This guide provides an introduction to using the Repy sandbox environment. It describes what restrictions are placed upon the sandboxed code with examples. At the end of reading this document you should be able to write Repy programs, manage the restrictions on programs, and understand whether Repy is appropriate for a specific task or program.
It is assumed that you have a basic understanding of network programming such as socket, ports, IP addresses, and etc. Also, a basic understanding of HTML is useful but not required. Lastly, you need a basic understanding of the Python programming language. If not, you might want to first read through the Python tutorial at http://www.python.org/doc/. You do not need to be a Python expert to use Repy, but as Repy is a subset of Python, being able to write a simple Python program is essential.
You have to install Repy before starting the tutorial. You can download Repy here.
If you want you can look at the installer options using the --usage option. You can also simply install the software using the defaults.
There is the link to file used in each section next to the title. All attached files work on Windows systems. Here is link to the zip file containing all files used in this tutorial. All attached files work on Windows systems.
restrictions.test, example.1.1.repy
Let's start with the file named example.1.1.repy, which prints the string "Hello World".
We use repy instead of py as the file extension for files in Repy.
if callfunc == 'initialize':
print "Hello World"There are two different ways to run Repy programs. You can run the code in your local machine and in the VMs you control.
To run a repy program from the command line, run the following with the correct values substituted in:
python <path to repy.py> <path to restrictions file> <path to source file>
For example, if your current working directory is the location where repy is installed, restrictions.test is in C:\seattle\examples\restrictions.test, and your source file is C:\seattle\examples\example.1.1.repy, you can run the repy program with the following command:
python repy.py "C:\seattle\examples\restrictions.test" "C:\seattle\examples\example.1.1.repy"To use repy functions from an interactive python interpreter, you can open Python and map the symbols from repyportability into your namespace. For example, to get a randomfloat through repy, do:
Justin-Capposs-MacBook-Pro:test2 justincappos$ python
Python 2.7.1 (r271:86832, Jun 16 2011, 16:59:05)
[GCC 4.2.1 (Based on Apple Inc. build 5658) (LLVM build 2335.15.00)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from repyportability import *
>>> randomfloat()
0.18776749685771188
Note that this will not provide the security and performance isolation from Repy. As a result, you can also do things that are not allowed in Repy.
First, make sure that you have the repy files (download) and restrictions.test in your seattle_repy directory.
Install repy by running the relevant installer. For windows, it is install.bat.
Then open a command prompt (Windows) or shell (Unix) and change to the seattle_repy directory in the installer. Execute the following command to run the example program listed above.
python repy.py restrictions.test example.1.1.repyThe output is the following:
Hello World
Terminated"Hello World" was printed, and then the last sentence means that the program was terminated successfully.
Not all users will see "Terminated". This only shows up on some operating systems. Other operating systems may have different messages.
You can also access the resources donated to you and run the program example.1.1.repy in the resources you can control. You need to follow the steps below in the shell in order to run the program in resources.
Step 1. Run programs in the Seattle
To run a program, you should use the experiment manager seash. Seash allows you to control the files running in sandboxes you control.
python seash.pyStep 2. Log in with your key
Before logging in, you have to load your public and private keys. You can get the keys at the SeattleClearinghouse website. You need to make sure that you have two files, your public and private key. The name of each file is your ID and the extension of files are publickey and privatekey.
For example, if your ID were john, the two files would be john.publickey and john.privatekey. These files must be placed in the directory where you run seash.
If you successfully logged in, you could notice that the prompt starts with you ID.
!> loadkeys john
!> as john
john@ !>Step 3. Locate the resources(computers) you can use
This command will tell the shell to locate resources that have been assigned to your account through the SeattleClearinghouse website. In order to assign resources to your account, you must go to the SeattleClearinghouse website, log into your account and get more resources under the 'My VMs' tab.
john@ !> browse
Added targets: %1(10.0.1.1:1224:v9), %2(10.0.1.2:2888:v9)
Added group 'browsegood' with 2 targets
The command browse produced the output that shows resources(targets) you can control. In the first target %1(10.0.1.1:1224:v9), %1 is the alias of the target, 10.0.1.1 is IP address, 1224 is port number, and v9 is VM name. The VM is the partial portion of whole donated resources. It means that the donated resources could be one VM or divided and assigned to more than one person.
