diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..dc33134
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,2 @@
+/.vscode/
+/data/
\ No newline at end of file
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000..70a18df
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1 @@
+This work is licensed under the Creative Commons Attribution-NonCommercial-NoDerivs 4.0 International License. To view a copy of this license, visit https://creativecommons.org/licenses/by-nc-nd/4.0/.
diff --git a/Project.toml b/Project.toml
new file mode 100644
index 0000000..d1fddc9
--- /dev/null
+++ b/Project.toml
@@ -0,0 +1,16 @@
+authors = ["Karandeep Singh", "Christoph Scheuch"]
+
+[deps]
+CSV = "336ed68f-0bac-5ca0-87d4-7b16caf5d00b"
+FileIO = "5789e2e9-d7fb-5bc7-8068-2c6fae9b9549"
+PlutoUI = "7f904dfe-b85e-4ff6-b463-dae2292396a8"
+Tidier = "f0413319-3358-4bb0-8e7c-0c83523a93bd"
+ZipFile = "a5390f91-8eb1-5f08-bee0-b1d1ffed6cea"
+
+[compat]
+CSV = "0.10.12"
+FileIO = "1.16.2"
+PlutoUI = "0.7.55"
+Tidier = "1.2.1"
+ZipFile = "0.10.1"
+julia = "1.9, 1.10"
diff --git a/README.md b/README.md
new file mode 100644
index 0000000..4e56c51
--- /dev/null
+++ b/README.md
@@ -0,0 +1,9 @@
+# Tidier Course
+
+
+
+Welcome to the **Tidier Course**, an interactive course designed to introduce you to Julia and the Tidier.jl ecosystem for data analysis. The course consists of a series of Jupyter Notebooks so that you can both learn and practice how to write Julia code through real data science examples.
+
+This course assumes a basic level of familiarity with programming but does not assume any prior knowledge of Julia. This course emphasizes the parts of Julia required to read in, explore, and analyze data. Because this course is primarily oriented around data science, many important aspects of Julia will *not* be covered in this course.
+
+This course is currently under construction. Check back for updated content.
\ No newline at end of file
diff --git a/data-pipelines.html b/data-pipelines.html
new file mode 100644
index 0000000..41e491f
--- /dev/null
+++ b/data-pipelines.html
@@ -0,0 +1,16 @@
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/data-pipelines.jl b/data-pipelines.jl
new file mode 100644
index 0000000..3981b2c
--- /dev/null
+++ b/data-pipelines.jl
@@ -0,0 +1,142 @@
+### A Pluto.jl notebook ###
+# v0.19.36
+
+using Markdown
+using InteractiveUtils
+
+# ╔═╡ d6823989-bb85-400d-87ec-2a365260f5fb
+# ╠═╡ show_logs = false
+using Pkg; Pkg.activate(".."); Pkg.instantiate()
+
+# ╔═╡ 51e24e5e-cfc7-4b02-978c-505e21e6df43
+using PlutoUI: TableOfContents
+
+# ╔═╡ 2eec5998-bb36-11ee-2283-67ea47c4f5ed
+md"""
+# Tidier Course: Data Pipelines
+"""
+
+# ╔═╡ a4baabcd-d425-449e-b7bb-f8b776582330
+html""""""
+
+# ╔═╡ c38f82c2-def3-4d1c-bda0-54e779e2583a
+md"""
+## The Structured Query Language (SQL)
+
+Let's rewind to our benchmarks for data aggregation tasks: [https://duckdblabs.github.io/db-benchmark/](https://duckdblabs.github.io/db-benchmark/).
+"""
+
+# ╔═╡ 99aa11d7-09f8-4ebb-9166-e248fc5af44f
+html""""""
+
+# ╔═╡ 78d16051-d5d9-4f9c-9316-ce4ddee39dce
+md"""
+DuckDB and ClickHouse were two of the fastest tools, and while both are implemented in C++, their primary interface to users is in SQL. SQL is the *lingua franca* of databases, and it is important background knowledge as a data scientist to understand its syntax, which is the source of its popularity as well as its primary limitation.
+
+Let's say we have a dataset called `patients`, which has columns `diagnosis`, `takes_medications`, and `age`. Each row represents a unique patient, `diagnosis` is the primary diagnosis, `takes_medications` is a string indicating whether a patients takes any medications ("yes") or not ("no"), and `age` is their current age.
+
+To compare the mean age among patients with diabetes who take medications versus those who do not take medications, we would write the following in SQL:
+
+```sql
+SELECT takes_medications, AVG(age) AS mean_age
+FROM patients
+WHERE diagnosis = 'diabetes'
+GROUP BY takes_medications;
+```
+
+The SQL syntax is fairly intuitive in that each verb (e.g., `SELECT`) has a clear purpose, and the full query itself reads a bit like a sentence that you could read aloud. However, hidden within this apparent simplicity is the fact that SQL queries don't actually run in the order in this order.
+
+The *actual* order in which this query runs is:
+
+1. `FROM patients`
+2. `WHERE diagnosis = 'diabetes'`
+3. `GROUP BY takes_medications`
+4. `SELECT takes_medications, AVG(age) AS mean_age`
+
+If you think about this, this makes sense. You first need to start with the dataset (`FROM patients`), then you need to limit the dataset to only those rows where the primary diagnosis is diabetes (`WHERE diagnosis = 'diabetes'`). Then, after grouping by whether or not a patient takes medications, we need to calculate the mean age for each group.
+
+The key lesson with SQL is:
+
+> The order in which you write the verbs in SQL is different from the order in which the verbs are processed by SQL.
+
+Much has been written about this issue (see: [https://jvns.ca/blog/2019/10/03/sql-queries-don-t-start-with-select/](https://jvns.ca/blog/2019/10/03/sql-queries-don-t-start-with-select/) and [https://www.flerlagetwins.com/2018/10/sql-part4.html](https://www.flerlagetwins.com/2018/10/sql-part4.html)).
+
+In case you're curious, this is a more complete comparison of how SQL queries are written vs. how they are processed by SQL.
+
+| What You Write in SQL | Order In Which It Runs |
+| ----------------------|------------------------|
+| SELECT | FROM |
+| DISTINCT | JOIN |
+| TOP | WHERE |
+| [AGGREGATION] | GROUP BY |
+| FROM | [AGGREGATION] |
+| JOIN | HAVING |
+| WHERE | SELECT |
+| GROUP BY | DISTINCT |
+| HAVING | ORDER BY |
+| ORDER BY | TOP / LIMIT |
+"""
+
+# ╔═╡ 2686a0fb-15e1-44d8-9565-1abdee13ec5b
+md"""
+## Why not run SQL queries in the same order they are written?
+
+While the fact that SQL queries form sentences that can be read aloud is convenient, this convenience comes at a cost. When queries get more complicated, they can no longer be read aloud, and the order of operations becomes much harder to keep track of. For more complex queries, it actually becomes cognitively less demanding to keep track of queries that are run in the same order that they are written.
+
+This idea of behind `PRQL` ([https://github.com/PRQL/prql](https://github.com/PRQL/prql)), which calls itself a "simple, powerful, pipelined, SQL replacement."
+
+This same query in PRQL would be written as:
+
+```
+from patients
+filter diagnosis == "diabetes"
+group {takes_medications}
+aggregate {age = avg age}
+```
+
+The fact that the analytic steps are written in the same order as they are performed seems trivial, but this is the big idea behind data pipelines. A data pipeline starts with a dataset, and each function transforms the data in a specific way until the end result answers an analytical question.
+"""
+
+# ╔═╡ 4fde78bb-3dc5-4849-ad24-29804a49740c
+md"""
+## Modern data pipelines
+
+Data pipelines were popularized by the `dplyr` and `ggplot2` R packages, which are two of the core packages that make up the `tidyverse` ecoystem in R. In fact, the `dplyr` R package was a key inspiration behind `PRQL` (see [https://prql-lang.org/faq/](https://prql-lang.org/faq/)). While `PRQL` brings the idea of data pipelines to a `SQL` syntax, modern data pipelines are much more expansive in their capabilities.
+
+While all data pipelines *start* with a dataset, they don't need to *end* with a dataset. Modern data pipelines often end with plots (as in `ggplot2` in R), statistical analyses, machine learning models, and more. These more advanced types of data pipelines is where SQL-like languages (like PRQL) show their limitations. While great for transforming data, SQL-like langauges do not have facilities for plotting and machine learning.
+
+Data pipelines implemented in a programming language like Python, R, or Julia are thus much more capable than in PRQL.
+"""
+
+# ╔═╡ 6a08598c-69bf-498c-9ac2-4e0a4b749598
+md"""
+## Summary
+
+- The Structured Query Language (SQL) is a popular way of working with datasets
+- SQL's simple-to-read syntax introduces complexity because the order in which SQL queries are written is different from the order in which SQL queries are run
+- PRQL is a SQL-like language that implements data pipelines
+- Data pipelines refer to data analysis pathways that start with a dataset and then sequentially transform the dataset
+- While data pipelines start with a dataset, modern data pipelines end with plots, statistical analyses, and machine learning models.
+"""
+
+# ╔═╡ 831bad3f-0e43-4226-a75c-7a7c4c569e53
+md"""
+# Appendix
+"""
+
+# ╔═╡ 0ddc3de7-c4a8-44c7-8cd3-4d63de3334c7
+TableOfContents()
+
+# ╔═╡ Cell order:
+# ╟─2eec5998-bb36-11ee-2283-67ea47c4f5ed
+# ╟─a4baabcd-d425-449e-b7bb-f8b776582330
+# ╟─c38f82c2-def3-4d1c-bda0-54e779e2583a
+# ╟─99aa11d7-09f8-4ebb-9166-e248fc5af44f
+# ╟─78d16051-d5d9-4f9c-9316-ce4ddee39dce
+# ╟─2686a0fb-15e1-44d8-9565-1abdee13ec5b
+# ╟─4fde78bb-3dc5-4849-ad24-29804a49740c
+# ╟─6a08598c-69bf-498c-9ac2-4e0a4b749598
+# ╟─831bad3f-0e43-4226-a75c-7a7c4c569e53
+# ╠═d6823989-bb85-400d-87ec-2a365260f5fb
+# ╠═51e24e5e-cfc7-4b02-978c-505e21e6df43
+# ╠═0ddc3de7-c4a8-44c7-8cd3-4d63de3334c7
diff --git a/data-pipelines.plutostate b/data-pipelines.plutostate
new file mode 100644
index 0000000..d15e794
Binary files /dev/null and b/data-pipelines.plutostate differ
diff --git a/header.html b/header.html
new file mode 100644
index 0000000..8b10686
--- /dev/null
+++ b/header.html
@@ -0,0 +1,18 @@
+
Tidier Course
+
+
+
+
+
+
\ No newline at end of file
diff --git a/images/duckdb_benchmark.jpeg b/images/duckdb_benchmark.jpeg
new file mode 100644
index 0000000..f3aa282
Binary files /dev/null and b/images/duckdb_benchmark.jpeg differ
diff --git a/index.html b/index.html
new file mode 100644
index 0000000..005f1ce
--- /dev/null
+++ b/index.html
@@ -0,0 +1,16 @@
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/index.jl b/index.jl
new file mode 100644
index 0000000..f98dcfc
--- /dev/null
+++ b/index.jl
@@ -0,0 +1,392 @@
+### A Pluto.jl notebook ###
+# v0.19.36
+
+using Markdown
+using InteractiveUtils
+
+# ╔═╡ 322a1b28-48a7-4df0-87a1-4259a6abc9ee
+ using HypertextLiteral, PlutoUI; TableOfContents()
+
+# ╔═╡ 24eb2142-1d07-4412-842f-8aacbaf58c16
+begin
+ html_string = join(readlines("header.html"), "\n")
+ HypertextLiteral.@htl("""$(HypertextLiteral.Bypass(html_string))""")
+end
+
+# ╔═╡ 2ce416e8-bb3d-11ee-3a9f-8dcc9a81f83c
+md"""
+Welcome to the **Tidier Course**, a course designed to introduce you to Julia and the Tidier.jl ecosystem for data analysis. The course consists of a series of Jupyter Notebooks so that you can both learn and practice how to write Julia code through real data science examples.
