このリポジトリには、私たちの論文「大規模マルチモーダルモデルにおける視覚言語調整を促進するための足場座標」の情報、データ、コードが含まれています。
[2024.02.22] 標準的なScaffoldプロンプティングを視覚言語タスクに適用するためのコードをリリースしました。
最先端の大規模マルチモーダルモデル(LMMs)は、視覚言語タスクにおいて優れた能力を示しています。高度な機能にもかかわらず、複数レベルの視覚情報を用いた複雑な推論が必要とされる困難なシナリオでは、LMMsのパフォーマンスはまだ限定的です。LMMsの既存のプロンプティング技術は、テキストによる推論の改善または画像前処理のためのツールの活用に焦点を当てており、LMMsにおける視覚言語調整を促進するシンプルで汎用的な視覚プロンプティング手法が欠けています。本研究では、視覚言語調整を促進するための足場となる座標をスキャフォールドするScaffoldプロンプティングを提案します。具体的には、Scaffoldは画像内にドットマトリックスを視覚情報のアンカーとして重ね合わせ、多次元座標をテキストの位置参照として活用します。様々な難しい視覚言語タスクでの広範な実験により、テキストのCoTプロンプティングを用いたGPT-4Vに対するScaffoldの優位性が実証されました。
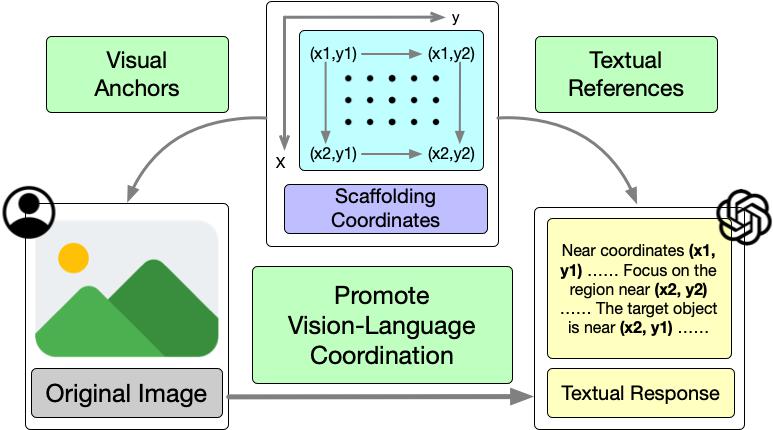
Scaffoldの全体的なフレームワークを上図に示し、視覚言語調整を促進するための全体的なアプローチを説明しています。
Scaffoldの詳細については、論文を参照してください:Scaffold
ここでは、GPT-4Vを使用して、Scaffoldプロンプティングを視覚言語タスクに適用するためのクイックガイドを紹介します。サンプルの質問と正解は data/examples/example.jsonl に、対応する画像は data/examples/imgs に配置されています。
ステップ0 準備。