Step 4. Access the resources(VMs)
john@ !> on browsegoodStep 5. Run a program
In this case, the program named example.1.1.repy is stored in the current directory. Note that the results will not be printed.
john@browsegood !> run example.1.1.repyStep 6. Look up the result of the program executed
In order to see the output, run show log, as is done below:
john@browsegood !> show log
Log from '10.0.1.1:1224:v9':
Hello World
Log from '10.0.1.2:2888:v9':
Hello WorldStep 7. Look up the information about the VMs you control
john@browsegood !> list
ID Own Name Status Owner Information
%1 * 10.0.1.1:1224:v9 Terminated
%2 * 10.0.1.2:2888:v9 Terminated Step 8. Exit from Seash
john@browsegood !> exitYou can find more practical examples in the Take home assignment page.
In this example, we'll wait for the user to browse a port we listen on. When the user browses our page, we'll display a hello world webpage and then exit.
def hello(ip,port,sockobj, thiscommhandle,listencommhandle):
sockobj.recv(512) # Receive HTTP header
htmlresponse = "<html><head><title>Hello World</title></head>" + \
"<body><h1> Hello World! </h1></body></html>"
sockobj.send("HTTP/1.1 200 OK\r\nContent-type: text/html\r\n" + \
"Content-length: %i\r\n\r\n%s" % (len(htmlresponse), htmlresponse))
stopcomm(thiscommhandle)
# close my connection with this user (we could also do sockobj.close())
if callfunc == 'initialize':
if len(callargs) > 1:
raise Exception("Too many call arguments")
# Running remotely:
# whenever this vessel gets a connection on its IPaddress:GENIport it'll call hello
elif len(callargs) == 1:
port = int(callargs[0])
ip = getmyip()
# Running locally:
# whenever we get a connection on 127.0.0.1:12345 we'll call hello
else:
port = 12345
ip = '127.0.0.1'
listencommhandle = waitforconn(ip,port,hello)
The initialize portion has two options. If you run it locally, it says, wait for a connection on 127.0.0.1 (the "local" IP of the computer), port 12345, and when you get, it calls the function hello().
127.0.0.1 is a special IP address.
It is localhost and means this computer. It is used to access the computer currently used.
Otherwise, you're running it remotely and need to pass it your Clearinghouse port. For convenience, Seattle Clearinghouse assigns the same UDP port to all of a user's VMs. To figure out which port you should use, log into the SeattleClearinghouse website and on the Profile page, look to see what port number it indicates. You'll see a page like below.
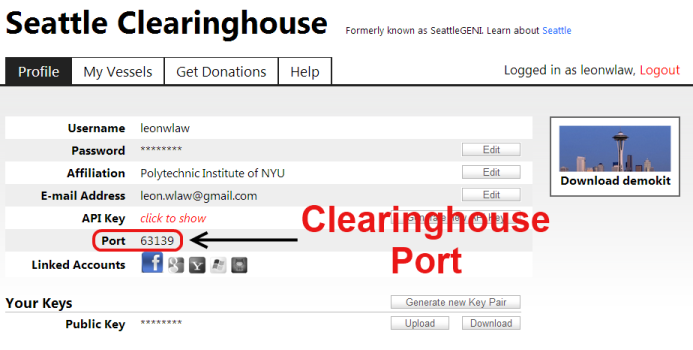
You should write your Clearinghouseport down as you'll need this value repeatedly.
The waitforconn() function returns a commhandle. A commhandle is a way for your program to refer to a connection. You can pass a commhandle to other functions to do operations. For example, when you want to close a connection you can call stopcomm with the commhandle for the connection that should be closed.
waitforconn(IP address, Port number, Callback function)
IP address : IP address to listen on
Port number : The port to bind to
Callback function : Callback function to be executed whenever a TCP connection is made to that IP/port
To read more about waitforconn(), visit the API
The function hello() sends the webpage (the text in quotes) using the sockobj and then closes the current connection (using the commhandle).
hello(IP address, Port number, Socket Object, commhandle1, commhandle2)
The ip address and port : the users are connecting to.
