DIA-NN - a universal software for data-independent acquisition (DIA) proteomics data processing by Demichev, Ralser and Lilley labs. In 2018, DIA-NN opened a new chapter in proteomics, introducing a number of algorithms which enabled reliable, robust and quantitatively accurate large-scale experiments using high-throughput methods.
DIA-NN is built on the following principles:
- Reliability achieved via stringent statistical control
- Robustness achieved via flexible modelling of the data and automatic parameter selection
- Reproducibility promoted by thorough recording of all analysis steps
- Ease of use: high degree of automation, an analysis can be set up in several mouse clicks, no bioinformatics expertise required
- Powerful tuning options to enable unconventional experiments
- Scalability and speed: up to 1000 mass spec runs processed per hour
Download: https://github.com/vdemichev/DiaNN/releases/tag/1.8 (it's recommended to use the latest version - DIA-NN 1.8)
Please cite
DIA-NN: neural networks and interference correction
enable deep proteome coverage in high throughput
Nature Methods, 2020
When using DIA-NN's ion mobility module for dia-PASEF analysis or using DIA-NN in combination with FragPipe-generated spectral libraries, please also cite
High sensitivity dia-PASEF proteomics with DIA-NN and FragPipe
biorxiv, 2021
Other key papers
- Using DIA-NN for large-scale plasma & serum proteomics:
Cell Systems, 2020 and Cell Systems, 2021 - Ultra-fast proteomics with DIA-NN and Scanning SWATH:
Nature Biotechnology, 2021
R package with some useful functions for dealing with DIA-NN's output reports: https://github.com/vdemichev/diann-rpackage
Visualisation of peptide positions in the protein: https://github.com/MannLabs/alphamap (AlphaMap by Mann lab)
Installation
Getting started
Raw data formats
Spectral library formats
Output
Library-free search
Creation of spectral libraries
Match-between-runs
Changing default settings
Command-line tool
Visualisation
Automated pipelines
PTMs
GUI settings reference
Command-line reference
Main output reference
Frequently asked questions (FAQ)
Contact
On Windows, download the .exe installer and run it. Make sure not to run the installer from a network drive. It is recommended to install DIA-NN into the default folder suggested by the installer.
On Linux, download the .deb or .rpm package. Install it using the preferred way for your Linux distribution, e.g. using gdebi for .deb installation on Ubuntu/Debian-based distributions. DIA-NN will be installed to the /usr/diann/[version number]/ folder. The Linux system must have glibc 2.27 or later (for example, Ubuntu 18.04 or CentOS 8 and later versions are fine).
It is also possible to run DIA-NN on Linux using Wine 6.8 or later.
DIA mass spectrometry data can be analysed in two ways: by searching against a sequence database (library-free mode), or by using a "spectral library" - a set of known spectra and retention times for selected peptides. We discuss in detail when to use each of these approaches in the Library-free search section. For both kinds of analyses, using DIA-NN is very simple:
- Click Raw (in the Input pane), select your raw mass spectrometry data files. See Raw data formats for information on supported formats.
- Click Add FASTA, add one or more sequence databases in UniProt format.
- If you want to use a spectral library, click Spectral library and select the library. Alternatively, for library-free analysis, select FASTA digest for library-free search/library generation (in the Precursor ion generation pane).
- Specify Main output file name in the Output pane and click Run.
- If you kept 'report.tsv' as the main output (located, by default, in the DIA-NN installation folder), it will contain the list of all precursor ions identified, along with different kinds of quantities, quality metrics and annotations. The output file report.pg_matrix.tsv will contain protein group quantities, report.gg_matrix.tsv - gene group quantities, report.pr_matrix.tsv - precursor ion quantities.
Now, the above information is sufficient for one to start using DIA-NN, it's indeed this easy! The rest of this Documentation might be helpful, but is not essential for 99% of the projects.
Comments
The above is how to run DIA-NN with default settings, and these yield optimal or almost optimal performance for most experiments. In some cases, however, it is better to adjust the settings, see Changing default settings for more details.
DIA-NN also offers powerful tuning options for fancy experiments. DIA-NN is implemented as a user-friendly graphical interface that automatically invokes a command-line tool. But the user can also pass options/commands to the command-line tool directly, via the Additional options text box in the interface. All these options start with a double dash -- followed by the option name and, if applicable, some parameters to be set. So if you see some option/command with -- in its name mentioned in this Documentation, it means this command is meant to be typed in the Additional options text box.
Formats supported: Sciex .wiff, Bruker .d, Thermo .raw, .mzML and .dia (format used by DIA-NN to store spectra). Conversion from any supported format to .dia is possible. When running on Linux (native builds, not Wine), only .d, .mzML, and .dia data are supported.
For .wiff support, download and install ProteoWizard - choose the version (64-bit) that supports "vendor files"). Then copy all files with 'Clearcore' or 'Sciex' in their name (these will be .dll files) from the ProteoWizard folder to the DIA-NN installation folder (the one which contains diann.exe, DIA-NN.exe and a bunch of other files).
Reading Thermo .raw files requires Thermo MS File Reader to be installed. It is essential to use specifically the version by the link above (3.0 SP3).
.mzML files should be centroided and contain data as spectra (e.g. SWATH) and not chromatograms.
Technology support
- DIA and SWATH are supported
- Acquisition schemes with overlapping windows are supported
- Gas-phase fractionation is supported
- Scanning SWATH is supported
- dia-PASEF is supported
- FAIMS with constant CV is supported
- FAIMS with multiple CVs is supported after splitting the runs, see here
- BoxCar-DIA is supported, but DIA-NN has not been optimised for it
- Bruker Impact II DIA data is supported after conversion to .mzML
- SILAC is supported (beta-stage), please contact by email for usage instructions
- MSX-DIA is not supported
Conversion
DIA-NN can convert all mass spec formats it supports to .dia. In most cases it is recommended to perform such conversion for all medium-scale and large-scale experiments, as .dia files can be loaded very quickly, speeding up the processing. One exception is dia-PASEF .d, for which conversion to .dia results in 2x-3x larger file size.
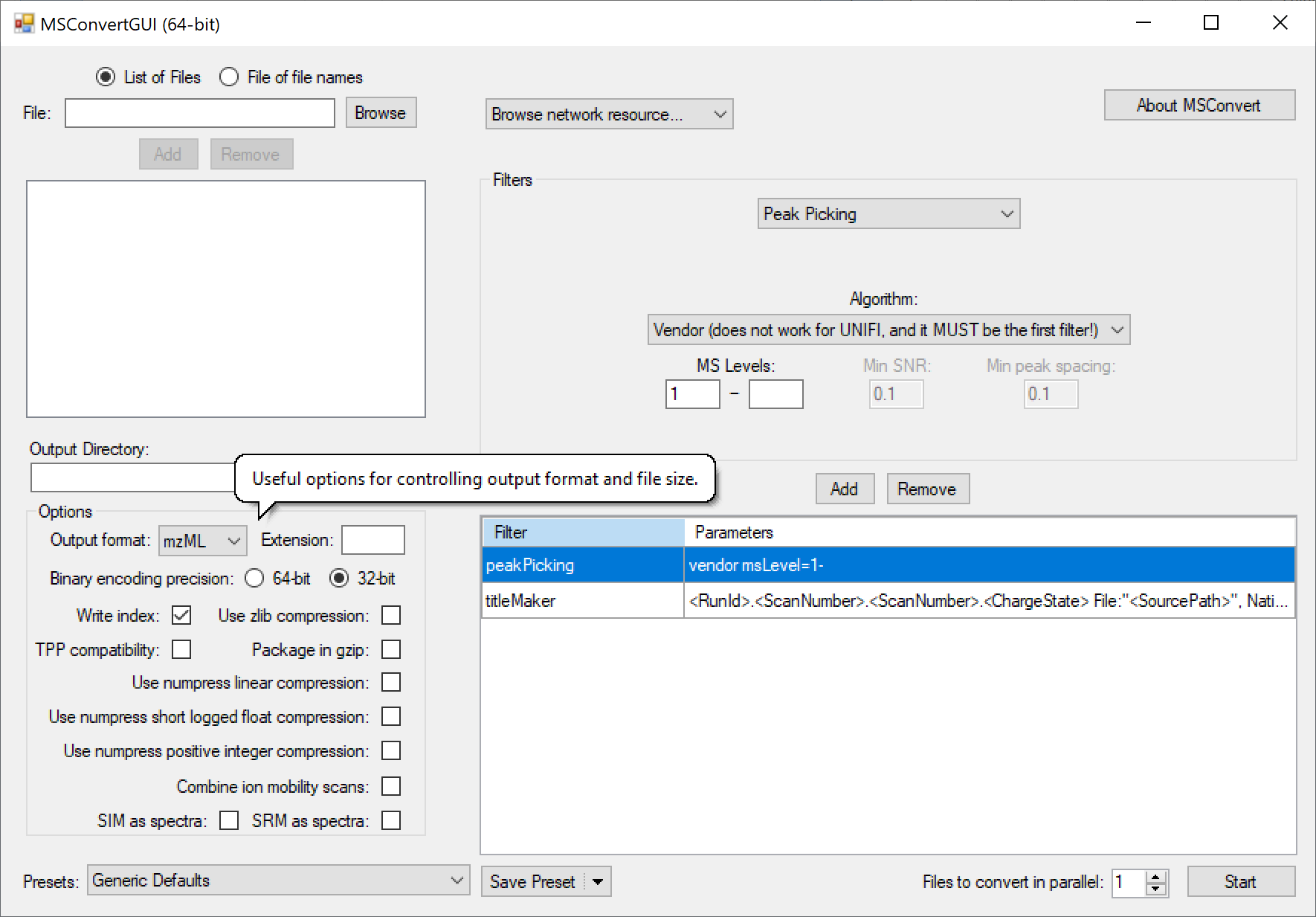
Many mass spec formats, including those few that are not supported by DIA-NN directly, can be converted to .mzML using the MSConvertGUI application from ProteoWizard. This works for all supported formats except Bruker .d and SCIEX Scanning SWATH - these need to be accessed by DIA-NN directly. The following MSConvert settings must be used for conversion:
DIA-NN supports comma-separated (.csv) or tab-separated (.tsv, .xls or .txt), .speclib (compact format used by DIA-NN), .sptxt (SpectraST, experimental) and .msp (NIST, experimental) library files.
In detail
Libraries in the PeakView format as well as libraries produced by FragPipe, TargetedFileConverter (part of OpenMS), exported from Spectronaut (Biognosys) in the .xls format or generated by DIA-NN itself are supported “as is”.
For .tsv/.xls/.txt libraries generated by other means, DIA-NN might require the header names to be specified (separated by commas) (for the columns it requires) using the --library-headers command. Use the * symbol instead of the name of a header to keep its recognition automatic. See below the descriptions of the respective columns (in the order the headers need to be specified).
Required columns:
- Modified & labelled peptide sequence
- Precursor charge
- Precursor m/z
- Reference retention time - arbitrary RT scale can be used
- Fragment ion m/z
- Relative intensity of the fragment ion
It is strongly recommended that columns containing the following are also present in the library:
- Protein IDs - identifiers for the protein isoforms
- Protein names
- Gene names
- Proteotypicity - a column containing 0/1 values, depending on whether the peptide in question is 'proteotypic', that is specific to a particular protein isoform, protein name or gene
- Decoy - Indicates whether the peptide is a decoy. If there are decoy peptides in the library, DIA-NN uses these and does not generate its own decoys. It is strongly recommended not to include any decoy peptides in the library.
- Fragment ion charge
- Fragment ion type - either y or b; for x and z fragments also specify fragment type as y, and for a and c - as b
- Fragment series number
- Fragment neutral loss type
- Q-value
- Elution group identifier - if not specified, DIA-NN will infer elution groups automatically; not needed for most workflows
- Exclude fragment indicator - a column containing 0/1 values, with 1 meaning that the fragment ion should not be used for quantification; not needed for most workflows
- Ion Mobility - 1/K0 value for the precursor, arbitrary IM scale can be used
For example, a --library-headers command which specifies all column names except for the 'Decoy' column can look like this:
--library-headers ModifiedPeptide,PrecursorCharge,PrecursorMz,Tr_recalibrated,ProductMz,LibraryIntensity,UniprotID,ProteinName,Genes,Proteotypic,*,FragmentCharge,FragmentType,FragmentSeriesNumber,FragmentLossType,QValue,ExcludeFromAssay,IonMobility
Use --sptxt-acc to set the fragment filtering mass accuracy (in ppm) when reading .sptxt/.msp libraries.
MaxQuant msms.txt can also be used (experimental) as a spectral library in DIA-NN, although fixed modifications might not be read correctly.
DIA-NN can convert any library it supports into its own .tsv (compatible with Spectronaut and OpenSWATH) as well as .speclib formats. For this, click Spectral library (Input pane), select the library you want to convert, select the Output library file name (Output pane), click Run.
All .tsv/.xls/.txt/.csv libraries are just simple tables with human-readable data, and can be explored/edited, if necessary, using Excel or (ideally) R/Python.
Importantly, when any library is being saved to this kind of text format, all numbers are rounded using certain decimal precision, meaning that they might not be exactly the same as in the original library (there might be a tiny difference). Thus, although the performance when analysing using a converted library will be comparable, the results will not match exactly.
The Output pane allows to specify where the output should be saved. There are four types of output files produced by DIA-NN: main report, matrices (easy-to-use even without statistical software such as R/Python), 'stats' report (for quality control) and PDF report. Below one can find information on each of these.
Main report
A text table containing precursor and protein IDs, as well as plenty of associated information. Most column names are self-explanatory, and the full reference can be found in Main output reference. The following keywords are used when naming columns:
- PG means protein group
- GG means gene group
- Quantity means non-normalised quantity
- Normalised means normalised quantity
- MaxLFQ means normalised protein quantity calculated using the MaxLFQ algorithm - it is strongly recommended to use these MaxLFQ quantities and not the regular quantities (also reported by DIA-NN)
- Global refers to a global q-value, that is calculated for the entire experiment
- Lib refers to the respective value saved in the spectral library, e.g. Lib.Q.Value means q-value for the respective library precursor
Matrices
These contain normalised quantities for protein groups, gene groups, unique genes (i.e. genes identified and quantified using only proteotypic, that is gene-specific, peptides) and precursors. They are filtered at 1% FDR, using global q-values for protein groups and both global and run-specific q-values for precursors. Use --matrix-spec-q to force additional filtering of the protein/gene matrices using run-specific protein group q-values. Sometimes DIA-NN will report a zero as the best estimate for a precursor or protein quantity. Such zero quantities are omitted from protein/gene matrices.
Stats report
Contains a number of QC metrics which can be used for data filtering, e.g. to exclude failed runs, or as a readout for method optimisation.
PDF report
A visualisation of a number of QC metrics, based on the main report as well as the stats report. The PDF report should be used only for quick preliminary assessment of the data and should not be used in publications.
Flexible reanalysis
The Output pane allows to control how to handle the '.quant files'. Now, to explain what these are, let us consider how DIA-NN processes raw data. It first performs the computationally-demanding part of the processing separately for each individual run in the experiment, and saves the identifications and quantitative information to a separate .quant file. Once all the runs are processed, it collects the information from all the .quant files and performs some cross-run steps, such as global q-value calculation, protein inference, calculation of final quantities and normalisation. This allows DIA-NN to be used in a very flexible manner. For example, you can stop the processing at any moment, and then resume processing starting with the run you stopped at. Or you can remove some runs from the experiment, add some extra runs, and quickly re-run the analysis, without the need to redo the analysis of the runs already processed. All this is enabled by the Use existing .quant files when available option. The .quant files are saved to/read from the Temp/.dia dir (or the same location as the raw files, if there is no temp folder specified). When using this option, the user must ensure that the .quant files had been generated with the exact same settings as applied in the current analysis, with the exception of Precursor FDR (provided it is <= 5%), Threads, Log level, MBR, Cross-run normalisation and Library generation - these settings can be different. It is actually possible to even transfer .quant files to another computer and reuse them there - without transferring the original raw files.
