diff --git a/README.md b/README.md
index 3f8b67a436..5b21de3d3b 100644
--- a/README.md
+++ b/README.md
@@ -148,3 +148,8 @@ Thanks to [JetBrains](https://www.jetbrains.com/?from=dlink) for providing a fre
Please refer to the [LICENSE](https://github.com/DataLinkDC/dinky/blob/dev/LICENSE) document.
+# Contributors
+
+
+  +
diff --git a/README_zh_CN.md b/README_zh_CN.md
index 2ec688593c..a497d493d3 100644
--- a/README_zh_CN.md
+++ b/README_zh_CN.md
@@ -148,4 +148,10 @@ Dinky 是一个 `开箱即用` 、`易扩展` ,以 `Apache Flink` 为基础,
## 版权
-请参考 [LICENSE](https://github.com/DataLinkDC/dinky/blob/dev/LICENSE) 文件。
\ No newline at end of file
+请参考 [LICENSE](https://github.com/DataLinkDC/dinky/blob/dev/LICENSE) 文件。
+
+# 贡献者
+
+
+
+
diff --git a/dinky-admin/src/main/java/org/dinky/service/impl/TaskServiceImpl.java b/dinky-admin/src/main/java/org/dinky/service/impl/TaskServiceImpl.java
index 43d4d5d36a..550be8e02b 100644
--- a/dinky-admin/src/main/java/org/dinky/service/impl/TaskServiceImpl.java
+++ b/dinky-admin/src/main/java/org/dinky/service/impl/TaskServiceImpl.java
@@ -511,14 +511,21 @@ public boolean changeTaskLifeRecyle(Integer taskId, JobLifeCycle lifeCycle) thro
boolean saved = saveOrUpdate(task.buildTask());
if (saved && Asserts.isNotNull(task.getJobInstanceId())) {
JobInstance jobInstance = jobInstanceService.getById(task.getJobInstanceId());
- jobInstance.setStep(lifeCycle.getValue());
- jobInstanceService.updateById(jobInstance);
- log.info("jobInstance [{}] step change to {}", jobInstance.getJid(), lifeCycle.getValue());
+ if (Asserts.isNotNull(jobInstance)) {
+ jobInstance.setStep(lifeCycle.getValue());
+ boolean updatedJobInstance = jobInstanceService.updateById(jobInstance);
+ if (updatedJobInstance) jobInstanceService.refreshJobInfoDetail(jobInstance.getId(), true);
+ log.warn(
+ "JobInstance [{}] step change to [{}] ,Trigger Force Refresh",
+ jobInstance.getName(),
+ lifeCycle.getValue());
+ }
}
return saved;
}
@Override
+ @Transactional(rollbackFor = Exception.class)
public boolean saveOrUpdateTask(Task task) {
Task byId = getById(task.getId());
if (byId != null && JobLifeCycle.PUBLISH.equalsValue(byId.getStep())) {
diff --git a/dinky-web/src/pages/DataStudio/LeftContainer/Project/function.tsx b/dinky-web/src/pages/DataStudio/LeftContainer/Project/function.tsx
index e3d76a29a8..36b02ad10f 100644
--- a/dinky-web/src/pages/DataStudio/LeftContainer/Project/function.tsx
+++ b/dinky-web/src/pages/DataStudio/LeftContainer/Project/function.tsx
@@ -80,19 +80,19 @@ export const buildStepValue = (step: number) => {
return {
title: l('global.table.lifecycle.dev'),
status: 'processing',
- color: '#1890ff'
+ color: 'cyan'
};
case 2:
return {
title: l('global.table.lifecycle.online'),
status: 'success',
- color: '#52c41a'
+ color: 'purple'
};
default:
return {
title: l('global.table.lifecycle.dev'),
status: 'default',
- color: '#1890ff'
+ color: 'cyan'
};
}
};
@@ -144,7 +144,8 @@ export const buildProjectTree = (
<>
);
diff --git a/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/FlinkTable.tsx b/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/FlinkTable.tsx
index dd539aaa97..bc2a4595fa 100644
--- a/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/FlinkTable.tsx
+++ b/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/FlinkTable.tsx
@@ -19,7 +19,12 @@
import StatusTag from '@/components/JobTags/StatusTag';
import { JobProps } from '@/pages/DevOps/JobDetail/data';
-import { parseByteStr, parseMilliSecondStr, parseNumStr } from '@/utils/function';
+import {
+ formatTimestampToYYYYMMDDHHMMSS,
+ parseByteStr,
+ parseMilliSecondStr,
+ parseNumStr
+} from '@/utils/function';
import { l } from '@/utils/intl';
import { ProCard, ProColumns, ProTable } from '@ant-design/pro-components';
import { Typography } from 'antd';
@@ -32,8 +37,10 @@ export type VerticesTableListItem = {
metrics: any;
parallelism: number;
startTime?: number;
+ 'start-time'?: number;
duration?: number;
endTime?: number;
+ 'end-time'?: number;
tasks: any;
};
@@ -101,15 +108,20 @@ const FlinkTable = (props: JobProps): JSX.Element => {
},
{
title: l('global.table.startTime'),
- dataIndex: 'startTime',
- valueType: 'dateTime'
+ render: (dom, entity) => {
+ return entity.startTime === -1 || entity['start-time'] === -1
+ ? '-'
+ : formatTimestampToYYYYMMDDHHMMSS(entity['start-time'] as number) ||
+ formatTimestampToYYYYMMDDHHMMSS(entity.startTime as number);
+ }
},
{
title: l('global.table.endTime'),
- dataIndex: 'endTime',
- valueType: 'dateTime',
render: (dom, entity) => {
- return entity.endTime === -1 ? '-' : entity.endTime;
+ return entity.endTime === -1 || entity['end-time'] === -1
+ ? '-'
+ : formatTimestampToYYYYMMDDHHMMSS(entity['end-time'] as number) ||
+ formatTimestampToYYYYMMDDHHMMSS(entity.endTime as number);
}
},
{
diff --git a/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/JobDesc.tsx b/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/JobDesc.tsx
index bb645801e7..99e50d90f6 100644
--- a/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/JobDesc.tsx
+++ b/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/JobDesc.tsx
@@ -88,7 +88,7 @@ const JobDesc = (props: JobProps) => {
- {jobDetail?.jobDataDto?.config?.executionConfig?.restartStrategy}
+ {jobDetail?.jobDataDto?.config['execution-config']['restart-strategy']}
@@ -109,13 +109,11 @@ const JobDesc = (props: JobProps) => {
- {jobDetail?.history?.configJson?.useSqlFragment
- ? l('button.enable')
- : l('button.disable')}
+ {jobDetail?.history?.configJson?.fragment ? l('button.enable') : l('button.disable')}
- {jobDetail?.history?.configJson?.useBatchModel
+ {jobDetail?.history?.configJson?.batchModel
? l('global.table.execmode.batch')
: l('global.table.execmode.streaming')}
@@ -125,7 +123,7 @@ const JobDesc = (props: JobProps) => {
- {jobDetail?.jobDataDto?.config?.executionConfig?.jobParallelism}
+ {jobDetail?.jobDataDto?.config['execution-config']['job-parallelism']}
@@ -137,7 +135,7 @@ const JobDesc = (props: JobProps) => {
- {jobDetail?.history?.configJson.savePointPath}
+ {jobDetail?.history?.configJson?.configJson['state.savepoints.dir'] ?? '-'}
diff --git a/dinky-web/src/pages/DevOps/JobDetail/index.tsx b/dinky-web/src/pages/DevOps/JobDetail/index.tsx
index 337d7ab1b4..e80134a2af 100644
--- a/dinky-web/src/pages/DevOps/JobDetail/index.tsx
+++ b/dinky-web/src/pages/DevOps/JobDetail/index.tsx
@@ -65,7 +65,7 @@ const JobDetail = (props: any) => {
pollingInterval: 3000
});
- const jobInfoDetail: Jobs.JobInfoDetail = data;
+ const jobInfoDetail = data as Jobs.JobInfoDetail;
const [tabKey, setTabKey] = useState(OperatorEnum.JOB_BASE_INFO);
diff --git a/dinky-web/src/types/DevOps/data.d.ts b/dinky-web/src/types/DevOps/data.d.ts
index 13d615472b..f25fff4868 100644
--- a/dinky-web/src/types/DevOps/data.d.ts
+++ b/dinky-web/src/types/DevOps/data.d.ts
@@ -18,7 +18,7 @@
*/
import { BaseBeanColumns } from '@/types/Public/data';
-import { Alert } from '@/types/RegCenter/data.d';
+import { Alert, Cluster } from '@/types/RegCenter/data.d';
/**
* about flink job
@@ -48,6 +48,62 @@ declare namespace Jobs {
useBatchModel: string;
};
+ export type ExecutorSetting = {
+ type: string;
+ host: string;
+ port: number;
+ useBatchModel: boolean;
+ checkpoint: string;
+ parallelism: number;
+ useSqlFragment: boolean;
+ useStatementSet: boolean;
+ savePointPath: string;
+ jobName: string;
+ config: Map;
+ variables: Map;
+ jarFiles: [];
+ jobManagerAddress: string;
+ plan: boolean;
+ remote: boolean;
+ validParallelism: boolean;
+ validJobName: boolean;
+ validHost: boolean;
+ validPort: boolean;
+ validConfig: boolean;
+ validVariables: boolean;
+ validJarFiles: boolean;
+ };
+
+ export type JobConfigJsonInfo = {
+ type: string;
+ checkpoint: string;
+ savePointStrategy: string;
+ savePointPath: string;
+ parallelism: number;
+ clusterId: number;
+ clusterConfigurationId: number;
+ step: number;
+ configJson: {
+ 'state.savepoints.dir': string;
+ };
+ useResult: boolean;
+ useChangeLog: boolean;
+ useAutoCancel: boolean;
+ useRemote: boolean;
+ address: string;
+ taskId: number;
+ jarFiles: [];
+ pyFiles: [];
+ jobName: string;
+ fragment: boolean;
+ statementSet: boolean;
+ batchModel: boolean;
+ maxRowNum: number;
+ gatewayConfig: any;
+ variables: Map;
+ executorSetting: ExecutorSetting;
+ };
+
export type History = {
id: number;
tenantId: number;
@@ -61,7 +117,7 @@ declare namespace Jobs {
type: string;
error: string;
result: string;
- configJson: JobConfig;
+ configJson: JobConfigJsonInfo;
startTime: string;
endTime: string;
taskId: number;
@@ -166,13 +222,18 @@ declare namespace Jobs {
jid: string;
name: string;
executionConfig: ExecutionConfig;
+ 'execution-config': ExecutionConfig;
};
export type ExecutionConfig = {
executionMode: string;
+ 'execution-mode': string;
restartStrategy: string;
+ 'restart-strategy': string;
jobParallelism: number;
- objectReuse: boolean;
+ 'job-parallelism': number;
+ 'object-reuse': boolean;
userConfig: any;
+ 'user-config': any;
};
export type JobDataDtoItem = {
@@ -191,8 +252,8 @@ declare namespace Jobs {
export type JobInfoDetail = {
id: number;
instance: JobInstance;
- clusterInstance: any;
- clusterConfiguration: any;
+ clusterInstance: Cluster.Instance;
+ clusterConfiguration: Cluster.Config;
history: History;
jobDataDto: JobDataDtoItem;
jobManagerConfiguration: any;
diff --git a/dinky-web/src/utils/function.tsx b/dinky-web/src/utils/function.tsx
index 755deca87d..e00484b843 100644
--- a/dinky-web/src/utils/function.tsx
+++ b/dinky-web/src/utils/function.tsx
@@ -45,7 +45,6 @@ import { l } from '@/utils/intl';
import { Monaco } from '@monaco-editor/react';
import dayjs from 'dayjs';
import cookies from 'js-cookie';
-import { trim } from 'lodash';
import { editor, KeyCode, KeyMod } from 'monaco-editor';
import path from 'path';
import { format } from 'sql-formatter';
@@ -619,6 +618,13 @@ export const formatDateToYYYYMMDDHHMMSS = (date: Date) => {
return dayjs(date).format(DATETIME_FORMAT);
};
+export const formatTimestampToYYYYMMDDHHMMSS = (timestamp: number) => {
+ if (timestamp == null) {
+ return '-';
+ }
+ return dayjs(timestamp).format(DATETIME_FORMAT);
+};
+
export const parseDateStringToDate = (dateString: Date) => {
return dayjs(dateString).toDate();
};
diff --git a/docs/docs/data_integration_guide/dinky_k8s_quick_start.mdx b/docs/docs/data_integration_guide/dinky_k8s_quick_start.mdx
index 74518fffce..f4e08b931f 100644
--- a/docs/docs/data_integration_guide/dinky_k8s_quick_start.mdx
+++ b/docs/docs/data_integration_guide/dinky_k8s_quick_start.mdx
@@ -3,6 +3,7 @@ sidebar_position: 1
id: dinky_k8s_quick_start
title: K8s集成
---
+
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
@@ -20,27 +21,21 @@ Dinky支持以下几种 Flink on k8s 运行模式:
**部分内容可参考 Flink 对应集成 k8s 文档链接**
-
-
-
-[https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
-
-
-
-
-[https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
-
-
-
-
-[https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
-
-
-
-
-[https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
-
-
+
+ [https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
+
+
+ [https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
+
+
+ [https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
+
+
+ [https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
+
+
+ [https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
+
@@ -144,52 +139,61 @@ ADD extends /opt/flink/lib # 把当前extends目录下的jar添加进依赖目
##### Kubernetes 配置
-| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
-|--------|--------------------------------------------------------|:----:|:---:|:----------:|
-| 暴露端口类型 | 支持NodePort与ClusterIP | 是 | 无 | NodePort |
-| Kubernetes 命名空间 | 集群所在的 Kubernetes 命名空间 | 是 | 无 | dinky |
-| K8s 提交账号 | 集群提交任务的账号 | 是 | 无 | default |
-| Flink 镜像地址 | 上一步打包的镜像地址 | 是 | 无 | dinky-flink-1.0.0-1.15.4 |
-| JobManager CPU 配置 | JobManager 资源配置 | 否 | 无 | 1 |
-| TaskManager CPU 配置 | TaskManager 资源配置 | 否 | 无 | 1 |
-| Flink 配置文件路径 | 仅指定到文件夹,dinky会自行读取文件夹下的配置文件并作为flink的默认配置 | 否 | 无 | /opt/flink/conf |
+| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
+|--------------------|------------------------------------------|:----:|:---:|:------------------------:|
+| 暴露端口类型 | 支持NodePort与ClusterIP | 是 | 无 | NodePort |
+| Kubernetes 命名空间 | 集群所在的 Kubernetes 命名空间 | 是 | 无 | dinky |
+| K8s 提交账号 | 集群提交任务的账号 | 是 | 无 | default |
+| Flink 镜像地址 | 上一步打包的镜像地址 | 是 | 无 | dinky-flink-1.0.0-1.15.4 |
+| JobManager CPU 配置 | JobManager 资源配置 | 否 | 无 | 1 |
+| TaskManager CPU 配置 | TaskManager 资源配置 | 否 | 无 | 1 |
+| Flink 配置文件路径 | 仅指定到文件夹,dinky会自行读取文件夹下的配置文件并作为flink的默认配置 | 否 | 无 | /opt/flink/conf |
> 如果您有其他的配置项需要添加,请点击添加配置项按钮,添加完毕后,点击保存即可
##### Kubernetes 连接与pod配置
-| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
-|--------|--------------------------------------------------------|:----:|:---:|:----------:|
-|K8s KubeConfig |集群的KubeConfig内容,如果不填写,则默认使用`~/.kube/config`文件 | 否 | 无 | 无 |
-|Default Pod Template |默认的Pod模板 | 否 | 无 | 无 |
-|JM Pod Template |JobManager的Pod模板 | 否 | 无 | 无 |
-|TM Pod Template |TaskManager的Pod模板 | 否 | 无 | 无 |
+| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
+|----------------------|-----------------------------------------------|:----:|:---:|:---:|
+| K8s KubeConfig | 集群的KubeConfig内容,如果不填写,则默认使用`~/.kube/config`文件 | 否 | 无 | 无 |
+| Default Pod Template | 默认的Pod模板 | 否 | 无 | 无 |
+| JM Pod Template | JobManager的Pod模板 | 否 | 无 | 无 |
+| TM Pod Template | TaskManager的Pod模板 | 否 | 无 | 无 |
##### 提交 FlinkSQL 配置项 (Application 模式必填)-公共配置
-| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
-|--------|----------------------------------------------------------------------------------------------------------|:----:|:---:|:--------------:|
-| Jar 文件路径 | 指定镜像内dinky-app的 Jar 文件路径,如果该集群配置用于提交 Application 模式任务时 则必填| 否 | 无 | local:///opt/flink/dinky-app-1.16-1.0.0-jar-with-dependencies.jar |
+| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
+|----------|------------------------------------------------------------|:----:|:---:|:-----------------------------------------------------------------:|
+| Jar 文件路径 | 指定镜像内dinky-app的 Jar 文件路径,如果该集群配置用于提交 Application 模式任务时 则必填 | 否 | 无 | local:///opt/flink/dinky-app-1.16-1.0.0-jar-with-dependencies.jar |
> 由于flink限制,k8s模式只能加载镜像内的jar包,也就是地址必须为local://开头,如果想要自定义jar提交,请查阅jar提交部分
#### Flink 预设配置(高优先级)-公共配置
-| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
-|-----------------|----|:----:|:---:|:--:|
-| JobManager 内存 | JobManager 内存大小! | 否 | 无 | 1g |
-| TaskManager 内存 | TaskManager 内存大小! | 否 | 无 | 1g |
-| TaskManager 堆内存 | TaskManager 堆内存大小! | 否 | 无 | 1g |
-| 插槽数 | 插槽数量 | 否 | 无 | 2 |
-| 保存点路径 | 对应SavePoint目录 | 否 | 无 | hdfs:///flink/savepoint |
-| 检查点路径 | 对应CheckPoint目录 | 否 | 无 | hdfs:///flink/checkpoint |
+| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
+|-----------------|--------------------|:----:|:---:|:------------------------:|
+| JobManager 内存 | JobManager 内存大小! | 否 | 无 | 1g |
+| TaskManager 内存 | TaskManager 内存大小! | 否 | 无 | 1g |
+| TaskManager 堆内存 | TaskManager 堆内存大小! | 否 | 无 | 1g |
+| 插槽数 | 插槽数量 | 否 | 无 | 2 |
+| 保存点路径 | 对应SavePoint目录 | 否 | 无 | hdfs:///flink/savepoint |
+| 检查点路径 | 对应CheckPoint目录 | 否 | 无 | hdfs:///flink/checkpoint |
## 启动session集群(可选)
+
除了您自己手动部署session集群外,dinky还提供了快捷方式部署Kubernetes session集群,在上面Kubernetes集群配置完成后,点击启动按钮即可向指定Kubernetes集群提交session集群
+
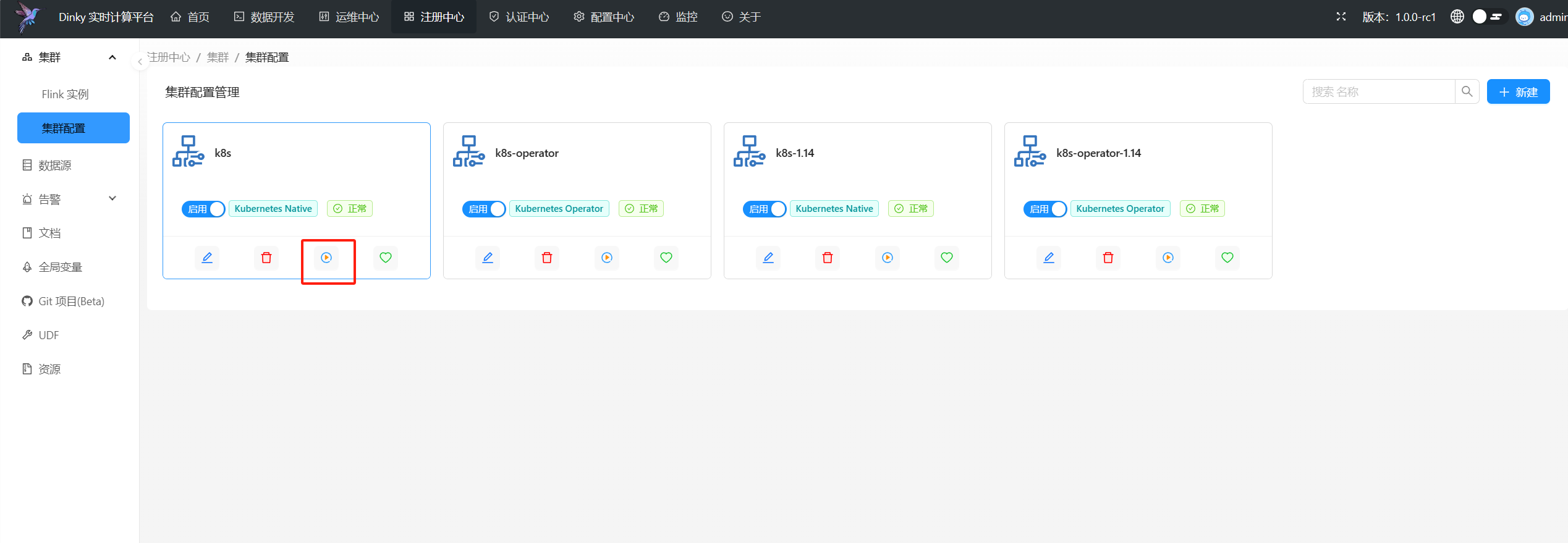
+
至此,所有准备工作均已完成完成,接下来就可以通过` kubernetes session`模式或`kubernetes application`模式进行任务提交啦。
+
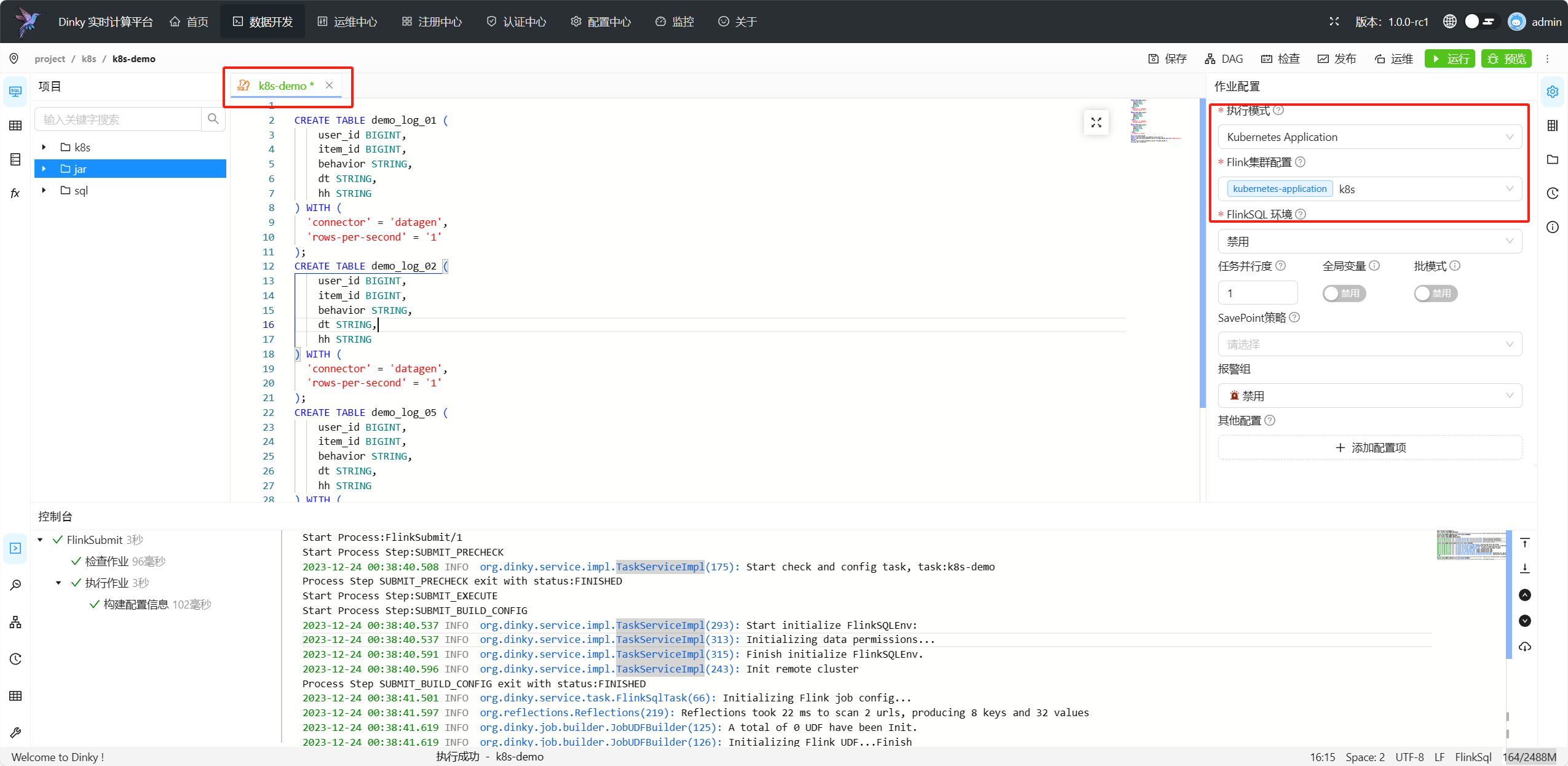
## 提交 kubernetes application 任务
+
进入数据开发页面,新建一个flink sql任务,选择集群类型为`kubernetes application`,集群选择为我们刚刚配置的集群,点击提交即可
-## 提交 kubernetes session 任务
+
+
+
+## 提交 kubernetes session 任务
+
进入数据开发页面,新建一个flink sql任务,选择集群类型为`kubernetes session`,集群选择为我们刚刚配置的集群,点击提交即可
图片同上
\ No newline at end of file
diff --git a/docs/docs/developer_guide/local_debug.md b/docs/docs/developer_guide/local_debug.md
index 8d1bbd6a94..69d99a8ecb 100644
--- a/docs/docs/developer_guide/local_debug.md
+++ b/docs/docs/developer_guide/local_debug.md
@@ -90,7 +90,7 @@ npm run dev
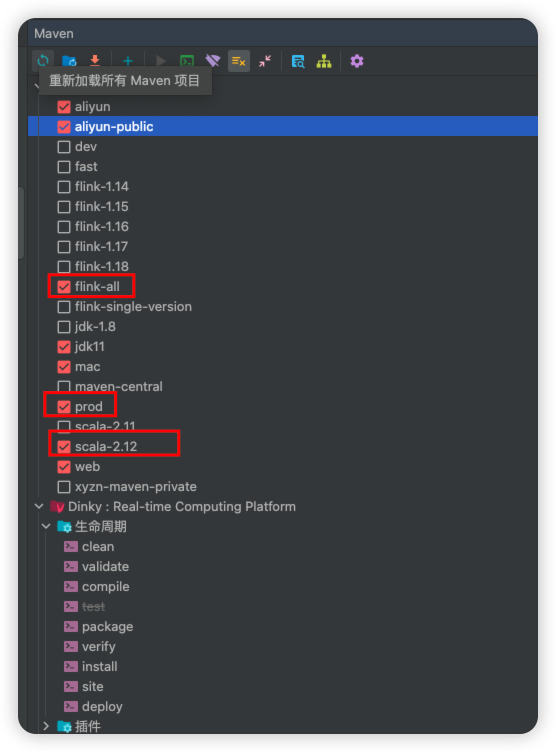
由于目前 Dinky 各个模块未发布到 Maven 中央仓库,所以需要先进行 Install 编译。从而在本地仓库中生成相应的依赖。
-如果你是第一次编译 Dinky,那么请勾选以下 Maven Profile,然后下图中的`生命周期 -> Install`进行编译。
+如果你是第一次编译 Dinky,那么请勾选以下 Maven Profile,然后双击下图中的`生命周期 -> Install`进行编译。
:::
diff --git a/docs/docs/extend/function_expansion/alert.md b/docs/docs/extend/function_expansion/alert.md
deleted file mode 100644
index abd034f218..0000000000
--- a/docs/docs/extend/function_expansion/alert.md
+++ /dev/null
@@ -1,169 +0,0 @@
----
-sidebar_position: 4
-id: alert
-title: 扩展报警插件
----
-
-
-
-
-Dinky 告警机制遵循 SPI,可随意扩展所需要的告警机制。如需扩展可在 dinky-alert 模块中进行可插拔式扩展。现已经支持的告警机制包括如下:
-
-- DingDingTalk
-- 企业微信: 同时支持**APP** 和 **WeChat 群聊** 方式
-- Email
-- 飞书
-
-Dinky 学习了 ``Apache Dolphinscheduler`` 的插件扩展机制,可以在 Dinky 中添加自定义的告警机制。
-
-## 准备工作
-- 本地开发环境搭建
- - 详见 [开发者本地调试手册](../../developer_guide/local_debug)
-
-## 后端开发
-- 在 **dinky-alert** 新建子模块 , 命名规则为 `dinky-alert-{报警类型}` 在子模块中实现相关告警机制
-- **代码层面** 根据告警场景自行实现报警逻辑
- - 注意事项:
- - 不可在父类的基础上修改代码,可以在子类中进行扩展 ,或者重写父类方法
- - 注意告警所使用到的常量需要继承**AlertBaseConstant** 其他差异的特殊常量在新建的模块中定义,参考其他告警类型代码
- - 扩展告警类型需要同时提交**测试用例**
-- 需要在新建的此模块的 **resource** 下 新建包 ``META-INF.services`` , 在此包中新建文件 ``org.dinky.alert.Alert`` 内容如下:
- - ``org.dinky.alert.{报警类型}.{报警类型Alert}`` 参考其他告警类型的此文件
-- 打包相关配置 修改如下:
- - 在 **dinky-core** 模块的 **pom.xml** 下 , 找到扩展告警相关的依赖 `放在一起方便管理` 并且新增如下内容:
- ```xml
-
- org.dinky
- 模块名称
- ${scope.runtime}
-
- ```
-
- - 在 **dinky-admin** 模块的 **pom.xml** 下 , 找到扩展告警相关的依赖 `放在一起方便管理` 并且新增如下内容:
- ```xml
-
- org.dinky
- 模块名称
- ${expand.scope}
-
- ```
-
-- 在 **dinky** 根下 **pom.xml** 中 ,新增如下内容:
- ```xml
-
- org.dinky
- 模块名称
- ${project.version}
-
- ```
-
-- 在 **dinky-assembly** 模块中 , 找到 ``package.xml`` 路径: **/dinky-assembly/src/main/assembly/package.xml** , 新增如下内容:
-```xml
-
- ${project.parent.basedir}/dinky-alert/模块名称/target
-
- lib
-
- 模块名称-${project.version}.jar
-
-
- ```
-
-
-----
-
-## 前端开发
-- **dinky-web** 为 Dinky 的前端模块
-- 扩展告警插件相关表单所在路径: `dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance`
- - 修改 `dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance/conf.ts`
-
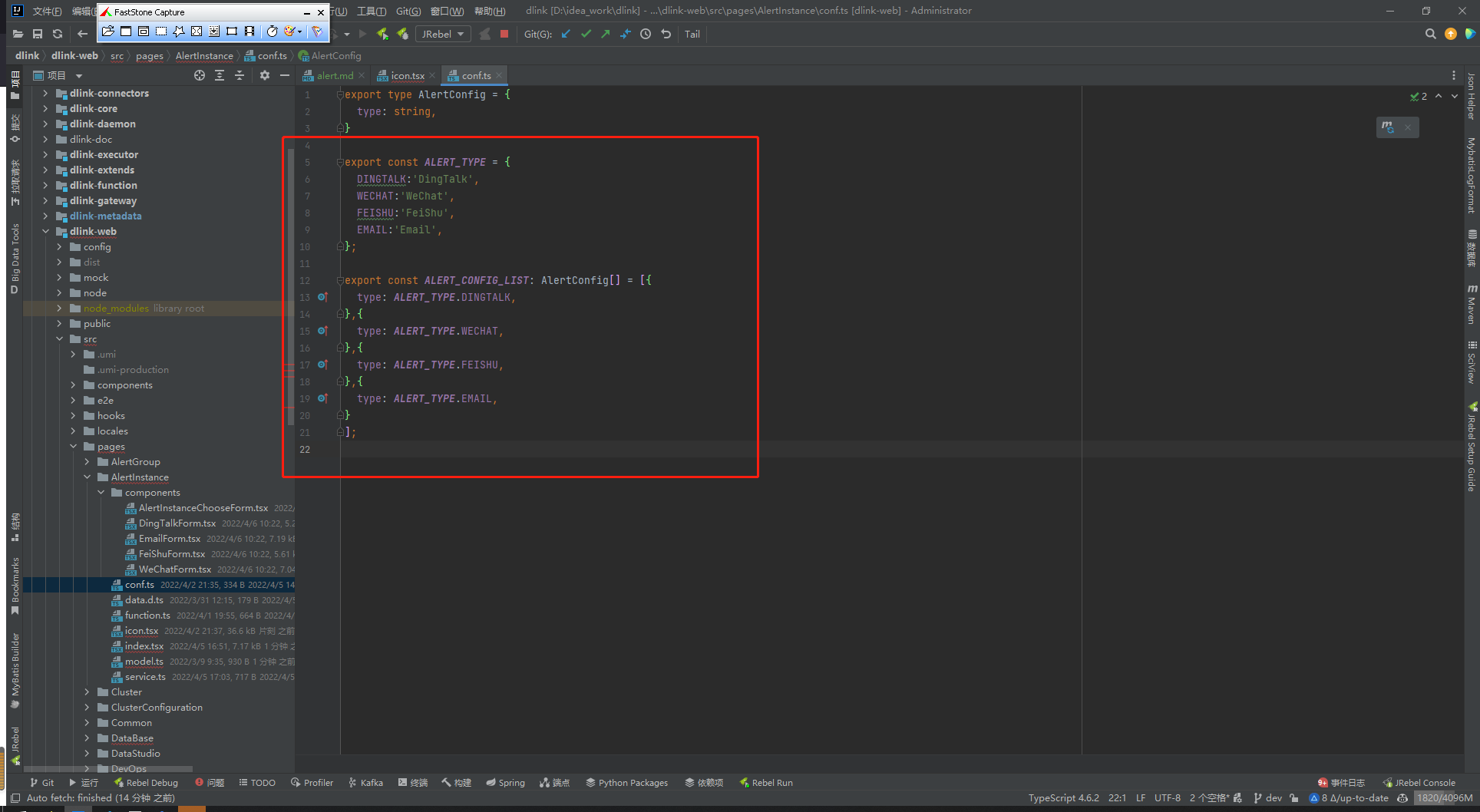
- **ALERT_TYPE** 添加如下 eg:
- ``` typescript
- EMAIL:'Email',
- ```
- **ALERT_CONFIG_LIST** 添加如下 eg:
- ```typescript
- {
- type: ALERT_TYPE.EMAIL,
- }
- ```
- **注意:** 此处属性值需要与后端 `AlertTypeEnum` 声明的值保持一致
-
-如下图:
-
-
-
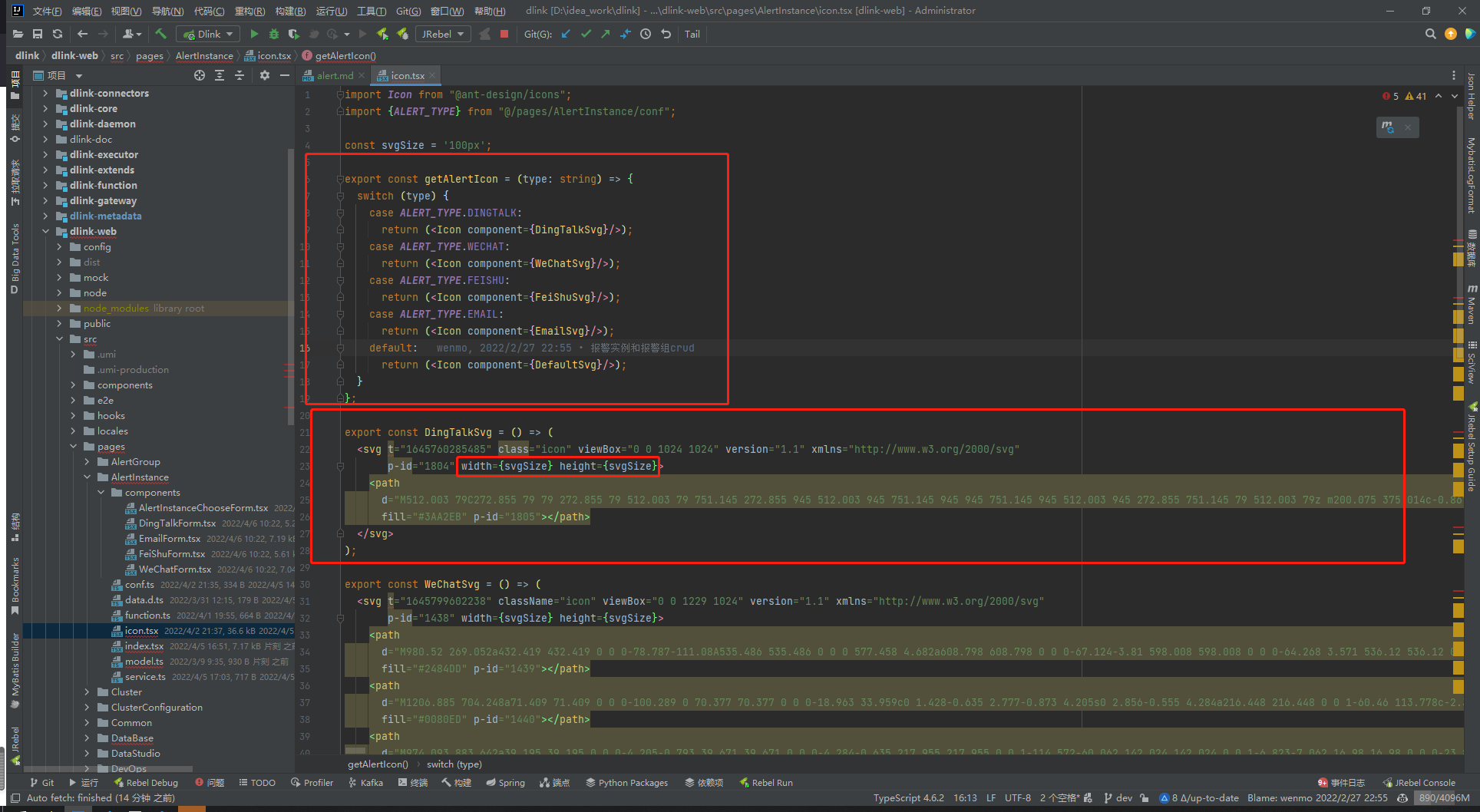
- 修改 `dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance/icon.tsx` 的 **getAlertIcon** 中
-
- 添加如下 eg:
-```typescript
- case ALERT_TYPE.EMAIL:
- return ();
-```
-同时在下方定义 SVG : `如不定义将使用默认 SVG`
-
-svg 获取: [https://www.iconfont.cn](https://www.iconfont.cn)
-``` typescript
-export const EmailSvg = () => (
- {svg 相关代码}
-);
-```
-**注意:** svg 相关代码中需要将 **width** **height** 统一更换为 **width={svgSize} height={svgSize}**
-
-如下图:
-
-
-
-
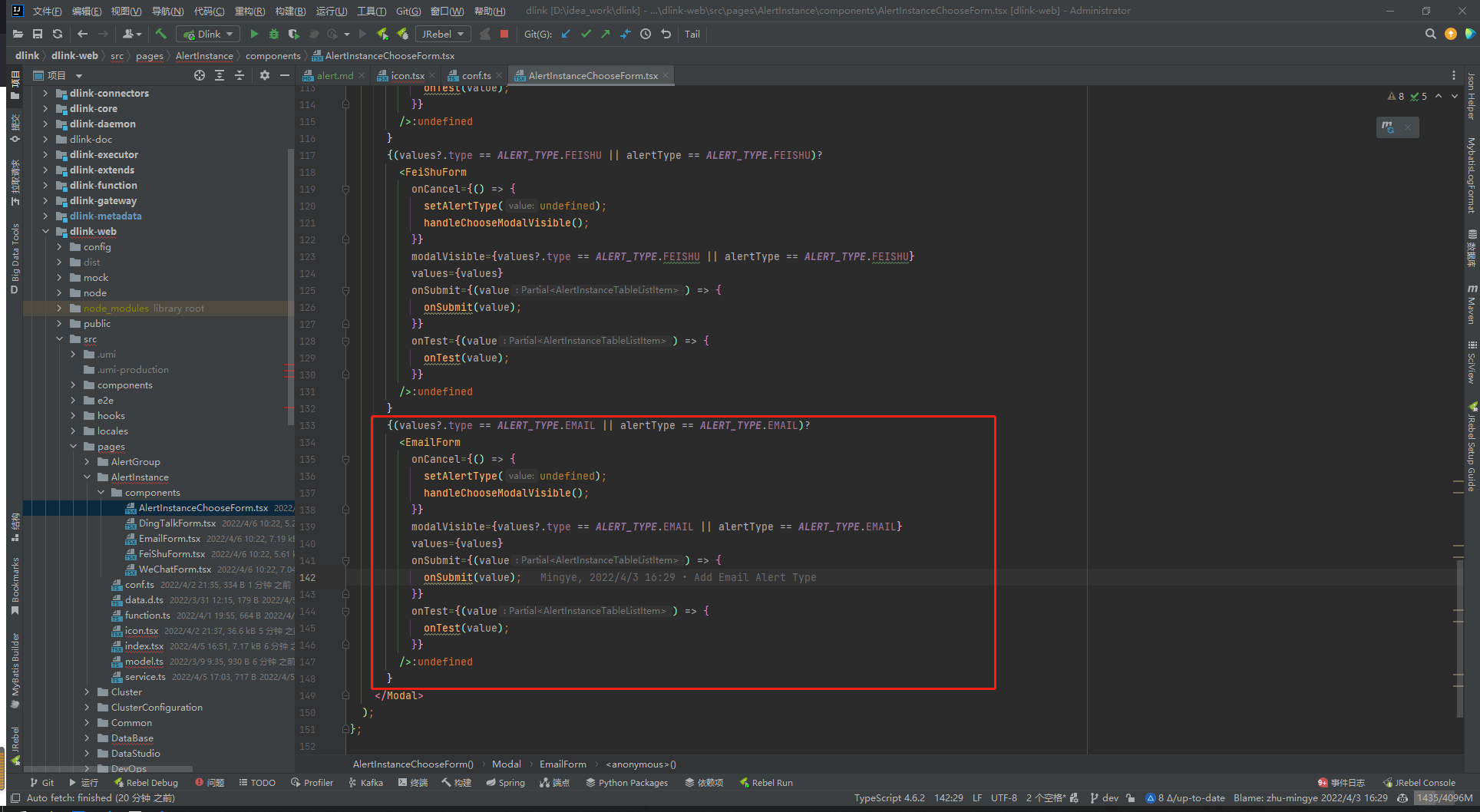
- - 修改 `dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance/components/AlertInstanceChooseForm.tsx`
-
- 追加如下 eg:
-```typescript
- {(values?.type == ALERT_TYPE.EMAIL || alertType == ALERT_TYPE.EMAIL)?