以下のコマンドを実行して、必要なモジュールをインストールする必要があります。
pip install -r requirements.txtScaffoldプロンプティングを独自のデータに適用したい場合は、データを data/examples/example.jsonl のサンプルと同じ形式で整理する必要があります。有効なサンプルの例は次のとおりです。
{
"question_id": 1,
"image_path": "data/examples/imgs/1.jpg",
"question": "次の文が正しいか誤っているかを判断してください:人はバナナに向かっている。",
"answer": 1
}そして、image_path で指定したパスに画像を配置する必要があります。
ステップ1 画像の処理。
以下のコマンドを実行することで、元の画像にドットマトリックスと座標を重ね合わせることができます。
python image_processor.py注意:私たちの実装では、ハイパーパラメータのデフォルト設定を採用しています。例えば、ドットマトリックスのサイズは image_processor.py を確認して変更してください。
ステップ2 GPT-4V APIを呼び出す。
まず、call-api.py の API_KEY の位置(TODOでマークされている)に自分のOpenAI APIキーを入力する必要があります。その後、以下のコマンドを実行してサンプルを実行できます。
python call-api.py \
--data-file data/examples/example.jsonl \
--mode scaffold \
--parallel 1最後に、結果は log ディレクトリに保存されます。

Scaffoldプロンプティングは、LMMsにおける視覚言語調整を強化するために設計されています。この手法には、画像のオーバーレイとテキストのガイドラインの両方が含まれています。したがって、視覚的および言語的な観点から手法の実装について紹介します。
