一些同学可能对计算机运行的速度还没有概念,就是感觉计算机运行速度应该会很快,那么在leetcode上做算法题目的时候为什么会超时呢?
计算机究竟1s可以执行多少次操作呢? 接下来探讨一下这个问题。
大家在leetcode上练习算法的时候应该都遇到过一种错误是“超时”。
也就是说程序运行的时间超过了规定的时间,一般OJ(online judge)的超时时间就是1s,也就是用例数据输入后最多要1s内得到结果,暂时还不清楚leetcode的判题规则,下文为了方便讲解,暂定超时时间就是1s。
如果写出了一个$O(n)$的算法 ,其实可以估算出来n是多大的时候算法的执行时间就会超过1s了。
如果n的规模已经足够让$O(n)$的算法运行时间超过了1s,就应该考虑log(n)的解法了。
计算机的运算速度主要看CPU的配置,以2015年MacPro为例,CPU配置:2.7 GHz Dual-Core Intel Core i5 。
也就是 2.7 GHz 奔腾双核,i5处理器,GHz是指什么呢,1Hz = 1/s,1Hz 是CPU的一次脉冲(可以理解为一次改变状态,也叫时钟周期),称之为为赫兹,那么1GHz等于多少赫兹呢
- 1GHz(兆赫)= 1000MHz(兆赫)
- 1MHz(兆赫)= 1百万赫兹
所以 1GHz = 10亿Hz,表示CPU可以一秒脉冲10亿次(有10亿个时钟周期),这里不要简单理解一个时钟周期就是一次CPU运算。
例如1 + 2 = 3,cpu要执行四次才能完整这个操作,步骤一:把1放入寄存器,步骤二:把2放入寄存器,步骤三:做加法,步骤四:保存3。
而且计算机的cpu也不会只运行我们自己写的程序上,同时cpu也要执行计算机的各种进程任务等等,我们的程序仅仅是其中的一个进程而已。
所以我们的程序在计算机上究竟1s真正能执行多少次操作呢?
在写测试程序测1s内处理多大数量级数据的时候,有三点需要注意:
- CPU执行每条指令所需的时间实际上并不相同,例如CPU执行加法和乘法操作的耗时实际上都是不一样的。
- 现在大多计算机系统的内存管理都有缓存技术,所以频繁访问相同地址的数据和访问不相邻元素所需的时间也是不同的。
- 计算机同时运行多个程序,每个程序里还有不同的进程线程在抢占资源。
尽管有很多因素影响,但是还是可以对自己程序的运行时间有一个大体的评估的。
引用算法4里面的一段话:
- 火箭科学家需要大致知道一枚试射火箭的着陆点是在大海里还是在城市中;
- 医学研究者需要知道一次药物测试是会杀死还是会治愈实验对象;
所以任何开发计算机程序的软件工程师都应该能够估计这个程序的运行时间是一秒钟还是一年。
这个是最基本的,所以以上误差就不算事了。
以下以C++代码为例:
测试硬件:2015年MacPro,CPU配置:2.7 GHz Dual-Core Intel Core i5
实现三个函数,时间复杂度分别是
// O(n)
void function1(long long n) {
long long k = 0;
for (long long i = 0; i < n; i++) {
k++;
}
}
// O(n^2)
void function2(long long n) {
long long k = 0;
for (long long i = 0; i < n; i++) {
for (long j = 0; j < n; j++) {
k++;
}
}
}// O(nlogn)
void function3(long long n) {
long long k = 0;
for (long long i = 0; i < n; i++) {
for (long long j = 1; j < n; j = j*2) { // 注意这里j=1
k++;
}
}
}
来看一下这三个函数随着n的规模变化,耗时会产生多大的变化,先测function1 ,就把 function2 和 function3 注释掉
int main() {
long long n; // 数据规模
while (1) {
cout << "输入n:";
cin >> n;
milliseconds start_time = duration_cast<milliseconds >(
system_clock::now().time_since_epoch()
);
function1(n);
// function2(n);
// function3(n);
milliseconds end_time = duration_cast<milliseconds >(
system_clock::now().time_since_epoch()
);
cout << "耗时:" << milliseconds(end_time).count() - milliseconds(start_time).count()
<<" ms"<< endl;
}
}来看一下运行的效果,如下图:
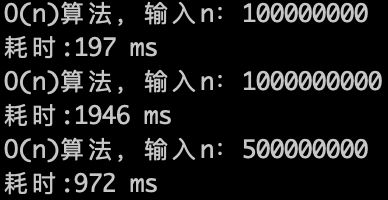
O(n)的算法,1s内大概计算机可以运行 5 * (10^8)次计算,可以推测一下$O(n^2)$ 的算法应该1s可以处理的数量级的规模是 5 * (10^8)开根号,实验数据如下。
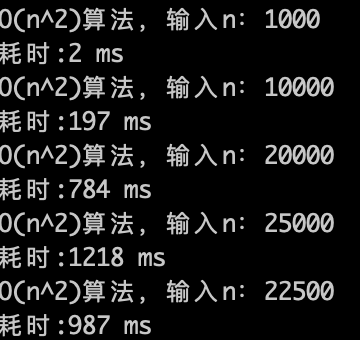
O(n^2)的算法,1s内大概计算机可以运行 22500次计算,验证了刚刚的推测。
在推测一下$O(n\log n)$的话, 1s可以处理的数据规模是什么呢?