- {
- setAlertType(undefined);
- handleChooseModalVisible();
- }}
- modalVisible={values?.type == ALERT_TYPE.EMAIL || alertType == ALERT_TYPE.EMAIL}
- values={values}
- onSubmit={(value) => {
- onSubmit(value);
- }}
- onTest={(value) => {
- onTest(value);
- }}
- />:undefined
- }
-```
-其中需要修改的地方为
-- `EMAIL` 替换为上述 **dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance/conf.ts** 中 **ALERT_TYPE** 的新增类型
-- `EmailForm` 为新建告警表单文件 **dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance/components/EmailForm.tsx** 中的 **EmailForm** .
-
-如下图:
-
-
- - 需要新建表单文件 , 命名规则: ``{告警类型}Form``
- - 该文件中除 **表单属性** 外 , 其余可参照其他类型告警 , 建议复制其他类型告警的表单 , 修改其中的表单属性即可
- - 注意:
- - 部分表单属性保存为 Json 格式
- - 需要修改 如下的表单配置
-
-
- ```typescript
- // 找到如下相关代码:
- const [formVals, setFormVals] = useState>({
- id: props.values?.id,
- name: props.values?.name,
- type: ALERT_TYPE.EMAIL, // 此处需要修改为新增的告警类型
- params: props.values?.params,
- enabled: props.values?.enabled,
- });
-
-```
-
-
-----
-:::tip 说明
-至此 , 基于 Dinky 扩展告警完成 , 如您也有扩展需求 ,请参照如何 [[Issuse]](../../developer_guide/contribution/issue) 和如何[[提交 PR]](../../developer_guide/contribution/pull_request)
-:::
\ No newline at end of file
diff --git a/docs/docs/extend/function_expansion/completion.md b/docs/docs/extend/function_expansion/completion.md
deleted file mode 100644
index 652aab6d32..0000000000
--- a/docs/docs/extend/function_expansion/completion.md
+++ /dev/null
@@ -1,44 +0,0 @@
----
-sidebar_position: 5
-id: completion
-title: FlinkSQL 编辑器自动补全函数
----
-
-
-
-
-## FlinkSQL 编辑器自动补全函数
-
-Dlink-0.3.2 版本上线了一个非常实用的功能——自动补全。
-
-我们在使用 IDEA 等工具时,提示方法并补全、生成的功能大大提升了开发效率。而 Dlink 的目标便是让 FlinkSQL 更加丝滑,所以其提供了自定义的自动补全功能。对比传统的使用 `Java` 字符串来编写 FlinkSQL 的方式,Dlink 的优势是巨大。
-
-在文档中心,我们可以根据自己的需要扩展相应的自动补全规则,如 `UDF`、`Connector With` 等 FlinkSQL 片段,甚至可以扩展任意可以想象到内容,如注释、模板、配置、算法等。
-
-具体新增规则的示例请看下文描述。
-
-## set 语法来设置执行环境参数
-
-对于一个 FlinkSQL 的任务来说,除了 sql 口径,其任务配置也十分重要。所以 Dlink-0.3.2 版本中提供了 `sql-client` 的 `set` 语法,可以通过 `set` 关键字来指定任务的执行配置(如 “ `set table.exec.resource.default-parallelism=2;` ” ),其优先级要高于 Dlink 自身的任务配置(面板右侧)。
-
-那么长的参数一般人谁记得住?等等,别忘了 Dlink 的新功能自动补全~
-
-配置实现输入 `parallelism` 子字符串来自动补全 `table.exec.resource.default-parallelism=` 。
-
-在文档中心中添加一个规则,名称为 `parallelism`,填充值为 `table.exec.resource.default-parallelism=`,其他内容随意。
-
-保存之后,来到编辑器输入 `par` .
-
-选中要补全的规则后,编辑器中自动补全了 `table.exec.resource.default-parallelism=` 。
-
-至此,有些小伙伴发现,是不是可以直接定义 `pl2` 来自动生成 `set table.exec.resource.default-parallelism=2;` ?
-
-当然可以的。
-
-还有小伙伴问,可不可以定义 `pl` 生成 `set table.exec.resource.default-parallelism=;` 后,光标自动定位到 `=` 于 `;` 之间?
-
-这个也可以的,只需要定义 `pl` 填充值为 `set table.exec.resource.default-parallelism=${1:};` ,即可实现。
-
-所以说,只要能想象到的都可以定义,这样的 Dlink 你爱了吗?
-
-嘘,还有点小 bug 后续修复呢。如果有什么建议及问题请及时指出哦。
\ No newline at end of file
diff --git a/docs/docs/extend/function_expansion/connector.md b/docs/docs/extend/function_expansion/connector.md
deleted file mode 100644
index ab25f82d72..0000000000
--- a/docs/docs/extend/function_expansion/connector.md
+++ /dev/null
@@ -1,38 +0,0 @@
----
-sidebar_position: 2
-id: connector
-title: 扩展连接器
----
-
-
-
-
-## Flink Connector 介绍
-
-Flink做为实时计算引擎,支持非常丰富的上下游存储系统的 Connectors。并从这些上下系统读写数据并进行计算。对于这些 Connectors 在 Flink 中统一称之为数据源(Source) 端和 目标(Sink) 端。
-
-- 数据源(Source)指的是输入流计算系统的上游存储系统来源。在当前的 FlinkSQL 模式的作业中,数据源可以是消息队列 Kafka、数据库 MySQL 等。
-- 目标(Sink)指的是流计算系统输出处理结果的目的地。在当前的流计算 FlinkSQL 模式的作业中,目标端可以是消息队列 Kafka、数据库 MySQL、OLAP引擎 Doris、ClickHouse 等。
-
-Dinky 实时计算平台支持支持 Flink 1.13、Flink 1.14、Flink 1.15、Flink 1.16 五个版本,对应的版本支持所有开源的上下游存储系统具体Connector信息详见Flink开源社区:
-
-- [Flink1.13](https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/table/overview/)
-- [Flink1.14](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/overview/)
-- [Flink1.15](https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/connectors/table/overview/)
-- [Flink1.16](https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/connectors/table/overview/)
-
-
-另外非 Flink 官网支持的 Connector 详见 github:
-
-- [Flink-CDC](https://github.com/ververica/flink-cdc-connectors/releases/)
-- [Hudi](https://github.com/apache/hudi/releases)
-- [Iceberg](https://github.com/apache/iceberg/releases)
-- [Doris](https://github.com/apache/incubator-doris-flink-connector/tags)
-- [Starrocks](https://github.com/StarRocks/flink-connector-starrocks/releases)
-- [ClickHouse](https://github.com/itinycheng/flink-connector-clickhouse)
-- [Pulsar](https://github.com/streamnative/pulsar-flink/releases)
-
-
-## 扩展 Connector
-
-将 Flink 集群上已扩展好的 Connector 直接放入 Dlink 的 lib 或者 plugins 下,然后重启即可。定制 Connector 过程同 Flink 官方一样。
diff --git a/docs/docs/extend/function_expansion/datasource.md b/docs/docs/extend/function_expansion/datasource.md
deleted file mode 100644
index 3e909022f6..0000000000
--- a/docs/docs/extend/function_expansion/datasource.md
+++ /dev/null
@@ -1,623 +0,0 @@
----
-sidebar_position: 3
-id: datasource
-title: 扩展数据源
----
-
-
-
-
- Dinky 数据源遵循 SPI,可随意扩展所需要的数据源。数据源扩展可在 dlink-metadata 模块中进行可插拔式扩展。现已经支持的数据源包括如下:
-
- - MySQL
- - Oracle
- - SQLServer
- - PostGreSQL
- - Phoenix
- - Doris(Starrocks)
- - ClickHouse
- - Hive ``需要的jar包: hive-jdbc-2.1.1.jar && hive-service-2.1.1.jar``
-
-使用以上数据源,详见注册中心[数据源管理](../../user_guide/register_center/datasource_manage),配置数据源连接
-:::tip 注意事项
- Dinky 不在对 Starorcks 进行额外扩展,Doris 和 Starorcks 底层并无差别,原则上只是功能区分。经社区测试验证,可采用 Doris 扩展连接 Starrocks。
-:::
-----
-
-## 准备工作
-- 本地开发环境搭建
- - 详见 [开发者本地调试手册](../../developer_guide/local_debug)
-
-## 后端开发
-- 本文以 Hive 数据源扩展为例
-- 在 **dlink-metadata** 模块中, 右键**新建子模块**, 命名规则: **dlink-metadata-{数据源名称}**
-- **代码层面**
- - 注意事项:
- - 不可在父类的基础上修改代码,可以在子类中进行扩展 ,或者重写父类方法
- - 扩展数据源需要同时提交**测试用例**
- - 在此模块的 **pom.xml** 中,添加所需依赖, 需要注意的是 : 数据源本身的 ``JDBC``的 jar 不要包含在打包中 , 而是后续部署时,添加在 ``plugins`` 下
- - 需要在此模块的 **resource** 下 新建包 ``META-INF.services`` , 在此包中新建文件 ``com.dlink.metadata.driver.Driver`` 内容如下:
- - ``com.dlink.metadata.driver.数据源类型Driver``
- 基础包:
-```bash
-顶层包名定义: com.dlink.metadata
- 子包含义:
- - constant: 常量定义 目前此模块中主要定义各种动态构建的执行 SQL
- - convert: 存放数据源的数据类型<->Java 类型的转换类 ps: 可以不定义 不定义使用 dlink-metadata-base 的默认转换 即调用父类的方法
- - driver: 存放数据源驱动类,获取元数据的主要类,类 extends AbstractJdbcDriver implements Driver
- - query : 存放解析获取元数据的主要类,类 extends AbstractDBQuery 方法不重写 默认使用父类
-```
-代码如下:
-
-HiveConstant
-```java
-public interface HiveConstant {
-
- /**
- * 查询所有database
- */
- String QUERY_ALL_DATABASE = " show databases";
- /**
- * 查询所有schema下的所有表
- */
- String QUERY_ALL_TABLES_BY_SCHEMA = "show tables";
- /**
- * 扩展信息Key
- */
- String DETAILED_TABLE_INFO = "Detailed Table Information";
- /**
- * 查询指定schema.table的扩展信息
- */
- String QUERY_TABLE_SCHEMA_EXTENED_INFOS = " describe extended `%s`.`%s`";
- /**
- * 查询指定schema.table的信息 列 列类型 列注释
- */
- String QUERY_TABLE_SCHEMA = " describe `%s`.`%s`";
- /**
- * 使用 DB
- */
- String USE_DB = "use `%s`";
- /**
- * 只查询指定schema.table的列名
- */
- String QUERY_TABLE_COLUMNS_ONLY = "show columns in `%s`.`%s`";
-}
-
-```
-
-HiveTypeConvert
-```java
-
-public class HiveTypeConvert implements ITypeConvert {
- // 主要是将获取到的数据类型转换为 Java 数据类型的映射 存储在 Column 中 , 此处根据扩展的数据源特性进行修改
- @Override
- public ColumnType convert(Column column) {
- if (Asserts.isNull(column)) {
- return ColumnType.STRING;
- }
- String t = column.getType().toLowerCase().trim();
- if (t.contains("char")) {
- return ColumnType.STRING;
- } else if (t.contains("boolean")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_BOOLEAN;
- }
- return ColumnType.BOOLEAN;
- } else if (t.contains("tinyint")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_BYTE;
- }
- return ColumnType.BYTE;
- } else if (t.contains("smallint")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_SHORT;
- }
- return ColumnType.SHORT;
- } else if (t.contains("bigint")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_LONG;
- }
- return ColumnType.LONG;
- } else if (t.contains("largeint")) {
- return ColumnType.STRING;
- } else if (t.contains("int")) {
- if (column.isNullable()) {
- return ColumnType.INTEGER;
- }
- return ColumnType.INT;
- } else if (t.contains("float")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_FLOAT;
- }
- return ColumnType.FLOAT;
- } else if (t.contains("double")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_DOUBLE;
- }
- return ColumnType.DOUBLE;
- } else if (t.contains("timestamp")) {
- return ColumnType.TIMESTAMP;
- } else if (t.contains("date")) {
- return ColumnType.STRING;
- } else if (t.contains("datetime")) {
- return ColumnType.STRING;
- } else if (t.contains("decimal")) {
- return ColumnType.DECIMAL;
- } else if (t.contains("time")) {
- return ColumnType.DOUBLE;
- }
- return ColumnType.STRING;
- }
-
- // 转换为 DB 的数据类型
- @Override
- public String convertToDB(ColumnType columnType) {
- switch (columnType) {
- case STRING:
- return "varchar";
- case BOOLEAN:
- case JAVA_LANG_BOOLEAN:
- return "boolean";
- case BYTE:
- case JAVA_LANG_BYTE:
- return "tinyint";
- case SHORT:
- case JAVA_LANG_SHORT:
- return "smallint";
- case LONG:
- case JAVA_LANG_LONG:
- return "bigint";
- case FLOAT:
- case JAVA_LANG_FLOAT:
- return "float";
- case DOUBLE:
- case JAVA_LANG_DOUBLE:
- return "double";
- case DECIMAL:
- return "decimal";
- case INT:
- case INTEGER:
- return "int";
- case TIMESTAMP:
- return "timestamp";
- default:
- return "varchar";
- }
- }
-}
-
-
-```
-
-
-HiveDriver
-```java
-
-public class HiveDriver extends AbstractJdbcDriver implements Driver {
- // 获取表的信息
- @Override
- public Table getTable(String schemaName, String tableName) {
- List
+
diff --git a/README_zh_CN.md b/README_zh_CN.md
index 2ec688593c..a497d493d3 100644
--- a/README_zh_CN.md
+++ b/README_zh_CN.md
@@ -148,4 +148,10 @@ Dinky 是一个 `开箱即用` 、`易扩展` ,以 `Apache Flink` 为基础,
## 版权
-请参考 [LICENSE](https://github.com/DataLinkDC/dinky/blob/dev/LICENSE) 文件。
\ No newline at end of file
+请参考 [LICENSE](https://github.com/DataLinkDC/dinky/blob/dev/LICENSE) 文件。
+
+# 贡献者
+
+
+
+
diff --git a/dinky-admin/src/main/java/org/dinky/service/impl/TaskServiceImpl.java b/dinky-admin/src/main/java/org/dinky/service/impl/TaskServiceImpl.java
index 43d4d5d36a..550be8e02b 100644
--- a/dinky-admin/src/main/java/org/dinky/service/impl/TaskServiceImpl.java
+++ b/dinky-admin/src/main/java/org/dinky/service/impl/TaskServiceImpl.java
@@ -511,14 +511,21 @@ public boolean changeTaskLifeRecyle(Integer taskId, JobLifeCycle lifeCycle) thro
boolean saved = saveOrUpdate(task.buildTask());
if (saved && Asserts.isNotNull(task.getJobInstanceId())) {
JobInstance jobInstance = jobInstanceService.getById(task.getJobInstanceId());
- jobInstance.setStep(lifeCycle.getValue());
- jobInstanceService.updateById(jobInstance);
- log.info("jobInstance [{}] step change to {}", jobInstance.getJid(), lifeCycle.getValue());
+ if (Asserts.isNotNull(jobInstance)) {
+ jobInstance.setStep(lifeCycle.getValue());
+ boolean updatedJobInstance = jobInstanceService.updateById(jobInstance);
+ if (updatedJobInstance) jobInstanceService.refreshJobInfoDetail(jobInstance.getId(), true);
+ log.warn(
+ "JobInstance [{}] step change to [{}] ,Trigger Force Refresh",
+ jobInstance.getName(),
+ lifeCycle.getValue());
+ }
}
return saved;
}
@Override
+ @Transactional(rollbackFor = Exception.class)
public boolean saveOrUpdateTask(Task task) {
Task byId = getById(task.getId());
if (byId != null && JobLifeCycle.PUBLISH.equalsValue(byId.getStep())) {
diff --git a/dinky-web/src/pages/DataStudio/LeftContainer/Project/function.tsx b/dinky-web/src/pages/DataStudio/LeftContainer/Project/function.tsx
index e3d76a29a8..36b02ad10f 100644
--- a/dinky-web/src/pages/DataStudio/LeftContainer/Project/function.tsx
+++ b/dinky-web/src/pages/DataStudio/LeftContainer/Project/function.tsx
@@ -80,19 +80,19 @@ export const buildStepValue = (step: number) => {
return {
title: l('global.table.lifecycle.dev'),
status: 'processing',
- color: '#1890ff'
+ color: 'cyan'
};
case 2:
return {
title: l('global.table.lifecycle.online'),
status: 'success',
- color: '#52c41a'
+ color: 'purple'
};
default:
return {
title: l('global.table.lifecycle.dev'),
status: 'default',
- color: '#1890ff'
+ color: 'cyan'
};
}
};
@@ -144,7 +144,8 @@ export const buildProjectTree = (
<>
);
diff --git a/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/FlinkTable.tsx b/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/FlinkTable.tsx
index dd539aaa97..bc2a4595fa 100644
--- a/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/FlinkTable.tsx
+++ b/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/FlinkTable.tsx
@@ -19,7 +19,12 @@
import StatusTag from '@/components/JobTags/StatusTag';
import { JobProps } from '@/pages/DevOps/JobDetail/data';
-import { parseByteStr, parseMilliSecondStr, parseNumStr } from '@/utils/function';
+import {
+ formatTimestampToYYYYMMDDHHMMSS,
+ parseByteStr,
+ parseMilliSecondStr,
+ parseNumStr
+} from '@/utils/function';
import { l } from '@/utils/intl';
import { ProCard, ProColumns, ProTable } from '@ant-design/pro-components';
import { Typography } from 'antd';
@@ -32,8 +37,10 @@ export type VerticesTableListItem = {
metrics: any;
parallelism: number;
startTime?: number;
+ 'start-time'?: number;
duration?: number;
endTime?: number;
+ 'end-time'?: number;
tasks: any;
};
@@ -101,15 +108,20 @@ const FlinkTable = (props: JobProps): JSX.Element => {
},
{
title: l('global.table.startTime'),
- dataIndex: 'startTime',
- valueType: 'dateTime'
+ render: (dom, entity) => {
+ return entity.startTime === -1 || entity['start-time'] === -1
+ ? '-'
+ : formatTimestampToYYYYMMDDHHMMSS(entity['start-time'] as number) ||
+ formatTimestampToYYYYMMDDHHMMSS(entity.startTime as number);
+ }
},
{
title: l('global.table.endTime'),
- dataIndex: 'endTime',
- valueType: 'dateTime',
render: (dom, entity) => {
- return entity.endTime === -1 ? '-' : entity.endTime;
+ return entity.endTime === -1 || entity['end-time'] === -1
+ ? '-'
+ : formatTimestampToYYYYMMDDHHMMSS(entity['end-time'] as number) ||
+ formatTimestampToYYYYMMDDHHMMSS(entity.endTime as number);
}
},
{
diff --git a/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/JobDesc.tsx b/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/JobDesc.tsx
index bb645801e7..99e50d90f6 100644
--- a/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/JobDesc.tsx
+++ b/dinky-web/src/pages/DevOps/JobDetail/JobOverview/components/JobDesc.tsx
@@ -88,7 +88,7 @@ const JobDesc = (props: JobProps) => {
- {jobDetail?.jobDataDto?.config?.executionConfig?.restartStrategy}
+ {jobDetail?.jobDataDto?.config['execution-config']['restart-strategy']}
@@ -109,13 +109,11 @@ const JobDesc = (props: JobProps) => {
- {jobDetail?.history?.configJson?.useSqlFragment
- ? l('button.enable')
- : l('button.disable')}
+ {jobDetail?.history?.configJson?.fragment ? l('button.enable') : l('button.disable')}
- {jobDetail?.history?.configJson?.useBatchModel
+ {jobDetail?.history?.configJson?.batchModel
? l('global.table.execmode.batch')
: l('global.table.execmode.streaming')}
@@ -125,7 +123,7 @@ const JobDesc = (props: JobProps) => {
- {jobDetail?.jobDataDto?.config?.executionConfig?.jobParallelism}
+ {jobDetail?.jobDataDto?.config['execution-config']['job-parallelism']}
@@ -137,7 +135,7 @@ const JobDesc = (props: JobProps) => {
- {jobDetail?.history?.configJson.savePointPath}
+ {jobDetail?.history?.configJson?.configJson['state.savepoints.dir'] ?? '-'}
diff --git a/dinky-web/src/pages/DevOps/JobDetail/index.tsx b/dinky-web/src/pages/DevOps/JobDetail/index.tsx
index 337d7ab1b4..e80134a2af 100644
--- a/dinky-web/src/pages/DevOps/JobDetail/index.tsx
+++ b/dinky-web/src/pages/DevOps/JobDetail/index.tsx
@@ -65,7 +65,7 @@ const JobDetail = (props: any) => {
pollingInterval: 3000
});
- const jobInfoDetail: Jobs.JobInfoDetail = data;
+ const jobInfoDetail = data as Jobs.JobInfoDetail;
const [tabKey, setTabKey] = useState(OperatorEnum.JOB_BASE_INFO);
diff --git a/dinky-web/src/types/DevOps/data.d.ts b/dinky-web/src/types/DevOps/data.d.ts
index 13d615472b..f25fff4868 100644
--- a/dinky-web/src/types/DevOps/data.d.ts
+++ b/dinky-web/src/types/DevOps/data.d.ts
@@ -18,7 +18,7 @@
*/
import { BaseBeanColumns } from '@/types/Public/data';
-import { Alert } from '@/types/RegCenter/data.d';
+import { Alert, Cluster } from '@/types/RegCenter/data.d';
/**
* about flink job
@@ -48,6 +48,62 @@ declare namespace Jobs {
useBatchModel: string;
};
+ export type ExecutorSetting = {
+ type: string;
+ host: string;
+ port: number;
+ useBatchModel: boolean;
+ checkpoint: string;
+ parallelism: number;
+ useSqlFragment: boolean;
+ useStatementSet: boolean;
+ savePointPath: string;
+ jobName: string;
+ config: Map;
+ variables: Map;
+ jarFiles: [];
+ jobManagerAddress: string;
+ plan: boolean;
+ remote: boolean;
+ validParallelism: boolean;
+ validJobName: boolean;
+ validHost: boolean;
+ validPort: boolean;
+ validConfig: boolean;
+ validVariables: boolean;
+ validJarFiles: boolean;
+ };
+
+ export type JobConfigJsonInfo = {
+ type: string;
+ checkpoint: string;
+ savePointStrategy: string;
+ savePointPath: string;
+ parallelism: number;
+ clusterId: number;
+ clusterConfigurationId: number;
+ step: number;
+ configJson: {
+ 'state.savepoints.dir': string;
+ };
+ useResult: boolean;
+ useChangeLog: boolean;
+ useAutoCancel: boolean;
+ useRemote: boolean;
+ address: string;
+ taskId: number;
+ jarFiles: [];
+ pyFiles: [];
+ jobName: string;
+ fragment: boolean;
+ statementSet: boolean;
+ batchModel: boolean;
+ maxRowNum: number;
+ gatewayConfig: any;
+ variables: Map;
+ executorSetting: ExecutorSetting;
+ };
+
export type History = {
id: number;
tenantId: number;
@@ -61,7 +117,7 @@ declare namespace Jobs {
type: string;
error: string;
result: string;
- configJson: JobConfig;
+ configJson: JobConfigJsonInfo;
startTime: string;
endTime: string;
taskId: number;
@@ -166,13 +222,18 @@ declare namespace Jobs {
jid: string;
name: string;
executionConfig: ExecutionConfig;
+ 'execution-config': ExecutionConfig;
};
export type ExecutionConfig = {
executionMode: string;
+ 'execution-mode': string;
restartStrategy: string;
+ 'restart-strategy': string;
jobParallelism: number;
- objectReuse: boolean;
+ 'job-parallelism': number;
+ 'object-reuse': boolean;
userConfig: any;
+ 'user-config': any;
};
export type JobDataDtoItem = {
@@ -191,8 +252,8 @@ declare namespace Jobs {
export type JobInfoDetail = {
id: number;
instance: JobInstance;
- clusterInstance: any;
- clusterConfiguration: any;
+ clusterInstance: Cluster.Instance;
+ clusterConfiguration: Cluster.Config;
history: History;
jobDataDto: JobDataDtoItem;
jobManagerConfiguration: any;
diff --git a/dinky-web/src/utils/function.tsx b/dinky-web/src/utils/function.tsx
index 755deca87d..e00484b843 100644
--- a/dinky-web/src/utils/function.tsx
+++ b/dinky-web/src/utils/function.tsx
@@ -45,7 +45,6 @@ import { l } from '@/utils/intl';
import { Monaco } from '@monaco-editor/react';
import dayjs from 'dayjs';
import cookies from 'js-cookie';
-import { trim } from 'lodash';
import { editor, KeyCode, KeyMod } from 'monaco-editor';
import path from 'path';
import { format } from 'sql-formatter';
@@ -619,6 +618,13 @@ export const formatDateToYYYYMMDDHHMMSS = (date: Date) => {
return dayjs(date).format(DATETIME_FORMAT);
};
+export const formatTimestampToYYYYMMDDHHMMSS = (timestamp: number) => {
+ if (timestamp == null) {
+ return '-';
+ }
+ return dayjs(timestamp).format(DATETIME_FORMAT);
+};
+
export const parseDateStringToDate = (dateString: Date) => {
return dayjs(dateString).toDate();
};
diff --git a/docs/docs/data_integration_guide/dinky_k8s_quick_start.mdx b/docs/docs/data_integration_guide/dinky_k8s_quick_start.mdx
index 74518fffce..f4e08b931f 100644
--- a/docs/docs/data_integration_guide/dinky_k8s_quick_start.mdx
+++ b/docs/docs/data_integration_guide/dinky_k8s_quick_start.mdx
@@ -3,6 +3,7 @@ sidebar_position: 1
id: dinky_k8s_quick_start
title: K8s集成
---
+
import Tabs from '@theme/Tabs';
import TabItem from '@theme/TabItem';
@@ -20,27 +21,21 @@ Dinky支持以下几种 Flink on k8s 运行模式:
**部分内容可参考 Flink 对应集成 k8s 文档链接**
-
-
-
-[https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
-
-
-
-
-[https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
-
-
-
-
-[https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
-
-
-
-
-[https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
-
-
+
+ [https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
+
+
+ [https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
+
+
+ [https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
+
+
+ [https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
+
+
+ [https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/docs/deployment/resource-providers/native_kubernetes/](https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/deployment/resource-providers/native_kubernetes/)
+
@@ -144,52 +139,61 @@ ADD extends /opt/flink/lib # 把当前extends目录下的jar添加进依赖目
##### Kubernetes 配置
-| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
-|--------|--------------------------------------------------------|:----:|:---:|:----------:|
-| 暴露端口类型 | 支持NodePort与ClusterIP | 是 | 无 | NodePort |
-| Kubernetes 命名空间 | 集群所在的 Kubernetes 命名空间 | 是 | 无 | dinky |
-| K8s 提交账号 | 集群提交任务的账号 | 是 | 无 | default |
-| Flink 镜像地址 | 上一步打包的镜像地址 | 是 | 无 | dinky-flink-1.0.0-1.15.4 |
-| JobManager CPU 配置 | JobManager 资源配置 | 否 | 无 | 1 |
-| TaskManager CPU 配置 | TaskManager 资源配置 | 否 | 无 | 1 |
-| Flink 配置文件路径 | 仅指定到文件夹,dinky会自行读取文件夹下的配置文件并作为flink的默认配置 | 否 | 无 | /opt/flink/conf |
+| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
+|--------------------|------------------------------------------|:----:|:---:|:------------------------:|
+| 暴露端口类型 | 支持NodePort与ClusterIP | 是 | 无 | NodePort |
+| Kubernetes 命名空间 | 集群所在的 Kubernetes 命名空间 | 是 | 无 | dinky |
+| K8s 提交账号 | 集群提交任务的账号 | 是 | 无 | default |
+| Flink 镜像地址 | 上一步打包的镜像地址 | 是 | 无 | dinky-flink-1.0.0-1.15.4 |
+| JobManager CPU 配置 | JobManager 资源配置 | 否 | 无 | 1 |
+| TaskManager CPU 配置 | TaskManager 资源配置 | 否 | 无 | 1 |
+| Flink 配置文件路径 | 仅指定到文件夹,dinky会自行读取文件夹下的配置文件并作为flink的默认配置 | 否 | 无 | /opt/flink/conf |
> 如果您有其他的配置项需要添加,请点击添加配置项按钮,添加完毕后,点击保存即可
##### Kubernetes 连接与pod配置
-| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
-|--------|--------------------------------------------------------|:----:|:---:|:----------:|
-|K8s KubeConfig |集群的KubeConfig内容,如果不填写,则默认使用`~/.kube/config`文件 | 否 | 无 | 无 |
-|Default Pod Template |默认的Pod模板 | 否 | 无 | 无 |
-|JM Pod Template |JobManager的Pod模板 | 否 | 无 | 无 |
-|TM Pod Template |TaskManager的Pod模板 | 否 | 无 | 无 |
+| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
+|----------------------|-----------------------------------------------|:----:|:---:|:---:|
+| K8s KubeConfig | 集群的KubeConfig内容,如果不填写,则默认使用`~/.kube/config`文件 | 否 | 无 | 无 |
+| Default Pod Template | 默认的Pod模板 | 否 | 无 | 无 |
+| JM Pod Template | JobManager的Pod模板 | 否 | 无 | 无 |
+| TM Pod Template | TaskManager的Pod模板 | 否 | 无 | 无 |
##### 提交 FlinkSQL 配置项 (Application 模式必填)-公共配置
-| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
-|--------|----------------------------------------------------------------------------------------------------------|:----:|:---:|:--------------:|
-| Jar 文件路径 | 指定镜像内dinky-app的 Jar 文件路径,如果该集群配置用于提交 Application 模式任务时 则必填| 否 | 无 | local:///opt/flink/dinky-app-1.16-1.0.0-jar-with-dependencies.jar |
+| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
+|----------|------------------------------------------------------------|:----:|:---:|:-----------------------------------------------------------------:|
+| Jar 文件路径 | 指定镜像内dinky-app的 Jar 文件路径,如果该集群配置用于提交 Application 模式任务时 则必填 | 否 | 无 | local:///opt/flink/dinky-app-1.16-1.0.0-jar-with-dependencies.jar |
> 由于flink限制,k8s模式只能加载镜像内的jar包,也就是地址必须为local://开头,如果想要自定义jar提交,请查阅jar提交部分
#### Flink 预设配置(高优先级)-公共配置
-| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
-|-----------------|----|:----:|:---:|:--:|
-| JobManager 内存 | JobManager 内存大小! | 否 | 无 | 1g |
-| TaskManager 内存 | TaskManager 内存大小! | 否 | 无 | 1g |
-| TaskManager 堆内存 | TaskManager 堆内存大小! | 否 | 无 | 1g |
-| 插槽数 | 插槽数量 | 否 | 无 | 2 |
-| 保存点路径 | 对应SavePoint目录 | 否 | 无 | hdfs:///flink/savepoint |
-| 检查点路径 | 对应CheckPoint目录 | 否 | 无 | hdfs:///flink/checkpoint |
+| 参数 | 说明 | 是否必填 | 默认值 | 示例值 |
+|-----------------|--------------------|:----:|:---:|:------------------------:|
+| JobManager 内存 | JobManager 内存大小! | 否 | 无 | 1g |
+| TaskManager 内存 | TaskManager 内存大小! | 否 | 无 | 1g |
+| TaskManager 堆内存 | TaskManager 堆内存大小! | 否 | 无 | 1g |
+| 插槽数 | 插槽数量 | 否 | 无 | 2 |
+| 保存点路径 | 对应SavePoint目录 | 否 | 无 | hdfs:///flink/savepoint |
+| 检查点路径 | 对应CheckPoint目录 | 否 | 无 | hdfs:///flink/checkpoint |
## 启动session集群(可选)
+
除了您自己手动部署session集群外,dinky还提供了快捷方式部署Kubernetes session集群,在上面Kubernetes集群配置完成后,点击启动按钮即可向指定Kubernetes集群提交session集群
+

+
至此,所有准备工作均已完成完成,接下来就可以通过` kubernetes session`模式或`kubernetes application`模式进行任务提交啦。
+
## 提交 kubernetes application 任务
+
进入数据开发页面,新建一个flink sql任务,选择集群类型为`kubernetes application`,集群选择为我们刚刚配置的集群,点击提交即可
-## 提交 kubernetes session 任务
+
+
+
+## 提交 kubernetes session 任务
+
进入数据开发页面,新建一个flink sql任务,选择集群类型为`kubernetes session`,集群选择为我们刚刚配置的集群,点击提交即可
图片同上
\ No newline at end of file
diff --git a/docs/docs/developer_guide/local_debug.md b/docs/docs/developer_guide/local_debug.md
index 8d1bbd6a94..69d99a8ecb 100644
--- a/docs/docs/developer_guide/local_debug.md
+++ b/docs/docs/developer_guide/local_debug.md
@@ -90,7 +90,7 @@ npm run dev
由于目前 Dinky 各个模块未发布到 Maven 中央仓库,所以需要先进行 Install 编译。从而在本地仓库中生成相应的依赖。
-如果你是第一次编译 Dinky,那么请勾选以下 Maven Profile,然后下图中的`生命周期 -> Install`进行编译。
+如果你是第一次编译 Dinky,那么请勾选以下 Maven Profile,然后双击下图中的`生命周期 -> Install`进行编译。
:::

diff --git a/docs/docs/extend/function_expansion/alert.md b/docs/docs/extend/function_expansion/alert.md
deleted file mode 100644
index abd034f218..0000000000
--- a/docs/docs/extend/function_expansion/alert.md
+++ /dev/null
@@ -1,169 +0,0 @@
----
-sidebar_position: 4
-id: alert
-title: 扩展报警插件
----
-
-
-
-
-Dinky 告警机制遵循 SPI,可随意扩展所需要的告警机制。如需扩展可在 dinky-alert 模块中进行可插拔式扩展。现已经支持的告警机制包括如下:
-
-- DingDingTalk
-- 企业微信: 同时支持**APP** 和 **WeChat 群聊** 方式
-- Email
-- 飞书
-
-Dinky 学习了 ``Apache Dolphinscheduler`` 的插件扩展机制,可以在 Dinky 中添加自定义的告警机制。
-
-## 准备工作
-- 本地开发环境搭建
- - 详见 [开发者本地调试手册](../../developer_guide/local_debug)
-
-## 后端开发
-- 在 **dinky-alert** 新建子模块 , 命名规则为 `dinky-alert-{报警类型}` 在子模块中实现相关告警机制
-- **代码层面** 根据告警场景自行实现报警逻辑
- - 注意事项:
- - 不可在父类的基础上修改代码,可以在子类中进行扩展 ,或者重写父类方法
- - 注意告警所使用到的常量需要继承**AlertBaseConstant** 其他差异的特殊常量在新建的模块中定义,参考其他告警类型代码
- - 扩展告警类型需要同时提交**测试用例**
-- 需要在新建的此模块的 **resource** 下 新建包 ``META-INF.services`` , 在此包中新建文件 ``org.dinky.alert.Alert`` 内容如下:
- - ``org.dinky.alert.{报警类型}.{报警类型Alert}`` 参考其他告警类型的此文件
-- 打包相关配置 修改如下:
- - 在 **dinky-core** 模块的 **pom.xml** 下 , 找到扩展告警相关的依赖 `放在一起方便管理` 并且新增如下内容:
- ```xml
-
- org.dinky
- 模块名称
- ${scope.runtime}
-
- ```
-
- - 在 **dinky-admin** 模块的 **pom.xml** 下 , 找到扩展告警相关的依赖 `放在一起方便管理` 并且新增如下内容:
- ```xml
-
- org.dinky
- 模块名称
- ${expand.scope}
-
- ```
-
-- 在 **dinky** 根下 **pom.xml** 中 ,新增如下内容:
- ```xml
-
- org.dinky
- 模块名称
- ${project.version}
-
- ```
-
-- 在 **dinky-assembly** 模块中 , 找到 ``package.xml`` 路径: **/dinky-assembly/src/main/assembly/package.xml** , 新增如下内容:
-```xml
-
- ${project.parent.basedir}/dinky-alert/模块名称/target
-
- lib
-
- 模块名称-${project.version}.jar
-
-
- ```
-
-
-----
-
-## 前端开发
-- **dinky-web** 为 Dinky 的前端模块
-- 扩展告警插件相关表单所在路径: `dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance`
- - 修改 `dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance/conf.ts`
-
- **ALERT_TYPE** 添加如下 eg:
- ``` typescript
- EMAIL:'Email',
- ```
- **ALERT_CONFIG_LIST** 添加如下 eg:
- ```typescript
- {
- type: ALERT_TYPE.EMAIL,
- }
- ```
- **注意:** 此处属性值需要与后端 `AlertTypeEnum` 声明的值保持一致
-
-如下图:
-
-
-
- 修改 `dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance/icon.tsx` 的 **getAlertIcon** 中
-
- 添加如下 eg:
-```typescript
- case ALERT_TYPE.EMAIL:
- return ();
-```
-同时在下方定义 SVG : `如不定义将使用默认 SVG`
-
-svg 获取: [https://www.iconfont.cn](https://www.iconfont.cn)
-``` typescript
-export const EmailSvg = () => (
- {svg 相关代码}
-);
-```
-**注意:** svg 相关代码中需要将 **width** **height** 统一更换为 **width={svgSize} height={svgSize}**
-
-如下图:
-
-
-
-
- - 修改 `dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance/components/AlertInstanceChooseForm.tsx`
-
- 追加如下 eg:
-```typescript
- {(values?.type == ALERT_TYPE.EMAIL || alertType == ALERT_TYPE.EMAIL)?
- {
- setAlertType(undefined);
- handleChooseModalVisible();
- }}
- modalVisible={values?.type == ALERT_TYPE.EMAIL || alertType == ALERT_TYPE.EMAIL}
- values={values}
- onSubmit={(value) => {
- onSubmit(value);
- }}
- onTest={(value) => {
- onTest(value);
- }}
- />:undefined
- }
-```
-其中需要修改的地方为
-- `EMAIL` 替换为上述 **dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance/conf.ts** 中 **ALERT_TYPE** 的新增类型
-- `EmailForm` 为新建告警表单文件 **dinky-web/src/pages/RegistrationCenter/AlertManage/AlertInstance/components/EmailForm.tsx** 中的 **EmailForm** .