DIA-NN has a very advanced library-free module, which is, for certain types of experiments, better than using a high quality project-specific spectral library. In general, the following makes library-free search perform better in comparison to spectral libraries (while the opposite favours spectral libraries):
- high peptide numbers detectable per run
- heterogeneous data (e.g. cancer tissue samples are quite heterogeneous, while replicate injections of the same sample are not)
- long chromatographic gradients as well as good separation of peptides in the ion mobility dimension
- large dataset (although processing a large dataset in library-free mode might take time)
Please note that in 99% of cases it is essential that MBR is enabled for a quantitative library-free analysis. It gets activated by default when using the DIA-NN GUI.
For most experiments it does indeed make sense to try library-free search. For medium and large-scale experiments it might make sense to first try library-free analysis of a subset of the data, to see whether the performance is OK (on the whole dataset it will typically be a lot better, so no need to be too stringent here). Ourselves we also often perform a quick preliminary QC assessment of the experiment using some public library.
It is often convenient to perform library-free analysis in two steps: by first creating an in silico-predicted spectral library from the sequence database, and then analysing with this library.
Legacy y-series fragmentation & RTs & IMs prediction workflow
By default, DIA-NN's library-free search relies on in silico deep learning predictor of spectra, RTs and IMs. However this predictor only supports a limited number of PTMs. DIA-NN also features a legacy predictor, which performs significantly worse but can be trained to support arbitrary modifications. To use it, disable deep learning and specify --learn-lib [library name], where [library name] is the absolute path to a spectral library which contains peptides with all the modifications of interest. The library should ideally contain between 5000 and 50000 precursors. if there are more, the training process might take time. Check that prediction worked OK (if the library contains too few fragments or is not CID/HCD-based, the prediction might fail), based on the performance data reported by DIA-NN, e.g. median Pearson correlation for predicted spectra should be 0.5 or greater.
Comment
Note that the larger the search space (the total number of precursors considered), the more difficult it is for the analysis software to identify peptides, and the more time the search takes. DIA-NN is very good at handling very large search spaces, but even DIA-NN cannot do magic and produce as good results with a 100 million search space, as it would with a 2 million search space. So one needs to be careful about enabling all possible variable modifications at once. For example, allowing max 5 variable modifications, while having methionine oxidation, phospho and deamidation enabled simultaneously, is probably not a good idea.
Here lies an important distinction between DIA and DDA data analysis. In DDA allowing all possible variable modifications makes a lot of sense also because the search engine needs to match the spectrum to something - and if it is not matched to the correct modified peptide, it will be matched falsely. In DIA the approach is fundamentally different: the best-matching spectrum is found in the data for each precursor ion being considered (this is a very simplified view just to illustrate the concept). So not being able to identify a particular spectrum is never a problem in DIA (in fact most spectra are highly multiplexed in DIA - that is originate from multiple peptides - and only a fraction of these can be identified). And therefore it only makes sense to enable a particular variable modification if either you are specifically interested in it, or if the modification is really ubiquitous.
See PTMs for information on distinguishing between peptidoforms bearing different sets of modifications.
DIA-NN can create a spectral library from any DIA dataset. This can be done in both spectral library-based and library-free modes: just select the Generate spectral library option in the output pane.
DIA-NN can further create an in silico-predicted spectral library out of either a sequence database (make sure FASTA digest is enabled) or another spectral library (often useful for public libraries): just run DIA-NN without specifying any raw files and enable the Deep learning-based spectra, RTs and IMs prediction option in the Precursor ion generation pane. The modifications currently supported by the deep learning predictor are: C(cam), M(ox), N-term acetyl, N/Q(dea), S/T/Y(phos), K(-GG). Of note, the predictor performs slightly better for unmodified peptides. If you would like to perform prediction for peptides bearing some other modification(s), can try the --strip-unknown-mods option - then DIA-NN will ignore all the modifications not yet supported by the deep learning predictor.
Spectral libraries can also be created from DDA data, and in fact offline fractionation + DDA has been the 'gold standard' way of creating libraries since the introduction of SWATH/DIA proteomics. For this we recommend using FragPipe, which is based on the ultra-fast and highly robust MSFragger search engine.
MBR is a powerful mode in DIA-NN, which is beneficial for most quantitative experiments, both with a spectral library and in library-free mode. MBR typically results in both higher average ID numbers, but also a lot better data completeness, that is a lot less missing values.
While processing any dataset, DIA-NN gathers a lot of useful information which could have been used to process the data better. And that is what is enabled by MBR. With MBR, DIA-NN first creates a spectral library from DIA data, and then re-processes the same dataset with this spectral library. The algorithmic innovation implemented in DIA-NN ensures that the FDR is stringently controlled: MBR has been validated on datasets ranging from 2 runs to over 1000 runs.
MBR should be enabled for any quantitative experiment, unless you have a very high quality project-specific spectral library, which you think (i) is likely to provide almost complete coverage of detectable peptides, that is there is no point in trying library-free search + MBR, and (ii) most of the peptides in the library are actually detectable in the DIA experiment. If only (i) is true, might be worth still trying MBR along with Library generation set to IDs profiling.
MBR should not be used for non-quantitative experiments, that is when you only want to create a spectral library, which you would then use on some other dataset.
When using MBR and relying on the main report instead of quantitative matrices, use the following q-value filters:
- Lib.Q.Value instead of Global.Q.Value
- When applying a filter to Q.Value that is more stringent than 1% (e.g. Q.Value < 0.001 filter), always apply the same filter to Lib.Q.Value
- Lib.PG.Q.Value instead of Global.PG.Q.Value
DIA-NN can be successfully used to process almost any experiment with default settings. In general, it is recommended to only change settings when specifically advised to do so in this Documentation (like below), for a specific experiment type, or if there is a very clear and compelling rationale for the change.
In many cases, one might want to change several parameters in the Algorithm pane.
- MBR should be enabled in most cases, see Match-between-runs.
- Mass accuracies: when set to 0.0, DIA-NN determines mass tolerances automatically, based either on the first run in the experiment (default), or, if Unrelated runs option is selected, for each run separately. However the automatic algorithm can be affected by the noise in the data, so even for replicate injections, say, acquired on TripleTOF 6600, it can easily yield recommended MS2 mass accuracy tolerances in the range 15ppm - 25ppm - this is perfectly OK. So what we prefer to do in most cases is run DIA-NN on several acquisitions from the experiment, with any spectral library (can choose some small one which allows for quick analysis), see what mass accuracies DIA-NN sets automatically (it prints its recommendations), and set the values to approximate averages of these. Also, often it is known already what DIA-NN parameters are optimal for particular LC-MS settings.
- Scan window: ideally should correspond to the approximate average number of data points per peak. Similarly to mass accuracies, can be determined by DIA-NN automatically, but we prefer to have it fixed to some average value.
- Quantification strategy: the default setting Any LC (high-accuracy) is the most general one, and most likely the best for method optimisation. However, when analysing 'real' data, if the experiment was not affected by severe peak broadening (and most experiments are fine), then using Robust LC is better. Further, although the high-accuracy mode provides the best possible quantification accuracy (as it employs an algorithm for direct subtraction of interfering signals from fragment ion chromatograms, before their integration), it does produce higher CV values. So when CV values are more important than accuracy (and this is the case for certain types of experiments), we recommend switching to the high-precision mode. Also, the high-precision mode is likely to be better for analysing dia-PASEF data.
- When using protein inference: if DIA-NN is instructed to infer proteins, as opposed to just relying on protein groups from the spectral library, and the analysis is performed for benchmarking purposes only, to just estimate how many protein groups are identifiable per run, it is recommended to use --relaxed-prot-inf, see Command-line reference.
Note that once you select a particular option in the DIA-NN GUI, some other settings might get activated automatically. For example, whenever you choose to perform an in silico FASTA database digest (for library-free search), or just generate a spectral library from DIA data, MBR will get automatically selected too - because in 99% of cases it is beneficial.