+
+This course assumes a basic level of familiarity with programming but does not assume any prior knowledge of Julia. This course emphasizes the parts of Julia required to read in, explore, and analyze data. Because this course is primarily oriented around data science, many important aspects of Julia will *not* be covered in this course.
+
+This course is currently under construction. Check back for updated content.
+"""
+
+# ╔═╡ 7f4c1edc-8d69-4be5-b940-385458e637c7
+md"""
+## Background
+
+Skip to the "Getting Started" section if you want to just start coding.
+
+- [Why Julia?]()
+- [What is Tidier.jl?]()
+- Installing Julia and its packages
+- Accessing help
+"""
+
+# ╔═╡ f87b5b7e-058c-42d0-9ac5-b7be8dece554
+md"""
+## Getting Started with Julia
+
+- Values and vectors
+- Pipes
+"""
+
+# ╔═╡ cb352ad1-468b-4c27-be50-78fbc56b418c
+md"""
+## Working with Data Frames
+
+- Data structures and types in Julia
+- Reading data into Julia
+- The verbs of data science
+- Grouping and combining verbs
+"""
+
+# ╔═╡ ce3edead-4cfa-4b53-bef6-a7acc2202ed1
+md"""
+## Tidy Data
+
+- Recoding data
+- Joining data frames
+- Reshaping data
+- Separating and uniting columns of data
+"""
+
+# ╔═╡ b6b55c15-ac7d-497c-94e7-3040b0e3eb40
+md"""
+## Data Types
+
+- Working with strings
+- Working with categorical data
+- Working with dates
+"""
+
+# ╔═╡ 8c580a03-fc34-4e90-a558-de5f68f4850a
+md"""
+## Telling Stories with Plots
+
+- Anscombe's quartet and the Datasaurus Dozen
+- Principles of visualization
+- Graphics with grammar
+- Geometric objets and mappings
+- Positions, labels, and facets
+- Coordinates, scales, and themes
+"""
+
+# ╔═╡ c81acba5-44fa-4c2c-9784-bbfa5c269905
+md"""
+## Analyzing text data
+- Tokenizing text
+- Why common words are not useful (and how tf-idf can help)
+"""
+
+# ╔═╡ a7a88a9b-ad26-4f62-9e3b-4e77094a10a3
+md"""
+## Additional reading
+- [Data Pipelines]()
+- [Tidyverse and its descendants]()
+"""
+
+# ╔═╡ 00000000-0000-0000-0000-000000000001
+PLUTO_PROJECT_TOML_CONTENTS = """
+[deps]
+HypertextLiteral = "ac1192a8-f4b3-4bfe-ba22-af5b92cd3ab2"
+PlutoUI = "7f904dfe-b85e-4ff6-b463-dae2292396a8"
+
+[compat]
+HypertextLiteral = "~0.9.5"
+PlutoUI = "~0.7.55"
+"""
+
+# ╔═╡ 00000000-0000-0000-0000-000000000002
+PLUTO_MANIFEST_TOML_CONTENTS = """
+# This file is machine-generated - editing it directly is not advised
+
+julia_version = "1.10.0"
+manifest_format = "2.0"
+project_hash = "df05af8ff4a6b88f41ec2079384918224692aa07"
+
+[[deps.AbstractPlutoDingetjes]]
+deps = ["Pkg"]
+git-tree-sha1 = "c278dfab760520b8bb7e9511b968bf4ba38b7acc"
+uuid = "6e696c72-6542-2067-7265-42206c756150"
+version = "1.2.3"
+
+[[deps.ArgTools]]
+uuid = "0dad84c5-d112-42e6-8d28-ef12dabb789f"
+version = "1.1.1"
+
+[[deps.Artifacts]]
+uuid = "56f22d72-fd6d-98f1-02f0-08ddc0907c33"
+
+[[deps.Base64]]
+uuid = "2a0f44e3-6c83-55bd-87e4-b1978d98bd5f"
+
+[[deps.ColorTypes]]
+deps = ["FixedPointNumbers", "Random"]
+git-tree-sha1 = "eb7f0f8307f71fac7c606984ea5fb2817275d6e4"
+uuid = "3da002f7-5984-5a60-b8a6-cbb66c0b333f"
+version = "0.11.4"
+
+[[deps.CompilerSupportLibraries_jll]]
+deps = ["Artifacts", "Libdl"]
+uuid = "e66e0078-7015-5450-92f7-15fbd957f2ae"
+version = "1.0.5+1"
+
+[[deps.Dates]]
+deps = ["Printf"]
+uuid = "ade2ca70-3891-5945-98fb-dc099432e06a"
+
+[[deps.Downloads]]
+deps = ["ArgTools", "FileWatching", "LibCURL", "NetworkOptions"]
+uuid = "f43a241f-c20a-4ad4-852c-f6b1247861c6"
+version = "1.6.0"
+
+[[deps.FileWatching]]
+uuid = "7b1f6079-737a-58dc-b8bc-7a2ca5c1b5ee"
+
+[[deps.FixedPointNumbers]]
+deps = ["Statistics"]
+git-tree-sha1 = "335bfdceacc84c5cdf16aadc768aa5ddfc5383cc"
+uuid = "53c48c17-4a7d-5ca2-90c5-79b7896eea93"
+version = "0.8.4"
+
+[[deps.Hyperscript]]
+deps = ["Test"]
+git-tree-sha1 = "179267cfa5e712760cd43dcae385d7ea90cc25a4"
+uuid = "47d2ed2b-36de-50cf-bf87-49c2cf4b8b91"
+version = "0.0.5"
+
+[[deps.HypertextLiteral]]
+deps = ["Tricks"]
+git-tree-sha1 = "7134810b1afce04bbc1045ca1985fbe81ce17653"
+uuid = "ac1192a8-f4b3-4bfe-ba22-af5b92cd3ab2"
+version = "0.9.5"
+
+[[deps.IOCapture]]
+deps = ["Logging", "Random"]
+git-tree-sha1 = "8b72179abc660bfab5e28472e019392b97d0985c"
+uuid = "b5f81e59-6552-4d32-b1f0-c071b021bf89"
+version = "0.2.4"
+
+[[deps.InteractiveUtils]]
+deps = ["Markdown"]
+uuid = "b77e0a4c-d291-57a0-90e8-8db25a27a240"
+
+[[deps.JSON]]
+deps = ["Dates", "Mmap", "Parsers", "Unicode"]
+git-tree-sha1 = "31e996f0a15c7b280ba9f76636b3ff9e2ae58c9a"
+uuid = "682c06a0-de6a-54ab-a142-c8b1cf79cde6"
+version = "0.21.4"
+
+[[deps.LibCURL]]
+deps = ["LibCURL_jll", "MozillaCACerts_jll"]
+uuid = "b27032c2-a3e7-50c8-80cd-2d36dbcbfd21"
+version = "0.6.4"
+
+[[deps.LibCURL_jll]]
+deps = ["Artifacts", "LibSSH2_jll", "Libdl", "MbedTLS_jll", "Zlib_jll", "nghttp2_jll"]
+uuid = "deac9b47-8bc7-5906-a0fe-35ac56dc84c0"
+version = "8.4.0+0"
+
+[[deps.LibGit2]]
+deps = ["Base64", "LibGit2_jll", "NetworkOptions", "Printf", "SHA"]
+uuid = "76f85450-5226-5b5a-8eaa-529ad045b433"
+
+[[deps.LibGit2_jll]]
+deps = ["Artifacts", "LibSSH2_jll", "Libdl", "MbedTLS_jll"]
+uuid = "e37daf67-58a4-590a-8e99-b0245dd2ffc5"
+version = "1.6.4+0"
+
+[[deps.LibSSH2_jll]]
+deps = ["Artifacts", "Libdl", "MbedTLS_jll"]
+uuid = "29816b5a-b9ab-546f-933c-edad1886dfa8"
+version = "1.11.0+1"
+
+[[deps.Libdl]]
+uuid = "8f399da3-3557-5675-b5ff-fb832c97cbdb"
+
+[[deps.LinearAlgebra]]
+deps = ["Libdl", "OpenBLAS_jll", "libblastrampoline_jll"]
+uuid = "37e2e46d-f89d-539d-b4ee-838fcccc9c8e"
+
+[[deps.Logging]]
+uuid = "56ddb016-857b-54e1-b83d-db4d58db5568"
+
+[[deps.MIMEs]]
+git-tree-sha1 = "65f28ad4b594aebe22157d6fac869786a255b7eb"
+uuid = "6c6e2e6c-3030-632d-7369-2d6c69616d65"
+version = "0.1.4"
+
+[[deps.Markdown]]
+deps = ["Base64"]
+uuid = "d6f4376e-aef5-505a-96c1-9c027394607a"
+
+[[deps.MbedTLS_jll]]
+deps = ["Artifacts", "Libdl"]
+uuid = "c8ffd9c3-330d-5841-b78e-0817d7145fa1"
+version = "2.28.2+1"
+
+[[deps.Mmap]]
+uuid = "a63ad114-7e13-5084-954f-fe012c677804"
+
+[[deps.MozillaCACerts_jll]]
+uuid = "14a3606d-f60d-562e-9121-12d972cd8159"
+version = "2023.1.10"
+
+[[deps.NetworkOptions]]
+uuid = "ca575930-c2e3-43a9-ace4-1e988b2c1908"
+version = "1.2.0"
+
+[[deps.OpenBLAS_jll]]
+deps = ["Artifacts", "CompilerSupportLibraries_jll", "Libdl"]
+uuid = "4536629a-c528-5b80-bd46-f80d51c5b363"
+version = "0.3.23+2"
+
+[[deps.Parsers]]
+deps = ["Dates", "PrecompileTools", "UUIDs"]
+git-tree-sha1 = "8489905bcdbcfac64d1daa51ca07c0d8f0283821"
+uuid = "69de0a69-1ddd-5017-9359-2bf0b02dc9f0"
+version = "2.8.1"
+
+[[deps.Pkg]]
+deps = ["Artifacts", "Dates", "Downloads", "FileWatching", "LibGit2", "Libdl", "Logging", "Markdown", "Printf", "REPL", "Random", "SHA", "Serialization", "TOML", "Tar", "UUIDs", "p7zip_jll"]
+uuid = "44cfe95a-1eb2-52ea-b672-e2afdf69b78f"
+version = "1.10.0"
+
+[[deps.PlutoUI]]
+deps = ["AbstractPlutoDingetjes", "Base64", "ColorTypes", "Dates", "FixedPointNumbers", "Hyperscript", "HypertextLiteral", "IOCapture", "InteractiveUtils", "JSON", "Logging", "MIMEs", "Markdown", "Random", "Reexport", "URIs", "UUIDs"]
+git-tree-sha1 = "68723afdb616445c6caaef6255067a8339f91325"
+uuid = "7f904dfe-b85e-4ff6-b463-dae2292396a8"
+version = "0.7.55"
+
+[[deps.PrecompileTools]]
+deps = ["Preferences"]
+git-tree-sha1 = "03b4c25b43cb84cee5c90aa9b5ea0a78fd848d2f"
+uuid = "aea7be01-6a6a-4083-8856-8a6e6704d82a"
+version = "1.2.0"
+
+[[deps.Preferences]]
+deps = ["TOML"]
+git-tree-sha1 = "00805cd429dcb4870060ff49ef443486c262e38e"
+uuid = "21216c6a-2e73-6563-6e65-726566657250"