-
-如下图:
-
-
- - 需要新建表单文件 , 命名规则: ``{告警类型}Form``
- - 该文件中除 **表单属性** 外 , 其余可参照其他类型告警 , 建议复制其他类型告警的表单 , 修改其中的表单属性即可
- - 注意:
- - 部分表单属性保存为 Json 格式
- - 需要修改 如下的表单配置
-
-
- ```typescript
- // 找到如下相关代码:
- const [formVals, setFormVals] = useState>({
- id: props.values?.id,
- name: props.values?.name,
- type: ALERT_TYPE.EMAIL, // 此处需要修改为新增的告警类型
- params: props.values?.params,
- enabled: props.values?.enabled,
- });
-
-```
-
-
-----
-:::tip 说明
-至此 , 基于 Dinky 扩展告警完成 , 如您也有扩展需求 ,请参照如何 [[Issuse]](../../developer_guide/contribution/issue) 和如何[[提交 PR]](../../developer_guide/contribution/pull_request)
-:::
\ No newline at end of file
diff --git a/docs/docs/extend/function_expansion/completion.md b/docs/docs/extend/function_expansion/completion.md
deleted file mode 100644
index 652aab6d32..0000000000
--- a/docs/docs/extend/function_expansion/completion.md
+++ /dev/null
@@ -1,44 +0,0 @@
----
-sidebar_position: 5
-id: completion
-title: FlinkSQL 编辑器自动补全函数
----
-
-
-
-
-## FlinkSQL 编辑器自动补全函数
-
-Dlink-0.3.2 版本上线了一个非常实用的功能——自动补全。
-
-我们在使用 IDEA 等工具时,提示方法并补全、生成的功能大大提升了开发效率。而 Dlink 的目标便是让 FlinkSQL 更加丝滑,所以其提供了自定义的自动补全功能。对比传统的使用 `Java` 字符串来编写 FlinkSQL 的方式,Dlink 的优势是巨大。
-
-在文档中心,我们可以根据自己的需要扩展相应的自动补全规则,如 `UDF`、`Connector With` 等 FlinkSQL 片段,甚至可以扩展任意可以想象到内容,如注释、模板、配置、算法等。
-
-具体新增规则的示例请看下文描述。
-
-## set 语法来设置执行环境参数
-
-对于一个 FlinkSQL 的任务来说,除了 sql 口径,其任务配置也十分重要。所以 Dlink-0.3.2 版本中提供了 `sql-client` 的 `set` 语法,可以通过 `set` 关键字来指定任务的执行配置(如 “ `set table.exec.resource.default-parallelism=2;` ” ),其优先级要高于 Dlink 自身的任务配置(面板右侧)。
-
-那么长的参数一般人谁记得住?等等,别忘了 Dlink 的新功能自动补全~
-
-配置实现输入 `parallelism` 子字符串来自动补全 `table.exec.resource.default-parallelism=` 。
-
-在文档中心中添加一个规则,名称为 `parallelism`,填充值为 `table.exec.resource.default-parallelism=`,其他内容随意。
-
-保存之后,来到编辑器输入 `par` .
-
-选中要补全的规则后,编辑器中自动补全了 `table.exec.resource.default-parallelism=` 。
-
-至此,有些小伙伴发现,是不是可以直接定义 `pl2` 来自动生成 `set table.exec.resource.default-parallelism=2;` ?
-
-当然可以的。
-
-还有小伙伴问,可不可以定义 `pl` 生成 `set table.exec.resource.default-parallelism=;` 后,光标自动定位到 `=` 于 `;` 之间?
-
-这个也可以的,只需要定义 `pl` 填充值为 `set table.exec.resource.default-parallelism=${1:};` ,即可实现。
-
-所以说,只要能想象到的都可以定义,这样的 Dlink 你爱了吗?
-
-嘘,还有点小 bug 后续修复呢。如果有什么建议及问题请及时指出哦。
\ No newline at end of file
diff --git a/docs/docs/extend/function_expansion/connector.md b/docs/docs/extend/function_expansion/connector.md
deleted file mode 100644
index ab25f82d72..0000000000
--- a/docs/docs/extend/function_expansion/connector.md
+++ /dev/null
@@ -1,38 +0,0 @@
----
-sidebar_position: 2
-id: connector
-title: 扩展连接器
----
-
-
-
-
-## Flink Connector 介绍
-
-Flink做为实时计算引擎,支持非常丰富的上下游存储系统的 Connectors。并从这些上下系统读写数据并进行计算。对于这些 Connectors 在 Flink 中统一称之为数据源(Source) 端和 目标(Sink) 端。
-
-- 数据源(Source)指的是输入流计算系统的上游存储系统来源。在当前的 FlinkSQL 模式的作业中,数据源可以是消息队列 Kafka、数据库 MySQL 等。
-- 目标(Sink)指的是流计算系统输出处理结果的目的地。在当前的流计算 FlinkSQL 模式的作业中,目标端可以是消息队列 Kafka、数据库 MySQL、OLAP引擎 Doris、ClickHouse 等。
-
-Dinky 实时计算平台支持支持 Flink 1.13、Flink 1.14、Flink 1.15、Flink 1.16 五个版本,对应的版本支持所有开源的上下游存储系统具体Connector信息详见Flink开源社区:
-
-- [Flink1.13](https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/table/overview/)
-- [Flink1.14](https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/table/overview/)
-- [Flink1.15](https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/connectors/table/overview/)
-- [Flink1.16](https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/connectors/table/overview/)
-
-
-另外非 Flink 官网支持的 Connector 详见 github:
-
-- [Flink-CDC](https://github.com/ververica/flink-cdc-connectors/releases/)
-- [Hudi](https://github.com/apache/hudi/releases)
-- [Iceberg](https://github.com/apache/iceberg/releases)
-- [Doris](https://github.com/apache/incubator-doris-flink-connector/tags)
-- [Starrocks](https://github.com/StarRocks/flink-connector-starrocks/releases)
-- [ClickHouse](https://github.com/itinycheng/flink-connector-clickhouse)
-- [Pulsar](https://github.com/streamnative/pulsar-flink/releases)
-
-
-## 扩展 Connector
-
-将 Flink 集群上已扩展好的 Connector 直接放入 Dlink 的 lib 或者 plugins 下,然后重启即可。定制 Connector 过程同 Flink 官方一样。
diff --git a/docs/docs/extend/function_expansion/datasource.md b/docs/docs/extend/function_expansion/datasource.md
deleted file mode 100644
index 3e909022f6..0000000000
--- a/docs/docs/extend/function_expansion/datasource.md
+++ /dev/null
@@ -1,623 +0,0 @@
----
-sidebar_position: 3
-id: datasource
-title: 扩展数据源
----
-
-
-
-
- Dinky 数据源遵循 SPI,可随意扩展所需要的数据源。数据源扩展可在 dlink-metadata 模块中进行可插拔式扩展。现已经支持的数据源包括如下:
-
- - MySQL
- - Oracle
- - SQLServer
- - PostGreSQL
- - Phoenix
- - Doris(Starrocks)
- - ClickHouse
- - Hive ``需要的jar包: hive-jdbc-2.1.1.jar && hive-service-2.1.1.jar``
-
-使用以上数据源,详见注册中心[数据源管理](../../user_guide/register_center/datasource_manage),配置数据源连接
-:::tip 注意事项
- Dinky 不在对 Starorcks 进行额外扩展,Doris 和 Starorcks 底层并无差别,原则上只是功能区分。经社区测试验证,可采用 Doris 扩展连接 Starrocks。
-:::
-----
-
-## 准备工作
-- 本地开发环境搭建
- - 详见 [开发者本地调试手册](../../developer_guide/local_debug)
-
-## 后端开发
-- 本文以 Hive 数据源扩展为例
-- 在 **dlink-metadata** 模块中, 右键**新建子模块**, 命名规则: **dlink-metadata-{数据源名称}**
-- **代码层面**
- - 注意事项:
- - 不可在父类的基础上修改代码,可以在子类中进行扩展 ,或者重写父类方法
- - 扩展数据源需要同时提交**测试用例**
- - 在此模块的 **pom.xml** 中,添加所需依赖, 需要注意的是 : 数据源本身的 ``JDBC``的 jar 不要包含在打包中 , 而是后续部署时,添加在 ``plugins`` 下
- - 需要在此模块的 **resource** 下 新建包 ``META-INF.services`` , 在此包中新建文件 ``com.dlink.metadata.driver.Driver`` 内容如下:
- - ``com.dlink.metadata.driver.数据源类型Driver``
- 基础包:
-```bash
-顶层包名定义: com.dlink.metadata
- 子包含义:
- - constant: 常量定义 目前此模块中主要定义各种动态构建的执行 SQL
- - convert: 存放数据源的数据类型<->Java 类型的转换类 ps: 可以不定义 不定义使用 dlink-metadata-base 的默认转换 即调用父类的方法
- - driver: 存放数据源驱动类,获取元数据的主要类,类 extends AbstractJdbcDriver implements Driver
- - query : 存放解析获取元数据的主要类,类 extends AbstractDBQuery 方法不重写 默认使用父类
-```
-代码如下:
-
-HiveConstant
-```java
-public interface HiveConstant {
-
- /**
- * 查询所有database
- */
- String QUERY_ALL_DATABASE = " show databases";
- /**
- * 查询所有schema下的所有表
- */
- String QUERY_ALL_TABLES_BY_SCHEMA = "show tables";
- /**
- * 扩展信息Key
- */
- String DETAILED_TABLE_INFO = "Detailed Table Information";
- /**
- * 查询指定schema.table的扩展信息
- */
- String QUERY_TABLE_SCHEMA_EXTENED_INFOS = " describe extended `%s`.`%s`";
- /**
- * 查询指定schema.table的信息 列 列类型 列注释
- */
- String QUERY_TABLE_SCHEMA = " describe `%s`.`%s`";
- /**
- * 使用 DB
- */
- String USE_DB = "use `%s`";
- /**
- * 只查询指定schema.table的列名
- */
- String QUERY_TABLE_COLUMNS_ONLY = "show columns in `%s`.`%s`";
-}
-
-```
-
-HiveTypeConvert
-```java
-
-public class HiveTypeConvert implements ITypeConvert {
- // 主要是将获取到的数据类型转换为 Java 数据类型的映射 存储在 Column 中 , 此处根据扩展的数据源特性进行修改
- @Override
- public ColumnType convert(Column column) {
- if (Asserts.isNull(column)) {
- return ColumnType.STRING;
- }
- String t = column.getType().toLowerCase().trim();
- if (t.contains("char")) {
- return ColumnType.STRING;
- } else if (t.contains("boolean")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_BOOLEAN;
- }
- return ColumnType.BOOLEAN;
- } else if (t.contains("tinyint")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_BYTE;
- }
- return ColumnType.BYTE;
- } else if (t.contains("smallint")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_SHORT;
- }
- return ColumnType.SHORT;
- } else if (t.contains("bigint")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_LONG;
- }
- return ColumnType.LONG;
- } else if (t.contains("largeint")) {
- return ColumnType.STRING;
- } else if (t.contains("int")) {
- if (column.isNullable()) {
- return ColumnType.INTEGER;
- }
- return ColumnType.INT;
- } else if (t.contains("float")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_FLOAT;
- }
- return ColumnType.FLOAT;
- } else if (t.contains("double")) {
- if (column.isNullable()) {
- return ColumnType.JAVA_LANG_DOUBLE;
- }
- return ColumnType.DOUBLE;
- } else if (t.contains("timestamp")) {
- return ColumnType.TIMESTAMP;
- } else if (t.contains("date")) {
- return ColumnType.STRING;
- } else if (t.contains("datetime")) {
- return ColumnType.STRING;
- } else if (t.contains("decimal")) {
- return ColumnType.DECIMAL;
- } else if (t.contains("time")) {
- return ColumnType.DOUBLE;
- }
- return ColumnType.STRING;
- }
-
- // 转换为 DB 的数据类型
- @Override
- public String convertToDB(ColumnType columnType) {
- switch (columnType) {
- case STRING:
- return "varchar";
- case BOOLEAN:
- case JAVA_LANG_BOOLEAN:
- return "boolean";
- case BYTE:
- case JAVA_LANG_BYTE:
- return "tinyint";
- case SHORT:
- case JAVA_LANG_SHORT:
- return "smallint";
- case LONG:
- case JAVA_LANG_LONG:
- return "bigint";
- case FLOAT:
- case JAVA_LANG_FLOAT:
- return "float";
- case DOUBLE:
- case JAVA_LANG_DOUBLE:
- return "double";
- case DECIMAL:
- return "decimal";
- case INT:
- case INTEGER:
- return "int";
- case TIMESTAMP:
- return "timestamp";
- default:
- return "varchar";
- }
- }
-}
-
-
-```
-
-
-HiveDriver
-```java
-
-public class HiveDriver extends AbstractJdbcDriver implements Driver {
- // 获取表的信息
- @Override
- public Table getTable(String schemaName, String tableName) {
- List tables = listTables(schemaName);
- Table table = null;
- for (Table item : tables) {
- if (Asserts.isEquals(item.getName(), tableName)) {
- table = item;
- break;
- }
- }
- if (Asserts.isNotNull(table)) {
- table.setColumns(listColumns(schemaName, table.getName()));
- }
- return table;
- }
-
-
-// 根据库名称获取表的信息
- @Override
- public List listTables(String schemaName) {
- List tableList = new ArrayList<>();
- PreparedStatement preparedStatement = null;
- ResultSet results = null;
- IDBQuery dbQuery = getDBQuery();
- String sql = dbQuery.tablesSql(schemaName);
- try {
- //此步骤是为了切换数据库 与其他数据源有所区别
- execute(String.format(HiveConstant.USE_DB, schemaName));
- preparedStatement = conn.prepareStatement(sql);
- results = preparedStatement.executeQuery();
- ResultSetMetaData metaData = results.getMetaData();
- List columnList = new ArrayList<>();
- for (int i = 1; i <= metaData.getColumnCount(); i++) {
- columnList.add(metaData.getColumnLabel(i));
- }
- while (results.next()) {
- String tableName = results.getString(dbQuery.tableName());
- if (Asserts.isNotNullString(tableName)) {
- Table tableInfo = new Table();
- tableInfo.setName(tableName);
- if (columnList.contains(dbQuery.tableComment())) {
- tableInfo.setComment(results.getString(dbQuery.tableComment()));
- }
- tableInfo.setSchema(schemaName);
- if (columnList.contains(dbQuery.tableType())) {
- tableInfo.setType(results.getString(dbQuery.tableType()));
- }
- if (columnList.contains(dbQuery.catalogName())) {
- tableInfo.setCatalog(results.getString(dbQuery.catalogName()));
- }
- if (columnList.contains(dbQuery.engine())) {
- tableInfo.setEngine(results.getString(dbQuery.engine()));
- }
- tableList.add(tableInfo);
- }
- }
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- close(preparedStatement, results);
- }
- return tableList;
- }
-
- //获取所有数据库 和 库下所有表
- @Override
- public List getSchemasAndTables() {
- return listSchemas();
- }
-
- //获取所有数据库
- @Override
- public List listSchemas() {
-
- List schemas = new ArrayList<>();
- PreparedStatement preparedStatement = null;
- ResultSet results = null;
- String schemasSql = getDBQuery().schemaAllSql();
- try {
- preparedStatement = conn.prepareStatement(schemasSql);
- results = preparedStatement.executeQuery();
- while (results.next()) {
- String schemaName = results.getString(getDBQuery().schemaName());
- if (Asserts.isNotNullString(schemaName)) {
- Schema schema = new Schema(schemaName);
- if (execute(String.format(HiveConstant.USE_DB, schemaName))) {
- // 获取库下的所有表 存储到schema中
- schema.setTables(listTables(schema.getName()));
- }
- schemas.add(schema);
- }
- }
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- close(preparedStatement, results);
- }
- return schemas;
- }
-
- // 根据库名表名获取表的列信息
- @Override
- public List listColumns(String schemaName, String tableName) {
- List columns = new ArrayList<>();
- PreparedStatement preparedStatement = null;
- ResultSet results = null;
- IDBQuery dbQuery = getDBQuery();
- String tableFieldsSql = dbQuery.columnsSql(schemaName, tableName);
- try {
- preparedStatement = conn.prepareStatement(tableFieldsSql);
- results = preparedStatement.executeQuery();
- ResultSetMetaData metaData = results.getMetaData();
- List columnList = new ArrayList<>();
- for (int i = 1; i <= metaData.getColumnCount(); i++) {
- columnList.add(metaData.getColumnLabel(i));
- }
- Integer positionId = 1;
- while (results.next()) {
- Column field = new Column();
- if (StringUtils.isEmpty(results.getString(dbQuery.columnName()))) {
- break;
- } else {
- if (columnList.contains(dbQuery.columnName())) {
- String columnName = results.getString(dbQuery.columnName());
- field.setName(columnName);
- }
- if (columnList.contains(dbQuery.columnType())) {
- field.setType(results.getString(dbQuery.columnType()));
- }
- if (columnList.contains(dbQuery.columnComment()) && Asserts.isNotNull(results.getString(dbQuery.columnComment()))) {
- String columnComment = results.getString(dbQuery.columnComment()).replaceAll("\"|'", "");
- field.setComment(columnComment);
- }
- field.setPosition(positionId++);
- field.setJavaType(getTypeConvert().convert(field));
- }
- columns.add(field);
- }
- } catch (SQLException e) {
- e.printStackTrace();
- } finally {
- close(preparedStatement, results);
- }
- return columns;
- }
-
- //获取建表的SQL
- @Override
- public String getCreateTableSql(Table table) {
- StringBuilder createTable = new StringBuilder();
- PreparedStatement preparedStatement = null;
- ResultSet results = null;
- String createTableSql = getDBQuery().createTableSql(table.getSchema(), table.getName());
- try {
- preparedStatement = conn.prepareStatement(createTableSql);
- results = preparedStatement.executeQuery();
- while (results.next()) {
- createTable.append(results.getString(getDBQuery().createTableName())).append("\n");
- }
- } catch (Exception e) {
- e.printStackTrace();
- } finally {
- close(preparedStatement, results);
- }
- return createTable.toString();
- }
-
- @Override
- public int executeUpdate(String sql) throws Exception {
- Asserts.checkNullString(sql, "Sql 语句为空");
- String querySQL = sql.trim().replaceAll(";$", "");
- int res = 0;
- try (Statement statement = conn.createStatement()) {
- res = statement.executeUpdate(querySQL);
- }
- return res;
- }
-
- @Override
- public JdbcSelectResult query(String sql, Integer limit) {
- if (Asserts.isNull(limit)) {
- limit = 100;
- }
- JdbcSelectResult result = new JdbcSelectResult();
- List> datas = new ArrayList<>();
- List columns = new ArrayList<>();
- List columnNameList = new ArrayList<>();
- PreparedStatement preparedStatement = null;
- ResultSet results = null;
- int count = 0;
- try {
- String querySQL = sql.trim().replaceAll(";$", "");
- preparedStatement = conn.prepareStatement(querySQL);
- results = preparedStatement.executeQuery();
- if (Asserts.isNull(results)) {
- result.setSuccess(true);
- close(preparedStatement, results);
- return result;
- }
- ResultSetMetaData metaData = results.getMetaData();
- for (int i = 1; i <= metaData.getColumnCount(); i++) {
- columnNameList.add(metaData.getColumnLabel(i));
- Column column = new Column();
- column.setName(metaData.getColumnLabel(i));
- column.setType(metaData.getColumnTypeName(i));
- column.setAutoIncrement(metaData.isAutoIncrement(i));
- column.setNullable(metaData.isNullable(i) == 0 ? false : true);
- column.setJavaType(getTypeConvert().convert(column));
- columns.add(column);
- }
- result.setColumns(columnNameList);
- while (results.next()) {
- LinkedHashMap data = new LinkedHashMap<>();
- for (int i = 0; i < columns.size(); i++) {
- data.put(columns.get(i).getName(), getTypeConvert().convertValue(results, columns.get(i).getName(), columns.get(i).getType()));
- }
- datas.add(data);
- count++;
- if (count >= limit) {
- break;
- }
- }
- result.setSuccess(true);
- } catch (Exception e) {
- result.setError(LogUtil.getError(e));
- result.setSuccess(false);
- } finally {
- close(preparedStatement, results);
- result.setRowData(datas);
- return result;
- } }
-
- @Override
- public IDBQuery getDBQuery() {
- return new HiveQuery();
- }
-
- @Override
- public ITypeConvert getTypeConvert() {
- return new HiveTypeConvert();
- }
-
- // 获取驱动类
- @Override
- String getDriverClass() {
- return "org.apache.hive.jdbc.HiveDriver";
- }
-
- // 改数据源表的类型 此处必须
- @Override
- public String getType() {
- return "Hive";
- }
- // 改数据源表的名称 此处必须
- @Override
- public String getName() {
- return "Hive";
- }
-
- // 映射 Flink 的数据类型
- @Override
- public Map getFlinkColumnTypeConversion() {
- HashMap map = new HashMap<>();
- map.put("BOOLEAN", "BOOLEAN");
- map.put("TINYINT", "TINYINT");
- map.put("SMALLINT", "SMALLINT");
- map.put("INT", "INT");
- map.put("VARCHAR", "STRING");
- map.put("TEXY", "STRING");
- map.put("INT", "INT");
- map.put("DATETIME", "TIMESTAMP");
- return map;
- }
-}
-
-
-
-```
-
-
-HiveQuery
-```java
-
-
-public class HiveQuery extends AbstractDBQuery {
- // 获取所有数据库的查询SQL 需要与 常量类(HiveConstant) 联合使用
- @Override
- public String schemaAllSql() {
- return HiveConstant.QUERY_ALL_DATABASE;
- }
-
- // 获取库下的所有表的SQL 需要与 常量类(HiveConstant) 联合使用
- @Override
- public String tablesSql(String schemaName) {
- return HiveConstant.QUERY_ALL_TABLES_BY_SCHEMA;
- }
-
- // 动态构建获取表的所有列的SQL 需要与 常量类(HiveConstant) 联合使用
- @Override
- public String columnsSql(String schemaName, String tableName) {
- return String.format(HiveConstant.QUERY_TABLE_SCHEMA, schemaName, tableName);
- }
-
- // 获取所有数据库的 result title
- @Override
- public String schemaName() {
- return "database_name";
- }
-
- // 获取建表语句的 result title
- @Override
- public String createTableName() {
- return "createtab_stmt";
- }
-
- // 获取所有表的 result title
- @Override
- public String tableName() {
