\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Making a notebook for Pythia inevitably requires some trial and error for formatting, among other things. If you feel the formatting is lacking in some way, feel free to adjust it in different ways until it is up to your standards. Copying and editing Markdown cells is a good way to try different formatting options.\n",
+ "\n",
+ "In addition, there are other types of boxes, known as `admonitions`, that can be inserted into a tutorial page:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " This is an info box. Info boxes contain additional information about tutorial concepts.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Success
\n", + " This is a success box. Success boxes are usually placed at the end of a set of examples, and usually show a message relating to the final state of the examples.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Warning
\n", + " This is a warning box. Warning boxes are usually used to indicate a situation where making a mistake, such as a typo, can cause issues with the tutorial content.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In addition, it is helpful and highly recommended to add cell tags to your Jupyter cells. These tags allow for [customization](https://jupyterbook.org/interactive/hiding.html) of content display, especially for code cells. In addition, cell tags provide a means for [demonstrating errors](https://jupyterbook.org/content/execute.html#dealing-with-code-that-raises-errors) without breaking any production environments. If you are unfamiliar with cell tags, you can review this [brief demonstration](https://jupyterbook.org/content/metadata.html#jupyter-cell-tags) provided by Jupyter Book; this demonstration covers cell tags in Jupyter Notebook and Jupyter Lab, as well as fully manual cell tags."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "Before adding a summary, you must first add another Markdown cell containing `---`, which marks the end of the content body. A good Summary section contains a brief single paragraph that summarizes the tutorial content. The key content elements and their relation to the tutorial objectives should also be covered. Finally, the most important concepts should be listed again in detail.\n",
+ "\n",
+ "### What's next?\n",
+ "This section should briefly describe the content in the page following your tutorial sequentially. You can find the page sequentially following yours using the Next link at the bottom of the page, or using the sidebar; Jupyter Book should pre-populate this. In addition, if your tutorial leads into other Pythia Foundations content, or tutorials found outside Pythia Foundations, these other tutorials can be linked to as well."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Resources and references\n",
+ "In this section, you must provide detailed citations and references to any external content used in your tutorial. Many types of external content are designed in as much detail as Pythia Foundations pages, and crediting the author is essential. In addition, this section can contain links to additional external content, such as reading, documentation, etc. Once this section is complete, your notebook is finished. After giving your new notebook a quick review, you can request the addition of the notebook to Pythia Foundations by sending the team a GitHub Pull Request. Here are a few final notes pertaining to working with Jupyter and Pythia:\n",
+ " - In order to confirm that your notebook runs from start to finish without errors, hangs, etc., go to the `Kernel` menu in Jupyter Lab and select `Restart Kernel and Run All Cells`.\n",
+ " - In order to prepare your notebook to be committed to Pythia Foundations, go to the `Kernel` menu in Jupyter Lab and select `Restart Kernel and Clear All Outputs`. After the notebook is committed, the Jupyter cells will be run and optimized for Pythia automatically.\n",
+ " - If you wish to take credit for your notebook, you can add contact information in this section; this is completely optional.\n",
+ " - It is very important that any code, information, images, etc. referenced in the above sections of your notebook contains appropriate attribution of authorship in this section.\n",
+ " - Finally, it is imperative that you must have a legal right to use any content included in your notebook. **Do not commit copyright infringement or plagiarism.**\n",
+ " \n",
+ "The Project Pythia team thanks you greatly for contributing to Pythia Foundations."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.9"
+ },
+ "nbdime-conflicts": {
+ "local_diff": [
+ {
+ "diff": [
+ {
+ "diff": [
+ {
+ "key": 0,
+ "op": "addrange",
+ "valuelist": [
+ "Python 3"
+ ]
+ },
+ {
+ "key": 0,
+ "length": 1,
+ "op": "removerange"
+ }
+ ],
+ "key": "display_name",
+ "op": "patch"
+ }
+ ],
+ "key": "kernelspec",
+ "op": "patch"
+ }
+ ],
+ "remote_diff": [
+ {
+ "diff": [
+ {
+ "diff": [
+ {
+ "key": 0,
+ "op": "addrange",
+ "valuelist": [
+ "Python3"
+ ]
+ },
+ {
+ "key": 0,
+ "length": 1,
+ "op": "removerange"
+ }
+ ],
+ "key": "display_name",
+ "op": "patch"
+ }
+ ],
+ "key": "kernelspec",
+ "op": "patch"
+ }
+ ]
+ },
+ "toc-autonumbering": false
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/_preview/468/_sources/core/cartopy.md b/_preview/468/_sources/core/cartopy.md
new file mode 100644
index 000000000..03a47555a
--- /dev/null
+++ b/_preview/468/_sources/core/cartopy.md
@@ -0,0 +1,20 @@
+# Cartopy
+
+This section contains tutorials on plotting maps with [Cartopy](https://scitools.org.uk/cartopy/docs/latest/); it is cross-referenced with tutorials on [Xarray](xarray) and [Matplotlib](matplotlib).
+
+---
+
+From the [Cartopy website](https://scitools.org.uk/cartopy/docs/latest):
+
+> Cartopy is a Python package designed for geospatial data processing in order to
+> produce maps and other geospatial data analyses.
+>
+> Cartopy makes use of the powerful PROJ.4, NumPy and Shapely libraries and includes a programmatic interface
+> built on top of Matplotlib for the creation of publication quality maps.
+>
+> Key features of Cartopy are its object-oriented [projection definitions](https://scitools.org.uk/cartopy/docs/latest/reference/crs.html#list-of-projections),
+> and its ability to transform points, lines, vectors, polygons and images between those projections.
+
+Before working through the Cartopy notebooks in this section of Pythia Foundations, you should first have a basic knowledge of [Matplotlib](matplotlib).
+
+In addition, please note that the geographic-features library used by Cartopy makes use of shapefiles directly served by [Natural Earth](https://www.naturalearthdata.com/).
diff --git a/_preview/468/_sources/core/cartopy/cartopy.ipynb b/_preview/468/_sources/core/cartopy/cartopy.ipynb
new file mode 100644
index 000000000..79f686b41
--- /dev/null
+++ b/_preview/468/_sources/core/cartopy/cartopy.ipynb
@@ -0,0 +1,757 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Danger
\n", + " This is a danger box. Danger boxes are usually used to indicate a situation where making a mistake, such as a typo, can cause more serious issues such as loss of data.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Add cartographic features to the map"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Cartopy provides other cartographic features via its `features` class, which was imported at the beginning of this page, under the name `cfeature`. These cartographic features are laid out as data in shapefiles. The shapefiles are downloaded when their cartographic features are used for the first time in a script or notebook, and they are downloaded from https://www.naturalearthdata.com/. Once downloaded, they \"live\" in your `~/.local/share/cartopy` directory (note the `~` represents your home directory)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can add these features to our subplot via the `add_feature` method; this method allows the definition of attributes using arguments, similar to Matplotlib's `plot` method. A list of the various Natural Earth shapefiles can be found at https://scitools.org.uk/cartopy/docs/latest/matplotlib/feature_interface.html. In this example, we add borders and U. S. state lines to our subplot:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ax.add_feature(cfeature.BORDERS, linewidth=0.5, edgecolor='black')\n",
+ "ax.add_feature(cfeature.STATES, linewidth=0.3, edgecolor='brown')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Once again, referencing the `Figure` object will re-render the figure in the notebook, now including the two features."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Explore some of Cartopy's map projections"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " To get the figure to display again with the features that we've added since the original display, just type the name of the Figure object in its own cell.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Mollweide Projection (often used with global satellite mosaics)\n",
+ "\n",
+ "To save typing later, we can define a projection object to store the definition of the map projection. We can then use this object in the `projection` kwarg of the `subplot` method when creating a `GeoAxes` object. This allows us to use this exact projection in later scripts or Jupyter Notebook cells using simply the object name, instead of repeating the same call to `ccrs`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(11, 8.5))\n",
+ "projMoll = ccrs.Mollweide(central_longitude=0)\n",
+ "ax = plt.subplot(1, 1, 1, projection=projMoll)\n",
+ "ax.set_title(\"Mollweide Projection\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Add in the cartographic shapefiles\n",
+ "\n",
+ "This example shows how to add cartographic features to the Mollweide projection defined earlier:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ax.coastlines()\n",
+ "ax.add_feature(cfeature.BORDERS, linewidth=0.5, edgecolor='blue')\n",
+ "fig"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Add a fancy background image to the map.\n",
+ "\n",
+ "We can also use the `stock_img` method to add a pre-created background to a Mollweide-projection plot:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ax.stock_img()\n",
+ "fig"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Lambert Azimuthal Equal Area Projection\n",
+ "\n",
+ "This example is similar to the above example set, except it uses a Lambert azimuthal equal-area projection instead:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(11, 8.5))\n",
+ "projLae = ccrs.LambertAzimuthalEqualArea(central_longitude=0.0, central_latitude=0.0)\n",
+ "ax = plt.subplot(1, 1, 1, projection=projLae)\n",
+ "ax.set_title(\"Lambert Azimuthal Equal Area Projection\")\n",
+ "ax.coastlines()\n",
+ "ax.add_feature(cfeature.BORDERS, linewidth=0.5, edgecolor='blue');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Create regional maps"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Cartopy's `set_extent` method\n",
+ "\n",
+ "For this example, let's create another PlateCarree projection, but this time, we'll use Cartopy's `set_extent` method to restrict the map coverage to a North American view. Let's also choose a lower resolution for coastlines, just to illustrate how one can specify that. In addition, let's also plot the latitude and longitude lines."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Natural Earth defines three resolutions for cartographic features, specified as the strings \"10m\", \"50m\", and \"110m\". Only one resolution can be used at a time, and the higher the number, the less detailed the feature becomes. You can view the documentation for this functionality at the following reference link: https://www.naturalearthdata.com/downloads/ "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "projPC = ccrs.PlateCarree()\n",
+ "lonW = -140\n",
+ "lonE = -40\n",
+ "latS = 15\n",
+ "latN = 65\n",
+ "cLat = (latN + latS) / 2\n",
+ "cLon = (lonW + lonE) / 2\n",
+ "res = '110m'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(11, 8.5))\n",
+ "ax = plt.subplot(1, 1, 1, projection=projPC)\n",
+ "ax.set_title('Plate Carree')\n",
+ "gl = ax.gridlines(\n",
+ " draw_labels=True, linewidth=2, color='gray', alpha=0.5, linestyle='--'\n",
+ ")\n",
+ "ax.set_extent([lonW, lonE, latS, latN], crs=projPC)\n",
+ "ax.coastlines(resolution=res, color='black')\n",
+ "ax.add_feature(cfeature.STATES, linewidth=0.3, edgecolor='brown')\n",
+ "ax.add_feature(cfeature.BORDERS, linewidth=0.5, edgecolor='blue');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " You can find a list of supported projections in Cartopy, with examples, at https://scitools.org.uk/cartopy/docs/latest/reference/crs.html\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The PlateCarree projection exaggerates the spatial extent of regions closer to the poles. In the following examples, we use `set_extent` with stereographic and Lambert-conformal projections, which display polar regions more accurately."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "projStr = ccrs.Stereographic(central_longitude=cLon, central_latitude=cLat)\n",
+ "fig = plt.figure(figsize=(11, 8.5))\n",
+ "ax = plt.subplot(1, 1, 1, projection=projStr)\n",
+ "ax.set_title('Stereographic')\n",
+ "gl = ax.gridlines(\n",
+ " draw_labels=True, linewidth=2, color='gray', alpha=0.5, linestyle='--'\n",
+ ")\n",
+ "ax.set_extent([lonW, lonE, latS, latN], crs=projPC)\n",
+ "ax.coastlines(resolution=res, color='black')\n",
+ "ax.add_feature(cfeature.STATES, linewidth=0.3, edgecolor='brown')\n",
+ "ax.add_feature(cfeature.BORDERS, linewidth=0.5, edgecolor='blue');"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "projLcc = ccrs.LambertConformal(central_longitude=cLon, central_latitude=cLat)\n",
+ "fig = plt.figure(figsize=(11, 8.5))\n",
+ "ax = plt.subplot(1, 1, 1, projection=projLcc)\n",
+ "ax.set_title('Lambert Conformal')\n",
+ "gl = ax.gridlines(\n",
+ " draw_labels=True, linewidth=2, color='gray', alpha=0.5, linestyle='--'\n",
+ ")\n",
+ "ax.set_extent([lonW, lonE, latS, latN], crs=projPC)\n",
+ "ax.coastlines(resolution='110m', color='black')\n",
+ "ax.add_feature(cfeature.STATES, linewidth=0.3, edgecolor='brown')\n",
+ "# End last line with a semicolon to suppress text output to the screen\n",
+ "ax.add_feature(cfeature.BORDERS, linewidth=0.5, edgecolor='blue');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " Please note, even though the calls to the `subplot` method use different projections, the calls to `set_extent` use PlateCarree. This ensures that the values we passed into `set_extent` will be transformed from degrees into the values appropriate for the projection we use for the map.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Create a regional map centered over New York State "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here we set the domain, which defines the geographical region to be plotted. (This is used in the next section in a `set_extent` call.) Since these coordinates are expressed in degrees, they correspond to a PlateCarree projection, even though the map projection is set to LambertConformal."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " Lat/lon labeling for projections other than Mercator and PlateCarree is a recent addition to Cartopy. As you can see, work still needs to be done to improve the placement of labels.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "latN = 45.2\n",
+ "latS = 40.2\n",
+ "lonW = -80.0\n",
+ "lonE = -71.5\n",
+ "cLat = (latN + latS) / 2\n",
+ "cLon = (lonW + lonE) / 2\n",
+ "projLccNY = ccrs.LambertConformal(central_longitude=cLon, central_latitude=cLat)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Add some predefined features\n",
+ "\n",
+ "Some cartographical features are predefined as constants in the `cartopy.feature` package. The resolution of these features depends on the amount of geographical area in your map, specified by `set_extent`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(15, 10))\n",
+ "ax = plt.subplot(1, 1, 1, projection=projLccNY)\n",
+ "ax.set_extent([lonW, lonE, latS, latN], crs=projPC)\n",
+ "ax.set_facecolor(cfeature.COLORS['water'])\n",
+ "ax.add_feature(cfeature.LAND)\n",
+ "ax.add_feature(cfeature.COASTLINE)\n",
+ "ax.add_feature(cfeature.BORDERS, linestyle='--')\n",
+ "ax.add_feature(cfeature.LAKES, alpha=0.5)\n",
+ "ax.add_feature(cfeature.STATES)\n",
+ "ax.add_feature(cfeature.RIVERS)\n",
+ "ax.set_title('New York and Vicinity');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Warning
\n", + " Be patient; when plotting a small geographical area, the high-resolution \"10m\" shapefiles are used by default. As a result, these plots take longer to create, especially if the shapefiles are not yet downloaded from Natural Earth. Similar issues can occur whenever a `GeoAxes` object is transformed from one coordinate system to another. (This will be covered in more detail in a subsequent page.)\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Use lower-resolution shapefiles from Natural Earth\n",
+ "\n",
+ "In this example, we create a new map. This map uses lower-resolution shapefiles from Natural Earth, and also eliminates the plotting of country borders.\n",
+ "\n",
+ "This example requires much more code than previous examples on this page. First, we must create new objects associated with lower-resolution shapefiles. This is performed by the `NaturalEarthFeature` method, which is part of the Cartopy `feature` class. Second, we call `add_feature` to add the new objects to our new map."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(15, 10))\n",
+ "ax = plt.subplot(1, 1, 1, projection=projLccNY)\n",
+ "ax.set_extent((lonW, lonE, latS, latN), crs=projPC)\n",
+ "\n",
+ "# The features with names such as cfeature.LAND, cfeature.OCEAN, are higher-resolution (10m)\n",
+ "# shapefiles from the Naturalearth repository. Lower resolution shapefiles (50m, 110m) can be\n",
+ "# used by using the cfeature.NaturalEarthFeature method as illustrated below.\n",
+ "\n",
+ "resolution = '110m'\n",
+ "\n",
+ "land_mask = cfeature.NaturalEarthFeature(\n",
+ " 'physical',\n",
+ " 'land',\n",
+ " scale=resolution,\n",
+ " edgecolor='face',\n",
+ " facecolor=cfeature.COLORS['land'],\n",
+ ")\n",
+ "sea_mask = cfeature.NaturalEarthFeature(\n",
+ " 'physical',\n",
+ " 'ocean',\n",
+ " scale=resolution,\n",
+ " edgecolor='face',\n",
+ " facecolor=cfeature.COLORS['water'],\n",
+ ")\n",
+ "lake_mask = cfeature.NaturalEarthFeature(\n",
+ " 'physical',\n",
+ " 'lakes',\n",
+ " scale=resolution,\n",
+ " edgecolor='face',\n",
+ " facecolor=cfeature.COLORS['water'],\n",
+ ")\n",
+ "state_borders = cfeature.NaturalEarthFeature(\n",
+ " category='cultural',\n",
+ " name='admin_1_states_provinces_lakes',\n",
+ " scale=resolution,\n",
+ " facecolor='none',\n",
+ ")\n",
+ "\n",
+ "ax.add_feature(land_mask)\n",
+ "ax.add_feature(sea_mask)\n",
+ "ax.add_feature(lake_mask)\n",
+ "ax.add_feature(state_borders, linestyle='solid', edgecolor='black')\n",
+ "ax.set_title('New York and Vicinity; lower resolution');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### A figure with two different regional maps\n",
+ "\n",
+ "Finally, let's create a figure with two subplots. On the first subplot, we'll repeat the high-resolution New York State map created earlier; on the second, we'll plot over a different part of the world."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create the figure object\n",
+ "fig = plt.figure(\n",
+ " figsize=(30, 24)\n",
+ ") # Notice we need a bigger \"canvas\" so these two maps will be of a decent size\n",
+ "\n",
+ "# First subplot\n",
+ "ax = plt.subplot(2, 1, 1, projection=projLccNY)\n",
+ "ax.set_extent([lonW, lonE, latS, latN], crs=projPC)\n",
+ "ax.set_facecolor(cfeature.COLORS['water'])\n",
+ "ax.add_feature(cfeature.LAND)\n",
+ "ax.add_feature(cfeature.COASTLINE)\n",
+ "ax.add_feature(cfeature.BORDERS, linestyle='--')\n",
+ "ax.add_feature(cfeature.LAKES, alpha=0.5)\n",
+ "ax.add_feature(cfeature.STATES)\n",
+ "ax.set_title('New York and Vicinity')\n",
+ "\n",
+ "# Set the domain for defining the second plot region.\n",
+ "latN = 70\n",
+ "latS = 30.2\n",
+ "lonW = -10\n",
+ "lonE = 50\n",
+ "cLat = (latN + latS) / 2\n",
+ "cLon = (lonW + lonE) / 2\n",
+ "\n",
+ "projLccEur = ccrs.LambertConformal(central_longitude=cLon, central_latitude=cLat)\n",
+ "\n",
+ "# Second subplot\n",
+ "ax2 = plt.subplot(2, 1, 2, projection=projLccEur)\n",
+ "ax2.set_extent([lonW, lonE, latS, latN], crs=projPC)\n",
+ "ax2.set_facecolor(cfeature.COLORS['water'])\n",
+ "ax2.add_feature(cfeature.LAND)\n",
+ "ax2.add_feature(cfeature.COASTLINE)\n",
+ "ax2.add_feature(cfeature.BORDERS, linestyle='--')\n",
+ "ax2.add_feature(cfeature.LAKES, alpha=0.5)\n",
+ "ax2.add_feature(cfeature.STATES)\n",
+ "ax2.set_title('Europe');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## An example of plotting data\n",
+ "\n",
+ "First, we'll create a lat-lon grid and define some data on it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "lon, lat = np.mgrid[-180:181, -90:91]\n",
+ "data = 2 * np.sin(3 * np.deg2rad(lon)) + 3 * np.cos(4 * np.deg2rad(lat))\n",
+ "plt.contourf(lon, lat, data)\n",
+ "plt.colorbar();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Plotting data on a Cartesian grid is equivalent to plotting data in the PlateCarree projection, where meridians and parallels are all straight lines with constant spacing. As a result of this simplicity, the global datasets we use often begin in the PlateCarree projection.\n",
+ "\n",
+ "Once we create our map again, we can plot these data values as a contour map. We must also specify the `transform` keyword argument. This is an argument to a contour-plotting method that specifies the projection type currently used by our data. The projection type specified by this argument will be transformed into the projection type specified in the `subplot` method. Let's plot our data in the Mollweide projection to see how shapes change under a transformation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(11, 8.5))\n",
+ "ax = plt.subplot(1, 1, 1, projection=projMoll)\n",
+ "ax.coastlines()\n",
+ "dataplot = ax.contourf(lon, lat, data, transform=ccrs.PlateCarree())\n",
+ "plt.colorbar(dataplot, orientation='horizontal');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "___"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Summary"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- Cartopy allows for the georeferencing of Matplotlib `Axes` objects.\n",
+ "- Cartopy's `crs` class supports a variety of map projections.\n",
+ "- Cartopy's `feature` class allows for a variety of cartographic features to be overlaid on a georeferenced plot or subplot."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "___"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## What's Next?"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In the next notebook, we will delve further into how one can transform data that is defined in one coordinate reference system (`crs`) so it displays properly on a map that uses a different `crs`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Resources and References\n",
+ "\n",
+ "1. [Cartopy Documentation](https://scitools.org.uk/cartopy/docs/latest/)\n",
+ "2. [Full list of projections in Cartopy](https://scitools.org.uk/cartopy/docs/latest/reference/crs.html) \n",
+ "3. [Maps with Cartopy (Ryan Abernathey)](https://rabernat.github.io/research_computing_2018/maps-with-cartopy.html)\n",
+ "4. [Map Projections (GeoCAT)](https://geocat-examples.readthedocs.io/en/latest/gallery/index.html#map-projections)\n",
+ "5. [NCAR xdev Cartopy Tutorial Video](https://www.youtube.com/watch?v=ivmd3RluMiw)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/_preview/468/_sources/core/data-formats.md b/_preview/468/_sources/core/data-formats.md
new file mode 100644
index 000000000..ea64ce755
--- /dev/null
+++ b/_preview/468/_sources/core/data-formats.md
@@ -0,0 +1,7 @@
+# Data Formats
+
+```{note}
+This content is under construction!
+```
+
+There are many data file formats used commonly in the geosciences, such as NetCDF and GRIB. This section contains tutorials on how to interact with these files in Python.
diff --git a/_preview/468/_sources/core/data-formats/netcdf-cf.ipynb b/_preview/468/_sources/core/data-formats/netcdf-cf.ipynb
new file mode 100644
index 000000000..2abb46f88
--- /dev/null
+++ b/_preview/468/_sources/core/data-formats/netcdf-cf.ipynb
@@ -0,0 +1,1021 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# NetCDF and CF: The Basics\n",
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Overview\n",
+ "This tutorial will begin with an introduction to netCDF. The CF data model will then be covered, and finally, important implementation details for netCDF. The structure of the tutorial is as follows:\n",
+ "\n",
+ "1. Demonstrating gridded data\n",
+ "1. Demonstrating observational data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Prerequisites\n",
+ "\n",
+ "| Concepts | Importance | Notes |\n",
+ "| --- | --- | --- |\n",
+ "| [Numpy Basics](../numpy/numpy-basics) | Necessary | |\n",
+ "| [Datetime](../datetime) | Necessary | |\n",
+ "\n",
+ "- **Time to learn**: 50 minutes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Imports\n",
+ "\n",
+ "Some of these imports will be familiar from previous tutorials. However, some of them likely look foreign; these will be covered in detail later in this tutorial."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from datetime import datetime, timedelta\n",
+ "\n",
+ "import numpy as np\n",
+ "from cftime import date2num\n",
+ "from netCDF4 import Dataset\n",
+ "from pyproj import Proj"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "## Gridded Data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's say we're working with some numerical weather forecast model output. First, we need to store the data in the netCDF format. Second, we need to ensure that the metadata follows the Climate and Forecasting conventions. These steps ensure that a dataset is available to as many scientific data tools as is possible. The examples in this section illustrate these steps in detail.\n",
+ "\n",
+ "To start, let's assume the following about our data:\n",
+ "* There are three spatial dimensions (`x`, `y`, and `press`) and one temporal dimension (`times`).\n",
+ "* The native coordinate system of the model is on a regular 3km x 3km grid (`x` and `y`) that represents the Earth on a Lambert conformal projection.\n",
+ "* The vertical dimension (`press`) consists of several discrete pressure levels in units of hPa.\n",
+ "* The time dimension consists of twelve consecutive hours (`times`), beginning at 2200 UTC on the current day.\n",
+ "\n",
+ "The following code generates the dimensional arrays just discussed:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start = datetime.utcnow().replace(hour=22, minute=0, second=0, microsecond=0)\n",
+ "times = np.array([start + timedelta(hours=h) for h in range(13)])\n",
+ "\n",
+ "x = np.arange(-150, 153, 3)\n",
+ "y = np.arange(-100, 100, 3)\n",
+ "\n",
+ "press = np.array([1000, 925, 850, 700, 500, 300, 250])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In addition to dimensional arrays, we also need a variable of interest, which holds the data values at each unique dimensional index. In these examples, this variable is called `temps`, and holds temperature data. Note that the dimensions correspond to the ones we just created above."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temps = np.random.randn(times.size, press.size, y.size, x.size)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Creating the file and dimensions\n",
+ "\n",
+ "The first step in setting up a new netCDF file is to create a new file in netCDF format and set up the shared dimensions we'll be using in the file. We'll be using the `netCDF4` library to do all of the requisite netCDF API calls."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nc = Dataset('forecast_model.nc', 'w', format='NETCDF4_CLASSIC', diskless=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Note:
\n", + " For high-resolution Natural Earth shapefiles such as this, while we could add Cartopy'sOCEAN feature, it currently takes much longer to render on the plot. You can create your own version of this example, with the OCEAN feature added, to see for yourself how much more rendering time is added. Instead, we take the strategy of first setting the facecolor of the entire subplot to match that of water bodies in Cartopy. When we then layer on the LAND feature, pixels that are not part of the LAND shapefile remain in the water facecolor, which is the same color as the OCEAN.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + "The netCDF file created in the above example resides in memory, not disk, due to the diskless=True argument. In order to create this file on disk, you must either remove this argument, or add the persist=True argument.
\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We start the setup of this new netCDF file by creating and adding global attribute metadata. These particular metadata elements are not required, but are recommended by the CF standard. In addition, adding these elements to the file is simple, and helps users keep track of the data. Therefore, it is helpful to add these metadata elements, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nc.Conventions = 'CF-1.7'\n",
+ "nc.title = 'Forecast model run'\n",
+ "nc.institution = 'Unidata'\n",
+ "nc.source = 'WRF-1.5'\n",
+ "nc.history = str(datetime.utcnow()) + ' Python'\n",
+ "nc.references = ''\n",
+ "nc.comment = ''"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This next example shows a plain-text representation of our netCDF file as it exists currently:\n",
+ "```\n",
+ "netcdf forecast_model {\n",
+ " attributes:\n",
+ " :Conventions = \"CF-1.7\" ;\n",
+ " :title = \"Forecast model run\" ;\n",
+ " :institution = \"Unidata\" ;\n",
+ " :source = \"WRF-1.5\" ;\n",
+ " :history = \"2019-07-16 02:21:52.005718 Python\" ;\n",
+ " :references = \"\" ;\n",
+ " :comment = \"\" ;\n",
+ "}\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Danger
\n", + "If you open an existing file with 'w' as the second argument, any data already in the file will be overwritten. If you would like to edit the file, or add to it, open it using 'a' as the second argument.
\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Variables are an important part of every netCDF file; they are used to define data fields. However, before we can add any variables to our file, we must first define the dimensions of the data. In this example, we create dimensions called `x`, `y`, and `pressure`, and set the size of each dimension to the size of the corresponding data array. We then create an additional dimension, `forecast_time`, and set the size as None. This defines the dimension as \"unlimited\", meaning that if additional data values are added later, the netCDF file grows along this dimension."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nc.createDimension('forecast_time', None)\n",
+ "nc.createDimension('x', x.size)\n",
+ "nc.createDimension('y', y.size)\n",
+ "nc.createDimension('pressure', press.size)\n",
+ "nc"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "When we view our file's CDL representation now, we can verify that the dimensions were successfully added to the netCDF file:\n",
+ "```\n",
+ "netcdf forecast_model {\n",
+ " dimensions:\n",
+ " forecast_time = UNLIMITED (currently 13) ;\n",
+ " x = 101 ;\n",
+ " y = 67 ;\n",
+ " pressure = 7 ;\n",
+ " attributes:\n",
+ " :Conventions = \"CF-1.7\" ;\n",
+ " :title = \"Forecast model run\" ;\n",
+ " :institution = \"Unidata\" ;\n",
+ " :source = \"WRF-1.5\" ;\n",
+ " :history = \"2019-07-16 02:21:52.005718 Python\" ;\n",
+ " :references = \"\" ;\n",
+ " :comment = \"\" ;\n",
+ "}\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Creating and filling a variable"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Thus far, we have only added basic information to this netCDF dataset; namely, the dataset dimensions and some broad metadata. As described briefly above, variables are used to define data fields in netCDF files. Here, we create a `netCDF4 variable` to hold a data field; in this case, the forecast air temperature. In order to create this netCDF4 variable, we must specify the data type of the values in the data field. We also must specify which dimensions contained in the netCDF file are relevant to this data field. Finally, we can specify whether or not to compress the data using a form of `zlib`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temps_var = nc.createVariable(\n",
+ " 'Temperature',\n",
+ " datatype=np.float32,\n",
+ " dimensions=('forecast_time', 'pressure', 'y', 'x'),\n",
+ " zlib=True,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We have now created a netCDF4 variable, but it does not yet define a data field. In this example, we use Python to associate our temperature data with the new variable:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temps_var[:] = temps\n",
+ "temps_var"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can also associate data with a variable sporadically. This example illustrates how to only associate one value per time step with the variable created earlier:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "next_slice = 0\n",
+ "for temp_slice in temps:\n",
+ " temps_var[next_slice] = temp_slice\n",
+ " next_slice += 1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "At this point, this is the CDL representation of our dataset:\n",
+ "```\n",
+ "netcdf forecast_model {\n",
+ " dimensions:\n",
+ " forecast_time = UNLIMITED (currently 13) ;\n",
+ " x = 101 ;\n",
+ " y = 67 ;\n",
+ " pressure = 7 ;\n",
+ " variables:\n",
+ " float Temperature(forecast_time, pressure, y, x) ;\n",
+ " attributes:\n",
+ " :Conventions = \"CF-1.7\" ;\n",
+ " :title = \"Forecast model run\" ;\n",
+ " :institution = \"Unidata\" ;\n",
+ " :source = \"WRF-1.5\" ;\n",
+ " :history = \"2019-07-16 02:21:52.005718 Python\" ;\n",
+ " :references = \"\" ;\n",
+ " :comment = \"\" ;\n",
+ "}\n",
+ "```\n",
+ "We can also define metadata for this variable in the form of attributes; some specific attributes are required by the CF conventions. For example, the CF conventions require a `units` attribute to be set for all variables that represent a dimensional quantity. In addition, the value of this attribute must be parsable by the [UDUNITS](https://www.unidata.ucar.edu/software/udunits/) library. In this example, the temperatures are in Kelvin, so we set the units attribute to `'Kelvin'`. Next, we set the `long_name` and `standard_name` attributes, which are recommended for most datasets, but optional. The `long_name` attribute contains a longer and more detailed description of a variable. On the other hand, the `standard_name` attribute names a variable using descriptive words from a predefined word list contained in the CF conventions. Defining these attributes allows users of your datasets to understand what each variable in a dataset represents. Sometimes, data fields do not have valid data values at every dimension point. In this case, the standard is to use a filler value for these missing data values, and to set the `missing_value` attribute to this filler value. In this case, however, there are no missing values, so the `missing_value` attribute can be set to any unused value, or not set at all.\n",
+ "\n",
+ "There are many different sets of recommendations for attributes on netCDF variables. For example, here is NASA's set of recommended attributes:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "> **NASA Dataset Interoperability Recommendations:**\n",
+ ">\n",
+ "> Section 2.2 - Include Basic CF Attributes\n",
+ ">\n",
+ "> Include where applicable: `units`, `long_name`, `standard_name`, `valid_min` / `valid_max`, `scale_factor` / `add_offset` and others."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temps_var.units = 'Kelvin'\n",
+ "temps_var.standard_name = 'air_temperature'\n",
+ "temps_var.long_name = 'Forecast air temperature'\n",
+ "temps_var.missing_value = -9999\n",
+ "temps_var"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here is the variable section of our dataset's CDL, with the new attributes added:\n",
+ "```\n",
+ " variables:\n",
+ " float Temperature(forecast_time, pressure, y, x) ;\n",
+ " Temperature:units = \"Kelvin\" ;\n",
+ " Temperature:standard_name = \"air_temperature\" ;\n",
+ " Temperature:long_name = \"Forecast air temperature\" ;\n",
+ " Temperature:missing_value = -9999.0 ;\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Coordinate variables"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Dimensions in a netCDF file only define size and alignment metadata. In order to properly orient data in time and space, it is necessary to create \"coordinate variables\", which define data values along each dimension. A coordinate variable is typically created as a one-dimensional variable, and has the same name as the corresponding dimension.\n",
+ "\n",
+ "To start, we define variables which define our `x` and `y` coordinate values. It is recommended to include certain attributes for each coordinate variable. First, you should include a `standard_name`, which allows for associating the variable with projections, among other things. (Projections will be covered in detail later in this page.) Second, you can include an `axis` attribute, which clearly defines the spatial or temporal direction referred to by the coordinate variable. This next example demonstrates how to set up these attributes:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x_var = nc.createVariable('x', np.float32, ('x',))\n",
+ "x_var[:] = x\n",
+ "x_var.units = 'km'\n",
+ "x_var.axis = 'X' # Optional\n",
+ "x_var.standard_name = 'projection_x_coordinate'\n",
+ "x_var.long_name = 'x-coordinate in projected coordinate system'\n",
+ "\n",
+ "y_var = nc.createVariable('y', np.float32, ('y',))\n",
+ "y_var[:] = y\n",
+ "y_var.units = 'km'\n",
+ "y_var.axis = 'Y' # Optional\n",
+ "y_var.standard_name = 'projection_y_coordinate'\n",
+ "y_var.long_name = 'y-coordinate in projected coordinate system'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our dataset contains vertical data of air pressure as well, so we must define a coordinate variable for this axis; we can simply call this new variable `pressure`. Since this axis represents air pressure data, we can set a `standard_name` of `'air_pressure'`. With this `standard_name` attribute set, it should be obvious to users of this dataset that this variable represents a vertical axis, but for extra clarification, we also set the `axis` attribute as `'Z'`. We can also specify one more attribute, called `positive`. This attribute indicates whether the variable values increase or decrease as the dimension values increase. Setting this attribute is optional for some data; air pressure is one example. However, we still set the attribute here, for the sake of completeness."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "press_var = nc.createVariable('pressure', np.float32, ('pressure',))\n",
+ "press_var[:] = press\n",
+ "press_var.units = 'hPa'\n",
+ "press_var.axis = 'Z' # Optional\n",
+ "press_var.standard_name = 'air_pressure'\n",
+ "press_var.positive = 'down' # Optional"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Time coordinates must contain a `units` attribute; this attribute is a string value, and must have a form similar to the string`'seconds since 2019-01-06 12:00:00.00'`. 'seconds', 'minutes', 'hours', and 'days' are the most commonly used time intervals in these strings. It is not recommended to use 'months' or 'years' in time strings, as the length of these time intervals can vary.\n",
+ "\n",
+ "Before we can write data, we need to first convert our list of Python `datetime` objects to numeric values usable in time strings. We can perform this conversion by setting a time string in the format described above, then using the `date2num` method from the `cftime` library. An example of this is shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "time_units = f'hours since {times[0]:%Y-%m-%d 00:00}'\n",
+ "time_vals = date2num(times, time_units)\n",
+ "time_vals"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now that the time string is set up, we have all of the necessary information to set up the attributes for a `forecast_time` coordinate variable. The creation of this variable is shown in the following example:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "time_var = nc.createVariable('forecast_time', np.int32, ('forecast_time',))\n",
+ "time_var[:] = time_vals\n",
+ "time_var.units = time_units\n",
+ "time_var.axis = 'T' # Optional\n",
+ "time_var.standard_name = 'time' # Optional\n",
+ "time_var.long_name = 'time'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This next example shows the CDL representation of the netCDF file's variables at this point. It is clear that much more information is now contained in this representation:\n",
+ "```\n",
+ " dimensions:\n",
+ " forecast_time = UNLIMITED (currently 13) ;\n",
+ " x = 101 ;\n",
+ " y = 67 ;\n",
+ " pressure = 7 ;\n",
+ " variables:\n",
+ " float x(x) ;\n",
+ " x:units = \"km\" ;\n",
+ " x:axis = \"X\" ;\n",
+ " x:standard_name = \"projection_x_coordinate\" ;\n",
+ " x:long_name = \"x-coordinate in projected coordinate system\" ;\n",
+ " float y(y) ;\n",
+ " y:units = \"km\" ;\n",
+ " y:axis = \"Y\" ;\n",
+ " y:standard_name = \"projection_y_coordinate\" ;\n",
+ " y:long_name = \"y-coordinate in projected coordinate system\" ;\n",
+ " float pressure(pressure) ;\n",
+ " pressure:units = \"hPa\" ;\n",
+ " pressure:axis = \"Z\" ;\n",
+ " pressure:standard_name = \"air_pressure\" ;\n",
+ " pressure:positive = \"down\" ;\n",
+ " float forecast_time(forecast_time) ;\n",
+ " forecast_time:units = \"hours since 2019-07-16 00:00\" ;\n",
+ " forecast_time:axis = \"T\" ;\n",
+ " forecast_time:standard_name = \"time\" ;\n",
+ " forecast_time:long_name = \"time\" ;\n",
+ " float Temperature(forecast_time, pressure, y, x) ;\n",
+ " Temperature:units = \"Kelvin\" ;\n",
+ " Temperature:standard_name = \"air_temperature\" ;\n",
+ " Temperature:long_name = \"Forecast air temperature\" ;\n",
+ " Temperature:missing_value = -9999.0 ;\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Auxiliary Coordinates"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our data are still not CF-compliant, because they do not contain latitude and longitude information, which is needed to properly locate the data. In order to add location data to a netCDF file, we must create so-called \"auxiliary coordinate variables\" for latitude and longitude. (In this case, the word \"auxiliary\" means that the variables are not simple one-dimensional variables.)\n",
+ "\n",
+ "In this next example, we use the `Proj` function, found in the `pyproj` library, to create projections of our coordinates. We can then use these projections to generate latitude and longitude values for our data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "X, Y = np.meshgrid(x, y)\n",
+ "lcc = Proj({'proj': 'lcc', 'lon_0': -105, 'lat_0': 40, 'a': 6371000.0, 'lat_1': 25})\n",
+ "lon, lat = lcc(X * 1000, Y * 1000, inverse=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now that we have latitude and longitude values, we can create variables for those values. Both of these variables are two-dimensional; the dimensions in question are `y` and `x`. In order to convey that it contains the longitude information, we must set up the longitude variable with a `units` attribute of `'degrees_east'`. In addition, we can provide further clarity by setting a `standard_name` attribute of `'longitude'`. The case is the same for latitude, except the units are `'degrees_north'` and the `standard_name` is `'latitude'`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "lon_var = nc.createVariable('lon', np.float64, ('y', 'x'))\n",
+ "lon_var[:] = lon\n",
+ "lon_var.units = 'degrees_east'\n",
+ "lon_var.standard_name = 'longitude' # Optional\n",
+ "lon_var.long_name = 'longitude coordinate'\n",
+ "\n",
+ "lat_var = nc.createVariable('lat', np.float64, ('y', 'x'))\n",
+ "lat_var[:] = lat\n",
+ "lat_var.units = 'degrees_north'\n",
+ "lat_var.standard_name = 'latitude' # Optional\n",
+ "lat_var.long_name = 'latitude coordinate'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now that the auxiliary coordinate variables are created, we must identify them as coordinates for the `Temperature` variable. In order to identify the variables in this way, we set the `coordinates` attribute of the `Temperature` variable to a space-separated list of variables to identify, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temps_var.coordinates = 'lon lat'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The portion of the CDL showing the new latitude and longitude variables, as well as the updated `Temperature` variable, is listed below:\n",
+ "```\n",
+ " double lon(y, x);\n",
+ " lon:units = \"degrees_east\";\n",
+ " lon:long_name = \"longitude coordinate\";\n",
+ " lon:standard_name = \"longitude\";\n",
+ " double lat(y, x);\n",
+ " lat:units = \"degrees_north\";\n",
+ " lat:long_name = \"latitude coordinate\";\n",
+ " lat:standard_name = \"latitude\";\n",
+ " float Temperature(time, y, x);\n",
+ " Temperature:units = \"Kelvin\" ;\n",
+ " Temperature:standard_name = \"air_temperature\" ;\n",
+ " Temperature:long_name = \"Forecast air temperature\" ;\n",
+ " Temperature:missing_value = -9999.0 ;\n",
+ " Temperature:coordinates = \"lon lat\";\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Coordinate System Information"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Since the grid containing our data uses a Lambert conformal projection, adding this information to the dataset's metadata can clear up some possible confusion. We can most easily add this metadata information by making use of a \"grid mapping\" variable. A grid mapping variable is a \"placeholder\" variable containing all required grid-mapping information. Other variables that need to access this information can then reference this placeholder variable in their `grid_mapping` attribute.\n",
+ "\n",
+ "In this example, we create a grid-mapping variable; this new variable is then set up for a Lambert-conformal conic projection on a spherical globe. By setting this variable's `grid_mapping_name` attribute, we can indicate which CF-supported grid mapping this variable refers to. There are additional attributes that can also be set; however, the available options depend on the specific mapping."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "proj_var = nc.createVariable('lambert_projection', np.int32, ())\n",
+ "proj_var.grid_mapping_name = 'lambert_conformal_conic'\n",
+ "proj_var.standard_parallel = 25.0\n",
+ "proj_var.latitude_of_projection_origin = 40.0\n",
+ "proj_var.longitude_of_central_meridian = -105.0\n",
+ "proj_var.semi_major_axis = 6371000.0\n",
+ "proj_var"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now that we have created a grid-mapping variable, we can specify the grid mapping by setting the `grid_mapping attribute` to the variable name. In this example, we set the `grid_mapping` attribute on the `Temperature` variable:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temps_var.grid_mapping = 'lambert_projection' # or proj_var.name"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here is the portion of the CDL containing the modified `Temperature` variable, as well as the new grid-mapping `lambert_projection` variable:\n",
+ "```\n",
+ " variables:\n",
+ " int lambert_projection ;\n",
+ " lambert_projection:grid_mapping_name = \"lambert_conformal_conic ;\n",
+ " lambert_projection:standard_parallel = 25.0 ;\n",
+ " lambert_projection:latitude_of_projection_origin = 40.0 ;\n",
+ " lambert_projection:longitude_of_central_meridian = -105.0 ;\n",
+ " lambert_projection:semi_major_axis = 6371000.0 ;\n",
+ " float Temperature(forecast_time, pressure, y, x) ;\n",
+ " Temperature:units = \"Kelvin\" ;\n",
+ " Temperature:standard_name = \"air_temperature\" ;\n",
+ " Temperature:long_name = \"Forecast air temperature\" ;\n",
+ " Temperature:missing_value = -9999.0 ;\n",
+ " Temperature:coordinates = \"lon lat\" ;\n",
+ " Temperature:grid_mapping = \"lambert_projection\" ;\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Cell Bounds\n",
+ "\n",
+ "The use of \"bounds\" attributes is not required, but highly recommended. Here is a relevant excerpt from the NASA Dataset Interoperability Recommendations:\n",
+ "> **NASA Dataset Interoperability Recommendations:**\n",
+ ">\n",
+ "> Section 2.3 - Use CF \"bounds\" attributes\n",
+ ">\n",
+ "> CF conventions state: \"When gridded data does not represent the point values of a field but instead represents some characteristic of the field within cells of finite 'volume,' a complete description of the variable should include metadata that describes the domain or extent of each cell, and the characteristic of the field that the cell values represent.\"\n",
+ "\n",
+ "In this set of examples, consider a rain gauge which is read every three hours, but only dumped every six hours. The netCDF file for this gauge's data readings might look like this:\n",
+ " \n",
+ "```\n",
+ "netcdf precip_bucket_bounds {\n",
+ " dimensions:\n",
+ " lat = 12 ;\n",
+ " lon = 19 ;\n",
+ " time = 8 ;\n",
+ " tbv = 2;\n",
+ " variables:\n",
+ " float lat(lat) ;\n",
+ " float lon(lon) ;\n",
+ " float time(time) ;\n",
+ " time:units = \"hours since 2019-07-12 00:00:00.00\";\n",
+ " time:bounds = \"time_bounds\" ;\n",
+ " float time_bounds(time,tbv)\n",
+ " float precip(time, lat, lon) ;\n",
+ " precip:units = \"inches\" ;\n",
+ " data:\n",
+ " time = 3, 6, 9, 12, 15, 18, 21, 24;\n",
+ " time_bounds = 0, 3, 0, 6, 6, 9, 6, 12, 12, 15, 12, 18, 18, 21, 18, 24;\n",
+ "}\n",
+ "```\n",
+ "\n",
+ "Considering the coordinate variable for time, and the `bounds` attribute set for this variable, the below graph illustrates the times of the gauge's data readings:\n",
+ "```\n",
+ "|---X\n",
+ "|-------X\n",
+ " |---X\n",
+ " |-------X\n",
+ " |---X\n",
+ " |-------X\n",
+ " |---X\n",
+ " |-------X\n",
+ "0 3 6 9 12 15 18 21 24\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "## Observational Data\n",
+ "\n",
+ "Thus far, we have only worked with data arranged on grids. One common type of data, called \"in-situ\" or \"observational\" data, is usually arranged in other ways. The CF conventions for this type of data are called *Conventions for DSG (Discrete Sampling Geometries)*.\n",
+ "\n",
+ "For data that are regularly sampled (e.g., from a vertical profiler site), this is straightforward. For these examples, we will be using vertical profile data from three hypothetical profilers, located in Boulder, Norman, and Albany. These hypothetical profilers report data for every 10 m of altitude, from altitudes of 10 m up to (but not including) 1000 m. This first example illustrates how to set up latitude, longitude, altitude, and other necessary data for these profilers:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "lons = np.array([-97.1, -105, -73.8])\n",
+ "lats = np.array([35.25, 40, 42.75])\n",
+ "heights = np.linspace(10, 1000, 10)\n",
+ "temps = np.random.randn(lats.size, heights.size)\n",
+ "stids = ['KBOU', 'KOUN', 'KALB']"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Creation and basic setup\n",
+ "First, we create a new netCDF file, and define dimensions for it, corresponding to altitude and latitude. Since we are working with observational profile data, we define these dimensions as `heights` and `station`. We then set the global `featureType` attribute to `'profile'`, which defines the file as holding profile data. In these examples, the term \"profile data\" is defined as \"an ordered set of data points along a vertical line at a fixed horizontal position and fixed time\". In addition, we define a placeholder dimension called str_len, which helps with storing station IDs as strings."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nc.close()\n",
+ "nc = Dataset('obs_data.nc', 'w', format='NETCDF4_CLASSIC', diskless=True)\n",
+ "nc.createDimension('station', lats.size)\n",
+ "nc.createDimension('heights', heights.size)\n",
+ "nc.createDimension('str_len', 4)\n",
+ "nc.Conventions = 'CF-1.7'\n",
+ "nc.featureType = 'profile'\n",
+ "nc"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "After this initial setup, the current state of our netCDF file is described in the following CDL:\n",
+ "```\n",
+ "netcdf obs_data {\n",
+ " dimensions:\n",
+ " station = 3 ;\n",
+ " heights = 10 ;\n",
+ " str_len = 4 ;\n",
+ " attributes:\n",
+ " :Conventions = \"CF-1.7\" ;\n",
+ " :featureType = \"profile\" ;\n",
+ "}\n",
+ "```\n",
+ "This example illustrates the setup of coordinate variables for latitude and longitude:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "lon_var = nc.createVariable('lon', np.float64, ('station',))\n",
+ "lon_var.units = 'degrees_east'\n",
+ "lon_var.standard_name = 'longitude'\n",
+ "\n",
+ "lat_var = nc.createVariable('lat', np.float64, ('station',))\n",
+ "lat_var.units = 'degrees_north'\n",
+ "lat_var.standard_name = 'latitude'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "When a coordinate variable refers to an instance of a feature, netCDF standards refer to it as an \"instance variable\". The latitude and longitude coordinate variables declared above are examples of instance variables. In this next example, we create an instance variable for altitude, referred to here as `heights`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "heights_var = nc.createVariable('heights', np.float32, ('heights',))\n",
+ "heights_var.units = 'meters'\n",
+ "heights_var.standard_name = 'altitude'\n",
+ "heights_var.positive = 'up'\n",
+ "heights_var[:] = heights"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Station IDs\n",
+ "Using the placeholder dimension defined earlier, we can write the station IDs of our profilers to a variable as well. The variable used to store these station IDs is two-dimensional; however, one of these dimensions only holds metadata designed to aid in converting strings to character arrays. We can also assign the attribute `cf_role` to this variable, with a value of `'profile_id'`. If certain software programs read this netCDF file, this attribute assists in identifying individual profiles."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "stid_var = nc.createVariable('stid', 'c', ('station', 'str_len'))\n",
+ "stid_var.cf_role = 'profile_id'\n",
+ "stid_var.long_name = 'Station identifier'\n",
+ "stid_var[:] = stids"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "After adding station ID information, our file's updated CDL should resemble this example:\n",
+ "```\n",
+ "netcdf obs_data {\n",
+ " dimensions:\n",
+ " station = 3 ;\n",
+ " heights = 10 ;\n",
+ " str_len = 4 ;\n",
+ " variables:\n",
+ " double lon(station) ;\n",
+ " lon:units = \"degrees_east\" ;\n",
+ " lon:standard_name = \"longitude\" ;\n",
+ " double lat(station) ;\n",
+ " lat:units = \"degrees_north\" ;\n",
+ " lat:standard_name = \"latitude\" ;\n",
+ " float heights(heights) ;\n",
+ " heights:units = \"meters\" ;\n",
+ " heights:standard_name = \"altitude\";\n",
+ " heights:positive = \"up\" ;\n",
+ " char stid(station, str_len) ;\n",
+ " stid:cf_role = \"profile_id\" ;\n",
+ " stid:long_name = \"Station identifier\" ;\n",
+ " attributes:\n",
+ " :Conventions = \"CF-1.7\" ;\n",
+ " :featureType = \"profile\" ;\n",
+ "}\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Writing the field\n",
+ "The final setup step for this netCDF file is to write our actual profile data to the file. In addition, we add an additional scalar variable, which holds the time of data capture for each profile:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "time_var = nc.createVariable('time', np.float32, ())\n",
+ "time_var.units = 'minutes since 2019-07-16 17:00'\n",
+ "time_var.standard_name = 'time'\n",
+ "time_var[:] = [5.0]\n",
+ "\n",
+ "temp_var = nc.createVariable('temperature', np.float32, ('station', 'heights'))\n",
+ "temp_var.units = 'celsius'\n",
+ "temp_var.standard_name = 'air_temperature'\n",
+ "temp_var.coordinates = 'lon lat heights time'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The auxiliary coordinate variables in this netCDF file are not proper coordinate variables, and are all associated with the `station` dimension. Therefore, the names of these variables must be listed in an attribute called `coordinates`. The final CDL of the variables, including the `coordinates` attribute, is shown below:\n",
+ "```\n",
+ " variables:\n",
+ " double lon(station) ;\n",
+ " lon:units = \"degrees_east\" ;\n",
+ " lon:standard_name = \"longitude\" ;\n",
+ " double lat(station) ;\n",
+ " lat:units = \"degrees_north\" ;\n",
+ " lat:standard_name = \"latitude\" ;\n",
+ " float heights(heights) ;\n",
+ " heights:units = \"meters\" ;\n",
+ " heights:standard_name = \"altitude\";\n",
+ " heights:positive = \"up\" ;\n",
+ " char stid(station, str_len) ;\n",
+ " stid:cf_role = \"profile_id\" ;\n",
+ " stid:long_name = \"Station identifier\" ;\n",
+ " float time ;\n",
+ " time:units = \"minutes since 2019-07-16 17:00\" ;\n",
+ " time:standard_name = \"time\" ;\n",
+ " float temperature(station, heights) ;\n",
+ " temperature:units = \"celsius\" ;\n",
+ " temperature:standard_name = \"air_temperature\" ;\n",
+ " temperature:coordinates = \"lon lat heights time\" ;\n",
+ "```\n",
+ "\n",
+ "These standards for storing DSG data in netCDF files can be used for profiler data, as shown in these examples, as well as timeseries and trajectory data, and any combination of these types of data models. You can also use these standards for datasets with differing amounts of data in each feature, using so-called \"ragged\" arrays. For more information on ragged arrays, or other elements of the CF DSG standards, see the [main documentation page](http://cfconventions.org/Data/cf-conventions/cf-conventions-1.7/cf-conventions.html#discrete-sampling-geometries), or try some of the [annotated DSG examples](http://cfconventions.org/Data/cf-conventions/cf-conventions-1.7/cf-conventions.html#appendix-examples-discrete-geometries)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "We have created examples of and discussed the structure of **netCDF** `Datasets`, both gridded and in-situ. In addition, we covered the Climate and Forecasting (**CF**) Conventions, and the setup of netCDF files that follow these conventions. netCDF `Datasets` are self-describing; in other words, their attributes, or *metadata*, are included. Other libraries in the Python scientific software ecosystem, such as `xarray` and `MetPy`, are therefore easily able to read in, write to, and analyze these `Datasets`.\n",
+ "\n",
+ "### What's Next?\n",
+ "In subsequent notebooks, we will work with netCDF `Datasets` built from actual, non-example data sources, both model and in-situ."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "## Resources and References\n",
+ "\n",
+ "- [CF Conventions doc (1.7)](http://cfconventions.org/Data/cf-conventions/cf-conventions-1.7/cf-conventions.html)\n",
+ "- [Jonathan Gregory's old CF presentation](http://cfconventions.org/Data/cf-documents/overview/viewgraphs.pdf)\n",
+ "- [NASA ESDS \"Dataset Interoperability Recommendations for Earth Science\"](https://earthdata.nasa.gov/user-resources/standards-and-references/dataset-interoperability-recommendations-for-earth-science)\n",
+ "- [CF Data Model (cfdm) python package tutorial](https://ncas-cms.github.io/cfdm/tutorial.html)\n",
+ "- [Tim Whiteaker's cfgeom python package (GitHub repo)](https://github.com/twhiteaker/CFGeom) and [(tutorial)]( https://twhiteaker.github.io/CFGeom/tutorial.html)\n",
+ "- [netCDF4 Documentation](https://unidata.github.io/netcdf4-python/)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/_preview/468/_sources/core/datetime.md b/_preview/468/_sources/core/datetime.md
new file mode 100644
index 000000000..185df93ec
--- /dev/null
+++ b/_preview/468/_sources/core/datetime.md
@@ -0,0 +1,14 @@
+# Datetime
+
+```{note}
+This content is under construction!
+```
+
+This section contains tutorials on dealing with times and calendars in scientific Python. The first and most basic of these tutorials covers the standard Python library known as [datetime](https://docs.python.org/3/library/datetime.html).
+
+When this chapter is fully built out, it will include a comprehensive guide to different time libraries, where to use them, and when they might be useful. This set of time libraries includes these libraries, among others:
+
+- [Numpy `datetime64`](https://numpy.org/doc/stable/reference/arrays.datetime.html) (for efficient vectorized date and time operations)
+- [cftime library](https://unidata.github.io/cftime/) (for dealing with dates and times in non-standard calendars)
+
+These tutorials will be cross-referenced with other tutorials on time-related topics, such as dealing with timeseries data in [Pandas](pandas) and [Xarray](xarray).
diff --git a/_preview/468/_sources/core/datetime/datetime.ipynb b/_preview/468/_sources/core/datetime/datetime.ipynb
new file mode 100644
index 000000000..4ce443e78
--- /dev/null
+++ b/_preview/468/_sources/core/datetime/datetime.ipynb
@@ -0,0 +1,562 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Times and Dates in Python"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Overview\n",
+ "\n",
+ "Time is an essential component of nearly all geoscience data. Timescales commonly used in science can have many different orders of magnitude, from mere microseconds to millions or even billions of years. Some of these magnitudes are listed below:\n",
+ "\n",
+ "- microseconds for lightning\n",
+ "- hours for a supercell thunderstorm\n",
+ "- days for a global weather model\n",
+ "- millennia and beyond for the earth's climate\n",
+ "\n",
+ "To properly analyze geoscience data, you must have a firm understanding of how to handle time in Python. \n",
+ "\n",
+ "In this notebook, we will:\n",
+ "\n",
+ "1. Introduce the [time](https://docs.python.org/3/library/time.html) and [datetime](https://docs.python.org/3/library/datetime.html) modules from the Python Standard Library\n",
+ "1. Look at formatted input and output of dates and times\n",
+ "1. See how we can do simple arithmetic on date and time data, by making use of the `timedelta` object\n",
+ "1. Briefly make use of the [pytz](https://pypi.org/project/pytz/) module to handle some thorny time zone issues in Python."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Prerequisites\n",
+ "\n",
+ "| Concepts | Importance | Notes |\n",
+ "| --- | --- | --- |\n",
+ "| [Python Quickstart](../../foundations/quickstart) | Necessary | Understanding strings |\n",
+ "| Basic Python string formatting | Helpful | Try this [Real Python string formatting tutorial](https://realpython.com/python-string-formatting/) |\n",
+ "\n",
+ "- **Time to learn**: 30 minutes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Imports\n",
+ "\n",
+ "For the examples on this page, we import three modules from the Python Standard Library, as well as one third-party module. The import syntax used here, as well as a discussion on this syntax and an overview of these modules, can be found in the next section."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Python Standard Library packages\n",
+ "# We'll discuss below WHY we alias the packages this way\n",
+ "import datetime as dt\n",
+ "import math\n",
+ "import time as tm\n",
+ "\n",
+ "# Third-party package for time zone handling, we'll discuss below!\n",
+ "import pytz"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## `Time` Versus `Datetime` modules \n",
+ "\n",
+ "### Some core terminology\n",
+ "\n",
+ "Every Python installation comes with a Standard Library, which includes many helpful modules; in these examples, we cover the [time](https://docs.python.org/3/library/time.html) and [datetime](https://docs.python.org/3/library/datetime.html) modules. Unfortunately, the use of dates and times in Python can be disorienting. There are many different terms used in Python relating to dates and times, and many such terms apply to multiple scopes, such as modules, classes, and functions. For example:\n",
+ "\n",
+ "- `datetime` **module** has a `datetime` **class**\n",
+ "- `datetime` **module** has a `time` **class**\n",
+ "- `datetime` **module** has a `date` **class**\n",
+ "- `time` **module** has a `time` function, which returns (almost always) [Unix time](#What-is-Unix-Time?)\n",
+ "- `datetime` **class** has a `date` method, which returns a `date` object\n",
+ "- `datetime` **class** has a `time` method, which returns a `time` object\n",
+ "\n",
+ "This confusion can be partially alleviated by aliasing our imported modules, we did above:\n",
+ "\n",
+ "```\n",
+ "import datetime as dt\n",
+ "import time as tm\n",
+ "```\n",
+ "\n",
+ "We can now reference the `datetime` module (aliased to `dt`) and `datetime` class unambiguously."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pisecond = dt.datetime(2021, 3, 14, 15, 9, 26)\n",
+ "print(pisecond)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Our variable `pisecond` now stores a particular date and time, which just happens to be $\\pi$-day 2021 down to the nearest second (3.1415926...)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "now = tm.time()\n",
+ "print(now)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The variable `now` holds the current time in seconds since January 1, 1970 00:00 UTC. For more information on this important, but seemingly esoteric time format, see the section on this page called \"[What is Unix Time](#What-is-Unix-Time?)\". In addition, if you are not familiar with UTC, there is a section on this page called \"[What is UTC](#What-is-UTC?)\"."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### `time` module\n",
+ "\n",
+ "The `time` module is well-suited for measuring [Unix time](#What-is-Unix-Time?). For example, when you are calculating how long it takes a Python function to run, you can employ the `time()` function, which can be found in the `time` module, to obtain Unix time before and after the function completes. You can then take the difference of those two times to determine how long the function was running. (Measuring the runtime of a block of code this way is known as \"benchmarking\".)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "start = tm.time()\n",
+ "tm.sleep(1) # The sleep function will stop the program for n seconds\n",
+ "end = tm.time()\n",
+ "diff = end - start\n",
+ "print(f\"The benchmark took {diff} seconds\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " This plain-text representation is known as netCDF Common Data Format Language, or CDL.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### What is Unix Time?\n",
+ "\n",
+ "Unix time is an example of system time, which is how a computer tracks the passage of time. Computers do not inherently know human representations of time; as such, they store time as a large binary number, indicating a number of time units after a set date and time. This is much easier for a computer to keep track of. In the case of Unix time, the time unit is seconds, and the set date and time is the epoch. Therefore, Unix time is the number of seconds since the epoch. The epoch is defined as January 1, 1970 00:00 [UTC](#What-is-UTC?). This is quite confusing for humans, but again, computers store time in a way that makes sense for them. It is represented \"under the hood\" as a [floating point number](https://en.wikipedia.org/wiki/Floating_point) which is how computers represent real (ℝ) numbers."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### `datetime` module\n",
+ "\n",
+ "The `datetime` module handles time with the Gregorian calendar (the calendar we, as humans, are familiar with); it is independent of Unix time. The `datetime` module uses an [object-oriented](#Thirty-second-introduction-to-Object-Oriented-programming) approach; it contains the `date`, `time`, `datetime`, `timedelta`, and `tzinfo` classes.\n",
+ "\n",
+ "- `date` class represents the day, month, and year\n",
+ "- `time` class represents the time of day\n",
+ "- `datetime` class is a combination of the `date` and `time` classes\n",
+ "- `timedelta` class represents a time duration\n",
+ "- `tzinfo` class represents time zones, and is an abstract class.\n",
+ "\n",
+ "The `datetime` module is effective for:\n",
+ "\n",
+ "- performing date and time arithmetic and calculating time duration\n",
+ "- reading and writing date and time strings with various formats\n",
+ "- handling time zones (with the help of third-party libraries)\n",
+ "\n",
+ "The `time` and `datetime` modules overlap in functionality, but in your geoscientific work, you will probably be using the `datetime` module more than the `time` module."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We'll delve into more details below, but here's a quick example of writing out our `pisecond` datetime object as a formatted string. Suppose we wanted to write out just the date, and write it in the _month/day/year_ format typically used in the US. We can do this using the `strftime()` method. This method formats datetime objects using format specifiers. An example of its usage is shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print('Pi day occurred on:', pisecond.strftime(format='%m/%d/%Y'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Reading and writing dates and times\n",
+ "\n",
+ "### Parsing lightning data timestamps with the `datetime.strptime` method\n",
+ "\n",
+ "In this example, we are analyzing [US NLDN lightning data](https://ghrc.nsstc.nasa.gov/uso/ds_docs/vaiconus/vaiconus_dataset.html). Here is a sample row of data:\n",
+ "\n",
+ " 06/27/07 16:18:21.898 18.739 -88.184 0.0 kA 0 1.0 0.4 2.5 8 1.2 13 G\n",
+ "\n",
+ "Part of the task involves parsing the `06/27/07 16:18:21.898` time string into a `datetime` object. (Although it is outside the scope of this page's tutorial, a full description of this lightning data format can be found [here](https://ghrc.nsstc.nasa.gov/uso/ds_docs/vaiconus/vaiconus_dataset.html#a6).) In order to parse this string or others that follow the same format, you will need to employ the [datetime.strptime()](https://docs.python.org/3/library/datetime.html#datetime.datetime.strptime) method from the `datetime` module. This method takes two arguments: \n",
+ "1. the date/time string you wish to parse\n",
+ "2. the format which describes exactly how the date and time are arranged. \n",
+ "\n",
+ "[The full range of formatting options for strftime() and strptime() is described in the Python documentation](https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior). In most cases, finding the correct formatting options inherently takes some degree of experimentation to get right. This is a situation where Python shines; you can use the IPython interpreter, or a Jupyter notebook, to quickly test numerous formatting options. Beyond the official documentation, Google and Stack Overflow are your friends in this process. \n",
+ "\n",
+ "After some trial and error (as described above), you can find that, in this example, the format string `'%m/%d/%y %H:%M:%S.%f'` will convert the date and time in the data to the correct format."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "strike_time = dt.datetime.strptime('06/27/07 16:18:21.898', '%m/%d/%y %H:%M:%S.%f')\n",
+ "# print strike_time to see if we have properly parsed our time\n",
+ "print(strike_time)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example usage of the `datetime` object\n",
+ "\n",
+ "Why did we bother doing this? This is a deceptively simple example; it may appear that we only took the string `06/27/07 16:18:21.898` and reformatted it to `2007-06-27 16:18:21.898000`.\n",
+ "\n",
+ "However, our new variable, `strike_time`, is in fact a `datetime` object that we can manipulate in many useful ways. \n",
+ "\n",
+ "Here are a few quick examples of the advantages of a datetime object:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Controlling the output format with `strftime()`\n",
+ "\n",
+ "The following example shows how to write out the time only, without a date, in a particular format:\n",
+ "```\n",
+ "16h 18m 21s\n",
+ "```\n",
+ "\n",
+ "We can do this with the [datetime.strftime()](https://docs.python.org/2/library/datetime.html#datetime.date.strftime) method, which takes a format identical to the one we employed for `strptime()`. After some trial and error from the IPython interpreter, we arrive at `'%Hh %Mm %Ss'`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(strike_time.strftime(format='%Hh %Mm %Ss'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### A simple query of just the year:\n",
+ "\n",
+ "Here's a useful shortcut that doesn't even need a format specifier:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "strike_time.year"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This works because the `datetime` object stores the data as individual attributes: \n",
+ "`year`, `month`, `day`, `hour`, `minute`, `second`, `microsecond`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### See how many days have elapsed since the strike:\n",
+ "\n",
+ "This example shows how to find the number of days since an event; in this case, the lightning strike described earlier:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "(dt.datetime.now() - strike_time).days"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The above example illustrates some simple arithmetic with `datetime` objects. This commonly-used feature will be covered in more detail in the next section."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Calculating coastal tides with the `timedelta` class\n",
+ "\n",
+ "In these examples, we will look at current data pertaining to coastal tides during a [tropical cyclone storm surge](http://www.nhc.noaa.gov/surge/).\n",
+ "\n",
+ "The [lunar day](http://oceanservice.noaa.gov/education/kits/tides/media/supp_tide05.html) is 24 hours and 50 minutes; there are two low tides and two high tides in that time duration. If we know the time of the current high tide, we can easily calculate the occurrence of the next low and high tides by using the [timedelta class](https://docs.python.org/3/library/datetime.html#timedelta-objects). (In reality, the *exact time* of tides is influenced by local coastal effects, in addition to the laws of celestial mechanics, but we will ignore that fact for this exercise.)\n",
+ "\n",
+ "The `timedelta` class is initialized by supplying time duration, usually supplied with [keyword arguments](https://docs.python.org/3/glossary.html#term-argument), to clearly express the length of time. The `timedelta` class allows you to perform arithmetic with dates and times using standard operators (i.e., `+`, `-`, `*`, `/`). You can use these operators with a `timedelta` object, and either another `timedelta` object, a datetime object, or a numeric literal, to obtain objects representing new dates and times.\n",
+ "\n",
+ "This convenient language feature is known as [operator overloading](https://en.wikipedia.org/wiki/Operator_overloading), and is another example of Python offering built-in functionality to make programming easier. (In some other languages, such as Java, you would have to call a method to perform such operations, which significantly obfuscates the code.) \n",
+ "\n",
+ "In addition, you can use these arithmetic operators with two datetime objects, as shown above with [lightning-strike data](#See-how-many-days-have-elapsed-since-the-strike:), to create `timedelta` objects. Let's examine all these features in the following code block."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "high_tide = dt.datetime(2016, 6, 1, 4, 38, 0)\n",
+ "lunar_day = dt.timedelta(hours=24, minutes=50)\n",
+ "tide_duration = lunar_day / 4 # Here we do some arithmetic on the timedelta object!\n",
+ "next_low_tide = (\n",
+ " high_tide + tide_duration\n",
+ ") # Here we add a timedelta object to a datetime object\n",
+ "next_high_tide = high_tide + (2 * tide_duration) # and so on\n",
+ "tide_length = next_high_tide - high_tide\n",
+ "print(f\"The time between high and low tide is {tide_duration}.\")\n",
+ "print(f\"The current high tide is {high_tide}.\")\n",
+ "print(f\"The next low tide is {next_low_tide}.\")\n",
+ "print(f\"The next high tide {next_high_tide}.\")\n",
+ "print(f\"The tide length is {tide_length}.\")\n",
+ "print(f\"The type of the 'tide_length' variable is {type(tide_length)}.\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "To illustrate that the difference of two times yields a `timedelta` object, we can use a built-in Python function called `type()`, which returns the type of its argument. In the above example, we call `type()` in the last `print` statement, and it returns the type of `timedelta`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Dealing with Time Zones\n",
+ "\n",
+ "Time zones can be a source of confusion and frustration in geoscientific data and in computer programming in general. Core date and time libraries in various programming languages, including Python, inevitably have design flaws, relating to time zones, date and time formatting, and other inherently complex issues. Third-party libraries are often created to fix the limitations of the core libraries, but this approach is frequently unsuccessful. To avoid time-zone-related issues, it is best to handle data in UTC; if data cannot be handled in UTC, efforts should be made to consistently use the same time zone for all data. However, this is not always possible; events such as severe weather are expected to be reported in a local time zone, which is not always consistent.\n",
+ "\n",
+ "### What is UTC?\n",
+ "\n",
+ "\"[UTC](https://en.wikipedia.org/wiki/Coordinated_Universal_Time)\" is a combination of the French and English abbreviations for Coordinated Universal Time. It is, in practice, equivalent to Greenwich Mean Time (GMT), the time zone at 0 degrees longitude. (The prime meridian, 0 degrees longitude, runs through Greenwich, a district of London, England.) In geoscientific data, times are often in UTC, although you should always verify that this is actually true to avoid time zone issues.\n",
+ "\n",
+ "### Time Zone Naive Versus Time Zone Aware `datetime` Objects\n",
+ "\n",
+ "When you create `datetime` objects in Python, they are \"time zone naive\", or, if the subject of time zones is assumed, simply \"naive\". This means that they are unaware of the time zone of the date and time they represent; time zone naive is the opposite of time zone aware. In many situations, you can happily go forward without this detail getting in the way of your work. As the [Python documentation states](https://docs.python.org/3/library/datetime.html#aware-and-naive-objects):\n",
+ ">Naive objects are easy to understand and to work with, at the cost of ignoring some aspects of reality. \n",
+ "\n",
+ "However, if you wish to convey time zone information, you will have to make your `datetime` objects time zone aware. The `datetime` library is able to easily convert the time zone to UTC, also converting the object to a time zone aware state, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "naive = dt.datetime.now()\n",
+ "aware = dt.datetime.now(dt.timezone.utc)\n",
+ "print(f\"I am time zone naive {naive}.\")\n",
+ "print(f\"I am time zone aware {aware}.\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Notice that `aware` has `+00:00` appended at the end, indicating zero hours offset from UTC.\n",
+ "\n",
+ "Our `naive` object shows the local time on whatever computer was used to run this code. If you're reading this online, chances are the code was executed on a cloud server that already uses UTC. If this is the case, `naive` and `aware` will differ only at the microsecond level, due to round-off error.\n",
+ "\n",
+ "In the code above, we used `dt.timezone.utc` to initialize the UTC timezone for our `aware` object. Unfortunately, at this time, the Python Standard Library does not fully support initializing datetime objects with arbitrary time zones; it also does not fully support conversions between time zones for datetime objects. However, there exist third-party libraries that provide some of this functionality; one such library is covered below."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Full time zone support with the `pytz` module\n",
+ "\n",
+ "For improved handling of time zones in Python, you will need the third-party [pytz](https://pypi.org/project/pytz/) module, whose classes build upon, or, in object-oriented programming terms, inherit from, classes from the `datetime` module.\n",
+ "\n",
+ "In this next example, we repeat the above exercise, but this time, we use a method from the `pytz` module to initialize the `aware` object in a different time zone:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "naive = dt.datetime.now()\n",
+ "aware = dt.datetime.now(pytz.timezone('US/Mountain'))\n",
+ "print(f\"I am time zone naive: {naive}.\")\n",
+ "print(f\"I am time zone aware: {aware}.\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The `pytz.timezone()` method takes a time zone string; if this string is formatted correctly, the method returns a `tzinfo` object, which can be used when making a datetime object time zone aware. This initializes the time zone for the newly aware object to a specific time zone matching the time zone string. The `-06:00` indicates that we are now operating in a time zone six hours behind UTC.\n",
+ "\n",
+ "### Print Time with a Different Time Zone\n",
+ "\n",
+ "If you have data that are in UTC, and wish to convert them to another time zone (in this example, US Mountain Time Zone), you will again need to make use of the `pytz` module.\n",
+ "\n",
+ "First, we will create a new datetime object with the [utcnow()](https://docs.python.org/3/library/datetime.html#datetime.datetime.utcnow) method. Despite the name of this method, the newly created object is time zone naive. Therefore, we must invoke the object's [replace()](https://docs.python.org/3/library/datetime.html#datetime.datetime.replace) method and specify UTC with a `tzinfo` object in order to make the object time zone aware. As described above, we can use the `pytz` module's timezone() method to create a new `tzinfo` object, again using the time zone string 'US/Mountain' (US Mountain Time Zone). To convert the datetime object `utc` from UTC to Mountain Time, we can then run the [astimezone()](https://docs.python.org/3/library/datetime.html#datetime.datetime.astimezone) method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "utc = dt.datetime.utcnow().replace(tzinfo=pytz.utc)\n",
+ "print(\"The UTC time is {}.\".format(utc.strftime('%B %d, %Y, %-I:%M%p')))\n",
+ "mountaintz = pytz.timezone(\"US/Mountain\")\n",
+ "ny = utc.astimezone(mountaintz)\n",
+ "print(\"The 'US/Mountain' time is {}.\".format(ny.strftime('%B %d, %Y, %-I:%M%p')))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In the above example, we also use the `strftime()` method to format the date and time string in a human-friendly format."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "\n",
+ "The Python Standard Library contains several modules for dealing with date and time data. We saw how we can avoid some name ambiguities by aliasing the module names; this can be done with import statements like `import datetime as dt` and `import time as tm`. The `tm.time()` method just returns the current [Unix time](#What-is-Unix-Time?) in seconds -- which can be useful for measuring elapsed time, but not all that useful for working with geophysical data.\n",
+ "\n",
+ "The `datetime` module contains various classes for storing, converting, comparing, and formatting date and time data on the Gregorian calendar. We saw how we can parse data files with date and time strings into `dt.datetime` objects using the `dt.datetime.strptime()` method. We also saw how to perform arithmetic using date and time data; this uses the `dt.timedelta` class to represent intervals of time.\n",
+ "\n",
+ "Finally, we looked at using the third-party [pytz](https://pypi.org/project/pytz/) module to handle time zone awareness and conversions.\n",
+ "\n",
+ "### What's Next?\n",
+ "\n",
+ "In subsequent tutorials, we will dig deeper into different time and date formats, and discuss how they are handled by important Python modules such as Numpy, Pandas, and Xarray."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Resources and References\n",
+ "\n",
+ "This page was based on and adapted from material in [Unidata's Python Training](https://unidata.github.io/python-training/python/times_and_dates/).\n",
+ "\n",
+ "For further reading on these modules, take a look at the official documentation for:\n",
+ "- [time](https://docs.python.org/3/library/time.html)\n",
+ "- [datetime](https://docs.python.org/3/library/datetime.html)\n",
+ "- [pytz](https://pypi.org/project/pytz/)\n",
+ "\n",
+ "For more information on Python string formatting, try:\n",
+ "- [Python string documentation](https://docs.python.org/3/library/string.html)\n",
+ "- RealPython's [string formatting tutorial](https://realpython.com/python-string-formatting/) (nicely written)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/_preview/468/_sources/core/matplotlib.md b/_preview/468/_sources/core/matplotlib.md
new file mode 100644
index 000000000..5312e9bdf
--- /dev/null
+++ b/_preview/468/_sources/core/matplotlib.md
@@ -0,0 +1,29 @@
+
+
+# Matplotlib
+
+[Matplotlib](https://matplotlib.org) is the go-to library for plotting within Python. Numerous packages and libraries build off of Matplotlib, making it the de facto standard Python plotting package. If you were to learn a single plotting tool to keep in your toolbox, this is it.
+
+## Why Matplotlib?
+
+Matplotlib is a plotting library for Python and is often the first plotting package Python learners encounter. You may be wondering, "Why learn Matplotlib? Why not [Seaborn](https://seaborn.pydata.org) or another plotting library first?"
+
+The simple answer to the much-asked question of "why Matplotlib?" is that it is extremely popular; in fact, Matplotlib is one of the most popular Python packages. Because of its history as Python's "go-to" plotting package, most other open source plotting libraries, including Seaborn, are built on top of Matplotlib; thus, these more specialized plotting packages inherit some of Matplotlib's capabilities, syntax, and limitations. Thus, you will find it useful to be familiar with Matplotlib when learning other plotting libraries.
+
+Matplotlib supports a variety of output formats, chart types, and interactive options, and runs well on most operating systems and graphic backends. The key features of Matplotlib are its extensibility and the [extensive documentation](https://matplotlib.org) available to the community. All of these things contribute to Matplotlib's popularity, which is the answer to the question of "Why Matplotlib", and the reason Matplotlib is the first plotting package we will introduce you to in this book.
+
+## In this section
+
+In this section of Pythia Foundations, you will find tutorials on basic plotting with [Matplotlib](https://matplotlib.org).
+
+From the [Matplotlib documentation](https://matplotlib.org), "Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python."
+
+Currently, Pythia Foundations provides a basic introduction to Matplotlib, as well as:
+
+- Histograms
+- Piecharts
+- Animations
+- Annotations
+- Colorbars
+- Contour plots
+- Customizing layouts
diff --git a/_preview/468/_sources/core/matplotlib/annotations-colorbars-layouts.ipynb b/_preview/468/_sources/core/matplotlib/annotations-colorbars-layouts.ipynb
new file mode 100644
index 000000000..691cd8ab9
--- /dev/null
+++ b/_preview/468/_sources/core/matplotlib/annotations-colorbars-layouts.ipynb
@@ -0,0 +1,687 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "a2d0abc7-ffd8-483e-87ae-bb169c5bcecf",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2583ef82-33dc-4df5-9f6d-f357d72f0b81",
+ "metadata": {},
+ "source": [
+ "# Annotations, Colorbars, and Advanced Layouts\n",
+ "\n",
+ "---\n",
+ "## Overview\n",
+ "\n",
+ "In this section we explore methods for customizing plots. The following topics will be covered:\n",
+ "\n",
+ "1. Adding annotations\n",
+ "1. Rendering equations\n",
+ "1. Colormap overview \n",
+ "1. Basic colorbars \n",
+ "1. Shared colorbars\n",
+ "1. Custom colorbars\n",
+ "1. Mosaic subplots"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "94250818-a557-4717-ae71-6aa45b9f212b",
+ "metadata": {},
+ "source": [
+ "## Prerequisites\n",
+ "\n",
+ "\n",
+ "| Concepts | Importance |\n",
+ "| --- | --- |\n",
+ "| [NumPy Basics](../numpy/numpy-basics) | Necessary |\n",
+ "| [Matplotlib Basics](matplotlib-basics) | Necessary |\n",
+ "\n",
+ "- **Time to learn**: *30-40 minutes*"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9deb8579-2995-46b4-a82f-1ab79a67155c",
+ "metadata": {},
+ "source": [
+ "## Imports\n",
+ "Here, we import the `matplotlib.pyplot` interface and `numpy`, in addition to the `scipy` statistics package (`scipy.stats`) for generating sample data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "00b72a52-d8e5-48e1-ac4c-35c2e3217de5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
+ "import scipy.stats as stats\n",
+ "from matplotlib.colors import LinearSegmentedColormap, ListedColormap, Normalize"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a4a423a8-5692-448f-aa78-3d16d3ace19d",
+ "metadata": {},
+ "source": [
+ "## Create Some Sample Data\n",
+ "By using `scipy.stats`, the Scipy statistics package described above, we can easily create a data array containing a normal distribution. We can plot these data points to confirm that the correct distribution was generated. The generated sample data will then be used later in this section. The code and sample plot for this data generation are as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cd97b1e4-0b10-4099-b288-0c9cb7624a11",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mu = 0\n",
+ "variance = 1\n",
+ "sigma = np.sqrt(variance)\n",
+ "\n",
+ "x = np.linspace(mu - 3 * sigma, mu + 3 * sigma, 200)\n",
+ "pdf = stats.norm.pdf(x, mu, sigma)\n",
+ "\n",
+ "plt.plot(x, pdf);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fbe53c79-98d1-4cda-bea9-4cf532ce835e",
+ "metadata": {},
+ "source": [
+ "## Adding Annotations\n",
+ "A common part of many people's workflows is adding annotations. A rough definition of 'annotation' is 'a note of explanation or comment added to text or a diagram'.\n",
+ "\n",
+ "We can add an annotation to a plot using `plt.text`. This method takes the x and y data coordinates at which to draw the annotation (as floating-point values), and the string containing the annotation text."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1b5598da-caf6-4bc6-aa59-e74954b77bce",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plt.plot(x, pdf)\n",
+ "plt.text(0, 0.05, 'here is some text!');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1ab0a677-90c8-43f9-9d0d-c2f9de698edb",
+ "metadata": {},
+ "source": [
+ "## Rendering Equations"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9e2bc873-0592-4813-81ab-79e3ea7f5855",
+ "metadata": {},
+ "source": [
+ "We can also add annotations with **equation formatting**, by using LaTeX syntax. The key is to use strings in the following format:\n",
+ "\n",
+ "```python\n",
+ "r'$some_equation$'\n",
+ "```\n",
+ "\n",
+ "Let's run an example that renders the following equation as an annotation:\n",
+ "\n",
+ "$$f(x) = \\frac{1}{\\mu\\sqrt{2\\pi}} e^{-\\frac{1}{2}\\left(\\frac{x-\\mu}{\\sigma}\\right)^2}$$\n",
+ "\n",
+ "The next code block and plot demonstrate rendering this equation as an annotation.\n",
+ "\n",
+ "If you are interested in learning more about LaTeX syntax, check out [their official documentation](https://latex-tutorial.com/tutorials/amsmath/).\n",
+ "\n",
+ "Furthermore, if the code is being executed in a Jupyter notebook run interactively (e.g., on Binder), you can double-click on the cell to see the LaTeX source for the rendered equation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9ae9caab-af46-42f5-ac36-47cafbcdaf68",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plt.plot(x, pdf)\n",
+ "\n",
+ "plt.text(\n",
+ " -1,\n",
+ " 0.05,\n",
+ " r'$f(x) = \\frac{1}{\\mu\\sqrt{2\\pi}} e^{-\\frac{1}{2}\\left(\\frac{x-\\mu}{\\sigma}\\right)^2}$',\n",
+ ");"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aad54e23-b488-4437-89ad-55e14e410f90",
+ "metadata": {},
+ "source": [
+ "As you can see, the equation was correctly rendered in the plot above. However, the equation appears quite small. We can increase the size of the text using the `fontsize` keyword argument, and center the equation using the `ha` (horizontal alignment) keyword argument.\n",
+ "\n",
+ "The following example illustrates the use of these keyword arguments, as well as creating a legend containing LaTeX notation:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f915a43f-dd59-462a-a52f-f2d39e53f6cd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fstr = r'$f(x) = \\frac{1}{\\mu\\sqrt{2\\pi}} e^{-\\frac{1}{2}\\left(\\frac{x-\\mu}{\\sigma}\\right)^2}$'\n",
+ "\n",
+ "plt.plot(x, pdf, label=r'$\\mu=0, \\,\\, \\sigma^2 = 1$')\n",
+ "plt.text(0, 0.05, fstr, fontsize=15, ha='center')\n",
+ "plt.legend();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "79bc5d01-186c-41df-b645-73d49cfc85d1",
+ "metadata": {},
+ "source": [
+ "### Add a Box Around the Text"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "210d8d70-e14c-47fa-a710-1d04e84496f4",
+ "metadata": {},
+ "source": [
+ "To improve readability, we can also add a box around the equation text. This is done using `bbox`.\n",
+ "\n",
+ "`bbox` is a keyword argument in `plt.text` that creates a box around text. It takes a dictionary that specifies options, behaving like additional keyword arguments inside of the `bbox` argument. In this case, we use the following dictionary keys:\n",
+ "* a rounded box style (`boxstyle = 'round'`)\n",
+ "* a light grey facecolor (`fc = 'lightgrey'`)\n",
+ "* a black edgecolor (`ec = 'k'`)\n",
+ "\n",
+ "This example demonstrates the correct use of `bbox`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3be0cb9a-8058-4357-97e4-089d556b3194",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(10, 8))\n",
+ "plt.plot(x, pdf)\n",
+ "\n",
+ "fstr = r'$f(x) = \\frac{1}{\\mu\\sqrt{2\\pi}} e^{-\\frac{1}{2}\\left(\\frac{x-\\mu}{\\sigma}\\right)^2}$'\n",
+ "plt.text(\n",
+ " 0,\n",
+ " 0.05,\n",
+ " fstr,\n",
+ " fontsize=18,\n",
+ " ha='center',\n",
+ " bbox=dict(boxstyle='round', fc='lightgrey', ec='k'),\n",
+ ")\n",
+ "\n",
+ "plt.xticks(fontsize=16)\n",
+ "plt.yticks(fontsize=16)\n",
+ "\n",
+ "plt.title(\"Normal Distribution with SciPy\", fontsize=24);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "91f4b661-131f-4d29-925f-0028f987be14",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "60564465-4b40-467b-a1a5-d10c4378329c",
+ "metadata": {},
+ "source": [
+ "## Colormap Overview\n",
+ "\n",
+ "Colormaps are a visually appealing method of looking at visualized data in a new and different way. They associate specific values with hues, using color to ease rapid understanding of plotted data; for example, displaying hotter temperatures as red and colder temperatures as blue."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b0179902-36d5-4b51-894c-f8aad2d92ad8",
+ "metadata": {},
+ "source": [
+ "### Classes of colormaps\n",
+ "\n",
+ "There are four different classes of colormaps, and many individual maps are contained in each class. To view some examples for each class, use the dropdown arrow next to the class name below.\n",
+ "\n",
+ "Info
\n", + " You can use the `timeit` module and the `timeit` Jupyter magic for more accurate benchmarking. Documentation on these can be found here.\n", + "\n",
+ "
\n",
+ "\n",
+ "1. Sequential: These colormaps incrementally increase or decrease in lightness and/or saturation of color. In general, they work best for ordered data.
\n", + "\n", + "\n", + "\n", + "\n", + "\n", + "\n", + "\n", + "\n", + "\n", + "\n", + "\n", + "\n", + "\n",
+ "
\n",
+ "\n",
+ "2. Diverging: These colormaps contain two colors that change in lightness and/or saturation in proportion to distance from the middle, and an unsaturated color in the middle. They are almost always used with data containing a natural zero point, such as sea level.
\n", + "\n", + "\n", + "\n", + "\n", + "\n",
+ "
\n",
+ "\n",
+ "3. Cyclic: These colormaps have two different colors that change in lightness and meet in the middle, and unsaturated colors at the beginning and end. They are usually best for data values that wrap around, such as longitude.
\n", + "\n", + "\n", + "\n", + "\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5ce3b4c7-1186-4067-9b34-552382bf614e",
+ "metadata": {},
+ "source": [
+ "### Other considerations\n",
+ "\n",
+ "There is a lot of info about choosing colormaps that could be its own tutorial. Two important considerations:\n",
+ "1. Color-blind friendly patterns: By using colormaps that do not contain both red and green, you can help people with the most common form of color blindness read your data plots more easily. The GeoCAT examples gallery has a section about [picking better colormaps](https://geocat-examples.readthedocs.io/en/latest/gallery/index.html#colors) that covers this issue in greater detail.\n",
+ "1. Grayscale conversion: It is not too uncommon for a plot originally rendered in color to be converted to black-and-white (monochrome grayscale). This reduces the usefulness of specific colormaps, as shown below.\n",
+ "\n",
+ "\n",
+ "\n",
+ "- For more information on these concerns, as well as colormap choices in general, see the documentation page [Choosing Colormaps in Matplotlib](https://matplotlib.org/stable/tutorials/colors/colormaps.html). "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "66f8b410-ce74-47ad-99be-0b7c670c6c05",
+ "metadata": {},
+ "source": [
+ "## Basic Colorbars"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cb557718-d4ee-41c9-834c-ceddf2e3329a",
+ "metadata": {},
+ "source": [
+ "Before we look at a colorbar, let's generate some fake X and Y data using `numpy.random`, and set a number of bins for a histogram:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "49665676-e0db-425d-9ac2-9a0cab084297",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "npts = 1000\n",
+ "nbins = 15\n",
+ "\n",
+ "x = np.random.normal(size=npts)\n",
+ "y = np.random.normal(size=npts)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "614c5189-a563-4856-a900-26bf3dcc849a",
+ "metadata": {},
+ "source": [
+ "Now we can use our fake data to plot a 2-D histogram with the number of bins set above. We then add a colorbar to the plot, using the default colormap `viridis`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bf3694f1-e8ed-40de-a50a-7e85b179868c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure()\n",
+ "ax = plt.gca()\n",
+ "\n",
+ "plt.hist2d(x, y, bins=nbins, density=True)\n",
+ "plt.colorbar();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dc8e6e2b-3850-4379-bf18-d78ee01739dc",
+ "metadata": {},
+ "source": [
+ "We can change which colormap to use by setting the keyword argument `cmap = 'colormap_name'` in the plotting function call. This sets the colormap not only for the plot, but for the colorbar as well. In this case, we use the `magma` colormap:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16c61ae2-14f6-4b14-8360-c832a46a42b1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure()\n",
+ "ax = plt.gca()\n",
+ "\n",
+ "plt.hist2d(x, y, bins=nbins, density=True, cmap='magma')\n",
+ "plt.colorbar();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7c80a5af-364b-4eda-87c0-10a709b1f32b",
+ "metadata": {},
+ "source": [
+ "## Shared Colorbars\n",
+ "Oftentimes, you are plotting multiple subplots, or multiple `Axes` objects, simultaneously. In these scenarios, you can create colorbars that span multiple plots, as shown in the following example:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "affb4b48-1656-4f70-a9d5-e7bfb0002e7b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = plt.subplots(nrows=1, ncols=2, constrained_layout=True)\n",
+ "\n",
+ "hist1 = ax[0].hist2d(x, y, bins=15, density=True, vmax=0.18)\n",
+ "hist2 = ax[1].hist2d(x, y, bins=30, density=True, vmax=0.18)\n",
+ "\n",
+ "fig.colorbar(hist1[3], ax=ax, location='bottom')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1662bf3c",
+ "metadata": {},
+ "source": [
+ "You may be wondering why the call to `fig.colorbar` uses the argument `hist1[3]`. The explanation is as follows: `hist1` is a tuple returned by `hist2d`, and `hist1[3]` contains a `matplotlib.collections.QuadMesh` that points to the colormap for the first histogram. To make sure that both histograms are using the same colormap with the same range of values, `vmax` is set to 0.18 for both plots. This ensures that both histograms are using colormaps that represent values from 0 (the default for histograms) to 0.18. Because the same data values are used for both plots, it doesn't matter whether we pass in `hist1[3]` or `hist2[3]` to `fig.colorbar`.\n",
+ "You can learn more about this topic by reviewing the [`matplotlib.axes.Axes.hist2d` documentation](https://matplotlib.org/stable/api/_as_gen/matplotlib.axes.Axes.hist2d.html)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84c50862",
+ "metadata": {},
+ "source": [
+ "In addition, there are many other types of plots that can also share colorbars. An actual use case that is quite common is to use shared colorbars to compare data between filled contour plots. The `vmin` and `vmax` keyword arguments behave the same way for `contourf` as they do for `hist2d`. However, there is a potential downside to using the `vmin` and `vmax` kwargs. When plotting two different datasets, the dataset with the smaller range of values won't show the full range of colors, even though the colormaps are the same. Thus, it can potentially matter which output from `contourf` is used to make a colorbar. The following examples demonstrate general plotting technique for filled contour plots with shared colorbars, as well as best practices for dealing with some of these logistical issues:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "28d4cea3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x2 = y2 = np.arange(-3, 3.01, 0.025)\n",
+ "X2, Y2 = np.meshgrid(x2, y2)\n",
+ "Z = np.sqrt(np.sin(X2) ** 2 + np.sin(Y2) ** 2)\n",
+ "Z2 = np.sqrt(2 * np.cos(X2) ** 2 + 2 * np.cos(Y2) ** 2)\n",
+ "\n",
+ "fig, ax = plt.subplots(nrows=1, ncols=2, constrained_layout=True)\n",
+ "c1 = ax[0].contourf(X2, Y2, Z, vmin=0, vmax=2)\n",
+ "c2 = ax[1].contourf(X2, Y2, Z2, vmin=0, vmax=2)\n",
+ "fig.colorbar(c1, ax=ax[0], location='bottom')\n",
+ "fig.colorbar(c2, ax=ax[1], location='bottom')\n",
+ "\n",
+ "fig.suptitle('Shared colormaps on data with different ranges')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5570ebb7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = plt.subplots(nrows=1, ncols=2, constrained_layout=True)\n",
+ "c1 = ax[0].contourf(X2, Y2, Z, vmin=0, vmax=2)\n",
+ "c2 = ax[1].contourf(X2, Y2, Z2, vmin=0, vmax=2)\n",
+ "fig.colorbar(c2, ax=ax, location='bottom')\n",
+ "\n",
+ "fig.suptitle('Using the contourf output from the data with a wider range')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92d072f8-7370-4ea5-92e0-4407cb5905bb",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Custom Colorbars\n",
+ "\n",
+ "Despite the availability of a large number of premade colorbar styles, it can still occasionally be helpful to create your own colorbars.\n",
+ "\n",
+ "Below are 2 similar examples of using custom colorbars.\n",
+ "\n",
+ "The first example uses a very discrete list of colors, simply named `colors`, and creates a colormap from this list by using the call `ListedColormap`. \n",
+ "\n",
+ "The second example uses the function `LinearSegmentedColormap` to create a new colormap, using interpolation and the `colors` list defined in the first example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "308cb21e-7d82-42b9-a02a-0b452d58d4ed",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "colors = [\n",
+ " 'white',\n",
+ " 'pink',\n",
+ " 'red',\n",
+ " 'orange',\n",
+ " 'yellow',\n",
+ " 'green',\n",
+ " 'blue',\n",
+ " 'purple',\n",
+ " 'black',\n",
+ "]\n",
+ "ccmap = ListedColormap(colors)\n",
+ "norm = Normalize(vmin=0, vmax=0.18)\n",
+ "\n",
+ "fig, ax = plt.subplots(nrows=1, ncols=2, constrained_layout=True)\n",
+ "\n",
+ "hist1 = ax[0].hist2d(x, y, bins=15, density=True, cmap=ccmap, norm=norm)\n",
+ "hist2 = ax[1].hist2d(x, y, bins=30, density=True, cmap=ccmap, norm=norm)\n",
+ "\n",
+ "cbar = fig.colorbar(hist1[3], ax=ax, location='bottom')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5c72b622-ba9b-4fdb-be25-27366eca3872",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "cbcmap = LinearSegmentedColormap.from_list(\"cbcmap\", colors)\n",
+ "\n",
+ "fig, ax = plt.subplots(nrows=1, ncols=2, constrained_layout=True)\n",
+ "\n",
+ "hist1 = ax[0].hist2d(x, y, bins=15, density=True, cmap=cbcmap, norm=norm)\n",
+ "hist2 = ax[1].hist2d(x, y, bins=30, density=True, cmap=cbcmap, norm=norm)\n",
+ "\n",
+ "cbar = fig.colorbar(hist1[3], ax=ax, location='bottom')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ea7f200f",
+ "metadata": {},
+ "source": [
+ "### The `Normalize` Class\n",
+ "Notice that both of these examples contain plotting functions that make use of the `norm` kwarg. This keyword argument takes an object of the `Normalize` class. A `Normalize` object is constructed with two numeric values, representing the start and end of the data. It then linearly normalizes the data in that range into an interval of [0,1]. If this sounds familiar, it is because this functionality was used in a previous histogram example. Feel free to review any previous examples if you need a refresher on particular topics. In this example, the values of the `vmin` and `vmax` kwargs used in `hist2d` are reused as arguments to the `Normalize` class constructor. This sets the values of `vmin` and `vmax` as the starting and ending data values for our `Normalize` object, which is passed to the `norm` kwarg of `hist2d` to normalize the data. There are many different options for normalizing data, and it is important to explicitly specify how you want your data normalized, especially when making a custom colormap.\n",
+ "\n",
+ "For information on nonlinear and other complex forms of normalization, review this [Colormap Normalization tutorial](https://matplotlib.org/stable/tutorials/colors/colormapnorms.html#)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e41f44e0-2c4f-4ce2-abe6-35d20b8c142e",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Mosaic Subplots\n",
+ "One of the helpful features recently added to Matplotlib is the `subplot_mosaic` method. This method allows you to specify the structure of your figure using specially formatted strings, and will generate subplots automatically based on that structure.\n",
+ "\n",
+ "For example, if we wanted two plots on top, and one on the bottom, we can construct them by passing the following string to `subplot_mosaic`:\n",
+ "\n",
+ "```python\n",
+ "\"\"\n",
+ "AB\n",
+ "CC\n",
+ "\"\"\n",
+ "```\n",
+ "\n",
+ "This creates three `Axes` objects corresponding to three subplots. The subplots `A` and `B` are on top of the subplot `C`, and the `C` subplot spans the combined width of `A` and `B`.\n",
+ "\n",
+ "Once we create the subplots, we can access them using the dictionary returned by `subplot_mosaic`. You can specify an `Axes` object (in this example, `your_axis`) in the dictionary (in this example, `axes_dict`) by using the syntax `axes_dict['your_axis']`. A full example of `subplot_mosaic` is as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7e080054-ce5c-451d-81f6-c4791a4b2537",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "axdict = plt.figure(constrained_layout=True).subplot_mosaic(\n",
+ " \"\"\"\n",
+ " AB\n",
+ " CC\n",
+ " \"\"\"\n",
+ ")\n",
+ "\n",
+ "histA = axdict['A'].hist2d(x, y, bins=15, density=True, cmap=cbcmap, norm=norm)\n",
+ "histB = axdict['B'].hist2d(x, y, bins=10, density=True, cmap=cbcmap, norm=norm)\n",
+ "histC = axdict['C'].hist2d(x, y, bins=30, density=True, cmap=cbcmap, norm=norm)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7569067a-7c59-46b0-b283-b108094010f1",
+ "metadata": {},
+ "source": [
+ "You'll notice there is not a colorbar plotted by default. When constructing the colorbar, we need to specify the following:\n",
+ "* Which plot to use for the colormapping (ex. `histA`)\n",
+ "* Which subplots (`Axes` objects) to merge colorbars across (ex. [`histA`, `histB`])\n",
+ "* Where to place the colorbar (ex. `bottom`)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3077f1b6-adba-411d-a5a5-430600f0e2fa",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "axdict = plt.figure(constrained_layout=True).subplot_mosaic(\n",
+ " \"\"\"\n",
+ " AB\n",
+ " CC\n",
+ " \"\"\"\n",
+ ")\n",
+ "\n",
+ "histA = axdict['A'].hist2d(x, y, bins=15, density=True, cmap=cbcmap, norm=norm)\n",
+ "histB = axdict['B'].hist2d(x, y, bins=10, density=True, cmap=cbcmap, norm=norm)\n",
+ "histC = axdict['C'].hist2d(x, y, bins=30, density=True, cmap=cbcmap, norm=norm)\n",
+ "\n",
+ "fig.colorbar(histA[3], ax=[axdict['A'], axdict['B']], location='bottom')\n",
+ "fig.colorbar(histC[3], ax=[axdict['C']], location='right');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "85b884b1-4db7-4d9d-9563-79750dbcfc67",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2f505b91-cb9a-4175-a1b7-91f501c1e2cc",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "* You can use features in Matplotlib to add text annotations to your plots, including equations in mathematical notation\n",
+ "* There are a number of considerations to take into account when choosing your colormap\n",
+ "* You can create your own colormaps with Matplotlib\n",
+ "* Various subplots and corresponding `Axes` objects in a figure can share colorbars\n",
+ " \n",
+ "## Resources and references\n",
+ "- [Matplotlib text documentation](https://matplotlib.org/stable/api/text_api.html#matplotlib.text.Text.set_math_fontfamily)\n",
+ "- [Matplotlib annotation documentation](https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.annotate.html)\n",
+ "- [Matplotlib's annotation examples](https://matplotlib.org/stable/tutorials/text/annotations.html)\n",
+ "- [Writing mathematical expressions in Matplotlib](https://matplotlib.org/stable/tutorials/text/mathtext.html)\n",
+ "- [Mathtext Examples](https://matplotlib.org/stable/gallery/text_labels_and_annotations/mathtext_examples.html#sphx-glr-gallery-text-labels-and-annotations-mathtext-examples-py)\n",
+ "- [Drawing fancy boxes with Matplotlib](https://matplotlib.org/stable/gallery/shapes_and_collections/fancybox_demo.html)\n",
+ "- [Plot Types Cheat Sheet](https://lnkd.in/dD5fE8V)\n",
+ "- [Choosing Colormaps in Matplotlib](https://matplotlib.org/stable/tutorials/colors/colormaps.html)\n",
+ "- [Making custom colormaps](https://matplotlib.org/stable/tutorials/colors/colormap-manipulation.html)\n",
+ "- [Complex figure and subplot composition](https://matplotlib.org/stable/tutorials/provisional/mosaic.html#)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "28649673-c9c6-4914-9f60-5c06c25e1e49",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.12"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/_preview/468/_sources/core/matplotlib/histograms-piecharts-animation.ipynb b/_preview/468/_sources/core/matplotlib/histograms-piecharts-animation.ipynb
new file mode 100644
index 000000000..1974c8e31
--- /dev/null
+++ b/_preview/468/_sources/core/matplotlib/histograms-piecharts-animation.ipynb
@@ -0,0 +1,462 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "3d9564ec",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e9eb4444",
+ "metadata": {},
+ "source": [
+ "# Histograms, Pie Charts, and Animations"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cba92e3a",
+ "metadata": {},
+ "source": [
+ "---\n",
+ "## Overview\n",
+ "\n",
+ "In this section we'll explore some more specialized plot types, including:\n",
+ "\n",
+ "1. Histograms\n",
+ "1. Pie Charts\n",
+ "1. Animations"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "56c73537",
+ "metadata": {},
+ "source": [
+ "## Prerequisites\n",
+ "| Concepts | Importance | Notes |\n",
+ "| --- | --- | --- |\n",
+ "| [NumPy Basics](../numpy/numpy-basics) | Necessary | |\n",
+ "| [Matplotlib Basics](matplotlib-basics) | Necessary | |\n",
+ "\n",
+ "* **Time to Learn**: 30 minutes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4440f2b1",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0702fe7b",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "148180d5",
+ "metadata": {},
+ "source": [
+ "Just like in the previous tutorial, we are going to import Matplotlib's `pyplot` interface as `plt`. We must also import `numpy` for working with data arrays."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d16d139c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "import numpy as np"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7310773f",
+ "metadata": {},
+ "source": [
+ "## Histograms\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a5ea8056",
+ "metadata": {},
+ "source": [
+ "We can plot a 1-D histogram using most 1-D data arrays.\n",
+ "\n",
+ "To get the 1-D data array for this example, we generate example data using NumPy’s normal-distribution random-number generator. For demonstration purposes, we've specified the random seed for reproducibility. The code for this number generation is as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "df424130",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "npts = 2500\n",
+ "nbins = 15\n",
+ "\n",
+ "np.random.seed(0)\n",
+ "x = np.random.normal(size=npts)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "32b9f3bd",
+ "metadata": {},
+ "source": [
+ "Now that we have our data array, we can make a histogram using `plt.hist`. In this case, we change the y-axis to represent probability, instead of count; this is performed by setting `density=True`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dfd7c0cc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plt.hist(x, bins=nbins, density=True)\n",
+ "plt.title('1D histogram')\n",
+ "plt.xlabel('Data')\n",
+ "plt.ylabel('Probability');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84fb255f",
+ "metadata": {},
+ "source": [
+ "Similarly, we can make a 2-D histogram, by first generating a second 1-D array, and then calling `plt.hist2d` with both 1-D arrays as arguments:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4ed3325e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "y = np.random.normal(size=npts)\n",
+ "\n",
+ "plt.hist2d(x, y, bins=nbins);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dd5a6bca",
+ "metadata": {},
+ "source": [
+ "## Pie Charts"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "35bc61ba",
+ "metadata": {},
+ "source": [
+ "Matplotlib also has the capability to plot pie charts, by way of `plt.pie`. The most basic implementation uses a 1-D array of wedge 'sizes' (i.e., percent values), as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9399feaa",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x = np.array([25, 15, 20, 40])\n",
+ "plt.pie(x);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1cec2e20",
+ "metadata": {},
+ "source": [
+ "Typically, you'll see examples where all of the values in the array `x` will sum to 100, but the data values provided to `plt.pie` do not necessarily have to add up to 100. The sum of the numbers provided will be normalized to 1, and the individual values will thereby be converted to percentages, regardless of the actual sum of the values. If this behavior is unwanted or unneeded, you can set `normalize=False`.\n",
+ "\n",
+ "If you set `normalize=False`, and the sum of the values of x is less than 1, then a partial pie chart is plotted. If the values sum to larger than 1, a `ValueError` will be raised."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "be883e4e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x = np.array([0.25, 0.20, 0.40])\n",
+ "plt.pie(x, normalize=False);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e747e452",
+ "metadata": {},
+ "source": [
+ "Let's do a more complicated example.\n",
+ "\n",
+ "Here we create a pie chart with various sizes associated with each color. Labels are derived by capitalizing each color in the array `colors`. Since colors can be specified by strings corresponding to named colors, this allows both the colors and the labels to be set from the same array, reducing code and effort.\n",
+ "\n",
+ "If you want to offset one or more wedges for effect, you can use the `explode` keyword argument. The value for this argument must be a list of floating-point numbers with the same length as the number of wedges. The numbers indicate the percentage of offset for each wedge. In this example, each wedge is not offset except for the pink (3rd index)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fa9ecaec",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "colors = ['red', 'blue', 'yellow', 'pink', 'green']\n",
+ "labels = [c.capitalize() for c in colors]\n",
+ "\n",
+ "sizes = [1, 3, 5, 7, 9]\n",
+ "explode = (0, 0, 0, 0.1, 0)\n",
+ "\n",
+ "\n",
+ "plt.pie(sizes, labels=labels, explode=explode, colors=colors, autopct='%1.1f%%');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c516ce4b",
+ "metadata": {},
+ "source": [
+ "## Animations"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "46c1acfc",
+ "metadata": {},
+ "source": [
+ "Matplotlib offers a single commonly-used animation tool, `FuncAnimation`. This tool must be imported separately through Matplotlib’s animation package, as shown below. You can find more information on animation with Matplotlib at the [official documentation page](https://matplotlib.org/stable/api/animation_api.html)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3879e346",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from matplotlib.animation import FuncAnimation"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a31e17ed",
+ "metadata": {},
+ "source": [
+ "`FuncAnimation` creates animations by repeatedly calling a function. Using this method involves three main steps:\n",
+ "\n",
+ "1. Create an initial state of the plot\n",
+ "1. Make a function that can \"progress\" the plot to the next frame of the animation\n",
+ "1. Create the animation using FuncAnimation"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e1abc210",
+ "metadata": {},
+ "source": [
+ "For this example, let's create an animated sine wave."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5455b9de",
+ "metadata": {},
+ "source": [
+ "### Step 1: Initial State\n",
+ "In the initial state step, we will define a function called `init`. This function will then create the animation plot in its initial state. However, please note that the successful use of `FuncAnimation` does not technically require such a function; in a later example, creating animations without an initial-state function is demonstrated."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1037bb3b",
+ "metadata": {},
+ "source": [
+ "First, we’ll define `Figure` and `Axes` objects. After that, we can create a line-plot object (referred to here as a line) with `plt.plot`. To create the initialization function, we set the line's data to be empty and then return the line.\n",
+ "\n",
+ "Please note, this code block will display a blank plot when run as a Jupyter notebook cell."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3feef13d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = plt.subplots()\n",
+ "ax.set_xlim(0, 2 * np.pi)\n",
+ "ax.set_ylim(-1.5, 1.5)\n",
+ "\n",
+ "(line,) = ax.plot([], [])\n",
+ "\n",
+ "\n",
+ "def init():\n",
+ " line.set_data([], [])\n",
+ " return (line,)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "679981fb",
+ "metadata": {},
+ "source": [
+ "### Step 2: Animation Progression Function\n",
+ "For this step, we create a progression function, which takes an index (usually named `n` or `i`), and returns the corresponding (in other words, `n`-th or `i`-th) frame of the animation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c5b606e2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def animate(i):\n",
+ " x = np.linspace(0, 2 * np.pi, 250)\n",
+ "\n",
+ " y = np.sin(2 * np.pi * (x - 0.1 * i))\n",
+ "\n",
+ " line.set_data(x, y)\n",
+ "\n",
+ " return (line,)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6ef0f128",
+ "metadata": {},
+ "source": [
+ "### Step 3: Using `FuncAnimation`\n",
+ "The last step is to feed the parts we created to `FuncAnimation`. Please note, when using the `FuncAnimation` function, it is important to save the output in a variable, even if you do not intend to use this output later. If you do not, Python’s garbage collector may attempt to save memory by deleting the animation data, and it will be unavailable for later use."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ecb3760",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "anim = FuncAnimation(fig, animate, init_func=init, frames=200, interval=20, blit=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cbc69df4",
+ "metadata": {},
+ "source": [
+ "In order to show the animation in a Jupyter notebook, we have to use the `rc` function. This function must be imported separately, and is used to set specific parameters in Matplotlib. In this case, we need to set the `html` parameter for animation plots to `html5`, instead of the default value of none. The code for this is written as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b464c460",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from matplotlib import rc\n",
+ "\n",
+ "rc('animation', html='html5')\n",
+ "\n",
+ "anim"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8be86c41-2ac0-4385-8b3f-70cf0139b19e",
+ "metadata": {},
+ "source": [
+ "### Saving an Animation\n",
+ "\n",
+ "To save an animation to a file, use the `save()` method of the animation variable, in this case `anim.save()`, as shown below. The arguments are the file name to save the animation to, in this case `animate.gif`, and the writer used to save the file. Here, the animation writer chosen is [Pillow](https://pillow.readthedocs.io/en/stable/index.html), a library for image processing in Python. There are many choices for an animation writer, which are described in detail in the Matplotlib writer documentation. The documentation for the Pillow writer is described on [this page](https://matplotlib.org/stable/api/_as_gen/matplotlib.animation.PillowWriter.html); links to other writer documentation pages are on the left side of the Pillow writer documentation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6a1693bd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "anim.save('animate.gif', writer='pillow');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "85b884b1-4db7-4d9d-9563-79750dbcfc67",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "076b1bf3",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "* Matplotlib supports many different plot types, including the less-commonly-used types described in this section. \n",
+ "* Some of these lesser-used plot types include histograms and pie charts.\n",
+ "* This section also covered animation of Matplotlib plots.\n",
+ "\n",
+ "\n",
+ "## What's Next\n",
+ "The next section introduces [more plotting functionality](annotations-colorbars-layouts), such as annotations, equation rendering, colormaps, and advanced layout.\n",
+ "\n",
+ "## Additional Resources\n",
+ "- [Plot Types Cheat Sheet](https://lnkd.in/dD5fE8V)\n",
+ "- [Matplotlib Documentation: Basic Pie Charts](https://matplotlib.org/stable/gallery/pie_and_polar_charts/pie_features.html)\n",
+ "- [Matplotlib Documentation: Histograms](https://matplotlib.org/stable/gallery/statistics/hist.html)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "370d8045-216c-4150-9ce5-5128721b3962",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/_preview/468/_sources/core/matplotlib/matplotlib-basics.ipynb b/_preview/468/_sources/core/matplotlib/matplotlib-basics.ipynb
new file mode 100644
index 000000000..cf48576ba
--- /dev/null
+++ b/_preview/468/_sources/core/matplotlib/matplotlib-basics.ipynb
@@ -0,0 +1,908 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Matplotlib Basics"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---\n",
+ "## Overview\n",
+ "We will cover the basics of using the Matplotlib library to create plots in Python, including a few different plots available within the library. This page is laid out as follows:\n",
+ "\n",
+ "1. Why Matplotlib?\n",
+ "1. Figure and axes\n",
+ "1. Basic line plots\n",
+ "1. Labels and grid lines\n",
+ "1. Customizing colors\n",
+ "1. Subplots\n",
+ "1. Scatterplots\n",
+ "1. Displaying Images\n",
+ "1. Contour and filled contour plots."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Prerequisites\n",
+ "| Concepts | Importance | Notes |\n",
+ "| --- | --- | --- |\n",
+ "| [NumPy Basics](../numpy/numpy-basics) | Necessary | |\n",
+ "| MATLAB plotting experience | Helpful | |\n",
+ "\n",
+ "* **Time to Learn**: 30 minutes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's import the Matplotlib library's `pyplot` interface; this interface is the simplest way to create new Matplotlib figures. To shorten this long name, we import it as `plt`; this helps keep things short, but clear."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "import numpy as np"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "4. Qualitative: These colormaps have no pattern, and are mostly bands of miscellaneous colors. You should only use these colormaps for unordered data without relationships.
\n", + "\n", + "\n", + "\n", + "\n", + "\n", + "\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Generate test data using `NumPy`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here, we generate some test data to use for experimenting with plotting:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "times = np.array(\n",
+ " [\n",
+ " 93.0,\n",
+ " 96.0,\n",
+ " 99.0,\n",
+ " 102.0,\n",
+ " 105.0,\n",
+ " 108.0,\n",
+ " 111.0,\n",
+ " 114.0,\n",
+ " 117.0,\n",
+ " 120.0,\n",
+ " 123.0,\n",
+ " 126.0,\n",
+ " 129.0,\n",
+ " 132.0,\n",
+ " 135.0,\n",
+ " 138.0,\n",
+ " 141.0,\n",
+ " 144.0,\n",
+ " 147.0,\n",
+ " 150.0,\n",
+ " 153.0,\n",
+ " 156.0,\n",
+ " 159.0,\n",
+ " 162.0,\n",
+ " ]\n",
+ ")\n",
+ "temps = np.array(\n",
+ " [\n",
+ " 310.7,\n",
+ " 308.0,\n",
+ " 296.4,\n",
+ " 289.5,\n",
+ " 288.5,\n",
+ " 287.1,\n",
+ " 301.1,\n",
+ " 308.3,\n",
+ " 311.5,\n",
+ " 305.1,\n",
+ " 295.6,\n",
+ " 292.4,\n",
+ " 290.4,\n",
+ " 289.1,\n",
+ " 299.4,\n",
+ " 307.9,\n",
+ " 316.6,\n",
+ " 293.9,\n",
+ " 291.2,\n",
+ " 289.8,\n",
+ " 287.1,\n",
+ " 285.8,\n",
+ " 303.3,\n",
+ " 310.0,\n",
+ " ]\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Figure and Axes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now, let's make our first plot with Matplotlib. Matplotlib has two core objects: the `Figure` and the `Axes`. The `Axes` object is an individual plot, containing an x-axis, a y-axis, labels, etc.; it also contains all of the various methods we might use for plotting. A `Figure` contains one or more `Axes` objects; it also contains methods for saving plots to files (e.g., PNG, SVG), among other similar high-level functionality. You may find the following diagram helpful:\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Basic Line Plots\n",
+ "\n",
+ "Let's create a `Figure` whose dimensions, if printed out on hardcopy, would be 10 inches wide and 6 inches long (assuming a landscape orientation). We then create an `Axes` object, consisting of a single subplot, on the `Figure`. After that, we call the `Axes` object's `plot` method, using the `times` array for the data along the x-axis (i.e., the independent values), and the `temps` array for the data along the y-axis (i.e., the dependent values).\n",
+ "\n",
+ "Info
\n", + " Matplotlib is a Python 2-D plotting library. It is used to produce publication quality figures in a variety of hard-copy formats and interactive environments across platforms.\n", + "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create a figure\n",
+ "fig = plt.figure(figsize=(10, 6))\n",
+ "\n",
+ "# Ask, out of a 1x1 grid of plots, the first axes.\n",
+ "ax = fig.add_subplot(1, 1, 1)\n",
+ "\n",
+ "# Plot times as x-variable and temperatures as y-variable\n",
+ "ax.plot(times, temps);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Labels and Grid Lines"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Adding labels to an `Axes` object"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Next, we add x-axis and y-axis labels to our `Axes` object, like this:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Add some labels to the plot\n",
+ "ax.set_xlabel('Time')\n",
+ "ax.set_ylabel('Temperature')\n",
+ "\n",
+ "# Prompt the notebook to re-display the figure after we modify it\n",
+ "fig"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also add a title to the plot and increase the font size:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ax.set_title('GFS Temperature Forecast', size=16)\n",
+ "\n",
+ "fig"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "There are many other functions and methods associated with `Axes` objects and labels, but they are too numerous to list here.\n",
+ "\n",
+ "Here, we set up another test array of temperature data, to be used later:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temps_1000 = np.array(\n",
+ " [\n",
+ " 316.0,\n",
+ " 316.3,\n",
+ " 308.9,\n",
+ " 304.0,\n",
+ " 302.0,\n",
+ " 300.8,\n",
+ " 306.2,\n",
+ " 309.8,\n",
+ " 313.5,\n",
+ " 313.3,\n",
+ " 308.3,\n",
+ " 304.9,\n",
+ " 301.0,\n",
+ " 299.2,\n",
+ " 302.6,\n",
+ " 309.0,\n",
+ " 311.8,\n",
+ " 304.7,\n",
+ " 304.6,\n",
+ " 301.8,\n",
+ " 300.6,\n",
+ " 299.9,\n",
+ " 306.3,\n",
+ " 311.3,\n",
+ " ]\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Adding labels and a grid"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here, we call `plot` more than once, in order to plot multiple series of temperature data on the same plot. We also specify the `label` keyword argument to the `plot` method to allow Matplotlib to automatically create legend labels. These legend labels are added via a call to the `legend` method. By utilizing the `grid()` method, we can also add gridlines to our plot."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(10, 6))\n",
+ "ax = fig.add_subplot(1, 1, 1)\n",
+ "\n",
+ "# Plot two series of data\n",
+ "# The label argument is used when generating a legend.\n",
+ "ax.plot(times, temps, label='Temperature (surface)')\n",
+ "ax.plot(times, temps_1000, label='Temperature (1000 mb)')\n",
+ "\n",
+ "# Add labels and title\n",
+ "ax.set_xlabel('Time')\n",
+ "ax.set_ylabel('Temperature')\n",
+ "ax.set_title('Temperature Forecast')\n",
+ "\n",
+ "# Add gridlines\n",
+ "ax.grid(True)\n",
+ "\n",
+ "# Add a legend to the upper left corner of the plot\n",
+ "ax.legend(loc='upper left');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Customizing colors"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We're not restricted to the default look for plot elements. Most plot elements have style attributes, such as `linestyle` and `color`, that can be modified to customize the look of a plot. For example, the `color` attribute can accept a wide array of color options, including keywords (named colors) like `red` or `blue`, or HTML color codes. Here, we use some different shades of red taken from the Tableau colorset in Matplotlib, by using the `tab:red` option for the color attribute."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(10, 6))\n",
+ "ax = fig.add_subplot(1, 1, 1)\n",
+ "\n",
+ "# Specify how our lines should look\n",
+ "ax.plot(times, temps, color='tab:red', label='Temperature (surface)')\n",
+ "ax.plot(\n",
+ " times,\n",
+ " temps_1000,\n",
+ " color='tab:red',\n",
+ " linestyle='--',\n",
+ " label='Temperature (isobaric level)',\n",
+ ")\n",
+ "\n",
+ "# Set the labels and title\n",
+ "ax.set_xlabel('Time')\n",
+ "ax.set_ylabel('Temperature')\n",
+ "ax.set_title('Temperature Forecast')\n",
+ "\n",
+ "# Add the grid\n",
+ "ax.grid(True)\n",
+ "\n",
+ "# Add a legend to the upper left corner of the plot\n",
+ "ax.legend(loc='upper left');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Subplots\n",
+ "\n",
+ "The term \"subplots\" refers to working with multiple plots, or panels, in a figure."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here, we create yet another set of test data, in this case dew-point data, to be used in later examples:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dewpoint = 0.9 * temps\n",
+ "dewpoint_1000 = 0.9 * temps_1000"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now, we can use subplots to plot this new data alongside the temperature data."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Using add_subplot to create two different subplots within the figure\n",
+ "We can use the `.add_subplot()` method to add subplots to our figure! This method takes the arguments `(rows, columns, subplot_number)`.\n",
+ "\n",
+ "For example, if we want a single row and two columns, we can use the following code block:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(10, 6))\n",
+ "\n",
+ "# Create a plot for temperature\n",
+ "ax = fig.add_subplot(1, 2, 1)\n",
+ "ax.plot(times, temps, color='tab:red')\n",
+ "\n",
+ "# Create a plot for dewpoint\n",
+ "ax2 = fig.add_subplot(1, 2, 2)\n",
+ "ax2.plot(times, dewpoint, color='tab:green');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can also call `plot.subplots()` with the keyword arguments `nrows` (number of rows) and `ncols` (number of columns). This initializes a new `Axes` object, called `ax`, with the specified number of rows and columns. This object also contains a 1-D list of subplots, with a size equal to `nrows` x `ncols`.\n",
+ "\n",
+ "You can index this list, using `ax[0].plot()`, for example, to decide which subplot you're plotting to. Here is some example code for this technique:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 6))\n",
+ "\n",
+ "ax[0].plot(times, temps, color='tab:red')\n",
+ "ax[1].plot(times, dewpoint, color='tab:green');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Adding titles to each subplot\n",
+ "We can add titles to these plots too; notice that these subplots are titled separately, by calling `ax.set_title` after plotting each subplot:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(10, 6))\n",
+ "\n",
+ "# Create a plot for temperature\n",
+ "ax = fig.add_subplot(1, 2, 1)\n",
+ "ax.plot(times, temps, color='tab:red')\n",
+ "ax.set_title('Temperature')\n",
+ "\n",
+ "# Create a plot for dewpoint\n",
+ "ax2 = fig.add_subplot(1, 2, 2)\n",
+ "ax2.plot(times, dewpoint, color='tab:green')\n",
+ "ax2.set_title('Dewpoint');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Using `ax.set_xlim` and `ax.set_ylim` to control the plot boundaries\n",
+ "\n",
+ "It is common when plotting data to set the extent (boundaries) of plots, which can be performed by calling `.set_xlim` and `.set_ylim` on the `Axes` object containing the plot or subplot(s):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(10, 6))\n",
+ "\n",
+ "# Create a plot for temperature\n",
+ "ax = fig.add_subplot(1, 2, 1)\n",
+ "ax.plot(times, temps, color='tab:red')\n",
+ "ax.set_title('Temperature')\n",
+ "ax.set_xlim(110, 130)\n",
+ "ax.set_ylim(290, 315)\n",
+ "\n",
+ "# Create a plot for dewpoint\n",
+ "ax2 = fig.add_subplot(1, 2, 2)\n",
+ "ax2.plot(times, dewpoint, color='tab:green')\n",
+ "ax2.set_title('Dewpoint')\n",
+ "ax2.set_xlim(110, 130);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Using `sharex` and `sharey` to share plot limits\n",
+ "\n",
+ "You may want to have both subplots share the same x/y axis limits. When setting up a new `Axes` object through a method like `add_subplot`, specify the keyword arguments `sharex=ax` and `sharey=ax`, where `ax` is the `Axes` object with which to share axis limits.\n",
+ "\n",
+ "Let's take a look at an example:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(10, 6))\n",
+ "\n",
+ "# Create a plot for temperature\n",
+ "ax = fig.add_subplot(1, 2, 1)\n",
+ "ax.plot(times, temps, color='tab:red')\n",
+ "ax.set_title('Temperature')\n",
+ "ax.set_ylim(260, 320)\n",
+ "\n",
+ "# Create a plot for dewpoint\n",
+ "ax2 = fig.add_subplot(1, 2, 2, sharex=ax, sharey=ax)\n",
+ "ax2.plot(times, dewpoint, color='tab:green')\n",
+ "ax2.set_title('Dewpoint');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Putting this all together"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " By default,ax.plot will create a line plot, as seen in the following example: \n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(10, 6))\n",
+ "ax = fig.add_subplot(1, 2, 1)\n",
+ "\n",
+ "# Specify how our lines should look\n",
+ "ax.plot(times, temps, color='tab:red', label='Temperature (surface)')\n",
+ "ax.plot(\n",
+ " times,\n",
+ " temps_1000,\n",
+ " color='tab:red',\n",
+ " linestyle=':',\n",
+ " label='Temperature (isobaric level)',\n",
+ ")\n",
+ "\n",
+ "# Add labels, grid, and legend\n",
+ "ax.set_xlabel('Time')\n",
+ "ax.set_ylabel('Temperature')\n",
+ "ax.set_title('Temperature Forecast')\n",
+ "ax.grid(True)\n",
+ "ax.legend(loc='upper left')\n",
+ "ax.set_ylim(257, 312)\n",
+ "ax.set_xlim(95, 162)\n",
+ "\n",
+ "\n",
+ "# Add our second plot - for dewpoint, changing the colors and labels\n",
+ "ax2 = fig.add_subplot(1, 2, 2, sharex=ax, sharey=ax)\n",
+ "ax2.plot(times, dewpoint, color='tab:green', label='Dewpoint (surface)')\n",
+ "ax2.plot(\n",
+ " times,\n",
+ " dewpoint_1000,\n",
+ " color='tab:green',\n",
+ " linestyle=':',\n",
+ " marker='o',\n",
+ " label='Dewpoint (isobaric level)',\n",
+ ")\n",
+ "\n",
+ "ax2.set_xlabel('Time')\n",
+ "ax2.set_ylabel('Dewpoint')\n",
+ "ax2.set_title('Dewpoint Forecast')\n",
+ "ax2.grid(True)\n",
+ "ax2.legend(loc='upper left');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Scatterplot\n",
+ "Some data cannot be plotted accurately as a line plot. Another type of plot that is popular in science is the marker plot, more commonly known as a scatter plot. A simple scatter plot can be created by setting the `linestyle` to `None`, and specifying a marker type, size, color, etc., like this:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(10, 6))\n",
+ "ax = fig.add_subplot(1, 1, 1)\n",
+ "\n",
+ "# Specify no line with circle markers\n",
+ "ax.plot(temps, temps_1000, linestyle='None', marker='o', markersize=5)\n",
+ "\n",
+ "ax.set_xlabel('Temperature (surface)')\n",
+ "ax.set_ylabel('Temperature (1000 hPa)')\n",
+ "ax.set_title('Temperature Cross Plot')\n",
+ "ax.grid(True);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " If desired, you can move the location of your legend; to do this, specify theloc keyword argument when calling ax.legend().\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(10, 6))\n",
+ "ax = fig.add_subplot(1, 1, 1)\n",
+ "\n",
+ "# Specify no line with circle markers\n",
+ "ax.scatter(temps, temps_1000)\n",
+ "\n",
+ "ax.set_xlabel('Temperature (surface)')\n",
+ "ax.set_ylabel('Temperature (1000 hPa)')\n",
+ "ax.set_title('Temperature Cross Plot')\n",
+ "ax.grid(True);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's put together the following:\n",
+ " * Beginning with our code above, add the `c` keyword argument to the `scatter` call; in this case, to color the points by the difference between the temperature at the surface and the temperature at 1000 hPa.\n",
+ " * Add a 1:1 line to the plot (slope of 1, intercept of zero). Use a black dashed line.\n",
+ " * Change the colormap to one more suited for a temperature-difference plot.\n",
+ " * Add a colorbar to the plot (have a look at the Matplotlib documentation for help)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(10, 6))\n",
+ "ax = fig.add_subplot(1, 1, 1)\n",
+ "\n",
+ "ax.plot([285, 320], [285, 320], color='black', linestyle='--')\n",
+ "s = ax.scatter(temps, temps_1000, c=(temps - temps_1000), cmap='bwr', vmin=-5, vmax=5)\n",
+ "fig.colorbar(s)\n",
+ "\n",
+ "ax.set_xlabel('Temperature (surface)')\n",
+ "ax.set_ylabel('Temperature (1000 hPa)')\n",
+ "ax.set_title('Temperature Cross Plot')\n",
+ "ax.grid(True);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Displaying Images\n",
+ "\n",
+ "`imshow` displays the values in an array as colored pixels, similar to a heat map.\n",
+ "\n",
+ "Here, we declare some fake data in a bivariate normal distribution, to illustrate the `imshow` method:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x = y = np.arange(-3.0, 3.0, 0.025)\n",
+ "X, Y = np.meshgrid(x, y)\n",
+ "Z1 = np.exp(-(X**2) - Y**2)\n",
+ "Z2 = np.exp(-((X - 1) ** 2) - (Y - 1) ** 2)\n",
+ "Z = (Z1 - Z2) * 2"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now pass this fake data to `imshow` to create a heat map of the distribution:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = plt.subplots()\n",
+ "im = ax.imshow(\n",
+ " Z, interpolation='bilinear', cmap='RdYlGn', origin='lower', extent=[-3, 3, -3, 3]\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Contour and Filled Contour Plots\n",
+ "\n",
+ "- `contour` creates contours around data.\n",
+ "- `contourf` creates filled contours around data."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's start with the `contour` method, which, as just mentioned, creates contours around data:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = plt.subplots()\n",
+ "ax.contour(X, Y, Z);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "After creating contours, we can label the lines using the `clabel` method, like this:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = plt.subplots()\n",
+ "c = ax.contour(X, Y, Z, levels=np.arange(-2, 2, 0.25))\n",
+ "ax.clabel(c);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As described above, the `contourf` (contour fill) method creates filled contours around data, like this:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = plt.subplots()\n",
+ "c = ax.contourf(X, Y, Z);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As a final example, let's create a heatmap figure with contours using the `contour` and `imshow` methods. First, we use `imshow` to create the heatmap, specifying a colormap using the `cmap` keyword argument. We then call `contour`, specifying black contours and an interval of 0.5. Here is the example code, and resulting figure:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, ax = plt.subplots()\n",
+ "im = ax.imshow(\n",
+ " Z, interpolation='bilinear', cmap='PiYG', origin='lower', extent=[-3, 3, -3, 3]\n",
+ ")\n",
+ "c = ax.contour(X, Y, Z, levels=np.arange(-2, 2, 0.5), colors='black')\n",
+ "ax.clabel(c);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "* `Matplotlib` can be used to visualize datasets you are working with.\n",
+ "* You can customize various features such as labels and styles.\n",
+ "* There are a wide variety of plotting options available, including (but not limited to):\n",
+ " * Line plots (`plot`)\n",
+ " * Scatter plots (`scatter`)\n",
+ " * Heatmaps (`imshow`)\n",
+ " * Contour line and contour fill plots (`contour`, `contourf`)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## What's Next?\n",
+ "In the next section, [more plotting functionality](histograms-piecharts-animation) is covered, such as histograms, pie charts, and animation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Resources and References\n",
+ "\n",
+ "The goal of this tutorial is to provide an overview of the use of the Matplotlib library. It covers creating simple line plots, but it is by no means comprehensive. For more information, try looking at the following documentation:\n",
+ "- [Matplotlib documentation](http://matplotlib.org)\n",
+ "- [Matplotlib examples gallery](https://matplotlib.org/stable/gallery/index.html)\n",
+ "- [GeoCAT examples gallery](https://geocat-examples.readthedocs.io/en/latest/gallery/index.html)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/_preview/468/_sources/core/numpy.md b/_preview/468/_sources/core/numpy.md
new file mode 100644
index 000000000..8229b0c8a
--- /dev/null
+++ b/_preview/468/_sources/core/numpy.md
@@ -0,0 +1,13 @@
+Info
\n", + " You can also use thescatter method, which is slower, but will give you more control, such as being able to color the points individually based upon a third variable.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a.sum()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now, with a reminder about how our array is shaped,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a.shape"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "we can specify `axis` to get _just_ the sum across each of our rows."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "np.sum(a, axis=0)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Or do the same and take the sum across columns:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "np.sum(a, axis=1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "After putting together some data and introducing some more advanced calculations, let's demonstrate a multi-layered example: calculating temperature advection. If you're not familiar with this (don't worry!), we'll be looking to calculate\n",
+ "\n",
+ "\\begin{equation*}\n",
+ "\\text{advection} = -\\vec{v} \\cdot \\nabla T\n",
+ "\\end{equation*}\n",
+ "\n",
+ "and to do so we'll start with some random $T$ and $\\vec{v}$ values,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp = np.random.randn(100, 50)\n",
+ "u = np.random.randn(100, 50)\n",
+ "v = np.random.randn(100, 50)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can calculate the `np.gradient` of our new $T(100x50)$ field as two separate component gradients,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "gradient_x, gradient_y = np.gradient(temp)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In order to calculate $-\\vec{v} \\cdot \\nabla T$, we will use `np.dstack` to turn our two separate component gradient fields into one multidimensional field containing $x$ and $y$ gradients at each of our $100x50$ points,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "grad_vectors = np.dstack([gradient_x, gradient_y])\n",
+ "print(grad_vectors.shape)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "and then do the same for our separate $u$ and $v$ wind components,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wind_vectors = np.dstack([u, v])\n",
+ "print(wind_vectors.shape)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, we can calculate the dot product of these two multidimensional fields of wind and temperature gradient components by hand as an element-wise multiplication, `*`, and then a `sum` of our separate components at each point (i.e., along the last `axis`),"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "advection = (wind_vectors * -grad_vectors).sum(axis=-1)\n",
+ "print(advection.shape)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Indexing arrays with boolean values\n",
+ "\n",
+ "### Array comparisons\n",
+ "NumPy can easily create arrays of boolean values and use those to select certain values to extract from an array"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create some synthetic data representing temperature and wind speed data\n",
+ "np.random.seed(19990503) # Make sure we all have the same data\n",
+ "temp = 20 * np.cos(np.linspace(0, 2 * np.pi, 100)) + 50 + 2 * np.random.randn(100)\n",
+ "speed = np.abs(\n",
+ " 10 * np.sin(np.linspace(0, 2 * np.pi, 100)) + 10 + 5 * np.random.randn(100)\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plt.plot(temp, 'tab:red')\n",
+ "plt.plot(speed, 'tab:blue');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "By doing a comparison between a NumPy array and a value, we get an\n",
+ "array of values representing the results of the comparison between\n",
+ "each element and the value"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp > 45"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This, which is its own NumPy array of `boolean` values, can be used as an index to another array of the same size. We can even use it as an index within the original `temp` array we used to compare,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp[temp > 45]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " Some of NumPy's functions can be accessed as `ndarray` methods!\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp[temp > 45].shape"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " This only returns the values from our original array meeting the indexing conditions, nothing more! Note the size,\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "If we store this array somewhere new,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp_45 = temp[temp > 45]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": [
+ "raises-exception"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "temp_45[temp < 45]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We find that our original `(100,)` shape array is too large to subset our new `(60,)` array."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "If their sizes _do_ match, the boolean array can come from a totally different array!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "speed > 10"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp[speed > 10]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Replacing values\n",
+ "To extend this, we can use this conditional indexing to _assign_ new values to certain positions within our array, somewhat like a masking operation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Make a copy so we don't modify the original data\n",
+ "temp2 = temp.copy()\n",
+ "speed2 = speed.copy()\n",
+ "\n",
+ "# Replace all places where speed is <10 with NaN (not a number)\n",
+ "temp2[speed < 10] = np.nan\n",
+ "speed2[speed < 10] = np.nan"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plt.plot(temp2, 'tab:red');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "and to put this in context,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plt.plot(temp, 'r:')\n",
+ "plt.plot(temp2, 'r')\n",
+ "plt.plot(speed, 'b:')\n",
+ "plt.plot(speed2, 'b');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "If we use parentheses to preserve the order of operations, we can combine these conditions with other bitwise operators like the `&` for `bitwise_and`,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "multi_mask = (temp < 45) & (speed > 10)\n",
+ "multi_mask"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp[multi_mask]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Heat index is only defined for temperatures >= 80F and relative humidity values >= 40%. Using the data generated below, we can use boolean indexing to extract the data where heat index has a valid value."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Here's the \"data\"\n",
+ "np.random.seed(19990503)\n",
+ "temp = 20 * np.cos(np.linspace(0, 2 * np.pi, 100)) + 80 + 2 * np.random.randn(100)\n",
+ "relative_humidity = np.abs(\n",
+ " 20 * np.cos(np.linspace(0, 4 * np.pi, 100)) + 50 + 5 * np.random.randn(100)\n",
+ ")\n",
+ "\n",
+ "# Create a mask for the two conditions described above\n",
+ "good_heat_index = (temp >= 80) & (relative_humidity >= 0.4)\n",
+ "\n",
+ "# Use this mask to grab the temperature and relative humidity values that together\n",
+ "# will give good heat index values\n",
+ "print(temp[good_heat_index])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Another bitwise operator we can find helpful is Python's `~` complement operator, which can give us the **inverse** of our specific mask to let us assign `np.nan` to every value _not_ satisfied in `good_heat_index`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plot_temp = temp.copy()\n",
+ "plot_temp[~good_heat_index] = np.nan\n",
+ "plt.plot(plot_temp, 'tab:red');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Indexing using arrays of indices\n",
+ "\n",
+ "You can also use a list or array of indices to extract particular values--this is a natural extension of the regular indexing. For instance, just as we can select the first element:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can also extract the first, fifth, and tenth elements as a list:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp[[0, 4, 9]]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "One of the ways this comes into play is trying to sort NumPy arrays using `argsort`. This function returns the indices of the array that give the items in sorted order. So for our `temp`,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "inds = np.argsort(temp)\n",
+ "inds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "i.e., our lowest value is at index `52`, next `57`, and so on. We can use this array of indices as an index for `temp`,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp[inds]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "to get a sorted array back!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "With some clever slicing, we can pull out the last 10, or 10 highest, values of `temp`,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ten_highest = inds[-10:]\n",
+ "print(temp[ten_highest])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "There are other NumPy `arg` functions that return indices for operating; check out the [NumPy docs](https://numpy.org/doc/stable/reference/routines.sort.html) on sorting your arrays!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "In this notebook we introduced the power of understanding the dimensions of our data by specifying math along `axis`, used `True` and `False` values to subset our data according to conditions, and used lists of positions within our array to sort our data.\n",
+ "\n",
+ "### What's Next\n",
+ "Taking some time to practice this is valuable to be able to quickly manipulate arrays of information in useful or scientific ways."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Resources and references\n",
+ "The [NumPy Users Guide](https://numpy.org/devdocs/user/quickstart.html#less-basic) expands further on some of these topics, as well as suggests various [Tutorials](https://numpy.org/learn/), lectures, and more at this stage."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.2"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/_preview/468/_sources/core/numpy/numpy-basics.ipynb b/_preview/468/_sources/core/numpy/numpy-basics.ipynb
new file mode 100644
index 000000000..3281deb5b
--- /dev/null
+++ b/_preview/468/_sources/core/numpy/numpy-basics.ipynb
@@ -0,0 +1,1047 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Warning
\n", + " Indexing arrays with arrays requires them to be the same size!\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "b = np.linspace(3, 4.5, 6)\n",
+ "a.shape, b.shape"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "tags": [
+ "raises-exception"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "a * b"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Constants\n",
+ "\n",
+ "NumPy provides us access to some useful constants as well - remember you should never be typing these in manually! Other libraries such as SciPy and MetPy have their own set of constants that are more domain specific."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "np.pi"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "np.e"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can use these for classic calculations you might be familiar with! Here we can create a range `t = [0, 2 pi]` by `pi/4`,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "t = np.arange(0, 2 * np.pi + np.pi / 4, np.pi / 4)\n",
+ "t"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "t / np.pi"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Array math functions\n",
+ "\n",
+ "NumPy also has math functions that can operate on arrays. Similar to the math operations, these greatly simplify and speed up these operations. Let's start with calculating $\\sin(t)$!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sin_t = np.sin(t)\n",
+ "sin_t"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "and clean it up a bit by `round`ing to three decimal places."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "np.round(sin_t, 3)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "cos_t = np.cos(t)\n",
+ "cos_t"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Warning
\n", + " These arrays must be the same shape!\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can convert between degrees and radians with only NumPy, by hand"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "t / np.pi * 180"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "or with built-in function `rad2deg`,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "degrees = np.rad2deg(t)\n",
+ "degrees"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We are similarly provided algorithms for operations including integration, bulk summing, and cumulative summing."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sine_integral = np.trapz(sin_t, t)\n",
+ "np.round(sine_integral, 3)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "cos_sum = np.sum(cos_t)\n",
+ "cos_sum"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "cos_csum = np.cumsum(cos_t)\n",
+ "print(cos_csum)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Indexing and subsetting arrays\n",
+ "\n",
+ "### Indexing\n",
+ "\n",
+ "We can use integer indexing to reach into our arrays and pull out individual elements. Let's make a toy 2-d array to explore. Here we create a 12-value `arange` and `reshape` it into a 3x4 array."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a = np.arange(12).reshape(3, 4)\n",
+ "a"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Recall that Python indexing starts at `0`, and we can begin indexing our array with the list-style `list[element]` notation,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "to pull out just our first _row_ of data within `a`. Similarly we can index in reverse with negative indices,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a[-1]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "to pull out just the last row of data within `a`. This notation extends to as many dimensions as make up our array as `array[m, n, p, ...]`. The following diagram shows these indices for an example, 2-dimensional `6x6` array,"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "For example, let's find the entry in our array corresponding to the 2nd row (`m=1` in Python) and the 3rd column (`n=2` in Python)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a[1, 2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can again use these negative indices to index backwards,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a[-1, -1]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "and even mix-and-match along dimensions,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a[1, -2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Slices\n",
+ "\n",
+ "Slicing syntax is written as `array[start:stop[:step]]`, where **all numbers are optional**.\n",
+ "- defaults: \n",
+ " - start = 0\n",
+ " - stop = len(dim)\n",
+ " - step = 1\n",
+ "- The second colon is **also optional** if no step is used.\n",
+ "\n",
+ "Let's pull out just the first row, `m=0` of `a` and see how this works!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "b = a[0]\n",
+ "b"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Laying out our default slice to see the entire array explicitly looks something like this,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "b[0:4:1]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "where again, these default values are optional,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "b[::]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "and even the second `:` is optional"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "b[:]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now to actually make our own slice, let's select all elements from `m=0` to `m=2`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "b[0:2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " Check out NumPy's list of mathematical functions here!\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This means that slices will include every value **up to** your `stop` index and not this index itself, like a half-open interval `[start, end)`. For example,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "b[3]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "reveals a different value than"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "b[0:3]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, a few more examples of this notation before reintroducing our 2-d array `a`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "b[2:] # m=2 through the end, can leave off the number"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "b[:3] # similarly, the same as our b[0:3]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Multidimensional slicing\n",
+ "This entire syntax can be extended to each dimension of multidimensional arrays."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "First let's pull out rows `0` through `2`, and then every `:` column for each of those"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a[0:2, :]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Similarly, let's get all rows for just column `2`,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a[:, 2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "or just take a look at the full row `:`, for every second column, `::2`,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a[:, ::2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "For any shape of array, you can use `...` to capture full slices of every non-specified dimension. Consider the 3-D array,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "c = a.reshape(2, 2, 3)\n",
+ "c"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "c[0, ...]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "and so this is equivalent to"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "c[0, :, :]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "for extracting every dimension across our first row. We can also flip this around,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "c[..., -1]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "to investigate every preceding dimension along our the last entry of our last axis, the same as `c[:, :, -1]`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "In this notebook we introduced NumPy and the `ndarray` that is so crucial to the entirety of the scientific Python community ecosystem. We created some arrays, used some of NumPy's own mathematical functions to manipulate them, and then introduced the world of NumPy indexing and selecting for even multi-dimensional arrays.\n",
+ "\n",
+ "### What's next?\n",
+ "This notebook is the gateway to nearly every other Pythia resource here. This information is crucial for understanding SciPy, pandas, xarray, and more. Continue into NumPy to explore some more intermediate and advanced topics!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Resources and references\n",
+ "- [NumPy User Guide](http://docs.scipy.org/doc/numpy/user/)\n",
+ "- [SciPy Lecture Notes](https://scipy-lectures.org/)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.15"
+ },
+ "toc": {
+ "base_numbering": 1,
+ "nav_menu": {},
+ "number_sections": true,
+ "sideBar": true,
+ "skip_h1_title": false,
+ "title_cell": "Table of Contents",
+ "title_sidebar": "Contents",
+ "toc_cell": false,
+ "toc_position": {},
+ "toc_section_display": true,
+ "toc_window_display": false
+ },
+ "toc-autonumbering": false
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/_preview/468/_sources/core/numpy/numpy-broadcasting.ipynb b/_preview/468/_sources/core/numpy/numpy-broadcasting.ipynb
new file mode 100644
index 000000000..ee6bee2ac
--- /dev/null
+++ b/_preview/468/_sources/core/numpy/numpy-broadcasting.ipynb
@@ -0,0 +1,939 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Warning
\n", + " Slice notation is exclusive of the final index.\n", + "
\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0be820cd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "filepath = DATASETS.fetch('enso_data.csv')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "68316c6c",
+ "metadata": {},
+ "source": [
+ "Once we have a valid path to a data file that Pandas knows how to read, we can open it, as shown in the following example:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e99652d5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df = pd.read_csv(filepath)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae9dcbbd",
+ "metadata": {},
+ "source": [
+ "If we print out our `DataFrame`, it will render as text by default, in a tabular-style ASCII output, as shown in the following example. However, if you are using a Jupyter notebook, there exists a better way to print `DataFrames`, as described below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "25a23571",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(df)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f22bb442",
+ "metadata": {},
+ "source": [
+ "As described above, there is a better way to print Pandas `DataFrames`. If you are using a Jupyter notebook, you can run a code cell containing the `DataFrame` object name, by itself, and it will display a nicely rendered table, as shown below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b8942e69",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "377d4803",
+ "metadata": {},
+ "source": [
+ "The `DataFrame` index, as described above, contains information characterizing rows; each row has a unique ID value, which is displayed in the index column. By default, the IDs for rows in a `DataFrame` are represented as sequential integers, which start at 0."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cde6999b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.index"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8af49ac9",
+ "metadata": {},
+ "source": [
+ "At the moment, the index column of our `DataFrame` is not very helpful for humans. However, Pandas has clever ways to make index columns more human-readable. The next example demonstrates how to use optional keyword arguments to convert `DataFrame` index IDs to a human-friendly datetime format."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b4657f7e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df = pd.read_csv(filepath, index_col=0, parse_dates=True)\n",
+ "\n",
+ "df"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b0d3ae28",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.index"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8d26ed71",
+ "metadata": {},
+ "source": [
+ "Each of our data rows is now helpfully labeled by a datetime-object-like index value; this means that we can now easily identify data values not only by named columns, but also by date labels on rows. This is a sneak preview of the `DatetimeIndex` functionality of Pandas; this functionality enables a large portion of Pandas' timeseries-related usage. Don't worry; `DatetimeIndex` will be discussed in full detail later on this page. In the meantime, let's look at the columns of data read in from the `.csv` file:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "847347f8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.columns"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "08d3b2fb",
+ "metadata": {},
+ "source": [
+ "## The pandas [`Series`](https://pandas.pydata.org/docs/user_guide/dsintro.html#series)...\n",
+ "\n",
+ "...is essentially any one of the columns of our `DataFrame`. A `Series` also includes the index column from the source `DataFrame`, in order to provide a label for each value in the `Series`.\n",
+ "\n",
+ "\n",
+ "\n",
+ "The pandas `Series` is a fast and capable 1-dimensional array of nearly any data type we could want, and it can behave very similarly to a NumPy `ndarray` or a Python `dict`. You can take a look at any of the `Series` that make up your `DataFrame`, either by using its column name and the Python `dict` notation, or by using dot-shorthand with the column name:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ee085815",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df[\"Nino34\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2fcc97fa",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " As described above, we are retrieving the datasets for these examples from Project Pythia's custom library of example data. In order to retrieve datasets from this library, you must use the statementfrom pythia_datasets import DATASETS. This is shown and described in the Imports section at the top of this page. The fetch() method of the DATASETS class will automatically download the data file specified as a string argument, in this case enso_data.csv, and cache the file locally, assuming the argument corresponds to a valid Pythia example dataset. This is illustrated in the following example.\n",
+ "\n",
+ "Tip: You can also use the dot notation illustrated below to specify a column name, but this syntax is mostly provided for convenience. For the most part, this notation is interchangeable with the dictionary notation; however, if the column name is not a valid Python identifier (e.g., it starts with a number or space), you cannot use dot notation.