+version = "1.4.1"
+
+[[deps.Printf]]
+deps = ["Unicode"]
+uuid = "de0858da-6303-5e67-8744-51eddeeeb8d7"
+
+[[deps.REPL]]
+deps = ["InteractiveUtils", "Markdown", "Sockets", "Unicode"]
+uuid = "3fa0cd96-eef1-5676-8a61-b3b8758bbffb"
+
+[[deps.Random]]
+deps = ["SHA"]
+uuid = "9a3f8284-a2c9-5f02-9a11-845980a1fd5c"
+
+[[deps.Reexport]]
+git-tree-sha1 = "45e428421666073eab6f2da5c9d310d99bb12f9b"
+uuid = "189a3867-3050-52da-a836-e630ba90ab69"
+version = "1.2.2"
+
+[[deps.SHA]]
+uuid = "ea8e919c-243c-51af-8825-aaa63cd721ce"
+version = "0.7.0"
+
+[[deps.Serialization]]
+uuid = "9e88b42a-f829-5b0c-bbe9-9e923198166b"
+
+[[deps.Sockets]]
+uuid = "6462fe0b-24de-5631-8697-dd941f90decc"
+
+[[deps.SparseArrays]]
+deps = ["Libdl", "LinearAlgebra", "Random", "Serialization", "SuiteSparse_jll"]
+uuid = "2f01184e-e22b-5df5-ae63-d93ebab69eaf"
+version = "1.10.0"
+
+[[deps.Statistics]]
+deps = ["LinearAlgebra", "SparseArrays"]
+uuid = "10745b16-79ce-11e8-11f9-7d13ad32a3b2"
+version = "1.10.0"
+
+[[deps.SuiteSparse_jll]]
+deps = ["Artifacts", "Libdl", "libblastrampoline_jll"]
+uuid = "bea87d4a-7f5b-5778-9afe-8cc45184846c"
+version = "7.2.1+1"
+
+[[deps.TOML]]
+deps = ["Dates"]
+uuid = "fa267f1f-6049-4f14-aa54-33bafae1ed76"
+version = "1.0.3"
+
+[[deps.Tar]]
+deps = ["ArgTools", "SHA"]
+uuid = "a4e569a6-e804-4fa4-b0f3-eef7a1d5b13e"
+version = "1.10.0"
+
+[[deps.Test]]
+deps = ["InteractiveUtils", "Logging", "Random", "Serialization"]
+uuid = "8dfed614-e22c-5e08-85e1-65c5234f0b40"
+
+[[deps.Tricks]]
+git-tree-sha1 = "eae1bb484cd63b36999ee58be2de6c178105112f"
+uuid = "410a4b4d-49e4-4fbc-ab6d-cb71b17b3775"
+version = "0.1.8"
+
+[[deps.URIs]]
+git-tree-sha1 = "67db6cc7b3821e19ebe75791a9dd19c9b1188f2b"
+uuid = "5c2747f8-b7ea-4ff2-ba2e-563bfd36b1d4"
+version = "1.5.1"
+
+[[deps.UUIDs]]
+deps = ["Random", "SHA"]
+uuid = "cf7118a7-6976-5b1a-9a39-7adc72f591a4"
+
+[[deps.Unicode]]
+uuid = "4ec0a83e-493e-50e2-b9ac-8f72acf5a8f5"
+
+[[deps.Zlib_jll]]
+deps = ["Libdl"]
+uuid = "83775a58-1f1d-513f-b197-d71354ab007a"
+version = "1.2.13+1"
+
+[[deps.libblastrampoline_jll]]
+deps = ["Artifacts", "Libdl"]
+uuid = "8e850b90-86db-534c-a0d3-1478176c7d93"
+version = "5.8.0+1"
+
+[[deps.nghttp2_jll]]
+deps = ["Artifacts", "Libdl"]
+uuid = "8e850ede-7688-5339-a07c-302acd2aaf8d"
+version = "1.52.0+1"
+
+[[deps.p7zip_jll]]
+deps = ["Artifacts", "Libdl"]
+uuid = "3f19e933-33d8-53b3-aaab-bd5110c3b7a0"
+version = "17.4.0+2"
+"""
+
+# ╔═╡ Cell order:
+# ╟─24eb2142-1d07-4412-842f-8aacbaf58c16
+# ╟─322a1b28-48a7-4df0-87a1-4259a6abc9ee
+# ╟─2ce416e8-bb3d-11ee-3a9f-8dcc9a81f83c
+# ╟─7f4c1edc-8d69-4be5-b940-385458e637c7
+# ╟─f87b5b7e-058c-42d0-9ac5-b7be8dece554
+# ╟─cb352ad1-468b-4c27-be50-78fbc56b418c
+# ╟─ce3edead-4cfa-4b53-bef6-a7acc2202ed1
+# ╟─b6b55c15-ac7d-497c-94e7-3040b0e3eb40
+# ╟─8c580a03-fc34-4e90-a558-de5f68f4850a
+# ╟─c81acba5-44fa-4c2c-9784-bbfa5c269905
+# ╟─a7a88a9b-ad26-4f62-9e3b-4e77094a10a3
+# ╟─00000000-0000-0000-0000-000000000001
+# ╟─00000000-0000-0000-0000-000000000002
diff --git a/index.plutostate b/index.plutostate
new file mode 100644
index 0000000..cc9f1f6
Binary files /dev/null and b/index.plutostate differ
diff --git a/pluto_export.json b/pluto_export.json
new file mode 100644
index 0000000..6006bbf
--- /dev/null
+++ b/pluto_export.json
@@ -0,0 +1 @@
+{"notebooks":{"what-is-tidier-jl.jl":{"id":"what-is-tidier-jl.jl","hash":"qjU7syHlZg1fBou1MWztxitv207HfhzGwYAAhIZDrrU","html_path":"what-is-tidier-jl.html","statefile_path":"what-is-tidier-jl.plutostate","notebookfile_path":"what-is-tidier-jl.jl","current_hash":"qjU7syHlZg1fBou1MWztxitv207HfhzGwYAAhIZDrrU","desired_hash":"qjU7syHlZg1fBou1MWztxitv207HfhzGwYAAhIZDrrU","frontmatter":{"title":"what-is-tidier-jl"}},"index.jl":{"id":"index.jl","hash":"5ziTs-P577NUFmqdE0E5bjD6s9-RPM_cybMSyhuWol0","html_path":"index.html","statefile_path":"index.plutostate","notebookfile_path":"index.jl","current_hash":"5ziTs-P577NUFmqdE0E5bjD6s9-RPM_cybMSyhuWol0","desired_hash":"5ziTs-P577NUFmqdE0E5bjD6s9-RPM_cybMSyhuWol0","frontmatter":{"title":"index"}},"tidyverse-and-its-descendants.jl":{"id":"tidyverse-and-its-descendants.jl","hash":"kPFLYMhcsR4qoAtzZZTfG_zRKrnTZgFIRWHNu69AedQ","html_path":"tidyverse-and-its-descendants.html","statefile_path":"tidyverse-and-its-descendants.plutostate","notebookfile_path":"tidyverse-and-its-descendants.jl","current_hash":"kPFLYMhcsR4qoAtzZZTfG_zRKrnTZgFIRWHNu69AedQ","desired_hash":"kPFLYMhcsR4qoAtzZZTfG_zRKrnTZgFIRWHNu69AedQ","frontmatter":{"title":"tidyverse-and-its-descendants"}},"data-pipelines.jl":{"id":"data-pipelines.jl","hash":"owKwbAiT0Ba32Zfp0Si_wsGv8J6lKOYjwXwHqLUHH5s","html_path":"data-pipelines.html","statefile_path":"data-pipelines.plutostate","notebookfile_path":"data-pipelines.jl","current_hash":"owKwbAiT0Ba32Zfp0Si_wsGv8J6lKOYjwXwHqLUHH5s","desired_hash":"owKwbAiT0Ba32Zfp0Si_wsGv8J6lKOYjwXwHqLUHH5s","frontmatter":{"title":"data-pipelines"}},"why-julia.jl":{"id":"why-julia.jl","hash":"rSuwGE6NsPblGieO0pYwnJTF2GdlrhcleCQ3a3jllUw","html_path":"why-julia.html","statefile_path":"why-julia.plutostate","notebookfile_path":"why-julia.jl","current_hash":"rSuwGE6NsPblGieO0pYwnJTF2GdlrhcleCQ3a3jllUw","desired_hash":"rSuwGE6NsPblGieO0pYwnJTF2GdlrhcleCQ3a3jllUw","frontmatter":{"title":"why-julia"}}},"pluto_version":"0.19.37","julia_version":"1.10.0","format_version":"1","title":null,"description":null,"collections":null,"binder_url":"https://mybinder.org/v2/gh/fonsp/pluto-on-binder/v0.19.37","slider_server_url":null}
\ No newline at end of file
diff --git a/pluto_state_cache/0_19_375ziTs-P577NUFmqdE0E5bjD6s9-RPM_cybMSyhuWol0.plutostate b/pluto_state_cache/0_19_375ziTs-P577NUFmqdE0E5bjD6s9-RPM_cybMSyhuWol0.plutostate
new file mode 100644
index 0000000..ee041a2
Binary files /dev/null and b/pluto_state_cache/0_19_375ziTs-P577NUFmqdE0E5bjD6s9-RPM_cybMSyhuWol0.plutostate differ
diff --git a/pluto_state_cache/0_19_379LjXuQmgWRoCCnG9Sif7Dss2q6XQE86i7VIG0lnxDW4.plutostate b/pluto_state_cache/0_19_379LjXuQmgWRoCCnG9Sif7Dss2q6XQE86i7VIG0lnxDW4.plutostate
new file mode 100644
index 0000000..88d4ffe
Binary files /dev/null and b/pluto_state_cache/0_19_379LjXuQmgWRoCCnG9Sif7Dss2q6XQE86i7VIG0lnxDW4.plutostate differ
diff --git a/pluto_state_cache/0_19_37GD3ijXrxZG-Clab0xSWquwpOdeJZePBGGbM22DyKE6g.plutostate b/pluto_state_cache/0_19_37GD3ijXrxZG-Clab0xSWquwpOdeJZePBGGbM22DyKE6g.plutostate
new file mode 100644
index 0000000..6b930cb
Binary files /dev/null and b/pluto_state_cache/0_19_37GD3ijXrxZG-Clab0xSWquwpOdeJZePBGGbM22DyKE6g.plutostate differ
diff --git a/pluto_state_cache/0_19_37GaX8BUn5W-uhAqPYo_OUhZjK8boEmBBjbCOcT_buHmM.plutostate b/pluto_state_cache/0_19_37GaX8BUn5W-uhAqPYo_OUhZjK8boEmBBjbCOcT_buHmM.plutostate
new file mode 100644
index 0000000..fec337c
Binary files /dev/null and b/pluto_state_cache/0_19_37GaX8BUn5W-uhAqPYo_OUhZjK8boEmBBjbCOcT_buHmM.plutostate differ
diff --git a/pluto_state_cache/0_19_37PRWS9ev5xAatim1oezOeXYM3AYXOH1QmH2rH7BJ0Br4.plutostate b/pluto_state_cache/0_19_37PRWS9ev5xAatim1oezOeXYM3AYXOH1QmH2rH7BJ0Br4.plutostate
new file mode 100644
index 0000000..63b75c4
Binary files /dev/null and b/pluto_state_cache/0_19_37PRWS9ev5xAatim1oezOeXYM3AYXOH1QmH2rH7BJ0Br4.plutostate differ
diff --git a/pluto_state_cache/0_19_37k2lQ2M7HCIhRWr4o8KxsCWVt6ZSETv7jCKkDSDmN2fA.plutostate b/pluto_state_cache/0_19_37k2lQ2M7HCIhRWr4o8KxsCWVt6ZSETv7jCKkDSDmN2fA.plutostate
new file mode 100644
index 0000000..c28d1e4
