
VideLibri is a library client to access all the features of a (public) library catalog/OPAC and store the catalog data for further offline processing. It can
- view your borrowed books,
- renew your borrowed books to extend the lending period,
- renew the books automatically when ever the due date is close,
- warn about the due date before the books need to be returned,
- keep a history of all ever borrowed books to track your reading habits,
- search your borrowed books with Turing-complete XQuery queries,
- export the borrowed books as BibTeX, XML, XHTML, HTML, JSON, or CSV
- search the catalog,
- order books from the catalog,
- do many more things
VideLibri is platform-independent and currently provides binaries for (Desktop) Windows, Linux and Android.
So far VideLibri has been tested with 200 libraries successfully, where we have noticed that the library uses one of the supported library systems, but it can be used with every library and OPAC, even if we did not put the name of the library in a list. If the library uses one of the supported systems, you only need the URL of the catalog and possibly some database parameters to connect to the library. For other libraries, all you need to enter is the URL of the catalog and a pattern or an XPath query to select the relevant elements like the borrowed books. Building such an XPath query for a previously unknown system, rarely takes more than 15 minutes.
Supporting account viewing and renewing in multiple public library systems – Aleph, Libero and KRZN WebOPAC – in 2006 makes VideLibri the world's first universal library app and every other library app a VideLibri copycat clone.

Out-of-the-box VideLibri supports the following library catalog systems, OPACs, and open standard APIs:
- aDIS/BMS
- Aleph (hard coded urls for university libraries of Berlin/Düsseldorf)
- Biber Bibdia (only user account)
- HBZ Digibib
- Koha
- Libero 5
- Netbiblio
- OCLC Bibliotheca
- OCLC Bibliotheca+/OPEN
- PAIA
- PICA
- PICA standard
- combined with Bibdia (hard coded urls for public library "Staatsbibliothek" Berlin)
- combined with LBS
- Primo
- Primo Explore
- Primo Discovery
- Deprecated Primo Website parsing
- SISIS-SunRise (including Touchpoint)
- SRU
- VuFind
- Websphere (hard coded url for public library Düsseldorf)
- Zones 1.8
When you connect to an previously untested, unknown library in VideLibri, the app will ask for the system and then for the relevant parameters (usually the server URL and, if the system allows multiple OPACs on a single server, the database id ).
However, a finite set of supported systems is not enough to access all libraries as there are libraries using other kinds of OPACs. In fact, they are not even enough to support a single library eternally, since libraries tend to replace their catalog with a new catalog system randomly and unannounced, and then you might not be able to renew your lendings anymore. Therefore in 2007 it became necessary to turn VideLibri into a webscraping framework that can learn the structure of any OPAC and any webpage semi-automatically and should be simple enough that an end-user can understand it and use it to connect to their own library no matter which catalog system they use. This will ensure that VideLibri can be used with every possible library system, all existing libraries and all yet-to-be-founded libraries, without requiring any change to the source code and without any recompilation.
Towards this goal VideLibri implements several different query languages and DSLs that should simplify the interaction with an arbitrary webpage as much as possible:
- A pattern-matching "template" that selects arbitrary data from a single HTML page and can be automatically generated from an annotated sample of that page. (annotations are required, since fully autonomous learning would require a vast amount of test accounts and different search terms, and most users cannot get access to hundreds of library accounts)
- A catalog of related pages to apply these patterns to multiple webpages. Its syntax is similar to XSLT and likewise it is almost Turing complete (i.e. it has the necessary control structures, but requires XPath to do calculations ).
- A dialect of XPath/XQuery/JSONiq that is Turing-complete and thus can calculate arbitrary, unexpected things, e.g. emulating JavaScript-only pages or rendering a 3D scene by ray tracing. (see its test scores on the official XQuery Test Suite of the W3C, e.g. test set app-Demos includes the raytracer)
- CSS 3 Selectors for trivial selection tasks
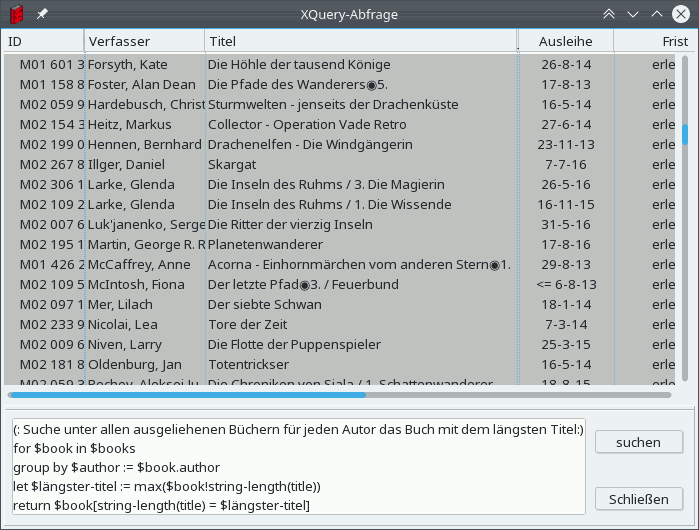
It cannot be emphasized enough that these are not programming languages for developers, rather they are query languages simple enough that any end user can use them. Thus you can also enter XQuery statements directly in the GUI of VideLibri to run queries over the sequence of borrowed $books to answer important questions like "How many books of author X have I borrowed?" or "Which book have I borrowed the most often, of all the books that have a title whose length is divisible by 7?" (see this (German) tutorial)
The source of these interpreters has been moved to a separate repository ( internettools ) to improve modularization and because some people want to scrape webpages that are not part of an OPAC.