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7d46cbb9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.Nino34"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dfed2a7c-5532-44d4-a2be-f1cc484d842c",
+ "metadata": {},
+ "source": [
+ "## Slicing and Dicing the `DataFrame` and `Series`\n",
+ "\n",
+ "In this section, we will expand on topics covered in the previous sections on this page. One of the most important concepts to learn about Pandas is that it allows you to _**access anything by its associated label**_, regardless of data organization structure."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "59128a2d-f23f-4b1c-93e7-63a85046b881",
+ "metadata": {},
+ "source": [
+ "### Indexing a `Series`\n",
+ "\n",
+ "As a review of previous examples, we'll start our next example by pulling a `Series` out of our `DataFrame` using its column label."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ec9ed333",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nino34_series = df[\"Nino34\"]\n",
+ "\n",
+ "nino34_series"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c84a81b9",
+ "metadata": {},
+ "source": [
+ "You can use syntax similar to that of NumPy `ndarrays` to index, select, and subset with Pandas `Series`, as shown in this example:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "39bb0ae3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nino34_series[3]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a1a55a7c",
+ "metadata": {},
+ "source": [
+ "You can also use labels alongside Python dictionary syntax to perform the same operations:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "62006988",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nino34_series[\"1982-04-01\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ce9788fd-a420-4c64-92b2-188818c52cc8",
+ "metadata": {},
+ "source": [
+ "You can probably figure out some ways to extend these indexing methods, as shown in the following examples:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "221e798d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nino34_series[0:12]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8ae4a117-2e37-4e01-bd06-2bef62f83741",
+ "metadata": {},
+ "source": [
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3cba4b8e-5dbb-4da6-ba5f-bc8a8a726b14",
+ "metadata": {},
+ "source": [
+ "However, there are many more ways to index a `Series`. The following example shows a powerful and useful indexing method:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f7a06967",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nino34_series[\"1982-01-01\":\"1982-12-01\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1d6b4d75-b6a5-4960-9f83-8adbff1e2830",
+ "metadata": {},
+ "source": [
+ "This is an example of label-based slicing. With label-based slicing, Pandas will automatically find a range of values based on the labels you specify."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b9c167aa-6b8d-4533-9e89-09d75af76025",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " Index-based slices are exclusive of the final value, similar to Python's usual indexing rules.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cebfac9a-9e8f-449a-a88d-b1196a49d87d",
+ "metadata": {},
+ "source": [
+ "If you already have some knowledge of xarray, you will quite likely know how to create `slice` objects by hand. This can also be used in pandas, as shown below. If you are completely unfamiliar with xarray, it will be covered on a [later Pythia tutorial page](../xarray)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "771d6f04",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nino34_series[slice(\"1982-01-01\", \"1982-12-01\")]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9798abf4",
+ "metadata": {},
+ "source": [
+ "### Using `.iloc` and `.loc` to index\n",
+ "\n",
+ "In this section, we introduce ways to access data that are preferred by Pandas over the methods listed above. When accessing by label, it is preferred to use the `.loc` method, and when accessing by index, the `.iloc` method is preferred. These methods behave similarly to the notation introduced above, but provide more speed, security, and rigor in your value selection. Using these methods can also help you avoid [chained assignment warnings](https://pandas.pydata.org/docs/user_guide/indexing.html#returning-a-view-versus-a-copy) generated by pandas."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d5eb9de2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nino34_series.iloc[3]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8d0bc3e8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nino34_series.iloc[0:12]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "59a10070",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nino34_series.loc[\"1982-04-01\"]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3e2b3fc1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nino34_series.loc[\"1982-01-01\":\"1982-12-01\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "722e3d11-4c27-4a4c-a31b-2d551587f2b3",
+ "metadata": {},
+ "source": [
+ "### Extending to the `DataFrame`\n",
+ "\n",
+ "These subsetting capabilities can also be used in a full `DataFrame`; however, if you use the same syntax, there are issues, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b8971371",
+ "metadata": {
+ "tags": [
+ "raises-exception"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "df[\"1982-01-01\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b89bf013-4492-461f-a1ef-a4f1a3423a4a",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " As opposed to index-based slices, label-based slices are inclusive of the final value.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b40c7ace-939b-4997-a185-be1ea8363d06",
+ "metadata": {},
+ "source": [
+ "When indexing a `DataFrame`, pandas will not assume as readily the intention of your code. In this case, using a row label by itself will not work; **with `DataFrames`, labels are used for identifying columns**."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b504ed93-d310-4384-b99b-08d3ddc96bb0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df[\"Nino34\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34196c97-5117-402c-a1d6-c05298ed8500",
+ "metadata": {},
+ "source": [
+ "As shown below, you also cannot subset columns in a `DataFrame` using integer indices:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c393a116-da08-4b99-b87d-de76e2614f00",
+ "metadata": {
+ "tags": [
+ "raises-exception"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "df[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d4e6213d",
+ "metadata": {},
+ "source": [
+ "From earlier examples, we know that we can use an index or label with a `DataFrame` to pull out a column as a `Series`, and we know that we can use an index or label with a `Series` to pull out a single value. Therefore, by chaining brackets, we can pull any individual data value out of the `DataFrame`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c61fa6d4",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "df[\"Nino34\"][\"1982-04-01\"]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3bd7cf95",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df[\"Nino34\"][3]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "afb0d6ef",
+ "metadata": {},
+ "source": [
+ "However, subsetting data using this chained-bracket technique is not preferred by Pandas. As described above, Pandas prefers us to use the `.loc` and `.iloc` methods for subsetting. In addition, these methods provide a clearer, more efficient way to extract specific data from a `DataFrame`, as illustrated below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9fb5df7b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.loc[\"1982-04-01\", \"Nino34\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "98d6e445-51ed-4128-bfeb-fb82abbe9cb8",
+ "metadata": {},
+ "source": [
+ "Danger
\n", + " Attempting to useSeries subsetting with a DataFrame can crash your program. A proper way to subset a DataFrame is shown below.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e710252f",
+ "metadata": {},
+ "source": [
+ "The `.loc` and `.iloc` methods also allow us to pull entire rows out of a `DataFrame`, as shown in these examples:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aad4fde6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.loc[\"1982-04-01\"]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f93737ba",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.loc[\"1982-01-01\":\"1982-12-01\"]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6c23cbca",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.iloc[3]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "22c07d7d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.iloc[0:12]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4c2ed15e",
+ "metadata": {},
+ "source": [
+ "In the next example, we illustrate how you can use slices of rows and lists of columns to create a smaller `DataFrame` out of an existing `DataFrame`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8390a35b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.loc[\n",
+ " \"1982-01-01\":\"1982-12-01\", # slice of rows\n",
+ " [\"Nino12\", \"Nino3\", \"Nino4\", \"Nino34\"], # list of columns\n",
+ "]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c128cc18-e433-4060-870d-19835b5e556e",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " When using this syntax to pull individual data values from a DataFrame, make sure to list the row first, and then the column.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2e2739dc",
+ "metadata": {},
+ "source": [
+ "## Exploratory Data Analysis\n",
+ "\n",
+ "### Get a Quick Look at the Beginning/End of your `DataFrame`\n",
+ "Pandas also gives you a few shortcuts to quickly investigate entire `DataFrames`. The `head` method shows the first five rows of a `DataFrame`, and the `tail` method shows the last five rows of a `DataFrame`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3c11b92a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.head()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3bf87294",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.tail()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cba9f221",
+ "metadata": {},
+ "source": [
+ "### Quick Plots of Your Data\n",
+ "A good way to explore your data is by making a simple plot. Pandas contains its own `plot` method; this allows us to plot Pandas series without needing `matplotlib`. In this example, we plot the `Nino34` series of our `df` `DataFrame` in this way:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bf317171",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.Nino34.plot();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "99c2c7a3",
+ "metadata": {},
+ "source": [
+ "Before, we called `.plot()`, which generated a single line plot. Line plots can be helpful for understanding some types of data, but there are other types of data that can be better understood with different plot types. For example, if your data values form a distribution, you can better understand them using a histogram plot.\n",
+ "\n",
+ "The code for plotting histogram data differs in two ways from the code above for the line plot. First, two series are being used from the `DataFrame` instead of one. Second, after calling the `plot` method, we call an additional method called `hist`, which converts the plot into a histogram."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5f85e2dd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df[['Nino12', 'Nino34']].plot.hist();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a4e07618",
+ "metadata": {},
+ "source": [
+ "The histogram plot helped us better understand our data; there are clear differences in the distributions. To even better understand this type of data, it may also be helpful to create a box plot. This can be done using the same line of code, with one change: we call the `box` method instead of `hist`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6329d231",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df[['Nino12', 'Nino34']].plot.box();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c338385b",
+ "metadata": {},
+ "source": [
+ "Just like the histogram plot, this box plot indicates a clear difference in the distributions. Using multiple types of plot in this way can be useful for verifying large datasets. The pandas plotting methods are capable of creating many different types of plots. To see how to use the plotting methods to generate each type of plot, please review the [pandas plot documentation](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.html)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "69fc4078",
+ "metadata": {},
+ "source": [
+ "#### Customize your Plot\n",
+ "The pandas plotting methods are, in fact, wrappers for similar methods in matplotlib. This means that you can customize pandas plots by including keyword arguments to the plotting methods. These keyword arguments, for the most part, are equivalent to their matplotlib counterparts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "da22f990",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.Nino34.plot(\n",
+ " color='black',\n",
+ " linewidth=2,\n",
+ " xlabel='Year',\n",
+ " ylabel='ENSO34 Index (degC)',\n",
+ " figsize=(8, 6),\n",
+ ");"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e7145ef6",
+ "metadata": {},
+ "source": [
+ "Although plotting data can provide a clear visual picture of data values, sometimes a more quantitative look at data is warranted. As elaborated on in the next section, this can be achieved using the `describe` method. The `describe` method is called on the entire `DataFrame`, and returns various summarized statistics for each column in the `DataFrame`.\n",
+ "### Basic Statistics\n",
+ "\n",
+ "We can garner statistics for a `DataFrame` by using the `describe` method. When this method is called on a `DataFrame`, a set of statistics is returned in tabular format. The columns match those of the `DataFrame`, and the rows indicate different statistics, such as minimum."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3b5c27a8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.describe()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a92bb8b3",
+ "metadata": {},
+ "source": [
+ "You can also view specific statistics using corresponding methods. In this example, we look at the mean values in the entire `DataFrame`, using the `mean` method. When such methods are called on the entire `DataFrame`, a `Series` is returned. The indices of this `Series` are the column names in the `DataFrame`, and the values are the calculated values (in this case, mean values) for the `DataFrame` columns."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "db9e4a16",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.mean()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1ff5aec7",
+ "metadata": {},
+ "source": [
+ "If you want a specific statistic for only one column in the `DataFrame`, pull the column out of the `DataFrame` with dot notation, then call the statistic function (in this case, mean) on that column, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9aa38e59",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.Nino34.mean()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7295e7b0",
+ "metadata": {},
+ "source": [
+ "### Subsetting Using the Datetime Column\n",
+ "\n",
+ "Slicing is a useful technique for subsetting a `DataFrame`, but there are also other options that can be equally useful. In this section, some of these additional techniques are covered.\n",
+ "\n",
+ "If your `DataFrame` uses datetime values for indices, you can select data from only one month using `df.index.month`. In this example, we specify the number 1, which only selects data from January."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a506724a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Uses the datetime column\n",
+ "df[df.index.month == 1]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "16d4e0e7",
+ "metadata": {},
+ "source": [
+ "This example shows how to create a new column containing the month portion of the datetime index for each data row. The value returned by `df.index.month` is used to obtain the data for this new column:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fe5d5ee4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df['month'] = df.index.month"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8750443f",
+ "metadata": {},
+ "source": [
+ "This next example illustrates how to use the new month column to calculate average monthly values over the other data columns. First, we use the `groupby` method to group the other columns by the month. Second, we take the average (mean) to obtain the monthly averages. Finally, we plot the resulting data as a line plot by simply calling `plot()`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f94c91f9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.groupby('month').mean().plot();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a0c9481b",
+ "metadata": {},
+ "source": [
+ "### Investigating Extreme Values"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fec15b77",
+ "metadata": {},
+ "source": [
+ "If you need to search for rows that meet a specific criterion, you can use **conditional indexing**. In this example, we search for rows where the Nino34 anomaly value (`Nino34anom`) is greater than 2:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "098fc88d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df[df.Nino34anom > 2]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f26bc439",
+ "metadata": {},
+ "source": [
+ "This example shows how to use the `sort_values` method on a `DataFrame`. This method sorts values in a `DataFrame` by the column specified as an argument."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8051c4f6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.sort_values('Nino34anom')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a293de79",
+ "metadata": {},
+ "source": [
+ "You can also reverse the ordering of the sort by specifying the `ascending` keyword argument as `False`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "be7ff8ce",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.sort_values('Nino34anom', ascending=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5504a0da",
+ "metadata": {},
+ "source": [
+ "### Resampling\n",
+ "In these examples, we illustrate a process known as resampling. Using resampling, you can change the frequency of index data values, reducing so-called 'noise' in a data plot. This is especially useful when working with timeseries data; plots can be equally effective with resampled data in these cases. The resampling performed in these examples converts monthly values to yearly averages. This is performed by passing the value '1Y' to the `resample` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "597cfeac",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.Nino34.plot();"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9e3ee506",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.Nino34.resample('1Y').mean().plot();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "16c80788",
+ "metadata": {},
+ "source": [
+ "### Applying operations to a DataFrame\n",
+ "\n",
+ "One of the most commonly used features in Pandas is the performing of calculations to multiple data values in a `DataFrame` simultaneously. Let's first look at a familiar concept: a function that converts single values. The following example uses such a function to convert temperature values from degrees Celsius to Kelvin."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c8afa857",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def convert_degc_to_kelvin(temperature_degc):\n",
+ " \"\"\"\n",
+ " Converts from degrees celsius to Kelvin\n",
+ " \"\"\"\n",
+ "\n",
+ " return temperature_degc + 273.15"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "34892381",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Convert a single value\n",
+ "convert_degc_to_kelvin(0)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "384a0bdb",
+ "metadata": {},
+ "source": [
+ "The following examples instead illustrate a new concept: using such functions with `DataFrames` and `Series`. For the first example, we start by creating a `Series`; in order to do so, we subset the `DataFrame` by the `Nino34` column. This has already been done earlier in this page; we do not need to create this `Series` again. We are using this particular `Series` for a reason: the data values are in degrees Celsius."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f09ee7c6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "nino34_series"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "28ac04e8",
+ "metadata": {},
+ "source": [
+ "Here, we look at a portion of an existing `DataFrame` column. Notice that this column portion is a Pandas `Series`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8718a43f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "type(df.Nino12[0:10])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ff1f569f",
+ "metadata": {},
+ "source": [
+ "As shown in the following example, each Pandas `Series` contains a representation of its data in numpy format. Therefore, it is possible to convert a Pandas `Series` into a numpy array; this is done using the `.values` method:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "61a8255f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "type(df.Nino12.values[0:10])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2a5693fe",
+ "metadata": {},
+ "source": [
+ "This example illustrates how to use the temperature-conversion function defined above on a `Series` object. Just as calling the function with a single value returns a single value, calling the function on a `Series` object returns another `Series` object. The function performs the temperature conversion on each data value in the `Series`, and returns a `Series` with all values converted."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ae197a92",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "convert_degc_to_kelvin(nino34_series)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "87871b82",
+ "metadata": {},
+ "source": [
+ "If we call the `.values` method on the `Series` passed to the function, the `Series` is converted to a numpy array, as described above. The function then converts each value in the numpy array, and returns a new numpy array with all values sorted."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84ec100b-60bd-4cb9-b596-40af2a04b95d",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " There are certain limitations to these subsetting techniques. For more information on these limitations, as well as a comparison ofDataFrame and Series indexing methods, see the Pandas indexing documentation.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "52ae68ee",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "convert_degc_to_kelvin(nino34_series.values)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "65b3cd56",
+ "metadata": {},
+ "source": [
+ "As described above, when our temperature-conversion function accepts a `Series` as an argument, it returns a `Series`. We can directly assign this returned `Series` to a new column in our `DataFrame`, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2d84dfe1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df['Nino34_degK'] = convert_degc_to_kelvin(nino34_series)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dd9a0811",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.Nino34_degK"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8c6dba3",
+ "metadata": {},
+ "source": [
+ "In this final example, we demonstrate the use of the `to_csv` method to save a `DataFrame` as a `.csv` file. This example also demonstrates the `read_csv` method, which reads `.csv` files into Pandas `DataFrames`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "054428db",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "df.to_csv('nino_analyzed_output.csv')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3f7d378f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pd.read_csv('nino_analyzed_output.csv', index_col=0, parse_dates=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9327e958",
+ "metadata": {},
+ "source": [
+ "---\n",
+ "## Summary\n",
+ "* Pandas is a very powerful tool for working with tabular (i.e., spreadsheet-style) data\n",
+ "* There are multiple ways of subsetting your pandas dataframe or series\n",
+ "* Pandas allows you to refer to subsets of data by label, which generally makes code more readable and more robust\n",
+ "* Pandas can be helpful for exploratory data analysis, including plotting and basic statistics\n",
+ "* One can apply calculations to pandas dataframes and save the output via `csv` files\n",
+ "\n",
+ "### What's Next?\n",
+ "In the next notebook, we will look more into using pandas for more in-depth data analysis.\n",
+ "\n",
+ "## Resources and References\n",
+ "1. [NOAA NCDC ENSO Dataset Used in this Example](https://www.ncdc.noaa.gov/teleconnections/enso/indicators/sst/)\n",
+ "1. [Getting Started with Pandas](https://pandas.pydata.org/docs/getting_started/index.html#getting-started)\n",
+ "1. [Pandas User Guide](https://pandas.pydata.org/docs/user_guide/index.html#user-guide)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/_preview/468/_sources/core/xarray.md b/_preview/468/_sources/core/xarray.md
new file mode 100644
index 000000000..27e827cc0
--- /dev/null
+++ b/_preview/468/_sources/core/xarray.md
@@ -0,0 +1,19 @@
+
+
+# Xarray
+
+This section contains tutorials on using [Xarray][xarray home]. Xarray is used widely in the geosciences and beyond for analysis of gridded N-dimensional datasets.
+
+---
+
+From the [Xarray website][xarray home]:
+
+> Xarray (formerly Xray) is an open source project and Python package that makes working with labelled multi-dimensional arrays simple, efficient, and fun!
+>
+> Xarray introduces labels in the form of dimensions, coordinates and attributes on top of raw NumPy-like arrays, which allows for a more intuitive, more concise, and less error-prone developer experience. The package includes a large and growing library of domain-agnostic functions for advanced analytics and visualization with these data structures.
+>
+> Xarray is inspired by and borrows heavily from pandas, the popular data analysis package focused on labelled tabular data. It is particularly tailored to working with netCDF files, which were the source of xarray’s data model, and integrates tightly with dask for parallel computing.
+
+You should have a basic familiarity with [Numpy arrays](numpy) prior to working through the Xarray notebooks presented here.
+
+[xarray home]: http://xarray.pydata.org/en/stable/
diff --git a/_preview/468/_sources/core/xarray/computation-masking.ipynb b/_preview/468/_sources/core/xarray/computation-masking.ipynb
new file mode 100644
index 000000000..3e3c29f5b
--- /dev/null
+++ b/_preview/468/_sources/core/xarray/computation-masking.ipynb
@@ -0,0 +1,907 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "7b494629-f859-4586-b235-e61fed184b9a",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# Computations and Masks with Xarray"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b1fb677c-11f3-4901-a7df-3cd3f9e45b6e",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "79f94c0a-b585-4510-97da-379daea2b873",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Overview\n",
+ "\n",
+ "In this tutorial, we will cover the following topics:\n",
+ "\n",
+ "1. Performing basic arithmetic on `DataArrays` and `Datasets`\n",
+ "2. Performing aggregation (i.e., reduction) along single or multiple dimensions of a `DataArray` or `Dataset`\n",
+ "3. Computing climatologies and anomalies of data using Xarray's \"split-apply-combine\" approach, via the `.groupby()` method\n",
+ "4. Performing weighted-reduction operations along single or multiple dimensions of a `DataArray` or `Dataset`\n",
+ "5. Providing a broad overview of Xarray's data-masking capability\n",
+ "6. Using the `.where()` method to mask Xarray data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "921b094b-d556-4a9e-a1bd-7a8560d8b335",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Prerequisites\n",
+ "\n",
+ "\n",
+ "| Concepts | Importance | Notes |\n",
+ "| --- | --- | --- |\n",
+ "| [Introduction to Xarray](xarray-intro) | Necessary | |\n",
+ "\n",
+ "\n",
+ "- **Time to learn**: 60 minutes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f6e62752-c323-4e24-8767-0754d1816556",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0af7bee1-3de3-453a-8ae8-bcd7910b4266",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Imports\n",
+ "\n",
+ "In order to work with data and plotting, we must import NumPy, Matplotlib, and Xarray. These packages are covered in greater detail in earlier tutorials. We also import a package that allows quick download of Pythia example datasets."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "06073287-7bdb-45b5-9cec-8cdf123adb49",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "import numpy as np\n",
+ "import xarray as xr\n",
+ "from pythia_datasets import DATASETS"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9719db5b-e645-4815-b8df-d454fa7703e7",
+ "metadata": {},
+ "source": [
+ "## Data Setup\n",
+ "\n",
+ "The bulk of the examples in this tutorial make use of a single dataset. This dataset contains monthly sea surface temperature (SST, call 'tos' here) data, and is obtained from the Community Earth System Model v2 (CESM2). (For this tutorial, however, the dataset will be retrieved from the Pythia example data repository.) The following example illustrates the process of retrieving this Global Climate Model dataset:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7837f8bd-da89-4718-ab02-d5107576d2d6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "filepath = DATASETS.fetch('CESM2_sst_data.nc')\n",
+ "ds = xr.open_dataset(filepath)\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b3f4e108-f55e-4c25-a00d-99dc00ba849a",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Arithmetic Operations\n",
+ "\n",
+ "In a similar fashion to NumPy arrays, performing an arithmetic operation on a `DataArray` will automatically perform the operation on all array values; this is known as vectorization. To illustrate the process of vectorization, the following example converts the air temperature data from units of degrees Celsius to units of Kelvin:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "09542eab-998d-4b2d-807c-dccd5bd4329e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos + 273.15"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6f35c8d6-b0e6-4371-ad80-e182ffcec51b",
+ "metadata": {},
+ "source": [
+ "In addition, there are many other arithmetic operations that can be performed on `DataArrays`. In this example, we demonstrate squaring the original Celsius values of our air temperature data:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "78c1ffc2-45cb-40cc-962e-c76021d9ab1c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos**2"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0bebb17b-6906-4ba7-a4ff-c07a9206e790",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Aggregation Methods \n",
+ "\n",
+ "A common practice in the field of data analysis is aggregation. Aggregation is the process of reducing data through methods such as `sum()`, `mean()`, `median()`, `min()`, and `max()`, in order to gain greater insight into the nature of large datasets. In this set of examples, we demonstrate correct usage of a select group of aggregation methods:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a4d79093-f013-4821-84f8-3c223141046e",
+ "metadata": {},
+ "source": [
+ "Compute the mean:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "59b84034-7d42-4080-932f-0eefd165953d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos.mean()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a75e0064-4363-4328-9a79-d87475ed1c81",
+ "metadata": {},
+ "source": [
+ "Notice that we did not specify the `dim` keyword argument; this means that the function was applied over all of the dataset's dimensions. In other words, the aggregation method computed the mean of every element of the temperature dataset across every temporal and spatial data point. However, if a dimension name is used with the `dim` keyword argument, the aggregation method computes an aggregation along the given dimension. In this next example, we use aggregation to calculate the temporal mean across all spatial data; this is performed by providing the dimension name `'time'` to the `dim` keyword argument:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a49b957e-ea24-414e-a422-c40a3723fbae",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos.mean(dim='time').plot(size=7);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "109f77cf-54bb-4cac-a667-2afeb2cfef9d",
+ "metadata": {},
+ "source": [
+ "There are many other combinations of aggregation methods and dimensions on which to perform these methods. In this example, we compute the temporal minimum:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ceddf519-7459-4eaf-ae0d-69b2ba135317",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos.min(dim=['time'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cb5f55c5-95bc-4fe3-a4fc-49958b6cf64c",
+ "metadata": {},
+ "source": [
+ "This example computes the spatial sum. Note that this dataset contains no altitude data; as such, the required spatial dimensions passed to the method consist only of latitude and longitude."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "487cafa8-c1cc-451a-96da-900c6ab961d5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos.sum(dim=['lat', 'lon'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b613fc00-5c75-4df1-b4e4-d391de84aab2",
+ "metadata": {},
+ "source": [
+ "For the last example in this set of aggregation examples, we compute the temporal median:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e0873a32-de0e-456e-8948-e6516ddb7fd1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos.median(dim='time')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b9790835-51ae-460b-87a4-618e7760d7a7",
+ "metadata": {},
+ "source": [
+ "In addition, there are many other commonly used aggregation methods in Xarray. Some of the more popular aggregation methods are summarized in the following table:\n",
+ "\n",
+ "| Aggregation | Description |\n",
+ "|--------------------------|---------------------------------|\n",
+ "| ``count()`` | Total number of items |\n",
+ "| ``mean()``, ``median()`` | Mean and median |\n",
+ "| ``min()``, ``max()`` | Minimum and maximum |\n",
+ "| ``std()``, ``var()`` | Standard deviation and variance |\n",
+ "| ``prod()`` | Compute product of elements |\n",
+ "| ``sum()`` | Compute sum of elements |\n",
+ "| ``argmin()``, ``argmax()``| Find index of minimum and maximum value |"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8704803f-300d-4631-a2fa-f62d18726d1c",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## GroupBy: Split, Apply, Combine\n",
+ "\n",
+ "While we can obtain useful summaries of datasets using simple aggregation methods, it is more often the case that aggregation must be performed over coordinate labels or groups. In order to perform this type of aggregation, it is helpful to use the **split-apply-combine** workflow. Fortunately, Xarray provides this functionality for `DataArrays` and `Datasets` by means of the `groupby` operation. The following figure illustrates the split-apply-combine workflow in detail:\n",
+ "\n",
+ "Warning
\n", + " It is recommended to only convertSeries to NumPy arrays when necessary; doing so removes the label information that enables much of the Pandas core functionality.\n",
+ " \n",
+ "\n",
+ "Based on the above figure, you can understand the split-apply-combine process performed by `groupby`. In detail, the steps of this process are:\n",
+ "\n",
+ "- The split step involves breaking up and grouping an xarray `Dataset` or `DataArray` depending on the value of the specified group key.\n",
+ "- The apply step involves computing some function, usually an aggregate, transformation, or filtering, within the individual groups.\n",
+ "- The combine step merges the results of these operations into an output xarray `Dataset` or `DataArray`.\n",
+ "\n",
+ "In this set of examples, we will remove the seasonal cycle (also known as a climatology) from our dataset using `groupby`. There are many types of input that can be provided to `groupby`; a full list can be found in [Xarray's `groupby` user guide](https://xarray.pydata.org/en/stable/user-guide/groupby.html)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "713cc8d8-7374-4c5b-be61-aec4b5b0ffe6",
+ "metadata": {},
+ "source": [
+ "In this first example, we plot data to illustrate the annual cycle described above. We first select the grid point closest to a specific latitude-longitude point. Once we have this grid point, we can plot a temporal series of sea-surface temperature (SST) data at that location. Reviewing the generated plot, the annual cycle of the data becomes clear."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c0348ee8-6e9b-4f50-a844-375ae00d2771",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos.sel(lon=310, lat=50, method='nearest').plot();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d1505625-cbcd-495b-a15f-8824e455415b",
+ "metadata": {},
+ "source": [
+ "### Split\n",
+ "\n",
+ "The first step of the split-apply-combine process is splitting. As described above, this step involves splitting a dataset into groups, with each group matching a group key. In this example, we split the SST data using months as a group key. Therefore, there is one resulting group for January data, one for February data, etc. This code illustrates how to perform such a split:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6e4fb25e-165f-4350-a93d-46a344f2d175",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos.groupby(ds.time.dt.month)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5d176ad8-15f1-4ecc-ab3e-898cef3b4e18",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ "Based on the above figure, you can understand the split-apply-combine process performed by `groupby`. In detail, the steps of this process are:\n",
+ "\n",
+ "- The split step involves breaking up and grouping an xarray `Dataset` or `DataArray` depending on the value of the specified group key.\n",
+ "- The apply step involves computing some function, usually an aggregate, transformation, or filtering, within the individual groups.\n",
+ "- The combine step merges the results of these operations into an output xarray `Dataset` or `DataArray`.\n",
+ "\n",
+ "In this set of examples, we will remove the seasonal cycle (also known as a climatology) from our dataset using `groupby`. There are many types of input that can be provided to `groupby`; a full list can be found in [Xarray's `groupby` user guide](https://xarray.pydata.org/en/stable/user-guide/groupby.html)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "713cc8d8-7374-4c5b-be61-aec4b5b0ffe6",
+ "metadata": {},
+ "source": [
+ "In this first example, we plot data to illustrate the annual cycle described above. We first select the grid point closest to a specific latitude-longitude point. Once we have this grid point, we can plot a temporal series of sea-surface temperature (SST) data at that location. Reviewing the generated plot, the annual cycle of the data becomes clear."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c0348ee8-6e9b-4f50-a844-375ae00d2771",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos.sel(lon=310, lat=50, method='nearest').plot();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d1505625-cbcd-495b-a15f-8824e455415b",
+ "metadata": {},
+ "source": [
+ "### Split\n",
+ "\n",
+ "The first step of the split-apply-combine process is splitting. As described above, this step involves splitting a dataset into groups, with each group matching a group key. In this example, we split the SST data using months as a group key. Therefore, there is one resulting group for January data, one for February data, etc. This code illustrates how to perform such a split:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6e4fb25e-165f-4350-a93d-46a344f2d175",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos.groupby(ds.time.dt.month)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5d176ad8-15f1-4ecc-ab3e-898cef3b4e18",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "In the above code example, we are extracting components of date/time data by way of the time coordinate's `.dt` attribute. This attribute is a `DatetimeAccessor` object that contains additional attributes for units of time, such as hour, day, and year. Since we are splitting the data into monthly data, we use the `month` attribute of .dt in this example. (In addition, there exists similar functionality in Pandas; see the [official documentation](https://pandas.pydata.org/docs/reference/api/pandas.Series.dt.month.html) for details.)\n",
+ " \n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ad273652-178c-4eda-80b6-6d39a11d6f1e",
+ "metadata": {},
+ "source": [
+ "In addition, there is a more concise syntax that can be used in specific instances. This syntax can be used if the variable on which the grouping is performed is already present in the dataset. The following example illustrates this syntax; it is functionally equivalent to the syntax used in the above example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c6990393-fb5f-4a10-b8e2-fd9c6917d9d2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos.groupby('time.month')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6b85dbf7-daf1-4889-8b3b-6991d290969f",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Apply & Combine \n",
+ "\n",
+ "Now that we have split our data into groups, the next step is to apply a calculation to the groups. There are two types of calculation that can be applied:\n",
+ "\n",
+ "- aggregation: reduces the size of the group\n",
+ "- transformation: preserves the group's full size\n",
+ "\n",
+ "After a calculation is applied to the groups, Xarray will automatically combine the groups back into a single object, completing the split-apply-combine workflow.\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### Compute climatology \n",
+ "\n",
+ "\n",
+ "In this example, we use the split-apply-combine workflow to calculate the monthly climatology at every point in the dataset. Notice that we are using the `month` `DatetimeAccessor`, as described above, as well as the `.mean()` aggregation function:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7e568c2f-7143-4346-85ce-a430db03316e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tos_clim = ds.tos.groupby('time.month').mean()\n",
+ "tos_clim"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2ef90862-aeb4-45b3-87fb-e9df8f197c81",
+ "metadata": {},
+ "source": [
+ "Now that we have a `DataArray` containing the climatology data, we can plot the data in different ways. In this example, we plot the climatology at a specific latitude-longitude point:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f908c377-67fa-449c-b8d1-82ba6a14baff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tos_clim.sel(lon=310, lat=50, method='nearest').plot();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0e5dc34b-99bc-494b-9c04-ed8388ab2e6c",
+ "metadata": {},
+ "source": [
+ "In this example, we plot the zonal mean climatology:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "22c61c11-2a48-4c6c-8009-6f20e0101237",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tos_clim.mean(dim='lon').transpose().plot.contourf(levels=12, cmap='turbo');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3411ebb7-9831-4e52-ab2e-7e4e7a1356ee",
+ "metadata": {},
+ "source": [
+ "Finally, this example calculates and plots the difference between the climatology for January and the climatology for December:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "19a2808b-81f9-40e5-ab31-d63bfce85eae",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "(tos_clim.sel(month=1) - tos_clim.sel(month=12)).plot(size=6, robust=True);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "266b8130-ca7d-4aec-a9a2-d7281ad64425",
+ "metadata": {},
+ "source": [
+ "#### Compute anomaly\n",
+ "\n",
+ "In this example, we compute the anomaly of the original data by removing the climatology from the data values. As shown in previous examples, the climatology is first calculated. The calculated climatology is then removed from the data using arithmetic and Xarray's `groupby` method:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4c9940df-5174-49bf-9117-eef1e14abec0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "gb = ds.tos.groupby('time.month')\n",
+ "tos_anom = gb - gb.mean(dim='time')\n",
+ "tos_anom"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "35fc2054-df48-4ea2-8433-632ba8755c61",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tos_anom.sel(lon=310, lat=50, method='nearest').plot();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c3c087dc-966d-48a0-bb99-ca63cf20ff05",
+ "metadata": {},
+ "source": [
+ "In this example, we compute and plot our dataset's mean global anomaly over time. In order to specify global data, we must provide both `lat` and `lon` to the `mean()` method's `dim` keyword argument:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5d3abf06-a341-45ac-a3f2-76131016c0b3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "unweighted_mean_global_anom = tos_anom.mean(dim=['lat', 'lon'])\n",
+ "unweighted_mean_global_anom.plot();"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d9f768be-a960-4417-bb1e-9785ca9ca4ea",
+ "metadata": {},
+ "source": [
+ "\n",
+ " \n",
+ "\n",
+ "Many geoscientific algorithms perform operations over data contained in many different grid cells. However, if the grid cells are not equivalent in size, the operation is not scientifically valid by default. Fortunately, this can be fixed by weighting the data in each grid cell by the size of the cell. Weighting data in Xarray is simple, as Xarray has a built-in weighting method, known as [`.weighted()`](https://xarray.pydata.org/en/stable/user-guide/computation.html#weighted-array-reductions).\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "908bcc38-bf93-478c-99e4-8bbafeec1f21",
+ "metadata": {},
+ "source": [
+ "In this example, we again make use of the Pythia example data library to load a new CESM2 dataset. Contained in this dataset are weights corresponding to the grid cells in our anomaly data:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a5878de6-f3ab-43e0-8f0d-12ab51631450",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "filepath2 = DATASETS.fetch('CESM2_grid_variables.nc')\n",
+ "areacello = xr.open_dataset(filepath2).areacello\n",
+ "areacello"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8a73a748-46b4-4350-b167-32725eebaec8",
+ "metadata": {},
+ "source": [
+ "In a similar fashion to a previous example, this example calculates mean global anomaly. However, this example makes use of the `.weighted()` method and the newly loaded CESM2 dataset to weight the grid cell data as described above:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b8f7e3a5-0748-4395-95b0-0e31d0a5d4d1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "weighted_mean_global_anom = tos_anom.weighted(areacello).mean(dim=['lat', 'lon'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "17da2e3a-3ca6-41f4-892e-b26021c492e6",
+ "metadata": {},
+ "source": [
+ "This example plots both unweighted and weighted mean data, which illustrates the degree of scientific error with unweighted data:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "802c5e99-7223-49b5-a867-91d943075d52",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "unweighted_mean_global_anom.plot(size=7)\n",
+ "weighted_mean_global_anom.plot()\n",
+ "plt.legend(['unweighted', 'weighted']);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3045c67e-21cd-4ef9-a49f-e12ae7db23cf",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Other high level computation functionality\n",
+ "\n",
+ "- `resample`: [This method behaves similarly to groupby, but is specialized for time dimensions, and can perform temporal upsampling and downsampling.](https://xarray.pydata.org/en/stable/user-guide/time-series.html#resampling-and-grouped-operations)\n",
+ "- `rolling`: [This method is used to compute aggregation functions, such as `mean`, on moving windows of data in a dataset.](https://xarray.pydata.org/en/stable/user-guide/computation.html#rolling-window-operations)\n",
+ "- `coarsen`: [This method provides generic functionality for performing downsampling operations on various types of data.](https://xarray.pydata.org/en/stable/user-guide/computation.html#coarsen-large-arrays)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "eaf4dc7d-dfac-419e-a875-fc0c70fcd08c",
+ "metadata": {},
+ "source": [
+ "This example illustrates the resampling of a dataset's time dimension to annual frequency:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a9cfb76b-c4ab-441e-a474-c66b7af944ad",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "r = ds.tos.resample(time='AS')\n",
+ "r"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6927f5be-d313-4d03-bab8-d22b3cb13899",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "r.mean()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "32370e4f-a1c4-4163-a926-b9e3a8d6d5c2",
+ "metadata": {},
+ "source": [
+ "This example illustrates using the `rolling` method to compute averages in a moving window of 5 months of data:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "342acbf1-4eee-4d0d-bb52-b394ffcd556d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "m_avg = ds.tos.rolling(time=5, center=True).mean()\n",
+ "m_avg"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0eb0cc4e-661a-4ab1-96ad-e096917ef104",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "lat = 50\n",
+ "lon = 310\n",
+ "\n",
+ "m_avg.isel(lat=lat, lon=lon).plot(size=6)\n",
+ "ds.tos.isel(lat=lat, lon=lon).plot()\n",
+ "plt.legend(['5-month moving average', 'monthly data']);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "da76db37-e833-42c5-a740-5dcf0877b43c",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Masking Data\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8a657ca8-fa2d-409c-9aaf-580828671018",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "Masking of data can be performed in Xarray by providing single or multiple conditions to either Xarray's `.where()` method or a `Dataset` or `DataArray`'s `.where()` method. Data values matching the condition(s) are converted into a single example value, effectively masking them from the scientifically important data. In the following set of examples, we use the `.where()` method to mask various data values in the `tos` `DataArray`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "59a59bef-b08c-4e0f-a48a-894565a962e7",
+ "metadata": {},
+ "source": [
+ "For reference, we will first print our entire sea-surface temperature (SST) dataset:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "afff083b-6c0b-4756-b1be-716a443d98a2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "386c7a1b-1a47-4f52-a42d-27fa997427d3",
+ "metadata": {},
+ "source": [
+ "### Using `where` with one condition"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8d48b6b-a40e-469f-861f-83d943d70f03",
+ "metadata": {},
+ "source": [
+ "In this set of examples, we are trying to analyze data at the last temporal value in the dataset. This first example illustrates the use of `.isel()` to perform this analysis:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ac3e42eb-1852-4580-9c52-e7237135ed01",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample = ds.tos.isel(time=-1)\n",
+ "sample"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ccdd1fa6-93fd-490d-8b05-c222ddcf953a",
+ "metadata": {},
+ "source": [
+ "As shown in the previous example, methods like `.isel()` and `.sel()` return data of a different shape than the original data provided to them. However, `.where()` preserves the shape of the original data by masking the values with a Boolean condition. Data values for which the condition is `True` are returned identical to the values passed in. On the other hand, data values for which the condition is `False` are returned as a preset example value. (This example value defaults to `nan`, but can be set to other values as well.)\n",
+ "\n",
+ "Before testing `.where()`, it is helpful to look at the [official documentation](http://xarray.pydata.org/en/stable/generated/xarray.DataArray.where.html). As stated above, the `.where()` method takes a Boolean condition. (Boolean conditions use operators such as less-than, greater-than, and equal-to, and return a value of `True` or `False`.) Most uses of `.where()` check whether or not specific data values are less than or greater than a constant value. As stated in the documentation, the data values specified in the Boolean condition of `.where()` can be any of the following:\n",
+ "\n",
+ "- a `DataArray`\n",
+ "- a `Dataset`\n",
+ "- a function\n",
+ "\n",
+ "In the following example, we make use of `.where()` to mask data with temperature values greater than `0`. Therefore, values greater than `0` are set to `nan`, as described above. (It is important to note that the Boolean condition matches values to keep, not values to mask out.)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "61abc5b3-aadf-4a96-98a2-c9c36094a863",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "masked_sample = sample.where(sample < 0.0)\n",
+ "masked_sample"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "09aeeee1-3924-4ccd-9b69-1be396c496b9",
+ "metadata": {},
+ "source": [
+ "In this example, we use Matplotlib to plot the original, unmasked data, as well as the masked data created in the previous example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "91457518-fc38-42e2-8b96-c5786e36f33f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig, axes = plt.subplots(ncols=2, figsize=(19, 6))\n",
+ "sample.plot(ax=axes[0])\n",
+ "masked_sample.plot(ax=axes[1]);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4dd6b000-b079-461c-9a0e-8fd2bced814b",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Using `where` with multiple conditions"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "538bd497-3059-4f6e-9c48-5104958f8528",
+ "metadata": {},
+ "source": [
+ "Those familiar with Boolean conditions know that such conditions can be combined by using logical operators. In the case of `.where()`, the relevant logical operators are bitwise or exclusive `'and'` (represented by the `&` symbol) and bitwise or exclusive 'or' (represented by the `|` symbol). This allows multiple masking conditions to be specified in a single use of `.where()`; however, be aware that if multiple conditions are specified in this way, each simple Boolean condition must be enclosed in parentheses. (If you are not familiar with Boolean conditions, or this section is confusing in any way, please review a detailed Boolean expression guide before continuing with the tutorial.) In this example, we provide multiple conditions to `.where()` using a more complex Boolean condition. This allows us to mask locations with temperature values less than 25, as well as locations with temperature values greater than 30. (As stated above, the Boolean condition matches values to keep, and everything else is masked out. Because we are now using more complex Boolean conditions, understanding the following example may be difficult. Please review a Boolean condition guide if needed.)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c9bf1c46-e7ed-43c1-8a45-e03d22295da1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample.where((sample > 25) & (sample < 30)).plot(size=6);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d1796fc8-039b-4c40-a6f4-b3a00c130770",
+ "metadata": {},
+ "source": [
+ "In addition to using `DataArrays` and `Datasets` in Boolean conditions provided to `.where()`, we can also use coordinate variables. In the following example, we make use of Boolean conditions containing `latitude` and `longitude` coordinates. This greatly simplifies the masking of regions outside of the [Niño 3.4 region](https://www.ncdc.noaa.gov/teleconnections/enso/indicators/sst/):\n",
+ "\n",
+ "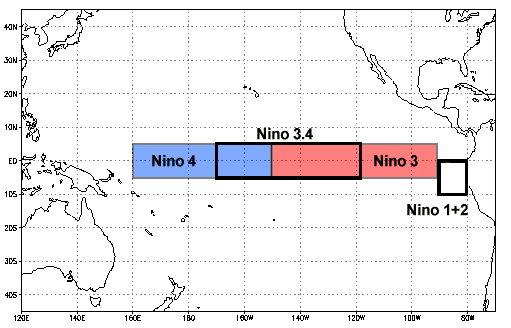\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "090f1997-8dea-4eed-aa55-ab3a180ecdd5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample.where(\n",
+ " (sample.lat < 5) & (sample.lat > -5) & (sample.lon > 190) & (sample.lon < 240)\n",
+ ").plot(size=6);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "47ebbbff-2409-43e1-90e9-2cd4c9777bdc",
+ "metadata": {},
+ "source": [
+ "### Using `where` with a custom fill value"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a1b76d95-f8b3-44ef-a7a5-c2028daaf500",
+ "metadata": {},
+ "source": [
+ "In the previous examples that make use of `.where()`, the masked data values are set to `nan`. However, this behavior can be modified by providing a second value, in numeric form, to `.where()`; if this numeric value is provided, it will be used instead of `nan` for masked data values. In this example, masked data values are set to `0` by providing a second value of `0` to the `.where()` method:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aae12476-4802-42a2-993b-29da6c383535",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sample.where((sample > 25) & (sample < 30), 0).plot(size=6);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5fad83ca-faf6-44c5-8d05-173b425118e1",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d2cb7356-714b-45cd-b109-d0b6965b6a0c",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Summary \n",
+ "\n",
+ "- In a similar manner to NumPy arrays, performing arithmetic on a `DataArray` affects all values simultaneously.\n",
+ "- Xarray allows for simple data aggregation, over single or multiple dimensions, by way of built-in methods such as `sum()` and `mean()`.\n",
+ "- Xarray supports the useful split-apply-combine workflow through the `groupby` method.\n",
+ "- Xarray allows replacing (masking) of data matching specific Boolean conditions by means of the `.where()` method.\n",
+ "\n",
+ "### What's next?\n",
+ "\n",
+ "The next tutorial illustrates the use of previously covered Xarray concepts in a geoscientifically relevant example: plotting the [Niño 3.4 Index](https://climatedataguide.ucar.edu/climate-data/nino-sst-indices-nino-12-3-34-4-oni-and-tni)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "374de3a3-807a-47be-9014-e1af98909456",
+ "metadata": {},
+ "source": [
+ "## Resources and References\n",
+ "\n",
+ "- `groupby`: [Useful for binning/grouping data and applying reductions and/or transformations on those groups](https://xarray.pydata.org/en/stable/user-guide/groupby.html)\n",
+ "- `resample`: [Functionality similar to groupby, specialized for time dimensions. Can be used for temporal upsampling and downsampling](https://xarray.pydata.org/en/stable/user-guide/time-series.html#resampling-and-grouped-operations)\n",
+ "- `rolling`: [Useful for computing aggregations on moving windows of your dataset, e.g., computing moving averages](https://xarray.pydata.org/en/stable/user-guide/computation.html#rolling-window-operations)\n",
+ "- `coarsen`: [Generic functionality for downsampling data](https://xarray.pydata.org/en/stable/user-guide/computation.html#coarsen-large-arrays)\n",
+ "\n",
+ "- `weighted`: [Useful for weighting data before applying reductions](https://xarray.pydata.org/en/stable/user-guide/computation.html#weighted-array-reductions)\n",
+ "\n",
+ "- [More xarray tutorials and videos](https://xarray.pydata.org/en/stable/tutorials-and-videos.html)\n",
+ "- [Xarray Documentation - Masking with `where()`](https://xarray.pydata.org/en/stable/user-guide/indexing.html#masking-with-where)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/_preview/468/_sources/core/xarray/dask-arrays-xarray.ipynb b/_preview/468/_sources/core/xarray/dask-arrays-xarray.ipynb
new file mode 100644
index 000000000..4f8e4996f
--- /dev/null
+++ b/_preview/468/_sources/core/xarray/dask-arrays-xarray.ipynb
@@ -0,0 +1,712 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "d59e6a58-b50e-4015-bbd8-b48608d44b26",
+ "metadata": {},
+ "source": [
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "013dde55-1cea-4fd8-b980-0fa06bdd5568",
+ "metadata": {},
+ "source": [
+ "# Dask Arrays with Xarray\n",
+ "\n",
+ "The scientific Python package known as Dask provides Dask Arrays: parallel, larger-than-memory, n-dimensional arrays that make use of blocked algorithms. They are analogous to Numpy arrays, but are distributed. These terms are defined below:\n",
+ "\n",
+ "* **Parallel** code uses many or all of the cores on the computer running the code.\n",
+ "* **Larger-than-memory** refers to algorithms that break up data arrays into small pieces, operate on these pieces in an optimized fashion, and stream data from a storage device. This allows a user or programmer to work with datasets of a size larger than the available memory.\n",
+ "* A **blocked algorithm** speeds up large computations by converting them into a series of smaller computations.\n",
+ "\n",
+ "In this tutorial, we cover the use of Xarray to wrap Dask arrays. By using Dask arrays instead of Numpy arrays in Xarray data objects, it becomes possible to execute analysis code in parallel with much less code and effort.\n",
+ "\n",
+ "\n",
+ "## Learning Objectives\n",
+ "\n",
+ "- Learn the distinction between *eager* and *lazy* execution, and performing both types of execution with Xarray\n",
+ "- Understand key features of Dask Arrays\n",
+ "- Learn to perform operations with Dask Arrays in similar ways to performing operations with NumPy arrays\n",
+ "- Understand the use of Xarray `DataArrays` and `Datasets` as \"Dask collections\", and the use of top-level Dask functions such as `dask.visualize()` on such collections\n",
+ "- Understand the ability to use Dask transparently in all built-in Xarray operations\n",
+ "\n",
+ "## Prerequisites\n",
+ "\n",
+ "\n",
+ "| Concepts | Importance | Notes |\n",
+ "| --- | --- | --- |\n",
+ "| [Introduction to NumPy](../numpy/numpy-basics) | Necessary | Familiarity with Data Arrays |\n",
+ "| [Introduction to Xarray](xarray-intro) | Necessary | Familiarity with Xarray Data Structures |\n",
+ "\n",
+ "\n",
+ "- **Time to learn**: *30-40 minutes*\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "027ccc87-420b-45dd-830a-38766dd6248f",
+ "metadata": {},
+ "source": [
+ "## Imports\n",
+ "\n",
+ "For this tutorial, as we are working with Dask, there are a number of Dask packages that must be imported. Also, this is technically an Xarray tutorial, so Xarray and NumPy must also be imported. Finally, the Pythia datasets package is imported, allowing access to the Project Pythia example data library."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8aa666b9-4af2-41b5-8e77-e28f9cecddd1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import dask\n",
+ "import dask.array as da\n",
+ "import numpy as np\n",
+ "import xarray as xr\n",
+ "from dask.diagnostics import ProgressBar\n",
+ "from dask.utils import format_bytes\n",
+ "from pythia_datasets import DATASETS"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "259bdc60-6e96-4258-8d71-e733ce2d9aca",
+ "metadata": {},
+ "source": [
+ "## Blocked algorithms\n",
+ "\n",
+ "As described above, the definition of \"blocked algorithm\" is an algorithm that replaces a large operation with many small operations. In the case of datasets, this means that a blocked algorithm separates a dataset into chunks, and performs an operation on each.\n",
+ "\n",
+ "As an example of how blocked algorithms work, consider a dataset containing a billion numbers, and assume that the sum of the numbers is needed. Using a non-blocked algorithm, all of the numbers are added in one operation, which is extremely inefficient. However, by using a blocked algorithm, the dataset is broken into chunks. (For the purposes of this example, assume that 1,000 chunks are created, with 1,000,000 numbers each.) The sum of the numbers in each chunk is taken, most likely in parallel, and then each of those sums are summed to obtain the final result.\n",
+ "\n",
+ "By using blocked algorithms, we achieve the result, in this case one sum of one billion numbers, through the results of many smaller operations, in this case one thousand sums of one million numbers each. (Also note that each of the one thousand sums must then be summed, making the total number of sums 1,001.) This allows for a much greater degree of parallelism, potentially speeding up the code execution dramatically."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "53b69958-355f-4121-a644-227adc1b14ef",
+ "metadata": {},
+ "source": [
+ "### `dask.array` contains these algorithms\n",
+ "\n",
+ "The main object type used in Dask is `dask.array`, which implements a subset of the `ndarray` (NumPy array) interface. However, unlike `ndarray`, `dask.array` uses blocked algorithms, which break up the array into smaller arrays, as described above. This allows for the execution of computations on arrays larger than memory, by using parallelism to divide the computation among multiple cores. Dask manages and coordinates blocked algorithms for any given computation by using Dask graphs, which lay out in detail the steps Dask takes to solve a problem. In addition, `dask.array` objects, known as Dask Arrays, are **lazy**; in other words, any computation performed on them is delayed until a specific method is called."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1aef9368-240b-423b-a3c7-0ab7baa8fa13",
+ "metadata": {},
+ "source": [
+ "### Create a `dask.array` object\n",
+ "\n",
+ "As stated earlier, Dask Arrays are loosely based on NumPy arrays. In the next set of examples, we illustrate the main differences between Dask Arrays and NumPy arrays. In order to illustrate the differences, we must have both a Dask Array object and a NumPy array object. Therefore, this first example creates a 3-D NumPy array of random data:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "690bc749-976e-4b78-a801-8d01ee363ad7",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "shape = (600, 200, 200)\n",
+ "arr = np.random.random(shape)\n",
+ "arr"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c36032d1-0fb6-43d2-a188-87e8e00bd5a4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "format_bytes(arr.nbytes)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8e7e54dc-342c-4d31-902a-ece54a813e7e",
+ "metadata": {},
+ "source": [
+ "As shown above, this NumPy array contains about 183 MB of data."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "905dffb1-0879-4842-8b76-2538592f6156",
+ "metadata": {},
+ "source": [
+ "As stated above, we must also create a Dask Array. This next example creates a Dask Array with the same dimension sizes as the existing NumPy array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "be84728a-7953-4561-aa7d-326f4a45e3aa",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "darr = da.random.random(shape, chunks=(300, 100, 200))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "632e9f08-3142-46d7-b457-e9bde0d1dce9",
+ "metadata": {},
+ "source": [
+ "By specifying values to the `chunks` keyword argument, we can specify the array pieces that Dask's blocked algorithms break the array into; in this case, we specify `(300, 100, 200)`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ebbafe88-bb79-436c-aa3b-a9c5f31ff1ec",
+ "metadata": {},
+ "source": [
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "013dde55-1cea-4fd8-b980-0fa06bdd5568",
+ "metadata": {},
+ "source": [
+ "# Dask Arrays with Xarray\n",
+ "\n",
+ "The scientific Python package known as Dask provides Dask Arrays: parallel, larger-than-memory, n-dimensional arrays that make use of blocked algorithms. They are analogous to Numpy arrays, but are distributed. These terms are defined below:\n",
+ "\n",
+ "* **Parallel** code uses many or all of the cores on the computer running the code.\n",
+ "* **Larger-than-memory** refers to algorithms that break up data arrays into small pieces, operate on these pieces in an optimized fashion, and stream data from a storage device. This allows a user or programmer to work with datasets of a size larger than the available memory.\n",
+ "* A **blocked algorithm** speeds up large computations by converting them into a series of smaller computations.\n",
+ "\n",
+ "In this tutorial, we cover the use of Xarray to wrap Dask arrays. By using Dask arrays instead of Numpy arrays in Xarray data objects, it becomes possible to execute analysis code in parallel with much less code and effort.\n",
+ "\n",
+ "\n",
+ "## Learning Objectives\n",
+ "\n",
+ "- Learn the distinction between *eager* and *lazy* execution, and performing both types of execution with Xarray\n",
+ "- Understand key features of Dask Arrays\n",
+ "- Learn to perform operations with Dask Arrays in similar ways to performing operations with NumPy arrays\n",
+ "- Understand the use of Xarray `DataArrays` and `Datasets` as \"Dask collections\", and the use of top-level Dask functions such as `dask.visualize()` on such collections\n",
+ "- Understand the ability to use Dask transparently in all built-in Xarray operations\n",
+ "\n",
+ "## Prerequisites\n",
+ "\n",
+ "\n",
+ "| Concepts | Importance | Notes |\n",
+ "| --- | --- | --- |\n",
+ "| [Introduction to NumPy](../numpy/numpy-basics) | Necessary | Familiarity with Data Arrays |\n",
+ "| [Introduction to Xarray](xarray-intro) | Necessary | Familiarity with Xarray Data Structures |\n",
+ "\n",
+ "\n",
+ "- **Time to learn**: *30-40 minutes*\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "027ccc87-420b-45dd-830a-38766dd6248f",
+ "metadata": {},
+ "source": [
+ "## Imports\n",
+ "\n",
+ "For this tutorial, as we are working with Dask, there are a number of Dask packages that must be imported. Also, this is technically an Xarray tutorial, so Xarray and NumPy must also be imported. Finally, the Pythia datasets package is imported, allowing access to the Project Pythia example data library."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8aa666b9-4af2-41b5-8e77-e28f9cecddd1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import dask\n",
+ "import dask.array as da\n",
+ "import numpy as np\n",
+ "import xarray as xr\n",
+ "from dask.diagnostics import ProgressBar\n",
+ "from dask.utils import format_bytes\n",
+ "from pythia_datasets import DATASETS"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "259bdc60-6e96-4258-8d71-e733ce2d9aca",
+ "metadata": {},
+ "source": [
+ "## Blocked algorithms\n",
+ "\n",
+ "As described above, the definition of \"blocked algorithm\" is an algorithm that replaces a large operation with many small operations. In the case of datasets, this means that a blocked algorithm separates a dataset into chunks, and performs an operation on each.\n",
+ "\n",
+ "As an example of how blocked algorithms work, consider a dataset containing a billion numbers, and assume that the sum of the numbers is needed. Using a non-blocked algorithm, all of the numbers are added in one operation, which is extremely inefficient. However, by using a blocked algorithm, the dataset is broken into chunks. (For the purposes of this example, assume that 1,000 chunks are created, with 1,000,000 numbers each.) The sum of the numbers in each chunk is taken, most likely in parallel, and then each of those sums are summed to obtain the final result.\n",
+ "\n",
+ "By using blocked algorithms, we achieve the result, in this case one sum of one billion numbers, through the results of many smaller operations, in this case one thousand sums of one million numbers each. (Also note that each of the one thousand sums must then be summed, making the total number of sums 1,001.) This allows for a much greater degree of parallelism, potentially speeding up the code execution dramatically."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "53b69958-355f-4121-a644-227adc1b14ef",
+ "metadata": {},
+ "source": [
+ "### `dask.array` contains these algorithms\n",
+ "\n",
+ "The main object type used in Dask is `dask.array`, which implements a subset of the `ndarray` (NumPy array) interface. However, unlike `ndarray`, `dask.array` uses blocked algorithms, which break up the array into smaller arrays, as described above. This allows for the execution of computations on arrays larger than memory, by using parallelism to divide the computation among multiple cores. Dask manages and coordinates blocked algorithms for any given computation by using Dask graphs, which lay out in detail the steps Dask takes to solve a problem. In addition, `dask.array` objects, known as Dask Arrays, are **lazy**; in other words, any computation performed on them is delayed until a specific method is called."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1aef9368-240b-423b-a3c7-0ab7baa8fa13",
+ "metadata": {},
+ "source": [
+ "### Create a `dask.array` object\n",
+ "\n",
+ "As stated earlier, Dask Arrays are loosely based on NumPy arrays. In the next set of examples, we illustrate the main differences between Dask Arrays and NumPy arrays. In order to illustrate the differences, we must have both a Dask Array object and a NumPy array object. Therefore, this first example creates a 3-D NumPy array of random data:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "690bc749-976e-4b78-a801-8d01ee363ad7",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "shape = (600, 200, 200)\n",
+ "arr = np.random.random(shape)\n",
+ "arr"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c36032d1-0fb6-43d2-a188-87e8e00bd5a4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "format_bytes(arr.nbytes)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8e7e54dc-342c-4d31-902a-ece54a813e7e",
+ "metadata": {},
+ "source": [
+ "As shown above, this NumPy array contains about 183 MB of data."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "905dffb1-0879-4842-8b76-2538592f6156",
+ "metadata": {},
+ "source": [
+ "As stated above, we must also create a Dask Array. This next example creates a Dask Array with the same dimension sizes as the existing NumPy array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "be84728a-7953-4561-aa7d-326f4a45e3aa",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "darr = da.random.random(shape, chunks=(300, 100, 200))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "632e9f08-3142-46d7-b457-e9bde0d1dce9",
+ "metadata": {},
+ "source": [
+ "By specifying values to the `chunks` keyword argument, we can specify the array pieces that Dask's blocked algorithms break the array into; in this case, we specify `(300, 100, 200)`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ebbafe88-bb79-436c-aa3b-a9c5f31ff1ec",
+ "metadata": {},
+ "source": [
+ "\n",
+ "
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ed467b75-9629-4fbc-a235-866459e4b881",
+ "metadata": {},
+ "source": [
+ "If you are viewing this page as a Jupyter Notebook, the next Jupyter cell will produce a rich information graphic giving in-depth details about the array and each individual chunk."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "42c13417-a5a2-4fd2-8610-a3cd70f4b93a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "darr"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "75988622-8ec1-45b0-a069-29ca74f53836",
+ "metadata": {},
+ "source": [
+ "The above graphic contains a symbolic representation of the array, including `shape`, `dtype`, and `chunksize`. (Your view may be different, depending on how you are accessing this page.) Notice that there is no data shown for this array; this is because Dask Arrays are lazy, as described above. Before we call a compute method for this array, we first illustrate the structure of a Dask graph. In this example, we show the Dask graph by calling `.visualize()` on the array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "44a7a6e4-bcfc-40c1-a095-8fa315bfef4e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "darr.visualize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37f4038c-f2b2-40c3-91cd-af2713dd23df",
+ "metadata": {},
+ "source": [
+ "As shown in the above Dask graph, our array has four chunks, each one created by a call to NumPy's \"random\" method (`np.random.random`). These chunks are concatenated into a single array after the calculation is performed."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c5b29134-62af-4a0b-8e44-9f99b5072b45",
+ "metadata": {},
+ "source": [
+ "### Manipulate a `dask.array` object as you would a numpy array\n",
+ "\n",
+ "\n",
+ "We can perform computations on the Dask Array created above in a similar fashion to NumPy arrays. These computations include arithmetic, slicing, and reductions, among others.\n",
+ "\n",
+ "Although the code for performing these computations is similar between NumPy arrays and Dask Arrays, the process by which they are performed is quite different. For example, it is possible to call `sum()` on both a NumPy array and a Dask Array; however, these two `sum()` calls are definitely not the same, as shown below.\n",
+ "\n",
+ "#### What's the difference?\n",
+ "\n",
+ "When `sum()` is called on a Dask Array, the computation is not performed; instead, an expression of the computation is built. The `sum()` computation, as well as any other computation methods called on the same Dask Array, are not performed until a specific method (known as a compute method) is called on the array. (This is known as **lazy execution**.) On the other hand, calling `sum()` on a NumPy array performs the calculation immediately; this is known as **eager execution**.\n",
+ "\n",
+ "#### Why the difference?\n",
+ "\n",
+ "As described earlier, a Dask Array is divided into chunks. Any computations run on the Dask Array run on each chunk individually. If the result of the computation is obtained before the computation runs through all of the chunks, Dask can stop the computation to save CPU time and memory resources.\n",
+ "\n",
+ "This example illustrates calling `sum()` on a Dask Array; it also includes a demonstration of lazy execution, as well as another Dask graph display:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cf14f2f0-a66e-4578-8a8d-f0c7701beb9c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "total = darr.sum()\n",
+ "total"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "36724be4-63ec-4b1c-9a9e-1a605a12a5a5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "total.visualize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "09186a60-51fc-49c1-91ac-3614af0202cc",
+ "metadata": {},
+ "source": [
+ "#### Compute the result\n",
+ "\n",
+ "As described above, Dask Array objects make use of lazy execution. Therefore, operations performed on a Dask Array wait to execute until a compute method is called. As more operations are queued in this way, the Dask Array's Dask graph increases in complexity, reflecting the steps Dask will take to perform all of the queued operations. \n",
+ "\n",
+ "In this example, we call a compute method, simply called `.compute()`, to run on the Dask Array all of the stored computations:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "36aff31f-2f06-4703-a2a6-cf692ab5eed3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%time\n",
+ "total.compute()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "af09c610-0e66-4ce8-a53a-fdd50471271d",
+ "metadata": {},
+ "source": [
+ "### Exercise with `dask.arrays`\n",
+ "\n",
+ "In this section of the page, the examples are hands-on exercises pertaining to Dask Arrays. If these exercises are not interesting to you, this section can be used strictly as examples regardless of how the page is viewed. However, if you wish to participate in the exercises, make sure that you are viewing this page as a Jupyter Notebook.\n",
+ "\n",
+ "For the first exercise, modify the chunk size or shape of the Dask Array created earlier. Call `.sum()` on the modified Dask Array, and visualize the Dask graph to view the changes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "11922e84-f13e-4db6-a8a0-cf75a5727cfb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "da.random.random(shape, chunks=(50, 200, 400)).sum().visualize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b275b5cc-51a6-48ff-a0a4-62bdc43e6530",
+ "metadata": {},
+ "source": [
+ "As is obvious from the above exercise, Dask quickly and easily determines a strategy for performing the operations, in this case a sum. This illustrates the appeal of Dask: automatic algorithm generation that scales from simple arithmetic problems to highly complex scientific equations with large datasets and multiple operations."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7a7dcaaa-6a6e-4f58-aa80-2890136158fd",
+ "metadata": {},
+ "source": [
+ "In this next set of examples, we demonstrate that increasing the complexity of the operations performed also increases the complexity of the Dask graph.\n",
+ "\n",
+ "In this example, we use randomly selected functions, arguments and Python slices to create a complex set of operations. We then visualize the Dask graph to illustrate the increased complexity:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e74a6817-8d06-4dd1-afec-98c53a8ae52a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z = darr.dot(darr.T).mean(axis=0)[::2, :].std(axis=1)\n",
+ "z"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a4ccffad-5bda-4108-a6c8-6628510f8363",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.visualize()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "35c59c2f-3e5c-443b-908f-4f14535d2802",
+ "metadata": {},
+ "source": [
+ "### Testing a bigger calculation\n",
+ "\n",
+ "While the earlier examples in this tutorial described well the basics of Dask, the size of the data in those examples, about 180 MB, is far too small for an actual use of Dask.\n",
+ "\n",
+ "In this example, we create a much larger array, more indicative of data actually used in Dask:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "482fb0fe-87d4-46fa-bb9d-ed38cc71d834",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "darr = da.random.random((4000, 100, 4000), chunks=(1000, 100, 500)).astype('float32')\n",
+ "darr"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6c0f8b73-41c1-49fb-9fa4-97cb10ae6f4d",
+ "metadata": {},
+ "source": [
+ "The dataset created in the previous example is much larger, approximately 6 GB. Depending on how many programs are running on your computer, this may be greater than the amount of free RAM on your computer. However, as Dask is larger-than-memory, the amount of free RAM does not impede Dask's ability to work on this dataset.\n",
+ "\n",
+ "In this example, we again perform randomly selected operations, but this time on the much larger dataset. We also visualize the Dask graph, and then run the compute method. However, as computing complex functions on large datasets is inherently time-consuming, we show a progress bar to track the progress of the computation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "51e9addb-cc13-46f5-b542-827f8bdd94b5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z = (darr + darr.T)[::2, :].mean(axis=2)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c44ed57c-2a31-4df1-897b-02b614279755",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.visualize()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f5bf25c1-7384-4953-bbb8-be0c3c4e02e9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with ProgressBar():\n",
+ " computed_ds = z.compute()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "116996d8-cc8a-4201-94d9-8152f4b6aa42",
+ "metadata": {},
+ "source": [
+ "## Dask Arrays with Xarray\n",
+ "\n",
+ "While directly interacting with Dask Arrays can be useful on occasion, more often than not Dask Arrays are interacted with through [Xarray](http://xarray.pydata.org/en/stable/\n",
+ "). Since Xarray wraps NumPy arrays, and Dask Arrays contain most of the functionality of NumPy arrays, Xarray can also wrap Dask Arrays, allowing anyone with knowledge of Xarray to easily start using the Dask interface."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "57d12474-e71a-400f-b103-824f0de7288b",
+ "metadata": {},
+ "source": [
+ "### Reading data with `Dask` and `Xarray`\n",
+ "\n",
+ "As demonstrated in previous examples, a Dask Array consists of many smaller arrays, called chunks:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d6e932e0-ff01-412b-9629-1fb5590ffb0a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "darr"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d7e0c25-3baa-45aa-bb4d-940480b2fbe9",
+ "metadata": {},
+ "source": [
+ "As shown in the following example, to read data into Xarray as Dask Arrays, simply specify the `chunks` keyword argument when calling the `open_dataset()` function:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3396e4e6-911b-4c40-a3f8-cdccf034a4ee",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = xr.open_dataset(DATASETS.fetch('CESM2_sst_data.nc'), chunks={})\n",
+ "ds.tos"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f7333413-63ba-41f6-bf6c-8f2046402931",
+ "metadata": {},
+ "source": [
+ "While it is a valid operation to pass an empty list to the `chunks` keyword argument, this technique does not specify how to chunk the data, and therefore the resulting Dask Array contains only one chunk.\n",
+ "\n",
+ "Correct usage of the `chunks` keyword argument specifies how many values in each dimension are contained in a single chunk. In this example, specifying the chunks keyword argument as `chunks={'time':90}` indicates to Xarray and Dask that 90 time slices are allocated to each chunk on the temporal axis.\n",
+ "\n",
+ "Since this dataset contains 180 total time slices, the data variable `tos` (holding the sea surface temperature data) is now split into two chunks in the temporal dimension."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4e7ac6b2-500f-4371-98ca-dc28dfe27648",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = xr.open_dataset(\n",
+ " DATASETS.fetch('CESM2_sst_data.nc'),\n",
+ " engine=\"netcdf4\",\n",
+ " chunks={\"time\": 90, \"lat\": 180, \"lon\": 360},\n",
+ ")\n",
+ "ds.tos"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8e175e4d-9950-48fb-b81c-4e67fa00b106",
+ "metadata": {},
+ "source": [
+ "It is fairly straightforward to retrieve a list of the chunks and their sizes for each dimension; simply call the `.chunks` method on an Xarray `DataArray`. In this example, we show that the `tos` `DataArray` now contains two chunks on the `time` dimension, with each chunk containing 90 time slices."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4265a298-275c-4f93-992f-6fe8de9a311a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.tos.chunks"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "54853249-beec-4d74-8881-82d9d253c3b7",
+ "metadata": {},
+ "source": [
+ "### Xarray data structures are first-class dask collections\n",
+ "\n",
+ "If an Xarray `Dataset` or `DataArray` object uses a Dask Array, rather than a NumPy array, it counts as a first-class Dask collection. This means that you can pass such an object to `dask.visualize()` and `dask.compute()`, in the same way as an individual Dask Array.\n",
+ "\n",
+ "In this example, we call `dask.visualize` on our Xarray `DataArray`, displaying a Dask graph for the `DataArray` object:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "333de4bb-db42-42e8-95f9-5db108962ae7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dask.visualize(ds)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d827f1b1-7d13-4707-93c2-45c2f99a7e60",
+ "metadata": {},
+ "source": [
+ "### Parallel and lazy computation using `dask.array` with Xarray\n",
+ "\n",
+ "\n",
+ "As described above, Xarray `Datasets` and `DataArrays` containing Dask Arrays are first-class Dask collections. Therefore, computations performed on such objects are deferred until a compute method is called. (This is the definition of lazy computation.)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a6cc7961-d43e-4dca-84f2-d3f82631e1f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z = ds.tos.mean(['lat', 'lon']).dot(ds.tos.T)\n",
+ "z"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "764537d7-b8e2-4f92-9b5e-cf81a1d8baa7",
+ "metadata": {},
+ "source": [
+ "As shown in the above example, the result of the applied operations is an Xarray `DataArray` that contains a Dask Array, an identical object type to the object that the operations were performed on. This is true for any operations that can be applied to Xarray `DataArrays`, including subsetting operations; this next example illustrates this:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "631fb768-f900-448a-a605-a93bea26bdc8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "z.isel(lat=0)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34679cf2-4907-44d7-b386-0c3cbc7ce6d2",
+ "metadata": {},
+ "source": [
+ "Because the data subset created above is also a first-class Dask collection, we can view its Dask graph using the `dask.visualize()` function, as shown in this example:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7ebf0c9e-ac35-4841-9294-2d9e1b6dbc24",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "dask.visualize(z)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "56bf9674-57f2-4b49-a5d5-95a4eafac587",
+ "metadata": {},
+ "source": [
+ "Since this object is a first-class Dask collection, the computations performed on it have been deferred. To run these computations, we must call a compute method, in this case `.compute()`. This example also uses a progress bar to track the computation progress."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "30082ac8-694a-4a48-bf03-840720aaa9b7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with ProgressBar():\n",
+ " computed_ds = z.compute()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7cf5002f-ed03-4318-935a-b5ce6e57434e",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f58e6da5-1492-4778-8821-aa03721e3db4",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "\n",
+ "This tutorial covered the use of Xarray to access Dask Arrays, and the use of the `chunks` keyword argument to open datasets with Dask data instead of NumPy data. Another important concept introduced in this tutorial is the usage of Xarray `Datasets` and `DataArrays` as Dask collections, allowing Xarray objects to be manipulated in a similar manner to Dask Arrays. Finally, the concepts of larger-than-memory datasets, lazy computation, and parallel computation, and how they relate to Xarray and Dask, were covered.\n",
+ "\n",
+ "### Dask Shortcomings\n",
+ "\n",
+ "Although Dask Arrays and NumPy arrays are generally interchangeable, NumPy offers some functionality that is lacking in Dask Arrays. The usage of Dask Array comes with the following relevant issues:\n",
+ "\n",
+ "1. Operations where the resulting shape depends on the array values can produce erratic behavior, or fail altogether, when used on a Dask Array. If the operation succeeds, the resulting Dask Array will have unknown chunk sizes, which can cause other sections of code to fail.\n",
+ "2. Operations that are by nature difficult to parallelize or less useful on very large datasets, such as `sort`, are not included in the Dask Array interface. Some of these operations have supported versions that are inherently more intuitive to parallelize, such as [`topk`](https://pytorch.org/docs/stable/generated/torch.topk.html).\n",
+ "3. Development of new Dask functionality is only initiated when such functionality is required; therefore, some lesser-used NumPy functions, such as `np.sometrue`, are not yet implemented in Dask. However, many of these functions can be added as community contributions, or have already been added in this manner.\n",
+ "\n",
+ "## Learn More\n",
+ "\n",
+ "For more in-depth information on Dask Arrays, visit the [official documentation page](https://docs.dask.org/en/latest/array.html). In addition, [this screencast](https://youtu.be/9h_61hXCDuI) reinforces the concepts covered in this tutorial. (If you are viewing this page as a Jupyter Notebook, the screencast will appear below as an embedded YouTube video.)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "21fbe02b-6bee-447b-bbc8-2ba8a0b96c87",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from IPython.display import YouTubeVideo\n",
+ "\n",
+ "YouTubeVideo(id=\"9h_61hXCDuI\", width=600, height=300)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c282d878-a11f-41a2-9737-caee406ad5c3",
+ "metadata": {},
+ "source": [
+ "## Resources and references\n",
+ "\n",
+ "* To find specific reference information about Dask and Xarray, see the official documentation pages listed below:\n",
+ " * [Dask Docs](https://dask.org/)\n",
+ " * [Dask Examples](https://examples.dask.org/)\n",
+ " * [Dask Code](https://github.com/dask/dask/)\n",
+ " * [Dask Blog](https://blog.dask.org/)\n",
+ " \n",
+ " * [Xarray Docs](https://xarray.pydata.org/)\n",
+ " \n",
+ "* If you require assistance with a specific issue involving Xarray or Dask, the following resources may be of use:\n",
+ " * Dask tag on StackOverflow, for usage questions\n",
+ " * [github discussions: dask](https://github.com/dask/dask/discussions) for general, non-bug, discussion, and usage questions\n",
+ " * [github issues: dask](https://github.com/dask/dask/issues/new) for bug reports and feature requests\n",
+ " * [github discussions: xarray](https://github.com/pydata/xarray/discussions) for general, non-bug, discussion, and usage questions\n",
+ " * [github issues: xarray](https://github.com/pydata/xarray/issues/new) for bug reports and feature requests\n",
+ " \n",
+ "* Certain sections of this tutorial are adapted from the following existing tutorials:\n",
+ " * [Dask Array Tutorial](https://tutorial.dask.org/02_array.html)\n",
+ " * [Parallel Computing with Xarray and Dask](https://tutorial.xarray.dev/intermediate/xarray_and_dask.html)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d7013ef8-33c4-4bd8-8acc-63cce238acb2",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.9"
+ },
+ "vscode": {
+ "interpreter": {
+ "hash": "b0fa6594d8f4cbf19f97940f81e996739fb7646882a419484c72d19e05852a7e"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/_preview/468/_sources/core/xarray/enso-xarray.ipynb b/_preview/468/_sources/core/xarray/enso-xarray.ipynb
new file mode 100644
index 000000000..a419fd5f3
--- /dev/null
+++ b/_preview/468/_sources/core/xarray/enso-xarray.ipynb
@@ -0,0 +1,405 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "# Calculating ENSO with Xarray\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Overview\n",
+ "\n",
+ "In this tutorial, we perform and demonstrate the following tasks:\n",
+ "\n",
+ "1. Load SST data from the CESM2 model\n",
+ "2. Mask data using `.where()`\n",
+ "3. Compute climatologies and anomalies using `.groupby()`\n",
+ "4. Use `.rolling()` to compute moving average\n",
+ "5. Compute, normalize, and plot the Niño 3.4 Index"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Prerequisites\n",
+ "\n",
+ "\n",
+ "| Concepts | Importance | Notes |\n",
+ "| --- | --- | --- |\n",
+ "| [Introduction to Xarray](xarray-intro) | Necessary | |\n",
+ "| [Computation and Masking](computation-masking) | Necessary | |\n",
+ "\n",
+ "\n",
+ "\n",
+ "- **Time to learn**: 20 minutes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Imports \n",
+ "\n",
+ "For this tutorial, we import several Python packages. As plotting ENSO data requires a geographically accurate map, Cartopy is imported to handle geographic features and map projections. Xarray is used to manage raw data, and Matplotlib allows for feature-rich data plotting. Finally, a custom Pythia package is imported, in this case allowing access to the Pythia example data library."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import cartopy.crs as ccrs\n",
+ "import matplotlib.pyplot as plt\n",
+ "import xarray as xr\n",
+ "from pythia_datasets import DATASETS"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## The Niño 3.4 Index"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "In this tutorial, we combine topics covered in previous Xarray tutorials to demonstrate a real-world example. The real-world scenario demonstrated in this tutorial is the computation of the [Niño 3.4 Index](https://climatedataguide.ucar.edu/climate-data/nino-sst-indices-nino-12-3-34-4-oni-and-tni), as shown in the CESM2 submission for the [CMIP6 project](https://esgf-node.llnl.gov/projects/cmip6/). A rough definition of Niño 3.4, in addition to a definition of Niño data computation, is listed below:\n",
+ "\n",
+ "> Niño 3.4 (5N-5S, 170W-120W): The Niño 3.4 anomalies may be thought of as representing the average equatorial SSTs across the Pacific from about the dateline to the South American coast. The Niño 3.4 index typically uses a 5-month running mean, and El Niño or La Niña events are defined when the Niño 3.4 SSTs exceed +/- 0.4C for a period of six months or more.\n",
+ "\n",
+ "> Niño X Index computation: a) Compute area averaged total SST from Niño X region; b) Compute monthly climatology (e.g., 1950-1979) for area averaged total SST from Niño X region, and subtract climatology from area averaged total SST time series to obtain anomalies; c) Smooth the anomalies with a 5-month running mean; d) Normalize the smoothed values by its standard deviation over the climatological period.\n",
+ "\n",
+ "\n",
+ "\n",
+ "The overall goal of this tutorial is to produce a plot of ENSO data using Xarray; this plot will resemble the Oceanic Niño Index plot shown below.\n",
+ "\n",
+ "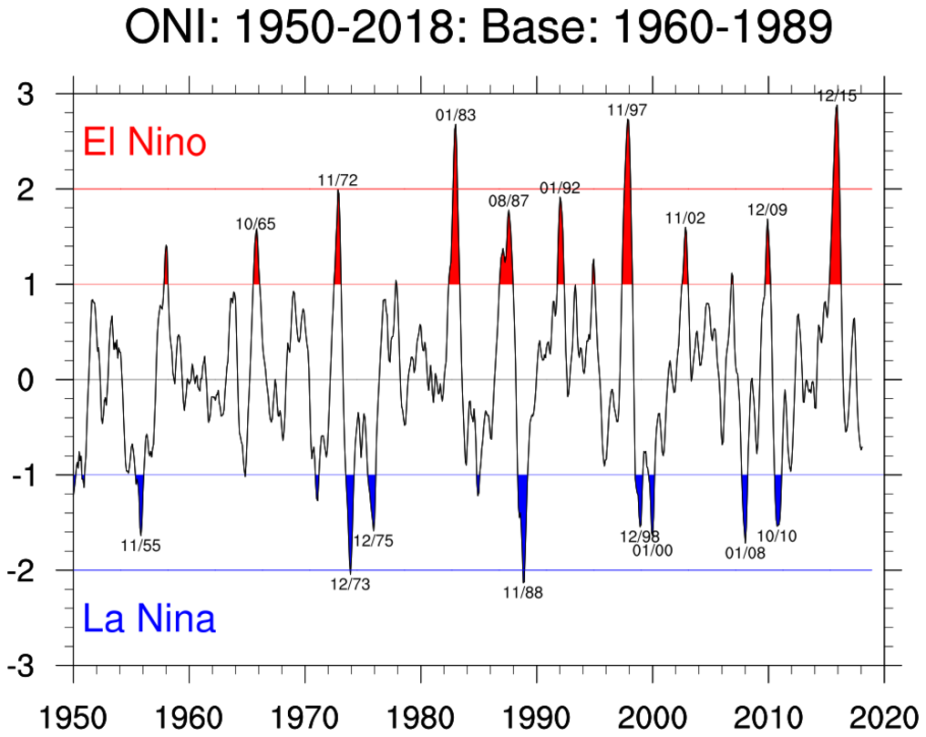"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "In this first example, we begin by opening datasets containing the sea-surface temperature (SST) and grid-cell size data. (These datasets are taken from the Pythia example data library, using the Pythia package imported above.) The two datasets are then combined into a single dataset using Xarray's `merge` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "filepath = DATASETS.fetch('CESM2_sst_data.nc')\n",
+ "data = xr.open_dataset(filepath)\n",
+ "filepath2 = DATASETS.fetch('CESM2_grid_variables.nc')\n",
+ "areacello = xr.open_dataset(filepath2).areacello\n",
+ "\n",
+ "ds = xr.merge([data, areacello])\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This example uses Matplotlib and Cartopy to plot the first time slice of the dataset on an actual geographic map. By doing so, we verify that the data values fit the pattern of SST data:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(12, 6))\n",
+ "ax = plt.axes(projection=ccrs.Robinson(central_longitude=180))\n",
+ "ax.coastlines()\n",
+ "ax.gridlines()\n",
+ "ds.tos.isel(time=0).plot(\n",
+ " ax=ax, transform=ccrs.PlateCarree(), vmin=-2, vmax=30, cmap='coolwarm'\n",
+ ");"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Select the Niño 3.4 region \n",
+ "\n",
+ "In this set of examples, we demonstrate the selection of data values from a dataset which are located in the Niño 3.4 geographic region. The following example illustrates a selection technique that uses the `sel()` or `isel()` method:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tos_nino34 = ds.sel(lat=slice(-5, 5), lon=slice(190, 240))\n",
+ "tos_nino34"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This example illustrates the alternate technique for selecting Niño 3.4 data, which makes use of the `where()` method:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tos_nino34 = ds.where(\n",
+ " (ds.lat < 5) & (ds.lat > -5) & (ds.lon > 190) & (ds.lon < 240), drop=True\n",
+ ")\n",
+ "tos_nino34"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, we plot the selected region to ensure it fits the definition of the Niño 3.4 region:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(12, 6))\n",
+ "ax = plt.axes(projection=ccrs.Robinson(central_longitude=180))\n",
+ "ax.coastlines()\n",
+ "ax.gridlines()\n",
+ "tos_nino34.tos.isel(time=0).plot(\n",
+ " ax=ax, transform=ccrs.PlateCarree(), vmin=-2, vmax=30, cmap='coolwarm'\n",
+ ")\n",
+ "ax.set_extent((120, 300, 10, -10))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Compute the anomalies\n",
+ "\n",
+ "There are three main steps to obtain the anomalies from the Niño 3.4 dataset created in the previous set of examples. First, we use the `groupby()` method to convert to monthly data. Second, we subtract the mean sea-surface temperature (SST) from the monthly data. Finally, we obtain the anomalies by computing a weighted average. These steps are illustrated in the next example:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "gb = tos_nino34.tos.groupby('time.month')\n",
+ "tos_nino34_anom = gb - gb.mean(dim='time')\n",
+ "index_nino34 = tos_nino34_anom.weighted(tos_nino34.areacello).mean(dim=['lat', 'lon'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In this example, we smooth the data curve by applying a `mean` function with a 5-month moving window to the anomaly dataset. We then plot the smoothed data against the original data to demonstrate:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "index_nino34_rolling_mean = index_nino34.rolling(time=5, center=True).mean()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "index_nino34.plot(size=8)\n",
+ "index_nino34_rolling_mean.plot()\n",
+ "plt.legend(['anomaly', '5-month running mean anomaly'])\n",
+ "plt.title('SST anomaly over the Niño 3.4 region');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Since the ENSO index conveys deviations from a norm, the calculation of Niño data requires a standard deviation. In this example, we calculate the standard deviation of the SST in the Niño 3.4 region data, across the entire time period of the data array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "std_dev = tos_nino34.tos.std()\n",
+ "std_dev"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The final step of the Niño 3.4 index calculation involves normalizing the data. In this example, we perform this normalization by dividing the smoothed anomaly data by the standard deviation calculated above:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "normalized_index_nino34_rolling_mean = index_nino34_rolling_mean / std_dev"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Visualize the computed Niño 3.4 index"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In this example, we use Matplotlib to generate a plot of our final Niño 3.4 data. This plot is set up to highlight values above 0.5, corresponding to El Niño (warm) events, and values below -0.5, corresponding to La Niña (cold) events."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(12, 6))\n",
+ "\n",
+ "plt.fill_between(\n",
+ " normalized_index_nino34_rolling_mean.time.data,\n",
+ " normalized_index_nino34_rolling_mean.where(\n",
+ " normalized_index_nino34_rolling_mean >= 0.4\n",
+ " ).data,\n",
+ " 0.4,\n",
+ " color='red',\n",
+ " alpha=0.9,\n",
+ ")\n",
+ "plt.fill_between(\n",
+ " normalized_index_nino34_rolling_mean.time.data,\n",
+ " normalized_index_nino34_rolling_mean.where(\n",
+ " normalized_index_nino34_rolling_mean <= -0.4\n",
+ " ).data,\n",
+ " -0.4,\n",
+ " color='blue',\n",
+ " alpha=0.9,\n",
+ ")\n",
+ "\n",
+ "normalized_index_nino34_rolling_mean.plot(color='black')\n",
+ "plt.axhline(0, color='black', lw=0.5)\n",
+ "plt.axhline(0.4, color='black', linewidth=0.5, linestyle='dotted')\n",
+ "plt.axhline(-0.4, color='black', linewidth=0.5, linestyle='dotted')\n",
+ "plt.title('Niño 3.4 Index');"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "\n",
+ "This tutorial covered the use of Xarray features, including selection, grouping, and statistical functions, to compute and visualize a data index important to climate science."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Resources and References\n",
+ "\n",
+ "- [Niño 3.4 index](https://climatedataguide.ucar.edu/climate-data/nino-sst-indices-nino-12-3-34-4-oni-and-tni)\n",
+ "- [Matplotlib's `fill_between` method](https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.fill_between.html)\n",
+ "- [Matplotlib's `axhline` method](https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.axhline.html) (see also its analogous `axvline` method)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.9"
+ },
+ "toc-autonumbering": false,
+ "toc-showcode": false,
+ "toc-showmarkdowntxt": false,
+ "toc-showtags": false
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/_preview/468/_sources/core/xarray/xarray-intro.ipynb b/_preview/468/_sources/core/xarray/xarray-intro.ipynb
new file mode 100644
index 000000000..bec195c1a
--- /dev/null
+++ b/_preview/468/_sources/core/xarray/xarray-intro.ipynb
@@ -0,0 +1,938 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "# Introduction to Xarray"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Overview\n",
+ "\n",
+ "The examples in this tutorial focus on the fundamentals of working with gridded, labeled data using Xarray. Xarray works by introducing additional abstractions into otherwise ordinary data arrays. In this tutorial, we demonstrate the usefulness of these abstractions. The examples in this tutorial explain how the proper usage of Xarray abstractions generally leads to simpler, more robust code.\n",
+ "\n",
+ "The following topics will be covered in this tutorial:\n",
+ "\n",
+ "1. Create a `DataArray`, one of the core object types in Xarray\n",
+ "1. Understand how to use named coordinates and metadata in a `DataArray`\n",
+ "1. Combine individual `DataArrays` into a `Dataset`, the other core object type in Xarray\n",
+ "1. Subset, slice, and interpolate the data using named coordinates\n",
+ "1. Open netCDF data using Xarray\n",
+ "1. Basic subsetting and aggregation of a `Dataset`\n",
+ "1. Brief introduction to plotting with Xarray"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Prerequisites\n",
+ "\n",
+ "| Concepts | Importance | Notes |\n",
+ "| --- | --- | --- |\n",
+ "| [NumPy Basics](../numpy/numpy-basics) | Necessary | |\n",
+ "| [Intermediate NumPy](../numpy/intermediate-numpy) | Helpful | Familiarity with indexing and slicing arrays |\n",
+ "| [NumPy Broadcasting](../numpy/numpy-broadcasting) | Helpful | Familiarity with array arithmetic and broadcasting |\n",
+ "| [Introduction to Pandas](../pandas/pandas) | Helpful | Familiarity with labeled data |\n",
+ "| [Datetime](../datetime/datetime) | Helpful | Familiarity with time formats and the `timedelta` object |\n",
+ "| [Understanding of NetCDF](some-link-to-external-resource) | Helpful | Familiarity with metadata structure |\n",
+ "\n",
+ "- **Time to learn**: 40 minutes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Imports"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In earlier tutorials, we explained the abbreviation of commonly used scientific Python package names in import statements. Just as `numpy` is abbreviated `np`, and just as `pandas` is abbreviated `pd`, the name `xarray` is often abbreviated `xr` in import statements. In addition, we also import `pythia_datasets`, which provides sample data used in these examples."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from datetime import timedelta\n",
+ "\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "import xarray as xr\n",
+ "from pythia_datasets import DATASETS"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Introducing the `DataArray` and `Dataset`\n",
+ "\n",
+ "As stated in earlier tutorials, NumPy arrays contain many useful features, making NumPy an essential part of the scientific Python stack. Xarray expands on these features, adding streamlined data manipulation capabilities. These capabilities are similar to those provided by Pandas, except that they are focused on gridded N-dimensional data instead of tabular data. Its interface is based largely on the netCDF data model (variables, attributes, and dimensions), but it goes beyond the traditional netCDF interfaces in order to provide additional useful functionality, similar to netCDF-java's [Common Data Model (CDM)](https://docs.unidata.ucar.edu/netcdf-java/current/userguide/common_data_model_overview.html). "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Creation of a `DataArray` object\n",
+ "\n",
+ "The `DataArray` in one of the most basic elements of Xarray; a `DataArray` object is similar to a numpy `ndarray` object. (For more information, see the documentation [here](http://xarray.pydata.org/en/stable/user-guide/data-structures.html#dataarray).) In addition to retaining most functionality from NumPy arrays, Xarray `DataArrays` provide two critical pieces of functionality:\n",
+ "\n",
+ "1. Coordinate names and values are stored with the data, making slicing and indexing much more powerful.\n",
+ "2. Attributes, similar to those in netCDF files, can be stored in a container built into the `DataArray`.\n",
+ "\n",
+ "In these examples, we create a NumPy array, and use it as a wrapper for a new `DataArray` object; we then explore some properties of a `DataArray`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Generate a random numpy array\n",
+ "\n",
+ "In this first example, we create a numpy array, holding random placeholder data of temperatures in Kelvin:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data = 283 + 5 * np.random.randn(5, 3, 4)\n",
+ "data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Wrap the array: first attempt\n",
+ "\n",
+ "For our first attempt at wrapping a NumPy array into a `DataArray`, we simply use the `DataArray` method of Xarray, passing the NumPy array we just created:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp = xr.DataArray(data)\n",
+ "temp"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Note two things:\n",
+ "\n",
+ "1. Since NumPy arrays have no dimension names, our new `DataArray` takes on placeholder dimension names, in this case `dim_0`, `dim_1`, and `dim_2`. In our next example, we demonstrate how to add more meaningful dimension names.\n",
+ "2. If you are viewing this page as a Jupyter Notebook, running the above example generates a rich display of the data contained in our `DataArray`. This display comes with many ways to explore the data; for example, clicking the array symbol expands or collapses the data view."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Assign dimension names\n",
+ "\n",
+ "Much of the power of Xarray comes from making use of named dimensions. In order to make full use of this, we need to provide more useful dimension names. We can generate these names when creating a `DataArray` by passing an ordered list of names to the `DataArray` method, using the keyword argument `dims`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp = xr.DataArray(data, dims=['time', 'lat', 'lon'])\n",
+ "temp"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This `DataArray` is already an improvement over a NumPy array; the `DataArray` contains names for each of the dimensions (or axes in NumPy parlance). An additional improvement is the association of coordinate-value arrays with data upon creation of a `DataArray`. In the next example, we illustrate the creation of NumPy arrays representing the coordinate values for each dimension of the `DataArray`, and how to associate these coordinate arrays with the data in our `DataArray`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Create a `DataArray` with named Coordinates\n",
+ "\n",
+ "#### Make time and space coordinates\n",
+ "\n",
+ "In this example, we use [Pandas](../pandas) to create an array of [datetime data](../datetime). This array will be used in a later example to add a named coordinate, called `time`, to a `DataArray`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "times = pd.date_range('2018-01-01', periods=5)\n",
+ "times"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Before associating coordinates with our `DataArray`, we must also create latitude and longitude coordinate arrays. In these examples, we use placeholder data, and create the arrays in NumPy format:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "lons = np.linspace(-120, -60, 4)\n",
+ "lats = np.linspace(25, 55, 3)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Initialize the `DataArray` with complete coordinate info\n",
+ "\n",
+ "In this example, we create a new `DataArray`. Similar to an earlier example, we use the `dims` keyword argument to specify the dimension names; however, in this case, we also specify the coordinate arrays using the `coords` keyword argument:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp = xr.DataArray(data, coords=[times, lats, lons], dims=['time', 'lat', 'lon'])\n",
+ "temp"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Set useful attributes\n",
+ "\n",
+ "As described above, `DataArrays` have a built-in container for attribute metadata. These attributes are similar to those in netCDF files, and are added to a `DataArray` using its `attrs` method:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp.attrs['units'] = 'kelvin'\n",
+ "temp.attrs['standard_name'] = 'air_temperature'\n",
+ "\n",
+ "temp"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Issues with preservation of attributes\n",
+ "\n",
+ "In this example, we illustrate an important concept relating to attributes. When a mathematical operation is performed on a `DataArray`, all of the coordinate arrays remain attached to the `DataArray`, but any attribute metadata assigned is lost. Attributes are removed in this way due to the fact that they may not convey correct or appropriate metadata after an arbitrary arithmetic operation.\n",
+ "\n",
+ "This example converts our DataArray values from Kelvin to degrees Celsius. Pay attention to the attributes in the Jupyter rich display below. (If you are not viewing this page as a Jupyter notebook, see the Xarray documentation to learn how to display the attributes.)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp_in_celsius = temp - 273.15\n",
+ "temp_in_celsius"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In addition, if you need more details on how Xarray handles metadata, you can review this [documentation page](http://xarray.pydata.org/en/stable/getting-started-guide/faq.html#approach-to-metadata)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### The `Dataset`: a container for `DataArray`s with shared coordinates\n",
+ "\n",
+ "Along with the `DataArray`, the other main object type in Xarray is the `Dataset`. `Datasets` are containers similar to Python dictionaries; each `Dataset` can hold one or more `DataArrays`. In addition, the `DataArrays` contained in a `Dataset` can share coordinates, although this behavior is optional. (For more information, see the [official documentation page](http://xarray.pydata.org/en/stable/user-guide/data-structures.html#dataset).)\n",
+ "\n",
+ "`Dataset` objects are most often created by loading data from a data file. We will cover this functionality in a later example; in this example, we will create a `Dataset` from two `DataArrays`. We will use our existing temperature `DataArray` for one of these `DataArrays`; the other one is created in the next example.\n",
+ "\n",
+ "In addition, both of these `DataArrays` will share coordinate axes. Therefore, the next example will also illustrate the usage of common coordinate axes across `DataArrays` in a `Dataset`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Create a pressure `DataArray` using the same coordinates\n",
+ "\n",
+ "In this example, we create a `DataArray` object to hold pressure data. This new `DataArray` is set up in a very similar fashion to the temperature `DataArray` created above."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pressure_data = 1000.0 + 5 * np.random.randn(5, 3, 4)\n",
+ "pressure = xr.DataArray(\n",
+ " pressure_data, coords=[times, lats, lons], dims=['time', 'lat', 'lon']\n",
+ ")\n",
+ "pressure.attrs['units'] = 'hPa'\n",
+ "pressure.attrs['standard_name'] = 'air_pressure'\n",
+ "\n",
+ "pressure"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Create a `Dataset` object\n",
+ "\n",
+ "Before we can create a `Dataset` object, we must first name each of the `DataArray` objects that will be added to the new `Dataset`.\n",
+ "\n",
+ "To name the `DataArrays` that will be added to our `Dataset`, we can set up a Python dictionary as shown in the next example. We can then pass this dictionary to the `Dataset` method using the keyword argument `data_vars`; this creates a new `Dataset` containing both of our `DataArrays`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = xr.Dataset(data_vars={'Temperature': temp, 'Pressure': pressure})\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As listed in the rich display above, the new `Dataset` object is aware that both `DataArrays` share the same coordinate axes. (Please note that if this page is not run as a Jupyter Notebook, the rich display may be unavailable.)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Access Data variables and Coordinates in a `Dataset`\n",
+ "\n",
+ "This set of examples illustrates different methods for retrieving `DataArrays` from a `Dataset`.\n",
+ "\n",
+ "This first example shows how to retrieve `DataArrays` using the \"dot\" notation:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.Pressure"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In addition, you can access `DataArrays` through a dictionary syntax, as shown in this example:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds['Pressure']"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "`Dataset` objects are mainly used for loading data from files, which will be covered later in this tutorial."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Subsetting and selection by coordinate values\n",
+ "\n",
+ "Much of the power of labeled coordinates comes from the ability to select data based on coordinate names and values instead of array indices. This functionality will be covered on a basic level in these examples. (Later tutorials will cover this topic in much greater detail.)\n",
+ "\n",
+ "### NumPy-like selection\n",
+ "\n",
+ "In these examples, we are trying to extract all of our spatial data for a single date; in this case, January 2, 2018. For our first example, we retrieve spatial data using index selection, as with a NumPy array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "indexed_selection = temp[1, :, :] # Index 1 along axis 0 is the time slice we want...\n",
+ "indexed_selection"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This example reveals one of the major shortcomings of index selection. In order to retrieve the correct data using index selection, anyone using a `DataArray` must have precise knowledge of the axes in the `DataArray`, including the order of the axes and the meaning of their indices.\n",
+ "\n",
+ "By using named coordinates, as shown in the next set of examples, we can avoid this cumbersome burden."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Selecting with `.sel()`\n",
+ "\n",
+ "In this example, we show how to select data based on coordinate values, by way of the `.sel()` method. This method takes one or more named coordinates in keyword-argument format, and returns data matching the coordinates."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "named_selection = temp.sel(time='2018-01-02')\n",
+ "named_selection"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This method yields the same result as the index selection, however:\n",
+ "- we didn't have to know anything about how the array was created or stored\n",
+ "- our code is agnostic about how many dimensions we are dealing with\n",
+ "- the intended meaning of our code is much clearer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Approximate selection and interpolation\n",
+ "\n",
+ "When working with temporal and spatial data, it is a common practice to sample data close to the coordinate points in a dataset. The following set of examples illustrates some common techniques for this practice.\n",
+ "\n",
+ "#### Nearest-neighbor sampling\n",
+ "\n",
+ "In this example, we are trying to sample a temporal data point within 2 days of the date `2018-01-07`. Since the final date on our `DataArray`'s temporal axis is `2018-01-05`, this is an appropriate problem.\n",
+ "\n",
+ "We can use the `.sel()` method to perform nearest-neighbor sampling, by setting the `method` keyword argument to 'nearest'. We can also optionally provide a `tolerance` argument; with temporal data, this is a `timedelta` object."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp.sel(time='2018-01-07', method='nearest', tolerance=timedelta(days=2))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Using the rich display above, we can see that `.sel` indeed returned the data at the temporal value corresponding to the date `2018-01-05`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Interpolation\n",
+ "\n",
+ "In this example, we are trying to extract a timeseries for Boulder, CO, which is located at 40°N latitude and 105°W longitude. Our `DataArray` does not contain a longitude data value of -105, so in order to retrieve this timeseries, we must interpolate between data points.\n",
+ "\n",
+ "The `.interp()` method allows us to retrieve data from any latitude and longitude by means of interpolation. This method uses coordinate-value selection, similarly to `.sel()`. (For more information on the `.interp()` method, see the official documentation [here](http://xarray.pydata.org/en/stable/interpolation.html).)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp.interp(lon=-105, lat=40)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Specifying Chunks
\n", + " In this tutorial, we specify Dask Array chunks in a block shape. However, there are many additional ways to specify chunks; see this documentation for more details.\n", + "\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Slicing along coordinates\n",
+ "\n",
+ "Frequently, it is useful to select a range, or _slice_, of data along one or more coordinates. In order to understand this process, you must first understand Python `slice` objects. If you are unfamiliar with `slice` objects, you should first read the official [Python slice documentation](https://docs.python.org/3/library/functions.html#slice). Once you are proficient using `slice` objects, you can create slices of data by passing `slice` objects to the `.sel` method, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp.sel(\n",
+ " time=slice('2018-01-01', '2018-01-03'), lon=slice(-110, -70), lat=slice(25, 45)\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " In order to interpolate data using Xarray, the SciPy package must be imported. You can learn more about SciPy from the official documentation.\n", + "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Because we are now working with a slice of data, instead of our full dataset, the lengths of our coordinate axes have been shortened, as shown in the Jupyter rich display above. (You may need to use a different display technique if you are not running this page as a Jupyter Notebook.)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### One more selection method: `.loc`\n",
+ "\n",
+ "In addition to using the `sel()` method to select data from a `DataArray`, you can also use the `.loc` attribute. Every `DataArray` has a `.loc` attribute; in order to leverage this attribute to select data, you can specify a coordinate value in square brackets, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp.loc['2018-01-02']"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This selection technique is similar to NumPy's index-based selection, as shown below:\n",
+ "```\n",
+ "temp[1,:,:]\n",
+ "```\n",
+ "However, this technique also resembles the `.sel()` method's fully label-based selection functionality. The advantages and disadvantages of using the `.loc` attribute are discussed in detail below.\n",
+ "\n",
+ "This example illustrates a significant disadvantage of using the `.loc` attribute. Namely, we specify the values for each coordinate, but cannot specify the dimension names; therefore, the dimensions must be specified in the correct order, and this order must already be known:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp.loc['2018-01-01':'2018-01-03', 25:45, -110:-70]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In contrast with the previous example, this example shows a useful advantage of using the `.loc` attribute. When using the `.loc` attribute, you can specify data slices using a syntax similar to NumPy in addition to, or instead of, using the slice function. Both of these slicing techniques are illustrated below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temp.loc['2018-01-01':'2018-01-03', slice(25, 45), -110:-70]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As described above, the arguments to `.loc` must be in the order of the `DataArray`'s dimensions. Attempting to slice data without ordering arguments properly can cause errors, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# This will generate an error\n",
+ "# temp.loc[-110:-70, 25:45,'2018-01-01':'2018-01-03']"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Opening netCDF data\n",
+ "\n",
+ "Xarray has close ties to the netCDF data format; as such, netCDF was chosen as the premier data file format for Xarray. Hence, Xarray can easily open netCDF datasets, provided they conform to certain limitations (for example, 1-dimensional coordinates).\n",
+ "\n",
+ "### Access netCDF data with `xr.open_dataset`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " As detailed in the documentation page linked above, theslice function uses the argument order (start, stop[, step]), where step is optional.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "filepath = DATASETS.fetch('NARR_19930313_0000.nc')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Once we have a valid path to a data file that Xarray knows how to read, we can open the data file and load it into Xarray; this is done by passing the path to Xarray's `open_dataset` method, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds = xr.open_dataset(filepath)\n",
+ "ds"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Subsetting the `Dataset`\n",
+ "\n",
+ "Xarray's `open_dataset()` method, shown in the previous example, returns a `Dataset` object, which must then be assigned to a variable; in this case, we call the variable `ds`. Once the netCDF dataset is loaded into an Xarray `Dataset`, we can pull individual `DataArrays` out of the `Dataset`, using the technique described earlier in this tutorial. In this example, we retrieve isobaric pressure data, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds.isobaric1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "(As described earlier in this tutorial, we can also use dictionary syntax to select specific `DataArrays`; in this case, we would write `ds['isobaric1']`.)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Many of the subsetting operations usable on `DataArrays` can also be used on `Datasets`. However, when used on `Datasets`, these operations are performed on every `DataArray` in the `Dataset`, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_1000 = ds.sel(isobaric1=1000.0)\n",
+ "ds_1000"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As shown above, the subsetting operation performed on the `Dataset` returned a new `Dataset`. If only a single `DataArray` is needed from this new `Dataset`, it can be retrieved using the familiar dot notation:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ds_1000.Temperature_isobaric"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Aggregation operations\n",
+ "\n",
+ "As covered earlier in this tutorial, you can use named dimensions in an Xarray `Dataset` to manually slice and index data. However, these dimension names also serve an additional purpose: you can use them to specify dimensions to aggregate on. There are many different aggregation operations available; in this example, we focus on `std` (standard deviation)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "u_winds = ds['u-component_of_wind_isobaric']\n",
+ "u_winds.std(dim=['x', 'y'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Info
\n", + " The data file for this example,NARR_19930313_0000.nc, is retrieved from Project Pythia's custom example data library. The DATASETS class imported at the top of this page contains a .fetch() method, which retrieves, downloads, and caches a Pythia example data file.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "For this set of examples, we will be using the sample dataset defined above. The calculations performed in these examples compute the mean temperature profile, defined as temperature as a function of pressure, over Colorado. For the purposes of these examples, the bounds of Colorado are defined as follows:\n",
+ " * x: -182km to 424km\n",
+ " * y: -1450km to -990km\n",
+ " \n",
+ "This dataset uses a Lambert Conformal projection; therefore, the data values shown above are projected to specific latitude and longitude values. In this example, these latitude and longitude values are 37°N to 41°N and 102°W to 109°W. Using the original data values and the `mean` aggregation function as shown below yields the following mean temperature profile data:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temps = ds.Temperature_isobaric\n",
+ "co_temps = temps.sel(x=slice(-182, 424), y=slice(-1450, -990))\n",
+ "prof = co_temps.mean(dim=['x', 'y'])\n",
+ "prof"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Plotting with Xarray\n",
+ "\n",
+ "As demonstrated earlier in this tutorial, there are many benefits to storing data as Xarray `DataArrays` and `Datasets`. In this section, we will cover another major benefit: Xarray greatly simplifies plotting of data stored as `DataArrays` and `Datasets`. One advantage of this is that many common plot elements, such as axis labels, are automatically generated and optimized for the data being plotted. The next set of examples demonstrates this and provides a general overview of plotting with Xarray.\n",
+ "\n",
+ "### Simple visualization with `.plot()`\n",
+ "\n",
+ "Similarly to [Pandas](../pandas/pandas), Xarray includes a built-in plotting interface, which makes use of [Matplotlib](../matplotlib) behind the scenes. In order to use this interface, you can call the `.plot()` method, which is included in every `DataArray`.\n",
+ "\n",
+ "In this example, we show how to create a basic plot from a `DataArray`. In this case, we are using the `prof` `DataArray` defined above, which contains a Colorado mean temperature profile."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prof.plot()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In the figure shown above, Xarray has generated a line plot, which uses the mean temperature profile and the `'isobaric'` coordinate variable as axes. In addition, the axis labels and unit information have been read automatically from the `DataArray`'s metadata."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Customizing the plot\n",
+ "\n",
+ "As mentioned above, the `.plot()` method of Xarray `DataArrays` uses Matplotlib behind the scenes. Therefore, knowledge of Matplotlib can help you more easily customize plots generated by Xarray.\n",
+ "\n",
+ "In this example, we need to customize the air temperature profile plot created above. There are two changes that need to be made:\n",
+ "- swap the axes, so that the Y (vertical) axis corresponds to isobaric levels\n",
+ "- invert the Y axis to match the model of air pressure decreasing at higher altitudes\n",
+ "\n",
+ "We can make these changes by adding certain keyword arguments when calling `.plot()`, as shown below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "prof.plot(y=\"isobaric1\", yincrease=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Plotting 2-D data\n",
+ "\n",
+ "In the previous example, we used `.plot()` to generate a plot from 1-D data, and the result was a line plot. In this section, we illustrate plotting of 2-D data.\n",
+ "\n",
+ "In this example, we illustrate basic plotting of a 2-D array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "temps.sel(isobaric1=1000).plot()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The figure above is generated by Matplotlib's `pcolormesh` method, which was automatically called by Xarray's `plot` method. This occurred because Xarray recognized that the `DataArray` object calling the `plot` method contained two distinct coordinate variables.\n",
+ "\n",
+ "The plot generated by the above example is a map of air temperatures over North America, on the 1000 hPa isobaric surface. If a different map projection or added geographic features are needed on this plot, the plot can easily be modified using [Cartopy](../cartopy)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Summary\n",
+ "\n",
+ "Xarray expands on Pandas' labeled-data functionality, bringing the usefulness of labeled data operations to N-dimensional data. As such, it has become a central workhorse in the geoscience community for the analysis of gridded datasets. Xarray allows us to open self-describing NetCDF files and make full use of the coordinate axes, labels, units, and other metadata. By making use of labeled coordinates, our code is often easier to write, easier to read, and more robust.\n",
+ "\n",
+ "### What's next?\n",
+ "\n",
+ "Additional notebooks to appear in this section will describe the following topics in greater detail:\n",
+ "- performing arithmetic and broadcasting operations with Xarray data structures\n",
+ "- using \"group by\" operations\n",
+ "- remote data access with OPeNDAP\n",
+ "- more advanced visualization, including map integration with Cartopy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Resources and references\n",
+ "\n",
+ "This tutorial contains content adapted from the material in [Unidata's Python Training](https://unidata.github.io/python-training/workshop/XArray/xarray-and-cf/).\n",
+ "\n",
+ "Most basic questions and issues with Xarray can be resolved with help from the material in the [Xarray documentation](http://xarray.pydata.org/en/stable/). Some of the most popular sections of this documentation are listed below:\n",
+ "- [Why Xarray](http://xarray.pydata.org/en/stable/getting-started-guide/why-xarray.html)\n",
+ "- [Quick overview](http://xarray.pydata.org/en/stable/getting-started-guide/quick-overview.html#)\n",
+ "- [Example gallery](http://xarray.pydata.org/en/stable/gallery.html)\n",
+ "\n",
+ "Another resource you may find useful is this [Xarray Tutorial collection](https://xarray-contrib.github.io/xarray-tutorial/), created from content hosted on GitHub."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/_preview/468/_sources/foundations/conda.md b/_preview/468/_sources/foundations/conda.md
new file mode 100644
index 000000000..f371876cb
--- /dev/null
+++ b/_preview/468/_sources/foundations/conda.md
@@ -0,0 +1,134 @@
+# Installing and Managing Python with Conda
+
+---
+
+## Overview
+
+Conda is an open-source, cross-platform, language-agnostic package manager and environment management system that allows you to quickly install, run, and update packages within your work environment(s).
+
+Here we will cover:
+
+1. What are packages?
+2. Installing Conda
+3. Creating a Conda environment
+4. Useful Conda commands
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| --------------------------------------------------------------------------------------------------------- | ---------- | ----- |
+| [Installing and Running Python](https://foundations.projectpythia.org/foundations/how-to-run-python.html) | Helpful | |
+
+- **Time to learn**: 20 minutes
+
+---
+
+## What are Packages?
+
+A Python package is a collection of modules, which, in turn, are essentially Python scripts that contain published functionality. There are Python packages for data input, data analysis, data visualization, etc. Each package offers a unique toolset and may have its own unique syntax rules.
+
+Package management is useful because you may want to update a package for one of your projects, but keep it at the same version in other projects to ensure that they continue to run as expected.
+
+## Installing Conda
+
+We recommend you install Miniconda. You can do that by following the [instructions for your machine](https://docs.conda.io/en/latest/miniconda.html).
+
+Miniconda only comes with the `conda` package management system; it is a pared-down version of the full Anaconda Python distribution.
+
+[Installing Anaconda](https://docs.anaconda.com/anaconda/install/) takes longer and uses up more disk space, but provides you with more functionality, including Spyder (a Python-specific integrated development environment or IDE) and Jupyter, in addition to other immediately installed packages. Also, the interface of Anaconda is great if you are uncomfortable with the terminal.
+
+We recommend Miniconda for two reasons:
+
+1. It's quicker and takes up less disk space.
+2. It encourages you to install only the packages you need in reproducible isolated environments for specific projects. This is generally a more robust way to work with open source tools.
+
+Once you have `conda` via the Miniconda installer, the next step is to create an environment and install packages.
+
+## Creating a Conda Environment
+
+A Conda environment is an interoperable collection of specific versions of packages or libraries that you install and use for a specific workflow. The Conda package manager takes care of dependencies, so everything works together in a predictable way. One huge advantage of using environments is that any changes you make to one environment will not affect your other environments at all, so you are much less likely to "break" something!
+
+To create a new Conda environment, type `conda create --name` and the name of your environment in your terminal, and then specify any packages that you would like to have installed. For example, to install a Jupyter-ready environment called `sample_environment`, type
+
+```
+conda create --name sample_environment python jupyterlab
+```
+
+Once the environment is created, you need to _activate_ it in the current terminal session (see below).
+
+It is a good idea to create a new environment for every project. Because Python is open source, new versions of the tools are released frequently. Isolated environments help guarantee that your scripts use the same versions of packages and libraries to ensure they run as expected. Similarly, it is best practice to NOT modify your `base` environment.
+
+## Useful Conda commands
+
+Some other Conda commands that you will find useful include:
+
+- Activating a specific environment
+
+```
+conda activate sample_environment
+```
+
+- Deactivating the current environment
+
+```
+conda deactivate
+```
+
+- Checking what packages/versions are installed in the current environment
+
+```
+conda list
+```
+
+- Installing a new package into the current environment
+
+```
+conda install somepackage
+```
+
+- Installing a specific version of a package into the current environment
+
+```
+conda install somepackage=0.17
+```
+
+- Updating all packages in the current environment to the latest versions
+
+```
+conda update --all
+```
+
+- Checking what conda environments you have
+
+```
+conda env list
+```
+
+- Deleting an environment
+
+```
+conda env remove --name sample_environment
+```
+
+You can find lots more information in the [Conda documentation](https://docs.conda.io/en/latest/) or this handy [Conda cheat sheet](https://docs.conda.io/projects/conda/en/latest/_downloads/843d9e0198f2a193a3484886fa28163c/conda-cheatsheet.pdf).
+
+If you're not a command line user, the Anaconda navigator offers GUI functionality for selecting environments and installing packages.
+
+---
+
+## Summary
+
+Conda is a package and environment management system that allows you to quickly install, run, and update packages within your work environment(s). This is important for gathering all of the tools necessary for your workflow. Conda can be managed in the command line or in the Anaconda GUI.
+
+### What's Next?
+
+- [How to Run Python in the Terminal](terminal.md)
+- [How to Run Python in a Jupyter Session](jupyter.md)
+
+## Resources and References
+
+- [Linux commands](https://cheatography.com/davechild/cheat-sheets/linux-command-line/)
+- [Conda documentation](https://docs.conda.io/en/latest/)
+- [Conda cheat sheet](https://docs.conda.io/projects/conda/en/latest/_downloads/843d9e0198f2a193a3484886fa28163c/conda-cheatsheet.pdf)
+- [Anaconda](https://docs.anaconda.com/anaconda/install/)
+- [Miniconda](https://docs.conda.io/en/latest/miniconda.html)
diff --git a/_preview/468/_sources/foundations/getting-started-github.md b/_preview/468/_sources/foundations/getting-started-github.md
new file mode 100644
index 000000000..c87e40b9b
--- /dev/null
+++ b/_preview/468/_sources/foundations/getting-started-github.md
@@ -0,0 +1,23 @@
+```{image} ../images/GitHub-logo.png
+:alt: GitHub Logo
+:width: 600px
+```
+
+# Getting Started with GitHub
+
+Python and Jupyter are cool technologies, but they only scratch the surface of why you might want to adopt Python for your geoscience workflow.
+
+This section will introduce GitHub, the de facto standard platform for collaboration and version control used by the open-source Python community.
+
+We will walk users through these topics:
+
+- [What is GitHub?](github/what-is-github), and how to create your free account
+- [What are GitHub Repositories](github/github-repos), and what are some Python-specific examples?
+- [Issues and Discussions](github/github-issues) on GitHub: what they're for and how to participate
+- [Cloning and Forking a Repository](github/github-cloning-forking) (and what's the difference?)
+- [Detailed GitHub Configuration](github/github-setup-advanced), including how to set up secure permissions and notifications
+- [Basic Version Control with _git_](github/basic-git): why you may need it, and how to get started
+- [What is a git _Branch_?](github/git-branches)
+- [What's a Pull Request](github/github-pull-request), and how do you open one?
+- [GitHub Workflows](github/github-workflows), sets of best practices for collaborative work
+- [Contributing to Project Pythia via GitHub](github/contribute-to-pythia)
diff --git a/_preview/468/_sources/foundations/getting-started-jupyter.ipynb b/_preview/468/_sources/foundations/getting-started-jupyter.ipynb
new file mode 100644
index 000000000..821910630
--- /dev/null
+++ b/_preview/468/_sources/foundations/getting-started-jupyter.ipynb
@@ -0,0 +1,275 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "RYdHzMOHLr1U"
+ },
+ "source": [
+ "Info
\n", + " Recall from previous tutorials that aggregations in NumPy operate over axes specified by numeric values. However, with Xarray objects, aggregation dimensions are instead specified through a list passed to thedim keyword argument.\n",
+ " +
+We could open an issue to suggest this change in order to get feedback on the idea before we take the time to edit files, but since this is such a small change, let's just create a PR.
+
+## Make the edits
+
+We will follow the [Forking Workflow](https://foundations.projectpythia.org/foundations/github/github-workflows.html#forking-workflow) described in the previous section of this tutorial, assuming `pythia-foundations` has already been forked:
+
+- Create a new branch with a descriptive name
+- Make the changes and commit them locally
+- Push to the remote repository
+- Open a PR on GitHub
+
+First, making the new branch,
+
+```bash
+git branch clarify-sst-tos
+git checkout clarify-sst-tos
+```
+
+There are a variety of ways to make changes, depending on the type of file, as well as preference. Here we want to edit a Jupyter Notebook (file extension `.ipynb`), so we can use JupyterLab. We find the file of interest at `/core/xarray/computation-masking.ipynb` and add in some text:
+
+
+
+We could open an issue to suggest this change in order to get feedback on the idea before we take the time to edit files, but since this is such a small change, let's just create a PR.
+
+## Make the edits
+
+We will follow the [Forking Workflow](https://foundations.projectpythia.org/foundations/github/github-workflows.html#forking-workflow) described in the previous section of this tutorial, assuming `pythia-foundations` has already been forked:
+
+- Create a new branch with a descriptive name
+- Make the changes and commit them locally
+- Push to the remote repository
+- Open a PR on GitHub
+
+First, making the new branch,
+
+```bash
+git branch clarify-sst-tos
+git checkout clarify-sst-tos
+```
+
+There are a variety of ways to make changes, depending on the type of file, as well as preference. Here we want to edit a Jupyter Notebook (file extension `.ipynb`), so we can use JupyterLab. We find the file of interest at `/core/xarray/computation-masking.ipynb` and add in some text:
+
+ +
+After saving and exiting (and checking for changes with a `git status`), we commit with the following:
+
+```bash
+git add core/xarray/computation-masking.ipynb
+git commit -m 'Mention that SST is called tos in the model'
+```
+
+Then pushing to our remote aliased `origin`:
+
+```bash
+git push origin clarify-sst-tos
+```
+
+## Create a Pull Request
+
+Now, going to our remote repo on GitHub, forked from `pythia-foundations`, we see that recent changes have been made. By clicking on the "Compare & pull request" button, we can open a PR, proposing that our changes be merged into the main branch of `ProjectPythia/pythia-foundations`.
+
+
+
+After saving and exiting (and checking for changes with a `git status`), we commit with the following:
+
+```bash
+git add core/xarray/computation-masking.ipynb
+git commit -m 'Mention that SST is called tos in the model'
+```
+
+Then pushing to our remote aliased `origin`:
+
+```bash
+git push origin clarify-sst-tos
+```
+
+## Create a Pull Request
+
+Now, going to our remote repo on GitHub, forked from `pythia-foundations`, we see that recent changes have been made. By clicking on the "Compare & pull request" button, we can open a PR, proposing that our changes be merged into the main branch of `ProjectPythia/pythia-foundations`.
+
+ +
+Project Pythia has an automated reviewer system: when a PR is created, two members of the organization will be randomly chosen to review it. If your PR is not immediately ready to be approved and merged, open it as a draft to delay the review process. As shown in this [Git Branches section](https://foundations.projectpythia.org/foundations/github/git-branches.html#merging-branches), the "Draft pull request" button is found using the arrow on the "Create pull request" button.
+
+Let's add the `content` tag and open this one as a draft for now:
+
+
+
+Project Pythia has an automated reviewer system: when a PR is created, two members of the organization will be randomly chosen to review it. If your PR is not immediately ready to be approved and merged, open it as a draft to delay the review process. As shown in this [Git Branches section](https://foundations.projectpythia.org/foundations/github/git-branches.html#merging-branches), the "Draft pull request" button is found using the arrow on the "Create pull request" button.
+
+Let's add the `content` tag and open this one as a draft for now:
+
+ +
+For any PR opened in `pythia-foundations`, there will be a few checks that need to pass before merging is allowed. Once the `deploy-book / build` check has completed (which will likely take a few minutes), there will be a Deployment Preview URL commented by the github-actions bot that will take you to a build of the Pythia Foundations book with your edits. There you can ensure your edits show up as expected.
+
+
+
+For any PR opened in `pythia-foundations`, there will be a few checks that need to pass before merging is allowed. Once the `deploy-book / build` check has completed (which will likely take a few minutes), there will be a Deployment Preview URL commented by the github-actions bot that will take you to a build of the Pythia Foundations book with your edits. There you can ensure your edits show up as expected.
+
+ +
+Once it is ready, click "Ready for review" to take it out of draft mode. Now we wait for any comments or reviews!
