language": "Java",
"stargazers_count": 1095,
"size": 21176,
"fork": false,
"created_at": "2009-05-21T01:24:46Z",
"updated_at": "2017-10-11T06:14:07Z",
"license": "Apache-2.0"
}We are now going to download all the data into $BIGCODE_WORKSPACE/repositories
docker-bigcode bigcode-fetcher download -i workspace/apache-commons-projects.json -o workspace/repositories
There should now be more than 20 repositories inside $BIGCODE_WORKSPACE/repositories/apache.
We will now generate the ASTs for all the data in the downloaded repositories.
docker-bigcode bigcode-astgen-java --batch -o workspace/apache-commons-asts 'workspace/repositories/**/*.java'
This will create three files:
$BIGCODE_WORKSPACE/apache-commons-asts.json: list of ASTs as documented in bigcode-astgen$BIGCODE_WORKSPACE/apache-commons-asts.json: the name of the file from which each AST was extracted$BIGCODE_WORKSPACE/apache-commons-asts_failed.txt: the list of files for which parse failed (should be empty for this dataset)
We can visualize the one of the generated AST. We will try with the first file in the dataset, but if there is a warning, you can try with some other index containing a smaller AST.
docker-bigcode bigcode-ast-tools visualize-ast workspace/apache-commons-asts.json -i 0 --no-open -o workspace/ast0.png
This should generate $BIGCODE_WORKSPACE/ast1.png, which should look something like this

First, we will generate a vocabulary. As we do not have much data, we will strip all identifiers.
docker-bigcode bigcode-ast-tools generate-vocabulary --strip-identifiers -o workspace/java-vocabulary-no-ids.tsv workspace/apache-commons-asts.json
This should generate $BIGCODE_WORKSPACE/java-vocabulary-no-ids.tsv which looks like this
head -n 5 $BIGCODE_WORKSPACE/java-vocabulary-no-ids.tsv
id type metaType count
0 SimpleName Other 465461
1 NameExpr Expr 173968
2 MethodCallExpr Expr 103814
3 ExpressionStmt Stmt 80921
We can visualize the distribution using
docker-bigcode bigcode-ast-tools visualize-vocabulary-distribution --no-open -v workspace/java-vocabulary-no-ids.tsv -o workspace/vocabulary-distribution.html
This will create $BIGCODE_WORKSPACE/vocabulary-distribution.html and the
distribution should look something like this

Next, we will generate skipgram-like data to train our model. To speedup the process, we will use only two ancestors as the context for each node and ignore children and siblings.
mkdir $BIGCODE_WORKSPACE/apache-commons-skipgram-data
docker-bigcode bigcode-ast-tools generate-skipgram-data -v workspace/java-vocabulary-no-ids.tsv --ancestors-window-size 2 --children-window-size 0 --without-siblings -o workspace/apache-commons-skipgram-data/skipgram-data workspace/apache-commons-asts.json
This will create $BIGCODE_WORKSPACE/apache-commons-skipgram-data/skipgram-data-001.txt.gz
(the number of files created depends on the number of cores) which
is a bunch of input, output pairs gunzipped:
gunzip -c $BIGCODE_WORKSPACE/apache-commons-skipgram-data/skipgram-data-001.txt.gz | head -n 20 | tail -n5
14,31
0,29
14,31
31,30
14,31
We will now learn 50 dimensions embeddings on this data using bigcode-embeddings tool.
docker-bigcode sh -c "bigcode-embeddings train -o workspace/java-simple-embeddings --vocab-size=$(tail -n+2 $BIGCODE_WORKSPACE/java-vocabulary-no-ids.tsv | wc -l) --emb-size=50 --optimizer=gradient-descent --batch-size=64 workspace/apache-commons-skipgram-data/skipgram-data*"
This might take a while (probably a few minutes depending on the computer), and for some reason stdout seems not to be flushed when using Docker, so there might be no output until the command finishes.
When the training finishes, there will be a bunch of generated files in $BIGCODE_WORKSPACE/java-simple-embeddings. These are Tensorflow files
and can be visualized using tensorboard
docker-bigcode tensorboard --logdir=workspace/java-simple-embeddings
Tensorboard should now be available at localhost:6006 in your browser.
The loss graph should hopefully look something like this

You can also take a look at the projector. By default, each node will be an
integer, but if click on Load data and select $BIGCODE_WORKSPACE/java-vocabulary-no-ids.tsv
it should give understandable data.
The projector output should look something like this