DIA-NN is implemented as a graphical user interface (GUI), which invokes a command-line tool (diann.exe). The command-line tool can also be used separately, e.g. as part of custom automated processing pipelines. Further, even when using the GUI, one can pass options/commands to the command-line tool, in the Additional options text box. Some of such useful options are mentioned in this Documentation, and the full reference is provided in Command-line reference.
When the GUI launches the command-line tool, it prints in the log window the exact set of commands it used. So in order to reproduce the behaviour observed when using the GUI (e.g. if you want to do the analysis on a Linux cluster), one can just pass exactly the same commands to the command-line tool directly.
diann.exe [commands]
Commands are processed in the order they are supplied, and with most commands this order can be arbitrary.
For convenience, as well as for handling experiments consisting of thousands of files, some of the options/commands can be stored in a config file. For this, create a text file with any extension, say, diann_config.cfg, type in any commands supported by DIA-NN in there, and then reference this file with --cfg diann_config.cfg (in the Additional options text box or in the command used to invoke the diann.exe command-line tool).
The DIA-NN GUI does not have built-in visualisation yet. However since the ability to visualise spectra and chromatograms is often crucial for data quality control and method optimisation, DIA-NN does feature powerful visualisation capabilities which rely on third-party analysis software, such as Excel, R or Python. The following command instructs DIA-NN to save full chromatograms at both MS1 and MS2 level for all PSMs for an arbitrary number of peptide sequences (these must be listed without any modifications, i.e. stripped sequences).
--vis [N],[Peptide 1],[Peptide 2],...
Specifically, chromatograms of length >= N will be extracted in the vicinity of the detected elution apex (for all runs in the experiment) and saved as a human- and machine-readable text table. Excel, R or Python can then be used to make visually-attractive plots based on these.
Peptide & modification positions within a protein can be visualised using AlphaMap by Mann lab https://github.com/MannLabs/alphamap.
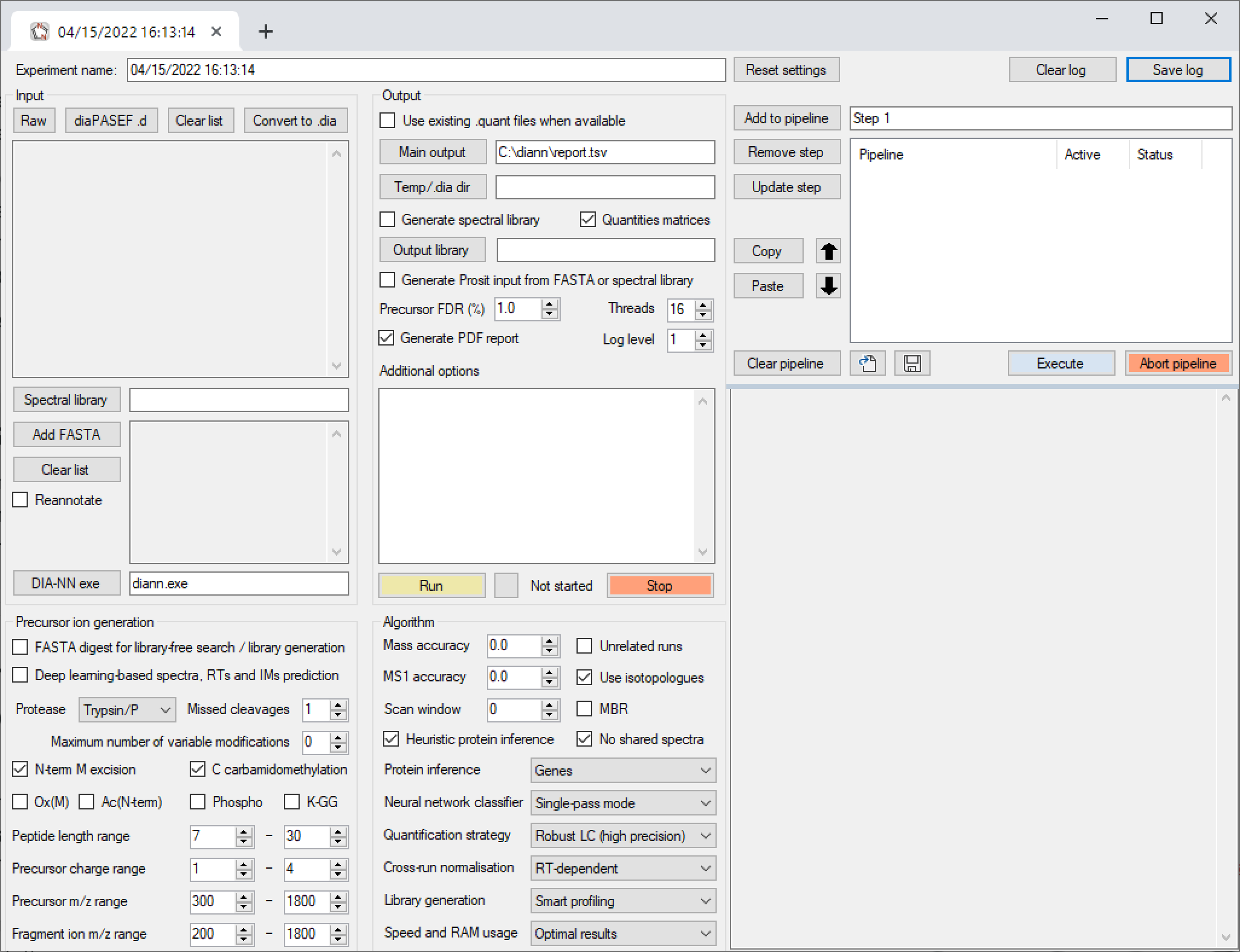
The pipeline window within the DIA-NN GUI allows to combine multiple analysis steps into pipelines. Each pipeline step is a set of settings as displayed by the GUI. One can add such steps to the pipeline, update existing steps, remove steps, move steps up/down in the pipeline, disable/enable (by double mouse-click) certain steps within the pipeline and save/load pipelines. Further, individual pipeline steps can be copy-pasted between different GUI tabs/windows (use Copy and Paste buttons for this).
DIA-NN GUI features built-in workflows (Precursor ion generation pane) for detecting methionine oxidation, N-terminal protein acetylation, phosphorylation and ubiquitination (via the detection of remnant -GG adducts on lysines).
Distinguishing between peptidoforms bearing different sets of modifications is a non-trivial problem in DIA: without special PTM scoring the effective peptidoform FDR can be in the range 5-10% for library-free analyses. DIA-NN implements a stringent target-decoy approach for PTM scoring, which is enabled by default for N-terminal acetylation, phosphorylation and ubiquitination and allows to control the FDR for distinguishing between peptidoforms. For other modifications, PTM scoring can be likewise activated using the --monitor-mod command. For ubiquitination this approach has been validated with two-species benchmarks to produce effective FDR well below 1%. For phosphorylation such validation is not possible (there is no obvious experimental design which would allow this), however DIA-NN's FDR appears well-controlled based on analysing samples with synthetic spike-in peptides acquired by Bekker-Jensen et al. Further, DIA-NN features an algorithm which reports PTM localisation confidence estimates (as posterior probabilities for correct localisation of all PTM sites on the peptide), and this algortihm has been likewise validated on the Bekker-Jensen et al data.
To the best of our knowledge, there is no published validation of the identification confidence for the detection of deamidated peptides (which are easy to confuse to heavier isotopologues, unless the mass spec has a very high resolution and a tight mass accuracy/tolerance setting is used by the search engine), even for DDA. One way to gain confidence in the identification of deamidated peptides, is to check if anything is identified if the mass delta for deamidation is declared to be 1.022694, instead of the correct value 0.984016. DIA-NN does pass this test successfully on several datasets (that is no IDs are reported when specifying this 'decoy modification mass'), but we do recommend also trying such 'decoy modification mass' search on several runs from the experiment to be analysed, if looking for deamidated peptides. In each case (correct or decoy mass), --monitor-mod should be used to enable PTM scoring for deamidation, and either PTM.Q.Value or Global.Q.Value/Lib.Q.Value used for filtering.
Of note, when the ultimate goal is the identification of proteins, it is largely irrelevant if a modified peptide is misidentified, by being matched to a spectrum originating from a different peptidoform.