+
+---
+
+## Summary
+
+- You can contribute to Project Pythia by suggesting edits or adding content with a Pull Request
diff --git a/_preview/468/_sources/foundations/github/git-branches.md b/_preview/468/_sources/foundations/github/git-branches.md
new file mode 100644
index 000000000..5ee0bd1bc
--- /dev/null
+++ b/_preview/468/_sources/foundations/github/git-branches.md
@@ -0,0 +1,304 @@
+```{image} ../../images/Git-Logo-2Color.png
+:alt: Git Logo
+:width: 400px
+```
+
+# Git Branches
+
+Git "branches" are an important component of many Git and GitHub workflows. If you plan to use GitHub to manage your own resources, or contribute to a GitHub hosted project, it is essential to have a basic understanding of what branches are and how to use them. For example, the best practices for a simple workflow for suggesting changes to a GitHub repository are: create your own fork of the repository, make a branch from your fork where your changes are made, and then suggest these changes move to the upstream repository with a Pull Request. This section of the GitHub chapter assumes you have read the prior GitHub sections, are at least somewhat familiar with git commands and the vocabulary ("cloning," "forking," "merging," "Pull Request" etc), and that you have already created your own fork of the [GitHub Sandbox Repository](https://github.com/ProjectPythia/github-sandbox) hosted by Project Pythia.
+
+## Overview:
+
+1. What are Git Branches
+1. Creating a New Branch
+1. Switching Branches
+1. Setting up a Remote Branch
+1. Merging Branches
+1. Deleting Branches
+1. Updating Your Branches
+1. Complete Workflow
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| ---------------------------------------------------------- | ----------- | ---------------------------- |
+| [What is GitHub?](what-is-github) | Necessary | GitHub user account required |
+| [GitHub Repositories](github-repos) | Necessary | |
+| [Issues and Discussions](github-issues) | Recommended | |
+| [Cloning and Forking a Repository](github-cloning-forking) | Necessary | |
+| [Configuring your GitHub Account](github-setup-advanced) | Recommended | |
+| [Basic Version Control with _git_](basic-git) | Necessary | |
+
+- **Time to learn**: 30 minutes
+
+---
+
+## What are Git branches?
+
+Git branches allow for non-linear or differing revision histories of a repository. At a point in time, you can split your repository into multiple development paths (branches) where you can make different commits in each, typically with the ultimate intention of merging these branches and development changes together at a later time.
+
+Branching is one of git's methods for helping with collaborative document editing, much like "change tracking" in Google Docs or Microsoft Word. It enables multiple people to edit copies of the same document content, while reducing or managing edit collisions, and with the ultimate aim of merging everyone's changes together later. It also allows the same person to edit multiple copies of the same document, but with different intentions. Some reasons for wanting to split your repository into multiple paths (i.e. branches) is to experiment with different methods of solving a problem (before deciding which method will ultimately be merged) and to work on different problems within the same codebase (without confusing which code changes are relevant to which problem).
+
+These branches can live on your computer (local) or on GitHub (remote). They are brought together through Git _pushes_, _pulls_, _merges_, and _Pull Requests_. _Pushing_ is how you transfer changes from your local repository to a remote repository. _Pulling_ is how you fetch upstream changes into your branch. _Merging_ is how you piece the forked history back together again (i.e. join two branches). And _Pull Requests_ are how you suggest the changes you've made on your branch to the upstream codebase.
+
+```{admonition} Pull Requests
+:class: info
+We will cover [Pull Requests]((github-pull-request)) more in-depthly in the next section.
+```
+
+One rule of thumb is for each development feature to have its own development branch until that feature is ready to be added to the upstream (remote) codebase. This allows you to compartmentalize your Pull Requests so that smaller working changes can be merged upstream independently of one another. For example, you might have a complete or near-complete feature on its own branch with an open Pull Request awaiting review. While you wait for feedback from the team before merging it, you can still work on a second feature on a second branch without affecting your first feature's Pull Request. **We encourage you to always do your work in a designated branch.**
+
+## Creating a New Branch
+
+```{admonition} Have you forked the repository?
+:class: info
+Having forked (NOT just cloned) the [GitHub Sandbox Repository](https://github.com/ProjectPythia/github-sandbox) is essential for following the steps in this book chapter. See the chapter on [GitHub Cloning and Forking](github-cloning-forking.md).
+```
+
+
+The above flowchart demonstrates forking a remote repository, labeled "Upstream", creating a local copy, labeled "Clone", creating a new branch, "branchA", and adding two commits, C3 and C4, to "branchA" of the local clone of the forked repository. Different commits can be added to different branches in any order without depending on or knowing about each other.
+
+From your terminal, navigate to your local clone of your `Github-Sandbox` Repository fork:
+
+```bash
+cd github-sandbox
+```
+
+Let's begin by checking the status of our repository:
+
+```bash
+git status
+```
+
+
+
+You will see that you are already on a branch called "main". And that this branch is up-to-date with "origin/main" and has nothing to commit.
+
+```{admonition} The Main Branch
+:class: info
+Historically, the `main` branch was called the `master` branch. The name change was relatively recent, so all of your GitHub repositories may not reflect this yet. See instructions to change your branch name at [Github's Branch Renaming documentation](https://github.com/github/renaming).
+```
+
+Now check the status of your remote repository with
+
+```bash
+git remote -v
+```
+
+
+
+We are set up to pull (denoted as 'fetch' in the output above) and push from the same remote repository.
+
+Next, check all of your exising Git branches with:
+
+```bash
+git branch -a
+```
+
+
+
+You will see one local branch (`main`) and your remote branch (`remotes/origin/HEAD` and `remotes/origin/main`, where `HEAD` points to `main`). `HEAD` is the pointer to the current branch reference, or in essence, a pointer to your last commit. More on this in a later section.
+
+Now, before we make some sample changes to our codebase, let's create a new branch where we'll make these changes:
+
+```bash
+git branch branchA
+```
+
+Check that this branch was created with:
+
+```bash
+git branch
+```
+
+
+
+This will display the current and the new branch. You'll notice that current or active branch, indicated by the "\*" is still the `main` branch. Thus, any changes we make to the contents of our local repository will still be made on `main`. We will need to switch branches to work in the new branch, `branchA`.
+
+## Switching Branches
+
+To switch branches use the command `git checkout` as in:
+
+```bash
+git checkout branchA
+```
+
+To check your current branch use `git status`:
+
+```bash
+git status
+```
+
+
+
+Notice that `git status` doesn't say anything about being up-to-date, as before. This is because this branch only exists locally, not in our upstream GitHub fork.
+
+## Setting up a Remote Branch
+
+While your clone lives locally on your laptop, a remote branch exists on your GitHub server. You have to tell GitHub about your local branch before these changes are reflected remotely in your upstream fork.
+
+
+The above flowchart demonstrates pushing two new local commits (C3 and C4) to the corresponding remote branch. Before the push, the changes from these commits exist ONLY locally and are not represented on your upstream GitHub repository. After the push, everything is up-to-date.
+
+Before we push this branch upstream, let's make some sample changes (like C3 or C4) by creating a new empty file, with the ending ".py".
+
+```bash
+touch hello.py
+```
+
+
+
+You can check that this file has been created by comparing an `ls` before and after this command, and also with a `git status` that will show your new untracked file.
+
+`git add` and `git commit` your new file and check the status again.
+
+
+
+Your new branch is now one commit ahead of your main branch. You can see this with a `git log.`
+
+
+
+In a real workflow, you would continue making edits and git commits on a branch until you are ready to push up to GitHub.
+
+Try to do this with
+
+```bash
+git push
+```
+
+
+
+You will get an error message, "fatal: The current branch `branchA` has no upstream branch." So what is the proper method for getting our local branch changes up to GitHub?
+
+First, we need to set an upstream branch to direct our local push to:
+
+```bash
+git push --set-upstream origin branchA
+```
+
+Thankfully, Git provided this command in the previous error message. If you cloned using HTTPS, you will be asked to enter your username and password, as described in [GitHub's PAT Creation page](https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/creating-a-personal-access-token).
+
+
+
+We can see that this worked by doing a `git branch -a`
+
+Notice the new branch called `remotes/origin/newbranch`. And when you do a `git status` you'll see that we are up to date with this new remote branch.
+
+
+
+On future commits you will not have to repeat these steps, as your remote branch will already be established. Simply push with `git push` to have your remote branch reflect your future local changes.
+
+## Merging Branches
+
+Merging is how you bring your split branches of a repository back together again.
+
+If you want to merge two _local_ branches together, the steps are as follows:
+
+Let's assume your two branches are named `branchA` and `branchB`, and you want your changes from `branchB` to now be reflected in `branchA`
+
+1. First checkout the branch you want to merge INTO:
+
+```bash
+git checkout branchA
+```
+
+2. Then execute a `merge`:
+
+```bash
+git merge branchB
+```
+
+If there were competing edits in the 2 branches that Git cannot automatically resolve, a **merge conflict** occurs. This typically happens if edits are to the same line in different commits. Conflicts can be [resolved in the command line](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/addressing-merge-conflicts/resolving-a-merge-conflict-using-the-command-line) or in your GUI of choice (such as Visual Studio Code).
+
+A **Pull Request** is essentially a merge that happens on an upstream remote. We will continue this demonstration and cover the specifics of merging via a [Pull Request](github-pull-request) more thoroughly in the next section.
+
+
+The above flowchart demonstrates a simple Pull Request where the upstream main repository has accepted the changes from the feature branch of your fork. The latest commit to the Upstream Main repository is now C4. Your Feature branch can now be safely deleted.
+
+## Deleting Branches
+
+After the feature you worked on has been completed and merged, you may want to delete your branch.
+
+
+To do this locally, you must first switch back to `main` or any non-target branch. Then you can enter
+
+```bash
+git branch -d
+
+Once it is ready, click "Ready for review" to take it out of draft mode. Now we wait for any comments or reviews!
+
+---
+
+## Summary
+
+- You can contribute to Project Pythia by suggesting edits or adding content with a Pull Request
diff --git a/_preview/468/_sources/foundations/github/git-branches.md b/_preview/468/_sources/foundations/github/git-branches.md
new file mode 100644
index 000000000..5ee0bd1bc
--- /dev/null
+++ b/_preview/468/_sources/foundations/github/git-branches.md
@@ -0,0 +1,304 @@
+```{image} ../../images/Git-Logo-2Color.png
+:alt: Git Logo
+:width: 400px
+```
+
+# Git Branches
+
+Git "branches" are an important component of many Git and GitHub workflows. If you plan to use GitHub to manage your own resources, or contribute to a GitHub hosted project, it is essential to have a basic understanding of what branches are and how to use them. For example, the best practices for a simple workflow for suggesting changes to a GitHub repository are: create your own fork of the repository, make a branch from your fork where your changes are made, and then suggest these changes move to the upstream repository with a Pull Request. This section of the GitHub chapter assumes you have read the prior GitHub sections, are at least somewhat familiar with git commands and the vocabulary ("cloning," "forking," "merging," "Pull Request" etc), and that you have already created your own fork of the [GitHub Sandbox Repository](https://github.com/ProjectPythia/github-sandbox) hosted by Project Pythia.
+
+## Overview:
+
+1. What are Git Branches
+1. Creating a New Branch
+1. Switching Branches
+1. Setting up a Remote Branch
+1. Merging Branches
+1. Deleting Branches
+1. Updating Your Branches
+1. Complete Workflow
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| ---------------------------------------------------------- | ----------- | ---------------------------- |
+| [What is GitHub?](what-is-github) | Necessary | GitHub user account required |
+| [GitHub Repositories](github-repos) | Necessary | |
+| [Issues and Discussions](github-issues) | Recommended | |
+| [Cloning and Forking a Repository](github-cloning-forking) | Necessary | |
+| [Configuring your GitHub Account](github-setup-advanced) | Recommended | |
+| [Basic Version Control with _git_](basic-git) | Necessary | |
+
+- **Time to learn**: 30 minutes
+
+---
+
+## What are Git branches?
+
+Git branches allow for non-linear or differing revision histories of a repository. At a point in time, you can split your repository into multiple development paths (branches) where you can make different commits in each, typically with the ultimate intention of merging these branches and development changes together at a later time.
+
+Branching is one of git's methods for helping with collaborative document editing, much like "change tracking" in Google Docs or Microsoft Word. It enables multiple people to edit copies of the same document content, while reducing or managing edit collisions, and with the ultimate aim of merging everyone's changes together later. It also allows the same person to edit multiple copies of the same document, but with different intentions. Some reasons for wanting to split your repository into multiple paths (i.e. branches) is to experiment with different methods of solving a problem (before deciding which method will ultimately be merged) and to work on different problems within the same codebase (without confusing which code changes are relevant to which problem).
+
+These branches can live on your computer (local) or on GitHub (remote). They are brought together through Git _pushes_, _pulls_, _merges_, and _Pull Requests_. _Pushing_ is how you transfer changes from your local repository to a remote repository. _Pulling_ is how you fetch upstream changes into your branch. _Merging_ is how you piece the forked history back together again (i.e. join two branches). And _Pull Requests_ are how you suggest the changes you've made on your branch to the upstream codebase.
+
+```{admonition} Pull Requests
+:class: info
+We will cover [Pull Requests]((github-pull-request)) more in-depthly in the next section.
+```
+
+One rule of thumb is for each development feature to have its own development branch until that feature is ready to be added to the upstream (remote) codebase. This allows you to compartmentalize your Pull Requests so that smaller working changes can be merged upstream independently of one another. For example, you might have a complete or near-complete feature on its own branch with an open Pull Request awaiting review. While you wait for feedback from the team before merging it, you can still work on a second feature on a second branch without affecting your first feature's Pull Request. **We encourage you to always do your work in a designated branch.**
+
+## Creating a New Branch
+
+```{admonition} Have you forked the repository?
+:class: info
+Having forked (NOT just cloned) the [GitHub Sandbox Repository](https://github.com/ProjectPythia/github-sandbox) is essential for following the steps in this book chapter. See the chapter on [GitHub Cloning and Forking](github-cloning-forking.md).
+```
+
+
+The above flowchart demonstrates forking a remote repository, labeled "Upstream", creating a local copy, labeled "Clone", creating a new branch, "branchA", and adding two commits, C3 and C4, to "branchA" of the local clone of the forked repository. Different commits can be added to different branches in any order without depending on or knowing about each other.
+
+From your terminal, navigate to your local clone of your `Github-Sandbox` Repository fork:
+
+```bash
+cd github-sandbox
+```
+
+Let's begin by checking the status of our repository:
+
+```bash
+git status
+```
+
+
+
+You will see that you are already on a branch called "main". And that this branch is up-to-date with "origin/main" and has nothing to commit.
+
+```{admonition} The Main Branch
+:class: info
+Historically, the `main` branch was called the `master` branch. The name change was relatively recent, so all of your GitHub repositories may not reflect this yet. See instructions to change your branch name at [Github's Branch Renaming documentation](https://github.com/github/renaming).
+```
+
+Now check the status of your remote repository with
+
+```bash
+git remote -v
+```
+
+
+
+We are set up to pull (denoted as 'fetch' in the output above) and push from the same remote repository.
+
+Next, check all of your exising Git branches with:
+
+```bash
+git branch -a
+```
+
+
+
+You will see one local branch (`main`) and your remote branch (`remotes/origin/HEAD` and `remotes/origin/main`, where `HEAD` points to `main`). `HEAD` is the pointer to the current branch reference, or in essence, a pointer to your last commit. More on this in a later section.
+
+Now, before we make some sample changes to our codebase, let's create a new branch where we'll make these changes:
+
+```bash
+git branch branchA
+```
+
+Check that this branch was created with:
+
+```bash
+git branch
+```
+
+
+
+This will display the current and the new branch. You'll notice that current or active branch, indicated by the "\*" is still the `main` branch. Thus, any changes we make to the contents of our local repository will still be made on `main`. We will need to switch branches to work in the new branch, `branchA`.
+
+## Switching Branches
+
+To switch branches use the command `git checkout` as in:
+
+```bash
+git checkout branchA
+```
+
+To check your current branch use `git status`:
+
+```bash
+git status
+```
+
+
+
+Notice that `git status` doesn't say anything about being up-to-date, as before. This is because this branch only exists locally, not in our upstream GitHub fork.
+
+## Setting up a Remote Branch
+
+While your clone lives locally on your laptop, a remote branch exists on your GitHub server. You have to tell GitHub about your local branch before these changes are reflected remotely in your upstream fork.
+
+
+The above flowchart demonstrates pushing two new local commits (C3 and C4) to the corresponding remote branch. Before the push, the changes from these commits exist ONLY locally and are not represented on your upstream GitHub repository. After the push, everything is up-to-date.
+
+Before we push this branch upstream, let's make some sample changes (like C3 or C4) by creating a new empty file, with the ending ".py".
+
+```bash
+touch hello.py
+```
+
+
+
+You can check that this file has been created by comparing an `ls` before and after this command, and also with a `git status` that will show your new untracked file.
+
+`git add` and `git commit` your new file and check the status again.
+
+
+
+Your new branch is now one commit ahead of your main branch. You can see this with a `git log.`
+
+
+
+In a real workflow, you would continue making edits and git commits on a branch until you are ready to push up to GitHub.
+
+Try to do this with
+
+```bash
+git push
+```
+
+
+
+You will get an error message, "fatal: The current branch `branchA` has no upstream branch." So what is the proper method for getting our local branch changes up to GitHub?
+
+First, we need to set an upstream branch to direct our local push to:
+
+```bash
+git push --set-upstream origin branchA
+```
+
+Thankfully, Git provided this command in the previous error message. If you cloned using HTTPS, you will be asked to enter your username and password, as described in [GitHub's PAT Creation page](https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/creating-a-personal-access-token).
+
+
+
+We can see that this worked by doing a `git branch -a`
+
+Notice the new branch called `remotes/origin/newbranch`. And when you do a `git status` you'll see that we are up to date with this new remote branch.
+
+
+
+On future commits you will not have to repeat these steps, as your remote branch will already be established. Simply push with `git push` to have your remote branch reflect your future local changes.
+
+## Merging Branches
+
+Merging is how you bring your split branches of a repository back together again.
+
+If you want to merge two _local_ branches together, the steps are as follows:
+
+Let's assume your two branches are named `branchA` and `branchB`, and you want your changes from `branchB` to now be reflected in `branchA`
+
+1. First checkout the branch you want to merge INTO:
+
+```bash
+git checkout branchA
+```
+
+2. Then execute a `merge`:
+
+```bash
+git merge branchB
+```
+
+If there were competing edits in the 2 branches that Git cannot automatically resolve, a **merge conflict** occurs. This typically happens if edits are to the same line in different commits. Conflicts can be [resolved in the command line](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/addressing-merge-conflicts/resolving-a-merge-conflict-using-the-command-line) or in your GUI of choice (such as Visual Studio Code).
+
+A **Pull Request** is essentially a merge that happens on an upstream remote. We will continue this demonstration and cover the specifics of merging via a [Pull Request](github-pull-request) more thoroughly in the next section.
+
+
+The above flowchart demonstrates a simple Pull Request where the upstream main repository has accepted the changes from the feature branch of your fork. The latest commit to the Upstream Main repository is now C4. Your Feature branch can now be safely deleted.
+
+## Deleting Branches
+
+After the feature you worked on has been completed and merged, you may want to delete your branch.
+
+
+To do this locally, you must first switch back to `main` or any non-target branch. Then you can enter
+
+```bash
+git branch -d  +
+---
+
+We see that in the repository, there exists five files. Above the list of files is this row:
+
+
+
+---
+
+We see that in the repository, there exists five files. Above the list of files is this row:
+
+ +
+---
+
+Click on the green **Code** button to the right:
+
+
+
+---
+
+Click on the green **Code** button to the right:
+
+ +
+---
+
+Select the **HTTPS** option, and click on the copy-to-clipboard icon:
+
+
+
+---
+
+Select the **HTTPS** option, and click on the copy-to-clipboard icon:
+
+ +
+---
+
+```{tip}
+This link points to where the repository "lives" on GitHub. We will use the term **origin** to refer to this location.
+```
+
+Now, open up a terminal on your local computer, and if desired, `cd` into a directory that you'd like to house whatever repos you clone. Type `git clone`, and then paste in the URL that you copied from GitHub (i.e., the **origin**):
+
+```
+git clone https://github.com/ProjectPythia/github-sandbox.git
+```
+
+You'll see something like the following:
+
+```
+Cloning into 'github-sandbox'...
+remote: Enumerating objects: 15, done.
+remote: Counting objects: 100% (15/15), done.
+remote: Compressing objects: 100% (14/14), done.
+remote: Total 15 (delta 3), reused 0 (delta 0), pack-reused 0
+Receiving objects: 100% (15/15), 7.41 KiB | 2.47 MiB/s, done.
+Resolving deltas: 100% (3/3), done.
+```
+
+```{admonition} Windows users
+:class: info
+While `git` is typically part of a Linux or Mac OS command-line shell, similar functionality must be installed if you are running Windows. Download and install the [Git for Windows](https://gitforwindows.org/) package.
+```
+
+Now, you can `cd` into the `github-sandbox` directory which has been created and populated with the exact contents of the **origin**'s repository at the time you cloned it. If you have a Python installation, you could then type
+
+```
+python sample.py
+```
+
+to run the sample Python script. You should see the following output:
+
+```
+Hello, Python learners!
+```
+
+By virtue of cloning the repo, _git_ automatically registers the URL of the **origin**'s repository on GitHub. You can show this by typing the following:
+
+```
+git remote -v
+```
+
+You should see:
+
+```
+origin git@github.com:ProjectPythia/github-sandbox.git (fetch)
+origin git@github.com:ProjectPythia/github-sandbox.git (push)
+```
+
+```{tip}
+We discuss the `git` command-line interface in the [Basic version control with git](basic-git) lesson.
+```
+
+**Congratulations!** You have now cloned a GitHub repository!
+
+Now, let's consider the 3rd scenario for cloning... which involves the related topic of _forking_.
+
+## Forking a repository
+
+Forking is similar to cloning, but has a bit more involved workflow. Scenarios where forking a repo is indicated include the following:
+
+1. You wish to collaborate on projects that are hosted on GitHub, but you are not one of that project's _maintainers_ (i.e., you do not have _write permissions_ on it).
+1. You wish to experiment with changing or adding new features to a project, and do not immediately intend to _merge_ them into the original project's repo (aka, the _upstream_ repository).
+
+In a fork, you create a copy of an existing repository, but store it in your own personal GitHub organization (recall that when you create a GitHub account, the _organization_ name is your GitHub user ID).
+
+Let's say we intend to make some changes to the [Project Pythia Sandbox](https://github.com/ProjectPythia/github-sandbox) repo, that ultimately we'll submit to the original repository as a _Pull request_.
+
+```{note}
+Be sure you have logged into GitHub at this time!
+```
+
+Notice at the top right of the screen, there is a _Fork_ button:
+
+
+
+---
+
+```{tip}
+This link points to where the repository "lives" on GitHub. We will use the term **origin** to refer to this location.
+```
+
+Now, open up a terminal on your local computer, and if desired, `cd` into a directory that you'd like to house whatever repos you clone. Type `git clone`, and then paste in the URL that you copied from GitHub (i.e., the **origin**):
+
+```
+git clone https://github.com/ProjectPythia/github-sandbox.git
+```
+
+You'll see something like the following:
+
+```
+Cloning into 'github-sandbox'...
+remote: Enumerating objects: 15, done.
+remote: Counting objects: 100% (15/15), done.
+remote: Compressing objects: 100% (14/14), done.
+remote: Total 15 (delta 3), reused 0 (delta 0), pack-reused 0
+Receiving objects: 100% (15/15), 7.41 KiB | 2.47 MiB/s, done.
+Resolving deltas: 100% (3/3), done.
+```
+
+```{admonition} Windows users
+:class: info
+While `git` is typically part of a Linux or Mac OS command-line shell, similar functionality must be installed if you are running Windows. Download and install the [Git for Windows](https://gitforwindows.org/) package.
+```
+
+Now, you can `cd` into the `github-sandbox` directory which has been created and populated with the exact contents of the **origin**'s repository at the time you cloned it. If you have a Python installation, you could then type
+
+```
+python sample.py
+```
+
+to run the sample Python script. You should see the following output:
+
+```
+Hello, Python learners!
+```
+
+By virtue of cloning the repo, _git_ automatically registers the URL of the **origin**'s repository on GitHub. You can show this by typing the following:
+
+```
+git remote -v
+```
+
+You should see:
+
+```
+origin git@github.com:ProjectPythia/github-sandbox.git (fetch)
+origin git@github.com:ProjectPythia/github-sandbox.git (push)
+```
+
+```{tip}
+We discuss the `git` command-line interface in the [Basic version control with git](basic-git) lesson.
+```
+
+**Congratulations!** You have now cloned a GitHub repository!
+
+Now, let's consider the 3rd scenario for cloning... which involves the related topic of _forking_.
+
+## Forking a repository
+
+Forking is similar to cloning, but has a bit more involved workflow. Scenarios where forking a repo is indicated include the following:
+
+1. You wish to collaborate on projects that are hosted on GitHub, but you are not one of that project's _maintainers_ (i.e., you do not have _write permissions_ on it).
+1. You wish to experiment with changing or adding new features to a project, and do not immediately intend to _merge_ them into the original project's repo (aka, the _upstream_ repository).
+
+In a fork, you create a copy of an existing repository, but store it in your own personal GitHub organization (recall that when you create a GitHub account, the _organization_ name is your GitHub user ID).
+
+Let's say we intend to make some changes to the [Project Pythia Sandbox](https://github.com/ProjectPythia/github-sandbox) repo, that ultimately we'll submit to the original repository as a _Pull request_.
+
+```{note}
+Be sure you have logged into GitHub at this time!
+```
+
+Notice at the top right of the screen, there is a _Fork_ button:
+
+ +
+---
+
+Click on it:
+
+
+
+---
+
+Click on it:
+
+ +
+---
+
+You should see your GitHub user ID (if you administer any other GitHub organizations, you will see them as well). Click on your user ID to complete the _fork_. After a few seconds, your browser will be redirected to the forked repo, now residing in your personal GitHub organization:
+
+
+
+---
+
+You should see your GitHub user ID (if you administer any other GitHub organizations, you will see them as well). Click on your user ID to complete the _fork_. After a few seconds, your browser will be redirected to the forked repo, now residing in your personal GitHub organization:
+
+ +
+---
+
+Notice that the _Fork_ button on the upper right has incremented by one, and there is also is a line relating your fork to the original repo:
+
+
+
+---
+
+Notice that the _Fork_ button on the upper right has incremented by one, and there is also is a line relating your fork to the original repo:
+
+ +
+---
+
+```{tip}
+We discuss *branches* in the [Git Branches](git-branches) lesson.
+```
+
+You now have a copy (essentially a clone) of the forked repository, which is now owned by you.
+
+You could, at this point, select one of the files in the repository and use GitHub's built-in editor to make changes to these text-based files. However, the typical use case that leverages the collaborative power of GitHub and its command-line cousin, _git_, involves _cloning_ your _forked_ copy of the repo to your local computer, where you can then perform your edits, and (in the case of software) test them on your system.
+
+Cloning your fork is the same as cloning the original repo. Click on the Code button, select the HTTPS protocol, copy the URL to the clipboard, and then run `git clone
+
+---
+
+```{tip}
+We discuss *branches* in the [Git Branches](git-branches) lesson.
+```
+
+You now have a copy (essentially a clone) of the forked repository, which is now owned by you.
+
+You could, at this point, select one of the files in the repository and use GitHub's built-in editor to make changes to these text-based files. However, the typical use case that leverages the collaborative power of GitHub and its command-line cousin, _git_, involves _cloning_ your _forked_ copy of the repo to your local computer, where you can then perform your edits, and (in the case of software) test them on your system.
+
+Cloning your fork is the same as cloning the original repo. Click on the Code button, select the HTTPS protocol, copy the URL to the clipboard, and then run `git clone  +
+By default, it shows all open Issues, but we can see all [closed Issues](https://github.com/ProjectPythia/pythia-foundations/issues?q=is%3Aissue+is%3Aclosed) by clicking "Closed".
+
+
+
+By default, it shows all open Issues, but we can see all [closed Issues](https://github.com/ProjectPythia/pythia-foundations/issues?q=is%3Aissue+is%3Aclosed) by clicking "Closed".
+
+ +
+Issues, Discussions, and Pull Requests are all numbered for easy reference. By opening, resolving, and then closing an issue, we are leaving behind a searchable public record of what the issue was, why we thought it was important, and how we resolved it. This is great for project management, since it gets old Issues out of the way without actually deleting them.
+
+Let's now examine [Issue \#144](https://github.com/ProjectPythia/pythia-foundations/issues/144).
+
+
+
+Issues, Discussions, and Pull Requests are all numbered for easy reference. By opening, resolving, and then closing an issue, we are leaving behind a searchable public record of what the issue was, why we thought it was important, and how we resolved it. This is great for project management, since it gets old Issues out of the way without actually deleting them.
+
+Let's now examine [Issue \#144](https://github.com/ProjectPythia/pythia-foundations/issues/144).
+
+ +
+As you can see, some broken links were found in one of the Pythia Foundations tutorials, likely because the site being linked recently had its structure changed. An additional comment was added, as well as a label to help filtering/sorting Issues by topic. We then see that this issue was mentioned (by typing the issue number) elsewhere in the repository. In this case, it was mentioned in [Pull Request \#145](https://github.com/ProjectPythia/pythia-foundations/pull/145), which makes the changes to fix the issue. We can also see that the PR has been merged, which means the changes have been incorporated into the main branch of the code.
+
+Like this example, Issues can notify others of bugs or typos, but they can also be used as "calls to action", whether you plan on addressing the issue yourself, or are hoping that someone else will be interested in making the changes. Issues [\#97](https://github.com/ProjectPythia/pythia-foundations/issues/97) and [\#98](https://github.com/ProjectPythia/pythia-foundations/issues/98) are examples of this, in which ideas for changes are proposed and then addressed at a later time.
+
+A new issue can be opened by pressing the "New issue" button on the top right of the Issues page. Depending on the repository, you may be prompted to choose from a template, or you may just see title and text boxes to fill out.
+
+## Discussions
+
+Discussions, on the other hand, are more open-ended and do not _necessarily_ suggest a change or addition to the repository. Here is the [Discussions page for Pythia Foundations](https://github.com/ProjectPythia/pythia-foundations/discussions):
+
+
+
+As you can see, some broken links were found in one of the Pythia Foundations tutorials, likely because the site being linked recently had its structure changed. An additional comment was added, as well as a label to help filtering/sorting Issues by topic. We then see that this issue was mentioned (by typing the issue number) elsewhere in the repository. In this case, it was mentioned in [Pull Request \#145](https://github.com/ProjectPythia/pythia-foundations/pull/145), which makes the changes to fix the issue. We can also see that the PR has been merged, which means the changes have been incorporated into the main branch of the code.
+
+Like this example, Issues can notify others of bugs or typos, but they can also be used as "calls to action", whether you plan on addressing the issue yourself, or are hoping that someone else will be interested in making the changes. Issues [\#97](https://github.com/ProjectPythia/pythia-foundations/issues/97) and [\#98](https://github.com/ProjectPythia/pythia-foundations/issues/98) are examples of this, in which ideas for changes are proposed and then addressed at a later time.
+
+A new issue can be opened by pressing the "New issue" button on the top right of the Issues page. Depending on the repository, you may be prompted to choose from a template, or you may just see title and text boxes to fill out.
+
+## Discussions
+
+Discussions, on the other hand, are more open-ended and do not _necessarily_ suggest a change or addition to the repository. Here is the [Discussions page for Pythia Foundations](https://github.com/ProjectPythia/pythia-foundations/discussions):
+
+ +
+Let's take a look at [Discussion \#156](https://github.com/ProjectPythia/pythia-foundations/discussions/156).
+
+
+
+Let's take a look at [Discussion \#156](https://github.com/ProjectPythia/pythia-foundations/discussions/156).
+
+ +
+This discussion brings up a resource relevant to the repository that could help others, but it is not suggesting a change like an issue would. Other Discussions might include announcements, Q&A, or general thoughts about the repository.
+
+GitHub also makes it simple to reference a Discussion in an Issue (and vice versa),
+which can help provide background and context for a piece of work.
+
+---
+
+## Summary
+
+- GitHub provides Issues and Discussions to facilitate collaboration.
+- Issues are specific and actionable, while Discussions are open-ended.
+- If you want to discuss a topic and you're not sure if it is an Issue
+ or a Discussion, just pick one. It will be okay. :-)
+
+### What's Next?
+
+We will work through cloning and forking an example repository.
+
+## References
+
+1. [What is GitHub Discussions? A complete guide](https://resources.github.com/devops/process/planning/discussions/)
diff --git a/_preview/468/_sources/foundations/github/github-pull-request.md b/_preview/468/_sources/foundations/github/github-pull-request.md
new file mode 100644
index 000000000..b1b720104
--- /dev/null
+++ b/_preview/468/_sources/foundations/github/github-pull-request.md
@@ -0,0 +1,169 @@
+```{image} ../../images/GitHub-logo.png
+:alt: GitHub Logo
+:width: 400px
+```
+
+# Opening a Pull Request on GitHub
+
+A Pull Request, aka a "merge request," is an event that occurs when a project contributor begins the process of merging new code changes from a feature branch with the main project repository.
+
+## Overview:
+
+1. What is a Pull Request?
+1. Opening a Pull Request
+1. Pull Request Features
+1. GitHub Workflows
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| --------------------------------------------- | ----------- | ----- |
+| [What is GitHub](what-is-github) | Necessary | |
+| [GitHub Repositories](github-repos) | Necessary | |
+| [Cloning and Forking](github-cloning-forking) | Necessary | |
+| [Basic Version Control with _git_](basic-git) | Necessary | |
+| [Issues and Discussions](github-issues) | Recommended | |
+| [Branches](git-branches) | Necessary | |
+
+- **Time to learn**: 60 minutes
+
+---
+
+## What is a Pull Request?
+
+A Pull Request (PR) is a formal mechanism for requesting that changes
+that you have made to one repository are integrated (merged) into
+another repository. Typically, the changes are reviewed by the
+maintainers of the destination repository, potentially triggering
+a cycle of revisions, before the PR is “merged”, and your changes
+become part of the destination repo.
+
+Just like Issues, PRs have
+their own discussion forum for communicating about the proposed
+changes. In fact, not only can maintainers or collaborators communicate
+about your PR via GitHub, they can also suggest changes and may
+even be able to make changes of their own by pushing follow-up
+commits. All of the activity, from start to finish, is tracked
+inside of the PR and can be reviewed at any time.
+
+When a contributor to a project creates a PR they are requesting
+that the owners of another destination repository pull a git
+branch from the contributor’s repository and merge the contents of
+the branch into a branch of the destination repository. This means
+that the contributor must provide four pieces of information: the
+contributor’s repository, the contributor’s branch, the destination
+repository, and finally, the destination branch.
+
+A typical sequence of steps consists of the following:
+
+1. A contributor clones a personal remote repository, creating a local copy
+1. The contributor creates a new branch in their local repository
+1. The contributor makes changes to the branch and commits them to
+ their local repository
+1. The contributor _pushes_ the branch to a remote repository
+1. The contributor submits a PR via GitHub
+
+After the maintainers or collaborators of the destination review
+the changes, and any suggested revisions are made, the project
+maintainer merges the feature into the destination repository and
+closes the PR.
+
+## Opening a Pull Request
+
+The demonstration is a continuation from the [GitHub Branches chapter](github-branches). Here, we will move from your local terminal to GitHub.
+
+### Navigate to Your Fork
+
+Go to your fork of the [GitHub Sandbox Repository](https://github.com/ProjectPythia/github-sandbox). One fast way to get to your fork, is to click the "fork" button and then follow the link underneath the message, "You've already forked github-sandbox."
+
+When you've navigated to your fork, you should see a message box alerting you that your branch `branchA` had recent changes with the option to generate an open Pull Request. This Pull Request would take the changes from your `branchA` branch and suggest them for the original upstream ProjectPythia github-sandbox repository. You'll also notice that you are on branch `main`, but that there are now 2 branches.
+
+
+
+### Switch Branches
+
+If you click on the branch `main` you'll see the list of these branches.
+
+
+
+There you can click on the branch `branchA` to switch branches.
+
+
+
+Here you will see the message, "This branch is 1 commit ahead of ProjectPythia:main." Next to this message you'll see either the option to "Contribute" (which opens a Pull Request) or "Fetch Upstream" (which pulls in changes from the original repository). And just above your files you'll see your most recent commit.
+
+### Open a Draft Pull Request
+
+Click on the "Open pull request" button under the "Contribute" drop-down.
+
+
+
+This will send you to a new page. Notice that you are now in "ProjectPythia/github-sandbox" and not your fork.
+
+
+
+The page will have the two branches you are comparing with an arrow indicating which branch is to be merged into which. Here, `base` is the upstream origin and `head` is your forked repository. If you wanted, you could click on these branches to switch the merge configuration. Underneath that you'll see a green message, "Able to merge. These branches can be automatically merged." This message means that there are no conflicts. We will discuss conflicts in a later chapter.
+
+In a one-commit PR, the PR title defaults to your commit message. You can change this if you'd like. There is also a space to add a commit message. This is your opportunity to explain your changes to the owners of the upstream repository.
+
+
+
+And if you scroll down, you'll see a summary of this PR with every commit and changed file listed.
+
+
+
+Click the arrow next to "Create Pull Request" to change this to a draft PR.
+
+
+
+Once you've clicked "Draft Pull Request," you will be directed to the page of your new PR. Here you can add more comments or request reviews.
+
+
+
+## Pull Request Features
+
+Now let's look at the features and discussions in an open (draft) PR.
+Clicking "Files Changed" allows you to see all of the changes that would be merged with this PR.
+
+
+
+If you are working in a repository that has automatic checks, it is a good idea to wait for these checks to pass successfully before you request reviewers or change to a non-draft PR. Do this by clicking "Ready for Review."
+
+
+
+When working on a project with a larger team, do NOT merge your Pull Request before you have the approval of your teammates. Every team has their own requirements and best practice workflows, and will discuss/approve/reject Pull Requests together. We will cover more about the ways to interact with PRs through conversations and reviews in a later section.
+
+To someone with write permissions on the repository, the ability to merge will look like this green button:
+
+
+However, this PR will NOT be merged, as the GitHub-Sandbox repository is intended to be static.
+
+## GitHub Workflows
+
+The above demonstration is an example of the Git **Forking Workflow**, because we forked the [GitHub Sandbox repository](https://github.com/ProjectPythia/github-sandbox) before making our feature branches. This is most common when you do NOT have write-access to the upstream repository.
+
+This differs from the **Feature Workflow**, where all contributors work on a single, remote GitHub repository in specific feature branches. This is common when all contributors DO have write-access to the upstream repository.
+
+The steps leading up to creating your PR depend on your workflow. The main difference in creating the PR is that
+the contributor now, for the Feature Workflow, navigates to the upstream, remote
+repository, not a personal remote fork, and initiates the PR there.
+
+We will cover [GitHub Workflows](github-workflows) in greater detail in the next chapter.
+
+---
+
+## Summary
+
+- A Pull Request (PR) is a formal mechanism for requesting that changes
+ that you have made to one repository are integrated (merged) into
+ another repository.
+- The steps that lead up to
+ the PR depend your GitHub Workflow.
+
+### What's Next?
+
+In the next lesson we will learn more about [Reviewing Pull Requests](review-pr).
+
+## References
+
+1. GitHub's [Collaborating with Pull Requests](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests)
diff --git a/_preview/468/_sources/foundations/github/github-repos.md b/_preview/468/_sources/foundations/github/github-repos.md
new file mode 100644
index 000000000..4782dddeb
--- /dev/null
+++ b/_preview/468/_sources/foundations/github/github-repos.md
@@ -0,0 +1,104 @@
+```{image} ../../images/GitHub-logo.png
+:alt: GitHub Logo
+:width: 400px
+```
+
+# GitHub Repositories
+
+## Overview:
+
+1. Explore GitHub Repositories
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| ----------------------------------------------------------------------------------------------- | ---------- | ----- |
+| [What is GitHub?](https://foundations.projectpythia.org/foundations/github/what-is-github.html) | Necessary | |
+
+- **Time to learn**: 15 minutes
+
+---
+
+## What is a GitHub repository?
+
+GitHub gives the following explanation of a [repository](https://docs.github.com/en/get-started/quickstart/hello-world):
+
+> A repository is usually used to organize a single project. Repositories can contain folders and files, images, videos, spreadsheets, and data sets -- anything your project needs. Often, repositories include a `README` file, a file with information about your project. GitHub makes it easy to add one at the same time you create your new repository. It also offers other common options such as a license file.
+
+In short, it is a _collection of files_. Each GitHub repository has an _owner_, which could be an individual or an organization. Repositories can also be set to _public_ or _private_, determining who can see and interact with it. While a repository can simply store files, GitHub is designed with **collaboration** in mind. Three key collaborative tools in GitHub are:
+
+1. **Issues**: report a bug, plan improvements, or provide feedback to others working on the repository.
+1. **Discussions**: post ideas or other conversations that are not as specific or actionable as an **Issue**.
+1. **Pull requests**: We will go into the specifics later, but a **Pull request** allows a user to _propose a change_ to any of the files within a repository.
+
+```{admonition} Tip
+:class: tip
+Typically, a GitHub repository will always include the **Issues** and **Pull requests** tabs. **Discussions** are not enabled by default, but are increasingly prevalent.
+```
+
+## What are some examples of repositories?
+
+All of the Python packages covered (e.g. [Numpy](https://github.com/numpy/numpy) and [Xarray](https://github.com/pydata/xarray)) in this Foundations book have associated GitHub repositories, as well as [Python itself](https://github.com/python/cpython):
+
+
+
+This discussion brings up a resource relevant to the repository that could help others, but it is not suggesting a change like an issue would. Other Discussions might include announcements, Q&A, or general thoughts about the repository.
+
+GitHub also makes it simple to reference a Discussion in an Issue (and vice versa),
+which can help provide background and context for a piece of work.
+
+---
+
+## Summary
+
+- GitHub provides Issues and Discussions to facilitate collaboration.
+- Issues are specific and actionable, while Discussions are open-ended.
+- If you want to discuss a topic and you're not sure if it is an Issue
+ or a Discussion, just pick one. It will be okay. :-)
+
+### What's Next?
+
+We will work through cloning and forking an example repository.
+
+## References
+
+1. [What is GitHub Discussions? A complete guide](https://resources.github.com/devops/process/planning/discussions/)
diff --git a/_preview/468/_sources/foundations/github/github-pull-request.md b/_preview/468/_sources/foundations/github/github-pull-request.md
new file mode 100644
index 000000000..b1b720104
--- /dev/null
+++ b/_preview/468/_sources/foundations/github/github-pull-request.md
@@ -0,0 +1,169 @@
+```{image} ../../images/GitHub-logo.png
+:alt: GitHub Logo
+:width: 400px
+```
+
+# Opening a Pull Request on GitHub
+
+A Pull Request, aka a "merge request," is an event that occurs when a project contributor begins the process of merging new code changes from a feature branch with the main project repository.
+
+## Overview:
+
+1. What is a Pull Request?
+1. Opening a Pull Request
+1. Pull Request Features
+1. GitHub Workflows
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| --------------------------------------------- | ----------- | ----- |
+| [What is GitHub](what-is-github) | Necessary | |
+| [GitHub Repositories](github-repos) | Necessary | |
+| [Cloning and Forking](github-cloning-forking) | Necessary | |
+| [Basic Version Control with _git_](basic-git) | Necessary | |
+| [Issues and Discussions](github-issues) | Recommended | |
+| [Branches](git-branches) | Necessary | |
+
+- **Time to learn**: 60 minutes
+
+---
+
+## What is a Pull Request?
+
+A Pull Request (PR) is a formal mechanism for requesting that changes
+that you have made to one repository are integrated (merged) into
+another repository. Typically, the changes are reviewed by the
+maintainers of the destination repository, potentially triggering
+a cycle of revisions, before the PR is “merged”, and your changes
+become part of the destination repo.
+
+Just like Issues, PRs have
+their own discussion forum for communicating about the proposed
+changes. In fact, not only can maintainers or collaborators communicate
+about your PR via GitHub, they can also suggest changes and may
+even be able to make changes of their own by pushing follow-up
+commits. All of the activity, from start to finish, is tracked
+inside of the PR and can be reviewed at any time.
+
+When a contributor to a project creates a PR they are requesting
+that the owners of another destination repository pull a git
+branch from the contributor’s repository and merge the contents of
+the branch into a branch of the destination repository. This means
+that the contributor must provide four pieces of information: the
+contributor’s repository, the contributor’s branch, the destination
+repository, and finally, the destination branch.
+
+A typical sequence of steps consists of the following:
+
+1. A contributor clones a personal remote repository, creating a local copy
+1. The contributor creates a new branch in their local repository
+1. The contributor makes changes to the branch and commits them to
+ their local repository
+1. The contributor _pushes_ the branch to a remote repository
+1. The contributor submits a PR via GitHub
+
+After the maintainers or collaborators of the destination review
+the changes, and any suggested revisions are made, the project
+maintainer merges the feature into the destination repository and
+closes the PR.
+
+## Opening a Pull Request
+
+The demonstration is a continuation from the [GitHub Branches chapter](github-branches). Here, we will move from your local terminal to GitHub.
+
+### Navigate to Your Fork
+
+Go to your fork of the [GitHub Sandbox Repository](https://github.com/ProjectPythia/github-sandbox). One fast way to get to your fork, is to click the "fork" button and then follow the link underneath the message, "You've already forked github-sandbox."
+
+When you've navigated to your fork, you should see a message box alerting you that your branch `branchA` had recent changes with the option to generate an open Pull Request. This Pull Request would take the changes from your `branchA` branch and suggest them for the original upstream ProjectPythia github-sandbox repository. You'll also notice that you are on branch `main`, but that there are now 2 branches.
+
+
+
+### Switch Branches
+
+If you click on the branch `main` you'll see the list of these branches.
+
+
+
+There you can click on the branch `branchA` to switch branches.
+
+
+
+Here you will see the message, "This branch is 1 commit ahead of ProjectPythia:main." Next to this message you'll see either the option to "Contribute" (which opens a Pull Request) or "Fetch Upstream" (which pulls in changes from the original repository). And just above your files you'll see your most recent commit.
+
+### Open a Draft Pull Request
+
+Click on the "Open pull request" button under the "Contribute" drop-down.
+
+
+
+This will send you to a new page. Notice that you are now in "ProjectPythia/github-sandbox" and not your fork.
+
+
+
+The page will have the two branches you are comparing with an arrow indicating which branch is to be merged into which. Here, `base` is the upstream origin and `head` is your forked repository. If you wanted, you could click on these branches to switch the merge configuration. Underneath that you'll see a green message, "Able to merge. These branches can be automatically merged." This message means that there are no conflicts. We will discuss conflicts in a later chapter.
+
+In a one-commit PR, the PR title defaults to your commit message. You can change this if you'd like. There is also a space to add a commit message. This is your opportunity to explain your changes to the owners of the upstream repository.
+
+
+
+And if you scroll down, you'll see a summary of this PR with every commit and changed file listed.
+
+
+
+Click the arrow next to "Create Pull Request" to change this to a draft PR.
+
+
+
+Once you've clicked "Draft Pull Request," you will be directed to the page of your new PR. Here you can add more comments or request reviews.
+
+
+
+## Pull Request Features
+
+Now let's look at the features and discussions in an open (draft) PR.
+Clicking "Files Changed" allows you to see all of the changes that would be merged with this PR.
+
+
+
+If you are working in a repository that has automatic checks, it is a good idea to wait for these checks to pass successfully before you request reviewers or change to a non-draft PR. Do this by clicking "Ready for Review."
+
+
+
+When working on a project with a larger team, do NOT merge your Pull Request before you have the approval of your teammates. Every team has their own requirements and best practice workflows, and will discuss/approve/reject Pull Requests together. We will cover more about the ways to interact with PRs through conversations and reviews in a later section.
+
+To someone with write permissions on the repository, the ability to merge will look like this green button:
+
+
+However, this PR will NOT be merged, as the GitHub-Sandbox repository is intended to be static.
+
+## GitHub Workflows
+
+The above demonstration is an example of the Git **Forking Workflow**, because we forked the [GitHub Sandbox repository](https://github.com/ProjectPythia/github-sandbox) before making our feature branches. This is most common when you do NOT have write-access to the upstream repository.
+
+This differs from the **Feature Workflow**, where all contributors work on a single, remote GitHub repository in specific feature branches. This is common when all contributors DO have write-access to the upstream repository.
+
+The steps leading up to creating your PR depend on your workflow. The main difference in creating the PR is that
+the contributor now, for the Feature Workflow, navigates to the upstream, remote
+repository, not a personal remote fork, and initiates the PR there.
+
+We will cover [GitHub Workflows](github-workflows) in greater detail in the next chapter.
+
+---
+
+## Summary
+
+- A Pull Request (PR) is a formal mechanism for requesting that changes
+ that you have made to one repository are integrated (merged) into
+ another repository.
+- The steps that lead up to
+ the PR depend your GitHub Workflow.
+
+### What's Next?
+
+In the next lesson we will learn more about [Reviewing Pull Requests](review-pr).
+
+## References
+
+1. GitHub's [Collaborating with Pull Requests](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests)
diff --git a/_preview/468/_sources/foundations/github/github-repos.md b/_preview/468/_sources/foundations/github/github-repos.md
new file mode 100644
index 000000000..4782dddeb
--- /dev/null
+++ b/_preview/468/_sources/foundations/github/github-repos.md
@@ -0,0 +1,104 @@
+```{image} ../../images/GitHub-logo.png
+:alt: GitHub Logo
+:width: 400px
+```
+
+# GitHub Repositories
+
+## Overview:
+
+1. Explore GitHub Repositories
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| ----------------------------------------------------------------------------------------------- | ---------- | ----- |
+| [What is GitHub?](https://foundations.projectpythia.org/foundations/github/what-is-github.html) | Necessary | |
+
+- **Time to learn**: 15 minutes
+
+---
+
+## What is a GitHub repository?
+
+GitHub gives the following explanation of a [repository](https://docs.github.com/en/get-started/quickstart/hello-world):
+
+> A repository is usually used to organize a single project. Repositories can contain folders and files, images, videos, spreadsheets, and data sets -- anything your project needs. Often, repositories include a `README` file, a file with information about your project. GitHub makes it easy to add one at the same time you create your new repository. It also offers other common options such as a license file.
+
+In short, it is a _collection of files_. Each GitHub repository has an _owner_, which could be an individual or an organization. Repositories can also be set to _public_ or _private_, determining who can see and interact with it. While a repository can simply store files, GitHub is designed with **collaboration** in mind. Three key collaborative tools in GitHub are:
+
+1. **Issues**: report a bug, plan improvements, or provide feedback to others working on the repository.
+1. **Discussions**: post ideas or other conversations that are not as specific or actionable as an **Issue**.
+1. **Pull requests**: We will go into the specifics later, but a **Pull request** allows a user to _propose a change_ to any of the files within a repository.
+
+```{admonition} Tip
+:class: tip
+Typically, a GitHub repository will always include the **Issues** and **Pull requests** tabs. **Discussions** are not enabled by default, but are increasingly prevalent.
+```
+
+## What are some examples of repositories?
+
+All of the Python packages covered (e.g. [Numpy](https://github.com/numpy/numpy) and [Xarray](https://github.com/pydata/xarray)) in this Foundations book have associated GitHub repositories, as well as [Python itself](https://github.com/python/cpython):
+
+ +
+
+
+ +
+
+
+ +
+As you can see by the recent timestamps, these repositories are actively changing; this reflects the adaptability of the [open-source software](https://opensource.org/osd) ecosystem surrounding Python.
+
+```{admonition} Tip
+:class: tip
+Notice that each of the three *Repositories* each exist as part of their own *Organization*. In other words, the NumPy repository exists within the NumPy organization; the Xarray repo exists within the Pydata org, and so forth.
+
+When you [create your own GitHub account](https://foundations.projectpythia.org/foundations/github/what-is-github.html), your user ID functions as the *organization*. Any repositories you create (and therefore, *own*) will exist within that org.
+```
+
+Another example is this project's [Pythia Foundations repository](https://github.com/ProjectPythia/pythia-foundations), on which this tutorial is stored. It is owned by the [Project Pythia organization](https://github.com/ProjectPythia). This organization also owns several other repositories that store the files needed to generate
+
+As you can see by the recent timestamps, these repositories are actively changing; this reflects the adaptability of the [open-source software](https://opensource.org/osd) ecosystem surrounding Python.
+
+```{admonition} Tip
+:class: tip
+Notice that each of the three *Repositories* each exist as part of their own *Organization*. In other words, the NumPy repository exists within the NumPy organization; the Xarray repo exists within the Pydata org, and so forth.
+
+When you [create your own GitHub account](https://foundations.projectpythia.org/foundations/github/what-is-github.html), your user ID functions as the *organization*. Any repositories you create (and therefore, *own*) will exist within that org.
+```
+
+Another example is this project's [Pythia Foundations repository](https://github.com/ProjectPythia/pythia-foundations), on which this tutorial is stored. It is owned by the [Project Pythia organization](https://github.com/ProjectPythia). This organization also owns several other repositories that store the files needed to generate 
+ +```{admonition} Did you know? +:class: info +It is possible to automate this process with a `CODEOWNERS` file and [GitHub actions](https://docs.github.com/en/actions). +``` + +To learn more about any topic relating to requesting a PR review, including topics such as CODEOWNERS files, please review the official [Requesting a Pull Request Review Documentation](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/requesting-a-pull-request-review). + +## Ways to View a Pull Request + +If you are unfamiliar with the process of reviewing a PR, the material in this tutorial section will describe the process in detail. The first step to reviewing a PR is to review the files changed by the PR. However, before reviewing the changed files, it is very helpful to view these files in a meaningful way. + +The first useful way to view changed files in a PR is through the PR's "Files Changed" tab. On this tab, added content is displayed in green, while removed content is displayed in red. + +

+ +This method of viewing changed files works well for most types of code; however, if the code is designed to be rendered as a webpage, Jupyter Notebook, or other similar format, a different method of viewing is recommended. + +There are some standard methods of easily viewing Jupyter Notebooks and rendered webpages in GitHub; these are commonly used by repositories with large amounts of this type of content. GitHub actions can be used to provide previews of the rendered content; there are also third-party services, such as [ReviewNB](https://www.reviewnb.com/), that allow for viewing of this content. Also, it is important to know that when viewing a preview of webpage content provided by GitHub actions, using any absolute links in the preview will take the web browser out of the preview and out of GitHub. + +Another popular way to easily view any type of PR content is to locally check out the PR branch. This can be accomplished by cloning the GitHub repo and switching in the local clone to the branch containing the PR. Viewing a PR through a local clone allows the reviewer to use any applications available through the terminal, including code editors, Jupyter applications, and Web browsers, to view the changed files quickly and easily. For more information on this process, please review the [documentation GitHub provides](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/reviewing-changes-in-pull-requests/checking-out-pull-requests-locally) on checking out pull requests locally. + +As described above, there are many ways to view changed files in a GitHub PR, including local clones, GitHub action previews, and services such as ReviewNB. However, these services may not detail the changes to the files listed in the PR; therefore, the "Files Changed" tab should be the main resource for deciding where to focus a review. + +## Providing a Pull Request Review + +There are many ways to provide a PR review. The most basic of these is to comment on specific lines. This type of review can be performed through the "Files Changed" tab. By clicking on the "+" icon next to a line of code, the reviewer can provide a comment, and either start a new review, or simply link the comment to the line of code. + +

+ +If the review consists mainly of comments relevant to specific lines of code, this review method is preferred. + +If you are the reviewer, and the review consists mainly of small edits that you can perform yourself, this is also the preferred review method. To start one of these small edits, open a comment on the line of code to be edited, as described above. You can then suggest the edit by clicking on the "+-" icon, circled in red in the screenshot below. This icon automatically populates the comment box with the line of code and formats it with Markdown. You must replace the line of code in the comment box with the edited version, then link the comment or start a new review as described above.
+ +

+ +If the review is more complex than simple edits to specific lines of code, you can find more detailed reviewing tools in the Review Changes menu in the top right. This menu contains a comment box, as well as options for specific types of review. These options are described in detail after the informational screenshot below. + +

+ +- The "Comment" option allows the reviewer to provide simple comments or questions on the PR before the review is finished and the PR merged. Please note that comments and questions that may hinder the PR merge process should not be handled in this way. + +- The "Approve" option is used to indicate that the reviewer wholeheartedly approves the content changes in the PR, and that these content changes should be merged into an important project branch as quickly as possible. This option is also known as the LGTM (let's get this merged) option. + +- The "Request changes" option is used to indicate that the content changes contain one or more elements that require improvement or resolution before the PR can be merged. + +After providing review text in the comment box, and selecting a review type, make sure to click on the "Submit Review" button to finish the review. + +## What to Look for When Reviewing + +There are specific elements of PRs that are more commonly prioritized during a review. To address these elements, most reviewers perform the following tasks: + +- Look at the description and linked GitHub issue to make sure the PR addresses the issue +- Attempt to figure out the details of the content changes in the PR, and the purpose of those changes +- Look at the content for spelling errors +- Provide feedback on the code itself + - Does the code contain input checks, debug statements, verification, or the like? + - If the code contains any of these checks, are they sufficiently robust? + - Is the code written in a way that allows for understanding of its purpose? + - As the reviewer, are you familiar with a way to simplify the code, or make the code more efficient? + - Does the code contain identifiers with conflicting or confusing names that need correcting? + - Do you, as the reviewer, notice any other issue with the code that may need to be dealt with in your review? +- If any of the content changed by the PR is meant to be rendered (e.g., as a webpage or Jupyter Notebook), preview this content to check for issues with design and functionality +- Finally, try to clearly state not only the changes made in your review, but also the issues not changed by your review. It is perfectly acceptable to not cover every item in this list; however, it is good practice to include the items covered in the review, and the nature of these changes. Most teams that manage a GitHub repository appreciate the inclusion of opinion and detail in a PR review. + +--- + +## Summary + +- PR Reviews safeguard the primary project branch (and other important project branches) in a GitHub repository. These reviews require contributors in a repository to perform a detailed examination of changes to code and other files. The files remain unchanged until these examinations are finished. +- There exist certain standards pertaining to PR reviews; in addition to following these standards, it is important to provide detail on the basis of your review. + +### What's Next? + +The next tutorial will cover standards and other details about [GitHub Workflows](github-workflows). + +## Resources and References + +1. GitHub's tutorial on [Collaborating with Pull Requests](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests) +2. GitHub's tutorial on [Requesting a Pull Request Review](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/requesting-a-pull-request-review) +3. GitHub's tutorial on [Checking Out Pull Requests Locally](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/reviewing-changes-in-pull-requests/checking-out-pull-requests-locally) diff --git a/_preview/468/_sources/foundations/github/what-is-github.md b/_preview/468/_sources/foundations/github/what-is-github.md new file mode 100644 index 000000000..c09073f22 --- /dev/null +++ b/_preview/468/_sources/foundations/github/what-is-github.md @@ -0,0 +1,135 @@ +```{image} ../../images/GitHub-logo.png +:alt: GitHub Logo +:width: 400px +``` + +# What is GitHub? + +## Overview: + +1. What is GitHub? +1. No experience necessary! +1. Free and open-source software (FOSS) +1. Version control systems (VCS) +1. GitHub = FOSS + VCS + Web +1. Register for a free GitHub account + +## Prerequisites + +| Concepts | Importance | Notes | +| -------- | ---------- | ----- | +| None | | | + +- **Time to learn**: 15 minutes + +--- + +## What is GitHub? + +[GitHub](https://github.com) is a web-based platform for the dissemination of free and open-source software. + +If you are reading this lesson, you are already using GitHub, as that is where Project Pythia hosts its content! + +GitHub provides the following: + +1. _Version control_ for free and open-source software and other digital assets +1. Project _discussion forums_ +1. _DevOps_ to facilitate building and testing software +1. _Bug_ reporting, patching, and tracking +1. _Documentation_ hosting +1. An environment that fosters _collaboration_ + +Although GitHub can host any digital asset, the most common use case for GitHub is for individuals or organizations to house _repositories_ of _free_ and _open-source software_: + +## No experience necessary! + +You do not need to be an experienced software developer or be proficient in version control to make use of GitHub! Perhaps, though, you have used a particular package (e.g., Xarray or Matplotlib) and have had questions about its usage, noticed a bug, or had an idea for a new feature for the package! You can participate in a project's development via GitHub the same way you might have interacted with its developers via email in the past. + +## Free and open-source software (FOSS) + +Much of what we term the _scientific Python software ecosystem_ consists of _free and open-source software_. Often abbreviated as **FOSS**, this means: + +1. The software is free of charge, and +1. The various files which contain the _software code_ are publicly available. + +```{admonition} Did you know? +:class: info +The [Python language](https://python.org) itself is an example of *FOSS*! +``` + +FOSS is nothing new. For example, the [Linux kernel source code](https://kernel.org) has been available to download for many years. + +```{admonition} Free $\neq$ open source! +:class: tip +Just because a software package may be free does not mean that its source code is open! For example, although Nvidia makes its video drivers available for free download, the source code for those drivers is proprietary. +``` + +Arguably, the greatest advantage of open-source software is that it enables _collaborative sharing_, and thus community feedback. + +Types of community input may include the following: + +1. _Issues_: usage questions, bug reports, feature requests +1. _Pull requests_: a user can ask that that their changes/additions be incorporated into the project +1. _Discussions_: a community forum on the open source project + +## Version control systems (VCS) + +We will discuss version control in more detail later in this series, but the need to track and manage changes to a project, especially one that involves software, has long been known. Over the years, FOSS developers have used VCS such as _cvs_, _svn_, and most recently, _git_. All of these systems are _command-line tools_. + +## FOSS and VCS on the Internet + +A successful FOSS project needs to be accessible via the web. As mentioned before, the Linux kernel and the Python language have long been available using first-generation remote access protocols such as FTP and HTTP, and SSH. Later, VCS tools such as cvs and svn established their own TCP protocols for remote access. With the advent of _git_, web-based services that supported HTTP(S) and SSH sprung up. Each of these VCS leverages the concept of a particular FOSS project as a code repository. + +```{admonition} Did you know? +:class: info +Linus Torvalds, the original developer (and still the lead maintainer) of **Linux**, is also the original developer of [Git](https://git-scm.com)! +``` + +```{admonition} Stay tuned! +:class: tip +We will discuss version control and the use of **Git** via the command line later in this series. +``` + +## FOSS + VCS + Web = GitHub + +Perhaps the most popular web-based platform that uses Git for FOSS VCS is [GitHub](https://github.com). GitHub hosts all of the Python software packages that Project Pythia covers as code repositories (we'll use the term Git repo, or more generally just repo henceforth to represent a GitHub code repository). + +For example, here is a screenshot from [Xarray's GitHub](https://github.com/pydata/xarray) Git repo: + +
 +
+```{note}
+The above screenshot is from one moment in time. When you visit the Xarray GitHub link above, it will no doubt look different!
+```
+
+## Register for a free GitHub account
+
+While one can freely browse GitHub repositories such as Xarray anonymously, it's necessary to log into a unique (and free) user account in order to take advantage of GitHub's full capabilities, such as:
+
+1. Opening Issues and Pull Requests
+1. Participating in Discussions
+1. Hosting your own repository
+
+Your next step (if you haven't already) should be to register for your free GitHub account. As with many online services, you will specify a user ID, password, and email address to use with your account.
+
+To do so, simply point your browser to the [GitHub sign-up page](https://github.com/join):
+
+
+
+```{note}
+The above screenshot is from one moment in time. When you visit the Xarray GitHub link above, it will no doubt look different!
+```
+
+## Register for a free GitHub account
+
+While one can freely browse GitHub repositories such as Xarray anonymously, it's necessary to log into a unique (and free) user account in order to take advantage of GitHub's full capabilities, such as:
+
+1. Opening Issues and Pull Requests
+1. Participating in Discussions
+1. Hosting your own repository
+
+Your next step (if you haven't already) should be to register for your free GitHub account. As with many online services, you will specify a user ID, password, and email address to use with your account.
+
+To do so, simply point your browser to the [GitHub sign-up page](https://github.com/join):
+
+ +
+While GitHub offers paid options, a free account is typically all that is needed!
+
+---
+
+## Summary
+
+- GitHub serves as a web-based platform for digital assets, particularly FOSS.
+- GitHub uses Git as its version control system.
+- You can set up a free user account on GitHub.
+
+### What's Next?
+
+In the next lesson, we will explore some GitHub repositories.
+
+## References
+
+1. [GitHub (Wikipedia)](https://en.wikipedia.org/wiki/GitHub)
diff --git a/_preview/468/_sources/foundations/how-to-run-python.md b/_preview/468/_sources/foundations/how-to-run-python.md
new file mode 100644
index 000000000..c0fd2116e
--- /dev/null
+++ b/_preview/468/_sources/foundations/how-to-run-python.md
@@ -0,0 +1,80 @@
+# Installing and Running Python
+
+---
+
+## Overview
+
+This section provides an overview of different ways to run Python code, and quickstart guides for:
+
+1. Choosing a Python platform
+2. Installing and managing Python with Conda
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| -------------------------------------------------------------------------------- | ---------- | ----- |
+| [Why Python?](https://foundations.projectpythia.org/foundations/why-python.html) | Helpful | |
+
+- **Time to learn**: 20 minutes
+
+---
+
+## Choosing a Python Platform
+
+There is no single official platform for the Python language. Here we provide a brief rundown of 3 popular platforms:
+
+1. The terminal,
+2. Jupyter notebooks, and
+3. IDEs (integrated development environments).
+
+Here we hope to provide you with enough information to understand the differences and similarities between each platform, so that you can make the best choice for your work environment and learn along effectively, regardless of your Python platform preference.
+
+In general, it is always best to test your programs in the same environment in which they will be run. The biggest factors to consider when choosing your platform are:
+
+- What are you already comfortable with?
+- What are the people around you using (peers, coworkers, instructors, etc.)?
+
+### Terminal
+
+For learners who are familiar with basic [Linux commands](https://cheatography.com/davechild/cheat-sheets/linux-command-line/) and text editors (such as Vim or Nano), running Python in the terminal is the quickest route straight to learning Python syntax without the covering the bells and whistles of a new platform. If you are running Python on a supercomputer, through an HTTP request or SSH tunneling, you might want to consider learning in the terminal.
+
+[How to Run Python in the Terminal](terminal.md)
+
+### Jupyter Notebooks
+
+We highly encourage the use of Jupyter notebooks: a free, open-source, interactive tool running inside a web browser that allows you to run Python code in "cells." This means that your workflow can alternate between code, output, and even Markdown-formatted explanatory sections that create an easy-to-follow analysis or "computational narrative" from start to finish. Jupyter notebooks are a great option for presentations or learning tools. For these reasons, Jupyter is very popular among scientists. Most lessons in this book will be taught via Jupyter notebooks.
+
+[How to Run Python in a Jupyter Session](jupyter.md)
+
+### Other IDEs
+
+If you code in other languages, you might already have a favorite IDE that will work just as well in Python. [Spyder](https://www.spyder-ide.org) is a Python specific IDE that comes with the [Anaconda download](https://www.anaconda.com/products/distribution). It is perhaps the most familiar IDE if you are coming from languages such as [Matlab](https://www.mathworks.com/products/matlab.html) that have a language specific platform and display a list of variables. [PyCharm](https://www.jetbrains.com/pycharm/) and [Visual Studio Code](https://code.visualstudio.com) are also popular IDEs. Many IDEs offer support for terminal execution, scripts, and Jupyter display. To learn about your specific IDE, visit its official documentation.
+
+_We recommend eventually learning how to develop and run Python code in each of these platforms._
+
+## Installing and managing Python with Conda
+
+Conda is an open-source, cross-platform, language-agnostic package manager and environment management system that allows you to quickly install, run, and update packages within your work environment(s). Conda is a vital component of the Python ecosystem. Understanding it is important, regardless of the platform you chose to run your Python code.
+
+[Learn more about Conda here](conda.md)
+
+---
+
+## Summary
+
+Python can be run on many different platforms. You may choose where to run Python based on a number of factors. The tutorials in this book will be formatted as Jupyter Notebooks.
+
+### What's Next?
+
+- [How to Run Python in the Terminal](terminal.md)
+- [How to Run Python in a Jupyter Session](jupyter.md)
+- [Learn more about Conda here](conda.md)
+
+## Resources and References
+
+- [Linux commands](https://cheatography.com/davechild/cheat-sheets/linux-command-line/)
+- [Spyder](https://www.spyder-ide.org)
+- [Anaconda](https://www.anaconda.com/products/distribution)
+- [Matlab](https://www.mathworks.com/products/matlab.html)
+- [PyCharm](https://www.jetbrains.com/pycharm/)
+- [Visual Studio Code](https://code.visualstudio.com)
diff --git a/_preview/468/_sources/foundations/jupyter.md b/_preview/468/_sources/foundations/jupyter.md
new file mode 100644
index 000000000..9fd45a415
--- /dev/null
+++ b/_preview/468/_sources/foundations/jupyter.md
@@ -0,0 +1,115 @@
+# Python in Jupyter
+
+---
+
+## Overview
+
+You'd like to learn to run Python in a Jupyter session. Here we will cover:
+
+1. Installing Python in Jupyter
+2. Running Python code in Jupyter
+3. Saving your notebook and exiting
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| --------------------------------------------------------------------------------------------------------- | ---------- | ----- |
+| [Installing and Running Python](https://foundations.projectpythia.org/foundations/how-to-run-python.html) | Helpful | |
+
+- **Time to learn**: 20 minutes
+
+---
+
+## Installing Python in Jupyter
+
+To run a Jupyter session, you will need to install some necessary packages into your Conda environment.
+
+Install `miniconda` by following the [instructions for your machine](https://docs.conda.io/en/latest/miniconda.html).
+
+[Learn more about Conda here](conda.md)
+
+Next, create a Conda environment with Jupyter Lab installed. In the terminal, type:
+
+```
+$ conda create --name pythia_foundations_env jupyterlab
+```
+
+Test that you have installed everything correctly by first activating your environment and then launching a Jupyter Lab session:
+
+```
+$ conda activate pythia_foundations_env
+$ jupyter lab
+```
+
+Or you can install the full [Anaconda](https://www.anaconda.com/products/distribution), and select **LAUNCH** under the Jupyter panel in the GUI.
+
+
+
+In both methods, a new window should open automatically in your default browser. You can change the browser when launching from the terminal with (for example):
+
+```
+jupyter lab —browser=chrome
+```
+
+## Running Python in Jupyter
+
+1. With your Conda environment activated and Jupyter session launched (see above), create a directory to store our work. Let's call it `pythia-foundations`.
+
+ 
+
+ You can do this in the GUI left sidebar by clicking the new-folder icon. If you prefer to use the command line, you can access a terminal by clicking the icon under the "Other" heading in the Launcher.
+
+2. Create a new `mysci.ipynb` file within the `pythia-foundations` folder:
+
+ Do this in the GUI on the left sidebar by clicking the "+" icon.
+
+ This will open a new launcher window where you can select a Python kernel under the "Notebooks" heading for your project. _You should see "Python 3" as in the screenshot above._ Depending on the details of your system, you might see some additional buttons with different kernels.
+
+ Selecting a kernel will open a Jupyter notebook instance and add an untitled file to the left sidebar navigator, which you can then rename to `mysci.ipynb`.
+
+ Select "Python 3" to use the Python version you just installed in the `pythia_foundations_env` conda environment.
+
+3. Change the first notebook cell to include the classic first command: printing, "Hello, world!".
+
+ ```python
+ print("Hello, world!")
+ ```
+
+4. Run your cell with {kbd}`Shift`\+{kbd}`Enter` and see that the results are printed below the cell.
+
+ 
+
+**Congratulations!** You have just set up your first Python environment and run your first Python code in a Jupyter notebook.
+
+## Saving your notebook and exiting
+
+When you are done with your work, it is time to save and exit.
+
+To save your file, you can click the disc icon in the upper left Jupyter toolbar or use keyboard shortcuts.
+
+Jupyter allows you to close the browser tab without shutting down the server. When you're done working on your notebook, _it's important to **click the "Shutdown" button** on the dashboard_ to free up memory, especially on a shared system.
+
+Then you can quit Jupyter by:
+
+- clicking the "Quit" button on the top right, or
+- typing `exit` into the terminal
+
+Alternatively you can simultaneously shutdown and exit the Jupyter session by typing
+{kbd}`Ctrl`\+{kbd}`C` in the terminal and confirming that you do want to
+"shutdown this notebook server."
+
+---
+
+## Summary
+
+Jupyter notebooks are a free, open-source, interactive tool running inside a web browser that allows you to run Python code in "cells." To run a Jupyter session you will need to install `jupyterlab` into your Conda environment. Jupyter sessions need to be shutdown, not just exited.
+
+### What's Next?
+
+- [How to Run Python in the Terminal](terminal.md)
+- [Learn more about Conda here](conda.md)
+- [Getting Started with Jupyter](getting-started-jupyter)
+
+## Resources and References
+
+- [Anaconda](https://www.anaconda.com/products/distribution)
diff --git a/_preview/468/_sources/foundations/jupyterlab.ipynb b/_preview/468/_sources/foundations/jupyterlab.ipynb
new file mode 100644
index 000000000..1c0446067
--- /dev/null
+++ b/_preview/468/_sources/foundations/jupyterlab.ipynb
@@ -0,0 +1,620 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hC-731NWXAnQ"
+ },
+ "source": [
+ "# JupyterLab"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3rIfwtTKpQLf"
+ },
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MkdbWkKzfegV",
+ "jp-MarkdownHeadingCollapsed": true,
+ "tags": []
+ },
+ "source": [
+ "## Overview\n",
+ "\n",
+ "JupyterLab is a popular web application on which users can create and write their Jupyter Notebooks, as well as explore data, install software, etc. This section will introduce the JupyterLab interface and cover details of JupyterLab Notebooks.\n",
+ "\n",
+ "1. Set Up\n",
+ "2. The JupyterLab Interface\n",
+ "3. Running JupyterLab Notebooks"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "yt-WtTrcpRpo"
+ },
+ "source": [
+ "## Prerequisites\n",
+ "| Concepts | Importance | Notes |\n",
+ "| --- | --- | --- |\n",
+ "| [Getting Started with Jupyter](getting-started-jupyter) | Helpful | |\n",
+ "| [Installing and Running Python: Python in Jupyter](https://foundations.projectpythia.org/foundations/jupyter.html) | Helpful | |\n",
+ "\n",
+ "- **Time to learn**: 50 minutes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nvLyiIa8pTI5"
+ },
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eRjK14BjeQXA",
+ "tags": []
+ },
+ "source": [
+ "## Set Up\n",
+ "\n",
+ "To launch the JupyterLab interface in your browser, follow the instructions in [Installing and Running Python: Python in Jupyter](https://foundations.projectpythia.org/foundations/jupyter.html).\n",
+ "\n",
+ "If, instead, you want to follow along using a provided remote JupyterLab instance, launch this notebook via [Binder](https://mybinder.org/) using the launch icon at the top of this page,\n",
+ "\n",
+ "\n",
+ "\n",
+ "and follow along from there! If launching Binder, take note of the `Launcher` tab in the upper-left (see interface below). Click there to find yourself in the same interface moving forward, and feel free to refer back to this tab to follow along."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Qe2fbSa2gS2X"
+ },
+ "source": [
+ "## The JupyterLab Interface\n",
+ "\n",
+ "Go to your browser and take a look at the JupyterLab interface.\n",
+ "\n",
+ "With a base installation of JupyterLab your screen should look similar to the image below.\n",
+ "\n",
+ "Notice:\n",
+ "- The **Menu Bar** at the top of the screen, containing the typical dropdown menus: \"File\", \"Edit\", \"View\", etc.\n",
+ "- Below that is the **Workspace Area** (currently contains the Launcher).\n",
+ "- The **Launcher** is a quick shortcut for accessing the Console/Terminal, for creating new Notebooks, or for creating new Text or Markdown files.\n",
+ "- On the left is a **Collapsible Sidebar**. It currently contains the File Browser, but you can also select the Running Tabs and Kernels, the Table of Contents, and the Extensions Manager.\n",
+ "- Below everything is the **Information Bar**, which is context sensitive. We will touch on this more.\n",
+ "\n",
+ "\n",
+ "\n",
+ "We will now take a closer look at certain aspects and features of the JupyterLab Interface."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "zpDZFM3ngsY6"
+ },
+ "source": [
+ "### Left Sidebar\n",
+ "\n",
+ "The Collapsible Left Sidebar is open to the **File Browser Tab** at launch. Clicking the File Browser Tab will collapse the sidebar or reopen it to this tab.\n",
+ "- Within this tab, you will see the \"+\" button, which allows you to create a new launcher. \n",
+ "- Next to that is the \"+ folder\" button which allows you to create a new folder that then appears below \"Name\" in the contents of your directory. Double click the folder to enter it, right click the folder for options, or press the \"root folder\" icon to return to the root directory. The root directory is the directory from which JupyterLab was launched. You cannot go above the root directory. \n",
+ "- The \"upload\" button (looks like an arrow pointing up) allows you to upload files to the current folder. \n",
+ "- The \"refresh\" button refreshes the File Browser.\n",
+ "\n",
+ "Below the File Browser Tab is the **Running Tabs and Kernels Tab**. Currently, this tab doesn't have much in it. We will revisit this when we have running kernels. Remember that Kernels are background processes, so closing a tab (Terminal or Notebook) doesn’t shut down the kernel. You have to do that manually. \n",
+ "\n",
+ "
+
+While GitHub offers paid options, a free account is typically all that is needed!
+
+---
+
+## Summary
+
+- GitHub serves as a web-based platform for digital assets, particularly FOSS.
+- GitHub uses Git as its version control system.
+- You can set up a free user account on GitHub.
+
+### What's Next?
+
+In the next lesson, we will explore some GitHub repositories.
+
+## References
+
+1. [GitHub (Wikipedia)](https://en.wikipedia.org/wiki/GitHub)
diff --git a/_preview/468/_sources/foundations/how-to-run-python.md b/_preview/468/_sources/foundations/how-to-run-python.md
new file mode 100644
index 000000000..c0fd2116e
--- /dev/null
+++ b/_preview/468/_sources/foundations/how-to-run-python.md
@@ -0,0 +1,80 @@
+# Installing and Running Python
+
+---
+
+## Overview
+
+This section provides an overview of different ways to run Python code, and quickstart guides for:
+
+1. Choosing a Python platform
+2. Installing and managing Python with Conda
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| -------------------------------------------------------------------------------- | ---------- | ----- |
+| [Why Python?](https://foundations.projectpythia.org/foundations/why-python.html) | Helpful | |
+
+- **Time to learn**: 20 minutes
+
+---
+
+## Choosing a Python Platform
+
+There is no single official platform for the Python language. Here we provide a brief rundown of 3 popular platforms:
+
+1. The terminal,
+2. Jupyter notebooks, and
+3. IDEs (integrated development environments).
+
+Here we hope to provide you with enough information to understand the differences and similarities between each platform, so that you can make the best choice for your work environment and learn along effectively, regardless of your Python platform preference.
+
+In general, it is always best to test your programs in the same environment in which they will be run. The biggest factors to consider when choosing your platform are:
+
+- What are you already comfortable with?
+- What are the people around you using (peers, coworkers, instructors, etc.)?
+
+### Terminal
+
+For learners who are familiar with basic [Linux commands](https://cheatography.com/davechild/cheat-sheets/linux-command-line/) and text editors (such as Vim or Nano), running Python in the terminal is the quickest route straight to learning Python syntax without the covering the bells and whistles of a new platform. If you are running Python on a supercomputer, through an HTTP request or SSH tunneling, you might want to consider learning in the terminal.
+
+[How to Run Python in the Terminal](terminal.md)
+
+### Jupyter Notebooks
+
+We highly encourage the use of Jupyter notebooks: a free, open-source, interactive tool running inside a web browser that allows you to run Python code in "cells." This means that your workflow can alternate between code, output, and even Markdown-formatted explanatory sections that create an easy-to-follow analysis or "computational narrative" from start to finish. Jupyter notebooks are a great option for presentations or learning tools. For these reasons, Jupyter is very popular among scientists. Most lessons in this book will be taught via Jupyter notebooks.
+
+[How to Run Python in a Jupyter Session](jupyter.md)
+
+### Other IDEs
+
+If you code in other languages, you might already have a favorite IDE that will work just as well in Python. [Spyder](https://www.spyder-ide.org) is a Python specific IDE that comes with the [Anaconda download](https://www.anaconda.com/products/distribution). It is perhaps the most familiar IDE if you are coming from languages such as [Matlab](https://www.mathworks.com/products/matlab.html) that have a language specific platform and display a list of variables. [PyCharm](https://www.jetbrains.com/pycharm/) and [Visual Studio Code](https://code.visualstudio.com) are also popular IDEs. Many IDEs offer support for terminal execution, scripts, and Jupyter display. To learn about your specific IDE, visit its official documentation.
+
+_We recommend eventually learning how to develop and run Python code in each of these platforms._
+
+## Installing and managing Python with Conda
+
+Conda is an open-source, cross-platform, language-agnostic package manager and environment management system that allows you to quickly install, run, and update packages within your work environment(s). Conda is a vital component of the Python ecosystem. Understanding it is important, regardless of the platform you chose to run your Python code.
+
+[Learn more about Conda here](conda.md)
+
+---
+
+## Summary
+
+Python can be run on many different platforms. You may choose where to run Python based on a number of factors. The tutorials in this book will be formatted as Jupyter Notebooks.
+
+### What's Next?
+
+- [How to Run Python in the Terminal](terminal.md)
+- [How to Run Python in a Jupyter Session](jupyter.md)
+- [Learn more about Conda here](conda.md)
+
+## Resources and References
+
+- [Linux commands](https://cheatography.com/davechild/cheat-sheets/linux-command-line/)
+- [Spyder](https://www.spyder-ide.org)
+- [Anaconda](https://www.anaconda.com/products/distribution)
+- [Matlab](https://www.mathworks.com/products/matlab.html)
+- [PyCharm](https://www.jetbrains.com/pycharm/)
+- [Visual Studio Code](https://code.visualstudio.com)
diff --git a/_preview/468/_sources/foundations/jupyter.md b/_preview/468/_sources/foundations/jupyter.md
new file mode 100644
index 000000000..9fd45a415
--- /dev/null
+++ b/_preview/468/_sources/foundations/jupyter.md
@@ -0,0 +1,115 @@
+# Python in Jupyter
+
+---
+
+## Overview
+
+You'd like to learn to run Python in a Jupyter session. Here we will cover:
+
+1. Installing Python in Jupyter
+2. Running Python code in Jupyter
+3. Saving your notebook and exiting
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| --------------------------------------------------------------------------------------------------------- | ---------- | ----- |
+| [Installing and Running Python](https://foundations.projectpythia.org/foundations/how-to-run-python.html) | Helpful | |
+
+- **Time to learn**: 20 minutes
+
+---
+
+## Installing Python in Jupyter
+
+To run a Jupyter session, you will need to install some necessary packages into your Conda environment.
+
+Install `miniconda` by following the [instructions for your machine](https://docs.conda.io/en/latest/miniconda.html).
+
+[Learn more about Conda here](conda.md)
+
+Next, create a Conda environment with Jupyter Lab installed. In the terminal, type:
+
+```
+$ conda create --name pythia_foundations_env jupyterlab
+```
+
+Test that you have installed everything correctly by first activating your environment and then launching a Jupyter Lab session:
+
+```
+$ conda activate pythia_foundations_env
+$ jupyter lab
+```
+
+Or you can install the full [Anaconda](https://www.anaconda.com/products/distribution), and select **LAUNCH** under the Jupyter panel in the GUI.
+
+
+
+In both methods, a new window should open automatically in your default browser. You can change the browser when launching from the terminal with (for example):
+
+```
+jupyter lab —browser=chrome
+```
+
+## Running Python in Jupyter
+
+1. With your Conda environment activated and Jupyter session launched (see above), create a directory to store our work. Let's call it `pythia-foundations`.
+
+ 
+
+ You can do this in the GUI left sidebar by clicking the new-folder icon. If you prefer to use the command line, you can access a terminal by clicking the icon under the "Other" heading in the Launcher.
+
+2. Create a new `mysci.ipynb` file within the `pythia-foundations` folder:
+
+ Do this in the GUI on the left sidebar by clicking the "+" icon.
+
+ This will open a new launcher window where you can select a Python kernel under the "Notebooks" heading for your project. _You should see "Python 3" as in the screenshot above._ Depending on the details of your system, you might see some additional buttons with different kernels.
+
+ Selecting a kernel will open a Jupyter notebook instance and add an untitled file to the left sidebar navigator, which you can then rename to `mysci.ipynb`.
+
+ Select "Python 3" to use the Python version you just installed in the `pythia_foundations_env` conda environment.
+
+3. Change the first notebook cell to include the classic first command: printing, "Hello, world!".
+
+ ```python
+ print("Hello, world!")
+ ```
+
+4. Run your cell with {kbd}`Shift`\+{kbd}`Enter` and see that the results are printed below the cell.
+
+ 
+
+**Congratulations!** You have just set up your first Python environment and run your first Python code in a Jupyter notebook.
+
+## Saving your notebook and exiting
+
+When you are done with your work, it is time to save and exit.
+
+To save your file, you can click the disc icon in the upper left Jupyter toolbar or use keyboard shortcuts.
+
+Jupyter allows you to close the browser tab without shutting down the server. When you're done working on your notebook, _it's important to **click the "Shutdown" button** on the dashboard_ to free up memory, especially on a shared system.
+
+Then you can quit Jupyter by:
+
+- clicking the "Quit" button on the top right, or
+- typing `exit` into the terminal
+
+Alternatively you can simultaneously shutdown and exit the Jupyter session by typing
+{kbd}`Ctrl`\+{kbd}`C` in the terminal and confirming that you do want to
+"shutdown this notebook server."
+
+---
+
+## Summary
+
+Jupyter notebooks are a free, open-source, interactive tool running inside a web browser that allows you to run Python code in "cells." To run a Jupyter session you will need to install `jupyterlab` into your Conda environment. Jupyter sessions need to be shutdown, not just exited.
+
+### What's Next?
+
+- [How to Run Python in the Terminal](terminal.md)
+- [Learn more about Conda here](conda.md)
+- [Getting Started with Jupyter](getting-started-jupyter)
+
+## Resources and References
+
+- [Anaconda](https://www.anaconda.com/products/distribution)
diff --git a/_preview/468/_sources/foundations/jupyterlab.ipynb b/_preview/468/_sources/foundations/jupyterlab.ipynb
new file mode 100644
index 000000000..1c0446067
--- /dev/null
+++ b/_preview/468/_sources/foundations/jupyterlab.ipynb
@@ -0,0 +1,620 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hC-731NWXAnQ"
+ },
+ "source": [
+ "# JupyterLab"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3rIfwtTKpQLf"
+ },
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "MkdbWkKzfegV",
+ "jp-MarkdownHeadingCollapsed": true,
+ "tags": []
+ },
+ "source": [
+ "## Overview\n",
+ "\n",
+ "JupyterLab is a popular web application on which users can create and write their Jupyter Notebooks, as well as explore data, install software, etc. This section will introduce the JupyterLab interface and cover details of JupyterLab Notebooks.\n",
+ "\n",
+ "1. Set Up\n",
+ "2. The JupyterLab Interface\n",
+ "3. Running JupyterLab Notebooks"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "yt-WtTrcpRpo"
+ },
+ "source": [
+ "## Prerequisites\n",
+ "| Concepts | Importance | Notes |\n",
+ "| --- | --- | --- |\n",
+ "| [Getting Started with Jupyter](getting-started-jupyter) | Helpful | |\n",
+ "| [Installing and Running Python: Python in Jupyter](https://foundations.projectpythia.org/foundations/jupyter.html) | Helpful | |\n",
+ "\n",
+ "- **Time to learn**: 50 minutes"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nvLyiIa8pTI5"
+ },
+ "source": [
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eRjK14BjeQXA",
+ "tags": []
+ },
+ "source": [
+ "## Set Up\n",
+ "\n",
+ "To launch the JupyterLab interface in your browser, follow the instructions in [Installing and Running Python: Python in Jupyter](https://foundations.projectpythia.org/foundations/jupyter.html).\n",
+ "\n",
+ "If, instead, you want to follow along using a provided remote JupyterLab instance, launch this notebook via [Binder](https://mybinder.org/) using the launch icon at the top of this page,\n",
+ "\n",
+ "\n",
+ "\n",
+ "and follow along from there! If launching Binder, take note of the `Launcher` tab in the upper-left (see interface below). Click there to find yourself in the same interface moving forward, and feel free to refer back to this tab to follow along."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Qe2fbSa2gS2X"
+ },
+ "source": [
+ "## The JupyterLab Interface\n",
+ "\n",
+ "Go to your browser and take a look at the JupyterLab interface.\n",
+ "\n",
+ "With a base installation of JupyterLab your screen should look similar to the image below.\n",
+ "\n",
+ "Notice:\n",
+ "- The **Menu Bar** at the top of the screen, containing the typical dropdown menus: \"File\", \"Edit\", \"View\", etc.\n",
+ "- Below that is the **Workspace Area** (currently contains the Launcher).\n",
+ "- The **Launcher** is a quick shortcut for accessing the Console/Terminal, for creating new Notebooks, or for creating new Text or Markdown files.\n",
+ "- On the left is a **Collapsible Sidebar**. It currently contains the File Browser, but you can also select the Running Tabs and Kernels, the Table of Contents, and the Extensions Manager.\n",
+ "- Below everything is the **Information Bar**, which is context sensitive. We will touch on this more.\n",
+ "\n",
+ "\n",
+ "\n",
+ "We will now take a closer look at certain aspects and features of the JupyterLab Interface."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "zpDZFM3ngsY6"
+ },
+ "source": [
+ "### Left Sidebar\n",
+ "\n",
+ "The Collapsible Left Sidebar is open to the **File Browser Tab** at launch. Clicking the File Browser Tab will collapse the sidebar or reopen it to this tab.\n",
+ "- Within this tab, you will see the \"+\" button, which allows you to create a new launcher. \n",
+ "- Next to that is the \"+ folder\" button which allows you to create a new folder that then appears below \"Name\" in the contents of your directory. Double click the folder to enter it, right click the folder for options, or press the \"root folder\" icon to return to the root directory. The root directory is the directory from which JupyterLab was launched. You cannot go above the root directory. \n",
+ "- The \"upload\" button (looks like an arrow pointing up) allows you to upload files to the current folder. \n",
+ "- The \"refresh\" button refreshes the File Browser.\n",
+ "\n",
+ "Below the File Browser Tab is the **Running Tabs and Kernels Tab**. Currently, this tab doesn't have much in it. We will revisit this when we have running kernels. Remember that Kernels are background processes, so closing a tab (Terminal or Notebook) doesn’t shut down the kernel. You have to do that manually. \n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "The **Table of Contents Tab** is auto-populated based on the headings and subheadings used in the Markdown cells of your notebook. It allows you to quickly jump between sections of the document.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "The **Table of Contents Tab** is auto-populated based on the headings and subheadings used in the Markdown cells of your notebook. It allows you to quickly jump between sections of the document.\n",
+ "\n",
+ " \n",
+ "\n",
+ "Last is the **Extensions Manager Tab** where you can customize or enhance any part of JupyterLab. These customizations could pertain to themes or keyboard shortcuts, for example. We will not be covering JupyterLab extensions, but you can read more about them [here](https://jupyterlab.readthedocs.io/en/stable/user/extensions.html).\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Last is the **Extensions Manager Tab** where you can customize or enhance any part of JupyterLab. These customizations could pertain to themes or keyboard shortcuts, for example. We will not be covering JupyterLab extensions, but you can read more about them [here](https://jupyterlab.readthedocs.io/en/stable/user/extensions.html).\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1WPljwIRg1KH"
+ },
+ "source": [
+ "### Terminals\n",
+ " \n",
+ "Let’s select the Running Tabs and Kernels Tab in the Left Sidebar and see how it changes when we've used the Launcher.\n",
+ "\n",
+ "Open a Terminal in the Launcher. It should look very similar to the desktop terminal that you initially launched JupyterLab from, but is running from within JupyterLab, within your existing Conda environment, and within the directory you launched JupyterLab from (the same root folder shown in the File Browser Tab). Notice that there is now a Terminal listed in the Running Terminals Tab.\n",
+ "\n",
+ "In the terminal you can use your usual terminal commands. For example, in the terminal window, run: \n",
+ "\n",
+ "```\n",
+ "$ mkdir test\n",
+ "```\n",
+ "\n",
+ "Select the File Browser Tab, refresh it, and see that your new folder is there.\n",
+ "\n",
+ "In the Terminal Window run:\n",
+ "\n",
+ "```\n",
+ "$ rmdir test\n",
+ "```\n",
+ "Hit refresh in the File Browser again to see that the directory is gone.\n",
+ "\n",
+ "\n",
+ "\n",
+ "Back with the Running Terminals and Kernels Tab open, click the \"X\" in your workspace to close the Terminal window. Notice that the Terminal is still running in the background! Click on the terminal in the Running Terminals and Kernels Tab to reopen it (and hit enter or return to get your prompt back). To truly close it, execute in the Terminal window:\n",
+ "\n",
+ "```\n",
+ "$ exit\n",
+ "```\n",
+ "\n",
+ "OR click the “X” shut down button in the Running Terminals tab.\n",
+ "\n",
+ "Doing so will return you to the Launcher. \n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1WPljwIRg1KH"
+ },
+ "source": [
+ "### Terminals\n",
+ " \n",
+ "Let’s select the Running Tabs and Kernels Tab in the Left Sidebar and see how it changes when we've used the Launcher.\n",
+ "\n",
+ "Open a Terminal in the Launcher. It should look very similar to the desktop terminal that you initially launched JupyterLab from, but is running from within JupyterLab, within your existing Conda environment, and within the directory you launched JupyterLab from (the same root folder shown in the File Browser Tab). Notice that there is now a Terminal listed in the Running Terminals Tab.\n",
+ "\n",
+ "In the terminal you can use your usual terminal commands. For example, in the terminal window, run: \n",
+ "\n",
+ "```\n",
+ "$ mkdir test\n",
+ "```\n",
+ "\n",
+ "Select the File Browser Tab, refresh it, and see that your new folder is there.\n",
+ "\n",
+ "In the Terminal Window run:\n",
+ "\n",
+ "```\n",
+ "$ rmdir test\n",
+ "```\n",
+ "Hit refresh in the File Browser again to see that the directory is gone.\n",
+ "\n",
+ "\n",
+ "\n",
+ "Back with the Running Terminals and Kernels Tab open, click the \"X\" in your workspace to close the Terminal window. Notice that the Terminal is still running in the background! Click on the terminal in the Running Terminals and Kernels Tab to reopen it (and hit enter or return to get your prompt back). To truly close it, execute in the Terminal window:\n",
+ "\n",
+ "```\n",
+ "$ exit\n",
+ "```\n",
+ "\n",
+ "OR click the “X” shut down button in the Running Terminals tab.\n",
+ "\n",
+ "Doing so will return you to the Launcher. \n",
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "iQAVvbtJg6pi"
+ },
+ "source": [
+ "### Consoles\n",
+ "\n",
+ "Back in the Launcher, click the “Python 3” Console button. There is only one console option right now, but you could install more kernels into your Conda environment. \n",
+ "\n",
+ "There will be three dots while the kernel starts, then what loads looks like an IPython console. This is a place to execute Python commands in a stand alone workspace which is good for testing. Notice that the kernel started in the Running Terminals and Kernels tab!\n",
+ "\n",
+ "Start in a “cell” at the bottom of the Console window. Type:\n",
+ "``` python\n",
+ "i = 5\n",
+ "print(i)\n",
+ "```\n",
+ "To execute the cell, type Shift+Enter. Notice that the console redisplays the code you wrote, labels it with a number, and displays (prints) the output to the screen. \n",
+ "\n",
+ "In the next cell, enter:\n",
+ "``` python\n",
+ "s = 'Hello, World!'\n",
+ "print(f's = {s}')\n",
+ "s\n",
+ "```\n",
+ "\n",
+ "The first line of this code designates a string `s` with the value \"Hello, World!\", the second line uses f-formatting to print the string, and the final line just calls up `s`. The last line in the cell will always be returned (its value displayed) regardless of whether you called `print`. Type Shift+Enter to execute the cell. Again the output is labeled (this time with a 2), and we see the input code, the printed standard-out statement, and the return statement. The “return value” and the values “printed to screen” are different!\n",
+ "\n",
+ "\n",
+ "\n",
+ "Close the window and shut down the Console in the Running Kernels tab. We’re back to the Launcher again."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "UDCCs37IhK7S"
+ },
+ "source": [
+ "### Text Editor\n",
+ "\n",
+ "Click on the “Text File” button in the Launcher.\n",
+ "Select the File Browser tab to see the new file `untitled.txt` you created.\n",
+ "\n",
+ "Enter this Python code into the new text file:\n",
+ "``` python\n",
+ "s = 'Hello, World!'\n",
+ "print(s)\n",
+ "```\n",
+ "\n",
+ "You may notice that the file has a dot instead of an \"X\" where you'd close it. This indicates that the file hasn't been saved or has unsaved changes. Save the file (\"command+s\" on Mac, \"control+s\" on Windows, or \"File▶Save Text\").\n",
+ "\n",
+ "Go to the File Browser tab, right-click the new file we created and “Rename” it to `hello.py`. Once the extension changes to `.py`, Jupyter recognizes that this is a Python file, and the text editor highlights the code based on Python syntax.\n",
+ "\n",
+ "Now, click the “+” button in the File Browser to create a new Launcher. In the Launcher tab, click on the “Terminal” button again to create a terminal. Now you have 2 tabs open: a text editor tab and a terminal tab. Drag the Terminal tab to the right side of the main work area to view both windows simultaneously. Click the File Browser tab to collapse the left sidebar and get more real estate! Alternatively, you could stack the windows one on top of the other.\n",
+ "\n",
+ "Run `ls` in the Terminal window to see the text file we just created. Execute `python hello.py` in the Terminal window. See the output in the Terminal window.\n",
+ "\n",
+ "\n",
+ "\n",
+ "Now, let’s close the Terminal tab and shut down the Terminal in the Running Kernels tab (or execute “exit” in the Terminal itself). You should just have the Text editor window open; now we're ready to look at Jupyter Notebooks.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "b0Zv8pF8e7Y0"
+ },
+ "source": [
+ "## Running JupyterLab Notebooks\n",
+ "\n",
+ "There are two ways to open a Jupyter Notebook. One way is to select the File Browser Tab, click the \"New Launcher\" button, and select a Python 3 Notebook from the Launcher. Another way is to go to the top Menu Bar and select \"File▶New▶Notebook\". JupyterLab will prompt you with a dialogue box to select the Kernel you want to use in your Notebook. Select the “Python 3” kernel.\n",
+ "\n",
+ "If you have the File Browser Tab open, notice you just created a file called `Untitled.ipynb.` You will also have a new window open in the main work area for your new Notebook.\n",
+ "\n",
+ "Let’s explore the Notebook interface:\n",
+ " \n",
+ "There is a **Toolbar** at the top with buttons that allow you to Save, Create New Cells, Cut/Paste/Copy Cells, Run the Cell, Stop the Kernel, and Refresh the Kernel. There is also a **dropdown menu** to select the kind of cell (Markdown, Raw, or Code). All the way to the right is the name of your Kernel (which you can click to change Kernels) and a **Kernel Status Icon** that indicates if something is being computed by the Kernel (by a dark circle) or not (by an empty circle).\n",
+ "\n",
+ "Below the Toolbar is the Notebook itself. You should see an empty cell at the top of the Notebook. This should look similar to the layout of the Console.\n",
+ "\n",
+ "The cell can be in 1 of 2 modes: command mode or edit mode.\n",
+ "If your cell is grayed out and you can’t see a blinking cursor in the cell, then the cell is in command mode. We’ll talk about command mode more later. Click inside the box, and the cell will turn white with a blinking cursor inside it; the cell is now in edit mode. The mode is also listed on the info bar at the bottom of the page. The cell is selected if the blue bar is on the left side of the cell.\n",
+ "\n",
+ "\n",
+ "\n",
+ "You may move the Notebook over so you can see your text file at the same time to compare, resizing the Notebook window as needed."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Dl5dbdlPwmLk"
+ },
+ "source": [
+ "### Code Cells\n",
+ "Click inside the first cell of the Notebook to switch the cell to edit mode.\n",
+ "Enter the following into the cell:\n",
+ "\n",
+ "``` python\n",
+ "print(2+2)\n",
+ "```\n",
+ "\n",
+ "Then type Shift+Enter to execute the cell.\n",
+ "\n",
+ "You'll see the output, `4`, printed directly below your code cell. Executing the cell automatically creates a new cell in edit mode below the first.\n",
+ "\n",
+ "In this new cell, enter:\n",
+ "\n",
+ "``` python\n",
+ "for i in range(4):\n",
+ " print(i) \n",
+ "```\n",
+ "\n",
+ "Execute the cell. A Jupyter code cell can run multiple lines of code; each Jupyter code cell can even contain a complete Python program! \n",
+ "\n",
+ "To demonstrate how to import code that you have written in a `.py` file, enter the following into the next cell:\n",
+ "\n",
+ "``` python\n",
+ "import hello\n",
+ "```\n",
+ "\n",
+ "Then type Shift+Enter. \n",
+ "\n",
+ "This single-line `import` statement runs the contents of your `hello.py` script file, and would do the same for any file regardless of length. \n",
+ "\n",
+ "Info
\n", + " The terminal is running on the local host when JupyterLab is launched locally, and remote host when invoked through Jupyter Hub.\n", + "\n",
+ "
\n",
+ "You've executed the cell with the Python 3 kernel, and it spit out the output, “Hello, World!” Since you've imported the `hello.py` module into the Notebook’s kernel runtime, you can now directly look at the variable “s” in this second cell.\n",
+ "Enter the following in the next cell:\n",
+ "\n",
+ "``` python\n",
+ "hello.s\n",
+ "```\n",
+ "\n",
+ "Hit Shift+Enter to execute.\n",
+ "\n",
+ "Again, it displays the value of the variable `s` from the “hello” module we just created. One difference is that this time the output is given its own label `[2]` matching the input label of the cell (whereas the output from cell `[1]` is not labelled). This is the difference between output sent to the screen vs. the return value of the cell.\n",
+ "\n",
+ "Let’s now import a module from the Python standard library:\n",
+ "\n",
+ "``` python\n",
+ "import time\n",
+ "time.sleep(10)\n",
+ "```\n",
+ "\n",
+ "Again, hit Shift+Enter. \n",
+ "\n",
+ "The `time.sleep(10)` function causes code to wait for 10 seconds, which is plenty of time to notice how the cell changes in time:\n",
+ " - The label of the cell is `[*]`, indicating that the kernel is running that cell \n",
+ " - In the top right corner of the Notebook, the status icon is a filled-in circle, indicating that the kernel is running\n",
+ "\n",
+ "After 10 seconds, the cell completes running, the label is updated to `[3], and the status icon returns to the “empty circle” state. If you rerun the cell, the label will update to `[4]`.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DTSoIqjAM4sg",
+ "jp-MarkdownHeadingCollapsed": true,
+ "tags": []
+ },
+ "source": [
+ "### Markdown Cells\n",
+ "Now, with the next cell selected (i.e., the blue bar appears to the left of the cell), whether in edit or command mode, go up to the “cell type” dropdown menu above and select “Markdown”.\n",
+ "Notice that the `[ ]` label goes away.\n",
+ "\n",
+ "Markdown is a markup language that allows you to format text in a plain-text editor. Here we will demonstrate some common Markdown syntax. You can learn more at [the Markdown Guide site](https://www.markdownguide.org/) or in our [Getting Started with Jupyter: Markdown](https://foundations.projectpythia.org/foundations/markdown.html) content.\n",
+ "Click on the cell and enter edit mode; we can now type in some markdown text like so:\n",
+ "\n",
+ "```markdown\n",
+ "# This is a heading!\n",
+ "And this is some text.\n",
+ "\n",
+ "## And this is a subheading\n",
+ "with a bulleted list in it:\n",
+ "\n",
+ " - one\n",
+ " - two\n",
+ " - three\n",
+ "```\n",
+ "\n",
+ "Then press Shift+Enter to render the markdown to HTML.\n",
+ "\n",
+ "Warning
\n", + " It is generally considered bad practice to include any output in a “.py” file meant to be imported and used within different Python scripts. Such a file should contain only function and class definitions.\n", + " \n",
+ "\n",
+ "Again, in the next cell, change the cell type to “Markdown”. To demonstrate displaying equations, enter:\n",
+ "\n",
+ "```markdown\n",
+ "## Some math\n",
+ "\n",
+ "And Jupyter’s version of markdown can display LaTeX:\n",
+ "\n",
+ "$$\n",
+ "e^x=\\sum_{i=0}^{\\infty} \\frac{1}{i!}x^i\n",
+ "$$\n",
+ "```\n",
+ "\n",
+ "When you are done, type Shift+Enter to render the markdown document.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "Again, in the next cell, change the cell type to “Markdown”. To demonstrate displaying equations, enter:\n",
+ "\n",
+ "```markdown\n",
+ "## Some math\n",
+ "\n",
+ "And Jupyter’s version of markdown can display LaTeX:\n",
+ "\n",
+ "$$\n",
+ "e^x=\\sum_{i=0}^{\\infty} \\frac{1}{i!}x^i\n",
+ "$$\n",
+ "```\n",
+ "\n",
+ "When you are done, type Shift+Enter to render the markdown document.\n",
+ "\n",
+ " \n",
+ "\n",
+ "You can also do inline equations with a single \"$\", for example\n",
+ "\n",
+ "```markdown\n",
+ "This is an equation: $i^4$.\n",
+ "```\n",
+ "\n",
+ "
\n",
+ "\n",
+ "You can also do inline equations with a single \"$\", for example\n",
+ "\n",
+ "```markdown\n",
+ "This is an equation: $i^4$.\n",
+ "```\n",
+ "\n",
+ " \n",
+ "\n",
+ "Note that the “markdown” source code is rendered into much prettier text, which we can take advantage of for narrating our work in the Notebook!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DPP39honNHSh",
+ "jp-MarkdownHeadingCollapsed": true,
+ "tags": []
+ },
+ "source": [
+ "### Raw Cells\n",
+ "\n",
+ "Now in a new cell selected, select “raw” from the “cell type” dropdown menu. Again, the `[ ]` label goes away, and you can enter the following in the cell:\n",
+ "\n",
+ "```text\n",
+ "i = 8\n",
+ "print(i)\n",
+ "```\n",
+ "\n",
+ "When you Shift+Enter the text isn’t rendered. \n",
+ "\n",
+ "This is a way of entering text/source that you do not want the Notebook to do anything with (i.e., no rendering). \n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "N89Z7vdgNMKx"
+ },
+ "source": [
+ "### Command Mode Shortcuts\n",
+ "\n",
+ "Now, select the “raw” cell you just created by clicking on the far left of the cell.\n",
+ "\n",
+ "You are now in “command mode”. The up and down arrows move to different cells. Don't hit “enter” which would switch the cell to “edit mode.\" Let’s explore command mode.\n",
+ "\n",
+ "You can change the cell type with `y` for code, `m` for markdown, or `r` for raw.\n",
+ "\n",
+ "You can add a new cell above the selected cell with `a` (or below the selected cell with `b`).\n",
+ "\n",
+ "You can cut (`x`), copy (`c`), and paste (`v`).\n",
+ "\n",
+ "You can move a cell up or down by clicking and dragging. \n",
+ "\n",
+ "
\n",
+ "\n",
+ "Note that the “markdown” source code is rendered into much prettier text, which we can take advantage of for narrating our work in the Notebook!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DPP39honNHSh",
+ "jp-MarkdownHeadingCollapsed": true,
+ "tags": []
+ },
+ "source": [
+ "### Raw Cells\n",
+ "\n",
+ "Now in a new cell selected, select “raw” from the “cell type” dropdown menu. Again, the `[ ]` label goes away, and you can enter the following in the cell:\n",
+ "\n",
+ "```text\n",
+ "i = 8\n",
+ "print(i)\n",
+ "```\n",
+ "\n",
+ "When you Shift+Enter the text isn’t rendered. \n",
+ "\n",
+ "This is a way of entering text/source that you do not want the Notebook to do anything with (i.e., no rendering). \n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "N89Z7vdgNMKx"
+ },
+ "source": [
+ "### Command Mode Shortcuts\n",
+ "\n",
+ "Now, select the “raw” cell you just created by clicking on the far left of the cell.\n",
+ "\n",
+ "You are now in “command mode”. The up and down arrows move to different cells. Don't hit “enter” which would switch the cell to “edit mode.\" Let’s explore command mode.\n",
+ "\n",
+ "You can change the cell type with `y` for code, `m` for markdown, or `r` for raw.\n",
+ "\n",
+ "You can add a new cell above the selected cell with `a` (or below the selected cell with `b`).\n",
+ "\n",
+ "You can cut (`x`), copy (`c`), and paste (`v`).\n",
+ "\n",
+ "You can move a cell up or down by clicking and dragging. \n",
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KySy3X-aauaR"
+ },
+ "source": [
+ "### Special Variables\n",
+ "\n",
+ "Now, in the empty cell at the end, enter one underscore:\n",
+ "\n",
+ "```\n",
+ "_\n",
+ "```\n",
+ "\n",
+ "This is a special character that means the last cell output. Two underscores means the second to last cell output, and three underscores means the third to last output. You can also refer to the output by label with:\n",
+ "\n",
+ "```\n",
+ "_2\n",
+ "```\n",
+ "\n",
+ "Warning
\n", + " Cells can be executed in any order you want. You just have to select the cell and Shift+Enter, and select the cells in any order you want. However, if you share your notebook, there is an implicit expectation to execute the cells in the order in which they are presented in the notebook. Be careful with this! If variables are reused or redefined between cells, reordering them could have unintended consequences!\n", + "\n",
+ "
\n",
+ "\n",
+ "You can equivalently use the variables `Out[2]` or `In[2]` to retrieve the output and input (as a string).\n",
+ "\n",
+ "Danger
\n", + " If the cell you to refer to does not have a return value, this will raise an error.\n", + " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "F0wU5mU2blds"
+ },
+ "source": [
+ "### Shell Commands\n",
+ "\n",
+ "In the next code cell, enter the following:\n",
+ "\n",
+ "``` ipython\n",
+ "!pwd\n",
+ "```\n",
+ "\n",
+ "The `!` allows you to write shell commands. A shell command is a command that is run by the host operating system, not the Python kernel. Executing this cell will \"print the working directory\" (i.e. your current directory).\n",
+ "\n",
+ "You can even use the output of shell commands as input to Python code. For example:\n",
+ "\n",
+ "``` ipython\n",
+ "files = !ls\n",
+ "print(files)\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "SLtXSO0bNRHC"
+ },
+ "source": [
+ "### Stopping & Restarting the Kernel\n",
+ "\n",
+ "All of your commands and their output have been remembered by the kernel. However, sometimes you may get code that takes too long to execute, and you need to stop it. For example, in the next code cell, run:\n",
+ "\n",
+ "``` python\n",
+ "time.sleep(1000)\n",
+ "```\n",
+ "\n",
+ "You can stop the kernel with the square “stop” button at the top Notebook toolbar. This results in a \"KeyboardInterrupt\" error.\n",
+ "\n",
+ "If you execute a notebook out of order, you can end up in a corrupted state (redefined variables, for example). To start fresh, you should restart the kernel with the circle-arrow button in the toolbar at the top. Now the kernel has forgotten everything, and you'll need to rerun each cell."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wdgosdLGNXtd"
+ },
+ "source": [
+ "### Magics\n",
+ "\n",
+ "A \"magic\" is a Jupyter Notebook command proceded by a `%` symbol. In the next code cell, enter the following:\n",
+ "\n",
+ "``` python\n",
+ "%timeit time.sleep(1)\n",
+ "```\n",
+ "\n",
+ "The “%timeit” magic is a timer that runs the command multiple times, measuring how long it takes and gathering timing statistics. Hit Shift+Enter to see it work. \n",
+ "\n",
+ "Multiline magics work on entire cells, and these have a double-`%`. For example, here is a multiline version of the timeit magic:\n",
+ "\n",
+ "``` python\n",
+ "%%timeit\n",
+ "\n",
+ "time.sleep(0.5)\n",
+ "time.sleep(0.5)\n",
+ "```\n",
+ "\n",
+ "Then press Shift+Enter to run it. This will time the entire cell.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "F0wU5mU2blds"
+ },
+ "source": [
+ "### Shell Commands\n",
+ "\n",
+ "In the next code cell, enter the following:\n",
+ "\n",
+ "``` ipython\n",
+ "!pwd\n",
+ "```\n",
+ "\n",
+ "The `!` allows you to write shell commands. A shell command is a command that is run by the host operating system, not the Python kernel. Executing this cell will \"print the working directory\" (i.e. your current directory).\n",
+ "\n",
+ "You can even use the output of shell commands as input to Python code. For example:\n",
+ "\n",
+ "``` ipython\n",
+ "files = !ls\n",
+ "print(files)\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "SLtXSO0bNRHC"
+ },
+ "source": [
+ "### Stopping & Restarting the Kernel\n",
+ "\n",
+ "All of your commands and their output have been remembered by the kernel. However, sometimes you may get code that takes too long to execute, and you need to stop it. For example, in the next code cell, run:\n",
+ "\n",
+ "``` python\n",
+ "time.sleep(1000)\n",
+ "```\n",
+ "\n",
+ "You can stop the kernel with the square “stop” button at the top Notebook toolbar. This results in a \"KeyboardInterrupt\" error.\n",
+ "\n",
+ "If you execute a notebook out of order, you can end up in a corrupted state (redefined variables, for example). To start fresh, you should restart the kernel with the circle-arrow button in the toolbar at the top. Now the kernel has forgotten everything, and you'll need to rerun each cell."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wdgosdLGNXtd"
+ },
+ "source": [
+ "### Magics\n",
+ "\n",
+ "A \"magic\" is a Jupyter Notebook command proceded by a `%` symbol. In the next code cell, enter the following:\n",
+ "\n",
+ "``` python\n",
+ "%timeit time.sleep(1)\n",
+ "```\n",
+ "\n",
+ "The “%timeit” magic is a timer that runs the command multiple times, measuring how long it takes and gathering timing statistics. Hit Shift+Enter to see it work. \n",
+ "\n",
+ "Multiline magics work on entire cells, and these have a double-`%`. For example, here is a multiline version of the timeit magic:\n",
+ "\n",
+ "``` python\n",
+ "%%timeit\n",
+ "\n",
+ "time.sleep(0.5)\n",
+ "time.sleep(0.5)\n",
+ "```\n",
+ "\n",
+ "Then press Shift+Enter to run it. This will time the entire cell.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Y3euwtAoexvZ"
+ },
+ "source": [
+ "## Shutting Down\n",
+ "\n",
+ "Before shutting down, save your notebook with the disc icon in the Notebook toolbar. Now, close both tabs (the notebook and the text editor). You're back to the Launcher.\n",
+ "\n",
+ "The notebook kernel is still running, though, so go to the Running Kernels tab and shut it down.\n",
+ "\n",
+ "Now we’re done. Go to “File▶Shut Down” to close both your browser tab and JupyterLab itself."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pp8SMkeLpfkf"
+ },
+ "source": [
+ "## Summary\n",
+ "\n",
+ "You are now familiar with the JupyterLab interface and running Jupyter Notebooks. Jupyter is popular for allowing you to intersperse Markdown text or equations between code cells. Jupyter offers some functionality that a Python script does not: certain keyboard shortcuts, special variables, shell scripting, and magics.\n",
+ "\n",
+ "### What's next?\n",
+ "\n",
+ "- [Markdown](markdown)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "lj8lTb4Aphra"
+ },
+ "source": [
+ "## Resources and references\n",
+ "\n",
+ "- [Jupyter Documentation](https://jupyter.org/)\n",
+ "- [JupyterLab Documentation](https://jupyterlab.readthedocs.io/en/stable/)\n",
+ "- [JupyterLab Extensions](https://jupyterlab.readthedocs.io/en/stable/user/extensions.html)\n",
+ "- [Markdown Guide](https://www.markdownguide.org/)\n",
+ "- [Xdev Python Tutorial Seminar Series - Jupyter Notebooks](https://youtu.be/xSzXvwzFsDU)"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "name": "jupyterlab.ipynb",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/_preview/468/_sources/foundations/markdown.md b/_preview/468/_sources/foundations/markdown.md
new file mode 100644
index 000000000..7aa8876b8
--- /dev/null
+++ b/_preview/468/_sources/foundations/markdown.md
@@ -0,0 +1,9 @@
+# Formatted Text in the Notebook with Markdown
+
+```{note}
+This content is under construction!
+```
+
+This section will give a tutorial on formatting text with Markdown: the simple, human-readable text language used extensively in Jupyter notebooks, GitHub Discussions, and elsewhere.
+
+We will show how this is useful both in notebooks and other places like GitHub Issues.
diff --git a/_preview/468/_sources/foundations/overview.md b/_preview/468/_sources/foundations/overview.md
new file mode 100644
index 000000000..85ccdcda4
--- /dev/null
+++ b/_preview/468/_sources/foundations/overview.md
@@ -0,0 +1,12 @@
+# Overview
+
+This section contains cross-referenced tutorial material for foundational computing skills that one needs in order to work effectively with the open-source Scientific Python stack.
+
+Familiarizing yourself with these topics first will allow a new user to get the most out the Python-specific material in the [Core Scientific Python Packages](../core/overview) section of the book!
+
+## Topics
+
+- [Why Python?](why-python): A brief preamble about Python's distinguishing features.
+- [Getting started with Python](getting-started-python): A quickstart Python example, followed by detailed tutorials on how to install and run Python on your own system.
+- [Getting started with Jupyter](getting-started-jupyter): All about the Jupyter ecosystem, which provides tools and environments for interactive, reproducible computing with Python.
+- [Getting started with GitHub](getting-started-github): Learn about the collaboration tools (GitHub) and version control software (git) that enables the open-source community.
diff --git a/_preview/468/_sources/foundations/quickstart.ipynb b/_preview/468/_sources/foundations/quickstart.ipynb
new file mode 100644
index 000000000..435acd12f
--- /dev/null
+++ b/_preview/468/_sources/foundations/quickstart.ipynb
@@ -0,0 +1,653 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "5d45c2b9",
+ "metadata": {},
+ "source": [
+ "# Quickstart: Zero to Python"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a52c17ad",
+ "metadata": {},
+ "source": [
+ "Brand new to Python? Here are some quick examples of what Python code looks like.\n",
+ "\n",
+ "This is **not** meant to be a comprehensive Python tutorial, just something to whet your appetite."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84eecdbd",
+ "metadata": {},
+ "source": [
+ "## Run this code from your browser!\n",
+ "\n",
+ "Of course you can simply read through these examples, but it's more fun to ***run them yourself***:\n",
+ "\n",
+ "- Find the **\"Rocket Ship\"** icon, **located near the top-right of this page**. Hover over this icon to see the drop-down menu.\n",
+ "- Click the `Binder` link from the drop-down menu.\n",
+ "- This page will open up as a [Jupyter notebook](jupyter.html) in a working Python environment in the cloud.\n",
+ "- Press Shift+Enter to execute each code cell\n",
+ "- Feel free to make changes and play around!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e02bc566",
+ "metadata": {},
+ "source": [
+ "## A very first Python program\n",
+ "\n",
+ "A Python program can be a single line:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8137f81a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"Hello interweb\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4c7a126b",
+ "metadata": {},
+ "source": [
+ "## Loops in Python"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "54deab97",
+ "metadata": {},
+ "source": [
+ "Let's start by making a `for` loop with some formatted output:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ba931e6d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for n in range(3):\n",
+ " print(f\"Hello interweb, this is iteration number {n}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "42e3baf4",
+ "metadata": {},
+ "source": [
+ "A few things to note:\n",
+ "\n",
+ "- Python defaults to counting from 0 (like C) rather than from 1 (like Fortran).\n",
+ "- Function calls in Python always use parentheses: `print()`\n",
+ "- The colon `:` denotes the beginning of a definition (here of the repeated code under the `for` loop).\n",
+ "- Code blocks are identified through indentations.\n",
+ "\n",
+ "To emphasize this last point, here is an example with a two-line repeated block:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "787f8e09",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for n in range(3):\n",
+ " print(\"Hello interweb!\")\n",
+ " print(f\"This is iteration number {n}.\")\n",
+ "print('And now we are done.')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cd787438",
+ "metadata": {},
+ "source": [
+ "## Basic flow control\n",
+ "\n",
+ "Like most languages, Python has an `if` statement for logical decisions:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "682eb657",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if n > 2:\n",
+ " print(\"n is greater than 2!\")\n",
+ "else:\n",
+ " print(\"n is not greater than 2!\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3a6b8582",
+ "metadata": {},
+ "source": [
+ "Python also defines the `True` and `False` logical constants:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b9367b41",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "n > 2"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a9164391",
+ "metadata": {},
+ "source": [
+ "There's also a `while` statement for conditional looping:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "12b978f3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "m = 0\n",
+ "while m < 3:\n",
+ " print(f\"This is iteration number {m}.\")\n",
+ " m += 1\n",
+ "print(m < 3)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5b066ae",
+ "metadata": {},
+ "source": [
+ "## Basic Python data types\n",
+ "\n",
+ "Python is a very flexible language, and many advanced data types are introduced through packages (more on this below). But some of the basic types include: "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ef3921ed",
+ "metadata": {},
+ "source": [
+ "### Integers (`int`)\n",
+ "\n",
+ "The number `m` above is a good example. We can use the built-in function `type()` to inspect what we've got in memory:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "184f8c79",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(type(m))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "861da01b",
+ "metadata": {},
+ "source": [
+ "### Floating point numbers (`float`)\n",
+ "\n",
+ "Floats can be entered in decimal notation:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7153a927",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(type(0.1))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8545d891",
+ "metadata": {},
+ "source": [
+ "or in scientific notation:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9bc33c68",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(type(4e7))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0a4ceb83",
+ "metadata": {},
+ "source": [
+ "where `4e7` is the Pythonic representation of the number $ 4 \\times 10^7 $."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "87da5d64",
+ "metadata": {},
+ "source": [
+ "### Character strings (`str`)\n",
+ "\n",
+ "You can use either single quotes `''` or double quotes `\" \"` to denote a string:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d4cc9304",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(type(\"orange\"))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ba603039",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(type('orange'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "597631d0",
+ "metadata": {},
+ "source": [
+ "### Lists\n",
+ "\n",
+ "A list is an ordered container of objects denoted by **square brackets**:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "be5d040f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mylist = [0, 1, 1, 2, 3, 5, 8]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "271edb6e",
+ "metadata": {},
+ "source": [
+ "Lists are useful for lots of reasons including iteration:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f6d0be16",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for number in mylist:\n",
+ " print(number)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f3f8a57e",
+ "metadata": {},
+ "source": [
+ "Lists do **not** have to contain all identical types:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f1673dc5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "myweirdlist = [0, 1, 1, \"apple\", 4e7]\n",
+ "for item in myweirdlist:\n",
+ " print(type(item))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c0f192ef",
+ "metadata": {},
+ "source": [
+ "This list contains a mix of `int` (integer), `float` (floating point number), and `str` (character string)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cb662954",
+ "metadata": {},
+ "source": [
+ "Because a list is *ordered*, we can access items by integer index:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8178ee98",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "myweirdlist[3]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "87e841a7",
+ "metadata": {},
+ "source": [
+ "remembering that we start counting from zero!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2edf60e3",
+ "metadata": {},
+ "source": [
+ "Python also allows lists to be created dynamically through *list comprehension* like this:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2acae924",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "squares = [i**2 for i in range(11)]\n",
+ "squares"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5c2663a4",
+ "metadata": {},
+ "source": [
+ "### Dictionaries (`dict`)\n",
+ "\n",
+ "A dictionary is a collection of *labeled objects*. Python uses curly braces `{}` to create dictionaries:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f4dbacdd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mypet = {\n",
+ " \"name\": \"Fluffy\",\n",
+ " \"species\": \"cat\",\n",
+ " \"age\": 4,\n",
+ "}\n",
+ "type(mypet)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c8e869ca",
+ "metadata": {},
+ "source": [
+ "We can then access items in the dictionary by label using square brackets:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "05c66d6e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mypet[\"species\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b2027506",
+ "metadata": {},
+ "source": [
+ "We can iterate through the keys (or labels) of a `dict`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "387dba3d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for key in mypet:\n",
+ " print(\"The key is:\", key)\n",
+ " print(\"The value is:\", mypet[key])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fb82a430",
+ "metadata": {},
+ "source": [
+ "## Arrays of numbers with NumPy\n",
+ "\n",
+ "The vast majority of scientific Python code makes use of *packages* that extend the base language in many useful ways.\n",
+ "\n",
+ "Almost all scientific computing requires ordered arrays of numbers, and fast methods for manipulating them. That's what [NumPy](../core/numpy.md) does in the Python world.\n",
+ "\n",
+ "Using any package requires an `import` statement, and (optionally) a nickname to be used locally, denoted by the keyword `as`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "53ba88cf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fb237b33",
+ "metadata": {},
+ "source": [
+ "Now all our calls to `numpy` functions will be preceeded by `np.`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a3391f8d",
+ "metadata": {},
+ "source": [
+ "Create a linearly space array of numbers:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ae024132",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# linspace() takes 3 arguments: start, end, total number of points\n",
+ "numbers = np.linspace(0.0, 1.0, 11)\n",
+ "numbers"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cc1c2474",
+ "metadata": {},
+ "source": [
+ "We've just created a new type of object defined by [NumPy](../core/numpy.md):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c3f3642d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "type(numbers)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "83325c40",
+ "metadata": {},
+ "source": [
+ "Do some arithmetic on that array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "12cc225d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "numbers + 1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fee4e53c",
+ "metadata": {},
+ "source": [
+ "Sum up all the numbers:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3cef5412",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "np.sum(numbers)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ebf2b669",
+ "metadata": {},
+ "source": [
+ "## Some basic graphics with Matplotlib\n",
+ "\n",
+ "[Matplotlib](../core/matplotlib.md) is the standard package for producing publication-quality graphics, and works hand-in-hand with [NumPy](../core/numpy.md) arrays.\n",
+ "\n",
+ "We usually use the `pyplot` submodule for day-to-day plotting commands:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "76f3329e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "66033cbc",
+ "metadata": {},
+ "source": [
+ "Define some data and make a line plot:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "32ca697e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "theta = np.linspace(0.0, 360.0)\n",
+ "sintheta = np.sin(np.deg2rad(theta))\n",
+ "\n",
+ "plt.plot(theta, sintheta, label='y = sin(x)', color='purple')\n",
+ "plt.grid()\n",
+ "plt.legend()\n",
+ "plt.xlabel('Degrees')\n",
+ "plt.title('Our first Pythonic plot', fontsize=14)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "04615882",
+ "metadata": {},
+ "source": [
+ "## What now?\n",
+ "\n",
+ "That was a whirlwind tour of some basic Python usage. \n",
+ "\n",
+ "Read on for more details on how to install and run Python and necessary packages on your own laptop."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "edbbb2ad-4544-4564-9750-6d738698fe2e",
+ "metadata": {},
+ "source": [
+ "## Resources and references\n",
+ "\n",
+ "- [Official Python tutorial (Python Docs)](https://docs.python.org/3/tutorial/index.html)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/_preview/468/_sources/foundations/terminal.md b/_preview/468/_sources/foundations/terminal.md
new file mode 100644
index 000000000..49568964d
--- /dev/null
+++ b/_preview/468/_sources/foundations/terminal.md
@@ -0,0 +1,102 @@
+# Python in the Terminal
+
+---
+
+## Overview
+
+You'd like to learn to run Python in the terminal. Here we will cover:
+
+1. Installing Python in the terminal
+2. Running Python code in the terminal
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| --------------------------------------------------------------------------------------------------------- | ---------- | ----- |
+| [Installing and Running Python](https://foundations.projectpythia.org/foundations/how-to-run-python.html) | Helpful | |
+
+- **Time to learn**: 20 minutes
+
+---
+
+## Installing Python in the Terminal
+
+If you are running Python in the terminal, it is best to install Miniconda. You can do that by following the [instructions for your machine](https://docs.conda.io/en/latest/miniconda.html).
+
+[Learn more about Conda here](conda.md)
+
+Then create a Conda environment with Python installed by typing the following into your terminal:
+
+```
+$ conda create --name pythia_foundations_env python
+```
+
+You can test this by running `python` in the command line.
+
+## Running Python in the Terminal
+
+On Windows, open **Anaconda Prompt**. On a Mac or Linux machine, simply open **Terminal**.
+
+1. Activate your Conda environment:
+
+ ```
+ $ conda activate pythia_foundations_env
+ ```
+
+2. Create a directory to store our work. Let's call it `pythia-foundations`.
+
+ ```
+ $ mkdir pythia-foundations
+ ```
+
+3. Go into the directory:
+
+ ```
+ $ cd pythia-foundations
+ ```
+
+4. Create a new Python file:
+
+ ```
+ $ touch mysci.py
+ ```
+
+5. And now that you've set up our workspace, edit the `mysci.py` script using your favorite text editor (e.g., nano):
+
+ ```
+ $ nano mysci.py
+ ```
+
+6. Change the script to include the classic first command: printing, "Hello, world!".
+
+ ```python
+ print("Hello, world!")
+ ```
+
+7. Save your file and exit the editor. How to do this is dependent on your chosen text editor.
+
+ - In Vim, revert to command mode by pressing `esc`. Then, the command is `:wq`.
+ - In Nano it is {kbd}`Ctrl`\+{kbd}`O` to save and {kbd}`Ctrl`\+{kbd}`X` to exit (where you will be prompted if you want to save it, if modified).
+
+8. In the terminal, execute your script:
+
+ ```
+ $ python mysci.py
+ ```
+
+**Congratulations!** You have just set up your first Python environment and run your first Python script in the terminal.
+
+---
+
+## Summary
+
+Running Python in the terminal is a good option if you are familiar with Linux commands or scripting on a supercomputer. It requires the use of a text editor.
+
+### What's Next?
+
+- [How to Run Python in a Jupyter Session](jupyter.md)
+- [Learn more about Conda here](conda.md)
+
+## Resources and References
+
+- [Linux commands](https://cheatography.com/davechild/cheat-sheets/linux-command-line/)
diff --git a/_preview/468/_sources/foundations/why-python.md b/_preview/468/_sources/foundations/why-python.md
new file mode 100644
index 000000000..cd31cf975
--- /dev/null
+++ b/_preview/468/_sources/foundations/why-python.md
@@ -0,0 +1,27 @@
+# Why Python?
+
+You're already here because you want to learn to use Python for your data analysis and visualizations.
+
+**Perhaps the #1 reason to use Python is because it is so widely used in the scientific community!**
+
+Python can be compared to other high-level, interpreted, object-oriented languages, but is especially great because it is free and open source!
+
+Want to know what these terms mean for you and your work? Read on!
+
+## High level languages
+
+Other high level languages include MatLab, IDL, and NCL. The advantage of high level languages is that they provide built-in functions, data structures, and other utilities that are commonly used, which means it takes less code to get real work done. The disadvantage of high level languages is that they tend to obscure the low level aspects of the machine such as memory use, how many floating point operations are happening, and other information related to performance. C, C++, and Fortran are all examples of lower level languages. The "higher" the level of language, the more computing fundamentals are abstracted.
+
+## Interpreted languages
+
+Most of your work is probably already in interpreted languages if you've ever used IDL, NCL, or MatLab (interpreted languages are typically also high level). So you are already familiar with the advantages of this: you don't have to worry about compiling or machine compatibility (it is portable). And you are probably familiar with their deficiencies: sometimes they can be slower than compiled languages and potentially more memory intensive.
+
+## Object Oriented languages
+
+Objects are custom datatypes. For every custom datatype, you usually have a set of operations you might want to conduct. For example, if you have an object that is a list of numbers, you might want to apply a mathematical operation, such as sum, onto this list object in bulk. Not every function can be applied to every datatype; it wouldn't make sense to apply a logarithm to a string of letters or to capitalize a list of numbers. Data and the operations applied to them are grouped together into one object.
+
+## Open source
+
+Python as a language is open source, which means that there is a community of developers behind its codebase. Anyone can join the developer community and contribute to deciding the future of the language. When someone identifies gaps in Python's abilities, they can write up the code to fill these gaps. The open source nature of Python means that Python as a language is very adaptable to the shifting needs of the user community. This harkens back to the idea that the widespread use of Python within the scientific community is a benefit to you! The large Python user base within your field has established high level community Python packages that are available to you in your workflow.
+
+Python is a language designed for rapid prototyping and efficient programming. It is easy to write new code quickly with less typing.
diff --git a/_preview/468/_sources/landing-page.md b/_preview/468/_sources/landing-page.md
new file mode 100644
index 000000000..b75d742b0
--- /dev/null
+++ b/_preview/468/_sources/landing-page.md
@@ -0,0 +1,11 @@
+# Pythia Foundations
+
+## A community learning resource for Python-based computing in the geosciences
+
+
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Y3euwtAoexvZ"
+ },
+ "source": [
+ "## Shutting Down\n",
+ "\n",
+ "Before shutting down, save your notebook with the disc icon in the Notebook toolbar. Now, close both tabs (the notebook and the text editor). You're back to the Launcher.\n",
+ "\n",
+ "The notebook kernel is still running, though, so go to the Running Kernels tab and shut it down.\n",
+ "\n",
+ "Now we’re done. Go to “File▶Shut Down” to close both your browser tab and JupyterLab itself."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pp8SMkeLpfkf"
+ },
+ "source": [
+ "## Summary\n",
+ "\n",
+ "You are now familiar with the JupyterLab interface and running Jupyter Notebooks. Jupyter is popular for allowing you to intersperse Markdown text or equations between code cells. Jupyter offers some functionality that a Python script does not: certain keyboard shortcuts, special variables, shell scripting, and magics.\n",
+ "\n",
+ "### What's next?\n",
+ "\n",
+ "- [Markdown](markdown)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "lj8lTb4Aphra"
+ },
+ "source": [
+ "## Resources and references\n",
+ "\n",
+ "- [Jupyter Documentation](https://jupyter.org/)\n",
+ "- [JupyterLab Documentation](https://jupyterlab.readthedocs.io/en/stable/)\n",
+ "- [JupyterLab Extensions](https://jupyterlab.readthedocs.io/en/stable/user/extensions.html)\n",
+ "- [Markdown Guide](https://www.markdownguide.org/)\n",
+ "- [Xdev Python Tutorial Seminar Series - Jupyter Notebooks](https://youtu.be/xSzXvwzFsDU)"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "collapsed_sections": [],
+ "name": "jupyterlab.ipynb",
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/_preview/468/_sources/foundations/markdown.md b/_preview/468/_sources/foundations/markdown.md
new file mode 100644
index 000000000..7aa8876b8
--- /dev/null
+++ b/_preview/468/_sources/foundations/markdown.md
@@ -0,0 +1,9 @@
+# Formatted Text in the Notebook with Markdown
+
+```{note}
+This content is under construction!
+```
+
+This section will give a tutorial on formatting text with Markdown: the simple, human-readable text language used extensively in Jupyter notebooks, GitHub Discussions, and elsewhere.
+
+We will show how this is useful both in notebooks and other places like GitHub Issues.
diff --git a/_preview/468/_sources/foundations/overview.md b/_preview/468/_sources/foundations/overview.md
new file mode 100644
index 000000000..85ccdcda4
--- /dev/null
+++ b/_preview/468/_sources/foundations/overview.md
@@ -0,0 +1,12 @@
+# Overview
+
+This section contains cross-referenced tutorial material for foundational computing skills that one needs in order to work effectively with the open-source Scientific Python stack.
+
+Familiarizing yourself with these topics first will allow a new user to get the most out the Python-specific material in the [Core Scientific Python Packages](../core/overview) section of the book!
+
+## Topics
+
+- [Why Python?](why-python): A brief preamble about Python's distinguishing features.
+- [Getting started with Python](getting-started-python): A quickstart Python example, followed by detailed tutorials on how to install and run Python on your own system.
+- [Getting started with Jupyter](getting-started-jupyter): All about the Jupyter ecosystem, which provides tools and environments for interactive, reproducible computing with Python.