Although we did not train with much data, the result should hopefully make some sense.
For example the closest letters from DoubleLiteralExpr are IntegerLiteralExpr and
StringLiteralExpr.
We can try to cluster the nodes in 5 clusters and generate a 2D visualization of the result using
# $MODEL_NAME is the last model saved by Tensorflow
MODEL_NAME=$(basename $(ls $BIGCODE_WORKSPACE/java-simple-embeddings/embeddings.bin-* | tail -n1) ".meta")
docker-bigcode bigcode-embeddings visualize clusters -m workspace/java-simple-embeddings/$MODEL_NAME -n 5 -l workspace/java-vocabulary-no-ids.tsv -o workspace/java-2d-embeddings.png
This will output the result in $BIGCODE_WORKSPACE/java-2d-embeddings.png and
will look something like this
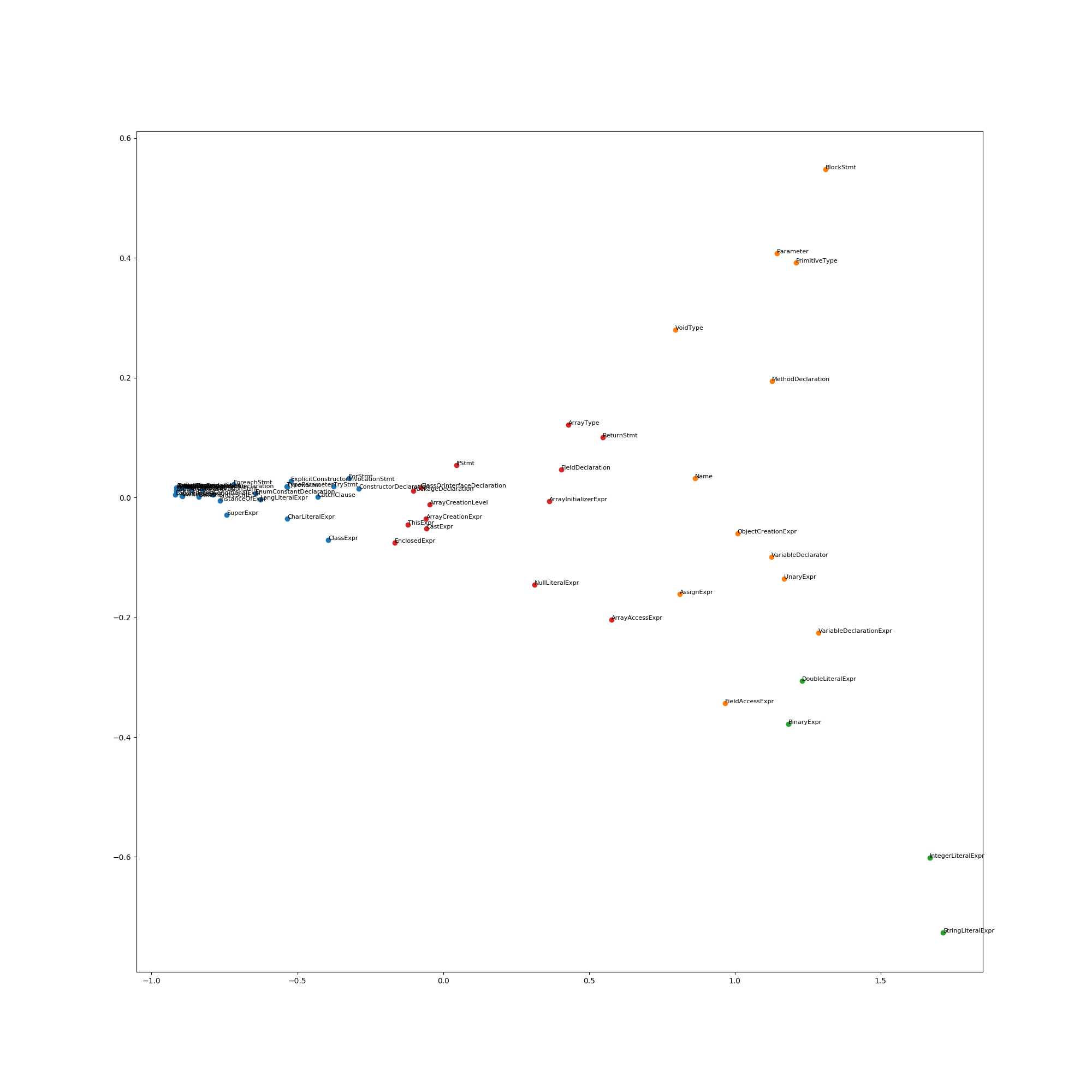
The results are not great given the few amount of data we used, but the same process can easily be used a with much bigger dataset to hopefully give better results.
This is the end of the tutorial, take a look at each module documentation for more information, and feel free to send PRs and contribute.