Binary files /dev/null and b/pluto_state_cache/0_19_37k2lQ2M7HCIhRWr4o8KxsCWVt6ZSETv7jCKkDSDmN2fA.plutostate differ
diff --git a/pluto_state_cache/0_19_37kPFLYMhcsR4qoAtzZZTfG_zRKrnTZgFIRWHNu69AedQ.plutostate b/pluto_state_cache/0_19_37kPFLYMhcsR4qoAtzZZTfG_zRKrnTZgFIRWHNu69AedQ.plutostate
new file mode 100644
index 0000000..8d80f0a
Binary files /dev/null and b/pluto_state_cache/0_19_37kPFLYMhcsR4qoAtzZZTfG_zRKrnTZgFIRWHNu69AedQ.plutostate differ
diff --git a/pluto_state_cache/0_19_37owKwbAiT0Ba32Zfp0Si_wsGv8J6lKOYjwXwHqLUHH5s.plutostate b/pluto_state_cache/0_19_37owKwbAiT0Ba32Zfp0Si_wsGv8J6lKOYjwXwHqLUHH5s.plutostate
new file mode 100644
index 0000000..a5a5069
Binary files /dev/null and b/pluto_state_cache/0_19_37owKwbAiT0Ba32Zfp0Si_wsGv8J6lKOYjwXwHqLUHH5s.plutostate differ
diff --git a/pluto_state_cache/0_19_37qjU7syHlZg1fBou1MWztxitv207HfhzGwYAAhIZDrrU.plutostate b/pluto_state_cache/0_19_37qjU7syHlZg1fBou1MWztxitv207HfhzGwYAAhIZDrrU.plutostate
new file mode 100644
index 0000000..eeb5484
Binary files /dev/null and b/pluto_state_cache/0_19_37qjU7syHlZg1fBou1MWztxitv207HfhzGwYAAhIZDrrU.plutostate differ
diff --git a/pluto_state_cache/0_19_37rSuwGE6NsPblGieO0pYwnJTF2GdlrhcleCQ3a3jllUw.plutostate b/pluto_state_cache/0_19_37rSuwGE6NsPblGieO0pYwnJTF2GdlrhcleCQ3a3jllUw.plutostate
new file mode 100644
index 0000000..08d4f98
Binary files /dev/null and b/pluto_state_cache/0_19_37rSuwGE6NsPblGieO0pYwnJTF2GdlrhcleCQ3a3jllUw.plutostate differ
diff --git a/pluto_state_cache/0_19_37ylxGLKyiZOCKq1zHrGrE1oktFvXYrFCGw3Lvfll90os.plutostate b/pluto_state_cache/0_19_37ylxGLKyiZOCKq1zHrGrE1oktFvXYrFCGw3Lvfll90os.plutostate
new file mode 100644
index 0000000..a58219e
Binary files /dev/null and b/pluto_state_cache/0_19_37ylxGLKyiZOCKq1zHrGrE1oktFvXYrFCGw3Lvfll90os.plutostate differ
diff --git a/structure.json b/structure.json
new file mode 100644
index 0000000..41848cc
--- /dev/null
+++ b/structure.json
@@ -0,0 +1,32 @@
+{
+ "sidebar": {
+ "title": "TidierCourse",
+ "elements": [
+ {
+ "type": "notebook",
+ "path": "index.jl",
+ "title": "Home"
+ },
+ {
+ "type": "notebook",
+ "path": "why-julia/why-julia.jl",
+ "title": "Why Julia"
+ },
+ {
+ "type": "notebook",
+ "path": "what-is-tidier-jl/what-is-tidier-jl.jl",
+ "title": "What is Tidier"
+ },
+ {
+ "type": "notebook",
+ "path": "data-pipelines/data-pipelines.jl",
+ "title": "Data Pipelines"
+ },
+ {
+ "type": "notebook",
+ "path": "tidyverse-and-its-descendants/tidyverse-and-its-descendants.jl",
+ "title": "Tidyverse and its Descendants"
+ }
+ ]
+ }
+}
\ No newline at end of file
diff --git a/tidyverse-and-its-descendants.html b/tidyverse-and-its-descendants.html
new file mode 100644
index 0000000..bfbf583
--- /dev/null
+++ b/tidyverse-and-its-descendants.html
@@ -0,0 +1,16 @@
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/tidyverse-and-its-descendants.jl b/tidyverse-and-its-descendants.jl
new file mode 100644
index 0000000..a1203c6
--- /dev/null
+++ b/tidyverse-and-its-descendants.jl
@@ -0,0 +1,158 @@
+### A Pluto.jl notebook ###
+# v0.19.36
+
+using Markdown
+using InteractiveUtils
+
+# ╔═╡ b8891864-439c-4962-a4b5-1d849009ca04
+# ╠═╡ show_logs = false
+using Pkg; Pkg.activate(".."); Pkg.instantiate()
+
+# ╔═╡ 0c798730-96c8-4add-b97b-a270c6f96c85
+using PlutoUI: TableOfContents
+
+# ╔═╡ bda1b780-f753-4d83-9b88-9b84242e55eb
+md"""
+# Tidier Course: Tidyverse and Its Descendants
+"""
+
+# ╔═╡ ecbe5053-c3b9-40c4-bcae-d935b6d31a03
+html""""""
+
+# ╔═╡ ffa569e5-86f8-4244-be9a-774335f3c2ee
+md"""
+## What is the tidyverse?
+
+Before we dive into Tidier.jl, it's worth understanding a bit about the tidyverse, including what it is and what it's not. This will help in conveying some of the key philosophies and design decisions in Tidier.jl.
+
+The tidyverse refers to a collection of R packages that popularized the idea of data pipelines in modern data analysis. The tidyverse is often referred to as a meta-package because while it exists as a single package, its primary role is to re-export a collection of underlying R packages. Many of these underlying packages actually existed before the tidyverse. However, with the formation of the tidyverse, the philosophy and approach underlying these packages were standardized to follow a consistent design and syntax.
+
+These underlying packages include but are not limited to the following:
+
+- `tibble`: for creating and displaying data frames
+- `dplyr`: for transforming and summarizing data
+- `tidyr`: for reshaping data
+- `readr`: for reading in data
+- `ggplot2`: for plotting data
+- `stringr`: for working with strings
+- `forcats`: for working with categorical variables
+- `lubridate`: for working with dates
+
+One important thing to note is that pretty much all of the capabilities enabled by the tidyverse are already natively supported in base R. In other words, the tidyverse doesn't exist simply because there's no way to accomplish these tasks without it. The tidyverse exists despite the fact that R is perfectly capable of doing each of these tasks.
+
+What makes the tidyverse special? In addition to being user-friendly and consistent in its approach across these family of packages, the tidyverse is special because it is *opinionated*. There are intentional design decisions made in the tidyverse that diverge from base R. These design decisions are largely why it is loved by so many (but also why it is disliked by some).
+"""
+
+# ╔═╡ 1804b400-13dd-4961-a24e-4a23a33706cc
+md"""
+## The tidyverse has spawned a number of descendants
+
+You might be wondering why so much attention in this course about Tidier.jl to the tidyverse R package upon which it is based. If you think of the tidyverse as *just* an R package, you are greatly underestimating its importance to data analysis across all data science languages.
+
+The concepts, syntax, and verbs articulated by the collection of tidyverse packages are so popular that they have been directly implemented in a number of other languages. They've even inspired the creation of entirely new languages like `PRQL`.
+
+For example, here are just a few examples of tidyverse implementations in programming languages *other* than R. By "implementation," I mean that the tools actively borrow both syntax and verbs (function names) from the original tidyverse.
+
+Tidyverse implementations in Python:
+
+- `siuba`: implements `dplyr`, `tidyr`, and a bit of `dbplyr`
+- `dplython`: implements `dplyr` and `tidyr`
+- `plydata`: implements `dplyr` and `tidyr`
+- `tidypolars`: implements `dplyr` and `tidyr`
+- `plotnine`: implements `ggplot2`
+
+Tidyverse implementations in JavaScript:
+
+- `tidy.js`: implements `dplyr` and `tidyr`
+- `DataLib`: implements `dplyr`, although it is no longer actively maintained and has been replaced by `Arquero`` and `dataflow-api`
+- `cxplot`: implements `ggplot2`
+
+If you can do data science in a language, its highly likely that *someone* has tried to implement tidyverse in it.
+"""
+
+# ╔═╡ f2d12946-b710-42b1-af67-5dde7165d790
+md"""
+## But isn't tidyverse syntax an "R thing"?
+
+Absolutely not! In fact, people who've used R for many years preceding the tidyverse often are the ones who push back against the tidyverse the most. The tidyverse has popularized a style of programming that is decidedly unique from normal R programming. While most of R uses what's called "standard evaluation," tidyverse embraces "non-standard evaluation," where scoping of variable names is dynamic, enabling a concise style of programming.