+- [Getting started with GitHub](getting-started-github): Learn about the collaboration tools (GitHub) and version control software (git) that enables the open-source community.
diff --git a/_preview/468/_sources/foundations/quickstart.ipynb b/_preview/468/_sources/foundations/quickstart.ipynb
new file mode 100644
index 000000000..435acd12f
--- /dev/null
+++ b/_preview/468/_sources/foundations/quickstart.ipynb
@@ -0,0 +1,653 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "5d45c2b9",
+ "metadata": {},
+ "source": [
+ "# Quickstart: Zero to Python"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a52c17ad",
+ "metadata": {},
+ "source": [
+ "Brand new to Python? Here are some quick examples of what Python code looks like.\n",
+ "\n",
+ "This is **not** meant to be a comprehensive Python tutorial, just something to whet your appetite."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84eecdbd",
+ "metadata": {},
+ "source": [
+ "## Run this code from your browser!\n",
+ "\n",
+ "Of course you can simply read through these examples, but it's more fun to ***run them yourself***:\n",
+ "\n",
+ "- Find the **\"Rocket Ship\"** icon, **located near the top-right of this page**. Hover over this icon to see the drop-down menu.\n",
+ "- Click the `Binder` link from the drop-down menu.\n",
+ "- This page will open up as a [Jupyter notebook](jupyter.html) in a working Python environment in the cloud.\n",
+ "- Press Shift+Enter to execute each code cell\n",
+ "- Feel free to make changes and play around!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e02bc566",
+ "metadata": {},
+ "source": [
+ "## A very first Python program\n",
+ "\n",
+ "A Python program can be a single line:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8137f81a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"Hello interweb\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4c7a126b",
+ "metadata": {},
+ "source": [
+ "## Loops in Python"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "54deab97",
+ "metadata": {},
+ "source": [
+ "Let's start by making a `for` loop with some formatted output:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ba931e6d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for n in range(3):\n",
+ " print(f\"Hello interweb, this is iteration number {n}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "42e3baf4",
+ "metadata": {},
+ "source": [
+ "A few things to note:\n",
+ "\n",
+ "- Python defaults to counting from 0 (like C) rather than from 1 (like Fortran).\n",
+ "- Function calls in Python always use parentheses: `print()`\n",
+ "- The colon `:` denotes the beginning of a definition (here of the repeated code under the `for` loop).\n",
+ "- Code blocks are identified through indentations.\n",
+ "\n",
+ "To emphasize this last point, here is an example with a two-line repeated block:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "787f8e09",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for n in range(3):\n",
+ " print(\"Hello interweb!\")\n",
+ " print(f\"This is iteration number {n}.\")\n",
+ "print('And now we are done.')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cd787438",
+ "metadata": {},
+ "source": [
+ "## Basic flow control\n",
+ "\n",
+ "Like most languages, Python has an `if` statement for logical decisions:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "682eb657",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if n > 2:\n",
+ " print(\"n is greater than 2!\")\n",
+ "else:\n",
+ " print(\"n is not greater than 2!\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3a6b8582",
+ "metadata": {},
+ "source": [
+ "Python also defines the `True` and `False` logical constants:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b9367b41",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "n > 2"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a9164391",
+ "metadata": {},
+ "source": [
+ "There's also a `while` statement for conditional looping:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "12b978f3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "m = 0\n",
+ "while m < 3:\n",
+ " print(f\"This is iteration number {m}.\")\n",
+ " m += 1\n",
+ "print(m < 3)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d5b066ae",
+ "metadata": {},
+ "source": [
+ "## Basic Python data types\n",
+ "\n",
+ "Python is a very flexible language, and many advanced data types are introduced through packages (more on this below). But some of the basic types include: "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ef3921ed",
+ "metadata": {},
+ "source": [
+ "### Integers (`int`)\n",
+ "\n",
+ "The number `m` above is a good example. We can use the built-in function `type()` to inspect what we've got in memory:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "184f8c79",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(type(m))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "861da01b",
+ "metadata": {},
+ "source": [
+ "### Floating point numbers (`float`)\n",
+ "\n",
+ "Floats can be entered in decimal notation:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7153a927",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(type(0.1))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8545d891",
+ "metadata": {},
+ "source": [
+ "or in scientific notation:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9bc33c68",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(type(4e7))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0a4ceb83",
+ "metadata": {},
+ "source": [
+ "where `4e7` is the Pythonic representation of the number $ 4 \\times 10^7 $."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "87da5d64",
+ "metadata": {},
+ "source": [
+ "### Character strings (`str`)\n",
+ "\n",
+ "You can use either single quotes `''` or double quotes `\" \"` to denote a string:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d4cc9304",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(type(\"orange\"))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ba603039",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(type('orange'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "597631d0",
+ "metadata": {},
+ "source": [
+ "### Lists\n",
+ "\n",
+ "A list is an ordered container of objects denoted by **square brackets**:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "be5d040f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mylist = [0, 1, 1, 2, 3, 5, 8]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "271edb6e",
+ "metadata": {},
+ "source": [
+ "Lists are useful for lots of reasons including iteration:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f6d0be16",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for number in mylist:\n",
+ " print(number)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f3f8a57e",
+ "metadata": {},
+ "source": [
+ "Lists do **not** have to contain all identical types:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f1673dc5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "myweirdlist = [0, 1, 1, \"apple\", 4e7]\n",
+ "for item in myweirdlist:\n",
+ " print(type(item))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c0f192ef",
+ "metadata": {},
+ "source": [
+ "This list contains a mix of `int` (integer), `float` (floating point number), and `str` (character string)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cb662954",
+ "metadata": {},
+ "source": [
+ "Because a list is *ordered*, we can access items by integer index:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8178ee98",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "myweirdlist[3]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "87e841a7",
+ "metadata": {},
+ "source": [
+ "remembering that we start counting from zero!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2edf60e3",
+ "metadata": {},
+ "source": [
+ "Python also allows lists to be created dynamically through *list comprehension* like this:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2acae924",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "squares = [i**2 for i in range(11)]\n",
+ "squares"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5c2663a4",
+ "metadata": {},
+ "source": [
+ "### Dictionaries (`dict`)\n",
+ "\n",
+ "A dictionary is a collection of *labeled objects*. Python uses curly braces `{}` to create dictionaries:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f4dbacdd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mypet = {\n",
+ " \"name\": \"Fluffy\",\n",
+ " \"species\": \"cat\",\n",
+ " \"age\": 4,\n",
+ "}\n",
+ "type(mypet)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c8e869ca",
+ "metadata": {},
+ "source": [
+ "We can then access items in the dictionary by label using square brackets:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "05c66d6e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mypet[\"species\"]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b2027506",
+ "metadata": {},
+ "source": [
+ "We can iterate through the keys (or labels) of a `dict`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "387dba3d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for key in mypet:\n",
+ " print(\"The key is:\", key)\n",
+ " print(\"The value is:\", mypet[key])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fb82a430",
+ "metadata": {},
+ "source": [
+ "## Arrays of numbers with NumPy\n",
+ "\n",
+ "The vast majority of scientific Python code makes use of *packages* that extend the base language in many useful ways.\n",
+ "\n",
+ "Almost all scientific computing requires ordered arrays of numbers, and fast methods for manipulating them. That's what [NumPy](../core/numpy.md) does in the Python world.\n",
+ "\n",
+ "Using any package requires an `import` statement, and (optionally) a nickname to be used locally, denoted by the keyword `as`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "53ba88cf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fb237b33",
+ "metadata": {},
+ "source": [
+ "Now all our calls to `numpy` functions will be preceeded by `np.`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a3391f8d",
+ "metadata": {},
+ "source": [
+ "Create a linearly space array of numbers:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ae024132",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# linspace() takes 3 arguments: start, end, total number of points\n",
+ "numbers = np.linspace(0.0, 1.0, 11)\n",
+ "numbers"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cc1c2474",
+ "metadata": {},
+ "source": [
+ "We've just created a new type of object defined by [NumPy](../core/numpy.md):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c3f3642d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "type(numbers)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "83325c40",
+ "metadata": {},
+ "source": [
+ "Do some arithmetic on that array:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "12cc225d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "numbers + 1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fee4e53c",
+ "metadata": {},
+ "source": [
+ "Sum up all the numbers:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3cef5412",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "np.sum(numbers)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ebf2b669",
+ "metadata": {},
+ "source": [
+ "## Some basic graphics with Matplotlib\n",
+ "\n",
+ "[Matplotlib](../core/matplotlib.md) is the standard package for producing publication-quality graphics, and works hand-in-hand with [NumPy](../core/numpy.md) arrays.\n",
+ "\n",
+ "We usually use the `pyplot` submodule for day-to-day plotting commands:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "76f3329e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "66033cbc",
+ "metadata": {},
+ "source": [
+ "Define some data and make a line plot:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "32ca697e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "theta = np.linspace(0.0, 360.0)\n",
+ "sintheta = np.sin(np.deg2rad(theta))\n",
+ "\n",
+ "plt.plot(theta, sintheta, label='y = sin(x)', color='purple')\n",
+ "plt.grid()\n",
+ "plt.legend()\n",
+ "plt.xlabel('Degrees')\n",
+ "plt.title('Our first Pythonic plot', fontsize=14)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "04615882",
+ "metadata": {},
+ "source": [
+ "## What now?\n",
+ "\n",
+ "That was a whirlwind tour of some basic Python usage. \n",
+ "\n",
+ "Read on for more details on how to install and run Python and necessary packages on your own laptop."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "edbbb2ad-4544-4564-9750-6d738698fe2e",
+ "metadata": {},
+ "source": [
+ "## Resources and references\n",
+ "\n",
+ "- [Official Python tutorial (Python Docs)](https://docs.python.org/3/tutorial/index.html)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/_preview/468/_sources/foundations/terminal.md b/_preview/468/_sources/foundations/terminal.md
new file mode 100644
index 000000000..49568964d
--- /dev/null
+++ b/_preview/468/_sources/foundations/terminal.md
@@ -0,0 +1,102 @@
+# Python in the Terminal
+
+---
+
+## Overview
+
+You'd like to learn to run Python in the terminal. Here we will cover:
+
+1. Installing Python in the terminal
+2. Running Python code in the terminal
+
+## Prerequisites
+
+| Concepts | Importance | Notes |
+| --------------------------------------------------------------------------------------------------------- | ---------- | ----- |
+| [Installing and Running Python](https://foundations.projectpythia.org/foundations/how-to-run-python.html) | Helpful | |
+
+- **Time to learn**: 20 minutes
+
+---
+
+## Installing Python in the Terminal
+
+If you are running Python in the terminal, it is best to install Miniconda. You can do that by following the [instructions for your machine](https://docs.conda.io/en/latest/miniconda.html).
+
+[Learn more about Conda here](conda.md)
+
+Then create a Conda environment with Python installed by typing the following into your terminal:
+
+```
+$ conda create --name pythia_foundations_env python
+```
+
+You can test this by running `python` in the command line.
+
+## Running Python in the Terminal
+
+On Windows, open **Anaconda Prompt**. On a Mac or Linux machine, simply open **Terminal**.
+
+1. Activate your Conda environment:
+
+ ```
+ $ conda activate pythia_foundations_env
+ ```
+
+2. Create a directory to store our work. Let's call it `pythia-foundations`.
+
+ ```
+ $ mkdir pythia-foundations
+ ```
+
+3. Go into the directory:
+
+ ```
+ $ cd pythia-foundations
+ ```
+
+4. Create a new Python file:
+
+ ```
+ $ touch mysci.py
+ ```
+
+5. And now that you've set up our workspace, edit the `mysci.py` script using your favorite text editor (e.g., nano):
+
+ ```
+ $ nano mysci.py
+ ```
+
+6. Change the script to include the classic first command: printing, "Hello, world!".
+
+ ```python
+ print("Hello, world!")
+ ```
+
+7. Save your file and exit the editor. How to do this is dependent on your chosen text editor.
+
+ - In Vim, revert to command mode by pressing `esc`. Then, the command is `:wq`.
+ - In Nano it is {kbd}`Ctrl`\+{kbd}`O` to save and {kbd}`Ctrl`\+{kbd}`X` to exit (where you will be prompted if you want to save it, if modified).
+
+8. In the terminal, execute your script:
+
+ ```
+ $ python mysci.py
+ ```
+
+**Congratulations!** You have just set up your first Python environment and run your first Python script in the terminal.
+
+---
+
+## Summary
+
+Running Python in the terminal is a good option if you are familiar with Linux commands or scripting on a supercomputer. It requires the use of a text editor.
+
+### What's Next?
+
+- [How to Run Python in a Jupyter Session](jupyter.md)
+- [Learn more about Conda here](conda.md)
+
+## Resources and References
+
+- [Linux commands](https://cheatography.com/davechild/cheat-sheets/linux-command-line/)
diff --git a/_preview/468/_sources/foundations/why-python.md b/_preview/468/_sources/foundations/why-python.md
new file mode 100644
index 000000000..cd31cf975
--- /dev/null
+++ b/_preview/468/_sources/foundations/why-python.md
@@ -0,0 +1,27 @@
+# Why Python?
+
+You're already here because you want to learn to use Python for your data analysis and visualizations.
+
+**Perhaps the #1 reason to use Python is because it is so widely used in the scientific community!**
+
+Python can be compared to other high-level, interpreted, object-oriented languages, but is especially great because it is free and open source!
+
+Want to know what these terms mean for you and your work? Read on!
+
+## High level languages
+
+Other high level languages include MatLab, IDL, and NCL. The advantage of high level languages is that they provide built-in functions, data structures, and other utilities that are commonly used, which means it takes less code to get real work done. The disadvantage of high level languages is that they tend to obscure the low level aspects of the machine such as memory use, how many floating point operations are happening, and other information related to performance. C, C++, and Fortran are all examples of lower level languages. The "higher" the level of language, the more computing fundamentals are abstracted.
+
+## Interpreted languages
+
+Most of your work is probably already in interpreted languages if you've ever used IDL, NCL, or MatLab (interpreted languages are typically also high level). So you are already familiar with the advantages of this: you don't have to worry about compiling or machine compatibility (it is portable). And you are probably familiar with their deficiencies: sometimes they can be slower than compiled languages and potentially more memory intensive.
+
+## Object Oriented languages
+
+Objects are custom datatypes. For every custom datatype, you usually have a set of operations you might want to conduct. For example, if you have an object that is a list of numbers, you might want to apply a mathematical operation, such as sum, onto this list object in bulk. Not every function can be applied to every datatype; it wouldn't make sense to apply a logarithm to a string of letters or to capitalize a list of numbers. Data and the operations applied to them are grouped together into one object.
+
+## Open source
+
+Python as a language is open source, which means that there is a community of developers behind its codebase. Anyone can join the developer community and contribute to deciding the future of the language. When someone identifies gaps in Python's abilities, they can write up the code to fill these gaps. The open source nature of Python means that Python as a language is very adaptable to the shifting needs of the user community. This harkens back to the idea that the widespread use of Python within the scientific community is a benefit to you! The large Python user base within your field has established high level community Python packages that are available to you in your workflow.
+
+Python is a language designed for rapid prototyping and efficient programming. It is easy to write new code quickly with less typing.
diff --git a/_preview/468/_sources/landing-page.md b/_preview/468/_sources/landing-page.md
new file mode 100644
index 000000000..b75d742b0
--- /dev/null
+++ b/_preview/468/_sources/landing-page.md
@@ -0,0 +1,11 @@
+# Pythia Foundations
+
+## A community learning resource for Python-based computing in the geosciences
+
+ +
+This collection covers the foundational skills everyone needs to get started with scientific computing in the open-source Python ecosystem.
+
+
+
+This collection covers the foundational skills everyone needs to get started with scientific computing in the open-source Python ecosystem.
+
+Short
+ */ + .o-tooltip--left { + position: relative; + } + + .o-tooltip--left:after { + opacity: 0; + visibility: hidden; + position: absolute; + content: attr(data-tooltip); + padding: .2em; + font-size: .8em; + left: -.2em; + background: grey; + color: white; + white-space: nowrap; + z-index: 2; + border-radius: 2px; + transform: translateX(-102%) translateY(0); + transition: opacity 0.2s cubic-bezier(0.64, 0.09, 0.08, 1), transform 0.2s cubic-bezier(0.64, 0.09, 0.08, 1); +} + +.o-tooltip--left:hover:after { + display: block; + opacity: 1; + visibility: visible; + transform: translateX(-100%) translateY(0); + transition: opacity 0.2s cubic-bezier(0.64, 0.09, 0.08, 1), transform 0.2s cubic-bezier(0.64, 0.09, 0.08, 1); + transition-delay: .5s; +} + +/* By default the copy button shouldn't show up when printing a page */ +@media print { + button.copybtn { + display: none; + } +} diff --git a/_preview/468/_static/copybutton.js b/_preview/468/_static/copybutton.js new file mode 100644 index 000000000..2ea7ff3e2 --- /dev/null +++ b/_preview/468/_static/copybutton.js @@ -0,0 +1,248 @@ +// Localization support +const messages = { + 'en': { + 'copy': 'Copy', + 'copy_to_clipboard': 'Copy to clipboard', + 'copy_success': 'Copied!', + 'copy_failure': 'Failed to copy', + }, + 'es' : { + 'copy': 'Copiar', + 'copy_to_clipboard': 'Copiar al portapapeles', + 'copy_success': '¡Copiado!', + 'copy_failure': 'Error al copiar', + }, + 'de' : { + 'copy': 'Kopieren', + 'copy_to_clipboard': 'In die Zwischenablage kopieren', + 'copy_success': 'Kopiert!', + 'copy_failure': 'Fehler beim Kopieren', + }, + 'fr' : { + 'copy': 'Copier', + 'copy_to_clipboard': 'Copier dans le presse-papier', + 'copy_success': 'Copié !', + 'copy_failure': 'Échec de la copie', + }, + 'ru': { + 'copy': 'Скопировать', + 'copy_to_clipboard': 'Скопировать в буфер', + 'copy_success': 'Скопировано!', + 'copy_failure': 'Не удалось скопировать', + }, + 'zh-CN': { + 'copy': '复制', + 'copy_to_clipboard': '复制到剪贴板', + 'copy_success': '复制成功!', + 'copy_failure': '复制失败', + }, + 'it' : { + 'copy': 'Copiare', + 'copy_to_clipboard': 'Copiato negli appunti', + 'copy_success': 'Copiato!', + 'copy_failure': 'Errore durante la copia', + } +} + +let locale = 'en' +if( document.documentElement.lang !== undefined + && messages[document.documentElement.lang] !== undefined ) { + locale = document.documentElement.lang +} + +let doc_url_root = DOCUMENTATION_OPTIONS.URL_ROOT; +if (doc_url_root == '#') { + doc_url_root = ''; +} + +/** + * SVG files for our copy buttons + */ +let iconCheck = `` + +// If the user specified their own SVG use that, otherwise use the default +let iconCopy = ``; +if (!iconCopy) { + iconCopy = `` +} + +/** + * Set up copy/paste for code blocks + */ + +const runWhenDOMLoaded = cb => { + if (document.readyState != 'loading') { + cb() + } else if (document.addEventListener) { + document.addEventListener('DOMContentLoaded', cb) + } else { + document.attachEvent('onreadystatechange', function() { + if (document.readyState == 'complete') cb() + }) + } +} + +const codeCellId = index => `codecell${index}` + +// Clears selected text since ClipboardJS will select the text when copying +const clearSelection = () => { + if (window.getSelection) { + window.getSelection().removeAllRanges() + } else if (document.selection) { + document.selection.empty() + } +} + +// Changes tooltip text for a moment, then changes it back +// We want the timeout of our `success` class to be a bit shorter than the +// tooltip and icon change, so that we can hide the icon before changing back. +var timeoutIcon = 2000; +var timeoutSuccessClass = 1500; + +const temporarilyChangeTooltip = (el, oldText, newText) => { + el.setAttribute('data-tooltip', newText) + el.classList.add('success') + // Remove success a little bit sooner than we change the tooltip + // So that we can use CSS to hide the copybutton first + setTimeout(() => el.classList.remove('success'), timeoutSuccessClass) + setTimeout(() => el.setAttribute('data-tooltip', oldText), timeoutIcon) +} + +// Changes the copy button icon for two seconds, then changes it back +const temporarilyChangeIcon = (el) => { + el.innerHTML = iconCheck; + setTimeout(() => {el.innerHTML = iconCopy}, timeoutIcon) +} + +const addCopyButtonToCodeCells = () => { + // If ClipboardJS hasn't loaded, wait a bit and try again. This + // happens because we load ClipboardJS asynchronously. + if (window.ClipboardJS === undefined) { + setTimeout(addCopyButtonToCodeCells, 250) + return + } + + // Add copybuttons to all of our code cells + const COPYBUTTON_SELECTOR = 'div.highlight pre'; + const codeCells = document.querySelectorAll(COPYBUTTON_SELECTOR) + codeCells.forEach((codeCell, index) => { + const id = codeCellId(index) + codeCell.setAttribute('id', id) + + const clipboardButton = id => + `` + codeCell.insertAdjacentHTML('afterend', clipboardButton(id)) + }) + +function escapeRegExp(string) { + return string.replace(/[.*+?^${}()|[\]\\]/g, '\\$&'); // $& means the whole matched string +} + +/** + * Removes excluded text from a Node. + * + * @param {Node} target Node to filter. + * @param {string} exclude CSS selector of nodes to exclude. + * @returns {DOMString} Text from `target` with text removed. + */ +function filterText(target, exclude) { + const clone = target.cloneNode(true); // clone as to not modify the live DOM + if (exclude) { + // remove excluded nodes + clone.querySelectorAll(exclude).forEach(node => node.remove()); + } + return clone.innerText; +} + +// Callback when a copy button is clicked. Will be passed the node that was clicked +// should then grab the text and replace pieces of text that shouldn't be used in output +function formatCopyText(textContent, copybuttonPromptText, isRegexp = false, onlyCopyPromptLines = true, removePrompts = true, copyEmptyLines = true, lineContinuationChar = "", hereDocDelim = "") { + var regexp; + var match; + + // Do we check for line continuation characters and "HERE-documents"? + var useLineCont = !!lineContinuationChar + var useHereDoc = !!hereDocDelim + + // create regexp to capture prompt and remaining line + if (isRegexp) { + regexp = new RegExp('^(' + copybuttonPromptText + ')(.*)') + } else { + regexp = new RegExp('^(' + escapeRegExp(copybuttonPromptText) + ')(.*)') + } + + const outputLines = []; + var promptFound = false; + var gotLineCont = false; + var gotHereDoc = false; + const lineGotPrompt = []; + for (const line of textContent.split('\n')) { + match = line.match(regexp) + if (match || gotLineCont || gotHereDoc) { + promptFound = regexp.test(line) + lineGotPrompt.push(promptFound) + if (removePrompts && promptFound) { + outputLines.push(match[2]) + } else { + outputLines.push(line) + } + gotLineCont = line.endsWith(lineContinuationChar) & useLineCont + if (line.includes(hereDocDelim) & useHereDoc) + gotHereDoc = !gotHereDoc + } else if (!onlyCopyPromptLines) { + outputLines.push(line) + } else if (copyEmptyLines && line.trim() === '') { + outputLines.push(line) + } + } + + // If no lines with the prompt were found then just use original lines + if (lineGotPrompt.some(v => v === true)) { + textContent = outputLines.join('\n'); + } + + // Remove a trailing newline to avoid auto-running when pasting + if (textContent.endsWith("\n")) { + textContent = textContent.slice(0, -1) + } + return textContent +} + + +var copyTargetText = (trigger) => { + var target = document.querySelector(trigger.attributes['data-clipboard-target'].value); + + // get filtered text + let exclude = '.linenos'; + + let text = filterText(target, exclude); + return formatCopyText(text, '', false, true, true, true, '', '') +} + + // Initialize with a callback so we can modify the text before copy + const clipboard = new ClipboardJS('.copybtn', {text: copyTargetText}) + + // Update UI with error/success messages + clipboard.on('success', event => { + clearSelection() + temporarilyChangeTooltip(event.trigger, messages[locale]['copy'], messages[locale]['copy_success']) + temporarilyChangeIcon(event.trigger) + }) + + clipboard.on('error', event => { + temporarilyChangeTooltip(event.trigger, messages[locale]['copy'], messages[locale]['copy_failure']) + }) +} + +runWhenDOMLoaded(addCopyButtonToCodeCells) \ No newline at end of file diff --git a/_preview/468/_static/copybutton_funcs.js b/_preview/468/_static/copybutton_funcs.js new file mode 100644 index 000000000..dbe1aaad7 --- /dev/null +++ b/_preview/468/_static/copybutton_funcs.js @@ -0,0 +1,73 @@ +function escapeRegExp(string) { + return string.replace(/[.*+?^${}()|[\]\\]/g, '\\$&'); // $& means the whole matched string +} + +/** + * Removes excluded text from a Node. + * + * @param {Node} target Node to filter. + * @param {string} exclude CSS selector of nodes to exclude. + * @returns {DOMString} Text from `target` with text removed. + */ +export function filterText(target, exclude) { + const clone = target.cloneNode(true); // clone as to not modify the live DOM + if (exclude) { + // remove excluded nodes + clone.querySelectorAll(exclude).forEach(node => node.remove()); + } + return clone.innerText; +} + +// Callback when a copy button is clicked. Will be passed the node that was clicked +// should then grab the text and replace pieces of text that shouldn't be used in output +export function formatCopyText(textContent, copybuttonPromptText, isRegexp = false, onlyCopyPromptLines = true, removePrompts = true, copyEmptyLines = true, lineContinuationChar = "", hereDocDelim = "") { + var regexp; + var match; + + // Do we check for line continuation characters and "HERE-documents"? + var useLineCont = !!lineContinuationChar + var useHereDoc = !!hereDocDelim + + // create regexp to capture prompt and remaining line + if (isRegexp) { + regexp = new RegExp('^(' + copybuttonPromptText + ')(.*)') + } else { + regexp = new RegExp('^(' + escapeRegExp(copybuttonPromptText) + ')(.*)') + } + + const outputLines = []; + var promptFound = false; + var gotLineCont = false; + var gotHereDoc = false; + const lineGotPrompt = []; + for (const line of textContent.split('\n')) { + match = line.match(regexp) + if (match || gotLineCont || gotHereDoc) { + promptFound = regexp.test(line) + lineGotPrompt.push(promptFound) + if (removePrompts && promptFound) { + outputLines.push(match[2]) + } else { + outputLines.push(line) + } + gotLineCont = line.endsWith(lineContinuationChar) & useLineCont + if (line.includes(hereDocDelim) & useHereDoc) + gotHereDoc = !gotHereDoc + } else if (!onlyCopyPromptLines) { + outputLines.push(line) + } else if (copyEmptyLines && line.trim() === '') { + outputLines.push(line) + } + } + + // If no lines with the prompt were found then just use original lines + if (lineGotPrompt.some(v => v === true)) { + textContent = outputLines.join('\n'); + } + + // Remove a trailing newline to avoid auto-running when pasting + if (textContent.endsWith("\n")) { + textContent = textContent.slice(0, -1) + } + return textContent +} diff --git a/_preview/468/_static/custom.css b/_preview/468/_static/custom.css new file mode 100644 index 000000000..098336238 --- /dev/null +++ b/_preview/468/_static/custom.css @@ -0,0 +1,37 @@ +.bd-main .bd-content .bd-article-container { + max-width: 100%; /* default is 60em */ +} +.bd-page-width { + max-width: 100%; /* default is 88rem */ +} + +kbd { + /* Based on: https://dylanatsmith.com/wrote/styling-the-kbd-element */ + + /* Key top color */ + background-color: rgb(238, 237, 237); + + /* Key legend */ + color: rgba(var(--pst-color-paragraph), 1); + font-size: 0.75em; + font-family: monospace; + font-weight: bold; + + /* Fancy border and shadow, to make it look like a key */ + border-radius: 0.3em; + border: 1px solid grey; + box-shadow: 0 2px 0 1px grey; + padding: 2px 5px; + margin-left: 1px; + margin-right: 1px; + line-height: 1; + position: relative; + top: -2px; + + cursor: default; /* instead of text selection cursor */ +} +kbd:hover { + /* Press-down on hover */ + box-shadow: 0 1px 0 0.5px grey; + top: 0px; +} diff --git a/_preview/468/_static/design-style.1e8bd061cd6da7fc9cf755528e8ffc24.min.css b/_preview/468/_static/design-style.1e8bd061cd6da7fc9cf755528e8ffc24.min.css new file mode 100644 index 000000000..eb19f698a --- /dev/null +++ b/_preview/468/_static/design-style.1e8bd061cd6da7fc9cf755528e8ffc24.min.css @@ -0,0 +1 @@ +.sd-bg-primary{background-color:var(--sd-color-primary) !important}.sd-bg-text-primary{color:var(--sd-color-primary-text) !important}button.sd-bg-primary:focus,button.sd-bg-primary:hover{background-color:var(--sd-color-primary-highlight) !important}a.sd-bg-primary:focus,a.sd-bg-primary:hover{background-color:var(--sd-color-primary-highlight) !important}.sd-bg-secondary{background-color:var(--sd-color-secondary) !important}.sd-bg-text-secondary{color:var(--sd-color-secondary-text) !important}button.sd-bg-secondary:focus,button.sd-bg-secondary:hover{background-color:var(--sd-color-secondary-highlight) !important}a.sd-bg-secondary:focus,a.sd-bg-secondary:hover{background-color:var(--sd-color-secondary-highlight) !important}.sd-bg-success{background-color:var(--sd-color-success) !important}.sd-bg-text-success{color:var(--sd-color-success-text) !important}button.sd-bg-success:focus,button.sd-bg-success:hover{background-color:var(--sd-color-success-highlight) !important}a.sd-bg-success:focus,a.sd-bg-success:hover{background-color:var(--sd-color-success-highlight) !important}.sd-bg-info{background-color:var(--sd-color-info) !important}.sd-bg-text-info{color:var(--sd-color-info-text) !important}button.sd-bg-info:focus,button.sd-bg-info:hover{background-color:var(--sd-color-info-highlight) !important}a.sd-bg-info:focus,a.sd-bg-info:hover{background-color:var(--sd-color-info-highlight) !important}.sd-bg-warning{background-color:var(--sd-color-warning) !important}.sd-bg-text-warning{color:var(--sd-color-warning-text) !important}button.sd-bg-warning:focus,button.sd-bg-warning:hover{background-color:var(--sd-color-warning-highlight) !important}a.sd-bg-warning:focus,a.sd-bg-warning:hover{background-color:var(--sd-color-warning-highlight) !important}.sd-bg-danger{background-color:var(--sd-color-danger) !important}.sd-bg-text-danger{color:var(--sd-color-danger-text) !important}button.sd-bg-danger:focus,button.sd-bg-danger:hover{background-color:var(--sd-color-danger-highlight) !important}a.sd-bg-danger:focus,a.sd-bg-danger:hover{background-color:var(--sd-color-danger-highlight) !important}.sd-bg-light{background-color:var(--sd-color-light) !important}.sd-bg-text-light{color:var(--sd-color-light-text) !important}button.sd-bg-light:focus,button.sd-bg-light:hover{background-color:var(--sd-color-light-highlight) !important}a.sd-bg-light:focus,a.sd-bg-light:hover{background-color:var(--sd-color-light-highlight) !important}.sd-bg-muted{background-color:var(--sd-color-muted) !important}.sd-bg-text-muted{color:var(--sd-color-muted-text) !important}button.sd-bg-muted:focus,button.sd-bg-muted:hover{background-color:var(--sd-color-muted-highlight) !important}a.sd-bg-muted:focus,a.sd-bg-muted:hover{background-color:var(--sd-color-muted-highlight) !important}.sd-bg-dark{background-color:var(--sd-color-dark) !important}.sd-bg-text-dark{color:var(--sd-color-dark-text) !important}button.sd-bg-dark:focus,button.sd-bg-dark:hover{background-color:var(--sd-color-dark-highlight) !important}a.sd-bg-dark:focus,a.sd-bg-dark:hover{background-color:var(--sd-color-dark-highlight) !important}.sd-bg-black{background-color:var(--sd-color-black) !important}.sd-bg-text-black{color:var(--sd-color-black-text) !important}button.sd-bg-black:focus,button.sd-bg-black:hover{background-color:var(--sd-color-black-highlight) !important}a.sd-bg-black:focus,a.sd-bg-black:hover{background-color:var(--sd-color-black-highlight) !important}.sd-bg-white{background-color:var(--sd-color-white) !important}.sd-bg-text-white{color:var(--sd-color-white-text) !important}button.sd-bg-white:focus,button.sd-bg-white:hover{background-color:var(--sd-color-white-highlight) !important}a.sd-bg-white:focus,a.sd-bg-white:hover{background-color:var(--sd-color-white-highlight) !important}.sd-text-primary,.sd-text-primary>p{color:var(--sd-color-primary) !important}a.sd-text-primary:focus,a.sd-text-primary:hover{color:var(--sd-color-primary-highlight) !important}.sd-text-secondary,.sd-text-secondary>p{color:var(--sd-color-secondary) !important}a.sd-text-secondary:focus,a.sd-text-secondary:hover{color:var(--sd-color-secondary-highlight) !important}.sd-text-success,.sd-text-success>p{color:var(--sd-color-success) !important}a.sd-text-success:focus,a.sd-text-success:hover{color:var(--sd-color-success-highlight) !important}.sd-text-info,.sd-text-info>p{color:var(--sd-color-info) !important}a.sd-text-info:focus,a.sd-text-info:hover{color:var(--sd-color-info-highlight) !important}.sd-text-warning,.sd-text-warning>p{color:var(--sd-color-warning) !important}a.sd-text-warning:focus,a.sd-text-warning:hover{color:var(--sd-color-warning-highlight) !important}.sd-text-danger,.sd-text-danger>p{color:var(--sd-color-danger) !important}a.sd-text-danger:focus,a.sd-text-danger:hover{color:var(--sd-color-danger-highlight) !important}.sd-text-light,.sd-text-light>p{color:var(--sd-color-light) !important}a.sd-text-light:focus,a.sd-text-light:hover{color:var(--sd-color-light-highlight) !important}.sd-text-muted,.sd-text-muted>p{color:var(--sd-color-muted) !important}a.sd-text-muted:focus,a.sd-text-muted:hover{color:var(--sd-color-muted-highlight) !important}.sd-text-dark,.sd-text-dark>p{color:var(--sd-color-dark) !important}a.sd-text-dark:focus,a.sd-text-dark:hover{color:var(--sd-color-dark-highlight) !important}.sd-text-black,.sd-text-black>p{color:var(--sd-color-black) !important}a.sd-text-black:focus,a.sd-text-black:hover{color:var(--sd-color-black-highlight) !important}.sd-text-white,.sd-text-white>p{color:var(--sd-color-white) !important}a.sd-text-white:focus,a.sd-text-white:hover{color:var(--sd-color-white-highlight) !important}.sd-outline-primary{border-color:var(--sd-color-primary) !important;border-style:solid !important;border-width:1px !important}a.sd-outline-primary:focus,a.sd-outline-primary:hover{border-color:var(--sd-color-primary-highlight) !important}.sd-outline-secondary{border-color:var(--sd-color-secondary) !important;border-style:solid !important;border-width:1px !important}a.sd-outline-secondary:focus,a.sd-outline-secondary:hover{border-color:var(--sd-color-secondary-highlight) !important}.sd-outline-success{border-color:var(--sd-color-success) !important;border-style:solid !important;border-width:1px !important}a.sd-outline-success:focus,a.sd-outline-success:hover{border-color:var(--sd-color-success-highlight) !important}.sd-outline-info{border-color:var(--sd-color-info) !important;border-style:solid !important;border-width:1px !important}a.sd-outline-info:focus,a.sd-outline-info:hover{border-color:var(--sd-color-info-highlight) !important}.sd-outline-warning{border-color:var(--sd-color-warning) !important;border-style:solid !important;border-width:1px !important}a.sd-outline-warning:focus,a.sd-outline-warning:hover{border-color:var(--sd-color-warning-highlight) !important}.sd-outline-danger{border-color:var(--sd-color-danger) !important;border-style:solid !important;border-width:1px !important}a.sd-outline-danger:focus,a.sd-outline-danger:hover{border-color:var(--sd-color-danger-highlight) !important}.sd-outline-light{border-color:var(--sd-color-light) !important;border-style:solid !important;border-width:1px !important}a.sd-outline-light:focus,a.sd-outline-light:hover{border-color:var(--sd-color-light-highlight) !important}.sd-outline-muted{border-color:var(--sd-color-muted) !important;border-style:solid !important;border-width:1px !important}a.sd-outline-muted:focus,a.sd-outline-muted:hover{border-color:var(--sd-color-muted-highlight) !important}.sd-outline-dark{border-color:var(--sd-color-dark) !important;border-style:solid !important;border-width:1px !important}a.sd-outline-dark:focus,a.sd-outline-dark:hover{border-color:var(--sd-color-dark-highlight) !important}.sd-outline-black{border-color:var(--sd-color-black) !important;border-style:solid !important;border-width:1px !important}a.sd-outline-black:focus,a.sd-outline-black:hover{border-color:var(--sd-color-black-highlight) !important}.sd-outline-white{border-color:var(--sd-color-white) !important;border-style:solid !important;border-width:1px !important}a.sd-outline-white:focus,a.sd-outline-white:hover{border-color:var(--sd-color-white-highlight) !important}.sd-bg-transparent{background-color:transparent !important}.sd-outline-transparent{border-color:transparent !important}.sd-text-transparent{color:transparent !important}.sd-p-0{padding:0 !important}.sd-pt-0,.sd-py-0{padding-top:0 !important}.sd-pr-0,.sd-px-0{padding-right:0 !important}.sd-pb-0,.sd-py-0{padding-bottom:0 !important}.sd-pl-0,.sd-px-0{padding-left:0 !important}.sd-p-1{padding:.25rem !important}.sd-pt-1,.sd-py-1{padding-top:.25rem !important}.sd-pr-1,.sd-px-1{padding-right:.25rem !important}.sd-pb-1,.sd-py-1{padding-bottom:.25rem !important}.sd-pl-1,.sd-px-1{padding-left:.25rem !important}.sd-p-2{padding:.5rem !important}.sd-pt-2,.sd-py-2{padding-top:.5rem !important}.sd-pr-2,.sd-px-2{padding-right:.5rem !important}.sd-pb-2,.sd-py-2{padding-bottom:.5rem !important}.sd-pl-2,.sd-px-2{padding-left:.5rem !important}.sd-p-3{padding:1rem !important}.sd-pt-3,.sd-py-3{padding-top:1rem !important}.sd-pr-3,.sd-px-3{padding-right:1rem !important}.sd-pb-3,.sd-py-3{padding-bottom:1rem !important}.sd-pl-3,.sd-px-3{padding-left:1rem !important}.sd-p-4{padding:1.5rem !important}.sd-pt-4,.sd-py-4{padding-top:1.5rem !important}.sd-pr-4,.sd-px-4{padding-right:1.5rem !important}.sd-pb-4,.sd-py-4{padding-bottom:1.5rem !important}.sd-pl-4,.sd-px-4{padding-left:1.5rem !important}.sd-p-5{padding:3rem !important}.sd-pt-5,.sd-py-5{padding-top:3rem !important}.sd-pr-5,.sd-px-5{padding-right:3rem !important}.sd-pb-5,.sd-py-5{padding-bottom:3rem !important}.sd-pl-5,.sd-px-5{padding-left:3rem !important}.sd-m-auto{margin:auto !important}.sd-mt-auto,.sd-my-auto{margin-top:auto !important}.sd-mr-auto,.sd-mx-auto{margin-right:auto !important}.sd-mb-auto,.sd-my-auto{margin-bottom:auto !important}.sd-ml-auto,.sd-mx-auto{margin-left:auto !important}.sd-m-0{margin:0 !important}.sd-mt-0,.sd-my-0{margin-top:0 !important}.sd-mr-0,.sd-mx-0{margin-right:0 !important}.sd-mb-0,.sd-my-0{margin-bottom:0 !important}.sd-ml-0,.sd-mx-0{margin-left:0 !important}.sd-m-1{margin:.25rem !important}.sd-mt-1,.sd-my-1{margin-top:.25rem !important}.sd-mr-1,.sd-mx-1{margin-right:.25rem !important}.sd-mb-1,.sd-my-1{margin-bottom:.25rem !important}.sd-ml-1,.sd-mx-1{margin-left:.25rem !important}.sd-m-2{margin:.5rem !important}.sd-mt-2,.sd-my-2{margin-top:.5rem !important}.sd-mr-2,.sd-mx-2{margin-right:.5rem !important}.sd-mb-2,.sd-my-2{margin-bottom:.5rem !important}.sd-ml-2,.sd-mx-2{margin-left:.5rem !important}.sd-m-3{margin:1rem !important}.sd-mt-3,.sd-my-3{margin-top:1rem !important}.sd-mr-3,.sd-mx-3{margin-right:1rem !important}.sd-mb-3,.sd-my-3{margin-bottom:1rem !important}.sd-ml-3,.sd-mx-3{margin-left:1rem !important}.sd-m-4{margin:1.5rem !important}.sd-mt-4,.sd-my-4{margin-top:1.5rem !important}.sd-mr-4,.sd-mx-4{margin-right:1.5rem !important}.sd-mb-4,.sd-my-4{margin-bottom:1.5rem !important}.sd-ml-4,.sd-mx-4{margin-left:1.5rem !important}.sd-m-5{margin:3rem !important}.sd-mt-5,.sd-my-5{margin-top:3rem !important}.sd-mr-5,.sd-mx-5{margin-right:3rem !important}.sd-mb-5,.sd-my-5{margin-bottom:3rem !important}.sd-ml-5,.sd-mx-5{margin-left:3rem !important}.sd-w-25{width:25% !important}.sd-w-50{width:50% !important}.sd-w-75{width:75% !important}.sd-w-100{width:100% !important}.sd-w-auto{width:auto !important}.sd-h-25{height:25% !important}.sd-h-50{height:50% !important}.sd-h-75{height:75% !important}.sd-h-100{height:100% !important}.sd-h-auto{height:auto !important}.sd-d-none{display:none !important}.sd-d-inline{display:inline !important}.sd-d-inline-block{display:inline-block !important}.sd-d-block{display:block !important}.sd-d-grid{display:grid !important}.sd-d-flex-row{display:-ms-flexbox !important;display:flex !important;flex-direction:row !important}.sd-d-flex-column{display:-ms-flexbox !important;display:flex !important;flex-direction:column !important}.sd-d-inline-flex{display:-ms-inline-flexbox !important;display:inline-flex !important}@media(min-width: 576px){.sd-d-sm-none{display:none !important}.sd-d-sm-inline{display:inline !important}.sd-d-sm-inline-block{display:inline-block !important}.sd-d-sm-block{display:block !important}.sd-d-sm-grid{display:grid !important}.sd-d-sm-flex{display:-ms-flexbox !important;display:flex !important}.sd-d-sm-inline-flex{display:-ms-inline-flexbox !important;display:inline-flex !important}}@media(min-width: 768px){.sd-d-md-none{display:none !important}.sd-d-md-inline{display:inline !important}.sd-d-md-inline-block{display:inline-block !important}.sd-d-md-block{display:block !important}.sd-d-md-grid{display:grid !important}.sd-d-md-flex{display:-ms-flexbox !important;display:flex !important}.sd-d-md-inline-flex{display:-ms-inline-flexbox !important;display:inline-flex !important}}@media(min-width: 992px){.sd-d-lg-none{display:none !important}.sd-d-lg-inline{display:inline !important}.sd-d-lg-inline-block{display:inline-block !important}.sd-d-lg-block{display:block !important}.sd-d-lg-grid{display:grid !important}.sd-d-lg-flex{display:-ms-flexbox !important;display:flex !important}.sd-d-lg-inline-flex{display:-ms-inline-flexbox !important;display:inline-flex !important}}@media(min-width: 1200px){.sd-d-xl-none{display:none !important}.sd-d-xl-inline{display:inline !important}.sd-d-xl-inline-block{display:inline-block !important}.sd-d-xl-block{display:block !important}.sd-d-xl-grid{display:grid !important}.sd-d-xl-flex{display:-ms-flexbox !important;display:flex !important}.sd-d-xl-inline-flex{display:-ms-inline-flexbox !important;display:inline-flex !important}}.sd-align-major-start{justify-content:flex-start !important}.sd-align-major-end{justify-content:flex-end !important}.sd-align-major-center{justify-content:center !important}.sd-align-major-justify{justify-content:space-between !important}.sd-align-major-spaced{justify-content:space-evenly !important}.sd-align-minor-start{align-items:flex-start !important}.sd-align-minor-end{align-items:flex-end !important}.sd-align-minor-center{align-items:center !important}.sd-align-minor-stretch{align-items:stretch !important}.sd-text-justify{text-align:justify !important}.sd-text-left{text-align:left !important}.sd-text-right{text-align:right !important}.sd-text-center{text-align:center !important}.sd-font-weight-light{font-weight:300 !important}.sd-font-weight-lighter{font-weight:lighter !important}.sd-font-weight-normal{font-weight:400 !important}.sd-font-weight-bold{font-weight:700 !important}.sd-font-weight-bolder{font-weight:bolder !important}.sd-font-italic{font-style:italic !important}.sd-text-decoration-none{text-decoration:none !important}.sd-text-lowercase{text-transform:lowercase !important}.sd-text-uppercase{text-transform:uppercase !important}.sd-text-capitalize{text-transform:capitalize !important}.sd-text-wrap{white-space:normal !important}.sd-text-nowrap{white-space:nowrap !important}.sd-text-truncate{overflow:hidden;text-overflow:ellipsis;white-space:nowrap}.sd-fs-1,.sd-fs-1>p{font-size:calc(1.375rem + 1.5vw) !important;line-height:unset !important}.sd-fs-2,.sd-fs-2>p{font-size:calc(1.325rem + 0.9vw) !important;line-height:unset !important}.sd-fs-3,.sd-fs-3>p{font-size:calc(1.3rem + 0.6vw) !important;line-height:unset !important}.sd-fs-4,.sd-fs-4>p{font-size:calc(1.275rem + 0.3vw) !important;line-height:unset !important}.sd-fs-5,.sd-fs-5>p{font-size:1.25rem !important;line-height:unset !important}.sd-fs-6,.sd-fs-6>p{font-size:1rem !important;line-height:unset !important}.sd-border-0{border:0 solid !important}.sd-border-top-0{border-top:0 solid !important}.sd-border-bottom-0{border-bottom:0 solid !important}.sd-border-right-0{border-right:0 solid !important}.sd-border-left-0{border-left:0 solid !important}.sd-border-1{border:1px solid !important}.sd-border-top-1{border-top:1px solid !important}.sd-border-bottom-1{border-bottom:1px solid !important}.sd-border-right-1{border-right:1px solid !important}.sd-border-left-1{border-left:1px solid !important}.sd-border-2{border:2px solid !important}.sd-border-top-2{border-top:2px solid !important}.sd-border-bottom-2{border-bottom:2px solid !important}.sd-border-right-2{border-right:2px solid !important}.sd-border-left-2{border-left:2px solid !important}.sd-border-3{border:3px solid !important}.sd-border-top-3{border-top:3px solid !important}.sd-border-bottom-3{border-bottom:3px solid !important}.sd-border-right-3{border-right:3px solid !important}.sd-border-left-3{border-left:3px solid !important}.sd-border-4{border:4px solid !important}.sd-border-top-4{border-top:4px solid !important}.sd-border-bottom-4{border-bottom:4px solid !important}.sd-border-right-4{border-right:4px solid !important}.sd-border-left-4{border-left:4px solid !important}.sd-border-5{border:5px solid !important}.sd-border-top-5{border-top:5px solid !important}.sd-border-bottom-5{border-bottom:5px solid !important}.sd-border-right-5{border-right:5px solid !important}.sd-border-left-5{border-left:5px solid !important}.sd-rounded-0{border-radius:0 !important}.sd-rounded-1{border-radius:.2rem !important}.sd-rounded-2{border-radius:.3rem !important}.sd-rounded-3{border-radius:.5rem !important}.sd-rounded-pill{border-radius:50rem !important}.sd-rounded-circle{border-radius:50% !important}.shadow-none{box-shadow:none !important}.sd-shadow-sm{box-shadow:0 .125rem .25rem var(--sd-color-shadow) !important}.sd-shadow-md{box-shadow:0 .5rem 1rem var(--sd-color-shadow) !important}.sd-shadow-lg{box-shadow:0 1rem 3rem var(--sd-color-shadow) !important}@keyframes sd-slide-from-left{0%{transform:translateX(-100%)}100%{transform:translateX(0)}}@keyframes sd-slide-from-right{0%{transform:translateX(200%)}100%{transform:translateX(0)}}@keyframes sd-grow100{0%{transform:scale(0);opacity:.5}100%{transform:scale(1);opacity:1}}@keyframes sd-grow50{0%{transform:scale(0.5);opacity:.5}100%{transform:scale(1);opacity:1}}@keyframes sd-grow50-rot20{0%{transform:scale(0.5) rotateZ(-20deg);opacity:.5}75%{transform:scale(1) rotateZ(5deg);opacity:1}95%{transform:scale(1) rotateZ(-1deg);opacity:1}100%{transform:scale(1) rotateZ(0);opacity:1}}.sd-animate-slide-from-left{animation:1s ease-out 0s 1 normal none running sd-slide-from-left}.sd-animate-slide-from-right{animation:1s ease-out 0s 1 normal none running sd-slide-from-right}.sd-animate-grow100{animation:1s ease-out 0s 1 normal none running sd-grow100}.sd-animate-grow50{animation:1s ease-out 0s 1 normal none running sd-grow50}.sd-animate-grow50-rot20{animation:1s ease-out 0s 1 normal none running sd-grow50-rot20}.sd-badge{display:inline-block;padding:.35em .65em;font-size:.75em;font-weight:700;line-height:1;text-align:center;white-space:nowrap;vertical-align:baseline;border-radius:.25rem}.sd-badge:empty{display:none}a.sd-badge{text-decoration:none}.sd-btn .sd-badge{position:relative;top:-1px}.sd-btn{background-color:transparent;border:1px solid transparent;border-radius:.25rem;cursor:pointer;display:inline-block;font-weight:400;font-size:1rem;line-height:1.5;padding:.375rem .75rem;text-align:center;text-decoration:none;transition:color .15s ease-in-out,background-color .15s ease-in-out,border-color .15s ease-in-out,box-shadow .15s ease-in-out;vertical-align:middle;user-select:none;-moz-user-select:none;-ms-user-select:none;-webkit-user-select:none}.sd-btn:hover{text-decoration:none}@media(prefers-reduced-motion: reduce){.sd-btn{transition:none}}.sd-btn-primary,.sd-btn-outline-primary:hover,.sd-btn-outline-primary:focus{color:var(--sd-color-primary-text) !important;background-color:var(--sd-color-primary) !important;border-color:var(--sd-color-primary) !important;border-width:1px !important;border-style:solid !important}.sd-btn-primary:hover,.sd-btn-primary:focus{color:var(--sd-color-primary-text) !important;background-color:var(--sd-color-primary-highlight) !important;border-color:var(--sd-color-primary-highlight) !important;border-width:1px !important;border-style:solid !important}.sd-btn-outline-primary{color:var(--sd-color-primary) !important;border-color:var(--sd-color-primary) !important;border-width:1px !important;border-style:solid !important}.sd-btn-secondary,.sd-btn-outline-secondary:hover,.sd-btn-outline-secondary:focus{color:var(--sd-color-secondary-text) !important;background-color:var(--sd-color-secondary) !important;border-color:var(--sd-color-secondary) !important;border-width:1px !important;border-style:solid !important}.sd-btn-secondary:hover,.sd-btn-secondary:focus{color:var(--sd-color-secondary-text) !important;background-color:var(--sd-color-secondary-highlight) !important;border-color:var(--sd-color-secondary-highlight) !important;border-width:1px !important;border-style:solid !important}.sd-btn-outline-secondary{color:var(--sd-color-secondary) !important;border-color:var(--sd-color-secondary) !important;border-width:1px !important;border-style:solid !important}.sd-btn-success,.sd-btn-outline-success:hover,.sd-btn-outline-success:focus{color:var(--sd-color-success-text) !important;background-color:var(--sd-color-success) !important;border-color:var(--sd-color-success) !important;border-width:1px !important;border-style:solid !important}.sd-btn-success:hover,.sd-btn-success:focus{color:var(--sd-color-success-text) !important;background-color:var(--sd-color-success-highlight) !important;border-color:var(--sd-color-success-highlight) !important;border-width:1px !important;border-style:solid !important}.sd-btn-outline-success{color:var(--sd-color-success) !important;border-color:var(--sd-color-success) !important;border-width:1px !important;border-style:solid !important}.sd-btn-info,.sd-btn-outline-info:hover,.sd-btn-outline-info:focus{color:var(--sd-color-info-text) !important;background-color:var(--sd-color-info) !important;border-color:var(--sd-color-info) !important;border-width:1px !important;border-style:solid !important}.sd-btn-info:hover,.sd-btn-info:focus{color:var(--sd-color-info-text) !important;background-color:var(--sd-color-info-highlight) !important;border-color:var(--sd-color-info-highlight) !important;border-width:1px !important;border-style:solid !important}.sd-btn-outline-info{color:var(--sd-color-info) !important;border-color:var(--sd-color-info) !important;border-width:1px !important;border-style:solid !important}.sd-btn-warning,.sd-btn-outline-warning:hover,.sd-btn-outline-warning:focus{color:var(--sd-color-warning-text) !important;background-color:var(--sd-color-warning) !important;border-color:var(--sd-color-warning) !important;border-width:1px !important;border-style:solid !important}.sd-btn-warning:hover,.sd-btn-warning:focus{color:var(--sd-color-warning-text) !important;background-color:var(--sd-color-warning-highlight) !important;border-color:var(--sd-color-warning-highlight) !important;border-width:1px !important;border-style:solid !important}.sd-btn-outline-warning{color:var(--sd-color-warning) !important;border-color:var(--sd-color-warning) !important;border-width:1px !important;border-style:solid !important}.sd-btn-danger,.sd-btn-outline-danger:hover,.sd-btn-outline-danger:focus{color:var(--sd-color-danger-text) !important;background-color:var(--sd-color-danger) !important;border-color:var(--sd-color-danger) !important;border-width:1px !important;border-style:solid !important}.sd-btn-danger:hover,.sd-btn-danger:focus{color:var(--sd-color-danger-text) !important;background-color:var(--sd-color-danger-highlight) !important;border-color:var(--sd-color-danger-highlight) !important;border-width:1px !important;border-style:solid !important}.sd-btn-outline-danger{color:var(--sd-color-danger) !important;border-color:var(--sd-color-danger) !important;border-width:1px !important;border-style:solid !important}.sd-btn-light,.sd-btn-outline-light:hover,.sd-btn-outline-light:focus{color:var(--sd-color-light-text) !important;background-color:var(--sd-color-light) !important;border-color:var(--sd-color-light) !important;border-width:1px !important;border-style:solid !important}.sd-btn-light:hover,.sd-btn-light:focus{color:var(--sd-color-light-text) !important;background-color:var(--sd-color-light-highlight) !important;border-color:var(--sd-color-light-highlight) !important;border-width:1px !important;border-style:solid !important}.sd-btn-outline-light{color:var(--sd-color-light) !important;border-color:var(--sd-color-light) !important;border-width:1px !important;border-style:solid !important}.sd-btn-muted,.sd-btn-outline-muted:hover,.sd-btn-outline-muted:focus{color:var(--sd-color-muted-text) !important;background-color:var(--sd-color-muted) !important;border-color:var(--sd-color-muted) !important;border-width:1px !important;border-style:solid !important}.sd-btn-muted:hover,.sd-btn-muted:focus{color:var(--sd-color-muted-text) !important;background-color:var(--sd-color-muted-highlight) !important;border-color:var(--sd-color-muted-highlight) !important;border-width:1px !important;border-style:solid !important}.sd-btn-outline-muted{color:var(--sd-color-muted) !important;border-color:var(--sd-color-muted) !important;border-width:1px !important;border-style:solid !important}.sd-btn-dark,.sd-btn-outline-dark:hover,.sd-btn-outline-dark:focus{color:var(--sd-color-dark-text) !important;background-color:var(--sd-color-dark) !important;border-color:var(--sd-color-dark) !important;border-width:1px !important;border-style:solid !important}.sd-btn-dark:hover,.sd-btn-dark:focus{color:var(--sd-color-dark-text) !important;background-color:var(--sd-color-dark-highlight) !important;border-color:var(--sd-color-dark-highlight) !important;border-width:1px !important;border-style:solid !important}.sd-btn-outline-dark{color:var(--sd-color-dark) !important;border-color:var(--sd-color-dark) !important;border-width:1px !important;border-style:solid !important}.sd-btn-black,.sd-btn-outline-black:hover,.sd-btn-outline-black:focus{color:var(--sd-color-black-text) !important;background-color:var(--sd-color-black) !important;border-color:var(--sd-color-black) !important;border-width:1px !important;border-style:solid !important}.sd-btn-black:hover,.sd-btn-black:focus{color:var(--sd-color-black-text) !important;background-color:var(--sd-color-black-highlight) !important;border-color:var(--sd-color-black-highlight) !important;border-width:1px !important;border-style:solid !important}.sd-btn-outline-black{color:var(--sd-color-black) !important;border-color:var(--sd-color-black) !important;border-width:1px !important;border-style:solid !important}.sd-btn-white,.sd-btn-outline-white:hover,.sd-btn-outline-white:focus{color:var(--sd-color-white-text) !important;background-color:var(--sd-color-white) !important;border-color:var(--sd-color-white) !important;border-width:1px !important;border-style:solid !important}.sd-btn-white:hover,.sd-btn-white:focus{color:var(--sd-color-white-text) !important;background-color:var(--sd-color-white-highlight) !important;border-color:var(--sd-color-white-highlight) !important;border-width:1px !important;border-style:solid !important}.sd-btn-outline-white{color:var(--sd-color-white) !important;border-color:var(--sd-color-white) !important;border-width:1px !important;border-style:solid !important}.sd-stretched-link::after{position:absolute;top:0;right:0;bottom:0;left:0;z-index:1;content:""}.sd-hide-link-text{font-size:0}.sd-octicon,.sd-material-icon{display:inline-block;fill:currentColor;vertical-align:middle}.sd-avatar-xs{border-radius:50%;object-fit:cover;object-position:center;width:1rem;height:1rem}.sd-avatar-sm{border-radius:50%;object-fit:cover;object-position:center;width:3rem;height:3rem}.sd-avatar-md{border-radius:50%;object-fit:cover;object-position:center;width:5rem;height:5rem}.sd-avatar-lg{border-radius:50%;object-fit:cover;object-position:center;width:7rem;height:7rem}.sd-avatar-xl{border-radius:50%;object-fit:cover;object-position:center;width:10rem;height:10rem}.sd-avatar-inherit{border-radius:50%;object-fit:cover;object-position:center;width:inherit;height:inherit}.sd-avatar-initial{border-radius:50%;object-fit:cover;object-position:center;width:initial;height:initial}.sd-card{background-clip:border-box;background-color:var(--sd-color-card-background);border:1px solid var(--sd-color-card-border);border-radius:.25rem;color:var(--sd-color-card-text);display:-ms-flexbox;display:flex;-ms-flex-direction:column;flex-direction:column;min-width:0;position:relative;word-wrap:break-word}.sd-card>hr{margin-left:0;margin-right:0}.sd-card-hover:hover{border-color:var(--sd-color-card-border-hover);transform:scale(1.01)}.sd-card-body{-ms-flex:1 1 auto;flex:1 1 auto;padding:1rem 1rem}.sd-card-title{margin-bottom:.5rem}.sd-card-subtitle{margin-top:-0.25rem;margin-bottom:0}.sd-card-text:last-child{margin-bottom:0}.sd-card-link:hover{text-decoration:none}.sd-card-link+.card-link{margin-left:1rem}.sd-card-header{padding:.5rem 1rem;margin-bottom:0;background-color:var(--sd-color-card-header);border-bottom:1px solid var(--sd-color-card-border)}.sd-card-header:first-child{border-radius:calc(0.25rem - 1px) calc(0.25rem - 1px) 0 0}.sd-card-footer{padding:.5rem 1rem;background-color:var(--sd-color-card-footer);border-top:1px solid var(--sd-color-card-border)}.sd-card-footer:last-child{border-radius:0 0 calc(0.25rem - 1px) calc(0.25rem - 1px)}.sd-card-header-tabs{margin-right:-0.5rem;margin-bottom:-0.5rem;margin-left:-0.5rem;border-bottom:0}.sd-card-header-pills{margin-right:-0.5rem;margin-left:-0.5rem}.sd-card-img-overlay{position:absolute;top:0;right:0;bottom:0;left:0;padding:1rem;border-radius:calc(0.25rem - 1px)}.sd-card-img,.sd-card-img-bottom,.sd-card-img-top{width:100%}.sd-card-img,.sd-card-img-top{border-top-left-radius:calc(0.25rem - 1px);border-top-right-radius:calc(0.25rem - 1px)}.sd-card-img,.sd-card-img-bottom{border-bottom-left-radius:calc(0.25rem - 1px);border-bottom-right-radius:calc(0.25rem - 1px)}.sd-cards-carousel{width:100%;display:flex;flex-wrap:nowrap;-ms-flex-direction:row;flex-direction:row;overflow-x:hidden;scroll-snap-type:x mandatory}.sd-cards-carousel.sd-show-scrollbar{overflow-x:auto}.sd-cards-carousel:hover,.sd-cards-carousel:focus{overflow-x:auto}.sd-cards-carousel>.sd-card{flex-shrink:0;scroll-snap-align:start}.sd-cards-carousel>.sd-card:not(:last-child){margin-right:3px}.sd-card-cols-1>.sd-card{width:90%}.sd-card-cols-2>.sd-card{width:45%}.sd-card-cols-3>.sd-card{width:30%}.sd-card-cols-4>.sd-card{width:22.5%}.sd-card-cols-5>.sd-card{width:18%}.sd-card-cols-6>.sd-card{width:15%}.sd-card-cols-7>.sd-card{width:12.8571428571%}.sd-card-cols-8>.sd-card{width:11.25%}.sd-card-cols-9>.sd-card{width:10%}.sd-card-cols-10>.sd-card{width:9%}.sd-card-cols-11>.sd-card{width:8.1818181818%}.sd-card-cols-12>.sd-card{width:7.5%}.sd-container,.sd-container-fluid,.sd-container-lg,.sd-container-md,.sd-container-sm,.sd-container-xl{margin-left:auto;margin-right:auto;padding-left:var(--sd-gutter-x, 0.75rem);padding-right:var(--sd-gutter-x, 0.75rem);width:100%}@media(min-width: 576px){.sd-container-sm,.sd-container{max-width:540px}}@media(min-width: 768px){.sd-container-md,.sd-container-sm,.sd-container{max-width:720px}}@media(min-width: 992px){.sd-container-lg,.sd-container-md,.sd-container-sm,.sd-container{max-width:960px}}@media(min-width: 1200px){.sd-container-xl,.sd-container-lg,.sd-container-md,.sd-container-sm,.sd-container{max-width:1140px}}.sd-row{--sd-gutter-x: 1.5rem;--sd-gutter-y: 0;display:-ms-flexbox;display:flex;-ms-flex-wrap:wrap;flex-wrap:wrap;margin-top:calc(var(--sd-gutter-y) * -1);margin-right:calc(var(--sd-gutter-x) * -0.5);margin-left:calc(var(--sd-gutter-x) * -0.5)}.sd-row>*{box-sizing:border-box;flex-shrink:0;width:100%;max-width:100%;padding-right:calc(var(--sd-gutter-x) * 0.5);padding-left:calc(var(--sd-gutter-x) * 0.5);margin-top:var(--sd-gutter-y)}.sd-col{flex:1 0 0%;-ms-flex:1 0 0%}.sd-row-cols-auto>*{flex:0 0 auto;width:auto}.sd-row-cols-1>*{flex:0 0 auto;-ms-flex:0 0 auto;width:100%}.sd-row-cols-2>*{flex:0 0 auto;-ms-flex:0 0 auto;width:50%}.sd-row-cols-3>*{flex:0 0 auto;-ms-flex:0 0 auto;width:33.3333333333%}.sd-row-cols-4>*{flex:0 0 auto;-ms-flex:0 0 auto;width:25%}.sd-row-cols-5>*{flex:0 0 auto;-ms-flex:0 0 auto;width:20%}.sd-row-cols-6>*{flex:0 0 auto;-ms-flex:0 0 auto;width:16.6666666667%}.sd-row-cols-7>*{flex:0 0 auto;-ms-flex:0 0 auto;width:14.2857142857%}.sd-row-cols-8>*{flex:0 0 auto;-ms-flex:0 0 auto;width:12.5%}.sd-row-cols-9>*{flex:0 0 auto;-ms-flex:0 0 auto;width:11.1111111111%}.sd-row-cols-10>*{flex:0 0 auto;-ms-flex:0 0 auto;width:10%}.sd-row-cols-11>*{flex:0 0 auto;-ms-flex:0 0 auto;width:9.0909090909%}.sd-row-cols-12>*{flex:0 0 auto;-ms-flex:0 0 auto;width:8.3333333333%}@media(min-width: 576px){.sd-col-sm{flex:1 0 0%;-ms-flex:1 0 0%}.sd-row-cols-sm-auto{flex:1 0 auto;-ms-flex:1 0 auto;width:100%}.sd-row-cols-sm-1>*{flex:0 0 auto;-ms-flex:0 0 auto;width:100%}.sd-row-cols-sm-2>*{flex:0 0 auto;-ms-flex:0 0 auto;width:50%}.sd-row-cols-sm-3>*{flex:0 0 auto;-ms-flex:0 0 auto;width:33.3333333333%}.sd-row-cols-sm-4>*{flex:0 0 auto;-ms-flex:0 0 auto;width:25%}.sd-row-cols-sm-5>*{flex:0 0 auto;-ms-flex:0 0 auto;width:20%}.sd-row-cols-sm-6>*{flex:0 0 auto;-ms-flex:0 0 auto;width:16.6666666667%}.sd-row-cols-sm-7>*{flex:0 0 auto;-ms-flex:0 0 auto;width:14.2857142857%}.sd-row-cols-sm-8>*{flex:0 0 auto;-ms-flex:0 0 auto;width:12.5%}.sd-row-cols-sm-9>*{flex:0 0 auto;-ms-flex:0 0 auto;width:11.1111111111%}.sd-row-cols-sm-10>*{flex:0 0 auto;-ms-flex:0 0 auto;width:10%}.sd-row-cols-sm-11>*{flex:0 0 auto;-ms-flex:0 0 auto;width:9.0909090909%}.sd-row-cols-sm-12>*{flex:0 0 auto;-ms-flex:0 0 auto;width:8.3333333333%}}@media(min-width: 768px){.sd-col-md{flex:1 0 0%;-ms-flex:1 0 0%}.sd-row-cols-md-auto{flex:1 0 auto;-ms-flex:1 0 auto;width:100%}.sd-row-cols-md-1>*{flex:0 0 auto;-ms-flex:0 0 auto;width:100%}.sd-row-cols-md-2>*{flex:0 0 auto;-ms-flex:0 0 auto;width:50%}.sd-row-cols-md-3>*{flex:0 0 auto;-ms-flex:0 0 auto;width:33.3333333333%}.sd-row-cols-md-4>*{flex:0 0 auto;-ms-flex:0 0 auto;width:25%}.sd-row-cols-md-5>*{flex:0 0 auto;-ms-flex:0 0 auto;width:20%}.sd-row-cols-md-6>*{flex:0 0 auto;-ms-flex:0 0 auto;width:16.6666666667%}.sd-row-cols-md-7>*{flex:0 0 auto;-ms-flex:0 0 auto;width:14.2857142857%}.sd-row-cols-md-8>*{flex:0 0 auto;-ms-flex:0 0 auto;width:12.5%}.sd-row-cols-md-9>*{flex:0 0 auto;-ms-flex:0 0 auto;width:11.1111111111%}.sd-row-cols-md-10>*{flex:0 0 auto;-ms-flex:0 0 auto;width:10%}.sd-row-cols-md-11>*{flex:0 0 auto;-ms-flex:0 0 auto;width:9.0909090909%}.sd-row-cols-md-12>*{flex:0 0 auto;-ms-flex:0 0 auto;width:8.3333333333%}}@media(min-width: 992px){.sd-col-lg{flex:1 0 0%;-ms-flex:1 0 0%}.sd-row-cols-lg-auto{flex:1 0 auto;-ms-flex:1 0 auto;width:100%}.sd-row-cols-lg-1>*{flex:0 0 auto;-ms-flex:0 0 auto;width:100%}.sd-row-cols-lg-2>*{flex:0 0 auto;-ms-flex:0 0 auto;width:50%}.sd-row-cols-lg-3>*{flex:0 0 auto;-ms-flex:0 0 auto;width:33.3333333333%}.sd-row-cols-lg-4>*{flex:0 0 auto;-ms-flex:0 0 auto;width:25%}.sd-row-cols-lg-5>*{flex:0 0 auto;-ms-flex:0 0 auto;width:20%}.sd-row-cols-lg-6>*{flex:0 0 auto;-ms-flex:0 0 auto;width:16.6666666667%}.sd-row-cols-lg-7>*{flex:0 0 auto;-ms-flex:0 0 auto;width:14.2857142857%}.sd-row-cols-lg-8>*{flex:0 0 auto;-ms-flex:0 0 auto;width:12.5%}.sd-row-cols-lg-9>*{flex:0 0 auto;-ms-flex:0 0 auto;width:11.1111111111%}.sd-row-cols-lg-10>*{flex:0 0 auto;-ms-flex:0 0 auto;width:10%}.sd-row-cols-lg-11>*{flex:0 0 auto;-ms-flex:0 0 auto;width:9.0909090909%}.sd-row-cols-lg-12>*{flex:0 0 auto;-ms-flex:0 0 auto;width:8.3333333333%}}@media(min-width: 1200px){.sd-col-xl{flex:1 0 0%;-ms-flex:1 0 0%}.sd-row-cols-xl-auto{flex:1 0 auto;-ms-flex:1 0 auto;width:100%}.sd-row-cols-xl-1>*{flex:0 0 auto;-ms-flex:0 0 auto;width:100%}.sd-row-cols-xl-2>*{flex:0 0 auto;-ms-flex:0 0 auto;width:50%}.sd-row-cols-xl-3>*{flex:0 0 auto;-ms-flex:0 0 auto;width:33.3333333333%}.sd-row-cols-xl-4>*{flex:0 0 auto;-ms-flex:0 0 auto;width:25%}.sd-row-cols-xl-5>*{flex:0 0 auto;-ms-flex:0 0 auto;width:20%}.sd-row-cols-xl-6>*{flex:0 0 auto;-ms-flex:0 0 auto;width:16.6666666667%}.sd-row-cols-xl-7>*{flex:0 0 auto;-ms-flex:0 0 auto;width:14.2857142857%}.sd-row-cols-xl-8>*{flex:0 0 auto;-ms-flex:0 0 auto;width:12.5%}.sd-row-cols-xl-9>*{flex:0 0 auto;-ms-flex:0 0 auto;width:11.1111111111%}.sd-row-cols-xl-10>*{flex:0 0 auto;-ms-flex:0 0 auto;width:10%}.sd-row-cols-xl-11>*{flex:0 0 auto;-ms-flex:0 0 auto;width:9.0909090909%}.sd-row-cols-xl-12>*{flex:0 0 auto;-ms-flex:0 0 auto;width:8.3333333333%}}.sd-col-auto{flex:0 0 auto;-ms-flex:0 0 auto;width:auto}.sd-col-1{flex:0 0 auto;-ms-flex:0 0 auto;width:8.3333333333%}.sd-col-2{flex:0 0 auto;-ms-flex:0 0 auto;width:16.6666666667%}.sd-col-3{flex:0 0 auto;-ms-flex:0 0 auto;width:25%}.sd-col-4{flex:0 0 auto;-ms-flex:0 0 auto;width:33.3333333333%}.sd-col-5{flex:0 0 auto;-ms-flex:0 0 auto;width:41.6666666667%}.sd-col-6{flex:0 0 auto;-ms-flex:0 0 auto;width:50%}.sd-col-7{flex:0 0 auto;-ms-flex:0 0 auto;width:58.3333333333%}.sd-col-8{flex:0 0 auto;-ms-flex:0 0 auto;width:66.6666666667%}.sd-col-9{flex:0 0 auto;-ms-flex:0 0 auto;width:75%}.sd-col-10{flex:0 0 auto;-ms-flex:0 0 auto;width:83.3333333333%}.sd-col-11{flex:0 0 auto;-ms-flex:0 0 auto;width:91.6666666667%}.sd-col-12{flex:0 0 auto;-ms-flex:0 0 auto;width:100%}.sd-g-0,.sd-gy-0{--sd-gutter-y: 0}.sd-g-0,.sd-gx-0{--sd-gutter-x: 0}.sd-g-1,.sd-gy-1{--sd-gutter-y: 0.25rem}.sd-g-1,.sd-gx-1{--sd-gutter-x: 0.25rem}.sd-g-2,.sd-gy-2{--sd-gutter-y: 0.5rem}.sd-g-2,.sd-gx-2{--sd-gutter-x: 0.5rem}.sd-g-3,.sd-gy-3{--sd-gutter-y: 1rem}.sd-g-3,.sd-gx-3{--sd-gutter-x: 1rem}.sd-g-4,.sd-gy-4{--sd-gutter-y: 1.5rem}.sd-g-4,.sd-gx-4{--sd-gutter-x: 1.5rem}.sd-g-5,.sd-gy-5{--sd-gutter-y: 3rem}.sd-g-5,.sd-gx-5{--sd-gutter-x: 3rem}@media(min-width: 576px){.sd-col-sm-auto{-ms-flex:0 0 auto;flex:0 0 auto;width:auto}.sd-col-sm-1{-ms-flex:0 0 auto;flex:0 0 auto;width:8.3333333333%}.sd-col-sm-2{-ms-flex:0 0 auto;flex:0 0 auto;width:16.6666666667%}.sd-col-sm-3{-ms-flex:0 0 auto;flex:0 0 auto;width:25%}.sd-col-sm-4{-ms-flex:0 0 auto;flex:0 0 auto;width:33.3333333333%}.sd-col-sm-5{-ms-flex:0 0 auto;flex:0 0 auto;width:41.6666666667%}.sd-col-sm-6{-ms-flex:0 0 auto;flex:0 0 auto;width:50%}.sd-col-sm-7{-ms-flex:0 0 auto;flex:0 0 auto;width:58.3333333333%}.sd-col-sm-8{-ms-flex:0 0 auto;flex:0 0 auto;width:66.6666666667%}.sd-col-sm-9{-ms-flex:0 0 auto;flex:0 0 auto;width:75%}.sd-col-sm-10{-ms-flex:0 0 auto;flex:0 0 auto;width:83.3333333333%}.sd-col-sm-11{-ms-flex:0 0 auto;flex:0 0 auto;width:91.6666666667%}.sd-col-sm-12{-ms-flex:0 0 auto;flex:0 0 auto;width:100%}.sd-g-sm-0,.sd-gy-sm-0{--sd-gutter-y: 0}.sd-g-sm-0,.sd-gx-sm-0{--sd-gutter-x: 0}.sd-g-sm-1,.sd-gy-sm-1{--sd-gutter-y: 0.25rem}.sd-g-sm-1,.sd-gx-sm-1{--sd-gutter-x: 0.25rem}.sd-g-sm-2,.sd-gy-sm-2{--sd-gutter-y: 0.5rem}.sd-g-sm-2,.sd-gx-sm-2{--sd-gutter-x: 0.5rem}.sd-g-sm-3,.sd-gy-sm-3{--sd-gutter-y: 1rem}.sd-g-sm-3,.sd-gx-sm-3{--sd-gutter-x: 1rem}.sd-g-sm-4,.sd-gy-sm-4{--sd-gutter-y: 1.5rem}.sd-g-sm-4,.sd-gx-sm-4{--sd-gutter-x: 1.5rem}.sd-g-sm-5,.sd-gy-sm-5{--sd-gutter-y: 3rem}.sd-g-sm-5,.sd-gx-sm-5{--sd-gutter-x: 3rem}}@media(min-width: 768px){.sd-col-md-auto{-ms-flex:0 0 auto;flex:0 0 auto;width:auto}.sd-col-md-1{-ms-flex:0 0 auto;flex:0 0 auto;width:8.3333333333%}.sd-col-md-2{-ms-flex:0 0 auto;flex:0 0 auto;width:16.6666666667%}.sd-col-md-3{-ms-flex:0 0 auto;flex:0 0 auto;width:25%}.sd-col-md-4{-ms-flex:0 0 auto;flex:0 0 auto;width:33.3333333333%}.sd-col-md-5{-ms-flex:0 0 auto;flex:0 0 auto;width:41.6666666667%}.sd-col-md-6{-ms-flex:0 0 auto;flex:0 0 auto;width:50%}.sd-col-md-7{-ms-flex:0 0 auto;flex:0 0 auto;width:58.3333333333%}.sd-col-md-8{-ms-flex:0 0 auto;flex:0 0 auto;width:66.6666666667%}.sd-col-md-9{-ms-flex:0 0 auto;flex:0 0 auto;width:75%}.sd-col-md-10{-ms-flex:0 0 auto;flex:0 0 auto;width:83.3333333333%}.sd-col-md-11{-ms-flex:0 0 auto;flex:0 0 auto;width:91.6666666667%}.sd-col-md-12{-ms-flex:0 0 auto;flex:0 0 auto;width:100%}.sd-g-md-0,.sd-gy-md-0{--sd-gutter-y: 0}.sd-g-md-0,.sd-gx-md-0{--sd-gutter-x: 0}.sd-g-md-1,.sd-gy-md-1{--sd-gutter-y: 0.25rem}.sd-g-md-1,.sd-gx-md-1{--sd-gutter-x: 0.25rem}.sd-g-md-2,.sd-gy-md-2{--sd-gutter-y: 0.5rem}.sd-g-md-2,.sd-gx-md-2{--sd-gutter-x: 0.5rem}.sd-g-md-3,.sd-gy-md-3{--sd-gutter-y: 1rem}.sd-g-md-3,.sd-gx-md-3{--sd-gutter-x: 1rem}.sd-g-md-4,.sd-gy-md-4{--sd-gutter-y: 1.5rem}.sd-g-md-4,.sd-gx-md-4{--sd-gutter-x: 1.5rem}.sd-g-md-5,.sd-gy-md-5{--sd-gutter-y: 3rem}.sd-g-md-5,.sd-gx-md-5{--sd-gutter-x: 3rem}}@media(min-width: 992px){.sd-col-lg-auto{-ms-flex:0 0 auto;flex:0 0 auto;width:auto}.sd-col-lg-1{-ms-flex:0 0 auto;flex:0 0 auto;width:8.3333333333%}.sd-col-lg-2{-ms-flex:0 0 auto;flex:0 0 auto;width:16.6666666667%}.sd-col-lg-3{-ms-flex:0 0 auto;flex:0 0 auto;width:25%}.sd-col-lg-4{-ms-flex:0 0 auto;flex:0 0 auto;width:33.3333333333%}.sd-col-lg-5{-ms-flex:0 0 auto;flex:0 0 auto;width:41.6666666667%}.sd-col-lg-6{-ms-flex:0 0 auto;flex:0 0 auto;width:50%}.sd-col-lg-7{-ms-flex:0 0 auto;flex:0 0 auto;width:58.3333333333%}.sd-col-lg-8{-ms-flex:0 0 auto;flex:0 0 auto;width:66.6666666667%}.sd-col-lg-9{-ms-flex:0 0 auto;flex:0 0 auto;width:75%}.sd-col-lg-10{-ms-flex:0 0 auto;flex:0 0 auto;width:83.3333333333%}.sd-col-lg-11{-ms-flex:0 0 auto;flex:0 0 auto;width:91.6666666667%}.sd-col-lg-12{-ms-flex:0 0 auto;flex:0 0 auto;width:100%}.sd-g-lg-0,.sd-gy-lg-0{--sd-gutter-y: 0}.sd-g-lg-0,.sd-gx-lg-0{--sd-gutter-x: 0}.sd-g-lg-1,.sd-gy-lg-1{--sd-gutter-y: 0.25rem}.sd-g-lg-1,.sd-gx-lg-1{--sd-gutter-x: 0.25rem}.sd-g-lg-2,.sd-gy-lg-2{--sd-gutter-y: 0.5rem}.sd-g-lg-2,.sd-gx-lg-2{--sd-gutter-x: 0.5rem}.sd-g-lg-3,.sd-gy-lg-3{--sd-gutter-y: 1rem}.sd-g-lg-3,.sd-gx-lg-3{--sd-gutter-x: 1rem}.sd-g-lg-4,.sd-gy-lg-4{--sd-gutter-y: 1.5rem}.sd-g-lg-4,.sd-gx-lg-4{--sd-gutter-x: 1.5rem}.sd-g-lg-5,.sd-gy-lg-5{--sd-gutter-y: 3rem}.sd-g-lg-5,.sd-gx-lg-5{--sd-gutter-x: 3rem}}@media(min-width: 1200px){.sd-col-xl-auto{-ms-flex:0 0 auto;flex:0 0 auto;width:auto}.sd-col-xl-1{-ms-flex:0 0 auto;flex:0 0 auto;width:8.3333333333%}.sd-col-xl-2{-ms-flex:0 0 auto;flex:0 0 auto;width:16.6666666667%}.sd-col-xl-3{-ms-flex:0 0 auto;flex:0 0 auto;width:25%}.sd-col-xl-4{-ms-flex:0 0 auto;flex:0 0 auto;width:33.3333333333%}.sd-col-xl-5{-ms-flex:0 0 auto;flex:0 0 auto;width:41.6666666667%}.sd-col-xl-6{-ms-flex:0 0 auto;flex:0 0 auto;width:50%}.sd-col-xl-7{-ms-flex:0 0 auto;flex:0 0 auto;width:58.3333333333%}.sd-col-xl-8{-ms-flex:0 0 auto;flex:0 0 auto;width:66.6666666667%}.sd-col-xl-9{-ms-flex:0 0 auto;flex:0 0 auto;width:75%}.sd-col-xl-10{-ms-flex:0 0 auto;flex:0 0 auto;width:83.3333333333%}.sd-col-xl-11{-ms-flex:0 0 auto;flex:0 0 auto;width:91.6666666667%}.sd-col-xl-12{-ms-flex:0 0 auto;flex:0 0 auto;width:100%}.sd-g-xl-0,.sd-gy-xl-0{--sd-gutter-y: 0}.sd-g-xl-0,.sd-gx-xl-0{--sd-gutter-x: 0}.sd-g-xl-1,.sd-gy-xl-1{--sd-gutter-y: 0.25rem}.sd-g-xl-1,.sd-gx-xl-1{--sd-gutter-x: 0.25rem}.sd-g-xl-2,.sd-gy-xl-2{--sd-gutter-y: 0.5rem}.sd-g-xl-2,.sd-gx-xl-2{--sd-gutter-x: 0.5rem}.sd-g-xl-3,.sd-gy-xl-3{--sd-gutter-y: 1rem}.sd-g-xl-3,.sd-gx-xl-3{--sd-gutter-x: 1rem}.sd-g-xl-4,.sd-gy-xl-4{--sd-gutter-y: 1.5rem}.sd-g-xl-4,.sd-gx-xl-4{--sd-gutter-x: 1.5rem}.sd-g-xl-5,.sd-gy-xl-5{--sd-gutter-y: 3rem}.sd-g-xl-5,.sd-gx-xl-5{--sd-gutter-x: 3rem}}.sd-flex-row-reverse{flex-direction:row-reverse !important}details.sd-dropdown{position:relative}details.sd-dropdown .sd-summary-title{font-weight:700;padding-right:3em !important;-moz-user-select:none;-ms-user-select:none;-webkit-user-select:none;user-select:none}details.sd-dropdown:hover{cursor:pointer}details.sd-dropdown .sd-summary-content{cursor:default}details.sd-dropdown summary{list-style:none;padding:1em}details.sd-dropdown summary .sd-octicon.no-title{vertical-align:middle}details.sd-dropdown[open] summary .sd-octicon.no-title{visibility:hidden}details.sd-dropdown summary::-webkit-details-marker{display:none}details.sd-dropdown summary:focus{outline:none}details.sd-dropdown .sd-summary-icon{margin-right:.5em}details.sd-dropdown .sd-summary-icon svg{opacity:.8}details.sd-dropdown summary:hover .sd-summary-up svg,details.sd-dropdown summary:hover .sd-summary-down svg{opacity:1;transform:scale(1.1)}details.sd-dropdown .sd-summary-up svg,details.sd-dropdown .sd-summary-down svg{display:block;opacity:.6}details.sd-dropdown .sd-summary-up,details.sd-dropdown .sd-summary-down{pointer-events:none;position:absolute;right:1em;top:1em}details.sd-dropdown[open]>.sd-summary-title .sd-summary-down{visibility:hidden}details.sd-dropdown:not([open])>.sd-summary-title .sd-summary-up{visibility:hidden}details.sd-dropdown:not([open]).sd-card{border:none}details.sd-dropdown:not([open])>.sd-card-header{border:1px solid var(--sd-color-card-border);border-radius:.25rem}details.sd-dropdown.sd-fade-in[open] summary~*{-moz-animation:sd-fade-in .5s ease-in-out;-webkit-animation:sd-fade-in .5s ease-in-out;animation:sd-fade-in .5s ease-in-out}details.sd-dropdown.sd-fade-in-slide-down[open] summary~*{-moz-animation:sd-fade-in .5s ease-in-out,sd-slide-down .5s ease-in-out;-webkit-animation:sd-fade-in .5s ease-in-out,sd-slide-down .5s ease-in-out;animation:sd-fade-in .5s ease-in-out,sd-slide-down .5s ease-in-out}.sd-col>.sd-dropdown{width:100%}.sd-summary-content>.sd-tab-set:first-child{margin-top:0}@keyframes sd-fade-in{0%{opacity:0}100%{opacity:1}}@keyframes sd-slide-down{0%{transform:translate(0, -10px)}100%{transform:translate(0, 0)}}.sd-tab-set{border-radius:.125rem;display:flex;flex-wrap:wrap;margin:1em 0;position:relative}.sd-tab-set>input{opacity:0;position:absolute}.sd-tab-set>input:checked+label{border-color:var(--sd-color-tabs-underline-active);color:var(--sd-color-tabs-label-active)}.sd-tab-set>input:checked+label+.sd-tab-content{display:block}.sd-tab-set>input:not(:checked)+label:hover{color:var(--sd-color-tabs-label-hover);border-color:var(--sd-color-tabs-underline-hover)}.sd-tab-set>input:focus+label{outline-style:auto}.sd-tab-set>input:not(.focus-visible)+label{outline:none;-webkit-tap-highlight-color:transparent}.sd-tab-set>label{border-bottom:.125rem solid transparent;margin-bottom:0;color:var(--sd-color-tabs-label-inactive);border-color:var(--sd-color-tabs-underline-inactive);cursor:pointer;font-size:var(--sd-fontsize-tabs-label);font-weight:700;padding:1em 1.25em .5em;transition:color 250ms;width:auto;z-index:1}html .sd-tab-set>label:hover{color:var(--sd-color-tabs-label-active)}.sd-col>.sd-tab-set{width:100%}.sd-tab-content{box-shadow:0 -0.0625rem var(--sd-color-tabs-overline),0 .0625rem var(--sd-color-tabs-underline);display:none;order:99;padding-bottom:.75rem;padding-top:.75rem;width:100%}.sd-tab-content>:first-child{margin-top:0 !important}.sd-tab-content>:last-child{margin-bottom:0 !important}.sd-tab-content>.sd-tab-set{margin:0}.sd-sphinx-override,.sd-sphinx-override *{-moz-box-sizing:border-box;-webkit-box-sizing:border-box;box-sizing:border-box}.sd-sphinx-override p{margin-top:0}:root{--sd-color-primary: #0071bc;--sd-color-secondary: #6c757d;--sd-color-success: #28a745;--sd-color-info: #17a2b8;--sd-color-warning: #f0b37e;--sd-color-danger: #dc3545;--sd-color-light: #f8f9fa;--sd-color-muted: #6c757d;--sd-color-dark: #212529;--sd-color-black: black;--sd-color-white: white;--sd-color-primary-highlight: #0060a0;--sd-color-secondary-highlight: #5c636a;--sd-color-success-highlight: #228e3b;--sd-color-info-highlight: #148a9c;--sd-color-warning-highlight: #cc986b;--sd-color-danger-highlight: #bb2d3b;--sd-color-light-highlight: #d3d4d5;--sd-color-muted-highlight: #5c636a;--sd-color-dark-highlight: #1c1f23;--sd-color-black-highlight: black;--sd-color-white-highlight: #d9d9d9;--sd-color-primary-text: #fff;--sd-color-secondary-text: #fff;--sd-color-success-text: #fff;--sd-color-info-text: #fff;--sd-color-warning-text: #212529;--sd-color-danger-text: #fff;--sd-color-light-text: #212529;--sd-color-muted-text: #fff;--sd-color-dark-text: #fff;--sd-color-black-text: #fff;--sd-color-white-text: #212529;--sd-color-shadow: rgba(0, 0, 0, 0.15);--sd-color-card-border: rgba(0, 0, 0, 0.125);--sd-color-card-border-hover: hsla(231, 99%, 66%, 1);--sd-color-card-background: transparent;--sd-color-card-text: inherit;--sd-color-card-header: transparent;--sd-color-card-footer: transparent;--sd-color-tabs-label-active: hsla(231, 99%, 66%, 1);--sd-color-tabs-label-hover: hsla(231, 99%, 66%, 1);--sd-color-tabs-label-inactive: hsl(0, 0%, 66%);--sd-color-tabs-underline-active: hsla(231, 99%, 66%, 1);--sd-color-tabs-underline-hover: rgba(178, 206, 245, 0.62);--sd-color-tabs-underline-inactive: transparent;--sd-color-tabs-overline: rgb(222, 222, 222);--sd-color-tabs-underline: rgb(222, 222, 222);--sd-fontsize-tabs-label: 1rem} diff --git a/_preview/468/_static/design-tabs.js b/_preview/468/_static/design-tabs.js new file mode 100644 index 000000000..36b38cf0d --- /dev/null +++ b/_preview/468/_static/design-tabs.js @@ -0,0 +1,27 @@ +var sd_labels_by_text = {}; + +function ready() { + const li = document.getElementsByClassName("sd-tab-label"); + for (const label of li) { + syncId = label.getAttribute("data-sync-id"); + if (syncId) { + label.onclick = onLabelClick; + if (!sd_labels_by_text[syncId]) { + sd_labels_by_text[syncId] = []; + } + sd_labels_by_text[syncId].push(label); + } + } +} + +function onLabelClick() { + // Activate other inputs with the same sync id. + syncId = this.getAttribute("data-sync-id"); + for (label of sd_labels_by_text[syncId]) { + if (label === this) continue; + label.previousElementSibling.checked = true; + } + window.localStorage.setItem("sphinx-design-last-tab", syncId); +} + +document.addEventListener("DOMContentLoaded", ready, false); diff --git a/_preview/468/_static/doctools.js b/_preview/468/_static/doctools.js new file mode 100644 index 000000000..4d67807d1 --- /dev/null +++ b/_preview/468/_static/doctools.js @@ -0,0 +1,156 @@ +/* + * doctools.js + * ~~~~~~~~~~~ + * + * Base JavaScript utilities for all Sphinx HTML documentation. + * + * :copyright: Copyright 2007-2024 by the Sphinx team, see AUTHORS. + * :license: BSD, see LICENSE for details. + * + */ +"use strict"; + +const BLACKLISTED_KEY_CONTROL_ELEMENTS = new Set([ + "TEXTAREA", + "INPUT", + "SELECT", + "BUTTON", +]); + +const _ready = (callback) => { + if (document.readyState !== "loading") { + callback(); + } else { + document.addEventListener("DOMContentLoaded", callback); + } +}; + +/** + * Small JavaScript module for the documentation. + */ +const Documentation = { + init: () => { + Documentation.initDomainIndexTable(); + Documentation.initOnKeyListeners(); + }, + + /** + * i18n support + */ + TRANSLATIONS: {}, + PLURAL_EXPR: (n) => (n === 1 ? 0 : 1), + LOCALE: "unknown", + + // gettext and ngettext don't access this so that the functions + // can safely bound to a different name (_ = Documentation.gettext) + gettext: (string) => { + const translated = Documentation.TRANSLATIONS[string]; + switch (typeof translated) { + case "undefined": + return string; // no translation + case "string": + return translated; // translation exists + default: + return translated[0]; // (singular, plural) translation tuple exists + } + }, + + ngettext: (singular, plural, n) => { + const translated = Documentation.TRANSLATIONS[singular]; + if (typeof translated !== "undefined") + return translated[Documentation.PLURAL_EXPR(n)]; + return n === 1 ? singular : plural; + }, + + addTranslations: (catalog) => { + Object.assign(Documentation.TRANSLATIONS, catalog.messages); + Documentation.PLURAL_EXPR = new Function( + "n", + `return (${catalog.plural_expr})` + ); + Documentation.LOCALE = catalog.locale; + }, + + /** + * helper function to focus on search bar + */ + focusSearchBar: () => { + document.querySelectorAll("input[name=q]")[0]?.focus(); + }, + + /** + * Initialise the domain index toggle buttons + */ + initDomainIndexTable: () => { + const toggler = (el) => { + const idNumber = el.id.substr(7); + const toggledRows = document.querySelectorAll(`tr.cg-${idNumber}`); + if (el.src.substr(-9) === "minus.png") { + el.src = `${el.src.substr(0, el.src.length - 9)}plus.png`; + toggledRows.forEach((el) => (el.style.display = "none")); + } else { + el.src = `${el.src.substr(0, el.src.length - 8)}minus.png`; + toggledRows.forEach((el) => (el.style.display = "")); + } + }; + + const togglerElements = document.querySelectorAll("img.toggler"); + togglerElements.forEach((el) => + el.addEventListener("click", (event) => toggler(event.currentTarget)) + ); + togglerElements.forEach((el) => (el.style.display = "")); + if (DOCUMENTATION_OPTIONS.COLLAPSE_INDEX) togglerElements.forEach(toggler); + }, + + initOnKeyListeners: () => { + // only install a listener if it is really needed + if ( + !DOCUMENTATION_OPTIONS.NAVIGATION_WITH_KEYS && + !DOCUMENTATION_OPTIONS.ENABLE_SEARCH_SHORTCUTS + ) + return; + + document.addEventListener("keydown", (event) => { + // bail for input elements + if (BLACKLISTED_KEY_CONTROL_ELEMENTS.has(document.activeElement.tagName)) return; + // bail with special keys + if (event.altKey || event.ctrlKey || event.metaKey) return; + + if (!event.shiftKey) { + switch (event.key) { + case "ArrowLeft": + if (!DOCUMENTATION_OPTIONS.NAVIGATION_WITH_KEYS) break; + + const prevLink = document.querySelector('link[rel="prev"]'); + if (prevLink && prevLink.href) { + window.location.href = prevLink.href; + event.preventDefault(); + } + break; + case "ArrowRight": + if (!DOCUMENTATION_OPTIONS.NAVIGATION_WITH_KEYS) break; + + const nextLink = document.querySelector('link[rel="next"]'); + if (nextLink && nextLink.href) { + window.location.href = nextLink.href; + event.preventDefault(); + } + break; + } + } + + // some keyboard layouts may need Shift to get / + switch (event.key) { + case "/": + if (!DOCUMENTATION_OPTIONS.ENABLE_SEARCH_SHORTCUTS) break; + Documentation.focusSearchBar(); + event.preventDefault(); + } + }); + }, +}; + +// quick alias for translations +const _ = Documentation.gettext; + +_ready(Documentation.init); diff --git a/_preview/468/_static/documentation_options.js b/_preview/468/_static/documentation_options.js new file mode 100644 index 000000000..dab586c0d --- /dev/null +++ b/_preview/468/_static/documentation_options.js @@ -0,0 +1,13 @@ +const DOCUMENTATION_OPTIONS = { + VERSION: '', + LANGUAGE: 'en', + COLLAPSE_INDEX: false, + BUILDER: 'html', + FILE_SUFFIX: '.html', + LINK_SUFFIX: '.html', + HAS_SOURCE: true, + SOURCELINK_SUFFIX: '', + NAVIGATION_WITH_KEYS: false, + SHOW_SEARCH_SUMMARY: true, + ENABLE_SEARCH_SHORTCUTS: true, +}; \ No newline at end of file diff --git a/_preview/468/_static/favicon.ico b/_preview/468/_static/favicon.ico new file mode 100644 index 000000000..da6ac735a Binary files /dev/null and b/_preview/468/_static/favicon.ico differ diff --git a/_preview/468/_static/file.png b/_preview/468/_static/file.png new file mode 100644 index 000000000..a858a410e Binary files /dev/null and b/_preview/468/_static/file.png differ diff --git a/_preview/468/_static/footer-logo-nsf.png b/_preview/468/_static/footer-logo-nsf.png new file mode 100644 index 000000000..11c788f2a Binary files /dev/null and b/_preview/468/_static/footer-logo-nsf.png differ diff --git a/_preview/468/_static/images/logo_binder.svg b/_preview/468/_static/images/logo_binder.svg new file mode 100644 index 000000000..45fecf751 --- /dev/null +++ b/_preview/468/_static/images/logo_binder.svg @@ -0,0 +1,19 @@ + + + diff --git a/_preview/468/_static/images/logo_colab.png b/_preview/468/_static/images/logo_colab.png new file mode 100644 index 000000000..b7560ec21 Binary files /dev/null and b/_preview/468/_static/images/logo_colab.png differ diff --git a/_preview/468/_static/images/logo_deepnote.svg b/_preview/468/_static/images/logo_deepnote.svg new file mode 100644 index 000000000..fa77ebfc2 --- /dev/null +++ b/_preview/468/_static/images/logo_deepnote.svg @@ -0,0 +1 @@ + diff --git a/_preview/468/_static/images/logo_jupyterhub.svg b/_preview/468/_static/images/logo_jupyterhub.svg new file mode 100644 index 000000000..60cfe9f22 --- /dev/null +++ b/_preview/468/_static/images/logo_jupyterhub.svg @@ -0,0 +1 @@ + diff --git a/_preview/468/_static/language_data.js b/_preview/468/_static/language_data.js new file mode 100644 index 000000000..367b8ed81 --- /dev/null +++ b/_preview/468/_static/language_data.js @@ -0,0 +1,199 @@ +/* + * language_data.js + * ~~~~~~~~~~~~~~~~ + * + * This script contains the language-specific data used by searchtools.js, + * namely the list of stopwords, stemmer, scorer and splitter. + * + * :copyright: Copyright 2007-2024 by the Sphinx team, see AUTHORS. + * :license: BSD, see LICENSE for details. + * + */ + +var stopwords = ["a", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in", "into", "is", "it", "near", "no", "not", "of", "on", "or", "such", "that", "the", "their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]; + + +/* Non-minified version is copied as a separate JS file, if available */ + +/** + * Porter Stemmer + */ +var Stemmer = function() { + + var step2list = { + ational: 'ate', + tional: 'tion', + enci: 'ence', + anci: 'ance', + izer: 'ize', + bli: 'ble', + alli: 'al', + entli: 'ent', + eli: 'e', + ousli: 'ous', + ization: 'ize', + ation: 'ate', + ator: 'ate', + alism: 'al', + iveness: 'ive', + fulness: 'ful', + ousness: 'ous', + aliti: 'al', + iviti: 'ive', + biliti: 'ble', + logi: 'log' + }; + + var step3list = { + icate: 'ic', + ative: '', + alize: 'al', + iciti: 'ic', + ical: 'ic', + ful: '', + ness: '' + }; + + var c = "[^aeiou]"; // consonant + var v = "[aeiouy]"; // vowel + var C = c + "[^aeiouy]*"; // consonant sequence + var V = v + "[aeiou]*"; // vowel sequence + + var mgr0 = "^(" + C + ")?" + V + C; // [C]VC... is m>0 + var meq1 = "^(" + C + ")?" + V + C + "(" + V + ")?$"; // [C]VC[V] is m=1 + var mgr1 = "^(" + C + ")?" + V + C + V + C; // [C]VCVC... is m>1 + var s_v = "^(" + C + ")?" + v; // vowel in stem + + this.stemWord = function (w) { + var stem; + var suffix; + var firstch; + var origword = w; + + if (w.length < 3) + return w; + + var re; + var re2; + var re3; + var re4; + + firstch = w.substr(0,1); + if (firstch == "y") + w = firstch.toUpperCase() + w.substr(1); + + // Step 1a + re = /^(.+?)(ss|i)es$/; + re2 = /^(.+?)([^s])s$/; + + if (re.test(w)) + w = w.replace(re,"$1$2"); + else if (re2.test(w)) + w = w.replace(re2,"$1$2"); + + // Step 1b + re = /^(.+?)eed$/; + re2 = /^(.+?)(ed|ing)$/; + if (re.test(w)) { + var fp = re.exec(w); + re = new RegExp(mgr0); + if (re.test(fp[1])) { + re = /.$/; + w = w.replace(re,""); + } + } + else if (re2.test(w)) { + var fp = re2.exec(w); + stem = fp[1]; + re2 = new RegExp(s_v); + if (re2.test(stem)) { + w = stem; + re2 = /(at|bl|iz)$/; + re3 = new RegExp("([^aeiouylsz])\\1$"); + re4 = new RegExp("^" + C + v + "[^aeiouwxy]$"); + if (re2.test(w)) + w = w + "e"; + else if (re3.test(w)) { + re = /.$/; + w = w.replace(re,""); + } + else if (re4.test(w)) + w = w + "e"; + } + } + + // Step 1c + re = /^(.+?)y$/; + if (re.test(w)) { + var fp = re.exec(w); + stem = fp[1]; + re = new RegExp(s_v); + if (re.test(stem)) + w = stem + "i"; + } + + // Step 2 + re = /^(.+?)(ational|tional|enci|anci|izer|bli|alli|entli|eli|ousli|ization|ation|ator|alism|iveness|fulness|ousness|aliti|iviti|biliti|logi)$/; + if (re.test(w)) { + var fp = re.exec(w); + stem = fp[1]; + suffix = fp[2]; + re = new RegExp(mgr0); + if (re.test(stem)) + w = stem + step2list[suffix]; + } + + // Step 3 + re = /^(.+?)(icate|ative|alize|iciti|ical|ful|ness)$/; + if (re.test(w)) { + var fp = re.exec(w); + stem = fp[1]; + suffix = fp[2]; + re = new RegExp(mgr0); + if (re.test(stem)) + w = stem + step3list[suffix]; + } + + // Step 4 + re = /^(.+?)(al|ance|ence|er|ic|able|ible|ant|ement|ment|ent|ou|ism|ate|iti|ous|ive|ize)$/; + re2 = /^(.+?)(s|t)(ion)$/; + if (re.test(w)) { + var fp = re.exec(w); + stem = fp[1]; + re = new RegExp(mgr1); + if (re.test(stem)) + w = stem; + } + else if (re2.test(w)) { + var fp = re2.exec(w); + stem = fp[1] + fp[2]; + re2 = new RegExp(mgr1); + if (re2.test(stem)) + w = stem; + } + + // Step 5 + re = /^(.+?)e$/; + if (re.test(w)) { + var fp = re.exec(w); + stem = fp[1]; + re = new RegExp(mgr1); + re2 = new RegExp(meq1); + re3 = new RegExp("^" + C + v + "[^aeiouwxy]$"); + if (re.test(stem) || (re2.test(stem) && !(re3.test(stem)))) + w = stem; + } + re = /ll$/; + re2 = new RegExp(mgr1); + if (re.test(w) && re2.test(w)) { + re = /.$/; + w = w.replace(re,""); + } + + // and turn initial Y back to y + if (firstch == "y") + w = firstch.toLowerCase() + w.substr(1); + return w; + } +} + diff --git a/_preview/468/_static/locales/ar/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/ar/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..15541a6a3 Binary files /dev/null and b/_preview/468/_static/locales/ar/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/ar/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/ar/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..edae2ec41 --- /dev/null +++ b/_preview/468/_static/locales/ar/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: ar\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "موضوع بواسطة" + +msgid "Open an issue" +msgstr "افتح قضية" + +msgid "Contents" +msgstr "محتويات" + +msgid "Download notebook file" +msgstr "تنزيل ملف دفتر الملاحظات" + +msgid "Sphinx Book Theme" +msgstr "موضوع كتاب أبو الهول" + +msgid "Fullscreen mode" +msgstr "وضع ملء الشاشة" + +msgid "Edit this page" +msgstr "قم بتحرير هذه الصفحة" + +msgid "By" +msgstr "بواسطة" + +msgid "Copyright" +msgstr "حقوق النشر" + +msgid "Source repository" +msgstr "مستودع المصدر" + +msgid "previous page" +msgstr "الصفحة السابقة" + +msgid "next page" +msgstr "الصفحة التالية" + +msgid "Toggle navigation" +msgstr "تبديل التنقل" + +msgid "repository" +msgstr "مخزن" + +msgid "suggest edit" +msgstr "أقترح تحرير" + +msgid "open issue" +msgstr "قضية مفتوحة" + +msgid "Launch" +msgstr "إطلاق" + +msgid "Print to PDF" +msgstr "طباعة إلى PDF" + +msgid "By the" +msgstr "بواسطة" + +msgid "Last updated on" +msgstr "آخر تحديث في" + +msgid "Download source file" +msgstr "تنزيل ملف المصدر" + +msgid "Download this page" +msgstr "قم بتنزيل هذه الصفحة" diff --git a/_preview/468/_static/locales/bg/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/bg/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..da9512003 Binary files /dev/null and b/_preview/468/_static/locales/bg/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/bg/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/bg/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..1f363b9d1 --- /dev/null +++ b/_preview/468/_static/locales/bg/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: bg\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Тема от" + +msgid "Open an issue" +msgstr "Отворете проблем" + +msgid "Contents" +msgstr "Съдържание" + +msgid "Download notebook file" +msgstr "Изтеглете файла на бележника" + +msgid "Sphinx Book Theme" +msgstr "Тема на книгата Sphinx" + +msgid "Fullscreen mode" +msgstr "Режим на цял екран" + +msgid "Edit this page" +msgstr "Редактирайте тази страница" + +msgid "By" +msgstr "От" + +msgid "Copyright" +msgstr "Авторско право" + +msgid "Source repository" +msgstr "Хранилище на източника" + +msgid "previous page" +msgstr "предишна страница" + +msgid "next page" +msgstr "Следваща страница" + +msgid "Toggle navigation" +msgstr "Превключване на навигацията" + +msgid "repository" +msgstr "хранилище" + +msgid "suggest edit" +msgstr "предложи редактиране" + +msgid "open issue" +msgstr "отворен брой" + +msgid "Launch" +msgstr "Стартиране" + +msgid "Print to PDF" +msgstr "Печат в PDF" + +msgid "By the" +msgstr "По" + +msgid "Last updated on" +msgstr "Последна актуализация на" + +msgid "Download source file" +msgstr "Изтеглете изходния файл" + +msgid "Download this page" +msgstr "Изтеглете тази страница" diff --git a/_preview/468/_static/locales/bn/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/bn/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..6b96639b7 Binary files /dev/null and b/_preview/468/_static/locales/bn/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/bn/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/bn/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..fa5437286 --- /dev/null +++ b/_preview/468/_static/locales/bn/LC_MESSAGES/booktheme.po @@ -0,0 +1,63 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: bn\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "থিম দ্বারা" + +msgid "Open an issue" +msgstr "একটি সমস্যা খুলুন" + +msgid "Download notebook file" +msgstr "নোটবুক ফাইল ডাউনলোড করুন" + +msgid "Sphinx Book Theme" +msgstr "স্পিনিক্স বুক থিম" + +msgid "Edit this page" +msgstr "এই পৃষ্ঠাটি সম্পাদনা করুন" + +msgid "By" +msgstr "দ্বারা" + +msgid "Copyright" +msgstr "কপিরাইট" + +msgid "Source repository" +msgstr "উত্স সংগ্রহস্থল" + +msgid "previous page" +msgstr "আগের পৃষ্ঠা" + +msgid "next page" +msgstr "পরবর্তী পৃষ্ঠা" + +msgid "Toggle navigation" +msgstr "নেভিগেশন টগল করুন" + +msgid "open issue" +msgstr "খোলা সমস্যা" + +msgid "Launch" +msgstr "শুরু করা" + +msgid "Print to PDF" +msgstr "পিডিএফ প্রিন্ট করুন" + +msgid "By the" +msgstr "দ্বারা" + +msgid "Last updated on" +msgstr "সর্বশেষ আপডেট" + +msgid "Download source file" +msgstr "উত্স ফাইল ডাউনলোড করুন" + +msgid "Download this page" +msgstr "এই পৃষ্ঠাটি ডাউনলোড করুন" diff --git a/_preview/468/_static/locales/ca/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/ca/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..a4dd30e9b Binary files /dev/null and b/_preview/468/_static/locales/ca/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/ca/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/ca/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..22f1569aa --- /dev/null +++ b/_preview/468/_static/locales/ca/LC_MESSAGES/booktheme.po @@ -0,0 +1,66 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: ca\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema del" + +msgid "Open an issue" +msgstr "Obriu un número" + +msgid "Download notebook file" +msgstr "Descarregar fitxer de quadern" + +msgid "Sphinx Book Theme" +msgstr "Tema del llibre Esfinx" + +msgid "Edit this page" +msgstr "Editeu aquesta pàgina" + +msgid "By" +msgstr "Per" + +msgid "Copyright" +msgstr "Copyright" + +msgid "Source repository" +msgstr "Dipòsit de fonts" + +msgid "previous page" +msgstr "Pàgina anterior" + +msgid "next page" +msgstr "pàgina següent" + +msgid "Toggle navigation" +msgstr "Commuta la navegació" + +msgid "suggest edit" +msgstr "suggerir edició" + +msgid "open issue" +msgstr "número obert" + +msgid "Launch" +msgstr "Llançament" + +msgid "Print to PDF" +msgstr "Imprimeix a PDF" + +msgid "By the" +msgstr "Per la" + +msgid "Last updated on" +msgstr "Darrera actualització el" + +msgid "Download source file" +msgstr "Baixeu el fitxer font" + +msgid "Download this page" +msgstr "Descarregueu aquesta pàgina" diff --git a/_preview/468/_static/locales/cs/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/cs/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..c39e01a6a Binary files /dev/null and b/_preview/468/_static/locales/cs/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/cs/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/cs/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..afecd9e79 --- /dev/null +++ b/_preview/468/_static/locales/cs/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: cs\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Téma od" + +msgid "Open an issue" +msgstr "Otevřete problém" + +msgid "Contents" +msgstr "Obsah" + +msgid "Download notebook file" +msgstr "Stáhnout soubor poznámkového bloku" + +msgid "Sphinx Book Theme" +msgstr "Téma knihy Sfinga" + +msgid "Fullscreen mode" +msgstr "Režim celé obrazovky" + +msgid "Edit this page" +msgstr "Upravit tuto stránku" + +msgid "By" +msgstr "Podle" + +msgid "Copyright" +msgstr "autorská práva" + +msgid "Source repository" +msgstr "Zdrojové úložiště" + +msgid "previous page" +msgstr "předchozí stránka" + +msgid "next page" +msgstr "další strana" + +msgid "Toggle navigation" +msgstr "Přepnout navigaci" + +msgid "repository" +msgstr "úložiště" + +msgid "suggest edit" +msgstr "navrhnout úpravy" + +msgid "open issue" +msgstr "otevřené číslo" + +msgid "Launch" +msgstr "Zahájení" + +msgid "Print to PDF" +msgstr "Tisk do PDF" + +msgid "By the" +msgstr "Podle" + +msgid "Last updated on" +msgstr "Naposledy aktualizováno" + +msgid "Download source file" +msgstr "Stáhněte si zdrojový soubor" + +msgid "Download this page" +msgstr "Stáhněte si tuto stránku" diff --git a/_preview/468/_static/locales/da/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/da/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..f43157d70 Binary files /dev/null and b/_preview/468/_static/locales/da/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/da/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/da/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..649c78a8d --- /dev/null +++ b/_preview/468/_static/locales/da/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: da\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema af" + +msgid "Open an issue" +msgstr "Åbn et problem" + +msgid "Contents" +msgstr "Indhold" + +msgid "Download notebook file" +msgstr "Download notesbog-fil" + +msgid "Sphinx Book Theme" +msgstr "Sphinx bogtema" + +msgid "Fullscreen mode" +msgstr "Fuldskærmstilstand" + +msgid "Edit this page" +msgstr "Rediger denne side" + +msgid "By" +msgstr "Ved" + +msgid "Copyright" +msgstr "ophavsret" + +msgid "Source repository" +msgstr "Kildelager" + +msgid "previous page" +msgstr "forrige side" + +msgid "next page" +msgstr "Næste side" + +msgid "Toggle navigation" +msgstr "Skift navigation" + +msgid "repository" +msgstr "lager" + +msgid "suggest edit" +msgstr "foreslå redigering" + +msgid "open issue" +msgstr "åbent nummer" + +msgid "Launch" +msgstr "Start" + +msgid "Print to PDF" +msgstr "Udskriv til PDF" + +msgid "By the" +msgstr "Ved" + +msgid "Last updated on" +msgstr "Sidst opdateret den" + +msgid "Download source file" +msgstr "Download kildefil" + +msgid "Download this page" +msgstr "Download denne side" diff --git a/_preview/468/_static/locales/de/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/de/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..648b565c7 Binary files /dev/null and b/_preview/468/_static/locales/de/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/de/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/de/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..f51d2eccd --- /dev/null +++ b/_preview/468/_static/locales/de/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: de\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Thema von der" + +msgid "Open an issue" +msgstr "Öffnen Sie ein Problem" + +msgid "Contents" +msgstr "Inhalt" + +msgid "Download notebook file" +msgstr "Notebook-Datei herunterladen" + +msgid "Sphinx Book Theme" +msgstr "Sphinx-Buch-Thema" + +msgid "Fullscreen mode" +msgstr "Vollbildmodus" + +msgid "Edit this page" +msgstr "Bearbeite diese Seite" + +msgid "By" +msgstr "Durch" + +msgid "Copyright" +msgstr "Urheberrechte ©" + +msgid "Source repository" +msgstr "Quell-Repository" + +msgid "previous page" +msgstr "vorherige Seite" + +msgid "next page" +msgstr "Nächste Seite" + +msgid "Toggle navigation" +msgstr "Navigation umschalten" + +msgid "repository" +msgstr "Repository" + +msgid "suggest edit" +msgstr "vorschlagen zu bearbeiten" + +msgid "open issue" +msgstr "offenes Thema" + +msgid "Launch" +msgstr "Starten" + +msgid "Print to PDF" +msgstr "In PDF drucken" + +msgid "By the" +msgstr "Bis zum" + +msgid "Last updated on" +msgstr "Zuletzt aktualisiert am" + +msgid "Download source file" +msgstr "Quelldatei herunterladen" + +msgid "Download this page" +msgstr "Laden Sie diese Seite herunter" diff --git a/_preview/468/_static/locales/el/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/el/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..fca6e9355 Binary files /dev/null and b/_preview/468/_static/locales/el/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/el/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/el/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..8bec7905b --- /dev/null +++ b/_preview/468/_static/locales/el/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: el\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Θέμα από το" + +msgid "Open an issue" +msgstr "Ανοίξτε ένα ζήτημα" + +msgid "Contents" +msgstr "Περιεχόμενα" + +msgid "Download notebook file" +msgstr "Λήψη αρχείου σημειωματάριου" + +msgid "Sphinx Book Theme" +msgstr "Θέμα βιβλίου Sphinx" + +msgid "Fullscreen mode" +msgstr "ΛΕΙΤΟΥΡΓΙΑ ΠΛΗΡΟΥΣ ΟΘΟΝΗΣ" + +msgid "Edit this page" +msgstr "Επεξεργαστείτε αυτήν τη σελίδα" + +msgid "By" +msgstr "Με" + +msgid "Copyright" +msgstr "Πνευματική ιδιοκτησία" + +msgid "Source repository" +msgstr "Αποθήκη πηγής" + +msgid "previous page" +msgstr "προηγούμενη σελίδα" + +msgid "next page" +msgstr "επόμενη σελίδα" + +msgid "Toggle navigation" +msgstr "Εναλλαγή πλοήγησης" + +msgid "repository" +msgstr "αποθήκη" + +msgid "suggest edit" +msgstr "προτείνω επεξεργασία" + +msgid "open issue" +msgstr "ανοιχτό ζήτημα" + +msgid "Launch" +msgstr "Εκτόξευση" + +msgid "Print to PDF" +msgstr "Εκτύπωση σε PDF" + +msgid "By the" +msgstr "Από το" + +msgid "Last updated on" +msgstr "Τελευταία ενημέρωση στις" + +msgid "Download source file" +msgstr "Λήψη αρχείου προέλευσης" + +msgid "Download this page" +msgstr "Λήψη αυτής της σελίδας" diff --git a/_preview/468/_static/locales/eo/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/eo/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..d1072bbec Binary files /dev/null and b/_preview/468/_static/locales/eo/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/eo/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/eo/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..d72a0481e --- /dev/null +++ b/_preview/468/_static/locales/eo/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: eo\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Temo de la" + +msgid "Open an issue" +msgstr "Malfermu numeron" + +msgid "Contents" +msgstr "Enhavo" + +msgid "Download notebook file" +msgstr "Elŝutu kajeran dosieron" + +msgid "Sphinx Book Theme" +msgstr "Sfinksa Libro-Temo" + +msgid "Fullscreen mode" +msgstr "Plenekrana reĝimo" + +msgid "Edit this page" +msgstr "Redaktu ĉi tiun paĝon" + +msgid "By" +msgstr "De" + +msgid "Copyright" +msgstr "Kopirajto" + +msgid "Source repository" +msgstr "Fonto-deponejo" + +msgid "previous page" +msgstr "antaŭa paĝo" + +msgid "next page" +msgstr "sekva paĝo" + +msgid "Toggle navigation" +msgstr "Ŝalti navigadon" + +msgid "repository" +msgstr "deponejo" + +msgid "suggest edit" +msgstr "sugesti redaktadon" + +msgid "open issue" +msgstr "malferma numero" + +msgid "Launch" +msgstr "Lanĉo" + +msgid "Print to PDF" +msgstr "Presi al PDF" + +msgid "By the" +msgstr "Per la" + +msgid "Last updated on" +msgstr "Laste ĝisdatigita la" + +msgid "Download source file" +msgstr "Elŝutu fontodosieron" + +msgid "Download this page" +msgstr "Elŝutu ĉi tiun paĝon" diff --git a/_preview/468/_static/locales/es/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/es/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..ba2ee4dc2 Binary files /dev/null and b/_preview/468/_static/locales/es/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/es/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/es/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..611834b29 --- /dev/null +++ b/_preview/468/_static/locales/es/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: es\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema por el" + +msgid "Open an issue" +msgstr "Abrir un problema" + +msgid "Contents" +msgstr "Contenido" + +msgid "Download notebook file" +msgstr "Descargar archivo de cuaderno" + +msgid "Sphinx Book Theme" +msgstr "Tema del libro de la esfinge" + +msgid "Fullscreen mode" +msgstr "Modo de pantalla completa" + +msgid "Edit this page" +msgstr "Edita esta página" + +msgid "By" +msgstr "Por" + +msgid "Copyright" +msgstr "Derechos de autor" + +msgid "Source repository" +msgstr "Repositorio de origen" + +msgid "previous page" +msgstr "pagina anterior" + +msgid "next page" +msgstr "siguiente página" + +msgid "Toggle navigation" +msgstr "Navegación de palanca" + +msgid "repository" +msgstr "repositorio" + +msgid "suggest edit" +msgstr "sugerir editar" + +msgid "open issue" +msgstr "Tema abierto" + +msgid "Launch" +msgstr "Lanzamiento" + +msgid "Print to PDF" +msgstr "Imprimir en PDF" + +msgid "By the" +msgstr "Por el" + +msgid "Last updated on" +msgstr "Ultima actualización en" + +msgid "Download source file" +msgstr "Descargar archivo fuente" + +msgid "Download this page" +msgstr "Descarga esta pagina" diff --git a/_preview/468/_static/locales/et/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/et/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..983b82391 Binary files /dev/null and b/_preview/468/_static/locales/et/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/et/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/et/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..345088f02 --- /dev/null +++ b/_preview/468/_static/locales/et/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: et\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Teema" + +msgid "Open an issue" +msgstr "Avage probleem" + +msgid "Contents" +msgstr "Sisu" + +msgid "Download notebook file" +msgstr "Laadige sülearvuti fail alla" + +msgid "Sphinx Book Theme" +msgstr "Sfinksiraamatu teema" + +msgid "Fullscreen mode" +msgstr "Täisekraanirežiim" + +msgid "Edit this page" +msgstr "Muutke seda lehte" + +msgid "By" +msgstr "Kõrval" + +msgid "Copyright" +msgstr "Autoriõigus" + +msgid "Source repository" +msgstr "Allikahoidla" + +msgid "previous page" +msgstr "eelmine leht" + +msgid "next page" +msgstr "järgmine leht" + +msgid "Toggle navigation" +msgstr "Lülita navigeerimine sisse" + +msgid "repository" +msgstr "hoidla" + +msgid "suggest edit" +msgstr "soovita muuta" + +msgid "open issue" +msgstr "avatud küsimus" + +msgid "Launch" +msgstr "Käivitage" + +msgid "Print to PDF" +msgstr "Prindi PDF-i" + +msgid "By the" +msgstr "Autor" + +msgid "Last updated on" +msgstr "Viimati uuendatud" + +msgid "Download source file" +msgstr "Laadige alla lähtefail" + +msgid "Download this page" +msgstr "Laadige see leht alla" diff --git a/_preview/468/_static/locales/fi/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/fi/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..d8ac05459 Binary files /dev/null and b/_preview/468/_static/locales/fi/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/fi/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/fi/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..d97a08dc3 --- /dev/null +++ b/_preview/468/_static/locales/fi/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: fi\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Teeman tekijä" + +msgid "Open an issue" +msgstr "Avaa ongelma" + +msgid "Contents" +msgstr "Sisällys" + +msgid "Download notebook file" +msgstr "Lataa muistikirjatiedosto" + +msgid "Sphinx Book Theme" +msgstr "Sphinx-kirjan teema" + +msgid "Fullscreen mode" +msgstr "Koko näytön tila" + +msgid "Edit this page" +msgstr "Muokkaa tätä sivua" + +msgid "By" +msgstr "Tekijä" + +msgid "Copyright" +msgstr "Tekijänoikeus" + +msgid "Source repository" +msgstr "Lähteen arkisto" + +msgid "previous page" +msgstr "Edellinen sivu" + +msgid "next page" +msgstr "seuraava sivu" + +msgid "Toggle navigation" +msgstr "Vaihda navigointia" + +msgid "repository" +msgstr "arkisto" + +msgid "suggest edit" +msgstr "ehdottaa muokkausta" + +msgid "open issue" +msgstr "avoin ongelma" + +msgid "Launch" +msgstr "Tuoda markkinoille" + +msgid "Print to PDF" +msgstr "Tulosta PDF-tiedostoon" + +msgid "By the" +msgstr "Mukaan" + +msgid "Last updated on" +msgstr "Viimeksi päivitetty" + +msgid "Download source file" +msgstr "Lataa lähdetiedosto" + +msgid "Download this page" +msgstr "Lataa tämä sivu" diff --git a/_preview/468/_static/locales/fr/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/fr/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..f663d39f0 Binary files /dev/null and b/_preview/468/_static/locales/fr/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/fr/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/fr/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..88f35173f --- /dev/null +++ b/_preview/468/_static/locales/fr/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: fr\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Thème par le" + +msgid "Open an issue" +msgstr "Ouvrez un problème" + +msgid "Contents" +msgstr "Contenu" + +msgid "Download notebook file" +msgstr "Télécharger le fichier notebook" + +msgid "Sphinx Book Theme" +msgstr "Thème du livre Sphinx" + +msgid "Fullscreen mode" +msgstr "Mode plein écran" + +msgid "Edit this page" +msgstr "Modifier cette page" + +msgid "By" +msgstr "Par" + +msgid "Copyright" +msgstr "droits d'auteur" + +msgid "Source repository" +msgstr "Dépôt source" + +msgid "previous page" +msgstr "page précédente" + +msgid "next page" +msgstr "page suivante" + +msgid "Toggle navigation" +msgstr "Basculer la navigation" + +msgid "repository" +msgstr "dépôt" + +msgid "suggest edit" +msgstr "suggestion de modification" + +msgid "open issue" +msgstr "signaler un problème" + +msgid "Launch" +msgstr "lancement" + +msgid "Print to PDF" +msgstr "Imprimer au format PDF" + +msgid "By the" +msgstr "Par le" + +msgid "Last updated on" +msgstr "Dernière mise à jour le" + +msgid "Download source file" +msgstr "Télécharger le fichier source" + +msgid "Download this page" +msgstr "Téléchargez cette page" diff --git a/_preview/468/_static/locales/hr/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/hr/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..eca4a1a28 Binary files /dev/null and b/_preview/468/_static/locales/hr/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/hr/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/hr/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..fb9440ac3 --- /dev/null +++ b/_preview/468/_static/locales/hr/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: hr\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema autora" + +msgid "Open an issue" +msgstr "Otvorite izdanje" + +msgid "Contents" +msgstr "Sadržaj" + +msgid "Download notebook file" +msgstr "Preuzmi datoteku bilježnice" + +msgid "Sphinx Book Theme" +msgstr "Tema knjige Sphinx" + +msgid "Fullscreen mode" +msgstr "Način preko cijelog zaslona" + +msgid "Edit this page" +msgstr "Uredite ovu stranicu" + +msgid "By" +msgstr "Po" + +msgid "Copyright" +msgstr "Autorska prava" + +msgid "Source repository" +msgstr "Izvorno spremište" + +msgid "previous page" +msgstr "Prethodna stranica" + +msgid "next page" +msgstr "sljedeća stranica" + +msgid "Toggle navigation" +msgstr "Uključi / isključi navigaciju" + +msgid "repository" +msgstr "spremište" + +msgid "suggest edit" +msgstr "predloži uređivanje" + +msgid "open issue" +msgstr "otvoreno izdanje" + +msgid "Launch" +msgstr "Pokrenite" + +msgid "Print to PDF" +msgstr "Ispis u PDF" + +msgid "By the" +msgstr "Od strane" + +msgid "Last updated on" +msgstr "Posljednje ažuriranje:" + +msgid "Download source file" +msgstr "Preuzmi izvornu datoteku" + +msgid "Download this page" +msgstr "Preuzmite ovu stranicu" diff --git a/_preview/468/_static/locales/id/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/id/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..d07a06a9d Binary files /dev/null and b/_preview/468/_static/locales/id/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/id/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/id/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..9ffb56f78 --- /dev/null +++ b/_preview/468/_static/locales/id/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: id\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema oleh" + +msgid "Open an issue" +msgstr "Buka masalah" + +msgid "Contents" +msgstr "Isi" + +msgid "Download notebook file" +msgstr "Unduh file notebook" + +msgid "Sphinx Book Theme" +msgstr "Tema Buku Sphinx" + +msgid "Fullscreen mode" +msgstr "Mode layar penuh" + +msgid "Edit this page" +msgstr "Edit halaman ini" + +msgid "By" +msgstr "Oleh" + +msgid "Copyright" +msgstr "hak cipta" + +msgid "Source repository" +msgstr "Repositori sumber" + +msgid "previous page" +msgstr "halaman sebelumnya" + +msgid "next page" +msgstr "halaman selanjutnya" + +msgid "Toggle navigation" +msgstr "Alihkan navigasi" + +msgid "repository" +msgstr "gudang" + +msgid "suggest edit" +msgstr "menyarankan edit" + +msgid "open issue" +msgstr "masalah terbuka" + +msgid "Launch" +msgstr "Meluncurkan" + +msgid "Print to PDF" +msgstr "Cetak ke PDF" + +msgid "By the" +msgstr "Oleh" + +msgid "Last updated on" +msgstr "Terakhir diperbarui saat" + +msgid "Download source file" +msgstr "Unduh file sumber" + +msgid "Download this page" +msgstr "Unduh halaman ini" diff --git a/_preview/468/_static/locales/it/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/it/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..53ba476ed Binary files /dev/null and b/_preview/468/_static/locales/it/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/it/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/it/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..04308dd21 --- /dev/null +++ b/_preview/468/_static/locales/it/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: it\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema di" + +msgid "Open an issue" +msgstr "Apri un problema" + +msgid "Contents" +msgstr "Contenuti" + +msgid "Download notebook file" +msgstr "Scarica il file del taccuino" + +msgid "Sphinx Book Theme" +msgstr "Tema del libro della Sfinge" + +msgid "Fullscreen mode" +msgstr "Modalità schermo intero" + +msgid "Edit this page" +msgstr "Modifica questa pagina" + +msgid "By" +msgstr "Di" + +msgid "Copyright" +msgstr "Diritto d'autore" + +msgid "Source repository" +msgstr "Repository di origine" + +msgid "previous page" +msgstr "pagina precedente" + +msgid "next page" +msgstr "pagina successiva" + +msgid "Toggle navigation" +msgstr "Attiva / disattiva la navigazione" + +msgid "repository" +msgstr "repository" + +msgid "suggest edit" +msgstr "suggerisci modifica" + +msgid "open issue" +msgstr "questione aperta" + +msgid "Launch" +msgstr "Lanciare" + +msgid "Print to PDF" +msgstr "Stampa in PDF" + +msgid "By the" +msgstr "Dal" + +msgid "Last updated on" +msgstr "Ultimo aggiornamento il" + +msgid "Download source file" +msgstr "Scarica il file sorgente" + +msgid "Download this page" +msgstr "Scarica questa pagina" diff --git a/_preview/468/_static/locales/iw/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/iw/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..a45c6575e Binary files /dev/null and b/_preview/468/_static/locales/iw/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/iw/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/iw/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..4ea190d3b --- /dev/null +++ b/_preview/468/_static/locales/iw/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: iw\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "נושא מאת" + +msgid "Open an issue" +msgstr "פתח גיליון" + +msgid "Contents" +msgstr "תוכן" + +msgid "Download notebook file" +msgstr "הורד קובץ מחברת" + +msgid "Sphinx Book Theme" +msgstr "נושא ספר ספינקס" + +msgid "Fullscreen mode" +msgstr "מצב מסך מלא" + +msgid "Edit this page" +msgstr "ערוך דף זה" + +msgid "By" +msgstr "על ידי" + +msgid "Copyright" +msgstr "זכויות יוצרים" + +msgid "Source repository" +msgstr "מאגר המקורות" + +msgid "previous page" +msgstr "עמוד קודם" + +msgid "next page" +msgstr "עמוד הבא" + +msgid "Toggle navigation" +msgstr "החלף ניווט" + +msgid "repository" +msgstr "מאגר" + +msgid "suggest edit" +msgstr "מציע לערוך" + +msgid "open issue" +msgstr "בעיה פתוחה" + +msgid "Launch" +msgstr "לְהַשִׁיק" + +msgid "Print to PDF" +msgstr "הדפס לקובץ PDF" + +msgid "By the" +msgstr "דרך" + +msgid "Last updated on" +msgstr "עודכן לאחרונה ב" + +msgid "Download source file" +msgstr "הורד את קובץ המקור" + +msgid "Download this page" +msgstr "הורד דף זה" diff --git a/_preview/468/_static/locales/ja/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/ja/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..1cefd29ce Binary files /dev/null and b/_preview/468/_static/locales/ja/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/ja/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/ja/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..77d5a0971 --- /dev/null +++ b/_preview/468/_static/locales/ja/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: ja\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "のテーマ" + +msgid "Open an issue" +msgstr "問題を報告" + +msgid "Contents" +msgstr "目次" + +msgid "Download notebook file" +msgstr "ノートブックファイルをダウンロード" + +msgid "Sphinx Book Theme" +msgstr "スフィンクスの本のテーマ" + +msgid "Fullscreen mode" +msgstr "全画面モード" + +msgid "Edit this page" +msgstr "このページを編集" + +msgid "By" +msgstr "著者" + +msgid "Copyright" +msgstr "Copyright" + +msgid "Source repository" +msgstr "ソースリポジトリ" + +msgid "previous page" +msgstr "前のページ" + +msgid "next page" +msgstr "次のページ" + +msgid "Toggle navigation" +msgstr "ナビゲーションを切り替え" + +msgid "repository" +msgstr "リポジトリ" + +msgid "suggest edit" +msgstr "編集を提案する" + +msgid "open issue" +msgstr "未解決の問題" + +msgid "Launch" +msgstr "起動" + +msgid "Print to PDF" +msgstr "PDFに印刷" + +msgid "By the" +msgstr "によって" + +msgid "Last updated on" +msgstr "最終更新日" + +msgid "Download source file" +msgstr "ソースファイルをダウンロード" + +msgid "Download this page" +msgstr "このページをダウンロード" diff --git a/_preview/468/_static/locales/ko/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/ko/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..06c7ec938 Binary files /dev/null and b/_preview/468/_static/locales/ko/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/ko/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/ko/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..6ee3d7813 --- /dev/null +++ b/_preview/468/_static/locales/ko/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: ko\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "테마별" + +msgid "Open an issue" +msgstr "이슈 열기" + +msgid "Contents" +msgstr "내용" + +msgid "Download notebook file" +msgstr "노트북 파일 다운로드" + +msgid "Sphinx Book Theme" +msgstr "스핑크스 도서 테마" + +msgid "Fullscreen mode" +msgstr "전체 화면으로보기" + +msgid "Edit this page" +msgstr "이 페이지 편집" + +msgid "By" +msgstr "으로" + +msgid "Copyright" +msgstr "저작권" + +msgid "Source repository" +msgstr "소스 저장소" + +msgid "previous page" +msgstr "이전 페이지" + +msgid "next page" +msgstr "다음 페이지" + +msgid "Toggle navigation" +msgstr "탐색 전환" + +msgid "repository" +msgstr "저장소" + +msgid "suggest edit" +msgstr "편집 제안" + +msgid "open issue" +msgstr "열린 문제" + +msgid "Launch" +msgstr "시작하다" + +msgid "Print to PDF" +msgstr "PDF로 인쇄" + +msgid "By the" +msgstr "에 의해" + +msgid "Last updated on" +msgstr "마지막 업데이트" + +msgid "Download source file" +msgstr "소스 파일 다운로드" + +msgid "Download this page" +msgstr "이 페이지 다운로드" diff --git a/_preview/468/_static/locales/lt/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/lt/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..4468ba04b Binary files /dev/null and b/_preview/468/_static/locales/lt/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/lt/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/lt/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..01be26798 --- /dev/null +++ b/_preview/468/_static/locales/lt/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: lt\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema" + +msgid "Open an issue" +msgstr "Atidarykite problemą" + +msgid "Contents" +msgstr "Turinys" + +msgid "Download notebook file" +msgstr "Atsisiųsti nešiojamojo kompiuterio failą" + +msgid "Sphinx Book Theme" +msgstr "Sfinkso knygos tema" + +msgid "Fullscreen mode" +msgstr "Pilno ekrano režimas" + +msgid "Edit this page" +msgstr "Redaguoti šį puslapį" + +msgid "By" +msgstr "Iki" + +msgid "Copyright" +msgstr "Autorių teisės" + +msgid "Source repository" +msgstr "Šaltinio saugykla" + +msgid "previous page" +msgstr "Ankstesnis puslapis" + +msgid "next page" +msgstr "Kitas puslapis" + +msgid "Toggle navigation" +msgstr "Perjungti naršymą" + +msgid "repository" +msgstr "saugykla" + +msgid "suggest edit" +msgstr "pasiūlyti redaguoti" + +msgid "open issue" +msgstr "atviras klausimas" + +msgid "Launch" +msgstr "Paleiskite" + +msgid "Print to PDF" +msgstr "Spausdinti į PDF" + +msgid "By the" +msgstr "Prie" + +msgid "Last updated on" +msgstr "Paskutinį kartą atnaujinta" + +msgid "Download source file" +msgstr "Atsisiųsti šaltinio failą" + +msgid "Download this page" +msgstr "Atsisiųskite šį puslapį" diff --git a/_preview/468/_static/locales/lv/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/lv/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..74aa4d898 Binary files /dev/null and b/_preview/468/_static/locales/lv/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/lv/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/lv/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..993a1e412 --- /dev/null +++ b/_preview/468/_static/locales/lv/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: lv\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Autora tēma" + +msgid "Open an issue" +msgstr "Atveriet problēmu" + +msgid "Contents" +msgstr "Saturs" + +msgid "Download notebook file" +msgstr "Lejupielādēt piezīmju grāmatiņu" + +msgid "Sphinx Book Theme" +msgstr "Sfinksa grāmatas tēma" + +msgid "Fullscreen mode" +msgstr "Pilnekrāna režīms" + +msgid "Edit this page" +msgstr "Rediģēt šo lapu" + +msgid "By" +msgstr "Autors" + +msgid "Copyright" +msgstr "Autortiesības" + +msgid "Source repository" +msgstr "Avota krātuve" + +msgid "previous page" +msgstr "iepriekšējā lapa" + +msgid "next page" +msgstr "nākamā lapaspuse" + +msgid "Toggle navigation" +msgstr "Pārslēgt navigāciju" + +msgid "repository" +msgstr "krātuve" + +msgid "suggest edit" +msgstr "ieteikt rediģēt" + +msgid "open issue" +msgstr "atklāts jautājums" + +msgid "Launch" +msgstr "Uzsākt" + +msgid "Print to PDF" +msgstr "Drukāt PDF formātā" + +msgid "By the" +msgstr "Ar" + +msgid "Last updated on" +msgstr "Pēdējoreiz atjaunināts" + +msgid "Download source file" +msgstr "Lejupielādēt avota failu" + +msgid "Download this page" +msgstr "Lejupielādējiet šo lapu" diff --git a/_preview/468/_static/locales/ml/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/ml/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..2736e8fcf Binary files /dev/null and b/_preview/468/_static/locales/ml/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/ml/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/ml/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..81daf7c8d --- /dev/null +++ b/_preview/468/_static/locales/ml/LC_MESSAGES/booktheme.po @@ -0,0 +1,66 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: ml\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "പ്രമേയം" + +msgid "Open an issue" +msgstr "ഒരു പ്രശ്നം തുറക്കുക" + +msgid "Download notebook file" +msgstr "നോട്ട്ബുക്ക് ഫയൽ ഡൺലോഡ് ചെയ്യുക" + +msgid "Sphinx Book Theme" +msgstr "സ്ഫിങ്ക്സ് പുസ്തക തീം" + +msgid "Edit this page" +msgstr "ഈ പേജ് എഡിറ്റുചെയ്യുക" + +msgid "By" +msgstr "എഴുതിയത്" + +msgid "Copyright" +msgstr "പകർപ്പവകാശം" + +msgid "Source repository" +msgstr "ഉറവിട ശേഖരം" + +msgid "previous page" +msgstr "മുൻപത്തെ താൾ" + +msgid "next page" +msgstr "അടുത്ത പേജ്" + +msgid "Toggle navigation" +msgstr "നാവിഗേഷൻ ടോഗിൾ ചെയ്യുക" + +msgid "suggest edit" +msgstr "എഡിറ്റുചെയ്യാൻ നിർദ്ദേശിക്കുക" + +msgid "open issue" +msgstr "തുറന്ന പ്രശ്നം" + +msgid "Launch" +msgstr "സമാരംഭിക്കുക" + +msgid "Print to PDF" +msgstr "PDF- ലേക്ക് പ്രിന്റുചെയ്യുക" + +msgid "By the" +msgstr "എഴുതിയത്" + +msgid "Last updated on" +msgstr "അവസാനം അപ്ഡേറ്റുചെയ്തത്" + +msgid "Download source file" +msgstr "ഉറവിട ഫയൽ ഡൗൺലോഡുചെയ്യുക" + +msgid "Download this page" +msgstr "ഈ പേജ് ഡൗൺലോഡുചെയ്യുക" diff --git a/_preview/468/_static/locales/mr/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/mr/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..fe530100d Binary files /dev/null and b/_preview/468/_static/locales/mr/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/mr/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/mr/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..fd857bff9 --- /dev/null +++ b/_preview/468/_static/locales/mr/LC_MESSAGES/booktheme.po @@ -0,0 +1,66 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: mr\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "द्वारा थीम" + +msgid "Open an issue" +msgstr "एक मुद्दा उघडा" + +msgid "Download notebook file" +msgstr "नोटबुक फाईल डाउनलोड करा" + +msgid "Sphinx Book Theme" +msgstr "स्फिंक्स बुक थीम" + +msgid "Edit this page" +msgstr "हे पृष्ठ संपादित करा" + +msgid "By" +msgstr "द्वारा" + +msgid "Copyright" +msgstr "कॉपीराइट" + +msgid "Source repository" +msgstr "स्त्रोत भांडार" + +msgid "previous page" +msgstr "मागील पान" + +msgid "next page" +msgstr "पुढील पृष्ठ" + +msgid "Toggle navigation" +msgstr "नेव्हिगेशन टॉगल करा" + +msgid "suggest edit" +msgstr "संपादन सुचवा" + +msgid "open issue" +msgstr "खुला मुद्दा" + +msgid "Launch" +msgstr "लाँच करा" + +msgid "Print to PDF" +msgstr "पीडीएफवर मुद्रित करा" + +msgid "By the" +msgstr "द्वारा" + +msgid "Last updated on" +msgstr "अखेरचे अद्यतनित" + +msgid "Download source file" +msgstr "स्त्रोत फाइल डाउनलोड करा" + +msgid "Download this page" +msgstr "हे पृष्ठ डाउनलोड करा" diff --git a/_preview/468/_static/locales/ms/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/ms/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..f02603fa2 Binary files /dev/null and b/_preview/468/_static/locales/ms/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/ms/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/ms/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..b616d70fe --- /dev/null +++ b/_preview/468/_static/locales/ms/LC_MESSAGES/booktheme.po @@ -0,0 +1,66 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: ms\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema oleh" + +msgid "Open an issue" +msgstr "Buka masalah" + +msgid "Download notebook file" +msgstr "Muat turun fail buku nota" + +msgid "Sphinx Book Theme" +msgstr "Tema Buku Sphinx" + +msgid "Edit this page" +msgstr "Edit halaman ini" + +msgid "By" +msgstr "Oleh" + +msgid "Copyright" +msgstr "hak cipta" + +msgid "Source repository" +msgstr "Repositori sumber" + +msgid "previous page" +msgstr "halaman sebelumnya" + +msgid "next page" +msgstr "muka surat seterusnya" + +msgid "Toggle navigation" +msgstr "Togol navigasi" + +msgid "suggest edit" +msgstr "cadangkan edit" + +msgid "open issue" +msgstr "isu terbuka" + +msgid "Launch" +msgstr "Lancarkan" + +msgid "Print to PDF" +msgstr "Cetak ke PDF" + +msgid "By the" +msgstr "Oleh" + +msgid "Last updated on" +msgstr "Terakhir dikemas kini pada" + +msgid "Download source file" +msgstr "Muat turun fail sumber" + +msgid "Download this page" +msgstr "Muat turun halaman ini" diff --git a/_preview/468/_static/locales/nl/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/nl/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..e59e7ecb3 Binary files /dev/null and b/_preview/468/_static/locales/nl/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/nl/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/nl/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..f16f4bcc2 --- /dev/null +++ b/_preview/468/_static/locales/nl/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: nl\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Thema door de" + +msgid "Open an issue" +msgstr "Open een probleem" + +msgid "Contents" +msgstr "Inhoud" + +msgid "Download notebook file" +msgstr "Download notebookbestand" + +msgid "Sphinx Book Theme" +msgstr "Sphinx-boekthema" + +msgid "Fullscreen mode" +msgstr "Volledig scherm" + +msgid "Edit this page" +msgstr "bewerk deze pagina" + +msgid "By" +msgstr "Door" + +msgid "Copyright" +msgstr "auteursrechten" + +msgid "Source repository" +msgstr "Bronopslagplaats" + +msgid "previous page" +msgstr "vorige pagina" + +msgid "next page" +msgstr "volgende bladzijde" + +msgid "Toggle navigation" +msgstr "Schakel navigatie" + +msgid "repository" +msgstr "repository" + +msgid "suggest edit" +msgstr "suggereren bewerken" + +msgid "open issue" +msgstr "open probleem" + +msgid "Launch" +msgstr "Lancering" + +msgid "Print to PDF" +msgstr "Afdrukken naar pdf" + +msgid "By the" +msgstr "Door de" + +msgid "Last updated on" +msgstr "Laatst geupdate op" + +msgid "Download source file" +msgstr "Download het bronbestand" + +msgid "Download this page" +msgstr "Download deze pagina" diff --git a/_preview/468/_static/locales/no/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/no/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..6cd15c88d Binary files /dev/null and b/_preview/468/_static/locales/no/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/no/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/no/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..b1d304ee2 --- /dev/null +++ b/_preview/468/_static/locales/no/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: no\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema av" + +msgid "Open an issue" +msgstr "Åpne et problem" + +msgid "Contents" +msgstr "Innhold" + +msgid "Download notebook file" +msgstr "Last ned notatbokfilen" + +msgid "Sphinx Book Theme" +msgstr "Sphinx boktema" + +msgid "Fullscreen mode" +msgstr "Fullskjerm-modus" + +msgid "Edit this page" +msgstr "Rediger denne siden" + +msgid "By" +msgstr "Av" + +msgid "Copyright" +msgstr "opphavsrett" + +msgid "Source repository" +msgstr "Kildedepot" + +msgid "previous page" +msgstr "forrige side" + +msgid "next page" +msgstr "neste side" + +msgid "Toggle navigation" +msgstr "Bytt navigasjon" + +msgid "repository" +msgstr "oppbevaringssted" + +msgid "suggest edit" +msgstr "foreslå redigering" + +msgid "open issue" +msgstr "åpent nummer" + +msgid "Launch" +msgstr "Start" + +msgid "Print to PDF" +msgstr "Skriv ut til PDF" + +msgid "By the" +msgstr "Ved" + +msgid "Last updated on" +msgstr "Sist oppdatert den" + +msgid "Download source file" +msgstr "Last ned kildefilen" + +msgid "Download this page" +msgstr "Last ned denne siden" diff --git a/_preview/468/_static/locales/pl/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/pl/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..9ebb584f7 Binary files /dev/null and b/_preview/468/_static/locales/pl/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/pl/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/pl/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..80d2c8965 --- /dev/null +++ b/_preview/468/_static/locales/pl/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: pl\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Motyw autorstwa" + +msgid "Open an issue" +msgstr "Otwórz problem" + +msgid "Contents" +msgstr "Zawartość" + +msgid "Download notebook file" +msgstr "Pobierz plik notatnika" + +msgid "Sphinx Book Theme" +msgstr "Motyw książki Sphinx" + +msgid "Fullscreen mode" +msgstr "Pełny ekran" + +msgid "Edit this page" +msgstr "Edytuj tę strone" + +msgid "By" +msgstr "Przez" + +msgid "Copyright" +msgstr "prawa autorskie" + +msgid "Source repository" +msgstr "Repozytorium źródłowe" + +msgid "previous page" +msgstr "Poprzednia strona" + +msgid "next page" +msgstr "Następna strona" + +msgid "Toggle navigation" +msgstr "Przełącz nawigację" + +msgid "repository" +msgstr "magazyn" + +msgid "suggest edit" +msgstr "zaproponuj edycję" + +msgid "open issue" +msgstr "otwarty problem" + +msgid "Launch" +msgstr "Uruchomić" + +msgid "Print to PDF" +msgstr "Drukuj do PDF" + +msgid "By the" +msgstr "Przez" + +msgid "Last updated on" +msgstr "Ostatnia aktualizacja" + +msgid "Download source file" +msgstr "Pobierz plik źródłowy" + +msgid "Download this page" +msgstr "Pobierz tę stronę" diff --git a/_preview/468/_static/locales/pt/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/pt/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..d0ddb8728 Binary files /dev/null and b/_preview/468/_static/locales/pt/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/pt/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/pt/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..45ac847f5 --- /dev/null +++ b/_preview/468/_static/locales/pt/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: pt\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema por" + +msgid "Open an issue" +msgstr "Abra um problema" + +msgid "Contents" +msgstr "Conteúdo" + +msgid "Download notebook file" +msgstr "Baixar arquivo de notebook" + +msgid "Sphinx Book Theme" +msgstr "Tema do livro Sphinx" + +msgid "Fullscreen mode" +msgstr "Modo tela cheia" + +msgid "Edit this page" +msgstr "Edite essa página" + +msgid "By" +msgstr "De" + +msgid "Copyright" +msgstr "direito autoral" + +msgid "Source repository" +msgstr "Repositório fonte" + +msgid "previous page" +msgstr "página anterior" + +msgid "next page" +msgstr "próxima página" + +msgid "Toggle navigation" +msgstr "Alternar de navegação" + +msgid "repository" +msgstr "repositório" + +msgid "suggest edit" +msgstr "sugerir edição" + +msgid "open issue" +msgstr "questão aberta" + +msgid "Launch" +msgstr "Lançamento" + +msgid "Print to PDF" +msgstr "Imprimir em PDF" + +msgid "By the" +msgstr "Pelo" + +msgid "Last updated on" +msgstr "Última atualização em" + +msgid "Download source file" +msgstr "Baixar arquivo fonte" + +msgid "Download this page" +msgstr "Baixe esta página" diff --git a/_preview/468/_static/locales/ro/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/ro/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..3c36ab1df Binary files /dev/null and b/_preview/468/_static/locales/ro/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/ro/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/ro/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..532b3b849 --- /dev/null +++ b/_preview/468/_static/locales/ro/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: ro\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema de" + +msgid "Open an issue" +msgstr "Deschideți o problemă" + +msgid "Contents" +msgstr "Cuprins" + +msgid "Download notebook file" +msgstr "Descărcați fișierul notebook" + +msgid "Sphinx Book Theme" +msgstr "Tema Sphinx Book" + +msgid "Fullscreen mode" +msgstr "Modul ecran întreg" + +msgid "Edit this page" +msgstr "Editați această pagină" + +msgid "By" +msgstr "De" + +msgid "Copyright" +msgstr "Drepturi de autor" + +msgid "Source repository" +msgstr "Depozit sursă" + +msgid "previous page" +msgstr "pagina anterioară" + +msgid "next page" +msgstr "pagina următoare" + +msgid "Toggle navigation" +msgstr "Comutare navigare" + +msgid "repository" +msgstr "repertoriu" + +msgid "suggest edit" +msgstr "sugerează editare" + +msgid "open issue" +msgstr "problema deschisă" + +msgid "Launch" +msgstr "Lansa" + +msgid "Print to PDF" +msgstr "Imprimați în PDF" + +msgid "By the" +msgstr "Langa" + +msgid "Last updated on" +msgstr "Ultima actualizare la" + +msgid "Download source file" +msgstr "Descărcați fișierul sursă" + +msgid "Download this page" +msgstr "Descarcă această pagină" diff --git a/_preview/468/_static/locales/ru/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/ru/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..6b8ca41f3 Binary files /dev/null and b/_preview/468/_static/locales/ru/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/ru/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/ru/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..b718b4827 --- /dev/null +++ b/_preview/468/_static/locales/ru/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: ru\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Тема от" + +msgid "Open an issue" +msgstr "Открыть вопрос" + +msgid "Contents" +msgstr "Содержание" + +msgid "Download notebook file" +msgstr "Скачать файл записной книжки" + +msgid "Sphinx Book Theme" +msgstr "Тема книги Сфинкс" + +msgid "Fullscreen mode" +msgstr "Полноэкранный режим" + +msgid "Edit this page" +msgstr "Редактировать эту страницу" + +msgid "By" +msgstr "По" + +msgid "Copyright" +msgstr "авторское право" + +msgid "Source repository" +msgstr "Исходный репозиторий" + +msgid "previous page" +msgstr "Предыдущая страница" + +msgid "next page" +msgstr "Следующая страница" + +msgid "Toggle navigation" +msgstr "Переключить навигацию" + +msgid "repository" +msgstr "хранилище" + +msgid "suggest edit" +msgstr "предложить редактировать" + +msgid "open issue" +msgstr "открытый вопрос" + +msgid "Launch" +msgstr "Запуск" + +msgid "Print to PDF" +msgstr "Распечатать в PDF" + +msgid "By the" +msgstr "Посредством" + +msgid "Last updated on" +msgstr "Последнее обновление" + +msgid "Download source file" +msgstr "Скачать исходный файл" + +msgid "Download this page" +msgstr "Загрузите эту страницу" diff --git a/_preview/468/_static/locales/sk/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/sk/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..59bd0ddfa Binary files /dev/null and b/_preview/468/_static/locales/sk/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/sk/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/sk/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..f6c423b63 --- /dev/null +++ b/_preview/468/_static/locales/sk/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: sk\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Téma od" + +msgid "Open an issue" +msgstr "Otvorte problém" + +msgid "Contents" +msgstr "Obsah" + +msgid "Download notebook file" +msgstr "Stiahnite si zošit" + +msgid "Sphinx Book Theme" +msgstr "Téma knihy Sfinga" + +msgid "Fullscreen mode" +msgstr "Režim celej obrazovky" + +msgid "Edit this page" +msgstr "Upraviť túto stránku" + +msgid "By" +msgstr "Autor:" + +msgid "Copyright" +msgstr "Autorské práva" + +msgid "Source repository" +msgstr "Zdrojové úložisko" + +msgid "previous page" +msgstr "predchádzajúca strana" + +msgid "next page" +msgstr "ďalšia strana" + +msgid "Toggle navigation" +msgstr "Prepnúť navigáciu" + +msgid "repository" +msgstr "Úložisko" + +msgid "suggest edit" +msgstr "navrhnúť úpravu" + +msgid "open issue" +msgstr "otvorené vydanie" + +msgid "Launch" +msgstr "Spustiť" + +msgid "Print to PDF" +msgstr "Tlač do PDF" + +msgid "By the" +msgstr "Podľa" + +msgid "Last updated on" +msgstr "Posledná aktualizácia dňa" + +msgid "Download source file" +msgstr "Stiahnite si zdrojový súbor" + +msgid "Download this page" +msgstr "Stiahnite si túto stránku" diff --git a/_preview/468/_static/locales/sl/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/sl/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..87bf26de6 Binary files /dev/null and b/_preview/468/_static/locales/sl/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/sl/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/sl/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..9822dc58d --- /dev/null +++ b/_preview/468/_static/locales/sl/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: sl\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema avtorja" + +msgid "Open an issue" +msgstr "Odprite številko" + +msgid "Contents" +msgstr "Vsebina" + +msgid "Download notebook file" +msgstr "Prenesite datoteko zvezka" + +msgid "Sphinx Book Theme" +msgstr "Tema knjige Sphinx" + +msgid "Fullscreen mode" +msgstr "Celozaslonski način" + +msgid "Edit this page" +msgstr "Uredite to stran" + +msgid "By" +msgstr "Avtor" + +msgid "Copyright" +msgstr "avtorske pravice" + +msgid "Source repository" +msgstr "Izvorno skladišče" + +msgid "previous page" +msgstr "Prejšnja stran" + +msgid "next page" +msgstr "Naslednja stran" + +msgid "Toggle navigation" +msgstr "Preklopi navigacijo" + +msgid "repository" +msgstr "odlagališče" + +msgid "suggest edit" +msgstr "predlagajte urejanje" + +msgid "open issue" +msgstr "odprto vprašanje" + +msgid "Launch" +msgstr "Kosilo" + +msgid "Print to PDF" +msgstr "Natisni v PDF" + +msgid "By the" +msgstr "Avtor" + +msgid "Last updated on" +msgstr "Nazadnje posodobljeno dne" + +msgid "Download source file" +msgstr "Prenesite izvorno datoteko" + +msgid "Download this page" +msgstr "Prenesite to stran" diff --git a/_preview/468/_static/locales/sr/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/sr/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..ec740f485 Binary files /dev/null and b/_preview/468/_static/locales/sr/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/sr/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/sr/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..e809230c5 --- /dev/null +++ b/_preview/468/_static/locales/sr/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: sr\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Тхеме би" + +msgid "Open an issue" +msgstr "Отворите издање" + +msgid "Contents" +msgstr "Садржај" + +msgid "Download notebook file" +msgstr "Преузмите датотеку бележнице" + +msgid "Sphinx Book Theme" +msgstr "Тема књиге Спхинк" + +msgid "Fullscreen mode" +msgstr "Режим целог екрана" + +msgid "Edit this page" +msgstr "Уредите ову страницу" + +msgid "By" +msgstr "Од стране" + +msgid "Copyright" +msgstr "Ауторско право" + +msgid "Source repository" +msgstr "Изворно спремиште" + +msgid "previous page" +msgstr "Претходна страница" + +msgid "next page" +msgstr "Следећа страна" + +msgid "Toggle navigation" +msgstr "Укључи / искључи навигацију" + +msgid "repository" +msgstr "спремиште" + +msgid "suggest edit" +msgstr "предложи уређивање" + +msgid "open issue" +msgstr "отворено издање" + +msgid "Launch" +msgstr "Лансирање" + +msgid "Print to PDF" +msgstr "Испис у ПДФ" + +msgid "By the" +msgstr "Од" + +msgid "Last updated on" +msgstr "Последње ажурирање" + +msgid "Download source file" +msgstr "Преузми изворну датотеку" + +msgid "Download this page" +msgstr "Преузмите ову страницу" diff --git a/_preview/468/_static/locales/sv/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/sv/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..b07dc76ff Binary files /dev/null and b/_preview/468/_static/locales/sv/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/sv/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/sv/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..2421b001d --- /dev/null +++ b/_preview/468/_static/locales/sv/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: sv\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema av" + +msgid "Open an issue" +msgstr "Öppna en problemrapport" + +msgid "Contents" +msgstr "Innehåll" + +msgid "Download notebook file" +msgstr "Ladda ner notebook-fil" + +msgid "Sphinx Book Theme" +msgstr "Sphinx Boktema" + +msgid "Fullscreen mode" +msgstr "Fullskärmsläge" + +msgid "Edit this page" +msgstr "Redigera den här sidan" + +msgid "By" +msgstr "Av" + +msgid "Copyright" +msgstr "Upphovsrätt" + +msgid "Source repository" +msgstr "Källkodsrepositorium" + +msgid "previous page" +msgstr "föregående sida" + +msgid "next page" +msgstr "nästa sida" + +msgid "Toggle navigation" +msgstr "Växla navigering" + +msgid "repository" +msgstr "repositorium" + +msgid "suggest edit" +msgstr "föreslå ändring" + +msgid "open issue" +msgstr "öppna problemrapport" + +msgid "Launch" +msgstr "Öppna" + +msgid "Print to PDF" +msgstr "Skriv ut till PDF" + +msgid "By the" +msgstr "Av den" + +msgid "Last updated on" +msgstr "Senast uppdaterad den" + +msgid "Download source file" +msgstr "Ladda ner källfil" + +msgid "Download this page" +msgstr "Ladda ner den här sidan" diff --git a/_preview/468/_static/locales/ta/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/ta/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..29f52e1f6 Binary files /dev/null and b/_preview/468/_static/locales/ta/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/ta/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/ta/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..500042f40 --- /dev/null +++ b/_preview/468/_static/locales/ta/LC_MESSAGES/booktheme.po @@ -0,0 +1,66 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: ta\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "வழங்கிய தீம்" + +msgid "Open an issue" +msgstr "சிக்கலைத் திறக்கவும்" + +msgid "Download notebook file" +msgstr "நோட்புக் கோப்பைப் பதிவிறக்கவும்" + +msgid "Sphinx Book Theme" +msgstr "ஸ்பிங்க்ஸ் புத்தக தீம்" + +msgid "Edit this page" +msgstr "இந்தப் பக்கத்தைத் திருத்தவும்" + +msgid "By" +msgstr "வழங்கியவர்" + +msgid "Copyright" +msgstr "பதிப்புரிமை" + +msgid "Source repository" +msgstr "மூல களஞ்சியம்" + +msgid "previous page" +msgstr "முந்தைய பக்கம்" + +msgid "next page" +msgstr "அடுத்த பக்கம்" + +msgid "Toggle navigation" +msgstr "வழிசெலுத்தலை நிலைமாற்று" + +msgid "suggest edit" +msgstr "திருத்த பரிந்துரைக்கவும்" + +msgid "open issue" +msgstr "திறந்த பிரச்சினை" + +msgid "Launch" +msgstr "தொடங்க" + +msgid "Print to PDF" +msgstr "PDF இல் அச்சிடுக" + +msgid "By the" +msgstr "மூலம்" + +msgid "Last updated on" +msgstr "கடைசியாக புதுப்பிக்கப்பட்டது" + +msgid "Download source file" +msgstr "மூல கோப்பைப் பதிவிறக்குக" + +msgid "Download this page" +msgstr "இந்தப் பக்கத்தைப் பதிவிறக்கவும்" diff --git a/_preview/468/_static/locales/te/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/te/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..0a5f4b46a Binary files /dev/null and b/_preview/468/_static/locales/te/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/te/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/te/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..b1afebba8 --- /dev/null +++ b/_preview/468/_static/locales/te/LC_MESSAGES/booktheme.po @@ -0,0 +1,66 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: te\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "ద్వారా థీమ్" + +msgid "Open an issue" +msgstr "సమస్యను తెరవండి" + +msgid "Download notebook file" +msgstr "నోట్బుక్ ఫైల్ను డౌన్లోడ్ చేయండి" + +msgid "Sphinx Book Theme" +msgstr "సింహిక పుస్తక థీమ్" + +msgid "Edit this page" +msgstr "ఈ పేజీని సవరించండి" + +msgid "By" +msgstr "ద్వారా" + +msgid "Copyright" +msgstr "కాపీరైట్" + +msgid "Source repository" +msgstr "మూల రిపోజిటరీ" + +msgid "previous page" +msgstr "ముందు పేజి" + +msgid "next page" +msgstr "తరువాతి పేజీ" + +msgid "Toggle navigation" +msgstr "నావిగేషన్ను టోగుల్ చేయండి" + +msgid "suggest edit" +msgstr "సవరించమని సూచించండి" + +msgid "open issue" +msgstr "ఓపెన్ ఇష్యూ" + +msgid "Launch" +msgstr "ప్రారంభించండి" + +msgid "Print to PDF" +msgstr "PDF కి ముద్రించండి" + +msgid "By the" +msgstr "ద్వారా" + +msgid "Last updated on" +msgstr "చివరిగా నవీకరించబడింది" + +msgid "Download source file" +msgstr "మూల ఫైల్ను డౌన్లోడ్ చేయండి" + +msgid "Download this page" +msgstr "ఈ పేజీని డౌన్లోడ్ చేయండి" diff --git a/_preview/468/_static/locales/tg/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/tg/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..b21c6c634 Binary files /dev/null and b/_preview/468/_static/locales/tg/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/tg/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/tg/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..29b8237b1 --- /dev/null +++ b/_preview/468/_static/locales/tg/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: tg\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Мавзӯъи аз" + +msgid "Open an issue" +msgstr "Масъаларо кушоед" + +msgid "Contents" +msgstr "Мундариҷа" + +msgid "Download notebook file" +msgstr "Файли дафтарро зеркашӣ кунед" + +msgid "Sphinx Book Theme" +msgstr "Сфинкс Мавзӯи китоб" + +msgid "Fullscreen mode" +msgstr "Ҳолати экрани пурра" + +msgid "Edit this page" +msgstr "Ин саҳифаро таҳрир кунед" + +msgid "By" +msgstr "Бо" + +msgid "Copyright" +msgstr "Ҳуқуқи муаллиф" + +msgid "Source repository" +msgstr "Анбори манбаъ" + +msgid "previous page" +msgstr "саҳифаи қаблӣ" + +msgid "next page" +msgstr "саҳифаи оянда" + +msgid "Toggle navigation" +msgstr "Гузаришро иваз кунед" + +msgid "repository" +msgstr "анбор" + +msgid "suggest edit" +msgstr "пешниҳод вироиш" + +msgid "open issue" +msgstr "барориши кушод" + +msgid "Launch" +msgstr "Оғоз" + +msgid "Print to PDF" +msgstr "Чоп ба PDF" + +msgid "By the" +msgstr "Бо" + +msgid "Last updated on" +msgstr "Last навсозӣ дар" + +msgid "Download source file" +msgstr "Файли манбаъро зеркашӣ кунед" + +msgid "Download this page" +msgstr "Ин саҳифаро зеркашӣ кунед" diff --git a/_preview/468/_static/locales/th/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/th/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..abede98aa Binary files /dev/null and b/_preview/468/_static/locales/th/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/th/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/th/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..ac65ee05c --- /dev/null +++ b/_preview/468/_static/locales/th/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: th\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "ธีมโดย" + +msgid "Open an issue" +msgstr "เปิดปัญหา" + +msgid "Contents" +msgstr "สารบัญ" + +msgid "Download notebook file" +msgstr "ดาวน์โหลดไฟล์สมุดบันทึก" + +msgid "Sphinx Book Theme" +msgstr "ธีมหนังสือสฟิงซ์" + +msgid "Fullscreen mode" +msgstr "โหมดเต็มหน้าจอ" + +msgid "Edit this page" +msgstr "แก้ไขหน้านี้" + +msgid "By" +msgstr "โดย" + +msgid "Copyright" +msgstr "ลิขสิทธิ์" + +msgid "Source repository" +msgstr "ที่เก็บซอร์ส" + +msgid "previous page" +msgstr "หน้าที่แล้ว" + +msgid "next page" +msgstr "หน้าต่อไป" + +msgid "Toggle navigation" +msgstr "ไม่ต้องสลับช่องทาง" + +msgid "repository" +msgstr "ที่เก็บ" + +msgid "suggest edit" +msgstr "แนะนำแก้ไข" + +msgid "open issue" +msgstr "เปิดปัญหา" + +msgid "Launch" +msgstr "เปิด" + +msgid "Print to PDF" +msgstr "พิมพ์เป็น PDF" + +msgid "By the" +msgstr "โดย" + +msgid "Last updated on" +msgstr "ปรับปรุงล่าสุดเมื่อ" + +msgid "Download source file" +msgstr "ดาวน์โหลดไฟล์ต้นฉบับ" + +msgid "Download this page" +msgstr "ดาวน์โหลดหน้านี้" diff --git a/_preview/468/_static/locales/tl/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/tl/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..8df1b7331 Binary files /dev/null and b/_preview/468/_static/locales/tl/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/tl/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/tl/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..662d66ca8 --- /dev/null +++ b/_preview/468/_static/locales/tl/LC_MESSAGES/booktheme.po @@ -0,0 +1,66 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: tl\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tema ng" + +msgid "Open an issue" +msgstr "Magbukas ng isyu" + +msgid "Download notebook file" +msgstr "Mag-download ng file ng notebook" + +msgid "Sphinx Book Theme" +msgstr "Tema ng Sphinx Book" + +msgid "Edit this page" +msgstr "I-edit ang pahinang ito" + +msgid "By" +msgstr "Ni" + +msgid "Copyright" +msgstr "Copyright" + +msgid "Source repository" +msgstr "Pinagmulan ng imbakan" + +msgid "previous page" +msgstr "Nakaraang pahina" + +msgid "next page" +msgstr "Susunod na pahina" + +msgid "Toggle navigation" +msgstr "I-toggle ang pag-navigate" + +msgid "suggest edit" +msgstr "iminumungkahi i-edit" + +msgid "open issue" +msgstr "bukas na isyu" + +msgid "Launch" +msgstr "Ilunsad" + +msgid "Print to PDF" +msgstr "I-print sa PDF" + +msgid "By the" +msgstr "Sa pamamagitan ng" + +msgid "Last updated on" +msgstr "Huling na-update noong" + +msgid "Download source file" +msgstr "Mag-download ng file ng pinagmulan" + +msgid "Download this page" +msgstr "I-download ang pahinang ito" diff --git a/_preview/468/_static/locales/tr/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/tr/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..029ae18af Binary files /dev/null and b/_preview/468/_static/locales/tr/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/tr/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/tr/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..d1ae72334 --- /dev/null +++ b/_preview/468/_static/locales/tr/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: tr\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Tarafından tema" + +msgid "Open an issue" +msgstr "Bir sorunu açın" + +msgid "Contents" +msgstr "İçindekiler" + +msgid "Download notebook file" +msgstr "Defter dosyasını indirin" + +msgid "Sphinx Book Theme" +msgstr "Sfenks Kitap Teması" + +msgid "Fullscreen mode" +msgstr "Tam ekran modu" + +msgid "Edit this page" +msgstr "Bu sayfayı düzenle" + +msgid "By" +msgstr "Tarafından" + +msgid "Copyright" +msgstr "Telif hakkı" + +msgid "Source repository" +msgstr "Kaynak kod deposu" + +msgid "previous page" +msgstr "önceki sayfa" + +msgid "next page" +msgstr "sonraki Sayfa" + +msgid "Toggle navigation" +msgstr "Gezinmeyi değiştir" + +msgid "repository" +msgstr "depo" + +msgid "suggest edit" +msgstr "düzenleme öner" + +msgid "open issue" +msgstr "Açık konu" + +msgid "Launch" +msgstr "Başlatmak" + +msgid "Print to PDF" +msgstr "PDF olarak yazdır" + +msgid "By the" +msgstr "Tarafından" + +msgid "Last updated on" +msgstr "Son güncelleme tarihi" + +msgid "Download source file" +msgstr "Kaynak dosyayı indirin" + +msgid "Download this page" +msgstr "Bu sayfayı indirin" diff --git a/_preview/468/_static/locales/uk/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/uk/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..16ab78909 Binary files /dev/null and b/_preview/468/_static/locales/uk/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/uk/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/uk/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..be49ab85e --- /dev/null +++ b/_preview/468/_static/locales/uk/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: uk\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Тема від" + +msgid "Open an issue" +msgstr "Відкрийте випуск" + +msgid "Contents" +msgstr "Зміст" + +msgid "Download notebook file" +msgstr "Завантажте файл блокнота" + +msgid "Sphinx Book Theme" +msgstr "Тема книги \"Сфінкс\"" + +msgid "Fullscreen mode" +msgstr "Повноекранний режим" + +msgid "Edit this page" +msgstr "Редагувати цю сторінку" + +msgid "By" +msgstr "Автор" + +msgid "Copyright" +msgstr "Авторське право" + +msgid "Source repository" +msgstr "Джерело сховища" + +msgid "previous page" +msgstr "Попередня сторінка" + +msgid "next page" +msgstr "Наступна сторінка" + +msgid "Toggle navigation" +msgstr "Переключити навігацію" + +msgid "repository" +msgstr "сховище" + +msgid "suggest edit" +msgstr "запропонувати редагувати" + +msgid "open issue" +msgstr "відкритий випуск" + +msgid "Launch" +msgstr "Запуск" + +msgid "Print to PDF" +msgstr "Друк у форматі PDF" + +msgid "By the" +msgstr "По" + +msgid "Last updated on" +msgstr "Останнє оновлення:" + +msgid "Download source file" +msgstr "Завантажити вихідний файл" + +msgid "Download this page" +msgstr "Завантажте цю сторінку" diff --git a/_preview/468/_static/locales/ur/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/ur/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..de8c84b93 Binary files /dev/null and b/_preview/468/_static/locales/ur/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/ur/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/ur/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..94bcab339 --- /dev/null +++ b/_preview/468/_static/locales/ur/LC_MESSAGES/booktheme.po @@ -0,0 +1,66 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: ur\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "کے ذریعہ تھیم" + +msgid "Open an issue" +msgstr "ایک مسئلہ کھولیں" + +msgid "Download notebook file" +msgstr "نوٹ بک فائل ڈاؤن لوڈ کریں" + +msgid "Sphinx Book Theme" +msgstr "سپنکس بک تھیم" + +msgid "Edit this page" +msgstr "اس صفحے میں ترمیم کریں" + +msgid "By" +msgstr "بذریعہ" + +msgid "Copyright" +msgstr "کاپی رائٹ" + +msgid "Source repository" +msgstr "ماخذ ذخیرہ" + +msgid "previous page" +msgstr "سابقہ صفحہ" + +msgid "next page" +msgstr "اگلا صفحہ" + +msgid "Toggle navigation" +msgstr "نیویگیشن ٹوگل کریں" + +msgid "suggest edit" +msgstr "ترمیم کی تجویز کریں" + +msgid "open issue" +msgstr "کھلا مسئلہ" + +msgid "Launch" +msgstr "لانچ کریں" + +msgid "Print to PDF" +msgstr "پی ڈی ایف پرنٹ کریں" + +msgid "By the" +msgstr "کی طرف" + +msgid "Last updated on" +msgstr "آخری بار تازہ کاری ہوئی" + +msgid "Download source file" +msgstr "سورس فائل ڈاؤن لوڈ کریں" + +msgid "Download this page" +msgstr "اس صفحے کو ڈاؤن لوڈ کریں" diff --git a/_preview/468/_static/locales/vi/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/vi/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..2bb32555c Binary files /dev/null and b/_preview/468/_static/locales/vi/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/vi/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/vi/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..116236dc6 --- /dev/null +++ b/_preview/468/_static/locales/vi/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: vi\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "Chủ đề của" + +msgid "Open an issue" +msgstr "Mở một vấn đề" + +msgid "Contents" +msgstr "Nội dung" + +msgid "Download notebook file" +msgstr "Tải xuống tệp sổ tay" + +msgid "Sphinx Book Theme" +msgstr "Chủ đề sách nhân sư" + +msgid "Fullscreen mode" +msgstr "Chế độ toàn màn hình" + +msgid "Edit this page" +msgstr "chỉnh sửa trang này" + +msgid "By" +msgstr "Bởi" + +msgid "Copyright" +msgstr "Bản quyền" + +msgid "Source repository" +msgstr "Kho nguồn" + +msgid "previous page" +msgstr "trang trước" + +msgid "next page" +msgstr "Trang tiếp theo" + +msgid "Toggle navigation" +msgstr "Chuyển đổi điều hướng thành" + +msgid "repository" +msgstr "kho" + +msgid "suggest edit" +msgstr "đề nghị chỉnh sửa" + +msgid "open issue" +msgstr "vấn đề mở" + +msgid "Launch" +msgstr "Phóng" + +msgid "Print to PDF" +msgstr "In sang PDF" + +msgid "By the" +msgstr "Bằng" + +msgid "Last updated on" +msgstr "Cập nhật lần cuối vào" + +msgid "Download source file" +msgstr "Tải xuống tệp nguồn" + +msgid "Download this page" +msgstr "Tải xuống trang này" diff --git a/_preview/468/_static/locales/zh_CN/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/zh_CN/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..0e3235d09 Binary files /dev/null and b/_preview/468/_static/locales/zh_CN/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/zh_CN/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/zh_CN/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..4f4ab579f --- /dev/null +++ b/_preview/468/_static/locales/zh_CN/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: zh_CN\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "主题作者:" + +msgid "Open an issue" +msgstr "创建议题" + +msgid "Contents" +msgstr "目录" + +msgid "Download notebook file" +msgstr "下载笔记本文件" + +msgid "Sphinx Book Theme" +msgstr "Sphinx Book 主题" + +msgid "Fullscreen mode" +msgstr "全屏模式" + +msgid "Edit this page" +msgstr "编辑此页面" + +msgid "By" +msgstr "作者:" + +msgid "Copyright" +msgstr "版权" + +msgid "Source repository" +msgstr "源码库" + +msgid "previous page" +msgstr "上一页" + +msgid "next page" +msgstr "下一页" + +msgid "Toggle navigation" +msgstr "显示或隐藏导航栏" + +msgid "repository" +msgstr "仓库" + +msgid "suggest edit" +msgstr "提出修改建议" + +msgid "open issue" +msgstr "创建议题" + +msgid "Launch" +msgstr "启动" + +msgid "Print to PDF" +msgstr "列印成 PDF" + +msgid "By the" +msgstr "作者:" + +msgid "Last updated on" +msgstr "上次更新时间:" + +msgid "Download source file" +msgstr "下载源文件" + +msgid "Download this page" +msgstr "下载此页面" diff --git a/_preview/468/_static/locales/zh_TW/LC_MESSAGES/booktheme.mo b/_preview/468/_static/locales/zh_TW/LC_MESSAGES/booktheme.mo new file mode 100644 index 000000000..9116fa95d Binary files /dev/null and b/_preview/468/_static/locales/zh_TW/LC_MESSAGES/booktheme.mo differ diff --git a/_preview/468/_static/locales/zh_TW/LC_MESSAGES/booktheme.po b/_preview/468/_static/locales/zh_TW/LC_MESSAGES/booktheme.po new file mode 100644 index 000000000..42b43b86e --- /dev/null +++ b/_preview/468/_static/locales/zh_TW/LC_MESSAGES/booktheme.po @@ -0,0 +1,75 @@ + +msgid "" +msgstr "" +"Project-Id-Version: Sphinx-Book-Theme\n" +"MIME-Version: 1.0\n" +"Content-Type: text/plain; charset=UTF-8\n" +"Content-Transfer-Encoding: 8bit\n" +"Language: zh_TW\n" +"Plural-Forms: nplurals=2; plural=(n != 1);\n" + +msgid "Theme by the" +msgstr "佈景主題作者:" + +msgid "Open an issue" +msgstr "開啟議題" + +msgid "Contents" +msgstr "目錄" + +msgid "Download notebook file" +msgstr "下載 Notebook 檔案" + +msgid "Sphinx Book Theme" +msgstr "Sphinx Book 佈景主題" + +msgid "Fullscreen mode" +msgstr "全螢幕模式" + +msgid "Edit this page" +msgstr "編輯此頁面" + +msgid "By" +msgstr "作者:" + +msgid "Copyright" +msgstr "Copyright" + +msgid "Source repository" +msgstr "來源儲存庫" + +msgid "previous page" +msgstr "上一頁" + +msgid "next page" +msgstr "下一頁" + +msgid "Toggle navigation" +msgstr "顯示或隱藏導覽列" + +msgid "repository" +msgstr "儲存庫" + +msgid "suggest edit" +msgstr "提出修改建議" + +msgid "open issue" +msgstr "公開的問題" + +msgid "Launch" +msgstr "啟動" + +msgid "Print to PDF" +msgstr "列印成 PDF" + +msgid "By the" +msgstr "作者:" + +msgid "Last updated on" +msgstr "最後更新時間:" + +msgid "Download source file" +msgstr "下載原始檔" + +msgid "Download this page" +msgstr "下載此頁面" diff --git a/_preview/468/_static/minus.png b/_preview/468/_static/minus.png new file mode 100644 index 000000000..d96755fda Binary files /dev/null and b/_preview/468/_static/minus.png differ diff --git a/_preview/468/_static/mystnb.4510f1fc1dee50b3e5859aac5469c37c29e427902b24a333a5f9fcb2f0b3ac41.css b/_preview/468/_static/mystnb.4510f1fc1dee50b3e5859aac5469c37c29e427902b24a333a5f9fcb2f0b3ac41.css new file mode 100644 index 000000000..335663106 --- /dev/null +++ b/_preview/468/_static/mystnb.4510f1fc1dee50b3e5859aac5469c37c29e427902b24a333a5f9fcb2f0b3ac41.css @@ -0,0 +1,2342 @@ +/* Variables */ +:root { + --mystnb-source-bg-color: #f7f7f7; + --mystnb-stdout-bg-color: #fcfcfc; + --mystnb-stderr-bg-color: #fdd; + --mystnb-traceback-bg-color: #fcfcfc; + --mystnb-source-border-color: #ccc; + --mystnb-source-margin-color: green; + --mystnb-stdout-border-color: #f7f7f7; + --mystnb-stderr-border-color: #f7f7f7; + --mystnb-traceback-border-color: #ffd6d6; + --mystnb-hide-prompt-opacity: 70%; + --mystnb-source-border-radius: .4em; + --mystnb-source-border-width: 1px; +} + +/* Whole cell */ +div.container.cell { + padding-left: 0; + margin-bottom: 1em; +} + +/* Removing all background formatting so we can control at the div level */ +.cell_input div.highlight, +.cell_output pre, +.cell_input pre, +.cell_output .output { + border: none; + box-shadow: none; +} + +.cell_output .output pre, +.cell_input pre { + margin: 0px; +} + +/* Input cells */ +div.cell div.cell_input, +div.cell details.above-input>summary { + padding-left: 0em; + padding-right: 0em; + border: var(--mystnb-source-border-width) var(--mystnb-source-border-color) solid; + background-color: var(--mystnb-source-bg-color); + border-left-color: var(--mystnb-source-margin-color); + border-left-width: medium; + border-radius: var(--mystnb-source-border-radius); +} + +div.cell_input>div, +div.cell_output div.output>div.highlight { + margin: 0em !important; + border: none !important; +} + +/* All cell outputs */ +.cell_output { + padding-left: 1em; + padding-right: 0em; + margin-top: 1em; +} + +/* Text outputs from cells */ +.cell_output .output.text_plain, +.cell_output .output.traceback, +.cell_output .output.stream, +.cell_output .output.stderr { + margin-top: 1em; + margin-bottom: 0em; + box-shadow: none; +} + +.cell_output .output.text_plain, +.cell_output .output.stream { + background: var(--mystnb-stdout-bg-color); + border: 1px solid var(--mystnb-stdout-border-color); +} + +.cell_output .output.stderr { + background: var(--mystnb-stderr-bg-color); + border: 1px solid var(--mystnb-stderr-border-color); +} + +.cell_output .output.traceback { + background: var(--mystnb-traceback-bg-color); + border: 1px solid var(--mystnb-traceback-border-color); +} + +/* Collapsible cell content */ +div.cell details.above-input div.cell_input { + border-top-left-radius: 0; + border-top-right-radius: 0; + border-top: var(--mystnb-source-border-width) var(--mystnb-source-border-color) dashed; +} + +div.cell div.cell_input.above-output-prompt { + border-bottom-left-radius: 0; + border-bottom-right-radius: 0; +} + +div.cell details.above-input>summary { + border-bottom-left-radius: 0; + border-bottom-right-radius: 0; + border-bottom: var(--mystnb-source-border-width) var(--mystnb-source-border-color) dashed; + padding-left: 1em; + margin-bottom: 0; +} + +div.cell details.above-output>summary { + background-color: var(--mystnb-source-bg-color); + padding-left: 1em; + padding-right: 0em; + border: var(--mystnb-source-border-width) var(--mystnb-source-border-color) solid; + border-radius: var(--mystnb-source-border-radius); + border-left-color: var(--mystnb-source-margin-color); + border-left-width: medium; +} + +div.cell details.below-input>summary { + background-color: var(--mystnb-source-bg-color); + padding-left: 1em; + padding-right: 0em; + border: var(--mystnb-source-border-width) var(--mystnb-source-border-color) solid; + border-top: none; + border-bottom-left-radius: var(--mystnb-source-border-radius); + border-bottom-right-radius: var(--mystnb-source-border-radius); + border-left-color: var(--mystnb-source-margin-color); + border-left-width: medium; +} + +div.cell details.hide>summary>span { + opacity: var(--mystnb-hide-prompt-opacity); +} + +div.cell details.hide[open]>summary>span.collapsed { + display: none; +} + +div.cell details.hide:not([open])>summary>span.expanded { + display: none; +} + +@keyframes collapsed-fade-in { + 0% { + opacity: 0; + } + + 100% { + opacity: 1; + } +} +div.cell details.hide[open]>summary~* { + -moz-animation: collapsed-fade-in 0.3s ease-in-out; + -webkit-animation: collapsed-fade-in 0.3s ease-in-out; + animation: collapsed-fade-in 0.3s ease-in-out; +} + +/* Math align to the left */ +.cell_output .MathJax_Display { + text-align: left !important; +} + +/* Pandas tables. Pulled from the Jupyter / nbsphinx CSS */ +div.cell_output table { + border: none; + border-collapse: collapse; + border-spacing: 0; + color: black; + font-size: 1em; + table-layout: fixed; +} + +div.cell_output thead { + border-bottom: 1px solid black; + vertical-align: bottom; +} + +div.cell_output tr, +div.cell_output th, +div.cell_output td { + text-align: right; + vertical-align: middle; + padding: 0.5em 0.5em; + line-height: normal; + white-space: normal; + max-width: none; + border: none; +} + +div.cell_output th { + font-weight: bold; +} + +div.cell_output tbody tr:nth-child(odd) { + background: #f5f5f5; +} + +div.cell_output tbody tr:hover { + background: rgba(66, 165, 245, 0.2); +} + +/** source code line numbers **/ +span.linenos { + opacity: 0.5; +} + +/* Inline text from `paste` operation */ + +span.pasted-text { + font-weight: bold; +} + +span.pasted-inline img { + max-height: 2em; +} + +tbody span.pasted-inline img { + max-height: none; +} + +/* Font colors for translated ANSI escape sequences +Color values are copied from Jupyter Notebook +https://github.com/jupyter/notebook/blob/52581f8eda9b319eb0390ac77fe5903c38f81e3e/notebook/static/notebook/less/ansicolors.less#L14-L21 +Background colors from +https://nbsphinx.readthedocs.io/en/latest/code-cells.html#ANSI-Colors +*/ +div.highlight .-Color-Bold { + font-weight: bold; +} + +div.highlight .-Color[class*=-Black] { + color: #3E424D +} + +div.highlight .-Color[class*=-Red] { + color: #E75C58 +} + +div.highlight .-Color[class*=-Green] { + color: #00A250 +} + +div.highlight .-Color[class*=-Yellow] { + color: #DDB62B +} + +div.highlight .-Color[class*=-Blue] { + color: #208FFB +} + +div.highlight .-Color[class*=-Magenta] { + color: #D160C4 +} + +div.highlight .-Color[class*=-Cyan] { + color: #60C6C8 +} + +div.highlight .-Color[class*=-White] { + color: #C5C1B4 +} + +div.highlight .-Color[class*=-BGBlack] { + background-color: #3E424D +} + +div.highlight .-Color[class*=-BGRed] { + background-color: #E75C58 +} + +div.highlight .-Color[class*=-BGGreen] { + background-color: #00A250 +} + +div.highlight .-Color[class*=-BGYellow] { + background-color: #DDB62B +} + +div.highlight .-Color[class*=-BGBlue] { + background-color: #208FFB +} + +div.highlight .-Color[class*=-BGMagenta] { + background-color: #D160C4 +} + +div.highlight .-Color[class*=-BGCyan] { + background-color: #60C6C8 +} + +div.highlight .-Color[class*=-BGWhite] { + background-color: #C5C1B4 +} + +/* Font colors for 8-bit ANSI */ + +div.highlight .-Color[class*=-C0] { + color: #000000 +} + +div.highlight .-Color[class*=-BGC0] { + background-color: #000000 +} + +div.highlight .-Color[class*=-C1] { + color: #800000 +} + +div.highlight .-Color[class*=-BGC1] { + background-color: #800000 +} + +div.highlight .-Color[class*=-C2] { + color: #008000 +} + +div.highlight .-Color[class*=-BGC2] { + background-color: #008000 +} + +div.highlight .-Color[class*=-C3] { + color: #808000 +} + +div.highlight .-Color[class*=-BGC3] { + background-color: #808000 +} + +div.highlight .-Color[class*=-C4] { + color: #000080 +} + +div.highlight .-Color[class*=-BGC4] { + background-color: #000080 +} + +div.highlight .-Color[class*=-C5] { + color: #800080 +} + +div.highlight .-Color[class*=-BGC5] { + background-color: #800080 +} + +div.highlight .-Color[class*=-C6] { + color: #008080 +} + +div.highlight .-Color[class*=-BGC6] { + background-color: #008080 +} + +div.highlight .-Color[class*=-C7] { + color: #C0C0C0 +} + +div.highlight .-Color[class*=-BGC7] { + background-color: #C0C0C0 +} + +div.highlight .-Color[class*=-C8] { + color: #808080 +} + +div.highlight .-Color[class*=-BGC8] { + background-color: #808080 +} + +div.highlight .-Color[class*=-C9] { + color: #FF0000 +} + +div.highlight .-Color[class*=-BGC9] { + background-color: #FF0000 +} + +div.highlight .-Color[class*=-C10] { + color: #00FF00 +} + +div.highlight .-Color[class*=-BGC10] { + background-color: #00FF00 +} + +div.highlight .-Color[class*=-C11] { + color: #FFFF00 +} + +div.highlight .-Color[class*=-BGC11] { + background-color: #FFFF00 +} + +div.highlight .-Color[class*=-C12] { + color: #0000FF +} + +div.highlight .-Color[class*=-BGC12] { + background-color: #0000FF +} + +div.highlight .-Color[class*=-C13] { + color: #FF00FF +} + +div.highlight .-Color[class*=-BGC13] { + background-color: #FF00FF +} + +div.highlight .-Color[class*=-C14] { + color: #00FFFF +} + +div.highlight .-Color[class*=-BGC14] { + background-color: #00FFFF +} + +div.highlight .-Color[class*=-C15] { + color: #FFFFFF +} + +div.highlight .-Color[class*=-BGC15] { + background-color: #FFFFFF +} + +div.highlight .-Color[class*=-C16] { + color: #000000 +} + +div.highlight .-Color[class*=-BGC16] { + background-color: #000000 +} + +div.highlight .-Color[class*=-C17] { + color: #00005F +} + +div.highlight .-Color[class*=-BGC17] { + background-color: #00005F +} + +div.highlight .-Color[class*=-C18] { + color: #000087 +} + +div.highlight .-Color[class*=-BGC18] { + background-color: #000087 +} + +div.highlight .-Color[class*=-C19] { + color: #0000AF +} + +div.highlight .-Color[class*=-BGC19] { + background-color: #0000AF +} + +div.highlight .-Color[class*=-C20] { + color: #0000D7 +} + +div.highlight .-Color[class*=-BGC20] { + background-color: #0000D7 +} + +div.highlight .-Color[class*=-C21] { + color: #0000FF +} + +div.highlight .-Color[class*=-BGC21] { + background-color: #0000FF +} + +div.highlight .-Color[class*=-C22] { + color: #005F00 +} + +div.highlight .-Color[class*=-BGC22] { + background-color: #005F00 +} + +div.highlight .-Color[class*=-C23] { + color: #005F5F +} + +div.highlight .-Color[class*=-BGC23] { + background-color: #005F5F +} + +div.highlight .-Color[class*=-C24] { + color: #005F87 +} + +div.highlight .-Color[class*=-BGC24] { + background-color: #005F87 +} + +div.highlight .-Color[class*=-C25] { + color: #005FAF +} + +div.highlight .-Color[class*=-BGC25] { + background-color: #005FAF +} + +div.highlight .-Color[class*=-C26] { + color: #005FD7 +} + +div.highlight .-Color[class*=-BGC26] { + background-color: #005FD7 +} + +div.highlight .-Color[class*=-C27] { + color: #005FFF +} + +div.highlight .-Color[class*=-BGC27] { + background-color: #005FFF +} + +div.highlight .-Color[class*=-C28] { + color: #008700 +} + +div.highlight .-Color[class*=-BGC28] { + background-color: #008700 +} + +div.highlight .-Color[class*=-C29] { + color: #00875F +} + +div.highlight .-Color[class*=-BGC29] { + background-color: #00875F +} + +div.highlight .-Color[class*=-C30] { + color: #008787 +} + +div.highlight .-Color[class*=-BGC30] { + background-color: #008787 +} + +div.highlight .-Color[class*=-C31] { + color: #0087AF +} + +div.highlight .-Color[class*=-BGC31] { + background-color: #0087AF +} + +div.highlight .-Color[class*=-C32] { + color: #0087D7 +} + +div.highlight .-Color[class*=-BGC32] { + background-color: #0087D7 +} + +div.highlight .-Color[class*=-C33] { + color: #0087FF +} + +div.highlight .-Color[class*=-BGC33] { + background-color: #0087FF +} + +div.highlight .-Color[class*=-C34] { + color: #00AF00 +} + +div.highlight .-Color[class*=-BGC34] { + background-color: #00AF00 +} + +div.highlight .-Color[class*=-C35] { + color: #00AF5F +} + +div.highlight .-Color[class*=-BGC35] { + background-color: #00AF5F +} + +div.highlight .-Color[class*=-C36] { + color: #00AF87 +} + +div.highlight .-Color[class*=-BGC36] { + background-color: #00AF87 +} + +div.highlight .-Color[class*=-C37] { + color: #00AFAF +} + +div.highlight .-Color[class*=-BGC37] { + background-color: #00AFAF +} + +div.highlight .-Color[class*=-C38] { + color: #00AFD7 +} + +div.highlight .-Color[class*=-BGC38] { + background-color: #00AFD7 +} + +div.highlight .-Color[class*=-C39] { + color: #00AFFF +} + +div.highlight .-Color[class*=-BGC39] { + background-color: #00AFFF +} + +div.highlight .-Color[class*=-C40] { + color: #00D700 +} + +div.highlight .-Color[class*=-BGC40] { + background-color: #00D700 +} + +div.highlight .-Color[class*=-C41] { + color: #00D75F +} + +div.highlight .-Color[class*=-BGC41] { + background-color: #00D75F +} + +div.highlight .-Color[class*=-C42] { + color: #00D787 +} + +div.highlight .-Color[class*=-BGC42] { + background-color: #00D787 +} + +div.highlight .-Color[class*=-C43] { + color: #00D7AF +} + +div.highlight .-Color[class*=-BGC43] { + background-color: #00D7AF +} + +div.highlight .-Color[class*=-C44] { + color: #00D7D7 +} + +div.highlight .-Color[class*=-BGC44] { + background-color: #00D7D7 +} + +div.highlight .-Color[class*=-C45] { + color: #00D7FF +} + +div.highlight .-Color[class*=-BGC45] { + background-color: #00D7FF +} + +div.highlight .-Color[class*=-C46] { + color: #00FF00 +} + +div.highlight .-Color[class*=-BGC46] { + background-color: #00FF00 +} + +div.highlight .-Color[class*=-C47] { + color: #00FF5F +} + +div.highlight .-Color[class*=-BGC47] { + background-color: #00FF5F +} + +div.highlight .-Color[class*=-C48] { + color: #00FF87 +} + +div.highlight .-Color[class*=-BGC48] { + background-color: #00FF87 +} + +div.highlight .-Color[class*=-C49] { + color: #00FFAF +} + +div.highlight .-Color[class*=-BGC49] { + background-color: #00FFAF +} + +div.highlight .-Color[class*=-C50] { + color: #00FFD7 +} + +div.highlight .-Color[class*=-BGC50] { + background-color: #00FFD7 +} + +div.highlight .-Color[class*=-C51] { + color: #00FFFF +} + +div.highlight .-Color[class*=-BGC51] { + background-color: #00FFFF +} + +div.highlight .-Color[class*=-C52] { + color: #5F0000 +} + +div.highlight .-Color[class*=-BGC52] { + background-color: #5F0000 +} + +div.highlight .-Color[class*=-C53] { + color: #5F005F +} + +div.highlight .-Color[class*=-BGC53] { + background-color: #5F005F +} + +div.highlight .-Color[class*=-C54] { + color: #5F0087 +} + +div.highlight .-Color[class*=-BGC54] { + background-color: #5F0087 +} + +div.highlight .-Color[class*=-C55] { + color: #5F00AF +} + +div.highlight .-Color[class*=-BGC55] { + background-color: #5F00AF +} + +div.highlight .-Color[class*=-C56] { + color: #5F00D7 +} + +div.highlight .-Color[class*=-BGC56] { + background-color: #5F00D7 +} + +div.highlight .-Color[class*=-C57] { + color: #5F00FF +} + +div.highlight .-Color[class*=-BGC57] { + background-color: #5F00FF +} + +div.highlight .-Color[class*=-C58] { + color: #5F5F00 +} + +div.highlight .-Color[class*=-BGC58] { + background-color: #5F5F00 +} + +div.highlight .-Color[class*=-C59] { + color: #5F5F5F +} + +div.highlight .-Color[class*=-BGC59] { + background-color: #5F5F5F +} + +div.highlight .-Color[class*=-C60] { + color: #5F5F87 +} + +div.highlight .-Color[class*=-BGC60] { + background-color: #5F5F87 +} + +div.highlight .-Color[class*=-C61] { + color: #5F5FAF +} + +div.highlight .-Color[class*=-BGC61] { + background-color: #5F5FAF +} + +div.highlight .-Color[class*=-C62] { + color: #5F5FD7 +} + +div.highlight .-Color[class*=-BGC62] { + background-color: #5F5FD7 +} + +div.highlight .-Color[class*=-C63] { + color: #5F5FFF +} + +div.highlight .-Color[class*=-BGC63] { + background-color: #5F5FFF +} + +div.highlight .-Color[class*=-C64] { + color: #5F8700 +} + +div.highlight .-Color[class*=-BGC64] { + background-color: #5F8700 +} + +div.highlight .-Color[class*=-C65] { + color: #5F875F +} + +div.highlight .-Color[class*=-BGC65] { + background-color: #5F875F +} + +div.highlight .-Color[class*=-C66] { + color: #5F8787 +} + +div.highlight .-Color[class*=-BGC66] { + background-color: #5F8787 +} + +div.highlight .-Color[class*=-C67] { + color: #5F87AF +} + +div.highlight .-Color[class*=-BGC67] { + background-color: #5F87AF +} + +div.highlight .-Color[class*=-C68] { + color: #5F87D7 +} + +div.highlight .-Color[class*=-BGC68] { + background-color: #5F87D7 +} + +div.highlight .-Color[class*=-C69] { + color: #5F87FF +} + +div.highlight .-Color[class*=-BGC69] { + background-color: #5F87FF +} + +div.highlight .-Color[class*=-C70] { + color: #5FAF00 +} + +div.highlight .-Color[class*=-BGC70] { + background-color: #5FAF00 +} + +div.highlight .-Color[class*=-C71] { + color: #5FAF5F +} + +div.highlight .-Color[class*=-BGC71] { + background-color: #5FAF5F +} + +div.highlight .-Color[class*=-C72] { + color: #5FAF87 +} + +div.highlight .-Color[class*=-BGC72] { + background-color: #5FAF87 +} + +div.highlight .-Color[class*=-C73] { + color: #5FAFAF +} + +div.highlight .-Color[class*=-BGC73] { + background-color: #5FAFAF +} + +div.highlight .-Color[class*=-C74] { + color: #5FAFD7 +} + +div.highlight .-Color[class*=-BGC74] { + background-color: #5FAFD7 +} + +div.highlight .-Color[class*=-C75] { + color: #5FAFFF +} + +div.highlight .-Color[class*=-BGC75] { + background-color: #5FAFFF +} + +div.highlight .-Color[class*=-C76] { + color: #5FD700 +} + +div.highlight .-Color[class*=-BGC76] { + background-color: #5FD700 +} + +div.highlight .-Color[class*=-C77] { + color: #5FD75F +} + +div.highlight .-Color[class*=-BGC77] { + background-color: #5FD75F +} + +div.highlight .-Color[class*=-C78] { + color: #5FD787 +} + +div.highlight .-Color[class*=-BGC78] { + background-color: #5FD787 +} + +div.highlight .-Color[class*=-C79] { + color: #5FD7AF +} + +div.highlight .-Color[class*=-BGC79] { + background-color: #5FD7AF +} + +div.highlight .-Color[class*=-C80] { + color: #5FD7D7 +} + +div.highlight .-Color[class*=-BGC80] { + background-color: #5FD7D7 +} + +div.highlight .-Color[class*=-C81] { + color: #5FD7FF +} + +div.highlight .-Color[class*=-BGC81] { + background-color: #5FD7FF +} + +div.highlight .-Color[class*=-C82] { + color: #5FFF00 +} + +div.highlight .-Color[class*=-BGC82] { + background-color: #5FFF00 +} + +div.highlight .-Color[class*=-C83] { + color: #5FFF5F +} + +div.highlight .-Color[class*=-BGC83] { + background-color: #5FFF5F +} + +div.highlight .-Color[class*=-C84] { + color: #5FFF87 +} + +div.highlight .-Color[class*=-BGC84] { + background-color: #5FFF87 +} + +div.highlight .-Color[class*=-C85] { + color: #5FFFAF +} + +div.highlight .-Color[class*=-BGC85] { + background-color: #5FFFAF +} + +div.highlight .-Color[class*=-C86] { + color: #5FFFD7 +} + +div.highlight .-Color[class*=-BGC86] { + background-color: #5FFFD7 +} + +div.highlight .-Color[class*=-C87] { + color: #5FFFFF +} + +div.highlight .-Color[class*=-BGC87] { + background-color: #5FFFFF +} + +div.highlight .-Color[class*=-C88] { + color: #870000 +} + +div.highlight .-Color[class*=-BGC88] { + background-color: #870000 +} + +div.highlight .-Color[class*=-C89] { + color: #87005F +} + +div.highlight .-Color[class*=-BGC89] { + background-color: #87005F +} + +div.highlight .-Color[class*=-C90] { + color: #870087 +} + +div.highlight .-Color[class*=-BGC90] { + background-color: #870087 +} + +div.highlight .-Color[class*=-C91] { + color: #8700AF +} + +div.highlight .-Color[class*=-BGC91] { + background-color: #8700AF +} + +div.highlight .-Color[class*=-C92] { + color: #8700D7 +} + +div.highlight .-Color[class*=-BGC92] { + background-color: #8700D7 +} + +div.highlight .-Color[class*=-C93] { + color: #8700FF +} + +div.highlight .-Color[class*=-BGC93] { + background-color: #8700FF +} + +div.highlight .-Color[class*=-C94] { + color: #875F00 +} + +div.highlight .-Color[class*=-BGC94] { + background-color: #875F00 +} + +div.highlight .-Color[class*=-C95] { + color: #875F5F +} + +div.highlight .-Color[class*=-BGC95] { + background-color: #875F5F +} + +div.highlight .-Color[class*=-C96] { + color: #875F87 +} + +div.highlight .-Color[class*=-BGC96] { + background-color: #875F87 +} + +div.highlight .-Color[class*=-C97] { + color: #875FAF +} + +div.highlight .-Color[class*=-BGC97] { + background-color: #875FAF +} + +div.highlight .-Color[class*=-C98] { + color: #875FD7 +} + +div.highlight .-Color[class*=-BGC98] { + background-color: #875FD7 +} + +div.highlight .-Color[class*=-C99] { + color: #875FFF +} + +div.highlight .-Color[class*=-BGC99] { + background-color: #875FFF +} + +div.highlight .-Color[class*=-C100] { + color: #878700 +} + +div.highlight .-Color[class*=-BGC100] { + background-color: #878700 +} + +div.highlight .-Color[class*=-C101] { + color: #87875F +} + +div.highlight .-Color[class*=-BGC101] { + background-color: #87875F +} + +div.highlight .-Color[class*=-C102] { + color: #878787 +} + +div.highlight .-Color[class*=-BGC102] { + background-color: #878787 +} + +div.highlight .-Color[class*=-C103] { + color: #8787AF +} + +div.highlight .-Color[class*=-BGC103] { + background-color: #8787AF +} + +div.highlight .-Color[class*=-C104] { + color: #8787D7 +} + +div.highlight .-Color[class*=-BGC104] { + background-color: #8787D7 +} + +div.highlight .-Color[class*=-C105] { + color: #8787FF +} + +div.highlight .-Color[class*=-BGC105] { + background-color: #8787FF +} + +div.highlight .-Color[class*=-C106] { + color: #87AF00 +} + +div.highlight .-Color[class*=-BGC106] { + background-color: #87AF00 +} + +div.highlight .-Color[class*=-C107] { + color: #87AF5F +} + +div.highlight .-Color[class*=-BGC107] { + background-color: #87AF5F +} + +div.highlight .-Color[class*=-C108] { + color: #87AF87 +} + +div.highlight .-Color[class*=-BGC108] { + background-color: #87AF87 +} + +div.highlight .-Color[class*=-C109] { + color: #87AFAF +} + +div.highlight .-Color[class*=-BGC109] { + background-color: #87AFAF +} + +div.highlight .-Color[class*=-C110] { + color: #87AFD7 +} + +div.highlight .-Color[class*=-BGC110] { + background-color: #87AFD7 +} + +div.highlight .-Color[class*=-C111] { + color: #87AFFF +} + +div.highlight .-Color[class*=-BGC111] { + background-color: #87AFFF +} + +div.highlight .-Color[class*=-C112] { + color: #87D700 +} + +div.highlight .-Color[class*=-BGC112] { + background-color: #87D700 +} + +div.highlight .-Color[class*=-C113] { + color: #87D75F +} + +div.highlight .-Color[class*=-BGC113] { + background-color: #87D75F +} + +div.highlight .-Color[class*=-C114] { + color: #87D787 +} + +div.highlight .-Color[class*=-BGC114] { + background-color: #87D787 +} + +div.highlight .-Color[class*=-C115] { + color: #87D7AF +} + +div.highlight .-Color[class*=-BGC115] { + background-color: #87D7AF +} + +div.highlight .-Color[class*=-C116] { + color: #87D7D7 +} + +div.highlight .-Color[class*=-BGC116] { + background-color: #87D7D7 +} + +div.highlight .-Color[class*=-C117] { + color: #87D7FF +} + +div.highlight .-Color[class*=-BGC117] { + background-color: #87D7FF +} + +div.highlight .-Color[class*=-C118] { + color: #87FF00 +} + +div.highlight .-Color[class*=-BGC118] { + background-color: #87FF00 +} + +div.highlight .-Color[class*=-C119] { + color: #87FF5F +} + +div.highlight .-Color[class*=-BGC119] { + background-color: #87FF5F +} + +div.highlight .-Color[class*=-C120] { + color: #87FF87 +} + +div.highlight .-Color[class*=-BGC120] { + background-color: #87FF87 +} + +div.highlight .-Color[class*=-C121] { + color: #87FFAF +} + +div.highlight .-Color[class*=-BGC121] { + background-color: #87FFAF +} + +div.highlight .-Color[class*=-C122] { + color: #87FFD7 +} + +div.highlight .-Color[class*=-BGC122] { + background-color: #87FFD7 +} + +div.highlight .-Color[class*=-C123] { + color: #87FFFF +} + +div.highlight .-Color[class*=-BGC123] { + background-color: #87FFFF +} + +div.highlight .-Color[class*=-C124] { + color: #AF0000 +} + +div.highlight .-Color[class*=-BGC124] { + background-color: #AF0000 +} + +div.highlight .-Color[class*=-C125] { + color: #AF005F +} + +div.highlight .-Color[class*=-BGC125] { + background-color: #AF005F +} + +div.highlight .-Color[class*=-C126] { + color: #AF0087 +} + +div.highlight .-Color[class*=-BGC126] { + background-color: #AF0087 +} + +div.highlight .-Color[class*=-C127] { + color: #AF00AF +} + +div.highlight .-Color[class*=-BGC127] { + background-color: #AF00AF +} + +div.highlight .-Color[class*=-C128] { + color: #AF00D7 +} + +div.highlight .-Color[class*=-BGC128] { + background-color: #AF00D7 +} + +div.highlight .-Color[class*=-C129] { + color: #AF00FF +} + +div.highlight .-Color[class*=-BGC129] { + background-color: #AF00FF +} + +div.highlight .-Color[class*=-C130] { + color: #AF5F00 +} + +div.highlight .-Color[class*=-BGC130] { + background-color: #AF5F00 +} + +div.highlight .-Color[class*=-C131] { + color: #AF5F5F +} + +div.highlight .-Color[class*=-BGC131] { + background-color: #AF5F5F +} + +div.highlight .-Color[class*=-C132] { + color: #AF5F87 +} + +div.highlight .-Color[class*=-BGC132] { + background-color: #AF5F87 +} + +div.highlight .-Color[class*=-C133] { + color: #AF5FAF +} + +div.highlight .-Color[class*=-BGC133] { + background-color: #AF5FAF +} + +div.highlight .-Color[class*=-C134] { + color: #AF5FD7 +} + +div.highlight .-Color[class*=-BGC134] { + background-color: #AF5FD7 +} + +div.highlight .-Color[class*=-C135] { + color: #AF5FFF +} + +div.highlight .-Color[class*=-BGC135] { + background-color: #AF5FFF +} + +div.highlight .-Color[class*=-C136] { + color: #AF8700 +} + +div.highlight .-Color[class*=-BGC136] { + background-color: #AF8700 +} + +div.highlight .-Color[class*=-C137] { + color: #AF875F +} + +div.highlight .-Color[class*=-BGC137] { + background-color: #AF875F +} + +div.highlight .-Color[class*=-C138] { + color: #AF8787 +} + +div.highlight .-Color[class*=-BGC138] { + background-color: #AF8787 +} + +div.highlight .-Color[class*=-C139] { + color: #AF87AF +} + +div.highlight .-Color[class*=-BGC139] { + background-color: #AF87AF +} + +div.highlight .-Color[class*=-C140] { + color: #AF87D7 +} + +div.highlight .-Color[class*=-BGC140] { + background-color: #AF87D7 +} + +div.highlight .-Color[class*=-C141] { + color: #AF87FF +} + +div.highlight .-Color[class*=-BGC141] { + background-color: #AF87FF +} + +div.highlight .-Color[class*=-C142] { + color: #AFAF00 +} + +div.highlight .-Color[class*=-BGC142] { + background-color: #AFAF00 +} + +div.highlight .-Color[class*=-C143] { + color: #AFAF5F +} + +div.highlight .-Color[class*=-BGC143] { + background-color: #AFAF5F +} + +div.highlight .-Color[class*=-C144] { + color: #AFAF87 +} + +div.highlight .-Color[class*=-BGC144] { + background-color: #AFAF87 +} + +div.highlight .-Color[class*=-C145] { + color: #AFAFAF +} + +div.highlight .-Color[class*=-BGC145] { + background-color: #AFAFAF +} + +div.highlight .-Color[class*=-C146] { + color: #AFAFD7 +} + +div.highlight .-Color[class*=-BGC146] { + background-color: #AFAFD7 +} + +div.highlight .-Color[class*=-C147] { + color: #AFAFFF +} + +div.highlight .-Color[class*=-BGC147] { + background-color: #AFAFFF +} + +div.highlight .-Color[class*=-C148] { + color: #AFD700 +} + +div.highlight .-Color[class*=-BGC148] { + background-color: #AFD700 +} + +div.highlight .-Color[class*=-C149] { + color: #AFD75F +} + +div.highlight .-Color[class*=-BGC149] { + background-color: #AFD75F +} + +div.highlight .-Color[class*=-C150] { + color: #AFD787 +} + +div.highlight .-Color[class*=-BGC150] { + background-color: #AFD787 +} + +div.highlight .-Color[class*=-C151] { + color: #AFD7AF +} + +div.highlight .-Color[class*=-BGC151] { + background-color: #AFD7AF +} + +div.highlight .-Color[class*=-C152] { + color: #AFD7D7 +} + +div.highlight .-Color[class*=-BGC152] { + background-color: #AFD7D7 +} + +div.highlight .-Color[class*=-C153] { + color: #AFD7FF +} + +div.highlight .-Color[class*=-BGC153] { + background-color: #AFD7FF +} + +div.highlight .-Color[class*=-C154] { + color: #AFFF00 +} + +div.highlight .-Color[class*=-BGC154] { + background-color: #AFFF00 +} + +div.highlight .-Color[class*=-C155] { + color: #AFFF5F +} + +div.highlight .-Color[class*=-BGC155] { + background-color: #AFFF5F +} + +div.highlight .-Color[class*=-C156] { + color: #AFFF87 +} + +div.highlight .-Color[class*=-BGC156] { + background-color: #AFFF87 +} + +div.highlight .-Color[class*=-C157] { + color: #AFFFAF +} + +div.highlight .-Color[class*=-BGC157] { + background-color: #AFFFAF +} + +div.highlight .-Color[class*=-C158] { + color: #AFFFD7 +} + +div.highlight .-Color[class*=-BGC158] { + background-color: #AFFFD7 +} + +div.highlight .-Color[class*=-C159] { + color: #AFFFFF +} + +div.highlight .-Color[class*=-BGC159] { + background-color: #AFFFFF +} + +div.highlight .-Color[class*=-C160] { + color: #D70000 +} + +div.highlight .-Color[class*=-BGC160] { + background-color: #D70000 +} + +div.highlight .-Color[class*=-C161] { + color: #D7005F +} + +div.highlight .-Color[class*=-BGC161] { + background-color: #D7005F +} + +div.highlight .-Color[class*=-C162] { + color: #D70087 +} + +div.highlight .-Color[class*=-BGC162] { + background-color: #D70087 +} + +div.highlight .-Color[class*=-C163] { + color: #D700AF +} + +div.highlight .-Color[class*=-BGC163] { + background-color: #D700AF +} + +div.highlight .-Color[class*=-C164] { + color: #D700D7 +} + +div.highlight .-Color[class*=-BGC164] { + background-color: #D700D7 +} + +div.highlight .-Color[class*=-C165] { + color: #D700FF +} + +div.highlight .-Color[class*=-BGC165] { + background-color: #D700FF +} + +div.highlight .-Color[class*=-C166] { + color: #D75F00 +} + +div.highlight .-Color[class*=-BGC166] { + background-color: #D75F00 +} + +div.highlight .-Color[class*=-C167] { + color: #D75F5F +} + +div.highlight .-Color[class*=-BGC167] { + background-color: #D75F5F +} + +div.highlight .-Color[class*=-C168] { + color: #D75F87 +} + +div.highlight .-Color[class*=-BGC168] { + background-color: #D75F87 +} + +div.highlight .-Color[class*=-C169] { + color: #D75FAF +} + +div.highlight .-Color[class*=-BGC169] { + background-color: #D75FAF +} + +div.highlight .-Color[class*=-C170] { + color: #D75FD7 +} + +div.highlight .-Color[class*=-BGC170] { + background-color: #D75FD7 +} + +div.highlight .-Color[class*=-C171] { + color: #D75FFF +} + +div.highlight .-Color[class*=-BGC171] { + background-color: #D75FFF +} + +div.highlight .-Color[class*=-C172] { + color: #D78700 +} + +div.highlight .-Color[class*=-BGC172] { + background-color: #D78700 +} + +div.highlight .-Color[class*=-C173] { + color: #D7875F +} + +div.highlight .-Color[class*=-BGC173] { + background-color: #D7875F +} + +div.highlight .-Color[class*=-C174] { + color: #D78787 +} + +div.highlight .-Color[class*=-BGC174] { + background-color: #D78787 +} + +div.highlight .-Color[class*=-C175] { + color: #D787AF +} + +div.highlight .-Color[class*=-BGC175] { + background-color: #D787AF +} + +div.highlight .-Color[class*=-C176] { + color: #D787D7 +} + +div.highlight .-Color[class*=-BGC176] { + background-color: #D787D7 +} + +div.highlight .-Color[class*=-C177] { + color: #D787FF +} + +div.highlight .-Color[class*=-BGC177] { + background-color: #D787FF +} + +div.highlight .-Color[class*=-C178] { + color: #D7AF00 +} + +div.highlight .-Color[class*=-BGC178] { + background-color: #D7AF00 +} + +div.highlight .-Color[class*=-C179] { + color: #D7AF5F +} + +div.highlight .-Color[class*=-BGC179] { + background-color: #D7AF5F +} + +div.highlight .-Color[class*=-C180] { + color: #D7AF87 +} + +div.highlight .-Color[class*=-BGC180] { + background-color: #D7AF87 +} + +div.highlight .-Color[class*=-C181] { + color: #D7AFAF +} + +div.highlight .-Color[class*=-BGC181] { + background-color: #D7AFAF +} + +div.highlight .-Color[class*=-C182] { + color: #D7AFD7 +} + +div.highlight .-Color[class*=-BGC182] { + background-color: #D7AFD7 +} + +div.highlight .-Color[class*=-C183] { + color: #D7AFFF +} + +div.highlight .-Color[class*=-BGC183] { + background-color: #D7AFFF +} + +div.highlight .-Color[class*=-C184] { + color: #D7D700 +} + +div.highlight .-Color[class*=-BGC184] { + background-color: #D7D700 +} + +div.highlight .-Color[class*=-C185] { + color: #D7D75F +} + +div.highlight .-Color[class*=-BGC185] { + background-color: #D7D75F +} + +div.highlight .-Color[class*=-C186] { + color: #D7D787 +} + +div.highlight .-Color[class*=-BGC186] { + background-color: #D7D787 +} + +div.highlight .-Color[class*=-C187] { + color: #D7D7AF +} + +div.highlight .-Color[class*=-BGC187] { + background-color: #D7D7AF +} + +div.highlight .-Color[class*=-C188] { + color: #D7D7D7 +} + +div.highlight .-Color[class*=-BGC188] { + background-color: #D7D7D7 +} + +div.highlight .-Color[class*=-C189] { + color: #D7D7FF +} + +div.highlight .-Color[class*=-BGC189] { + background-color: #D7D7FF +} + +div.highlight .-Color[class*=-C190] { + color: #D7FF00 +} + +div.highlight .-Color[class*=-BGC190] { + background-color: #D7FF00 +} + +div.highlight .-Color[class*=-C191] { + color: #D7FF5F +} + +div.highlight .-Color[class*=-BGC191] { + background-color: #D7FF5F +} + +div.highlight .-Color[class*=-C192] { + color: #D7FF87 +} + +div.highlight .-Color[class*=-BGC192] { + background-color: #D7FF87 +} + +div.highlight .-Color[class*=-C193] { + color: #D7FFAF +} + +div.highlight .-Color[class*=-BGC193] { + background-color: #D7FFAF +} + +div.highlight .-Color[class*=-C194] { + color: #D7FFD7 +} + +div.highlight .-Color[class*=-BGC194] { + background-color: #D7FFD7 +} + +div.highlight .-Color[class*=-C195] { + color: #D7FFFF +} + +div.highlight .-Color[class*=-BGC195] { + background-color: #D7FFFF +} + +div.highlight .-Color[class*=-C196] { + color: #FF0000 +} + +div.highlight .-Color[class*=-BGC196] { + background-color: #FF0000 +} + +div.highlight .-Color[class*=-C197] { + color: #FF005F +} + +div.highlight .-Color[class*=-BGC197] { + background-color: #FF005F +} + +div.highlight .-Color[class*=-C198] { + color: #FF0087 +} + +div.highlight .-Color[class*=-BGC198] { + background-color: #FF0087 +} + +div.highlight .-Color[class*=-C199] { + color: #FF00AF +} + +div.highlight .-Color[class*=-BGC199] { + background-color: #FF00AF +} + +div.highlight .-Color[class*=-C200] { + color: #FF00D7 +} + +div.highlight .-Color[class*=-BGC200] { + background-color: #FF00D7 +} + +div.highlight .-Color[class*=-C201] { + color: #FF00FF +} + +div.highlight .-Color[class*=-BGC201] { + background-color: #FF00FF +} + +div.highlight .-Color[class*=-C202] { + color: #FF5F00 +} + +div.highlight .-Color[class*=-BGC202] { + background-color: #FF5F00 +} + +div.highlight .-Color[class*=-C203] { + color: #FF5F5F +} + +div.highlight .-Color[class*=-BGC203] { + background-color: #FF5F5F +} + +div.highlight .-Color[class*=-C204] { + color: #FF5F87 +} + +div.highlight .-Color[class*=-BGC204] { + background-color: #FF5F87 +} + +div.highlight .-Color[class*=-C205] { + color: #FF5FAF +} + +div.highlight .-Color[class*=-BGC205] { + background-color: #FF5FAF +} + +div.highlight .-Color[class*=-C206] { + color: #FF5FD7 +} + +div.highlight .-Color[class*=-BGC206] { + background-color: #FF5FD7 +} + +div.highlight .-Color[class*=-C207] { + color: #FF5FFF +} + +div.highlight .-Color[class*=-BGC207] { + background-color: #FF5FFF +} + +div.highlight .-Color[class*=-C208] { + color: #FF8700 +} + +div.highlight .-Color[class*=-BGC208] { + background-color: #FF8700 +} + +div.highlight .-Color[class*=-C209] { + color: #FF875F +} + +div.highlight .-Color[class*=-BGC209] { + background-color: #FF875F +} + +div.highlight .-Color[class*=-C210] { + color: #FF8787 +} + +div.highlight .-Color[class*=-BGC210] { + background-color: #FF8787 +} + +div.highlight .-Color[class*=-C211] { + color: #FF87AF +} + +div.highlight .-Color[class*=-BGC211] { + background-color: #FF87AF +} + +div.highlight .-Color[class*=-C212] { + color: #FF87D7 +} + +div.highlight .-Color[class*=-BGC212] { + background-color: #FF87D7 +} + +div.highlight .-Color[class*=-C213] { + color: #FF87FF +} + +div.highlight .-Color[class*=-BGC213] { + background-color: #FF87FF +} + +div.highlight .-Color[class*=-C214] { + color: #FFAF00 +} + +div.highlight .-Color[class*=-BGC214] { + background-color: #FFAF00 +} + +div.highlight .-Color[class*=-C215] { + color: #FFAF5F +} + +div.highlight .-Color[class*=-BGC215] { + background-color: #FFAF5F +} + +div.highlight .-Color[class*=-C216] { + color: #FFAF87 +} + +div.highlight .-Color[class*=-BGC216] { + background-color: #FFAF87 +} + +div.highlight .-Color[class*=-C217] { + color: #FFAFAF +} + +div.highlight .-Color[class*=-BGC217] { + background-color: #FFAFAF +} + +div.highlight .-Color[class*=-C218] { + color: #FFAFD7 +} + +div.highlight .-Color[class*=-BGC218] { + background-color: #FFAFD7 +} + +div.highlight .-Color[class*=-C219] { + color: #FFAFFF +} + +div.highlight .-Color[class*=-BGC219] { + background-color: #FFAFFF +} + +div.highlight .-Color[class*=-C220] { + color: #FFD700 +} + +div.highlight .-Color[class*=-BGC220] { + background-color: #FFD700 +} + +div.highlight .-Color[class*=-C221] { + color: #FFD75F +} + +div.highlight .-Color[class*=-BGC221] { + background-color: #FFD75F +} + +div.highlight .-Color[class*=-C222] { + color: #FFD787 +} + +div.highlight .-Color[class*=-BGC222] { + background-color: #FFD787 +} + +div.highlight .-Color[class*=-C223] { + color: #FFD7AF +} + +div.highlight .-Color[class*=-BGC223] { + background-color: #FFD7AF +} + +div.highlight .-Color[class*=-C224] { + color: #FFD7D7 +} + +div.highlight .-Color[class*=-BGC224] { + background-color: #FFD7D7 +} + +div.highlight .-Color[class*=-C225] { + color: #FFD7FF +} + +div.highlight .-Color[class*=-BGC225] { + background-color: #FFD7FF +} + +div.highlight .-Color[class*=-C226] { + color: #FFFF00 +} + +div.highlight .-Color[class*=-BGC226] { + background-color: #FFFF00 +} + +div.highlight .-Color[class*=-C227] { + color: #FFFF5F +} + +div.highlight .-Color[class*=-BGC227] { + background-color: #FFFF5F +} + +div.highlight .-Color[class*=-C228] { + color: #FFFF87 +} + +div.highlight .-Color[class*=-BGC228] { + background-color: #FFFF87 +} + +div.highlight .-Color[class*=-C229] { + color: #FFFFAF +} + +div.highlight .-Color[class*=-BGC229] { + background-color: #FFFFAF +} + +div.highlight .-Color[class*=-C230] { + color: #FFFFD7 +} + +div.highlight .-Color[class*=-BGC230] { + background-color: #FFFFD7 +} + +div.highlight .-Color[class*=-C231] { + color: #FFFFFF +} + +div.highlight .-Color[class*=-BGC231] { + background-color: #FFFFFF +} + +div.highlight .-Color[class*=-C232] { + color: #080808 +} + +div.highlight .-Color[class*=-BGC232] { + background-color: #080808 +} + +div.highlight .-Color[class*=-C233] { + color: #121212 +} + +div.highlight .-Color[class*=-BGC233] { + background-color: #121212 +} + +div.highlight .-Color[class*=-C234] { + color: #1C1C1C +} + +div.highlight .-Color[class*=-BGC234] { + background-color: #1C1C1C +} + +div.highlight .-Color[class*=-C235] { + color: #262626 +} + +div.highlight .-Color[class*=-BGC235] { + background-color: #262626 +} + +div.highlight .-Color[class*=-C236] { + color: #303030 +} + +div.highlight .-Color[class*=-BGC236] { + background-color: #303030 +} + +div.highlight .-Color[class*=-C237] { + color: #3A3A3A +} + +div.highlight .-Color[class*=-BGC237] { + background-color: #3A3A3A +} + +div.highlight .-Color[class*=-C238] { + color: #444444 +} + +div.highlight .-Color[class*=-BGC238] { + background-color: #444444 +} + +div.highlight .-Color[class*=-C239] { + color: #4E4E4E +} + +div.highlight .-Color[class*=-BGC239] { + background-color: #4E4E4E +} + +div.highlight .-Color[class*=-C240] { + color: #585858 +} + +div.highlight .-Color[class*=-BGC240] { + background-color: #585858 +} + +div.highlight .-Color[class*=-C241] { + color: #626262 +} + +div.highlight .-Color[class*=-BGC241] { + background-color: #626262 +} + +div.highlight .-Color[class*=-C242] { + color: #6C6C6C +} + +div.highlight .-Color[class*=-BGC242] { + background-color: #6C6C6C +} + +div.highlight .-Color[class*=-C243] { + color: #767676 +} + +div.highlight .-Color[class*=-BGC243] { + background-color: #767676 +} + +div.highlight .-Color[class*=-C244] { + color: #808080 +} + +div.highlight .-Color[class*=-BGC244] { + background-color: #808080 +} + +div.highlight .-Color[class*=-C245] { + color: #8A8A8A +} + +div.highlight .-Color[class*=-BGC245] { + background-color: #8A8A8A +} + +div.highlight .-Color[class*=-C246] { + color: #949494 +} + +div.highlight .-Color[class*=-BGC246] { + background-color: #949494 +} + +div.highlight .-Color[class*=-C247] { + color: #9E9E9E +} + +div.highlight .-Color[class*=-BGC247] { + background-color: #9E9E9E +} + +div.highlight .-Color[class*=-C248] { + color: #A8A8A8 +} + +div.highlight .-Color[class*=-BGC248] { + background-color: #A8A8A8 +} + +div.highlight .-Color[class*=-C249] { + color: #B2B2B2 +} + +div.highlight .-Color[class*=-BGC249] { + background-color: #B2B2B2 +} + +div.highlight .-Color[class*=-C250] { + color: #BCBCBC +} + +div.highlight .-Color[class*=-BGC250] { + background-color: #BCBCBC +} + +div.highlight .-Color[class*=-C251] { + color: #C6C6C6 +} + +div.highlight .-Color[class*=-BGC251] { + background-color: #C6C6C6 +} + +div.highlight .-Color[class*=-C252] { + color: #D0D0D0 +} + +div.highlight .-Color[class*=-BGC252] { + background-color: #D0D0D0 +} + +div.highlight .-Color[class*=-C253] { + color: #DADADA +} + +div.highlight .-Color[class*=-BGC253] { + background-color: #DADADA +} + +div.highlight .-Color[class*=-C254] { + color: #E4E4E4 +} + +div.highlight .-Color[class*=-BGC254] { + background-color: #E4E4E4 +} + +div.highlight .-Color[class*=-C255] { + color: #EEEEEE +} + +div.highlight .-Color[class*=-BGC255] { + background-color: #EEEEEE +} diff --git a/_preview/468/_static/play-solid.svg b/_preview/468/_static/play-solid.svg new file mode 100644 index 000000000..bcd81f7a6 --- /dev/null +++ b/_preview/468/_static/play-solid.svg @@ -0,0 +1 @@ + \ No newline at end of file diff --git a/_preview/468/_static/plus.png b/_preview/468/_static/plus.png new file mode 100644 index 000000000..7107cec93 Binary files /dev/null and b/_preview/468/_static/plus.png differ diff --git a/_preview/468/_static/pygments.css b/_preview/468/_static/pygments.css new file mode 100644 index 000000000..997797f27 --- /dev/null +++ b/_preview/468/_static/pygments.css @@ -0,0 +1,152 @@ +html[data-theme="light"] .highlight pre { line-height: 125%; } +html[data-theme="light"] .highlight td.linenos .normal { color: inherit; background-color: transparent; padding-left: 5px; padding-right: 5px; } +html[data-theme="light"] .highlight span.linenos { color: inherit; background-color: transparent; padding-left: 5px; padding-right: 5px; } +html[data-theme="light"] .highlight td.linenos .special { color: #000000; background-color: #ffffc0; padding-left: 5px; padding-right: 5px; } +html[data-theme="light"] .highlight span.linenos.special { color: #000000; background-color: #ffffc0; padding-left: 5px; padding-right: 5px; } +html[data-theme="light"] .highlight .hll { background-color: #7971292e } +html[data-theme="light"] .highlight { background: #fefefe; color: #545454 } +html[data-theme="light"] .highlight .c { color: #797129 } /* Comment */ +html[data-theme="light"] .highlight .err { color: #d91e18 } /* Error */ +html[data-theme="light"] .highlight .k { color: #7928a1 } /* Keyword */ +html[data-theme="light"] .highlight .l { color: #797129 } /* Literal */ +html[data-theme="light"] .highlight .n { color: #545454 } /* Name */ +html[data-theme="light"] .highlight .o { color: #008000 } /* Operator */ +html[data-theme="light"] .highlight .p { color: #545454 } /* Punctuation */ +html[data-theme="light"] .highlight .ch { color: #797129 } /* Comment.Hashbang */ +html[data-theme="light"] .highlight .cm { color: #797129 } /* Comment.Multiline */ +html[data-theme="light"] .highlight .cp { color: #797129 } /* Comment.Preproc */ +html[data-theme="light"] .highlight .cpf { color: #797129 } /* Comment.PreprocFile */ +html[data-theme="light"] .highlight .c1 { color: #797129 } /* Comment.Single */ +html[data-theme="light"] .highlight .cs { color: #797129 } /* Comment.Special */ +html[data-theme="light"] .highlight .gd { color: #007faa } /* Generic.Deleted */ +html[data-theme="light"] .highlight .ge { font-style: italic } /* Generic.Emph */ +html[data-theme="light"] .highlight .gh { color: #007faa } /* Generic.Heading */ +html[data-theme="light"] .highlight .gs { font-weight: bold } /* Generic.Strong */ +html[data-theme="light"] .highlight .gu { color: #007faa } /* Generic.Subheading */ +html[data-theme="light"] .highlight .kc { color: #7928a1 } /* Keyword.Constant */ +html[data-theme="light"] .highlight .kd { color: #7928a1 } /* Keyword.Declaration */ +html[data-theme="light"] .highlight .kn { color: #7928a1 } /* Keyword.Namespace */ +html[data-theme="light"] .highlight .kp { color: #7928a1 } /* Keyword.Pseudo */ +html[data-theme="light"] .highlight .kr { color: #7928a1 } /* Keyword.Reserved */ +html[data-theme="light"] .highlight .kt { color: #797129 } /* Keyword.Type */ +html[data-theme="light"] .highlight .ld { color: #797129 } /* Literal.Date */ +html[data-theme="light"] .highlight .m { color: #797129 } /* Literal.Number */ +html[data-theme="light"] .highlight .s { color: #008000 } /* Literal.String */ +html[data-theme="light"] .highlight .na { color: #797129 } /* Name.Attribute */ +html[data-theme="light"] .highlight .nb { color: #797129 } /* Name.Builtin */ +html[data-theme="light"] .highlight .nc { color: #007faa } /* Name.Class */ +html[data-theme="light"] .highlight .no { color: #007faa } /* Name.Constant */ +html[data-theme="light"] .highlight .nd { color: #797129 } /* Name.Decorator */ +html[data-theme="light"] .highlight .ni { color: #008000 } /* Name.Entity */ +html[data-theme="light"] .highlight .ne { color: #7928a1 } /* Name.Exception */ +html[data-theme="light"] .highlight .nf { color: #007faa } /* Name.Function */ +html[data-theme="light"] .highlight .nl { color: #797129 } /* Name.Label */ +html[data-theme="light"] .highlight .nn { color: #545454 } /* Name.Namespace */ +html[data-theme="light"] .highlight .nx { color: #545454 } /* Name.Other */ +html[data-theme="light"] .highlight .py { color: #007faa } /* Name.Property */ +html[data-theme="light"] .highlight .nt { color: #007faa } /* Name.Tag */ +html[data-theme="light"] .highlight .nv { color: #d91e18 } /* Name.Variable */ +html[data-theme="light"] .highlight .ow { color: #7928a1 } /* Operator.Word */ +html[data-theme="light"] .highlight .pm { color: #545454 } /* Punctuation.Marker */ +html[data-theme="light"] .highlight .w { color: #545454 } /* Text.Whitespace */ +html[data-theme="light"] .highlight .mb { color: #797129 } /* Literal.Number.Bin */ +html[data-theme="light"] .highlight .mf { color: #797129 } /* Literal.Number.Float */ +html[data-theme="light"] .highlight .mh { color: #797129 } /* Literal.Number.Hex */ +html[data-theme="light"] .highlight .mi { color: #797129 } /* Literal.Number.Integer */ +html[data-theme="light"] .highlight .mo { color: #797129 } /* Literal.Number.Oct */ +html[data-theme="light"] .highlight .sa { color: #008000 } /* Literal.String.Affix */ +html[data-theme="light"] .highlight .sb { color: #008000 } /* Literal.String.Backtick */ +html[data-theme="light"] .highlight .sc { color: #008000 } /* Literal.String.Char */ +html[data-theme="light"] .highlight .dl { color: #008000 } /* Literal.String.Delimiter */ +html[data-theme="light"] .highlight .sd { color: #008000 } /* Literal.String.Doc */ +html[data-theme="light"] .highlight .s2 { color: #008000 } /* Literal.String.Double */ +html[data-theme="light"] .highlight .se { color: #008000 } /* Literal.String.Escape */ +html[data-theme="light"] .highlight .sh { color: #008000 } /* Literal.String.Heredoc */ +html[data-theme="light"] .highlight .si { color: #008000 } /* Literal.String.Interpol */ +html[data-theme="light"] .highlight .sx { color: #008000 } /* Literal.String.Other */ +html[data-theme="light"] .highlight .sr { color: #d91e18 } /* Literal.String.Regex */ +html[data-theme="light"] .highlight .s1 { color: #008000 } /* Literal.String.Single */ +html[data-theme="light"] .highlight .ss { color: #007faa } /* Literal.String.Symbol */ +html[data-theme="light"] .highlight .bp { color: #797129 } /* Name.Builtin.Pseudo */ +html[data-theme="light"] .highlight .fm { color: #007faa } /* Name.Function.Magic */ +html[data-theme="light"] .highlight .vc { color: #d91e18 } /* Name.Variable.Class */ +html[data-theme="light"] .highlight .vg { color: #d91e18 } /* Name.Variable.Global */ +html[data-theme="light"] .highlight .vi { color: #d91e18 } /* Name.Variable.Instance */ +html[data-theme="light"] .highlight .vm { color: #797129 } /* Name.Variable.Magic */ +html[data-theme="light"] .highlight .il { color: #797129 } /* Literal.Number.Integer.Long */ +html[data-theme="dark"] .highlight pre { line-height: 125%; } +html[data-theme="dark"] .highlight td.linenos .normal { color: inherit; background-color: transparent; padding-left: 5px; padding-right: 5px; } +html[data-theme="dark"] .highlight span.linenos { color: inherit; background-color: transparent; padding-left: 5px; padding-right: 5px; } +html[data-theme="dark"] .highlight td.linenos .special { color: #000000; background-color: #ffffc0; padding-left: 5px; padding-right: 5px; } +html[data-theme="dark"] .highlight span.linenos.special { color: #000000; background-color: #ffffc0; padding-left: 5px; padding-right: 5px; } +html[data-theme="dark"] .highlight .hll { background-color: #ffd9002e } +html[data-theme="dark"] .highlight { background: #2b2b2b; color: #f8f8f2 } +html[data-theme="dark"] .highlight .c { color: #ffd900 } /* Comment */ +html[data-theme="dark"] .highlight .err { color: #ffa07a } /* Error */ +html[data-theme="dark"] .highlight .k { color: #dcc6e0 } /* Keyword */ +html[data-theme="dark"] .highlight .l { color: #ffd900 } /* Literal */ +html[data-theme="dark"] .highlight .n { color: #f8f8f2 } /* Name */ +html[data-theme="dark"] .highlight .o { color: #abe338 } /* Operator */ +html[data-theme="dark"] .highlight .p { color: #f8f8f2 } /* Punctuation */ +html[data-theme="dark"] .highlight .ch { color: #ffd900 } /* Comment.Hashbang */ +html[data-theme="dark"] .highlight .cm { color: #ffd900 } /* Comment.Multiline */ +html[data-theme="dark"] .highlight .cp { color: #ffd900 } /* Comment.Preproc */ +html[data-theme="dark"] .highlight .cpf { color: #ffd900 } /* Comment.PreprocFile */ +html[data-theme="dark"] .highlight .c1 { color: #ffd900 } /* Comment.Single */ +html[data-theme="dark"] .highlight .cs { color: #ffd900 } /* Comment.Special */ +html[data-theme="dark"] .highlight .gd { color: #00e0e0 } /* Generic.Deleted */ +html[data-theme="dark"] .highlight .ge { font-style: italic } /* Generic.Emph */ +html[data-theme="dark"] .highlight .gh { color: #00e0e0 } /* Generic.Heading */ +html[data-theme="dark"] .highlight .gs { font-weight: bold } /* Generic.Strong */ +html[data-theme="dark"] .highlight .gu { color: #00e0e0 } /* Generic.Subheading */ +html[data-theme="dark"] .highlight .kc { color: #dcc6e0 } /* Keyword.Constant */ +html[data-theme="dark"] .highlight .kd { color: #dcc6e0 } /* Keyword.Declaration */ +html[data-theme="dark"] .highlight .kn { color: #dcc6e0 } /* Keyword.Namespace */ +html[data-theme="dark"] .highlight .kp { color: #dcc6e0 } /* Keyword.Pseudo */ +html[data-theme="dark"] .highlight .kr { color: #dcc6e0 } /* Keyword.Reserved */ +html[data-theme="dark"] .highlight .kt { color: #ffd900 } /* Keyword.Type */ +html[data-theme="dark"] .highlight .ld { color: #ffd900 } /* Literal.Date */ +html[data-theme="dark"] .highlight .m { color: #ffd900 } /* Literal.Number */ +html[data-theme="dark"] .highlight .s { color: #abe338 } /* Literal.String */ +html[data-theme="dark"] .highlight .na { color: #ffd900 } /* Name.Attribute */ +html[data-theme="dark"] .highlight .nb { color: #ffd900 } /* Name.Builtin */ +html[data-theme="dark"] .highlight .nc { color: #00e0e0 } /* Name.Class */ +html[data-theme="dark"] .highlight .no { color: #00e0e0 } /* Name.Constant */ +html[data-theme="dark"] .highlight .nd { color: #ffd900 } /* Name.Decorator */ +html[data-theme="dark"] .highlight .ni { color: #abe338 } /* Name.Entity */ +html[data-theme="dark"] .highlight .ne { color: #dcc6e0 } /* Name.Exception */ +html[data-theme="dark"] .highlight .nf { color: #00e0e0 } /* Name.Function */ +html[data-theme="dark"] .highlight .nl { color: #ffd900 } /* Name.Label */ +html[data-theme="dark"] .highlight .nn { color: #f8f8f2 } /* Name.Namespace */ +html[data-theme="dark"] .highlight .nx { color: #f8f8f2 } /* Name.Other */ +html[data-theme="dark"] .highlight .py { color: #00e0e0 } /* Name.Property */ +html[data-theme="dark"] .highlight .nt { color: #00e0e0 } /* Name.Tag */ +html[data-theme="dark"] .highlight .nv { color: #ffa07a } /* Name.Variable */ +html[data-theme="dark"] .highlight .ow { color: #dcc6e0 } /* Operator.Word */ +html[data-theme="dark"] .highlight .pm { color: #f8f8f2 } /* Punctuation.Marker */ +html[data-theme="dark"] .highlight .w { color: #f8f8f2 } /* Text.Whitespace */ +html[data-theme="dark"] .highlight .mb { color: #ffd900 } /* Literal.Number.Bin */ +html[data-theme="dark"] .highlight .mf { color: #ffd900 } /* Literal.Number.Float */ +html[data-theme="dark"] .highlight .mh { color: #ffd900 } /* Literal.Number.Hex */ +html[data-theme="dark"] .highlight .mi { color: #ffd900 } /* Literal.Number.Integer */ +html[data-theme="dark"] .highlight .mo { color: #ffd900 } /* Literal.Number.Oct */ +html[data-theme="dark"] .highlight .sa { color: #abe338 } /* Literal.String.Affix */ +html[data-theme="dark"] .highlight .sb { color: #abe338 } /* Literal.String.Backtick */ +html[data-theme="dark"] .highlight .sc { color: #abe338 } /* Literal.String.Char */ +html[data-theme="dark"] .highlight .dl { color: #abe338 } /* Literal.String.Delimiter */ +html[data-theme="dark"] .highlight .sd { color: #abe338 } /* Literal.String.Doc */ +html[data-theme="dark"] .highlight .s2 { color: #abe338 } /* Literal.String.Double */ +html[data-theme="dark"] .highlight .se { color: #abe338 } /* Literal.String.Escape */ +html[data-theme="dark"] .highlight .sh { color: #abe338 } /* Literal.String.Heredoc */ +html[data-theme="dark"] .highlight .si { color: #abe338 } /* Literal.String.Interpol */ +html[data-theme="dark"] .highlight .sx { color: #abe338 } /* Literal.String.Other */ +html[data-theme="dark"] .highlight .sr { color: #ffa07a } /* Literal.String.Regex */ +html[data-theme="dark"] .highlight .s1 { color: #abe338 } /* Literal.String.Single */ +html[data-theme="dark"] .highlight .ss { color: #00e0e0 } /* Literal.String.Symbol */ +html[data-theme="dark"] .highlight .bp { color: #ffd900 } /* Name.Builtin.Pseudo */ +html[data-theme="dark"] .highlight .fm { color: #00e0e0 } /* Name.Function.Magic */ +html[data-theme="dark"] .highlight .vc { color: #ffa07a } /* Name.Variable.Class */ +html[data-theme="dark"] .highlight .vg { color: #ffa07a } /* Name.Variable.Global */ +html[data-theme="dark"] .highlight .vi { color: #ffa07a } /* Name.Variable.Instance */ +html[data-theme="dark"] .highlight .vm { color: #ffd900 } /* Name.Variable.Magic */ +html[data-theme="dark"] .highlight .il { color: #ffd900 } /* Literal.Number.Integer.Long */ \ No newline at end of file diff --git a/_preview/468/_static/pythia_logo-white-rtext.svg b/_preview/468/_static/pythia_logo-white-rtext.svg new file mode 100644 index 000000000..fa2a5c6cf --- /dev/null +++ b/_preview/468/_static/pythia_logo-white-rtext.svg @@ -0,0 +1,225 @@ + + diff --git a/_preview/468/_static/sbt-webpack-macros.html b/_preview/468/_static/sbt-webpack-macros.html new file mode 100644 index 000000000..6cbf559fa --- /dev/null +++ b/_preview/468/_static/sbt-webpack-macros.html @@ -0,0 +1,11 @@ + +{% macro head_pre_bootstrap() %} + +{% endmacro %} + +{% macro body_post() %} + +{% endmacro %} diff --git a/_preview/468/_static/scripts/bootstrap.js b/_preview/468/_static/scripts/bootstrap.js new file mode 100644 index 000000000..4e209b0e1 --- /dev/null +++ b/_preview/468/_static/scripts/bootstrap.js @@ -0,0 +1,3 @@ +/*! For license information please see bootstrap.js.LICENSE.txt */ +(()=>{"use strict";var t={d:(e,i)=>{for(var n in i)t.o(i,n)&&!t.o(e,n)&&Object.defineProperty(e,n,{enumerable:!0,get:i[n]})},o:(t,e)=>Object.prototype.hasOwnProperty.call(t,e),r:t=>{"undefined"!=typeof Symbol&&Symbol.toStringTag&&Object.defineProperty(t,Symbol.toStringTag,{value:"Module"}),Object.defineProperty(t,"__esModule",{value:!0})}},e={};t.r(e),t.d(e,{afterMain:()=>E,afterRead:()=>v,afterWrite:()=>C,applyStyles:()=>$,arrow:()=>J,auto:()=>a,basePlacements:()=>l,beforeMain:()=>y,beforeRead:()=>_,beforeWrite:()=>A,bottom:()=>s,clippingParents:()=>d,computeStyles:()=>it,createPopper:()=>Dt,createPopperBase:()=>St,createPopperLite:()=>$t,detectOverflow:()=>_t,end:()=>h,eventListeners:()=>st,flip:()=>bt,hide:()=>wt,left:()=>r,main:()=>w,modifierPhases:()=>O,offset:()=>Et,placements:()=>g,popper:()=>f,popperGenerator:()=>Lt,popperOffsets:()=>At,preventOverflow:()=>Tt,read:()=>b,reference:()=>p,right:()=>o,start:()=>c,top:()=>n,variationPlacements:()=>m,viewport:()=>u,write:()=>T});var i={};t.r(i),t.d(i,{Alert:()=>Oe,Button:()=>ke,Carousel:()=>ri,Collapse:()=>yi,Dropdown:()=>Vi,Modal:()=>xn,Offcanvas:()=>Vn,Popover:()=>fs,ScrollSpy:()=>Ts,Tab:()=>Ks,Toast:()=>lo,Tooltip:()=>hs});var n="top",s="bottom",o="right",r="left",a="auto",l=[n,s,o,r],c="start",h="end",d="clippingParents",u="viewport",f="popper",p="reference",m=l.reduce((function(t,e){return t.concat([e+"-"+c,e+"-"+h])}),[]),g=[].concat(l,[a]).reduce((function(t,e){return t.concat([e,e+"-"+c,e+"-"+h])}),[]),_="beforeRead",b="read",v="afterRead",y="beforeMain",w="main",E="afterMain",A="beforeWrite",T="write",C="afterWrite",O=[_,b,v,y,w,E,A,T,C];function x(t){return t?(t.nodeName||"").toLowerCase():null}function k(t){if(null==t)return window;if("[object Window]"!==t.toString()){var e=t.ownerDocument;return e&&e.defaultView||window}return t}function L(t){return t instanceof k(t).Element||t instanceof Element}function S(t){return t instanceof k(t).HTMLElement||t instanceof HTMLElement}function D(t){return"undefined"!=typeof ShadowRoot&&(t instanceof k(t).ShadowRoot||t instanceof ShadowRoot)}const $={name:"applyStyles",enabled:!0,phase:"write",fn:function(t){var e=t.state;Object.keys(e.elements).forEach((function(t){var i=e.styles[t]||{},n=e.attributes[t]||{},s=e.elements[t];S(s)&&x(s)&&(Object.assign(s.style,i),Object.keys(n).forEach((function(t){var e=n[t];!1===e?s.removeAttribute(t):s.setAttribute(t,!0===e?"":e)})))}))},effect:function(t){var e=t.state,i={popper:{position:e.options.strategy,left:"0",top:"0",margin:"0"},arrow:{position:"absolute"},reference:{}};return Object.assign(e.elements.popper.style,i.popper),e.styles=i,e.elements.arrow&&Object.assign(e.elements.arrow.style,i.arrow),function(){Object.keys(e.elements).forEach((function(t){var n=e.elements[t],s=e.attributes[t]||{},o=Object.keys(e.styles.hasOwnProperty(t)?e.styles[t]:i[t]).reduce((function(t,e){return t[e]="",t}),{});S(n)&&x(n)&&(Object.assign(n.style,o),Object.keys(s).forEach((function(t){n.removeAttribute(t)})))}))}},requires:["computeStyles"]};function I(t){return t.split("-")[0]}var N=Math.max,P=Math.min,M=Math.round;function j(){var t=navigator.userAgentData;return null!=t&&t.brands&&Array.isArray(t.brands)?t.brands.map((function(t){return t.brand+"/"+t.version})).join(" "):navigator.userAgent}function F(){return!/^((?!chrome|android).)*safari/i.test(j())}function H(t,e,i){void 0===e&&(e=!1),void 0===i&&(i=!1);var n=t.getBoundingClientRect(),s=1,o=1;e&&S(t)&&(s=t.offsetWidth>0&&M(n.width)/t.offsetWidth||1,o=t.offsetHeight>0&&M(n.height)/t.offsetHeight||1);var r=(L(t)?k(t):window).visualViewport,a=!F()&&i,l=(n.left+(a&&r?r.offsetLeft:0))/s,c=(n.top+(a&&r?r.offsetTop:0))/o,h=n.width/s,d=n.height/o;return{width:h,height:d,top:c,right:l+h,bottom:c+d,left:l,x:l,y:c}}function B(t){var e=H(t),i=t.offsetWidth,n=t.offsetHeight;return Math.abs(e.width-i)<=1&&(i=e.width),Math.abs(e.height-n)<=1&&(n=e.height),{x:t.offsetLeft,y:t.offsetTop,width:i,height:n}}function W(t,e){var i=e.getRootNode&&e.getRootNode();if(t.contains(e))return!0;if(i&&D(i)){var n=e;do{if(n&&t.isSameNode(n))return!0;n=n.parentNode||n.host}while(n)}return!1}function z(t){return k(t).getComputedStyle(t)}function R(t){return["table","td","th"].indexOf(x(t))>=0}function q(t){return((L(t)?t.ownerDocument:t.document)||window.document).documentElement}function V(t){return"html"===x(t)?t:t.assignedSlot||t.parentNode||(D(t)?t.host:null)||q(t)}function Y(t){return S(t)&&"fixed"!==z(t).position?t.offsetParent:null}function K(t){for(var e=k(t),i=Y(t);i&&R(i)&&"static"===z(i).position;)i=Y(i);return i&&("html"===x(i)||"body"===x(i)&&"static"===z(i).position)?e:i||function(t){var e=/firefox/i.test(j());if(/Trident/i.test(j())&&S(t)&&"fixed"===z(t).position)return null;var i=V(t);for(D(i)&&(i=i.host);S(i)&&["html","body"].indexOf(x(i))<0;){var n=z(i);if("none"!==n.transform||"none"!==n.perspective||"paint"===n.contain||-1!==["transform","perspective"].indexOf(n.willChange)||e&&"filter"===n.willChange||e&&n.filter&&"none"!==n.filter)return i;i=i.parentNode}return null}(t)||e}function Q(t){return["top","bottom"].indexOf(t)>=0?"x":"y"}function X(t,e,i){return N(t,P(e,i))}function U(t){return Object.assign({},{top:0,right:0,bottom:0,left:0},t)}function G(t,e){return e.reduce((function(e,i){return e[i]=t,e}),{})}const J={name:"arrow",enabled:!0,phase:"main",fn:function(t){var e,i=t.state,a=t.name,c=t.options,h=i.elements.arrow,d=i.modifiersData.popperOffsets,u=I(i.placement),f=Q(u),p=[r,o].indexOf(u)>=0?"height":"width";if(h&&d){var m=function(t,e){return U("number"!=typeof(t="function"==typeof t?t(Object.assign({},e.rects,{placement:e.placement})):t)?t:G(t,l))}(c.padding,i),g=B(h),_="y"===f?n:r,b="y"===f?s:o,v=i.rects.reference[p]+i.rects.reference[f]-d[f]-i.rects.popper[p],y=d[f]-i.rects.reference[f],w=K(h),E=w?"y"===f?w.clientHeight||0:w.clientWidth||0:0,A=v/2-y/2,T=m[_],C=E-g[p]-m[b],O=E/2-g[p]/2+A,x=X(T,O,C),k=f;i.modifiersData[a]=((e={})[k]=x,e.centerOffset=x-O,e)}},effect:function(t){var e=t.state,i=t.options.element,n=void 0===i?"[data-popper-arrow]":i;null!=n&&("string"!=typeof n||(n=e.elements.popper.querySelector(n)))&&W(e.elements.popper,n)&&(e.elements.arrow=n)},requires:["popperOffsets"],requiresIfExists:["preventOverflow"]};function Z(t){return t.split("-")[1]}var tt={top:"auto",right:"auto",bottom:"auto",left:"auto"};function et(t){var e,i=t.popper,a=t.popperRect,l=t.placement,c=t.variation,d=t.offsets,u=t.position,f=t.gpuAcceleration,p=t.adaptive,m=t.roundOffsets,g=t.isFixed,_=d.x,b=void 0===_?0:_,v=d.y,y=void 0===v?0:v,w="function"==typeof m?m({x:b,y}):{x:b,y};b=w.x,y=w.y;var E=d.hasOwnProperty("x"),A=d.hasOwnProperty("y"),T=r,C=n,O=window;if(p){var x=K(i),L="clientHeight",S="clientWidth";x===k(i)&&"static"!==z(x=q(i)).position&&"absolute"===u&&(L="scrollHeight",S="scrollWidth"),(l===n||(l===r||l===o)&&c===h)&&(C=s,y-=(g&&x===O&&O.visualViewport?O.visualViewport.height:x[L])-a.height,y*=f?1:-1),l!==r&&(l!==n&&l!==s||c!==h)||(T=o,b-=(g&&x===O&&O.visualViewport?O.visualViewport.width:x[S])-a.width,b*=f?1:-1)}var D,$=Object.assign({position:u},p&&tt),I=!0===m?function(t,e){var i=t.x,n=t.y,s=e.devicePixelRatio||1;return{x:M(i*s)/s||0,y:M(n*s)/s||0}}({x:b,y},k(i)):{x:b,y};return b=I.x,y=I.y,f?Object.assign({},$,((D={})[C]=A?"0":"",D[T]=E?"0":"",D.transform=(O.devicePixelRatio||1)<=1?"translate("+b+"px, "+y+"px)":"translate3d("+b+"px, "+y+"px, 0)",D)):Object.assign({},$,((e={})[C]=A?y+"px":"",e[T]=E?b+"px":"",e.transform="",e))}const it={name:"computeStyles",enabled:!0,phase:"beforeWrite",fn:function(t){var e=t.state,i=t.options,n=i.gpuAcceleration,s=void 0===n||n,o=i.adaptive,r=void 0===o||o,a=i.roundOffsets,l=void 0===a||a,c={placement:I(e.placement),variation:Z(e.placement),popper:e.elements.popper,popperRect:e.rects.popper,gpuAcceleration:s,isFixed:"fixed"===e.options.strategy};null!=e.modifiersData.popperOffsets&&(e.styles.popper=Object.assign({},e.styles.popper,et(Object.assign({},c,{offsets:e.modifiersData.popperOffsets,position:e.options.strategy,adaptive:r,roundOffsets:l})))),null!=e.modifiersData.arrow&&(e.styles.arrow=Object.assign({},e.styles.arrow,et(Object.assign({},c,{offsets:e.modifiersData.arrow,position:"absolute",adaptive:!1,roundOffsets:l})))),e.attributes.popper=Object.assign({},e.attributes.popper,{"data-popper-placement":e.placement})},data:{}};var nt={passive:!0};const st={name:"eventListeners",enabled:!0,phase:"write",fn:function(){},effect:function(t){var e=t.state,i=t.instance,n=t.options,s=n.scroll,o=void 0===s||s,r=n.resize,a=void 0===r||r,l=k(e.elements.popper),c=[].concat(e.scrollParents.reference,e.scrollParents.popper);return o&&c.forEach((function(t){t.addEventListener("scroll",i.update,nt)})),a&&l.addEventListener("resize",i.update,nt),function(){o&&c.forEach((function(t){t.removeEventListener("scroll",i.update,nt)})),a&&l.removeEventListener("resize",i.update,nt)}},data:{}};var ot={left:"right",right:"left",bottom:"top",top:"bottom"};function rt(t){return t.replace(/left|right|bottom|top/g,(function(t){return ot[t]}))}var at={start:"end",end:"start"};function lt(t){return t.replace(/start|end/g,(function(t){return at[t]}))}function ct(t){var e=k(t);return{scrollLeft:e.pageXOffset,scrollTop:e.pageYOffset}}function ht(t){return H(q(t)).left+ct(t).scrollLeft}function dt(t){var e=z(t),i=e.overflow,n=e.overflowX,s=e.overflowY;return/auto|scroll|overlay|hidden/.test(i+s+n)}function ut(t){return["html","body","#document"].indexOf(x(t))>=0?t.ownerDocument.body:S(t)&&dt(t)?t:ut(V(t))}function ft(t,e){var i;void 0===e&&(e=[]);var n=ut(t),s=n===(null==(i=t.ownerDocument)?void 0:i.body),o=k(n),r=s?[o].concat(o.visualViewport||[],dt(n)?n:[]):n,a=e.concat(r);return s?a:a.concat(ft(V(r)))}function pt(t){return Object.assign({},t,{left:t.x,top:t.y,right:t.x+t.width,bottom:t.y+t.height})}function mt(t,e,i){return e===u?pt(function(t,e){var i=k(t),n=q(t),s=i.visualViewport,o=n.clientWidth,r=n.clientHeight,a=0,l=0;if(s){o=s.width,r=s.height;var c=F();(c||!c&&"fixed"===e)&&(a=s.offsetLeft,l=s.offsetTop)}return{width:o,height:r,x:a+ht(t),y:l}}(t,i)):L(e)?function(t,e){var i=H(t,!1,"fixed"===e);return i.top=i.top+t.clientTop,i.left=i.left+t.clientLeft,i.bottom=i.top+t.clientHeight,i.right=i.left+t.clientWidth,i.width=t.clientWidth,i.height=t.clientHeight,i.x=i.left,i.y=i.top,i}(e,i):pt(function(t){var e,i=q(t),n=ct(t),s=null==(e=t.ownerDocument)?void 0:e.body,o=N(i.scrollWidth,i.clientWidth,s?s.scrollWidth:0,s?s.clientWidth:0),r=N(i.scrollHeight,i.clientHeight,s?s.scrollHeight:0,s?s.clientHeight:0),a=-n.scrollLeft+ht(t),l=-n.scrollTop;return"rtl"===z(s||i).direction&&(a+=N(i.clientWidth,s?s.clientWidth:0)-o),{width:o,height:r,x:a,y:l}}(q(t)))}function gt(t){var e,i=t.reference,a=t.element,l=t.placement,d=l?I(l):null,u=l?Z(l):null,f=i.x+i.width/2-a.width/2,p=i.y+i.height/2-a.height/2;switch(d){case n:e={x:f,y:i.y-a.height};break;case s:e={x:f,y:i.y+i.height};break;case o:e={x:i.x+i.width,y:p};break;case r:e={x:i.x-a.width,y:p};break;default:e={x:i.x,y:i.y}}var m=d?Q(d):null;if(null!=m){var g="y"===m?"height":"width";switch(u){case c:e[m]=e[m]-(i[g]/2-a[g]/2);break;case h:e[m]=e[m]+(i[g]/2-a[g]/2)}}return e}function _t(t,e){void 0===e&&(e={});var i=e,r=i.placement,a=void 0===r?t.placement:r,c=i.strategy,h=void 0===c?t.strategy:c,m=i.boundary,g=void 0===m?d:m,_=i.rootBoundary,b=void 0===_?u:_,v=i.elementContext,y=void 0===v?f:v,w=i.altBoundary,E=void 0!==w&&w,A=i.padding,T=void 0===A?0:A,C=U("number"!=typeof T?T:G(T,l)),O=y===f?p:f,k=t.rects.popper,D=t.elements[E?O:y],$=function(t,e,i,n){var s="clippingParents"===e?function(t){var e=ft(V(t)),i=["absolute","fixed"].indexOf(z(t).position)>=0&&S(t)?K(t):t;return L(i)?e.filter((function(t){return L(t)&&W(t,i)&&"body"!==x(t)})):[]}(t):[].concat(e),o=[].concat(s,[i]),r=o[0],a=o.reduce((function(e,i){var s=mt(t,i,n);return e.top=N(s.top,e.top),e.right=P(s.right,e.right),e.bottom=P(s.bottom,e.bottom),e.left=N(s.left,e.left),e}),mt(t,r,n));return a.width=a.right-a.left,a.height=a.bottom-a.top,a.x=a.left,a.y=a.top,a}(L(D)?D:D.contextElement||q(t.elements.popper),g,b,h),I=H(t.elements.reference),M=gt({reference:I,element:k,strategy:"absolute",placement:a}),j=pt(Object.assign({},k,M)),F=y===f?j:I,B={top:$.top-F.top+C.top,bottom:F.bottom-$.bottom+C.bottom,left:$.left-F.left+C.left,right:F.right-$.right+C.right},R=t.modifiersData.offset;if(y===f&&R){var Y=R[a];Object.keys(B).forEach((function(t){var e=[o,s].indexOf(t)>=0?1:-1,i=[n,s].indexOf(t)>=0?"y":"x";B[t]+=Y[i]*e}))}return B}const bt={name:"flip",enabled:!0,phase:"main",fn:function(t){var e=t.state,i=t.options,h=t.name;if(!e.modifiersData[h]._skip){for(var d=i.mainAxis,u=void 0===d||d,f=i.altAxis,p=void 0===f||f,_=i.fallbackPlacements,b=i.padding,v=i.boundary,y=i.rootBoundary,w=i.altBoundary,E=i.flipVariations,A=void 0===E||E,T=i.allowedAutoPlacements,C=e.options.placement,O=I(C),x=_||(O!==C&&A?function(t){if(I(t)===a)return[];var e=rt(t);return[lt(t),e,lt(e)]}(C):[rt(C)]),k=[C].concat(x).reduce((function(t,i){return t.concat(I(i)===a?function(t,e){void 0===e&&(e={});var i=e,n=i.placement,s=i.boundary,o=i.rootBoundary,r=i.padding,a=i.flipVariations,c=i.allowedAutoPlacements,h=void 0===c?g:c,d=Z(n),u=d?a?m:m.filter((function(t){return Z(t)===d})):l,f=u.filter((function(t){return h.indexOf(t)>=0}));0===f.length&&(f=u);var p=f.reduce((function(e,i){return e[i]=_t(t,{placement:i,boundary:s,rootBoundary:o,padding:r})[I(i)],e}),{});return Object.keys(p).sort((function(t,e){return p[t]-p[e]}))}(e,{placement:i,boundary:v,rootBoundary:y,padding:b,flipVariations:A,allowedAutoPlacements:T}):i)}),[]),L=e.rects.reference,S=e.rects.popper,D=new Map,$=!0,N=k[0],P=0;P',title:"",trigger:"hover focus"},cs={allowList:"object",animation:"boolean",boundary:"(string|element)",container:"(string|element|boolean)",customClass:"(string|function)",delay:"(number|object)",fallbackPlacements:"array",html:"boolean",offset:"(array|string|function)",placement:"(string|function)",popperConfig:"(null|object|function)",sanitize:"boolean",sanitizeFn:"(null|function)",selector:"(string|boolean)",template:"string",title:"(string|element|function)",trigger:"string"};class hs extends ve{constructor(t,i){if(void 0===e)throw new TypeError("Bootstrap's tooltips require Popper (https://popper.js.org)");super(t,i),this._isEnabled=!0,this._timeout=0,this._isHovered=null,this._activeTrigger={},this._popper=null,this._templateFactory=null,this._newContent=null,this.tip=null,this._setListeners(),this._config.selector||this._fixTitle()}static get Default(){return ls}static get DefaultType(){return cs}static get NAME(){return"tooltip"}enable(){this._isEnabled=!0}disable(){this._isEnabled=!1}toggleEnabled(){this._isEnabled=!this._isEnabled}toggle(){this._isEnabled&&(this._activeTrigger.click=!this._activeTrigger.click,this._isShown()?this._leave():this._enter())}dispose(){clearTimeout(this._timeout),fe.off(this._element.closest(ns),ss,this._hideModalHandler),this._element.getAttribute("data-bs-original-title")&&this._element.setAttribute("title",this._element.getAttribute("data-bs-original-title")),this._disposePopper(),super.dispose()}show(){if("none"===this._element.style.display)throw new Error("Please use show on visible elements");if(!this._isWithContent()||!this._isEnabled)return;const t=fe.trigger(this._element,this.constructor.eventName("show")),e=(zt(this._element)||this._element.ownerDocument.documentElement).contains(this._element);if(t.defaultPrevented||!e)return;this._disposePopper();const i=this._getTipElement();this._element.setAttribute("aria-describedby",i.getAttribute("id"));const{container:n}=this._config;if(this._element.ownerDocument.documentElement.contains(this.tip)||(n.append(i),fe.trigger(this._element,this.constructor.eventName("inserted"))),this._popper=this._createPopper(i),i.classList.add(is),"ontouchstart"in document.documentElement)for(const t of[].concat(...document.body.children))fe.on(t,"mouseover",Rt);this._queueCallback((()=>{fe.trigger(this._element,this.constructor.eventName("shown")),!1===this._isHovered&&this._leave(),this._isHovered=!1}),this.tip,this._isAnimated())}hide(){if(this._isShown()&&!fe.trigger(this._element,this.constructor.eventName("hide")).defaultPrevented){if(this._getTipElement().classList.remove(is),"ontouchstart"in document.documentElement)for(const t of[].concat(...document.body.children))fe.off(t,"mouseover",Rt);this._activeTrigger.click=!1,this._activeTrigger[rs]=!1,this._activeTrigger[os]=!1,this._isHovered=null,this._queueCallback((()=>{this._isWithActiveTrigger()||(this._isHovered||this._disposePopper(),this._element.removeAttribute("aria-describedby"),fe.trigger(this._element,this.constructor.eventName("hidden")))}),this.tip,this._isAnimated())}}update(){this._popper&&this._popper.update()}_isWithContent(){return Boolean(this._getTitle())}_getTipElement(){return this.tip||(this.tip=this._createTipElement(this._newContent||this._getContentForTemplate())),this.tip}_createTipElement(t){const e=this._getTemplateFactory(t).toHtml();if(!e)return null;e.classList.remove(es,is),e.classList.add(`bs-${this.constructor.NAME}-auto`);const i=(t=>{do{t+=Math.floor(1e6*Math.random())}while(document.getElementById(t));return t})(this.constructor.NAME).toString();return e.setAttribute("id",i),this._isAnimated()&&e.classList.add(es),e}setContent(t){this._newContent=t,this._isShown()&&(this._disposePopper(),this.show())}_getTemplateFactory(t){return this._templateFactory?this._templateFactory.changeContent(t):this._templateFactory=new Zn({...this._config,content:t,extraClass:this._resolvePossibleFunction(this._config.customClass)}),this._templateFactory}_getContentForTemplate(){return{".tooltip-inner":this._getTitle()}}_getTitle(){return this._resolvePossibleFunction(this._config.title)||this._element.getAttribute("data-bs-original-title")}_initializeOnDelegatedTarget(t){return this.constructor.getOrCreateInstance(t.delegateTarget,this._getDelegateConfig())}_isAnimated(){return this._config.animation||this.tip&&this.tip.classList.contains(es)}_isShown(){return this.tip&&this.tip.classList.contains(is)}_createPopper(t){const e=Xt(this._config.placement,[this,t,this._element]),i=as[e.toUpperCase()];return Dt(this._element,t,this._getPopperConfig(i))}_getOffset(){const{offset:t}=this._config;return"string"==typeof t?t.split(",").map((t=>Number.parseInt(t,10))):"function"==typeof t?e=>t(e,this._element):t}_resolvePossibleFunction(t){return Xt(t,[this._element])}_getPopperConfig(t){const e={placement:t,modifiers:[{name:"flip",options:{fallbackPlacements:this._config.fallbackPlacements}},{name:"offset",options:{offset:this._getOffset()}},{name:"preventOverflow",options:{boundary:this._config.boundary}},{name:"arrow",options:{element:`.${this.constructor.NAME}-arrow`}},{name:"preSetPlacement",enabled:!0,phase:"beforeMain",fn:t=>{this._getTipElement().setAttribute("data-popper-placement",t.state.placement)}}]};return{...e,...Xt(this._config.popperConfig,[e])}}_setListeners(){const t=this._config.trigger.split(" ");for(const e of t)if("click"===e)fe.on(this._element,this.constructor.eventName("click"),this._config.selector,(t=>{this._initializeOnDelegatedTarget(t).toggle()}));else if("manual"!==e){const t=e===os?this.constructor.eventName("mouseenter"):this.constructor.eventName("focusin"),i=e===os?this.constructor.eventName("mouseleave"):this.constructor.eventName("focusout");fe.on(this._element,t,this._config.selector,(t=>{const e=this._initializeOnDelegatedTarget(t);e._activeTrigger["focusin"===t.type?rs:os]=!0,e._enter()})),fe.on(this._element,i,this._config.selector,(t=>{const e=this._initializeOnDelegatedTarget(t);e._activeTrigger["focusout"===t.type?rs:os]=e._element.contains(t.relatedTarget),e._leave()}))}this._hideModalHandler=()=>{this._element&&this.hide()},fe.on(this._element.closest(ns),ss,this._hideModalHandler)}_fixTitle(){const t=this._element.getAttribute("title");t&&(this._element.getAttribute("aria-label")||this._element.textContent.trim()||this._element.setAttribute("aria-label",t),this._element.setAttribute("data-bs-original-title",t),this._element.removeAttribute("title"))}_enter(){this._isShown()||this._isHovered?this._isHovered=!0:(this._isHovered=!0,this._setTimeout((()=>{this._isHovered&&this.show()}),this._config.delay.show))}_leave(){this._isWithActiveTrigger()||(this._isHovered=!1,this._setTimeout((()=>{this._isHovered||this.hide()}),this._config.delay.hide))}_setTimeout(t,e){clearTimeout(this._timeout),this._timeout=setTimeout(t,e)}_isWithActiveTrigger(){return Object.values(this._activeTrigger).includes(!0)}_getConfig(t){const e=_e.getDataAttributes(this._element);for(const t of Object.keys(e))ts.has(t)&&delete e[t];return t={...e,..."object"==typeof t&&t?t:{}},t=this._mergeConfigObj(t),t=this._configAfterMerge(t),this._typeCheckConfig(t),t}_configAfterMerge(t){return t.container=!1===t.container?document.body:Ht(t.container),"number"==typeof t.delay&&(t.delay={show:t.delay,hide:t.delay}),"number"==typeof t.title&&(t.title=t.title.toString()),"number"==typeof t.content&&(t.content=t.content.toString()),t}_getDelegateConfig(){const t={};for(const[e,i]of Object.entries(this._config))this.constructor.Default[e]!==i&&(t[e]=i);return t.selector=!1,t.trigger="manual",t}_disposePopper(){this._popper&&(this._popper.destroy(),this._popper=null),this.tip&&(this.tip.remove(),this.tip=null)}static jQueryInterface(t){return this.each((function(){const e=hs.getOrCreateInstance(this,t);if("string"==typeof t){if(void 0===e[t])throw new TypeError(`No method named "${t}"`);e[t]()}}))}}Qt(hs);const ds={...hs.Default,content:"",offset:[0,8],placement:"right",template:'
',trigger:"click"},us={...hs.DefaultType,content:"(null|string|element|function)"};class fs extends hs{static get Default(){return ds}static get DefaultType(){return us}static get NAME(){return"popover"}_isWithContent(){return this._getTitle()||this._getContent()}_getContentForTemplate(){return{".popover-header":this._getTitle(),".popover-body":this._getContent()}}_getContent(){return this._resolvePossibleFunction(this._config.content)}static jQueryInterface(t){return this.each((function(){const e=fs.getOrCreateInstance(this,t);if("string"==typeof t){if(void 0===e[t])throw new TypeError(`No method named "${t}"`);e[t]()}}))}}Qt(fs);const ps=".bs.scrollspy",ms=`activate${ps}`,gs=`click${ps}`,_s=`load${ps}.data-api`,bs="active",vs="[href]",ys=".nav-link",ws=`${ys}, .nav-item > ${ys}, .list-group-item`,Es={offset:null,rootMargin:"0px 0px -25%",smoothScroll:!1,target:null,threshold:[.1,.5,1]},As={offset:"(number|null)",rootMargin:"string",smoothScroll:"boolean",target:"element",threshold:"array"};class Ts extends ve{constructor(t,e){super(t,e),this._targetLinks=new Map,this._observableSections=new Map,this._rootElement="visible"===getComputedStyle(this._element).overflowY?null:this._element,this._activeTarget=null,this._observer=null,this._previousScrollData={visibleEntryTop:0,parentScrollTop:0},this.refresh()}static get Default(){return Es}static get DefaultType(){return As}static get NAME(){return"scrollspy"}refresh(){this._initializeTargetsAndObservables(),this._maybeEnableSmoothScroll(),this._observer?this._observer.disconnect():this._observer=this._getNewObserver();for(const t of this._observableSections.values())this._observer.observe(t)}dispose(){this._observer.disconnect(),super.dispose()}_configAfterMerge(t){return t.target=Ht(t.target)||document.body,t.rootMargin=t.offset?`${t.offset}px 0px -30%`:t.rootMargin,"string"==typeof t.threshold&&(t.threshold=t.threshold.split(",").map((t=>Number.parseFloat(t)))),t}_maybeEnableSmoothScroll(){this._config.smoothScroll&&(fe.off(this._config.target,gs),fe.on(this._config.target,gs,vs,(t=>{const e=this._observableSections.get(t.target.hash);if(e){t.preventDefault();const i=this._rootElement||window,n=e.offsetTop-this._element.offsetTop;if(i.scrollTo)return void i.scrollTo({top:n,behavior:"smooth"});i.scrollTop=n}})))}_getNewObserver(){const t={root:this._rootElement,threshold:this._config.threshold,rootMargin:this._config.rootMargin};return new IntersectionObserver((t=>this._observerCallback(t)),t)}_observerCallback(t){const e=t=>this._targetLinks.get(`#${t.target.id}`),i=t=>{this._previousScrollData.visibleEntryTop=t.target.offsetTop,this._process(e(t))},n=(this._rootElement||document.documentElement).scrollTop,s=n>=this._previousScrollData.parentScrollTop;this._previousScrollData.parentScrollTop=n;for(const o of t){if(!o.isIntersecting){this._activeTarget=null,this._clearActiveClass(e(o));continue}const t=o.target.offsetTop>=this._previousScrollData.visibleEntryTop;if(s&&t){if(i(o),!n)return}else s||t||i(o)}}_initializeTargetsAndObservables(){this._targetLinks=new Map,this._observableSections=new Map;const t=we.find(vs,this._config.target);for(const e of t){if(!e.hash||Wt(e))continue;const t=we.findOne(decodeURI(e.hash),this._element);Bt(t)&&(this._targetLinks.set(decodeURI(e.hash),e),this._observableSections.set(e.hash,t))}}_process(t){this._activeTarget!==t&&(this._clearActiveClass(this._config.target),this._activeTarget=t,t.classList.add(bs),this._activateParents(t),fe.trigger(this._element,ms,{relatedTarget:t}))}_activateParents(t){if(t.classList.contains("dropdown-item"))we.findOne(".dropdown-toggle",t.closest(".dropdown")).classList.add(bs);else for(const e of we.parents(t,".nav, .list-group"))for(const t of we.prev(e,ws))t.classList.add(bs)}_clearActiveClass(t){t.classList.remove(bs);const e=we.find(`${vs}.${bs}`,t);for(const t of e)t.classList.remove(bs)}static jQueryInterface(t){return this.each((function(){const e=Ts.getOrCreateInstance(this,t);if("string"==typeof t){if(void 0===e[t]||t.startsWith("_")||"constructor"===t)throw new TypeError(`No method named "${t}"`);e[t]()}}))}}fe.on(window,_s,(()=>{for(const t of we.find('[data-bs-spy="scroll"]'))Ts.getOrCreateInstance(t)})),Qt(Ts);const Cs=".bs.tab",Os=`hide${Cs}`,xs=`hidden${Cs}`,ks=`show${Cs}`,Ls=`shown${Cs}`,Ss=`click${Cs}`,Ds=`keydown${Cs}`,$s=`load${Cs}`,Is="ArrowLeft",Ns="ArrowRight",Ps="ArrowUp",Ms="ArrowDown",js="Home",Fs="End",Hs="active",Bs="fade",Ws="show",zs=".dropdown-toggle",Rs=`:not(${zs})`,qs='[data-bs-toggle="tab"], [data-bs-toggle="pill"], [data-bs-toggle="list"]',Vs=`.nav-link${Rs}, .list-group-item${Rs}, [role="tab"]${Rs}, ${qs}`,Ys=`.${Hs}[data-bs-toggle="tab"], .${Hs}[data-bs-toggle="pill"], .${Hs}[data-bs-toggle="list"]`;class Ks extends ve{constructor(t){super(t),this._parent=this._element.closest('.list-group, .nav, [role="tablist"]'),this._parent&&(this._setInitialAttributes(this._parent,this._getChildren()),fe.on(this._element,Ds,(t=>this._keydown(t))))}static get NAME(){return"tab"}show(){const t=this._element;if(this._elemIsActive(t))return;const e=this._getActiveElem(),i=e?fe.trigger(e,Os,{relatedTarget:t}):null;fe.trigger(t,ks,{relatedTarget:e}).defaultPrevented||i&&i.defaultPrevented||(this._deactivate(e,t),this._activate(t,e))}_activate(t,e){t&&(t.classList.add(Hs),this._activate(we.getElementFromSelector(t)),this._queueCallback((()=>{"tab"===t.getAttribute("role")?(t.removeAttribute("tabindex"),t.setAttribute("aria-selected",!0),this._toggleDropDown(t,!0),fe.trigger(t,Ls,{relatedTarget:e})):t.classList.add(Ws)}),t,t.classList.contains(Bs)))}_deactivate(t,e){t&&(t.classList.remove(Hs),t.blur(),this._deactivate(we.getElementFromSelector(t)),this._queueCallback((()=>{"tab"===t.getAttribute("role")?(t.setAttribute("aria-selected",!1),t.setAttribute("tabindex","-1"),this._toggleDropDown(t,!1),fe.trigger(t,xs,{relatedTarget:e})):t.classList.remove(Ws)}),t,t.classList.contains(Bs)))}_keydown(t){if(![Is,Ns,Ps,Ms,js,Fs].includes(t.key))return;t.stopPropagation(),t.preventDefault();const e=this._getChildren().filter((t=>!Wt(t)));let i;if([js,Fs].includes(t.key))i=e[t.key===js?0:e.length-1];else{const n=[Ns,Ms].includes(t.key);i=Gt(e,t.target,n,!0)}i&&(i.focus({preventScroll:!0}),Ks.getOrCreateInstance(i).show())}_getChildren(){return we.find(Vs,this._parent)}_getActiveElem(){return this._getChildren().find((t=>this._elemIsActive(t)))||null}_setInitialAttributes(t,e){this._setAttributeIfNotExists(t,"role","tablist");for(const t of e)this._setInitialAttributesOnChild(t)}_setInitialAttributesOnChild(t){t=this._getInnerElement(t);const e=this._elemIsActive(t),i=this._getOuterElement(t);t.setAttribute("aria-selected",e),i!==t&&this._setAttributeIfNotExists(i,"role","presentation"),e||t.setAttribute("tabindex","-1"),this._setAttributeIfNotExists(t,"role","tab"),this._setInitialAttributesOnTargetPanel(t)}_setInitialAttributesOnTargetPanel(t){const e=we.getElementFromSelector(t);e&&(this._setAttributeIfNotExists(e,"role","tabpanel"),t.id&&this._setAttributeIfNotExists(e,"aria-labelledby",`${t.id}`))}_toggleDropDown(t,e){const i=this._getOuterElement(t);if(!i.classList.contains("dropdown"))return;const n=(t,n)=>{const s=we.findOne(t,i);s&&s.classList.toggle(n,e)};n(zs,Hs),n(".dropdown-menu",Ws),i.setAttribute("aria-expanded",e)}_setAttributeIfNotExists(t,e,i){t.hasAttribute(e)||t.setAttribute(e,i)}_elemIsActive(t){return t.classList.contains(Hs)}_getInnerElement(t){return t.matches(Vs)?t:we.findOne(Vs,t)}_getOuterElement(t){return t.closest(".nav-item, .list-group-item")||t}static jQueryInterface(t){return this.each((function(){const e=Ks.getOrCreateInstance(this);if("string"==typeof t){if(void 0===e[t]||t.startsWith("_")||"constructor"===t)throw new TypeError(`No method named "${t}"`);e[t]()}}))}}fe.on(document,Ss,qs,(function(t){["A","AREA"].includes(this.tagName)&&t.preventDefault(),Wt(this)||Ks.getOrCreateInstance(this).show()})),fe.on(window,$s,(()=>{for(const t of we.find(Ys))Ks.getOrCreateInstance(t)})),Qt(Ks);const Qs=".bs.toast",Xs=`mouseover${Qs}`,Us=`mouseout${Qs}`,Gs=`focusin${Qs}`,Js=`focusout${Qs}`,Zs=`hide${Qs}`,to=`hidden${Qs}`,eo=`show${Qs}`,io=`shown${Qs}`,no="hide",so="show",oo="showing",ro={animation:"boolean",autohide:"boolean",delay:"number"},ao={animation:!0,autohide:!0,delay:5e3};class lo extends ve{constructor(t,e){super(t,e),this._timeout=null,this._hasMouseInteraction=!1,this._hasKeyboardInteraction=!1,this._setListeners()}static get Default(){return ao}static get DefaultType(){return ro}static get NAME(){return"toast"}show(){fe.trigger(this._element,eo).defaultPrevented||(this._clearTimeout(),this._config.animation&&this._element.classList.add("fade"),this._element.classList.remove(no),qt(this._element),this._element.classList.add(so,oo),this._queueCallback((()=>{this._element.classList.remove(oo),fe.trigger(this._element,io),this._maybeScheduleHide()}),this._element,this._config.animation))}hide(){this.isShown()&&(fe.trigger(this._element,Zs).defaultPrevented||(this._element.classList.add(oo),this._queueCallback((()=>{this._element.classList.add(no),this._element.classList.remove(oo,so),fe.trigger(this._element,to)}),this._element,this._config.animation)))}dispose(){this._clearTimeout(),this.isShown()&&this._element.classList.remove(so),super.dispose()}isShown(){return this._element.classList.contains(so)}_maybeScheduleHide(){this._config.autohide&&(this._hasMouseInteraction||this._hasKeyboardInteraction||(this._timeout=setTimeout((()=>{this.hide()}),this._config.delay)))}_onInteraction(t,e){switch(t.type){case"mouseover":case"mouseout":this._hasMouseInteraction=e;break;case"focusin":case"focusout":this._hasKeyboardInteraction=e}if(e)return void this._clearTimeout();const i=t.relatedTarget;this._element===i||this._element.contains(i)||this._maybeScheduleHide()}_setListeners(){fe.on(this._element,Xs,(t=>this._onInteraction(t,!0))),fe.on(this._element,Us,(t=>this._onInteraction(t,!1))),fe.on(this._element,Gs,(t=>this._onInteraction(t,!0))),fe.on(this._element,Js,(t=>this._onInteraction(t,!1)))}_clearTimeout(){clearTimeout(this._timeout),this._timeout=null}static jQueryInterface(t){return this.each((function(){const e=lo.getOrCreateInstance(this,t);if("string"==typeof t){if(void 0===e[t])throw new TypeError(`No method named "${t}"`);e[t](this)}}))}}function co(t){"loading"!=document.readyState?t():document.addEventListener("DOMContentLoaded",t)}Ee(lo),Qt(lo),co((function(){[].slice.call(document.querySelectorAll('[data-bs-toggle="tooltip"]')).map((function(t){return new hs(t,{delay:{show:500,hide:100}})}))})),co((function(){document.getElementById("pst-back-to-top").addEventListener("click",(function(){document.body.scrollTop=0,document.documentElement.scrollTop=0}))})),co((function(){var t=document.getElementById("pst-back-to-top"),e=document.getElementsByClassName("bd-header")[0].getBoundingClientRect();window.addEventListener("scroll",(function(){this.oldScroll>this.scrollY&&this.scrollY>e.bottom?t.style.display="block":t.style.display="none",this.oldScroll=this.scrollY}))})),window.bootstrap=i})();
+//# sourceMappingURL=bootstrap.js.map
\ No newline at end of file
diff --git a/_preview/468/_static/scripts/bootstrap.js.LICENSE.txt b/_preview/468/_static/scripts/bootstrap.js.LICENSE.txt
new file mode 100644
index 000000000..10f979d07
--- /dev/null
+++ b/_preview/468/_static/scripts/bootstrap.js.LICENSE.txt
@@ -0,0 +1,5 @@
+/*!