Does DIA-NN need to recognise modifications in the spectral library?
In general, no. If fragment ions in the spectral library are properly annotated, the modifications do not need to be recognised. For example, it's perfectly fine to just use (Glyco) as the modification name for different glycans on peptides in the library. However DIA-NN must recognise the modifications it searches, if it needs to create a library directly from DIA data (in Smart profiling and Full profiling modes). For this, the modifications, unless already recognised (DIA-NN supports many common modifications and can also load the whole UniMod database, see the --full-unimod option), need to be declared using --mod.
Description of selected options
Input pane
- Reannotate option allows to reannotate the spectral library with protein information from the FASTA database, using the specified digest specificity
Precursor ion generation pane
- FASTA digest instructs DIA-NN to in silico digest the sequence database, for library-free search or to generate a spectral library in silico
- Deep learning-based spectra, RTs and IMs prediction instructs DIA-NN to perform deep learning-based prediction of spectra, retention times and ion mobility values. This allows not only to make in silico spectral libraries from sequence databases, but also to replace spectra/RTs/IMs in existing libraries with predicted values
Output pane
- Use existing .quant files when available reuse IDs/quantification information from a previous analysis, see Output
- Temp/.dia dir specify where .quant files or converted .dia files will be saved, see Output
Algorithm pane
- Mass Accuracy set the MS2 mass tolerance (in ppm), see [Changing default settings](#changing default settings)
- Mass Accuracy MS1 set the MS1 mass tolerance (in ppm), see [Changing default settings](#changing default settings)
- Scan window sets the scan window radius to a specific value. Ideally, should be approximately equal to the average number of data points per peak, see [Changing default settings](#changing default settings)
- Unrelated runs determine mass accuracies and scan window, if automatic, independently for different runs, see [Changing default settings](#changing default settings)
- Use isotopologues whether to extract chromatograms for heavy isotopologues and use them to score PSMs
- MBR enables MBR, should be enabled for most quantitative experiments, see MBR
- Remove likely interferences whether to use a spectrum centric-like algorithm to remove interfering precursors. This algorithm is particularly important when considering variable modifications
- Neural network classifier here 'single-pass' mode is the default option and is recommended. The 'double-pass' mode might be slightly better in most scenarios, but it is almost twice slower and it might make reported FDR values slightly less conservative. However if DIA-NN is analysing some very challenging samples, with which it clearly struggles to identify enough peptides, especially in library-free mode, it is worth trying double-pass to see if it improves things.
- Protein inference this setting primarily affects proteotypicity definition, the default "Genes" is recommended for almost all applications, provided the gene-level information is actually present in the database (non-UniProt databases might lack it). When set to "Off", protein groups from the spectral library are used - this makes sense if protein inference has already been performed during library generation
- Quantification strategy see [Changing default settings](#changing default settings)
- Cross-run normalisation whether to use global, RT-dependent (recommended) or also signal-dependent (experimental, be very careful about it) cross-run normalisation. Normalisation can also be disabled completely using --no-norm
- Library generation this setting determines if and how empirical RTs/IMs and spectra are added to the newly generated library, instead of the theoretical values. Smart profiling is strongly recommended for almost all workflows. When analysing with a high-quality project-specific library, can switch to IDs profiling or IDs, RT and IM profiling. Full profiling means always using empirical information, and might only be beneficial when having less than ~1000 peptides identified per run, and only if downstream processing is not very sensitive to a bit higher FDR.
- Speed and RAM usage this setting is primarily useful for library-free analyses. The first three modes will typically have little difference in terms of ID numbers, while the Ultra-fast mode is rather extreme: about 5x faster, but ID numbers are not as good, and the effective FDR might be somewhat higher
Description of available options/commands
Note that some options below are strongly detrimental to performance and are only there for benchmarking purposes. So the recommendation is to only use the options which are expected to be beneficial for a particular experiment based on some clear rationale.
- --cfg [file name] specifies a file to load options/commands from
- --clear-mods makes DIA-NN 'forget' all built-in modification (PTM) names
- --compact-report instructs DIA-NN to provide less information in the main report
- --convert makes DIA-NN convert the mass spec files to the .dia format. The files are either saved to the same location as the input files, or in the Temp/.dia dir, if it is specified (in the GUI or using the --temp option)
- --cut [specificty 1],[specificity 2],... specifies cleavage specificity for the in silico digest. Cleavage sites (pairs of amino acids) are listed separated by commas, '*' indicates any amino acid, and '!' indicates that the respective site will not be cleaved. Examples: "--cut K*,R*,!*P" - canonical tryptic specificity, "--cut " - digest disabled
- --dir [folder] specifies a folder containing raw files to be processed. All files in the folder must be in .raw, .mzML or .dia format
- --duplicate-proteins instructs DIA-NN not to skip entries in the sequence database with duplicate IDs (while by default if several entries have the same protein ID, all but the first entry will be skipped)
- --exact-fdr approximate FDR estimation for confident peptides based on parametric modelling will be disabled
- --ext [string] adds a string to the end of each file name (specified with --f)
- --f [file name] specifies a run to be analysed, use multiple --f commands to specify multiple runs
- --fasta [file name] specifies a sequence database in FASTA format (full support for UniProt proteomes), use multiple --fasta commands to specify multiple databases
- --fasta-filter [file name] only consider peptides matching the stripped sequences specified in the text file provided (one sequence per line), when processing a sequence database
- --fasta-search instructs DIA-NN to perform an in silico digest of the sequence database
- --fixed-mod [name],[mass],[sites],[optional: 'label'] - adds the modification name to the list of recognised names and specifies the modification as fixed. Same syntax as for --var-mod.
- --force-swissprot only consider SwissProt (i.e. marked with '>sp|') sequences when processing a sequence database
- --full-unimod loads the complete UniMod modification database and disables the automatic conversion of modification names to the UniMod format
- --gen-spec-lib instructs DIA-NN to generate a spectral library
- --gen-fr-restriction annotates the library with fragment exclusion information, based on the runs being analysed (fragments least affected by interferences are selected for quantification, why the rest are excluded)
- --global-mass-cal disables RT-dependent mass calibration
- --global-norm instructs DIA-NN to use simple global normalisation instead of RT-dependent normalisation
- --il-eq isoleucine and leucine will be considered equivalent when annotating peptides with protein information
- --individual-mass-acc mass accuracies, if set to automatic, will be determined independently for different runs
- --individual-reports a separate output report will be created for each run
- --individual-windows scan window, if set to automatic, will be determined independently for different runs
- --int-removal 0 disables the removal of interfering precursors
- --learn-lib [file name] specifies a 'training library' for the legacy predictor, see Library-free search
- --lib [file name] specifies a spectral library. The use of multiple --lib commands (experimental) allows to load multiple libraries in .tsv format
- --library-headers [name 1],[name 2],... specifies column names in the spectral library to be used, in the order described in Spectral library formats. Use '*' (without quotes) instead of the column name if a particular column is irrelevant, or if DIA-NN already recognises its name
- --mass-acc [N] sets the MS2 mass accuracy to N ppm
- --mass-acc-cal [N] sets the mass accuracy used during the calibration phase of the search to N ppm (default is 100 ppm, which is adjusted automatically to lower values based on the data)
- --mass-acc-ms1 [N] sets the MS1 mass accuracy to N ppm
- --matrices output quantities matrices
- --matrix-qvalue [x] sets the q-value used to filter the output matrices
- --matrix-spec-q run-specific protein q-value filtering will be used, in addition to the global q-value filtering, when saving protein matrices. The ability to filter based on run-specific protein q-values, which allows to generate highly reliable data, is one of the advantages of DIA-NN
- --max-fr specifies the maximum number of fragments per precursors in the spectral library being saved
- --max-pep-len [N] sets the maximum precursor length for the in silico library generation or library-free search
- --max-pr-charge [N] sets the maximum precursor charge for the in silico library generation or library-free search
- --met-excision enables protein N-term methionine excision as variable modification for the in silico digest
- --min-fr specifies the minimum number of fragments per precursors in the spectral library being saved
- --mean-peak sets the minimum peak height to consider. Must be 0.01 or greater
- --min-pep-len [N] sets the minimum precursor length for the in silico library generation or library-free search