Socket Object : End-point of a bidirectional communication flow across the Internet.
Commhandle1 : Handle created by connection
Commhandle2 : Handle created for establishing connection, which hello is registered on
In the Berkeley sockets API in the C language,
Commhandle1 is the new socket created by accept function,
and commhadle2 is initial socket created by socket function.
Running locally
To run this program locally, you can type like below.
python repy.py restrictions.test example.1.2.repyThen open a web browser and in the address bar type: 127.0.0.1:12345 (this says to navigate to the "local" IP of the computer at port 12345). You should see the hello world webpage.
To stop the program, press CTRL-C.
Running remotely
Open seash the same as in the previous example but choose a single VM.
default@ !> on %1
default@%1 !>Then, run this program passing it your Clearinghouse port.
default@%1 !> run example.1.2.repy Clearinghouseport
default@%1 !> list
ID Own Name Status Owner Information
%1 IP address:port:VMname Started Notice that the program is "Started" instead of "Terminated". It's still running!
Now open a web browser and in the address bar type: IP_of_%1:Clearinghouseport. For example, if 1.2.3.4 is the IP address of %1, and your port is 54321 then open your browser and in the address bar type http://1.2.3.4:54321. If the node doesn't respond, try again. You should see the hello world webpage.
To stop the program, in the shell type:
default@%1 !> stop # This will stop any programs that are still running...
default@%1 !> list
ID Own Name Status Owner Information
%1 IP address:port:VMname Stopped Notice that the program is now "Stopped". It's not running
In this example, we'll add a counter to our helloworld program. First we'll try some perfectly valid python code that will not work in Repy.
def hello(ip,port,sockobj, thiscommhandle,listencommhandle):
sockobj.recv(512) # Receive HTTP header
global pagecount # GLOBALS ARE NOT ALLOWED IN REPY
pagecount = pagecount + 1
htmlresponse = "<html><head><title>Hello World</title></head>" + \
"<body><h1> Hello World!</h1><p>You are visitor " + \
str(mycontext['pagecount']) + "</p></body></html>"
sockobj.send("HTTP/1.1 200 OK\r\nContent-type: text/html\r\n" + \
"Content-length: %i\r\n\r\n%s" % (len(htmlresponse), htmlresponse))
stopcomm(thiscommhandle) # close my connection with this user
if callfunc == 'initialize':
global pagecount # GLOBALS ARE NOT ALLOWED IN REPY
pagecount = 0
if len(callargs) > 1:
raise Exception("Too many call arguments")
# Running remotely:
# whenever this vessel gets a connection on its IPaddress:GENIport it'll call hello
elif len(callargs) == 1:
port = int(callargs[0])
ip = getmyip()
# Running locally:
# whenever we get a connection on 127.0.0.1:12345 we'll call hello
else:
port = 12345
ip = '127.0.0.1'
listencommhandle = waitforconn(ip,port,hello)This code will not work because globals do not exist in Repy. However, there is a mycontext dictionary provided for this purpose. The code can be written as follows:
def hello(ip,port,sockobj, thiscommhandle,listencommhandle):
sockobj.recv(512) # Receive HTTP header
mycontext['pagecount'] = mycontext['pagecount'] + 1
htmlresponse = "<html><head><title>Hello World</title></head>" + \
"<body><h1> Hello World!</h1><p>You are visitor " + \
str(mycontext['pagecount']) + "</p></body></html>"
sockobj.send("HTTP/1.1 200 OK\r\nContent-type: text/html\r\n" + \
"Content-length: %i\r\n\r\n%s" % (len(htmlresponse), htmlresponse))
stopcomm(thiscommhandle) # close my connection with this user
if callfunc == 'initialize':
mycontext['pagecount'] = 0
if len(callargs) > 1:
raise Exception("Too many call arguments")
# Running remotely:
# whenever this vessel gets a connection on its IPaddress:GENIport it'll call hello
elif len(callargs) == 1:
port = int(callargs[0])
ip = getmyip()
# Running locally:
# whenever we get a connection on 127.0.0.1:12345 we'll call hello
else:
port = 12345
ip = '127.0.0.1'
listencommhandle = waitforconn(ip,port,hello)Start the program using the shell, then open a web browser and in the address bar type: IP_of_VM:Clearinghouseport. You should see the hello world webpage and a count of 1. You can refresh the page and the count should increment. Once again,use the shell to stop the program
The previous program would run forever, waiting for a user to connect so it could display a webpage. What if you wanted the program to stop running after 1 minute? To do this, we'll register a timer that will close the connection.