+ * Bootstrap v5.3.2 (https://getbootstrap.com/)
+ * Copyright 2011-2023 The Bootstrap Authors (https://github.com/twbs/bootstrap/graphs/contributors)
+ * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)
+ */
diff --git a/_preview/468/_static/scripts/bootstrap.js.map b/_preview/468/_static/scripts/bootstrap.js.map
new file mode 100644
index 000000000..64e212b1e
--- /dev/null
+++ b/_preview/468/_static/scripts/bootstrap.js.map
@@ -0,0 +1 @@
+{"version":3,"file":"scripts/bootstrap.js","mappings":";mBACA,IAAIA,EAAsB,CCA1BA,EAAwB,CAACC,EAASC,KACjC,IAAI,IAAIC,KAAOD,EACXF,EAAoBI,EAAEF,EAAYC,KAASH,EAAoBI,EAAEH,EAASE,IAC5EE,OAAOC,eAAeL,EAASE,EAAK,CAAEI,YAAY,EAAMC,IAAKN,EAAWC,IAE1E,ECNDH,EAAwB,CAACS,EAAKC,IAAUL,OAAOM,UAAUC,eAAeC,KAAKJ,EAAKC,GCClFV,EAAyBC,IACH,oBAAXa,QAA0BA,OAAOC,aAC1CV,OAAOC,eAAeL,EAASa,OAAOC,YAAa,CAAEC,MAAO,WAE7DX,OAAOC,eAAeL,EAAS,aAAc,CAAEe,OAAO,GAAO,01BCLvD,IAAI,EAAM,MACNC,EAAS,SACTC,EAAQ,QACRC,EAAO,OACPC,EAAO,OACPC,EAAiB,CAAC,EAAKJ,EAAQC,EAAOC,GACtCG,EAAQ,QACRC,EAAM,MACNC,EAAkB,kBAClBC,EAAW,WACXC,EAAS,SACTC,EAAY,YACZC,EAAmCP,EAAeQ,QAAO,SAAUC,EAAKC,GACjF,OAAOD,EAAIE,OAAO,CAACD,EAAY,IAAMT,EAAOS,EAAY,IAAMR,GAChE,GAAG,IACQ,EAA0B,GAAGS,OAAOX,EAAgB,CAACD,IAAOS,QAAO,SAAUC,EAAKC,GAC3F,OAAOD,EAAIE,OAAO,CAACD,EAAWA,EAAY,IAAMT,EAAOS,EAAY,IAAMR,GAC3E,GAAG,IAEQU,EAAa,aACbC,EAAO,OACPC,EAAY,YAEZC,EAAa,aACbC,EAAO,OACPC,EAAY,YAEZC,EAAc,cACdC,EAAQ,QACRC,EAAa,aACbC,EAAiB,CAACT,EAAYC,EAAMC,EAAWC,EAAYC,EAAMC,EAAWC,EAAaC,EAAOC,GC9B5F,SAASE,EAAYC,GAClC,OAAOA,GAAWA,EAAQC,UAAY,IAAIC,cAAgB,IAC5D,CCFe,SAASC,EAAUC,GAChC,GAAY,MAARA,EACF,OAAOC,OAGT,GAAwB,oBAApBD,EAAKE,WAAkC,CACzC,IAAIC,EAAgBH,EAAKG,cACzB,OAAOA,GAAgBA,EAAcC,aAAwBH,MAC/D,CAEA,OAAOD,CACT,CCTA,SAASK,EAAUL,GAEjB,OAAOA,aADUD,EAAUC,GAAMM,SACIN,aAAgBM,OACvD,CAEA,SAASC,EAAcP,GAErB,OAAOA,aADUD,EAAUC,GAAMQ,aACIR,aAAgBQ,WACvD,CAEA,SAASC,EAAaT,GAEpB,MAA0B,oBAAfU,aAKJV,aADUD,EAAUC,GAAMU,YACIV,aAAgBU,WACvD,CCwDA,SACEC,KAAM,cACNC,SAAS,EACTC,MAAO,QACPC,GA5EF,SAAqBC,GACnB,IAAIC,EAAQD,EAAKC,MACjB3D,OAAO4D,KAAKD,EAAME,UAAUC,SAAQ,SAAUR,GAC5C,IAAIS,EAAQJ,EAAMK,OAAOV,IAAS,CAAC,EAC/BW,EAAaN,EAAMM,WAAWX,IAAS,CAAC,EACxCf,EAAUoB,EAAME,SAASP,GAExBJ,EAAcX,IAAaD,EAAYC,KAO5CvC,OAAOkE,OAAO3B,EAAQwB,MAAOA,GAC7B/D,OAAO4D,KAAKK,GAAYH,SAAQ,SAAUR,GACxC,IAAI3C,EAAQsD,EAAWX,IAET,IAAV3C,EACF4B,EAAQ4B,gBAAgBb,GAExBf,EAAQ6B,aAAad,GAAgB,IAAV3C,EAAiB,GAAKA,EAErD,IACF,GACF,EAoDE0D,OAlDF,SAAgBC,GACd,IAAIX,EAAQW,EAAMX,MACdY,EAAgB,CAClBlD,OAAQ,CACNmD,SAAUb,EAAMc,QAAQC,SACxB5D,KAAM,IACN6D,IAAK,IACLC,OAAQ,KAEVC,MAAO,CACLL,SAAU,YAEZlD,UAAW,CAAC,GASd,OAPAtB,OAAOkE,OAAOP,EAAME,SAASxC,OAAO0C,MAAOQ,EAAclD,QACzDsC,EAAMK,OAASO,EAEXZ,EAAME,SAASgB,OACjB7E,OAAOkE,OAAOP,EAAME,SAASgB,MAAMd,MAAOQ,EAAcM,OAGnD,WACL7E,OAAO4D,KAAKD,EAAME,UAAUC,SAAQ,SAAUR,GAC5C,IAAIf,EAAUoB,EAAME,SAASP,GACzBW,EAAaN,EAAMM,WAAWX,IAAS,CAAC,EAGxCS,EAFkB/D,OAAO4D,KAAKD,EAAMK,OAAOzD,eAAe+C,GAAQK,EAAMK,OAAOV,GAAQiB,EAAcjB,IAE7E9B,QAAO,SAAUuC,EAAOe,GAElD,OADAf,EAAMe,GAAY,GACXf,CACT,GAAG,CAAC,GAECb,EAAcX,IAAaD,EAAYC,KAI5CvC,OAAOkE,OAAO3B,EAAQwB,MAAOA,GAC7B/D,OAAO4D,KAAKK,GAAYH,SAAQ,SAAUiB,GACxCxC,EAAQ4B,gBAAgBY,EAC1B,IACF,GACF,CACF,EASEC,SAAU,CAAC,kBCjFE,SAASC,EAAiBvD,GACvC,OAAOA,EAAUwD,MAAM,KAAK,EAC9B,CCHO,IAAI,EAAMC,KAAKC,IACX,EAAMD,KAAKE,IACXC,EAAQH,KAAKG,MCFT,SAASC,IACtB,IAAIC,EAASC,UAAUC,cAEvB,OAAc,MAAVF,GAAkBA,EAAOG,QAAUC,MAAMC,QAAQL,EAAOG,QACnDH,EAAOG,OAAOG,KAAI,SAAUC,GACjC,OAAOA,EAAKC,MAAQ,IAAMD,EAAKE,OACjC,IAAGC,KAAK,KAGHT,UAAUU,SACnB,CCTe,SAASC,IACtB,OAAQ,iCAAiCC,KAAKd,IAChD,CCCe,SAASe,EAAsB/D,EAASgE,EAAcC,QAC9C,IAAjBD,IACFA,GAAe,QAGO,IAApBC,IACFA,GAAkB,GAGpB,IAAIC,EAAalE,EAAQ+D,wBACrBI,EAAS,EACTC,EAAS,EAETJ,GAAgBrD,EAAcX,KAChCmE,EAASnE,EAAQqE,YAAc,GAAItB,EAAMmB,EAAWI,OAAStE,EAAQqE,aAAmB,EACxFD,EAASpE,EAAQuE,aAAe,GAAIxB,EAAMmB,EAAWM,QAAUxE,EAAQuE,cAAoB,GAG7F,IACIE,GADOhE,EAAUT,GAAWG,EAAUH,GAAWK,QAC3BoE,eAEtBC,GAAoBb,KAAsBI,EAC1CU,GAAKT,EAAW3F,MAAQmG,GAAoBD,EAAiBA,EAAeG,WAAa,IAAMT,EAC/FU,GAAKX,EAAW9B,KAAOsC,GAAoBD,EAAiBA,EAAeK,UAAY,IAAMV,EAC7FE,EAAQJ,EAAWI,MAAQH,EAC3BK,EAASN,EAAWM,OAASJ,EACjC,MAAO,CACLE,MAAOA,EACPE,OAAQA,EACRpC,IAAKyC,EACLvG,MAAOqG,EAAIL,EACXjG,OAAQwG,EAAIL,EACZjG,KAAMoG,EACNA,EAAGA,EACHE,EAAGA,EAEP,CCrCe,SAASE,EAAc/E,GACpC,IAAIkE,EAAaH,EAAsB/D,GAGnCsE,EAAQtE,EAAQqE,YAChBG,EAASxE,EAAQuE,aAUrB,OARI3B,KAAKoC,IAAId,EAAWI,MAAQA,IAAU,IACxCA,EAAQJ,EAAWI,OAGjB1B,KAAKoC,IAAId,EAAWM,OAASA,IAAW,IAC1CA,EAASN,EAAWM,QAGf,CACLG,EAAG3E,EAAQ4E,WACXC,EAAG7E,EAAQ8E,UACXR,MAAOA,EACPE,OAAQA,EAEZ,CCvBe,SAASS,EAASC,EAAQC,GACvC,IAAIC,EAAWD,EAAME,aAAeF,EAAME,cAE1C,GAAIH,EAAOD,SAASE,GAClB,OAAO,EAEJ,GAAIC,GAAYvE,EAAauE,GAAW,CACzC,IAAIE,EAAOH,EAEX,EAAG,CACD,GAAIG,GAAQJ,EAAOK,WAAWD,GAC5B,OAAO,EAITA,EAAOA,EAAKE,YAAcF,EAAKG,IACjC,OAASH,EACX,CAGF,OAAO,CACT,CCrBe,SAAS,EAAiBtF,GACvC,OAAOG,EAAUH,GAAS0F,iBAAiB1F,EAC7C,CCFe,SAAS2F,EAAe3F,GACrC,MAAO,CAAC,QAAS,KAAM,MAAM4F,QAAQ7F,EAAYC,KAAa,CAChE,CCFe,SAAS6F,EAAmB7F,GAEzC,QAASS,EAAUT,GAAWA,EAAQO,cACtCP,EAAQ8F,WAAazF,OAAOyF,UAAUC,eACxC,CCFe,SAASC,EAAchG,GACpC,MAA6B,SAAzBD,EAAYC,GACPA,EAMPA,EAAQiG,cACRjG,EAAQwF,aACR3E,EAAab,GAAWA,EAAQyF,KAAO,OAEvCI,EAAmB7F,EAGvB,CCVA,SAASkG,EAAoBlG,GAC3B,OAAKW,EAAcX,IACoB,UAAvC,EAAiBA,GAASiC,SAInBjC,EAAQmG,aAHN,IAIX,CAwCe,SAASC,EAAgBpG,GAItC,IAHA,IAAIK,EAASF,EAAUH,GACnBmG,EAAeD,EAAoBlG,GAEhCmG,GAAgBR,EAAeQ,IAA6D,WAA5C,EAAiBA,GAAclE,UACpFkE,EAAeD,EAAoBC,GAGrC,OAAIA,IAA+C,SAA9BpG,EAAYoG,IAA0D,SAA9BpG,EAAYoG,IAAwE,WAA5C,EAAiBA,GAAclE,UAC3H5B,EAGF8F,GAhDT,SAA4BnG,GAC1B,IAAIqG,EAAY,WAAWvC,KAAKd,KAGhC,GAFW,WAAWc,KAAKd,MAEfrC,EAAcX,IAII,UAFX,EAAiBA,GAEnBiC,SACb,OAAO,KAIX,IAAIqE,EAAcN,EAAchG,GAMhC,IAJIa,EAAayF,KACfA,EAAcA,EAAYb,MAGrB9E,EAAc2F,IAAgB,CAAC,OAAQ,QAAQV,QAAQ7F,EAAYuG,IAAgB,GAAG,CAC3F,IAAIC,EAAM,EAAiBD,GAI3B,GAAsB,SAAlBC,EAAIC,WAA4C,SAApBD,EAAIE,aAA0C,UAAhBF,EAAIG,UAAiF,IAA1D,CAAC,YAAa,eAAed,QAAQW,EAAII,aAAsBN,GAAgC,WAAnBE,EAAII,YAA2BN,GAAaE,EAAIK,QAAyB,SAAfL,EAAIK,OACjO,OAAON,EAEPA,EAAcA,EAAYd,UAE9B,CAEA,OAAO,IACT,CAgByBqB,CAAmB7G,IAAYK,CACxD,CCpEe,SAASyG,EAAyB3H,GAC/C,MAAO,CAAC,MAAO,UAAUyG,QAAQzG,IAAc,EAAI,IAAM,GAC3D,CCDO,SAAS4H,EAAOjE,EAAK1E,EAAOyE,GACjC,OAAO,EAAQC,EAAK,EAAQ1E,EAAOyE,GACrC,CCFe,SAASmE,EAAmBC,GACzC,OAAOxJ,OAAOkE,OAAO,CAAC,ECDf,CACLS,IAAK,EACL9D,MAAO,EACPD,OAAQ,EACRE,KAAM,GDHuC0I,EACjD,CEHe,SAASC,EAAgB9I,EAAOiD,GAC7C,OAAOA,EAAKpC,QAAO,SAAUkI,EAAS5J,GAEpC,OADA4J,EAAQ5J,GAAOa,EACR+I,CACT,GAAG,CAAC,EACN,CC4EA,SACEpG,KAAM,QACNC,SAAS,EACTC,MAAO,OACPC,GApEF,SAAeC,GACb,IAAIiG,EAEAhG,EAAQD,EAAKC,MACbL,EAAOI,EAAKJ,KACZmB,EAAUf,EAAKe,QACfmF,EAAejG,EAAME,SAASgB,MAC9BgF,EAAgBlG,EAAMmG,cAAcD,cACpCE,EAAgB9E,EAAiBtB,EAAMjC,WACvCsI,EAAOX,EAAyBU,GAEhCE,EADa,CAACnJ,EAAMD,GAAOsH,QAAQ4B,IAAkB,EAClC,SAAW,QAElC,GAAKH,GAAiBC,EAAtB,CAIA,IAAIL,EAxBgB,SAAyBU,EAASvG,GAItD,OAAO4F,EAAsC,iBAH7CW,EAA6B,mBAAZA,EAAyBA,EAAQlK,OAAOkE,OAAO,CAAC,EAAGP,EAAMwG,MAAO,CAC/EzI,UAAWiC,EAAMjC,aACbwI,GACkDA,EAAUT,EAAgBS,EAASlJ,GAC7F,CAmBsBoJ,CAAgB3F,EAAQyF,QAASvG,GACjD0G,EAAY/C,EAAcsC,GAC1BU,EAAmB,MAATN,EAAe,EAAMlJ,EAC/ByJ,EAAmB,MAATP,EAAepJ,EAASC,EAClC2J,EAAU7G,EAAMwG,MAAM7I,UAAU2I,GAAOtG,EAAMwG,MAAM7I,UAAU0I,GAAQH,EAAcG,GAAQrG,EAAMwG,MAAM9I,OAAO4I,GAC9GQ,EAAYZ,EAAcG,GAAQrG,EAAMwG,MAAM7I,UAAU0I,GACxDU,EAAoB/B,EAAgBiB,GACpCe,EAAaD,EAA6B,MAATV,EAAeU,EAAkBE,cAAgB,EAAIF,EAAkBG,aAAe,EAAI,EAC3HC,EAAoBN,EAAU,EAAIC,EAAY,EAG9CpF,EAAMmE,EAAcc,GACpBlF,EAAMuF,EAAaN,EAAUJ,GAAOT,EAAce,GAClDQ,EAASJ,EAAa,EAAIN,EAAUJ,GAAO,EAAIa,EAC/CE,EAAS1B,EAAOjE,EAAK0F,EAAQ3F,GAE7B6F,EAAWjB,EACfrG,EAAMmG,cAAcxG,KAASqG,EAAwB,CAAC,GAAyBsB,GAAYD,EAAQrB,EAAsBuB,aAAeF,EAASD,EAAQpB,EAnBzJ,CAoBF,EAkCEtF,OAhCF,SAAgBC,GACd,IAAIX,EAAQW,EAAMX,MAEdwH,EADU7G,EAAMG,QACWlC,QAC3BqH,OAAoC,IAArBuB,EAA8B,sBAAwBA,EAErD,MAAhBvB,IAKwB,iBAAjBA,IACTA,EAAejG,EAAME,SAASxC,OAAO+J,cAAcxB,MAOhDpC,EAAS7D,EAAME,SAASxC,OAAQuI,KAIrCjG,EAAME,SAASgB,MAAQ+E,EACzB,EASE5E,SAAU,CAAC,iBACXqG,iBAAkB,CAAC,oBCxFN,SAASC,EAAa5J,GACnC,OAAOA,EAAUwD,MAAM,KAAK,EAC9B,CCOA,IAAIqG,GAAa,CACf5G,IAAK,OACL9D,MAAO,OACPD,OAAQ,OACRE,KAAM,QAeD,SAAS0K,GAAYlH,GAC1B,IAAImH,EAEApK,EAASiD,EAAMjD,OACfqK,EAAapH,EAAMoH,WACnBhK,EAAY4C,EAAM5C,UAClBiK,EAAYrH,EAAMqH,UAClBC,EAAUtH,EAAMsH,QAChBpH,EAAWF,EAAME,SACjBqH,EAAkBvH,EAAMuH,gBACxBC,EAAWxH,EAAMwH,SACjBC,EAAezH,EAAMyH,aACrBC,EAAU1H,EAAM0H,QAChBC,EAAaL,EAAQ1E,EACrBA,OAAmB,IAAf+E,EAAwB,EAAIA,EAChCC,EAAaN,EAAQxE,EACrBA,OAAmB,IAAf8E,EAAwB,EAAIA,EAEhCC,EAAgC,mBAAjBJ,EAA8BA,EAAa,CAC5D7E,EAAGA,EACHE,IACG,CACHF,EAAGA,EACHE,GAGFF,EAAIiF,EAAMjF,EACVE,EAAI+E,EAAM/E,EACV,IAAIgF,EAAOR,EAAQrL,eAAe,KAC9B8L,EAAOT,EAAQrL,eAAe,KAC9B+L,EAAQxL,EACRyL,EAAQ,EACRC,EAAM5J,OAEV,GAAIkJ,EAAU,CACZ,IAAIpD,EAAeC,EAAgBtH,GAC/BoL,EAAa,eACbC,EAAY,cAEZhE,IAAiBhG,EAAUrB,IAGmB,WAA5C,EAFJqH,EAAeN,EAAmB/G,IAECmD,UAAsC,aAAbA,IAC1DiI,EAAa,eACbC,EAAY,gBAOZhL,IAAc,IAAQA,IAAcZ,GAAQY,IAAcb,IAAU8K,IAAczK,KACpFqL,EAAQ3L,EAGRwG,IAFc4E,GAAWtD,IAAiB8D,GAAOA,EAAIxF,eAAiBwF,EAAIxF,eAAeD,OACzF2B,EAAa+D,IACEf,EAAW3E,OAC1BK,GAAKyE,EAAkB,GAAK,GAG1BnK,IAAcZ,IAASY,IAAc,GAAOA,IAAcd,GAAW+K,IAAczK,KACrFoL,EAAQzL,EAGRqG,IAFc8E,GAAWtD,IAAiB8D,GAAOA,EAAIxF,eAAiBwF,EAAIxF,eAAeH,MACzF6B,EAAagE,IACEhB,EAAW7E,MAC1BK,GAAK2E,EAAkB,GAAK,EAEhC,CAEA,IAgBMc,EAhBFC,EAAe5M,OAAOkE,OAAO,CAC/BM,SAAUA,GACTsH,GAAYP,IAEXsB,GAAyB,IAAjBd,EAlFd,SAA2BrI,EAAM8I,GAC/B,IAAItF,EAAIxD,EAAKwD,EACTE,EAAI1D,EAAK0D,EACT0F,EAAMN,EAAIO,kBAAoB,EAClC,MAAO,CACL7F,EAAG5B,EAAM4B,EAAI4F,GAAOA,GAAO,EAC3B1F,EAAG9B,EAAM8B,EAAI0F,GAAOA,GAAO,EAE/B,CA0EsCE,CAAkB,CACpD9F,EAAGA,EACHE,GACC1E,EAAUrB,IAAW,CACtB6F,EAAGA,EACHE,GAMF,OAHAF,EAAI2F,EAAM3F,EACVE,EAAIyF,EAAMzF,EAENyE,EAGK7L,OAAOkE,OAAO,CAAC,EAAG0I,IAAeD,EAAiB,CAAC,GAAkBJ,GAASF,EAAO,IAAM,GAAIM,EAAeL,GAASF,EAAO,IAAM,GAAIO,EAAe5D,WAAayD,EAAIO,kBAAoB,IAAM,EAAI,aAAe7F,EAAI,OAASE,EAAI,MAAQ,eAAiBF,EAAI,OAASE,EAAI,SAAUuF,IAG5R3M,OAAOkE,OAAO,CAAC,EAAG0I,IAAenB,EAAkB,CAAC,GAAmBc,GAASF,EAAOjF,EAAI,KAAO,GAAIqE,EAAgBa,GAASF,EAAOlF,EAAI,KAAO,GAAIuE,EAAgB1C,UAAY,GAAI0C,GAC9L,CA4CA,UACEnI,KAAM,gBACNC,SAAS,EACTC,MAAO,cACPC,GA9CF,SAAuBwJ,GACrB,IAAItJ,EAAQsJ,EAAMtJ,MACdc,EAAUwI,EAAMxI,QAChByI,EAAwBzI,EAAQoH,gBAChCA,OAA4C,IAA1BqB,GAA0CA,EAC5DC,EAAoB1I,EAAQqH,SAC5BA,OAAiC,IAAtBqB,GAAsCA,EACjDC,EAAwB3I,EAAQsH,aAChCA,OAAyC,IAA1BqB,GAA0CA,EACzDR,EAAe,CACjBlL,UAAWuD,EAAiBtB,EAAMjC,WAClCiK,UAAWL,EAAa3H,EAAMjC,WAC9BL,OAAQsC,EAAME,SAASxC,OACvBqK,WAAY/H,EAAMwG,MAAM9I,OACxBwK,gBAAiBA,EACjBG,QAAoC,UAA3BrI,EAAMc,QAAQC,UAGgB,MAArCf,EAAMmG,cAAcD,gBACtBlG,EAAMK,OAAO3C,OAASrB,OAAOkE,OAAO,CAAC,EAAGP,EAAMK,OAAO3C,OAAQmK,GAAYxL,OAAOkE,OAAO,CAAC,EAAG0I,EAAc,CACvGhB,QAASjI,EAAMmG,cAAcD,cAC7BrF,SAAUb,EAAMc,QAAQC,SACxBoH,SAAUA,EACVC,aAAcA,OAIe,MAA7BpI,EAAMmG,cAAcjF,QACtBlB,EAAMK,OAAOa,MAAQ7E,OAAOkE,OAAO,CAAC,EAAGP,EAAMK,OAAOa,MAAO2G,GAAYxL,OAAOkE,OAAO,CAAC,EAAG0I,EAAc,CACrGhB,QAASjI,EAAMmG,cAAcjF,MAC7BL,SAAU,WACVsH,UAAU,EACVC,aAAcA,OAIlBpI,EAAMM,WAAW5C,OAASrB,OAAOkE,OAAO,CAAC,EAAGP,EAAMM,WAAW5C,OAAQ,CACnE,wBAAyBsC,EAAMjC,WAEnC,EAQE2L,KAAM,CAAC,GCrKT,IAAIC,GAAU,CACZA,SAAS,GAsCX,UACEhK,KAAM,iBACNC,SAAS,EACTC,MAAO,QACPC,GAAI,WAAe,EACnBY,OAxCF,SAAgBX,GACd,IAAIC,EAAQD,EAAKC,MACb4J,EAAW7J,EAAK6J,SAChB9I,EAAUf,EAAKe,QACf+I,EAAkB/I,EAAQgJ,OAC1BA,OAA6B,IAApBD,GAAoCA,EAC7CE,EAAkBjJ,EAAQkJ,OAC1BA,OAA6B,IAApBD,GAAoCA,EAC7C9K,EAASF,EAAUiB,EAAME,SAASxC,QAClCuM,EAAgB,GAAGjM,OAAOgC,EAAMiK,cAActM,UAAWqC,EAAMiK,cAAcvM,QAYjF,OAVIoM,GACFG,EAAc9J,SAAQ,SAAU+J,GAC9BA,EAAaC,iBAAiB,SAAUP,EAASQ,OAAQT,GAC3D,IAGEK,GACF/K,EAAOkL,iBAAiB,SAAUP,EAASQ,OAAQT,IAG9C,WACDG,GACFG,EAAc9J,SAAQ,SAAU+J,GAC9BA,EAAaG,oBAAoB,SAAUT,EAASQ,OAAQT,GAC9D,IAGEK,GACF/K,EAAOoL,oBAAoB,SAAUT,EAASQ,OAAQT,GAE1D,CACF,EASED,KAAM,CAAC,GC/CT,IAAIY,GAAO,CACTnN,KAAM,QACND,MAAO,OACPD,OAAQ,MACR+D,IAAK,UAEQ,SAASuJ,GAAqBxM,GAC3C,OAAOA,EAAUyM,QAAQ,0BAA0B,SAAUC,GAC3D,OAAOH,GAAKG,EACd,GACF,CCVA,IAAI,GAAO,CACTnN,MAAO,MACPC,IAAK,SAEQ,SAASmN,GAA8B3M,GACpD,OAAOA,EAAUyM,QAAQ,cAAc,SAAUC,GAC/C,OAAO,GAAKA,EACd,GACF,CCPe,SAASE,GAAgB3L,GACtC,IAAI6J,EAAM9J,EAAUC,GAGpB,MAAO,CACL4L,WAHe/B,EAAIgC,YAInBC,UAHcjC,EAAIkC,YAKtB,CCNe,SAASC,GAAoBpM,GAQ1C,OAAO+D,EAAsB8B,EAAmB7F,IAAUzB,KAAOwN,GAAgB/L,GAASgM,UAC5F,CCXe,SAASK,GAAerM,GAErC,IAAIsM,EAAoB,EAAiBtM,GACrCuM,EAAWD,EAAkBC,SAC7BC,EAAYF,EAAkBE,UAC9BC,EAAYH,EAAkBG,UAElC,MAAO,6BAA6B3I,KAAKyI,EAAWE,EAAYD,EAClE,CCLe,SAASE,GAAgBtM,GACtC,MAAI,CAAC,OAAQ,OAAQ,aAAawF,QAAQ7F,EAAYK,KAAU,EAEvDA,EAAKG,cAAcoM,KAGxBhM,EAAcP,IAASiM,GAAejM,GACjCA,EAGFsM,GAAgB1G,EAAc5F,GACvC,CCJe,SAASwM,GAAkB5M,EAAS6M,GACjD,IAAIC,OAES,IAATD,IACFA,EAAO,IAGT,IAAIvB,EAAeoB,GAAgB1M,GAC/B+M,EAASzB,KAAqE,OAAlDwB,EAAwB9M,EAAQO,oBAAyB,EAASuM,EAAsBH,MACpH1C,EAAM9J,EAAUmL,GAChB0B,EAASD,EAAS,CAAC9C,GAAK7K,OAAO6K,EAAIxF,gBAAkB,GAAI4H,GAAef,GAAgBA,EAAe,IAAMA,EAC7G2B,EAAcJ,EAAKzN,OAAO4N,GAC9B,OAAOD,EAASE,EAChBA,EAAY7N,OAAOwN,GAAkB5G,EAAcgH,IACrD,CCzBe,SAASE,GAAiBC,GACvC,OAAO1P,OAAOkE,OAAO,CAAC,EAAGwL,EAAM,CAC7B5O,KAAM4O,EAAKxI,EACXvC,IAAK+K,EAAKtI,EACVvG,MAAO6O,EAAKxI,EAAIwI,EAAK7I,MACrBjG,OAAQ8O,EAAKtI,EAAIsI,EAAK3I,QAE1B,CCqBA,SAAS4I,GAA2BpN,EAASqN,EAAgBlL,GAC3D,OAAOkL,IAAmBxO,EAAWqO,GCzBxB,SAAyBlN,EAASmC,GAC/C,IAAI8H,EAAM9J,EAAUH,GAChBsN,EAAOzH,EAAmB7F,GAC1ByE,EAAiBwF,EAAIxF,eACrBH,EAAQgJ,EAAKhF,YACb9D,EAAS8I,EAAKjF,aACd1D,EAAI,EACJE,EAAI,EAER,GAAIJ,EAAgB,CAClBH,EAAQG,EAAeH,MACvBE,EAASC,EAAeD,OACxB,IAAI+I,EAAiB1J,KAEjB0J,IAAmBA,GAA+B,UAAbpL,KACvCwC,EAAIF,EAAeG,WACnBC,EAAIJ,EAAeK,UAEvB,CAEA,MAAO,CACLR,MAAOA,EACPE,OAAQA,EACRG,EAAGA,EAAIyH,GAAoBpM,GAC3B6E,EAAGA,EAEP,CDDwD2I,CAAgBxN,EAASmC,IAAa1B,EAAU4M,GAdxG,SAAoCrN,EAASmC,GAC3C,IAAIgL,EAAOpJ,EAAsB/D,GAAS,EAAoB,UAAbmC,GASjD,OARAgL,EAAK/K,IAAM+K,EAAK/K,IAAMpC,EAAQyN,UAC9BN,EAAK5O,KAAO4O,EAAK5O,KAAOyB,EAAQ0N,WAChCP,EAAK9O,OAAS8O,EAAK/K,IAAMpC,EAAQqI,aACjC8E,EAAK7O,MAAQ6O,EAAK5O,KAAOyB,EAAQsI,YACjC6E,EAAK7I,MAAQtE,EAAQsI,YACrB6E,EAAK3I,OAASxE,EAAQqI,aACtB8E,EAAKxI,EAAIwI,EAAK5O,KACd4O,EAAKtI,EAAIsI,EAAK/K,IACP+K,CACT,CAG0HQ,CAA2BN,EAAgBlL,GAAY+K,GEtBlK,SAAyBlN,GACtC,IAAI8M,EAEAQ,EAAOzH,EAAmB7F,GAC1B4N,EAAY7B,GAAgB/L,GAC5B2M,EAA0D,OAAlDG,EAAwB9M,EAAQO,oBAAyB,EAASuM,EAAsBH,KAChGrI,EAAQ,EAAIgJ,EAAKO,YAAaP,EAAKhF,YAAaqE,EAAOA,EAAKkB,YAAc,EAAGlB,EAAOA,EAAKrE,YAAc,GACvG9D,EAAS,EAAI8I,EAAKQ,aAAcR,EAAKjF,aAAcsE,EAAOA,EAAKmB,aAAe,EAAGnB,EAAOA,EAAKtE,aAAe,GAC5G1D,GAAKiJ,EAAU5B,WAAaI,GAAoBpM,GAChD6E,GAAK+I,EAAU1B,UAMnB,MAJiD,QAA7C,EAAiBS,GAAQW,GAAMS,YACjCpJ,GAAK,EAAI2I,EAAKhF,YAAaqE,EAAOA,EAAKrE,YAAc,GAAKhE,GAGrD,CACLA,MAAOA,EACPE,OAAQA,EACRG,EAAGA,EACHE,EAAGA,EAEP,CFCkMmJ,CAAgBnI,EAAmB7F,IACrO,CG1Be,SAASiO,GAAe9M,GACrC,IAOIkI,EAPAtK,EAAYoC,EAAKpC,UACjBiB,EAAUmB,EAAKnB,QACfb,EAAYgC,EAAKhC,UACjBqI,EAAgBrI,EAAYuD,EAAiBvD,GAAa,KAC1DiK,EAAYjK,EAAY4J,EAAa5J,GAAa,KAClD+O,EAAUnP,EAAU4F,EAAI5F,EAAUuF,MAAQ,EAAItE,EAAQsE,MAAQ,EAC9D6J,EAAUpP,EAAU8F,EAAI9F,EAAUyF,OAAS,EAAIxE,EAAQwE,OAAS,EAGpE,OAAQgD,GACN,KAAK,EACH6B,EAAU,CACR1E,EAAGuJ,EACHrJ,EAAG9F,EAAU8F,EAAI7E,EAAQwE,QAE3B,MAEF,KAAKnG,EACHgL,EAAU,CACR1E,EAAGuJ,EACHrJ,EAAG9F,EAAU8F,EAAI9F,EAAUyF,QAE7B,MAEF,KAAKlG,EACH+K,EAAU,CACR1E,EAAG5F,EAAU4F,EAAI5F,EAAUuF,MAC3BO,EAAGsJ,GAEL,MAEF,KAAK5P,EACH8K,EAAU,CACR1E,EAAG5F,EAAU4F,EAAI3E,EAAQsE,MACzBO,EAAGsJ,GAEL,MAEF,QACE9E,EAAU,CACR1E,EAAG5F,EAAU4F,EACbE,EAAG9F,EAAU8F,GAInB,IAAIuJ,EAAW5G,EAAgBV,EAAyBU,GAAiB,KAEzE,GAAgB,MAAZ4G,EAAkB,CACpB,IAAI1G,EAAmB,MAAb0G,EAAmB,SAAW,QAExC,OAAQhF,GACN,KAAK1K,EACH2K,EAAQ+E,GAAY/E,EAAQ+E,IAAarP,EAAU2I,GAAO,EAAI1H,EAAQ0H,GAAO,GAC7E,MAEF,KAAK/I,EACH0K,EAAQ+E,GAAY/E,EAAQ+E,IAAarP,EAAU2I,GAAO,EAAI1H,EAAQ0H,GAAO,GAKnF,CAEA,OAAO2B,CACT,CC3De,SAASgF,GAAejN,EAAOc,QAC5B,IAAZA,IACFA,EAAU,CAAC,GAGb,IAAIoM,EAAWpM,EACXqM,EAAqBD,EAASnP,UAC9BA,OAAmC,IAAvBoP,EAAgCnN,EAAMjC,UAAYoP,EAC9DC,EAAoBF,EAASnM,SAC7BA,OAAiC,IAAtBqM,EAA+BpN,EAAMe,SAAWqM,EAC3DC,EAAoBH,EAASI,SAC7BA,OAAiC,IAAtBD,EAA+B7P,EAAkB6P,EAC5DE,EAAwBL,EAASM,aACjCA,OAAyC,IAA1BD,EAAmC9P,EAAW8P,EAC7DE,EAAwBP,EAASQ,eACjCA,OAA2C,IAA1BD,EAAmC/P,EAAS+P,EAC7DE,EAAuBT,EAASU,YAChCA,OAAuC,IAAzBD,GAA0CA,EACxDE,EAAmBX,EAAS3G,QAC5BA,OAA+B,IAArBsH,EAA8B,EAAIA,EAC5ChI,EAAgBD,EAAsC,iBAAZW,EAAuBA,EAAUT,EAAgBS,EAASlJ,IACpGyQ,EAAaJ,IAAmBhQ,EAASC,EAAYD,EACrDqK,EAAa/H,EAAMwG,MAAM9I,OACzBkB,EAAUoB,EAAME,SAAS0N,EAAcE,EAAaJ,GACpDK,EJkBS,SAAyBnP,EAAS0O,EAAUE,EAAczM,GACvE,IAAIiN,EAAmC,oBAAbV,EAlB5B,SAA4B1O,GAC1B,IAAIpB,EAAkBgO,GAAkB5G,EAAchG,IAElDqP,EADoB,CAAC,WAAY,SAASzJ,QAAQ,EAAiB5F,GAASiC,WAAa,GACnDtB,EAAcX,GAAWoG,EAAgBpG,GAAWA,EAE9F,OAAKS,EAAU4O,GAKRzQ,EAAgBgI,QAAO,SAAUyG,GACtC,OAAO5M,EAAU4M,IAAmBpI,EAASoI,EAAgBgC,IAAmD,SAAhCtP,EAAYsN,EAC9F,IANS,EAOX,CAK6DiC,CAAmBtP,GAAW,GAAGZ,OAAOsP,GAC/F9P,EAAkB,GAAGQ,OAAOgQ,EAAqB,CAACR,IAClDW,EAAsB3Q,EAAgB,GACtC4Q,EAAe5Q,EAAgBK,QAAO,SAAUwQ,EAASpC,GAC3D,IAAIF,EAAOC,GAA2BpN,EAASqN,EAAgBlL,GAK/D,OAJAsN,EAAQrN,IAAM,EAAI+K,EAAK/K,IAAKqN,EAAQrN,KACpCqN,EAAQnR,MAAQ,EAAI6O,EAAK7O,MAAOmR,EAAQnR,OACxCmR,EAAQpR,OAAS,EAAI8O,EAAK9O,OAAQoR,EAAQpR,QAC1CoR,EAAQlR,KAAO,EAAI4O,EAAK5O,KAAMkR,EAAQlR,MAC/BkR,CACT,GAAGrC,GAA2BpN,EAASuP,EAAqBpN,IAK5D,OAJAqN,EAAalL,MAAQkL,EAAalR,MAAQkR,EAAajR,KACvDiR,EAAahL,OAASgL,EAAanR,OAASmR,EAAapN,IACzDoN,EAAa7K,EAAI6K,EAAajR,KAC9BiR,EAAa3K,EAAI2K,EAAapN,IACvBoN,CACT,CInC2BE,CAAgBjP,EAAUT,GAAWA,EAAUA,EAAQ2P,gBAAkB9J,EAAmBzE,EAAME,SAASxC,QAAS4P,EAAUE,EAAczM,GACjKyN,EAAsB7L,EAAsB3C,EAAME,SAASvC,WAC3DuI,EAAgB2G,GAAe,CACjClP,UAAW6Q,EACX5P,QAASmJ,EACThH,SAAU,WACVhD,UAAWA,IAET0Q,EAAmB3C,GAAiBzP,OAAOkE,OAAO,CAAC,EAAGwH,EAAY7B,IAClEwI,EAAoBhB,IAAmBhQ,EAAS+Q,EAAmBD,EAGnEG,EAAkB,CACpB3N,IAAK+M,EAAmB/M,IAAM0N,EAAkB1N,IAAM6E,EAAc7E,IACpE/D,OAAQyR,EAAkBzR,OAAS8Q,EAAmB9Q,OAAS4I,EAAc5I,OAC7EE,KAAM4Q,EAAmB5Q,KAAOuR,EAAkBvR,KAAO0I,EAAc1I,KACvED,MAAOwR,EAAkBxR,MAAQ6Q,EAAmB7Q,MAAQ2I,EAAc3I,OAExE0R,EAAa5O,EAAMmG,cAAckB,OAErC,GAAIqG,IAAmBhQ,GAAUkR,EAAY,CAC3C,IAAIvH,EAASuH,EAAW7Q,GACxB1B,OAAO4D,KAAK0O,GAAiBxO,SAAQ,SAAUhE,GAC7C,IAAI0S,EAAW,CAAC3R,EAAOD,GAAQuH,QAAQrI,IAAQ,EAAI,GAAK,EACpDkK,EAAO,CAAC,EAAKpJ,GAAQuH,QAAQrI,IAAQ,EAAI,IAAM,IACnDwS,EAAgBxS,IAAQkL,EAAOhB,GAAQwI,CACzC,GACF,CAEA,OAAOF,CACT,CCyEA,UACEhP,KAAM,OACNC,SAAS,EACTC,MAAO,OACPC,GA5HF,SAAcC,GACZ,IAAIC,EAAQD,EAAKC,MACbc,EAAUf,EAAKe,QACfnB,EAAOI,EAAKJ,KAEhB,IAAIK,EAAMmG,cAAcxG,GAAMmP,MAA9B,CAoCA,IAhCA,IAAIC,EAAoBjO,EAAQkM,SAC5BgC,OAAsC,IAAtBD,GAAsCA,EACtDE,EAAmBnO,EAAQoO,QAC3BC,OAAoC,IAArBF,GAAqCA,EACpDG,EAA8BtO,EAAQuO,mBACtC9I,EAAUzF,EAAQyF,QAClB+G,EAAWxM,EAAQwM,SACnBE,EAAe1M,EAAQ0M,aACvBI,EAAc9M,EAAQ8M,YACtB0B,EAAwBxO,EAAQyO,eAChCA,OAA2C,IAA1BD,GAA0CA,EAC3DE,EAAwB1O,EAAQ0O,sBAChCC,EAAqBzP,EAAMc,QAAQ/C,UACnCqI,EAAgB9E,EAAiBmO,GAEjCJ,EAAqBD,IADHhJ,IAAkBqJ,GACqCF,EAjC/E,SAAuCxR,GACrC,GAAIuD,EAAiBvD,KAAeX,EAClC,MAAO,GAGT,IAAIsS,EAAoBnF,GAAqBxM,GAC7C,MAAO,CAAC2M,GAA8B3M,GAAY2R,EAAmBhF,GAA8BgF,GACrG,CA0B6IC,CAA8BF,GAA3E,CAAClF,GAAqBkF,KAChHG,EAAa,CAACH,GAAoBzR,OAAOqR,GAAoBxR,QAAO,SAAUC,EAAKC,GACrF,OAAOD,EAAIE,OAAOsD,EAAiBvD,KAAeX,ECvCvC,SAA8B4C,EAAOc,QAClC,IAAZA,IACFA,EAAU,CAAC,GAGb,IAAIoM,EAAWpM,EACX/C,EAAYmP,EAASnP,UACrBuP,EAAWJ,EAASI,SACpBE,EAAeN,EAASM,aACxBjH,EAAU2G,EAAS3G,QACnBgJ,EAAiBrC,EAASqC,eAC1BM,EAAwB3C,EAASsC,sBACjCA,OAAkD,IAA1BK,EAAmC,EAAgBA,EAC3E7H,EAAYL,EAAa5J,GACzB6R,EAAa5H,EAAYuH,EAAiB3R,EAAsBA,EAAoB4H,QAAO,SAAUzH,GACvG,OAAO4J,EAAa5J,KAAeiK,CACrC,IAAK3K,EACDyS,EAAoBF,EAAWpK,QAAO,SAAUzH,GAClD,OAAOyR,EAAsBhL,QAAQzG,IAAc,CACrD,IAEiC,IAA7B+R,EAAkBC,SACpBD,EAAoBF,GAItB,IAAII,EAAYF,EAAkBjS,QAAO,SAAUC,EAAKC,GAOtD,OANAD,EAAIC,GAAakP,GAAejN,EAAO,CACrCjC,UAAWA,EACXuP,SAAUA,EACVE,aAAcA,EACdjH,QAASA,IACRjF,EAAiBvD,IACbD,CACT,GAAG,CAAC,GACJ,OAAOzB,OAAO4D,KAAK+P,GAAWC,MAAK,SAAUC,EAAGC,GAC9C,OAAOH,EAAUE,GAAKF,EAAUG,EAClC,GACF,CDC6DC,CAAqBpQ,EAAO,CACnFjC,UAAWA,EACXuP,SAAUA,EACVE,aAAcA,EACdjH,QAASA,EACTgJ,eAAgBA,EAChBC,sBAAuBA,IACpBzR,EACP,GAAG,IACCsS,EAAgBrQ,EAAMwG,MAAM7I,UAC5BoK,EAAa/H,EAAMwG,MAAM9I,OACzB4S,EAAY,IAAIC,IAChBC,GAAqB,EACrBC,EAAwBb,EAAW,GAE9Bc,EAAI,EAAGA,EAAId,EAAWG,OAAQW,IAAK,CAC1C,IAAI3S,EAAY6R,EAAWc,GAEvBC,EAAiBrP,EAAiBvD,GAElC6S,EAAmBjJ,EAAa5J,KAAeT,EAC/CuT,EAAa,CAAC,EAAK5T,GAAQuH,QAAQmM,IAAmB,EACtDrK,EAAMuK,EAAa,QAAU,SAC7B1F,EAAW8B,GAAejN,EAAO,CACnCjC,UAAWA,EACXuP,SAAUA,EACVE,aAAcA,EACdI,YAAaA,EACbrH,QAASA,IAEPuK,EAAoBD,EAAaD,EAAmB1T,EAAQC,EAAOyT,EAAmB3T,EAAS,EAE/FoT,EAAc/J,GAAOyB,EAAWzB,KAClCwK,EAAoBvG,GAAqBuG,IAG3C,IAAIC,EAAmBxG,GAAqBuG,GACxCE,EAAS,GAUb,GARIhC,GACFgC,EAAOC,KAAK9F,EAASwF,IAAmB,GAGtCxB,GACF6B,EAAOC,KAAK9F,EAAS2F,IAAsB,EAAG3F,EAAS4F,IAAqB,GAG1EC,EAAOE,OAAM,SAAUC,GACzB,OAAOA,CACT,IAAI,CACFV,EAAwB1S,EACxByS,GAAqB,EACrB,KACF,CAEAF,EAAUc,IAAIrT,EAAWiT,EAC3B,CAEA,GAAIR,EAqBF,IAnBA,IAEIa,EAAQ,SAAeC,GACzB,IAAIC,EAAmB3B,EAAW4B,MAAK,SAAUzT,GAC/C,IAAIiT,EAASV,EAAU9T,IAAIuB,GAE3B,GAAIiT,EACF,OAAOA,EAAOS,MAAM,EAAGH,GAAIJ,OAAM,SAAUC,GACzC,OAAOA,CACT,GAEJ,IAEA,GAAII,EAEF,OADAd,EAAwBc,EACjB,OAEX,EAESD,EAnBY/B,EAAiB,EAAI,EAmBZ+B,EAAK,GAGpB,UAFFD,EAAMC,GADmBA,KAOpCtR,EAAMjC,YAAc0S,IACtBzQ,EAAMmG,cAAcxG,GAAMmP,OAAQ,EAClC9O,EAAMjC,UAAY0S,EAClBzQ,EAAM0R,OAAQ,EA5GhB,CA8GF,EAQEhK,iBAAkB,CAAC,UACnBgC,KAAM,CACJoF,OAAO,IE7IX,SAAS6C,GAAexG,EAAUY,EAAM6F,GAQtC,YAPyB,IAArBA,IACFA,EAAmB,CACjBrO,EAAG,EACHE,EAAG,IAIA,CACLzC,IAAKmK,EAASnK,IAAM+K,EAAK3I,OAASwO,EAAiBnO,EACnDvG,MAAOiO,EAASjO,MAAQ6O,EAAK7I,MAAQ0O,EAAiBrO,EACtDtG,OAAQkO,EAASlO,OAAS8O,EAAK3I,OAASwO,EAAiBnO,EACzDtG,KAAMgO,EAAShO,KAAO4O,EAAK7I,MAAQ0O,EAAiBrO,EAExD,CAEA,SAASsO,GAAsB1G,GAC7B,MAAO,CAAC,EAAKjO,EAAOD,EAAQE,GAAM2U,MAAK,SAAUC,GAC/C,OAAO5G,EAAS4G,IAAS,CAC3B,GACF,CA+BA,UACEpS,KAAM,OACNC,SAAS,EACTC,MAAO,OACP6H,iBAAkB,CAAC,mBACnB5H,GAlCF,SAAcC,GACZ,IAAIC,EAAQD,EAAKC,MACbL,EAAOI,EAAKJ,KACZ0Q,EAAgBrQ,EAAMwG,MAAM7I,UAC5BoK,EAAa/H,EAAMwG,MAAM9I,OACzBkU,EAAmB5R,EAAMmG,cAAc6L,gBACvCC,EAAoBhF,GAAejN,EAAO,CAC5C0N,eAAgB,cAEdwE,EAAoBjF,GAAejN,EAAO,CAC5C4N,aAAa,IAEXuE,EAA2BR,GAAeM,EAAmB5B,GAC7D+B,EAAsBT,GAAeO,EAAmBnK,EAAY6J,GACpES,EAAoBR,GAAsBM,GAC1CG,EAAmBT,GAAsBO,GAC7CpS,EAAMmG,cAAcxG,GAAQ,CAC1BwS,yBAA0BA,EAC1BC,oBAAqBA,EACrBC,kBAAmBA,EACnBC,iBAAkBA,GAEpBtS,EAAMM,WAAW5C,OAASrB,OAAOkE,OAAO,CAAC,EAAGP,EAAMM,WAAW5C,OAAQ,CACnE,+BAAgC2U,EAChC,sBAAuBC,GAE3B,GCJA,IACE3S,KAAM,SACNC,SAAS,EACTC,MAAO,OACPwB,SAAU,CAAC,iBACXvB,GA5BF,SAAgBa,GACd,IAAIX,EAAQW,EAAMX,MACdc,EAAUH,EAAMG,QAChBnB,EAAOgB,EAAMhB,KACb4S,EAAkBzR,EAAQuG,OAC1BA,OAA6B,IAApBkL,EAA6B,CAAC,EAAG,GAAKA,EAC/C7I,EAAO,EAAW7L,QAAO,SAAUC,EAAKC,GAE1C,OADAD,EAAIC,GA5BD,SAAiCA,EAAWyI,EAAOa,GACxD,IAAIjB,EAAgB9E,EAAiBvD,GACjCyU,EAAiB,CAACrV,EAAM,GAAKqH,QAAQ4B,IAAkB,GAAK,EAAI,EAEhErG,EAAyB,mBAAXsH,EAAwBA,EAAOhL,OAAOkE,OAAO,CAAC,EAAGiG,EAAO,CACxEzI,UAAWA,KACPsJ,EACFoL,EAAW1S,EAAK,GAChB2S,EAAW3S,EAAK,GAIpB,OAFA0S,EAAWA,GAAY,EACvBC,GAAYA,GAAY,GAAKF,EACtB,CAACrV,EAAMD,GAAOsH,QAAQ4B,IAAkB,EAAI,CACjD7C,EAAGmP,EACHjP,EAAGgP,GACD,CACFlP,EAAGkP,EACHhP,EAAGiP,EAEP,CASqBC,CAAwB5U,EAAWiC,EAAMwG,MAAOa,GAC1DvJ,CACT,GAAG,CAAC,GACA8U,EAAwBlJ,EAAK1J,EAAMjC,WACnCwF,EAAIqP,EAAsBrP,EAC1BE,EAAImP,EAAsBnP,EAEW,MAArCzD,EAAMmG,cAAcD,gBACtBlG,EAAMmG,cAAcD,cAAc3C,GAAKA,EACvCvD,EAAMmG,cAAcD,cAAczC,GAAKA,GAGzCzD,EAAMmG,cAAcxG,GAAQ+J,CAC9B,GC1BA,IACE/J,KAAM,gBACNC,SAAS,EACTC,MAAO,OACPC,GApBF,SAAuBC,GACrB,IAAIC,EAAQD,EAAKC,MACbL,EAAOI,EAAKJ,KAKhBK,EAAMmG,cAAcxG,GAAQkN,GAAe,CACzClP,UAAWqC,EAAMwG,MAAM7I,UACvBiB,QAASoB,EAAMwG,MAAM9I,OACrBqD,SAAU,WACVhD,UAAWiC,EAAMjC,WAErB,EAQE2L,KAAM,CAAC,GCgHT,IACE/J,KAAM,kBACNC,SAAS,EACTC,MAAO,OACPC,GA/HF,SAAyBC,GACvB,IAAIC,EAAQD,EAAKC,MACbc,EAAUf,EAAKe,QACfnB,EAAOI,EAAKJ,KACZoP,EAAoBjO,EAAQkM,SAC5BgC,OAAsC,IAAtBD,GAAsCA,EACtDE,EAAmBnO,EAAQoO,QAC3BC,OAAoC,IAArBF,GAAsCA,EACrD3B,EAAWxM,EAAQwM,SACnBE,EAAe1M,EAAQ0M,aACvBI,EAAc9M,EAAQ8M,YACtBrH,EAAUzF,EAAQyF,QAClBsM,EAAkB/R,EAAQgS,OAC1BA,OAA6B,IAApBD,GAAoCA,EAC7CE,EAAwBjS,EAAQkS,aAChCA,OAAyC,IAA1BD,EAAmC,EAAIA,EACtD5H,EAAW8B,GAAejN,EAAO,CACnCsN,SAAUA,EACVE,aAAcA,EACdjH,QAASA,EACTqH,YAAaA,IAEXxH,EAAgB9E,EAAiBtB,EAAMjC,WACvCiK,EAAYL,EAAa3H,EAAMjC,WAC/BkV,GAAmBjL,EACnBgF,EAAWtH,EAAyBU,GACpC8I,ECrCY,MDqCSlC,ECrCH,IAAM,IDsCxB9G,EAAgBlG,EAAMmG,cAAcD,cACpCmK,EAAgBrQ,EAAMwG,MAAM7I,UAC5BoK,EAAa/H,EAAMwG,MAAM9I,OACzBwV,EAA4C,mBAAjBF,EAA8BA,EAAa3W,OAAOkE,OAAO,CAAC,EAAGP,EAAMwG,MAAO,CACvGzI,UAAWiC,EAAMjC,aACbiV,EACFG,EAA2D,iBAAtBD,EAAiC,CACxElG,SAAUkG,EACVhE,QAASgE,GACP7W,OAAOkE,OAAO,CAChByM,SAAU,EACVkC,QAAS,GACRgE,GACCE,EAAsBpT,EAAMmG,cAAckB,OAASrH,EAAMmG,cAAckB,OAAOrH,EAAMjC,WAAa,KACjG2L,EAAO,CACTnG,EAAG,EACHE,EAAG,GAGL,GAAKyC,EAAL,CAIA,GAAI8I,EAAe,CACjB,IAAIqE,EAEAC,EAAwB,MAAbtG,EAAmB,EAAM7P,EACpCoW,EAAuB,MAAbvG,EAAmB/P,EAASC,EACtCoJ,EAAmB,MAAb0G,EAAmB,SAAW,QACpC3F,EAASnB,EAAc8G,GACvBtL,EAAM2F,EAAS8D,EAASmI,GACxB7R,EAAM4F,EAAS8D,EAASoI,GACxBC,EAAWV,GAAU/K,EAAWzB,GAAO,EAAI,EAC3CmN,EAASzL,IAAc1K,EAAQ+S,EAAc/J,GAAOyB,EAAWzB,GAC/DoN,EAAS1L,IAAc1K,GAASyK,EAAWzB,IAAQ+J,EAAc/J,GAGjEL,EAAejG,EAAME,SAASgB,MAC9BwF,EAAYoM,GAAU7M,EAAetC,EAAcsC,GAAgB,CACrE/C,MAAO,EACPE,OAAQ,GAENuQ,GAAqB3T,EAAMmG,cAAc,oBAAsBnG,EAAMmG,cAAc,oBAAoBI,QxBhFtG,CACLvF,IAAK,EACL9D,MAAO,EACPD,OAAQ,EACRE,KAAM,GwB6EFyW,GAAkBD,GAAmBL,GACrCO,GAAkBF,GAAmBJ,GAMrCO,GAAWnO,EAAO,EAAG0K,EAAc/J,GAAMI,EAAUJ,IACnDyN,GAAYd,EAAkB5C,EAAc/J,GAAO,EAAIkN,EAAWM,GAAWF,GAAkBT,EAA4BnG,SAAWyG,EAASK,GAAWF,GAAkBT,EAA4BnG,SACxMgH,GAAYf,GAAmB5C,EAAc/J,GAAO,EAAIkN,EAAWM,GAAWD,GAAkBV,EAA4BnG,SAAW0G,EAASI,GAAWD,GAAkBV,EAA4BnG,SACzMjG,GAAoB/G,EAAME,SAASgB,OAAS8D,EAAgBhF,EAAME,SAASgB,OAC3E+S,GAAelN,GAAiC,MAAbiG,EAAmBjG,GAAkBsF,WAAa,EAAItF,GAAkBuF,YAAc,EAAI,EAC7H4H,GAAwH,OAAjGb,EAA+C,MAAvBD,OAA8B,EAASA,EAAoBpG,IAAqBqG,EAAwB,EAEvJc,GAAY9M,EAAS2M,GAAYE,GACjCE,GAAkBzO,EAAOmN,EAAS,EAAQpR,EAF9B2F,EAAS0M,GAAYG,GAAsBD,IAEKvS,EAAK2F,EAAQyL,EAAS,EAAQrR,EAAK0S,IAAa1S,GAChHyE,EAAc8G,GAAYoH,GAC1B1K,EAAKsD,GAAYoH,GAAkB/M,CACrC,CAEA,GAAI8H,EAAc,CAChB,IAAIkF,GAEAC,GAAyB,MAAbtH,EAAmB,EAAM7P,EAErCoX,GAAwB,MAAbvH,EAAmB/P,EAASC,EAEvCsX,GAAUtO,EAAcgJ,GAExBuF,GAAmB,MAAZvF,EAAkB,SAAW,QAEpCwF,GAAOF,GAAUrJ,EAASmJ,IAE1BK,GAAOH,GAAUrJ,EAASoJ,IAE1BK,IAAuD,IAAxC,CAAC,EAAKzX,GAAMqH,QAAQ4B,GAEnCyO,GAAyH,OAAjGR,GAAgD,MAAvBjB,OAA8B,EAASA,EAAoBlE,IAAoBmF,GAAyB,EAEzJS,GAAaF,GAAeF,GAAOF,GAAUnE,EAAcoE,IAAQ1M,EAAW0M,IAAQI,GAAuB1B,EAA4BjE,QAEzI6F,GAAaH,GAAeJ,GAAUnE,EAAcoE,IAAQ1M,EAAW0M,IAAQI,GAAuB1B,EAA4BjE,QAAUyF,GAE5IK,GAAmBlC,GAAU8B,G1BzH9B,SAAwBlT,EAAK1E,EAAOyE,GACzC,IAAIwT,EAAItP,EAAOjE,EAAK1E,EAAOyE,GAC3B,OAAOwT,EAAIxT,EAAMA,EAAMwT,CACzB,C0BsHoDC,CAAeJ,GAAYN,GAASO,IAAcpP,EAAOmN,EAASgC,GAAaJ,GAAMF,GAAS1B,EAASiC,GAAaJ,IAEpKzO,EAAcgJ,GAAW8F,GACzBtL,EAAKwF,GAAW8F,GAAmBR,EACrC,CAEAxU,EAAMmG,cAAcxG,GAAQ+J,CAvE5B,CAwEF,EAQEhC,iBAAkB,CAAC,WE1HN,SAASyN,GAAiBC,EAAyBrQ,EAAcsD,QAC9D,IAAZA,IACFA,GAAU,GAGZ,ICnBoCrJ,ECJOJ,EFuBvCyW,EAA0B9V,EAAcwF,GACxCuQ,EAAuB/V,EAAcwF,IAf3C,SAAyBnG,GACvB,IAAImN,EAAOnN,EAAQ+D,wBACfI,EAASpB,EAAMoK,EAAK7I,OAAStE,EAAQqE,aAAe,EACpDD,EAASrB,EAAMoK,EAAK3I,QAAUxE,EAAQuE,cAAgB,EAC1D,OAAkB,IAAXJ,GAA2B,IAAXC,CACzB,CAU4DuS,CAAgBxQ,GACtEJ,EAAkBF,EAAmBM,GACrCgH,EAAOpJ,EAAsByS,EAAyBE,EAAsBjN,GAC5EyB,EAAS,CACXc,WAAY,EACZE,UAAW,GAET7C,EAAU,CACZ1E,EAAG,EACHE,EAAG,GAkBL,OAfI4R,IAA4BA,IAA4BhN,MACxB,SAA9B1J,EAAYoG,IAChBkG,GAAetG,MACbmF,GCnCgC9K,EDmCT+F,KClCdhG,EAAUC,IAAUO,EAAcP,GCJxC,CACL4L,YAFyChM,EDQbI,GCNR4L,WACpBE,UAAWlM,EAAQkM,WDGZH,GAAgB3L,IDoCnBO,EAAcwF,KAChBkD,EAAUtF,EAAsBoC,GAAc,IACtCxB,GAAKwB,EAAauH,WAC1BrE,EAAQxE,GAAKsB,EAAasH,WACjB1H,IACTsD,EAAQ1E,EAAIyH,GAAoBrG,KAI7B,CACLpB,EAAGwI,EAAK5O,KAAO2M,EAAOc,WAAa3C,EAAQ1E,EAC3CE,EAAGsI,EAAK/K,IAAM8I,EAAOgB,UAAY7C,EAAQxE,EACzCP,MAAO6I,EAAK7I,MACZE,OAAQ2I,EAAK3I,OAEjB,CGvDA,SAASoS,GAAMC,GACb,IAAItT,EAAM,IAAIoO,IACVmF,EAAU,IAAIC,IACdC,EAAS,GAKb,SAAS3F,EAAK4F,GACZH,EAAQI,IAAID,EAASlW,MACN,GAAG3B,OAAO6X,EAASxU,UAAY,GAAIwU,EAASnO,kBAAoB,IACtEvH,SAAQ,SAAU4V,GACzB,IAAKL,EAAQM,IAAID,GAAM,CACrB,IAAIE,EAAc9T,EAAI3F,IAAIuZ,GAEtBE,GACFhG,EAAKgG,EAET,CACF,IACAL,EAAO3E,KAAK4E,EACd,CAQA,OAzBAJ,EAAUtV,SAAQ,SAAU0V,GAC1B1T,EAAIiP,IAAIyE,EAASlW,KAAMkW,EACzB,IAiBAJ,EAAUtV,SAAQ,SAAU0V,GACrBH,EAAQM,IAAIH,EAASlW,OAExBsQ,EAAK4F,EAET,IACOD,CACT,CCvBA,IAAIM,GAAkB,CACpBnY,UAAW,SACX0X,UAAW,GACX1U,SAAU,YAGZ,SAASoV,KACP,IAAK,IAAI1B,EAAO2B,UAAUrG,OAAQsG,EAAO,IAAIpU,MAAMwS,GAAO6B,EAAO,EAAGA,EAAO7B,EAAM6B,IAC/ED,EAAKC,GAAQF,UAAUE,GAGzB,OAAQD,EAAKvE,MAAK,SAAUlT,GAC1B,QAASA,GAAoD,mBAAlCA,EAAQ+D,sBACrC,GACF,CAEO,SAAS4T,GAAgBC,QACL,IAArBA,IACFA,EAAmB,CAAC,GAGtB,IAAIC,EAAoBD,EACpBE,EAAwBD,EAAkBE,iBAC1CA,OAA6C,IAA1BD,EAAmC,GAAKA,EAC3DE,EAAyBH,EAAkBI,eAC3CA,OAA4C,IAA3BD,EAAoCV,GAAkBU,EAC3E,OAAO,SAAsBjZ,EAAWD,EAAQoD,QAC9B,IAAZA,IACFA,EAAU+V,GAGZ,ICxC6B/W,EAC3BgX,EDuCE9W,EAAQ,CACVjC,UAAW,SACXgZ,iBAAkB,GAClBjW,QAASzE,OAAOkE,OAAO,CAAC,EAAG2V,GAAiBW,GAC5C1Q,cAAe,CAAC,EAChBjG,SAAU,CACRvC,UAAWA,EACXD,OAAQA,GAEV4C,WAAY,CAAC,EACbD,OAAQ,CAAC,GAEP2W,EAAmB,GACnBC,GAAc,EACdrN,EAAW,CACb5J,MAAOA,EACPkX,WAAY,SAAoBC,GAC9B,IAAIrW,EAAsC,mBAArBqW,EAAkCA,EAAiBnX,EAAMc,SAAWqW,EACzFC,IACApX,EAAMc,QAAUzE,OAAOkE,OAAO,CAAC,EAAGsW,EAAgB7W,EAAMc,QAASA,GACjEd,EAAMiK,cAAgB,CACpBtM,UAAW0B,EAAU1B,GAAa6N,GAAkB7N,GAAaA,EAAU4Q,eAAiB/C,GAAkB7N,EAAU4Q,gBAAkB,GAC1I7Q,OAAQ8N,GAAkB9N,IAI5B,IElE4B+X,EAC9B4B,EFiEMN,EDhCG,SAAwBtB,GAErC,IAAIsB,EAAmBvB,GAAMC,GAE7B,OAAO/W,EAAeb,QAAO,SAAUC,EAAK+B,GAC1C,OAAO/B,EAAIE,OAAO+Y,EAAiBvR,QAAO,SAAUqQ,GAClD,OAAOA,EAAShW,QAAUA,CAC5B,IACF,GAAG,GACL,CCuB+ByX,EElEK7B,EFkEsB,GAAGzX,OAAO2Y,EAAkB3W,EAAMc,QAAQ2U,WEjE9F4B,EAAS5B,EAAU5X,QAAO,SAAUwZ,EAAQE,GAC9C,IAAIC,EAAWH,EAAOE,EAAQ5X,MAK9B,OAJA0X,EAAOE,EAAQ5X,MAAQ6X,EAAWnb,OAAOkE,OAAO,CAAC,EAAGiX,EAAUD,EAAS,CACrEzW,QAASzE,OAAOkE,OAAO,CAAC,EAAGiX,EAAS1W,QAASyW,EAAQzW,SACrD4I,KAAMrN,OAAOkE,OAAO,CAAC,EAAGiX,EAAS9N,KAAM6N,EAAQ7N,QAC5C6N,EACEF,CACT,GAAG,CAAC,GAEGhb,OAAO4D,KAAKoX,GAAQlV,KAAI,SAAUhG,GACvC,OAAOkb,EAAOlb,EAChB,MF4DM,OAJA6D,EAAM+W,iBAAmBA,EAAiBvR,QAAO,SAAUiS,GACzD,OAAOA,EAAE7X,OACX,IA+FFI,EAAM+W,iBAAiB5W,SAAQ,SAAUJ,GACvC,IAAIJ,EAAOI,EAAKJ,KACZ+X,EAAe3X,EAAKe,QACpBA,OAA2B,IAAjB4W,EAA0B,CAAC,EAAIA,EACzChX,EAASX,EAAKW,OAElB,GAAsB,mBAAXA,EAAuB,CAChC,IAAIiX,EAAYjX,EAAO,CACrBV,MAAOA,EACPL,KAAMA,EACNiK,SAAUA,EACV9I,QAASA,IAKXkW,EAAiB/F,KAAK0G,GAFT,WAAmB,EAGlC,CACF,IA/GS/N,EAASQ,QAClB,EAMAwN,YAAa,WACX,IAAIX,EAAJ,CAIA,IAAIY,EAAkB7X,EAAME,SACxBvC,EAAYka,EAAgBla,UAC5BD,EAASma,EAAgBna,OAG7B,GAAKyY,GAAiBxY,EAAWD,GAAjC,CAKAsC,EAAMwG,MAAQ,CACZ7I,UAAWwX,GAAiBxX,EAAWqH,EAAgBtH,GAAoC,UAA3BsC,EAAMc,QAAQC,UAC9ErD,OAAQiG,EAAcjG,IAOxBsC,EAAM0R,OAAQ,EACd1R,EAAMjC,UAAYiC,EAAMc,QAAQ/C,UAKhCiC,EAAM+W,iBAAiB5W,SAAQ,SAAU0V,GACvC,OAAO7V,EAAMmG,cAAc0P,EAASlW,MAAQtD,OAAOkE,OAAO,CAAC,EAAGsV,EAASnM,KACzE,IAEA,IAAK,IAAIoO,EAAQ,EAAGA,EAAQ9X,EAAM+W,iBAAiBhH,OAAQ+H,IACzD,IAAoB,IAAhB9X,EAAM0R,MAAV,CAMA,IAAIqG,EAAwB/X,EAAM+W,iBAAiBe,GAC/ChY,EAAKiY,EAAsBjY,GAC3BkY,EAAyBD,EAAsBjX,QAC/CoM,OAAsC,IAA3B8K,EAAoC,CAAC,EAAIA,EACpDrY,EAAOoY,EAAsBpY,KAEf,mBAAPG,IACTE,EAAQF,EAAG,CACTE,MAAOA,EACPc,QAASoM,EACTvN,KAAMA,EACNiK,SAAUA,KACN5J,EAdR,MAHEA,EAAM0R,OAAQ,EACdoG,GAAS,CAzBb,CATA,CAqDF,EAGA1N,QC1I2BtK,ED0IV,WACf,OAAO,IAAImY,SAAQ,SAAUC,GAC3BtO,EAASgO,cACTM,EAAQlY,EACV,GACF,EC7IG,WAUL,OATK8W,IACHA,EAAU,IAAImB,SAAQ,SAAUC,GAC9BD,QAAQC,UAAUC,MAAK,WACrBrB,OAAUsB,EACVF,EAAQpY,IACV,GACF,KAGKgX,CACT,GDmIIuB,QAAS,WACPjB,IACAH,GAAc,CAChB,GAGF,IAAKd,GAAiBxY,EAAWD,GAC/B,OAAOkM,EAmCT,SAASwN,IACPJ,EAAiB7W,SAAQ,SAAUL,GACjC,OAAOA,GACT,IACAkX,EAAmB,EACrB,CAEA,OAvCApN,EAASsN,WAAWpW,GAASqX,MAAK,SAAUnY,IACrCiX,GAAenW,EAAQwX,eAC1BxX,EAAQwX,cAActY,EAE1B,IAmCO4J,CACT,CACF,CACO,IAAI2O,GAA4BhC,KGzLnC,GAA4BA,GAAgB,CAC9CI,iBAFqB,CAAC6B,GAAgB,GAAe,GAAe,EAAa,GAAQ,GAAM,GAAiB,EAAO,MCJrH,GAA4BjC,GAAgB,CAC9CI,iBAFqB,CAAC6B,GAAgB,GAAe,GAAe,KCatE,MAAMC,GAAa,IAAIlI,IACjBmI,GAAO,CACX,GAAAtH,CAAIxS,EAASzC,EAAKyN,GACX6O,GAAWzC,IAAIpX,IAClB6Z,GAAWrH,IAAIxS,EAAS,IAAI2R,KAE9B,MAAMoI,EAAcF,GAAWjc,IAAIoC,GAI9B+Z,EAAY3C,IAAI7Z,IAA6B,IAArBwc,EAAYC,KAKzCD,EAAYvH,IAAIjV,EAAKyN,GAHnBiP,QAAQC,MAAM,+EAA+E7W,MAAM8W,KAAKJ,EAAY1Y,QAAQ,MAIhI,EACAzD,IAAG,CAACoC,EAASzC,IACPsc,GAAWzC,IAAIpX,IACV6Z,GAAWjc,IAAIoC,GAASpC,IAAIL,IAE9B,KAET,MAAA6c,CAAOpa,EAASzC,GACd,IAAKsc,GAAWzC,IAAIpX,GAClB,OAEF,MAAM+Z,EAAcF,GAAWjc,IAAIoC,GACnC+Z,EAAYM,OAAO9c,GAGM,IAArBwc,EAAYC,MACdH,GAAWQ,OAAOra,EAEtB,GAYIsa,GAAiB,gBAOjBC,GAAgBC,IAChBA,GAAYna,OAAOoa,KAAOpa,OAAOoa,IAAIC,SAEvCF,EAAWA,EAAS5O,QAAQ,iBAAiB,CAAC+O,EAAOC,IAAO,IAAIH,IAAIC,OAAOE,QAEtEJ,GA4CHK,GAAuB7a,IAC3BA,EAAQ8a,cAAc,IAAIC,MAAMT,IAAgB,EAE5C,GAAYU,MACXA,GAA4B,iBAAXA,UAGO,IAAlBA,EAAOC,SAChBD,EAASA,EAAO,SAEgB,IAApBA,EAAOE,UAEjBC,GAAaH,GAEb,GAAUA,GACLA,EAAOC,OAASD,EAAO,GAAKA,EAEf,iBAAXA,GAAuBA,EAAO7J,OAAS,EACzCrL,SAAS+C,cAAc0R,GAAcS,IAEvC,KAEHI,GAAYpb,IAChB,IAAK,GAAUA,IAAgD,IAApCA,EAAQqb,iBAAiBlK,OAClD,OAAO,EAET,MAAMmK,EAAgF,YAA7D5V,iBAAiB1F,GAASub,iBAAiB,cAE9DC,EAAgBxb,EAAQyb,QAAQ,uBACtC,IAAKD,EACH,OAAOF,EAET,GAAIE,IAAkBxb,EAAS,CAC7B,MAAM0b,EAAU1b,EAAQyb,QAAQ,WAChC,GAAIC,GAAWA,EAAQlW,aAAegW,EACpC,OAAO,EAET,GAAgB,OAAZE,EACF,OAAO,CAEX,CACA,OAAOJ,CAAgB,EAEnBK,GAAa3b,IACZA,GAAWA,EAAQkb,WAAaU,KAAKC,gBAGtC7b,EAAQ8b,UAAU7W,SAAS,mBAGC,IAArBjF,EAAQ+b,SACV/b,EAAQ+b,SAEV/b,EAAQgc,aAAa,aAAoD,UAArChc,EAAQic,aAAa,aAE5DC,GAAiBlc,IACrB,IAAK8F,SAASC,gBAAgBoW,aAC5B,OAAO,KAIT,GAAmC,mBAAxBnc,EAAQqF,YAA4B,CAC7C,MAAM+W,EAAOpc,EAAQqF,cACrB,OAAO+W,aAAgBtb,WAAasb,EAAO,IAC7C,CACA,OAAIpc,aAAmBc,WACdd,EAIJA,EAAQwF,WAGN0W,GAAelc,EAAQwF,YAFrB,IAEgC,EAErC6W,GAAO,OAUPC,GAAStc,IACbA,EAAQuE,YAAY,EAGhBgY,GAAY,IACZlc,OAAOmc,SAAW1W,SAAS6G,KAAKqP,aAAa,qBACxC3b,OAAOmc,OAET,KAEHC,GAA4B,GAgB5BC,GAAQ,IAAuC,QAAjC5W,SAASC,gBAAgB4W,IACvCC,GAAqBC,IAhBAC,QAiBN,KACjB,MAAMC,EAAIR,KAEV,GAAIQ,EAAG,CACL,MAAMhc,EAAO8b,EAAOG,KACdC,EAAqBF,EAAE7b,GAAGH,GAChCgc,EAAE7b,GAAGH,GAAQ8b,EAAOK,gBACpBH,EAAE7b,GAAGH,GAAMoc,YAAcN,EACzBE,EAAE7b,GAAGH,GAAMqc,WAAa,KACtBL,EAAE7b,GAAGH,GAAQkc,EACNJ,EAAOK,gBAElB,GA5B0B,YAAxBpX,SAASuX,YAENZ,GAA0BtL,QAC7BrL,SAASyF,iBAAiB,oBAAoB,KAC5C,IAAK,MAAMuR,KAAYL,GACrBK,GACF,IAGJL,GAA0BpK,KAAKyK,IAE/BA,GAkBA,EAEEQ,GAAU,CAACC,EAAkB9F,EAAO,GAAI+F,EAAeD,IACxB,mBAArBA,EAAkCA,KAAoB9F,GAAQ+F,EAExEC,GAAyB,CAACX,EAAUY,EAAmBC,GAAoB,KAC/E,IAAKA,EAEH,YADAL,GAAQR,GAGV,MACMc,EAhKiC5d,KACvC,IAAKA,EACH,OAAO,EAIT,IAAI,mBACF6d,EAAkB,gBAClBC,GACEzd,OAAOqF,iBAAiB1F,GAC5B,MAAM+d,EAA0BC,OAAOC,WAAWJ,GAC5CK,EAAuBF,OAAOC,WAAWH,GAG/C,OAAKC,GAA4BG,GAKjCL,EAAqBA,EAAmBlb,MAAM,KAAK,GACnDmb,EAAkBA,EAAgBnb,MAAM,KAAK,GAtDf,KAuDtBqb,OAAOC,WAAWJ,GAAsBG,OAAOC,WAAWH,KANzD,CAMoG,EA2IpFK,CAAiCT,GADlC,EAExB,IAAIU,GAAS,EACb,MAAMC,EAAU,EACdrR,aAEIA,IAAW0Q,IAGfU,GAAS,EACTV,EAAkBjS,oBAAoB6O,GAAgB+D,GACtDf,GAAQR,GAAS,EAEnBY,EAAkBnS,iBAAiB+O,GAAgB+D,GACnDC,YAAW,KACJF,GACHvD,GAAqB6C,EACvB,GACCE,EAAiB,EAYhBW,GAAuB,CAAC1R,EAAM2R,EAAeC,EAAeC,KAChE,MAAMC,EAAa9R,EAAKsE,OACxB,IAAI+H,EAAQrM,EAAKjH,QAAQ4Y,GAIzB,OAAe,IAAXtF,GACMuF,GAAiBC,EAAiB7R,EAAK8R,EAAa,GAAK9R,EAAK,IAExEqM,GAASuF,EAAgB,GAAK,EAC1BC,IACFxF,GAASA,EAAQyF,GAAcA,GAE1B9R,EAAKjK,KAAKC,IAAI,EAAGD,KAAKE,IAAIoW,EAAOyF,EAAa,KAAI,EAerDC,GAAiB,qBACjBC,GAAiB,OACjBC,GAAgB,SAChBC,GAAgB,CAAC,EACvB,IAAIC,GAAW,EACf,MAAMC,GAAe,CACnBC,WAAY,YACZC,WAAY,YAERC,GAAe,IAAIrI,IAAI,CAAC,QAAS,WAAY,UAAW,YAAa,cAAe,aAAc,iBAAkB,YAAa,WAAY,YAAa,cAAe,YAAa,UAAW,WAAY,QAAS,oBAAqB,aAAc,YAAa,WAAY,cAAe,cAAe,cAAe,YAAa,eAAgB,gBAAiB,eAAgB,gBAAiB,aAAc,QAAS,OAAQ,SAAU,QAAS,SAAU,SAAU,UAAW,WAAY,OAAQ,SAAU,eAAgB,SAAU,OAAQ,mBAAoB,mBAAoB,QAAS,QAAS,WAM/lB,SAASsI,GAAarf,EAASsf,GAC7B,OAAOA,GAAO,GAAGA,MAAQN,QAAgBhf,EAAQgf,UAAYA,IAC/D,CACA,SAASO,GAAiBvf,GACxB,MAAMsf,EAAMD,GAAarf,GAGzB,OAFAA,EAAQgf,SAAWM,EACnBP,GAAcO,GAAOP,GAAcO,IAAQ,CAAC,EACrCP,GAAcO,EACvB,CAiCA,SAASE,GAAYC,EAAQC,EAAUC,EAAqB,MAC1D,OAAOliB,OAAOmiB,OAAOH,GAAQ7M,MAAKiN,GAASA,EAAMH,WAAaA,GAAYG,EAAMF,qBAAuBA,GACzG,CACA,SAASG,GAAoBC,EAAmB1B,EAAS2B,GACvD,MAAMC,EAAiC,iBAAZ5B,EAErBqB,EAAWO,EAAcD,EAAqB3B,GAAW2B,EAC/D,IAAIE,EAAYC,GAAaJ,GAI7B,OAHKX,GAAahI,IAAI8I,KACpBA,EAAYH,GAEP,CAACE,EAAaP,EAAUQ,EACjC,CACA,SAASE,GAAWpgB,EAAS+f,EAAmB1B,EAAS2B,EAAoBK,GAC3E,GAAiC,iBAAtBN,IAAmC/f,EAC5C,OAEF,IAAKigB,EAAaP,EAAUQ,GAAaJ,GAAoBC,EAAmB1B,EAAS2B,GAIzF,GAAID,KAAqBd,GAAc,CACrC,MAAMqB,EAAepf,GACZ,SAAU2e,GACf,IAAKA,EAAMU,eAAiBV,EAAMU,gBAAkBV,EAAMW,iBAAmBX,EAAMW,eAAevb,SAAS4a,EAAMU,eAC/G,OAAOrf,EAAGjD,KAAKwiB,KAAMZ,EAEzB,EAEFH,EAAWY,EAAaZ,EAC1B,CACA,MAAMD,EAASF,GAAiBvf,GAC1B0gB,EAAWjB,EAAOS,KAAeT,EAAOS,GAAa,CAAC,GACtDS,EAAmBnB,GAAYkB,EAAUhB,EAAUO,EAAc5B,EAAU,MACjF,GAAIsC,EAEF,YADAA,EAAiBN,OAASM,EAAiBN,QAAUA,GAGvD,MAAMf,EAAMD,GAAaK,EAAUK,EAAkBnU,QAAQgT,GAAgB,KACvE1d,EAAK+e,EA5Db,SAAoCjgB,EAASwa,EAAUtZ,GACrD,OAAO,SAASmd,EAAQwB,GACtB,MAAMe,EAAc5gB,EAAQ6gB,iBAAiBrG,GAC7C,IAAK,IAAI,OACPxN,GACE6S,EAAO7S,GAAUA,IAAWyT,KAAMzT,EAASA,EAAOxH,WACpD,IAAK,MAAMsb,KAAcF,EACvB,GAAIE,IAAe9T,EASnB,OANA+T,GAAWlB,EAAO,CAChBW,eAAgBxT,IAEdqR,EAAQgC,QACVW,GAAaC,IAAIjhB,EAAS6f,EAAMqB,KAAM1G,EAAUtZ,GAE3CA,EAAGigB,MAAMnU,EAAQ,CAAC6S,GAG/B,CACF,CAwC2BuB,CAA2BphB,EAASqe,EAASqB,GAvExE,SAA0B1f,EAASkB,GACjC,OAAO,SAASmd,EAAQwB,GAOtB,OANAkB,GAAWlB,EAAO,CAChBW,eAAgBxgB,IAEdqe,EAAQgC,QACVW,GAAaC,IAAIjhB,EAAS6f,EAAMqB,KAAMhgB,GAEjCA,EAAGigB,MAAMnhB,EAAS,CAAC6f,GAC5B,CACF,CA6DoFwB,CAAiBrhB,EAAS0f,GAC5Gxe,EAAGye,mBAAqBM,EAAc5B,EAAU,KAChDnd,EAAGwe,SAAWA,EACdxe,EAAGmf,OAASA,EACZnf,EAAG8d,SAAWM,EACdoB,EAASpB,GAAOpe,EAChBlB,EAAQuL,iBAAiB2U,EAAWhf,EAAI+e,EAC1C,CACA,SAASqB,GAActhB,EAASyf,EAAQS,EAAW7B,EAASsB,GAC1D,MAAMze,EAAKse,GAAYC,EAAOS,GAAY7B,EAASsB,GAC9Cze,IAGLlB,EAAQyL,oBAAoByU,EAAWhf,EAAIqgB,QAAQ5B,WAC5CF,EAAOS,GAAWhf,EAAG8d,UAC9B,CACA,SAASwC,GAAyBxhB,EAASyf,EAAQS,EAAWuB,GAC5D,MAAMC,EAAoBjC,EAAOS,IAAc,CAAC,EAChD,IAAK,MAAOyB,EAAY9B,KAAUpiB,OAAOmkB,QAAQF,GAC3CC,EAAWE,SAASJ,IACtBH,GAActhB,EAASyf,EAAQS,EAAWL,EAAMH,SAAUG,EAAMF,mBAGtE,CACA,SAASQ,GAAaN,GAGpB,OADAA,EAAQA,EAAMjU,QAAQiT,GAAgB,IAC/BI,GAAaY,IAAUA,CAChC,CACA,MAAMmB,GAAe,CACnB,EAAAc,CAAG9hB,EAAS6f,EAAOxB,EAAS2B,GAC1BI,GAAWpgB,EAAS6f,EAAOxB,EAAS2B,GAAoB,EAC1D,EACA,GAAA+B,CAAI/hB,EAAS6f,EAAOxB,EAAS2B,GAC3BI,GAAWpgB,EAAS6f,EAAOxB,EAAS2B,GAAoB,EAC1D,EACA,GAAAiB,CAAIjhB,EAAS+f,EAAmB1B,EAAS2B,GACvC,GAAiC,iBAAtBD,IAAmC/f,EAC5C,OAEF,MAAOigB,EAAaP,EAAUQ,GAAaJ,GAAoBC,EAAmB1B,EAAS2B,GACrFgC,EAAc9B,IAAcH,EAC5BN,EAASF,GAAiBvf,GAC1B0hB,EAAoBjC,EAAOS,IAAc,CAAC,EAC1C+B,EAAclC,EAAkBmC,WAAW,KACjD,QAAwB,IAAbxC,EAAX,CAQA,GAAIuC,EACF,IAAK,MAAME,KAAgB1kB,OAAO4D,KAAKoe,GACrC+B,GAAyBxhB,EAASyf,EAAQ0C,EAAcpC,EAAkBlN,MAAM,IAGpF,IAAK,MAAOuP,EAAavC,KAAUpiB,OAAOmkB,QAAQF,GAAoB,CACpE,MAAMC,EAAaS,EAAYxW,QAAQkT,GAAe,IACjDkD,IAAejC,EAAkB8B,SAASF,IAC7CL,GAActhB,EAASyf,EAAQS,EAAWL,EAAMH,SAAUG,EAAMF,mBAEpE,CAXA,KAPA,CAEE,IAAKliB,OAAO4D,KAAKqgB,GAAmBvQ,OAClC,OAEFmQ,GAActhB,EAASyf,EAAQS,EAAWR,EAAUO,EAAc5B,EAAU,KAE9E,CAYF,EACA,OAAAgE,CAAQriB,EAAS6f,EAAOpI,GACtB,GAAqB,iBAAVoI,IAAuB7f,EAChC,OAAO,KAET,MAAM+c,EAAIR,KAGV,IAAI+F,EAAc,KACdC,GAAU,EACVC,GAAiB,EACjBC,GAAmB,EAJH5C,IADFM,GAAaN,IAMZ9C,IACjBuF,EAAcvF,EAAEhC,MAAM8E,EAAOpI,GAC7BsF,EAAE/c,GAASqiB,QAAQC,GACnBC,GAAWD,EAAYI,uBACvBF,GAAkBF,EAAYK,gCAC9BF,EAAmBH,EAAYM,sBAEjC,MAAMC,EAAM9B,GAAW,IAAIhG,MAAM8E,EAAO,CACtC0C,UACAO,YAAY,IACVrL,GAUJ,OATIgL,GACFI,EAAIE,iBAEFP,GACFxiB,EAAQ8a,cAAc+H,GAEpBA,EAAIJ,kBAAoBH,GAC1BA,EAAYS,iBAEPF,CACT,GAEF,SAAS9B,GAAWljB,EAAKmlB,EAAO,CAAC,GAC/B,IAAK,MAAOzlB,EAAKa,KAAUX,OAAOmkB,QAAQoB,GACxC,IACEnlB,EAAIN,GAAOa,CACb,CAAE,MAAO6kB,GACPxlB,OAAOC,eAAeG,EAAKN,EAAK,CAC9B2lB,cAAc,EACdtlB,IAAG,IACMQ,GAGb,CAEF,OAAOP,CACT,CASA,SAASslB,GAAc/kB,GACrB,GAAc,SAAVA,EACF,OAAO,EAET,GAAc,UAAVA,EACF,OAAO,EAET,GAAIA,IAAU4f,OAAO5f,GAAOkC,WAC1B,OAAO0d,OAAO5f,GAEhB,GAAc,KAAVA,GAA0B,SAAVA,EAClB,OAAO,KAET,GAAqB,iBAAVA,EACT,OAAOA,EAET,IACE,OAAOglB,KAAKC,MAAMC,mBAAmBllB,GACvC,CAAE,MAAO6kB,GACP,OAAO7kB,CACT,CACF,CACA,SAASmlB,GAAiBhmB,GACxB,OAAOA,EAAIqO,QAAQ,UAAU4X,GAAO,IAAIA,EAAItjB,iBAC9C,CACA,MAAMujB,GAAc,CAClB,gBAAAC,CAAiB1jB,EAASzC,EAAKa,GAC7B4B,EAAQ6B,aAAa,WAAW0hB,GAAiBhmB,KAAQa,EAC3D,EACA,mBAAAulB,CAAoB3jB,EAASzC,GAC3ByC,EAAQ4B,gBAAgB,WAAW2hB,GAAiBhmB,KACtD,EACA,iBAAAqmB,CAAkB5jB,GAChB,IAAKA,EACH,MAAO,CAAC,EAEV,MAAM0B,EAAa,CAAC,EACdmiB,EAASpmB,OAAO4D,KAAKrB,EAAQ8jB,SAASld,QAAOrJ,GAAOA,EAAI2kB,WAAW,QAAU3kB,EAAI2kB,WAAW,cAClG,IAAK,MAAM3kB,KAAOsmB,EAAQ,CACxB,IAAIE,EAAUxmB,EAAIqO,QAAQ,MAAO,IACjCmY,EAAUA,EAAQC,OAAO,GAAG9jB,cAAgB6jB,EAAQlR,MAAM,EAAGkR,EAAQ5S,QACrEzP,EAAWqiB,GAAWZ,GAAcnjB,EAAQ8jB,QAAQvmB,GACtD,CACA,OAAOmE,CACT,EACAuiB,iBAAgB,CAACjkB,EAASzC,IACjB4lB,GAAcnjB,EAAQic,aAAa,WAAWsH,GAAiBhmB,QAgB1E,MAAM2mB,GAEJ,kBAAWC,GACT,MAAO,CAAC,CACV,CACA,sBAAWC,GACT,MAAO,CAAC,CACV,CACA,eAAWpH,GACT,MAAM,IAAIqH,MAAM,sEAClB,CACA,UAAAC,CAAWC,GAIT,OAHAA,EAAS9D,KAAK+D,gBAAgBD,GAC9BA,EAAS9D,KAAKgE,kBAAkBF,GAChC9D,KAAKiE,iBAAiBH,GACfA,CACT,CACA,iBAAAE,CAAkBF,GAChB,OAAOA,CACT,CACA,eAAAC,CAAgBD,EAAQvkB,GACtB,MAAM2kB,EAAa,GAAU3kB,GAAWyjB,GAAYQ,iBAAiBjkB,EAAS,UAAY,CAAC,EAE3F,MAAO,IACFygB,KAAKmE,YAAYT,WACM,iBAAfQ,EAA0BA,EAAa,CAAC,KAC/C,GAAU3kB,GAAWyjB,GAAYG,kBAAkB5jB,GAAW,CAAC,KAC7C,iBAAXukB,EAAsBA,EAAS,CAAC,EAE/C,CACA,gBAAAG,CAAiBH,EAAQM,EAAcpE,KAAKmE,YAAYR,aACtD,IAAK,MAAO7hB,EAAUuiB,KAAkBrnB,OAAOmkB,QAAQiD,GAAc,CACnE,MAAMzmB,EAAQmmB,EAAOhiB,GACfwiB,EAAY,GAAU3mB,GAAS,UAjiBrC4c,OADSA,EAkiB+C5c,GAhiBnD,GAAG4c,IAELvd,OAAOM,UAAUuC,SAASrC,KAAK+c,GAAQL,MAAM,eAAe,GAAGza,cA+hBlE,IAAK,IAAI8kB,OAAOF,GAAehhB,KAAKihB,GAClC,MAAM,IAAIE,UAAU,GAAGxE,KAAKmE,YAAY5H,KAAKkI,0BAA0B3iB,qBAA4BwiB,yBAAiCD,MAExI,CAtiBW9J,KAuiBb,EAqBF,MAAMmK,WAAsBjB,GAC1B,WAAAU,CAAY5kB,EAASukB,GACnBa,SACAplB,EAAUmb,GAAWnb,MAIrBygB,KAAK4E,SAAWrlB,EAChBygB,KAAK6E,QAAU7E,KAAK6D,WAAWC,GAC/BzK,GAAKtH,IAAIiO,KAAK4E,SAAU5E,KAAKmE,YAAYW,SAAU9E,MACrD,CAGA,OAAA+E,GACE1L,GAAKM,OAAOqG,KAAK4E,SAAU5E,KAAKmE,YAAYW,UAC5CvE,GAAaC,IAAIR,KAAK4E,SAAU5E,KAAKmE,YAAYa,WACjD,IAAK,MAAMC,KAAgBjoB,OAAOkoB,oBAAoBlF,MACpDA,KAAKiF,GAAgB,IAEzB,CACA,cAAAE,CAAe9I,EAAU9c,EAAS6lB,GAAa,GAC7CpI,GAAuBX,EAAU9c,EAAS6lB,EAC5C,CACA,UAAAvB,CAAWC,GAIT,OAHAA,EAAS9D,KAAK+D,gBAAgBD,EAAQ9D,KAAK4E,UAC3Cd,EAAS9D,KAAKgE,kBAAkBF,GAChC9D,KAAKiE,iBAAiBH,GACfA,CACT,CAGA,kBAAOuB,CAAY9lB,GACjB,OAAO8Z,GAAKlc,IAAIud,GAAWnb,GAAUygB,KAAK8E,SAC5C,CACA,0BAAOQ,CAAoB/lB,EAASukB,EAAS,CAAC,GAC5C,OAAO9D,KAAKqF,YAAY9lB,IAAY,IAAIygB,KAAKzgB,EAA2B,iBAAXukB,EAAsBA,EAAS,KAC9F,CACA,kBAAWyB,GACT,MA5CY,OA6Cd,CACA,mBAAWT,GACT,MAAO,MAAM9E,KAAKzD,MACpB,CACA,oBAAWyI,GACT,MAAO,IAAIhF,KAAK8E,UAClB,CACA,gBAAOU,CAAUllB,GACf,MAAO,GAAGA,IAAO0f,KAAKgF,WACxB,EAUF,MAAMS,GAAclmB,IAClB,IAAIwa,EAAWxa,EAAQic,aAAa,kBACpC,IAAKzB,GAAyB,MAAbA,EAAkB,CACjC,IAAI2L,EAAgBnmB,EAAQic,aAAa,QAMzC,IAAKkK,IAAkBA,EAActE,SAAS,OAASsE,EAAcjE,WAAW,KAC9E,OAAO,KAILiE,EAActE,SAAS,OAASsE,EAAcjE,WAAW,OAC3DiE,EAAgB,IAAIA,EAAcxjB,MAAM,KAAK,MAE/C6X,EAAW2L,GAAmC,MAAlBA,EAAwB5L,GAAc4L,EAAcC,QAAU,IAC5F,CACA,OAAO5L,CAAQ,EAEX6L,GAAiB,CACrBzT,KAAI,CAAC4H,EAAUxa,EAAU8F,SAASC,kBACzB,GAAG3G,UAAUsB,QAAQ3C,UAAU8iB,iBAAiB5iB,KAAK+B,EAASwa,IAEvE8L,QAAO,CAAC9L,EAAUxa,EAAU8F,SAASC,kBAC5BrF,QAAQ3C,UAAU8K,cAAc5K,KAAK+B,EAASwa,GAEvD+L,SAAQ,CAACvmB,EAASwa,IACT,GAAGpb,UAAUY,EAAQumB,UAAU3f,QAAOzB,GAASA,EAAMqhB,QAAQhM,KAEtE,OAAAiM,CAAQzmB,EAASwa,GACf,MAAMiM,EAAU,GAChB,IAAIC,EAAW1mB,EAAQwF,WAAWiW,QAAQjB,GAC1C,KAAOkM,GACLD,EAAQpU,KAAKqU,GACbA,EAAWA,EAASlhB,WAAWiW,QAAQjB,GAEzC,OAAOiM,CACT,EACA,IAAAE,CAAK3mB,EAASwa,GACZ,IAAIoM,EAAW5mB,EAAQ6mB,uBACvB,KAAOD,GAAU,CACf,GAAIA,EAASJ,QAAQhM,GACnB,MAAO,CAACoM,GAEVA,EAAWA,EAASC,sBACtB,CACA,MAAO,EACT,EAEA,IAAAvhB,CAAKtF,EAASwa,GACZ,IAAIlV,EAAOtF,EAAQ8mB,mBACnB,KAAOxhB,GAAM,CACX,GAAIA,EAAKkhB,QAAQhM,GACf,MAAO,CAAClV,GAEVA,EAAOA,EAAKwhB,kBACd,CACA,MAAO,EACT,EACA,iBAAAC,CAAkB/mB,GAChB,MAAMgnB,EAAa,CAAC,IAAK,SAAU,QAAS,WAAY,SAAU,UAAW,aAAc,4BAA4BzjB,KAAIiX,GAAY,GAAGA,2BAAiC7W,KAAK,KAChL,OAAO8c,KAAK7N,KAAKoU,EAAYhnB,GAAS4G,QAAOqgB,IAAOtL,GAAWsL,IAAO7L,GAAU6L,IAClF,EACA,sBAAAC,CAAuBlnB,GACrB,MAAMwa,EAAW0L,GAAYlmB,GAC7B,OAAIwa,GACK6L,GAAeC,QAAQ9L,GAAYA,EAErC,IACT,EACA,sBAAA2M,CAAuBnnB,GACrB,MAAMwa,EAAW0L,GAAYlmB,GAC7B,OAAOwa,EAAW6L,GAAeC,QAAQ9L,GAAY,IACvD,EACA,+BAAA4M,CAAgCpnB,GAC9B,MAAMwa,EAAW0L,GAAYlmB,GAC7B,OAAOwa,EAAW6L,GAAezT,KAAK4H,GAAY,EACpD,GAUI6M,GAAuB,CAACC,EAAWC,EAAS,UAChD,MAAMC,EAAa,gBAAgBF,EAAU7B,YACvC1kB,EAAOumB,EAAUtK,KACvBgE,GAAac,GAAGhc,SAAU0hB,EAAY,qBAAqBzmB,OAAU,SAAU8e,GAI7E,GAHI,CAAC,IAAK,QAAQgC,SAASpB,KAAKgH,UAC9B5H,EAAMkD,iBAEJpH,GAAW8E,MACb,OAEF,MAAMzT,EAASqZ,GAAec,uBAAuB1G,OAASA,KAAKhF,QAAQ,IAAI1a,KAC9DumB,EAAUvB,oBAAoB/Y,GAGtCua,IACX,GAAE,EAiBEG,GAAc,YACdC,GAAc,QAAQD,KACtBE,GAAe,SAASF,KAQ9B,MAAMG,WAAc1C,GAElB,eAAWnI,GACT,MAfW,OAgBb,CAGA,KAAA8K,GAEE,GADmB9G,GAAaqB,QAAQ5B,KAAK4E,SAAUsC,IACxClF,iBACb,OAEFhC,KAAK4E,SAASvJ,UAAU1B,OAlBF,QAmBtB,MAAMyL,EAAapF,KAAK4E,SAASvJ,UAAU7W,SApBrB,QAqBtBwb,KAAKmF,gBAAe,IAAMnF,KAAKsH,mBAAmBtH,KAAK4E,SAAUQ,EACnE,CAGA,eAAAkC,GACEtH,KAAK4E,SAASjL,SACd4G,GAAaqB,QAAQ5B,KAAK4E,SAAUuC,IACpCnH,KAAK+E,SACP,CAGA,sBAAOtI,CAAgBqH,GACrB,OAAO9D,KAAKuH,MAAK,WACf,MAAMld,EAAO+c,GAAM9B,oBAAoBtF,MACvC,GAAsB,iBAAX8D,EAAX,CAGA,QAAqB/K,IAAjB1O,EAAKyZ,IAAyBA,EAAOrC,WAAW,MAAmB,gBAAXqC,EAC1D,MAAM,IAAIU,UAAU,oBAAoBV,MAE1CzZ,EAAKyZ,GAAQ9D,KAJb,CAKF,GACF,EAOF4G,GAAqBQ,GAAO,SAM5BjL,GAAmBiL,IAcnB,MAKMI,GAAyB,4BAO/B,MAAMC,WAAe/C,GAEnB,eAAWnI,GACT,MAfW,QAgBb,CAGA,MAAAmL,GAEE1H,KAAK4E,SAASxjB,aAAa,eAAgB4e,KAAK4E,SAASvJ,UAAUqM,OAjB3C,UAkB1B,CAGA,sBAAOjL,CAAgBqH,GACrB,OAAO9D,KAAKuH,MAAK,WACf,MAAMld,EAAOod,GAAOnC,oBAAoBtF,MACzB,WAAX8D,GACFzZ,EAAKyZ,IAET,GACF,EAOFvD,GAAac,GAAGhc,SAjCe,2BAiCmBmiB,IAAwBpI,IACxEA,EAAMkD,iBACN,MAAMqF,EAASvI,EAAM7S,OAAOyO,QAAQwM,IACvBC,GAAOnC,oBAAoBqC,GACnCD,QAAQ,IAOfvL,GAAmBsL,IAcnB,MACMG,GAAc,YACdC,GAAmB,aAAaD,KAChCE,GAAkB,YAAYF,KAC9BG,GAAiB,WAAWH,KAC5BI,GAAoB,cAAcJ,KAClCK,GAAkB,YAAYL,KAK9BM,GAAY,CAChBC,YAAa,KACbC,aAAc,KACdC,cAAe,MAEXC,GAAgB,CACpBH,YAAa,kBACbC,aAAc,kBACdC,cAAe,mBAOjB,MAAME,WAAc9E,GAClB,WAAAU,CAAY5kB,EAASukB,GACnBa,QACA3E,KAAK4E,SAAWrlB,EACXA,GAAYgpB,GAAMC,gBAGvBxI,KAAK6E,QAAU7E,KAAK6D,WAAWC,GAC/B9D,KAAKyI,QAAU,EACfzI,KAAK0I,sBAAwB5H,QAAQlhB,OAAO+oB,cAC5C3I,KAAK4I,cACP,CAGA,kBAAWlF,GACT,OAAOwE,EACT,CACA,sBAAWvE,GACT,OAAO2E,EACT,CACA,eAAW/L,GACT,MA/CW,OAgDb,CAGA,OAAAwI,GACExE,GAAaC,IAAIR,KAAK4E,SAAUgD,GAClC,CAGA,MAAAiB,CAAOzJ,GACAY,KAAK0I,sBAIN1I,KAAK8I,wBAAwB1J,KAC/BY,KAAKyI,QAAUrJ,EAAM2J,SAJrB/I,KAAKyI,QAAUrJ,EAAM4J,QAAQ,GAAGD,OAMpC,CACA,IAAAE,CAAK7J,GACCY,KAAK8I,wBAAwB1J,KAC/BY,KAAKyI,QAAUrJ,EAAM2J,QAAU/I,KAAKyI,SAEtCzI,KAAKkJ,eACLrM,GAAQmD,KAAK6E,QAAQsD,YACvB,CACA,KAAAgB,CAAM/J,GACJY,KAAKyI,QAAUrJ,EAAM4J,SAAW5J,EAAM4J,QAAQtY,OAAS,EAAI,EAAI0O,EAAM4J,QAAQ,GAAGD,QAAU/I,KAAKyI,OACjG,CACA,YAAAS,GACE,MAAME,EAAYjnB,KAAKoC,IAAIyb,KAAKyI,SAChC,GAAIW,GAnEgB,GAoElB,OAEF,MAAM9b,EAAY8b,EAAYpJ,KAAKyI,QACnCzI,KAAKyI,QAAU,EACVnb,GAGLuP,GAAQvP,EAAY,EAAI0S,KAAK6E,QAAQwD,cAAgBrI,KAAK6E,QAAQuD,aACpE,CACA,WAAAQ,GACM5I,KAAK0I,uBACPnI,GAAac,GAAGrB,KAAK4E,SAAUoD,IAAmB5I,GAASY,KAAK6I,OAAOzJ,KACvEmB,GAAac,GAAGrB,KAAK4E,SAAUqD,IAAiB7I,GAASY,KAAKiJ,KAAK7J,KACnEY,KAAK4E,SAASvJ,UAAU5E,IAlFG,mBAoF3B8J,GAAac,GAAGrB,KAAK4E,SAAUiD,IAAkBzI,GAASY,KAAK6I,OAAOzJ,KACtEmB,GAAac,GAAGrB,KAAK4E,SAAUkD,IAAiB1I,GAASY,KAAKmJ,MAAM/J,KACpEmB,GAAac,GAAGrB,KAAK4E,SAAUmD,IAAgB3I,GAASY,KAAKiJ,KAAK7J,KAEtE,CACA,uBAAA0J,CAAwB1J,GACtB,OAAOY,KAAK0I,wBA3FS,QA2FiBtJ,EAAMiK,aA5FrB,UA4FyDjK,EAAMiK,YACxF,CAGA,kBAAOb,GACL,MAAO,iBAAkBnjB,SAASC,iBAAmB7C,UAAU6mB,eAAiB,CAClF,EAeF,MAEMC,GAAc,eACdC,GAAiB,YAKjBC,GAAa,OACbC,GAAa,OACbC,GAAiB,OACjBC,GAAkB,QAClBC,GAAc,QAAQN,KACtBO,GAAa,OAAOP,KACpBQ,GAAkB,UAAUR,KAC5BS,GAAqB,aAAaT,KAClCU,GAAqB,aAAaV,KAClCW,GAAmB,YAAYX,KAC/BY,GAAwB,OAAOZ,KAAcC,KAC7CY,GAAyB,QAAQb,KAAcC,KAC/Ca,GAAsB,WACtBC,GAAsB,SAMtBC,GAAkB,UAClBC,GAAgB,iBAChBC,GAAuBF,GAAkBC,GAKzCE,GAAmB,CACvB,UAAoBd,GACpB,WAAqBD,IAEjBgB,GAAY,CAChBC,SAAU,IACVC,UAAU,EACVC,MAAO,QACPC,MAAM,EACNC,OAAO,EACPC,MAAM,GAEFC,GAAgB,CACpBN,SAAU,mBAEVC,SAAU,UACVC,MAAO,mBACPC,KAAM,mBACNC,MAAO,UACPC,KAAM,WAOR,MAAME,WAAiBzG,GACrB,WAAAP,CAAY5kB,EAASukB,GACnBa,MAAMplB,EAASukB,GACf9D,KAAKoL,UAAY,KACjBpL,KAAKqL,eAAiB,KACtBrL,KAAKsL,YAAa,EAClBtL,KAAKuL,aAAe,KACpBvL,KAAKwL,aAAe,KACpBxL,KAAKyL,mBAAqB7F,GAAeC,QArCjB,uBAqC8C7F,KAAK4E,UAC3E5E,KAAK0L,qBACD1L,KAAK6E,QAAQkG,OAASV,IACxBrK,KAAK2L,OAET,CAGA,kBAAWjI,GACT,OAAOiH,EACT,CACA,sBAAWhH,GACT,OAAOuH,EACT,CACA,eAAW3O,GACT,MAnFW,UAoFb,CAGA,IAAA1X,GACEmb,KAAK4L,OAAOnC,GACd,CACA,eAAAoC,IAIOxmB,SAASymB,QAAUnR,GAAUqF,KAAK4E,WACrC5E,KAAKnb,MAET,CACA,IAAAqhB,GACElG,KAAK4L,OAAOlC,GACd,CACA,KAAAoB,GACM9K,KAAKsL,YACPlR,GAAqB4F,KAAK4E,UAE5B5E,KAAK+L,gBACP,CACA,KAAAJ,GACE3L,KAAK+L,iBACL/L,KAAKgM,kBACLhM,KAAKoL,UAAYa,aAAY,IAAMjM,KAAK6L,mBAAmB7L,KAAK6E,QAAQ+F,SAC1E,CACA,iBAAAsB,GACOlM,KAAK6E,QAAQkG,OAGd/K,KAAKsL,WACP/K,GAAae,IAAItB,KAAK4E,SAAUkF,IAAY,IAAM9J,KAAK2L,UAGzD3L,KAAK2L,QACP,CACA,EAAAQ,CAAG1T,GACD,MAAM2T,EAAQpM,KAAKqM,YACnB,GAAI5T,EAAQ2T,EAAM1b,OAAS,GAAK+H,EAAQ,EACtC,OAEF,GAAIuH,KAAKsL,WAEP,YADA/K,GAAae,IAAItB,KAAK4E,SAAUkF,IAAY,IAAM9J,KAAKmM,GAAG1T,KAG5D,MAAM6T,EAActM,KAAKuM,cAAcvM,KAAKwM,cAC5C,GAAIF,IAAgB7T,EAClB,OAEF,MAAMtC,EAAQsC,EAAQ6T,EAAc7C,GAAaC,GACjD1J,KAAK4L,OAAOzV,EAAOiW,EAAM3T,GAC3B,CACA,OAAAsM,GACM/E,KAAKwL,cACPxL,KAAKwL,aAAazG,UAEpBJ,MAAMI,SACR,CAGA,iBAAAf,CAAkBF,GAEhB,OADAA,EAAO2I,gBAAkB3I,EAAO8G,SACzB9G,CACT,CACA,kBAAA4H,GACM1L,KAAK6E,QAAQgG,UACftK,GAAac,GAAGrB,KAAK4E,SAAUmF,IAAiB3K,GAASY,KAAK0M,SAAStN,KAE9C,UAAvBY,KAAK6E,QAAQiG,QACfvK,GAAac,GAAGrB,KAAK4E,SAAUoF,IAAoB,IAAMhK,KAAK8K,UAC9DvK,GAAac,GAAGrB,KAAK4E,SAAUqF,IAAoB,IAAMjK,KAAKkM,uBAE5DlM,KAAK6E,QAAQmG,OAASzC,GAAMC,eAC9BxI,KAAK2M,yBAET,CACA,uBAAAA,GACE,IAAK,MAAMC,KAAOhH,GAAezT,KArIX,qBAqImC6N,KAAK4E,UAC5DrE,GAAac,GAAGuL,EAAK1C,IAAkB9K,GAASA,EAAMkD,mBAExD,MAmBMuK,EAAc,CAClBzE,aAAc,IAAMpI,KAAK4L,OAAO5L,KAAK8M,kBAAkBnD,KACvDtB,cAAe,IAAMrI,KAAK4L,OAAO5L,KAAK8M,kBAAkBlD,KACxDzB,YAtBkB,KACS,UAAvBnI,KAAK6E,QAAQiG,QAYjB9K,KAAK8K,QACD9K,KAAKuL,cACPwB,aAAa/M,KAAKuL,cAEpBvL,KAAKuL,aAAe1N,YAAW,IAAMmC,KAAKkM,qBAjLjB,IAiL+DlM,KAAK6E,QAAQ+F,UAAS,GAOhH5K,KAAKwL,aAAe,IAAIjD,GAAMvI,KAAK4E,SAAUiI,EAC/C,CACA,QAAAH,CAAStN,GACP,GAAI,kBAAkB/b,KAAK+b,EAAM7S,OAAOya,SACtC,OAEF,MAAM1Z,EAAYod,GAAiBtL,EAAMtiB,KACrCwQ,IACF8R,EAAMkD,iBACNtC,KAAK4L,OAAO5L,KAAK8M,kBAAkBxf,IAEvC,CACA,aAAAif,CAAchtB,GACZ,OAAOygB,KAAKqM,YAAYlnB,QAAQ5F,EAClC,CACA,0BAAAytB,CAA2BvU,GACzB,IAAKuH,KAAKyL,mBACR,OAEF,MAAMwB,EAAkBrH,GAAeC,QAAQ0E,GAAiBvK,KAAKyL,oBACrEwB,EAAgB5R,UAAU1B,OAAO2Q,IACjC2C,EAAgB9rB,gBAAgB,gBAChC,MAAM+rB,EAAqBtH,GAAeC,QAAQ,sBAAsBpN,MAAWuH,KAAKyL,oBACpFyB,IACFA,EAAmB7R,UAAU5E,IAAI6T,IACjC4C,EAAmB9rB,aAAa,eAAgB,QAEpD,CACA,eAAA4qB,GACE,MAAMzsB,EAAUygB,KAAKqL,gBAAkBrL,KAAKwM,aAC5C,IAAKjtB,EACH,OAEF,MAAM4tB,EAAkB5P,OAAO6P,SAAS7tB,EAAQic,aAAa,oBAAqB,IAClFwE,KAAK6E,QAAQ+F,SAAWuC,GAAmBnN,KAAK6E,QAAQ4H,eAC1D,CACA,MAAAb,CAAOzV,EAAO5W,EAAU,MACtB,GAAIygB,KAAKsL,WACP,OAEF,MAAMvN,EAAgBiC,KAAKwM,aACrBa,EAASlX,IAAUsT,GACnB6D,EAAc/tB,GAAWue,GAAqBkC,KAAKqM,YAAatO,EAAesP,EAAQrN,KAAK6E,QAAQoG,MAC1G,GAAIqC,IAAgBvP,EAClB,OAEF,MAAMwP,EAAmBvN,KAAKuM,cAAce,GACtCE,EAAehI,GACZjF,GAAaqB,QAAQ5B,KAAK4E,SAAUY,EAAW,CACpD1F,cAAewN,EACfhgB,UAAW0S,KAAKyN,kBAAkBtX,GAClCuD,KAAMsG,KAAKuM,cAAcxO,GACzBoO,GAAIoB,IAIR,GADmBC,EAAa3D,IACjB7H,iBACb,OAEF,IAAKjE,IAAkBuP,EAGrB,OAEF,MAAMI,EAAY5M,QAAQd,KAAKoL,WAC/BpL,KAAK8K,QACL9K,KAAKsL,YAAa,EAClBtL,KAAKgN,2BAA2BO,GAChCvN,KAAKqL,eAAiBiC,EACtB,MAAMK,EAAuBN,EA3OR,sBADF,oBA6ObO,EAAiBP,EA3OH,qBACA,qBA2OpBC,EAAYjS,UAAU5E,IAAImX,GAC1B/R,GAAOyR,GACPvP,EAAc1C,UAAU5E,IAAIkX,GAC5BL,EAAYjS,UAAU5E,IAAIkX,GAQ1B3N,KAAKmF,gBAPoB,KACvBmI,EAAYjS,UAAU1B,OAAOgU,EAAsBC,GACnDN,EAAYjS,UAAU5E,IAAI6T,IAC1BvM,EAAc1C,UAAU1B,OAAO2Q,GAAqBsD,EAAgBD,GACpE3N,KAAKsL,YAAa,EAClBkC,EAAa1D,GAAW,GAEY/L,EAAeiC,KAAK6N,eACtDH,GACF1N,KAAK2L,OAET,CACA,WAAAkC,GACE,OAAO7N,KAAK4E,SAASvJ,UAAU7W,SAhQV,QAiQvB,CACA,UAAAgoB,GACE,OAAO5G,GAAeC,QAAQ4E,GAAsBzK,KAAK4E,SAC3D,CACA,SAAAyH,GACE,OAAOzG,GAAezT,KAAKqY,GAAexK,KAAK4E,SACjD,CACA,cAAAmH,GACM/L,KAAKoL,YACP0C,cAAc9N,KAAKoL,WACnBpL,KAAKoL,UAAY,KAErB,CACA,iBAAA0B,CAAkBxf,GAChB,OAAI2O,KACK3O,IAAcqc,GAAiBD,GAAaD,GAE9Cnc,IAAcqc,GAAiBF,GAAaC,EACrD,CACA,iBAAA+D,CAAkBtX,GAChB,OAAI8F,KACK9F,IAAUuT,GAAaC,GAAiBC,GAE1CzT,IAAUuT,GAAaE,GAAkBD,EAClD,CAGA,sBAAOlN,CAAgBqH,GACrB,OAAO9D,KAAKuH,MAAK,WACf,MAAMld,EAAO8gB,GAAS7F,oBAAoBtF,KAAM8D,GAChD,GAAsB,iBAAXA,GAIX,GAAsB,iBAAXA,EAAqB,CAC9B,QAAqB/K,IAAjB1O,EAAKyZ,IAAyBA,EAAOrC,WAAW,MAAmB,gBAAXqC,EAC1D,MAAM,IAAIU,UAAU,oBAAoBV,MAE1CzZ,EAAKyZ,IACP,OAREzZ,EAAK8hB,GAAGrI,EASZ,GACF,EAOFvD,GAAac,GAAGhc,SAAU+kB,GAvSE,uCAuS2C,SAAUhL,GAC/E,MAAM7S,EAASqZ,GAAec,uBAAuB1G,MACrD,IAAKzT,IAAWA,EAAO8O,UAAU7W,SAAS6lB,IACxC,OAEFjL,EAAMkD,iBACN,MAAMyL,EAAW5C,GAAS7F,oBAAoB/Y,GACxCyhB,EAAahO,KAAKxE,aAAa,oBACrC,OAAIwS,GACFD,EAAS5B,GAAG6B,QACZD,EAAS7B,qBAGyC,SAAhDlJ,GAAYQ,iBAAiBxD,KAAM,UACrC+N,EAASlpB,YACTkpB,EAAS7B,sBAGX6B,EAAS7H,YACT6H,EAAS7B,oBACX,IACA3L,GAAac,GAAGzhB,OAAQuqB,IAAuB,KAC7C,MAAM8D,EAAYrI,GAAezT,KA5TR,6BA6TzB,IAAK,MAAM4b,KAAYE,EACrB9C,GAAS7F,oBAAoByI,EAC/B,IAOF5R,GAAmBgP,IAcnB,MAEM+C,GAAc,eAEdC,GAAe,OAAOD,KACtBE,GAAgB,QAAQF,KACxBG,GAAe,OAAOH,KACtBI,GAAiB,SAASJ,KAC1BK,GAAyB,QAAQL,cACjCM,GAAoB,OACpBC,GAAsB,WACtBC,GAAwB,aAExBC,GAA6B,WAAWF,OAAwBA,KAKhEG,GAAyB,8BACzBC,GAAY,CAChBpqB,OAAQ,KACRijB,QAAQ,GAEJoH,GAAgB,CACpBrqB,OAAQ,iBACRijB,OAAQ,WAOV,MAAMqH,WAAiBrK,GACrB,WAAAP,CAAY5kB,EAASukB,GACnBa,MAAMplB,EAASukB,GACf9D,KAAKgP,kBAAmB,EACxBhP,KAAKiP,cAAgB,GACrB,MAAMC,EAAatJ,GAAezT,KAAKyc,IACvC,IAAK,MAAMO,KAAQD,EAAY,CAC7B,MAAMnV,EAAW6L,GAAea,uBAAuB0I,GACjDC,EAAgBxJ,GAAezT,KAAK4H,GAAU5T,QAAOkpB,GAAgBA,IAAiBrP,KAAK4E,WAChF,OAAb7K,GAAqBqV,EAAc1e,QACrCsP,KAAKiP,cAAcrd,KAAKud,EAE5B,CACAnP,KAAKsP,sBACAtP,KAAK6E,QAAQpgB,QAChBub,KAAKuP,0BAA0BvP,KAAKiP,cAAejP,KAAKwP,YAEtDxP,KAAK6E,QAAQ6C,QACf1H,KAAK0H,QAET,CAGA,kBAAWhE,GACT,OAAOmL,EACT,CACA,sBAAWlL,GACT,OAAOmL,EACT,CACA,eAAWvS,GACT,MA9DW,UA+Db,CAGA,MAAAmL,GACM1H,KAAKwP,WACPxP,KAAKyP,OAELzP,KAAK0P,MAET,CACA,IAAAA,GACE,GAAI1P,KAAKgP,kBAAoBhP,KAAKwP,WAChC,OAEF,IAAIG,EAAiB,GAQrB,GALI3P,KAAK6E,QAAQpgB,SACfkrB,EAAiB3P,KAAK4P,uBAhEH,wCAgE4CzpB,QAAO5G,GAAWA,IAAYygB,KAAK4E,WAAU9hB,KAAIvD,GAAWwvB,GAASzJ,oBAAoB/lB,EAAS,CAC/JmoB,QAAQ,OAGRiI,EAAejf,QAAUif,EAAe,GAAGX,iBAC7C,OAGF,GADmBzO,GAAaqB,QAAQ5B,KAAK4E,SAAUuJ,IACxCnM,iBACb,OAEF,IAAK,MAAM6N,KAAkBF,EAC3BE,EAAeJ,OAEjB,MAAMK,EAAY9P,KAAK+P,gBACvB/P,KAAK4E,SAASvJ,UAAU1B,OAAO8U,IAC/BzO,KAAK4E,SAASvJ,UAAU5E,IAAIiY,IAC5B1O,KAAK4E,SAAS7jB,MAAM+uB,GAAa,EACjC9P,KAAKuP,0BAA0BvP,KAAKiP,eAAe,GACnDjP,KAAKgP,kBAAmB,EACxB,MAQMgB,EAAa,SADUF,EAAU,GAAGrL,cAAgBqL,EAAU1d,MAAM,KAE1E4N,KAAKmF,gBATY,KACfnF,KAAKgP,kBAAmB,EACxBhP,KAAK4E,SAASvJ,UAAU1B,OAAO+U,IAC/B1O,KAAK4E,SAASvJ,UAAU5E,IAAIgY,GAAqBD,IACjDxO,KAAK4E,SAAS7jB,MAAM+uB,GAAa,GACjCvP,GAAaqB,QAAQ5B,KAAK4E,SAAUwJ,GAAc,GAItBpO,KAAK4E,UAAU,GAC7C5E,KAAK4E,SAAS7jB,MAAM+uB,GAAa,GAAG9P,KAAK4E,SAASoL,MACpD,CACA,IAAAP,GACE,GAAIzP,KAAKgP,mBAAqBhP,KAAKwP,WACjC,OAGF,GADmBjP,GAAaqB,QAAQ5B,KAAK4E,SAAUyJ,IACxCrM,iBACb,OAEF,MAAM8N,EAAY9P,KAAK+P,gBACvB/P,KAAK4E,SAAS7jB,MAAM+uB,GAAa,GAAG9P,KAAK4E,SAASthB,wBAAwBwsB,OAC1EjU,GAAOmE,KAAK4E,UACZ5E,KAAK4E,SAASvJ,UAAU5E,IAAIiY,IAC5B1O,KAAK4E,SAASvJ,UAAU1B,OAAO8U,GAAqBD,IACpD,IAAK,MAAM5M,KAAW5B,KAAKiP,cAAe,CACxC,MAAM1vB,EAAUqmB,GAAec,uBAAuB9E,GAClDriB,IAAYygB,KAAKwP,SAASjwB,IAC5BygB,KAAKuP,0BAA0B,CAAC3N,IAAU,EAE9C,CACA5B,KAAKgP,kBAAmB,EAOxBhP,KAAK4E,SAAS7jB,MAAM+uB,GAAa,GACjC9P,KAAKmF,gBAPY,KACfnF,KAAKgP,kBAAmB,EACxBhP,KAAK4E,SAASvJ,UAAU1B,OAAO+U,IAC/B1O,KAAK4E,SAASvJ,UAAU5E,IAAIgY,IAC5BlO,GAAaqB,QAAQ5B,KAAK4E,SAAU0J,GAAe,GAGvBtO,KAAK4E,UAAU,EAC/C,CACA,QAAA4K,CAASjwB,EAAUygB,KAAK4E,UACtB,OAAOrlB,EAAQ8b,UAAU7W,SAASgqB,GACpC,CAGA,iBAAAxK,CAAkBF,GAGhB,OAFAA,EAAO4D,OAAS5G,QAAQgD,EAAO4D,QAC/B5D,EAAOrf,OAASiW,GAAWoJ,EAAOrf,QAC3Bqf,CACT,CACA,aAAAiM,GACE,OAAO/P,KAAK4E,SAASvJ,UAAU7W,SA3IL,uBAChB,QACC,QA0Ib,CACA,mBAAA8qB,GACE,IAAKtP,KAAK6E,QAAQpgB,OAChB,OAEF,MAAMqhB,EAAW9F,KAAK4P,uBAAuBhB,IAC7C,IAAK,MAAMrvB,KAAWumB,EAAU,CAC9B,MAAMmK,EAAWrK,GAAec,uBAAuBnnB,GACnD0wB,GACFjQ,KAAKuP,0BAA0B,CAAChwB,GAAUygB,KAAKwP,SAASS,GAE5D,CACF,CACA,sBAAAL,CAAuB7V,GACrB,MAAM+L,EAAWF,GAAezT,KAAKwc,GAA4B3O,KAAK6E,QAAQpgB,QAE9E,OAAOmhB,GAAezT,KAAK4H,EAAUiG,KAAK6E,QAAQpgB,QAAQ0B,QAAO5G,IAAYumB,EAAS1E,SAAS7hB,IACjG,CACA,yBAAAgwB,CAA0BW,EAAcC,GACtC,GAAKD,EAAaxf,OAGlB,IAAK,MAAMnR,KAAW2wB,EACpB3wB,EAAQ8b,UAAUqM,OArKK,aAqKyByI,GAChD5wB,EAAQ6B,aAAa,gBAAiB+uB,EAE1C,CAGA,sBAAO1T,CAAgBqH,GACrB,MAAMe,EAAU,CAAC,EAIjB,MAHsB,iBAAXf,GAAuB,YAAYzgB,KAAKygB,KACjDe,EAAQ6C,QAAS,GAEZ1H,KAAKuH,MAAK,WACf,MAAMld,EAAO0kB,GAASzJ,oBAAoBtF,KAAM6E,GAChD,GAAsB,iBAAXf,EAAqB,CAC9B,QAA4B,IAAjBzZ,EAAKyZ,GACd,MAAM,IAAIU,UAAU,oBAAoBV,MAE1CzZ,EAAKyZ,IACP,CACF,GACF,EAOFvD,GAAac,GAAGhc,SAAUkpB,GAAwBK,IAAwB,SAAUxP,IAErD,MAAzBA,EAAM7S,OAAOya,SAAmB5H,EAAMW,gBAAmD,MAAjCX,EAAMW,eAAeiH,UAC/E5H,EAAMkD,iBAER,IAAK,MAAM/iB,KAAWqmB,GAAee,gCAAgC3G,MACnE+O,GAASzJ,oBAAoB/lB,EAAS,CACpCmoB,QAAQ,IACPA,QAEP,IAMAvL,GAAmB4S,IAcnB,MAAMqB,GAAS,WAETC,GAAc,eACdC,GAAiB,YAGjBC,GAAiB,UACjBC,GAAmB,YAGnBC,GAAe,OAAOJ,KACtBK,GAAiB,SAASL,KAC1BM,GAAe,OAAON,KACtBO,GAAgB,QAAQP,KACxBQ,GAAyB,QAAQR,KAAcC,KAC/CQ,GAAyB,UAAUT,KAAcC,KACjDS,GAAuB,QAAQV,KAAcC,KAC7CU,GAAoB,OAMpBC,GAAyB,4DACzBC,GAA6B,GAAGD,MAA0BD,KAC1DG,GAAgB,iBAIhBC,GAAgBnV,KAAU,UAAY,YACtCoV,GAAmBpV,KAAU,YAAc,UAC3CqV,GAAmBrV,KAAU,aAAe,eAC5CsV,GAAsBtV,KAAU,eAAiB,aACjDuV,GAAkBvV,KAAU,aAAe,cAC3CwV,GAAiBxV,KAAU,cAAgB,aAG3CyV,GAAY,CAChBC,WAAW,EACX1jB,SAAU,kBACV2jB,QAAS,UACT5pB,OAAQ,CAAC,EAAG,GACZ6pB,aAAc,KACdvzB,UAAW,UAEPwzB,GAAgB,CACpBH,UAAW,mBACX1jB,SAAU,mBACV2jB,QAAS,SACT5pB,OAAQ,0BACR6pB,aAAc,yBACdvzB,UAAW,2BAOb,MAAMyzB,WAAiBrN,GACrB,WAAAP,CAAY5kB,EAASukB,GACnBa,MAAMplB,EAASukB,GACf9D,KAAKgS,QAAU,KACfhS,KAAKiS,QAAUjS,KAAK4E,SAAS7f,WAE7Bib,KAAKkS,MAAQtM,GAAe/gB,KAAKmb,KAAK4E,SAAUuM,IAAe,IAAMvL,GAAeM,KAAKlG,KAAK4E,SAAUuM,IAAe,IAAMvL,GAAeC,QAAQsL,GAAenR,KAAKiS,SACxKjS,KAAKmS,UAAYnS,KAAKoS,eACxB,CAGA,kBAAW1O,GACT,OAAOgO,EACT,CACA,sBAAW/N,GACT,OAAOmO,EACT,CACA,eAAWvV,GACT,OAAO6T,EACT,CAGA,MAAA1I,GACE,OAAO1H,KAAKwP,WAAaxP,KAAKyP,OAASzP,KAAK0P,MAC9C,CACA,IAAAA,GACE,GAAIxU,GAAW8E,KAAK4E,WAAa5E,KAAKwP,WACpC,OAEF,MAAM1P,EAAgB,CACpBA,cAAeE,KAAK4E,UAGtB,IADkBrE,GAAaqB,QAAQ5B,KAAK4E,SAAU+L,GAAc7Q,GACtDkC,iBAAd,CASA,GANAhC,KAAKqS,gBAMD,iBAAkBhtB,SAASC,kBAAoB0a,KAAKiS,QAAQjX,QAzExC,eA0EtB,IAAK,MAAMzb,IAAW,GAAGZ,UAAU0G,SAAS6G,KAAK4Z,UAC/CvF,GAAac,GAAG9hB,EAAS,YAAaqc,IAG1CoE,KAAK4E,SAAS0N,QACdtS,KAAK4E,SAASxjB,aAAa,iBAAiB,GAC5C4e,KAAKkS,MAAM7W,UAAU5E,IAAIua,IACzBhR,KAAK4E,SAASvJ,UAAU5E,IAAIua,IAC5BzQ,GAAaqB,QAAQ5B,KAAK4E,SAAUgM,GAAe9Q,EAhBnD,CAiBF,CACA,IAAA2P,GACE,GAAIvU,GAAW8E,KAAK4E,YAAc5E,KAAKwP,WACrC,OAEF,MAAM1P,EAAgB,CACpBA,cAAeE,KAAK4E,UAEtB5E,KAAKuS,cAAczS,EACrB,CACA,OAAAiF,GACM/E,KAAKgS,SACPhS,KAAKgS,QAAQhZ,UAEf2L,MAAMI,SACR,CACA,MAAAha,GACEiV,KAAKmS,UAAYnS,KAAKoS,gBAClBpS,KAAKgS,SACPhS,KAAKgS,QAAQjnB,QAEjB,CAGA,aAAAwnB,CAAczS,GAEZ,IADkBS,GAAaqB,QAAQ5B,KAAK4E,SAAU6L,GAAc3Q,GACtDkC,iBAAd,CAMA,GAAI,iBAAkB3c,SAASC,gBAC7B,IAAK,MAAM/F,IAAW,GAAGZ,UAAU0G,SAAS6G,KAAK4Z,UAC/CvF,GAAaC,IAAIjhB,EAAS,YAAaqc,IAGvCoE,KAAKgS,SACPhS,KAAKgS,QAAQhZ,UAEfgH,KAAKkS,MAAM7W,UAAU1B,OAAOqX,IAC5BhR,KAAK4E,SAASvJ,UAAU1B,OAAOqX,IAC/BhR,KAAK4E,SAASxjB,aAAa,gBAAiB,SAC5C4hB,GAAYE,oBAAoBlD,KAAKkS,MAAO,UAC5C3R,GAAaqB,QAAQ5B,KAAK4E,SAAU8L,GAAgB5Q,EAhBpD,CAiBF,CACA,UAAA+D,CAAWC,GAET,GAAgC,iBADhCA,EAASa,MAAMd,WAAWC,IACRxlB,YAA2B,GAAUwlB,EAAOxlB,YAAgE,mBAA3CwlB,EAAOxlB,UAAUgF,sBAElG,MAAM,IAAIkhB,UAAU,GAAG4L,GAAO3L,+GAEhC,OAAOX,CACT,CACA,aAAAuO,GACE,QAAsB,IAAX,EACT,MAAM,IAAI7N,UAAU,gEAEtB,IAAIgO,EAAmBxS,KAAK4E,SACG,WAA3B5E,KAAK6E,QAAQvmB,UACfk0B,EAAmBxS,KAAKiS,QACf,GAAUjS,KAAK6E,QAAQvmB,WAChCk0B,EAAmB9X,GAAWsF,KAAK6E,QAAQvmB,WACA,iBAA3B0hB,KAAK6E,QAAQvmB,YAC7Bk0B,EAAmBxS,KAAK6E,QAAQvmB,WAElC,MAAMuzB,EAAe7R,KAAKyS,mBAC1BzS,KAAKgS,QAAU,GAAoBQ,EAAkBxS,KAAKkS,MAAOL,EACnE,CACA,QAAArC,GACE,OAAOxP,KAAKkS,MAAM7W,UAAU7W,SAASwsB,GACvC,CACA,aAAA0B,GACE,MAAMC,EAAiB3S,KAAKiS,QAC5B,GAAIU,EAAetX,UAAU7W,SArKN,WAsKrB,OAAOgtB,GAET,GAAImB,EAAetX,UAAU7W,SAvKJ,aAwKvB,OAAOitB,GAET,GAAIkB,EAAetX,UAAU7W,SAzKA,iBA0K3B,MA5JsB,MA8JxB,GAAImuB,EAAetX,UAAU7W,SA3KE,mBA4K7B,MA9JyB,SAkK3B,MAAMouB,EAAkF,QAA1E3tB,iBAAiB+a,KAAKkS,OAAOpX,iBAAiB,iBAAiB6K,OAC7E,OAAIgN,EAAetX,UAAU7W,SArLP,UAsLbouB,EAAQvB,GAAmBD,GAE7BwB,EAAQrB,GAAsBD,EACvC,CACA,aAAAc,GACE,OAAkD,OAA3CpS,KAAK4E,SAAS5J,QAnLD,UAoLtB,CACA,UAAA6X,GACE,MAAM,OACJ7qB,GACEgY,KAAK6E,QACT,MAAsB,iBAAX7c,EACFA,EAAO9F,MAAM,KAAKY,KAAInF,GAAS4f,OAAO6P,SAASzvB,EAAO,MAEzC,mBAAXqK,EACF8qB,GAAc9qB,EAAO8qB,EAAY9S,KAAK4E,UAExC5c,CACT,CACA,gBAAAyqB,GACE,MAAMM,EAAwB,CAC5Br0B,UAAWshB,KAAK0S,gBAChBtc,UAAW,CAAC,CACV9V,KAAM,kBACNmB,QAAS,CACPwM,SAAU+R,KAAK6E,QAAQ5W,WAExB,CACD3N,KAAM,SACNmB,QAAS,CACPuG,OAAQgY,KAAK6S,iBAanB,OAPI7S,KAAKmS,WAAsC,WAAzBnS,KAAK6E,QAAQ+M,WACjC5O,GAAYC,iBAAiBjD,KAAKkS,MAAO,SAAU,UACnDa,EAAsB3c,UAAY,CAAC,CACjC9V,KAAM,cACNC,SAAS,KAGN,IACFwyB,KACAlW,GAAQmD,KAAK6E,QAAQgN,aAAc,CAACkB,IAE3C,CACA,eAAAC,EAAgB,IACdl2B,EAAG,OACHyP,IAEA,MAAM6f,EAAQxG,GAAezT,KAhOF,8DAgO+B6N,KAAKkS,OAAO/rB,QAAO5G,GAAWob,GAAUpb,KAC7F6sB,EAAM1b,QAMXoN,GAAqBsO,EAAO7f,EAAQzP,IAAQ0zB,IAAmBpE,EAAMhL,SAAS7U,IAAS+lB,OACzF,CAGA,sBAAO7V,CAAgBqH,GACrB,OAAO9D,KAAKuH,MAAK,WACf,MAAMld,EAAO0nB,GAASzM,oBAAoBtF,KAAM8D,GAChD,GAAsB,iBAAXA,EAAX,CAGA,QAA4B,IAAjBzZ,EAAKyZ,GACd,MAAM,IAAIU,UAAU,oBAAoBV,MAE1CzZ,EAAKyZ,IAJL,CAKF,GACF,CACA,iBAAOmP,CAAW7T,GAChB,GA5QuB,IA4QnBA,EAAMuI,QAAgD,UAAfvI,EAAMqB,MA/QnC,QA+QuDrB,EAAMtiB,IACzE,OAEF,MAAMo2B,EAActN,GAAezT,KAAK+e,IACxC,IAAK,MAAMxJ,KAAUwL,EAAa,CAChC,MAAMC,EAAUpB,GAAS1M,YAAYqC,GACrC,IAAKyL,IAAyC,IAA9BA,EAAQtO,QAAQ8M,UAC9B,SAEF,MAAMyB,EAAehU,EAAMgU,eACrBC,EAAeD,EAAahS,SAAS+R,EAAQjB,OACnD,GAAIkB,EAAahS,SAAS+R,EAAQvO,WAA2C,WAA9BuO,EAAQtO,QAAQ8M,YAA2B0B,GAA8C,YAA9BF,EAAQtO,QAAQ8M,WAA2B0B,EACnJ,SAIF,GAAIF,EAAQjB,MAAM1tB,SAAS4a,EAAM7S,UAA2B,UAAf6S,EAAMqB,MA/RvC,QA+R2DrB,EAAMtiB,KAAqB,qCAAqCuG,KAAK+b,EAAM7S,OAAOya,UACvJ,SAEF,MAAMlH,EAAgB,CACpBA,cAAeqT,EAAQvO,UAEN,UAAfxF,EAAMqB,OACRX,EAAciH,WAAa3H,GAE7B+T,EAAQZ,cAAczS,EACxB,CACF,CACA,4BAAOwT,CAAsBlU,GAI3B,MAAMmU,EAAU,kBAAkBlwB,KAAK+b,EAAM7S,OAAOya,SAC9CwM,EAjTW,WAiTKpU,EAAMtiB,IACtB22B,EAAkB,CAAClD,GAAgBC,IAAkBpP,SAAShC,EAAMtiB,KAC1E,IAAK22B,IAAoBD,EACvB,OAEF,GAAID,IAAYC,EACd,OAEFpU,EAAMkD,iBAGN,MAAMoR,EAAkB1T,KAAK+F,QAAQkL,IAA0BjR,KAAO4F,GAAeM,KAAKlG,KAAMiR,IAAwB,IAAMrL,GAAe/gB,KAAKmb,KAAMiR,IAAwB,IAAMrL,GAAeC,QAAQoL,GAAwB7R,EAAMW,eAAehb,YACpPwF,EAAWwnB,GAASzM,oBAAoBoO,GAC9C,GAAID,EAIF,OAHArU,EAAMuU,kBACNppB,EAASmlB,YACTnlB,EAASyoB,gBAAgB5T,GAGvB7U,EAASilB,aAEXpQ,EAAMuU,kBACNppB,EAASklB,OACTiE,EAAgBpB,QAEpB,EAOF/R,GAAac,GAAGhc,SAAUyrB,GAAwBG,GAAwBc,GAASuB,uBACnF/S,GAAac,GAAGhc,SAAUyrB,GAAwBK,GAAeY,GAASuB,uBAC1E/S,GAAac,GAAGhc,SAAUwrB,GAAwBkB,GAASkB,YAC3D1S,GAAac,GAAGhc,SAAU0rB,GAAsBgB,GAASkB,YACzD1S,GAAac,GAAGhc,SAAUwrB,GAAwBI,IAAwB,SAAU7R,GAClFA,EAAMkD,iBACNyP,GAASzM,oBAAoBtF,MAAM0H,QACrC,IAMAvL,GAAmB4V,IAcnB,MAAM6B,GAAS,WAETC,GAAoB,OACpBC,GAAkB,gBAAgBF,KAClCG,GAAY,CAChBC,UAAW,iBACXC,cAAe,KACf7O,YAAY,EACZzK,WAAW,EAEXuZ,YAAa,QAGTC,GAAgB,CACpBH,UAAW,SACXC,cAAe,kBACf7O,WAAY,UACZzK,UAAW,UACXuZ,YAAa,oBAOf,MAAME,WAAiB3Q,GACrB,WAAAU,CAAYL,GACVa,QACA3E,KAAK6E,QAAU7E,KAAK6D,WAAWC,GAC/B9D,KAAKqU,aAAc,EACnBrU,KAAK4E,SAAW,IAClB,CAGA,kBAAWlB,GACT,OAAOqQ,EACT,CACA,sBAAWpQ,GACT,OAAOwQ,EACT,CACA,eAAW5X,GACT,OAAOqX,EACT,CAGA,IAAAlE,CAAKrT,GACH,IAAK2D,KAAK6E,QAAQlK,UAEhB,YADAkC,GAAQR,GAGV2D,KAAKsU,UACL,MAAM/0B,EAAUygB,KAAKuU,cACjBvU,KAAK6E,QAAQO,YACfvJ,GAAOtc,GAETA,EAAQ8b,UAAU5E,IAAIod,IACtB7T,KAAKwU,mBAAkB,KACrB3X,GAAQR,EAAS,GAErB,CACA,IAAAoT,CAAKpT,GACE2D,KAAK6E,QAAQlK,WAIlBqF,KAAKuU,cAAclZ,UAAU1B,OAAOka,IACpC7T,KAAKwU,mBAAkB,KACrBxU,KAAK+E,UACLlI,GAAQR,EAAS,KANjBQ,GAAQR,EAQZ,CACA,OAAA0I,GACO/E,KAAKqU,cAGV9T,GAAaC,IAAIR,KAAK4E,SAAUkP,IAChC9T,KAAK4E,SAASjL,SACdqG,KAAKqU,aAAc,EACrB,CAGA,WAAAE,GACE,IAAKvU,KAAK4E,SAAU,CAClB,MAAM6P,EAAWpvB,SAASqvB,cAAc,OACxCD,EAAST,UAAYhU,KAAK6E,QAAQmP,UAC9BhU,KAAK6E,QAAQO,YACfqP,EAASpZ,UAAU5E,IArFD,QAuFpBuJ,KAAK4E,SAAW6P,CAClB,CACA,OAAOzU,KAAK4E,QACd,CACA,iBAAAZ,CAAkBF,GAGhB,OADAA,EAAOoQ,YAAcxZ,GAAWoJ,EAAOoQ,aAChCpQ,CACT,CACA,OAAAwQ,GACE,GAAItU,KAAKqU,YACP,OAEF,MAAM90B,EAAUygB,KAAKuU,cACrBvU,KAAK6E,QAAQqP,YAAYS,OAAOp1B,GAChCghB,GAAac,GAAG9hB,EAASu0B,IAAiB,KACxCjX,GAAQmD,KAAK6E,QAAQoP,cAAc,IAErCjU,KAAKqU,aAAc,CACrB,CACA,iBAAAG,CAAkBnY,GAChBW,GAAuBX,EAAU2D,KAAKuU,cAAevU,KAAK6E,QAAQO,WACpE,EAeF,MAEMwP,GAAc,gBACdC,GAAkB,UAAUD,KAC5BE,GAAoB,cAAcF,KAGlCG,GAAmB,WACnBC,GAAY,CAChBC,WAAW,EACXC,YAAa,MAGTC,GAAgB,CACpBF,UAAW,UACXC,YAAa,WAOf,MAAME,WAAkB3R,GACtB,WAAAU,CAAYL,GACVa,QACA3E,KAAK6E,QAAU7E,KAAK6D,WAAWC,GAC/B9D,KAAKqV,WAAY,EACjBrV,KAAKsV,qBAAuB,IAC9B,CAGA,kBAAW5R,GACT,OAAOsR,EACT,CACA,sBAAWrR,GACT,OAAOwR,EACT,CACA,eAAW5Y,GACT,MAtCW,WAuCb,CAGA,QAAAgZ,GACMvV,KAAKqV,YAGLrV,KAAK6E,QAAQoQ,WACfjV,KAAK6E,QAAQqQ,YAAY5C,QAE3B/R,GAAaC,IAAInb,SAAUuvB,IAC3BrU,GAAac,GAAGhc,SAAUwvB,IAAiBzV,GAASY,KAAKwV,eAAepW,KACxEmB,GAAac,GAAGhc,SAAUyvB,IAAmB1V,GAASY,KAAKyV,eAAerW,KAC1EY,KAAKqV,WAAY,EACnB,CACA,UAAAK,GACO1V,KAAKqV,YAGVrV,KAAKqV,WAAY,EACjB9U,GAAaC,IAAInb,SAAUuvB,IAC7B,CAGA,cAAAY,CAAepW,GACb,MAAM,YACJ8V,GACElV,KAAK6E,QACT,GAAIzF,EAAM7S,SAAWlH,UAAY+Z,EAAM7S,SAAW2oB,GAAeA,EAAY1wB,SAAS4a,EAAM7S,QAC1F,OAEF,MAAM1L,EAAW+kB,GAAeU,kBAAkB4O,GAC1B,IAApBr0B,EAAS6P,OACXwkB,EAAY5C,QACHtS,KAAKsV,uBAAyBP,GACvCl0B,EAASA,EAAS6P,OAAS,GAAG4hB,QAE9BzxB,EAAS,GAAGyxB,OAEhB,CACA,cAAAmD,CAAerW,GA1ED,QA2ERA,EAAMtiB,MAGVkjB,KAAKsV,qBAAuBlW,EAAMuW,SAAWZ,GA7EzB,UA8EtB,EAeF,MAAMa,GAAyB,oDACzBC,GAA0B,cAC1BC,GAAmB,gBACnBC,GAAkB,eAMxB,MAAMC,GACJ,WAAA7R,GACEnE,KAAK4E,SAAWvf,SAAS6G,IAC3B,CAGA,QAAA+pB,GAEE,MAAMC,EAAgB7wB,SAASC,gBAAgBuC,YAC/C,OAAO1F,KAAKoC,IAAI3E,OAAOu2B,WAAaD,EACtC,CACA,IAAAzG,GACE,MAAM5rB,EAAQmc,KAAKiW,WACnBjW,KAAKoW,mBAELpW,KAAKqW,sBAAsBrW,KAAK4E,SAAUkR,IAAkBQ,GAAmBA,EAAkBzyB,IAEjGmc,KAAKqW,sBAAsBT,GAAwBE,IAAkBQ,GAAmBA,EAAkBzyB,IAC1Gmc,KAAKqW,sBAAsBR,GAAyBE,IAAiBO,GAAmBA,EAAkBzyB,GAC5G,CACA,KAAAwO,GACE2N,KAAKuW,wBAAwBvW,KAAK4E,SAAU,YAC5C5E,KAAKuW,wBAAwBvW,KAAK4E,SAAUkR,IAC5C9V,KAAKuW,wBAAwBX,GAAwBE,IACrD9V,KAAKuW,wBAAwBV,GAAyBE,GACxD,CACA,aAAAS,GACE,OAAOxW,KAAKiW,WAAa,CAC3B,CAGA,gBAAAG,GACEpW,KAAKyW,sBAAsBzW,KAAK4E,SAAU,YAC1C5E,KAAK4E,SAAS7jB,MAAM+K,SAAW,QACjC,CACA,qBAAAuqB,CAAsBtc,EAAU2c,EAAera,GAC7C,MAAMsa,EAAiB3W,KAAKiW,WAS5BjW,KAAK4W,2BAA2B7c,GARHxa,IAC3B,GAAIA,IAAYygB,KAAK4E,UAAYhlB,OAAOu2B,WAAa52B,EAAQsI,YAAc8uB,EACzE,OAEF3W,KAAKyW,sBAAsBl3B,EAASm3B,GACpC,MAAMJ,EAAkB12B,OAAOqF,iBAAiB1F,GAASub,iBAAiB4b,GAC1En3B,EAAQwB,MAAM81B,YAAYH,EAAe,GAAGra,EAASkB,OAAOC,WAAW8Y,QAAsB,GAGjG,CACA,qBAAAG,CAAsBl3B,EAASm3B,GAC7B,MAAMI,EAAcv3B,EAAQwB,MAAM+Z,iBAAiB4b,GAC/CI,GACF9T,GAAYC,iBAAiB1jB,EAASm3B,EAAeI,EAEzD,CACA,uBAAAP,CAAwBxc,EAAU2c,GAWhC1W,KAAK4W,2BAA2B7c,GAVHxa,IAC3B,MAAM5B,EAAQqlB,GAAYQ,iBAAiBjkB,EAASm3B,GAEtC,OAAV/4B,GAIJqlB,GAAYE,oBAAoB3jB,EAASm3B,GACzCn3B,EAAQwB,MAAM81B,YAAYH,EAAe/4B,IAJvC4B,EAAQwB,MAAMg2B,eAAeL,EAIgB,GAGnD,CACA,0BAAAE,CAA2B7c,EAAUid,GACnC,GAAI,GAAUjd,GACZid,EAASjd,QAGX,IAAK,MAAMkd,KAAOrR,GAAezT,KAAK4H,EAAUiG,KAAK4E,UACnDoS,EAASC,EAEb,EAeF,MAEMC,GAAc,YAGdC,GAAe,OAAOD,KACtBE,GAAyB,gBAAgBF,KACzCG,GAAiB,SAASH,KAC1BI,GAAe,OAAOJ,KACtBK,GAAgB,QAAQL,KACxBM,GAAiB,SAASN,KAC1BO,GAAsB,gBAAgBP,KACtCQ,GAA0B,oBAAoBR,KAC9CS,GAA0B,kBAAkBT,KAC5CU,GAAyB,QAAQV,cACjCW,GAAkB,aAElBC,GAAoB,OACpBC,GAAoB,eAKpBC,GAAY,CAChBvD,UAAU,EACVnC,OAAO,EACPzH,UAAU,GAENoN,GAAgB,CACpBxD,SAAU,mBACVnC,MAAO,UACPzH,SAAU,WAOZ,MAAMqN,WAAcxT,GAClB,WAAAP,CAAY5kB,EAASukB,GACnBa,MAAMplB,EAASukB,GACf9D,KAAKmY,QAAUvS,GAAeC,QArBV,gBAqBmC7F,KAAK4E,UAC5D5E,KAAKoY,UAAYpY,KAAKqY,sBACtBrY,KAAKsY,WAAatY,KAAKuY,uBACvBvY,KAAKwP,UAAW,EAChBxP,KAAKgP,kBAAmB,EACxBhP,KAAKwY,WAAa,IAAIxC,GACtBhW,KAAK0L,oBACP,CAGA,kBAAWhI,GACT,OAAOsU,EACT,CACA,sBAAWrU,GACT,OAAOsU,EACT,CACA,eAAW1b,GACT,MA1DW,OA2Db,CAGA,MAAAmL,CAAO5H,GACL,OAAOE,KAAKwP,SAAWxP,KAAKyP,OAASzP,KAAK0P,KAAK5P,EACjD,CACA,IAAA4P,CAAK5P,GACCE,KAAKwP,UAAYxP,KAAKgP,kBAGRzO,GAAaqB,QAAQ5B,KAAK4E,SAAU0S,GAAc,CAClExX,kBAEYkC,mBAGdhC,KAAKwP,UAAW,EAChBxP,KAAKgP,kBAAmB,EACxBhP,KAAKwY,WAAW/I,OAChBpqB,SAAS6G,KAAKmP,UAAU5E,IAAIohB,IAC5B7X,KAAKyY,gBACLzY,KAAKoY,UAAU1I,MAAK,IAAM1P,KAAK0Y,aAAa5Y,KAC9C,CACA,IAAA2P,GACOzP,KAAKwP,WAAYxP,KAAKgP,mBAGTzO,GAAaqB,QAAQ5B,KAAK4E,SAAUuS,IACxCnV,mBAGdhC,KAAKwP,UAAW,EAChBxP,KAAKgP,kBAAmB,EACxBhP,KAAKsY,WAAW5C,aAChB1V,KAAK4E,SAASvJ,UAAU1B,OAAOme,IAC/B9X,KAAKmF,gBAAe,IAAMnF,KAAK2Y,cAAc3Y,KAAK4E,SAAU5E,KAAK6N,gBACnE,CACA,OAAA9I,GACExE,GAAaC,IAAI5gB,OAAQs3B,IACzB3W,GAAaC,IAAIR,KAAKmY,QAASjB,IAC/BlX,KAAKoY,UAAUrT,UACf/E,KAAKsY,WAAW5C,aAChB/Q,MAAMI,SACR,CACA,YAAA6T,GACE5Y,KAAKyY,eACP,CAGA,mBAAAJ,GACE,OAAO,IAAIjE,GAAS,CAClBzZ,UAAWmG,QAAQd,KAAK6E,QAAQ4P,UAEhCrP,WAAYpF,KAAK6N,eAErB,CACA,oBAAA0K,GACE,OAAO,IAAInD,GAAU,CACnBF,YAAalV,KAAK4E,UAEtB,CACA,YAAA8T,CAAa5Y,GAENza,SAAS6G,KAAK1H,SAASwb,KAAK4E,WAC/Bvf,SAAS6G,KAAKyoB,OAAO3U,KAAK4E,UAE5B5E,KAAK4E,SAAS7jB,MAAM6wB,QAAU,QAC9B5R,KAAK4E,SAASzjB,gBAAgB,eAC9B6e,KAAK4E,SAASxjB,aAAa,cAAc,GACzC4e,KAAK4E,SAASxjB,aAAa,OAAQ,UACnC4e,KAAK4E,SAASnZ,UAAY,EAC1B,MAAMotB,EAAYjT,GAAeC,QA7GT,cA6GsC7F,KAAKmY,SAC/DU,IACFA,EAAUptB,UAAY,GAExBoQ,GAAOmE,KAAK4E,UACZ5E,KAAK4E,SAASvJ,UAAU5E,IAAIqhB,IAU5B9X,KAAKmF,gBATsB,KACrBnF,KAAK6E,QAAQyN,OACftS,KAAKsY,WAAW/C,WAElBvV,KAAKgP,kBAAmB,EACxBzO,GAAaqB,QAAQ5B,KAAK4E,SAAU2S,GAAe,CACjDzX,iBACA,GAEoCE,KAAKmY,QAASnY,KAAK6N,cAC7D,CACA,kBAAAnC,GACEnL,GAAac,GAAGrB,KAAK4E,SAAU+S,IAAyBvY,IAhJvC,WAiJXA,EAAMtiB,MAGNkjB,KAAK6E,QAAQgG,SACf7K,KAAKyP,OAGPzP,KAAK8Y,6BAA4B,IAEnCvY,GAAac,GAAGzhB,OAAQ43B,IAAgB,KAClCxX,KAAKwP,WAAaxP,KAAKgP,kBACzBhP,KAAKyY,eACP,IAEFlY,GAAac,GAAGrB,KAAK4E,SAAU8S,IAAyBtY,IAEtDmB,GAAae,IAAItB,KAAK4E,SAAU6S,IAAqBsB,IAC/C/Y,KAAK4E,WAAaxF,EAAM7S,QAAUyT,KAAK4E,WAAamU,EAAOxsB,SAGjC,WAA1ByT,KAAK6E,QAAQ4P,SAIbzU,KAAK6E,QAAQ4P,UACfzU,KAAKyP,OAJLzP,KAAK8Y,6BAKP,GACA,GAEN,CACA,UAAAH,GACE3Y,KAAK4E,SAAS7jB,MAAM6wB,QAAU,OAC9B5R,KAAK4E,SAASxjB,aAAa,eAAe,GAC1C4e,KAAK4E,SAASzjB,gBAAgB,cAC9B6e,KAAK4E,SAASzjB,gBAAgB,QAC9B6e,KAAKgP,kBAAmB,EACxBhP,KAAKoY,UAAU3I,MAAK,KAClBpqB,SAAS6G,KAAKmP,UAAU1B,OAAOke,IAC/B7X,KAAKgZ,oBACLhZ,KAAKwY,WAAWnmB,QAChBkO,GAAaqB,QAAQ5B,KAAK4E,SAAUyS,GAAe,GAEvD,CACA,WAAAxJ,GACE,OAAO7N,KAAK4E,SAASvJ,UAAU7W,SAjLT,OAkLxB,CACA,0BAAAs0B,GAEE,GADkBvY,GAAaqB,QAAQ5B,KAAK4E,SAAUwS,IACxCpV,iBACZ,OAEF,MAAMiX,EAAqBjZ,KAAK4E,SAASvX,aAAehI,SAASC,gBAAgBsC,aAC3EsxB,EAAmBlZ,KAAK4E,SAAS7jB,MAAMiL,UAEpB,WAArBktB,GAAiClZ,KAAK4E,SAASvJ,UAAU7W,SAASuzB,MAGjEkB,IACHjZ,KAAK4E,SAAS7jB,MAAMiL,UAAY,UAElCgU,KAAK4E,SAASvJ,UAAU5E,IAAIshB,IAC5B/X,KAAKmF,gBAAe,KAClBnF,KAAK4E,SAASvJ,UAAU1B,OAAOoe,IAC/B/X,KAAKmF,gBAAe,KAClBnF,KAAK4E,SAAS7jB,MAAMiL,UAAYktB,CAAgB,GAC/ClZ,KAAKmY,QAAQ,GACfnY,KAAKmY,SACRnY,KAAK4E,SAAS0N,QAChB,CAMA,aAAAmG,GACE,MAAMQ,EAAqBjZ,KAAK4E,SAASvX,aAAehI,SAASC,gBAAgBsC,aAC3E+uB,EAAiB3W,KAAKwY,WAAWvC,WACjCkD,EAAoBxC,EAAiB,EAC3C,GAAIwC,IAAsBF,EAAoB,CAC5C,MAAMn3B,EAAWma,KAAU,cAAgB,eAC3C+D,KAAK4E,SAAS7jB,MAAMe,GAAY,GAAG60B,KACrC,CACA,IAAKwC,GAAqBF,EAAoB,CAC5C,MAAMn3B,EAAWma,KAAU,eAAiB,cAC5C+D,KAAK4E,SAAS7jB,MAAMe,GAAY,GAAG60B,KACrC,CACF,CACA,iBAAAqC,GACEhZ,KAAK4E,SAAS7jB,MAAMq4B,YAAc,GAClCpZ,KAAK4E,SAAS7jB,MAAMs4B,aAAe,EACrC,CAGA,sBAAO5c,CAAgBqH,EAAQhE,GAC7B,OAAOE,KAAKuH,MAAK,WACf,MAAMld,EAAO6tB,GAAM5S,oBAAoBtF,KAAM8D,GAC7C,GAAsB,iBAAXA,EAAX,CAGA,QAA4B,IAAjBzZ,EAAKyZ,GACd,MAAM,IAAIU,UAAU,oBAAoBV,MAE1CzZ,EAAKyZ,GAAQhE,EAJb,CAKF,GACF,EAOFS,GAAac,GAAGhc,SAAUuyB,GA9OK,4BA8O2C,SAAUxY,GAClF,MAAM7S,EAASqZ,GAAec,uBAAuB1G,MACjD,CAAC,IAAK,QAAQoB,SAASpB,KAAKgH,UAC9B5H,EAAMkD,iBAER/B,GAAae,IAAI/U,EAAQ+qB,IAAcgC,IACjCA,EAAUtX,kBAIdzB,GAAae,IAAI/U,EAAQ8qB,IAAgB,KACnC1c,GAAUqF,OACZA,KAAKsS,OACP,GACA,IAIJ,MAAMiH,EAAc3T,GAAeC,QAnQb,eAoQlB0T,GACFrB,GAAM7S,YAAYkU,GAAa9J,OAEpByI,GAAM5S,oBAAoB/Y,GAClCmb,OAAO1H,KACd,IACA4G,GAAqBsR,IAMrB/b,GAAmB+b,IAcnB,MAEMsB,GAAc,gBACdC,GAAiB,YACjBC,GAAwB,OAAOF,KAAcC,KAE7CE,GAAoB,OACpBC,GAAuB,UACvBC,GAAoB,SAEpBC,GAAgB,kBAChBC,GAAe,OAAOP,KACtBQ,GAAgB,QAAQR,KACxBS,GAAe,OAAOT,KACtBU,GAAuB,gBAAgBV,KACvCW,GAAiB,SAASX,KAC1BY,GAAe,SAASZ,KACxBa,GAAyB,QAAQb,KAAcC,KAC/Ca,GAAwB,kBAAkBd,KAE1Ce,GAAY,CAChB9F,UAAU,EACV5J,UAAU,EACVpgB,QAAQ,GAEJ+vB,GAAgB,CACpB/F,SAAU,mBACV5J,SAAU,UACVpgB,OAAQ,WAOV,MAAMgwB,WAAkB/V,GACtB,WAAAP,CAAY5kB,EAASukB,GACnBa,MAAMplB,EAASukB,GACf9D,KAAKwP,UAAW,EAChBxP,KAAKoY,UAAYpY,KAAKqY,sBACtBrY,KAAKsY,WAAatY,KAAKuY,uBACvBvY,KAAK0L,oBACP,CAGA,kBAAWhI,GACT,OAAO6W,EACT,CACA,sBAAW5W,GACT,OAAO6W,EACT,CACA,eAAWje,GACT,MApDW,WAqDb,CAGA,MAAAmL,CAAO5H,GACL,OAAOE,KAAKwP,SAAWxP,KAAKyP,OAASzP,KAAK0P,KAAK5P,EACjD,CACA,IAAA4P,CAAK5P,GACCE,KAAKwP,UAGSjP,GAAaqB,QAAQ5B,KAAK4E,SAAUmV,GAAc,CAClEja,kBAEYkC,mBAGdhC,KAAKwP,UAAW,EAChBxP,KAAKoY,UAAU1I,OACV1P,KAAK6E,QAAQpa,SAChB,IAAIurB,IAAkBvG,OAExBzP,KAAK4E,SAASxjB,aAAa,cAAc,GACzC4e,KAAK4E,SAASxjB,aAAa,OAAQ,UACnC4e,KAAK4E,SAASvJ,UAAU5E,IAAImjB,IAW5B5Z,KAAKmF,gBAVoB,KAClBnF,KAAK6E,QAAQpa,SAAUuV,KAAK6E,QAAQ4P,UACvCzU,KAAKsY,WAAW/C,WAElBvV,KAAK4E,SAASvJ,UAAU5E,IAAIkjB,IAC5B3Z,KAAK4E,SAASvJ,UAAU1B,OAAOigB,IAC/BrZ,GAAaqB,QAAQ5B,KAAK4E,SAAUoV,GAAe,CACjDla,iBACA,GAEkCE,KAAK4E,UAAU,GACvD,CACA,IAAA6K,GACOzP,KAAKwP,WAGQjP,GAAaqB,QAAQ5B,KAAK4E,SAAUqV,IACxCjY,mBAGdhC,KAAKsY,WAAW5C,aAChB1V,KAAK4E,SAAS8V,OACd1a,KAAKwP,UAAW,EAChBxP,KAAK4E,SAASvJ,UAAU5E,IAAIojB,IAC5B7Z,KAAKoY,UAAU3I,OAUfzP,KAAKmF,gBAToB,KACvBnF,KAAK4E,SAASvJ,UAAU1B,OAAOggB,GAAmBE,IAClD7Z,KAAK4E,SAASzjB,gBAAgB,cAC9B6e,KAAK4E,SAASzjB,gBAAgB,QACzB6e,KAAK6E,QAAQpa,SAChB,IAAIurB,IAAkB3jB,QAExBkO,GAAaqB,QAAQ5B,KAAK4E,SAAUuV,GAAe,GAEfna,KAAK4E,UAAU,IACvD,CACA,OAAAG,GACE/E,KAAKoY,UAAUrT,UACf/E,KAAKsY,WAAW5C,aAChB/Q,MAAMI,SACR,CAGA,mBAAAsT,GACE,MASM1d,EAAYmG,QAAQd,KAAK6E,QAAQ4P,UACvC,OAAO,IAAIL,GAAS,CAClBJ,UA3HsB,qBA4HtBrZ,YACAyK,YAAY,EACZ8O,YAAalU,KAAK4E,SAAS7f,WAC3BkvB,cAAetZ,EAfK,KACU,WAA1BqF,KAAK6E,QAAQ4P,SAIjBzU,KAAKyP,OAHHlP,GAAaqB,QAAQ5B,KAAK4E,SAAUsV,GAG3B,EAUgC,MAE/C,CACA,oBAAA3B,GACE,OAAO,IAAInD,GAAU,CACnBF,YAAalV,KAAK4E,UAEtB,CACA,kBAAA8G,GACEnL,GAAac,GAAGrB,KAAK4E,SAAU0V,IAAuBlb,IA5IvC,WA6ITA,EAAMtiB,MAGNkjB,KAAK6E,QAAQgG,SACf7K,KAAKyP,OAGPlP,GAAaqB,QAAQ5B,KAAK4E,SAAUsV,IAAqB,GAE7D,CAGA,sBAAOzd,CAAgBqH,GACrB,OAAO9D,KAAKuH,MAAK,WACf,MAAMld,EAAOowB,GAAUnV,oBAAoBtF,KAAM8D,GACjD,GAAsB,iBAAXA,EAAX,CAGA,QAAqB/K,IAAjB1O,EAAKyZ,IAAyBA,EAAOrC,WAAW,MAAmB,gBAAXqC,EAC1D,MAAM,IAAIU,UAAU,oBAAoBV,MAE1CzZ,EAAKyZ,GAAQ9D,KAJb,CAKF,GACF,EAOFO,GAAac,GAAGhc,SAAUg1B,GA7JK,gCA6J2C,SAAUjb,GAClF,MAAM7S,EAASqZ,GAAec,uBAAuB1G,MAIrD,GAHI,CAAC,IAAK,QAAQoB,SAASpB,KAAKgH,UAC9B5H,EAAMkD,iBAEJpH,GAAW8E,MACb,OAEFO,GAAae,IAAI/U,EAAQ4tB,IAAgB,KAEnCxf,GAAUqF,OACZA,KAAKsS,OACP,IAIF,MAAMiH,EAAc3T,GAAeC,QAAQiU,IACvCP,GAAeA,IAAgBhtB,GACjCkuB,GAAUpV,YAAYkU,GAAa9J,OAExBgL,GAAUnV,oBAAoB/Y,GACtCmb,OAAO1H,KACd,IACAO,GAAac,GAAGzhB,OAAQ85B,IAAuB,KAC7C,IAAK,MAAM3f,KAAY6L,GAAezT,KAAK2nB,IACzCW,GAAUnV,oBAAoBvL,GAAU2V,MAC1C,IAEFnP,GAAac,GAAGzhB,OAAQw6B,IAAc,KACpC,IAAK,MAAM76B,KAAWqmB,GAAezT,KAAK,gDACG,UAAvClN,iBAAiB1F,GAASiC,UAC5Bi5B,GAAUnV,oBAAoB/lB,GAASkwB,MAE3C,IAEF7I,GAAqB6T,IAMrBte,GAAmBse,IAUnB,MACME,GAAmB,CAEvB,IAAK,CAAC,QAAS,MAAO,KAAM,OAAQ,OAHP,kBAI7B9pB,EAAG,CAAC,SAAU,OAAQ,QAAS,OAC/B+pB,KAAM,GACN9pB,EAAG,GACH+pB,GAAI,GACJC,IAAK,GACLC,KAAM,GACNC,IAAK,GACLC,GAAI,GACJC,GAAI,GACJC,GAAI,GACJC,GAAI,GACJC,GAAI,GACJC,GAAI,GACJC,GAAI,GACJC,GAAI,GACJnqB,EAAG,GACHub,IAAK,CAAC,MAAO,SAAU,MAAO,QAAS,QAAS,UAChD6O,GAAI,GACJC,GAAI,GACJC,EAAG,GACHC,IAAK,GACLC,EAAG,GACHC,MAAO,GACPC,KAAM,GACNC,IAAK,GACLC,IAAK,GACLC,OAAQ,GACRC,EAAG,GACHC,GAAI,IAIAC,GAAgB,IAAI/lB,IAAI,CAAC,aAAc,OAAQ,OAAQ,WAAY,WAAY,SAAU,MAAO,eAShGgmB,GAAmB,0DACnBC,GAAmB,CAACx6B,EAAWy6B,KACnC,MAAMC,EAAgB16B,EAAUvC,SAASC,cACzC,OAAI+8B,EAAqBpb,SAASqb,IAC5BJ,GAAc1lB,IAAI8lB,IACb3b,QAAQwb,GAAiBj5B,KAAKtB,EAAU26B,YAM5CF,EAAqBr2B,QAAOw2B,GAAkBA,aAA0BpY,SAAQ9R,MAAKmqB,GAASA,EAAMv5B,KAAKo5B,IAAe,EA0C3HI,GAAY,CAChBC,UAAWnC,GACXoC,QAAS,CAAC,EAEVC,WAAY,GACZnwB,MAAM,EACNowB,UAAU,EACVC,WAAY,KACZC,SAAU,eAENC,GAAgB,CACpBN,UAAW,SACXC,QAAS,SACTC,WAAY,oBACZnwB,KAAM,UACNowB,SAAU,UACVC,WAAY,kBACZC,SAAU,UAENE,GAAqB,CACzBC,MAAO,iCACPvjB,SAAU,oBAOZ,MAAMwjB,WAAwB9Z,GAC5B,WAAAU,CAAYL,GACVa,QACA3E,KAAK6E,QAAU7E,KAAK6D,WAAWC,EACjC,CAGA,kBAAWJ,GACT,OAAOmZ,EACT,CACA,sBAAWlZ,GACT,OAAOyZ,EACT,CACA,eAAW7gB,GACT,MA3CW,iBA4Cb,CAGA,UAAAihB,GACE,OAAOxgC,OAAOmiB,OAAOa,KAAK6E,QAAQkY,SAASj6B,KAAIghB,GAAU9D,KAAKyd,yBAAyB3Z,KAAS3d,OAAO2a,QACzG,CACA,UAAA4c,GACE,OAAO1d,KAAKwd,aAAa9sB,OAAS,CACpC,CACA,aAAAitB,CAAcZ,GAMZ,OALA/c,KAAK4d,cAAcb,GACnB/c,KAAK6E,QAAQkY,QAAU,IAClB/c,KAAK6E,QAAQkY,WACbA,GAEE/c,IACT,CACA,MAAA6d,GACE,MAAMC,EAAkBz4B,SAASqvB,cAAc,OAC/CoJ,EAAgBC,UAAY/d,KAAKge,eAAehe,KAAK6E,QAAQsY,UAC7D,IAAK,MAAOpjB,EAAUkkB,KAASjhC,OAAOmkB,QAAQnB,KAAK6E,QAAQkY,SACzD/c,KAAKke,YAAYJ,EAAiBG,EAAMlkB,GAE1C,MAAMojB,EAAWW,EAAgBhY,SAAS,GACpCkX,EAAahd,KAAKyd,yBAAyBzd,KAAK6E,QAAQmY,YAI9D,OAHIA,GACFG,EAAS9hB,UAAU5E,OAAOumB,EAAW96B,MAAM,MAEtCi7B,CACT,CAGA,gBAAAlZ,CAAiBH,GACfa,MAAMV,iBAAiBH,GACvB9D,KAAK4d,cAAc9Z,EAAOiZ,QAC5B,CACA,aAAAa,CAAcO,GACZ,IAAK,MAAOpkB,EAAUgjB,KAAY//B,OAAOmkB,QAAQgd,GAC/CxZ,MAAMV,iBAAiB,CACrBlK,WACAujB,MAAOP,GACNM,GAEP,CACA,WAAAa,CAAYf,EAAUJ,EAAShjB,GAC7B,MAAMqkB,EAAkBxY,GAAeC,QAAQ9L,EAAUojB,GACpDiB,KAGLrB,EAAU/c,KAAKyd,yBAAyBV,IAKpC,GAAUA,GACZ/c,KAAKqe,sBAAsB3jB,GAAWqiB,GAAUqB,GAG9Cpe,KAAK6E,QAAQhY,KACfuxB,EAAgBL,UAAY/d,KAAKge,eAAejB,GAGlDqB,EAAgBE,YAAcvB,EAX5BqB,EAAgBzkB,SAYpB,CACA,cAAAqkB,CAAeG,GACb,OAAOne,KAAK6E,QAAQoY,SApJxB,SAAsBsB,EAAYzB,EAAW0B,GAC3C,IAAKD,EAAW7tB,OACd,OAAO6tB,EAET,GAAIC,GAAgD,mBAArBA,EAC7B,OAAOA,EAAiBD,GAE1B,MACME,GADY,IAAI7+B,OAAO8+B,WACKC,gBAAgBJ,EAAY,aACxD19B,EAAW,GAAGlC,UAAU8/B,EAAgBvyB,KAAKkU,iBAAiB,MACpE,IAAK,MAAM7gB,KAAWsB,EAAU,CAC9B,MAAM+9B,EAAcr/B,EAAQC,SAASC,cACrC,IAAKzC,OAAO4D,KAAKk8B,GAAW1b,SAASwd,GAAc,CACjDr/B,EAAQoa,SACR,QACF,CACA,MAAMklB,EAAgB,GAAGlgC,UAAUY,EAAQ0B,YACrC69B,EAAoB,GAAGngC,OAAOm+B,EAAU,MAAQ,GAAIA,EAAU8B,IAAgB,IACpF,IAAK,MAAM78B,KAAa88B,EACjBtC,GAAiBx6B,EAAW+8B,IAC/Bv/B,EAAQ4B,gBAAgBY,EAAUvC,SAGxC,CACA,OAAOi/B,EAAgBvyB,KAAK6xB,SAC9B,CA2HmCgB,CAAaZ,EAAKne,KAAK6E,QAAQiY,UAAW9c,KAAK6E,QAAQqY,YAAciB,CACtG,CACA,wBAAAV,CAAyBU,GACvB,OAAOthB,GAAQshB,EAAK,CAACne,MACvB,CACA,qBAAAqe,CAAsB9+B,EAAS6+B,GAC7B,GAAIpe,KAAK6E,QAAQhY,KAGf,OAFAuxB,EAAgBL,UAAY,QAC5BK,EAAgBzJ,OAAOp1B,GAGzB6+B,EAAgBE,YAAc/+B,EAAQ++B,WACxC,EAeF,MACMU,GAAwB,IAAI1oB,IAAI,CAAC,WAAY,YAAa,eAC1D2oB,GAAoB,OAEpBC,GAAoB,OAEpBC,GAAiB,SACjBC,GAAmB,gBACnBC,GAAgB,QAChBC,GAAgB,QAahBC,GAAgB,CACpBC,KAAM,OACNC,IAAK,MACLC,MAAOzjB,KAAU,OAAS,QAC1B0jB,OAAQ,SACRC,KAAM3jB,KAAU,QAAU,QAEtB4jB,GAAY,CAChB/C,UAAWnC,GACXmF,WAAW,EACX7xB,SAAU,kBACV8xB,WAAW,EACXC,YAAa,GACbC,MAAO,EACPjwB,mBAAoB,CAAC,MAAO,QAAS,SAAU,QAC/CnD,MAAM,EACN7E,OAAQ,CAAC,EAAG,GACZtJ,UAAW,MACXmzB,aAAc,KACdoL,UAAU,EACVC,WAAY,KACZnjB,UAAU,EACVojB,SAAU,+GACV+C,MAAO,GACPte,QAAS,eAELue,GAAgB,CACpBrD,UAAW,SACXgD,UAAW,UACX7xB,SAAU,mBACV8xB,UAAW,2BACXC,YAAa,oBACbC,MAAO,kBACPjwB,mBAAoB,QACpBnD,KAAM,UACN7E,OAAQ,0BACRtJ,UAAW,oBACXmzB,aAAc,yBACdoL,SAAU,UACVC,WAAY,kBACZnjB,SAAU,mBACVojB,SAAU,SACV+C,MAAO,4BACPte,QAAS,UAOX,MAAMwe,WAAgB1b,GACpB,WAAAP,CAAY5kB,EAASukB,GACnB,QAAsB,IAAX,EACT,MAAM,IAAIU,UAAU,+DAEtBG,MAAMplB,EAASukB,GAGf9D,KAAKqgB,YAAa,EAClBrgB,KAAKsgB,SAAW,EAChBtgB,KAAKugB,WAAa,KAClBvgB,KAAKwgB,eAAiB,CAAC,EACvBxgB,KAAKgS,QAAU,KACfhS,KAAKygB,iBAAmB,KACxBzgB,KAAK0gB,YAAc,KAGnB1gB,KAAK2gB,IAAM,KACX3gB,KAAK4gB,gBACA5gB,KAAK6E,QAAQ9K,UAChBiG,KAAK6gB,WAET,CAGA,kBAAWnd,GACT,OAAOmc,EACT,CACA,sBAAWlc,GACT,OAAOwc,EACT,CACA,eAAW5jB,GACT,MAxGW,SAyGb,CAGA,MAAAukB,GACE9gB,KAAKqgB,YAAa,CACpB,CACA,OAAAU,GACE/gB,KAAKqgB,YAAa,CACpB,CACA,aAAAW,GACEhhB,KAAKqgB,YAAcrgB,KAAKqgB,UAC1B,CACA,MAAA3Y,GACO1H,KAAKqgB,aAGVrgB,KAAKwgB,eAAeS,OAASjhB,KAAKwgB,eAAeS,MAC7CjhB,KAAKwP,WACPxP,KAAKkhB,SAGPlhB,KAAKmhB,SACP,CACA,OAAApc,GACEgI,aAAa/M,KAAKsgB,UAClB/f,GAAaC,IAAIR,KAAK4E,SAAS5J,QAAQmkB,IAAiBC,GAAkBpf,KAAKohB,mBAC3EphB,KAAK4E,SAASpJ,aAAa,2BAC7BwE,KAAK4E,SAASxjB,aAAa,QAAS4e,KAAK4E,SAASpJ,aAAa,2BAEjEwE,KAAKqhB,iBACL1c,MAAMI,SACR,CACA,IAAA2K,GACE,GAAoC,SAAhC1P,KAAK4E,SAAS7jB,MAAM6wB,QACtB,MAAM,IAAIhO,MAAM,uCAElB,IAAM5D,KAAKshB,mBAAoBthB,KAAKqgB,WAClC,OAEF,MAAM/G,EAAY/Y,GAAaqB,QAAQ5B,KAAK4E,SAAU5E,KAAKmE,YAAYqB,UAlItD,SAoIX+b,GADa9lB,GAAeuE,KAAK4E,WACL5E,KAAK4E,SAAS9kB,cAAcwF,iBAAiBd,SAASwb,KAAK4E,UAC7F,GAAI0U,EAAUtX,mBAAqBuf,EACjC,OAIFvhB,KAAKqhB,iBACL,MAAMV,EAAM3gB,KAAKwhB,iBACjBxhB,KAAK4E,SAASxjB,aAAa,mBAAoBu/B,EAAInlB,aAAa,OAChE,MAAM,UACJukB,GACE/f,KAAK6E,QAYT,GAXK7E,KAAK4E,SAAS9kB,cAAcwF,gBAAgBd,SAASwb,KAAK2gB,OAC7DZ,EAAUpL,OAAOgM,GACjBpgB,GAAaqB,QAAQ5B,KAAK4E,SAAU5E,KAAKmE,YAAYqB,UAhJpC,cAkJnBxF,KAAKgS,QAAUhS,KAAKqS,cAAcsO,GAClCA,EAAItlB,UAAU5E,IAAIyoB,IAMd,iBAAkB75B,SAASC,gBAC7B,IAAK,MAAM/F,IAAW,GAAGZ,UAAU0G,SAAS6G,KAAK4Z,UAC/CvF,GAAac,GAAG9hB,EAAS,YAAaqc,IAU1CoE,KAAKmF,gBAPY,KACf5E,GAAaqB,QAAQ5B,KAAK4E,SAAU5E,KAAKmE,YAAYqB,UAhKrC,WAiKQ,IAApBxF,KAAKugB,YACPvgB,KAAKkhB,SAEPlhB,KAAKugB,YAAa,CAAK,GAEKvgB,KAAK2gB,IAAK3gB,KAAK6N,cAC/C,CACA,IAAA4B,GACE,GAAKzP,KAAKwP,aAGQjP,GAAaqB,QAAQ5B,KAAK4E,SAAU5E,KAAKmE,YAAYqB,UA/KtD,SAgLHxD,iBAAd,CAQA,GALYhC,KAAKwhB,iBACbnmB,UAAU1B,OAAOulB,IAIjB,iBAAkB75B,SAASC,gBAC7B,IAAK,MAAM/F,IAAW,GAAGZ,UAAU0G,SAAS6G,KAAK4Z,UAC/CvF,GAAaC,IAAIjhB,EAAS,YAAaqc,IAG3CoE,KAAKwgB,eAA4B,OAAI,EACrCxgB,KAAKwgB,eAAelB,KAAiB,EACrCtf,KAAKwgB,eAAenB,KAAiB,EACrCrf,KAAKugB,WAAa,KAYlBvgB,KAAKmF,gBAVY,KACXnF,KAAKyhB,yBAGJzhB,KAAKugB,YACRvgB,KAAKqhB,iBAEPrhB,KAAK4E,SAASzjB,gBAAgB,oBAC9Bof,GAAaqB,QAAQ5B,KAAK4E,SAAU5E,KAAKmE,YAAYqB,UAzMpC,WAyM8D,GAEnDxF,KAAK2gB,IAAK3gB,KAAK6N,cA1B7C,CA2BF,CACA,MAAA9iB,GACMiV,KAAKgS,SACPhS,KAAKgS,QAAQjnB,QAEjB,CAGA,cAAAu2B,GACE,OAAOxgB,QAAQd,KAAK0hB,YACtB,CACA,cAAAF,GAIE,OAHKxhB,KAAK2gB,MACR3gB,KAAK2gB,IAAM3gB,KAAK2hB,kBAAkB3hB,KAAK0gB,aAAe1gB,KAAK4hB,2BAEtD5hB,KAAK2gB,GACd,CACA,iBAAAgB,CAAkB5E,GAChB,MAAM4D,EAAM3gB,KAAK6hB,oBAAoB9E,GAASc,SAG9C,IAAK8C,EACH,OAAO,KAETA,EAAItlB,UAAU1B,OAAOslB,GAAmBC,IAExCyB,EAAItlB,UAAU5E,IAAI,MAAMuJ,KAAKmE,YAAY5H,aACzC,MAAMulB,EAvuGKC,KACb,GACEA,GAAU5/B,KAAK6/B,MA/BH,IA+BS7/B,KAAK8/B,gBACnB58B,SAAS68B,eAAeH,IACjC,OAAOA,CAAM,EAmuGGI,CAAOniB,KAAKmE,YAAY5H,MAAM1c,WAK5C,OAJA8gC,EAAIv/B,aAAa,KAAM0gC,GACnB9hB,KAAK6N,eACP8S,EAAItlB,UAAU5E,IAAIwoB,IAEb0B,CACT,CACA,UAAAyB,CAAWrF,GACT/c,KAAK0gB,YAAc3D,EACf/c,KAAKwP,aACPxP,KAAKqhB,iBACLrhB,KAAK0P,OAET,CACA,mBAAAmS,CAAoB9E,GAYlB,OAXI/c,KAAKygB,iBACPzgB,KAAKygB,iBAAiB9C,cAAcZ,GAEpC/c,KAAKygB,iBAAmB,IAAIlD,GAAgB,IACvCvd,KAAK6E,QAGRkY,UACAC,WAAYhd,KAAKyd,yBAAyBzd,KAAK6E,QAAQmb,eAGpDhgB,KAAKygB,gBACd,CACA,sBAAAmB,GACE,MAAO,CACL,iBAA0B5hB,KAAK0hB,YAEnC,CACA,SAAAA,GACE,OAAO1hB,KAAKyd,yBAAyBzd,KAAK6E,QAAQqb,QAAUlgB,KAAK4E,SAASpJ,aAAa,yBACzF,CAGA,4BAAA6mB,CAA6BjjB,GAC3B,OAAOY,KAAKmE,YAAYmB,oBAAoBlG,EAAMW,eAAgBC,KAAKsiB,qBACzE,CACA,WAAAzU,GACE,OAAO7N,KAAK6E,QAAQib,WAAa9f,KAAK2gB,KAAO3gB,KAAK2gB,IAAItlB,UAAU7W,SAASy6B,GAC3E,CACA,QAAAzP,GACE,OAAOxP,KAAK2gB,KAAO3gB,KAAK2gB,IAAItlB,UAAU7W,SAAS06B,GACjD,CACA,aAAA7M,CAAcsO,GACZ,MAAMjiC,EAAYme,GAAQmD,KAAK6E,QAAQnmB,UAAW,CAACshB,KAAM2gB,EAAK3gB,KAAK4E,WAC7D2d,EAAahD,GAAc7gC,EAAU+lB,eAC3C,OAAO,GAAoBzE,KAAK4E,SAAU+b,EAAK3gB,KAAKyS,iBAAiB8P,GACvE,CACA,UAAA1P,GACE,MAAM,OACJ7qB,GACEgY,KAAK6E,QACT,MAAsB,iBAAX7c,EACFA,EAAO9F,MAAM,KAAKY,KAAInF,GAAS4f,OAAO6P,SAASzvB,EAAO,MAEzC,mBAAXqK,EACF8qB,GAAc9qB,EAAO8qB,EAAY9S,KAAK4E,UAExC5c,CACT,CACA,wBAAAy1B,CAAyBU,GACvB,OAAOthB,GAAQshB,EAAK,CAACne,KAAK4E,UAC5B,CACA,gBAAA6N,CAAiB8P,GACf,MAAMxP,EAAwB,CAC5Br0B,UAAW6jC,EACXnsB,UAAW,CAAC,CACV9V,KAAM,OACNmB,QAAS,CACPuO,mBAAoBgQ,KAAK6E,QAAQ7U,qBAElC,CACD1P,KAAM,SACNmB,QAAS,CACPuG,OAAQgY,KAAK6S,eAEd,CACDvyB,KAAM,kBACNmB,QAAS,CACPwM,SAAU+R,KAAK6E,QAAQ5W,WAExB,CACD3N,KAAM,QACNmB,QAAS,CACPlC,QAAS,IAAIygB,KAAKmE,YAAY5H,eAE/B,CACDjc,KAAM,kBACNC,SAAS,EACTC,MAAO,aACPC,GAAI4J,IAGF2V,KAAKwhB,iBAAiBpgC,aAAa,wBAAyBiJ,EAAK1J,MAAMjC,UAAU,KAIvF,MAAO,IACFq0B,KACAlW,GAAQmD,KAAK6E,QAAQgN,aAAc,CAACkB,IAE3C,CACA,aAAA6N,GACE,MAAM4B,EAAWxiB,KAAK6E,QAAQjD,QAAQ1f,MAAM,KAC5C,IAAK,MAAM0f,KAAW4gB,EACpB,GAAgB,UAAZ5gB,EACFrB,GAAac,GAAGrB,KAAK4E,SAAU5E,KAAKmE,YAAYqB,UAjVlC,SAiV4DxF,KAAK6E,QAAQ9K,UAAUqF,IAC/EY,KAAKqiB,6BAA6BjjB,GAC1CsI,QAAQ,SAEb,GA3VU,WA2VN9F,EAA4B,CACrC,MAAM6gB,EAAU7gB,IAAYyd,GAAgBrf,KAAKmE,YAAYqB,UAnV5C,cAmV0ExF,KAAKmE,YAAYqB,UArV5F,WAsVVkd,EAAW9gB,IAAYyd,GAAgBrf,KAAKmE,YAAYqB,UAnV7C,cAmV2ExF,KAAKmE,YAAYqB,UArV5F,YAsVjBjF,GAAac,GAAGrB,KAAK4E,SAAU6d,EAASziB,KAAK6E,QAAQ9K,UAAUqF,IAC7D,MAAM+T,EAAUnT,KAAKqiB,6BAA6BjjB,GAClD+T,EAAQqN,eAA8B,YAAfphB,EAAMqB,KAAqB6e,GAAgBD,KAAiB,EACnFlM,EAAQgO,QAAQ,IAElB5gB,GAAac,GAAGrB,KAAK4E,SAAU8d,EAAU1iB,KAAK6E,QAAQ9K,UAAUqF,IAC9D,MAAM+T,EAAUnT,KAAKqiB,6BAA6BjjB,GAClD+T,EAAQqN,eAA8B,aAAfphB,EAAMqB,KAAsB6e,GAAgBD,IAAiBlM,EAAQvO,SAASpgB,SAAS4a,EAAMU,eACpHqT,EAAQ+N,QAAQ,GAEpB,CAEFlhB,KAAKohB,kBAAoB,KACnBphB,KAAK4E,UACP5E,KAAKyP,MACP,EAEFlP,GAAac,GAAGrB,KAAK4E,SAAS5J,QAAQmkB,IAAiBC,GAAkBpf,KAAKohB,kBAChF,CACA,SAAAP,GACE,MAAMX,EAAQlgB,KAAK4E,SAASpJ,aAAa,SACpC0kB,IAGAlgB,KAAK4E,SAASpJ,aAAa,eAAkBwE,KAAK4E,SAAS0Z,YAAY3Y,QAC1E3F,KAAK4E,SAASxjB,aAAa,aAAc8+B,GAE3ClgB,KAAK4E,SAASxjB,aAAa,yBAA0B8+B,GACrDlgB,KAAK4E,SAASzjB,gBAAgB,SAChC,CACA,MAAAggC,GACMnhB,KAAKwP,YAAcxP,KAAKugB,WAC1BvgB,KAAKugB,YAAa,GAGpBvgB,KAAKugB,YAAa,EAClBvgB,KAAK2iB,aAAY,KACX3iB,KAAKugB,YACPvgB,KAAK0P,MACP,GACC1P,KAAK6E,QAAQob,MAAMvQ,MACxB,CACA,MAAAwR,GACMlhB,KAAKyhB,yBAGTzhB,KAAKugB,YAAa,EAClBvgB,KAAK2iB,aAAY,KACV3iB,KAAKugB,YACRvgB,KAAKyP,MACP,GACCzP,KAAK6E,QAAQob,MAAMxQ,MACxB,CACA,WAAAkT,CAAY/kB,EAASglB,GACnB7V,aAAa/M,KAAKsgB,UAClBtgB,KAAKsgB,SAAWziB,WAAWD,EAASglB,EACtC,CACA,oBAAAnB,GACE,OAAOzkC,OAAOmiB,OAAOa,KAAKwgB,gBAAgBpf,UAAS,EACrD,CACA,UAAAyC,CAAWC,GACT,MAAM+e,EAAiB7f,GAAYG,kBAAkBnD,KAAK4E,UAC1D,IAAK,MAAMke,KAAiB9lC,OAAO4D,KAAKiiC,GAClC7D,GAAsBroB,IAAImsB,WACrBD,EAAeC,GAU1B,OAPAhf,EAAS,IACJ+e,KACmB,iBAAX/e,GAAuBA,EAASA,EAAS,CAAC,GAEvDA,EAAS9D,KAAK+D,gBAAgBD,GAC9BA,EAAS9D,KAAKgE,kBAAkBF,GAChC9D,KAAKiE,iBAAiBH,GACfA,CACT,CACA,iBAAAE,CAAkBF,GAchB,OAbAA,EAAOic,WAAiC,IAArBjc,EAAOic,UAAsB16B,SAAS6G,KAAOwO,GAAWoJ,EAAOic,WACtD,iBAAjBjc,EAAOmc,QAChBnc,EAAOmc,MAAQ,CACbvQ,KAAM5L,EAAOmc,MACbxQ,KAAM3L,EAAOmc,QAGW,iBAAjBnc,EAAOoc,QAChBpc,EAAOoc,MAAQpc,EAAOoc,MAAMrgC,YAEA,iBAAnBikB,EAAOiZ,UAChBjZ,EAAOiZ,QAAUjZ,EAAOiZ,QAAQl9B,YAE3BikB,CACT,CACA,kBAAAwe,GACE,MAAMxe,EAAS,CAAC,EAChB,IAAK,MAAOhnB,EAAKa,KAAUX,OAAOmkB,QAAQnB,KAAK6E,SACzC7E,KAAKmE,YAAYT,QAAQ5mB,KAASa,IACpCmmB,EAAOhnB,GAAOa,GASlB,OANAmmB,EAAO/J,UAAW,EAClB+J,EAAOlC,QAAU,SAKVkC,CACT,CACA,cAAAud,GACMrhB,KAAKgS,UACPhS,KAAKgS,QAAQhZ,UACbgH,KAAKgS,QAAU,MAEbhS,KAAK2gB,MACP3gB,KAAK2gB,IAAIhnB,SACTqG,KAAK2gB,IAAM,KAEf,CAGA,sBAAOlkB,CAAgBqH,GACrB,OAAO9D,KAAKuH,MAAK,WACf,MAAMld,EAAO+1B,GAAQ9a,oBAAoBtF,KAAM8D,GAC/C,GAAsB,iBAAXA,EAAX,CAGA,QAA4B,IAAjBzZ,EAAKyZ,GACd,MAAM,IAAIU,UAAU,oBAAoBV,MAE1CzZ,EAAKyZ,IAJL,CAKF,GACF,EAOF3H,GAAmBikB,IAcnB,MAGM2C,GAAY,IACb3C,GAAQ1c,QACXqZ,QAAS,GACT/0B,OAAQ,CAAC,EAAG,GACZtJ,UAAW,QACXy+B,SAAU,8IACVvb,QAAS,SAELohB,GAAgB,IACjB5C,GAAQzc,YACXoZ,QAAS,kCAOX,MAAMkG,WAAgB7C,GAEpB,kBAAW1c,GACT,OAAOqf,EACT,CACA,sBAAWpf,GACT,OAAOqf,EACT,CACA,eAAWzmB,GACT,MA7BW,SA8Bb,CAGA,cAAA+kB,GACE,OAAOthB,KAAK0hB,aAAe1hB,KAAKkjB,aAClC,CAGA,sBAAAtB,GACE,MAAO,CACL,kBAAkB5hB,KAAK0hB,YACvB,gBAAoB1hB,KAAKkjB,cAE7B,CACA,WAAAA,GACE,OAAOljB,KAAKyd,yBAAyBzd,KAAK6E,QAAQkY,QACpD,CAGA,sBAAOtgB,CAAgBqH,GACrB,OAAO9D,KAAKuH,MAAK,WACf,MAAMld,EAAO44B,GAAQ3d,oBAAoBtF,KAAM8D,GAC/C,GAAsB,iBAAXA,EAAX,CAGA,QAA4B,IAAjBzZ,EAAKyZ,GACd,MAAM,IAAIU,UAAU,oBAAoBV,MAE1CzZ,EAAKyZ,IAJL,CAKF,GACF,EAOF3H,GAAmB8mB,IAcnB,MAEME,GAAc,gBAEdC,GAAiB,WAAWD,KAC5BE,GAAc,QAAQF,KACtBG,GAAwB,OAAOH,cAE/BI,GAAsB,SAEtBC,GAAwB,SAExBC,GAAqB,YAGrBC,GAAsB,GAAGD,mBAA+CA,uBAGxEE,GAAY,CAChB37B,OAAQ,KAER47B,WAAY,eACZC,cAAc,EACdt3B,OAAQ,KACRu3B,UAAW,CAAC,GAAK,GAAK,IAElBC,GAAgB,CACpB/7B,OAAQ,gBAER47B,WAAY,SACZC,aAAc,UACdt3B,OAAQ,UACRu3B,UAAW,SAOb,MAAME,WAAkBtf,GACtB,WAAAP,CAAY5kB,EAASukB,GACnBa,MAAMplB,EAASukB,GAGf9D,KAAKikB,aAAe,IAAI/yB,IACxB8O,KAAKkkB,oBAAsB,IAAIhzB,IAC/B8O,KAAKmkB,aAA6D,YAA9Cl/B,iBAAiB+a,KAAK4E,UAAU5Y,UAA0B,KAAOgU,KAAK4E,SAC1F5E,KAAKokB,cAAgB,KACrBpkB,KAAKqkB,UAAY,KACjBrkB,KAAKskB,oBAAsB,CACzBC,gBAAiB,EACjBC,gBAAiB,GAEnBxkB,KAAKykB,SACP,CAGA,kBAAW/gB,GACT,OAAOigB,EACT,CACA,sBAAWhgB,GACT,OAAOogB,EACT,CACA,eAAWxnB,GACT,MAhEW,WAiEb,CAGA,OAAAkoB,GACEzkB,KAAK0kB,mCACL1kB,KAAK2kB,2BACD3kB,KAAKqkB,UACPrkB,KAAKqkB,UAAUO,aAEf5kB,KAAKqkB,UAAYrkB,KAAK6kB,kBAExB,IAAK,MAAMC,KAAW9kB,KAAKkkB,oBAAoB/kB,SAC7Ca,KAAKqkB,UAAUU,QAAQD,EAE3B,CACA,OAAA/f,GACE/E,KAAKqkB,UAAUO,aACfjgB,MAAMI,SACR,CAGA,iBAAAf,CAAkBF,GAShB,OAPAA,EAAOvX,OAASmO,GAAWoJ,EAAOvX,SAAWlH,SAAS6G,KAGtD4X,EAAO8f,WAAa9f,EAAO9b,OAAS,GAAG8b,EAAO9b,oBAAsB8b,EAAO8f,WAC3C,iBAArB9f,EAAOggB,YAChBhgB,EAAOggB,UAAYhgB,EAAOggB,UAAU5hC,MAAM,KAAKY,KAAInF,GAAS4f,OAAOC,WAAW7f,MAEzEmmB,CACT,CACA,wBAAA6gB,GACO3kB,KAAK6E,QAAQgf,eAKlBtjB,GAAaC,IAAIR,KAAK6E,QAAQtY,OAAQ82B,IACtC9iB,GAAac,GAAGrB,KAAK6E,QAAQtY,OAAQ82B,GAAaG,IAAuBpkB,IACvE,MAAM4lB,EAAoBhlB,KAAKkkB,oBAAoB/mC,IAAIiiB,EAAM7S,OAAOtB,MACpE,GAAI+5B,EAAmB,CACrB5lB,EAAMkD,iBACN,MAAM3G,EAAOqE,KAAKmkB,cAAgBvkC,OAC5BmE,EAASihC,EAAkB3gC,UAAY2b,KAAK4E,SAASvgB,UAC3D,GAAIsX,EAAKspB,SAKP,YAJAtpB,EAAKspB,SAAS,CACZtjC,IAAKoC,EACLmhC,SAAU,WAMdvpB,EAAKlQ,UAAY1H,CACnB,KAEJ,CACA,eAAA8gC,GACE,MAAMpjC,EAAU,CACdka,KAAMqE,KAAKmkB,aACXL,UAAW9jB,KAAK6E,QAAQif,UACxBF,WAAY5jB,KAAK6E,QAAQ+e,YAE3B,OAAO,IAAIuB,sBAAqBhkB,GAAWnB,KAAKolB,kBAAkBjkB,IAAU1f,EAC9E,CAGA,iBAAA2jC,CAAkBjkB,GAChB,MAAMkkB,EAAgB/H,GAAStd,KAAKikB,aAAa9mC,IAAI,IAAImgC,EAAM/wB,OAAO4N,MAChEob,EAAW+H,IACftd,KAAKskB,oBAAoBC,gBAAkBjH,EAAM/wB,OAAOlI,UACxD2b,KAAKslB,SAASD,EAAc/H,GAAO,EAE/BkH,GAAmBxkB,KAAKmkB,cAAgB9+B,SAASC,iBAAiBmG,UAClE85B,EAAkBf,GAAmBxkB,KAAKskB,oBAAoBE,gBACpExkB,KAAKskB,oBAAoBE,gBAAkBA,EAC3C,IAAK,MAAMlH,KAASnc,EAAS,CAC3B,IAAKmc,EAAMkI,eAAgB,CACzBxlB,KAAKokB,cAAgB,KACrBpkB,KAAKylB,kBAAkBJ,EAAc/H,IACrC,QACF,CACA,MAAMoI,EAA2BpI,EAAM/wB,OAAOlI,WAAa2b,KAAKskB,oBAAoBC,gBAEpF,GAAIgB,GAAmBG,GAGrB,GAFAnQ,EAAS+H,IAEJkH,EACH,YAMCe,GAAoBG,GACvBnQ,EAAS+H,EAEb,CACF,CACA,gCAAAoH,GACE1kB,KAAKikB,aAAe,IAAI/yB,IACxB8O,KAAKkkB,oBAAsB,IAAIhzB,IAC/B,MAAMy0B,EAAc/f,GAAezT,KAAKqxB,GAAuBxjB,KAAK6E,QAAQtY,QAC5E,IAAK,MAAMq5B,KAAUD,EAAa,CAEhC,IAAKC,EAAO36B,MAAQiQ,GAAW0qB,GAC7B,SAEF,MAAMZ,EAAoBpf,GAAeC,QAAQggB,UAAUD,EAAO36B,MAAO+U,KAAK4E,UAG1EjK,GAAUqqB,KACZhlB,KAAKikB,aAAalyB,IAAI8zB,UAAUD,EAAO36B,MAAO26B,GAC9C5lB,KAAKkkB,oBAAoBnyB,IAAI6zB,EAAO36B,KAAM+5B,GAE9C,CACF,CACA,QAAAM,CAAS/4B,GACHyT,KAAKokB,gBAAkB73B,IAG3ByT,KAAKylB,kBAAkBzlB,KAAK6E,QAAQtY,QACpCyT,KAAKokB,cAAgB73B,EACrBA,EAAO8O,UAAU5E,IAAI8sB,IACrBvjB,KAAK8lB,iBAAiBv5B,GACtBgU,GAAaqB,QAAQ5B,KAAK4E,SAAUwe,GAAgB,CAClDtjB,cAAevT,IAEnB,CACA,gBAAAu5B,CAAiBv5B,GAEf,GAAIA,EAAO8O,UAAU7W,SA9LQ,iBA+L3BohB,GAAeC,QArLc,mBAqLsBtZ,EAAOyO,QAtLtC,cAsLkEK,UAAU5E,IAAI8sB,SAGtG,IAAK,MAAMwC,KAAangB,GAAeI,QAAQzZ,EA9LnB,qBAiM1B,IAAK,MAAMxJ,KAAQ6iB,GAAeM,KAAK6f,EAAWrC,IAChD3gC,EAAKsY,UAAU5E,IAAI8sB,GAGzB,CACA,iBAAAkC,CAAkBhhC,GAChBA,EAAO4W,UAAU1B,OAAO4pB,IACxB,MAAMyC,EAAcpgB,GAAezT,KAAK,GAAGqxB,MAAyBD,KAAuB9+B,GAC3F,IAAK,MAAM9E,KAAQqmC,EACjBrmC,EAAK0b,UAAU1B,OAAO4pB,GAE1B,CAGA,sBAAO9mB,CAAgBqH,GACrB,OAAO9D,KAAKuH,MAAK,WACf,MAAMld,EAAO25B,GAAU1e,oBAAoBtF,KAAM8D,GACjD,GAAsB,iBAAXA,EAAX,CAGA,QAAqB/K,IAAjB1O,EAAKyZ,IAAyBA,EAAOrC,WAAW,MAAmB,gBAAXqC,EAC1D,MAAM,IAAIU,UAAU,oBAAoBV,MAE1CzZ,EAAKyZ,IAJL,CAKF,GACF,EAOFvD,GAAac,GAAGzhB,OAAQ0jC,IAAuB,KAC7C,IAAK,MAAM2C,KAAOrgB,GAAezT,KApOT,0BAqOtB6xB,GAAU1e,oBAAoB2gB,EAChC,IAOF9pB,GAAmB6nB,IAcnB,MAEMkC,GAAc,UACdC,GAAe,OAAOD,KACtBE,GAAiB,SAASF,KAC1BG,GAAe,OAAOH,KACtBI,GAAgB,QAAQJ,KACxBK,GAAuB,QAAQL,KAC/BM,GAAgB,UAAUN,KAC1BO,GAAsB,OAAOP,KAC7BQ,GAAiB,YACjBC,GAAkB,aAClBC,GAAe,UACfC,GAAiB,YACjBC,GAAW,OACXC,GAAU,MACVC,GAAoB,SACpBC,GAAoB,OACpBC,GAAoB,OAEpBC,GAA2B,mBAE3BC,GAA+B,QAAQD,MAIvCE,GAAuB,2EACvBC,GAAsB,YAFOF,uBAAiDA,mBAA6CA,OAE/EC,KAC5CE,GAA8B,IAAIP,8BAA6CA,+BAA8CA,4BAMnI,MAAMQ,WAAY9iB,GAChB,WAAAP,CAAY5kB,GACVolB,MAAMplB,GACNygB,KAAKiS,QAAUjS,KAAK4E,SAAS5J,QAdN,uCAelBgF,KAAKiS,UAOVjS,KAAKynB,sBAAsBznB,KAAKiS,QAASjS,KAAK0nB,gBAC9CnnB,GAAac,GAAGrB,KAAK4E,SAAU4hB,IAAepnB,GAASY,KAAK0M,SAAStN,KACvE,CAGA,eAAW7C,GACT,MAnDW,KAoDb,CAGA,IAAAmT,GAEE,MAAMiY,EAAY3nB,KAAK4E,SACvB,GAAI5E,KAAK4nB,cAAcD,GACrB,OAIF,MAAME,EAAS7nB,KAAK8nB,iBACdC,EAAYF,EAAStnB,GAAaqB,QAAQimB,EAAQ1B,GAAc,CACpErmB,cAAe6nB,IACZ,KACapnB,GAAaqB,QAAQ+lB,EAAWtB,GAAc,CAC9DvmB,cAAe+nB,IAEH7lB,kBAAoB+lB,GAAaA,EAAU/lB,mBAGzDhC,KAAKgoB,YAAYH,EAAQF,GACzB3nB,KAAKioB,UAAUN,EAAWE,GAC5B,CAGA,SAAAI,CAAU1oC,EAAS2oC,GACZ3oC,IAGLA,EAAQ8b,UAAU5E,IAAIuwB,IACtBhnB,KAAKioB,UAAUriB,GAAec,uBAAuBnnB,IAcrDygB,KAAKmF,gBAZY,KACsB,QAAjC5lB,EAAQic,aAAa,SAIzBjc,EAAQ4B,gBAAgB,YACxB5B,EAAQ6B,aAAa,iBAAiB,GACtC4e,KAAKmoB,gBAAgB5oC,GAAS,GAC9BghB,GAAaqB,QAAQriB,EAAS+mC,GAAe,CAC3CxmB,cAAeooB,KAPf3oC,EAAQ8b,UAAU5E,IAAIywB,GAQtB,GAE0B3nC,EAASA,EAAQ8b,UAAU7W,SAASyiC,KACpE,CACA,WAAAe,CAAYzoC,EAAS2oC,GACd3oC,IAGLA,EAAQ8b,UAAU1B,OAAOqtB,IACzBznC,EAAQm7B,OACR1a,KAAKgoB,YAAYpiB,GAAec,uBAAuBnnB,IAcvDygB,KAAKmF,gBAZY,KACsB,QAAjC5lB,EAAQic,aAAa,SAIzBjc,EAAQ6B,aAAa,iBAAiB,GACtC7B,EAAQ6B,aAAa,WAAY,MACjC4e,KAAKmoB,gBAAgB5oC,GAAS,GAC9BghB,GAAaqB,QAAQriB,EAAS6mC,GAAgB,CAC5CtmB,cAAeooB,KAPf3oC,EAAQ8b,UAAU1B,OAAOutB,GAQzB,GAE0B3nC,EAASA,EAAQ8b,UAAU7W,SAASyiC,KACpE,CACA,QAAAva,CAAStN,GACP,IAAK,CAACsnB,GAAgBC,GAAiBC,GAAcC,GAAgBC,GAAUC,IAAS3lB,SAAShC,EAAMtiB,KACrG,OAEFsiB,EAAMuU,kBACNvU,EAAMkD,iBACN,MAAMwD,EAAW9F,KAAK0nB,eAAevhC,QAAO5G,IAAY2b,GAAW3b,KACnE,IAAI6oC,EACJ,GAAI,CAACtB,GAAUC,IAAS3lB,SAAShC,EAAMtiB,KACrCsrC,EAAoBtiB,EAAS1G,EAAMtiB,MAAQgqC,GAAW,EAAIhhB,EAASpV,OAAS,OACvE,CACL,MAAM2c,EAAS,CAACsZ,GAAiBE,IAAgBzlB,SAAShC,EAAMtiB,KAChEsrC,EAAoBtqB,GAAqBgI,EAAU1G,EAAM7S,OAAQ8gB,GAAQ,EAC3E,CACI+a,IACFA,EAAkB9V,MAAM,CACtB+V,eAAe,IAEjBb,GAAIliB,oBAAoB8iB,GAAmB1Y,OAE/C,CACA,YAAAgY,GAEE,OAAO9hB,GAAezT,KAAKm1B,GAAqBtnB,KAAKiS,QACvD,CACA,cAAA6V,GACE,OAAO9nB,KAAK0nB,eAAev1B,MAAKzN,GAASsb,KAAK4nB,cAAcljC,MAAW,IACzE,CACA,qBAAA+iC,CAAsBhjC,EAAQqhB,GAC5B9F,KAAKsoB,yBAAyB7jC,EAAQ,OAAQ,WAC9C,IAAK,MAAMC,KAASohB,EAClB9F,KAAKuoB,6BAA6B7jC,EAEtC,CACA,4BAAA6jC,CAA6B7jC,GAC3BA,EAAQsb,KAAKwoB,iBAAiB9jC,GAC9B,MAAM+jC,EAAWzoB,KAAK4nB,cAAcljC,GAC9BgkC,EAAY1oB,KAAK2oB,iBAAiBjkC,GACxCA,EAAMtD,aAAa,gBAAiBqnC,GAChCC,IAAchkC,GAChBsb,KAAKsoB,yBAAyBI,EAAW,OAAQ,gBAE9CD,GACH/jC,EAAMtD,aAAa,WAAY,MAEjC4e,KAAKsoB,yBAAyB5jC,EAAO,OAAQ,OAG7Csb,KAAK4oB,mCAAmClkC,EAC1C,CACA,kCAAAkkC,CAAmClkC,GACjC,MAAM6H,EAASqZ,GAAec,uBAAuBhiB,GAChD6H,IAGLyT,KAAKsoB,yBAAyB/7B,EAAQ,OAAQ,YAC1C7H,EAAMyV,IACR6F,KAAKsoB,yBAAyB/7B,EAAQ,kBAAmB,GAAG7H,EAAMyV,MAEtE,CACA,eAAAguB,CAAgB5oC,EAASspC,GACvB,MAAMH,EAAY1oB,KAAK2oB,iBAAiBppC,GACxC,IAAKmpC,EAAUrtB,UAAU7W,SApKN,YAqKjB,OAEF,MAAMkjB,EAAS,CAAC3N,EAAUia,KACxB,MAAMz0B,EAAUqmB,GAAeC,QAAQ9L,EAAU2uB,GAC7CnpC,GACFA,EAAQ8b,UAAUqM,OAAOsM,EAAW6U,EACtC,EAEFnhB,EAAOyf,GAA0BH,IACjCtf,EA5K2B,iBA4KIwf,IAC/BwB,EAAUtnC,aAAa,gBAAiBynC,EAC1C,CACA,wBAAAP,CAAyB/oC,EAASwC,EAAWpE,GACtC4B,EAAQgc,aAAaxZ,IACxBxC,EAAQ6B,aAAaW,EAAWpE,EAEpC,CACA,aAAAiqC,CAAczY,GACZ,OAAOA,EAAK9T,UAAU7W,SAASwiC,GACjC,CAGA,gBAAAwB,CAAiBrZ,GACf,OAAOA,EAAKpJ,QAAQuhB,IAAuBnY,EAAOvJ,GAAeC,QAAQyhB,GAAqBnY,EAChG,CAGA,gBAAAwZ,CAAiBxZ,GACf,OAAOA,EAAKnU,QA5LO,gCA4LoBmU,CACzC,CAGA,sBAAO1S,CAAgBqH,GACrB,OAAO9D,KAAKuH,MAAK,WACf,MAAMld,EAAOm9B,GAAIliB,oBAAoBtF,MACrC,GAAsB,iBAAX8D,EAAX,CAGA,QAAqB/K,IAAjB1O,EAAKyZ,IAAyBA,EAAOrC,WAAW,MAAmB,gBAAXqC,EAC1D,MAAM,IAAIU,UAAU,oBAAoBV,MAE1CzZ,EAAKyZ,IAJL,CAKF,GACF,EAOFvD,GAAac,GAAGhc,SAAUkhC,GAAsBc,IAAsB,SAAUjoB,GAC1E,CAAC,IAAK,QAAQgC,SAASpB,KAAKgH,UAC9B5H,EAAMkD,iBAEJpH,GAAW8E,OAGfwnB,GAAIliB,oBAAoBtF,MAAM0P,MAChC,IAKAnP,GAAac,GAAGzhB,OAAQ6mC,IAAqB,KAC3C,IAAK,MAAMlnC,KAAWqmB,GAAezT,KAAKo1B,IACxCC,GAAIliB,oBAAoB/lB,EAC1B,IAMF4c,GAAmBqrB,IAcnB,MAEMxiB,GAAY,YACZ8jB,GAAkB,YAAY9jB,KAC9B+jB,GAAiB,WAAW/jB,KAC5BgkB,GAAgB,UAAUhkB,KAC1BikB,GAAiB,WAAWjkB,KAC5BkkB,GAAa,OAAOlkB,KACpBmkB,GAAe,SAASnkB,KACxBokB,GAAa,OAAOpkB,KACpBqkB,GAAc,QAAQrkB,KAEtBskB,GAAkB,OAClBC,GAAkB,OAClBC,GAAqB,UACrB7lB,GAAc,CAClBmc,UAAW,UACX2J,SAAU,UACVxJ,MAAO,UAEHvc,GAAU,CACdoc,WAAW,EACX2J,UAAU,EACVxJ,MAAO,KAOT,MAAMyJ,WAAchlB,GAClB,WAAAP,CAAY5kB,EAASukB,GACnBa,MAAMplB,EAASukB,GACf9D,KAAKsgB,SAAW,KAChBtgB,KAAK2pB,sBAAuB,EAC5B3pB,KAAK4pB,yBAA0B,EAC/B5pB,KAAK4gB,eACP,CAGA,kBAAWld,GACT,OAAOA,EACT,CACA,sBAAWC,GACT,OAAOA,EACT,CACA,eAAWpH,GACT,MA/CS,OAgDX,CAGA,IAAAmT,GACoBnP,GAAaqB,QAAQ5B,KAAK4E,SAAUwkB,IACxCpnB,mBAGdhC,KAAK6pB,gBACD7pB,KAAK6E,QAAQib,WACf9f,KAAK4E,SAASvJ,UAAU5E,IA/CN,QAsDpBuJ,KAAK4E,SAASvJ,UAAU1B,OAAO2vB,IAC/BztB,GAAOmE,KAAK4E,UACZ5E,KAAK4E,SAASvJ,UAAU5E,IAAI8yB,GAAiBC,IAC7CxpB,KAAKmF,gBARY,KACfnF,KAAK4E,SAASvJ,UAAU1B,OAAO6vB,IAC/BjpB,GAAaqB,QAAQ5B,KAAK4E,SAAUykB,IACpCrpB,KAAK8pB,oBAAoB,GAKG9pB,KAAK4E,SAAU5E,KAAK6E,QAAQib,WAC5D,CACA,IAAArQ,GACOzP,KAAK+pB,YAGQxpB,GAAaqB,QAAQ5B,KAAK4E,SAAUskB,IACxClnB,mBAQdhC,KAAK4E,SAASvJ,UAAU5E,IAAI+yB,IAC5BxpB,KAAKmF,gBANY,KACfnF,KAAK4E,SAASvJ,UAAU5E,IAAI6yB,IAC5BtpB,KAAK4E,SAASvJ,UAAU1B,OAAO6vB,GAAoBD,IACnDhpB,GAAaqB,QAAQ5B,KAAK4E,SAAUukB,GAAa,GAGrBnpB,KAAK4E,SAAU5E,KAAK6E,QAAQib,YAC5D,CACA,OAAA/a,GACE/E,KAAK6pB,gBACD7pB,KAAK+pB,WACP/pB,KAAK4E,SAASvJ,UAAU1B,OAAO4vB,IAEjC5kB,MAAMI,SACR,CACA,OAAAglB,GACE,OAAO/pB,KAAK4E,SAASvJ,UAAU7W,SAAS+kC,GAC1C,CAIA,kBAAAO,GACO9pB,KAAK6E,QAAQ4kB,WAGdzpB,KAAK2pB,sBAAwB3pB,KAAK4pB,0BAGtC5pB,KAAKsgB,SAAWziB,YAAW,KACzBmC,KAAKyP,MAAM,GACVzP,KAAK6E,QAAQob,QAClB,CACA,cAAA+J,CAAe5qB,EAAO6qB,GACpB,OAAQ7qB,EAAMqB,MACZ,IAAK,YACL,IAAK,WAEDT,KAAK2pB,qBAAuBM,EAC5B,MAEJ,IAAK,UACL,IAAK,WAEDjqB,KAAK4pB,wBAA0BK,EAIrC,GAAIA,EAEF,YADAjqB,KAAK6pB,gBAGP,MAAMvc,EAAclO,EAAMU,cACtBE,KAAK4E,WAAa0I,GAAetN,KAAK4E,SAASpgB,SAAS8oB,IAG5DtN,KAAK8pB,oBACP,CACA,aAAAlJ,GACErgB,GAAac,GAAGrB,KAAK4E,SAAUkkB,IAAiB1pB,GAASY,KAAKgqB,eAAe5qB,GAAO,KACpFmB,GAAac,GAAGrB,KAAK4E,SAAUmkB,IAAgB3pB,GAASY,KAAKgqB,eAAe5qB,GAAO,KACnFmB,GAAac,GAAGrB,KAAK4E,SAAUokB,IAAe5pB,GAASY,KAAKgqB,eAAe5qB,GAAO,KAClFmB,GAAac,GAAGrB,KAAK4E,SAAUqkB,IAAgB7pB,GAASY,KAAKgqB,eAAe5qB,GAAO,IACrF,CACA,aAAAyqB,GACE9c,aAAa/M,KAAKsgB,UAClBtgB,KAAKsgB,SAAW,IAClB,CAGA,sBAAO7jB,CAAgBqH,GACrB,OAAO9D,KAAKuH,MAAK,WACf,MAAMld,EAAOq/B,GAAMpkB,oBAAoBtF,KAAM8D,GAC7C,GAAsB,iBAAXA,EAAqB,CAC9B,QAA4B,IAAjBzZ,EAAKyZ,GACd,MAAM,IAAIU,UAAU,oBAAoBV,MAE1CzZ,EAAKyZ,GAAQ9D,KACf,CACF,GACF,ECr0IK,SAASkqB,GAAc7tB,GACD,WAAvBhX,SAASuX,WAAyBP,IACjChX,SAASyF,iBAAiB,mBAAoBuR,EACrD,CDy0IAuK,GAAqB8iB,IAMrBvtB,GAAmButB,IEpyInBQ,IAzCA,WAC2B,GAAG93B,MAAM5U,KAChC6H,SAAS+a,iBAAiB,+BAETtd,KAAI,SAAUqnC,GAC/B,OAAO,IAAI,GAAkBA,EAAkB,CAC7ClK,MAAO,CAAEvQ,KAAM,IAAKD,KAAM,MAE9B,GACF,IAiCAya,IA5BA,WACY7kC,SAAS68B,eAAe,mBAC9Bp3B,iBAAiB,SAAS,WAC5BzF,SAAS6G,KAAKT,UAAY,EAC1BpG,SAASC,gBAAgBmG,UAAY,CACvC,GACF,IAuBAy+B,IArBA,WACE,IAAIE,EAAM/kC,SAAS68B,eAAe,mBAC9BmI,EAAShlC,SACVilC,uBAAuB,aAAa,GACpChnC,wBACH1D,OAAOkL,iBAAiB,UAAU,WAC5BkV,KAAKuqB,UAAYvqB,KAAKwqB,SAAWxqB,KAAKwqB,QAAUH,EAAOzsC,OACzDwsC,EAAIrpC,MAAM6wB,QAAU,QAEpBwY,EAAIrpC,MAAM6wB,QAAU,OAEtB5R,KAAKuqB,UAAYvqB,KAAKwqB,OACxB,GACF,IAUA5qC,OAAO6qC,UAAY","sources":["webpack://pydata_sphinx_theme/webpack/bootstrap","webpack://pydata_sphinx_theme/webpack/runtime/define property getters","webpack://pydata_sphinx_theme/webpack/runtime/hasOwnProperty shorthand","webpack://pydata_sphinx_theme/webpack/runtime/make namespace object","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/enums.