- --min-pr-charge [N] sets the minimum precursor charge for the in silico library generation or library-free search
- --min-pr-mz [N] sets the minimum precursor m/z for the in silico library generation or library-free search
- --missed-cleavages [N] sets the maximum number of missed cleavages
- --mod [name],[mass],[optional: 'label'] declares a modification name. Examples: "--mod UniMod:5,43.005814", "--mod SILAC-Lys8,8.014199,label"
- --mod-only only consider peptides bearing the modifications listed with --monitor-mod
- --monitor-mod [name] apply PTM scoring & site localisation for a particular modification. This modification must have been declared as variable using --var-mod
- --nn-single-seq only use one (best) precursor per stripped sequence for the training of the neural network classifier
- --no-calibration disables mass calibration
- --no-isotopes do not extract chromatograms for heavy isotopologues
- --no-cut-after-mod [name] discard peptides generated via in silico cuts after residues bearing a particular modification
- --no-fr-selection the selection of fragments for quantification based on the quality assessment of the respective extracted chromatograms will be disabled
- --no-ifs-removal turns off interference subtraction from fragment ion chromatograms - equivalent to the "high precision" quantification mode
- --no-im-window disables IM-windowed search
- --no-maxlfq disables MaxLFQ for protein quantification
- --no-norm disables cross-run normalisation
- --no-prot-inf disables protein inference (that is protein grouping) - protein groups from the spectral library will be used instead
- --no-quant-files instructs DIA-NN not to save .quant files to disk and store them in memory instead
- --no-rt-window disables RT-windowed search
- --no-stats disables the generation of the stats file
- --no-stratification disables precursor stratification based on the modification status. Stratification works in combination with --monitor-mod to ensure that no matter how few modified peptides are reported, the FDR specifically across modified peptides is well controlled
- --no-swissprot instruct DIA-NN not to give preference for SwissProt proteins when inferring protein groups
- --original-mods disables the automatic conversion of known modifications to the UniMod format names
- --out [file name] specifies the name of the main output report. The names of all other report files will be derived from this one
- --out-lib [file name] specifies the name of a spectral library to be generated
- --out-measured-rt instructs DIA-NN to save raw empirical retention times in the spectral library being generated, instead of saving RTs aligned to a particular scale
- --peak-center instructs DIA-NN to use chromatographic peak height for quantification - equivalent to the "Robust LC" quantification mode
- --pg-level [N] controls the protein inference mode, with 0 - isoforms, 1 - protein names (as in UniProt), 2 - genes
- --predictor instructs DIA-NN to perform deep learning-based prediction of spectra, retention times and ion mobility values
- --prefix [string] adds a string at the beginning of each file name (specified with --f) - convenient when working with automatic scripts for the generation of config files
- --quant-fr [N] sets the number of top fragment ions among which the fragments that will be used for quantification are chosen. Default value is 6
- --reanalyse enables MBR
- --reannotate reannotate the spectral library with protein information from the FASTA database, using the specified digest specificity
- --ref [file name] (experimental) specify a special (small) spectral library which will be used exclusively for calibration - this function can speed up calibration in library-free searches
- --regular-swath all runs will be analysed as if they were not Scanning SWATH runs
- --relaxed-prot-inf instructs DIA-NN to use a very heuristical protein inference algorithm (similar to the one used by FragPipe and many other software tools), wherein DIA-NN aims to make sure that no protein is present simultaneously in multiple protein groups. This mode (i) is recommended for method optimisation & benchmarks, (ii) might be convenient for gene set enrichment analysis and related kinds of downstream processing. However the default protein inference strategy of DIA-NN is more reliable for differential expression analyses (this is one of the advantages of DIA-NN).
- --report-lib-info adds extra library information on the precursor and its fragments to the main output report
- --restrict-fr some fragments will not be used for quantification, based on the value in the ExcludeFromAssay spectral library column
- --scanning-swath all runs will be analysed as if they were Scanning SWATH runs
- --smart-profiling enables an intelligent algorithm which determines how to extract spectra, when creating a spectral library from DIA data. This is highly recommended and should almost always be enabled
- --species-genes instructs DIA-NN to add the organism identifier to the gene names - useful for distinguishing genes from different species, when analysing mixed samples. Works with UniProt sequence databases.
- --sptxt-acc [N] sets the fragment filtering mass accuracy (in ppm) when reading .sptxt/.msp libraries
- --strip-unknown-mods instructs DIA-NN to ignore modifications that are not supported by the deep learning predictor, when performing the prediction
- --target-fr [N] fragment ions beyond this number will only be included in the spectral library being created (from DIA data) if they have high-quality chromatograms. Default value is 6
- --temp [folder] specifies the Temp/.dia directory
- --threads [N] specifies the number of CPU threads to use
- --use-quant use existing .quant files, if available
- --verbose [N] sets the level of detail of the log. Reasonable values are in the range 0 - 4
- --var-mod [name],[mass],[sites],[optional: 'label'] - adds the modification name to the list of recognised names and specifies the modification as variable. [sites] can contain a list of amino acids and 'n' which codes for the N-terminus of the peptide. '*n' indicates protein N-terminus. Examples: "--var-mod UniMod:21,79.966331,STY" - phosphorylation, "--var-mod UniMod:1,42.010565,*n" - N-terminal protein acetylation. Similar to --mod can be followed by 'label'
- --var-mods sets the maximum number of variable modifications
- --vis [N],[Peptide 1],[Peptide 2],... instructs DIA-NN to extract and save chromatograms in the vicinity of the detected elution apex, for all PSMs matching the stripped sequences provided, for all runs in the experiment
- --window [N] sets the scan window radius to a specific value. Ideally, should be approximately equal to the average number of data points per peak
Description of selected columns in the main report
- Protein.Group - inferred proteins. See the description of the Protein inference GUI setting and the --relaxed-prot-inf option.
- Protein.Ids - all proteins matched to the precursor in the library or, in case of library-free search, in the sequence database
- Protein.Names names (UniProt names) of the proteins in the Protein.Group
- Genes gene names corresponding to the proteins in the Protein.Group. Note that protein and gene names will only be present in the output if either (i) Protein inference is disabled in DIA-NN and no sequence (FASTA) database is provided - then protein & gene names from the spectral library will be used, or (ii) protein IDs in the Protein.Group can be found in the sequence database provided, or (iii) the Reannotate function is used. (ii) and (iii) also require that DIA-NN recognises protein & gene names as recorded in the sequence database (e.g. the UniProt format is supported)
- Q.Value run-specific precursor q-value
- PEP an estimate of the posterior error probability for the precursor identification, based on scoring with neural networks. This estimate is not precise and typically it is overly conservative - its purpose it to facilitate additional output filtering for (very rare) scenarios when extra confidence in specific IDs is required
- Global.Q.Value global precursor q-value
- Protein.Q.Value run-specific q-value for the unique protein/gene, that is protein/gene identified with proteotypic (=specific to it) peptides
- PG.Q.Value run-specific q-value for the protein group
- Global.PG.Q.Value global q-value for the protein group
- GG.Q.Value run-specific q-value for the gene group (identified by the value in the Genes column)
- Lib.Q.Value q-value for the respective library entry, 'global' if the library was created by DIA-NN. In case of MBR, this applies to the library created after the first MBR pass
- Lib.PG.Q.Value only relevant for MBR: global q-value for the protein group calculated after the first MBR pass
- Ms1.Profile.Corr correlation between MS1 and MS2 chromatograms, high score in itself is a good indicator that the set of modifications on the peptidoform is correctly identified (this does not apply when using the Ultra-fast mode without MBR)
- Ms1.Area non-normalised MS1 peak area
- Mass.Evidence an MS2-level score, high values (e.g. higher than 0.5-1.0) are in itself good indicators that the set of modifications on the peptidoform is correclty identified
- CScore the score that has been used to calculate the q-value
- Fragment.Quant.Raw raw uncorrected quantities for the top fragment ions, ordered by their reference intensities. Use --report-lib-info to obtain fragment annotation
- Fragment.Quant.Corrected framgnet quantities after interference subtraction (in the high accuracy mode)
- PTM.Q.Value run-specific q-value for correct identification of the set of modifications on the peptidoform. Note that there is not Global.PTM.Q.Value - because in DIA-NN Global.Q.Value also incorporates PTM confidence scoring and should be used instead
- PTM.Site.Confidence run-specific confidence in site localisation (=estimated 1 - Site.PEP, where Site.PEP is the posterior error probability for incorrect modification localisation)
- Lib.PTM.Site.Confidence the site localisation confidence recorded in the library. In case of MBR, this applies to the library created after the first MBR pass
Q: Why DIA-NN?