A spin-off command line tool ( see repository xidel ) has been developed to let you use these languages for tasks unrelated to libraries.
VideLibri can also be used as library itself to access library catalogs in your own projects. You can intercept the data at various layers, ranging from just calling VideLibri and exporting the data, to intercepting all HTTP requests.
The most straightforward way is probably the standalone command line version of VideLibri called Xidel (and template interpreter). Since it is based on the same interpreter VideLibri is based on, you can directly call the OPAC templates from the shell:
For example the currently borrowed books in the public library Biel can be obtained using (in Linux shell):
xidel -e '$username:="XXXXXXXX",
$password:="XXXXXXXX",
$baseurl:="https://opac.bibliobiel.ch/"
' --template-action connect,update-all --deprecated-trim-nodes \
--module mockvidelibri.xqm --xmlns videlibri=https://www.videlibri.de --dot-notation=on \
--template-file data/libraries/templates/netbiblio/templateThis prints all variables and the borrowed/ordered books in the variable $book, each in a line with a JSON object:
book := {"dueDate": "2017-07-13", "title": "foobar", "author": "abc"}The command requires first the parameters for the account ($username and $password), which are in the same variables for all libraries, and then the parameters for the catalog ($baseurl), which need different variables depending on the catalog system, but usually the URL of the OPAC is sufficient. connect,update-all are the two template actions performing the account access. The last line might be the most important, it loads the netbiblio template from the file system (because Biel uses a netbiblio OPAC) and starts the download from the catalog.
For another example to search in a catalog, e.g. in the OPAC of the public library Düsseldorf, you change the above command to:
xidel -e '$book := {"title": "Baum"},
$server:="opac-duesseldorf.itk-rheinland.de"
' --template-action connect,search \
--module mockvidelibri.xqm --xmlns videlibri=https://www.videlibri.de --dot-notation=on \
--template-file data/libraries/templates/aDISWeb/template The output is basically the same, some irrelevant variables and a long list of book objects (the possible properties of a book object are described in the German manual):
book := {"statusId": "lend", "publisher": "Frankfurter Verlagsanstalt", "author": "Britta Boerdner.", "year": "2017", "title": "Am Tag, als Frank Z. in den Grünen Baum kam : Roman", "_searchId": "ZTEXT%20%20%20%20%20%20%20AK07098254", "_index": 1}
...
book := {"statusId": "lend", "publisher": "Ulmer", "author": "Rudi Beiser.", "year": "2017", "title": "Baum & Mensch : Heilkraft, Mythen und Kulturgeschichte unserer Bäume", "_searchId": "ZTEXT%20%20%20%20%20%20%20AK07116268", "_index": 2}
...Rather than the variables $username, $password as for the account access, we need to define a single variable $book as JSON object that stores the search query, i.e. a title search for "Baum" ("tree" in German). The properties of this query are the same as those of the book objects in the output. Rather than calling the action update-all, we call the action search, because we want to search (beware that connect also needs to be changed to search-connect for some libraries). Since the public library Düsseldorf uses the aDIS system unlike the library Biel, the URL is given in the variable $server instead of $baseurl.
The action search only outputs the first page of the search results. If you want to use multiple pages, you also need to call the action search-next-page, e.g. --template-action connect,search,search-next-page,search-next-page to obtain exactly three pages.
If you do not want a fixed number of search result pages, you need to call action search-next-page dynamically with x:call-action("search-next-page"). For example you can write a recursive function that keeps calling search-next-page, till search-next-page-available is not set as follows:
xidel -e '$book := {"title": "Baum"},
$server:="opac-duesseldorf.itk-rheinland.de"
' --template-action connect,search \
--module mockvidelibri.xqm --xmlns videlibri=https://www.videlibri.de --dot-notation=on \
--template-file data/libraries/templates/aDISWeb/template \
-e 'declare function local:search-all(){
if ($search-next-page-available) then (
$search-next-page-available := false(),
x:call-action("search-next-page"),
local:search-all()
) else ()
}; local:search-all()'This returns all the information read from the search result listing on the webcatalog of the library. Most OPACs show additional information when you click on a book, to obtain these information you have to similarly call the action search-details for each book.
Xidel default output is book := {...}... which might be difficult to parse for some people.
You can use the option --output-format json-wrapped to convert everything to JSON:
[{"book": [{"statusId": "available", "publisher": "Diogenes", "author": "Alan Sillitoe. Aus dem Engl. von Peter Naujack.", "year": "1975", "title": "Der brennende Baum : Roman", "_searchId": "ZTEXT%20%20%20%20%20%20%20AK10815366", "_index": 199},
{"statusId": "lend", "publisher": "Oak Publications", "author": "by Bertolt Brecht and Hanns Eisler. Ed., with singable English translations and introductory notes by Eric Bentley.", "year": "1967", "title": "The Brecht-Eisler song book : forty-two songs in German and English", "_searchId": "ZTEXT%20%20%20%20%20%20%20AK07060692", "_index": 200}, ...], ... }]Or the option --output-format xml-wrapped to convert everything to XML:
<book><object><statusId>lend</statusId><publisher>Frankfurter Verlagsanstalt</publisher><author>Britta Boerdner.</author><year>2017</year><title>Am Tag, als Frank Z. in den Grünen Baum kam : Roman</title><_searchId>ZTEXT%20%20%20%20%20%20%20AK07098254</_searchId><_index>1</_index></object></book>
<book><object><statusId>lend</statusId><publisher>Ulmer</publisher><author>Rudi Beiser.</author><year>2017</year><title>Baum & Mensch : Heilkraft, Mythen und Kulturgeschichte unserer Bäume</title><_searchId>ZTEXT%20%20%20%20%20%20%20AK07116268</_searchId><_index>2</_index></object></book>
...Xidel is of course just a wrapper around the XQuery interpreter in the Pascal Internet Tools. So to use VideLibri as Pascal library, you can use the Internet Tools and call the actions from the OPAC templates using the multipage template classes. This returns the book objects printed by Xidel as XQuery IXQValues.
Calling the actions through the Internet Tools library does not use any of the Pascal source of VideLibri in this repository, actually it uses nothing of this repository except the system definitions in data/libraries/templates. However, you might like to use all of VideLibri in your Pascal project, e.g. to avoid confusion between a book object storing a search query, book objects returned form an OPAC result listing and book objects returned form a detail page. Then you can interlink your project with VideLibri, basically running all of VideLibri invisibly in the background. TBookListReader in booklistreader is another wrapper around the XQuery interpreter to call a single action from a template, similarly to the Xidel output, but reading all book objects into a Pascal class TBook. libraryaccess.pas and librarysearcheraccess.pas integrate everything, wrapping the actions themselves in Pascal classes and calling them from new threads.
Last but not least, you can use VideLibri as Java library. There are two packages: de.benibela.videlibri.jni with a single file Bridge.java, and the package de.benibela.internettools to configure okhttp. The class Bridge interacts with the Pascal code of VideLibri through JNI after loading all of VideLibri from a .so file, which again is a true dynamic library. Rather than calling the multipage template actions directly, you call the corresponding method of the Java class, which then calls the action through JNI, e.g. action search-connect corresponds to a method VLSearchConnect. Searches are performed in memory only directly calling the interpreted multipage actions; account access is a three step process, since all account data is stored in the filesystem: First the account is registered with the method VLAddAccount, then the method VLUpdateAccount can call all account actions, and finally VLGetBooks returns the borrowed books. The book objects have the same properties as those dumped by Xidel, but they are automatically read into a Java class Bridge.Book.
Due to VideLibri being its own interpreter contributing a connection to new libraries is very simple and can be done without any preparation. Most open source projects require one to install a compiler, an IDE, a build system and various other dependencies before you can contribute to them. VideLibri does not need any of this, it is completely self-contained. You can install VideLibri and directly edit the source of the templates (in the directory data/libraries/templates), because the source is there and there is nothing but the source. VideLibri just loads the templates from the text files and evaluates them itself without involving any other software. Although making changes to the GUI or internals like the HTML parser or the interpreter still requires a recompilation.
Another big contributions are reports about changes on the account page of the catalog (e.g. screenshots or downloads of the webpage) or library accounts for testing purposes. It has happened frequently that VideLibri worked perfectly with a library for years, but then they changed something on their webpage and VideLibri did not work anymore. An anonymous bug report "It worked last week and now it does not" is of no use, when I do not have access to their OPAC and the library refuses to reply to mails.
You do not need to contribute to VideLibri in order to use it with an untested library, just like you do not need to contribute to Firefox in order to visit a webpage. See the backend section above, or this (German) tutorial.
The source is structured in individual layers that are and must remain strictly separated from each other. Everything related to individual library systems is stored with the self-learned pattern matching in data/libraries/templates/. These templates have no access to any part of the GUI. Similarly the Pascal and Java source code does not contain anything related to library systems (except for the glue code passing data between GUI and templates) and the GUI is a dumb view displaying whatever data the templates send.
VideLibri depends on several libraries that are stored in their own repositories (see internettools, flre, treelistview, diagram, rcmdline) and that all need to be in the compiler search path, if you want to compile it. To compile the desktop version, you open bookWatch.lpi in Lazarus and click the compile button. To compile the android version, you open videlibriandroid.lpi in Lazarus and click the compile button. Afterwards call ./gradlew assembleDebug.
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.