- messages that sent into particular topic will be appended in the same order
- consumer see messages in order that were written
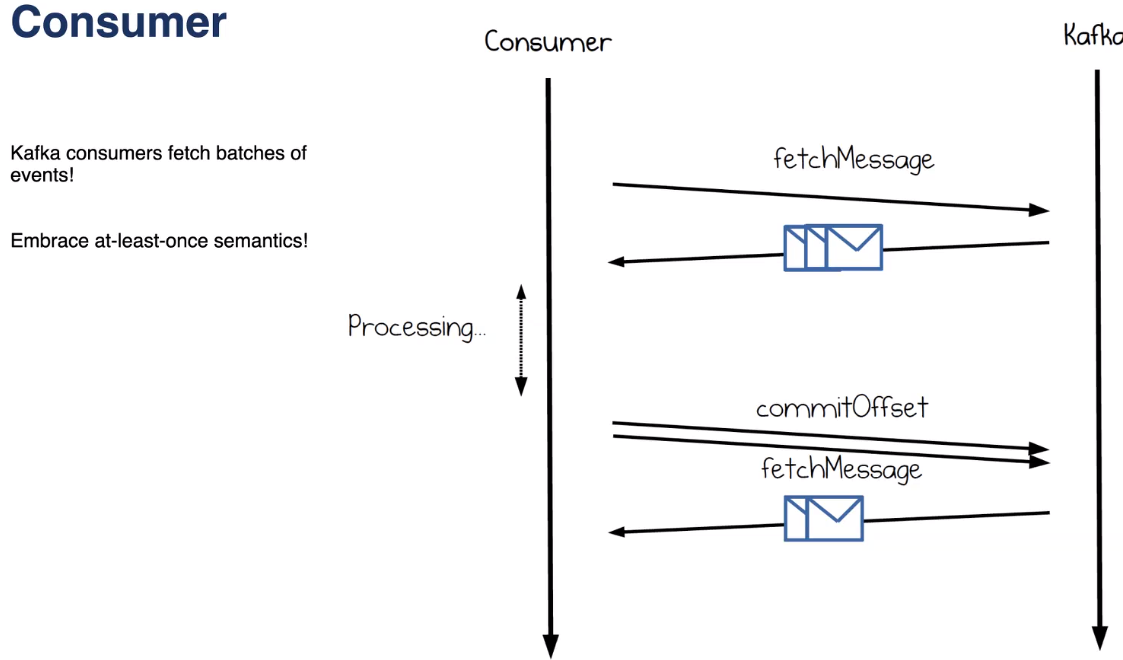
- "At-least-once" message delivery guaranteed - for consumer who crushed before it commited offset
- "At-most-once" delivery - ( custom realization ) consumer will never read the same message again, even when crushed before process it
- it is better to have many small messages instead of big one
- Integration tests should have real-world messages
git clone https://github.com/apache/kafka.git kafka- Topics category of messages, consists from Partitions
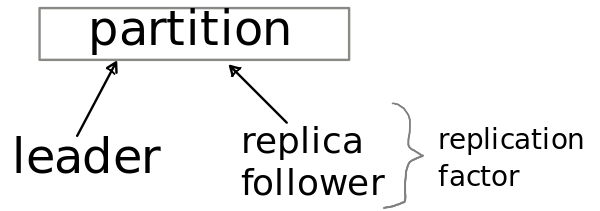
- Partition ( Leader and Followers )
part of the Topic, can be replicated (replication factor) across Brokers, must have at least one Leader and 0..* Followers
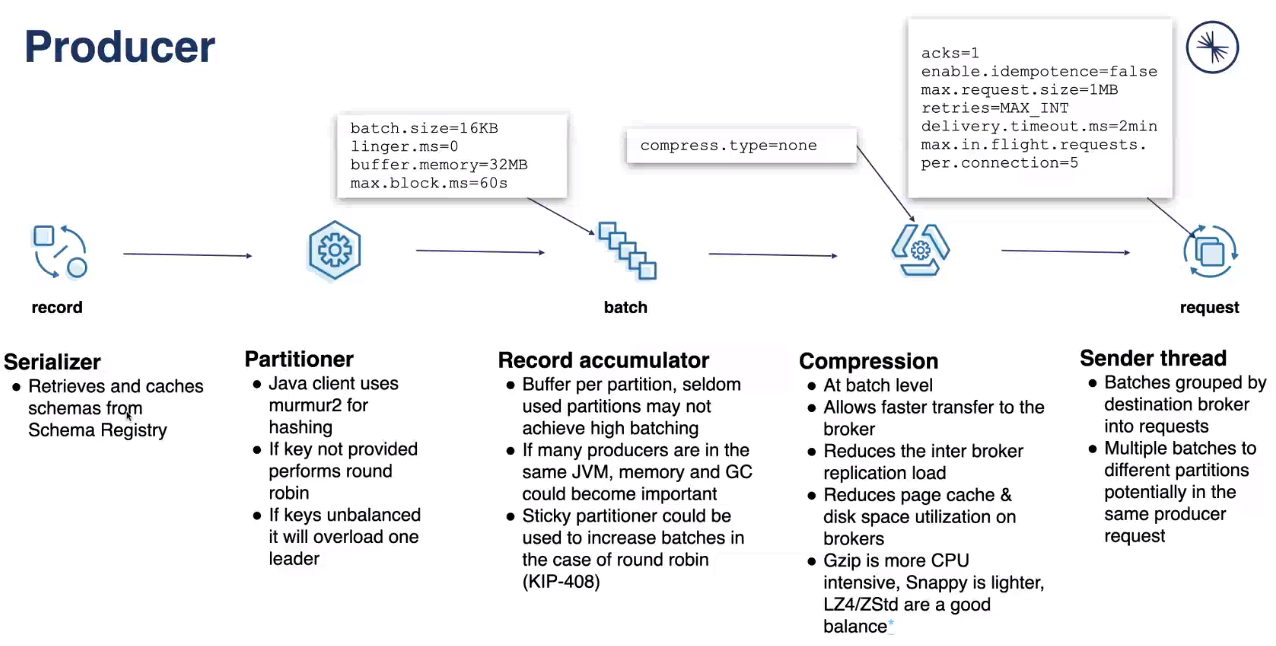
when you save message, it will be saved into one of the partitions depends on:
partition number | hash of the key | round robin
partition size calculator
- Leader main partition in certain period of time, contains InSyncReplica's - list of Followers that are alive in current time
- Committed Messages when all InSyncReplicas wrote message, Consumer can read it after, Producer can wait for it or not
- Brokers one of the server of Kafka ( one of the server of cluster )
- Producers some process that publish message into specific topic
- Consumers topics subscriber