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getNodeName.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getWindow.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/instanceOf.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/modifiers/applyStyles.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/getBasePlacement.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/math.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/userAgent.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/isLayoutViewport.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getBoundingClientRect.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getLayoutRect.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/contains.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getComputedStyle.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/isTableElement.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getDocumentElement.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getParentNode.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getOffsetParent.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/getMainAxisFromPlacement.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/within.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/mergePaddingObject.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/getFreshSideObject.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/expandToHashMap.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/modifiers/arrow.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/getVariation.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/modifiers/computeStyles.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/modifiers/eventListeners.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/getOppositePlacement.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/getOppositeVariationPlacement.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getWindowScroll.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getWindowScrollBarX.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/isScrollParent.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getScrollParent.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/listScrollParents.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/rectToClientRect.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getClippingRect.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getViewportRect.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getDocumentRect.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/computeOffsets.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/detectOverflow.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/modifiers/flip.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/computeAutoPlacement.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/modifiers/hide.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/modifiers/offset.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/modifiers/popperOffsets.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/modifiers/preventOverflow.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/getAltAxis.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getCompositeRect.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getNodeScroll.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/dom-utils/getHTMLElementScroll.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/orderModifiers.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/createPopper.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/debounce.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/utils/mergeByName.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/popper.js","webpack://pydata_sphinx_theme/./node_modules/@popperjs/core/lib/popper-lite.js","webpack://pydata_sphinx_theme/./node_modules/bootstrap/dist/js/bootstrap.esm.js","webpack://pydata_sphinx_theme/./src/pydata_sphinx_theme/assets/scripts/mixin.js","webpack://pydata_sphinx_theme/./src/pydata_sphinx_theme/assets/scripts/bootstrap.js"],"sourcesContent":["// The require scope\nvar __webpack_require__ = {};\n\n","// define getter functions for harmony exports\n__webpack_require__.d = (exports, definition) => {\n\tfor(var key in definition) {\n\t\tif(__webpack_require__.o(definition, key) && !__webpack_require__.o(exports, key)) {\n\t\t\tObject.defineProperty(exports, key, { enumerable: true, get: definition[key] });\n\t\t}\n\t}\n};","__webpack_require__.o = (obj, prop) => (Object.prototype.hasOwnProperty.call(obj, prop))","// define __esModule on exports\n__webpack_require__.r = (exports) => {\n\tif(typeof Symbol !== 'undefined' && Symbol.toStringTag) {\n\t\tObject.defineProperty(exports, Symbol.toStringTag, { value: 'Module' });\n\t}\n\tObject.defineProperty(exports, '__esModule', { value: true });\n};","export var top = 'top';\nexport var bottom = 'bottom';\nexport var right = 'right';\nexport var left = 'left';\nexport var auto = 'auto';\nexport var basePlacements = [top, bottom, right, left];\nexport var start = 'start';\nexport var end = 'end';\nexport var clippingParents = 'clippingParents';\nexport var viewport = 'viewport';\nexport var popper = 'popper';\nexport var reference = 'reference';\nexport var variationPlacements = /*#__PURE__*/basePlacements.reduce(function (acc, placement) {\n return acc.concat([placement + \"-\" + start, placement + \"-\" + end]);\n}, []);\nexport var placements = /*#__PURE__*/[].concat(basePlacements, [auto]).reduce(function (acc, placement) {\n return acc.concat([placement, placement + \"-\" + start, placement + \"-\" + end]);\n}, []); // modifiers that need to read the DOM\n\nexport var beforeRead = 'beforeRead';\nexport var read = 'read';\nexport var afterRead = 'afterRead'; // pure-logic modifiers\n\nexport var beforeMain = 'beforeMain';\nexport var main = 'main';\nexport var afterMain = 'afterMain'; // modifier with the purpose to write to the DOM (or write into a framework state)\n\nexport var beforeWrite = 'beforeWrite';\nexport var write = 'write';\nexport var afterWrite = 'afterWrite';\nexport var modifierPhases = [beforeRead, read, afterRead, beforeMain, main, afterMain, beforeWrite, write, afterWrite];","export default function getNodeName(element) {\n return element ? (element.nodeName || '').toLowerCase() : null;\n}","export default function getWindow(node) {\n if (node == null) {\n return window;\n }\n\n if (node.toString() !== '[object Window]') {\n var ownerDocument = node.ownerDocument;\n return ownerDocument ? ownerDocument.defaultView || window : window;\n }\n\n return node;\n}","import getWindow from \"./getWindow.js\";\n\nfunction isElement(node) {\n var OwnElement = getWindow(node).Element;\n return node instanceof OwnElement || node instanceof Element;\n}\n\nfunction isHTMLElement(node) {\n var OwnElement = getWindow(node).HTMLElement;\n return node instanceof OwnElement || node instanceof HTMLElement;\n}\n\nfunction isShadowRoot(node) {\n // IE 11 has no ShadowRoot\n if (typeof ShadowRoot === 'undefined') {\n return false;\n }\n\n var OwnElement = getWindow(node).ShadowRoot;\n return node instanceof OwnElement || node instanceof ShadowRoot;\n}\n\nexport { isElement, isHTMLElement, isShadowRoot };","import getNodeName from \"../dom-utils/getNodeName.js\";\nimport { isHTMLElement } from \"../dom-utils/instanceOf.js\"; // This modifier takes the styles prepared by the `computeStyles` modifier\n// and applies them to the HTMLElements such as popper and arrow\n\nfunction applyStyles(_ref) {\n var state = _ref.state;\n Object.keys(state.elements).forEach(function (name) {\n var style = state.styles[name] || {};\n var attributes = state.attributes[name] || {};\n var element = state.elements[name]; // arrow is optional + virtual elements\n\n if (!isHTMLElement(element) || !getNodeName(element)) {\n return;\n } // Flow doesn't support to extend this property, but it's the most\n // effective way to apply styles to an HTMLElement\n // $FlowFixMe[cannot-write]\n\n\n Object.assign(element.style, style);\n Object.keys(attributes).forEach(function (name) {\n var value = attributes[name];\n\n if (value === false) {\n element.removeAttribute(name);\n } else {\n element.setAttribute(name, value === true ? '' : value);\n }\n });\n });\n}\n\nfunction effect(_ref2) {\n var state = _ref2.state;\n var initialStyles = {\n popper: {\n position: state.options.strategy,\n left: '0',\n top: '0',\n margin: '0'\n },\n arrow: {\n position: 'absolute'\n },\n reference: {}\n };\n Object.assign(state.elements.popper.style, initialStyles.popper);\n state.styles = initialStyles;\n\n if (state.elements.arrow) {\n Object.assign(state.elements.arrow.style, initialStyles.arrow);\n }\n\n return function () {\n Object.keys(state.elements).forEach(function (name) {\n var element = state.elements[name];\n var attributes = state.attributes[name] || {};\n var styleProperties = Object.keys(state.styles.hasOwnProperty(name) ? state.styles[name] : initialStyles[name]); // Set all values to an empty string to unset them\n\n var style = styleProperties.reduce(function (style, property) {\n style[property] = '';\n return style;\n }, {}); // arrow is optional + virtual elements\n\n if (!isHTMLElement(element) || !getNodeName(element)) {\n return;\n }\n\n Object.assign(element.style, style);\n Object.keys(attributes).forEach(function (attribute) {\n element.removeAttribute(attribute);\n });\n });\n };\n} // eslint-disable-next-line import/no-unused-modules\n\n\nexport default {\n name: 'applyStyles',\n enabled: true,\n phase: 'write',\n fn: applyStyles,\n effect: effect,\n requires: ['computeStyles']\n};","import { auto } from \"../enums.js\";\nexport default function getBasePlacement(placement) {\n return placement.split('-')[0];\n}","export var max = Math.max;\nexport var min = Math.min;\nexport var round = Math.round;","export default function getUAString() {\n var uaData = navigator.userAgentData;\n\n if (uaData != null && uaData.brands && Array.isArray(uaData.brands)) {\n return uaData.brands.map(function (item) {\n return item.brand + \"/\" + item.version;\n }).join(' ');\n }\n\n return navigator.userAgent;\n}","import getUAString from \"../utils/userAgent.js\";\nexport default function isLayoutViewport() {\n return !/^((?!chrome|android).)*safari/i.test(getUAString());\n}","import { isElement, isHTMLElement } from \"./instanceOf.js\";\nimport { round } from \"../utils/math.js\";\nimport getWindow from \"./getWindow.js\";\nimport isLayoutViewport from \"./isLayoutViewport.js\";\nexport default function getBoundingClientRect(element, includeScale, isFixedStrategy) {\n if (includeScale === void 0) {\n includeScale = false;\n }\n\n if (isFixedStrategy === void 0) {\n isFixedStrategy = false;\n }\n\n var clientRect = element.getBoundingClientRect();\n var scaleX = 1;\n var scaleY = 1;\n\n if (includeScale && isHTMLElement(element)) {\n scaleX = element.offsetWidth > 0 ? round(clientRect.width) / element.offsetWidth || 1 : 1;\n scaleY = element.offsetHeight > 0 ? round(clientRect.height) / element.offsetHeight || 1 : 1;\n }\n\n var _ref = isElement(element) ? getWindow(element) : window,\n visualViewport = _ref.visualViewport;\n\n var addVisualOffsets = !isLayoutViewport() && isFixedStrategy;\n var x = (clientRect.left + (addVisualOffsets && visualViewport ? visualViewport.offsetLeft : 0)) / scaleX;\n var y = (clientRect.top + (addVisualOffsets && visualViewport ? visualViewport.offsetTop : 0)) / scaleY;\n var width = clientRect.width / scaleX;\n var height = clientRect.height / scaleY;\n return {\n width: width,\n height: height,\n top: y,\n right: x + width,\n bottom: y + height,\n left: x,\n x: x,\n y: y\n };\n}","import getBoundingClientRect from \"./getBoundingClientRect.js\"; // Returns the layout rect of an element relative to its offsetParent. Layout\n// means it doesn't take into account transforms.\n\nexport default function getLayoutRect(element) {\n var clientRect = getBoundingClientRect(element); // Use the clientRect sizes if it's not been transformed.\n // Fixes https://github.com/popperjs/popper-core/issues/1223\n\n var width = element.offsetWidth;\n var height = element.offsetHeight;\n\n if (Math.abs(clientRect.width - width) <= 1) {\n width = clientRect.width;\n }\n\n if (Math.abs(clientRect.height - height) <= 1) {\n height = clientRect.height;\n }\n\n return {\n x: element.offsetLeft,\n y: element.offsetTop,\n width: width,\n height: height\n };\n}","import { isShadowRoot } from \"./instanceOf.js\";\nexport default function contains(parent, child) {\n var rootNode = child.getRootNode && child.getRootNode(); // First, attempt with faster native method\n\n if (parent.contains(child)) {\n return true;\n } // then fallback to custom implementation with Shadow DOM support\n else if (rootNode && isShadowRoot(rootNode)) {\n var next = child;\n\n do {\n if (next && parent.isSameNode(next)) {\n return true;\n } // $FlowFixMe[prop-missing]: need a better way to handle this...\n\n\n next = next.parentNode || next.host;\n } while (next);\n } // Give up, the result is false\n\n\n return false;\n}","import getWindow from \"./getWindow.js\";\nexport default function getComputedStyle(element) {\n return getWindow(element).getComputedStyle(element);\n}","import getNodeName from \"./getNodeName.js\";\nexport default function isTableElement(element) {\n return ['table', 'td', 'th'].indexOf(getNodeName(element)) >= 0;\n}","import { isElement } from \"./instanceOf.js\";\nexport default function getDocumentElement(element) {\n // $FlowFixMe[incompatible-return]: assume body is always available\n return ((isElement(element) ? element.ownerDocument : // $FlowFixMe[prop-missing]\n element.document) || window.document).documentElement;\n}","import getNodeName from \"./getNodeName.js\";\nimport getDocumentElement from \"./getDocumentElement.js\";\nimport { isShadowRoot } from \"./instanceOf.js\";\nexport default function getParentNode(element) {\n if (getNodeName(element) === 'html') {\n return element;\n }\n\n return (// this is a quicker (but less type safe) way to save quite some bytes from the bundle\n // $FlowFixMe[incompatible-return]\n // $FlowFixMe[prop-missing]\n element.assignedSlot || // step into the shadow DOM of the parent of a slotted node\n element.parentNode || ( // DOM Element detected\n isShadowRoot(element) ? element.host : null) || // ShadowRoot detected\n // $FlowFixMe[incompatible-call]: HTMLElement is a Node\n getDocumentElement(element) // fallback\n\n );\n}","import getWindow from \"./getWindow.js\";\nimport getNodeName from \"./getNodeName.js\";\nimport getComputedStyle from \"./getComputedStyle.js\";\nimport { isHTMLElement, isShadowRoot } from \"./instanceOf.js\";\nimport isTableElement from \"./isTableElement.js\";\nimport getParentNode from \"./getParentNode.js\";\nimport getUAString from \"../utils/userAgent.js\";\n\nfunction getTrueOffsetParent(element) {\n if (!isHTMLElement(element) || // https://github.com/popperjs/popper-core/issues/837\n getComputedStyle(element).position === 'fixed') {\n return null;\n }\n\n return element.offsetParent;\n} // `.offsetParent` reports `null` for fixed elements, while absolute elements\n// return the containing block\n\n\nfunction getContainingBlock(element) {\n var isFirefox = /firefox/i.test(getUAString());\n var isIE = /Trident/i.test(getUAString());\n\n if (isIE && isHTMLElement(element)) {\n // In IE 9, 10 and 11 fixed elements containing block is always established by the viewport\n var elementCss = getComputedStyle(element);\n\n if (elementCss.position === 'fixed') {\n return null;\n }\n }\n\n var currentNode = getParentNode(element);\n\n if (isShadowRoot(currentNode)) {\n currentNode = currentNode.host;\n }\n\n while (isHTMLElement(currentNode) && ['html', 'body'].indexOf(getNodeName(currentNode)) < 0) {\n var css = getComputedStyle(currentNode); // This is non-exhaustive but covers the most common CSS properties that\n // create a containing block.\n // https://developer.mozilla.org/en-US/docs/Web/CSS/Containing_block#identifying_the_containing_block\n\n if (css.transform !== 'none' || css.perspective !== 'none' || css.contain === 'paint' || ['transform', 'perspective'].indexOf(css.willChange) !== -1 || isFirefox && css.willChange === 'filter' || isFirefox && css.filter && css.filter !== 'none') {\n return currentNode;\n } else {\n currentNode = currentNode.parentNode;\n }\n }\n\n return null;\n} // Gets the closest ancestor positioned element. Handles some edge cases,\n// such as table ancestors and cross browser bugs.\n\n\nexport default function getOffsetParent(element) {\n var window = getWindow(element);\n var offsetParent = getTrueOffsetParent(element);\n\n while (offsetParent && isTableElement(offsetParent) && getComputedStyle(offsetParent).position === 'static') {\n offsetParent = getTrueOffsetParent(offsetParent);\n }\n\n if (offsetParent && (getNodeName(offsetParent) === 'html' || getNodeName(offsetParent) === 'body' && getComputedStyle(offsetParent).position === 'static')) {\n return window;\n }\n\n return offsetParent || getContainingBlock(element) || window;\n}","export default function getMainAxisFromPlacement(placement) {\n return ['top', 'bottom'].indexOf(placement) >= 0 ? 'x' : 'y';\n}","import { max as mathMax, min as mathMin } from \"./math.js\";\nexport function within(min, value, max) {\n return mathMax(min, mathMin(value, max));\n}\nexport function withinMaxClamp(min, value, max) {\n var v = within(min, value, max);\n return v > max ? max : v;\n}","import getFreshSideObject from \"./getFreshSideObject.js\";\nexport default function mergePaddingObject(paddingObject) {\n return Object.assign({}, getFreshSideObject(), paddingObject);\n}","export default function getFreshSideObject() {\n return {\n top: 0,\n right: 0,\n bottom: 0,\n left: 0\n };\n}","export default function expandToHashMap(value, keys) {\n return keys.reduce(function (hashMap, key) {\n hashMap[key] = value;\n return hashMap;\n }, {});\n}","import getBasePlacement from \"../utils/getBasePlacement.js\";\nimport getLayoutRect from \"../dom-utils/getLayoutRect.js\";\nimport contains from \"../dom-utils/contains.js\";\nimport getOffsetParent from \"../dom-utils/getOffsetParent.js\";\nimport getMainAxisFromPlacement from \"../utils/getMainAxisFromPlacement.js\";\nimport { within } from \"../utils/within.js\";\nimport mergePaddingObject from \"../utils/mergePaddingObject.js\";\nimport expandToHashMap from \"../utils/expandToHashMap.js\";\nimport { left, right, basePlacements, top, bottom } from \"../enums.js\"; // eslint-disable-next-line import/no-unused-modules\n\nvar toPaddingObject = function toPaddingObject(padding, state) {\n padding = typeof padding === 'function' ? padding(Object.assign({}, state.rects, {\n placement: state.placement\n })) : padding;\n return mergePaddingObject(typeof padding !== 'number' ? padding : expandToHashMap(padding, basePlacements));\n};\n\nfunction arrow(_ref) {\n var _state$modifiersData$;\n\n var state = _ref.state,\n name = _ref.name,\n options = _ref.options;\n var arrowElement = state.elements.arrow;\n var popperOffsets = state.modifiersData.popperOffsets;\n var basePlacement = getBasePlacement(state.placement);\n var axis = getMainAxisFromPlacement(basePlacement);\n var isVertical = [left, right].indexOf(basePlacement) >= 0;\n var len = isVertical ? 'height' : 'width';\n\n if (!arrowElement || !popperOffsets) {\n return;\n }\n\n var paddingObject = toPaddingObject(options.padding, state);\n var arrowRect = getLayoutRect(arrowElement);\n var minProp = axis === 'y' ? top : left;\n var maxProp = axis === 'y' ? bottom : right;\n var endDiff = state.rects.reference[len] + state.rects.reference[axis] - popperOffsets[axis] - state.rects.popper[len];\n var startDiff = popperOffsets[axis] - state.rects.reference[axis];\n var arrowOffsetParent = getOffsetParent(arrowElement);\n var clientSize = arrowOffsetParent ? axis === 'y' ? arrowOffsetParent.clientHeight || 0 : arrowOffsetParent.clientWidth || 0 : 0;\n var centerToReference = endDiff / 2 - startDiff / 2; // Make sure the arrow doesn't overflow the popper if the center point is\n // outside of the popper bounds\n\n var min = paddingObject[minProp];\n var max = clientSize - arrowRect[len] - paddingObject[maxProp];\n var center = clientSize / 2 - arrowRect[len] / 2 + centerToReference;\n var offset = within(min, center, max); // Prevents breaking syntax highlighting...\n\n var axisProp = axis;\n state.modifiersData[name] = (_state$modifiersData$ = {}, _state$modifiersData$[axisProp] = offset, _state$modifiersData$.centerOffset = offset - center, _state$modifiersData$);\n}\n\nfunction effect(_ref2) {\n var state = _ref2.state,\n options = _ref2.options;\n var _options$element = options.element,\n arrowElement = _options$element === void 0 ? '[data-popper-arrow]' : _options$element;\n\n if (arrowElement == null) {\n return;\n } // CSS selector\n\n\n if (typeof arrowElement === 'string') {\n arrowElement = state.elements.popper.querySelector(arrowElement);\n\n if (!arrowElement) {\n return;\n }\n }\n\n if (!contains(state.elements.popper, arrowElement)) {\n return;\n }\n\n state.elements.arrow = arrowElement;\n} // eslint-disable-next-line import/no-unused-modules\n\n\nexport default {\n name: 'arrow',\n enabled: true,\n phase: 'main',\n fn: arrow,\n effect: effect,\n requires: ['popperOffsets'],\n requiresIfExists: ['preventOverflow']\n};","export default function getVariation(placement) {\n return placement.split('-')[1];\n}","import { top, left, right, bottom, end } from \"../enums.js\";\nimport getOffsetParent from \"../dom-utils/getOffsetParent.js\";\nimport getWindow from \"../dom-utils/getWindow.js\";\nimport getDocumentElement from \"../dom-utils/getDocumentElement.js\";\nimport getComputedStyle from \"../dom-utils/getComputedStyle.js\";\nimport getBasePlacement from \"../utils/getBasePlacement.js\";\nimport getVariation from \"../utils/getVariation.js\";\nimport { round } from \"../utils/math.js\"; // eslint-disable-next-line import/no-unused-modules\n\nvar unsetSides = {\n top: 'auto',\n right: 'auto',\n bottom: 'auto',\n left: 'auto'\n}; // Round the offsets to the nearest suitable subpixel based on the DPR.\n// Zooming can change the DPR, but it seems to report a value that will\n// cleanly divide the values into the appropriate subpixels.\n\nfunction roundOffsetsByDPR(_ref, win) {\n var x = _ref.x,\n y = _ref.y;\n var dpr = win.devicePixelRatio || 1;\n return {\n x: round(x * dpr) / dpr || 0,\n y: round(y * dpr) / dpr || 0\n };\n}\n\nexport function mapToStyles(_ref2) {\n var _Object$assign2;\n\n var popper = _ref2.popper,\n popperRect = _ref2.popperRect,\n placement = _ref2.placement,\n variation = _ref2.variation,\n offsets = _ref2.offsets,\n position = _ref2.position,\n gpuAcceleration = _ref2.gpuAcceleration,\n adaptive = _ref2.adaptive,\n roundOffsets = _ref2.roundOffsets,\n isFixed = _ref2.isFixed;\n var _offsets$x = offsets.x,\n x = _offsets$x === void 0 ? 0 : _offsets$x,\n _offsets$y = offsets.y,\n y = _offsets$y === void 0 ? 0 : _offsets$y;\n\n var _ref3 = typeof roundOffsets === 'function' ? roundOffsets({\n x: x,\n y: y\n }) : {\n x: x,\n y: y\n };\n\n x = _ref3.x;\n y = _ref3.y;\n var hasX = offsets.hasOwnProperty('x');\n var hasY = offsets.hasOwnProperty('y');\n var sideX = left;\n var sideY = top;\n var win = window;\n\n if (adaptive) {\n var offsetParent = getOffsetParent(popper);\n var heightProp = 'clientHeight';\n var widthProp = 'clientWidth';\n\n if (offsetParent === getWindow(popper)) {\n offsetParent = getDocumentElement(popper);\n\n if (getComputedStyle(offsetParent).position !== 'static' && position === 'absolute') {\n heightProp = 'scrollHeight';\n widthProp = 'scrollWidth';\n }\n } // $FlowFixMe[incompatible-cast]: force type refinement, we compare offsetParent with window above, but Flow doesn't detect it\n\n\n offsetParent = offsetParent;\n\n if (placement === top || (placement === left || placement === right) && variation === end) {\n sideY = bottom;\n var offsetY = isFixed && offsetParent === win && win.visualViewport ? win.visualViewport.height : // $FlowFixMe[prop-missing]\n offsetParent[heightProp];\n y -= offsetY - popperRect.height;\n y *= gpuAcceleration ? 1 : -1;\n }\n\n if (placement === left || (placement === top || placement === bottom) && variation === end) {\n sideX = right;\n var offsetX = isFixed && offsetParent === win && win.visualViewport ? win.visualViewport.width : // $FlowFixMe[prop-missing]\n offsetParent[widthProp];\n x -= offsetX - popperRect.width;\n x *= gpuAcceleration ? 1 : -1;\n }\n }\n\n var commonStyles = Object.assign({\n position: position\n }, adaptive && unsetSides);\n\n var _ref4 = roundOffsets === true ? roundOffsetsByDPR({\n x: x,\n y: y\n }, getWindow(popper)) : {\n x: x,\n y: y\n };\n\n x = _ref4.x;\n y = _ref4.y;\n\n if (gpuAcceleration) {\n var _Object$assign;\n\n return Object.assign({}, commonStyles, (_Object$assign = {}, _Object$assign[sideY] = hasY ? '0' : '', _Object$assign[sideX] = hasX ? '0' : '', _Object$assign.transform = (win.devicePixelRatio || 1) <= 1 ? \"translate(\" + x + \"px, \" + y + \"px)\" : \"translate3d(\" + x + \"px, \" + y + \"px, 0)\", _Object$assign));\n }\n\n return Object.assign({}, commonStyles, (_Object$assign2 = {}, _Object$assign2[sideY] = hasY ? y + \"px\" : '', _Object$assign2[sideX] = hasX ? x + \"px\" : '', _Object$assign2.transform = '', _Object$assign2));\n}\n\nfunction computeStyles(_ref5) {\n var state = _ref5.state,\n options = _ref5.options;\n var _options$gpuAccelerat = options.gpuAcceleration,\n gpuAcceleration = _options$gpuAccelerat === void 0 ? true : _options$gpuAccelerat,\n _options$adaptive = options.adaptive,\n adaptive = _options$adaptive === void 0 ? true : _options$adaptive,\n _options$roundOffsets = options.roundOffsets,\n roundOffsets = _options$roundOffsets === void 0 ? true : _options$roundOffsets;\n var commonStyles = {\n placement: getBasePlacement(state.placement),\n variation: getVariation(state.placement),\n popper: state.elements.popper,\n popperRect: state.rects.popper,\n gpuAcceleration: gpuAcceleration,\n isFixed: state.options.strategy === 'fixed'\n };\n\n if (state.modifiersData.popperOffsets != null) {\n state.styles.popper = Object.assign({}, state.styles.popper, mapToStyles(Object.assign({}, commonStyles, {\n offsets: state.modifiersData.popperOffsets,\n position: state.options.strategy,\n adaptive: adaptive,\n roundOffsets: roundOffsets\n })));\n }\n\n if (state.modifiersData.arrow != null) {\n state.styles.arrow = Object.assign({}, state.styles.arrow, mapToStyles(Object.assign({}, commonStyles, {\n offsets: state.modifiersData.arrow,\n position: 'absolute',\n adaptive: false,\n roundOffsets: roundOffsets\n })));\n }\n\n state.attributes.popper = Object.assign({}, state.attributes.popper, {\n 'data-popper-placement': state.placement\n });\n} // eslint-disable-next-line import/no-unused-modules\n\n\nexport default {\n name: 'computeStyles',\n enabled: true,\n phase: 'beforeWrite',\n fn: computeStyles,\n data: {}\n};","import getWindow from \"../dom-utils/getWindow.js\"; // eslint-disable-next-line import/no-unused-modules\n\nvar passive = {\n passive: true\n};\n\nfunction effect(_ref) {\n var state = _ref.state,\n instance = _ref.instance,\n options = _ref.options;\n var _options$scroll = options.scroll,\n scroll = _options$scroll === void 0 ? true : _options$scroll,\n _options$resize = options.resize,\n resize = _options$resize === void 0 ? true : _options$resize;\n var window = getWindow(state.elements.popper);\n var scrollParents = [].concat(state.scrollParents.reference, state.scrollParents.popper);\n\n if (scroll) {\n scrollParents.forEach(function (scrollParent) {\n scrollParent.addEventListener('scroll', instance.update, passive);\n });\n }\n\n if (resize) {\n window.addEventListener('resize', instance.update, passive);\n }\n\n return function () {\n if (scroll) {\n scrollParents.forEach(function (scrollParent) {\n scrollParent.removeEventListener('scroll', instance.update, passive);\n });\n }\n\n if (resize) {\n window.removeEventListener('resize', instance.update, passive);\n }\n };\n} // eslint-disable-next-line import/no-unused-modules\n\n\nexport default {\n name: 'eventListeners',\n enabled: true,\n phase: 'write',\n fn: function fn() {},\n effect: effect,\n data: {}\n};","var hash = {\n left: 'right',\n right: 'left',\n bottom: 'top',\n top: 'bottom'\n};\nexport default function getOppositePlacement(placement) {\n return placement.replace(/left|right|bottom|top/g, function (matched) {\n return hash[matched];\n });\n}","var hash = {\n start: 'end',\n end: 'start'\n};\nexport default function getOppositeVariationPlacement(placement) {\n return placement.replace(/start|end/g, function (matched) {\n return hash[matched];\n });\n}","import getWindow from \"./getWindow.js\";\nexport default function getWindowScroll(node) {\n var win = getWindow(node);\n var scrollLeft = win.pageXOffset;\n var scrollTop = win.pageYOffset;\n return {\n scrollLeft: scrollLeft,\n scrollTop: scrollTop\n };\n}","import getBoundingClientRect from \"./getBoundingClientRect.js\";\nimport getDocumentElement from \"./getDocumentElement.js\";\nimport getWindowScroll from \"./getWindowScroll.js\";\nexport default function getWindowScrollBarX(element) {\n // If has a CSS width greater than the viewport, then this will be\n // incorrect for RTL.\n // Popper 1 is broken in this case and never had a bug report so let's assume\n // it's not an issue. I don't think anyone ever specifies width on \n // anyway.\n // Browsers where the left scrollbar doesn't cause an issue report `0` for\n // this (e.g. Edge 2019, IE11, Safari)\n return getBoundingClientRect(getDocumentElement(element)).left + getWindowScroll(element).scrollLeft;\n}","import getComputedStyle from \"./getComputedStyle.js\";\nexport default function isScrollParent(element) {\n // Firefox wants us to check `-x` and `-y` variations as well\n var _getComputedStyle = getComputedStyle(element),\n overflow = _getComputedStyle.overflow,\n overflowX = _getComputedStyle.overflowX,\n overflowY = _getComputedStyle.overflowY;\n\n return /auto|scroll|overlay|hidden/.test(overflow + overflowY + overflowX);\n}","import getParentNode from \"./getParentNode.js\";\nimport isScrollParent from \"./isScrollParent.js\";\nimport getNodeName from \"./getNodeName.js\";\nimport { isHTMLElement } from \"./instanceOf.js\";\nexport default function getScrollParent(node) {\n if (['html', 'body', '#document'].indexOf(getNodeName(node)) >= 0) {\n // $FlowFixMe[incompatible-return]: assume body is always available\n return node.ownerDocument.body;\n }\n\n if (isHTMLElement(node) && isScrollParent(node)) {\n return node;\n }\n\n return getScrollParent(getParentNode(node));\n}","import getScrollParent from \"./getScrollParent.js\";\nimport getParentNode from \"./getParentNode.js\";\nimport getWindow from \"./getWindow.js\";\nimport isScrollParent from \"./isScrollParent.js\";\n/*\ngiven a DOM element, return the list of all scroll parents, up the list of ancesors\nuntil we get to the top window object. This list is what we attach scroll listeners\nto, because if any of these parent elements scroll, we'll need to re-calculate the\nreference element's position.\n*/\n\nexport default function listScrollParents(element, list) {\n var _element$ownerDocumen;\n\n if (list === void 0) {\n list = [];\n }\n\n var scrollParent = getScrollParent(element);\n var isBody = scrollParent === ((_element$ownerDocumen = element.ownerDocument) == null ? void 0 : _element$ownerDocumen.body);\n var win = getWindow(scrollParent);\n var target = isBody ? [win].concat(win.visualViewport || [], isScrollParent(scrollParent) ? scrollParent : []) : scrollParent;\n var updatedList = list.concat(target);\n return isBody ? updatedList : // $FlowFixMe[incompatible-call]: isBody tells us target will be an HTMLElement here\n updatedList.concat(listScrollParents(getParentNode(target)));\n}","export default function rectToClientRect(rect) {\n return Object.assign({}, rect, {\n left: rect.x,\n top: rect.y,\n right: rect.x + rect.width,\n bottom: rect.y + rect.height\n });\n}","import { viewport } from \"../enums.js\";\nimport getViewportRect from \"./getViewportRect.js\";\nimport getDocumentRect from \"./getDocumentRect.js\";\nimport listScrollParents from \"./listScrollParents.js\";\nimport getOffsetParent from \"./getOffsetParent.js\";\nimport getDocumentElement from \"./getDocumentElement.js\";\nimport getComputedStyle from \"./getComputedStyle.js\";\nimport { isElement, isHTMLElement } from \"./instanceOf.js\";\nimport getBoundingClientRect from \"./getBoundingClientRect.js\";\nimport getParentNode from \"./getParentNode.js\";\nimport contains from \"./contains.js\";\nimport getNodeName from \"./getNodeName.js\";\nimport rectToClientRect from \"../utils/rectToClientRect.js\";\nimport { max, min } from \"../utils/math.js\";\n\nfunction getInnerBoundingClientRect(element, strategy) {\n var rect = getBoundingClientRect(element, false, strategy === 'fixed');\n rect.top = rect.top + element.clientTop;\n rect.left = rect.left + element.clientLeft;\n rect.bottom = rect.top + element.clientHeight;\n rect.right = rect.left + element.clientWidth;\n rect.width = element.clientWidth;\n rect.height = element.clientHeight;\n rect.x = rect.left;\n rect.y = rect.top;\n return rect;\n}\n\nfunction getClientRectFromMixedType(element, clippingParent, strategy) {\n return clippingParent === viewport ? rectToClientRect(getViewportRect(element, strategy)) : isElement(clippingParent) ? getInnerBoundingClientRect(clippingParent, strategy) : rectToClientRect(getDocumentRect(getDocumentElement(element)));\n} // A \"clipping parent\" is an overflowable container with the characteristic of\n// clipping (or hiding) overflowing elements with a position different from\n// `initial`\n\n\nfunction getClippingParents(element) {\n var clippingParents = listScrollParents(getParentNode(element));\n var canEscapeClipping = ['absolute', 'fixed'].indexOf(getComputedStyle(element).position) >= 0;\n var clipperElement = canEscapeClipping && isHTMLElement(element) ? getOffsetParent(element) : element;\n\n if (!isElement(clipperElement)) {\n return [];\n } // $FlowFixMe[incompatible-return]: https://github.com/facebook/flow/issues/1414\n\n\n return clippingParents.filter(function (clippingParent) {\n return isElement(clippingParent) && contains(clippingParent, clipperElement) && getNodeName(clippingParent) !== 'body';\n });\n} // Gets the maximum area that the element is visible in due to any number of\n// clipping parents\n\n\nexport default function getClippingRect(element, boundary, rootBoundary, strategy) {\n var mainClippingParents = boundary === 'clippingParents' ? getClippingParents(element) : [].concat(boundary);\n var clippingParents = [].concat(mainClippingParents, [rootBoundary]);\n var firstClippingParent = clippingParents[0];\n var clippingRect = clippingParents.reduce(function (accRect, clippingParent) {\n var rect = getClientRectFromMixedType(element, clippingParent, strategy);\n accRect.top = max(rect.top, accRect.top);\n accRect.right = min(rect.right, accRect.right);\n accRect.bottom = min(rect.bottom, accRect.bottom);\n accRect.left = max(rect.left, accRect.left);\n return accRect;\n }, getClientRectFromMixedType(element, firstClippingParent, strategy));\n clippingRect.width = clippingRect.right - clippingRect.left;\n clippingRect.height = clippingRect.bottom - clippingRect.top;\n clippingRect.x = clippingRect.left;\n clippingRect.y = clippingRect.top;\n return clippingRect;\n}","import getWindow from \"./getWindow.js\";\nimport getDocumentElement from \"./getDocumentElement.js\";\nimport getWindowScrollBarX from \"./getWindowScrollBarX.js\";\nimport isLayoutViewport from \"./isLayoutViewport.js\";\nexport default function getViewportRect(element, strategy) {\n var win = getWindow(element);\n var html = getDocumentElement(element);\n var visualViewport = win.visualViewport;\n var width = html.clientWidth;\n var height = html.clientHeight;\n var x = 0;\n var y = 0;\n\n if (visualViewport) {\n width = visualViewport.width;\n height = visualViewport.height;\n var layoutViewport = isLayoutViewport();\n\n if (layoutViewport || !layoutViewport && strategy === 'fixed') {\n x = visualViewport.offsetLeft;\n y = visualViewport.offsetTop;\n }\n }\n\n return {\n width: width,\n height: height,\n x: x + getWindowScrollBarX(element),\n y: y\n };\n}","import getDocumentElement from \"./getDocumentElement.js\";\nimport getComputedStyle from \"./getComputedStyle.js\";\nimport getWindowScrollBarX from \"./getWindowScrollBarX.js\";\nimport getWindowScroll from \"./getWindowScroll.js\";\nimport { max } from \"../utils/math.js\"; // Gets the entire size of the scrollable document area, even extending outside\n// of the `` and `` rect bounds if horizontally scrollable\n\nexport default function getDocumentRect(element) {\n var _element$ownerDocumen;\n\n var html = getDocumentElement(element);\n var winScroll = getWindowScroll(element);\n var body = (_element$ownerDocumen = element.ownerDocument) == null ? void 0 : _element$ownerDocumen.body;\n var width = max(html.scrollWidth, html.clientWidth, body ? body.scrollWidth : 0, body ? body.clientWidth : 0);\n var height = max(html.scrollHeight, html.clientHeight, body ? body.scrollHeight : 0, body ? body.clientHeight : 0);\n var x = -winScroll.scrollLeft + getWindowScrollBarX(element);\n var y = -winScroll.scrollTop;\n\n if (getComputedStyle(body || html).direction === 'rtl') {\n x += max(html.clientWidth, body ? body.clientWidth : 0) - width;\n }\n\n return {\n width: width,\n height: height,\n x: x,\n y: y\n };\n}","import getBasePlacement from \"./getBasePlacement.js\";\nimport getVariation from \"./getVariation.js\";\nimport getMainAxisFromPlacement from \"./getMainAxisFromPlacement.js\";\nimport { top, right, bottom, left, start, end } from \"../enums.js\";\nexport default function computeOffsets(_ref) {\n var reference = _ref.reference,\n element = _ref.element,\n placement = _ref.placement;\n var basePlacement = placement ? getBasePlacement(placement) : null;\n var variation = placement ? getVariation(placement) : null;\n var commonX = reference.x + reference.width / 2 - element.width / 2;\n var commonY = reference.y + reference.height / 2 - element.height / 2;\n var offsets;\n\n switch (basePlacement) {\n case top:\n offsets = {\n x: commonX,\n y: reference.y - element.height\n };\n break;\n\n case bottom:\n offsets = {\n x: commonX,\n y: reference.y + reference.height\n };\n break;\n\n case right:\n offsets = {\n x: reference.x + reference.width,\n y: commonY\n };\n break;\n\n case left:\n offsets = {\n x: reference.x - element.width,\n y: commonY\n };\n break;\n\n default:\n offsets = {\n x: reference.x,\n y: reference.y\n };\n }\n\n var mainAxis = basePlacement ? getMainAxisFromPlacement(basePlacement) : null;\n\n if (mainAxis != null) {\n var len = mainAxis === 'y' ? 'height' : 'width';\n\n switch (variation) {\n case start:\n offsets[mainAxis] = offsets[mainAxis] - (reference[len] / 2 - element[len] / 2);\n break;\n\n case end:\n offsets[mainAxis] = offsets[mainAxis] + (reference[len] / 2 - element[len] / 2);\n break;\n\n default:\n }\n }\n\n return offsets;\n}","import getClippingRect from \"../dom-utils/getClippingRect.js\";\nimport getDocumentElement from \"../dom-utils/getDocumentElement.js\";\nimport getBoundingClientRect from \"../dom-utils/getBoundingClientRect.js\";\nimport computeOffsets from \"./computeOffsets.js\";\nimport rectToClientRect from \"./rectToClientRect.js\";\nimport { clippingParents, reference, popper, bottom, top, right, basePlacements, viewport } from \"../enums.js\";\nimport { isElement } from \"../dom-utils/instanceOf.js\";\nimport mergePaddingObject from \"./mergePaddingObject.js\";\nimport expandToHashMap from \"./expandToHashMap.js\"; // eslint-disable-next-line import/no-unused-modules\n\nexport default function detectOverflow(state, options) {\n if (options === void 0) {\n options = {};\n }\n\n var _options = options,\n _options$placement = _options.placement,\n placement = _options$placement === void 0 ? state.placement : _options$placement,\n _options$strategy = _options.strategy,\n strategy = _options$strategy === void 0 ? state.strategy : _options$strategy,\n _options$boundary = _options.boundary,\n boundary = _options$boundary === void 0 ? clippingParents : _options$boundary,\n _options$rootBoundary = _options.rootBoundary,\n rootBoundary = _options$rootBoundary === void 0 ? viewport : _options$rootBoundary,\n _options$elementConte = _options.elementContext,\n elementContext = _options$elementConte === void 0 ? popper : _options$elementConte,\n _options$altBoundary = _options.altBoundary,\n altBoundary = _options$altBoundary === void 0 ? false : _options$altBoundary,\n _options$padding = _options.padding,\n padding = _options$padding === void 0 ? 0 : _options$padding;\n var paddingObject = mergePaddingObject(typeof padding !== 'number' ? padding : expandToHashMap(padding, basePlacements));\n var altContext = elementContext === popper ? reference : popper;\n var popperRect = state.rects.popper;\n var element = state.elements[altBoundary ? altContext : elementContext];\n var clippingClientRect = getClippingRect(isElement(element) ? element : element.contextElement || getDocumentElement(state.elements.popper), boundary, rootBoundary, strategy);\n var referenceClientRect = getBoundingClientRect(state.elements.reference);\n var popperOffsets = computeOffsets({\n reference: referenceClientRect,\n element: popperRect,\n strategy: 'absolute',\n placement: placement\n });\n var popperClientRect = rectToClientRect(Object.assign({}, popperRect, popperOffsets));\n var elementClientRect = elementContext === popper ? popperClientRect : referenceClientRect; // positive = overflowing the clipping rect\n // 0 or negative = within the clipping rect\n\n var overflowOffsets = {\n top: clippingClientRect.top - elementClientRect.top + paddingObject.top,\n bottom: elementClientRect.bottom - clippingClientRect.bottom + paddingObject.bottom,\n left: clippingClientRect.left - elementClientRect.left + paddingObject.left,\n right: elementClientRect.right - clippingClientRect.right + paddingObject.right\n };\n var offsetData = state.modifiersData.offset; // Offsets can be applied only to the popper element\n\n if (elementContext === popper && offsetData) {\n var offset = offsetData[placement];\n Object.keys(overflowOffsets).forEach(function (key) {\n var multiply = [right, bottom].indexOf(key) >= 0 ? 1 : -1;\n var axis = [top, bottom].indexOf(key) >= 0 ? 'y' : 'x';\n overflowOffsets[key] += offset[axis] * multiply;\n });\n }\n\n return overflowOffsets;\n}","import getOppositePlacement from \"../utils/getOppositePlacement.js\";\nimport getBasePlacement from \"../utils/getBasePlacement.js\";\nimport getOppositeVariationPlacement from \"../utils/getOppositeVariationPlacement.js\";\nimport detectOverflow from \"../utils/detectOverflow.js\";\nimport computeAutoPlacement from \"../utils/computeAutoPlacement.js\";\nimport { bottom, top, start, right, left, auto } from \"../enums.js\";\nimport getVariation from \"../utils/getVariation.js\"; // eslint-disable-next-line import/no-unused-modules\n\nfunction getExpandedFallbackPlacements(placement) {\n if (getBasePlacement(placement) === auto) {\n return [];\n }\n\n var oppositePlacement = getOppositePlacement(placement);\n return [getOppositeVariationPlacement(placement), oppositePlacement, getOppositeVariationPlacement(oppositePlacement)];\n}\n\nfunction flip(_ref) {\n var state = _ref.state,\n options = _ref.options,\n name = _ref.name;\n\n if (state.modifiersData[name]._skip) {\n return;\n }\n\n var _options$mainAxis = options.mainAxis,\n checkMainAxis = _options$mainAxis === void 0 ? true : _options$mainAxis,\n _options$altAxis = options.altAxis,\n checkAltAxis = _options$altAxis === void 0 ? true : _options$altAxis,\n specifiedFallbackPlacements = options.fallbackPlacements,\n padding = options.padding,\n boundary = options.boundary,\n rootBoundary = options.rootBoundary,\n altBoundary = options.altBoundary,\n _options$flipVariatio = options.flipVariations,\n flipVariations = _options$flipVariatio === void 0 ? true : _options$flipVariatio,\n allowedAutoPlacements = options.allowedAutoPlacements;\n var preferredPlacement = state.options.placement;\n var basePlacement = getBasePlacement(preferredPlacement);\n var isBasePlacement = basePlacement === preferredPlacement;\n var fallbackPlacements = specifiedFallbackPlacements || (isBasePlacement || !flipVariations ? [getOppositePlacement(preferredPlacement)] : getExpandedFallbackPlacements(preferredPlacement));\n var placements = [preferredPlacement].concat(fallbackPlacements).reduce(function (acc, placement) {\n return acc.concat(getBasePlacement(placement) === auto ? computeAutoPlacement(state, {\n placement: placement,\n boundary: boundary,\n rootBoundary: rootBoundary,\n padding: padding,\n flipVariations: flipVariations,\n allowedAutoPlacements: allowedAutoPlacements\n }) : placement);\n }, []);\n var referenceRect = state.rects.reference;\n var popperRect = state.rects.popper;\n var checksMap = new Map();\n var makeFallbackChecks = true;\n var firstFittingPlacement = placements[0];\n\n for (var i = 0; i < placements.length; i++) {\n var placement = placements[i];\n\n var _basePlacement = getBasePlacement(placement);\n\n var isStartVariation = getVariation(placement) === start;\n var isVertical = [top, bottom].indexOf(_basePlacement) >= 0;\n var len = isVertical ? 'width' : 'height';\n var overflow = detectOverflow(state, {\n placement: placement,\n boundary: boundary,\n rootBoundary: rootBoundary,\n altBoundary: altBoundary,\n padding: padding\n });\n var mainVariationSide = isVertical ? isStartVariation ? right : left : isStartVariation ? bottom : top;\n\n if (referenceRect[len] > popperRect[len]) {\n mainVariationSide = getOppositePlacement(mainVariationSide);\n }\n\n var altVariationSide = getOppositePlacement(mainVariationSide);\n var checks = [];\n\n if (checkMainAxis) {\n checks.push(overflow[_basePlacement] <= 0);\n }\n\n if (checkAltAxis) {\n checks.push(overflow[mainVariationSide] <= 0, overflow[altVariationSide] <= 0);\n }\n\n if (checks.every(function (check) {\n return check;\n })) {\n firstFittingPlacement = placement;\n makeFallbackChecks = false;\n break;\n }\n\n checksMap.set(placement, checks);\n }\n\n if (makeFallbackChecks) {\n // `2` may be desired in some cases – research later\n var numberOfChecks = flipVariations ? 3 : 1;\n\n var _loop = function _loop(_i) {\n var fittingPlacement = placements.find(function (placement) {\n var checks = checksMap.get(placement);\n\n if (checks) {\n return checks.slice(0, _i).every(function (check) {\n return check;\n });\n }\n });\n\n if (fittingPlacement) {\n firstFittingPlacement = fittingPlacement;\n return \"break\";\n }\n };\n\n for (var _i = numberOfChecks; _i > 0; _i--) {\n var _ret = _loop(_i);\n\n if (_ret === \"break\") break;\n }\n }\n\n if (state.placement !== firstFittingPlacement) {\n state.modifiersData[name]._skip = true;\n state.placement = firstFittingPlacement;\n state.reset = true;\n }\n} // eslint-disable-next-line import/no-unused-modules\n\n\nexport default {\n name: 'flip',\n enabled: true,\n phase: 'main',\n fn: flip,\n requiresIfExists: ['offset'],\n data: {\n _skip: false\n }\n};","import getVariation from \"./getVariation.js\";\nimport { variationPlacements, basePlacements, placements as allPlacements } from \"../enums.js\";\nimport detectOverflow from \"./detectOverflow.js\";\nimport getBasePlacement from \"./getBasePlacement.js\";\nexport default function computeAutoPlacement(state, options) {\n if (options === void 0) {\n options = {};\n }\n\n var _options = options,\n placement = _options.placement,\n boundary = _options.boundary,\n rootBoundary = _options.rootBoundary,\n padding = _options.padding,\n flipVariations = _options.flipVariations,\n _options$allowedAutoP = _options.allowedAutoPlacements,\n allowedAutoPlacements = _options$allowedAutoP === void 0 ? allPlacements : _options$allowedAutoP;\n var variation = getVariation(placement);\n var placements = variation ? flipVariations ? variationPlacements : variationPlacements.filter(function (placement) {\n return getVariation(placement) === variation;\n }) : basePlacements;\n var allowedPlacements = placements.filter(function (placement) {\n return allowedAutoPlacements.indexOf(placement) >= 0;\n });\n\n if (allowedPlacements.length === 0) {\n allowedPlacements = placements;\n } // $FlowFixMe[incompatible-type]: Flow seems to have problems with two array unions...\n\n\n var overflows = allowedPlacements.reduce(function (acc, placement) {\n acc[placement] = detectOverflow(state, {\n placement: placement,\n boundary: boundary,\n rootBoundary: rootBoundary,\n padding: padding\n })[getBasePlacement(placement)];\n return acc;\n }, {});\n return Object.keys(overflows).sort(function (a, b) {\n return overflows[a] - overflows[b];\n });\n}","import { top, bottom, left, right } from \"../enums.js\";\nimport detectOverflow from \"../utils/detectOverflow.js\";\n\nfunction getSideOffsets(overflow, rect, preventedOffsets) {\n if (preventedOffsets === void 0) {\n preventedOffsets = {\n x: 0,\n y: 0\n };\n }\n\n return {\n top: overflow.top - rect.height - preventedOffsets.y,\n right: overflow.right - rect.width + preventedOffsets.x,\n bottom: overflow.bottom - rect.height + preventedOffsets.y,\n left: overflow.left - rect.width - preventedOffsets.x\n };\n}\n\nfunction isAnySideFullyClipped(overflow) {\n return [top, right, bottom, left].some(function (side) {\n return overflow[side] >= 0;\n });\n}\n\nfunction hide(_ref) {\n var state = _ref.state,\n name = _ref.name;\n var referenceRect = state.rects.reference;\n var popperRect = state.rects.popper;\n var preventedOffsets = state.modifiersData.preventOverflow;\n var referenceOverflow = detectOverflow(state, {\n elementContext: 'reference'\n });\n var popperAltOverflow = detectOverflow(state, {\n altBoundary: true\n });\n var referenceClippingOffsets = getSideOffsets(referenceOverflow, referenceRect);\n var popperEscapeOffsets = getSideOffsets(popperAltOverflow, popperRect, preventedOffsets);\n var isReferenceHidden = isAnySideFullyClipped(referenceClippingOffsets);\n var hasPopperEscaped = isAnySideFullyClipped(popperEscapeOffsets);\n state.modifiersData[name] = {\n referenceClippingOffsets: referenceClippingOffsets,\n popperEscapeOffsets: popperEscapeOffsets,\n isReferenceHidden: isReferenceHidden,\n hasPopperEscaped: hasPopperEscaped\n };\n state.attributes.popper = Object.assign({}, state.attributes.popper, {\n 'data-popper-reference-hidden': isReferenceHidden,\n 'data-popper-escaped': hasPopperEscaped\n });\n} // eslint-disable-next-line import/no-unused-modules\n\n\nexport default {\n name: 'hide',\n enabled: true,\n phase: 'main',\n requiresIfExists: ['preventOverflow'],\n fn: hide\n};","import getBasePlacement from \"../utils/getBasePlacement.js\";\nimport { top, left, right, placements } from \"../enums.js\"; // eslint-disable-next-line import/no-unused-modules\n\nexport function distanceAndSkiddingToXY(placement, rects, offset) {\n var basePlacement = getBasePlacement(placement);\n var invertDistance = [left, top].indexOf(basePlacement) >= 0 ? -1 : 1;\n\n var _ref = typeof offset === 'function' ? offset(Object.assign({}, rects, {\n placement: placement\n })) : offset,\n skidding = _ref[0],\n distance = _ref[1];\n\n skidding = skidding || 0;\n distance = (distance || 0) * invertDistance;\n return [left, right].indexOf(basePlacement) >= 0 ? {\n x: distance,\n y: skidding\n } : {\n x: skidding,\n y: distance\n };\n}\n\nfunction offset(_ref2) {\n var state = _ref2.state,\n options = _ref2.options,\n name = _ref2.name;\n var _options$offset = options.offset,\n offset = _options$offset === void 0 ? [0, 0] : _options$offset;\n var data = placements.reduce(function (acc, placement) {\n acc[placement] = distanceAndSkiddingToXY(placement, state.rects, offset);\n return acc;\n }, {});\n var _data$state$placement = data[state.placement],\n x = _data$state$placement.x,\n y = _data$state$placement.y;\n\n if (state.modifiersData.popperOffsets != null) {\n state.modifiersData.popperOffsets.x += x;\n state.modifiersData.popperOffsets.y += y;\n }\n\n state.modifiersData[name] = data;\n} // eslint-disable-next-line import/no-unused-modules\n\n\nexport default {\n name: 'offset',\n enabled: true,\n phase: 'main',\n requires: ['popperOffsets'],\n fn: offset\n};","import computeOffsets from \"../utils/computeOffsets.js\";\n\nfunction popperOffsets(_ref) {\n var state = _ref.state,\n name = _ref.name;\n // Offsets are the actual position the popper needs to have to be\n // properly positioned near its reference element\n // This is the most basic placement, and will be adjusted by\n // the modifiers in the next step\n state.modifiersData[name] = computeOffsets({\n reference: state.rects.reference,\n element: state.rects.popper,\n strategy: 'absolute',\n placement: state.placement\n });\n} // eslint-disable-next-line import/no-unused-modules\n\n\nexport default {\n name: 'popperOffsets',\n enabled: true,\n phase: 'read',\n fn: popperOffsets,\n data: {}\n};","import { top, left, right, bottom, start } from \"../enums.js\";\nimport getBasePlacement from \"../utils/getBasePlacement.js\";\nimport getMainAxisFromPlacement from \"../utils/getMainAxisFromPlacement.js\";\nimport getAltAxis from \"../utils/getAltAxis.js\";\nimport { within, withinMaxClamp } from \"../utils/within.js\";\nimport getLayoutRect from \"../dom-utils/getLayoutRect.js\";\nimport getOffsetParent from \"../dom-utils/getOffsetParent.js\";\nimport detectOverflow from \"../utils/detectOverflow.js\";\nimport getVariation from \"../utils/getVariation.js\";\nimport getFreshSideObject from \"../utils/getFreshSideObject.js\";\nimport { min as mathMin, max as mathMax } from \"../utils/math.js\";\n\nfunction preventOverflow(_ref) {\n var state = _ref.state,\n options = _ref.options,\n name = _ref.name;\n var _options$mainAxis = options.mainAxis,\n checkMainAxis = _options$mainAxis === void 0 ? true : _options$mainAxis,\n _options$altAxis = options.altAxis,\n checkAltAxis = _options$altAxis === void 0 ? false : _options$altAxis,\n boundary = options.boundary,\n rootBoundary = options.rootBoundary,\n altBoundary = options.altBoundary,\n padding = options.padding,\n _options$tether = options.tether,\n tether = _options$tether === void 0 ? true : _options$tether,\n _options$tetherOffset = options.tetherOffset,\n tetherOffset = _options$tetherOffset === void 0 ? 0 : _options$tetherOffset;\n var overflow = detectOverflow(state, {\n boundary: boundary,\n rootBoundary: rootBoundary,\n padding: padding,\n altBoundary: altBoundary\n });\n var basePlacement = getBasePlacement(state.placement);\n var variation = getVariation(state.placement);\n var isBasePlacement = !variation;\n var mainAxis = getMainAxisFromPlacement(basePlacement);\n var altAxis = getAltAxis(mainAxis);\n var popperOffsets = state.modifiersData.popperOffsets;\n var referenceRect = state.rects.reference;\n var popperRect = state.rects.popper;\n var tetherOffsetValue = typeof tetherOffset === 'function' ? tetherOffset(Object.assign({}, state.rects, {\n placement: state.placement\n })) : tetherOffset;\n var normalizedTetherOffsetValue = typeof tetherOffsetValue === 'number' ? {\n mainAxis: tetherOffsetValue,\n altAxis: tetherOffsetValue\n } : Object.assign({\n mainAxis: 0,\n altAxis: 0\n }, tetherOffsetValue);\n var offsetModifierState = state.modifiersData.offset ? state.modifiersData.offset[state.placement] : null;\n var data = {\n x: 0,\n y: 0\n };\n\n if (!popperOffsets) {\n return;\n }\n\n if (checkMainAxis) {\n var _offsetModifierState$;\n\n var mainSide = mainAxis === 'y' ? top : left;\n var altSide = mainAxis === 'y' ? bottom : right;\n var len = mainAxis === 'y' ? 'height' : 'width';\n var offset = popperOffsets[mainAxis];\n var min = offset + overflow[mainSide];\n var max = offset - overflow[altSide];\n var additive = tether ? -popperRect[len] / 2 : 0;\n var minLen = variation === start ? referenceRect[len] : popperRect[len];\n var maxLen = variation === start ? -popperRect[len] : -referenceRect[len]; // We need to include the arrow in the calculation so the arrow doesn't go\n // outside the reference bounds\n\n var arrowElement = state.elements.arrow;\n var arrowRect = tether && arrowElement ? getLayoutRect(arrowElement) : {\n width: 0,\n height: 0\n };\n var arrowPaddingObject = state.modifiersData['arrow#persistent'] ? state.modifiersData['arrow#persistent'].padding : getFreshSideObject();\n var arrowPaddingMin = arrowPaddingObject[mainSide];\n var arrowPaddingMax = arrowPaddingObject[altSide]; // If the reference length is smaller than the arrow length, we don't want\n // to include its full size in the calculation. If the reference is small\n // and near the edge of a boundary, the popper can overflow even if the\n // reference is not overflowing as well (e.g. virtual elements with no\n // width or height)\n\n var arrowLen = within(0, referenceRect[len], arrowRect[len]);\n var minOffset = isBasePlacement ? referenceRect[len] / 2 - additive - arrowLen - arrowPaddingMin - normalizedTetherOffsetValue.mainAxis : minLen - arrowLen - arrowPaddingMin - normalizedTetherOffsetValue.mainAxis;\n var maxOffset = isBasePlacement ? -referenceRect[len] / 2 + additive + arrowLen + arrowPaddingMax + normalizedTetherOffsetValue.mainAxis : maxLen + arrowLen + arrowPaddingMax + normalizedTetherOffsetValue.mainAxis;\n var arrowOffsetParent = state.elements.arrow && getOffsetParent(state.elements.arrow);\n var clientOffset = arrowOffsetParent ? mainAxis === 'y' ? arrowOffsetParent.clientTop || 0 : arrowOffsetParent.clientLeft || 0 : 0;\n var offsetModifierValue = (_offsetModifierState$ = offsetModifierState == null ? void 0 : offsetModifierState[mainAxis]) != null ? _offsetModifierState$ : 0;\n var tetherMin = offset + minOffset - offsetModifierValue - clientOffset;\n var tetherMax = offset + maxOffset - offsetModifierValue;\n var preventedOffset = within(tether ? mathMin(min, tetherMin) : min, offset, tether ? mathMax(max, tetherMax) : max);\n popperOffsets[mainAxis] = preventedOffset;\n data[mainAxis] = preventedOffset - offset;\n }\n\n if (checkAltAxis) {\n var _offsetModifierState$2;\n\n var _mainSide = mainAxis === 'x' ? top : left;\n\n var _altSide = mainAxis === 'x' ? bottom : right;\n\n var _offset = popperOffsets[altAxis];\n\n var _len = altAxis === 'y' ? 'height' : 'width';\n\n var _min = _offset + overflow[_mainSide];\n\n var _max = _offset - overflow[_altSide];\n\n var isOriginSide = [top, left].indexOf(basePlacement) !== -1;\n\n var _offsetModifierValue = (_offsetModifierState$2 = offsetModifierState == null ? void 0 : offsetModifierState[altAxis]) != null ? _offsetModifierState$2 : 0;\n\n var _tetherMin = isOriginSide ? _min : _offset - referenceRect[_len] - popperRect[_len] - _offsetModifierValue + normalizedTetherOffsetValue.altAxis;\n\n var _tetherMax = isOriginSide ? _offset + referenceRect[_len] + popperRect[_len] - _offsetModifierValue - normalizedTetherOffsetValue.altAxis : _max;\n\n var _preventedOffset = tether && isOriginSide ? withinMaxClamp(_tetherMin, _offset, _tetherMax) : within(tether ? _tetherMin : _min, _offset, tether ? _tetherMax : _max);\n\n popperOffsets[altAxis] = _preventedOffset;\n data[altAxis] = _preventedOffset - _offset;\n }\n\n state.modifiersData[name] = data;\n} // eslint-disable-next-line import/no-unused-modules\n\n\nexport default {\n name: 'preventOverflow',\n enabled: true,\n phase: 'main',\n fn: preventOverflow,\n requiresIfExists: ['offset']\n};","export default function getAltAxis(axis) {\n return axis === 'x' ? 'y' : 'x';\n}","import getBoundingClientRect from \"./getBoundingClientRect.js\";\nimport getNodeScroll from \"./getNodeScroll.js\";\nimport getNodeName from \"./getNodeName.js\";\nimport { isHTMLElement } from \"./instanceOf.js\";\nimport getWindowScrollBarX from \"./getWindowScrollBarX.js\";\nimport getDocumentElement from \"./getDocumentElement.js\";\nimport isScrollParent from \"./isScrollParent.js\";\nimport { round } from \"../utils/math.js\";\n\nfunction isElementScaled(element) {\n var rect = element.getBoundingClientRect();\n var scaleX = round(rect.width) / element.offsetWidth || 1;\n var scaleY = round(rect.height) / element.offsetHeight || 1;\n return scaleX !== 1 || scaleY !== 1;\n} // Returns the composite rect of an element relative to its offsetParent.\n// Composite means it takes into account transforms as well as layout.\n\n\nexport default function getCompositeRect(elementOrVirtualElement, offsetParent, isFixed) {\n if (isFixed === void 0) {\n isFixed = false;\n }\n\n var isOffsetParentAnElement = isHTMLElement(offsetParent);\n var offsetParentIsScaled = isHTMLElement(offsetParent) && isElementScaled(offsetParent);\n var documentElement = getDocumentElement(offsetParent);\n var rect = getBoundingClientRect(elementOrVirtualElement, offsetParentIsScaled, isFixed);\n var scroll = {\n scrollLeft: 0,\n scrollTop: 0\n };\n var offsets = {\n x: 0,\n y: 0\n };\n\n if (isOffsetParentAnElement || !isOffsetParentAnElement && !isFixed) {\n if (getNodeName(offsetParent) !== 'body' || // https://github.com/popperjs/popper-core/issues/1078\n isScrollParent(documentElement)) {\n scroll = getNodeScroll(offsetParent);\n }\n\n if (isHTMLElement(offsetParent)) {\n offsets = getBoundingClientRect(offsetParent, true);\n offsets.x += offsetParent.clientLeft;\n offsets.y += offsetParent.clientTop;\n } else if (documentElement) {\n offsets.x = getWindowScrollBarX(documentElement);\n }\n }\n\n return {\n x: rect.left + scroll.scrollLeft - offsets.x,\n y: rect.top + scroll.scrollTop - offsets.y,\n width: rect.width,\n height: rect.height\n };\n}","import getWindowScroll from \"./getWindowScroll.js\";\nimport getWindow from \"./getWindow.js\";\nimport { isHTMLElement } from \"./instanceOf.js\";\nimport getHTMLElementScroll from \"./getHTMLElementScroll.js\";\nexport default function getNodeScroll(node) {\n if (node === getWindow(node) || !isHTMLElement(node)) {\n return getWindowScroll(node);\n } else {\n return getHTMLElementScroll(node);\n }\n}","export default function getHTMLElementScroll(element) {\n return {\n scrollLeft: element.scrollLeft,\n scrollTop: element.scrollTop\n };\n}","import { modifierPhases } from \"../enums.js\"; // source: https://stackoverflow.com/questions/49875255\n\nfunction order(modifiers) {\n var map = new Map();\n var visited = new Set();\n var result = [];\n modifiers.forEach(function (modifier) {\n map.set(modifier.name, modifier);\n }); // On visiting object, check for its dependencies and visit them recursively\n\n function sort(modifier) {\n visited.add(modifier.name);\n var requires = [].concat(modifier.requires || [], modifier.requiresIfExists || []);\n requires.forEach(function (dep) {\n if (!visited.has(dep)) {\n var depModifier = map.get(dep);\n\n if (depModifier) {\n sort(depModifier);\n }\n }\n });\n result.push(modifier);\n }\n\n modifiers.forEach(function (modifier) {\n if (!visited.has(modifier.name)) {\n // check for visited object\n sort(modifier);\n }\n });\n return result;\n}\n\nexport default function orderModifiers(modifiers) {\n // order based on dependencies\n var orderedModifiers = order(modifiers); // order based on phase\n\n return modifierPhases.reduce(function (acc, phase) {\n return acc.concat(orderedModifiers.filter(function (modifier) {\n return modifier.phase === phase;\n }));\n }, []);\n}","import getCompositeRect from \"./dom-utils/getCompositeRect.js\";\nimport getLayoutRect from \"./dom-utils/getLayoutRect.js\";\nimport listScrollParents from \"./dom-utils/listScrollParents.js\";\nimport getOffsetParent from \"./dom-utils/getOffsetParent.js\";\nimport orderModifiers from \"./utils/orderModifiers.js\";\nimport debounce from \"./utils/debounce.js\";\nimport mergeByName from \"./utils/mergeByName.js\";\nimport detectOverflow from \"./utils/detectOverflow.js\";\nimport { isElement } from \"./dom-utils/instanceOf.js\";\nvar DEFAULT_OPTIONS = {\n placement: 'bottom',\n modifiers: [],\n strategy: 'absolute'\n};\n\nfunction areValidElements() {\n for (var _len = arguments.length, args = new Array(_len), _key = 0; _key < _len; _key++) {\n args[_key] = arguments[_key];\n }\n\n return !args.some(function (element) {\n return !(element && typeof element.getBoundingClientRect === 'function');\n });\n}\n\nexport function popperGenerator(generatorOptions) {\n if (generatorOptions === void 0) {\n generatorOptions = {};\n }\n\n var _generatorOptions = generatorOptions,\n _generatorOptions$def = _generatorOptions.defaultModifiers,\n defaultModifiers = _generatorOptions$def === void 0 ? [] : _generatorOptions$def,\n _generatorOptions$def2 = _generatorOptions.defaultOptions,\n defaultOptions = _generatorOptions$def2 === void 0 ? DEFAULT_OPTIONS : _generatorOptions$def2;\n return function createPopper(reference, popper, options) {\n if (options === void 0) {\n options = defaultOptions;\n }\n\n var state = {\n placement: 'bottom',\n orderedModifiers: [],\n options: Object.assign({}, DEFAULT_OPTIONS, defaultOptions),\n modifiersData: {},\n elements: {\n reference: reference,\n popper: popper\n },\n attributes: {},\n styles: {}\n };\n var effectCleanupFns = [];\n var isDestroyed = false;\n var instance = {\n state: state,\n setOptions: function setOptions(setOptionsAction) {\n var options = typeof setOptionsAction === 'function' ? setOptionsAction(state.options) : setOptionsAction;\n cleanupModifierEffects();\n state.options = Object.assign({}, defaultOptions, state.options, options);\n state.scrollParents = {\n reference: isElement(reference) ? listScrollParents(reference) : reference.contextElement ? listScrollParents(reference.contextElement) : [],\n popper: listScrollParents(popper)\n }; // Orders the modifiers based on their dependencies and `phase`\n // properties\n\n var orderedModifiers = orderModifiers(mergeByName([].concat(defaultModifiers, state.options.modifiers))); // Strip out disabled modifiers\n\n state.orderedModifiers = orderedModifiers.filter(function (m) {\n return m.enabled;\n });\n runModifierEffects();\n return instance.update();\n },\n // Sync update – it will always be executed, even if not necessary. This\n // is useful for low frequency updates where sync behavior simplifies the\n // logic.\n // For high frequency updates (e.g. `resize` and `scroll` events), always\n // prefer the async Popper#update method\n forceUpdate: function forceUpdate() {\n if (isDestroyed) {\n return;\n }\n\n var _state$elements = state.elements,\n reference = _state$elements.reference,\n popper = _state$elements.popper; // Don't proceed if `reference` or `popper` are not valid elements\n // anymore\n\n if (!areValidElements(reference, popper)) {\n return;\n } // Store the reference and popper rects to be read by modifiers\n\n\n state.rects = {\n reference: getCompositeRect(reference, getOffsetParent(popper), state.options.strategy === 'fixed'),\n popper: getLayoutRect(popper)\n }; // Modifiers have the ability to reset the current update cycle. The\n // most common use case for this is the `flip` modifier changing the\n // placement, which then needs to re-run all the modifiers, because the\n // logic was previously ran for the previous placement and is therefore\n // stale/incorrect\n\n state.reset = false;\n state.placement = state.options.placement; // On each update cycle, the `modifiersData` property for each modifier\n // is filled with the initial data specified by the modifier. This means\n // it doesn't persist and is fresh on each update.\n // To ensure persistent data, use `${name}#persistent`\n\n state.orderedModifiers.forEach(function (modifier) {\n return state.modifiersData[modifier.name] = Object.assign({}, modifier.data);\n });\n\n for (var index = 0; index < state.orderedModifiers.length; index++) {\n if (state.reset === true) {\n state.reset = false;\n index = -1;\n continue;\n }\n\n var _state$orderedModifie = state.orderedModifiers[index],\n fn = _state$orderedModifie.fn,\n _state$orderedModifie2 = _state$orderedModifie.options,\n _options = _state$orderedModifie2 === void 0 ? {} : _state$orderedModifie2,\n name = _state$orderedModifie.name;\n\n if (typeof fn === 'function') {\n state = fn({\n state: state,\n options: _options,\n name: name,\n instance: instance\n }) || state;\n }\n }\n },\n // Async and optimistically optimized update – it will not be executed if\n // not necessary (debounced to run at most once-per-tick)\n update: debounce(function () {\n return new Promise(function (resolve) {\n instance.forceUpdate();\n resolve(state);\n });\n }),\n destroy: function destroy() {\n cleanupModifierEffects();\n isDestroyed = true;\n }\n };\n\n if (!areValidElements(reference, popper)) {\n return instance;\n }\n\n instance.setOptions(options).then(function (state) {\n if (!isDestroyed && options.onFirstUpdate) {\n options.onFirstUpdate(state);\n }\n }); // Modifiers have the ability to execute arbitrary code before the first\n // update cycle runs. They will be executed in the same order as the update\n // cycle. This is useful when a modifier adds some persistent data that\n // other modifiers need to use, but the modifier is run after the dependent\n // one.\n\n function runModifierEffects() {\n state.orderedModifiers.forEach(function (_ref) {\n var name = _ref.name,\n _ref$options = _ref.options,\n options = _ref$options === void 0 ? {} : _ref$options,\n effect = _ref.effect;\n\n if (typeof effect === 'function') {\n var cleanupFn = effect({\n state: state,\n name: name,\n instance: instance,\n options: options\n });\n\n var noopFn = function noopFn() {};\n\n effectCleanupFns.push(cleanupFn || noopFn);\n }\n });\n }\n\n function cleanupModifierEffects() {\n effectCleanupFns.forEach(function (fn) {\n return fn();\n });\n effectCleanupFns = [];\n }\n\n return instance;\n };\n}\nexport var createPopper = /*#__PURE__*/popperGenerator(); // eslint-disable-next-line import/no-unused-modules\n\nexport { detectOverflow };","export default function debounce(fn) {\n var pending;\n return function () {\n if (!pending) {\n pending = new Promise(function (resolve) {\n Promise.resolve().then(function () {\n pending = undefined;\n resolve(fn());\n });\n });\n }\n\n return pending;\n };\n}","export default function mergeByName(modifiers) {\n var merged = modifiers.reduce(function (merged, current) {\n var existing = merged[current.name];\n merged[current.name] = existing ? Object.assign({}, existing, current, {\n options: Object.assign({}, existing.options, current.options),\n data: Object.assign({}, existing.data, current.data)\n }) : current;\n return merged;\n }, {}); // IE11 does not support Object.values\n\n return Object.keys(merged).map(function (key) {\n return merged[key];\n });\n}","import { popperGenerator, detectOverflow } from \"./createPopper.js\";\nimport eventListeners from \"./modifiers/eventListeners.js\";\nimport popperOffsets from \"./modifiers/popperOffsets.js\";\nimport computeStyles from \"./modifiers/computeStyles.js\";\nimport applyStyles from \"./modifiers/applyStyles.js\";\nimport offset from \"./modifiers/offset.js\";\nimport flip from \"./modifiers/flip.js\";\nimport preventOverflow from \"./modifiers/preventOverflow.js\";\nimport arrow from \"./modifiers/arrow.js\";\nimport hide from \"./modifiers/hide.js\";\nvar defaultModifiers = [eventListeners, popperOffsets, computeStyles, applyStyles, offset, flip, preventOverflow, arrow, hide];\nvar createPopper = /*#__PURE__*/popperGenerator({\n defaultModifiers: defaultModifiers\n}); // eslint-disable-next-line import/no-unused-modules\n\nexport { createPopper, popperGenerator, defaultModifiers, detectOverflow }; // eslint-disable-next-line import/no-unused-modules\n\nexport { createPopper as createPopperLite } from \"./popper-lite.js\"; // eslint-disable-next-line import/no-unused-modules\n\nexport * from \"./modifiers/index.js\";","import { popperGenerator, detectOverflow } from \"./createPopper.js\";\nimport eventListeners from \"./modifiers/eventListeners.js\";\nimport popperOffsets from \"./modifiers/popperOffsets.js\";\nimport computeStyles from \"./modifiers/computeStyles.js\";\nimport applyStyles from \"./modifiers/applyStyles.js\";\nvar defaultModifiers = [eventListeners, popperOffsets, computeStyles, applyStyles];\nvar createPopper = /*#__PURE__*/popperGenerator({\n defaultModifiers: defaultModifiers\n}); // eslint-disable-next-line import/no-unused-modules\n\nexport { createPopper, popperGenerator, defaultModifiers, detectOverflow };","/*!\n * Bootstrap v5.3.2 (https://getbootstrap.com/)\n * Copyright 2011-2023 The Bootstrap Authors (https://github.com/twbs/bootstrap/graphs/contributors)\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n */\nimport * as Popper from '@popperjs/core';\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap dom/data.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n/**\n * Constants\n */\n\nconst elementMap = new Map();\nconst Data = {\n set(element, key, instance) {\n if (!elementMap.has(element)) {\n elementMap.set(element, new Map());\n }\n const instanceMap = elementMap.get(element);\n\n // make it clear we only want one instance per element\n // can be removed later when multiple key/instances are fine to be used\n if (!instanceMap.has(key) && instanceMap.size !== 0) {\n // eslint-disable-next-line no-console\n console.error(`Bootstrap doesn't allow more than one instance per element. Bound instance: ${Array.from(instanceMap.keys())[0]}.`);\n return;\n }\n instanceMap.set(key, instance);\n },\n get(element, key) {\n if (elementMap.has(element)) {\n return elementMap.get(element).get(key) || null;\n }\n return null;\n },\n remove(element, key) {\n if (!elementMap.has(element)) {\n return;\n }\n const instanceMap = elementMap.get(element);\n instanceMap.delete(key);\n\n // free up element references if there are no instances left for an element\n if (instanceMap.size === 0) {\n elementMap.delete(element);\n }\n }\n};\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap util/index.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\nconst MAX_UID = 1000000;\nconst MILLISECONDS_MULTIPLIER = 1000;\nconst TRANSITION_END = 'transitionend';\n\n/**\n * Properly escape IDs selectors to handle weird IDs\n * @param {string} selector\n * @returns {string}\n */\nconst parseSelector = selector => {\n if (selector && window.CSS && window.CSS.escape) {\n // document.querySelector needs escaping to handle IDs (html5+) containing for instance /\n selector = selector.replace(/#([^\\s\"#']+)/g, (match, id) => `#${CSS.escape(id)}`);\n }\n return selector;\n};\n\n// Shout-out Angus Croll (https://goo.gl/pxwQGp)\nconst toType = object => {\n if (object === null || object === undefined) {\n return `${object}`;\n }\n return Object.prototype.toString.call(object).match(/\\s([a-z]+)/i)[1].toLowerCase();\n};\n\n/**\n * Public Util API\n */\n\nconst getUID = prefix => {\n do {\n prefix += Math.floor(Math.random() * MAX_UID);\n } while (document.getElementById(prefix));\n return prefix;\n};\nconst getTransitionDurationFromElement = element => {\n if (!element) {\n return 0;\n }\n\n // Get transition-duration of the element\n let {\n transitionDuration,\n transitionDelay\n } = window.getComputedStyle(element);\n const floatTransitionDuration = Number.parseFloat(transitionDuration);\n const floatTransitionDelay = Number.parseFloat(transitionDelay);\n\n // Return 0 if element or transition duration is not found\n if (!floatTransitionDuration && !floatTransitionDelay) {\n return 0;\n }\n\n // If multiple durations are defined, take the first\n transitionDuration = transitionDuration.split(',')[0];\n transitionDelay = transitionDelay.split(',')[0];\n return (Number.parseFloat(transitionDuration) + Number.parseFloat(transitionDelay)) * MILLISECONDS_MULTIPLIER;\n};\nconst triggerTransitionEnd = element => {\n element.dispatchEvent(new Event(TRANSITION_END));\n};\nconst isElement = object => {\n if (!object || typeof object !== 'object') {\n return false;\n }\n if (typeof object.jquery !== 'undefined') {\n object = object[0];\n }\n return typeof object.nodeType !== 'undefined';\n};\nconst getElement = object => {\n // it's a jQuery object or a node element\n if (isElement(object)) {\n return object.jquery ? object[0] : object;\n }\n if (typeof object === 'string' && object.length > 0) {\n return document.querySelector(parseSelector(object));\n }\n return null;\n};\nconst isVisible = element => {\n if (!isElement(element) || element.getClientRects().length === 0) {\n return false;\n }\n const elementIsVisible = getComputedStyle(element).getPropertyValue('visibility') === 'visible';\n // Handle `details` element as its content may falsie appear visible when it is closed\n const closedDetails = element.closest('details:not([open])');\n if (!closedDetails) {\n return elementIsVisible;\n }\n if (closedDetails !== element) {\n const summary = element.closest('summary');\n if (summary && summary.parentNode !== closedDetails) {\n return false;\n }\n if (summary === null) {\n return false;\n }\n }\n return elementIsVisible;\n};\nconst isDisabled = element => {\n if (!element || element.nodeType !== Node.ELEMENT_NODE) {\n return true;\n }\n if (element.classList.contains('disabled')) {\n return true;\n }\n if (typeof element.disabled !== 'undefined') {\n return element.disabled;\n }\n return element.hasAttribute('disabled') && element.getAttribute('disabled') !== 'false';\n};\nconst findShadowRoot = element => {\n if (!document.documentElement.attachShadow) {\n return null;\n }\n\n // Can find the shadow root otherwise it'll return the document\n if (typeof element.getRootNode === 'function') {\n const root = element.getRootNode();\n return root instanceof ShadowRoot ? root : null;\n }\n if (element instanceof ShadowRoot) {\n return element;\n }\n\n // when we don't find a shadow root\n if (!element.parentNode) {\n return null;\n }\n return findShadowRoot(element.parentNode);\n};\nconst noop = () => {};\n\n/**\n * Trick to restart an element's animation\n *\n * @param {HTMLElement} element\n * @return void\n *\n * @see https://www.charistheo.io/blog/2021/02/restart-a-css-animation-with-javascript/#restarting-a-css-animation\n */\nconst reflow = element => {\n element.offsetHeight; // eslint-disable-line no-unused-expressions\n};\n\nconst getjQuery = () => {\n if (window.jQuery && !document.body.hasAttribute('data-bs-no-jquery')) {\n return window.jQuery;\n }\n return null;\n};\nconst DOMContentLoadedCallbacks = [];\nconst onDOMContentLoaded = callback => {\n if (document.readyState === 'loading') {\n // add listener on the first call when the document is in loading state\n if (!DOMContentLoadedCallbacks.length) {\n document.addEventListener('DOMContentLoaded', () => {\n for (const callback of DOMContentLoadedCallbacks) {\n callback();\n }\n });\n }\n DOMContentLoadedCallbacks.push(callback);\n } else {\n callback();\n }\n};\nconst isRTL = () => document.documentElement.dir === 'rtl';\nconst defineJQueryPlugin = plugin => {\n onDOMContentLoaded(() => {\n const $ = getjQuery();\n /* istanbul ignore if */\n if ($) {\n const name = plugin.NAME;\n const JQUERY_NO_CONFLICT = $.fn[name];\n $.fn[name] = plugin.jQueryInterface;\n $.fn[name].Constructor = plugin;\n $.fn[name].noConflict = () => {\n $.fn[name] = JQUERY_NO_CONFLICT;\n return plugin.jQueryInterface;\n };\n }\n });\n};\nconst execute = (possibleCallback, args = [], defaultValue = possibleCallback) => {\n return typeof possibleCallback === 'function' ? possibleCallback(...args) : defaultValue;\n};\nconst executeAfterTransition = (callback, transitionElement, waitForTransition = true) => {\n if (!waitForTransition) {\n execute(callback);\n return;\n }\n const durationPadding = 5;\n const emulatedDuration = getTransitionDurationFromElement(transitionElement) + durationPadding;\n let called = false;\n const handler = ({\n target\n }) => {\n if (target !