理论上应该是比
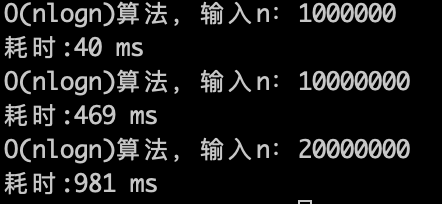
这是在我个人PC上测出来的数据,不能说是十分精确,但数量级是差不多的,大家也可以在自己的计算机上测一下。
整体测试数据整理如下:

至于
#include <iostream>
#include <chrono>
#include <thread>
using namespace std;
using namespace chrono;
// O(n)
void function1(long long n) {
long long k = 0;
for (long long i = 0; i < n; i++) {
k++;
}
}
// O(n^2)
void function2(long long n) {
long long k = 0;
for (long long i = 0; i < n; i++) {
for (long j = 0; j < n; j++) {
k++;
}
}
}
// O(nlogn)
void function3(long long n) {
long long k = 0;
for (long long i = 0; i < n; i++) {
for (long long j = 1; j < n; j = j*2) { // 注意这里j=1
k++;
}
}
}
int main() {
long long n; // 数据规模
while (1) {
cout << "输入n:";
cin >> n;
milliseconds start_time = duration_cast<milliseconds >(
system_clock::now().time_since_epoch()
);
function1(n);
// function2(n);
// function3(n);
milliseconds end_time = duration_cast<milliseconds >(
system_clock::now().time_since_epoch()
);
cout << "耗时:" << milliseconds(end_time).count() - milliseconds(start_time).count()
<<" ms"<< endl;
}
}
Java版本
import java.util.Scanner;
public class TimeComplexity {
// o(n)
public static void function1(long n) {
System.out.println("o(n)算法");
long k = 0;
for (long i = 0; i < n; i++) {
k++;
}
}
// o(n^2)
public static void function2(long n) {
System.out.println("o(n^2)算法");
long k = 0;
for (long i = 0; i < n; i++) {
for (long j = 0; j < n; j++) {
k++;
}
}
}
// o(nlogn)
public static void function3(long n) {
System.out.println("o(nlogn)算法");
long k = 0;
for (long i = 0; i < n; i++) {
for (long j = 1; j < n; j = j * 2) { // 注意这里j=1
k++;
}
}
}
public static void main(String[] args) {
while(true) {
Scanner in = new Scanner(System.in);
System.out.print("输入n: ");
int n = in.nextInt();
long startTime = System.currentTimeMillis();
function1(n);
// function2(n);
// function3(n);
long endTime = System.currentTimeMillis();
long costTime = endTime - startTime;
System.out.println("算法耗时 == " + costTime + "ms");
}
}
}本文详细分析了在leetcode上做题程序为什么会有超时,以及从硬件配置上大体知道CPU的执行速度,然后亲自做一个实验来看看$O(n)$的算法,跑一秒钟,这个n究竟是做大,最后给出不同时间复杂度,一秒内可以运算出来的n的大小。
建议录友们也都自己做一做实验,测一测,看看是不是和我的测出来的结果差不多。
这样,大家应该对程序超时时候的数据规模有一个整体的认识了。
就酱,如果感觉「代码随想录」很干货,就帮忙宣传一波吧,很多录友发现这里之后都感觉相见恨晚!