+
+Let's take a look at the same example we covered in the SQL and PRQL code. Let's compare the mean age among patients with diabetes who take medications versus those who do not take medications:
+
+```r
+patients |>
+ filter(diagnosis == "diabetes") |>
+ group_by(takes_medications) |>
+ summarize(age = mean(age))
+```
+
+**Everything** about this code is non-idiomatic in R!
+
+The use of pipes (`|>`) is non-idiomatic and was popularized by tidyverse. In fact, tidyverse adopted its own pipe (`%>%`) because there was no pipe built into R. After this pipe became popular, it spawned the adoption of a pipe into base R. The popularity of pipes also brought upon the standardization of the dataframe-in, dataframe-out syntax. Each top-level function takes a data frame as its first argument and returns a data frame, making it easy to chain operations together.
+
+How do we know that `diagnosis` refers to a column name and not to a global variable? Dynamic scoping implemented using non-standard evaluation. This code first looks for a column named `diagnosis` in the `patients` data frame, and if it can't be found, *then* it looks for a `diagnosis` variable in the parent environment. Note: there *are* ways to explicitly specify which environment the variable should be pulled from in the tidyverse.
+"""
+
+# ╔═╡ b7386c91-d95f-46af-8c50-3cd0e971864a
+md"""
+## What are some of the other implementations in R?
+
+*Even in R*, there are multiple implementations of the tidyverse.
+
+| R package | Backend (language) |
+|-----------------------|-----------------------|
+| dtplyr | data.table (C) |
+| tidytable | data.table (C) |
+| tidypolars | polars (Rust) |
+| arrow | Arrow (C++) |
+| collapse | C/C++ |
+| poorman | R |
+
+Why do these implementations exist?
+
+Most of these exist because the original tidyverse implementation isn't fast enough. The original implementation of tidyverse (dplyr, specifically) uses C++ as a backend, and you can see here that people have tried to connect up the tidyverse to faster and faster backends to make it more speedy -- a perfect encapsulation of the two-language problem.
+
+What I hope you appreciate from this is that in general, people *love* the tidyverse syntax. They do want to use the best and fastest tools, but they want to access these tools using the tidyverse syntax if at all possible -- which often is possible!
+"""
+
+# ╔═╡ 5b8a701e-bf77-4a7c-b83f-b948d0adabc9
+md"""
+## The tidyverse is a domain-specific language
+
+While its developers emphasize the connection between tidyverse and the larger R ecosystem, the fact that the tidyverse approach has been adopted in other languages, and that multiple implementations of it exist even in R, suggests that the tidyverse is more of a domain-specific language.
+
+It's true that the way in which it is implemented in R has historically been unique because of R's extensive meta-programming capabilities. This is why other implementations feel slightly clunky to use as compared to the R implementation.
+
+But Julia *also* has very similar meta-programming capabilities, making it the perfect language to port the tidyverse.
+"""
+
+# ╔═╡ 9c74ce19-3da6-4444-a07e-5c2343c17b43
+md"""
+## Summary
+
+- The tidyverse is an opinionated collection of packages for data transformation, reshaping, and visualization.
+- The tidyverse popularized the idea of data pipelines and has spun off a number of other implementations in R, Python, and JavaScript.
+- The tidyverse is non-idiomatic even in R, so it should be thought of more as a domain-specific language than something specific to R.
+- Julia has similar meta-programming capabilities to R, making it a perfect language to port the tidyverse.
+"""
+
+# ╔═╡ c4c66ebb-d6ac-4e04-8454-4ba859caf72b
+md"""
+# Appendix
+"""
+
+# ╔═╡ 7a3cc4c6-5697-49ec-a115-500cd959d153
+TableOfContents()
+
+# ╔═╡ Cell order:
+# ╟─bda1b780-f753-4d83-9b88-9b84242e55eb
+# ╟─ecbe5053-c3b9-40c4-bcae-d935b6d31a03
+# ╟─ffa569e5-86f8-4244-be9a-774335f3c2ee
+# ╟─1804b400-13dd-4961-a24e-4a23a33706cc
+# ╟─f2d12946-b710-42b1-af67-5dde7165d790
+# ╟─b7386c91-d95f-46af-8c50-3cd0e971864a
+# ╟─5b8a701e-bf77-4a7c-b83f-b948d0adabc9
+# ╟─9c74ce19-3da6-4444-a07e-5c2343c17b43
+# ╟─c4c66ebb-d6ac-4e04-8454-4ba859caf72b
+# ╠═b8891864-439c-4962-a4b5-1d849009ca04
+# ╠═0c798730-96c8-4add-b97b-a270c6f96c85
+# ╠═7a3cc4c6-5697-49ec-a115-500cd959d153
diff --git a/tidyverse-and-its-descendants.plutostate b/tidyverse-and-its-descendants.plutostate
new file mode 100644
index 0000000..f1095d5
Binary files /dev/null and b/tidyverse-and-its-descendants.plutostate differ
diff --git a/what-is-tidier-jl.html b/what-is-tidier-jl.html
new file mode 100644
index 0000000..4b45f0e
--- /dev/null
+++ b/what-is-tidier-jl.html
@@ -0,0 +1,16 @@
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/why-julia.jl b/why-julia.jl
new file mode 100644
index 0000000..a6f64eb
--- /dev/null
+++ b/why-julia.jl
@@ -0,0 +1,149 @@
+### A Pluto.jl notebook ###
+# v0.19.36
+
+using Markdown
+using InteractiveUtils
+
+# ╔═╡ 44afa588-b452-4068-8c0f-b86b20610ab3
+# ╠═╡ show_logs = false
+using Pkg; Pkg.activate(".."); Pkg.instantiate()
+
+# ╔═╡ 1a83143f-ee1b-4641-ac4b-6b2c814060bf
+using PlutoUI: TableOfContents
+
+# ╔═╡ e5e107c2-bb3b-11ee-06db-754133546dbc
+md"""
+# Tidier Course: Why Julia?
+"""
+
+# ╔═╡ c295fb3d-134c-49e2-a1c7-ea24196bb79c
+html"""
+
+"""
+
+# ╔═╡ b61a62f6-4486-43d9-9ef0-ad3bd67348c7
+md"""
+## Preface
+
+Welcome to the **Tidier Course**, an interactive course designed to introduce you to Julia and the Tidier ecosystem for data analysis. The course consists of a series of Jupyter Notebooks so that you can both learn and practice how to write Julia code through real data science examples.
+
+This course assumes a basic level of familiarity with programming but does not assume any prior knowledge of Julia. This course emphasizes the parts of Julia required to read in, explore, and analyze data. Because this course is primarily oriented around data science, many important aspects of Julia will *not* be covered in this course.
+
+If you do happen to have familiarity with either R or Python, we will make a concerted effort to highlight ways in which Julia is both *similar* to and *different* from both of these languages. If Julia is the first language you're learning for data science, this course should tell you most of what you'll need to know.
+"""
+
+# ╔═╡ 79a07af6-1c5b-4c65-a780-eb12db42c153
+md"""
+## Why Julia?
+
+Clearly, Python and R are more commonly used languages, so it's a natural question to ask: **why use Julia?**
+
+While Julia has many virtues as a language, probably the most important one is this: it has a fairly simple syntax resembling a mix of Python and R, but unlike either of this languages, it's **much faster** out of the box. If you've used either Python and R, you may wonder how this could be true. Both Python and R *seem* to be quite speedy to work with, especially when you're working with modern data science packages.
+
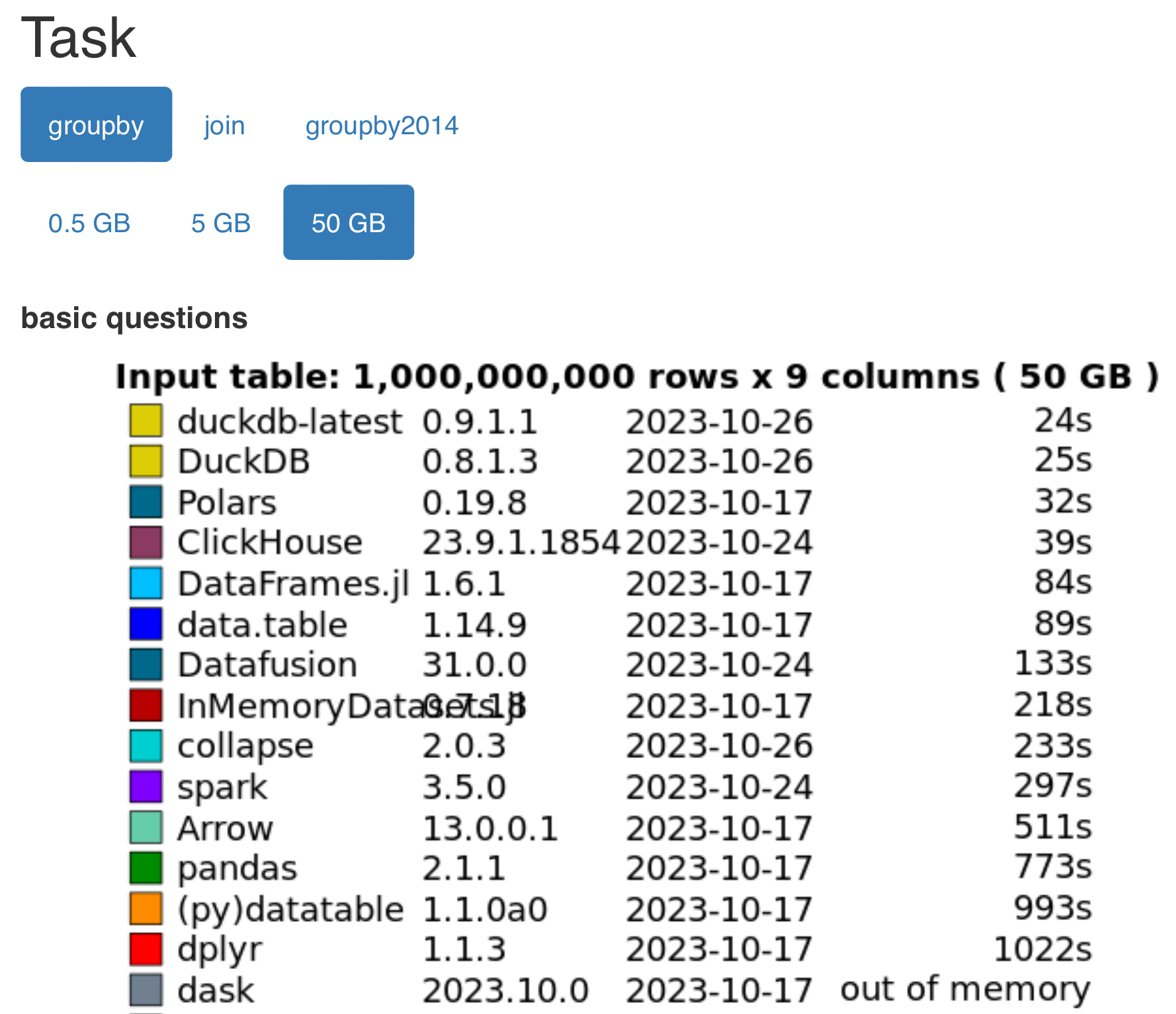
+For example, let's take a look at recent h2o/DuckDB benchmarks for data aggregation tasks: [https://duckdblabs.github.io/db-benchmark/](https://duckdblabs.github.io/db-benchmark/).
