[TOC]
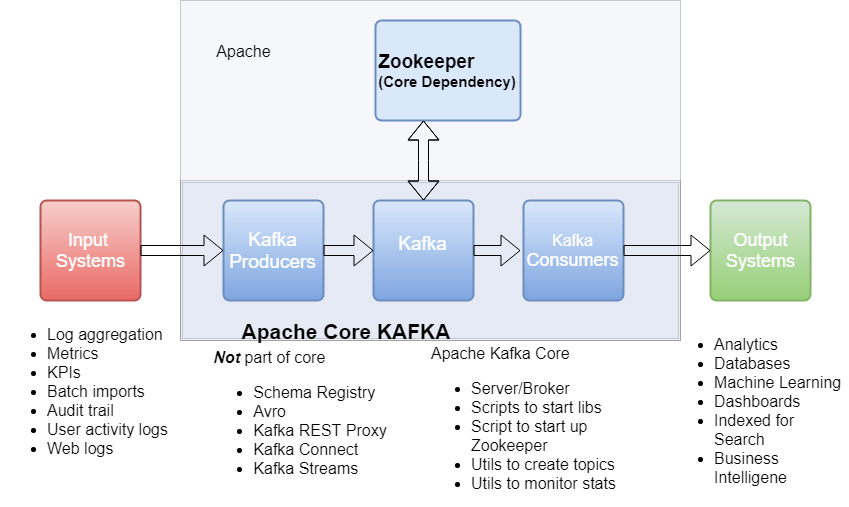
- a distributed pub-sub messaging system that resolves N^2 relationships to N. Publishers and subscribers can operate at their own rates.
- super fast with zero-copy technology(DMA)
- support fault-tolerant data persistence
第一个成功创建 /controller 节点的 Broker 会被指定为Controller: 当 Broker 启动时,会尝试读取 zookeeper /controller 中的“brokerid ”,如果读取到的值不是-1,则表示已经有节点竞选成为 Controller 了,当前节点就会放弃竞选;而如果读取到的值为-1,ZooKeeper 就会尝试创建 /controller 节点,当该 Broker 去创建的时候,可能还有其他 Broker 一起同时创建节点,但只有一个 Broker 能够创建成功,即成为唯一的 Controller。
- 集群Broker管理(新增 Broker、Broker 主动关闭、Broker 故障)
- 创建、删除topic,增加partition并分配leader分区
- preferred leader选举
- 分区重分配
ZooKeeper 赋予客户端监控 znode 变更的能力,即所谓的 Watch 通知功能。一旦 znode 节点被创建、删除,子节点数量发生变化,抑或是 znode 所存的数据本身变更,ZooKeeper 会通过节点变更监听器 (ChangeHandler) 的方式显式通知客户端(Controller)。
Leader partition in failed broker will be unavailable, then controller will decide which one will be the next leader among the available partitions. And copy data from leader to follower.