- return "tab_name";
- }
-
- // 获取表注释的 result title
- @Override
- public String tableComment() {
- return "comment";
- }
-
- // 获取列名的 result title
- @Override
- public String columnName() {
- return "col_name";
- }
-
- // 获取列的数据类型的 result title
- @Override
- public String columnType() {
- return "data_type";
- }
-
- // 获取列注释的 result title
- @Override
- public String columnComment() {
- return "comment";
- }
-
-}
-
-```
-
-- 以上代码开发完成 在此模块下进行测试 建议使用单元测试进行测试 , 如您 PR , 则测试用例必须提交,同时需要注意敏感信息的处理
-
-- 通过仅仅上述的代码可知 Dinky 的代码扩展性极强 , 可根据数据源的特性随时重写父类的方法 , 进而轻松实现扩展
-
-
-
-
-- 如果上述过程 测试没有问题 需要整合进入项目中 , 请看以下步骤:
-- 打包相关配置 修改如下:
- - 在 **dlink-core** 模块的 **pom.xml** 下 , 找到扩展数据源相关的依赖 `放在一起方便管理` 并且新增如下内容:
-```xml
-
- com.dlink
- 模块名称
- ${scope.runtime}
-
-```
- - 在 **dlink** 根下 **pom.xml** 中 ,新增如下内容:
-```xml
-
- com.dlink
- 模块名称
- ${project.version}
-
-```
-
- - 在 **dlink-assembly** 模块中 , 找到 ``package.xml`` 路径: **/dlink-assembly/src/main/assembly/package.xml** , 新增如下内容:
-```xml
-
- ${project.parent.basedir}/dlink-metadata/模块名称/target
-
- lib
-
- 模块名称-${project.version}.jar
-
-
- ```
-
-至此 如您的代码没有问题的话 后端代码扩展就已经完成了 !
-
-----
-
-## 前端开发
-- **dinky-web** 为 Dinky 的前端模块
-- 扩展数据源相关表单所在路径: `dinky-web/src/pages/DataBase/`
- - 修改 `dinky-web/src/pages/DataBase/components/DBForm.tsx` 的 **const data** 中 添加如下:
-eg:
-```shell
- {
- type: 'Hive',
- },
-```
-如下图:
-
-
-注意: ``此处数据源类型遵照大驼峰命名规则``
-
- - 添加数据源logo图片
- - 路径: `dinky-web/public/database/`
- - logo 图下载参考: [https://www.iconfont.cn](https://www.iconfont.cn)
- - logo 图片存放位置: `dinky-web/public/database`
- - 修改 `dinky-web/src/pages/DataBase/DB.ts` , 添加如下:
-eg:
-```shell
- case 'hive':
- imageUrl += 'hive.png'; # 需要和添加的图片名称保持一致
- break;
-```
-如下图:
-
- - 创建数据源相关表单属性在: `dinky-web/src/pages/DataBase/components/DataBaseForm.tsx` 此处无需修改
-
-----
-
-:::info 说明
-至此 , 基于 Dinky 扩展数据源完成 , 如您也有扩展需求 ,请参照如何 [[Issuse]](../../developer_guide/contribution/issue) 和如何 [[提交 PR]](../../developer_guide/contribution/pull_request)
-:::
diff --git a/docs/docs/extend/function_expansion/flinktaskmonitor.md b/docs/docs/extend/function_expansion/flinktaskmonitor.md
deleted file mode 100644
index 000b5e5abf..0000000000
--- a/docs/docs/extend/function_expansion/flinktaskmonitor.md
+++ /dev/null
@@ -1,61 +0,0 @@
----
-sidebar_position: 6
-id: flinktaskmonitor
-title: flink 任务运行监控
----
-
-
-
-
-## 说明
-
-本文章主要说明对运行过程中的 flink 任务的监控,采用 **prometheus+pushgateway+grafana** 方式,为非平台内部监控方案。
-
-## 前提
-
-公司的服务器已经安装了 prometheus 和 pushgateway 网关服务,如果为安装,需要运维人员进行安装,或是自行安装。
-
-## 介绍
-
-Flink 提供的 Metrics 可以在 Flink 内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。
-由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的 Task 日志。 Metrics 可以很好的帮助开发人员了解作业的当前状况。
-
-Flink 官方支持 Prometheus,并且提供了对接 Prometheus 的 jar 包,很方便就可以集成。
-在 FLINK_HEME/plugins/metrics-prometheus 目录下可以找到 **flink-metrics-prometheus** 包。
-
-flink 的 plugin 目录下的 jar 包无需拷贝到 lib 目录下,可在运行时被 flink 加载。
-
-## 配置步骤
-
-### 修改Flink配置
-
-修改 **flink-conf.yaml** 文件,该文件和集群配置有关,如果是 Standalone,Yarn Session 和 Kubernetes Session 模式,则需要修改启动本地集群或 session 集群时的 flink 目录下的 flink-conf.yaml 文件。
-如果是 Yarn Per-job、Yarn Application 和 Kubernetes Application 模式,则需要修改创建集群时指定的 flink 配置目录下的 flink-conf.yaml 文件,
-同时需要将上面提到的 **flink-metrics-prometheus** 上传到平台的 **plugins** 目录和 **hdfs** 上的 **flink lib** 目录下。
-
-```shell
-vim flink-conf.yaml
-```
-
-添加如下配置:
-
-```yaml
-##### 与 Prometheus 集成配置 #####
-metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
-# PushGateway 的主机名与端口号
-metrics.reporter.promgateway.host: node01
-metrics.reporter.promgateway.port: 9091
-# Flink metric 在前端展示的标签(前缀)与随机后缀
-metrics.reporter.promgateway.jobName: flink-application
-metrics.reporter.promgateway.randomJobNameSuffix: true
-metrics.reporter.promgateway.deleteOnShutdown: false
-metrics.reporter.promgateway.interval: 30 SECONDS
-```
-
-之后启动 flink 任务,然后就可以通过 grafana 来查询 prometheus 中网关的数据了。
-
-### grafana 监控方案
-
-https://grafana.com/search/?term=flink&type=dashboard
-
-通过上面网站搜索 flink ,我们就可以找到其他用户共享的他们使用的 flink 任务监控方案,从结果中找到自己喜欢的监控方案,下载对应的 json 文件后,上传到 grafana 即可实现对任务的监控。
\ No newline at end of file
diff --git a/docs/docs/extend/function_expansion/flinkversion.md b/docs/docs/extend/function_expansion/flinkversion.md
deleted file mode 100644
index 1b30ced135..0000000000
--- a/docs/docs/extend/function_expansion/flinkversion.md
+++ /dev/null
@@ -1,21 +0,0 @@
----
-sidebar_position: 1
-id: flinkversion
-title: 扩展 Flink 版本
----
-
-
-
-
-## 扩展其他版本的 Flink
-
-**dlink-catalog-mysql**、**dlink-client**、**dlink-app**。
-
-**lib** 目录下默认的上面三个依赖对应的 flink 版本可能和你想要使用的 flink 版本不一致,需要进入到平台的 **lib** 目录下查看具体的上面三个依赖对应的 flink 版本,
-如果不一致,则需要删除 **lib** 目录下的对应的上面三个依赖包,然后从 **extends** 和 **jar** 目录下找到合适的包,拷贝到 **lib** 目录下。
-
-比如 **lib** 目录下的 **dlink-client-1.14-0.6.7.jar** ,表示使用的 flink 版本为 1.14.x ,
-如果你在 **plugins** 目录下上传的 flink 用到的 jar 包的版本不是 1.14.x ,就需要更换 **dlink-client** 包。
-
-
-切换版本时需要同时更新 plugins 下的 Flink 依赖。
\ No newline at end of file
diff --git a/docs/docs/extend/integrate.md b/docs/docs/extend/integrate.md
deleted file mode 100644
index f60208f3e8..0000000000
--- a/docs/docs/extend/integrate.md
+++ /dev/null
@@ -1,68 +0,0 @@
----
-sidebar_position: 1
-id: integrate
-title: 集成
----
-
-
-
-**声明:** Dinky并没有维护下面列出的库,其中有一部分是生产实践,一部分还未做过相关生产实践。欢迎使用Dinky已经集成的第三方库。
-
-## 关系型数据库
- - MySQL
- - PostGreSQL
- - Oracle
- - SQLServer
-
-## OLAP引擎
- - Doris
- - ClickHouse
- - Phoenix
- - Hive
-
-
-
-## 消息队列
-
- - Kafka
- - Pulsar
-
-
-以上均采用FlinkSQL Connector与Dinky集成使用,下面链接提供了FlinkSQL相关Connector包,请在[maven仓库](https://repo.maven.apache.org/maven2/org/apache/flink/)自行下载。
-
-
-## CDC工具
-
- - [Flink CDC](https://github.com/ververica/flink-cdc-connectors/releases/)
-
-
-## 调度平台
-
- - **Oozie**
- - **dolphinscheduler:** [Apache dolphinscheduler](https://dolphinscheduler.apache.org/zh-cn/)大数据调度平台
-
-
-对于调度平台,需支持HTTP服务即可
-
-## 数据湖
-
- - Hudi
- - Iceberg
-
-
-[Hudi](https://github.com/apache/hudi) 及 [Iceberg](https://github.com/apache/iceberg) 请移步到github自行编译或者下载
-
-## HADOOP
- - [flink-shaded-hadoop-3-uber](https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/flink/flink-shaded-hadoop-3-uber)
-
-## 其他
-
- - **dataspherestudio:** 微众银行开源[数据中台](https://github.com/WeBankFinTech/DataSphereStudio)
-
-
-与Dinky的集成实践请移步最佳实践中的集成指南
-
-
-
-
-
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/_category_.json b/docs/docs/extend/practice_guide/_category_.json
deleted file mode 100644
index 1f9f8d8546..0000000000
--- a/docs/docs/extend/practice_guide/_category_.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "label": "实践指南",
- "position": 3
-}
diff --git a/docs/docs/extend/practice_guide/aggtable.md b/docs/docs/extend/practice_guide/aggtable.md
deleted file mode 100644
index 3923ce0c83..0000000000
--- a/docs/docs/extend/practice_guide/aggtable.md
+++ /dev/null
@@ -1,373 +0,0 @@
----
-sidebar_position: 3
-id: aggtable
-title: AGGTABLE 表值聚合的实践
----
-
-
-
-## 摘要
-
-本文讲述了 Dlink 对 Flink 的表值聚合功能的应用与增强。增强主要在于定义了 AGGTABLE 来通过 FlinkSql 进行表值聚合的实现,以下将通过两个示例 top2 与 to_map 进行讲解。
-
-## 准备工作
-
-### 准备测试表
-
-#### 学生表(student)
-
-```sql
-DROP TABLE IF EXISTS `student`;
-CREATE TABLE `student` (
- `sid` int(11) NOT NULL,
- `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
- PRIMARY KEY (`sid`) USING BTREE
-) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-
-INSERT INTO `student` VALUES (1, '小明');
-INSERT INTO `student` VALUES (2, '小红');
-INSERT INTO `student` VALUES (3, '小黑');
-INSERT INTO `student` VALUES (4, '小白');
-```
-
-#### 一维成绩表(score)
-
-```sql
-DROP TABLE IF EXISTS `score`;
-CREATE TABLE `score` (
- `cid` int(11) NOT NULL,
- `sid` int(11) NULL DEFAULT NULL,
- `cls` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
- `score` int(11) NULL DEFAULT NULL,
- PRIMARY KEY (`cid`) USING BTREE
-) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-
-INSERT INTO `score` VALUES (1, 1, 'chinese', 90);
-INSERT INTO `score` VALUES (2, 1, 'math', 100);
-INSERT INTO `score` VALUES (3, 1, 'english', 95);
-INSERT INTO `score` VALUES (4, 2, 'chinese', 98);
-INSERT INTO `score` VALUES (5, 2, 'english', 99);
-INSERT INTO `score` VALUES (6, 3, 'chinese', 99);
-INSERT INTO `score` VALUES (7, 3, 'english', 100);
-```
-
-#### 前二排名表(scoretop2)
-
-```sql
-DROP TABLE IF EXISTS `scoretop2`;
-CREATE TABLE `scoretop2` (
- `cls` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
- `score` int(11) NULL DEFAULT NULL,
- `rank` int(11) NOT NULL,
- PRIMARY KEY (`cls`, `rank`) USING BTREE
-) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-```
-
-#### 二维成绩单表(studentscore)
-
-```sql
-DROP TABLE IF EXISTS `studentscore`;
-CREATE TABLE `studentscore` (
- `sid` int(11) NOT NULL,
- `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
- `chinese` int(11) NULL DEFAULT NULL,
- `math` int(11) NULL DEFAULT NULL,
- `english` int(11) NULL DEFAULT NULL,
- PRIMARY KEY (`sid`) USING BTREE
-) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-```
-
-### 问题提出
-
-#### 输出各科成绩前二的分数
-
-要求输出已有学科排名前二的分数到scoretop2表中。
-
-#### 输出二维成绩单
-
-要求将一维成绩表转化为二维成绩单,其中不存在的成绩得分为0,并输出至studentscore表中。
-
-## Dlink 的 AGGTABLE
-
- 本文以 Flink 官方的 Table Aggregate Functions 示例 Top2 为例进行比较说明,传送门 https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/table/functions/udfs/#table-aggregate-functions
-
-### 官方 Table API 实现
-
-```java
-import org.apache.flink.api.java.tuple.Tuple2;
-import org.apache.flink.table.api.*;
-import org.apache.flink.table.functions.TableAggregateFunction;
-import org.apache.flink.util.Collector;
-import static org.apache.flink.table.api.Expressions.*;
-
-// mutable accumulator of structured type for the aggregate function
-public static class Top2Accumulator {
- public Integer first;
- public Integer second;
-}
-
-// function that takes (value INT), stores intermediate results in a structured
-// type of Top2Accumulator, and returns the result as a structured type of Tuple2
-// for value and rank
-public static class Top2 extends TableAggregateFunction, Top2Accumulator> {
-
- @Override
- public Top2Accumulator createAccumulator() {
- Top2Accumulator acc = new Top2Accumulator();
- acc.first = Integer.MIN_VALUE;
- acc.second = Integer.MIN_VALUE;
- return acc;
- }
-
- public void accumulate(Top2Accumulator acc, Integer value) {
- if (value > acc.first) {
- acc.second = acc.first;
- acc.first = value;
- } else if (value > acc.second) {
- acc.second = value;
- }
- }
-
- public void merge(Top2Accumulator acc, Iterable it) {
- for (Top2Accumulator otherAcc : it) {
- accumulate(acc, otherAcc.first);
- accumulate(acc, otherAcc.second);
- }
- }
-
- public void emitValue(Top2Accumulator acc, Collector> out) {
- // emit the value and rank
- if (acc.first != Integer.MIN_VALUE) {
- out.collect(Tuple2.of(acc.first, 1));
- }
- if (acc.second != Integer.MIN_VALUE) {
- out.collect(Tuple2.of(acc.second, 2));
- }
- }
-}
-
-TableEnvironment env = TableEnvironment.create(...);
-
-// call function "inline" without registration in Table API
-env
- .from("MyTable")
- .groupBy($("myField"))
- .flatAggregate(call(Top2.class, $("value")))
- .select($("myField"), $("f0"), $("f1"));
-
-// call function "inline" without registration in Table API
-// but use an alias for a better naming of Tuple2's fields
-env
- .from("MyTable")
- .groupBy($("myField"))
- .flatAggregate(call(Top2.class, $("value")).as("value", "rank"))
- .select($("myField"), $("value"), $("rank"));
-
-// register function
-env.createTemporarySystemFunction("Top2", Top2.class);
-
-// call registered function in Table API
-env
- .from("MyTable")
- .groupBy($("myField"))
- .flatAggregate(call("Top2", $("value")).as("value", "rank"))
- .select($("myField"), $("value"), $("rank"));
-```
-
-### Dlink FlinkSql 实现
-
-#### 示例
-
-```sql
-CREATE AGGTABLE aggdemo AS
-SELECT myField,value,rank
-FROM MyTable
-GROUP BY myField
-AGG BY TOP2(value) as (value,rank);
-```
-
-#### 优势
-
- 可以通过 FlinkSql 来实现表值聚合的需求,降低了开发与维护成本。
-
-#### 缺点
-
- 语法固定,示例关键字必须存在并进行描述,where 可以加在 FROM 和 GROUP BY 之间。
-
-## Dlink 本地实现各科成绩前二
-
- 本示例通过 Dlink 的本地环境进行演示实现。
-
-### 进入Dlink
-
-
-
- 只有版本号大于等于 0.2.2-rc1 的 Dlink 才支持本文 AGGTABLE 的使用。
-
-### 编写 FlinkSQL
-
-```sql
-jdbcconfig:='connector' = 'jdbc',
- 'url' = 'jdbc:mysql://127.0.0.1:3306/data?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true',
- 'username'='dlink',
- 'password'='dlink',;
-CREATE TABLE student (
- sid INT,
- name STRING,
- PRIMARY KEY (sid) NOT ENFORCED
-) WITH (
- ${jdbcconfig}
- 'table-name' = 'student'
-);
-CREATE TABLE score (
- cid INT,
- sid INT,
- cls STRING,
- score INT,
- PRIMARY KEY (cid) NOT ENFORCED
-) WITH (
- ${jdbcconfig}
- 'table-name' = 'score'
-);
-CREATE TABLE scoretop2 (
- cls STRING,
- score INT,
- `rank` INT,
- PRIMARY KEY (cls,`rank`) NOT ENFORCED
-) WITH (
- ${jdbcconfig}
- 'table-name' = 'scoretop2'
-);
-CREATE AGGTABLE aggscore AS
-SELECT cls,score,rank
-FROM score
-GROUP BY cls
-AGG BY TOP2(score) as (score,rank);
-
-insert into scoretop2
-select
-b.cls,b.score,b.`rank`
-from aggscore b
-```
-
- 本 Sql 使用了 Dinky 的增强特性 Fragment 机制,对 jdbc 的配置进行了定义。
-
-### 维护 FlinkSQL 及配置
-
-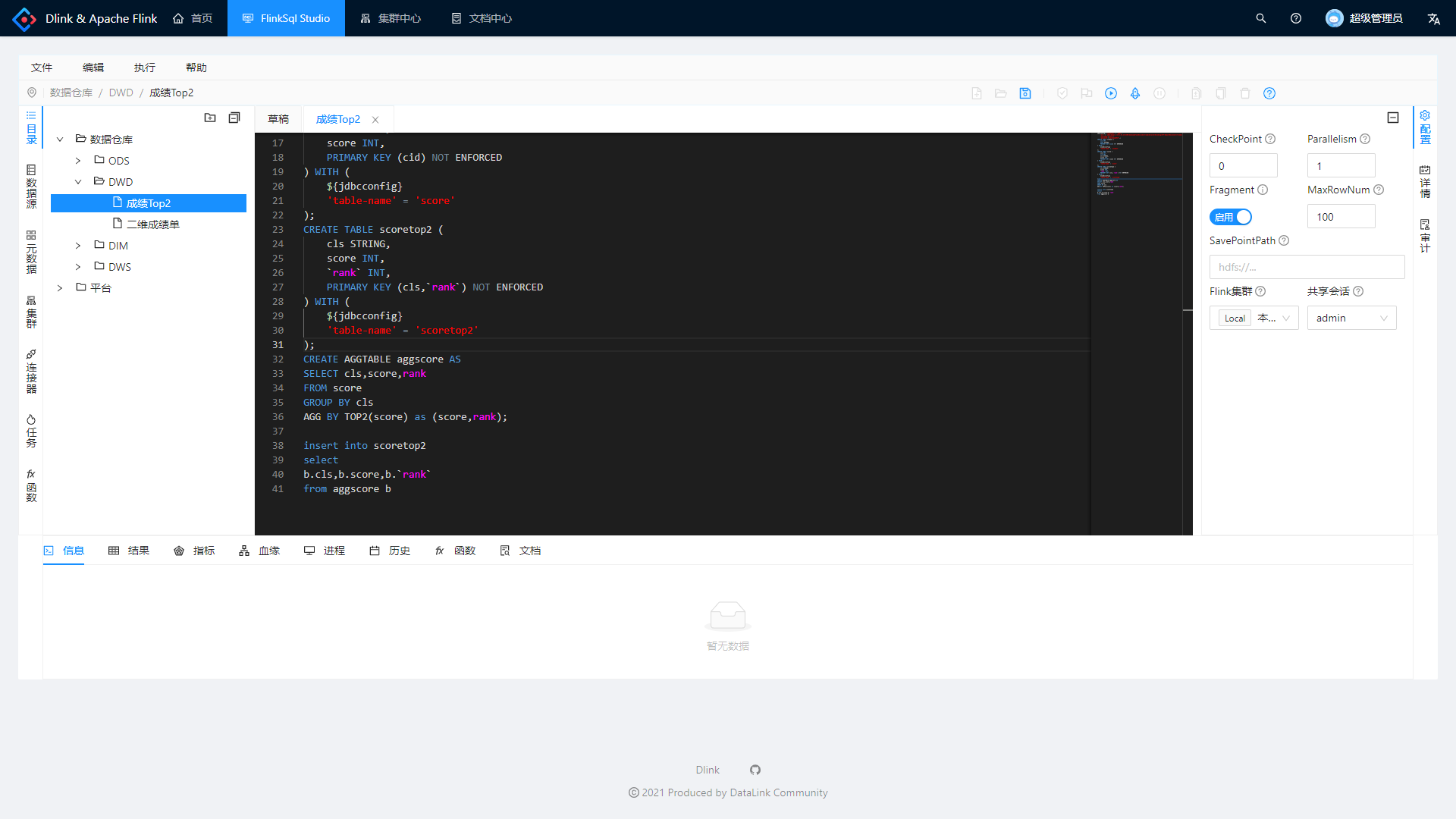
-
- 编写 FlinkSQL ,配置开启 Fragment 机制,设置 Flink 集群为本地执行。点击保存。
-
-### 同步执行INSERT
-
-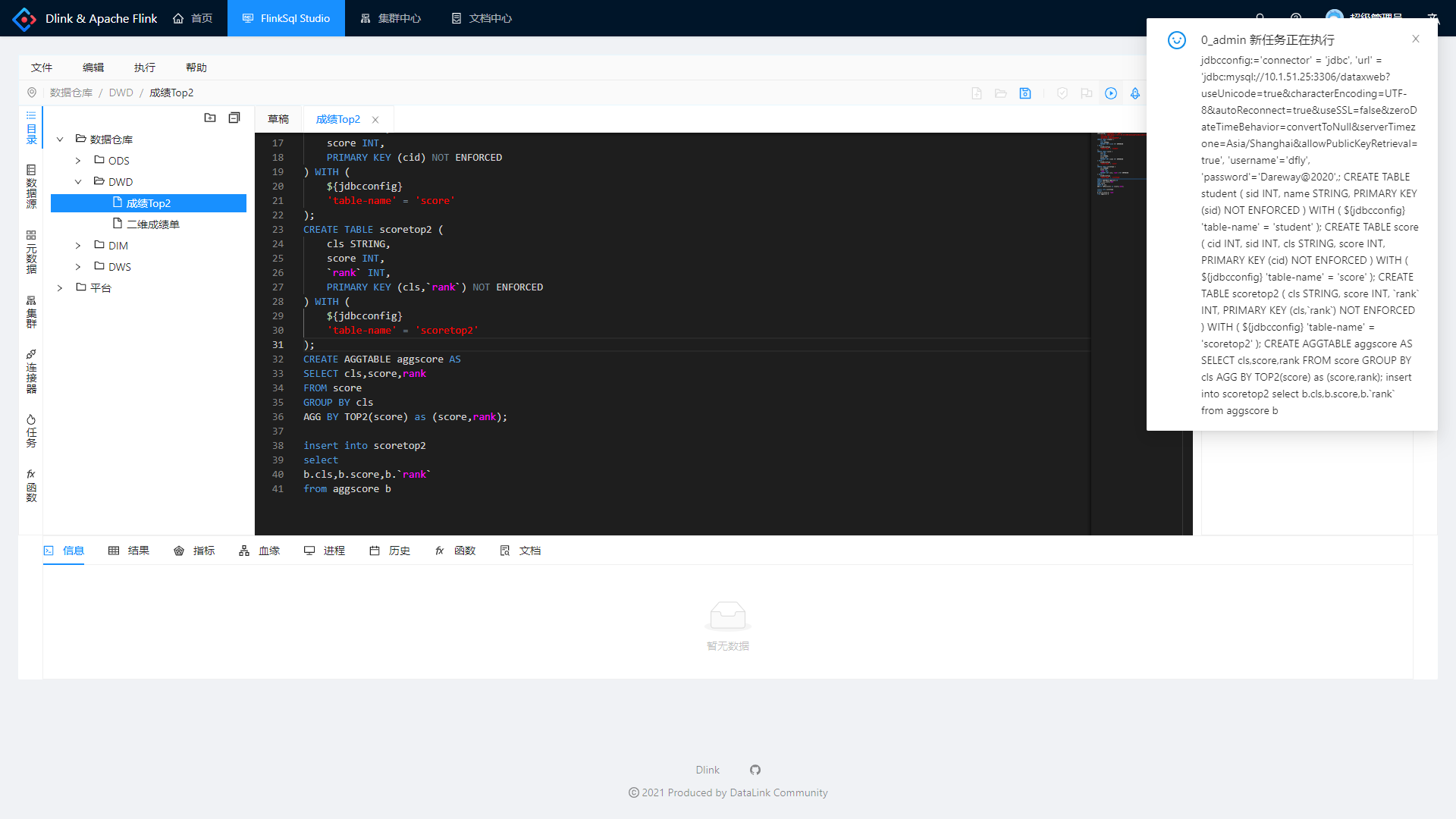
-
- 点击同步执行按钮运行当前编辑器中的 FlinkSQL 语句集。弹出提示信息,等待执行完成后自动关闭并刷新信息和结果。
-
- 当前版本使用异步提交功能将直接提交任务到集群,Studio 不负责执行结果的记录。提交任务前请保存 FlinkSQL 和配置,否则将提交旧的语句和配置。
-
-### 执行反馈
-
-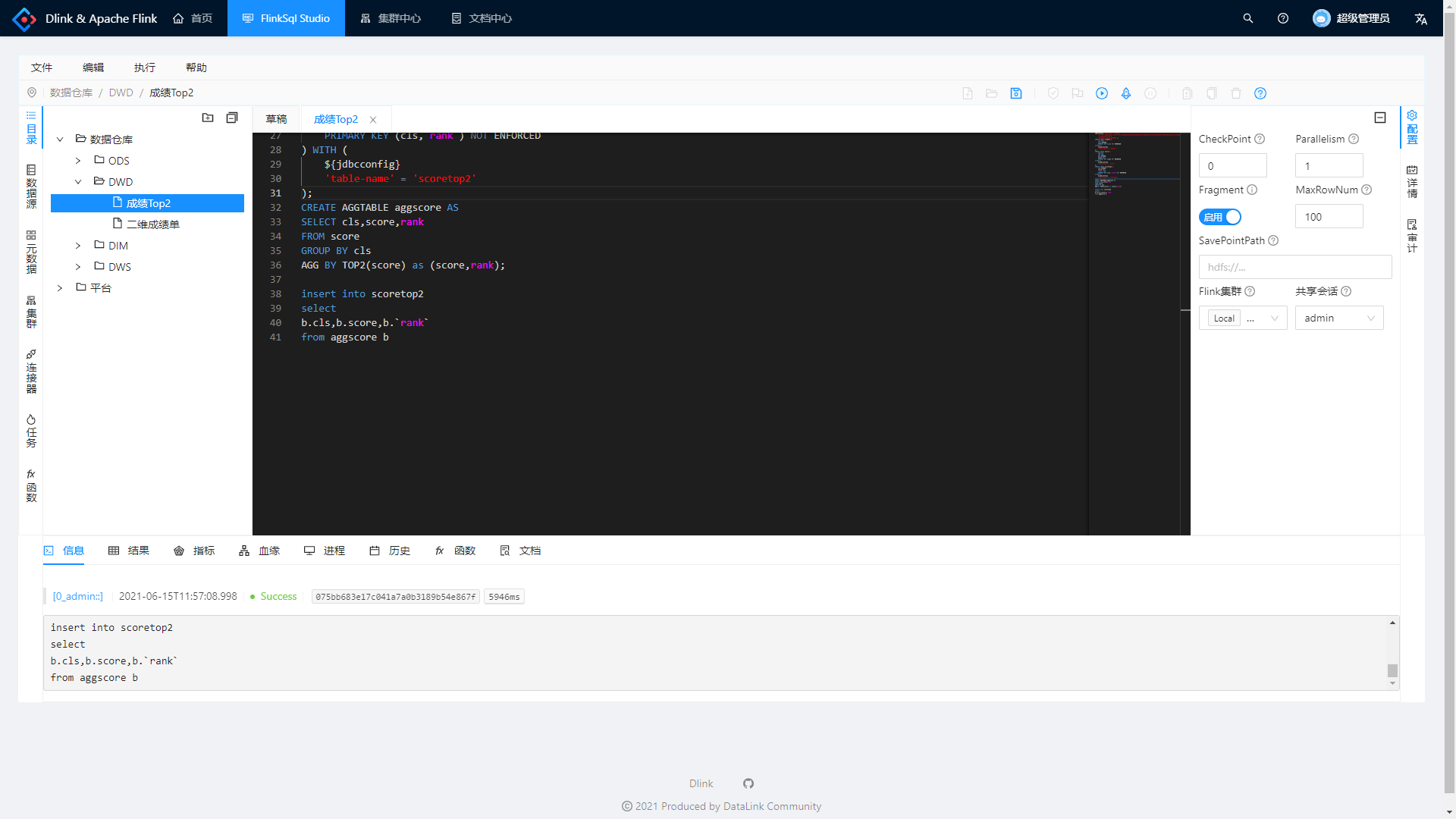
-
- 本地执行成功,“0_admin” 为本地会话,里面存储了 Catalog。
-
-### 同步执行SELECT查看中间过程
-
-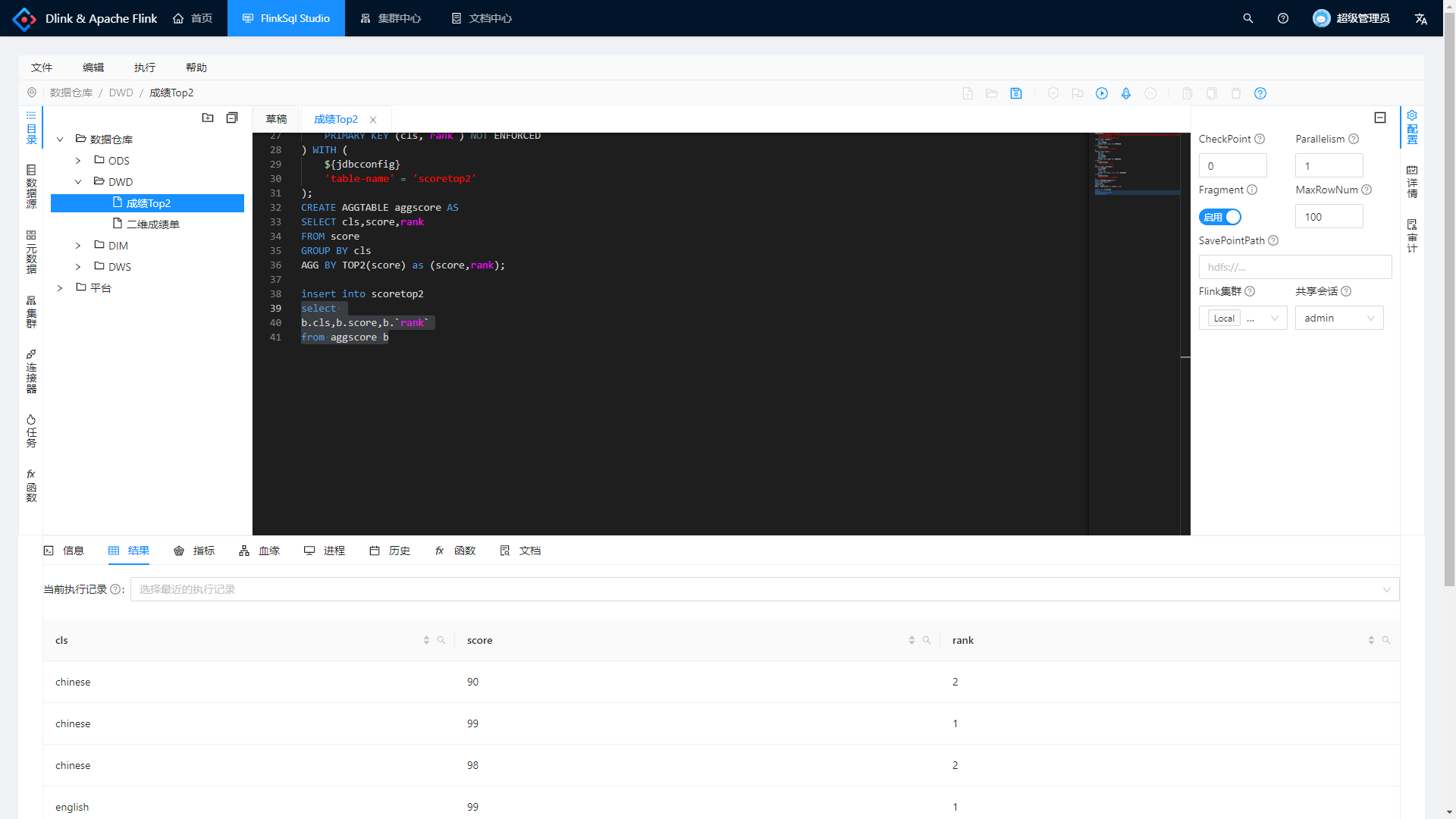
-
- 由于当前会话中已经存储了表的定义,此时直接选中 select 语句点击同步执行可以重新计算并展示其计算过程中产生的结果,由于 Flink 表值聚合操作机制,该结果非最终结果。
-
-### 同步执行SELECT查看最终结果
-
-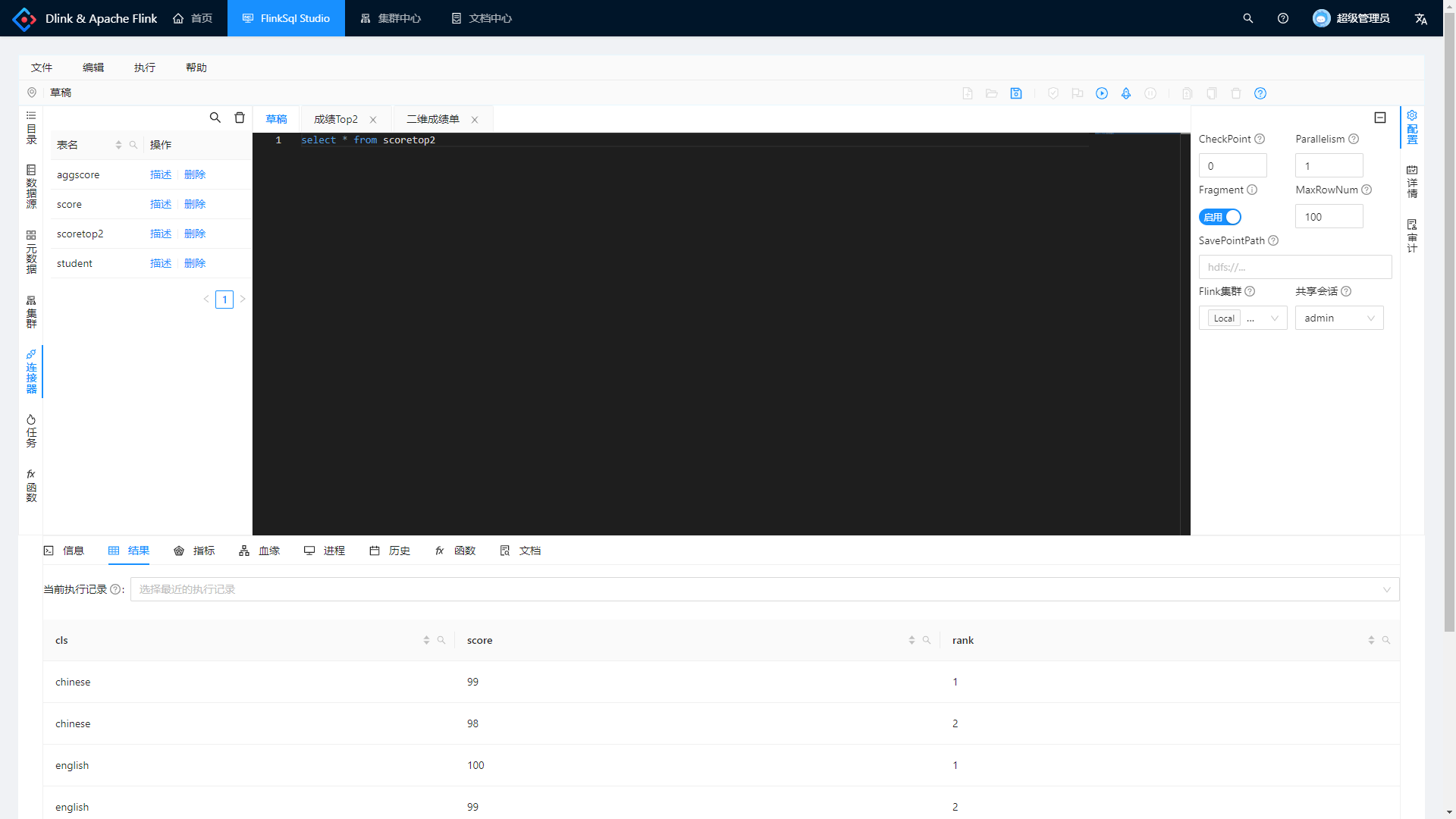
-
-
- 在草稿的页面使用相同的会话可以共享 Catalog,此时只需要执行 select 查询 sink 表就可以预览最终的统计结果。
-
-### 查看Mysql表的数据
-
-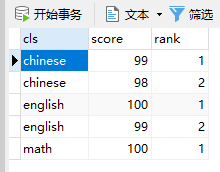
-
-
-
- sink 表中只有五条数据,结果是正确的。
-
-## Dlink 远程实现二维成绩单
-
- 本示例通过 Dlink 控制远程集群来实现。
-
- 远程集群的 lib 中需要上传 dlink-function.jar 。
-
-### 编写FlinkSQL
-
-```sql
-jdbcconfig:='connector' = 'jdbc',
- 'url' = 'jdbc:mysql://127.0.0.1:3306/data?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true',
- 'username'='dlink',
- 'password'='dlink',;
-CREATE TABLE student (
- sid INT,
- name STRING,
- PRIMARY KEY (sid) NOT ENFORCED
-) WITH (
- ${jdbcconfig}
- 'table-name' = 'student'
-);
-CREATE TABLE score (
- cid INT,
- sid INT,
- cls STRING,
- score INT,
- PRIMARY KEY (cid) NOT ENFORCED
-) WITH (
- ${jdbcconfig}
- 'table-name' = 'score'
-);
-CREATE TABLE studentscore (
- sid INT,
- name STRING,
- chinese INT,
- math INT,
- english INT,
- PRIMARY KEY (sid) NOT ENFORCED
-) WITH (
- ${jdbcconfig}
- 'table-name' = 'studentscore'
-);
-CREATE AGGTABLE aggscore2 AS
-SELECT sid,data
-FROM score
-GROUP BY sid
-AGG BY TO_MAP(cls,score) as (data);
-
-insert into studentscore
-select
-a.sid,a.name,
-cast(GET_KEY(b.data,'chinese','0') as int),
-cast(GET_KEY(b.data,'math','0') as int),
-cast(GET_KEY(b.data,'english','0') as int)
-from student a
-left join aggscore2 b on a.sid=b.sid
-```
-
- 本实例通过表值聚合将分组后的多行转单列然后通过 GET_KEY 取值的思路来实现。同时,也使用了 Fragment 机制。
-
-### 同步执行
-
-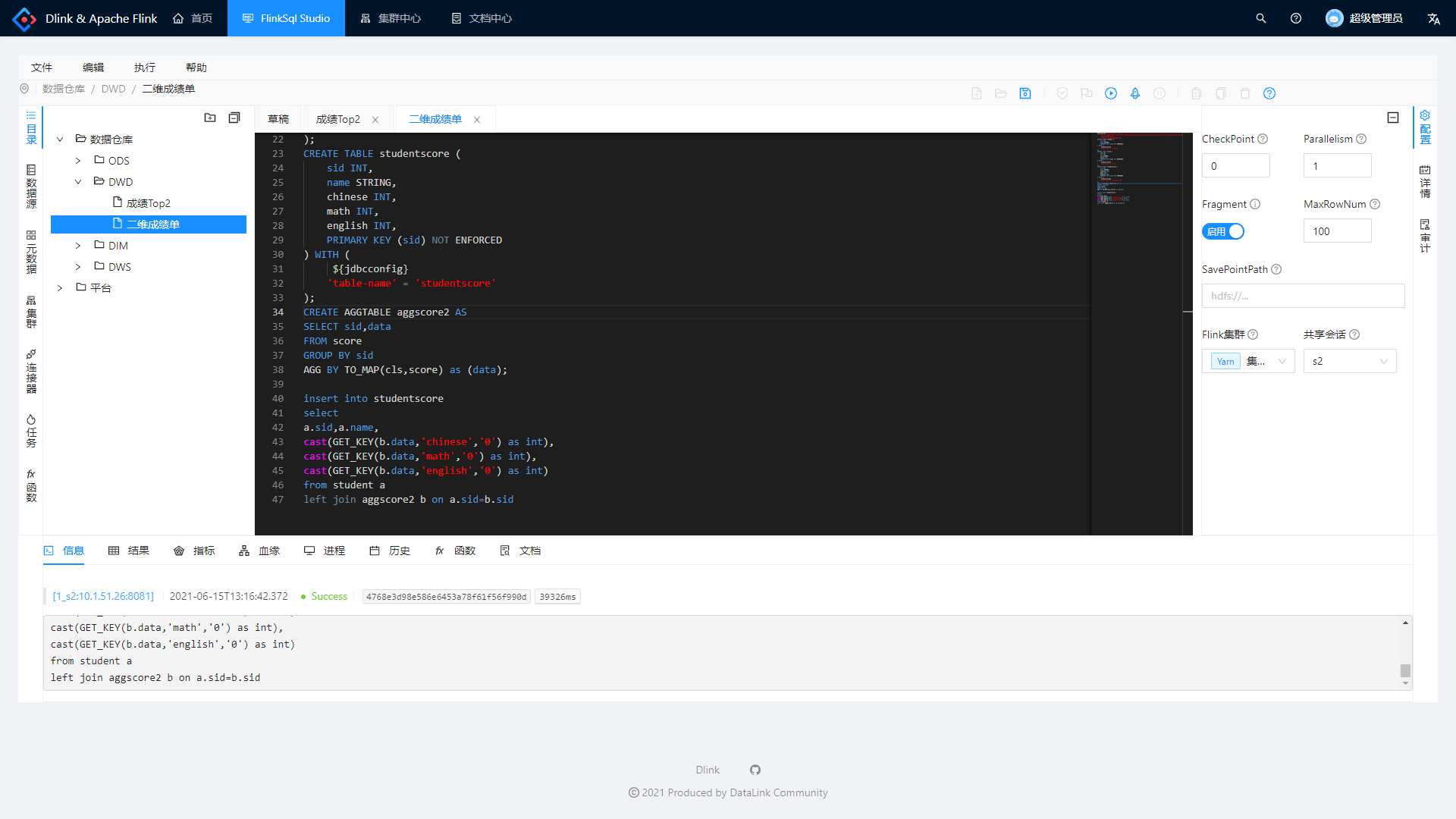
-
- 与示例一相似,不同点在于需要更改集群配置为 远程集群。远程集群的注册在集群中心注册,Hosts 需要填写 JobManager 的地址,HA模式则使用英文逗号分割可能出现的地址,如“127.0.0.1:8081,127.0.0.2:8081,127.0.0.3:8081”。心跳监测正常的集群实例即可用于任务执行或提交。
-
-### Flink UI
-
-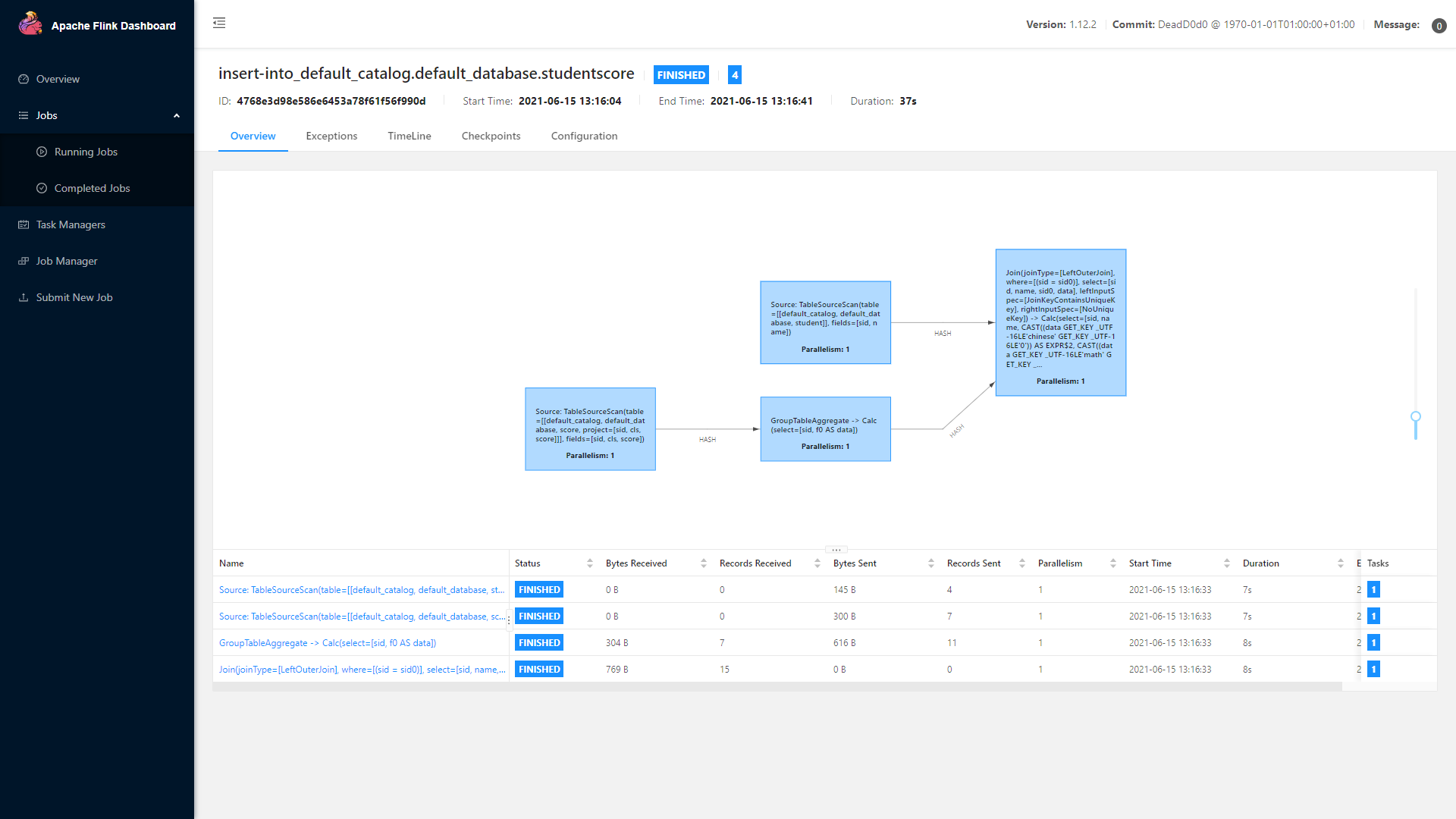
-
- 打开集群的 Flink UI 可以发现刚刚提交的批任务,此时可以发现集群版本号为 1.14.0 ,而 Dlink 默认版本为 1.14.0 ,所以一般大版本内可以互相兼容。
-
-### 查看Mysql表的数据
-
-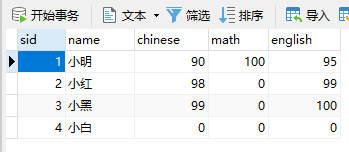
-
- 查看 Mysql 表的最终数据,发现存在四条结果,且也符合问题的要求。
-
diff --git a/docs/docs/extend/practice_guide/cdc_kafka_multi_source_merge.md b/docs/docs/extend/practice_guide/cdc_kafka_multi_source_merge.md
deleted file mode 100644
index 9bdef8b133..0000000000
--- a/docs/docs/extend/practice_guide/cdc_kafka_multi_source_merge.md
+++ /dev/null
@@ -1,351 +0,0 @@
----
-sidebar_position: 5
-id: cdc_kafka_multi_source_merge
-title: Flink CDC 和 Kafka 多源合并
----
-
-
-
-
-# Flink CDC 和 Kafka 进行多源合并和下游同步更新
-
-
-
-
-编辑:谢帮桂
-
-# 前言
-
-
-
-
-
-本文主要是针对 Flink SQL 使用 Flink CDC 无法实现多库多表的多源合并问题,以及多源合并后如何对下游 Kafka 同步更新的问题,因为目前 Flink SQL 也只能进行单表 Flink CDC 的作业操作,这会导致数据库 CDC 的连接数过多。
-
-但是 Flink CDC 的 DataStream API 是可以进行多库多表的同步操作的,本文希望利用 Flink CDC 的 DataStream API 进行多源合并后导入一个总线 Kafka,下游只需连接总线 Kafka 就可以实现 Flink SQL 的多源合并问题,资源复用。
-
-# 环境
-
-
-
-
-
-|Flink|1.13.3|
-|:----|:----|
-|Flink CDC|2.0|
-|Kafka|2.13|
-|Java|1.8|
-|Dinky|5.0|
-
-我们先打印一下 Flink CDC 默认的序列化 JSON 格式如下:
-
-```json
-SourceRecord{sourcePartition={server=mysql_binlog_source}, sourceOffset={ts_sec=1643273051, file=mysql_bin.000002, pos=5348135, row=1, server_id=1, event=2}}
-ConnectRecord{topic='mysql_binlog_source.gmall.spu_info', kafkaPartition=null, key=Struct{id=12}, keySchema=Schema{mysql_binlog_source.gmall.spu_info.Key:STRUCT}, value=Struct{before=Struct{id=12,spu_name=华为智慧屏 14222K1 全面屏智能电视机,description=华为智慧屏 4K 全面屏智能电视机,category3_id=86,tm_id=3},after=Struct{id=12,spu_name=华为智慧屏 2K 全面屏智能电视机,description=华为智慧屏 4K 全面屏智能电视机,category3_id=86,tm_id=3},source=Struct{version=1.4.1.Final,connector=mysql,name=mysql_binlog_source,ts_ms=1643273051000,db=gmall,table=spu_info,server_id=1,file=mysql_bin.000002,pos=5348268,row=0,thread=3742},op=u,ts_ms=1643272979401}, valueSchema=Schema{mysql_binlog_source.gmall.spu_info.Envelope:STRUCT}, timestamp=null, headers=ConnectHeaders(headers=)}
-```
-
-可以看到,这种格式的 JSON,传给下游有很大的问题,要实现多源合并和同步更新,我们要解决以下两个问题。
-
-**①总线 Kafka 传来的 Json,无法识别源库和源表来进行具体的表创建操作,因为不是固定的 Json 格式,建表 with 配置里也无法指定具体的库和表。**
-
-**②总线 Kafka 传来的 Json 如何进行 CRUD 等事件对 Kafka 流的同步操作,特别是 Delete,下游 kafka 如何感知来更新 ChangeLog。**
-
-# 查看文档
-
-
-
-
-
-
-
-
-
-
-
-
-我们可以看到红框部分,基于 Debezium 格式的 json 可以在 Kafka connector 建表中可以实现表的 CRUD 同步操作。只要总线 Kafka 的 json 格式符合该模式就可以对下游 kafka 进行 CRUD 的同步更新,刚好 Flink CDC 也是基于 Debezium。