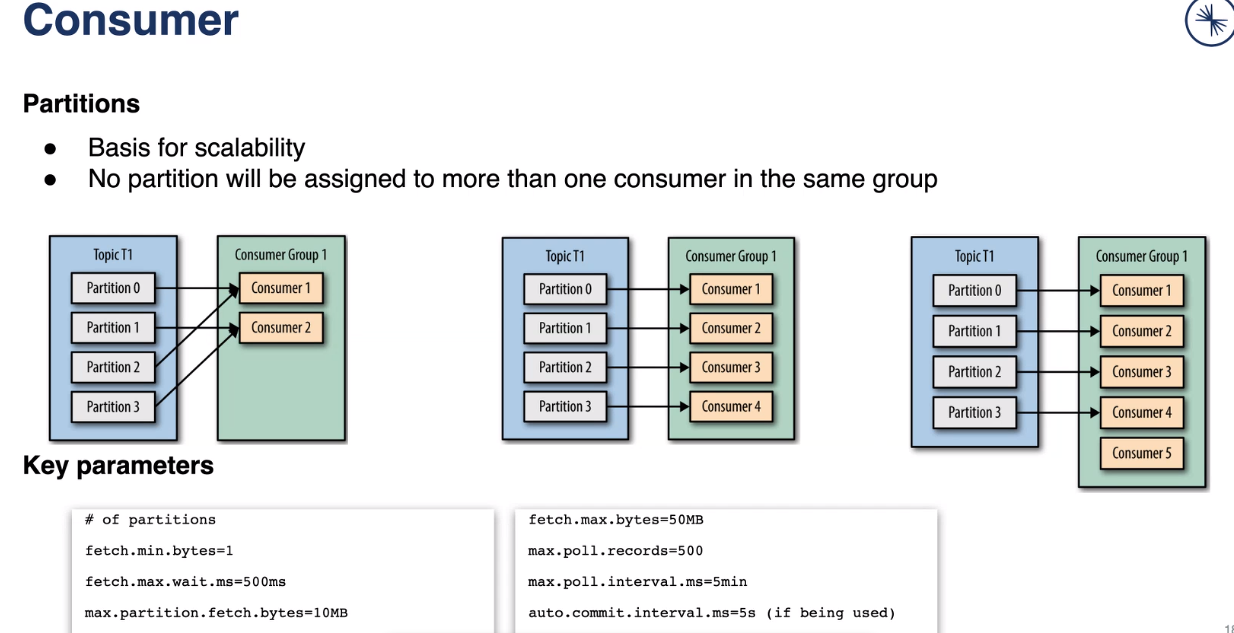
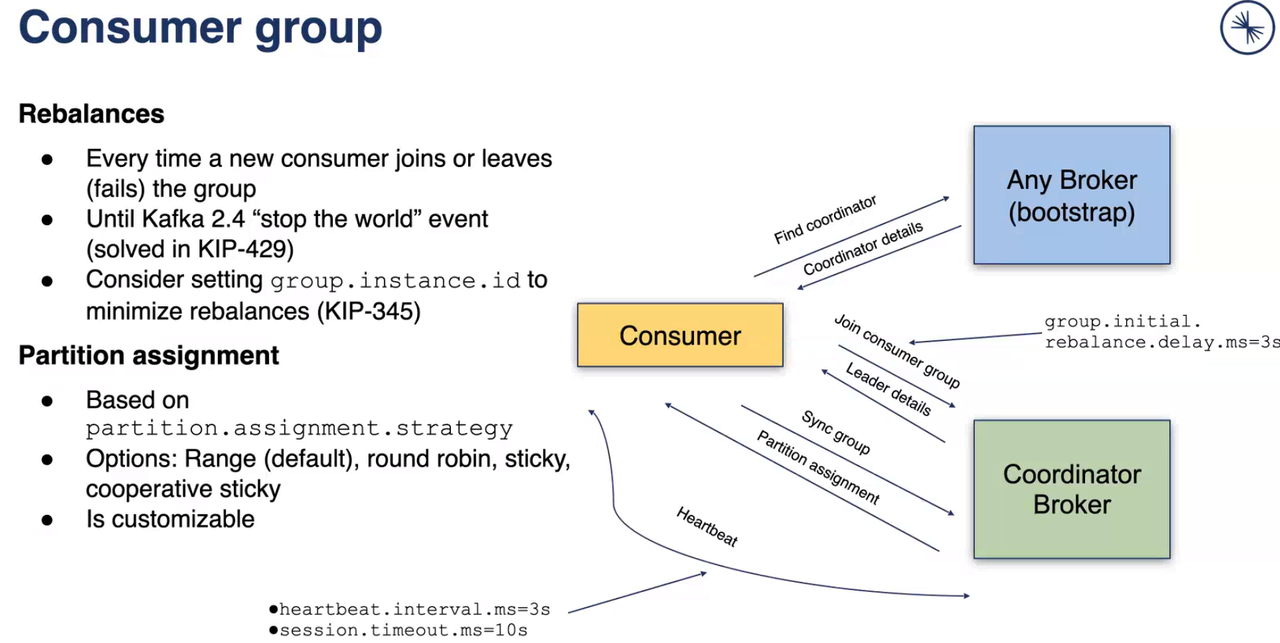
- Consumer Group group of consumers, have one Load Balancer for one group, consumer instance from different group will receive own copy of message ( one message per group )



- must be started before using Kafka ( zookeeper-server-start.sh, kafka-server-start.sh )
- cluster membership
- electing a controller
- topic configuration leader, which topic exists
- Quotas
- ACLs
./kafka-acls.sh
zookeeper-server-start.sh
kafka-server-start.sh config/server.propertiesflowchart LR
ksql --> ks["kafka \n stream"]
ks --> cp[consumer\nproducer]
@startuml
[ksql] as ksql
rectangle "kafka stream jar" as stream #lightgreen
[app] as app
[consumer \n producer] as consumer
[kafka] as kafkap
ksql -right--> stream : use
app o-- stream : aggregate
stream -right--> consumer
consumer -up-> kafka
@enduml# create stream
maprcli stream create -path sample-stream -produceperm p -consumeperm p -topicperm p
# generate dummy data
/opt/mapr/ksql/ksql-4.1.1/bin/ksql-datagen quickstart=pageviews format=delimited topic=sample-stream:pageviews maxInterval=5000/opt/mapr/ksql/ksql-4.1.1/bin/ksql http://ubs000130.vantage.org:8084it is storage of messages with ability to look into window ( time based ) using ConfluenceKafkaSQL
- stream processing
- connectors
- mater. views
- pull query
- push query
