CrabNet matbench results - possibly neglecting 25% of the training data it could have used #19
Comments
|
Email response from @MahamadSalah74
|
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
@anthony-wang,
In the CrabNet matbench notebook, it does train/val/test splits. However, if #15 (comment) is correct such that the validation data (i.e.
val.csv) doesn't contribute to hyperparameter tuning, then that 25% of the training data is essentially getting thrown away, correct?In other words, the CrabNet results are based on only 75% of the training data compared to what the other
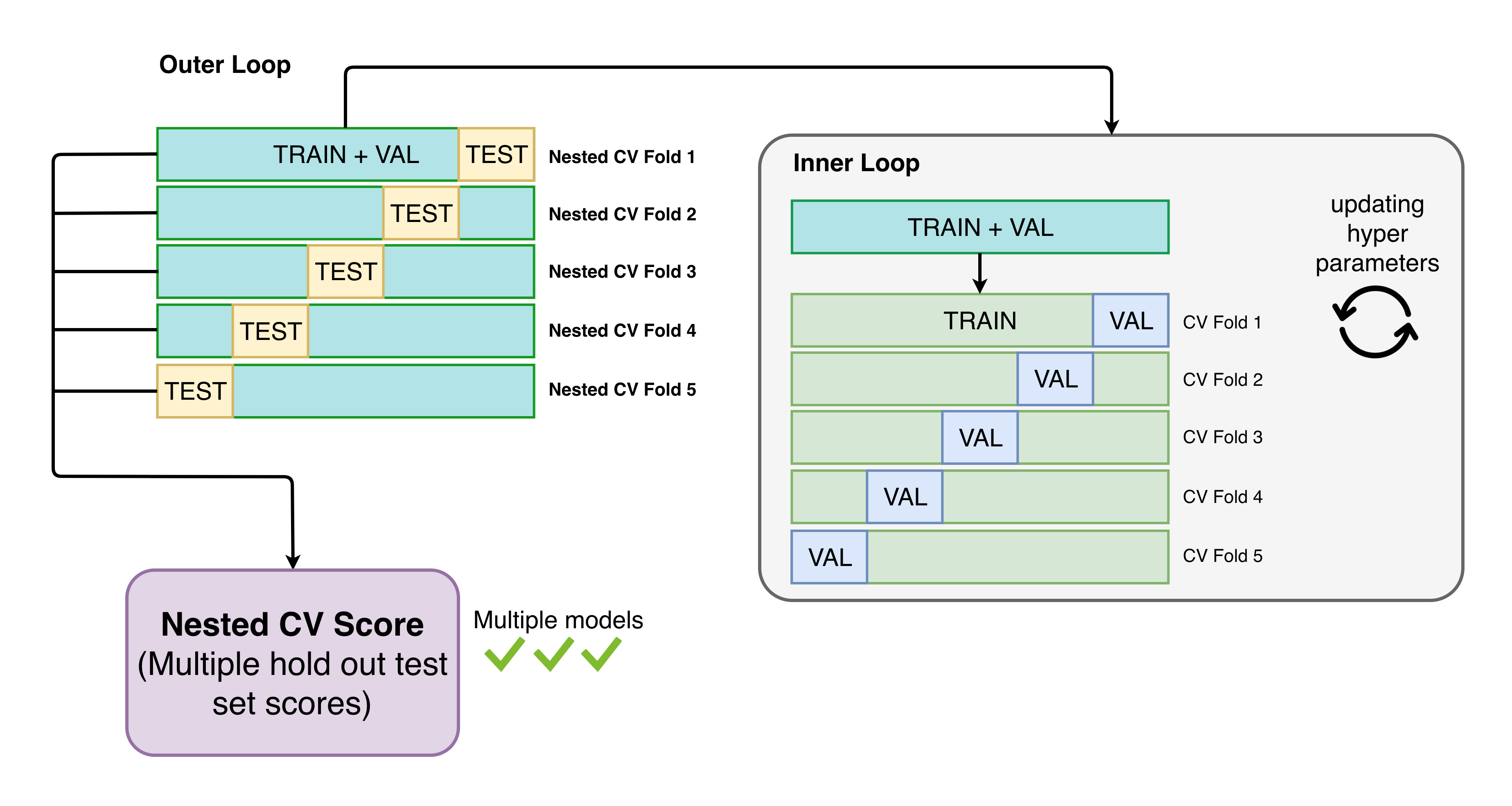
matbenchmodels use for training. From what I understand, the train/val/test split in the context ofmatbenchonly really makes sense if you're doing hyperparameter optimization in a nested CV scheme, as follows:(Source: https://hackingmaterials.lbl.gov/automatminer/advanced.html)
To correct this, I think all that needs to be done is change:
to
which makes it so there's data bleeding between
train_dfandval_df, butval_dfends up being essentially just a dummy dataset so that CrabNet doesn't error out when aval.csvisn't available.Sterling
The text was updated successfully, but these errors were encountered: