This is tool for converting Babylon .bgl dictionaries to structured HTML, for creation of a Kindle-compatible dictionaries.
BabylonToHtml takes a Babylon .bgl file (which can be downloaded freely from Babylon's free content section, and converts it to a well-structured HTML.
The produced HTML can be used with MobiPocket Creator to create a .prc formatted eBook, which can be used natively as a dictionary on Kindle devices.
See my blog post Using Babylon-based dictionaries on your Kindle for additional information about this tool's purpose.
The binary structure of .BGL files has already been cracked (not by me). This knowledge is commonly out in the open and shared across various open-source projects. I have combined a few of those resources into one easy-to-use command-line utility.
-
One source was dictconv, a dictionary conversion tool for Linux which comes with its full C++ source. I used parts of this code (ported by me into C#) in order to analyse the meta-data of the dictionary file (text encoding, author etc).
-
Another resource is is an open-source project named ThaiLanguageTools. It's written in C# but the contents of the code looks suspiciously similar to the code of dictconv mentioned above (similar variable names, comments etc) which suggests it's a porting as well.
-
The content of Babylon's .BGL files is encoded in compressed GZip format. In order to decompress the data, I have incorporated the free open-source SharpZipLib into the project as well (as source code, so there is only one executable needed to run my app in the end. no additional DLLs).
-
To all the above I added my very own simple HTML generator. It structures the entries from the dictionary file in a markup compatible with the next step (converting it into an eBook).
BabylonToHtml tool runs in a command prompt window. Running it without any additional parameters, you'll receive some basic help:

- In most cases all you have to provide is the name (and potentially the path) of your .BGL file.
- The output .HTML is encoded in UTF-8 (Unicode). However, the entries read from the .BGL dictionary are encoded with specific character sets (and sometimes with more than one).For example: in a Chinese - Bulgarian dictionary the source language entries are encoded with Chinese characters and the target language entries are encoded in Cyrillic.
- BabylonToHtml will try, by default, to get the right encoding (this info is available in the meta-data of the .BGL file in most cases), but it may make mistakes.
- These encodings can be enforced:
It is possible to set the codepage of the source language by specifying the -se command line argument.
It is possible to set the codepage of the target language by specifying the -te command line argument.
So something like the following should be sufficient in most cases:
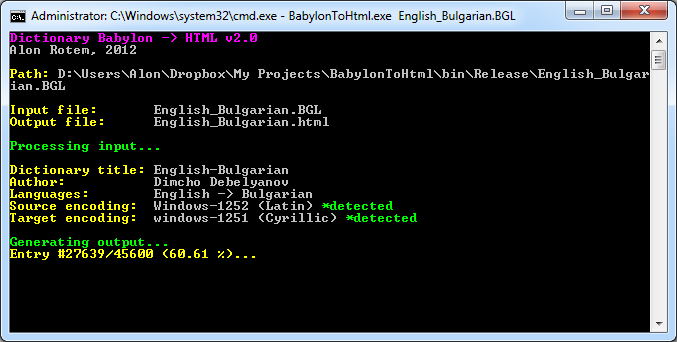
If your .BGL file does not reside in the same folder with the .EXE, a full path should be specified (may be wrapped with double-quotes if needed).The encoding (and other information about your dictionary) is be parsed and progress of the process is presented...
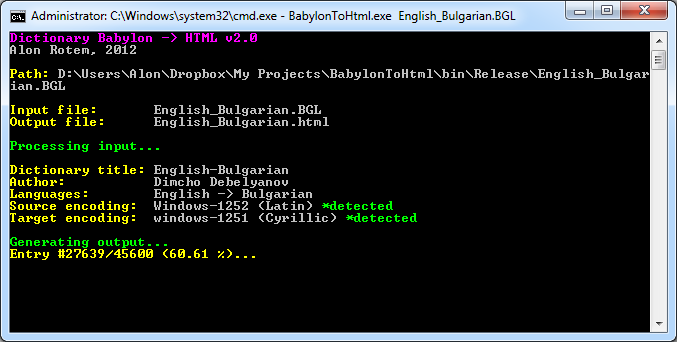
Once the process is done, a new HTML file resides next to the original .BGL file.
The new file's name matches the original .BGL file (just with .HTML extension):

{kind=link}
##Why is this project on GitHub?##
My blog-post presenting this project, "Using Babylon-based dictionaries on your Kindle", got a lot of attention. It seems many people liked the idea of importing Babylon dictionaries to Kindle. Many people asked about an option to produce an English-to-Hebrew dictionary, but not just.
The outputs of this project at runtime, the HTML (and then the .prc file), are not perfect. There are a few key problems which need to be adderssed:
- There are unresolved portions of the produced dictionary, which are wrapped by <charset c=T>****;</charset> blocks. Those are probably unicode characters which need to be resolved.
- There are unresolved portions of the produced dictionary, which are delimited with dollar-signs, e.g:
$506274$ or cos$531761$. Not 100% sure how those should be treated/resolved. - The encoding is actually force-resolved in the code, no matter what the user says (it gets overridden by the dictionary analysis code). This needs to be fixed.
- Specifically for Hebrew dictionaries: Kindle (at least Kindle v2) always aligs the text to left-to-right. Not just the letters (that's easy), but also the order of the words themselves. To know which word will appear where is impossible (this depends on the screen's size and selected unicode font (in the case of Kindle 2, a hacked font needs to be installed, as explained here).
Having not much time to address these issues, I've come to a decision to open this project to the public, for whoever wants and can improve it.
So there you have it!
As I stated above (and in my blog post), Babylon's .bgl format is well known and there are other projects which parse it. Some were suggested by commentators of the post directly and some by email. Here are a few, which may come-in handy for anyone who'd like to contribute to this project and its known issues listed above:
-
Forum thread: BGL (babylon glossary) to GLS (babylon glossary source)
-
BGL-Reverse - another open-source reverse engineered BGL parser.
-
PyGlossary - yet another open-source reverse engineered BGL parser, this time in Python.
| BabylonToHtml.exe English_Bulgarian.BGL |