[TOC]
参见 阮一峰:全文搜索引擎Elasticsearch入门教程

Master Node:可以理解为主节点,用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等,以及管理集群各个节点的状态包括集群节点的协调、调度。elasticsearch集群中可以定义多个主节点,但是,在同一时刻,只有一个主节点起作用,其它定义的主节点,是作为主节点的候选节点存在。当一个主节点故障后,集群会从候选主节点中选举出新的主节点。也就是说,主节点的产生都是由选举产生的。Master节点它仅仅是对索引的管理、集群状态的管理。像其它的对数据的存储、查询都不需要经过这个Master节点。因此在ES集群中。它的压力是比较小的。所以,我们在构建ES的集群当中,Master节点可以不用选择太好的配置,但是我们一定要保证服务器的安全性。因此,必须要保证主节点的稳定性。
Data Node: 存储数据的节点,数据的读取、写入最终的作用都会落到这个上面。数据的分片、搜索、整合等 这些操作都会在数据节点来完成。因此,数据节点的操作都是比较消耗CPU、内存、I/O资源。所以,我们在选择data Node数据节点的时候,硬件配置一定要高一些。高的硬件配置可以获得高效的存储和分析能力。因为最终的结果都是需要到这个节点上来。
**Client Node:**可选节点。作任务分发使用。它也会存储一些元数据信息,但是不会对数据做任何修改,仅仅用来存储。它的好处是可以分担datanode的一部分压力。因为ES查询是两层汇聚的结果,第一层是在datanode上做查询结果的汇聚。然后把结果发送到client Node 上来。Cllient Node收到结果后会再做第二次的结果汇聚。然后client会把最终的结果返回给用户。
那么从上面的结构图我们可以看到ES集群的工作流程:
1,搜索查询,比如Kibana去查询ES的时候,默认走的是Client Node。然后由Client Node将请求转发到datanode上。datanode上的结构返回给client Node.然后再返回给客户端。
2,索引查询,比如我们调用API去查询的时候,走的是MasterNode,然后由master 将请求转发到相应的数据节点上,然后再由Master将结果返回。
3,最终我们都知道,所有的服务请求都到了datanode上。所以,它的压力是最大的。
-
Isolation Elasticsearch 用乐观并发控制(Optimistic Concurrency Control)来保证新版本的数据不会被旧版本的数据覆盖。
-
Consitency: Quorum
写入前先检查有多少个replica可供写入,如果达到写入条件,则进行写操作,否则,Elasticsearch 会等待更多的replica出现,默认为一分钟。
有如下三种设置来判断是否允许写操作:
One:只要主分片可用,就可以进行写操作。
All:只有当主分片和所有副本都可用时,才允许写操作。
Quorum(k-wu-wo/reng,法定人数):是 Elasticsearch 的默认选项。当有大部分的分片可用时才允许写操作。其中,对 “大部分” 的计算公式为 int ((primary+number_of_replicas)/2)+1。
-
Durability
首先,当有数据写入时,为了提升写入的速度,并没有数据直接写在磁盘上,而是先写入到内存中,但是为了防止数据的丢失,会追加一份数据到事务日志里(disk)。
因为内存中的数据还会继续写入,所以内存中的数据并不是以段的形式存储的,是检索不到的。
JVM->(refresh) OS buffer -> disk,
- JVM refresh to OS buffer一秒钟一次,JVM中的数据对user不可见。
- WAL 写满时(清空log)再做一次referesh, 生成version id.
-
Scalability: consistent hashing for sharding.
Write

-
coordinator is the first one tha receive user's request, calculate which node contains the
-
客户端向 Node 1(协调节点)发送写请求。
-
Node 1 通过文档的 _id(默认是 _id,但不表示一定是 _id)确定文档属于哪个分片(在本例中是编号为 0 的分片)。请求会被转发到master replica所在的节点 Node 3 上。
-
Node 3 在主分片上执行请求,如果成功,则将请求并行转发到 Node 1 和 Node 2 的副本分片上。
-
一旦Quorum的副本分片都报告成功(默认),则 Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
Read
- Coordinate node收到请求后,随意从master和slave replica中选择一个,进行转发,收集数据,回复。
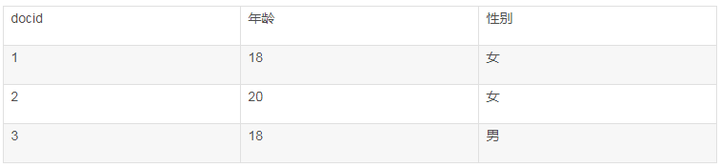
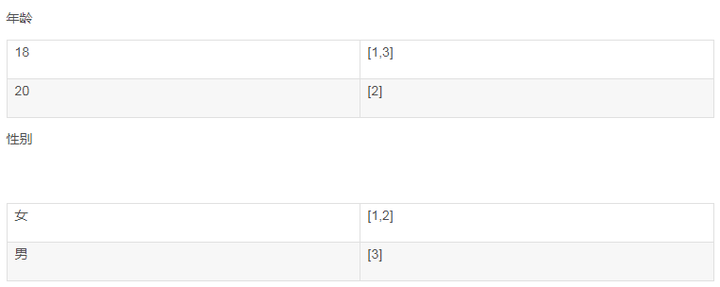
为什么要build index? 如果一个数据有很多tag, 可以很快根据tag检索到数据。并且tag之间还可以做And, Or, Nor等一系列操作。
-
Forward index
等于创建表。如果是直接写入,可以变成以下的格式:
如果是twitter post这种,可以通过文本操作,得到post id得到关键词。
-
Inverted Index
通过field得到a list of docid that have this field
key为term, value为posting list.