- load balance: 由于所有的读写操作都发生在leader partition上,于是为了均衡broker上的load,尽量把不同topic的leader放在不同的机器上,不同的rack上。
- 默认情况下auto.leader.rebalance.enabled为true,表示允许 Kafka 定期地对一些 Topic 分区进行 Leader 重选举。大部分情况下,Broker的失败很短暂,这意味着Broker通常会在短时间内恢复。所以当节点离开群集时,与其相关联的元数据并不会被立即删除。
-
Controller election
当Controller is unavailable, eg
Broker3, 它的ZooKeeper会话过期了,之前注册的/controller节点被删除。集群中其他Broker会收到zookeeper的这一通知。第一个成功创建 /controller 节点的 Broker 会被指定为Controller. 例如Broker2变成了新的controller. -
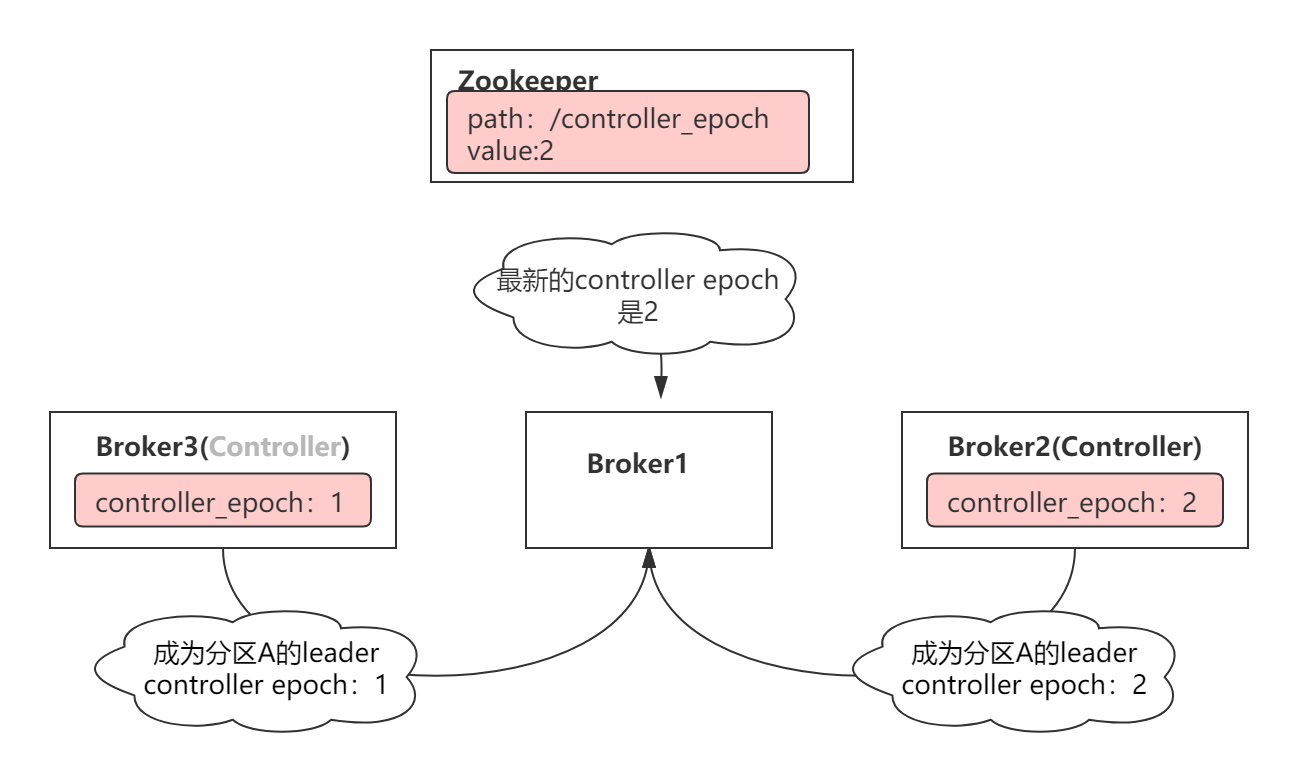
集群中出现两个Controller
此时
Broker3和Broker2都会认为自己是Controller, 它们可能一起发出具有冲突的命令。 -
Epoch Number
Kafka是通过使用epoch number来完成的。epoch number只是单调递增的数字,第一次选出Controller时,epoch number值为1,如果再次选出新的Controller,则epoch number将为2,依次单调递增。
每个新选出的controller通过Zookeeper 的条件递增操作获得一个全新的、数值更大的epoch number 。其他Broker 在知道当前epoch number 后,如果收到由controller发出的包含较旧(较小)epoch number的消息,就会忽略它们,即Broker根据最大的epoch number来区分当前最新的controller。