A: Proteomic depth, quantitative precision, reliability and speed. In particular, DIA-NN is transformative for (i) experiments acquired with fast chromatographic gradients and (ii) library-free analyses. Further, it uniquely supports Scanning SWATH (we co-developed it in parallel with DIA-NN) and seems to perform particularly well on dia-PASEF data.
Q: I have a regular experiment, which parts of this Documentation do I really need to read?
A: Getting Started is sufficient to start working with DIA-NN. Afterwards can also look at Changing default settings. If something is not working, check Raw data formats and Spectral library formats. If you think you might want to analyse your data without a spectral library, check Library-free search.
Q: I am new to DIA proteomics, what papers would you suggest?
A: Ludwig et al 2018 is an excellent introduction to DIA. The DIA-NN paper describes how neural network classifier in DIA-NN enables confident proteomics with fast methods and is an example of how to benchmark DIA software performance. Please note that the field of DIA proteomics is developing very rapidly, and things get outdated very quickly. For example, the latest version of DIA-NN is overwhelmingly better in every aspect than DIA-NN 1.6, which was featured in the initial DIA-NN paper.
Q: How to reduce memory usage/speed up DIA-NN when analysing in library-free mode?
A: Try adjusting the Speed and RAM usage setting. Can even try the Ultra-fast mode there, it does sacrifice identification performance, and it might have somewhat higher effective FDR, but it is about ~5x faster. Another option is to reduce the precursor mass range, that is search mass ranges 400-500, 500-600, 600-700, etc, separately - create a spectral library from DIA data separately for each mass range, then merge these libraries (e.g. by supplying multiple --lib commands to DIA-NN) and reanalyse the whole dataset with the merged library.
The most important factor in library-free searches is the search space size. So here are some ways to reduce the search space and thus speed up library-free analyses:
- Only search peptides which are likely to be detectable in your experiment. For example, for plasma/serum library-free analyses can consider using peptides from the PeptideAtlas Human Plasma Non-Glyco 2017-04 build. Technically, the way to implement this is to make a FASTA database wherein each entry corresponds to a single peptide sequence, in combination with "--cut " to disable the digest. Once an in silico spectral library is generated, can Reannotate it with protein information. Alternatively, can convert the predicted library from .speclib to .tsv, using DIA-NN, pull protein information from PeptideAtlas and annotate using R/Python.
- Don't consider charge 1 precursors, that is use "--min-pr-charge 2". This is particularly relevant for dia-PASEF.
- To speed up deep learning-based prediction, limit the precursor mass range to the actual mass range of your runs.
- Use --ref to speed up calibration.
Q: How do I ensure reproducibility of my analyses?
A: DIA-NN has a strong focus on reproducibility. First, the pipeline functionality (and the ability to save pipelines) allows to conveniently store the experiment settings - with DIA-NN it can never happen that a user forgets what settings were used for a particular analysis. Second, DIA-NN's log contains complete information on the settings used and is automatically saved for each experiment, along with a separate pipeline step - which allows to easily rerun the analysis, even if the user forgot to save the whole pipeline.
In terms of computational reproducibility, please note the following:
- DIA-NN's analysis using a spectral library will always be the same across different Windows machines.
- In silico prediction of spectra/RTs/IMs using deep learning will yield very slightly different results depending on the instruction set supported by the CPU - that's why DIA-NN prints this instruction set upon being launched. This is a consequence of computational optimisations for modern architectures as implemented in the Pytorch deep learning framework used by DIA-NN.
- DIA-NN's analysis on any Linux machine will be very slightly different from that on Windows, because certain mathematical functions are calculated slightly differently by Linux libraries. It is not guaranteed but very likely that analysis results will be the same across all reasonable Linux machines. So for reproducibility purposes in practice it is enough to just keep track of what kind of Linux distribution with what glibc version is being used.
Important: .speclib (a compact DIA-NN-specific format) libraries automatically created by DIA-NN contain information from both the original .tsv library (if any) and the FASTA database (if any) used to annotate the library. For full reproducibility, it is important to have it recorded how exactly the .speclib library was created (e.g. need to remember where DIA-NN saved the respective log). Note that DIA-NN always saves a .speclib library when it loads any non-.speclib library, and an older version will get overwritten if located in the same folder. Alternatively, can just always rely solely on .tsv libraries.
Q: What is the purpose of the diann R package? A: Ourselves we primarily use it for MaxLFQ protein quantification after we do batch correction at the precursor level (for large experiments). Of note, the recent version of the iq R package actually does a better job at calculating MaxLFQ quantities: it is over an order of magnitude faster. So can also use the iq package.
Q: How do I do batch correction?
A: Ideally on the precursor-level. Then can calculate protein quantities with MaxLFQ, using corrected precursor quantities. And then, if necessary, do another round of batch correction, now on the protein level. In many cases just doing protein-level batch correction, directly using protein quantities reported by DIA-NN, will also work quite well. Finally, can just incorporate batch information as covariates into statistical models.
Q: Do I need imputation?
A: For many downstream applications - no. Most statistical tests are fine handling missing values. When imputation is necessary (e.g. for certain kinds of machine learning, or when a protein is completely absent in some of the biological conditions), we prefer to perform it on the protein level. Note that many papers that discuss imputation methods for proteomic data benchmark them on DDA data. The fundamental difference between DDA and DIA is that in DIA if a value is missing it is a lot more likely that the respective precursor/protein is indeed quite low-abundant. Because of this, minimal value imputation, for example, performs better for DIA than it does for DDA. An important consideration with imputation is that Gaussian statistical methods (like t-test) should be used with caution on imputed data, if the latter is strongly non-Gaussian.
Q: Can I implement incremental data processing of large-scale experiments based on DIA-NN?
A: Yes! Sometimes it is important to have an ability to analyse the data incrementally, e.g. first process one cohort of patients, then in a half a year samples from another cohort arrive, and it would be great to merge the data but keep all protein quantities for the old samples unchanged. This is fully supported by DIA-NN, and there are several options on how to implement this.
- Option 1. Process each batch separately, then do batch correction. This is the easiest way and might actually work quite well in some cases.
- Option 2. First, fix mass accuracies and the scan window setting. Second, use a spectral library which specifies which fragment ions should or should not be used for peptide quantification (using an ExlcudeFromAssay column), in combination with --restrict-fr and --no-fr-selection. Can generate such an annotation for the library using --gen-fr-restriction, see Command-line reference.This will minimise the batch effects introduced by the separate processing of mass spec batches.
- Option 3. In addition to 2, disable normalisation in DIA-NN (--no-norm) and disable MaxLFQ (--no-maxlfq). Then all precursor and protein quantities will be calculated completely independently for different samples, and thus there will be no batch effects associated with data processing. One can then perform, separately for each batch, normalisation & "batch correction" with a script in R/Python, utilising the QC samples processed within each batch. For example, can replace each precursor quantity with [(precursor quantity) / (average quantity of this precursor in QC samples in the same batch)] * (average quantity of this precursor in QC samples of batch #1).
Q: What if I do not need the quatities of the older samples to stay the same and just want to save time on processing?
A: Also possible. Just have the .quant files saved somewhere, and reanalyse the expanded dataset while reusing the old .quant files, see Output. The --cfg option, which allows to put some commands in a separate file (e.g. all the --f commands specifying the input mass spec files), might prove to be convenient here.
Q: When designing an experiment, what number of data points per peak should I aim for?