-
-那这里就已经解决了问题②。
-
-剩下问题①,如何解决传来的多库多表进行指定表和库的识别,毕竟建表语句没有进行 where 的设置参数。
-
-再往下翻文档:
-
-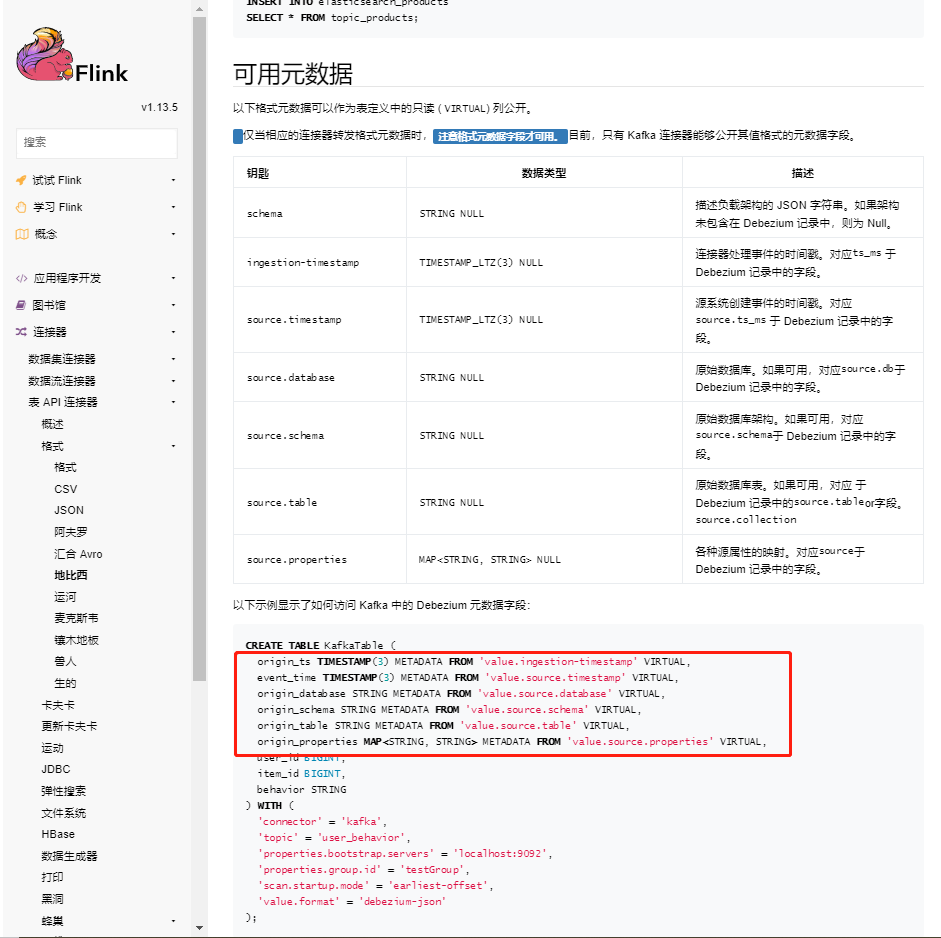
-
-可以看到,基于 Debezium-json 格式,可以把上面的 schema 定义的 json 格式的元数据给取出来放在字段里。
-
-比如,我把 table 和 database 给放在建表语句里,那样我就可以在 select 语句中进行库和表的过滤了。
-
-如下:
-
-```sql
-CREATE TABLE Kafka_Table (
- origin_database STRING METADATA FROM 'value.source.database' VIRTUAL, //schema 定义的 json 里的元数据字段
- origin_table STRING METADATA FROM 'value.source.table' VIRTUAL,
- `id` INT,
- `spu_name` STRING,
- `description` STRING,
- `category3_id` INT,
- `tm_id` INT
-) WITH (
- 'connector' = 'kafka',
- 'topic' = 'input_kafka4',
- 'properties.group.id' = '57',
- 'properties.bootstrap.servers' = '10.1.64.156:9092',
- 'scan.startup.mode' = 'latest-offset',
- 'debezium-json.ignore-parse-errors' = 'true',
- 'format' = 'debezium-json'
-);
-
-select * from Kafka_Table where origin_database='gmall' and origin_table = 'spu_info'; //这里就实现了指定库和表的过滤操作
-```
-那这样问题②就解决了。
-那我们现在就要做两个事情:
-
-**①写一个Flink CDC 的 DataStream 项目进行多库多表同步,传给总线 Kafka。**
-
-**②自定义总线 Kafka 的 json 格式。**
-
-# 新建Flink CDC的dataStream项目
-
-
-
-
-
-```java
-import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
-import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
-import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
-import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
-import org.apache.flink.api.common.serialization.SimpleStringSchema;
-import org.apache.flink.runtime.state.filesystem.FsStateBackend;
-import org.apache.flink.streaming.api.CheckpointingMode;
-import org.apache.flink.streaming.api.datastream.DataStreamSource;
-import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
-import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
-
-public class FlinkCDC {
-
- public static void main(String[] args) throws Exception {
-
- //1.获取执行环境
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
-
- //1.1 设置 CK&状态后端
- //略
-
- //2.通过 FlinkCDC 构建 SourceFunction 并读取数据
- DebeziumSourceFunction sourceFunction = MySQLSource.builder()
- .hostname("10.1.64.157")
- .port(3306)
- .username("root")
- .password("123456")
- .databaseList("gmall") //这个注释,就是多库同步
- //.tableList("gmall.spu_info") //这个注释,就是多表同步
- .deserializer(new CustomerDeserialization()) //这里需要自定义序列化格式
- //.deserializer(new StringDebeziumDeserializationSchema()) //默认是这个序列化格式
- .startupOptions(StartupOptions.latest())
- .build();
- DataStreamSource streamSource = env.addSource(sourceFunction);
-
- //3.打印数据并将数据写入 Kafka
- streamSource.print();
- String sinkTopic = "input_kafka4";
- streamSource.addSink(getKafkaProducer("10.1.64.156:9092",sinkTopic));
-
- //4.启动任务
- env.execute("FlinkCDC");
- }
-
- //kafka 生产者
- public static FlinkKafkaProducer getKafkaProducer(String brokers,String topic) {
- return new FlinkKafkaProducer(brokers,
- topic,
- new SimpleStringSchema());
- }
-
-}
-```
-
-##
-# 自定义序列化类
-
-
-
-
-
-```java
-
-import com.alibaba.fastjson.JSONObject;
-import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
-import io.debezium.data.Envelope;
-import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
-import org.apache.flink.api.common.typeinfo.TypeInformation;
-import org.apache.flink.util.Collector;
-import org.apache.kafka.connect.data.Field;
-import org.apache.kafka.connect.data.Schema;
-import org.apache.kafka.connect.data.Struct;
-import org.apache.kafka.connect.source.SourceRecord;
-import java.util.ArrayList;
-import java.util.List;
-
-public class CustomerDeserialization implements DebeziumDeserializationSchema {
-
-
- @Override
- public void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception {
-
- //1.创建 JSON 对象用于存储最终数据
- JSONObject result = new JSONObject();
-
- //2.获取库名&表名放入 source
- String topic = sourceRecord.topic();
- String[] fields = topic.split("\\.");
- String database = fields[1];
- String tableName = fields[2];
- JSONObject source = new JSONObject();
- source.put("database",database);
- source.put("table",tableName);
-
- Struct value = (Struct) sourceRecord.value();
- //3.获取"before"数据
- Struct before = value.getStruct("before");
- JSONObject beforeJson = new JSONObject();
- if (before != null) {
- Schema beforeSchema = before.schema();
- List beforeFields = beforeSchema.fields();
- for (Field field : beforeFields) {
- Object beforeValue = before.get(field);
- beforeJson.put(field.name(), beforeValue);
- }
- }
-
- //4.获取"after"数据
- Struct after = value.getStruct("after");
- JSONObject afterJson = new JSONObject();
- if (after != null) {
- Schema afterSchema = after.schema();
- List afterFields = afterSchema.fields();
- for (Field field : afterFields) {
- Object afterValue = after.get(field);
- afterJson.put(field.name(), afterValue);
- }
- }
-
- //5.获取操作类型 CREATE UPDATE DELETE 进行符合 Debezium-op 的字母
- Envelope.Operation operation = Envelope.operationFor(sourceRecord);
- String type = operation.toString().toLowerCase();
- if ("insert".equals(type)) {
- type = "c";
- }
- if ("update".equals(type)) {
- type = "u";
- }
- if ("delete".equals(type)) {
- type = "d";
- }
- if ("create".equals(type)) {
- type = "c";
- }
-
- //6.将字段写入 JSON 对象
- result.put("source", source);
- result.put("before", beforeJson);
- result.put("after", afterJson);
- result.put("op", type);
-
- //7.输出数据
- collector.collect(result.toJSONString());
-
- }
-
- @Override
- public TypeInformation getProducedType() {
- return BasicTypeInfo.STRING_TYPE_INFO;
- }
-}
-```
-
-OK,运行 flinkCDC 项目,同步的数据库表插入一条记录,得出以下自定义格式后的 JSON:
-
-```json
-{
- "op": "u",
- "before": {
- "spu_name": "香奈儿(Chanel)女士香水 5 号香水 粉邂逅柔情淡香水 EDT ",
- "tm_id": 11,
- "description": "香奈儿(Chanel)女士香水 5 号香水 粉邂逅柔情淡香水 EDT 111",
- "id": 11,
- "category3_id": 473
- },
- "source": {
- "database": "gmall",
- "table": "spu_info"
- },
- "after": {
- "spu_name": "香奈儿(Chanel)女士香水 5 号香水 粉邂逅柔情淡香水 EDTss ",
- "tm_id": 11,
- "description": "香奈儿(Chanel)女士香水 5 号香水 粉邂逅柔情淡香水 EDT 111",
- "id": 11,
- "category3_id": 473
- }
-}
-```
-PS:没放 schema{}这个对象,看文档说加了识别会影响效率。
-# 总线 Kafka
-
-
-
-
-
-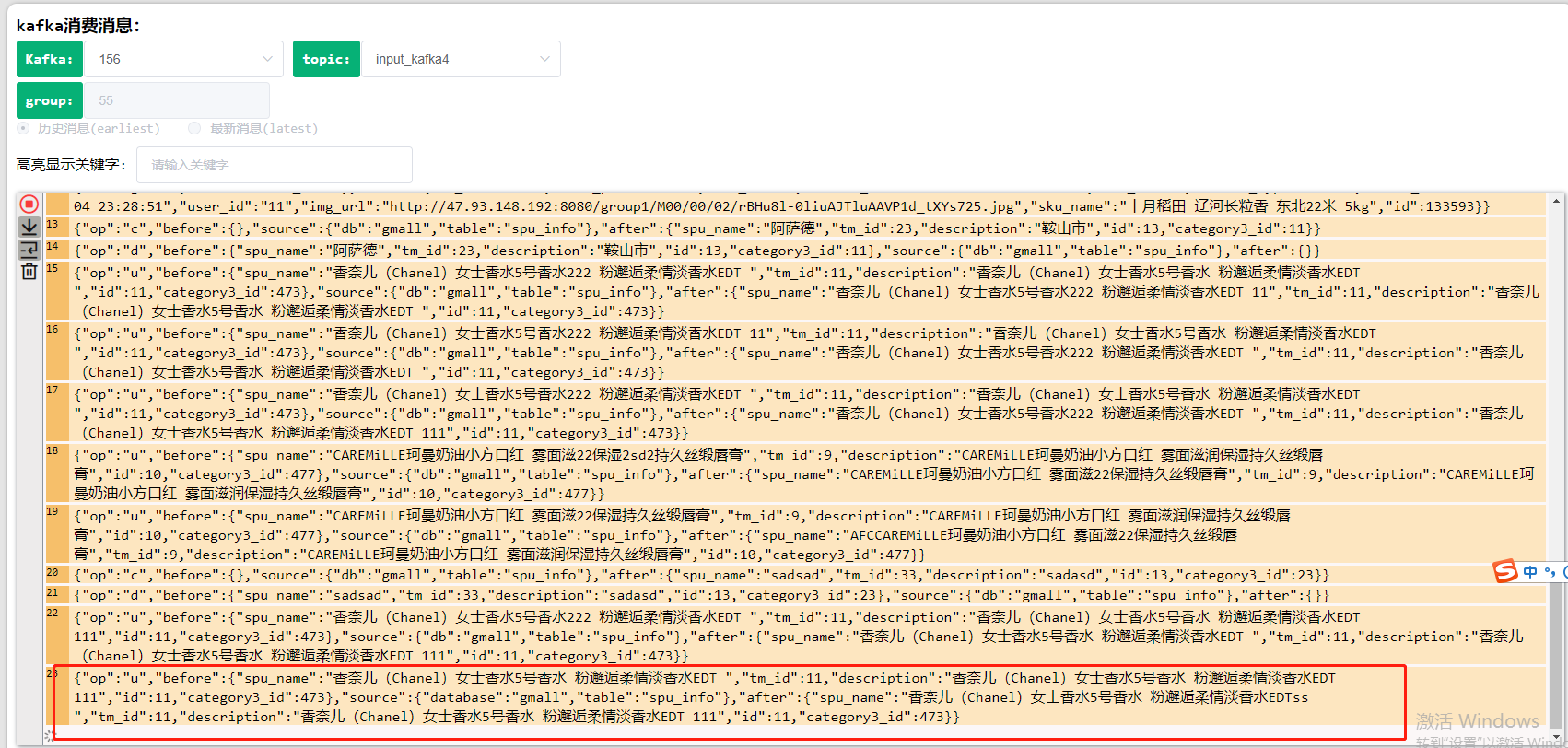
-
-
-# Dinky 里面进行建表,提交作业
-
-
-
-
-
-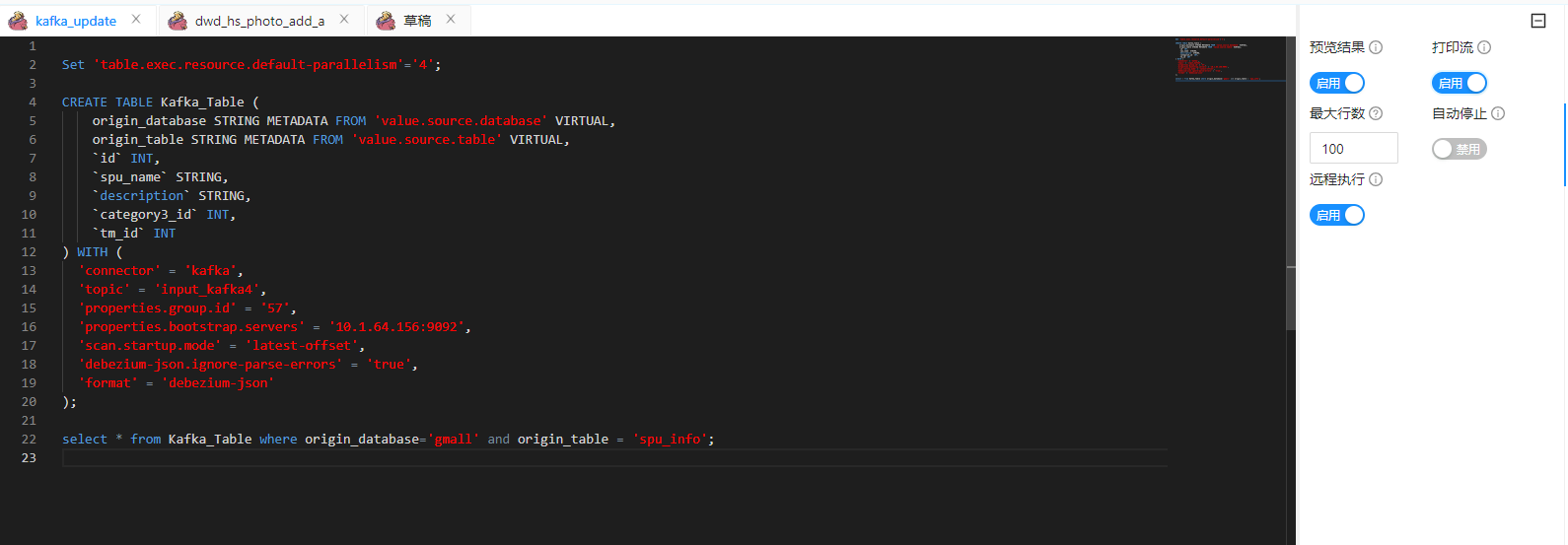
-PS:yarn-session 模式,记得开启预览结果和打印流,不然观察不到数据 changelog
-
-
-# 查看结果
-
-
-
-
-
-
-
-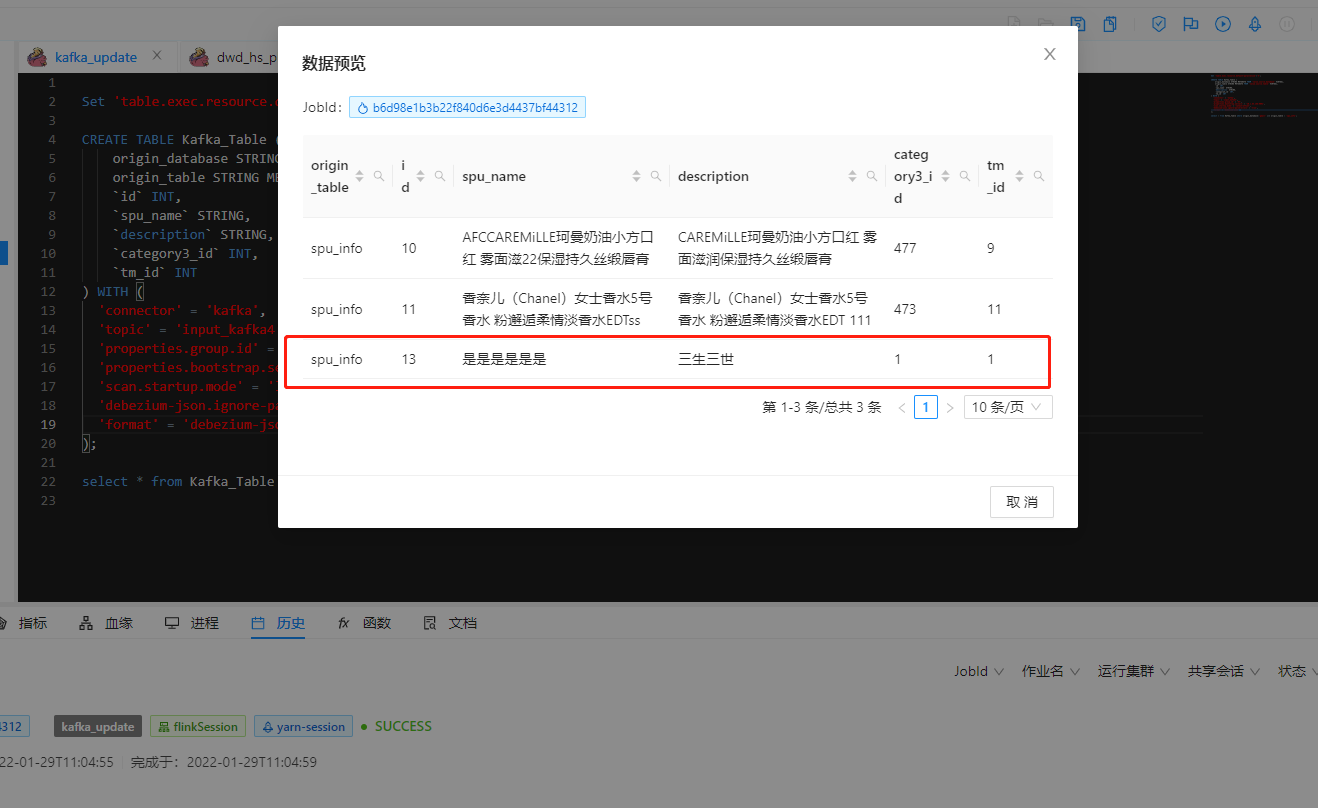
-
-可以看到在指定库和表中新增一条数据,在下游 kafka 作业中实现了同步更新,然后试试对数据库该表的记录进行 delete,效果如下:
-
-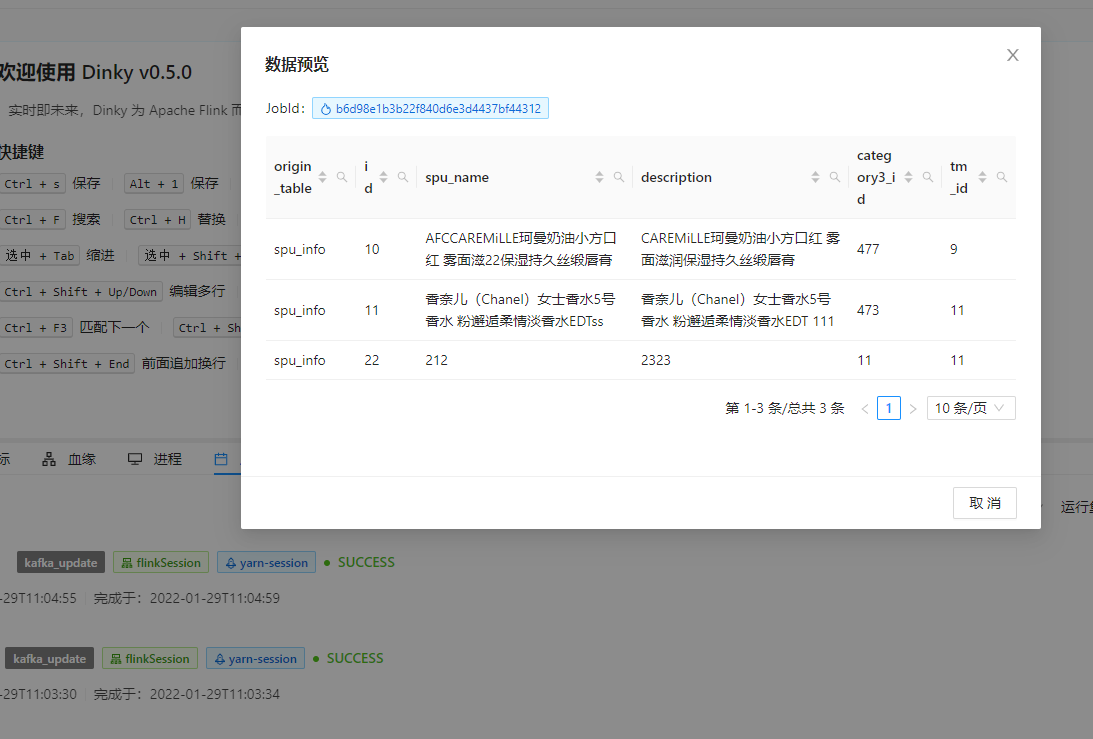
-
-可以看到"是是是.."这条记录同步删除了。
-
-此时 Flink CDC 的记录是这样:
-
-
-
-原理主要是 op 去同步下游 kafka 的 changeLog 里的 op
-
-我们浏览一下 changeLog:(Dinky 选中打印流即可)
-
-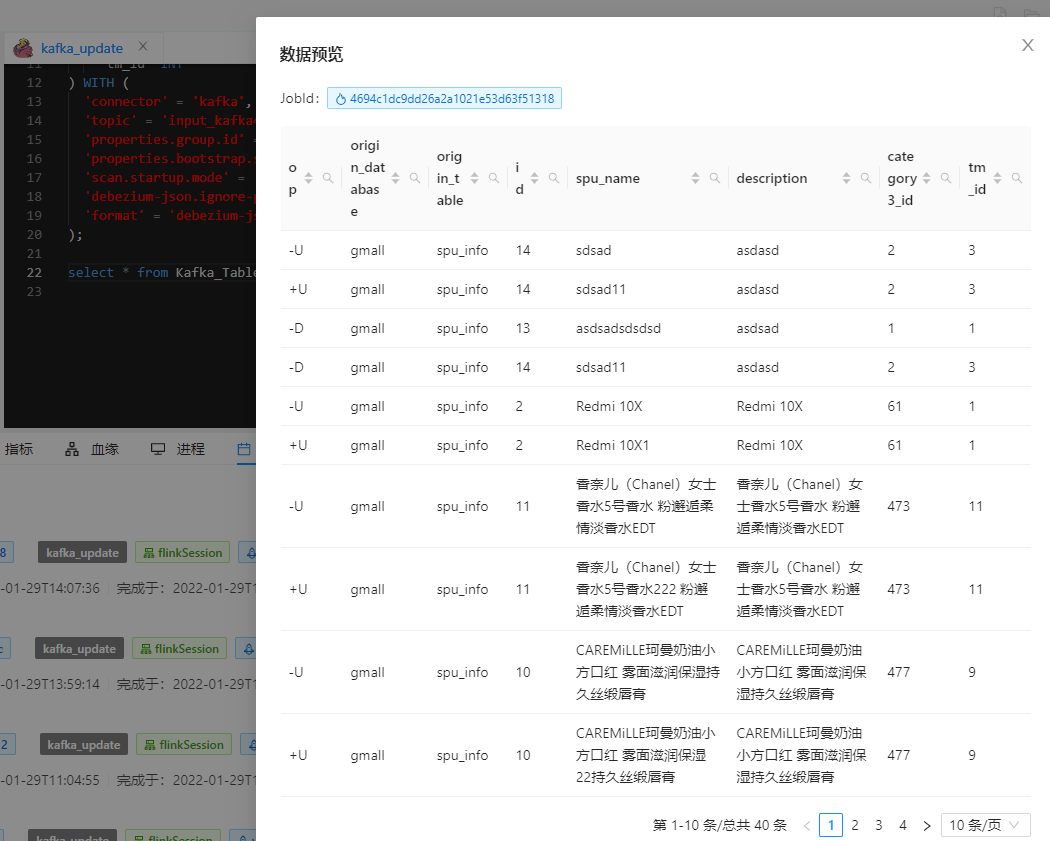
-
-可以看到,op 自动识别总线 kafka 发来的 JSON 进行了同步来记录操作。
-
-后续我们就可以插入 upsert-kafka 表进行具体的表操作了。
-
-**完成!这样只需建一个 DataStream 的总线 jar,在 Dinky 中进行提交,后续下游的作业只需要 kafka 去接总线 kafka 就可以进行 Flink CDC 在 Flink SQL 里的多源合并和同步更新。**
-
-灵感和代码来自于尚硅谷,请支持 Dinky 和尚硅谷,另外是在测试环境进行,生产环境调优自行解决,如有更好的实践欢迎对文档进行 pr,感谢!
-
-
-
diff --git a/docs/docs/extend/practice_guide/clickhouse.md b/docs/docs/extend/practice_guide/clickhouse.md
deleted file mode 100644
index 3222bbaf70..0000000000
--- a/docs/docs/extend/practice_guide/clickhouse.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-sidebar_position: 7
-id: clickhouse
-title: Clickhouse
----
-
-
-
-
-敬请期待
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/cross_join.md b/docs/docs/extend/practice_guide/cross_join.md
deleted file mode 100644
index 984f14588b..0000000000
--- a/docs/docs/extend/practice_guide/cross_join.md
+++ /dev/null
@@ -1,116 +0,0 @@
----
-sidebar_position: 17
-id: cross_join
-title: cross join
----
-
-## 列转行
-
-也就是将数组展开,一行变多行,使用到 `cross join unnest()` 语句。
-
-读取 hive 表数据,然后写入 hive 表。
-
-### source
-
-`source_table` 表信息如下
-
-```sql
-CREATE TABLE `test.source_table`(
- `col1` string,
- `col2` array COMMENT '数组类型的字段')
-ROW FORMAT SERDE
- 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
-STORED AS INPUTFORMAT
- 'org.apache.hadoop.mapred.TextInputFormat'
-OUTPUTFORMAT
- 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
-LOCATION
- 'hdfs://hadoopCluster/user/hive/warehouse/test.db/source_table'
-TBLPROPERTIES (
- 'transient_lastDdlTime'='1659261419')
-;
-```
-
-`source_table` 表数据如下
-
-
-
-### sink
-
-`sink_table` 表信息如下
-
-```sql
-CREATE TABLE `test.sink_table`(
- `col1` string,
- `col2` string)
-ROW FORMAT SERDE
- 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
-STORED AS INPUTFORMAT
- 'org.apache.hadoop.mapred.TextInputFormat'
-OUTPUTFORMAT
- 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
-LOCATION
- 'hdfs://hadoopCluster/user/hive/warehouse/test.db/sink_table'
-TBLPROPERTIES (
- 'transient_lastDdlTime'='1659261915')
-;
-```
-
-`sink_table` 表数据如下
-
-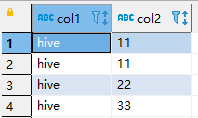
-
-### flink sql 语句
-
-下面将使用两种方言演示如何将数组中的数据展开
-
-#### 使用flink方言
-
-```sql
-set 'table.local-time-zone' = 'GMT+08:00';
-
--- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
--- 创建catalog
-create catalog hive with (
- 'type' = 'hive',
- 'hadoop-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf',
- 'hive-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf'
-)
-;
-
-use catalog hive;
-
-
-insert overwrite test.sink_table
-select col1, a.col
-from test.source_table
-cross join unnest(col2) as a (col)
-;
-```
-
-#### 使用hive方言
-
-```sql
-set 'table.local-time-zone' = 'GMT+08:00';
-
--- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
--- 创建catalog
-create catalog hive with (
- 'type' = 'hive',
- 'hadoop-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf',
- 'hive-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf'
-)
-;
-
-use catalog hive;
-
-load module hive;
-
-set 'table.sql-dialect' = 'hive';
-
-insert overwrite table test.sink_table
-select col1, a.col
-from test.source_table
-lateral view explode(col2) a as col
-;
-```
diff --git a/docs/docs/extend/practice_guide/dataspherestudio.md b/docs/docs/extend/practice_guide/dataspherestudio.md
deleted file mode 100644
index 2dd3e26971..0000000000
--- a/docs/docs/extend/practice_guide/dataspherestudio.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-sidebar_position: 13
-id: dataspherestudio
-title: DataSphere Studio
----
-
-
-
-
-## 敬请期待
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/dolphinscheduler.md b/docs/docs/extend/practice_guide/dolphinscheduler.md
deleted file mode 100644
index 48d38b2693..0000000000
--- a/docs/docs/extend/practice_guide/dolphinscheduler.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-sidebar_position: 12
-id: dolphinscheduler
-title: Dolphinscheduler
----
-
-
-
-
-## 敬请期待
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/doris.md b/docs/docs/extend/practice_guide/doris.md
deleted file mode 100644
index ed8800eaec..0000000000
--- a/docs/docs/extend/practice_guide/doris.md
+++ /dev/null
@@ -1,208 +0,0 @@
----
-sidebar_position: 8
-id: doris
-title: Doris
----
-
-
-
-
-## 背景
-
-Apache Doris是一个现代化的MPP分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。
-
-目前 Doris 的生态正在建设中,本文将分享如何基于 Dlink 实现 Mysql 变动数据通过 Flink 实时入库 Doris。
-
-## 准备
-
-老规矩,列清各组件版本:
-
-| 组件 | 版本 |
-| :-------------: | :----------: |
-| Flink | 1.13.3 |
-| Flink-mysql-cdc | 2.1.0 |
-| Doris | 0.15.1-rc09 |
-| doris-flink | 1.0-SNAPSHOT |
-| Mysql | 8.0.13 |
-| Dlink | 0.4.0 |
-
-需要注意的是,本文的 Doris 是基于 OracleJDK1.8 和 Scala 2.11 通过源码进行编译打包的,所以所有组件的 scala 均为 2.11,此处和 Doris 社区略有不同。
-
-## 部署
-
-本文的 Flink 和 Doris 的部署不做描述,详情请查阅官网。
-
-[Doris]: https://doris.apache.org/master/zh-CN/extending-doris/flink-doris-connector.html#%E4%BD%BF%E7%94%A8%E6%96%B9%E6%B3%95 "Doris"
-
-本文在 Dlink 部署成功的基础上进行,如需查看具体部署步骤,请阅读《flink sql 知其所以然(十六):flink sql 开发企业级利器之 Dlink》。
-
-Dlink 的 plugins 下添加 `doris-flink-1.0-SNAPSHOT.jar` 和 `flink-sql-connector-mysql-cdc-2.1.0.jar` 。重启 Dlink。
-
-```java
-plugins/ -- Flink 相关扩展
-|- doris-flink-1.0-SNAPSHOT.jar
-|- flink-csv-1.13.3.jar
-|- flink-dist_2.11-1.13.3.jar
-|- flink-format-changelog-json-2.1.0.jar
-|- flink-json-1.13.3.jar
-|- flink-shaded-zookeeper-3.4.14.jar
-|- flink-sql-connector-mysql-cdc-2.1.0.jar
-|- flink-table_2.11-1.13.3.jar
-|- flink-table-blink_2.11-1.13.3.jar
-```
-
-当然,如果您想直接使用 FLINK_HOME 的话,可以在 `auto.sh` 文件中 `SETTING` 变量添加`$FLINK_HOME/lib` 。
-
-## 数据表
-
-### 学生表 (student)
-
-```sql
--- Mysql
-DROP TABLE IF EXISTS `student`;
-CREATE TABLE `student` (
- `sid` int(11) NOT NULL,
- `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
- PRIMARY KEY (`sid`) USING BTREE
-) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-
-INSERT INTO `student` VALUES (1, '小红');
-INSERT INTO `student` VALUES (2, '小黑');
-INSERT INTO `student` VALUES (3, '小黄');
-```
-
-### 成绩表(score)
-
-```sql
--- Mysql
-DROP TABLE IF EXISTS `score`;
-CREATE TABLE `score` (
- `cid` int(11) NOT NULL,
- `sid` int(11) NULL DEFAULT NULL,
- `cls` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
- `score` int(11) NULL DEFAULT NULL,
- PRIMARY KEY (`cid`) USING BTREE
-) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-
-INSERT INTO `score` VALUES (1, 1, 'chinese', 90);
-INSERT INTO `score` VALUES (2, 1, 'math', 95);
-INSERT INTO `score` VALUES (3, 1, 'english', 93);
-INSERT INTO `score` VALUES (4, 2, 'chinese', 92);
-INSERT INTO `score` VALUES (5, 2, 'math', 75);
-INSERT INTO `score` VALUES (6, 2, 'english', 80);
-INSERT INTO `score` VALUES (7, 3, 'chinese', 100);
-INSERT INTO `score` VALUES (8, 3, 'math', 60);
-```
-
-### 学生成绩宽表(scoreinfo)
-
-```sql
--- Doris
-CREATE TABLE scoreinfo
-(
- cid INT,
- sid INT,
- name VARCHAR(32),
- cls VARCHAR(32),
- score INT
-)
-UNIQUE KEY(cid)
-DISTRIBUTED BY HASH(cid) BUCKETS 10
-PROPERTIES("replication_num" = "1");
-```
-
-
-
-## FlinkSQL
-
-```sql
-CREATE TABLE student (
- sid INT,
- name STRING,
- PRIMARY KEY (sid) NOT ENFORCED
-) WITH (
-'connector' = 'mysql-cdc',
-'hostname' = '127.0.0.1',
-'port' = '3306',
-'username' = 'test',
-'password' = '123456',
-'database-name' = 'test',
-'table-name' = 'student');
-CREATE TABLE score (
- cid INT,
- sid INT,
- cls STRING,
- score INT,
- PRIMARY KEY (cid) NOT ENFORCED
-) WITH (
-'connector' = 'mysql-cdc',
-'hostname' = '127.0.0.1',
-'port' = '3306',
-'username' = 'test',
-'password' = '123456',
-'database-name' = 'test',
-'table-name' = 'score');
-CREATE TABLE scoreinfo (
- cid INT,
- sid INT,
- name STRING,
- cls STRING,
- score INT,
- PRIMARY KEY (cid) NOT ENFORCED
-) WITH (
-'connector' = 'doris',
-'fenodes' = '127.0.0.1:8030' ,
-'table.identifier' = 'test.scoreinfo',
-'username' = 'root',
-'password'=''
-);
-insert into scoreinfo
-select
-a.cid,a.sid,b.name,a.cls,a.score
-from score a
-left join student b on a.sid = b.sid
-```
-
-## 调试
-
-### 在 Dinky 中提交
-
-本示例采用了 yarn-session 的方式进行提交。
-http://pic.dinky.org.cn/dinky/docs/zh-CN/extend/practice_guide
-
-
-### FlinkWebUI
-
-
-
-上图可见,流任务已经成功被 Dinky 提交的远程集群了。
-
-### Doris 查询
-
-
-
-上图可见,Doris 已经被写入了历史全量数据。
-
-### 增量测试
-
-在 Mysql 中执行新增语句:
-
-```sql
-INSERT INTO `score` VALUES (9, 3, 'english', 100);
-```
-
-Doris 成功被追加:
-
-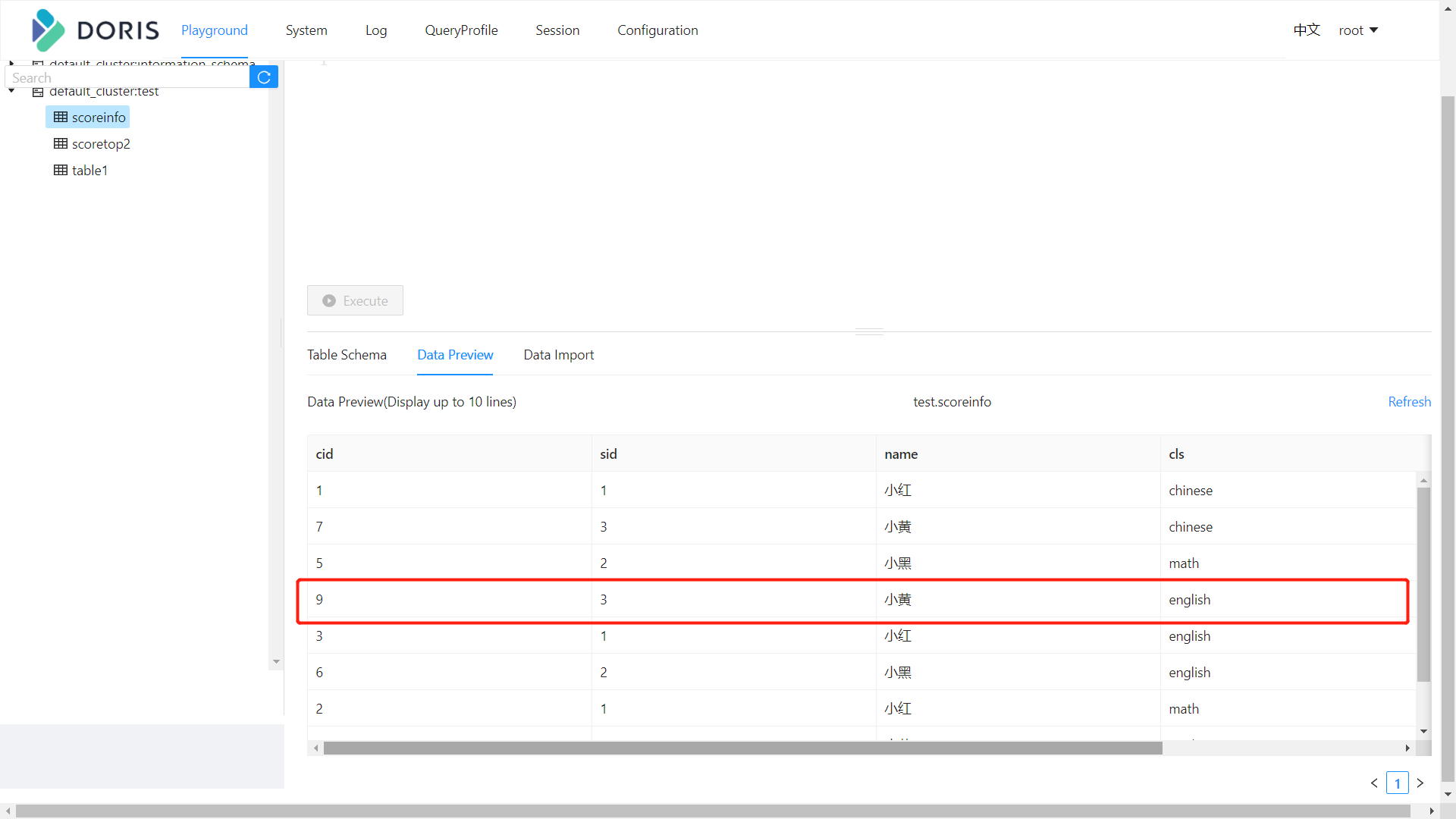
-
-### 变动测试
-
-在 Mysql 中执行新增语句:
-
-```sql
-update score set score = 100 where cid = 1
-```
-
-Doris 成功被修改:
-
-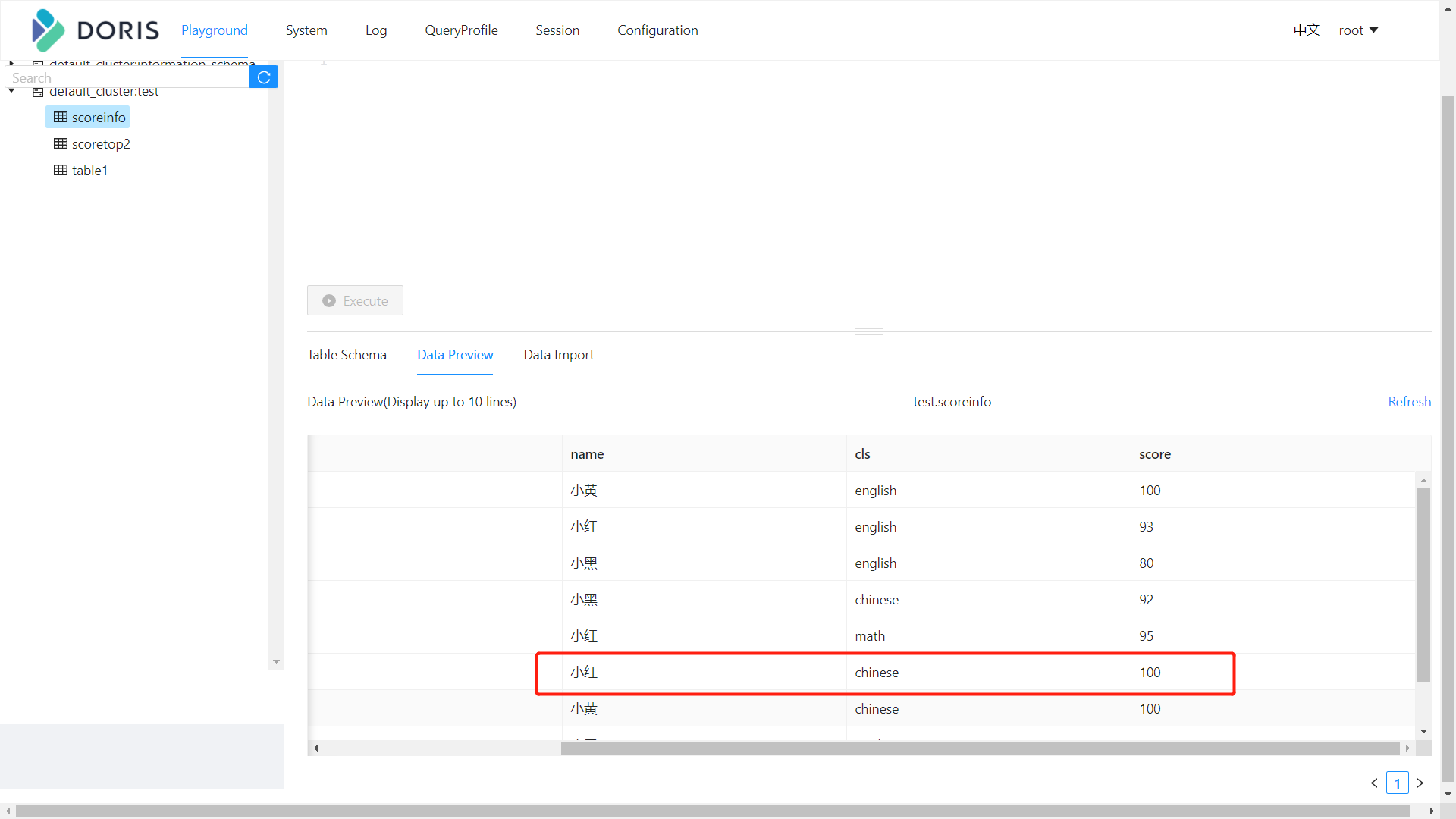
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/flinkcdc.md b/docs/docs/extend/practice_guide/flinkcdc.md
deleted file mode 100644
index 11c33227b3..0000000000
--- a/docs/docs/extend/practice_guide/flinkcdc.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-sidebar_position: 4
-id: flinkcdc
-title: Flink CDC
----
-
-
-
-
-## 扩展 Flink-CDC
-
-把 `flink-sql-connector-mysql-cdc-2.1.0.jar` 等 CDC 依赖加入到 Dlink 的 `plugins` 下即可。
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/hive.md b/docs/docs/extend/practice_guide/hive.md
deleted file mode 100644
index 3a27e84952..0000000000
--- a/docs/docs/extend/practice_guide/hive.md
+++ /dev/null
@@ -1,98 +0,0 @@
----
-sidebar_position: 6
-id: hive
-title: Hive
----
-
-
-
-## 前言
-
-最近有很多小伙伴问,Dinky 如何连接 Hive 进行数据开发?
-
-关于 Dinky 连接 Hive 的步骤同 Flink 的 `sql-client ` ,只不过它没有默认加载的配置文件。下文将详细讲述对 Hive 操作的全过程。
-
-## 准备工作
-
-由于搭建 Hive 的开发环境会涉及到重多组件和插件,那其版本对应问题也是至关重要,它能帮我们避免很多不必要的问题,当然小版本号之间具备一定的兼容性。
-
-我们先来梳理下本教程的各个组件版本:
-
-| 组件 | 版本 |
-|:------:| :----: |
-| Dinky | 0.3.2 |
-| Flink | 1.12.4 |
-| Hadoop | 2.7.7 |
-| Hive | 2.3.6 |
-| Mysql | 8.0.15 |
-
-再来梳理下本教程的各个插件版本:
-
-| 所属组件 | 插件 | 版本 |
-|:-------------:|:-----------------------------------------------------:|:---------------------:|
-| Dinky | dlink-client | 1.12 |
-| Dinky & Flink | flink-sql-connector-hive | 2.3.6_2.11-1.12.3 |
-| Dinky & Flink | flink-shaded-hadoop-3-uber | 3.1.1.7.2.8.0-224-9.0 |
-| Hive | hive-exec & hive-jdbc & hive-metastore & hive-service | 2.1.1(根据自身hive版本定) |
-
-## 部署扩展
-
-部署扩展的工作非常简单(前提是 Dlink 部署完成并成功连接 Flink 集群,相关部署步骤请查看《Dlink实时计算平台——部署篇》),只需要把 `flink-sql-connector-hive-2.3.6_2.11-1.12.3.jar` 和 `flink-shaded-hadoop-3-uber-3.1.1.7.2.8.0-224-9.0.jar` 两个插件分别加入到 Dlink 的 plugins 目录与 Flink 的 lib 目录下即可,然后重启二者。当然,还需要放置 `hive-site.xml`,位置自定义,Dlink 可以访问到即可。
-
-## 创建 Hive Catalog
-
-已知,Hive 已经新建了一个数据库实例 `hdb` ,创建了一张表 `htest`,列为 `name` 和 `age`,存储位置默认为 `hdfs:///usr/local/hadoop/hive-2.3.9/warehouse/hdb.db` 。(此处为何 2.3.9 呢,因为 `flink-sql-connector-hive-2.3.6_2.11-1.12.3.jar` 只支持到最高版本 2.3.6,小编先装了个 2.3.9 后装了个 2.3.6,尴尬 > _ < ~)
-
-```sql
-CREATE CATALOG myhive WITH (
- 'type' = 'hive',
- 'default-database' = 'hdb',
- 'hive-conf-dir' = '/usr/local/dlink/hive-conf'
-);
--- set the HiveCatalog as the current catalog of the session
-USE CATALOG myhive;
-select * from htest
-```
-
-在 Dinky 编辑器中输入以上 sql ,创建 Hive Catalog,并查询一张表。
-
-其中,`hive-conf-dir` 需要指定 `hive-site.xml` 的路径,其他同 Flink 官方解释。
-
-执行查询后(记得选中执行配置的预览结果),可以从查询结果中查看到 htest 表中只有一条数据。(这是正确的,因为小编太懒了,只随手模拟了一条数据)
-
-此时可以使用 FlinkSQL 愉快地操作 Hive 的数据了。
-
-## 使用 Hive Dialect
-
-很熟悉 Hive 的语法以及需要对 Hive 执行其自身特性的语句怎么办?