def hello(ip,port,sockobj, thiscommhandle,listencommhandle):
sockobj.recv(512) # Receive HTTP header
mycontext['pagecount'] = mycontext['pagecount'] + 1
htmlresponse = "<html><head><title>Hello World</title></head>" + \
"<body><h1> Hello World!</h1><p>You are visitor " + \
str(mycontext['pagecount']) + "</p><p>I've been running " + \
str(getruntime())+" seconds</p></body></html>"
sockobj.send("HTTP/1.1 200 OK\r\nContent-type: text/html\r\n" + \
"Content-length: %i\r\n\r\n%s" % (len(htmlresponse), htmlresponse))
stopcomm(thiscommhandle) # close my connection with this user
def stop_listening(commhandle):
stopcomm(commhandle) # this will deregister hello
if callfunc == 'initialize':
mycontext['pagecount'] = 0
if len(callargs) > 1:
raise Exception("Too many call arguments")
# Running remotely:
# whenever this vessel gets a connection on its IPaddress:GENIport it'll call hello
elif len(callargs) == 1:
port = int(callargs[0])
ip = getmyip()
# Running locally:
# whenever we get a connection on 127.0.0.1:12345 we'll call hello
else:
port = 12345
ip = '127.0.0.1'
listencommhandle = waitforconn(ip,port,hello)
# wait 60 seconds, then call stop_listening with listencommhandle
eventhandle = settimer(60, stop_listening, (listencommhandle,))
The timer (when called) will stop the communication. settimer returns an eventhandle. An eventhandle is similar to a commhandle in that it can be used to interact with an event. listencommhandle is not the arguments of settimer but that of stop_listening. The comma next to stop_listening and parentheses surrounding listencommhandle indicate that.
getruntime() is used to provide the amount of time that has elapsed since the program was started. Note that it may be possible for the elapsed time to be > 60 seconds in this program because there may be some lag between when the program started and when your code ran or a delay in running the stop_listening event.
Start the program and then open a web browser and in the address bar type: IPaddress_of_VM:Clearinghouseport. You'll notice that the webpage displays and after 1 minute the program will stop listening and stop itself. You'll see that the program's status is "Terminated" because it caused itself to exit (as opposed to "Stopped" where you stopped it while it was running).
We know how to set a timer to close the connection in 60 seconds, but that doesn't help us to keep the connection open. To have the connection kept open while requests continue to happen, every time we get a request we'll cancel the existing timer and set a new timer for 10 seconds in the future that will close the connection. The timer(when called) will stop the communication. canceltimer stops a timer (if it hasn't already started).
def hello(ip,port,sockobj, thiscommhandle,listencommhandle):
sockobj.recv(512) # Receive HTTP header
mycontext['pagecount'] = mycontext['pagecount'] + 1
htmlresponse = "<html><head><title>Hello World</title></head>" + \
"<body><h1> Hello World!</h1><p>You are visitor " + \
str(mycontext['pagecount']) + "</p></body></html>"
sockobj.send("HTTP/1.1 200 OK\r\nContent-type: text/html\r\n" + \
"Content-length: %i\r\n\r\n%s" % (len(htmlresponse), htmlresponse))
stopcomm(thiscommhandle) # close my connection with this user
# stop the previous timer...
canceltimer(mycontext['stopevent'])