create table pageviews_original_table (viewtime bigint, userid varchar, pageid varchar) with (kafka_topic='sample-stream:pageviews', value_format='DELIMITED', key='viewtime')
select * from pageviews_original_table;bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic mytopic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --describe --topic mytopic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --config retention.ms=360000 --topic mytopicor just enable "autocreation"
auto.create.topics.enable=true
can be marked "for deletion"
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic mytopicbin/kafka-topics.sh --create --zookeeper localhost:2181 --listkafka-topics --describe --zookeeper localhost:2181 --topic mytopicnamebin/kafka-topics.sh --alter --zookeeper localhost:2181 --partitions 5 --topic mytopic
bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic mytopic --config retention.ms=72000
bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic mytopic --deleteConfig retention.ms=72000
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic mytopic
PRODUCER_CONFIG=/path/to/config.properties
TOPIC_NAME=my-topic
BROKER=192.168.1.140:9988
bin/kafka-console-producer.sh --producer.config $PRODUCER_CONFIG \
--broker-list $BROKER --topic $TOPIC_NAME Properties props = new Properties();
props.put("bootstrap.servers", "localhost:4242");
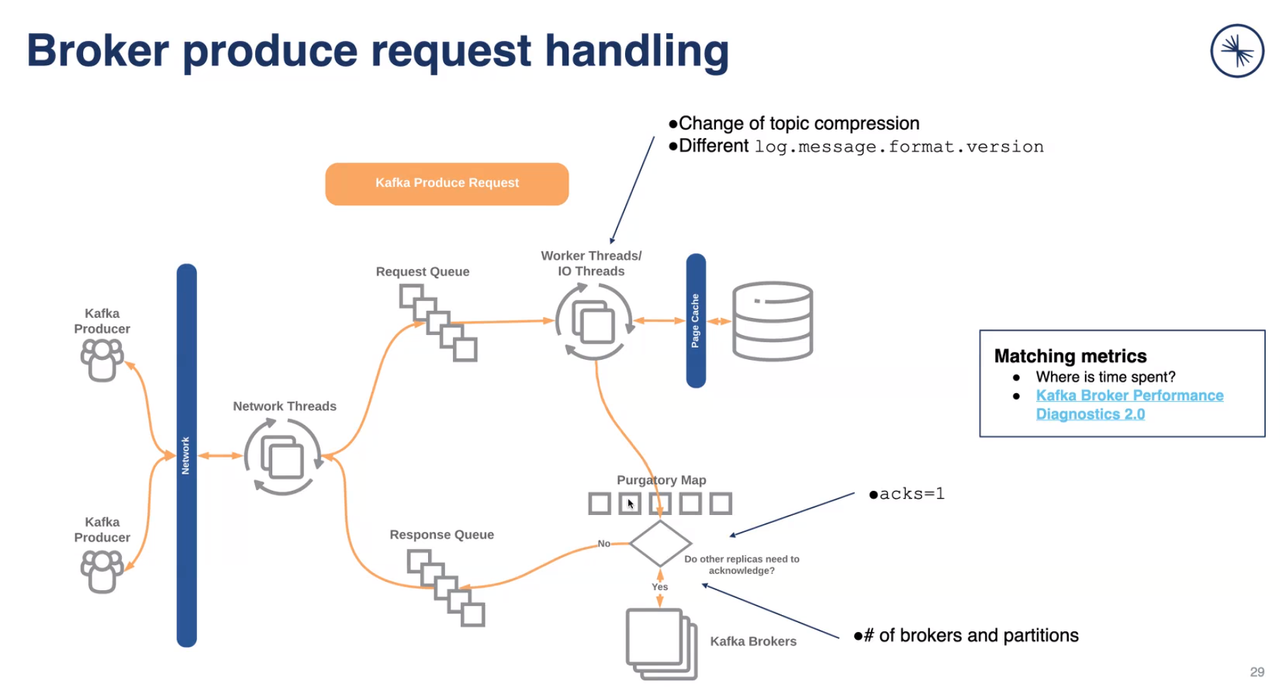
props.put("acks", "all"); // 0 - no wait; 1 - leader write into local log; all - leader write into local log and wait ACK from full set of InSyncReplications