- 0: producer发送数据,不关心数据是否到达kafka, 然后发送下一条数据。效率高,但容易丢失。
- 1: producer发送数据,等待leader的应答。leader在把data写入自己的log后,即会reply producer. 然后aync, 等待follower poll data. 效率稍低,并且有leader crush before replicating data into follower的风险
- -1: producer发送数据,需要等待所有replica(leader + follower)的回复.
kafka默认值为1.
where producer append at the end of the log stream in immutable and monotonic fashion and subscribers/consumers can maintain their own pointers to indicate current message processing. To avoid disk high seek time.

What happens when we fetch data from memory and send it over the network.
- To fetch data from the memory, it copies data from the Kernel Context into the Application Context.
- To send those data to the Internet, it copies data from the Application Context into the Kernel Context.

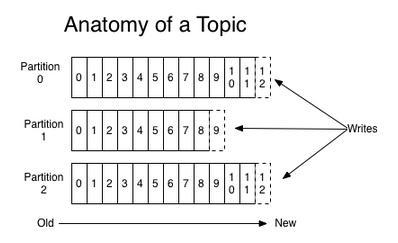
为了负载均衡,一个topic会有好几个分区,会存在不同的broker/rack上。其中,partition是以文件夹的形式存储在具体Broker本机上。
Data Partitioning and replication takes place using consistent hashing.

对于一个partition(在Broker中以文件夹的形式存在),里面又有很多大小相等的segment数据文件。
一个segment分别为index file和data file,这两个文件是一一对应的,后缀”.index”和”.log”分别表示索引文件和数据文件;index文件中,存有Message的offset和在log中的地址。
为了实现Producer的Idempotency,Kafka引入了Producer ID(即PID)和Sequence Number。每个新的Producer在初始化的时候会被分配一个唯一的PID,该PID对用户完全透明而不会暴露给用户。
对于每个PID,该Producer发送数据的每个<Topic, Partition>都对应一个从0开始单调递增的Sequence Number。
类似地,Broker端也会为每个<PID, Topic, Partition>维护一个序号,并且每次Commit一条消息时将其对应序号递增。对于接收的每条消息,如果其序号比Broker维护的序号(即最后一次Commit的消息的序号)大一,则Broker会接受它,否则将其丢弃。
可以解决两个问题:
- Broker保存消息后,发送ACK前宕机,Producer认为消息未发送成功并重试,不会造成数据重复
- 前一条消息发送失败,后一条消息不会发送成功,否则会造成数据乱序。

Leader中的Committed表示已完全备份的消息,对消费者可见,Committed到LEO表示未完全备份的消息,对消费者不可见。
LEO(last end offset):日志末端位移,记录了该副本对象底层日志文件中下一条消息的位移值,副本写入消息的时候,会自动更新 LEO 值。
HW(high watermark):从名字可以知道,该值叫高水印值,HW 一定不会大于 LEO 值,小于 HW 值的消息被认为是“已提交”或“已备份”的消息,并对消费者可见。HW=min(LEO of all replica)
ISR(In-Sync Replica set) :leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),每个Partition都会有一个ISR,而且是由leader动态维护.
- 如果一个flower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其从ISR中移除
- 当ISR中所有Replica都向Leader发送ACK(副本的LEO)时,leader更新HW(commit).
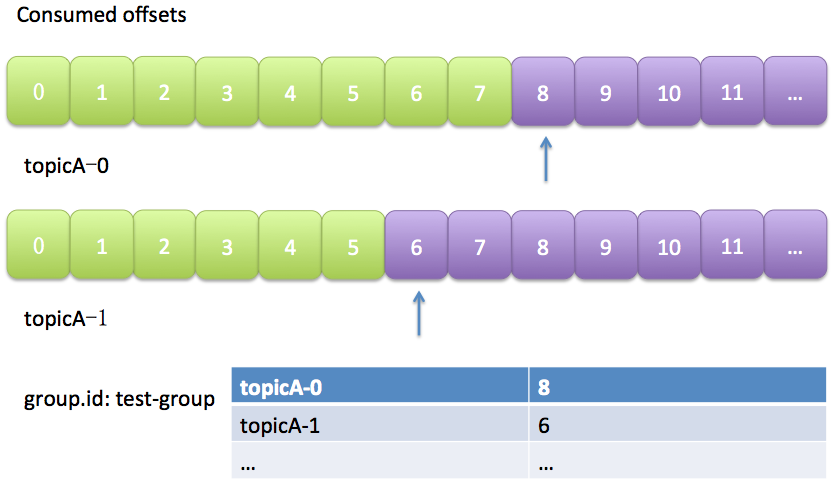
A consumer group contains mutiple consumer instances, share a group ID. 组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition). 来增加Consumer throughput.
消费者在消费的过程中需要记录自己消费了多少数据,即消费位置信息。在Kafka中这个位置信息有个专门的术语:位移(offset)。
-
自动保存
老版本的位移是提交到zookeeper中的,图就不画了,总之目录结构是:
/consumers/group.id/offsets/<topic>/<partitionId>,但是zookeeper其实并不适合进行大批量的读写操作,尤其是写操作。新版本增加了
__consumeroffsets topic, 这样利用自带的replica机制,来做数据备份,以及减少对zookeeper的依赖 -
手动
可以保存在第三方,比如Redis中