-
-同 Flink 官方解释一样,只需要使用 `SET table.sql-dialect=hive` 来启用方言即可。注意有两种方言 `default` 和 `hive` ,它们的使用可以随意切换哦~
-
-```sql
-CREATE CATALOG myhive WITH (
- 'type' = 'hive',
- 'default-database' = 'hdb',
- 'hive-conf-dir' = '/usr/local/dlink/hive-conf'
-);
--- set the HiveCatalog as the current catalog of the session
-USE CATALOG myhive;
--- set hive dialect
-SET table.sql-dialect=hive;
--- alter table location
-alter table htest set location 'hdfs:///usr/htest';
--- set default dialect
-SET table.sql-dialect=default;
-select * from htest;
-```
-
-上述 sql 中添加了 Hive Dialect 的使用,FlinkSQL 本身不支持 `alter table .. set location ..` 的语法,使用 Hive Dialect 则可以实现语法的切换。本 sql 内容对 htest 表进行存储位置的改变,将其更改为一个新的路径,然后再执行查询。
-
-由上图可见,被更改过 location 的 htest 此时查询没有数据,是正确的。
-
-然后将 location 更改为之前的路径,再执行查询,则可见原来的那条数据,如下图所示。
-
-## 总结
-
-由上所知,Dlink 以更加友好的交互方式展现了 Flink 集成 Hive 的部分功能,当然其他更多的 Hive 功能需要您自己在使用的过程中去体验与挖掘。
-
-目前,Dlink 支持 Flink 绝大多数特性与功能,集成与拓展方式与 Flink 官方文档描述一致,只需要在 Dlink 的 plugins 目录下添加依赖即可。
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/hudi.md b/docs/docs/extend/practice_guide/hudi.md
deleted file mode 100644
index c64f2a4dd1..0000000000
--- a/docs/docs/extend/practice_guide/hudi.md
+++ /dev/null
@@ -1,298 +0,0 @@
----
-sidebar_position: 9
-id: hudi
-title: Hudi
----
-
-
-
-## 背景资料
-
-Apache hudi (发音为“ hoodie”)是下一代流式数据湖平台。Apache Hudi 将核心仓库和数据库功能直接引入到数据库中。Hudi 提供表、事务、高效的升级/删除、高级索引、流式摄入服务、数据集群/压缩优化和并发,同时保持数据以开放源码文件格式存储 , Apache Hudi 不仅非常适合流式工作负载,而且它还允许您创建高效的增量批处理管道。
-
-实时数仓流批一体已经成为大势所趋。
-
-为什么要使用 Hudi ?
-
-1. 目前业务架构较为繁重
-
-2. 维护多套框架
-
-3. 数据更新频率较大
-
-## 准备&&部署
-
-| 组件 | 版本 | 备注 |
-| ------------- | ----------------------------------- | ---------- |
-| Flink | 1.13.5 | 集成到CM |
-| Flink-SQL-CDC | 2.1.1 | |
-| Hudi | 0.10.0-patch | 打过补丁的 |
-| Mysql | 8.0.13 | 阿里云 |
-| Dlink | dlink-release-0.5.0-SNAPSHOT.tar.gz | |
-| Scala | 2.12 | |
-
-### 1. 部署Flink1.13.5
-
-flink 集成到CM中
-
-此步骤略。
-
-### 2. 集成Hudi 0.10.0
-
- ①. 地址: https://github.com/danny0405/hudi/tree/010-patch 打过补丁的 大佬请忽略^_^
-
- a. 下载压缩包 分支010-patch 不要下载 master 上传 解压
-
- b. unzip 010-patch.zip
-
- c. 找到 `packging--hudi-flink-bundle` 下的 `pom.xml`,更改 `flink-bundel-shade-hive2` 下的 `hive-version` 更改为 `2.1.1-chd6.3.2` 的版本。
-
-```shell
-vim pom.xml # 修改hive版本为 : 2.1.1-cdh6.3.2
-```
-
- d. 执行编译:
-
-```shell
-mvn clean install -DskipTests -DskipITs -Dcheckstyle.skip=true -Drat.skip=true -Dhadoop.version=3.0.0 -Pflink-bundle-shade-hive2 -Dscala-2.12
-```
-
- 因为 `chd6.3.0` 使用的是 `hadoop3.0.0` ,所以要指定 `hadoop` 的版本, `hive` 使用的是 `2.1.1` 的版本,也要指定 `hive` 的版本,不然使用 `sync to hive` 的时候,会报类的冲突问题。 `scala` 版本是 `2.12` 。
-
- 同时 flink 集成到 cm 的时候也是 `scala2.12` 版本统一。
-
-编译完成如下图:
-
-
-
-②. 把相关应的jar包 放到相对应的目录下
-
-```shell
-# hudi的包
-ln -s /opt/module/hudi-0.10.0/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.10.0.jar /opt/cloudera/parcels/CDH/jars/
-ln -s /opt/module/hudi-0.10.0/hudi-hive-sync-bundle/target/hudi-hive-sync-bundle-0.10.0.jar /opt/cloudera/parcels/CDH/jars/
-ln -s /opt/module/hudi-0.10.0/hudi-hive-sync-bundle/target/hudi-hive-sync-bundle-0.10.0.jar /opt/cloudera/parcels/CDH/lib/hive/lib
-# 同步sync to hive 每台节点都要放
-cp /opt/module/hudi-0.10.0/hudi-flink-bundle/target/hudi-flink-bundle_2.12-0.10.0.jar /opt/cloudera/parcels/FLINK/lib/flink/lib/
-# 以下三个jar 放到flink/lib 下 否则同步数据到hive的时候会报错
-cp /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.5/lib/
-cp /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-common-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.5/lib/
-cp /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-3.0.0-cdh6.3.2.jar /opt/module/flink-1.13.5/lib/
-# 执行以下命令
-cd /opt/module/flink-1.13.5/lib/
-scp -r ./* cdh5:`pwd`
-scp -r ./* cdh6:`pwd`
-scp -r ./* cdh7:`pwd`
-```
-
-
-
-### 3. 安装 Dlink-0.5.0
-
-a. github 地址: https://github.com/DataLinkDC/dlink
-
-b. 部署步骤见 github-readme.md 传送门: https://github.com/DataLinkDC/dlink/blob/main/README.md
-
-ps: 注意 还需要将 `hudi-flink-bundle_2.12-0.10.0.jar` 这个包放到 dlink的 `plugins` 下 。
-
-`plugins` 下的包 如下图所示:
-
-
-
-c. 访问: [http://ip:port/#/user/login](http://cdh7.vision.com:8811/#/user/login) 默认用户: admin 密码: admin
-
-d. 创建集群实例:
-
-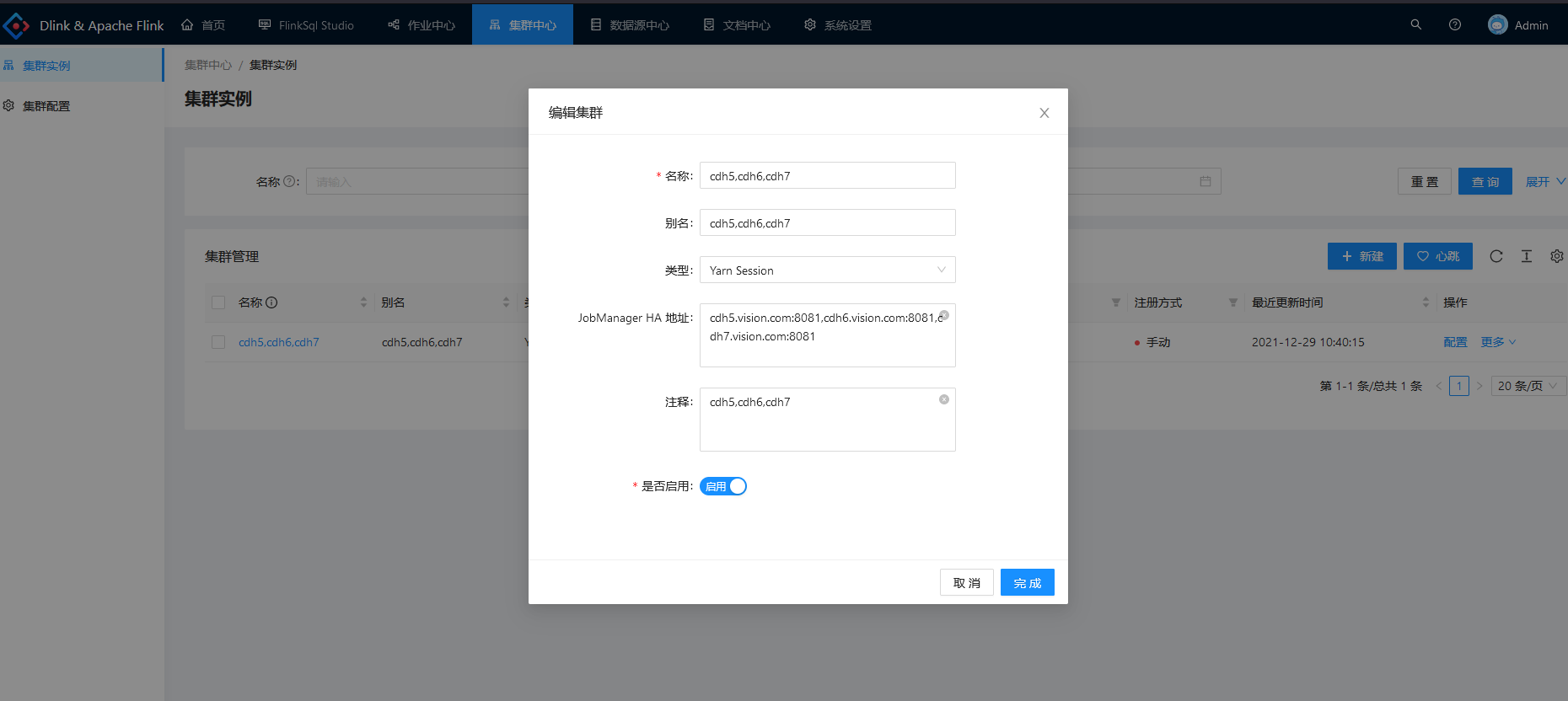
-
-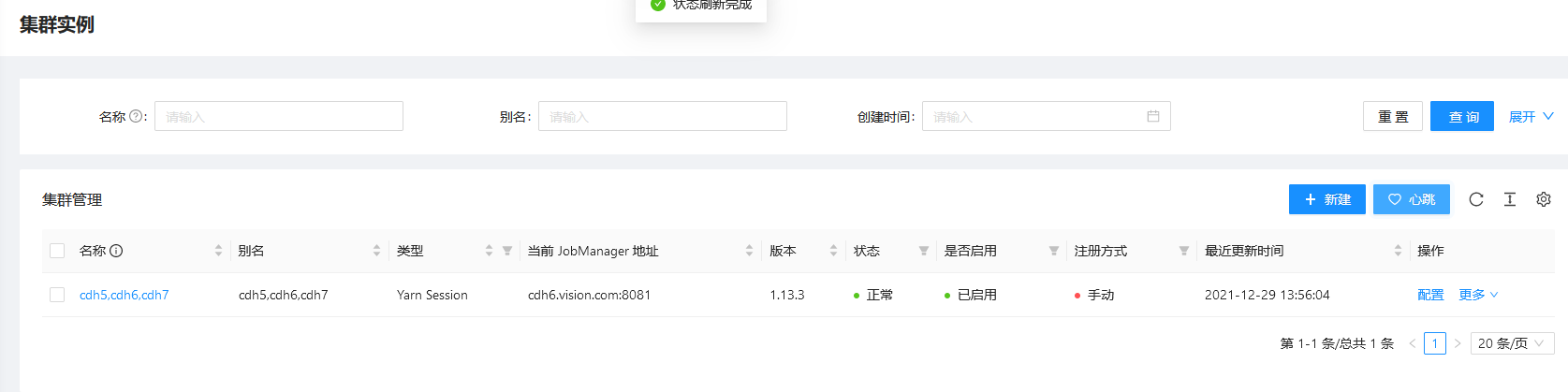
-
-## 数据表
-
-### 1. DDL准备
-
-(以下ddl 通过Python程序模板生成 大佬请略过! O(∩_∩)O )
-
-```sql
-------------- '订单表' order_mysql_goods_order -----------------
-CREATE TABLE source_order_mysql_goods_order (
- `goods_order_id` bigint COMMENT '自增主键id'
- , `goods_order_uid` string COMMENT '订单uid'
- , `customer_uid` string COMMENT '客户uid'
- , `customer_name` string COMMENT '客户name'
- , `student_uid` string COMMENT '学生uid'
- , `order_status` bigint COMMENT '订单状态 1:待付款 2:部分付款 3:付款审核 4:已付款 5:已取消'
- , `is_end` bigint COMMENT '订单是否完结 1.未完结 2.已完结'
- , `discount_deduction` bigint COMMENT '优惠总金额(单位:分)'
- , `contract_deduction` bigint COMMENT '老合同抵扣金额(单位:分)'
- , `wallet_deduction` bigint COMMENT '钱包抵扣金额(单位:分)'
- , `original_price` bigint COMMENT '订单原价(单位:分)'
- , `real_price` bigint COMMENT '实付金额(单位:分)'
- , `pay_success_time` timestamp(3) COMMENT '完全支付时间'
- , `tags` string COMMENT '订单标签(1新签 2续费 3扩科 4报名-合新 5转班-合新 6续费-合新 7试听-合新)'
- , `status` bigint COMMENT '是否有效(1.生效 2.失效 3.超时未付款)'
- , `remark` string COMMENT '订单备注'
- , `delete_flag` bigint COMMENT '是否删除(1.否,2.是)'
- , `test_flag` bigint COMMENT '是否测试数据(1.否,2.是)'
- , `create_time` timestamp(3) COMMENT '创建时间'
- , `update_time` timestamp(3) COMMENT '更新时间'
- , `create_by` string COMMENT '创建人uid(唯一标识)'
- , `update_by` string COMMENT '更新人uid(唯一标识)'
- ,PRIMARY KEY(goods_order_id) NOT ENFORCED
-) COMMENT '订单表'
-WITH (
- 'connector' = 'mysql-cdc'
- ,'hostname' = 'rm-bp1t34384933232rds.aliyuncs.com'
- ,'port' = '3306'
- ,'username' = 'app_kfkdr'
- ,'password' = 'CV122fff0E40'
- ,'server-time-zone' = 'UTC'
- ,'scan.incremental.snapshot.enabled' = 'true'
- ,'debezium.snapshot.mode'='latest-offset' -- 或者key是scan.startup.mode,initial表示要历史数据,latest-offset表示不要历史数据
- ,'debezium.datetime.format.date'='yyyy-MM-dd'
- ,'debezium.datetime.format.time'='HH-mm-ss'
- ,'debezium.datetime.format.datetime'='yyyy-MM-dd HH-mm-ss'
- ,'debezium.datetime.format.timestamp'='yyyy-MM-dd HH-mm-ss'
- ,'debezium.datetime.format.timestamp.zone'='UTC+8'
- ,'database-name' = 'order'
- ,'table-name' = 'goods_order'
- -- ,'server-id' = '2675788754-2675788754'
-);
-CREATE TABLE sink_order_mysql_goods_order(
- `goods_order_id` bigint COMMENT '自增主键id'
- , `goods_order_uid` string COMMENT '订单uid'
- , `customer_uid` string COMMENT '客户uid'
- , `customer_name` string COMMENT '客户name'
- , `student_uid` string COMMENT '学生uid'
- , `order_status` bigint COMMENT '订单状态 1:待付款 2:部分付款 3:付款审核 4:已付款 5:已取消'
- , `is_end` bigint COMMENT '订单是否完结 1.未完结 2.已完结'
- , `discount_deduction` bigint COMMENT '优惠总金额(单位:分)'
- , `contract_deduction` bigint COMMENT '老合同抵扣金额(单位:分)'
- , `wallet_deduction` bigint COMMENT '钱包抵扣金额(单位:分)'
- , `original_price` bigint COMMENT '订单原价(单位:分)'
- , `real_price` bigint COMMENT '实付金额(单位:分)'
- , `pay_success_time` timestamp(3) COMMENT '完全支付时间'
- , `tags` string COMMENT '订单标签(1新签 2续费 3扩科 4报名-合新 5转班-合新 6续费-合新 7试听-合新)'
- , `status` bigint COMMENT '是否有效(1.生效 2.失效 3.超时未付款)'
- , `remark` string COMMENT '订单备注'
- , `delete_flag` bigint COMMENT '是否删除(1.否,2.是)'
- , `test_flag` bigint COMMENT '是否测试数据(1.否,2.是)'
- , `create_time` timestamp(3) COMMENT '创建时间'
- , `update_time` timestamp(3) COMMENT '更新时间'
- , `create_by` string COMMENT '创建人uid(唯一标识)'
- , `update_by` string COMMENT '更新人uid(唯一标识)'
- ,PRIMARY KEY (goods_order_id) NOT ENFORCED
-) COMMENT '订单表'
-WITH (
- 'connector' = 'hudi'
- , 'path' = 'hdfs://cluster1/data/bizdata/cdc/mysql/order/goods_order' -- 路径会自动创建
- , 'hoodie.datasource.write.recordkey.field' = 'goods_order_id' -- 主键
- , 'write.precombine.field' = 'update_time' -- 相同的键值时,取此字段最大值,默认ts字段
- , 'read.streaming.skip_compaction' = 'true' -- 避免重复消费问题
- , 'write.bucket_assign.tasks' = '2' -- 并发写的 bucekt 数
- , 'write.tasks' = '2'
- , 'compaction.tasks' = '1'
- , 'write.operation' = 'upsert' -- UPSERT(插入更新)\INSERT(插入)\BULK_INSERT(批插入)(upsert性能会低些,不适合埋点上报)
- , 'write.rate.limit' = '20000' -- 限制每秒多少条
- , 'table.type' = 'COPY_ON_WRITE' -- 默认COPY_ON_WRITE ,
- , 'compaction.async.enabled' = 'true' -- 在线压缩
- , 'compaction.trigger.strategy' = 'num_or_time' -- 按次数压缩
- , 'compaction.delta_commits' = '20' -- 默认为5
- , 'compaction.delta_seconds' = '60' -- 默认为1小时
- , 'hive_sync.enable' = 'true' -- 启用hive同步
- , 'hive_sync.mode' = 'hms' -- 启用hive hms同步,默认jdbc
- , 'hive_sync.metastore.uris' = 'thrift://cdh2.vision.com:9083' -- required, metastore的端口
- , 'hive_sync.jdbc_url' = 'jdbc:hive2://cdh1.vision.com:10000' -- required, hiveServer地址
- , 'hive_sync.table' = 'order_mysql_goods_order' -- required, hive 新建的表名 会自动同步hudi的表结构和数据到hive
- , 'hive_sync.db' = 'cdc_ods' -- required, hive 新建的数据库名
- , 'hive_sync.username' = 'hive' -- required, HMS 用户名
- , 'hive_sync.password' = '123456' -- required, HMS 密码
- , 'hive_sync.skip_ro_suffix' = 'true' -- 去除ro后缀
-);
----------- source_order_mysql_goods_order=== TO ==>> sink_order_mysql_goods_order ------------
-insert into sink_order_mysql_goods_order select * from source_order_mysql_goods_order;
-```
-
-## 调试
-
-### 1.对上述SQL执行语法校验:
-
-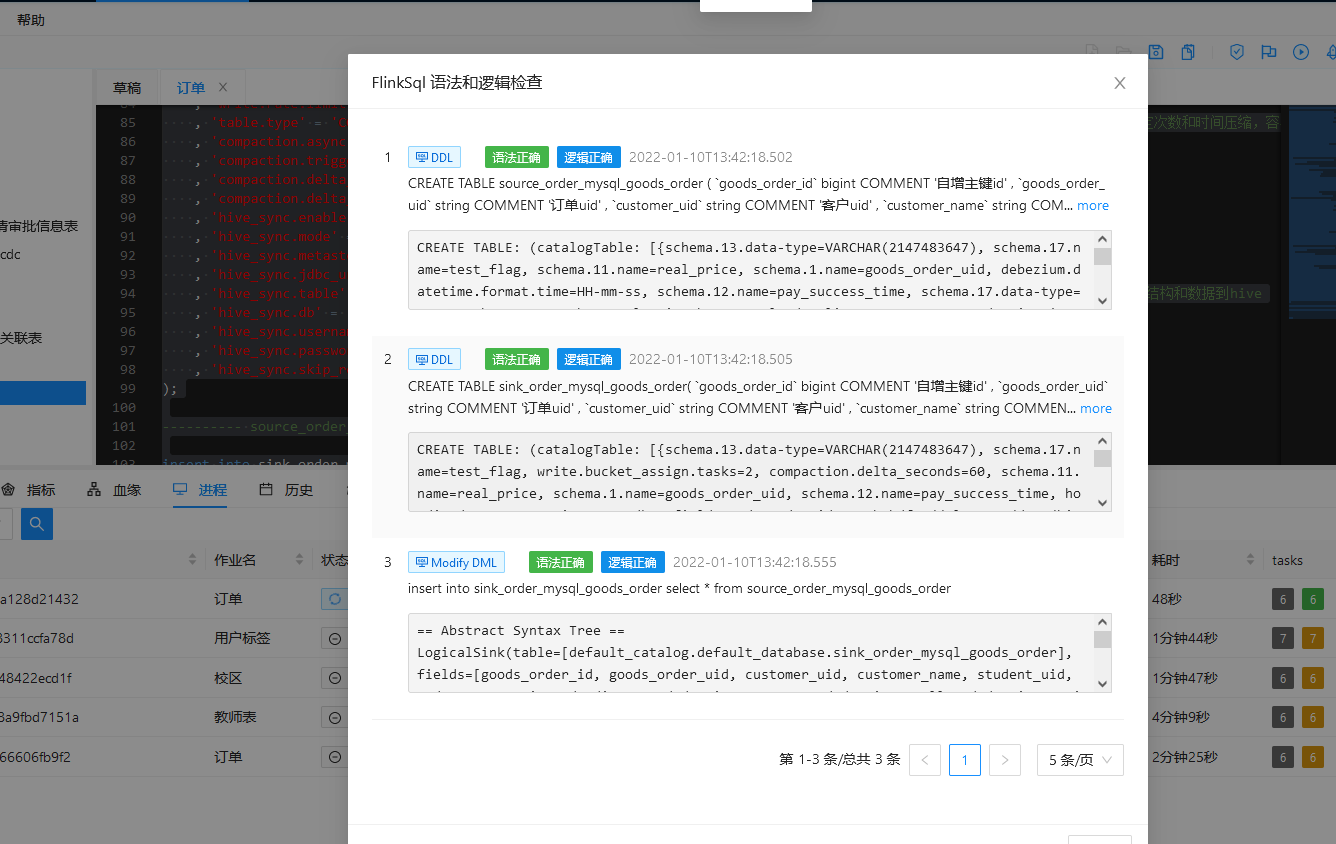
-
-### 2. 获取JobPlan
-
-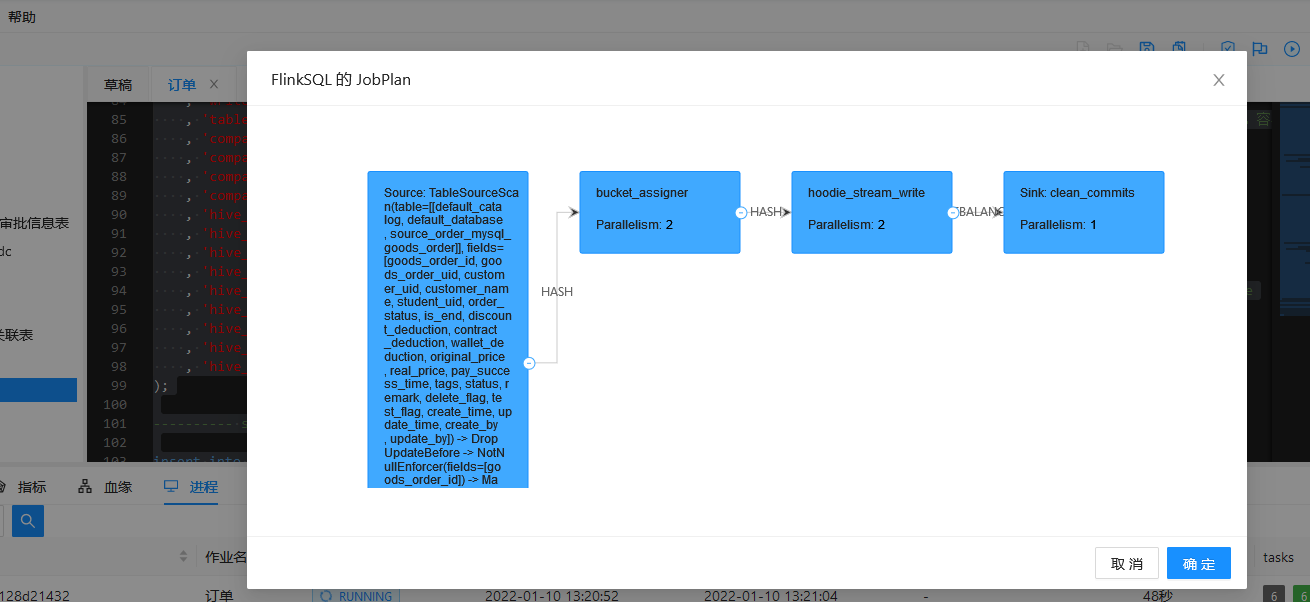
-
-### 3. 执行任务
-
-
-
-### 4. dlink 查看执行的任务
-
-
-
-### 5. Flink-webUI 查看 作业
-
-
-
-### 6. 查看hdfs路径下数据
-
-
-
-### 7. 查看hive表:
-
-
-
-查看订单号对应的数据
-
-
-
-### 8.更新数据操作
-
-
-
-```sql
- UPDATE `order`.`goods_order`
- SET
- `remark` = 'cdc_test update'
- WHERE
- `goods_order_id` = 73270;
-```
-
-再次查看 hive 数据 发现已经更新
-
-
-
-### 9.删除数据操作
-
-(内部业务中采用逻辑删除 不使用物理删除 此例仅演示/测试使用 谨慎操作)
-
-```sql
- delete from `order`.`goods_order` where goods_order_id='73270';
-```
-
-
-
-
-
-### 10.将此数据再次插入
-
-
-
-```sql
-INSERT INTO `order`.`goods_order`(`goods_order_id`, `goods_order_uid`, `customer_uid`, `customer_name`, `student_uid`, `order_status`, `is_end`, `discount_deduction`, `contract_deduction`, `wallet_deduction`, `original_price`, `real_price`, `pay_success_time`, `tags`, `status`, `remark`, `delete_flag`, `test_flag`, `create_time`, `update_time`, `create_by`, `update_by`) VALUES (73270, '202112121667480848077045760', 'VA100002435', 'weweweywu', 'S100002435', 4, 1, 2000000, 0, 0, 2000000, 0, '2021-12-12 18:51:41', '1', 1, '', 1, 1, '2021-12-12 18:51:41', '2022-01-10 13:53:59', 'VA100681', 'VA100681');
-```
-
-再次查询hive数据 数据正常进入。
-
-
-
-至此 Dlink在Flink-SQL-CDC 到Hudi Sync Hive 测试结束
-
-## 结论
-
-通过 Dlink + Flink-Mysql-CDC + Hudi 的方式大大降低了我们流式入湖的成本,其中 Flink-Mysql-CDC 简化了CDC的架构与成本,而 Hudi 高性能的读写更有利于变动数据的存储,最后 Dlink 则将整个数据开发过程 sql 平台化,使我们的开发运维更加专业且舒适,期待 Dlink 后续的发展。
-
-
-## 作者
-zhumingye
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/iceberg.md b/docs/docs/extend/practice_guide/iceberg.md
deleted file mode 100644
index d869f2d86b..0000000000
--- a/docs/docs/extend/practice_guide/iceberg.md
+++ /dev/null
@@ -1,9 +0,0 @@
----
-sidebar_position: 10
-id: iceberg
-title: Iceberg
----
-
-
-
-## 敬请期待
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/kafka_to_hive.md b/docs/docs/extend/practice_guide/kafka_to_hive.md
deleted file mode 100644
index 1334cddc39..0000000000
--- a/docs/docs/extend/practice_guide/kafka_to_hive.md
+++ /dev/null
@@ -1,208 +0,0 @@
----
-sidebar_position: 14
-id: kafka_to_hive
-title: kafka写入hive
----
-
-
-
-
-## 写入无分区表
-
-下面的案例演示的是将 kafka 表中的数据,经过处理之后,直接写入 hive 无分区表,具体 hive 表中的数据什么时候可见,具体请查看 `insert` 语句中对 hive 表使用的 sql 提示。
-
-### hive 表
-
-```sql
-CREATE TABLE `test.order_info`(
- `id` int COMMENT '订单id',
- `product_count` int COMMENT '购买商品数量',
- `one_price` double COMMENT '单个商品价格')
-ROW FORMAT SERDE
- 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
-STORED AS INPUTFORMAT
- 'org.apache.hadoop.mapred.TextInputFormat'
-OUTPUTFORMAT
- 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
-LOCATION
- 'hdfs://hadoopCluster/user/hive/warehouse/test.db/order_info'
-TBLPROPERTIES (
- 'transient_lastDdlTime'='1659250044')
-;
-```
-
-### flink sql 语句
-
-```sql
--- 如果是 flink-1.13.x ,则需要手动设置该参数
-set 'table.dynamic-table-options.enabled' = 'true';
-
--- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
--- 创建catalog
-create catalog hive with (
- 'type' = 'hive',
- 'hadoop-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf',
- 'hive-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf'
-)
-;
-
-use catalog hive;
-
--- 创建连接 kafka 的虚拟表作为 source,此处使用 temporary ,是为了不让创建的虚拟表元数据保存到 hive,可以让任务重启是不出错。
--- 如果想让虚拟表元数据保存到 hive ,则可以在创建语句中加入 if not exist 语句。
-CREATE temporary TABLE source_kafka(
- id integer comment '订单id',
- product_count integer comment '购买商品数量',
- one_price double comment '单个商品价格'
-) WITH (
- 'connector' = 'kafka',
- 'topic' = 'data_gen_source',
- 'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
- 'properties.group.id' = 'for_source_test',
- 'scan.startup.mode' = 'latest-offset',
- 'format' = 'csv',
- 'csv.field-delimiter' = ' '
-)
-;
-
-insert into test.order_info
--- 下面的语法是 flink sql 提示,用于在语句中使用到表时手动设置一些临时的参数
-/*+
-OPTIONS(
- -- 设置写入的文件滚动时间间隔
- 'sink.rolling-policy.rollover-interval' = '10 s',
- -- 设置检查文件是否需要滚动的时间间隔
- 'sink.rolling-policy.check-interval' = '1 s',
- -- sink 并行度
- 'sink.parallelism' = '1'
-)
- */
-select id, product_count, one_price
-from source_kafka
-;
-```
-
-flink sql 写入 hive ,依赖的是 fileSystem 连接器,该连接器写入到文件系统的文件可见性,依赖于 flink 任务的 checkpoint ,
-所以 dlink 界面提交任务时,一定要开启 checkpoint ,也就是设置 checkpoint 的时间间隔参数 `execution.checkpointing.interval` ,如下图所示,设置为 10000 毫秒。
-
-
-
-任务运行之后,就可以看到如下的 fink ui 界面了
-
-
-
-本案例使用 streaming 方式运行, checkpoint 时间为 10 s,文件滚动时间为 10 s,在配置的时间过后,就可以看到 hive 中的数据了
-
-
-
-从 hdfs 上查看 hive 表对应文件的数据,如下图所示
-
-
-
-可以看到,1 分钟滚动生成了 6 个文件,最新文件为 .part 开头的文件,在 hdfs 中,以 `.` 开头的文件,是不可见的,说明这个文件是由于我关闭了 flink sql 任务,然后文件无法滚动造成的。
-
-有关读写 hive 的一些配置和读写 hive 表时其数据的可见性,可以看考[读写hive](https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/connectors/table/hive/hive_read_write/)页面。
-
-## 写入分区表
-
-### hive 表
-
-```sql
-CREATE TABLE `test.order_info_have_partition`(
- `product_count` int COMMENT '购买商品数量',
- `one_price` double COMMENT '单个商品价格')
-PARTITIONED BY (
- `minute` string COMMENT '订单时间,分钟级别',
- `order_id` int COMMENT '订单id')
-ROW FORMAT SERDE
- 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
-STORED AS INPUTFORMAT
- 'org.apache.hadoop.mapred.TextInputFormat'
-OUTPUTFORMAT
- 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
-LOCATION
- 'hdfs://hadoopCluster/user/hive/warehouse/test.db/order_info_have_partition'
-TBLPROPERTIES (
- 'transient_lastDdlTime'='1659254559')
-;
-```
-
-### flink sql 语句
-
-```sql
--- 如果是 flink-1.13.x ,则需要手动设置该参数
-set 'table.dynamic-table-options.enabled' = 'true';
-
--- 在需要读取hive或者是写入hive表时,必须创建hive catalog。
--- 创建catalog
-create catalog hive with (
- 'type' = 'hive',
- 'hadoop-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf',
- 'hive-conf-dir' = '/data/soft/dlink-0.6.6/hadoop-conf'
-)
-;
-
-use catalog hive;
-
--- 创建连接 kafka 的虚拟表作为 source,此处使用 temporary ,是为了不让创建的虚拟表元数据保存到 hive,可以让任务重启是不出错。
--- 如果想让虚拟表元数据保存到 hive ,则可以在创建语句中加入 if not exist 语句。
-CREATE temporary TABLE source_kafka(
- event_time TIMESTAMP(3) METADATA FROM 'timestamp',
- id integer comment '订单id',
- product_count integer comment '购买商品数量',
- one_price double comment '单个商品价格'
-) WITH (
- 'connector' = 'kafka',
- 'topic' = 'data_gen_source',
- 'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
- 'properties.group.id' = 'for_source_test',
- 'scan.startup.mode' = 'latest-offset',
- 'format' = 'csv',
- 'csv.field-delimiter' = ' '
-)
-;
-
-insert into test.order_info_have_partition
--- 下面的语法是 flink sql 提示,用于在语句中使用到表时手动设置一些临时的参数
-/*+
-OPTIONS(
- -- 设置分区提交触发器为分区时间
- 'sink.partition-commit.trigger' = 'partition-time',
--- 'partition.time-extractor.timestamp-pattern' = '$year-$month-$day $hour:$minute',
- -- 设置时间提取器的时间格式,要和分区字段值的格式保持一直
- 'partition.time-extractor.timestamp-formatter' = 'yyyy-MM-dd_HH:mm',
- -- 设置分区提交延迟时间,这儿设置 1 分钟,是因为分区时间为 1 分钟间隔
- 'sink.partition-commit.delay' = '1 m',
- -- 设置水印时区
- 'sink.partition-commit.watermark-time-zone' = 'GMT+08:00',
- -- 设置分区提交策略,这儿是将分区提交到元数据存储,并且在分区目录下生成 success 文件
- 'sink.partition-commit.policy.kind' = 'metastore,success-file',
- -- sink 并行度
- 'sink.parallelism' = '1'
-)
- */
-select
- product_count,
- one_price,
- -- 不要让分区值中带有空格,分区值最后会变成目录名,有空格的话,可能会有一些未知问题
- date_format(event_time, 'yyyy-MM-dd_HH:mm') as `minute`,
- id as order_id
-from source_kafka
-;
-```
-
-flink sql 任务运行的 UI 界面如下
-
-
-
-1 分钟之后查看 hive 表中数据,如下
-
-
-
-查看 hive 表对应 hdfs 上的文件,可以看到
-
-
-
-从上图可以看到,具体的分区目录下生成了 `_SUCCESS` 文件,表示该分区提交成功。
-
-
diff --git a/docs/docs/extend/practice_guide/kudu.md b/docs/docs/extend/practice_guide/kudu.md
deleted file mode 100644
index e988d82547..0000000000
--- a/docs/docs/extend/practice_guide/kudu.md
+++ /dev/null
@@ -1,118 +0,0 @@
----
-sidebar_position: 13
-id: kudu
-title: kudu
----
-
-
-
-# Kudu
-
-> 编辑: roohom
-
-
-
-## 说在前面
-
-下面介绍如何通过Dinky整合Kudu,以支持写SQL来实现数据的读取或写入Kudu。
-
-Flink官网介绍了如何去自定义一个支持Source或者Sink的[Connector](https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sourcessinks/),这不是本文探讨的重点,本文侧重于用别人已经写好的Connector去与Dinky做集成以支持读写Kudu。
-
-> 注意:以下内容基于Flink1.13.6 Dinky0.6.2,当然其他版本同理。
-
-
-
-## 准备工作
-
-在Kudu上创建一个表,这里为test
-
-
-
-我们还需要一个Flink可以使用的针对kudu的Connector,我们找到[**[flink-connector-kudu](https://github.com/collabH/flink-connector-kudu)**]这个项目,clone该项目并在本地适当根据本地所使用组件的版本修改代码进行编译。
-
-1、修改pom
-
-~~~xml
-1.13.6
-1.14.0
-
-
-
- org.apache.maven.plugins
- maven-shade-plugin
- 3.2.4
-
-
- package
-
- shade
-
-
-
-
-
-~~~
-
-这里将Flink版本修改为1.13.6, 并且使用1.14.0版本的kudu-client,因为项目作者在README中已经说明了使用1.10.0会存在问题,并且添加了shade方式打包
-
-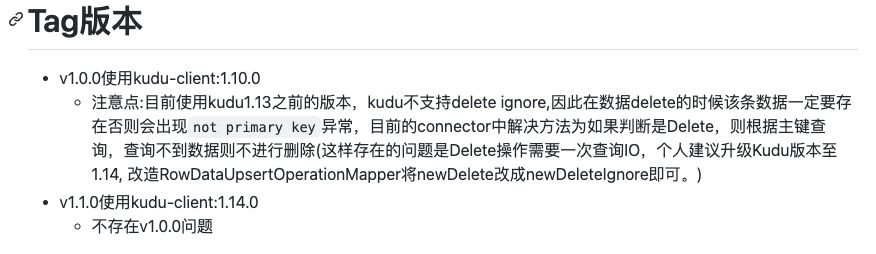
-
-2、修改`org.colloh.flink.kudu.connector.table.catalog.KuduCatalogFactory`
-
-
-
-## 构建及使用
-
-1、OK,准备工作完毕,我们将项目编译打包(步骤略),将得到的jar放在flink的lib目录下以及dinky的plugins目录下,如果需要使用yarn-application模式提交任务,还需要将jar放在HDFS上合适位置让flink能访问到。
-
-2、OK,重启Dinky,如果使用yarn-session模式,咱们需要重启得到一个session集群,进入dinky的注册中心配置一个合适的集群实例
-
-
-
-3、接下来我们去dinky的数据开发界面,写一个读取的SQL demo
-
-~~~sql
-CREATE TABLE IF NOT EXISTS kudu_test (
- id BIGINT,
- name STRING
-) WITH (
- 'connector' = 'kudu',
- 'kudu.masters' = 'cdh001:7051,cdh002:7051,cdh003:7051',
- 'kudu.table' = 'impala::xxx.test',
- 'kudu.hash-columns' = 'id',
- 'kudu.primary-key-columns' = 'id'
-);
-
-SELECT * FROM kudu_test;
-
-~~~
-
-点击运行
-
-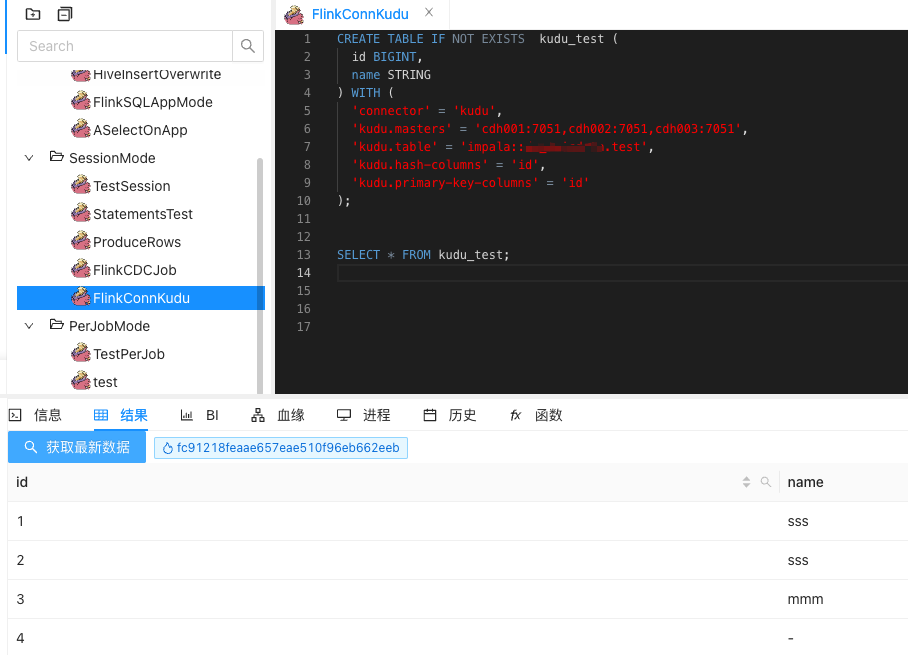
-
-4、再来一个写入数据的SQL demo
-
-~~~sql
-CREATE TABLE IF NOT EXISTS kudu_test (
- id BIGINT,
- name STRING
-) WITH (
- 'connector' = 'kudu',
- 'kudu.masters' = 'cdh001:7051,cdh002:7051,cdh003:7051',
- 'kudu.table' = 'impala::xxx.test',
- 'kudu.hash-columns' = 'id',
- 'kudu.primary-key-columns' = 'id'
-);
-
-INSERT INTO kudu_test
-SELECT 5 AS id , NULLIF('', '') AS name;
-~~~
-
-
-
-成功运行,再去查看kudu表的数据
-
-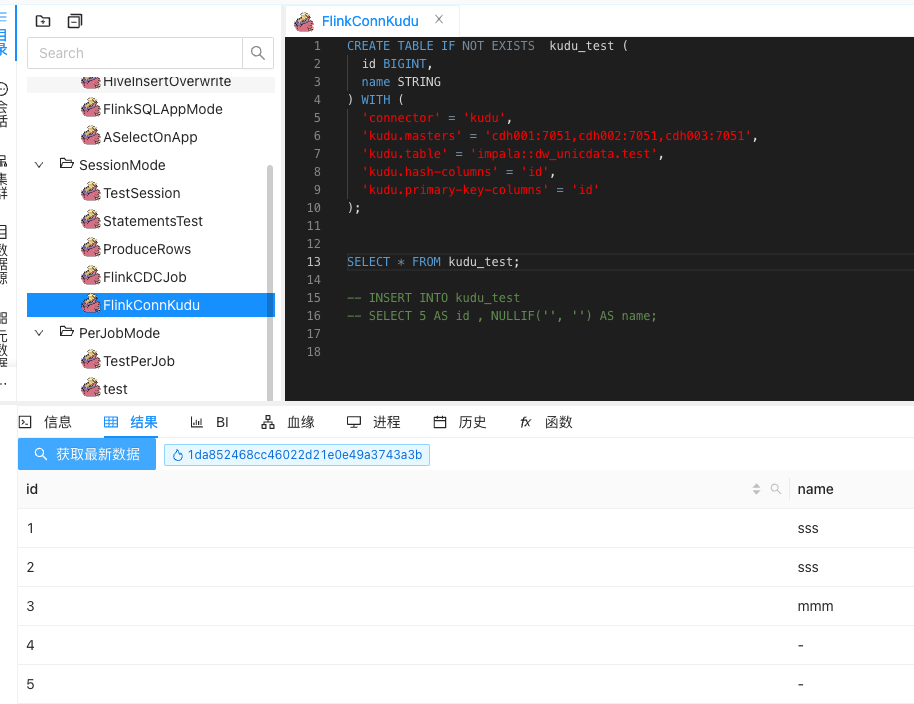
-
-集成完毕。
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/lookup_join.md b/docs/docs/extend/practice_guide/lookup_join.md
deleted file mode 100644
index 59c6dfdf29..0000000000
--- a/docs/docs/extend/practice_guide/lookup_join.md
+++ /dev/null
@@ -1,128 +0,0 @@
----
-sidebar_position: 15
-id: lookup_join
-title: lookup join
----
-
-
-
-## lookup join
-
-该例中,将 mysql 表作为维表,里面保存订单信息,之后去关联订单流水表,最后输出完整的订单流水信息数据到 kafka。
-
-### kafka 主题 (order_water)
-
-订单流水表读取的是 kafka `order_water` 主题中的数据,数据内容如下
-
-
-
-### mysql 表 (dim.order_info)
-
-**表结构**
-
-```sql
-CREATE TABLE `order_info` (
- `id` int(11) NOT NULL COMMENT '订单id',
- `user_name` varchar(50) DEFAULT NULL COMMENT '订单所属用户',
- `order_source` varchar(50) DEFAULT NULL COMMENT '订单所属来源',
- PRIMARY KEY (`id`)
-) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-```
-
-**数据**
-
-
-
-### flink sql 语句
-
-```sql
-set 'table.local-time-zone' = 'GMT+08:00';
-
--- 订单流水
-CREATE temporary TABLE order_flow(
- id int comment '订单id',
- product_count int comment '购买商品数量',
- one_price double comment '单个商品价格',
- -- 一定要添加处理时间字段,lookup join 需要该字段
- proc_time as proctime()
-) WITH (
- 'connector' = 'kafka',
- 'topic' = 'order_water',
- 'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
- 'properties.group.id' = 'for_source_test',
- 'scan.startup.mode' = 'latest-offset',
- 'format' = 'csv',
- 'csv.field-delimiter' = ' '
-)
-;
-
--- 订单信息
-create table order_info (
- id int PRIMARY KEY NOT ENFORCED comment '订单id',
- user_name string comment '订单所属用户',
- order_source string comment '订单所属来源'
-) with (
- 'connector' = 'jdbc',
- 'url' = 'jdbc:mysql://node01:3306/dim?useSSL=false',
- 'table-name' = 'order_info',
- 'username' = 'root',
- 'password' = 'root'
-)
-;
-
--- 创建连接 kafka 的虚拟表作为 sink
-create table sink_kafka(
- id int PRIMARY KEY NOT ENFORCED comment '订单id',
- user_name string comment '订单所属用户',
- order_source string comment '订单所属来源',
- product_count int comment '购买商品数量',
- one_price double comment '单个商品价格',
- total_price double comment '总价格'
-) with (
- 'connector' = 'upsert-kafka',
- 'topic' = 'for_sink',
- 'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
- 'key.format' = 'csv',
- 'value.format' = 'csv',
- 'value.csv.field-delimiter' = ' '
-)
-;
-
--- 真正要执行的任务
-insert into sink_kafka
-select
- a.id,
- b.user_name,
- b.order_source,
- a.product_count,
- a.one_price,
- a.product_count * a.one_price as total_price
-from order_flow as a
--- 一定要添加 for system_time as of 语句,否则读取 mysql 的子任务会被认为是有界流,只读取一次,之后 mysql 维表中变化后的数据无法被读取
-left join order_info for system_time as of a.proc_time as b
-on a.id = b.id
-;
-```
-
-flink sql 任务运行之后,flink UI 界面显示为
-
-
-
-最后查看写入 kafka 中的数据为
-
-
-
-此时,修改 mysql 中的数据,修改之后为
-
-
-
-再查看写入 kafka 中的数据为
-
-
-
-**其他**
-
-如果 kafka 中的订单流数据中的某个订单 id 在维表 mysql 中找不到,而且 flink sql 任务中使用的是 left join 连接,
-则匹配不到的订单中的 user_name 和 product_count 字段将为空字符串,具体如下图所示
-
-
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/principle.md b/docs/docs/extend/practice_guide/principle.md
deleted file mode 100644
index 406e6be73f..0000000000
--- a/docs/docs/extend/practice_guide/principle.md
+++ /dev/null
@@ -1,178 +0,0 @@
----
-sidebar_position: 2
-id: principle
-title: Dlink 核心概念及实现原理详解
----
-
-
-
-
-## Dlink 是什么
-
-Dlink 是一个基于 Apache Flink 二次开发的网页版的 FlinkSQL Studio,可以连接多个 Flink 集群实例,并在线开发、执行、提交 FlinkSQL 语句以及预览其运行结果,支持 Flink 官方所有语法并进行了些许增强。
-
-## 与 Flink 的不同
-
-Dlink 基于 Flink 源码二次开发,主要应用于 SQL 任务的管理与执行。以下将介绍 Dlink-0.2.3 与 Flink 的不同。
-
-### Dlink 的原理
-
-
-