+"""
+
+# ╔═╡ 9bf1568e-9e97-487a-94e7-70be221e6df3
+html"""
+
+"""
+
+# ╔═╡ 39662edf-f4f5-43f0-8626-4be8d990db35
+md"""
+For grouped aggregation tasks on a 50 GB data frame, the fastest solutions are:
+
+- DuckDB: available in Python, R, and Julia
+- Polars: available in Python and Rust
+- ClickHouse: standalone solution
+- DataFrames.jl: available in Julia
+- data.table: available in R
+
+Let's take a closer look at each one of these.
+
+**DuckDB** and **ClickHouse** are examples of database management systems in which data frames represented in memory can be accessed using the Structured Query Language (SQL). DuckDB is an especially popular tool because it comes with companion packages in Python, R, and Julia. **Polars** is most commonly accessed using a Python package, and the speed of polars has led to an interesting moment in the Python community, where the **pandas** package remains very popular despite being among the slower-performing tools on this benchmark. The **data.table** was originally distributed as an R package, with a slower-performing Python port available in the form of the **pydatatable** package. And then there's the **DataFrames.jl** package, which is the fastest Julia solution for this benchmark and among the top tools overall.
+
+While these all seem roughly similar, there is one aspect of the Julia **DataFrames.jl** package that sets it apart. To appreciate this, we need to take another look at how each of these packages is implemented behind the scenes.
+
+How are each of these tools implemented?
+
+- DuckDB: implemented in C++
+- Polars: implemented in Rust
+- ClickHouse: implemented in C++
+- DataFrames.jl: implemented in Julia
+- data.table: implemented in C
+
+Even though the users may work with a package like DuckDB in Python or R, the speed of this package actually comes from C++ code. And while C++ has many virtues as a memory-safe, production-ready programming language, it is generally not anyone's first choice as a data science language.
+
+And if you were to decide you wanted to improve DuckDB to make it work better, you couldn't necessarily do this even if you were an expert in both Python and R. You'd need to learn C++. Well, that's perhaps a bit of an oversimplification. In reality, because DuckDB is an open-source project, you could open a GitHub issue suggesting a new feature and rely on their capable team to implement it.
+
+But the larger point is still valid:
+
+> **DataFrames.jl** is the *only* fast data analysis tool written in the same language as its user base.
+
+(While polars *can* be used directly in Rust, its user base largely consists of Python users.)
+"""
+
+# ╔═╡ e6a7fc77-8e25-47d2-be78-5518826ab85a
+md"""
+## The two-language problem
+
+Data scientists generally prefer languages with a concise syntax (like Python and R), but a lot of the speed in Python and R packages comes from using faster languages like C, C++, and Rust.
+
+This tension between the frontend language (the one used by the data scientist) and the backend language (the one used in implementing the tool to make it run fast) has been termed the "two-language problem."
+
+Because the backend language does all the hard computational work, the frontend language is sometimes referred to (with a hint of disdain) as the "glue" language. The entire purpose of the glue language is to glue together the bits of backend code.
+
+What's unique about Julia is that it is **both a glue language and a backend language**. How is this possible?
+
+Like Python and R, Julia has a concise syntax. Similar to C, C++, and Rust, Julia is compiled, which allows optimizations that help code run really fast. But unlike C, C++, and Rust, there is no "Compile" button that you need to press. Julia is compiled on-the-fly as you use it. This means that you get the benefits of both concise syntax and speed.
+"""
+
+# ╔═╡ 4a352113-70f2-45d5-9515-98f1fea00ad4
+md"""
+## What are the downsides of Julia?
+
+The two downsides of using Julia are:
+
+- It has a less robust package ecosystem than R or Python.
+- Because code needs to compile before it runs, there is sometimes a lag associated with the first time code runs.
+
+Both of these are fairly minor and readily addressed.
+
+Between `PyCall.jl`, `PythonCall.jl`, and `RCall.jl`, you can access all Python and R packages using Julia syntax. While this might seem like a bit of a cop-out, it's actually the best of both worlds. You get access to packages from more established languages without having to worry about your glue language being slow. If anything, your glue language may be *faster* than the underlying Python or R code that you're calling.
+
+The issue of code compilation used to be a major problem in Julia until recently. As of version 1.9+, Julia packages are able to precompile their code and save it. This does mean that packages take a bit longer to install, but once installed, packages taking advantage of this precompilation run fast right from the beginning. While you may notice a momentary pause when running new functions that you've defined, most major Julia packages (including DataFrames.jl) take advantage of this precompilation.
+"""
+
+# ╔═╡ 6cfa4f75-1aa3-4d4e-a81f-fb46adaf1b9a
+md"""
+## Summary
+
+In this section, we learned that:
+
+- Julia has a simple and concise syntax, like Python and R
+- Julia is fast, like C, C++, and Rust
+- Julia plays nicely with both Python and R packages, giving you access to the full breadth of data science packages
+"""
+
+# ╔═╡ a0f21837-8df9-42d5-8e55-1cafe478777d
+md"""
+# Appendix
+"""
+
+# ╔═╡ 08f6a882-f687-4a1a-83ca-f47399022fca
+TableOfContents()
+
+# ╔═╡ Cell order:
+# ╟─e5e107c2-bb3b-11ee-06db-754133546dbc
+# ╟─c295fb3d-134c-49e2-a1c7-ea24196bb79c
+# ╟─b61a62f6-4486-43d9-9ef0-ad3bd67348c7
+# ╟─79a07af6-1c5b-4c65-a780-eb12db42c153
+# ╟─9bf1568e-9e97-487a-94e7-70be221e6df3
+# ╟─39662edf-f4f5-43f0-8626-4be8d990db35
+# ╟─e6a7fc77-8e25-47d2-be78-5518826ab85a
+# ╟─4a352113-70f2-45d5-9515-98f1fea00ad4
+# ╟─6cfa4f75-1aa3-4d4e-a81f-fb46adaf1b9a
+# ╟─a0f21837-8df9-42d5-8e55-1cafe478777d
+# ╠═44afa588-b452-4068-8c0f-b86b20610ab3
+# ╠═1a83143f-ee1b-4641-ac4b-6b2c814060bf
+# ╠═08f6a882-f687-4a1a-83ca-f47399022fca
diff --git a/why-julia.plutostate b/why-julia.plutostate
new file mode 100644
index 0000000..0c9877a
Binary files /dev/null and b/why-julia.plutostate differ
 """
+
+# ╔═╡ 78d16051-d5d9-4f9c-9316-ce4ddee39dce
+md"""
+DuckDB and ClickHouse were two of the fastest tools, and while both are implemented in C++, their primary interface to users is in SQL. SQL is the *lingua franca* of databases, and it is important background knowledge as a data scientist to understand its syntax, which is the source of its popularity as well as its primary limitation.
+
+Let's say we have a dataset called `patients`, which has columns `diagnosis`, `takes_medications`, and `age`. Each row represents a unique patient, `diagnosis` is the primary diagnosis, `takes_medications` is a string indicating whether a patients takes any medications ("yes") or not ("no"), and `age` is their current age.
+
+To compare the mean age among patients with diabetes who take medications versus those who do not take medications, we would write the following in SQL:
+
+```sql
+SELECT takes_medications, AVG(age) AS mean_age
+FROM patients
+WHERE diagnosis = 'diabetes'
+GROUP BY takes_medications;
+```
+
+The SQL syntax is fairly intuitive in that each verb (e.g., `SELECT`) has a clear purpose, and the full query itself reads a bit like a sentence that you could read aloud. However, hidden within this apparent simplicity is the fact that SQL queries don't actually run in the order in this order.
+
+The *actual* order in which this query runs is:
+
+1. `FROM patients`
+2. `WHERE diagnosis = 'diabetes'`
+3. `GROUP BY takes_medications`
+4. `SELECT takes_medications, AVG(age) AS mean_age`
+
+If you think about this, this makes sense. You first need to start with the dataset (`FROM patients`), then you need to limit the dataset to only those rows where the primary diagnosis is diabetes (`WHERE diagnosis = 'diabetes'`). Then, after grouping by whether or not a patient takes medications, we need to calculate the mean age for each group.
+
+The key lesson with SQL is:
+
+> The order in which you write the verbs in SQL is different from the order in which the verbs are processed by SQL.
+
+Much has been written about this issue (see: [https://jvns.ca/blog/2019/10/03/sql-queries-don-t-start-with-select/](https://jvns.ca/blog/2019/10/03/sql-queries-don-t-start-with-select/) and [https://www.flerlagetwins.com/2018/10/sql-part4.html](https://www.flerlagetwins.com/2018/10/sql-part4.html)).
+
+In case you're curious, this is a more complete comparison of how SQL queries are written vs. how they are processed by SQL.
+
+| What You Write in SQL | Order In Which It Runs |
+| ----------------------|------------------------|
+| SELECT | FROM |
+| DISTINCT | JOIN |
+| TOP | WHERE |
+| [AGGREGATION] | GROUP BY |
+| FROM | [AGGREGATION] |
+| JOIN | HAVING |
+| WHERE | SELECT |
+| GROUP BY | DISTINCT |
+| HAVING | ORDER BY |
+| ORDER BY | TOP / LIMIT |
+"""
+
+# ╔═╡ 2686a0fb-15e1-44d8-9565-1abdee13ec5b
+md"""
+## Why not run SQL queries in the same order they are written?
+
+While the fact that SQL queries form sentences that can be read aloud is convenient, this convenience comes at a cost. When queries get more complicated, they can no longer be read aloud, and the order of operations becomes much harder to keep track of. For more complex queries, it actually becomes cognitively less demanding to keep track of queries that are run in the same order that they are written.
+
+This idea of behind `PRQL` ([https://github.com/PRQL/prql](https://github.com/PRQL/prql)), which calls itself a "simple, powerful, pipelined, SQL replacement."
+
+This same query in PRQL would be written as:
+
+```
+from patients
+filter diagnosis == "diabetes"
+group {takes_medications}
+aggregate {age = avg age}
+```
+
+The fact that the analytic steps are written in the same order as they are performed seems trivial, but this is the big idea behind data pipelines. A data pipeline starts with a dataset, and each function transforms the data in a specific way until the end result answers an analytical question.
+"""
+
+# ╔═╡ 4fde78bb-3dc5-4849-ad24-29804a49740c
+md"""
+## Modern data pipelines
+
+Data pipelines were popularized by the `dplyr` and `ggplot2` R packages, which are two of the core packages that make up the `tidyverse` ecoystem in R. In fact, the `dplyr` R package was a key inspiration behind `PRQL` (see [https://prql-lang.org/faq/](https://prql-lang.org/faq/)). While `PRQL` brings the idea of data pipelines to a `SQL` syntax, modern data pipelines are much more expansive in their capabilities.