# start a new one for 10 seconds from now...
eventhandle = settimer(10, stop_listening, (listencommhandle,))
mycontext['stopevent'] = eventhandle
def stop_listening(commhandle):
stopcomm(commhandle) # this will deregister hello
if callfunc == 'initialize':
mycontext['pagecount'] = 0
if len(callargs) > 1:
raise Exception("Too many call arguments")
# Running remotely:
# whenever this vessel gets a connection on its IPaddress:GENIport it'll call hello
elif len(callargs) == 1:
port = int(callargs[0])
ip = getmyip()
# Running locally:
# whenever we get a connection on 127.0.0.1:12345 we'll call hello
else:
port = 12345
ip = '127.0.0.1'
listencommhandle = waitforconn(ip,port,hello)
eventhandle = settimer(10, stop_listening, (listencommhandle,))
mycontext['stopevent'] = eventhandleTry running the program and then try browsing the webpage a few times and then wait. You'll notice the connection closes 10 seconds after you stop browsing.
The wily reader may have noticed that the previous program has a race condition. It is possible to have multiple browser windows browse 127.0.0.1 at the same time. It is possible for browser window A to cancel the timer, but before it adds the new eventhandle to mycontext!['stopevent'], window B could also try to cancel the timer and set up its own event. Now there are two events that will stop communications and only one of these will be listed in mycontext!['stopevent']. This means that regardless of how often a user views the webpages, the other event will fire because there is no reference to the eventhandle. The connection will be closed (not what we want!). It would be difficult to trigger this condition manually, but we'll use a command "sleep" to pause the current function for some amount of time to allow us to trigger the bug so that we can see it in practice.
def hello(ip,port,sockobj, thiscommhandle,listencommhandle):
sockobj.recv(512) # Receive HTTP header
mycontext['pagecount'] = mycontext['pagecount'] + 1
htmlresponse = "<html><head><title>Hello World</title></head>" + \
"<body><h1> Hello World!</h1><p>You are visitor " + \
str(mycontext['pagecount']) + "</p></body></html>"
sockobj.send("HTTP/1.1 200 OK\r\nContent-type: text/html\r\n" + \
"Content-length: %i\r\n\r\n%s" % (len(htmlresponse), htmlresponse))
stopcomm(thiscommhandle) # close my connection with this user
canceltimer(mycontext['stopevent'])
sleep(5) # give me 5 seconds to trigger the race
# wait 10 seconds, then call stop_listening with listencommhandle
eventhandle = settimer(10, stop_listening, (listencommhandle,))
mycontext['stopevent'] = eventhandle
def stop_listening(commhandle):
stopcomm(commhandle) # this will deregister hello
if callfunc == 'initialize':
mycontext['pagecount'] = 0
if len(callargs) > 1:
raise Exception("Too many call arguments")
# Running remotely:
# whenever this vessel gets a connection on its IPaddress:GENIport it'll call hello
elif len(callargs) == 1:
port = int(callargs[0])
ip = getmyip()
# Running locally:
# whenever we get a connection on 127.0.0.1:12345 we'll call hello
else:
port = 12345
ip = '127.0.0.1'
listencommhandle = waitforconn(ip,port,hello)
# wait 10 seconds, then call stop_listening with listencommhandle
eventhandle = settimer(10, stop_listening, (listencommhandle,))
mycontext['stopevent'] = eventhandleTry browsing the webpage a few times rapidly and then browse every 3-5 seconds. You'll notice the program closes automatically even though it shouldn't (because you kept browsing).
One way to fix a race condition is using a lock. You can get a lock by calling getlock(). A lock supports two operations: acquire and release and is similar to the Python threading Lock class.