props.put("client.id", "unique_client_id"); // nice to have
props.put("retries", 0); // can change ordering of the message in case of retriying
props.put("batch.size", 16384); // collect messages into batch
props.put("linger.ms", 1); // additional wait time before sending batch
props.put("compression.type", ""); // type of compression: none, gzip, snappy, lz4
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.metrics(); //
for(int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("mytopic", Integer.toString(i), Integer.toString(i)));
producer.flush(); // immediatelly send, even if 'linger.ms' is greater than 0
producer.close();
producer.partitionsFor("mytopic")partition will be selected
consumer console ( console consumer )
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic mytopic --from-beginning
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic mytopic --from-beginning --consumer.config my_own_config.properties
bin/kafka-console-consumer.sh --bootstrap-server mus07.mueq.adac.com:9092 --new-consumer --topic session-ingest-stage-1 --offset 20 --partition 0 --consumer.config kafka-log4j.properties
bin/kafka-console-consumer.sh --bootstrap-server mus07.mueq.adac.com:9092 --group my-consumer-2 --topic session-ingest-stage-1 --from-beginning --consumer.config kafka-log4j.properties
# read information about partitions
java kafka.tools.GetOffsetShell --broker-list musnn071001:9092 --topic session-ingest-stage-1
# get number of messages in partitions, partitions messages count
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic session-ingest-stage-1bin/kafka-consumer-groups.sh --zoopkeeper localhost:2181 --describe --group mytopic-consumer-group- automatic commit offset (enable.auto.commit=true) with period (auto.commit.interval.ms=1000)
- manual offset commit (enable.auto.commit=false)
- property "auto.offset.reset=latest" start with consuming only newly appeared messages in the topic after connection/creation
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:4242"); // list of host/port pairs to connect to cluster
props.put("client.id", "unique_client_id"); // nice to have
props.put("group.id", "unique_group_id"); // nice to have
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("fetch.min.bytes", 0); // if value 1 - will be fetched immediatelly
props.put("enable.auto.commit", "true"); //
// timeout of detecting failures of consumer, Kafka group coordinator will wait for heartbeat from consumer within this period of time
props.put("session.timeout.ms", "1000");
// expected time between heartbeats to the consumer coordinator,
// is consumer session stays active,
// facilitate rebalancing when new consumers join/leave group,
// must be set lower than *session.timeout.ms*
props.put("heartbeat.interval.ms", "");NOT THREAD Safe !!!