-### Dlink 的 FlinkSQL 执行原理
-
-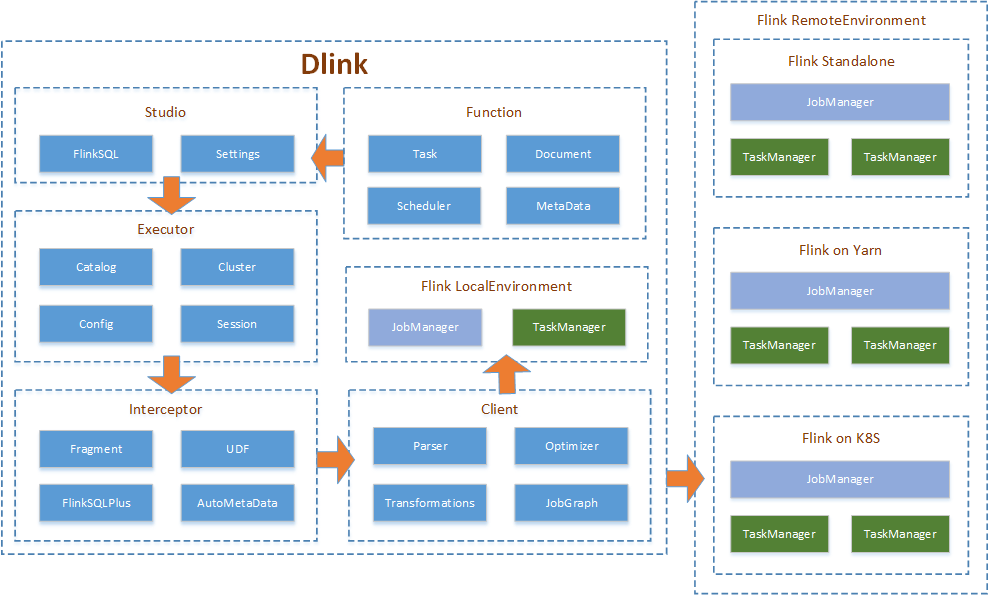
-
-### Connector 的扩展
-
-Dlink 的 Connector 的使用与扩展同 Flink 的完全一致,即当使用 Flink 集成 Dlink 时,只需要将 Flink 扩展的依赖加入 Dlink 的 lib 下即可。
-
-当然,Dlink 自身源码也提供了一些 Connector ,它们遵循 Flink 的扩展要求,可以直接被加入到 Flink 的 lib 下进行使用。
-
-### 多版本支持
-
-Dlink 的单机版只能同时稳定连接同一大版本号下的不同版本的 Flink 集群实例,连接其他大版本号的集群实例在提交任务时可能存在问题;而 DataLink 中的 Dlink 微服务版可以同时稳定连接所有版本号的 Flink 集群实例。
-
-Dlink 提供了多版本的 `dlink-client.jar`,根据需求选择对应版本的依赖加入到 lib 下即可稳定连接该版本的 Flink 集群实例。
-
-### Catalog 共享
-
-Dlink 提供了共享会话对 Flink 的 Catalog、环境配置等进行了长期管理,可以实现团队开发共享 Catalog 的效果。
-
-### Sql 语法增强
-
-Dlink 对 FlinkSQL 的语法进行增强,主要表现为 Sql 片段与表值聚合 Sql 化。
-
-#### Sql 片段
-
-```sql
-sf:=select * from;tb:=student;
-${sf} ${tb}
-## 效果等同于
-select * from student
-```
-
-#### 表值聚合
-
-```sql
-CREATE AGGTABLE aggdemo AS
-SELECT myField,value,rank
-FROM MyTable
-GROUP BY myField
-AGG BY TOP2(value) as (value,rank);
-```
-
-### 同步执行结果预览
-
-Dlink 可以对同步执行的 FlinkSQL 进行运行完成的结果预览,同 `sql-client`。
-
-## 概念原理
-
-在 Dlink 中具有六个概念,当熟悉他们的原理时,可以搭配出更强大的使用效果。
-
-### 本地环境
-
-本地环境即为`LocalEnvironment`,是在本地模式运行 Flink 程序的句柄,在本地的 JVM (standalone 或嵌入其他程序)里运行程序,通过调用`ExecutionEnvironment.createLocalEnvironment()`方法来实现。
-
-Dlink 通过本地环境来实现隔离调试,本地环境执行时所需要的 `connector` 等资源在 `lib` 目录下引入。本地环境执行过程包含完整的 sql 执行过程。
-
-### 远程环境
-
-远程环境即为`RemoteEnvironment`,是在远程模式中向指定集群提交 Flink 程序的句柄,在目标集群的环境里运行程序,通过调用`ExecutionEnvironment.createRemoteEnvironment(host,port)`方法来实现,其中 host 为 `rest.address` ,port 为 `rest.port` 。
-
-Dlink 可以对任意 standalone、on yarn等运行模式的远程集群进行 sql 提交。远程环境执行过程只包含 sql 任务的准备工作,即解析、优化、转化物理执行计划、生成算子、提交作业执行图。所以远程环境执行时所需要的 connector 等资源也需要在 lib 目录下引入。
-
-### 共享会话
-
-共享会话为用户与执行环境的操作会话,主要包含 Catalog、片段、执行环境配置等内容。可以认为官方的 `sql-client` 是一个会话,保留了本次命令窗口的操作结果,当退出 `sql-client` 后,会话结束。
-
-Dlink 的共享会话相当于可以启动多个 `sql-client` 来进行会话操作,并且其他用户可以使用您的会话 key ,在对应环境中共享您的会话的所有信息。例如,通过执行环境 + 共享会话可以确定唯一的 Catalog。
-
-### 临时会话
-
-临时会话指不启用共享会话,您每次交互执行操作时,都会创建临时的独立的会话,操作解释后立即释放,适合作业解耦处理。
-
-Dlink 的临时会话相当于只启动一个 `sql-client` ,执行完语句后立即关闭再启动。
-
-### 同步执行
-
-同步执行指通过 Studio 进行操作时为同步等待,当语句运行完成后返回运行结果。
-
-Dlink 的语句与官方语句一致,并做了些许增强。Dlink 将所有语句划分为三种类型,即 `DDL`、`DQL` 和 `DML` 。对于同步执行来说, `DDL` 和 `DQL` 均为等待语句执行完成后返回运行结果,而 `DML` 语句则立即返回异步提交操作的执行结果。
-
-### 异步提交
-
-异步提交指通过 Studio 进行操作时为异步操作,当语句被执行后立马返回操作执行结果。
-
-对于三种语句类型,Dlink 的异步提交均立即返回异步操作的执行结果。当前版本的 Dlink 的异步提交不进行历史记录。
-
-### 搭配使用
-
-| 执行环境 | 会话 | 运行方式 | 适用场景 |
-| -------- | -------- | -------- | ------------------------------------------------------------ |
-| 本地环境 | 临时会话 | 同步执行 | 无集群或集群不可用的情况下单独开发FlinkSQL作业,需要查看运行结果 |
-| 本地环境 | 共享会话 | 同步执行 | 无集群或集群不可用的情况下复用Catalog或让同事排查bug,需要查看运行结果 |
-| 本地环境 | 临时会话 | 异步提交 | 无集群或集群不可用的情况下快速启动一个作业,不需要查看运行结果 |
-| 本地环境 | 共享会话 | 异步提交 | 共享会话效果无效 |
-| 远程环境 | 临时会话 | 同步执行 | 依靠集群单独开发FlinkSQL作业,需要查看运行结果 |
-| 远程环境 | 共享会话 | 同步执行 | 依靠集群复用Catalog或让同事排查bug,需要查看运行结果 |
-| 远程环境 | 临时会话 | 异步提交 | 快速向集群提交任务,不需要查看运行结果 |
-| 远程环境 | 共享会话 | 异步提交 | 共享会话效果无效 |
-
-
-
-## 源码扩展
-
-Dlink 的源码是非常简单的, Spring Boot 项目轻松上手。
-
-### 项目结构
-
-```java
-dlink -- 父项目
-|-dlink-admin -- 管理中心
-|-dlink-client -- Client 中心
-| |-dlink-client-1.13 -- Client-1.13 实现
-|-dlink-connectors -- Connectors 中心
-| |-dlink-connector-jdbc -- Jdbc 扩展
-|-dlink-core -- 执行中心
-|-dlink-doc -- 文档
-| |-bin -- 启动脚本
-| |-bug -- bug 反馈
-| |-config -- 配置文件
-| |-doc -- 使用文档
-| |-sql -- sql脚本
-|-dlink-function -- 函数中心
-|-dinky-web -- React 前端
-```
-
-### 模块介绍
-
-#### dlink-admin
-
-该模块为管理模块,基于 `Spring Boot + MybatisPlus` 框架开发,目前版本对作业、目录、文档、集群、语句等功能模块进行管理。
-
-#### dlink-client
-
-该模块为 Client 的封装模块,依赖了 `flink-client`,并自定义了新功能的实现如 `CustomTableEnvironmentImpl`、`SqlManager ` 等。
-
-通过该模块完成对不同版本的 Flink 集群的适配工作。
-
-#### dlink-connectors
-
-该模块为 Connector 的封装模块,用于扩展 Flink 的 `Connector`。
-
-#### dlink-core
-
-该模块为 Dlink 的核心处理模块,里面涉及了共享会话、拦截器、执行器等任务执行过程使用到的功能。
-
-#### dlink-doc
-
-该模块为 Dlink 的文档模块,部署相关资源以及使用文档等资料都在该模块下。
-
-#### dlink-function
-
-该模块为 UDF 的封装模块,用于扩展 Flink 的 `UDF` 。
-
-#### dinky-web
-
-该模块为 Dlink 的前端工程,基于 `Ant Design Pro` 开发,属于 `React` 技术栈,其中的 Sql 在线编辑器是基于 `Monaco Editor` 开发。
diff --git a/docs/docs/extend/practice_guide/temporal_join.md b/docs/docs/extend/practice_guide/temporal_join.md
deleted file mode 100644
index 7ebe7aac2c..0000000000
--- a/docs/docs/extend/practice_guide/temporal_join.md
+++ /dev/null
@@ -1,165 +0,0 @@
----
-sidebar_position: 16
-id: temporal_join
-title: temporal join
----
-
-
-## temporal join (时态连接)
-
-
-该案例中,将 upsert kafka 主题 `order_info` 中的数据作为维表数据,然后去关联订单流水表,最后输出完整的订单流水信息数据到 kafka。
-
-### kafka 主题 (order_water)
-
-订单流水表读取的是 kafka `order_water` 主题中的数据,数据内容如下
-
-
-
-### kafka 主题 (order_info)
-
-订单信息维表读取的是 kafka `order_info` 主题中的数据,数据内容如下
-
-
-
-### flink sql 语句
-
-```sql
-set 'table.local-time-zone' = 'GMT+08:00';
--- 如果 source kafka 主题中有些分区没有数据,就会导致水印无法向下游传播,此时需要手动设置空闲时间
-set 'table.exec.source.idle-timeout' = '1 s';
-
--- 订单流水
-CREATE temporary TABLE order_flow(
- id int comment '订单id',
- product_count int comment '购买商品数量',
- one_price double comment '单个商品价格',
- -- 定义订单时间为数据写入 kafka 的时间
- order_time TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' VIRTUAL,
- WATERMARK FOR order_time AS order_time
-) WITH (
- 'connector' = 'kafka',
- 'topic' = 'order_water',
- 'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
- 'properties.group.id' = 'for_source_test',
- 'scan.startup.mode' = 'latest-offset',
- 'format' = 'csv',
- 'csv.field-delimiter' = ' '
-)
-;
-
--- 订单信息
-create table order_info (
- id int PRIMARY KEY NOT ENFORCED comment '订单id',
- user_name string comment '订单所属用户',
- order_source string comment '订单所属来源',
- update_time TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' VIRTUAL,
- WATERMARK FOR update_time AS update_time
-) with (
- 'connector' = 'upsert-kafka',
- 'topic' = 'order_info',
- 'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
- 'key.format' = 'csv',
- 'value.format' = 'csv',
- 'value.csv.field-delimiter' = ' '
-)
-;
-
--- 创建连接 kafka 的虚拟表作为 sink
-create table sink_kafka(
- id int PRIMARY KEY NOT ENFORCED comment '订单id',
- user_name string comment '订单所属用户',
- order_source string comment '订单所属来源',
- product_count int comment '购买商品数量',
- one_price double comment '单个商品价格',
- total_price double comment '总价格'
-) with (
- 'connector' = 'upsert-kafka',
- 'topic' = 'for_sink',
- 'properties.bootstrap.servers' = 'node01:9092,node02:9092,node03:9092',
- 'key.format' = 'csv',
- 'value.format' = 'csv',
- 'value.csv.field-delimiter' = ' '
-)
-;
-
--- 真正要执行的任务
-insert into sink_kafka
-select
- order_flow.id,
- order_info.user_name,
- order_info.order_source,
- order_flow.product_count,
- order_flow.one_price,
- order_flow.product_count * order_flow.one_price as total_price
-from order_flow
-left join order_info FOR SYSTEM_TIME AS OF order_flow.order_time
-on order_flow.id = order_info.id
-;
-```
-
-flink sql 任务运行的 flink UI 界面如下
-
-
-
-查看结果写入的 kafka `for_sink` 主题的数据为
-
-
-
-此时新增数据到 kafka 维表主题 `order_info` 中,新增的数据如下
-
-
-
-再查看结果写入的 kafka `for_sink` 主题的数据为
-
-
-
-**注意**
-
-经过测试发现,当将 upsert kafka 作为 source 时,主题中的数据必须有 **key**,否则会抛出无法反序列化数据的错误,具体如下
-
-```log
-[INFO] [2022-07-31 21:18:22][org.apache.flink.runtime.executiongraph.ExecutionGraph]Source: order_info[5] (2/8) (f8b093cf4f7159f9511058eb4b100b2e) switched from RUNNING to FAILED on bbc9c6a6-0a76-4efe-a7ea-0c00a19ab400 @ 127.0.0.1 (dataPort=-1).
-java.io.IOException: Failed to deserialize consumer record due to
- at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:56) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
- at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:33) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
- at org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:143) ~[flink-connector-base-1.15.1.jar:1.15.1]
- at org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:385) ~[flink-streaming-java-1.15.1.jar:1.15.1]
- at org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68) ~[flink-streaming-java-1.15.1.jar:1.15.1]
- at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65) ~[flink-streaming-java-1.15.1.jar:1.15.1]
- at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:519) ~[flink-streaming-java-1.15.1.jar:1.15.1]
- at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203) ~[flink-streaming-java-1.15.1.jar:1.15.1]
- at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:804) ~[flink-streaming-java-1.15.1.jar:1.15.1]
- at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:753) ~[flink-streaming-java-1.15.1.jar:1.15.1]
- at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:948) ~[flink-runtime-1.15.1.jar:1.15.1]
- at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:927) ~[flink-runtime-1.15.1.jar:1.15.1]
- at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:741) ~[flink-runtime-1.15.1.jar:1.15.1]
- at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563) ~[flink-runtime-1.15.1.jar:1.15.1]
- at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_311]
-Caused by: java.io.IOException: Failed to deserialize consumer record ConsumerRecord(topic = order_info, partition = 0, leaderEpoch = 0, offset = 7, CreateTime = 1659273502239, serialized key size = 0, serialized value size = 18, headers = RecordHeaders(headers = [], isReadOnly = false), key = [B@2add8ff2, value = [B@2a633689).
- at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:57) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
- at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
- ... 14 more
-Caused by: java.io.IOException: Failed to deserialize CSV row ''.
- at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:162) ~[flink-csv-1.15.1.jar:1.15.1]
- at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:47) ~[flink-csv-1.15.1.jar:1.15.1]
- at org.apache.flink.api.common.serialization.DeserializationSchema.deserialize(DeserializationSchema.java:82) ~[flink-core-1.15.1.jar:1.15.1]
- at org.apache.flink.streaming.connectors.kafka.table.DynamicKafkaDeserializationSchema.deserialize(DynamicKafkaDeserializationSchema.java:119) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
- at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:54) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
- at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
- ... 14 more
-Caused by: org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.exc.MismatchedInputException: No content to map due to end-of-input
- at [Source: UNKNOWN; line: -1, column: -1]
- at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.exc.MismatchedInputException.from(MismatchedInputException.java:59) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
- at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.DeserializationContext.reportInputMismatch(DeserializationContext.java:1601) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
- at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectReader._initForReading(ObjectReader.java:358) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
- at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectReader._bindAndClose(ObjectReader.java:2023) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
- at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectReader.readValue(ObjectReader.java:1528) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
- at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:155) ~[flink-csv-1.15.1.jar:1.15.1]
- at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:47) ~[flink-csv-1.15.1.jar:1.15.1]
- at org.apache.flink.api.common.serialization.DeserializationSchema.deserialize(DeserializationSchema.java:82) ~[flink-core-1.15.1.jar:1.15.1]
- at org.apache.flink.streaming.connectors.kafka.table.DynamicKafkaDeserializationSchema.deserialize(DynamicKafkaDeserializationSchema.java:119) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
- at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:54) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
- at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
- ... 14 more
-```
\ No newline at end of file
diff --git a/docs/docs/extend/practice_guide/udf.md b/docs/docs/extend/practice_guide/udf.md
deleted file mode 100644
index 51d6bfee48..0000000000
--- a/docs/docs/extend/practice_guide/udf.md
+++ /dev/null
@@ -1,11 +0,0 @@
----
-sidebar_position: 11
-id: udf
-title: UDF
----
-
-
-
-## 扩展 UDF
-
-将 Flink 集群上已扩展好的 UDF 直接放入 Dlink 的 lib 或者 plugins 下,然后重启即可。定制 UDF 过程同 Flink 官方一样。
diff --git a/docs/docs/extend/practice_guide/yarnsubmit.md b/docs/docs/extend/practice_guide/yarnsubmit.md
deleted file mode 100644
index 2c9a4435ac..0000000000
--- a/docs/docs/extend/practice_guide/yarnsubmit.md
+++ /dev/null
@@ -1,206 +0,0 @@
----
-sidebar_position: 1
-id: yarnsubmit
-title: Yarn提交实践指南
----
-
-
-
- ## Yarn-Session 实践
-
- ### 注册 Session 集群
-
-
-
- ### 创建 Session 集群
-
-进入集群中心进行远程集群的注册。点击新建按钮配置远程集群的参数。图中示例配置了一个 Flink on Yarn 的高可用集群,其中 JobManager HA 地址需要填写集群中所有可能被作为 JobManager 的 RestAPI 地址,多个地址间使用英文逗号分隔。表单提交时可能需要较长时间的等待,因为 dlink 正在努力的计算当前活跃的 JobManager 地址。
-
-保存成功后,页面将展示出当前的 JobManager 地址以及被注册集群的版本号,状态为正常时表示可用。
-
-注意:只有具备 JobManager 实例的 Flink 集群才可以被成功注册到 dlink 中。( Yarn-Per-Job 和 Yarn-Application 也具有 JobManager,当然也可以手动注册,但无法提交任务)
-
-如状态异常时,请检查被注册的 Flink 集群地址是否能正常访问,默认端口号为8081,可能更改配置后发生了变化,查看位置为 Flink Web 的 JobManager 的 Configuration 中的 rest 相关属性。
-
-### 执行 Hello World
-
-万物都具有 Hello World 的第一步,当然 Dinky 也是具有的。我们选取了基于 datagen 的流查询作为第一行 Flink Sql。具体如下:
-
-```sql
-CREATE TABLE Orders (
- order_number BIGINT,
- price DECIMAL(32,2),
- buyer ROW,
- order_time TIMESTAMP(3)
-) WITH (
- 'connector' = 'datagen',
- 'rows-per-second' = '1'
-);
-select order_number,price,order_time from Orders
-```
-
-该例子使用到了 datagen,需要在 dlink 的 plugins 目录下添加 flink-table.jar。
-
-点击 **数据开发** 进入开发页面:
-
-
-
-在中央的编辑器中编辑 Flink Sql。
-
-右边作业配置:
-
-1. 执行模式:选中 Yarn-session;
-2. Flink 集群:选中上文注册的测试集群;
-3. SavePoint 策略:选中禁用;
-4. 按需进行其他配置。
-
-右边执行配置:
-
-1. 预览结果:启用;
-2. 远程执行:启用。
-
-点击快捷操作栏的三角号按钮同步执行该 FlinkSQL 任务。
-
-### 预览数据
-
-
-
-切换到历史选项卡点击刷新可以查看提交进度。切换到结果选项卡,等待片刻点击获取最新数据即可预览 SELECT。
-
-### 停止任务
-
-
-
-切换到进程选项卡,选则对应的集群实例,查询当前任务,可执行停止操作。
-
-## Yarn-Per-Job 实践
-
-### 注册集群配置
-
-进入集群中心——集群配置,注册配置。
-
-
-
-1. Hadoop 配置文件路径:指定配置文件路径(末尾无/),需要包含以下文件:core-site.xml,hdfs-site.xml,yarn-site.xml;
-2. Flink 配置 lib 路径:指定 lib 的 hdfs 路径(末尾无/),需要包含 Flink 运行时的所有依赖,即 flink 的 lib 目录下的所有 jar;
-3. Flink 配置文件路径:指定配置文件 flink-conf.yaml 的具体路径(末尾无/);
-4. 按需配置其他参数(重写效果);
-5. 配置基本信息(标识、名称等);
-6. 点击测试或者保存。
-
-### 执行升级版 Hello World
-
-之前的 hello world 是个 SELECT 任务,改良下变为 INSERT 任务:
-
-```sql
-CREATE TABLE Orders (
- order_number INT,
- price DECIMAL(32,2),
- order_time TIMESTAMP(3)
-) WITH (
- 'connector' = 'datagen',
- 'rows-per-second' = '1',
- 'fields.order_number.kind' = 'sequence',
- 'fields.order_number.start' = '1',
- 'fields.order_number.end' = '1000'
-);
-CREATE TABLE pt (
-ordertotal INT,
-numtotal INT
-) WITH (
- 'connector' = 'print'
-);
-insert into pt select 1 as ordertotal ,sum(order_number)*2 as numtotal from Orders
-```
-
-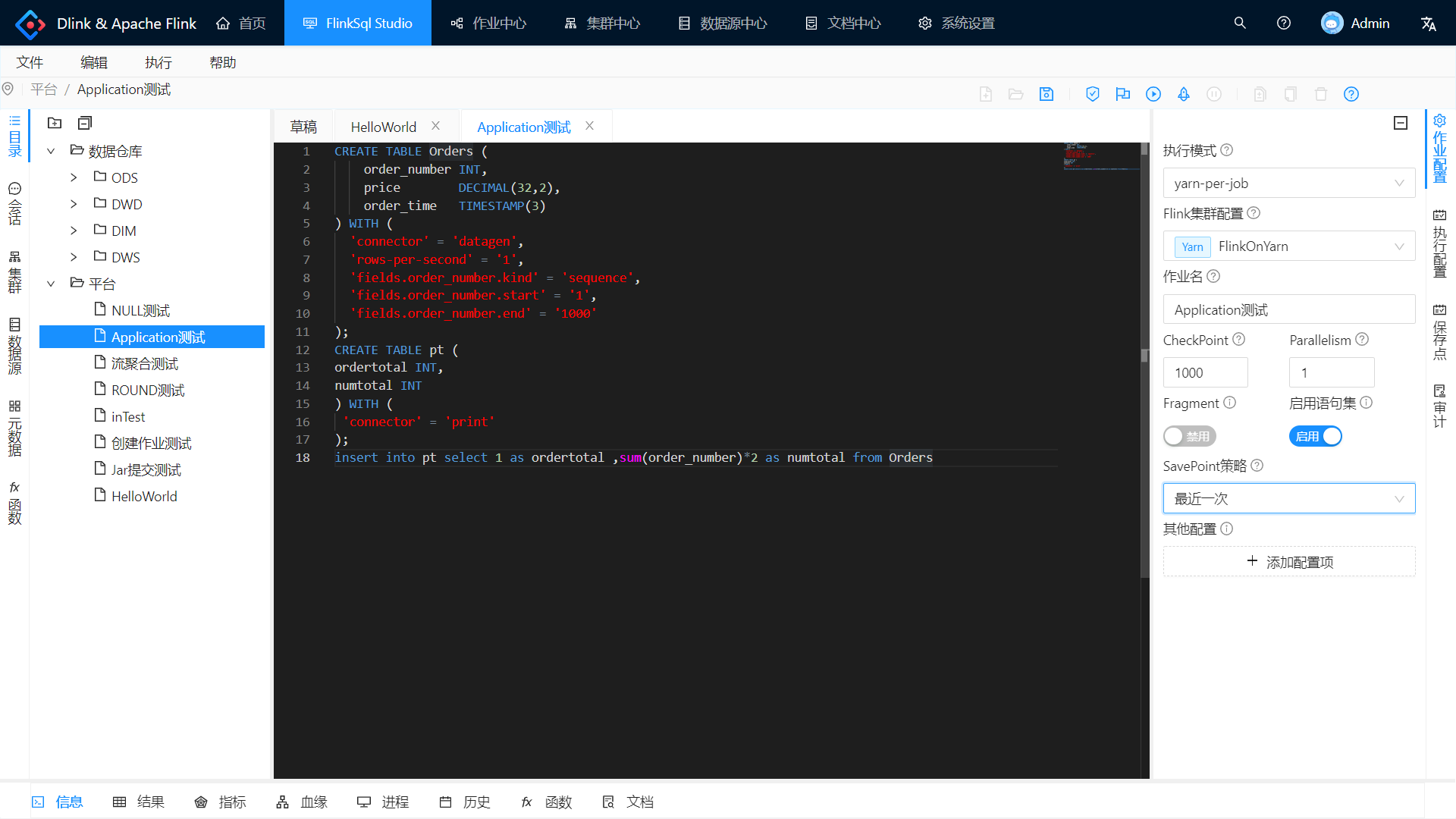
-
-编写 Flink SQL;
-
-作业配置:
-
-1. 执行模式:选中 yarn-per-job ;
-2. Flink 集群配置:选中刚刚注册的配置;
-3. SavePoint 策略:选中最近一次。
-
-快捷操作栏:
-
-1. 点击保存按钮保存当前所有配置;
-2. 点击小火箭异步提交作业。
-
-
-
-注意,执行历史需要手动刷新。
-
-### 自动注册集群
-
-点击集群中心——集群实例,即可发现自动注册的 Per-Job 集群。
-
-
-
-### 查看 Flink Web UI
-
-提交成功后,点击历史的蓝色地址即可快速打开 Flink Web UI地址。
-
-
-
-### 从 Savepoint 处停止
-
-在进程选项卡中选择自动注册的 Per-Job 集群,查看任务并 SavePoint-Cancel。
-
-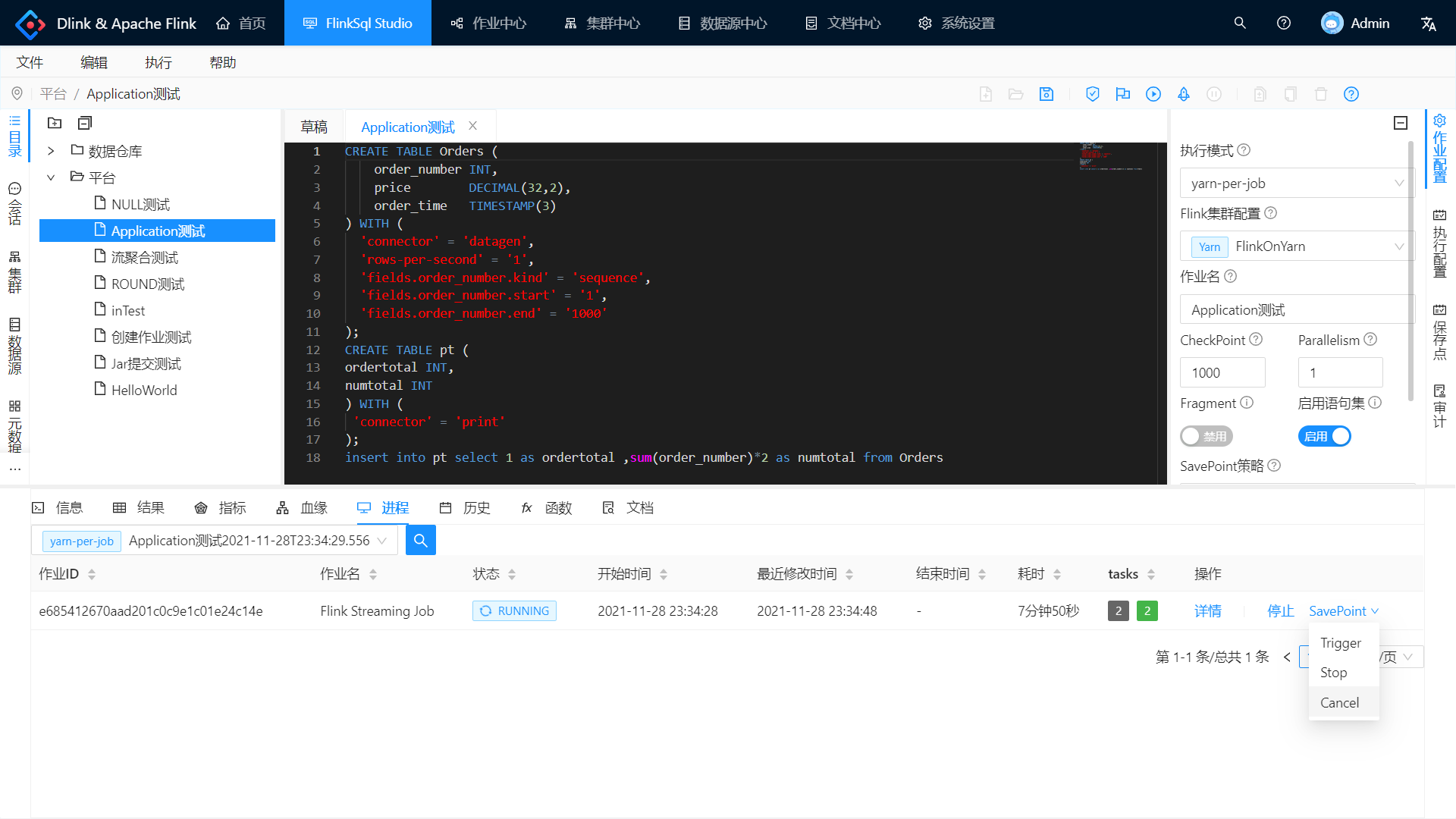
-
-在右侧保存点选项卡可以查看该任务的所有 SavePoint 记录。
-
-
-### 从 SavePoint 处启动
-
-再次点击小火箭提交任务。
-
-
-查看对应 Flink Web UI,从 Stdout 输出中证实 SavePoint 恢复成功。
-
-## Yarn-Application 实践
-
-### 注册集群配置
-
-使用之前注册的集群配置即可。
-
-### 上传 dlink-app.jar
-
-第一次使用时,需要将 dlink-app.jar 上传到 hdfs 指定目录,目录可修改如下:
-
-
-
-50070 端口 浏览文件系统如下:
-
-
-
-### 执行升级版 Hello World
-
-作业配置:
-
-1. 执行模式:选中 yarn-application ;
-
-快捷操作栏:
-
-1. 点击保存按钮保存当前所有配置;
-2. 点击小火箭异步提交作业。
-
-### 其他同 Per-Job
-
-其他操作同 yarn-per-job ,本文不再做描述。
-
-### 提交 User Jar
-
-作业中心—— Jar 管理,注册 User Jar 配置。
-
-
-
-右边作业配置的可执行 Jar 选择刚刚注册的 Jar 配置,保存后点击小火箭提交作业。
-
-
-
-由于提交了个批作业,Yarn 可以发现已经执行完成并销毁集群了。
-
-
diff --git a/docs/docs/faq.md b/docs/docs/faq.md
index 2c717ec870..bcc79870ae 100644
--- a/docs/docs/faq.md
+++ b/docs/docs/faq.md
@@ -1,5 +1,5 @@
---
-sidebar_position: 14
+sidebar_position: 15
id: faq
title: FAQ
---
diff --git a/docs/docs/thanks.md b/docs/docs/thanks.md
index 61af4c9530..7cf7b606b8 100644
--- a/docs/docs/thanks.md
+++ b/docs/docs/thanks.md
@@ -4,37 +4,55 @@ id: thanks
title: 致谢
---
-### 首先我们要感谢以下开源组织,为我们的项目提供了宝贵的资源和支持
-[Apache Flink](https://github.com/apache/flink)
+> 以下排名不分先后
+
+### 开源项目
+[Apache Flink](https://github.com/apache/flink)
- Apache Flink 是一个分布式流处理框架,支持事件驱动的应用程序。它提供了高吞吐量、低延迟的数据处理能力,适用于实时数据分析和处理。
-[Ant Design Pro](https://github.com/ant-design/ant-design-pro)
+[CDC Connectors for Apache Flink®](https://ververica.github.io/flink-cdc-connectors/master/index.html)
+- CDC Connectors for Apache Flink® 是一个开源项目,它提供了从数据库到 Apache Flink 的 CDC 连接器。这些连接器允许从数据库中读取更改数据捕获(CDC)数据,并将其发送到 Apache Flink 作业。
+[Ant Design Pro](https://github.com/ant-design/ant-design-pro)
- Ant Design Pro 是基于 Ant Design 设计体系的 React 实现,是一个企业级的 UI 设计语言和 React 组件库。它提供了一套完整的前端开发解决方案,用于构建现代化的企业级应用。
[Docusaurus]( https://github.com/facebook/docusaurus/)
-
- Docusaurus是一个由 Facebook 开源的静态网站生成器,用于构建易于维护和部署的文档网站。它被广泛用于开源项目和团队的文档撰写。
[Mybatis Plus](https://github.com/baomidou/mybatis-plus)
-
- Mybatis Plus 是 Mybatis 的增强工具,简化了 Mybatis 的开发流程。它提供了更多的特性和便利方法,帮助开发者更高效地进行数据库操作。
[Monaco Editor](https://github.com/Microsoft/monaco-editor)
-
- Monaco Editor是一个基于浏览器的代码编辑器,由 Microsoft 开发。它被广泛用于各种在线开发工具和集成开发环境(IDE)。
[SpringBoot](https://spring.io/projects/spring-boot)
-
- SpringBoot是一种用于创建独立的、基于 Spring 框架的 Java 应用程序的框架。它简化了 Spring 应用的开发过程,提供了一种快速构建应用的方式。
- 此外,特别感谢 [JetBrains](https://www.jetbrains.com/?from=dlink) 提供的免费开源 License 赞助,JetBrains是一家软件开发工具提供商,提供了许多受欢迎的集成开发环境,如 IntelliJ IDEA。他们支持开源社区,为一些开源项目提供免费的开源许可证,以促进软件开发的进步。
-(以上排名不分先后)
+[HuTool](https://hutool.cn/)
+- HuTool 是一个 Java 工具包,它提供了一系列工具类,帮助开发者更高效地进行 Java 开发。
+
+[SMS4J](https://sms4j.com/doc3/)
+- SMS4J 是一个集成各个短信厂商的短信发送平台,它提供了一套统一的短信发送接口,帮助开发者更方便地进行短信发送。Dinky 项目短信告警功能就是基于 SMS4J 实现的。
+
+[FlinkSQL数据脱敏和行级权限解决方案](https://github.com/HamaWhiteGG/flink-sql-security)
+- FlinkSQL数据脱敏和行级权限解决方案是一个基于 Apache Flink 的数据脱敏和行级权限解决方案,它提供了一套完整的数据脱敏和行级权限解决方案,帮助开发者更方便地进行数据脱敏和行级权限控制。Dinky 中的行级权限功能基于该解决方案实现。
+
+[Sa-Token](http://sa-token.dev33.cn/)
+- Sa-Token 是一款简单易用、功能强大的Java权限认证框架。它提供了一套简单、灵活、高效的权限认证方案,帮助开发者更方便地进行权限认证。Dinky 项目的登录认证功能/权限控制基于 Sa-Token 实现。
+
[](https://www.jetbrains.com/?from=dlink)
+此外,特别感谢 [JetBrains](https://www.jetbrains.com/?from=dlink) 提供的免费开源 License 赞助,JetBrains是一家软件开发工具提供商,提供了许多受欢迎的集成开发环境,如 IntelliJ IDEA。他们支持开源社区,为一些开源项目提供免费的开源许可证,以促进软件开发的进步
+
+### 贡献者
+
+
+
+
+
+
- 最后,我们要感谢各位Dinky贡献者对项目的辛勤努力和无私奉献,我们欢迎更多的开发者和贡献者加入Dinky的大家庭!如果您对我们的项目感兴趣,不论是提交 bug 报告、贡献代码、提出建议,还是分享您的使用经验,我们都非常欢迎。在这个开源社区中,每个人的贡献都有着巨大的价值,您的参与将使我们的项目更加丰富多彩。
diff --git a/docs/docs/upgrade.md b/docs/docs/upgrade.md
index fd207ec60d..c4111a181f 100644
--- a/docs/docs/upgrade.md
+++ b/docs/docs/upgrade.md
@@ -1,5 +1,5 @@
---
-sidebar_position: 13
+sidebar_position: 14
id: upgrade
title: 升级指南
---
diff --git a/docs/docs/user_guide/devops_center/deveops_center_intro.md b/docs/docs/user_guide/devops_center/deveops_center_intro.md
deleted file mode 100644
index 7ade6fd51c..0000000000
--- a/docs/docs/user_guide/devops_center/deveops_center_intro.md
+++ /dev/null
@@ -1,36 +0,0 @@
----
-sidebar_position: 1
-id: deveops_center_intro
-title: 运维中心概述
----
-
-运维中心包括 FlinkSQL 任务运维、周期任务运维、手动任务运维、作业监控等运维功能模块,为您提供任务操作与状态等多方位的运维能力。
-
-## 运维中心功能模块
-
-当您在数据开发中完成作业开发,并提交和发布至集群后,即可在运维中心对任务进行运维操作,包括作业实例运行详情查看,针对作业任务的关键指标查看、集群信息、作业快照、异常信息、作业日志、自动调优、配置信息、FlinkSQL、数据地图、即席查询、历史版本、告警记录。
-
-下表为运维中心各模块功能使用的简单说明:
-
-| 模块 | 说明 |
-|:--------:|:------------------------:|
-| 作业实例 | 查看及修改 FlinkSQL 的作业实例状态 |
-| 作业总览 | 查看 FlinkSQL 各监控指标 |
-| 集群信息 | 查看 FlinkSQL 的集群实例信息 |
-| 作业快照 | 查看 该任务的 CheckPoint SavePoint
并且可以基于某一个 CheckPoint/SavePoint 重启该任务 |
-| 异常信息 | 查看 FlinkSQL 启动及运行时的异常 |
-| 作业日志 | 完整的 FlinkSQL 日志 |
-| 自动调优 | - |
-| 配置信息 | 查看 FlinkSQL 的作业配置 |
-| FlinkSQL | 查看 FlinkSQL 的 SQL 语句 |
-| 数据地图 | 查看 FlinkSQL 的字段血缘 |
-| 即席查询 | |
-| 历史版本 | 对比查看 FlinkSQL 作业发布后的多个版本 |
-| 告警记录 | 查看 FlinkSQL 提交和发布后的告警信息 |
-| 一键上下线 | 已发布的作业可以进行一键上下线 |
-
-:::warning 注意事项
-
- 仅异步提交和发布功能,支持在运维中心查看监控任务。
-
-:::
\ No newline at end of file
diff --git a/docs/docs/user_guide/devops_center/indicators_list.md b/docs/docs/user_guide/devops_center/indicators_list.md
deleted file mode 100644
index 911b74eb0d..0000000000
--- a/docs/docs/user_guide/devops_center/indicators_list.md
+++ /dev/null
@@ -1,62 +0,0 @@
----
-sidebar_position: 3
-id: indicators_list
-title: 监控指标一览
----
-
-通过查阅监控指标一览,您可以了解到监控指标中每个指标的指标含义。这有助于您更好的使用 Dinky 的监控功能。
-
-:::info 信息
-
-您可以在运维中心查看以下指标,同时也可以 [修改作业状态](./job_instance_status#修改作业状态)
-
-:::
-
-## 作业总览
-
-| 指标名称 | 指标含义 |
-| :------: |:---------------:|
-| 作业状态 | Flink 的 Task 状态 |
-| 重启次数 | 未实现 |
-| 耗时 | Flink 作业总耗时 |
-| 启动时间 | 作业实例启动时间 |
-| 更新时间 | 作业实例更新时间 |
-| 完成时间 | 作业实例完成时间 |
-
-
-| 指标名称 | 指标含义 |
-| :------: |:----------------:|
-| 名称 | Flink Task 名称 |
-| 状态 | Task 状态 |
-| 接收字节 | 从上游 Task 接收的字节数 |
-| 接收记录 | 从上游 Task 接收的记录数 |
-| 发送字节 | 发给下游 Task 的字节数 |
-| 发送记录 | 发给下游 Task 的记录数 |
-| 并行度 | Task 并行读 |
-| 开始时间 | Task 开始时间 |
-| 结束时间 | Task 完成时间 |
-| 算子 | Task 具体的算子各状态的数量 |
-
-:::tip 说明
-
-如果作业只有一个 Task 时,接收字节、接收记录、发送字节、发送记录是均无法从上下游 Task 获取相关 Metrics 统计信息,所以显示为 0。
-如果非要查看具体的 Metrics,可以通过 Flink 配置更改 chain 策略。
-
-:::
-
-## 配置信息
-
-| 指标名称 | 指标含义 |
-|:-------------------:|:---------------------:|
-| 执行模式 | 作业的执行模式 |
-| 集群实例 | 手动或自动注册的集群实例 |
-| 集群配置 | 手动注册的集群配置 |
-| 共享会话 | 是否开启共享会话及其 Key |
-| 片段机制 | 是否开启全局变量 |
-| 语句集 | 是否开启 Insert 语句集 |
-| 任务类型 | FlinkSQL、FlinkJar、SQL |
-| 批模式 | 是否开启 batch mode |
-| SavePoint 机制 | 最近一次、最早一次、指定一次 |
-| SavePoint | SavePoint 机制对应的 Path |
-| Flink Configuration | 自定义的其他 Flink 配置 |
-
diff --git a/docs/docs/user_guide/devops_center/job_details.md b/docs/docs/user_guide/devops_center/job_details.md
index 871ef991f5..99b57c6e35 100644
--- a/docs/docs/user_guide/devops_center/job_details.md
+++ b/docs/docs/user_guide/devops_center/job_details.md
@@ -1,17 +1,112 @@
---
-sidebar_position: 4
+sidebar_position: 2
+position: 2
id: job_details
-title: 作业详情
+title: 任务详情
---
-1.在运维中心,单击**点击目标作业名**
-2.单击**作业总览**,进入作业详情页面,可以看到各个模块的详情信息。
+:::info 信息
-
+在此页面内,可以直观的看到 Flink 任务的详细信息.