We can avoid race conditions by the following changes:
def hello(ip,port,sockobj, thiscommhandle,listencommhandle):
sockobj.recv(512) # Receive HTTP header
mycontext['pagecount'] = mycontext['pagecount'] + 1
htmlresponse = "<html><head><title>Hello World</title></head>" + \
"<body><h1> Hello World!</h1><p>You are visitor " + \
str(mycontext['pagecount']) + "</p></body></html>"
sockobj.send("HTTP/1.1 200 OK\r\nContent-type: text/html\r\n" + \
"Content-length: %i\r\n\r\n%s" % (len(htmlresponse), htmlresponse))
stopcomm(thiscommhandle) # close my connection with this user
mycontext['stoplock'].acquire() # acquire the lock
canceltimer(mycontext['stopevent'])
# wait 10 seconds, then call stop_listening with listencommhandle
eventhandle = settimer(10, stop_listening, (listencommhandle,))
mycontext['stopevent'] = eventhandle
mycontext['stoplock'].release() # release the lock
def stop_listening(commhandle):
stopcomm(commhandle) # this will deregister hello
if callfunc == 'initialize':
mycontext['pagecount'] = 0
mycontext['stoplock'] = getlock()
if len(callargs) > 1:
raise Exception("Too many call arguments")
# Running remotely:
# whenever this vessel gets a connection on its IPaddress:GENIport it'll call hello
elif len(callargs) == 1:
port = int(callargs[0])
ip = getmyip()
# Running locally:
# whenever we get a connection on 127.0.0.1:12345 we'll call hello
else:
port = 12345
ip = '127.0.0.1'
listencommhandle = waitforconn(ip,port,hello)
# wait 10 seconds, then call stop_listening with listencommhandle
eventhandle = settimer(10, stop_listening, (listencommhandle,))
mycontext['stopevent'] = eventhandleNow if you run the program repeatedly, it shouldn't be possible to trigger a race condition. Note that since only one event can be in the section of the code protected with locks, if you put a sleep in there and rapidly browse, you may have your program slow down because there are not enough free threads / events.
Race conditions can happen with threads created by several different functions including waitforconn, recvmess, and settimer. Remember that any callbacks or timers may be executing at the same time as your other code. If you need to prevent multiple threads from modifying a variable or executing a piece of code at the same time, use a lock!
We'll now switch gears from our hello world web server and focus instead on writing data to files. The first program we'll write the string "hello world" to a file and then read it back out and print it.
if callfunc == 'initialize':
# just like python's open() function
myfileobject = open("hello.file","w")
# we also could have used myfileobject.write("hello world\n")
print >> myfileobject, "hello world"
myfileobject.close()
# we can use file instead of open. They work the same...
newfileobject = file("hello.file","r")
print newfileobject.read()
newfileobject.close()This program should print hello world (and an extra newline from print). The Repy file object is similar to python's file object so you can do things like:
for line in file("hello.file","r"):
# code here
...In this example, we'll change our program to write information to a few different files and after we're finished, we'll remove the files. Instead of coding in the program which files to write information to, we'll let our command line arguments specify which files to write.
if callfunc == 'initialize':
for filename in callargs: # callargs has all of the command line arguments in it.
# just like python's open() function
myfileobject = open(filename,"w")
# we also could have used myfileobject.write("hello world\n")
print >> myfileobject, "hello world"
myfileobject.close()
# now we'll go through and print the files in this directory
# (it may include things other than our files).
print listdir()
for filename in callargs: # let's remove our files now...
removefile(filename)
print "The files:",callargs," should now be missing from ",listdir() You should see output that first lists the file names in the current directory (along with the files you chose to write) and then shows the listing missing the files. Note that if you choose file names with characters like "/", " ", "@", or other non-alphanumeric characters you will get an error because Repy programs are not allowed to use certain characters in file names.
In this example, we'll retrieve a webpage and print it on the screen. We're not going to translate all of the HTML or remove the HTTP headers, so it will be a bit messy.
if callfunc == 'initialize':
# open a connection to the google web server
socketobject = openconn("www.google.com",80)
# this is a HTTP request...
socketobject.send("GET /index.html HTTP/1.1\r\nHost: www.google.com\r\n\r\n")
while True:
print socketobject.recv(4096)You should see google's webpage along with some numbers and other information (this is the HTTP protocol). However, the program does not stop (at least until you press CTRL-C)! This is because HTTP 1.1 allows us to issue multiple page requests on a single connection.