視覚的には、各入力画像に、一様に分布した長方形のドットマトリックスを重ね合わせ、各ドットに多次元のデカルト座標をラベル付けします。これらのドットは視覚的な位置のアンカーとして機能し、その座標はテキスト応答におけるテキストの参照として利用されます。
テキスト的には、LMMsへのタスク指示の前にテキストのガイダンスを付加します。これには、ドットマトリックスと座標の簡単な説明と、それらを効果的に使用するためのいくつかの一般的なガイドラインが含まれます。
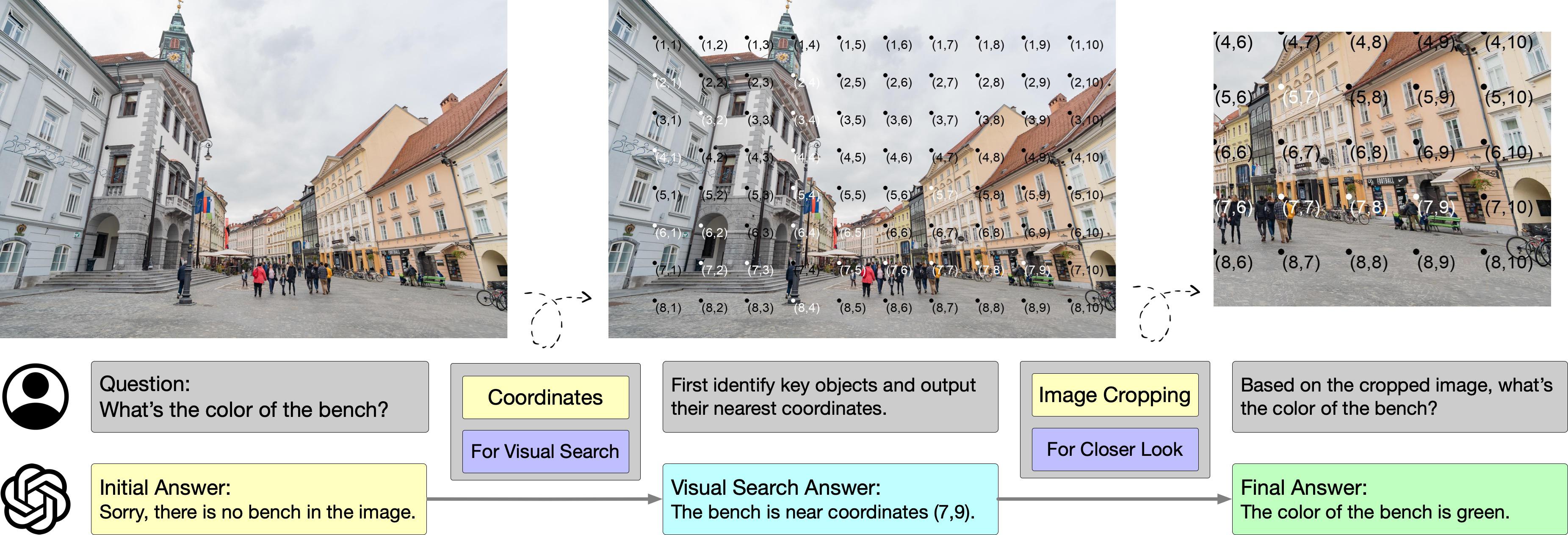
ここでは、私たちの実験からいくつかのケースを紹介します。
-
空間推論能力の向上。

-
構成的推論能力の改善。

-
高解像度画像における視覚検索能力の引き出し。

GPT-4Vを使用して11の難しい視覚言語ベンチマークで広範な実験を行い、結果は次のとおりです。
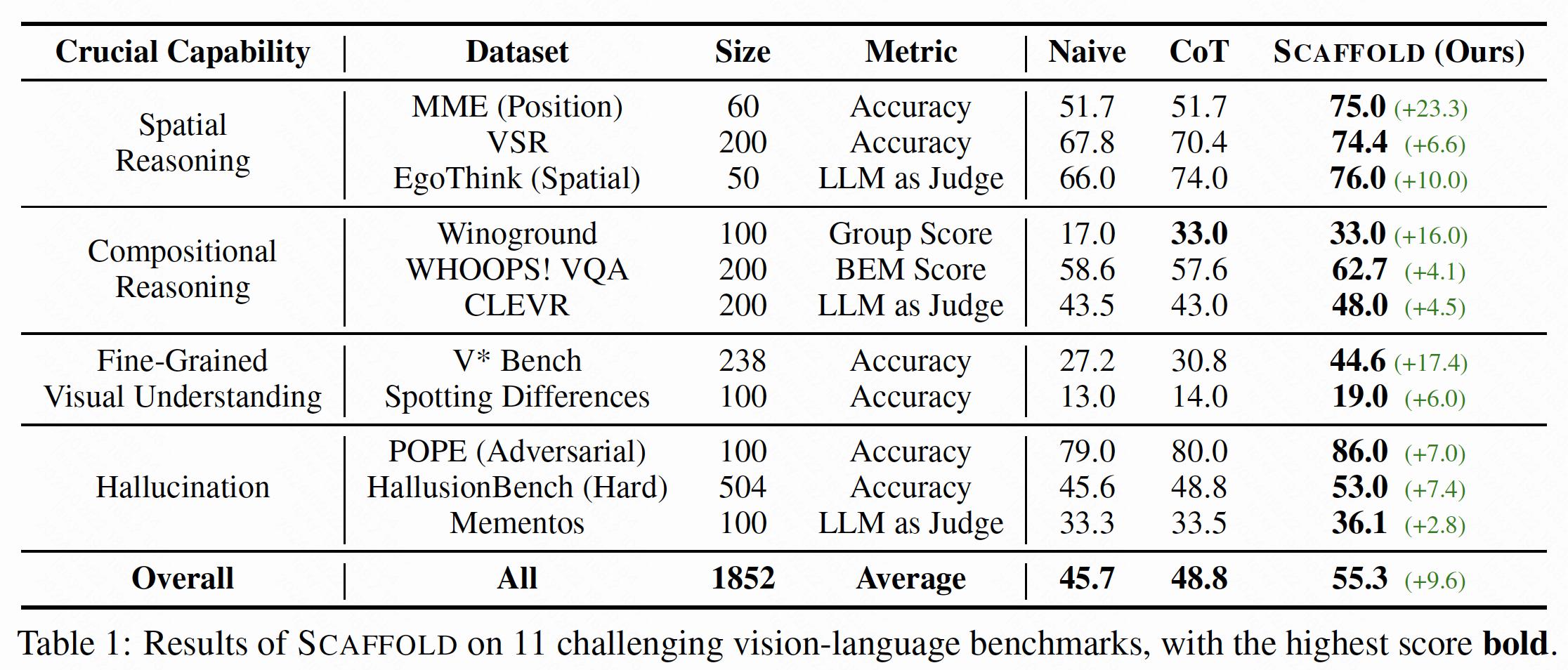
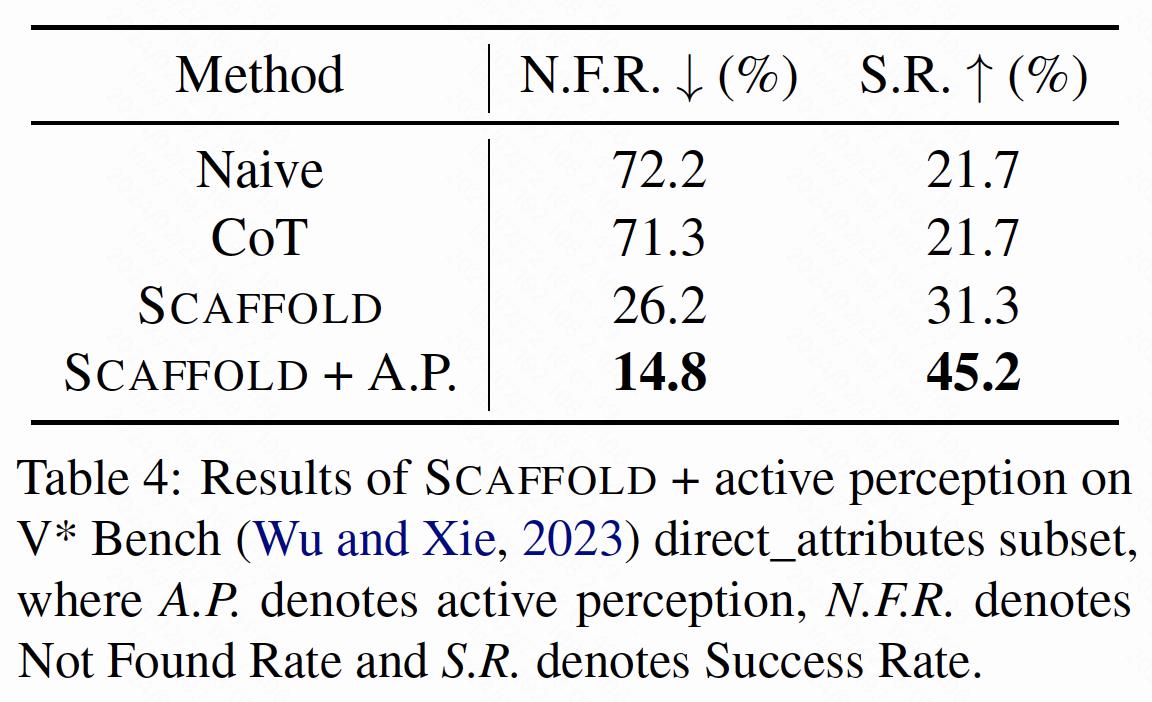
さらに、Scaffoldと能動知覚を組み合わせ、V* Bench direct_attributesサブセットで実験を行いました。次に詳述する結果は、Scaffoldが能動知覚のための効果的な足場として機能できることを示しています。
@misc{lei2024scaffolding,
title={Scaffolding Coordinates to Promote Vision-Language Coordination in Large Multi-Modal Models},
author={Xuanyu Lei and Zonghan Yang and Xinrui Chen and Peng Li and Yang Liu},
year={2024},
eprint={2402.12058},
archivePrefix={arXiv},
primaryClass={cs.CV}
}