[TOC]
Redis是开源免费的,一个高性能的key-value非关系型数据库。
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。 - Memcache不支持持久化 - snapshot + log的模式进行持久化
Redis不仅仅支持简单的key-value类型的数据,同时还提供String,list,set,zset,hash等数据结构的存储。
不支持Transaction, 但支持Batch操作的atomicity.
Redis支持数据的备份,即master-slave模式的数据备份。由于是Eventually Consistency, write to master到read from replica可能会有延迟。
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
Atomicity – Redis的所有操作都是原子性的,同时Redis还支持对batch的操作。
丰富的特性 – Redis还支持 publish/subscribe, 通知, 设置key有效期等等特性。
- Session缓存, 拓展: 单点登录的解决方案(Session)->cache
- newest N: List
- Top N: zest(有序集合,通过树实现)
- 时效性的数据,比如手机验证码: expire
- redis采用的是定时删除(定时删除需要计时器浪费cpu资源。redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采时定期删除策略,会导致很多key到时间没有删除。)
- 惰性删除策略(也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。)
- 内存淘汰机制(allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。)Redis配置文件中可以设置maxmemory,内存的最大使用量,到达限度时会执行内存淘汰机制。
- 计数器: 原子性,自增/减方法(NCR/DECR)
- 去除大量数据中的重复数据: set
- 构建队列:list集合
- 发布订阅消息系统: pub/sub模式
- Geo, 以某一经纬度为中心,找出某一半径内的元素。
http协议无状态的,就是用户连接只要获取响应,服务器不记录用户状态,于是通过Cookie+session来保存用户状态。
Cookie是由客户端保存的小型文本文件,其内容为一系列的键值对,在浏览器访问同一个域名的不同页面时,会在HTTP请求中附上Cookie。Cookie可以保存在内存中(关闭浏览器即消失),也可以保存在硬盘中(到达过期时间后消失)。每当用户访问一个网站时,服务器程序会分配给它一个唯一的id,这个id就是设置在Cookie中的。从获取网站的Cookie到浏览器关闭的这个周期,被称为一个会话——Session。为了保证就算load-balancer router request到不同的服务器,也能保持用户的登录状态,于是需要每个server都能read到session的信息。
单线程NIO模型(epoll),主要是为了避免线程切换提升效率(尽量减少时间长操作,避免redis阻塞),在redis.conf中可以最大客户端数量,官方推荐最大值10000.
- 可以进行batch操作,通过Optimistic Lock来保证atomicity. eg:
watch a; # optimistic lock
multi; # begin batch
read a;
write a = a+1;
exec;
-
Lua script Redis中内嵌了对Lua环境的支持,允许开发者使用Lua语言编写脚本传到Redis中执行,Redis客户端可以使用Lua脚本,直接在服务端原子的执行多个Redis命令。 使用脚本的好处:
-
减少网络开销,在Lua脚本中可以把多个命令放在同一个脚本中运行
-
原子操作,redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。换句话说,编写脚本的过程中无需担心会出现竞态条件
-
复用性,客户端发送的脚本会永远存储在redis中,这意味着其他客户端可以复用这一脚本来完成同样的逻辑Lua是一个高效的轻量级脚本语言(javascript、shell、sql、python、ruby…),用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
-
Redis relies on slave to achieve data replicate and isolation read/write. Master serve the write, and slave serve the read. As a read-heavy system, this pattern usually works good.
-
RDB持久化:将Redis在内存中的数据定时
dump到磁盘上,实际操作过程是fork一个子进程,先将数据写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储.- 优点: 相比于
AOF机制,如果数据量比较大,RDB的启动效率会更高(记录的是源数据,而非数据操作) - 缺点: 数据的可用性得不到太大的保障,如果在定时持久化之前出现宕机现象,此前没来得及写入磁盘的数据都将丢失
- 缺点: 如果数据量较大,
fork子进程的操作可能会使服务短暂停止(通常是几百毫秒)

- 优点: 相比于
-
AOF持久化: 将Redis的操作日志以文件追加的方式写入文件,只记录写、删除操作,查询操作不会记录(类似于MySQL的Binlog日志)