-:::info 信息
+并且可以在点击某一Dag 节点后,查看该节点的详细信息.
+
+以及支持读取该算子的 CheckPoint 信息(注意: 该功能需要 Flink 任务开启 CheckPoint 功能)
+:::
+
+
+## 头部功能区域
+
+
+
+> 头部按钮功能区放置了一些常用的操作按钮, 以便于您快速的进行操作.包括:
+
+- `编辑`: 注意: 此按钮并非修改任务信息的功能,而是在某些情况下任务失联,无法连接任务关联的集群,需要重新映射集群信息,以便于 Dinky 侧能够正确的连接到远端 Flink 集群,以便重新获取任务详细信息.
+- `刷新`: 手动刷新当前任务实例的信息
+- `FlinkWebUI`: 跳转到远端 Flink 任务的 WebUI 页面
+- `重新启动`: 重新启动当前任务实例,并生成新的任务实例,并非在当前任务实例上进行重启
+- `智能停止`: 触发此操作后,会在当前任务实例上触发 SavePoint 操作,并在 SavePoint 成功后,停止当前任务实例(注意: 该操作后台会检测当前任务是否配置了 SavePoint 路径,如果没有配置,则不会触发 SavePoint 操作,直接停止任务实例,由 Flink 端调用 SavePoint+Stop 操作)
+- `SavePoint 触发`: 触发此操作后,会在当前任务实例上触发 SavePoint 操作 (注意: 此操作不会停止当前任务实例,请确保该任务配置了 SavePoint 路径)
+- `SavePoint 暂停`: 暂停当前任务实例的 SavePoint 操作
+- `SavePoint 停止`: 触发此操作后,会在当前任务实例上触发 SavePoint 操作,并在 SavePoint 成功后,停止当前任务实例(注意: 此操作会停止当前任务实例,请确保该任务配置了 SavePoint 路径)
+- `普通停止`: 停止当前任务实例,并不会触发 SavePoint 操作
+
+
+## 作业信息
+
+
+
+如上图所示, 该 Tag 展示了 Flink 任务的基本信息, 包含了 Dinky 侧定义的一些配置, 以及远端 Flink 任务的运行状态, Dag 执行图, 任务的 输入输出记录等信息.
+
+:::tip 提示
+
+- 在配置信息展示区域,可以点击 `Flink实例` 的值,直接跳转至该任务使用的 Flink 实例
+
+:::
+
+
+## 作业日志
+
+
+
+如上图所示, 该 Tag 展示了 Flink 任务的日志信息, 包含 Root Exception, 以及 Flink JobManager 和 TaskManager 的日志信息.以便于您快速的定位问题.
+
+## 版本信息
- 如果您要使用并查看运维中心的更多功能,请详见操作指南
+
+如上图所示, 该 Tag 展示了 Flink 任务的历史版本信息, 包含了 Flink 任务的历史版本, 以及每个版本的详细信息,此功能在每次任务执行`发布`时,会自动记录当前任务的版本信息,以便于您快速的回滚到某个版本.点击左侧列表中的 `版本号` 即可查看该版本的详细信息.
+:::warning 注意
+注意: 此功能提供删除历史版本的功能,但是请谨慎操作,删除后无法恢复.
:::
+## 作业快照
+
+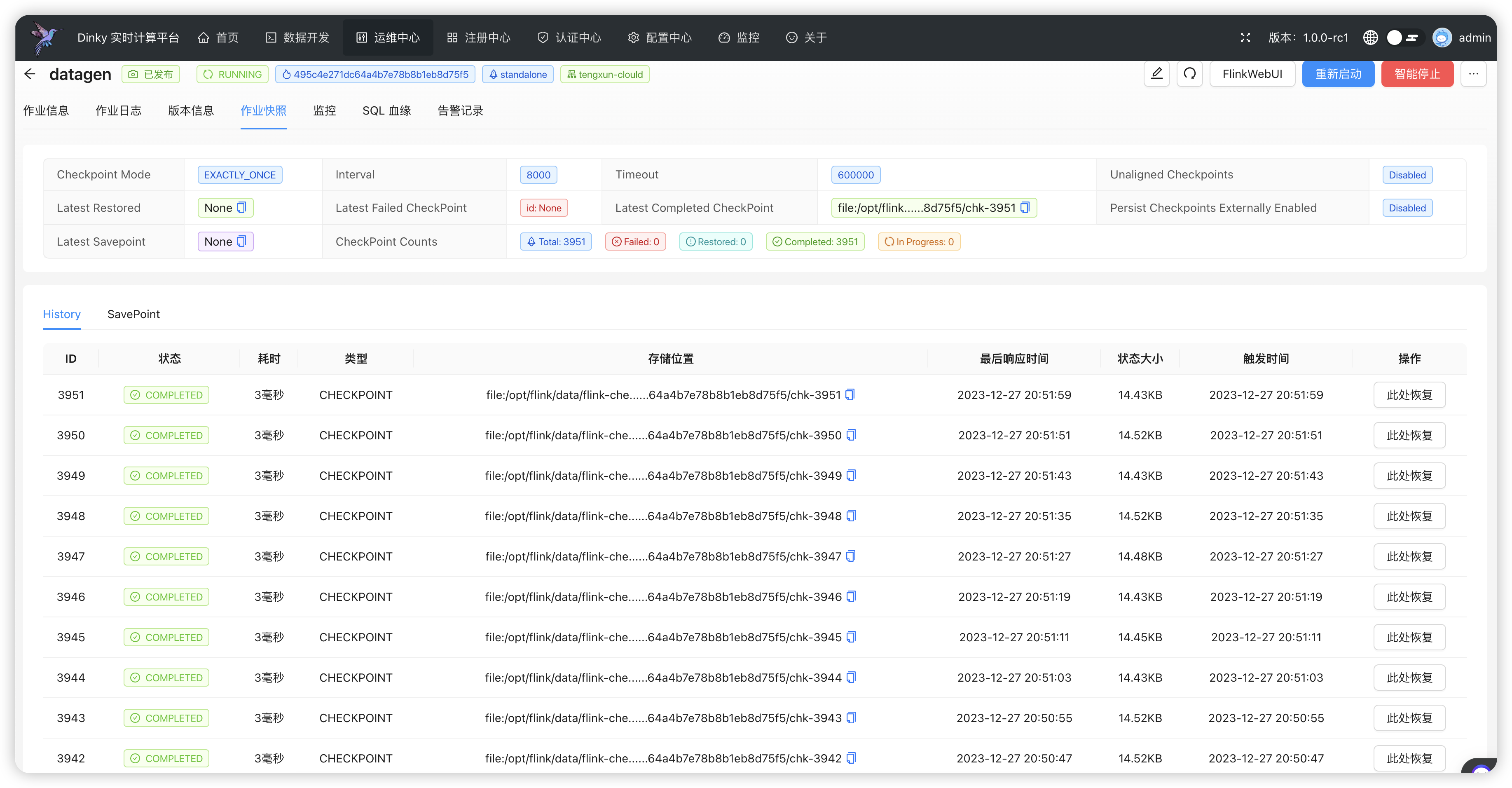
+
+如上图所示, 该 Tag 展示了 Flink 任务的 CheckPoint 信息, 包含了 CheckPoint 列表和 SavePoint 列表, 以及每个 CheckPoint 的详细信息.
+
+:::tip 提示
+在 CheckPoint 列表中,可以点击 `此处恢复` 按钮,触发从该 CheckPoint 恢复任务的操作,并停止当前任务实例,启动新的任务实例
+:::
+
+
+## 监控
+
+
+
+如上图所示, 该 Tag 展示了 Flink 任务的监控信息, 包含了 Flink 任务的监控指标, 以及每个指标的详细信息.此功能需要再任务运行时,自行配置 Flink 任务的监控指标.
+
+:::tip 拓展
+此功能产生的监控数据 由 Apache Paimon 进行存储,存储方式为`本地文件存储`, 并由后端通过 SSE(Server-Sent Events) 技术进行实时推送,以便于前端实时展示监控数据.
+:::
+
+:::warning 注意
+此功能必须要在任务状态为 `运行中` 时才能正常使用,否则 `任务监控配置` 按钮则不会出现,无法新增监控指标和实时刷新监控指标,但是该任务下已经定义的监控指标,依然可以正常查看.
+:::
+
+## SQL 血缘
+
+
+
+如上图所示, 该 Tag 展示了 Flink 任务的 SQL 血缘信息,可以直观的看到 Flink 任务的 SQL 血缘关系,以及字段之间的最终关系.
+:::tip RoadMap
+目前 SQL 血缘功能还在开发中,后续会支持更多的功能,包括:
+- [ ] 连接线展示其转换逻辑关系
+- [ ] 血缘关系图的导出
+- [ ] 血缘关系图的搜索
+- [ ] 全局血缘影响分析
+- ...
+:::
+
+## 告警记录
+
+
+
+如上图所示, 该 Tag 展示了 Flink 任务的告警信息,可以直观的看到 Flink 任务的告警信息,以及告警的详细信息.
+
+:::warning 注意
+
+任务告警只有当 任务的生命周期为 `已发布`时,且满足告警规则,并关联了告警组,当任务某个指标满足告警规则时,会触发告警,并在此处展示.
+
+:::
\ No newline at end of file
diff --git a/docs/docs/user_guide/devops_center/job_instance_status.md b/docs/docs/user_guide/devops_center/job_instance_status.md
deleted file mode 100644
index 7f8488a4b8..0000000000
--- a/docs/docs/user_guide/devops_center/job_instance_status.md
+++ /dev/null
@@ -1,150 +0,0 @@
----
-sidebar_position: 2
-id: job_instance_status
-title: 作业实例状态
----
-
-如果您已经提交作业或者发布上线作业,可通过运维中心查看和修改作业实例状态。默认显示当前实例,切换后显示历史实例。
-
-**当前实例**
-
-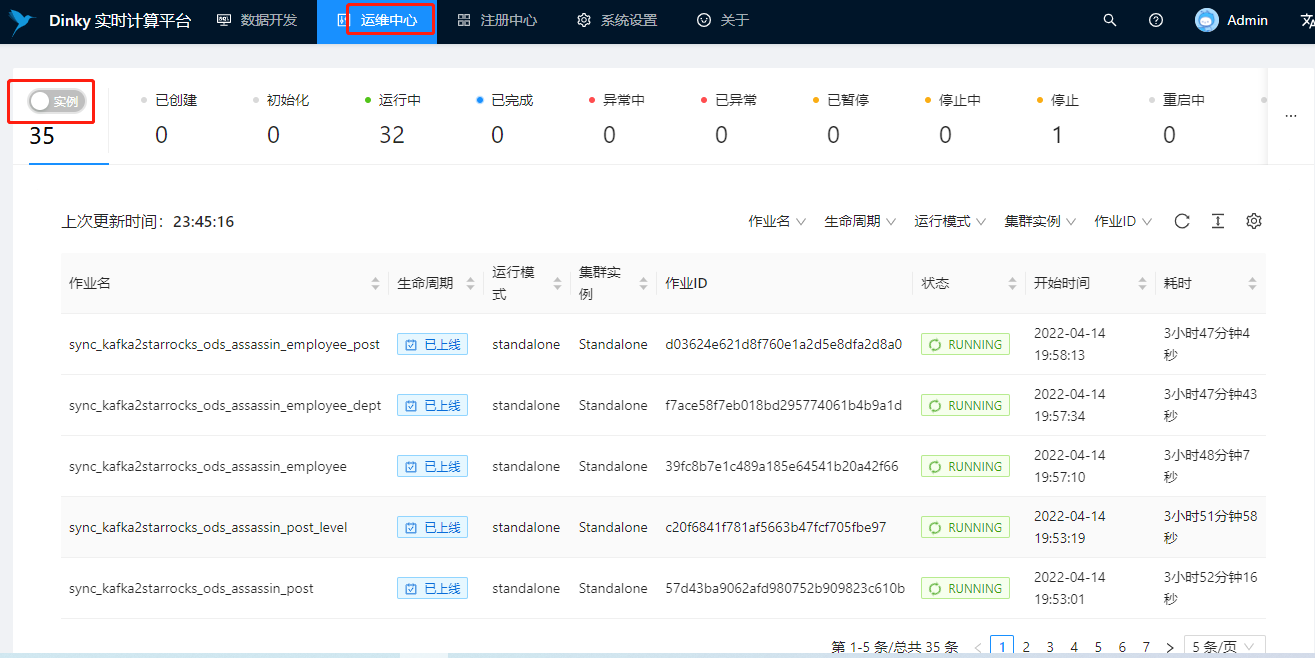
-
-**历史实例**
-
-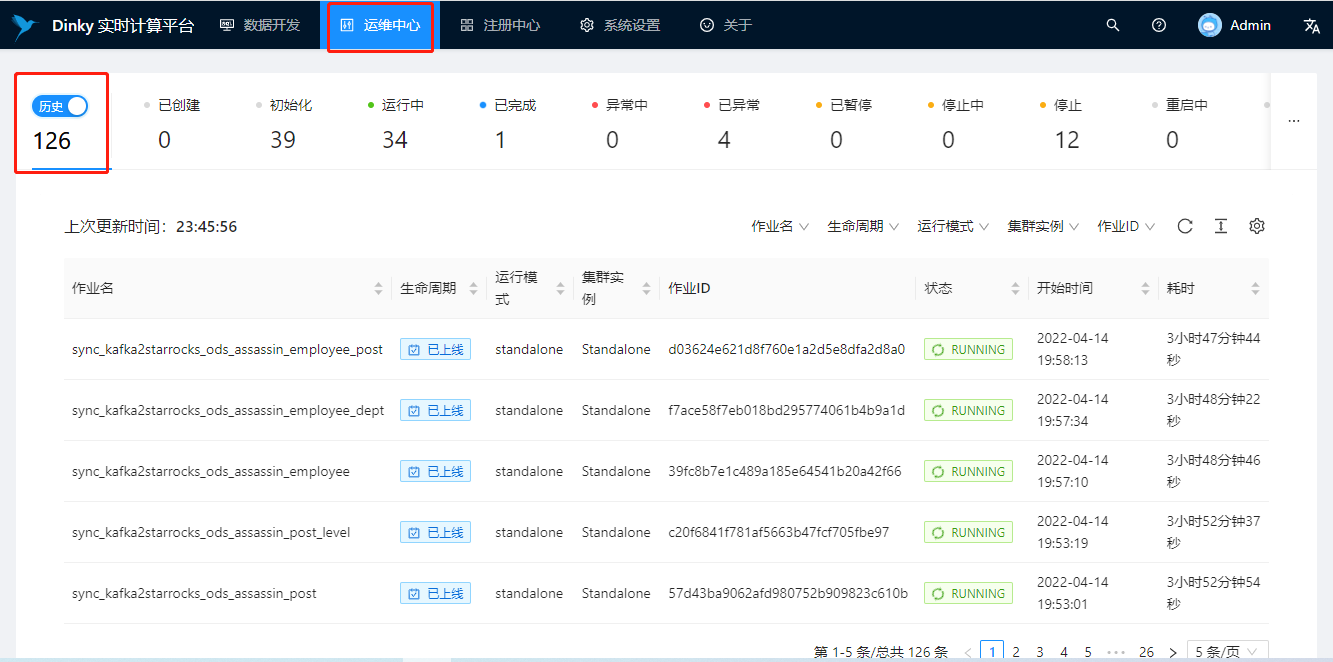
-
-## 实例状态
-
-运行信息为您展示作业的实时运行信息。您可以通过作业的状态来分析、判断作业的状态是否健康、是否达到您的预期。**Task状态** 为您显示作业各状态的数量。Task存在以下11种状态,均为 Flink 作业状态
-
-- 已创建
-- 初始化
-- 运行中
-- 已完成
-- 异常中
-- 已异常
-- 已暂停
-- 停止中
-- 停止
-- 重启中
-- 未知
-
-作业提交或者发布后,可看到作业实例的详情信息。
-
-:::tip 说明
-
-如果作业长时间处于初始化状态而未发生改变时,一般是后台发生了异常,却没有被 Dinky 捕捉到,需要自行查看 log 来排查问题。
-目前 Per-Job 和 Application 作业在停止时会被识别为 **未知** 状态。如果网络受限或者集群已被手动关闭,作业也会被识别为 **未知**。
-
-:::
-
-## 作业实例信息
-
-作业实例详细包含配置信息及运行状态和时间,各字段的含义
-
-| 字段名称 | 说明 |
-| :------: |:-------------------------------------------------------------------------------------------------------------------:|
-| 作业名 | 创建的作业名称,即pipeline.name |
-| 生命周期 | 开发中
已发布
已上线 |
-| 运行模式 | Standalone
Yarn Session
Yarn Per-job
Yarn Application
Kubernetes Session
Kubernetes Application |
-| 集群实例 | 手动或自动注册的 Flink 集群 |
-| 作业ID | Flink 作业的 JID |
-| 状态 | 实例状态 |
-| 开始时间 | 作业创建时的时间 |
-| 耗时 | 作业运行的时长 |
-
-:::tip 说明
-
-如果作业状态有问题,可以进入作业信息后点击刷新按钮强制刷新作业实例状态。
-
-:::
-
-## 修改作业状态
-
-1.在运维中心,单击**点击目标作业名**
-
-2.单击**作业总览**,进入作业详情页面
-
-3.根据需要单击以下按钮,修改作业状态
-
-
-
-其中,每个按钮含义如下表所示
-
-| 操作名称 | 说明 |
-| :------------: |:---------------------------:|
-| 重新启动 | 作业只重新启动 |
-| 停止 | 作业只停止 |
-| 重新上线 | 作业重新启动,并且从保存点恢复 |
-| 下线 | 作业触发 SavePoint 并同时停止 |
-| SavePoint 触发 | 作业触发 SavePoint 操作,创建一个新的保存点 |
-| SavePoint 暂停 | 作业触发 SavePoint 操作,并暂停作业 |
-| SavePoint 停止 | 作业触发 SavePoint 操作,并停止作业 |
-| 普通停止 | 作业只停止 |
-
-## 一键上下线功能说明
-
-一键上下线功能,只针对发布后的作业
-
-1、 一键上线:
- (1)点击一键上线后,出现检索和操作弹窗;
- (2)点击下拉框可以根据目录进行针对性的检索,检索结果出现在下面;
- (3)点击全选可以进行全选;
- (4)右上角,可以选择默认保存点或者最新保存点启动;
- (I) 默认保存点:以studio页面,任务页面的任务内部配置的保存点策略和点位为准;
- (II)最新保存点:会检索此instance的最后一次成功的保存点,进行任务保存点策略和点位的修改;
- (5)点击提交,即可开始提交任务
- (6)可以转向上线明细功能,进行操作结果和状态的查看;
-
-2、 上线明细:
- (1)名称:任务名称
- (2)状态:
- (I)INIT:初始化
- (II)OPERATING_BEFORE:操作前准备,一般指正在排队等待;
- (III)TASK_STATUS_NO_DONE:任务不是完成状态,任务真正执行时,状态不一致;
- (IV)OPERATING:正在操作
- (V)EXCEPTION:系统发生异常
- (VI)SUCCESS:成功
- (VII)FAIL:失败
- (3)结果:
- (I)0:CodeEnum.SUCCESS
- (II)1:CodeEnum.ERROR
- (III)5:CodeEnum.EXCEPTION
- (IV)401:CodeEnum.NOTLOGIN
- (4)信息: 上线结果描述
- 异常的情况下,打印异常截取
- 鼠标放到该字段对应位置,可以查看超长内容
- (5)点位配置选择:
- DEFAULT_CONFIG:默认配置
- LATEST:最新保存点
-
-
-3、 一键下线:
- (1)点击一键下线后,出现检索和操作弹窗;
- (2)点击下拉框可以根据目录进行针对性的检索,检索结果出现在下面;
- (3)点击全选可以进行全选;
- (5)点击提交,即可开始提交任务
- (6)可以转向下线明细功能,进行操作结果和状态的查看;
-
-4、 下线明细:
- (1)名称:任务名称
- (2)状态:
- (I)INIT:初始化
- (II)OPERATING_BEFORE:操作前准备,一般指正在排队等待;
- (III)TASK_STATUS_NO_DONE:任务不是完成状态,任务真正执行时,状态不一致;
- (IV)OPERATING:正在操作
- (V)EXCEPTION:系统发生异常
- (VI)SUCCESS:成功
- (VII)FAIL:失败
- (3)结果:
- (I)0:CodeEnum.SUCCESS
- (II)1:CodeEnum.ERROR
- (III)5:CodeEnum.EXCEPTION
- (IV)401:CodeEnum.NOTLOGIN
- (4)信息: 上线结果描述
- 异常的情况下,打印异常截取
- 鼠标放到该字段对应位置,可以查看超长内容
-
-
-
diff --git a/docs/docs/user_guide/devops_center/job_overview.md b/docs/docs/user_guide/devops_center/job_overview.md
new file mode 100644
index 0000000000..baddd22f15
--- /dev/null
+++ b/docs/docs/user_guide/devops_center/job_overview.md
@@ -0,0 +1,26 @@
+---
+sidebar_position: 1
+position: 1
+id: job_overview
+title: 任务总览
+---
+
+:::info 简介
+
+运维中心包括 FlinkSQL 任务运维、FlinkJar 任务运维.
+
+在运维中心,您可以查看作业实例运行详情,针对任务的关键指标查看,集群信息,作业快照,异常信息,作业日志,配置信息,FlinkSQL,SQL 血缘,历史版本,告警记录。
+
+以便全方位的了解 Flink 任务的运行情况,及时发现问题,解决问题。
+
+请注意: 目前只针对于 Flink 任务进行运维管理, 普通 DB SQL 任务暂不支持.
+:::
+
+## 任务总览
+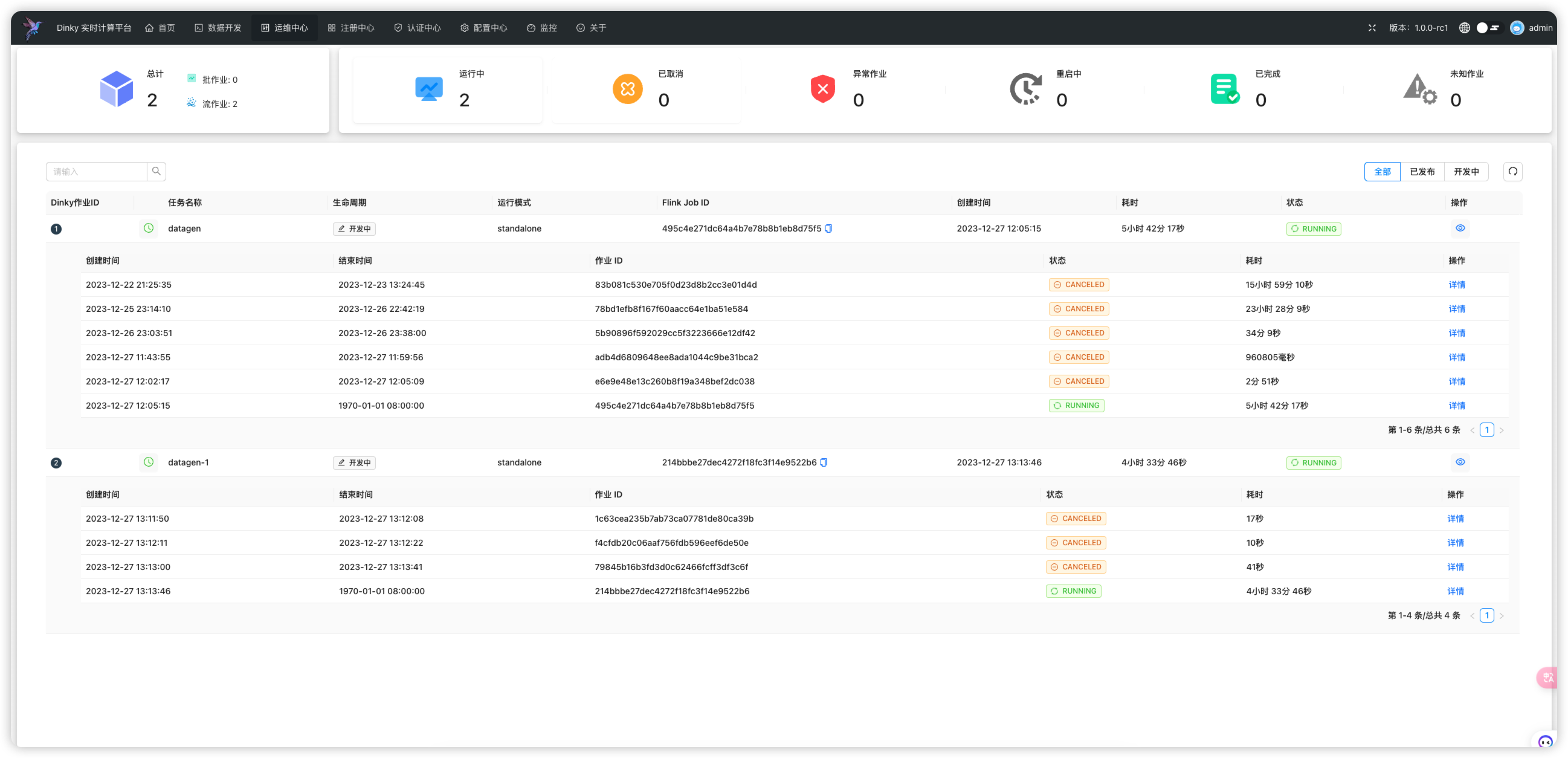
+
+- 可以点击 `指标卡片` 进行筛选对应状态下的任务,如 `运行中`, `已取消`, `异常作业`, `重启中`, `已完成`, `未知作业`
+- 在此页面内,可以直观的看到 Flink 任务的运行状态. 生命周期,及任务耗时等信息.
+- 在列表区 右上角可以进行筛选任务所属的`生命周期`
+- 如上图所示.子表格中展示的是 `该任务名称所有的历史任务`,可以按需查看历史任务的详情信息.可以点击作业名称左侧的小图标进行打开/关闭
+- 如果您需要查看某个任务的详情,可以点击操作栏的 `小眼睛图标` 进行查看[任务详情](job_details)
diff --git a/docs/docs/user_guide/metrics_overview.md b/docs/docs/user_guide/metrics_overview.md
index 6ff84a6981..7e47a419fb 100644
--- a/docs/docs/user_guide/metrics_overview.md
+++ b/docs/docs/user_guide/metrics_overview.md
@@ -7,7 +7,7 @@ title: 监控
:::info 简介
Dinky1.0增加了Metrics监控功能,可以实现对 Dinky Server的 JVM 信息的监控
-如需要查看 Dinky Server 的实时的 JVM 等信息,需要再 **配置中心** > **全局配置** > **[Metrics 配置](../system_setting/global_settings/metrics_setting)** 中开启 Dinky JVM Monitor 开关
+如需要查看 Dinky Server 的实时的 JVM 等信息,需要再 **配置中心** > **全局配置** > **[Metrics 配置](./system_setting/global_settings/metrics_setting)** 中开启 Dinky JVM Monitor 开关
注意: 在 Dinky v1.0.0 版本及以上,Metrics 监控功能默认关闭,需要手动开启,否则无法正常监控
diff --git a/docs/docs/user_guide/system_setting/alert_strategy.md b/docs/docs/user_guide/system_setting/alert_strategy.md
index 76e84867fd..bd3384d36c 100644
--- a/docs/docs/user_guide/system_setting/alert_strategy.md
+++ b/docs/docs/user_guide/system_setting/alert_strategy.md
@@ -27,17 +27,16 @@ title: 告警策略
### 触发规则
-| 规则名称 | 说明 | 可选规则 |
-|---------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------|
-| 作业 ID | 指 Flink 作业的 ID | = |
-| 运行时间 | Flink 作业运行时间,即耗时 | >,<,=,<=,>=,!= ,= |
-| 作业状态 | Flink 作业状态,可对如下状态值判断:
FINISHED
RUNNING
FAILED
CANCELED
INITIALIZING
RESTARTING
CREATED
FAILING
SUSPENDED
CANCELLING
RECONNECTING
UNKNOWN | = |
-| 执行模式 | local
yarn-session
yarn-per-job
yarn-application
kubernetes-session
kubernetes-per-job
kubernetes-application | = | | 无 | | 无 |
-| 批模式 | 可选值:
True,False | = | | 无 | | 无 |
-| CheckPoint 时间 | 自定义时间 | >,<, = |
-| CheckPoint 失败 | 可选值:
True,False | = |
-| 任务产生异常 | 可选值:
True,False | = | | 无 |
-
+| 规则名称 | 说明 | 可选规则 | 值类型 | 示例值 |
+|---------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------|--------------|----------------------------------|
+| 作业 ID | 指 Flink 作业的 ID | = | 字符串 | 495c4e271dc64a4b7e78b8b1eb8d75f5 |
+| 运行时间 | Flink 作业运行时间,即耗时 | >,<,=,<=,>=,!= ,= | 数值(单位:毫秒) | 1000 |
+| 作业状态 | Flink 作业状态,可对如下状态值判断:
FINISHED
RUNNING
FAILED
CANCELED
INITIALIZING
RESTARTING
CREATED
FAILING
SUSPENDED
CANCELLING
RECONNECTING
UNKNOWN | = | 字符串 | 'FINISHED' |
+| 执行模式 | local
yarn-session
yarn-per-job
yarn-application
kubernetes-session
kubernetes-per-job
kubernetes-application | = | 字符串 | yarn-session | | 无 |
+| 批模式 | 可选值:
True,False | = | 下拉框(值类型:字符串) | True | 无 |
+| CheckPoint 时间 | 自定义时间 | >,<,=,<=,>=,!= ,= | 数值(单位:毫秒) | 1000 |
+| CheckPoint 失败 | 可选值:
True,False | = | 下拉框(值类型:字符串) | True |
+| 任务产生异常 | 可选值:
True,False | = | 下拉框(值类型:字符串) | True |
## 自定义告警策略