A: We typically aim for 3-3.5 data points per peak at FWHM (full width at half maximum), which is about 6-7 data points in total. If you set Scan window to 0 in DIA-NN, it will print its estimate for the average "Peak width" - this is actually the estimate for the number of data points at FWHM. For example, for LFQbench data this figure is approximately 3.0-3.1. This is enough to achieve good precision of quantification. In terms of identification performance, methods with longer cycle time and hence less data points per peak typically yield better ID numbers, and thus are preferable when the sole purpose is to generate a spectral library, which would then be used on a different dataset.
Q: How useful are MS1 scans for DIA?
A: For what is called 'regular proteomics' - not particularly useful. However MS1 information is crucially important when looking for modified peptides. Also, MS1 scans are, in most cases, quite inexpensive time-wise, so it is almost always worth having them. Also, for SILAC, for example, MS1-based quantification can sometimes be preferable.
Q: How to choose the FDR/q-value threshold?
A: Depends on the downstream analysis. In general, relaxing FDR filtering up to 5% might be reasonable in some cases. But it is only justified if it leads to a significant improvement in identification numbers. One option is to reduce the numbers of missing values by applying 1% global q-value filter and, say, 3% or 5% run-specific q-value filter. Again, only justified if the numbers of missing values are reduced significantly. Numbers of modified peptides detected sometimes strongly depend on the q-value filter threshold chosen, with 2% or 3% yielding significantly more IDs than 1% filtering. In such cases it might be worth it to also relax global q-value filter to 2% or 3%.
When it comes to protein q-value filtering, it is a common practice to only filter using global 1% q-value, to ensure at least 99% of proteins are correctly detected in at least one run in the experiment. This also guarantees low effective run-specific protein FDR, provided the spectral library used contains a lot more precursors and proteins than are actually detectable in the DIA experiment. For example, if the spectral library contains 11k proteins and 500k precursors, but only 3k proteins pass 1% global q-value filter, and only 100k precursors map to these proteins, then if the output is filtered at 1% run-specific precursor q-value and 1% global protein q-value, the effective run-specific protein FDR will also be well controlled at about 1%. However if almost all the proteins in the library pass 1% global q-value threshold, 1% global protein q-value filtering has no effect. As a consequence, the effective run-specific protein FDR is only controlled indirectly by run-specific precursor q-value, and empirically it usually results in up to 5-6% effective run-specific protein FDR, given 1% run-specific precursor q-value filtering.
Is having 5% effective run-specific protein FDR a problem? In many cases it is not. Suppose a protein passes 1% run-specific protein q-value filtering in 50% of the runs, and in the other 50% it is quantified but has run-specific q-value > 1%. What are the options? One is to just use those quantities, most of them are likely to be correct. Another is to impute by replacing them via random sampling from some distribution, for example. For most applications the first option is clearly better.
However in some cases one might want to be very confident in protein identifications in specific runs. And here what helps a lot is the ability of DIA-NN to calculate run-specific protein q-values, which is absent from many alternative software options.
Q: How to compare the identification performance of two DIA software tools?
A: This is often tricky because FDR estimates are never precise. For example, recently we benchmarked (see Figure S1 therein) DIA-NN on data acquired with different chromatographic gradients, and what we observed is that although DIA-NN is always somewhat conservative in its FDR estimates (that is when it reports FDR = 1%, the effective FDR as estimated with a two-species spectral library method is in fact lower than 1%), the accuracy of its estimates varies a bit, depending on the data. When comparing different software tools, the differences in FDR estimation accuracy will often be even larger, due to different algorithms used. And certain kinds of data are very sensitive to the FDR threshold, e.g. the ID number can be, say, 20k peptides at 1% FDR, and go up to 30k at 2%. So if software A says it's 1%, real FDR is also 1%, and it reports 20k, while software B says it's 1%, but real FDR is 2%, and it still reports 20k, these two software tools are actually quite far from each other in terms of real performance.
Because of this, it is important to always independently estimate the FDR using an unbiased benchmarking procedure, which is not affected by the internal FDR estimates of the software tools. One of the ways to do that is use two-species spectral libraries, wherein peptides and proteins from one of the species act as 'decoys' (but the processing software does not know that) and are not expected to be found in the sample. Two important considerations here. First, need to make sure that the peptides from the decoy species are properly annotated as not belonging to the target species, and make sure that they absolutely cannot be present in the sample and that they are not among the common contaminants. Because of this it is not recommended, for example, to use a human library as a decoy when analysing a non-human sample. Second, it is important to apply the pi0 correction when estimating false discovery rates, that is estimate the prior probability of incorrect identification, see an example here. Of note, when estimating precursor-level FDR using this method, it is absolutely essential not to apply any kind of protein q-value filtering.
Finally, an important consideration is to make sure to compare apples to apples. For example, it only makes sense to compare global protein q-value filtering in one software with that in another, and not to compare global protein q-value filtering to run-specific one.
Q: How to compare the quantification performance of two DIA software tools?
A: The basic level at which this is often done is comparing the CV values. Or, better, comparing the numbers of precursors quantified with CVs less than a given threshold, e.g. 0.1 or 0.2. The difficulty here is that there are algorithms which can significantly improve CV values, but at the same time make quantification less reliable, because what is being integrated is not only the signal from the target precursor, but also signal from some (unknown) interfering precursor. One example is provided by DIA-NN's high accuracy and high precision modes: the high accuracy mode demonstrates better accuracy, while high precision mode yields lower CV values.
LFQbench-type experiments, featuring two mixtures of different species digests, allow to assess the accuracy of quantification. So what makes sense is to require a quantification method to yield both reasonably good accuracy and reasonably good CV values. However there is currently no known way to determine which quantification method is the best, provided the methods considered are OK in terms of both accuracy and CVs. Of note, using the number of proteins detected as differentially abundant in LFQbench as a readout does not work well: most interfering signals come from the species injected in 1:1 ratio, and therefore "integrating interferences" in this case has little to no negative effect on the ability to detect differential abundance.
Q: What happens if I process data from some related strains of my favourite organism, using a canonical spectral library?
A: If you don't have the genomes of those related strains sequenced, what might happen is that a canonical peptide in the library will get matched to a spectrum originating from a mutated peptide. For example, it can happen that PEPTIDE is matched to a spectrum originating from PNPTIDE. Will this happen often? Probably not. However if you really want to avoid this, what makes sense to do is filter DIA-NN's main report based on Ms1.Profile.Corr (e.g. require it to be at least 0.9) and/or Mass.Evidence. For example, a filter Ms1.Profile.Corr + 0.5 * Mass.Evidence > 0.9 is sensible.
Q: What if I don't know what kind of modifications might be there on my peptides and I want to make sure that the peptidoform is correctly identified?
A: The solution is the same as for the previous question: filtering based on Ms1.Profile.Corr and/or Mass.Evidence.
Q: Can I install multiple versions of DIA-NN on the same PC?
A: Yes! And this is one of the advantages of DIA-NN. You can keep the old versions for however long you need them, to enable reproducible reprocessing of old experiments, while also having the latest cutting-edge DIA-NN installed.
Q: Are DIA-NN version numbers indicative of the performance?
A: No, they are just chronological. In fact, the performance improvement from 1.7.12 to 1.7.16, for example, is greater than from 1.6 to 1.7.12.
Q: I have a cool idea, can DIA-NN do [some magic]?
A: Maybe DIA-NN already supports it (there are some major capabilities that are implemented in DIA-NN but not yet reflected in this Documentation), maybe it is realistic to implement. Please email!
Please post any questions, feedback, comments or suggestions on the GitHub Discussion board (alternatively can create a GitHub issue) or email Vadim Demichev (email: my first name dot my last name at gmail dot com). General discussions on proteomics & mass specs are also welcome on the GitHub Discussion board. Can also contact me via Twitter @VDBiology or LinkedIn. If a query is unanswered for several days, please post a reminder.
For questions of the type "I ran DIA-NN on some experiment and the results are surprising/strange/not as expected, why is that?", please attach, whenever possible, the full DIA-NN log recorded at Log level = 3 (can be saved using the "Save log" button).