In this example, we'll change the previous program to exit after we receive the data from google. To do this we'll use a function called exitall(). This function causes the program to abort and all threads to exit immediately. We can add this to a timer to the previous example as follows:
if callfunc == 'initialize':
# open a connection to the google web server
socketobject = openconn("www.google.com",80)
# this is a HTTP request...
socketobject.send("GET /index.html HTTP/1.1\r\nHost: www.google.com\r\n\r\n")
# We'll loop and print information from google.
# We don't "speak" HTTP, so we'll set a timer to exit in 3 seconds
settimer(3, exitall, ())
while True:
print socketobject.recv(4096)Alternatively, we could instead close the socket and check this condition. Example code that shows this is below
if callfunc == 'initialize':
# open a connection to the google web server
socketobject = openconn("www.google.com",80)
# this is a HTTP request...
socketobject.send("GET /index.html HTTP/1.1\r\nHost: www.google.com\r\n\r\n")
# We'll loop and print information from google.
# We don't "speak" HTTP, so we'll set a timer to close the socket in 3 seconds
settimer(3, socketobject.close, ())
while True:
try:
print socketobject.recv(4096)
except Exception, e: # we got an exception. Did they close the socket?
if str(e) != "Socket closed":
raise
breakIn this example, we'll look up some IP addresses using gethostname_ex:
if callfunc == 'initialize':
print gethostbyname_ex("www.google.com")
print gethostbyname_ex("www.wikipedia.com")
print getmyip()This will print IP address, hostname and other information for google and wikipedia and will also print the current computer's IP address. For more information about the format of the data returned from gethostbyname_ex see the API.
In this example, we'll manually send a NTP (time) lookup message and print the raw data that is returned. Rather than hard code a server into our program, we'll randomly choose a server from a list of publicly available time servers. A lot of the complexity in this program comes with encoding and decoding NTP data.
# See RFC 2030 (http://www.ietf.org/rfc/rfc2030.txt) for details about NTP
# this unpacks the data from the packet and changes it to a float
def convert_timestamp_to_float(timestamp):
integerpart = (ord(timestamp[0])<<24) + (ord(timestamp[1])<<16) + \
(ord(timestamp[2])<<8) + (ord(timestamp[3]))
floatpart = (ord(timestamp[4])<<24) + (ord(timestamp[5])<<16) + \
(ord(timestamp[6])<<8) + (ord(timestamp[7]))
return integerpart + floatpart / float(2**32)
def decode_NTP_packet(ip, port, mess, ch):
print "From "+str(ip)+":"+str(port)+", I received NTP data."
print "NTP Reference Identifier:",mess[12:16]
print "NTP Transmit Time (in seconds since Jan 1st, 1900):", convert_timestamp_to_float(mess[40:48])
stopcomm(ch)
if callfunc == 'initialize':
ip = getmyip()
timeservers = ["time-a.nist.gov", "time-b.nist.gov",
"time-a.timefreq.bldrdoc.gov", "time-b.timefreq.bldrdoc.gov",
"time-c.timefreq.bldrdoc.gov", "utcnist.colorado.edu", "time.nist.gov",
"time-nw.nist.gov", "nist1.symmetricom.com", "nist1-dc.WiTime.net",
"nist1-ny.WiTime.net", "nist1-sj.WiTime.net", "nist.expertsmi.com",
"nist.netservicesgroup.com"]
# choose a random time server from the list
servername = timeservers[int(randomfloat()*len(timeservers))]
print "Using: ", servername
# this sends a request, version 3 in "client mode"
ntp_request_string = chr(27)+chr(0)*47
recvmess(ip,12345, decode_NTP_packet)
sendmess(servername,123, ntp_request_string, ip, 12345) # port 123 is used for NTPThis will print the number of seconds since Jan 1st, 1900 from a time server. If you run the program multiple times, you'll see it chooses servers randomly from the timeservers list.
One thing to note, connection functions like opencomm and waitforcomm use different ports (TCP) than message functions like sendmess and recvmess (UDP).
Getting the time from a synchronized time source is a handy thing to do (so this isn't bad code to repurpose for your code). You shouldn't ask for the time repeatedly from the time servers though (they consider requests more frequent than 4 seconds apart to be a DoS attack). You can ask once for a global reference time and then use getruntime to measure the elapsed time.