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
ConsumerRecords<String, String> records = consumer.pool(100); // time in ms- by topic
consumer.subscribe(Arrays.asList("mytopic_1", "mytopic_2"));
- by partition
TopicPartition partition0 = new TopicPartition("mytopic_1", 0);
TopicPartition partition1 = new TopicPartition("mytopic_1", 1);
consumer.assign(Arrays.asList(partition0, partition1));
- seek to position
seek(partition0, 1024);
seekToBeginning(parition0, partition1);
seekToEnd(parition0, partition1);
:TODO: in-memory DB ( Rocks DB )
- manage copying data between Kafka and another system
- connector either a source or a sink
- connector can split "job" to "tasks" ( to copy subset of data )
- partitioned streams for source/sink, each record into it: [key,value,offset]
- standalone/distributed mode
- Two ways of wokring with Stream:
- KSQL (KSQLDB)
- Flink
engine for running queries on cluster
start connect
bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties
connect settings
name=local-file-source
connector.class=org.apache.kafka.connect.file.FileStreamSourceConnector
tasks.max=1
file=my_test_file.txt
topic=topic_for_me
after execution you can check the topic
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic topic_for_me --from-beginningkafka cli (producer & consumer)
apt-get install kafkacatdocker run
docker run -it --network=host edenhill/kcat:1.7.1BROKER_HOST=192.168.1.150
BROKER_PORT=3388
TOPIC=my-topic
kafkacat -C -b $BROKER_HOST:$BROKER_PORT -t $TOPIC
# -X security.protocol=sasl_ssl \
# -X sasl.mechanisms=PLAIN \
# -X sasl.username=$SASL_USER \
# -X sasl.password=$SASL_PASS \kafkacat -C -b $BROKER_HOST:$BROKER_PORT -t $TOPIC -o beginningkafkacat -C -b $BROKER_HOST:$BROKER_PORT -t $TOPIC -o -5kafkacat -C -b $BROKER_HOST:$BROKER_PORT -t $TOPIC -c 5
# Print messages with a specific output
kafkacat -C -b $BROKER_HOST:$BROKER_PORT -t $TOPIC -c 5 -f 'Key: %k, message: %s \n'
# more complex output
kafkacat -C -b $BROKER_HOST:$BROKER_PORT -t $TOPIC -c 5 -f '\nKey (%K bytes): %k\t\nValue (%S bytes): %s\nTimestamp: %T\tPartition: %p\tOffset: %o\nHeaders: %h\n--\n' -edate_start=`date +'%Y-%m-%d %H:%M:%S' --date="2 hour ago"`
date_end=`date +'%Y-%m-%d %H:%M:%S'`
kafkacat -C -b $BROKER_HOST:$BROKER_PORT -t $TOPIC -o s@$date_start -o e@$date_endkafkacat -C -b $BROKER_HOST:$BROKER_PORT -t $TOPIC -K\tkafkacat -C -b $BROKER_HOST:$BROKER_PORT -t $TOPIC -o beginning -K\t | grep $MESSAGE_KEY
# shrink time of the scan from "beginning" to something more expectedkafkacat -C -b $BROKER_HOST:$BROKER_PORT -t $TOPIC -c 5 -P -l /path/to/file