+
+While all data pipelines *start* with a dataset, they don't need to *end* with a dataset. Modern data pipelines often end with plots (as in `ggplot2` in R), statistical analyses, machine learning models, and more. These more advanced types of data pipelines is where SQL-like languages (like PRQL) show their limitations. While great for transforming data, SQL-like langauges do not have facilities for plotting and machine learning.
+
+Data pipelines implemented in a programming language like Python, R, or Julia are thus much more capable than in PRQL.
+"""
+
+# ╔═╡ 6a08598c-69bf-498c-9ac2-4e0a4b749598
+md"""
+## Summary
+
+- The Structured Query Language (SQL) is a popular way of working with datasets
+- SQL's simple-to-read syntax introduces complexity because the order in which SQL queries are written is different from the order in which SQL queries are run
+- PRQL is a SQL-like language that implements data pipelines
+- Data pipelines refer to data analysis pathways that start with a dataset and then sequentially transform the dataset
+- While data pipelines start with a dataset, modern data pipelines end with plots, statistical analyses, and machine learning models.
+"""
+
+# ╔═╡ 831bad3f-0e43-4226-a75c-7a7c4c569e53
+md"""
+# Appendix
+"""
+
+# ╔═╡ 0ddc3de7-c4a8-44c7-8cd3-4d63de3334c7
+TableOfContents()
+
+# ╔═╡ Cell order:
+# ╟─2eec5998-bb36-11ee-2283-67ea47c4f5ed
+# ╟─a4baabcd-d425-449e-b7bb-f8b776582330
+# ╟─c38f82c2-def3-4d1c-bda0-54e779e2583a
+# ╟─99aa11d7-09f8-4ebb-9166-e248fc5af44f
+# ╟─78d16051-d5d9-4f9c-9316-ce4ddee39dce
+# ╟─2686a0fb-15e1-44d8-9565-1abdee13ec5b
+# ╟─4fde78bb-3dc5-4849-ad24-29804a49740c
+# ╟─6a08598c-69bf-498c-9ac2-4e0a4b749598
+# ╟─831bad3f-0e43-4226-a75c-7a7c4c569e53
+# ╠═d6823989-bb85-400d-87ec-2a365260f5fb
+# ╠═51e24e5e-cfc7-4b02-978c-505e21e6df43
+# ╠═0ddc3de7-c4a8-44c7-8cd3-4d63de3334c7
diff --git a/data-pipelines.plutostate b/data-pipelines.plutostate
new file mode 100644
index 0000000..d15e794
Binary files /dev/null and b/data-pipelines.plutostate differ
diff --git a/header.html b/header.html
new file mode 100644
index 0000000..8b10686
--- /dev/null
+++ b/header.html
@@ -0,0 +1,18 @@
+
"""
+
+# ╔═╡ 78d16051-d5d9-4f9c-9316-ce4ddee39dce
+md"""
+DuckDB and ClickHouse were two of the fastest tools, and while both are implemented in C++, their primary interface to users is in SQL. SQL is the *lingua franca* of databases, and it is important background knowledge as a data scientist to understand its syntax, which is the source of its popularity as well as its primary limitation.
+
+Let's say we have a dataset called `patients`, which has columns `diagnosis`, `takes_medications`, and `age`. Each row represents a unique patient, `diagnosis` is the primary diagnosis, `takes_medications` is a string indicating whether a patients takes any medications ("yes") or not ("no"), and `age` is their current age.
+
+To compare the mean age among patients with diabetes who take medications versus those who do not take medications, we would write the following in SQL:
+
+```sql
+SELECT takes_medications, AVG(age) AS mean_age
+FROM patients
+WHERE diagnosis = 'diabetes'
+GROUP BY takes_medications;
+```
+
+The SQL syntax is fairly intuitive in that each verb (e.g., `SELECT`) has a clear purpose, and the full query itself reads a bit like a sentence that you could read aloud. However, hidden within this apparent simplicity is the fact that SQL queries don't actually run in the order in this order.
+
+The *actual* order in which this query runs is:
+
+1. `FROM patients`
+2. `WHERE diagnosis = 'diabetes'`
+3. `GROUP BY takes_medications`
+4. `SELECT takes_medications, AVG(age) AS mean_age`
+
+If you think about this, this makes sense. You first need to start with the dataset (`FROM patients`), then you need to limit the dataset to only those rows where the primary diagnosis is diabetes (`WHERE diagnosis = 'diabetes'`). Then, after grouping by whether or not a patient takes medications, we need to calculate the mean age for each group.
+
+The key lesson with SQL is:
+
+> The order in which you write the verbs in SQL is different from the order in which the verbs are processed by SQL.
+
+Much has been written about this issue (see: [https://jvns.ca/blog/2019/10/03/sql-queries-don-t-start-with-select/](https://jvns.ca/blog/2019/10/03/sql-queries-don-t-start-with-select/) and [https://www.flerlagetwins.com/2018/10/sql-part4.html](https://www.flerlagetwins.com/2018/10/sql-part4.html)).
+
+In case you're curious, this is a more complete comparison of how SQL queries are written vs. how they are processed by SQL.
+
+| What You Write in SQL | Order In Which It Runs |
+| ----------------------|------------------------|
+| SELECT | FROM |
+| DISTINCT | JOIN |
+| TOP | WHERE |
+| [AGGREGATION] | GROUP BY |
+| FROM | [AGGREGATION] |
+| JOIN | HAVING |
+| WHERE | SELECT |
+| GROUP BY | DISTINCT |
+| HAVING | ORDER BY |
+| ORDER BY | TOP / LIMIT |
+"""
+
+# ╔═╡ 2686a0fb-15e1-44d8-9565-1abdee13ec5b
+md"""
+## Why not run SQL queries in the same order they are written?
+
+While the fact that SQL queries form sentences that can be read aloud is convenient, this convenience comes at a cost. When queries get more complicated, they can no longer be read aloud, and the order of operations becomes much harder to keep track of. For more complex queries, it actually becomes cognitively less demanding to keep track of queries that are run in the same order that they are written.
+
+This idea of behind `PRQL` ([https://github.com/PRQL/prql](https://github.com/PRQL/prql)), which calls itself a "simple, powerful, pipelined, SQL replacement."
+
+This same query in PRQL would be written as:
+
+```
+from patients
+filter diagnosis == "diabetes"
+group {takes_medications}
+aggregate {age = avg age}
+```
+
+The fact that the analytic steps are written in the same order as they are performed seems trivial, but this is the big idea behind data pipelines. A data pipeline starts with a dataset, and each function transforms the data in a specific way until the end result answers an analytical question.
+"""
+
+# ╔═╡ 4fde78bb-3dc5-4849-ad24-29804a49740c
+md"""
+## Modern data pipelines
+
+Data pipelines were popularized by the `dplyr` and `ggplot2` R packages, which are two of the core packages that make up the `tidyverse` ecoystem in R. In fact, the `dplyr` R package was a key inspiration behind `PRQL` (see [https://prql-lang.org/faq/](https://prql-lang.org/faq/)). While `PRQL` brings the idea of data pipelines to a `SQL` syntax, modern data pipelines are much more expansive in their capabilities.
+
+While all data pipelines *start* with a dataset, they don't need to *end* with a dataset. Modern data pipelines often end with plots (as in `ggplot2` in R), statistical analyses, machine learning models, and more. These more advanced types of data pipelines is where SQL-like languages (like PRQL) show their limitations. While great for transforming data, SQL-like langauges do not have facilities for plotting and machine learning.
+
+Data pipelines implemented in a programming language like Python, R, or Julia are thus much more capable than in PRQL.
+"""
+
+# ╔═╡ 6a08598c-69bf-498c-9ac2-4e0a4b749598
+md"""
+## Summary
+
+- The Structured Query Language (SQL) is a popular way of working with datasets
+- SQL's simple-to-read syntax introduces complexity because the order in which SQL queries are written is different from the order in which SQL queries are run
+- PRQL is a SQL-like language that implements data pipelines
+- Data pipelines refer to data analysis pathways that start with a dataset and then sequentially transform the dataset
+- While data pipelines start with a dataset, modern data pipelines end with plots, statistical analyses, and machine learning models.
+"""
+
+# ╔═╡ 831bad3f-0e43-4226-a75c-7a7c4c569e53
+md"""
+# Appendix
+"""
+
+# ╔═╡ 0ddc3de7-c4a8-44c7-8cd3-4d63de3334c7
+TableOfContents()
+
+# ╔═╡ Cell order:
+# ╟─2eec5998-bb36-11ee-2283-67ea47c4f5ed
+# ╟─a4baabcd-d425-449e-b7bb-f8b776582330
+# ╟─c38f82c2-def3-4d1c-bda0-54e779e2583a
+# ╟─99aa11d7-09f8-4ebb-9166-e248fc5af44f
+# ╟─78d16051-d5d9-4f9c-9316-ce4ddee39dce
+# ╟─2686a0fb-15e1-44d8-9565-1abdee13ec5b
+# ╟─4fde78bb-3dc5-4849-ad24-29804a49740c
+# ╟─6a08598c-69bf-498c-9ac2-4e0a4b749598
+# ╟─831bad3f-0e43-4226-a75c-7a7c4c569e53
+# ╠═d6823989-bb85-400d-87ec-2a365260f5fb
+# ╠═51e24e5e-cfc7-4b02-978c-505e21e6df43
+# ╠═0ddc3de7-c4a8-44c7-8cd3-4d63de3334c7
diff --git a/data-pipelines.plutostate b/data-pipelines.plutostate
new file mode 100644
index 0000000..d15e794
Binary files /dev/null and b/data-pipelines.plutostate differ
diff --git a/header.html b/header.html
new file mode 100644
index 0000000..8b10686
--- /dev/null
+++ b/header.html
@@ -0,0 +1,18 @@
+ +"""
+
+# ╔═╡ 39662edf-f4f5-43f0-8626-4be8d990db35
+md"""
+For grouped aggregation tasks on a 50 GB data frame, the fastest solutions are:
+
+- DuckDB: available in Python, R, and Julia
+- Polars: available in Python and Rust
+- ClickHouse: standalone solution
+- DataFrames.jl: available in Julia
+- data.table: available in R
+
+Let's take a closer look at each one of these.
+
+**DuckDB** and **ClickHouse** are examples of database management systems in which data frames represented in memory can be accessed using the Structured Query Language (SQL). DuckDB is an especially popular tool because it comes with companion packages in Python, R, and Julia. **Polars** is most commonly accessed using a Python package, and the speed of polars has led to an interesting moment in the Python community, where the **pandas** package remains very popular despite being among the slower-performing tools on this benchmark. The **data.table** was originally distributed as an R package, with a slower-performing Python port available in the form of the **pydatatable** package. And then there's the **DataFrames.jl** package, which is the fastest Julia solution for this benchmark and among the top tools overall.
+
+While these all seem roughly similar, there is one aspect of the Julia **DataFrames.jl** package that sets it apart. To appreciate this, we need to take another look at how each of these packages is implemented behind the scenes.
+
+How are each of these tools implemented?