In the previous examples, we've been running code on our local system which we have control over. When deploying Repy programs, you may instead end up running your code on systems that don't belong to you. Since you don't control these systems, the users are likely to have a set of restrictions on what you can do on their computer. You may be unable to write files to disk, not be able to send packets to certain IP addresses, or prevented from performing operations.
To get a restriction / restrictions file, in the shell type: show resources. If you look at a restrictions file, you'll see a bunch of lines like this (ignore the resource lines for now):
call sendmess allow
call stopcomm allow # it doesn't make sense to restrict
call recvmess allow
call openconn allow
call waitforconn allow
call socket.close allow # let's not restrict
call socket.send allow # let's not restrict
call socket.recv allow # let's not restrict
# open and file.__init__ both have built in restrictions...
call open arg 0 is junk_test.out allow # can write to junk_test.out
call open arg 1 is r allow # allow an explicit read
call open noargs is 1 allow # allow an implicit read
call file.__init__ arg 0 is junk_test.out allow # can write to junk_test.out
call file.__init__ arg 1 is r allow # allow an explicit read
call file.__init__ noargs is 1 allow # allow an implicit read
call file.close allow # shouldn't restrict
call file.flush allow # they are free to use
call file.next allow # free to use as well...
call file.read allow # allow read
call file.readline allow # shouldn't restrict
call file.readlines allow # shouldn't restrict
call file.seek allow # seek doesn't restrict
call file.write allow # shouldn't restrict (open restricts)
call file.writelines allow # shouldn't restrict (open restricts)
call sleep allow # harmless
call settimer allow # we can't really do anything smart
call canceltimer allow # should be okay
call exitall allow # should be harmless
call log.write allow # allows printing to the log
call log.writelines allow # a different format of printing to the log
call getmyip allow # They can get the external IP address
call listdir allow # They can list the files they created
call removefile allow # They can remove the files they create
call randomfloat allow # can get random numbers
call getruntime allow # can get the elapsed time
call getlock allow # can get a lockThese lines specify which functions the program is allowed to call. They may also list the arguments that can be passed. When you create a program, you should decide which actions it needs to perform. It is easier for you to locate computers you can run on if your program has fewer requirements. You can specify that a function can only be called with a certain number of arguments or certain arguments. This can be helpful to restrict your program to use certain filenames or functions.
In the previous section, we looked at restrictions; a mechanism for allowing or denying an action. These aren't adequate for many cases. For example, you can say a program can or cannot write files, but you cannot say that a program can only write 1MB worth of files. This is where resources come in. They put limits on the number of resources a program can consume.
If you look at a restrictions / resources file, you'll see a bunch of lines like this:
resource cpu .10
resource memory 10000000 # 10 Million bytes
resource diskused 10000000 # 10 MB
resource events 10
resource filewrite 10000
resource fileread 10000
resource filesopened 5
resource insockets 5
resource outsockets 5
resource netsend 10000
resource netrecv 10000
resource loopsend 1000000
resource looprecv 1000000
resource lograte 30000
resource random 100
resource messport 12345
resource messport 12346
resource connport 12345These lines specify the type and quantity of resources the program can consume. Some resources like CPU, the netsend / recv rate, random number generation rate, etc. are for renewable resources. Renewable resources are resources that replenish themselves over time. For example, if your program is using too much CPU, it will be paused temporarily to allow other programs to run. Trying to use too much of a renewable resource will cause a call to run slowly.
Alternatively, other resources like memory, disk used, sockets, etc. are not renewable. In other words, the resource has a hard limit and is does does not automatically replenish itself over time. When you use too much of one of these resources, the call in your program which causes it to be over the limit may raise an exception or in some cases the program may be killed outright.
For more information about resources and restrictions see the resources and restrictions guide.
This concludes a brief tour of the Repy functionality. This guide has covered all of the API calls for Repy. For more detailed information see the Library Reference and the Resources and Restrictions guide. You should now be able to build your own Repy applications that can run on hundreds of computers. Good luck!