-
Query
如何Build term index?Trie
假设我们有很多个term,比如:
Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照这样的顺序排列,找出某个特定的term一定很慢,因为term没有排序,需要全部过滤一遍才能找出特定的term。排序之后就变成了:
Ada,Carla,Elin,Kate,Patty,Sara,Selena
这样我们可以用二分查找的方式,比全遍历更快地找出目标的term。这个就是 term dictionary。有了term dictionary之后,可以用 logN 次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的(一次random access大概需要10ms的时间)。所以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个term dictionary本身又太大了,无法完整地放到内存里。于是就有了term index。term index有点像一本字典的大的章节表。比如:
A开头的term ……………. Xxx页
C开头的term ……………. Xxx页
E开头的term ……………. Xxx页
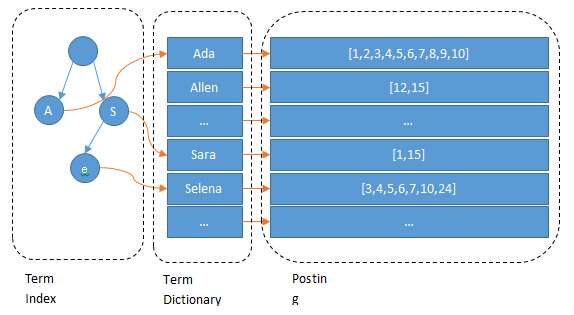
Trie不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。比如,Allen在找到A,定位到Ada的offset之后,后面就是Allen的offset. 再加上一些压缩技术(搜索 Lucene Finite State Transducers) term index 的尺寸可以只有所有term的尺寸的几十分之一,使得用内存缓存整个term index变成可能。整体上来说就是这样的效果。
Term Dictionary可以用B+树继续优化。
-
Union index
有时候有多个条件需要过滤。例如,age = 18, 女性。于是在得到两个postlist之后,要对他们做合并操作
-
利用skip list合并
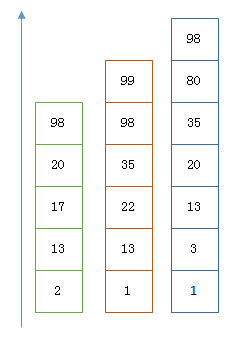
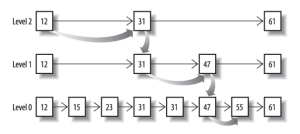
AND合并这三条postlist. 从最短的list开始。然后从小到大遍历。遍历的过程可以跳过一些元素,比如我们遍历到绿色的 13 的时候,就可以跳过蓝色的 3 了,因为 3 比 13 要小。
例如目前绿色遍历到13, 在红色和蓝色的skip list中寻找13. 可以把Skip List当成一个BST, 寻找元素的时间复杂度为O(lgn)
利用Frame of reference编码对于postlist进行压缩
-
利用Bitset合并
如果postlist为
[1,3,4,7,10], 对应的 bitset 就是:[1,0,1,1,0,0,1,0,0,1].其用一个 byte 就可以代表 8 个文档。所以 100 万个文档只需要 12.5 万个 byte。但是考虑到文档可能有数十亿之多,在内存里保存 bitset 仍然是很奢侈的事情。而且对于个每一个 filter 都要消耗一个 bitset,比如 age=18 缓存起来的话是一个 bitset,18<=age<25 是另外一个 filter 缓存起来也要一个 bitset。
- 可以很压缩地保存上亿个 bit 代表对应的文档是否匹配 filter;
- 这个压缩的 bitset 仍然可以很快地进行 AND 和 OR 的逻辑操作。
Lucene 使用的这个数据结构叫做 Roaring Bitmap。
其压缩的思路其实很简单。与其保存 100 个 0,占用 100 个 bit。还不如保存 0 一次,然后声明这个 0 重复了 100 遍
-
Summary: Elasticsearch 对其性能有详细的对比( https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps )。简单的结论是:因为 Frame of Reference 编码是如此 高效,对于简单的相等条件的过滤缓存成纯内存的 bitset 还不如需要访问磁盘的 skip list 的方式要快。
-