+
+- DuckDB: implemented in C++
+- Polars: implemented in Rust
+- ClickHouse: implemented in C++
+- DataFrames.jl: implemented in Julia
+- data.table: implemented in C
+
+Even though the users may work with a package like DuckDB in Python or R, the speed of this package actually comes from C++ code. And while C++ has many virtues as a memory-safe, production-ready programming language, it is generally not anyone's first choice as a data science language.
+
+And if you were to decide you wanted to improve DuckDB to make it work better, you couldn't necessarily do this even if you were an expert in both Python and R. You'd need to learn C++. Well, that's perhaps a bit of an oversimplification. In reality, because DuckDB is an open-source project, you could open a GitHub issue suggesting a new feature and rely on their capable team to implement it.
+
+But the larger point is still valid:
+
+> **DataFrames.jl** is the *only* fast data analysis tool written in the same language as its user base.
+
+(While polars *can* be used directly in Rust, its user base largely consists of Python users.)
+"""
+
+# ╔═╡ e6a7fc77-8e25-47d2-be78-5518826ab85a
+md"""
+## The two-language problem
+
+Data scientists generally prefer languages with a concise syntax (like Python and R), but a lot of the speed in Python and R packages comes from using faster languages like C, C++, and Rust.
+
+This tension between the frontend language (the one used by the data scientist) and the backend language (the one used in implementing the tool to make it run fast) has been termed the "two-language problem."
+
+Because the backend language does all the hard computational work, the frontend language is sometimes referred to (with a hint of disdain) as the "glue" language. The entire purpose of the glue language is to glue together the bits of backend code.
+
+What's unique about Julia is that it is **both a glue language and a backend language**. How is this possible?
+
+Like Python and R, Julia has a concise syntax. Similar to C, C++, and Rust, Julia is compiled, which allows optimizations that help code run really fast. But unlike C, C++, and Rust, there is no "Compile" button that you need to press. Julia is compiled on-the-fly as you use it. This means that you get the benefits of both concise syntax and speed.
+"""
+
+# ╔═╡ 4a352113-70f2-45d5-9515-98f1fea00ad4
+md"""
+## What are the downsides of Julia?
+
+The two downsides of using Julia are:
+
+- It has a less robust package ecosystem than R or Python.
+- Because code needs to compile before it runs, there is sometimes a lag associated with the first time code runs.
+
+Both of these are fairly minor and readily addressed.
+
+Between `PyCall.jl`, `PythonCall.jl`, and `RCall.jl`, you can access all Python and R packages using Julia syntax. While this might seem like a bit of a cop-out, it's actually the best of both worlds. You get access to packages from more established languages without having to worry about your glue language being slow. If anything, your glue language may be *faster* than the underlying Python or R code that you're calling.
+
+The issue of code compilation used to be a major problem in Julia until recently. As of version 1.9+, Julia packages are able to precompile their code and save it. This does mean that packages take a bit longer to install, but once installed, packages taking advantage of this precompilation run fast right from the beginning. While you may notice a momentary pause when running new functions that you've defined, most major Julia packages (including DataFrames.jl) take advantage of this precompilation.
+"""
+
+# ╔═╡ 6cfa4f75-1aa3-4d4e-a81f-fb46adaf1b9a
+md"""
+## Summary
+
+In this section, we learned that:
+
+- Julia has a simple and concise syntax, like Python and R
+- Julia is fast, like C, C++, and Rust
+- Julia plays nicely with both Python and R packages, giving you access to the full breadth of data science packages
+"""
+
+# ╔═╡ a0f21837-8df9-42d5-8e55-1cafe478777d
+md"""
+# Appendix
+"""
+
+# ╔═╡ 08f6a882-f687-4a1a-83ca-f47399022fca
+TableOfContents()
+
+# ╔═╡ Cell order:
+# ╟─e5e107c2-bb3b-11ee-06db-754133546dbc
+# ╟─c295fb3d-134c-49e2-a1c7-ea24196bb79c
+# ╟─b61a62f6-4486-43d9-9ef0-ad3bd67348c7
+# ╟─79a07af6-1c5b-4c65-a780-eb12db42c153
+# ╟─9bf1568e-9e97-487a-94e7-70be221e6df3
+# ╟─39662edf-f4f5-43f0-8626-4be8d990db35
+# ╟─e6a7fc77-8e25-47d2-be78-5518826ab85a
+# ╟─4a352113-70f2-45d5-9515-98f1fea00ad4
+# ╟─6cfa4f75-1aa3-4d4e-a81f-fb46adaf1b9a
+# ╟─a0f21837-8df9-42d5-8e55-1cafe478777d
+# ╠═44afa588-b452-4068-8c0f-b86b20610ab3
+# ╠═1a83143f-ee1b-4641-ac4b-6b2c814060bf
+# ╠═08f6a882-f687-4a1a-83ca-f47399022fca
diff --git a/why-julia.plutostate b/why-julia.plutostate
new file mode 100644
index 0000000..0c9877a
Binary files /dev/null and b/why-julia.plutostate differ
+"""
+
+# ╔═╡ 39662edf-f4f5-43f0-8626-4be8d990db35
+md"""
+For grouped aggregation tasks on a 50 GB data frame, the fastest solutions are:
+
+- DuckDB: available in Python, R, and Julia
+- Polars: available in Python and Rust
+- ClickHouse: standalone solution
+- DataFrames.jl: available in Julia
+- data.table: available in R
+
+Let's take a closer look at each one of these.
+
+**DuckDB** and **ClickHouse** are examples of database management systems in which data frames represented in memory can be accessed using the Structured Query Language (SQL). DuckDB is an especially popular tool because it comes with companion packages in Python, R, and Julia. **Polars** is most commonly accessed using a Python package, and the speed of polars has led to an interesting moment in the Python community, where the **pandas** package remains very popular despite being among the slower-performing tools on this benchmark. The **data.table** was originally distributed as an R package, with a slower-performing Python port available in the form of the **pydatatable** package. And then there's the **DataFrames.jl** package, which is the fastest Julia solution for this benchmark and among the top tools overall.
+
+While these all seem roughly similar, there is one aspect of the Julia **DataFrames.jl** package that sets it apart. To appreciate this, we need to take another look at how each of these packages is implemented behind the scenes.
+
+How are each of these tools implemented?
+
+- DuckDB: implemented in C++
+- Polars: implemented in Rust
+- ClickHouse: implemented in C++
+- DataFrames.jl: implemented in Julia
+- data.table: implemented in C
+
+Even though the users may work with a package like DuckDB in Python or R, the speed of this package actually comes from C++ code. And while C++ has many virtues as a memory-safe, production-ready programming language, it is generally not anyone's first choice as a data science language.
+
+And if you were to decide you wanted to improve DuckDB to make it work better, you couldn't necessarily do this even if you were an expert in both Python and R. You'd need to learn C++. Well, that's perhaps a bit of an oversimplification. In reality, because DuckDB is an open-source project, you could open a GitHub issue suggesting a new feature and rely on their capable team to implement it.
+
+But the larger point is still valid:
+
+> **DataFrames.jl** is the *only* fast data analysis tool written in the same language as its user base.
+
+(While polars *can* be used directly in Rust, its user base largely consists of Python users.)
+"""
+
+# ╔═╡ e6a7fc77-8e25-47d2-be78-5518826ab85a
+md"""
+## The two-language problem
+
+Data scientists generally prefer languages with a concise syntax (like Python and R), but a lot of the speed in Python and R packages comes from using faster languages like C, C++, and Rust.
+
+This tension between the frontend language (the one used by the data scientist) and the backend language (the one used in implementing the tool to make it run fast) has been termed the "two-language problem."
+
+Because the backend language does all the hard computational work, the frontend language is sometimes referred to (with a hint of disdain) as the "glue" language. The entire purpose of the glue language is to glue together the bits of backend code.
+
+What's unique about Julia is that it is **both a glue language and a backend language**. How is this possible?
+
+Like Python and R, Julia has a concise syntax. Similar to C, C++, and Rust, Julia is compiled, which allows optimizations that help code run really fast. But unlike C, C++, and Rust, there is no "Compile" button that you need to press. Julia is compiled on-the-fly as you use it. This means that you get the benefits of both concise syntax and speed.
+"""
+
+# ╔═╡ 4a352113-70f2-45d5-9515-98f1fea00ad4
+md"""
+## What are the downsides of Julia?
+
+The two downsides of using Julia are:
+
+- It has a less robust package ecosystem than R or Python.
+- Because code needs to compile before it runs, there is sometimes a lag associated with the first time code runs.
+
+Both of these are fairly minor and readily addressed.
+
+Between `PyCall.jl`, `PythonCall.jl`, and `RCall.jl`, you can access all Python and R packages using Julia syntax. While this might seem like a bit of a cop-out, it's actually the best of both worlds. You get access to packages from more established languages without having to worry about your glue language being slow. If anything, your glue language may be *faster* than the underlying Python or R code that you're calling.
+
+The issue of code compilation used to be a major problem in Julia until recently. As of version 1.9+, Julia packages are able to precompile their code and save it. This does mean that packages take a bit longer to install, but once installed, packages taking advantage of this precompilation run fast right from the beginning. While you may notice a momentary pause when running new functions that you've defined, most major Julia packages (including DataFrames.jl) take advantage of this precompilation.
+"""
+
+# ╔═╡ 6cfa4f75-1aa3-4d4e-a81f-fb46adaf1b9a
+md"""
+## Summary
+
+In this section, we learned that:
+
+- Julia has a simple and concise syntax, like Python and R
+- Julia is fast, like C, C++, and Rust
+- Julia plays nicely with both Python and R packages, giving you access to the full breadth of data science packages
+"""
+
+# ╔═╡ a0f21837-8df9-42d5-8e55-1cafe478777d
+md"""
+# Appendix
+"""
+
+# ╔═╡ 08f6a882-f687-4a1a-83ca-f47399022fca
+TableOfContents()
+
+# ╔═╡ Cell order:
+# ╟─e5e107c2-bb3b-11ee-06db-754133546dbc
+# ╟─c295fb3d-134c-49e2-a1c7-ea24196bb79c
+# ╟─b61a62f6-4486-43d9-9ef0-ad3bd67348c7
+# ╟─79a07af6-1c5b-4c65-a780-eb12db42c153
+# ╟─9bf1568e-9e97-487a-94e7-70be221e6df3
+# ╟─39662edf-f4f5-43f0-8626-4be8d990db35
+# ╟─e6a7fc77-8e25-47d2-be78-5518826ab85a
+# ╟─4a352113-70f2-45d5-9515-98f1fea00ad4
+# ╟─6cfa4f75-1aa3-4d4e-a81f-fb46adaf1b9a
+# ╟─a0f21837-8df9-42d5-8e55-1cafe478777d
+# ╠═44afa588-b452-4068-8c0f-b86b20610ab3
+# ╠═1a83143f-ee1b-4641-ac4b-6b2c814060bf
+# ╠═08f6a882-f687-4a1a-83ca-f47399022fca
diff --git a/why-julia.plutostate b/why-julia.plutostate
new file mode 100644
index 0000000..0c9877a
Binary files /dev/null and b/why-julia.plutostate differ