优点:log采用append模式,即使写入过程中,server挂机,也不会miss log
缺点:AOF文件通常较大。RDB恢复得更快。
一般设置为disable.
This system works using three main mechanisms:
-
When a master and a replica instances are well-connected, the master keeps the replica updated by sending a stream of commands(write command) to the replica.
-
When the link between the master and the replica breaks, for network issues or because a timeout is sensed in the master or the replica, the replica reconnects and attempts to proceed with a partial resynchronization: it means that it will try to just obtain the part of the stream of commands it missed during the disconnection.
-
When a partial resynchronization is not possible, the replica will ask for a full resynchronization. This will involve a more complex process in which the master needs to create a **snapshot ** of all its data, send it to the replica, and then continue sending the stream of commands as the dataset changes.
Usually happends when have a new replica join the cluster.
If a master is not working as expected, Sentinel can start a failover process where a replica is promoted to master, the other additional replicas are reconfigured to use the new master, and the applications using the Redis server are informed about the new address to use when connecting.
为了解决master选举问题,又引出了一个单点问题,也就是哨兵的可用性如何解决,在一个一主多从的Redis系统中,可以使用多个哨兵进行监控任务以保证系统足够稳定。此时哨兵不仅会监控master和slave,同时还会互相监控;这种方式称为Sentinel cluster,哨兵集群需要解决故障发现、和master决策的协商机制问题:
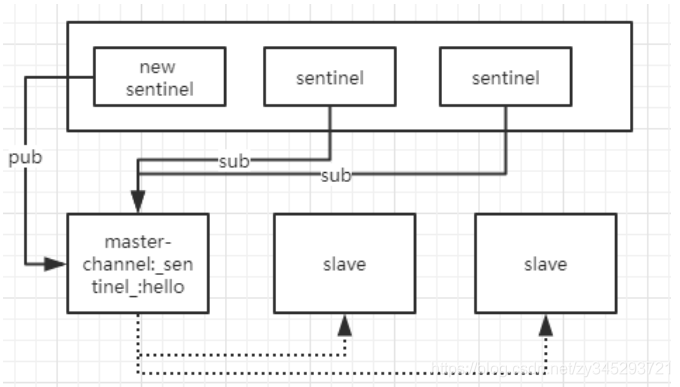
Build a cluster of sentinel:
- 需要相互monitoring的sentinel都向他们共同监视的master节点订阅channel:sentinel:hello
- 新加入的sentinel节点向这个channel发布一条消息,包含自己本身的信息,这样订阅了这个channel的sentinel 就可以发现这个新的sentinel
- 新加入的sentinel和其他sentinel节点建立长连接(long live connection)
Master的故障发现和Automatic failover(Raft):
- sentinel节点会定期向master节点发送心跳包来判断存活状态,一旦master节点没有正确响应,sentinel会把master设置为“主观不可用状态”,
- 然后它会把“主观不可用”发送给其他所有的sentinel节点去确认,当确认的sentinel节点数大于>quorum时,则会认为master是“客观不可用”,
- 接着就开始进入选举新的master流程;但是这里又会遇到一个问题,就是sentinel中,本身是一个集群,如果多个节点同时发现master节点达到客观不可用状态,那谁来决策选择哪个节点作为maste呢?
- 这个时候就需要从sentinel集群中选择一个leader来做决策。而这里用到了一致性算法Raft算法、它和Paxos算法类似,都是分布式一致性算法。但是它比Paxos算法要更容易理解;Raft和Paxos算法一样,也是基于投票算法,只要保证过半数节点通过提议即可;
- 基于Raft协议,如果Sentinel数目为
2n+1, 可以容忍n个节点失败。
在redis3.0之前,我们是通过在客户端去做的分片,通过hash环的方式对key进行分片存储。分片虽然能够解决各个节点的存储压力,但是导致维护成本高、增加、移除节点比较繁琐。因此在redis3.0以后的版本最大的一个好处就是支持集群功能,集群的特点在于拥有和单机实例一样的性能,同时在网络分区以后能够提供一定的可访问性以及对主数据库故障恢复的支持。

-
集群完全去中心化,采用多主多从;所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
-
客户端与 Redis 节点直连,不需要中间代理层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
-
每一个分区都是由一个Redis主机和多个从机组成,片区和片区之间是相互平行的。
-
每一个master节点负责维护一部分槽,以及槽所映射的键值数据。
-
redis cluster主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster,数据量不是很大时,使用sentinel就够了。redis cluster的性能和高可用性均优于哨兵模式。

-
Scalability: Redis Cluster采用虚拟哈希槽分区而非一致性hash算法,预先分配16384(2^14)个卡槽,所有的键根据哈希函数映射到 0 ~ 16383整数槽内,每一个分区内的master节点负责维护一部分槽以及槽所映射的键值数据。**这种结构很容易添加或者删除节点,并且无论是添加删除或者修改某一个节点,都不会造成集群不可用的状态。**使用哈希槽的好处就在于可以方便的添加 或 移除节点,当添加或移除节点时,只需要移动对应槽和数据移动到对应节点就行。
-
Decentralized structure: **Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽。**所以客服端请求任意一个节点,都能获取到slot对应的node信息。所以master数目不适合过多,这样的话master之间的heartbeat信息会造成network congestion.
当一个 Redis 新节点运行并加入现有集群后,我们需要为其迁移槽和槽对应的数据。首先要为新节点指定槽的迁移计划,确保迁移后每个节点负责相似数量的槽,从而保证这些节点的数据均匀。如下图:向有三个master集群中加入M4(即node-4),集群中槽和数据的迁移。
- M4向M1, M2, M3, 发送migrate命令,准备migrate data
- migrate data完毕后,集群内所有master节点发送 cluster setslot { slot } node { targetNodeId } 命令,通知槽分配给目标节点。为了保证槽节点映射变更及时传播,需要遍历发送给所有主节点更新被迁移的槽执行新节点
How to guarantee data consistency?
当node3在迁移状态时,仍然从node2进行

- 首先需要确认下线节点是否有负责的槽,如果有,需要把槽和对应的数据迁移到其它节点,保证节点下线后整个集群槽节点映射的完整性。
- 当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记该节点后可以正常关闭。
- 下线节点需要将节点自己负责的槽迁移到其他节点,原理与之前节点扩容的迁移槽过程一致。迁移完槽后,还需要通知集群内所有节点忘记下线的节点,也就是说让其它节点不再与要下线的节点进行 Gossip 消息交换。
-
Moved重定向:
client->server, 如果server计算到key不属于自己的bucket, 于是会返回
moved redirect exception, 并且包含目标节点的信息 -
Ack重定向:
在对集群进行扩容和缩容时,需要对槽及槽中数据进行迁移。当槽及槽中数据正在迁移时,客服端请求目标节点时,目标节点中的槽已经迁移支别的节点上了,此时目标节点会返回
ask redirect给client.