== transitionElement) {\n return;\n }\n called = true;\n transitionElement.removeEventListener(TRANSITION_END, handler);\n execute(callback);\n };\n transitionElement.addEventListener(TRANSITION_END, handler);\n setTimeout(() => {\n if (!called) {\n triggerTransitionEnd(transitionElement);\n }\n }, emulatedDuration);\n};\n\n/**\n * Return the previous/next element of a list.\n *\n * @param {array} list The list of elements\n * @param activeElement The active element\n * @param shouldGetNext Choose to get next or previous element\n * @param isCycleAllowed\n * @return {Element|elem} The proper element\n */\nconst getNextActiveElement = (list, activeElement, shouldGetNext, isCycleAllowed) => {\n const listLength = list.length;\n let index = list.indexOf(activeElement);\n\n // if the element does not exist in the list return an element\n // depending on the direction and if cycle is allowed\n if (index === -1) {\n return !shouldGetNext && isCycleAllowed ? list[listLength - 1] : list[0];\n }\n index += shouldGetNext ? 1 : -1;\n if (isCycleAllowed) {\n index = (index + listLength) % listLength;\n }\n return list[Math.max(0, Math.min(index, listLength - 1))];\n};\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap dom/event-handler.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst namespaceRegex = /[^.]*(?=\\..*)\\.|.*/;\nconst stripNameRegex = /\\..*/;\nconst stripUidRegex = /::\\d+$/;\nconst eventRegistry = {}; // Events storage\nlet uidEvent = 1;\nconst customEvents = {\n mouseenter: 'mouseover',\n mouseleave: 'mouseout'\n};\nconst nativeEvents = new Set(['click', 'dblclick', 'mouseup', 'mousedown', 'contextmenu', 'mousewheel', 'DOMMouseScroll', 'mouseover', 'mouseout', 'mousemove', 'selectstart', 'selectend', 'keydown', 'keypress', 'keyup', 'orientationchange', 'touchstart', 'touchmove', 'touchend', 'touchcancel', 'pointerdown', 'pointermove', 'pointerup', 'pointerleave', 'pointercancel', 'gesturestart', 'gesturechange', 'gestureend', 'focus', 'blur', 'change', 'reset', 'select', 'submit', 'focusin', 'focusout', 'load', 'unload', 'beforeunload', 'resize', 'move', 'DOMContentLoaded', 'readystatechange', 'error', 'abort', 'scroll']);\n\n/**\n * Private methods\n */\n\nfunction makeEventUid(element, uid) {\n return uid && `${uid}::${uidEvent++}` || element.uidEvent || uidEvent++;\n}\nfunction getElementEvents(element) {\n const uid = makeEventUid(element);\n element.uidEvent = uid;\n eventRegistry[uid] = eventRegistry[uid] || {};\n return eventRegistry[uid];\n}\nfunction bootstrapHandler(element, fn) {\n return function handler(event) {\n hydrateObj(event, {\n delegateTarget: element\n });\n if (handler.oneOff) {\n EventHandler.off(element, event.type, fn);\n }\n return fn.apply(element, [event]);\n };\n}\nfunction bootstrapDelegationHandler(element, selector, fn) {\n return function handler(event) {\n const domElements = element.querySelectorAll(selector);\n for (let {\n target\n } = event; target && target !== this; target = target.parentNode) {\n for (const domElement of domElements) {\n if (domElement !== target) {\n continue;\n }\n hydrateObj(event, {\n delegateTarget: target\n });\n if (handler.oneOff) {\n EventHandler.off(element, event.type, selector, fn);\n }\n return fn.apply(target, [event]);\n }\n }\n };\n}\nfunction findHandler(events, callable, delegationSelector = null) {\n return Object.values(events).find(event => event.callable === callable && event.delegationSelector === delegationSelector);\n}\nfunction normalizeParameters(originalTypeEvent, handler, delegationFunction) {\n const isDelegated = typeof handler === 'string';\n // TODO: tooltip passes `false` instead of selector, so we need to check\n const callable = isDelegated ? delegationFunction : handler || delegationFunction;\n let typeEvent = getTypeEvent(originalTypeEvent);\n if (!nativeEvents.has(typeEvent)) {\n typeEvent = originalTypeEvent;\n }\n return [isDelegated, callable, typeEvent];\n}\nfunction addHandler(element, originalTypeEvent, handler, delegationFunction, oneOff) {\n if (typeof originalTypeEvent !== 'string' || !element) {\n return;\n }\n let [isDelegated, callable, typeEvent] = normalizeParameters(originalTypeEvent, handler, delegationFunction);\n\n // in case of mouseenter or mouseleave wrap the handler within a function that checks for its DOM position\n // this prevents the handler from being dispatched the same way as mouseover or mouseout does\n if (originalTypeEvent in customEvents) {\n const wrapFunction = fn => {\n return function (event) {\n if (!event.relatedTarget || event.relatedTarget !== event.delegateTarget && !event.delegateTarget.contains(event.relatedTarget)) {\n return fn.call(this, event);\n }\n };\n };\n callable = wrapFunction(callable);\n }\n const events = getElementEvents(element);\n const handlers = events[typeEvent] || (events[typeEvent] = {});\n const previousFunction = findHandler(handlers, callable, isDelegated ? handler : null);\n if (previousFunction) {\n previousFunction.oneOff = previousFunction.oneOff && oneOff;\n return;\n }\n const uid = makeEventUid(callable, originalTypeEvent.replace(namespaceRegex, ''));\n const fn = isDelegated ? bootstrapDelegationHandler(element, handler, callable) : bootstrapHandler(element, callable);\n fn.delegationSelector = isDelegated ? handler : null;\n fn.callable = callable;\n fn.oneOff = oneOff;\n fn.uidEvent = uid;\n handlers[uid] = fn;\n element.addEventListener(typeEvent, fn, isDelegated);\n}\nfunction removeHandler(element, events, typeEvent, handler, delegationSelector) {\n const fn = findHandler(events[typeEvent], handler, delegationSelector);\n if (!fn) {\n return;\n }\n element.removeEventListener(typeEvent, fn, Boolean(delegationSelector));\n delete events[typeEvent][fn.uidEvent];\n}\nfunction removeNamespacedHandlers(element, events, typeEvent, namespace) {\n const storeElementEvent = events[typeEvent] || {};\n for (const [handlerKey, event] of Object.entries(storeElementEvent)) {\n if (handlerKey.includes(namespace)) {\n removeHandler(element, events, typeEvent, event.callable, event.delegationSelector);\n }\n }\n}\nfunction getTypeEvent(event) {\n // allow to get the native events from namespaced events ('click.bs.button' --> 'click')\n event = event.replace(stripNameRegex, '');\n return customEvents[event] || event;\n}\nconst EventHandler = {\n on(element, event, handler, delegationFunction) {\n addHandler(element, event, handler, delegationFunction, false);\n },\n one(element, event, handler, delegationFunction) {\n addHandler(element, event, handler, delegationFunction, true);\n },\n off(element, originalTypeEvent, handler, delegationFunction) {\n if (typeof originalTypeEvent !== 'string' || !element) {\n return;\n }\n const [isDelegated, callable, typeEvent] = normalizeParameters(originalTypeEvent, handler, delegationFunction);\n const inNamespace = typeEvent !== originalTypeEvent;\n const events = getElementEvents(element);\n const storeElementEvent = events[typeEvent] || {};\n const isNamespace = originalTypeEvent.startsWith('.');\n if (typeof callable !== 'undefined') {\n // Simplest case: handler is passed, remove that listener ONLY.\n if (!Object.keys(storeElementEvent).length) {\n return;\n }\n removeHandler(element, events, typeEvent, callable, isDelegated ? handler : null);\n return;\n }\n if (isNamespace) {\n for (const elementEvent of Object.keys(events)) {\n removeNamespacedHandlers(element, events, elementEvent, originalTypeEvent.slice(1));\n }\n }\n for (const [keyHandlers, event] of Object.entries(storeElementEvent)) {\n const handlerKey = keyHandlers.replace(stripUidRegex, '');\n if (!inNamespace || originalTypeEvent.includes(handlerKey)) {\n removeHandler(element, events, typeEvent, event.callable, event.delegationSelector);\n }\n }\n },\n trigger(element, event, args) {\n if (typeof event !== 'string' || !element) {\n return null;\n }\n const $ = getjQuery();\n const typeEvent = getTypeEvent(event);\n const inNamespace = event !== typeEvent;\n let jQueryEvent = null;\n let bubbles = true;\n let nativeDispatch = true;\n let defaultPrevented = false;\n if (inNamespace && $) {\n jQueryEvent = $.Event(event, args);\n $(element).trigger(jQueryEvent);\n bubbles = !jQueryEvent.isPropagationStopped();\n nativeDispatch = !jQueryEvent.isImmediatePropagationStopped();\n defaultPrevented = jQueryEvent.isDefaultPrevented();\n }\n const evt = hydrateObj(new Event(event, {\n bubbles,\n cancelable: true\n }), args);\n if (defaultPrevented) {\n evt.preventDefault();\n }\n if (nativeDispatch) {\n element.dispatchEvent(evt);\n }\n if (evt.defaultPrevented && jQueryEvent) {\n jQueryEvent.preventDefault();\n }\n return evt;\n }\n};\nfunction hydrateObj(obj, meta = {}) {\n for (const [key, value] of Object.entries(meta)) {\n try {\n obj[key] = value;\n } catch (_unused) {\n Object.defineProperty(obj, key, {\n configurable: true,\n get() {\n return value;\n }\n });\n }\n }\n return obj;\n}\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap dom/manipulator.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\nfunction normalizeData(value) {\n if (value === 'true') {\n return true;\n }\n if (value === 'false') {\n return false;\n }\n if (value === Number(value).toString()) {\n return Number(value);\n }\n if (value === '' || value === 'null') {\n return null;\n }\n if (typeof value !== 'string') {\n return value;\n }\n try {\n return JSON.parse(decodeURIComponent(value));\n } catch (_unused) {\n return value;\n }\n}\nfunction normalizeDataKey(key) {\n return key.replace(/[A-Z]/g, chr => `-${chr.toLowerCase()}`);\n}\nconst Manipulator = {\n setDataAttribute(element, key, value) {\n element.setAttribute(`data-bs-${normalizeDataKey(key)}`, value);\n },\n removeDataAttribute(element, key) {\n element.removeAttribute(`data-bs-${normalizeDataKey(key)}`);\n },\n getDataAttributes(element) {\n if (!element) {\n return {};\n }\n const attributes = {};\n const bsKeys = Object.keys(element.dataset).filter(key => key.startsWith('bs') && !key.startsWith('bsConfig'));\n for (const key of bsKeys) {\n let pureKey = key.replace(/^bs/, '');\n pureKey = pureKey.charAt(0).toLowerCase() + pureKey.slice(1, pureKey.length);\n attributes[pureKey] = normalizeData(element.dataset[key]);\n }\n return attributes;\n },\n getDataAttribute(element, key) {\n return normalizeData(element.getAttribute(`data-bs-${normalizeDataKey(key)}`));\n }\n};\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap util/config.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Class definition\n */\n\nclass Config {\n // Getters\n static get Default() {\n return {};\n }\n static get DefaultType() {\n return {};\n }\n static get NAME() {\n throw new Error('You have to implement the static method \"NAME\", for each component!');\n }\n _getConfig(config) {\n config = this._mergeConfigObj(config);\n config = this._configAfterMerge(config);\n this._typeCheckConfig(config);\n return config;\n }\n _configAfterMerge(config) {\n return config;\n }\n _mergeConfigObj(config, element) {\n const jsonConfig = isElement(element) ? Manipulator.getDataAttribute(element, 'config') : {}; // try to parse\n\n return {\n ...this.constructor.Default,\n ...(typeof jsonConfig === 'object' ? jsonConfig : {}),\n ...(isElement(element) ? Manipulator.getDataAttributes(element) : {}),\n ...(typeof config === 'object' ? config : {})\n };\n }\n _typeCheckConfig(config, configTypes = this.constructor.DefaultType) {\n for (const [property, expectedTypes] of Object.entries(configTypes)) {\n const value = config[property];\n const valueType = isElement(value) ? 'element' : toType(value);\n if (!new RegExp(expectedTypes).test(valueType)) {\n throw new TypeError(`${this.constructor.NAME.toUpperCase()}: Option \"${property}\" provided type \"${valueType}\" but expected type \"${expectedTypes}\".`);\n }\n }\n }\n}\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap base-component.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst VERSION = '5.3.2';\n\n/**\n * Class definition\n */\n\nclass BaseComponent extends Config {\n constructor(element, config) {\n super();\n element = getElement(element);\n if (!element) {\n return;\n }\n this._element = element;\n this._config = this._getConfig(config);\n Data.set(this._element, this.constructor.DATA_KEY, this);\n }\n\n // Public\n dispose() {\n Data.remove(this._element, this.constructor.DATA_KEY);\n EventHandler.off(this._element, this.constructor.EVENT_KEY);\n for (const propertyName of Object.getOwnPropertyNames(this)) {\n this[propertyName] = null;\n }\n }\n _queueCallback(callback, element, isAnimated = true) {\n executeAfterTransition(callback, element, isAnimated);\n }\n _getConfig(config) {\n config = this._mergeConfigObj(config, this._element);\n config = this._configAfterMerge(config);\n this._typeCheckConfig(config);\n return config;\n }\n\n // Static\n static getInstance(element) {\n return Data.get(getElement(element), this.DATA_KEY);\n }\n static getOrCreateInstance(element, config = {}) {\n return this.getInstance(element) || new this(element, typeof config === 'object' ? config : null);\n }\n static get VERSION() {\n return VERSION;\n }\n static get DATA_KEY() {\n return `bs.${this.NAME}`;\n }\n static get EVENT_KEY() {\n return `.${this.DATA_KEY}`;\n }\n static eventName(name) {\n return `${name}${this.EVENT_KEY}`;\n }\n}\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap dom/selector-engine.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\nconst getSelector = element => {\n let selector = element.getAttribute('data-bs-target');\n if (!selector || selector === '#') {\n let hrefAttribute = element.getAttribute('href');\n\n // The only valid content that could double as a selector are IDs or classes,\n // so everything starting with `#` or `.`. If a \"real\" URL is used as the selector,\n // `document.querySelector` will rightfully complain it is invalid.\n // See https://github.com/twbs/bootstrap/issues/32273\n if (!hrefAttribute || !hrefAttribute.includes('#') && !hrefAttribute.startsWith('.')) {\n return null;\n }\n\n // Just in case some CMS puts out a full URL with the anchor appended\n if (hrefAttribute.includes('#') && !hrefAttribute.startsWith('#')) {\n hrefAttribute = `#${hrefAttribute.split('#')[1]}`;\n }\n selector = hrefAttribute && hrefAttribute !== '#' ? parseSelector(hrefAttribute.trim()) : null;\n }\n return selector;\n};\nconst SelectorEngine = {\n find(selector, element = document.documentElement) {\n return [].concat(...Element.prototype.querySelectorAll.call(element, selector));\n },\n findOne(selector, element = document.documentElement) {\n return Element.prototype.querySelector.call(element, selector);\n },\n children(element, selector) {\n return [].concat(...element.children).filter(child => child.matches(selector));\n },\n parents(element, selector) {\n const parents = [];\n let ancestor = element.parentNode.closest(selector);\n while (ancestor) {\n parents.push(ancestor);\n ancestor = ancestor.parentNode.closest(selector);\n }\n return parents;\n },\n prev(element, selector) {\n let previous = element.previousElementSibling;\n while (previous) {\n if (previous.matches(selector)) {\n return [previous];\n }\n previous = previous.previousElementSibling;\n }\n return [];\n },\n // TODO: this is now unused; remove later along with prev()\n next(element, selector) {\n let next = element.nextElementSibling;\n while (next) {\n if (next.matches(selector)) {\n return [next];\n }\n next = next.nextElementSibling;\n }\n return [];\n },\n focusableChildren(element) {\n const focusables = ['a', 'button', 'input', 'textarea', 'select', 'details', '[tabindex]', '[contenteditable=\"true\"]'].map(selector => `${selector}:not([tabindex^=\"-\"])`).join(',');\n return this.find(focusables, element).filter(el => !isDisabled(el) && isVisible(el));\n },\n getSelectorFromElement(element) {\n const selector = getSelector(element);\n if (selector) {\n return SelectorEngine.findOne(selector) ? selector : null;\n }\n return null;\n },\n getElementFromSelector(element) {\n const selector = getSelector(element);\n return selector ? SelectorEngine.findOne(selector) : null;\n },\n getMultipleElementsFromSelector(element) {\n const selector = getSelector(element);\n return selector ? SelectorEngine.find(selector) : [];\n }\n};\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap util/component-functions.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\nconst enableDismissTrigger = (component, method = 'hide') => {\n const clickEvent = `click.dismiss${component.EVENT_KEY}`;\n const name = component.NAME;\n EventHandler.on(document, clickEvent, `[data-bs-dismiss=\"${name}\"]`, function (event) {\n if (['A', 'AREA'].includes(this.tagName)) {\n event.preventDefault();\n }\n if (isDisabled(this)) {\n return;\n }\n const target = SelectorEngine.getElementFromSelector(this) || this.closest(`.${name}`);\n const instance = component.getOrCreateInstance(target);\n\n // Method argument is left, for Alert and only, as it doesn't implement the 'hide' method\n instance[method]();\n });\n};\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap alert.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$f = 'alert';\nconst DATA_KEY$a = 'bs.alert';\nconst EVENT_KEY$b = `.${DATA_KEY$a}`;\nconst EVENT_CLOSE = `close${EVENT_KEY$b}`;\nconst EVENT_CLOSED = `closed${EVENT_KEY$b}`;\nconst CLASS_NAME_FADE$5 = 'fade';\nconst CLASS_NAME_SHOW$8 = 'show';\n\n/**\n * Class definition\n */\n\nclass Alert extends BaseComponent {\n // Getters\n static get NAME() {\n return NAME$f;\n }\n\n // Public\n close() {\n const closeEvent = EventHandler.trigger(this._element, EVENT_CLOSE);\n if (closeEvent.defaultPrevented) {\n return;\n }\n this._element.classList.remove(CLASS_NAME_SHOW$8);\n const isAnimated = this._element.classList.contains(CLASS_NAME_FADE$5);\n this._queueCallback(() => this._destroyElement(), this._element, isAnimated);\n }\n\n // Private\n _destroyElement() {\n this._element.remove();\n EventHandler.trigger(this._element, EVENT_CLOSED);\n this.dispose();\n }\n\n // Static\n static jQueryInterface(config) {\n return this.each(function () {\n const data = Alert.getOrCreateInstance(this);\n if (typeof config !== 'string') {\n return;\n }\n if (data[config] === undefined || config.startsWith('_') || config === 'constructor') {\n throw new TypeError(`No method named \"${config}\"`);\n }\n data[config](this);\n });\n }\n}\n\n/**\n * Data API implementation\n */\n\nenableDismissTrigger(Alert, 'close');\n\n/**\n * jQuery\n */\n\ndefineJQueryPlugin(Alert);\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap button.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$e = 'button';\nconst DATA_KEY$9 = 'bs.button';\nconst EVENT_KEY$a = `.${DATA_KEY$9}`;\nconst DATA_API_KEY$6 = '.data-api';\nconst CLASS_NAME_ACTIVE$3 = 'active';\nconst SELECTOR_DATA_TOGGLE$5 = '[data-bs-toggle=\"button\"]';\nconst EVENT_CLICK_DATA_API$6 = `click${EVENT_KEY$a}${DATA_API_KEY$6}`;\n\n/**\n * Class definition\n */\n\nclass Button extends BaseComponent {\n // Getters\n static get NAME() {\n return NAME$e;\n }\n\n // Public\n toggle() {\n // Toggle class and sync the `aria-pressed` attribute with the return value of the `.toggle()` method\n this._element.setAttribute('aria-pressed', this._element.classList.toggle(CLASS_NAME_ACTIVE$3));\n }\n\n // Static\n static jQueryInterface(config) {\n return this.each(function () {\n const data = Button.getOrCreateInstance(this);\n if (config === 'toggle') {\n data[config]();\n }\n });\n }\n}\n\n/**\n * Data API implementation\n */\n\nEventHandler.on(document, EVENT_CLICK_DATA_API$6, SELECTOR_DATA_TOGGLE$5, event => {\n event.preventDefault();\n const button = event.target.closest(SELECTOR_DATA_TOGGLE$5);\n const data = Button.getOrCreateInstance(button);\n data.toggle();\n});\n\n/**\n * jQuery\n */\n\ndefineJQueryPlugin(Button);\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap util/swipe.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$d = 'swipe';\nconst EVENT_KEY$9 = '.bs.swipe';\nconst EVENT_TOUCHSTART = `touchstart${EVENT_KEY$9}`;\nconst EVENT_TOUCHMOVE = `touchmove${EVENT_KEY$9}`;\nconst EVENT_TOUCHEND = `touchend${EVENT_KEY$9}`;\nconst EVENT_POINTERDOWN = `pointerdown${EVENT_KEY$9}`;\nconst EVENT_POINTERUP = `pointerup${EVENT_KEY$9}`;\nconst POINTER_TYPE_TOUCH = 'touch';\nconst POINTER_TYPE_PEN = 'pen';\nconst CLASS_NAME_POINTER_EVENT = 'pointer-event';\nconst SWIPE_THRESHOLD = 40;\nconst Default$c = {\n endCallback: null,\n leftCallback: null,\n rightCallback: null\n};\nconst DefaultType$c = {\n endCallback: '(function|null)',\n leftCallback: '(function|null)',\n rightCallback: '(function|null)'\n};\n\n/**\n * Class definition\n */\n\nclass Swipe extends Config {\n constructor(element, config) {\n super();\n this._element = element;\n if (!element || !Swipe.isSupported()) {\n return;\n }\n this._config = this._getConfig(config);\n this._deltaX = 0;\n this._supportPointerEvents = Boolean(window.PointerEvent);\n this._initEvents();\n }\n\n // Getters\n static get Default() {\n return Default$c;\n }\n static get DefaultType() {\n return DefaultType$c;\n }\n static get NAME() {\n return NAME$d;\n }\n\n // Public\n dispose() {\n EventHandler.off(this._element, EVENT_KEY$9);\n }\n\n // Private\n _start(event) {\n if (!this._supportPointerEvents) {\n this._deltaX = event.touches[0].clientX;\n return;\n }\n if (this._eventIsPointerPenTouch(event)) {\n this._deltaX = event.clientX;\n }\n }\n _end(event) {\n if (this._eventIsPointerPenTouch(event)) {\n this._deltaX = event.clientX - this._deltaX;\n }\n this._handleSwipe();\n execute(this._config.endCallback);\n }\n _move(event) {\n this._deltaX = event.touches && event.touches.length > 1 ? 0 : event.touches[0].clientX - this._deltaX;\n }\n _handleSwipe() {\n const absDeltaX = Math.abs(this._deltaX);\n if (absDeltaX <= SWIPE_THRESHOLD) {\n return;\n }\n const direction = absDeltaX / this._deltaX;\n this._deltaX = 0;\n if (!direction) {\n return;\n }\n execute(direction > 0 ? this._config.rightCallback : this._config.leftCallback);\n }\n _initEvents() {\n if (this._supportPointerEvents) {\n EventHandler.on(this._element, EVENT_POINTERDOWN, event => this._start(event));\n EventHandler.on(this._element, EVENT_POINTERUP, event => this._end(event));\n this._element.classList.add(CLASS_NAME_POINTER_EVENT);\n } else {\n EventHandler.on(this._element, EVENT_TOUCHSTART, event => this._start(event));\n EventHandler.on(this._element, EVENT_TOUCHMOVE, event => this._move(event));\n EventHandler.on(this._element, EVENT_TOUCHEND, event => this._end(event));\n }\n }\n _eventIsPointerPenTouch(event) {\n return this._supportPointerEvents && (event.pointerType === POINTER_TYPE_PEN || event.pointerType === POINTER_TYPE_TOUCH);\n }\n\n // Static\n static isSupported() {\n return 'ontouchstart' in document.documentElement || navigator.maxTouchPoints > 0;\n }\n}\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap carousel.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$c = 'carousel';\nconst DATA_KEY$8 = 'bs.carousel';\nconst EVENT_KEY$8 = `.${DATA_KEY$8}`;\nconst DATA_API_KEY$5 = '.data-api';\nconst ARROW_LEFT_KEY$1 = 'ArrowLeft';\nconst ARROW_RIGHT_KEY$1 = 'ArrowRight';\nconst TOUCHEVENT_COMPAT_WAIT = 500; // Time for mouse compat events to fire after touch\n\nconst ORDER_NEXT = 'next';\nconst ORDER_PREV = 'prev';\nconst DIRECTION_LEFT = 'left';\nconst DIRECTION_RIGHT = 'right';\nconst EVENT_SLIDE = `slide${EVENT_KEY$8}`;\nconst EVENT_SLID = `slid${EVENT_KEY$8}`;\nconst EVENT_KEYDOWN$1 = `keydown${EVENT_KEY$8}`;\nconst EVENT_MOUSEENTER$1 = `mouseenter${EVENT_KEY$8}`;\nconst EVENT_MOUSELEAVE$1 = `mouseleave${EVENT_KEY$8}`;\nconst EVENT_DRAG_START = `dragstart${EVENT_KEY$8}`;\nconst EVENT_LOAD_DATA_API$3 = `load${EVENT_KEY$8}${DATA_API_KEY$5}`;\nconst EVENT_CLICK_DATA_API$5 = `click${EVENT_KEY$8}${DATA_API_KEY$5}`;\nconst CLASS_NAME_CAROUSEL = 'carousel';\nconst CLASS_NAME_ACTIVE$2 = 'active';\nconst CLASS_NAME_SLIDE = 'slide';\nconst CLASS_NAME_END = 'carousel-item-end';\nconst CLASS_NAME_START = 'carousel-item-start';\nconst CLASS_NAME_NEXT = 'carousel-item-next';\nconst CLASS_NAME_PREV = 'carousel-item-prev';\nconst SELECTOR_ACTIVE = '.active';\nconst SELECTOR_ITEM = '.carousel-item';\nconst SELECTOR_ACTIVE_ITEM = SELECTOR_ACTIVE + SELECTOR_ITEM;\nconst SELECTOR_ITEM_IMG = '.carousel-item img';\nconst SELECTOR_INDICATORS = '.carousel-indicators';\nconst SELECTOR_DATA_SLIDE = '[data-bs-slide], [data-bs-slide-to]';\nconst SELECTOR_DATA_RIDE = '[data-bs-ride=\"carousel\"]';\nconst KEY_TO_DIRECTION = {\n [ARROW_LEFT_KEY$1]: DIRECTION_RIGHT,\n [ARROW_RIGHT_KEY$1]: DIRECTION_LEFT\n};\nconst Default$b = {\n interval: 5000,\n keyboard: true,\n pause: 'hover',\n ride: false,\n touch: true,\n wrap: true\n};\nconst DefaultType$b = {\n interval: '(number|boolean)',\n // TODO:v6 remove boolean support\n keyboard: 'boolean',\n pause: '(string|boolean)',\n ride: '(boolean|string)',\n touch: 'boolean',\n wrap: 'boolean'\n};\n\n/**\n * Class definition\n */\n\nclass Carousel extends BaseComponent {\n constructor(element, config) {\n super(element, config);\n this._interval = null;\n this._activeElement = null;\n this._isSliding = false;\n this.touchTimeout = null;\n this._swipeHelper = null;\n this._indicatorsElement = SelectorEngine.findOne(SELECTOR_INDICATORS, this._element);\n this._addEventListeners();\n if (this._config.ride === CLASS_NAME_CAROUSEL) {\n this.cycle();\n }\n }\n\n // Getters\n static get Default() {\n return Default$b;\n }\n static get DefaultType() {\n return DefaultType$b;\n }\n static get NAME() {\n return NAME$c;\n }\n\n // Public\n next() {\n this._slide(ORDER_NEXT);\n }\n nextWhenVisible() {\n // FIXME TODO use `document.visibilityState`\n // Don't call next when the page isn't visible\n // or the carousel or its parent isn't visible\n if (!document.hidden && isVisible(this._element)) {\n this.next();\n }\n }\n prev() {\n this._slide(ORDER_PREV);\n }\n pause() {\n if (this._isSliding) {\n triggerTransitionEnd(this._element);\n }\n this._clearInterval();\n }\n cycle() {\n this._clearInterval();\n this._updateInterval();\n this._interval = setInterval(() => this.nextWhenVisible(), this._config.interval);\n }\n _maybeEnableCycle() {\n if (!this._config.ride) {\n return;\n }\n if (this._isSliding) {\n EventHandler.one(this._element, EVENT_SLID, () => this.cycle());\n return;\n }\n this.cycle();\n }\n to(index) {\n const items = this._getItems();\n if (index > items.length - 1 || index < 0) {\n return;\n }\n if (this._isSliding) {\n EventHandler.one(this._element, EVENT_SLID, () => this.to(index));\n return;\n }\n const activeIndex = this._getItemIndex(this._getActive());\n if (activeIndex === index) {\n return;\n }\n const order = index > activeIndex ? ORDER_NEXT : ORDER_PREV;\n this._slide(order, items[index]);\n }\n dispose() {\n if (this._swipeHelper) {\n this._swipeHelper.dispose();\n }\n super.dispose();\n }\n\n // Private\n _configAfterMerge(config) {\n config.defaultInterval = config.interval;\n return config;\n }\n _addEventListeners() {\n if (this._config.keyboard) {\n EventHandler.on(this._element, EVENT_KEYDOWN$1, event => this._keydown(event));\n }\n if (this._config.pause === 'hover') {\n EventHandler.on(this._element, EVENT_MOUSEENTER$1, () => this.pause());\n EventHandler.on(this._element, EVENT_MOUSELEAVE$1, () => this._maybeEnableCycle());\n }\n if (this._config.touch && Swipe.isSupported()) {\n this._addTouchEventListeners();\n }\n }\n _addTouchEventListeners() {\n for (const img of SelectorEngine.find(SELECTOR_ITEM_IMG, this._element)) {\n EventHandler.on(img, EVENT_DRAG_START, event => event.preventDefault());\n }\n const endCallBack = () => {\n if (this._config.pause !== 'hover') {\n return;\n }\n\n // If it's a touch-enabled device, mouseenter/leave are fired as\n // part of the mouse compatibility events on first tap - the carousel\n // would stop cycling until user tapped out of it;\n // here, we listen for touchend, explicitly pause the carousel\n // (as if it's the second time we tap on it, mouseenter compat event\n // is NOT fired) and after a timeout (to allow for mouse compatibility\n // events to fire) we explicitly restart cycling\n\n this.pause();\n if (this.touchTimeout) {\n clearTimeout(this.touchTimeout);\n }\n this.touchTimeout = setTimeout(() => this._maybeEnableCycle(), TOUCHEVENT_COMPAT_WAIT + this._config.interval);\n };\n const swipeConfig = {\n leftCallback: () => this._slide(this._directionToOrder(DIRECTION_LEFT)),\n rightCallback: () => this._slide(this._directionToOrder(DIRECTION_RIGHT)),\n endCallback: endCallBack\n };\n this._swipeHelper = new Swipe(this._element, swipeConfig);\n }\n _keydown(event) {\n if (/input|textarea/i.test(event.target.tagName)) {\n return;\n }\n const direction = KEY_TO_DIRECTION[event.key];\n if (direction) {\n event.preventDefault();\n this._slide(this._directionToOrder(direction));\n }\n }\n _getItemIndex(element) {\n return this._getItems().indexOf(element);\n }\n _setActiveIndicatorElement(index) {\n if (!this._indicatorsElement) {\n return;\n }\n const activeIndicator = SelectorEngine.findOne(SELECTOR_ACTIVE, this._indicatorsElement);\n activeIndicator.classList.remove(CLASS_NAME_ACTIVE$2);\n activeIndicator.removeAttribute('aria-current');\n const newActiveIndicator = SelectorEngine.findOne(`[data-bs-slide-to=\"${index}\"]`, this._indicatorsElement);\n if (newActiveIndicator) {\n newActiveIndicator.classList.add(CLASS_NAME_ACTIVE$2);\n newActiveIndicator.setAttribute('aria-current', 'true');\n }\n }\n _updateInterval() {\n const element = this._activeElement || this._getActive();\n if (!element) {\n return;\n }\n const elementInterval = Number.parseInt(element.getAttribute('data-bs-interval'), 10);\n this._config.interval = elementInterval || this._config.defaultInterval;\n }\n _slide(order, element = null) {\n if (this._isSliding) {\n return;\n }\n const activeElement = this._getActive();\n const isNext = order === ORDER_NEXT;\n const nextElement = element || getNextActiveElement(this._getItems(), activeElement, isNext, this._config.wrap);\n if (nextElement === activeElement) {\n return;\n }\n const nextElementIndex = this._getItemIndex(nextElement);\n const triggerEvent = eventName => {\n return EventHandler.trigger(this._element, eventName, {\n relatedTarget: nextElement,\n direction: this._orderToDirection(order),\n from: this._getItemIndex(activeElement),\n to: nextElementIndex\n });\n };\n const slideEvent = triggerEvent(EVENT_SLIDE);\n if (slideEvent.defaultPrevented) {\n return;\n }\n if (!activeElement || !nextElement) {\n // Some weirdness is happening, so we bail\n // TODO: change tests that use empty divs to avoid this check\n return;\n }\n const isCycling = Boolean(this._interval);\n this.pause();\n this._isSliding = true;\n this._setActiveIndicatorElement(nextElementIndex);\n this._activeElement = nextElement;\n const directionalClassName = isNext ? CLASS_NAME_START : CLASS_NAME_END;\n const orderClassName = isNext ? CLASS_NAME_NEXT : CLASS_NAME_PREV;\n nextElement.classList.add(orderClassName);\n reflow(nextElement);\n activeElement.classList.add(directionalClassName);\n nextElement.classList.add(directionalClassName);\n const completeCallBack = () => {\n nextElement.classList.remove(directionalClassName, orderClassName);\n nextElement.classList.add(CLASS_NAME_ACTIVE$2);\n activeElement.classList.remove(CLASS_NAME_ACTIVE$2, orderClassName, directionalClassName);\n this._isSliding = false;\n triggerEvent(EVENT_SLID);\n };\n this._queueCallback(completeCallBack, activeElement, this._isAnimated());\n if (isCycling) {\n this.cycle();\n }\n }\n _isAnimated() {\n return this._element.classList.contains(CLASS_NAME_SLIDE);\n }\n _getActive() {\n return SelectorEngine.findOne(SELECTOR_ACTIVE_ITEM, this._element);\n }\n _getItems() {\n return SelectorEngine.find(SELECTOR_ITEM, this._element);\n }\n _clearInterval() {\n if (this._interval) {\n clearInterval(this._interval);\n this._interval = null;\n }\n }\n _directionToOrder(direction) {\n if (isRTL()) {\n return direction === DIRECTION_LEFT ? ORDER_PREV : ORDER_NEXT;\n }\n return direction === DIRECTION_LEFT ? ORDER_NEXT : ORDER_PREV;\n }\n _orderToDirection(order) {\n if (isRTL()) {\n return order === ORDER_PREV ? DIRECTION_LEFT : DIRECTION_RIGHT;\n }\n return order === ORDER_PREV ? DIRECTION_RIGHT : DIRECTION_LEFT;\n }\n\n // Static\n static jQueryInterface(config) {\n return this.each(function () {\n const data = Carousel.getOrCreateInstance(this, config);\n if (typeof config === 'number') {\n data.to(config);\n return;\n }\n if (typeof config === 'string') {\n if (data[config] === undefined || config.startsWith('_') || config === 'constructor') {\n throw new TypeError(`No method named \"${config}\"`);\n }\n data[config]();\n }\n });\n }\n}\n\n/**\n * Data API implementation\n */\n\nEventHandler.on(document, EVENT_CLICK_DATA_API$5, SELECTOR_DATA_SLIDE, function (event) {\n const target = SelectorEngine.getElementFromSelector(this);\n if (!target || !target.classList.contains(CLASS_NAME_CAROUSEL)) {\n return;\n }\n event.preventDefault();\n const carousel = Carousel.getOrCreateInstance(target);\n const slideIndex = this.getAttribute('data-bs-slide-to');\n if (slideIndex) {\n carousel.to(slideIndex);\n carousel._maybeEnableCycle();\n return;\n }\n if (Manipulator.getDataAttribute(this, 'slide') === 'next') {\n carousel.next();\n carousel._maybeEnableCycle();\n return;\n }\n carousel.prev();\n carousel._maybeEnableCycle();\n});\nEventHandler.on(window, EVENT_LOAD_DATA_API$3, () => {\n const carousels = SelectorEngine.find(SELECTOR_DATA_RIDE);\n for (const carousel of carousels) {\n Carousel.getOrCreateInstance(carousel);\n }\n});\n\n/**\n * jQuery\n */\n\ndefineJQueryPlugin(Carousel);\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap collapse.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$b = 'collapse';\nconst DATA_KEY$7 = 'bs.collapse';\nconst EVENT_KEY$7 = `.${DATA_KEY$7}`;\nconst DATA_API_KEY$4 = '.data-api';\nconst EVENT_SHOW$6 = `show${EVENT_KEY$7}`;\nconst EVENT_SHOWN$6 = `shown${EVENT_KEY$7}`;\nconst EVENT_HIDE$6 = `hide${EVENT_KEY$7}`;\nconst EVENT_HIDDEN$6 = `hidden${EVENT_KEY$7}`;\nconst EVENT_CLICK_DATA_API$4 = `click${EVENT_KEY$7}${DATA_API_KEY$4}`;\nconst CLASS_NAME_SHOW$7 = 'show';\nconst CLASS_NAME_COLLAPSE = 'collapse';\nconst CLASS_NAME_COLLAPSING = 'collapsing';\nconst CLASS_NAME_COLLAPSED = 'collapsed';\nconst CLASS_NAME_DEEPER_CHILDREN = `:scope .${CLASS_NAME_COLLAPSE} .${CLASS_NAME_COLLAPSE}`;\nconst CLASS_NAME_HORIZONTAL = 'collapse-horizontal';\nconst WIDTH = 'width';\nconst HEIGHT = 'height';\nconst SELECTOR_ACTIVES = '.collapse.show, .collapse.collapsing';\nconst SELECTOR_DATA_TOGGLE$4 = '[data-bs-toggle=\"collapse\"]';\nconst Default$a = {\n parent: null,\n toggle: true\n};\nconst DefaultType$a = {\n parent: '(null|element)',\n toggle: 'boolean'\n};\n\n/**\n * Class definition\n */\n\nclass Collapse extends BaseComponent {\n constructor(element, config) {\n super(element, config);\n this._isTransitioning = false;\n this._triggerArray = [];\n const toggleList = SelectorEngine.find(SELECTOR_DATA_TOGGLE$4);\n for (const elem of toggleList) {\n const selector = SelectorEngine.getSelectorFromElement(elem);\n const filterElement = SelectorEngine.find(selector).filter(foundElement => foundElement === this._element);\n if (selector !== null && filterElement.length) {\n this._triggerArray.push(elem);\n }\n }\n this._initializeChildren();\n if (!this._config.parent) {\n this._addAriaAndCollapsedClass(this._triggerArray, this._isShown());\n }\n if (this._config.toggle) {\n this.toggle();\n }\n }\n\n // Getters\n static get Default() {\n return Default$a;\n }\n static get DefaultType() {\n return DefaultType$a;\n }\n static get NAME() {\n return NAME$b;\n }\n\n // Public\n toggle() {\n if (this._isShown()) {\n this.hide();\n } else {\n this.show();\n }\n }\n show() {\n if (this._isTransitioning || this._isShown()) {\n return;\n }\n let activeChildren = [];\n\n // find active children\n if (this._config.parent) {\n activeChildren = this._getFirstLevelChildren(SELECTOR_ACTIVES).filter(element => element !== this._element).map(element => Collapse.getOrCreateInstance(element, {\n toggle: false\n }));\n }\n if (activeChildren.length && activeChildren[0]._isTransitioning) {\n return;\n }\n const startEvent = EventHandler.trigger(this._element, EVENT_SHOW$6);\n if (startEvent.defaultPrevented) {\n return;\n }\n for (const activeInstance of activeChildren) {\n activeInstance.hide();\n }\n const dimension = this._getDimension();\n this._element.classList.remove(CLASS_NAME_COLLAPSE);\n this._element.classList.add(CLASS_NAME_COLLAPSING);\n this._element.style[dimension] = 0;\n this._addAriaAndCollapsedClass(this._triggerArray, true);\n this._isTransitioning = true;\n const complete = () => {\n this._isTransitioning = false;\n this._element.classList.remove(CLASS_NAME_COLLAPSING);\n this._element.classList.add(CLASS_NAME_COLLAPSE, CLASS_NAME_SHOW$7);\n this._element.style[dimension] = '';\n EventHandler.trigger(this._element, EVENT_SHOWN$6);\n };\n const capitalizedDimension = dimension[0].toUpperCase() + dimension.slice(1);\n const scrollSize = `scroll${capitalizedDimension}`;\n this._queueCallback(complete, this._element, true);\n this._element.style[dimension] = `${this._element[scrollSize]}px`;\n }\n hide() {\n if (this._isTransitioning || !this._isShown()) {\n return;\n }\n const startEvent = EventHandler.trigger(this._element, EVENT_HIDE$6);\n if (startEvent.defaultPrevented) {\n return;\n }\n const dimension = this._getDimension();\n this._element.style[dimension] = `${this._element.getBoundingClientRect()[dimension]}px`;\n reflow(this._element);\n this._element.classList.add(CLASS_NAME_COLLAPSING);\n this._element.classList.remove(CLASS_NAME_COLLAPSE, CLASS_NAME_SHOW$7);\n for (const trigger of this._triggerArray) {\n const element = SelectorEngine.getElementFromSelector(trigger);\n if (element && !this._isShown(element)) {\n this._addAriaAndCollapsedClass([trigger], false);\n }\n }\n this._isTransitioning = true;\n const complete = () => {\n this._isTransitioning = false;\n this._element.classList.remove(CLASS_NAME_COLLAPSING);\n this._element.classList.add(CLASS_NAME_COLLAPSE);\n EventHandler.trigger(this._element, EVENT_HIDDEN$6);\n };\n this._element.style[dimension] = '';\n this._queueCallback(complete, this._element, true);\n }\n _isShown(element = this._element) {\n return element.classList.contains(CLASS_NAME_SHOW$7);\n }\n\n // Private\n _configAfterMerge(config) {\n config.toggle = Boolean(config.toggle); // Coerce string values\n config.parent = getElement(config.parent);\n return config;\n }\n _getDimension() {\n return this._element.classList.contains(CLASS_NAME_HORIZONTAL) ? WIDTH : HEIGHT;\n }\n _initializeChildren() {\n if (!this._config.parent) {\n return;\n }\n const children = this._getFirstLevelChildren(SELECTOR_DATA_TOGGLE$4);\n for (const element of children) {\n const selected = SelectorEngine.getElementFromSelector(element);\n if (selected) {\n this._addAriaAndCollapsedClass([element], this._isShown(selected));\n }\n }\n }\n _getFirstLevelChildren(selector) {\n const children = SelectorEngine.find(CLASS_NAME_DEEPER_CHILDREN, this._config.parent);\n // remove children if greater depth\n return SelectorEngine.find(selector, this._config.parent).filter(element => !children.includes(element));\n }\n _addAriaAndCollapsedClass(triggerArray, isOpen) {\n if (!triggerArray.length) {\n return;\n }\n for (const element of triggerArray) {\n element.classList.toggle(CLASS_NAME_COLLAPSED, !isOpen);\n element.setAttribute('aria-expanded', isOpen);\n }\n }\n\n // Static\n static jQueryInterface(config) {\n const _config = {};\n if (typeof config === 'string' && /show|hide/.test(config)) {\n _config.toggle = false;\n }\n return this.each(function () {\n const data = Collapse.getOrCreateInstance(this, _config);\n if (typeof config === 'string') {\n if (typeof data[config] === 'undefined') {\n throw new TypeError(`No method named \"${config}\"`);\n }\n data[config]();\n }\n });\n }\n}\n\n/**\n * Data API implementation\n */\n\nEventHandler.on(document, EVENT_CLICK_DATA_API$4, SELECTOR_DATA_TOGGLE$4, function (event) {\n // preventDefault only for elements (which change the URL) not inside the collapsible element\n if (event.target.tagName === 'A' || event.delegateTarget && event.delegateTarget.tagName === 'A') {\n event.preventDefault();\n }\n for (const element of SelectorEngine.getMultipleElementsFromSelector(this)) {\n Collapse.getOrCreateInstance(element, {\n toggle: false\n }).toggle();\n }\n});\n\n/**\n * jQuery\n */\n\ndefineJQueryPlugin(Collapse);\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap dropdown.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$a = 'dropdown';\nconst DATA_KEY$6 = 'bs.dropdown';\nconst EVENT_KEY$6 = `.${DATA_KEY$6}`;\nconst DATA_API_KEY$3 = '.data-api';\nconst ESCAPE_KEY$2 = 'Escape';\nconst TAB_KEY$1 = 'Tab';\nconst ARROW_UP_KEY$1 = 'ArrowUp';\nconst ARROW_DOWN_KEY$1 = 'ArrowDown';\nconst RIGHT_MOUSE_BUTTON = 2; // MouseEvent.button value for the secondary button, usually the right button\n\nconst EVENT_HIDE$5 = `hide${EVENT_KEY$6}`;\nconst EVENT_HIDDEN$5 = `hidden${EVENT_KEY$6}`;\nconst EVENT_SHOW$5 = `show${EVENT_KEY$6}`;\nconst EVENT_SHOWN$5 = `shown${EVENT_KEY$6}`;\nconst EVENT_CLICK_DATA_API$3 = `click${EVENT_KEY$6}${DATA_API_KEY$3}`;\nconst EVENT_KEYDOWN_DATA_API = `keydown${EVENT_KEY$6}${DATA_API_KEY$3}`;\nconst EVENT_KEYUP_DATA_API = `keyup${EVENT_KEY$6}${DATA_API_KEY$3}`;\nconst CLASS_NAME_SHOW$6 = 'show';\nconst CLASS_NAME_DROPUP = 'dropup';\nconst CLASS_NAME_DROPEND = 'dropend';\nconst CLASS_NAME_DROPSTART = 'dropstart';\nconst CLASS_NAME_DROPUP_CENTER = 'dropup-center';\nconst CLASS_NAME_DROPDOWN_CENTER = 'dropdown-center';\nconst SELECTOR_DATA_TOGGLE$3 = '[data-bs-toggle=\"dropdown\"]:not(.disabled):not(:disabled)';\nconst SELECTOR_DATA_TOGGLE_SHOWN = `${SELECTOR_DATA_TOGGLE$3}.${CLASS_NAME_SHOW$6}`;\nconst SELECTOR_MENU = '.dropdown-menu';\nconst SELECTOR_NAVBAR = '.navbar';\nconst SELECTOR_NAVBAR_NAV = '.navbar-nav';\nconst SELECTOR_VISIBLE_ITEMS = '.dropdown-menu .dropdown-item:not(.disabled):not(:disabled)';\nconst PLACEMENT_TOP = isRTL() ? 'top-end' : 'top-start';\nconst PLACEMENT_TOPEND = isRTL() ? 'top-start' : 'top-end';\nconst PLACEMENT_BOTTOM = isRTL() ? 'bottom-end' : 'bottom-start';\nconst PLACEMENT_BOTTOMEND = isRTL() ? 'bottom-start' : 'bottom-end';\nconst PLACEMENT_RIGHT = isRTL() ? 'left-start' : 'right-start';\nconst PLACEMENT_LEFT = isRTL() ? 'right-start' : 'left-start';\nconst PLACEMENT_TOPCENTER = 'top';\nconst PLACEMENT_BOTTOMCENTER = 'bottom';\nconst Default$9 = {\n autoClose: true,\n boundary: 'clippingParents',\n display: 'dynamic',\n offset: [0, 2],\n popperConfig: null,\n reference: 'toggle'\n};\nconst DefaultType$9 = {\n autoClose: '(boolean|string)',\n boundary: '(string|element)',\n display: 'string',\n offset: '(array|string|function)',\n popperConfig: '(null|object|function)',\n reference: '(string|element|object)'\n};\n\n/**\n * Class definition\n */\n\nclass Dropdown extends BaseComponent {\n constructor(element, config) {\n super(element, config);\n this._popper = null;\n this._parent = this._element.parentNode; // dropdown wrapper\n // TODO: v6 revert #37011 & change markup https://getbootstrap.com/docs/5.3/forms/input-group/\n this._menu = SelectorEngine.next(this._element, SELECTOR_MENU)[0] || SelectorEngine.prev(this._element, SELECTOR_MENU)[0] || SelectorEngine.findOne(SELECTOR_MENU, this._parent);\n this._inNavbar = this._detectNavbar();\n }\n\n // Getters\n static get Default() {\n return Default$9;\n }\n static get DefaultType() {\n return DefaultType$9;\n }\n static get NAME() {\n return NAME$a;\n }\n\n // Public\n toggle() {\n return this._isShown() ? this.hide() : this.show();\n }\n show() {\n if (isDisabled(this._element) || this._isShown()) {\n return;\n }\n const relatedTarget = {\n relatedTarget: this._element\n };\n const showEvent = EventHandler.trigger(this._element, EVENT_SHOW$5, relatedTarget);\n if (showEvent.defaultPrevented) {\n return;\n }\n this._createPopper();\n\n // If this is a touch-enabled device we add extra\n // empty mouseover listeners to the body's immediate children;\n // only needed because of broken event delegation on iOS\n // https://www.quirksmode.org/blog/archives/2014/02/mouse_event_bub.html\n if ('ontouchstart' in document.documentElement && !this._parent.closest(SELECTOR_NAVBAR_NAV)) {\n for (const element of [].concat(...document.body.children)) {\n EventHandler.on(element, 'mouseover', noop);\n }\n }\n this._element.focus();\n this._element.setAttribute('aria-expanded', true);\n this._menu.classList.add(CLASS_NAME_SHOW$6);\n this._element.classList.add(CLASS_NAME_SHOW$6);\n EventHandler.trigger(this._element, EVENT_SHOWN$5, relatedTarget);\n }\n hide() {\n if (isDisabled(this._element) || !this._isShown()) {\n return;\n }\n const relatedTarget = {\n relatedTarget: this._element\n };\n this._completeHide(relatedTarget);\n }\n dispose() {\n if (this._popper) {\n this._popper.destroy();\n }\n super.dispose();\n }\n update() {\n this._inNavbar = this._detectNavbar();\n if (this._popper) {\n this._popper.update();\n }\n }\n\n // Private\n _completeHide(relatedTarget) {\n const hideEvent = EventHandler.trigger(this._element, EVENT_HIDE$5, relatedTarget);\n if (hideEvent.defaultPrevented) {\n return;\n }\n\n // If this is a touch-enabled device we remove the extra\n // empty mouseover listeners we added for iOS support\n if ('ontouchstart' in document.documentElement) {\n for (const element of [].concat(...document.body.children)) {\n EventHandler.off(element, 'mouseover', noop);\n }\n }\n if (this._popper) {\n this._popper.destroy();\n }\n this._menu.classList.remove(CLASS_NAME_SHOW$6);\n this._element.classList.remove(CLASS_NAME_SHOW$6);\n this._element.setAttribute('aria-expanded', 'false');\n Manipulator.removeDataAttribute(this._menu, 'popper');\n EventHandler.trigger(this._element, EVENT_HIDDEN$5, relatedTarget);\n }\n _getConfig(config) {\n config = super._getConfig(config);\n if (typeof config.reference === 'object' && !isElement(config.reference) && typeof config.reference.getBoundingClientRect !== 'function') {\n // Popper virtual elements require a getBoundingClientRect method\n throw new TypeError(`${NAME$a.toUpperCase()}: Option \"reference\" provided type \"object\" without a required \"getBoundingClientRect\" method.`);\n }\n return config;\n }\n _createPopper() {\n if (typeof Popper === 'undefined') {\n throw new TypeError('Bootstrap\\'s dropdowns require Popper (https://popper.js.org)');\n }\n let referenceElement = this._element;\n if (this._config.reference === 'parent') {\n referenceElement = this._parent;\n } else if (isElement(this._config.reference)) {\n referenceElement = getElement(this._config.reference);\n } else if (typeof this._config.reference === 'object') {\n referenceElement = this._config.reference;\n }\n const popperConfig = this._getPopperConfig();\n this._popper = Popper.createPopper(referenceElement, this._menu, popperConfig);\n }\n _isShown() {\n return this._menu.classList.contains(CLASS_NAME_SHOW$6);\n }\n _getPlacement() {\n const parentDropdown = this._parent;\n if (parentDropdown.classList.contains(CLASS_NAME_DROPEND)) {\n return PLACEMENT_RIGHT;\n }\n if (parentDropdown.classList.contains(CLASS_NAME_DROPSTART)) {\n return PLACEMENT_LEFT;\n }\n if (parentDropdown.classList.contains(CLASS_NAME_DROPUP_CENTER)) {\n return PLACEMENT_TOPCENTER;\n }\n if (parentDropdown.classList.contains(CLASS_NAME_DROPDOWN_CENTER)) {\n return PLACEMENT_BOTTOMCENTER;\n }\n\n // We need to trim the value because custom properties can also include spaces\n const isEnd = getComputedStyle(this._menu).getPropertyValue('--bs-position').trim() === 'end';\n if (parentDropdown.classList.contains(CLASS_NAME_DROPUP)) {\n return isEnd ? PLACEMENT_TOPEND : PLACEMENT_TOP;\n }\n return isEnd ? PLACEMENT_BOTTOMEND : PLACEMENT_BOTTOM;\n }\n _detectNavbar() {\n return this._element.closest(SELECTOR_NAVBAR) !== null;\n }\n _getOffset() {\n const {\n offset\n } = this._config;\n if (typeof offset === 'string') {\n return offset.split(',').map(value => Number.parseInt(value, 10));\n }\n if (typeof offset === 'function') {\n return popperData => offset(popperData, this._element);\n }\n return offset;\n }\n _getPopperConfig() {\n const defaultBsPopperConfig = {\n placement: this._getPlacement(),\n modifiers: [{\n name: 'preventOverflow',\n options: {\n boundary: this._config.boundary\n }\n }, {\n name: 'offset',\n options: {\n offset: this._getOffset()\n }\n }]\n };\n\n // Disable Popper if we have a static display or Dropdown is in Navbar\n if (this._inNavbar || this._config.display === 'static') {\n Manipulator.setDataAttribute(this._menu, 'popper', 'static'); // TODO: v6 remove\n defaultBsPopperConfig.modifiers = [{\n name: 'applyStyles',\n enabled: false\n }];\n }\n return {\n ...defaultBsPopperConfig,\n ...execute(this._config.popperConfig, [defaultBsPopperConfig])\n };\n }\n _selectMenuItem({\n key,\n target\n }) {\n const items = SelectorEngine.find(SELECTOR_VISIBLE_ITEMS, this._menu).filter(element => isVisible(element));\n if (!items.length) {\n return;\n }\n\n // if target isn't included in items (e.g. when expanding the dropdown)\n // allow cycling to get the last item in case key equals ARROW_UP_KEY\n getNextActiveElement(items, target, key === ARROW_DOWN_KEY$1, !items.includes(target)).focus();\n }\n\n // Static\n static jQueryInterface(config) {\n return this.each(function () {\n const data = Dropdown.getOrCreateInstance(this, config);\n if (typeof config !== 'string') {\n return;\n }\n if (typeof data[config] === 'undefined') {\n throw new TypeError(`No method named \"${config}\"`);\n }\n data[config]();\n });\n }\n static clearMenus(event) {\n if (event.button === RIGHT_MOUSE_BUTTON || event.type === 'keyup' && event.key !== TAB_KEY$1) {\n return;\n }\n const openToggles = SelectorEngine.find(SELECTOR_DATA_TOGGLE_SHOWN);\n for (const toggle of openToggles) {\n const context = Dropdown.getInstance(toggle);\n if (!context || context._config.autoClose === false) {\n continue;\n }\n const composedPath = event.composedPath();\n const isMenuTarget = composedPath.includes(context._menu);\n if (composedPath.includes(context._element) || context._config.autoClose === 'inside' && !isMenuTarget || context._config.autoClose === 'outside' && isMenuTarget) {\n continue;\n }\n\n // Tab navigation through the dropdown menu or events from contained inputs shouldn't close the menu\n if (context._menu.contains(event.target) && (event.type === 'keyup' && event.key === TAB_KEY$1 || /input|select|option|textarea|form/i.test(event.target.tagName))) {\n continue;\n }\n const relatedTarget = {\n relatedTarget: context._element\n };\n if (event.type === 'click') {\n relatedTarget.clickEvent = event;\n }\n context._completeHide(relatedTarget);\n }\n }\n static dataApiKeydownHandler(event) {\n // If not an UP | DOWN | ESCAPE key => not a dropdown command\n // If input/textarea && if key is other than ESCAPE => not a dropdown command\n\n const isInput = /input|textarea/i.test(event.target.tagName);\n const isEscapeEvent = event.key === ESCAPE_KEY$2;\n const isUpOrDownEvent = [ARROW_UP_KEY$1, ARROW_DOWN_KEY$1].includes(event.key);\n if (!isUpOrDownEvent && !isEscapeEvent) {\n return;\n }\n if (isInput && !isEscapeEvent) {\n return;\n }\n event.preventDefault();\n\n // TODO: v6 revert #37011 & change markup https://getbootstrap.com/docs/5.3/forms/input-group/\n const getToggleButton = this.matches(SELECTOR_DATA_TOGGLE$3) ? this : SelectorEngine.prev(this, SELECTOR_DATA_TOGGLE$3)[0] || SelectorEngine.next(this, SELECTOR_DATA_TOGGLE$3)[0] || SelectorEngine.findOne(SELECTOR_DATA_TOGGLE$3, event.delegateTarget.parentNode);\n const instance = Dropdown.getOrCreateInstance(getToggleButton);\n if (isUpOrDownEvent) {\n event.stopPropagation();\n instance.show();\n instance._selectMenuItem(event);\n return;\n }\n if (instance._isShown()) {\n // else is escape and we check if it is shown\n event.stopPropagation();\n instance.hide();\n getToggleButton.focus();\n }\n }\n}\n\n/**\n * Data API implementation\n */\n\nEventHandler.on(document, EVENT_KEYDOWN_DATA_API, SELECTOR_DATA_TOGGLE$3, Dropdown.dataApiKeydownHandler);\nEventHandler.on(document, EVENT_KEYDOWN_DATA_API, SELECTOR_MENU, Dropdown.dataApiKeydownHandler);\nEventHandler.on(document, EVENT_CLICK_DATA_API$3, Dropdown.clearMenus);\nEventHandler.on(document, EVENT_KEYUP_DATA_API, Dropdown.clearMenus);\nEventHandler.on(document, EVENT_CLICK_DATA_API$3, SELECTOR_DATA_TOGGLE$3, function (event) {\n event.preventDefault();\n Dropdown.getOrCreateInstance(this).toggle();\n});\n\n/**\n * jQuery\n */\n\ndefineJQueryPlugin(Dropdown);\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap util/backdrop.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$9 = 'backdrop';\nconst CLASS_NAME_FADE$4 = 'fade';\nconst CLASS_NAME_SHOW$5 = 'show';\nconst EVENT_MOUSEDOWN = `mousedown.bs.${NAME$9}`;\nconst Default$8 = {\n className: 'modal-backdrop',\n clickCallback: null,\n isAnimated: false,\n isVisible: true,\n // if false, we use the backdrop helper without adding any element to the dom\n rootElement: 'body' // give the choice to place backdrop under different elements\n};\n\nconst DefaultType$8 = {\n className: 'string',\n clickCallback: '(function|null)',\n isAnimated: 'boolean',\n isVisible: 'boolean',\n rootElement: '(element|string)'\n};\n\n/**\n * Class definition\n */\n\nclass Backdrop extends Config {\n constructor(config) {\n super();\n this._config = this._getConfig(config);\n this._isAppended = false;\n this._element = null;\n }\n\n // Getters\n static get Default() {\n return Default$8;\n }\n static get DefaultType() {\n return DefaultType$8;\n }\n static get NAME() {\n return NAME$9;\n }\n\n // Public\n show(callback) {\n if (!this._config.isVisible) {\n execute(callback);\n return;\n }\n this._append();\n const element = this._getElement();\n if (this._config.isAnimated) {\n reflow(element);\n }\n element.classList.add(CLASS_NAME_SHOW$5);\n this._emulateAnimation(() => {\n execute(callback);\n });\n }\n hide(callback) {\n if (!this._config.isVisible) {\n execute(callback);\n return;\n }\n this._getElement().classList.remove(CLASS_NAME_SHOW$5);\n this._emulateAnimation(() => {\n this.dispose();\n execute(callback);\n });\n }\n dispose() {\n if (!this._isAppended) {\n return;\n }\n EventHandler.off(this._element, EVENT_MOUSEDOWN);\n this._element.remove();\n this._isAppended = false;\n }\n\n // Private\n _getElement() {\n if (!this._element) {\n const backdrop = document.createElement('div');\n backdrop.className = this._config.className;\n if (this._config.isAnimated) {\n backdrop.classList.add(CLASS_NAME_FADE$4);\n }\n this._element = backdrop;\n }\n return this._element;\n }\n _configAfterMerge(config) {\n // use getElement() with the default \"body\" to get a fresh Element on each instantiation\n config.rootElement = getElement(config.rootElement);\n return config;\n }\n _append() {\n if (this._isAppended) {\n return;\n }\n const element = this._getElement();\n this._config.rootElement.append(element);\n EventHandler.on(element, EVENT_MOUSEDOWN, () => {\n execute(this._config.clickCallback);\n });\n this._isAppended = true;\n }\n _emulateAnimation(callback) {\n executeAfterTransition(callback, this._getElement(), this._config.isAnimated);\n }\n}\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap util/focustrap.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$8 = 'focustrap';\nconst DATA_KEY$5 = 'bs.focustrap';\nconst EVENT_KEY$5 = `.${DATA_KEY$5}`;\nconst EVENT_FOCUSIN$2 = `focusin${EVENT_KEY$5}`;\nconst EVENT_KEYDOWN_TAB = `keydown.tab${EVENT_KEY$5}`;\nconst TAB_KEY = 'Tab';\nconst TAB_NAV_FORWARD = 'forward';\nconst TAB_NAV_BACKWARD = 'backward';\nconst Default$7 = {\n autofocus: true,\n trapElement: null // The element to trap focus inside of\n};\n\nconst DefaultType$7 = {\n autofocus: 'boolean',\n trapElement: 'element'\n};\n\n/**\n * Class definition\n */\n\nclass FocusTrap extends Config {\n constructor(config) {\n super();\n this._config = this._getConfig(config);\n this._isActive = false;\n this._lastTabNavDirection = null;\n }\n\n // Getters\n static get Default() {\n return Default$7;\n }\n static get DefaultType() {\n return DefaultType$7;\n }\n static get NAME() {\n return NAME$8;\n }\n\n // Public\n activate() {\n if (this._isActive) {\n return;\n }\n if (this._config.autofocus) {\n this._config.trapElement.focus();\n }\n EventHandler.off(document, EVENT_KEY$5); // guard against infinite focus loop\n EventHandler.on(document, EVENT_FOCUSIN$2, event => this._handleFocusin(event));\n EventHandler.on(document, EVENT_KEYDOWN_TAB, event => this._handleKeydown(event));\n this._isActive = true;\n }\n deactivate() {\n if (!this._isActive) {\n return;\n }\n this._isActive = false;\n EventHandler.off(document, EVENT_KEY$5);\n }\n\n // Private\n _handleFocusin(event) {\n const {\n trapElement\n } = this._config;\n if (event.target === document || event.target === trapElement || trapElement.contains(event.target)) {\n return;\n }\n const elements = SelectorEngine.focusableChildren(trapElement);\n if (elements.length === 0) {\n trapElement.focus();\n } else if (this._lastTabNavDirection === TAB_NAV_BACKWARD) {\n elements[elements.length - 1].focus();\n } else {\n elements[0].focus();\n }\n }\n _handleKeydown(event) {\n if (event.key !== TAB_KEY) {\n return;\n }\n this._lastTabNavDirection = event.shiftKey ? TAB_NAV_BACKWARD : TAB_NAV_FORWARD;\n }\n}\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap util/scrollBar.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst SELECTOR_FIXED_CONTENT = '.fixed-top, .fixed-bottom, .is-fixed, .sticky-top';\nconst SELECTOR_STICKY_CONTENT = '.sticky-top';\nconst PROPERTY_PADDING = 'padding-right';\nconst PROPERTY_MARGIN = 'margin-right';\n\n/**\n * Class definition\n */\n\nclass ScrollBarHelper {\n constructor() {\n this._element = document.body;\n }\n\n // Public\n getWidth() {\n // https://developer.mozilla.org/en-US/docs/Web/API/Window/innerWidth#usage_notes\n const documentWidth = document.documentElement.clientWidth;\n return Math.abs(window.innerWidth - documentWidth);\n }\n hide() {\n const width = this.getWidth();\n this._disableOverFlow();\n // give padding to element to balance the hidden scrollbar width\n this._setElementAttributes(this._element, PROPERTY_PADDING, calculatedValue => calculatedValue + width);\n // trick: We adjust positive paddingRight and negative marginRight to sticky-top elements to keep showing fullwidth\n this._setElementAttributes(SELECTOR_FIXED_CONTENT, PROPERTY_PADDING, calculatedValue => calculatedValue + width);\n this._setElementAttributes(SELECTOR_STICKY_CONTENT, PROPERTY_MARGIN, calculatedValue => calculatedValue - width);\n }\n reset() {\n this._resetElementAttributes(this._element, 'overflow');\n this._resetElementAttributes(this._element, PROPERTY_PADDING);\n this._resetElementAttributes(SELECTOR_FIXED_CONTENT, PROPERTY_PADDING);\n this._resetElementAttributes(SELECTOR_STICKY_CONTENT, PROPERTY_MARGIN);\n }\n isOverflowing() {\n return this.getWidth() > 0;\n }\n\n // Private\n _disableOverFlow() {\n this._saveInitialAttribute(this._element, 'overflow');\n this._element.style.overflow = 'hidden';\n }\n _setElementAttributes(selector, styleProperty, callback) {\n const scrollbarWidth = this.getWidth();\n const manipulationCallBack = element => {\n if (element !== this._element && window.innerWidth > element.clientWidth + scrollbarWidth) {\n return;\n }\n this._saveInitialAttribute(element, styleProperty);\n const calculatedValue = window.getComputedStyle(element).getPropertyValue(styleProperty);\n element.style.setProperty(styleProperty, `${callback(Number.parseFloat(calculatedValue))}px`);\n };\n this._applyManipulationCallback(selector, manipulationCallBack);\n }\n _saveInitialAttribute(element, styleProperty) {\n const actualValue = element.style.getPropertyValue(styleProperty);\n if (actualValue) {\n Manipulator.setDataAttribute(element, styleProperty, actualValue);\n }\n }\n _resetElementAttributes(selector, styleProperty) {\n const manipulationCallBack = element => {\n const value = Manipulator.getDataAttribute(element, styleProperty);\n // We only want to remove the property if the value is `null`; the value can also be zero\n if (value === null) {\n element.style.removeProperty(styleProperty);\n return;\n }\n Manipulator.removeDataAttribute(element, styleProperty);\n element.style.setProperty(styleProperty, value);\n };\n this._applyManipulationCallback(selector, manipulationCallBack);\n }\n _applyManipulationCallback(selector, callBack) {\n if (isElement(selector)) {\n callBack(selector);\n return;\n }\n for (const sel of SelectorEngine.find(selector, this._element)) {\n callBack(sel);\n }\n }\n}\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap modal.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$7 = 'modal';\nconst DATA_KEY$4 = 'bs.modal';\nconst EVENT_KEY$4 = `.${DATA_KEY$4}`;\nconst DATA_API_KEY$2 = '.data-api';\nconst ESCAPE_KEY$1 = 'Escape';\nconst EVENT_HIDE$4 = `hide${EVENT_KEY$4}`;\nconst EVENT_HIDE_PREVENTED$1 = `hidePrevented${EVENT_KEY$4}`;\nconst EVENT_HIDDEN$4 = `hidden${EVENT_KEY$4}`;\nconst EVENT_SHOW$4 = `show${EVENT_KEY$4}`;\nconst EVENT_SHOWN$4 = `shown${EVENT_KEY$4}`;\nconst EVENT_RESIZE$1 = `resize${EVENT_KEY$4}`;\nconst EVENT_CLICK_DISMISS = `click.dismiss${EVENT_KEY$4}`;\nconst EVENT_MOUSEDOWN_DISMISS = `mousedown.dismiss${EVENT_KEY$4}`;\nconst EVENT_KEYDOWN_DISMISS$1 = `keydown.dismiss${EVENT_KEY$4}`;\nconst EVENT_CLICK_DATA_API$2 = `click${EVENT_KEY$4}${DATA_API_KEY$2}`;\nconst CLASS_NAME_OPEN = 'modal-open';\nconst CLASS_NAME_FADE$3 = 'fade';\nconst CLASS_NAME_SHOW$4 = 'show';\nconst CLASS_NAME_STATIC = 'modal-static';\nconst OPEN_SELECTOR$1 = '.modal.show';\nconst SELECTOR_DIALOG = '.modal-dialog';\nconst SELECTOR_MODAL_BODY = '.modal-body';\nconst SELECTOR_DATA_TOGGLE$2 = '[data-bs-toggle=\"modal\"]';\nconst Default$6 = {\n backdrop: true,\n focus: true,\n keyboard: true\n};\nconst DefaultType$6 = {\n backdrop: '(boolean|string)',\n focus: 'boolean',\n keyboard: 'boolean'\n};\n\n/**\n * Class definition\n */\n\nclass Modal extends BaseComponent {\n constructor(element, config) {\n super(element, config);\n this._dialog = SelectorEngine.findOne(SELECTOR_DIALOG, this._element);\n this._backdrop = this._initializeBackDrop();\n this._focustrap = this._initializeFocusTrap();\n this._isShown = false;\n this._isTransitioning = false;\n this._scrollBar = new ScrollBarHelper();\n this._addEventListeners();\n }\n\n // Getters\n static get Default() {\n return Default$6;\n }\n static get DefaultType() {\n return DefaultType$6;\n }\n static get NAME() {\n return NAME$7;\n }\n\n // Public\n toggle(relatedTarget) {\n return this._isShown ? this.hide() : this.show(relatedTarget);\n }\n show(relatedTarget) {\n if (this._isShown || this._isTransitioning) {\n return;\n }\n const showEvent = EventHandler.trigger(this._element, EVENT_SHOW$4, {\n relatedTarget\n });\n if (showEvent.defaultPrevented) {\n return;\n }\n this._isShown = true;\n this._isTransitioning = true;\n this._scrollBar.hide();\n document.body.classList.add(CLASS_NAME_OPEN);\n this._adjustDialog();\n this._backdrop.show(() => this._showElement(relatedTarget));\n }\n hide() {\n if (!this._isShown || this._isTransitioning) {\n return;\n }\n const hideEvent = EventHandler.trigger(this._element, EVENT_HIDE$4);\n if (hideEvent.defaultPrevented) {\n return;\n }\n this._isShown = false;\n this._isTransitioning = true;\n this._focustrap.deactivate();\n this._element.classList.remove(CLASS_NAME_SHOW$4);\n this._queueCallback(() => this._hideModal(), this._element, this._isAnimated());\n }\n dispose() {\n EventHandler.off(window, EVENT_KEY$4);\n EventHandler.off(this._dialog, EVENT_KEY$4);\n this._backdrop.dispose();\n this._focustrap.deactivate();\n super.dispose();\n }\n handleUpdate() {\n this._adjustDialog();\n }\n\n // Private\n _initializeBackDrop() {\n return new Backdrop({\n isVisible: Boolean(this._config.backdrop),\n // 'static' option will be translated to true, and booleans will keep their value,\n isAnimated: this._isAnimated()\n });\n }\n _initializeFocusTrap() {\n return new FocusTrap({\n trapElement: this._element\n });\n }\n _showElement(relatedTarget) {\n // try to append dynamic modal\n if (!document.body.contains(this._element)) {\n document.body.append(this._element);\n }\n this._element.style.display = 'block';\n this._element.removeAttribute('aria-hidden');\n this._element.setAttribute('aria-modal', true);\n this._element.setAttribute('role', 'dialog');\n this._element.scrollTop = 0;\n const modalBody = SelectorEngine.findOne(SELECTOR_MODAL_BODY, this._dialog);\n if (modalBody) {\n modalBody.scrollTop = 0;\n }\n reflow(this._element);\n this._element.classList.add(CLASS_NAME_SHOW$4);\n const transitionComplete = () => {\n if (this._config.focus) {\n this._focustrap.activate();\n }\n this._isTransitioning = false;\n EventHandler.trigger(this._element, EVENT_SHOWN$4, {\n relatedTarget\n });\n };\n this._queueCallback(transitionComplete, this._dialog, this._isAnimated());\n }\n _addEventListeners() {\n EventHandler.on(this._element, EVENT_KEYDOWN_DISMISS$1, event => {\n if (event.key !== ESCAPE_KEY$1) {\n return;\n }\n if (this._config.keyboard) {\n this.hide();\n return;\n }\n this._triggerBackdropTransition();\n });\n EventHandler.on(window, EVENT_RESIZE$1, () => {\n if (this._isShown && !this._isTransitioning) {\n this._adjustDialog();\n }\n });\n EventHandler.on(this._element, EVENT_MOUSEDOWN_DISMISS, event => {\n // a bad trick to segregate clicks that may start inside dialog but end outside, and avoid listen to scrollbar clicks\n EventHandler.one(this._element, EVENT_CLICK_DISMISS, event2 => {\n if (this._element !== event.target || this._element !== event2.target) {\n return;\n }\n if (this._config.backdrop === 'static') {\n this._triggerBackdropTransition();\n return;\n }\n if (this._config.backdrop) {\n this.hide();\n }\n });\n });\n }\n _hideModal() {\n this._element.style.display = 'none';\n this._element.setAttribute('aria-hidden', true);\n this._element.removeAttribute('aria-modal');\n this._element.removeAttribute('role');\n this._isTransitioning = false;\n this._backdrop.hide(() => {\n document.body.classList.remove(CLASS_NAME_OPEN);\n this._resetAdjustments();\n this._scrollBar.reset();\n EventHandler.trigger(this._element, EVENT_HIDDEN$4);\n });\n }\n _isAnimated() {\n return this._element.classList.contains(CLASS_NAME_FADE$3);\n }\n _triggerBackdropTransition() {\n const hideEvent = EventHandler.trigger(this._element, EVENT_HIDE_PREVENTED$1);\n if (hideEvent.defaultPrevented) {\n return;\n }\n const isModalOverflowing = this._element.scrollHeight > document.documentElement.clientHeight;\n const initialOverflowY = this._element.style.overflowY;\n // return if the following background transition hasn't yet completed\n if (initialOverflowY === 'hidden' || this._element.classList.contains(CLASS_NAME_STATIC)) {\n return;\n }\n if (!isModalOverflowing) {\n this._element.style.overflowY = 'hidden';\n }\n this._element.classList.add(CLASS_NAME_STATIC);\n this._queueCallback(() => {\n this._element.classList.remove(CLASS_NAME_STATIC);\n this._queueCallback(() => {\n this._element.style.overflowY = initialOverflowY;\n }, this._dialog);\n }, this._dialog);\n this._element.focus();\n }\n\n /**\n * The following methods are used to handle overflowing modals\n */\n\n _adjustDialog() {\n const isModalOverflowing = this._element.scrollHeight > document.documentElement.clientHeight;\n const scrollbarWidth = this._scrollBar.getWidth();\n const isBodyOverflowing = scrollbarWidth > 0;\n if (isBodyOverflowing && !isModalOverflowing) {\n const property = isRTL() ? 'paddingLeft' : 'paddingRight';\n this._element.style[property] = `${scrollbarWidth}px`;\n }\n if (!isBodyOverflowing && isModalOverflowing) {\n const property = isRTL() ? 'paddingRight' : 'paddingLeft';\n this._element.style[property] = `${scrollbarWidth}px`;\n }\n }\n _resetAdjustments() {\n this._element.style.paddingLeft = '';\n this._element.style.paddingRight = '';\n }\n\n // Static\n static jQueryInterface(config, relatedTarget) {\n return this.each(function () {\n const data = Modal.getOrCreateInstance(this, config);\n if (typeof config !== 'string') {\n return;\n }\n if (typeof data[config] === 'undefined') {\n throw new TypeError(`No method named \"${config}\"`);\n }\n data[config](relatedTarget);\n });\n }\n}\n\n/**\n * Data API implementation\n */\n\nEventHandler.on(document, EVENT_CLICK_DATA_API$2, SELECTOR_DATA_TOGGLE$2, function (event) {\n const target = SelectorEngine.getElementFromSelector(this);\n if (['A', 'AREA'].includes(this.tagName)) {\n event.preventDefault();\n }\n EventHandler.one(target, EVENT_SHOW$4, showEvent => {\n if (showEvent.defaultPrevented) {\n // only register focus restorer if modal will actually get shown\n return;\n }\n EventHandler.one(target, EVENT_HIDDEN$4, () => {\n if (isVisible(this)) {\n this.focus();\n }\n });\n });\n\n // avoid conflict when clicking modal toggler while another one is open\n const alreadyOpen = SelectorEngine.findOne(OPEN_SELECTOR$1);\n if (alreadyOpen) {\n Modal.getInstance(alreadyOpen).hide();\n }\n const data = Modal.getOrCreateInstance(target);\n data.toggle(this);\n});\nenableDismissTrigger(Modal);\n\n/**\n * jQuery\n */\n\ndefineJQueryPlugin(Modal);\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap offcanvas.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$6 = 'offcanvas';\nconst DATA_KEY$3 = 'bs.offcanvas';\nconst EVENT_KEY$3 = `.${DATA_KEY$3}`;\nconst DATA_API_KEY$1 = '.data-api';\nconst EVENT_LOAD_DATA_API$2 = `load${EVENT_KEY$3}${DATA_API_KEY$1}`;\nconst ESCAPE_KEY = 'Escape';\nconst CLASS_NAME_SHOW$3 = 'show';\nconst CLASS_NAME_SHOWING$1 = 'showing';\nconst CLASS_NAME_HIDING = 'hiding';\nconst CLASS_NAME_BACKDROP = 'offcanvas-backdrop';\nconst OPEN_SELECTOR = '.offcanvas.show';\nconst EVENT_SHOW$3 = `show${EVENT_KEY$3}`;\nconst EVENT_SHOWN$3 = `shown${EVENT_KEY$3}`;\nconst EVENT_HIDE$3 = `hide${EVENT_KEY$3}`;\nconst EVENT_HIDE_PREVENTED = `hidePrevented${EVENT_KEY$3}`;\nconst EVENT_HIDDEN$3 = `hidden${EVENT_KEY$3}`;\nconst EVENT_RESIZE = `resize${EVENT_KEY$3}`;\nconst EVENT_CLICK_DATA_API$1 = `click${EVENT_KEY$3}${DATA_API_KEY$1}`;\nconst EVENT_KEYDOWN_DISMISS = `keydown.dismiss${EVENT_KEY$3}`;\nconst SELECTOR_DATA_TOGGLE$1 = '[data-bs-toggle=\"offcanvas\"]';\nconst Default$5 = {\n backdrop: true,\n keyboard: true,\n scroll: false\n};\nconst DefaultType$5 = {\n backdrop: '(boolean|string)',\n keyboard: 'boolean',\n scroll: 'boolean'\n};\n\n/**\n * Class definition\n */\n\nclass Offcanvas extends BaseComponent {\n constructor(element, config) {\n super(element, config);\n this._isShown = false;\n this._backdrop = this._initializeBackDrop();\n this._focustrap = this._initializeFocusTrap();\n this._addEventListeners();\n }\n\n // Getters\n static get Default() {\n return Default$5;\n }\n static get DefaultType() {\n return DefaultType$5;\n }\n static get NAME() {\n return NAME$6;\n }\n\n // Public\n toggle(relatedTarget) {\n return this._isShown ? this.hide() : this.show(relatedTarget);\n }\n show(relatedTarget) {\n if (this._isShown) {\n return;\n }\n const showEvent = EventHandler.trigger(this._element, EVENT_SHOW$3, {\n relatedTarget\n });\n if (showEvent.defaultPrevented) {\n return;\n }\n this._isShown = true;\n this._backdrop.show();\n if (!this._config.scroll) {\n new ScrollBarHelper().hide();\n }\n this._element.setAttribute('aria-modal', true);\n this._element.setAttribute('role', 'dialog');\n this._element.classList.add(CLASS_NAME_SHOWING$1);\n const completeCallBack = () => {\n if (!this._config.scroll || this._config.backdrop) {\n this._focustrap.activate();\n }\n this._element.classList.add(CLASS_NAME_SHOW$3);\n this._element.classList.remove(CLASS_NAME_SHOWING$1);\n EventHandler.trigger(this._element, EVENT_SHOWN$3, {\n relatedTarget\n });\n };\n this._queueCallback(completeCallBack, this._element, true);\n }\n hide() {\n if (!this._isShown) {\n return;\n }\n const hideEvent = EventHandler.trigger(this._element, EVENT_HIDE$3);\n if (hideEvent.defaultPrevented) {\n return;\n }\n this._focustrap.deactivate();\n this._element.blur();\n this._isShown = false;\n this._element.classList.add(CLASS_NAME_HIDING);\n this._backdrop.hide();\n const completeCallback = () => {\n this._element.classList.remove(CLASS_NAME_SHOW$3, CLASS_NAME_HIDING);\n this._element.removeAttribute('aria-modal');\n this._element.removeAttribute('role');\n if (!this._config.scroll) {\n new ScrollBarHelper().reset();\n }\n EventHandler.trigger(this._element, EVENT_HIDDEN$3);\n };\n this._queueCallback(completeCallback, this._element, true);\n }\n dispose() {\n this._backdrop.dispose();\n this._focustrap.deactivate();\n super.dispose();\n }\n\n // Private\n _initializeBackDrop() {\n const clickCallback = () => {\n if (this._config.backdrop === 'static') {\n EventHandler.trigger(this._element, EVENT_HIDE_PREVENTED);\n return;\n }\n this.hide();\n };\n\n // 'static' option will be translated to true, and booleans will keep their value\n const isVisible = Boolean(this._config.backdrop);\n return new Backdrop({\n className: CLASS_NAME_BACKDROP,\n isVisible,\n isAnimated: true,\n rootElement: this._element.parentNode,\n clickCallback: isVisible ? clickCallback : null\n });\n }\n _initializeFocusTrap() {\n return new FocusTrap({\n trapElement: this._element\n });\n }\n _addEventListeners() {\n EventHandler.on(this._element, EVENT_KEYDOWN_DISMISS, event => {\n if (event.key !== ESCAPE_KEY) {\n return;\n }\n if (this._config.keyboard) {\n this.hide();\n return;\n }\n EventHandler.trigger(this._element, EVENT_HIDE_PREVENTED);\n });\n }\n\n // Static\n static jQueryInterface(config) {\n return this.each(function () {\n const data = Offcanvas.getOrCreateInstance(this, config);\n if (typeof config !== 'string') {\n return;\n }\n if (data[config] === undefined || config.startsWith('_') || config === 'constructor') {\n throw new TypeError(`No method named \"${config}\"`);\n }\n data[config](this);\n });\n }\n}\n\n/**\n * Data API implementation\n */\n\nEventHandler.on(document, EVENT_CLICK_DATA_API$1, SELECTOR_DATA_TOGGLE$1, function (event) {\n const target = SelectorEngine.getElementFromSelector(this);\n if (['A', 'AREA'].includes(this.tagName)) {\n event.preventDefault();\n }\n if (isDisabled(this)) {\n return;\n }\n EventHandler.one(target, EVENT_HIDDEN$3, () => {\n // focus on trigger when it is closed\n if (isVisible(this)) {\n this.focus();\n }\n });\n\n // avoid conflict when clicking a toggler of an offcanvas, while another is open\n const alreadyOpen = SelectorEngine.findOne(OPEN_SELECTOR);\n if (alreadyOpen && alreadyOpen !== target) {\n Offcanvas.getInstance(alreadyOpen).hide();\n }\n const data = Offcanvas.getOrCreateInstance(target);\n data.toggle(this);\n});\nEventHandler.on(window, EVENT_LOAD_DATA_API$2, () => {\n for (const selector of SelectorEngine.find(OPEN_SELECTOR)) {\n Offcanvas.getOrCreateInstance(selector).show();\n }\n});\nEventHandler.on(window, EVENT_RESIZE, () => {\n for (const element of SelectorEngine.find('[aria-modal][class*=show][class*=offcanvas-]')) {\n if (getComputedStyle(element).position !== 'fixed') {\n Offcanvas.getOrCreateInstance(element).hide();\n }\n }\n});\nenableDismissTrigger(Offcanvas);\n\n/**\n * jQuery\n */\n\ndefineJQueryPlugin(Offcanvas);\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap util/sanitizer.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n// js-docs-start allow-list\nconst ARIA_ATTRIBUTE_PATTERN = /^aria-[\\w-]*$/i;\nconst DefaultAllowlist = {\n // Global attributes allowed on any supplied element below.\n '*': ['class', 'dir', 'id', 'lang', 'role', ARIA_ATTRIBUTE_PATTERN],\n a: ['target', 'href', 'title', 'rel'],\n area: [],\n b: [],\n br: [],\n col: [],\n code: [],\n div: [],\n em: [],\n hr: [],\n h1: [],\n h2: [],\n h3: [],\n h4: [],\n h5: [],\n h6: [],\n i: [],\n img: ['src', 'srcset', 'alt', 'title', 'width', 'height'],\n li: [],\n ol: [],\n p: [],\n pre: [],\n s: [],\n small: [],\n span: [],\n sub: [],\n sup: [],\n strong: [],\n u: [],\n ul: []\n};\n// js-docs-end allow-list\n\nconst uriAttributes = new Set(['background', 'cite', 'href', 'itemtype', 'longdesc', 'poster', 'src', 'xlink:href']);\n\n/**\n * A pattern that recognizes URLs that are safe wrt. XSS in URL navigation\n * contexts.\n *\n * Shout-out to Angular https://github.com/angular/angular/blob/15.2.8/packages/core/src/sanitization/url_sanitizer.ts#L38\n */\n// eslint-disable-next-line unicorn/better-regex\nconst SAFE_URL_PATTERN = /^(?!javascript:)(?:[a-z0-9+.-]+:|[^&:/?#]*(?:[/?#]|$))/i;\nconst allowedAttribute = (attribute, allowedAttributeList) => {\n const attributeName = attribute.nodeName.toLowerCase();\n if (allowedAttributeList.includes(attributeName)) {\n if (uriAttributes.has(attributeName)) {\n return Boolean(SAFE_URL_PATTERN.test(attribute.nodeValue));\n }\n return true;\n }\n\n // Check if a regular expression validates the attribute.\n return allowedAttributeList.filter(attributeRegex => attributeRegex instanceof RegExp).some(regex => regex.test(attributeName));\n};\nfunction sanitizeHtml(unsafeHtml, allowList, sanitizeFunction) {\n if (!unsafeHtml.length) {\n return unsafeHtml;\n }\n if (sanitizeFunction && typeof sanitizeFunction === 'function') {\n return sanitizeFunction(unsafeHtml);\n }\n const domParser = new window.DOMParser();\n const createdDocument = domParser.parseFromString(unsafeHtml, 'text/html');\n const elements = [].concat(...createdDocument.body.querySelectorAll('*'));\n for (const element of elements) {\n const elementName = element.nodeName.toLowerCase();\n if (!Object.keys(allowList).includes(elementName)) {\n element.remove();\n continue;\n }\n const attributeList = [].concat(...element.attributes);\n const allowedAttributes = [].concat(allowList['*'] || [], allowList[elementName] || []);\n for (const attribute of attributeList) {\n if (!allowedAttribute(attribute, allowedAttributes)) {\n element.removeAttribute(attribute.nodeName);\n }\n }\n }\n return createdDocument.body.innerHTML;\n}\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap util/template-factory.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$5 = 'TemplateFactory';\nconst Default$4 = {\n allowList: DefaultAllowlist,\n content: {},\n // { selector : text , selector2 : text2 , }\n extraClass: '',\n html: false,\n sanitize: true,\n sanitizeFn: null,\n template: ''\n};\nconst DefaultType$4 = {\n allowList: 'object',\n content: 'object',\n extraClass: '(string|function)',\n html: 'boolean',\n sanitize: 'boolean',\n sanitizeFn: '(null|function)',\n template: 'string'\n};\nconst DefaultContentType = {\n entry: '(string|element|function|null)',\n selector: '(string|element)'\n};\n\n/**\n * Class definition\n */\n\nclass TemplateFactory extends Config {\n constructor(config) {\n super();\n this._config = this._getConfig(config);\n }\n\n // Getters\n static get Default() {\n return Default$4;\n }\n static get DefaultType() {\n return DefaultType$4;\n }\n static get NAME() {\n return NAME$5;\n }\n\n // Public\n getContent() {\n return Object.values(this._config.content).map(config => this._resolvePossibleFunction(config)).filter(Boolean);\n }\n hasContent() {\n return this.getContent().length > 0;\n }\n changeContent(content) {\n this._checkContent(content);\n this._config.content = {\n ...this._config.content,\n ...content\n };\n return this;\n }\n toHtml() {\n const templateWrapper = document.createElement('div');\n templateWrapper.innerHTML = this._maybeSanitize(this._config.template);\n for (const [selector, text] of Object.entries(this._config.content)) {\n this._setContent(templateWrapper, text, selector);\n }\n const template = templateWrapper.children[0];\n const extraClass = this._resolvePossibleFunction(this._config.extraClass);\n if (extraClass) {\n template.classList.add(...extraClass.split(' '));\n }\n return template;\n }\n\n // Private\n _typeCheckConfig(config) {\n super._typeCheckConfig(config);\n this._checkContent(config.content);\n }\n _checkContent(arg) {\n for (const [selector, content] of Object.entries(arg)) {\n super._typeCheckConfig({\n selector,\n entry: content\n }, DefaultContentType);\n }\n }\n _setContent(template, content, selector) {\n const templateElement = SelectorEngine.findOne(selector, template);\n if (!templateElement) {\n return;\n }\n content = this._resolvePossibleFunction(content);\n if (!content) {\n templateElement.remove();\n return;\n }\n if (isElement(content)) {\n this._putElementInTemplate(getElement(content), templateElement);\n return;\n }\n if (this._config.html) {\n templateElement.innerHTML = this._maybeSanitize(content);\n return;\n }\n templateElement.textContent = content;\n }\n _maybeSanitize(arg) {\n return this._config.sanitize ? sanitizeHtml(arg, this._config.allowList, this._config.sanitizeFn) : arg;\n }\n _resolvePossibleFunction(arg) {\n return execute(arg, [this]);\n }\n _putElementInTemplate(element, templateElement) {\n if (this._config.html) {\n templateElement.innerHTML = '';\n templateElement.append(element);\n return;\n }\n templateElement.textContent = element.textContent;\n }\n}\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap tooltip.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$4 = 'tooltip';\nconst DISALLOWED_ATTRIBUTES = new Set(['sanitize', 'allowList', 'sanitizeFn']);\nconst CLASS_NAME_FADE$2 = 'fade';\nconst CLASS_NAME_MODAL = 'modal';\nconst CLASS_NAME_SHOW$2 = 'show';\nconst SELECTOR_TOOLTIP_INNER = '.tooltip-inner';\nconst SELECTOR_MODAL = `.${CLASS_NAME_MODAL}`;\nconst EVENT_MODAL_HIDE = 'hide.bs.modal';\nconst TRIGGER_HOVER = 'hover';\nconst TRIGGER_FOCUS = 'focus';\nconst TRIGGER_CLICK = 'click';\nconst TRIGGER_MANUAL = 'manual';\nconst EVENT_HIDE$2 = 'hide';\nconst EVENT_HIDDEN$2 = 'hidden';\nconst EVENT_SHOW$2 = 'show';\nconst EVENT_SHOWN$2 = 'shown';\nconst EVENT_INSERTED = 'inserted';\nconst EVENT_CLICK$1 = 'click';\nconst EVENT_FOCUSIN$1 = 'focusin';\nconst EVENT_FOCUSOUT$1 = 'focusout';\nconst EVENT_MOUSEENTER = 'mouseenter';\nconst EVENT_MOUSELEAVE = 'mouseleave';\nconst AttachmentMap = {\n AUTO: 'auto',\n TOP: 'top',\n RIGHT: isRTL() ? 'left' : 'right',\n BOTTOM: 'bottom',\n LEFT: isRTL() ? 'right' : 'left'\n};\nconst Default$3 = {\n allowList: DefaultAllowlist,\n animation: true,\n boundary: 'clippingParents',\n container: false,\n customClass: '',\n delay: 0,\n fallbackPlacements: ['top', 'right', 'bottom', 'left'],\n html: false,\n offset: [0, 6],\n placement: 'top',\n popperConfig: null,\n sanitize: true,\n sanitizeFn: null,\n selector: false,\n template: '
' + '' + '' + '
',\n title: '',\n trigger: 'hover focus'\n};\nconst DefaultType$3 = {\n allowList: 'object',\n animation: 'boolean',\n boundary: '(string|element)',\n container: '(string|element|boolean)',\n customClass: '(string|function)',\n delay: '(number|object)',\n fallbackPlacements: 'array',\n html: 'boolean',\n offset: '(array|string|function)',\n placement: '(string|function)',\n popperConfig: '(null|object|function)',\n sanitize: 'boolean',\n sanitizeFn: '(null|function)',\n selector: '(string|boolean)',\n template: 'string',\n title: '(string|element|function)',\n trigger: 'string'\n};\n\n/**\n * Class definition\n */\n\nclass Tooltip extends BaseComponent {\n constructor(element, config) {\n if (typeof Popper === 'undefined') {\n throw new TypeError('Bootstrap\\'s tooltips require Popper (https://popper.js.org)');\n }\n super(element, config);\n\n // Private\n this._isEnabled = true;\n this._timeout = 0;\n this._isHovered = null;\n this._activeTrigger = {};\n this._popper = null;\n this._templateFactory = null;\n this._newContent = null;\n\n // Protected\n this.tip = null;\n this._setListeners();\n if (!this._config.selector) {\n this._fixTitle();\n }\n }\n\n // Getters\n static get Default() {\n return Default$3;\n }\n static get DefaultType() {\n return DefaultType$3;\n }\n static get NAME() {\n return NAME$4;\n }\n\n // Public\n enable() {\n this._isEnabled = true;\n }\n disable() {\n this._isEnabled = false;\n }\n toggleEnabled() {\n this._isEnabled = !this._isEnabled;\n }\n toggle() {\n if (!this._isEnabled) {\n return;\n }\n this._activeTrigger.click = !this._activeTrigger.click;\n if (this._isShown()) {\n this._leave();\n return;\n }\n this._enter();\n }\n dispose() {\n clearTimeout(this._timeout);\n EventHandler.off(this._element.closest(SELECTOR_MODAL), EVENT_MODAL_HIDE, this._hideModalHandler);\n if (this._element.getAttribute('data-bs-original-title')) {\n this._element.setAttribute('title', this._element.getAttribute('data-bs-original-title'));\n }\n this._disposePopper();\n super.dispose();\n }\n show() {\n if (this._element.style.display === 'none') {\n throw new Error('Please use show on visible elements');\n }\n if (!(this._isWithContent() && this._isEnabled)) {\n return;\n }\n const showEvent = EventHandler.trigger(this._element, this.constructor.eventName(EVENT_SHOW$2));\n const shadowRoot = findShadowRoot(this._element);\n const isInTheDom = (shadowRoot || this._element.ownerDocument.documentElement).contains(this._element);\n if (showEvent.defaultPrevented || !isInTheDom) {\n return;\n }\n\n // TODO: v6 remove this or make it optional\n this._disposePopper();\n const tip = this._getTipElement();\n this._element.setAttribute('aria-describedby', tip.getAttribute('id'));\n const {\n container\n } = this._config;\n if (!this._element.ownerDocument.documentElement.contains(this.tip)) {\n container.append(tip);\n EventHandler.trigger(this._element, this.constructor.eventName(EVENT_INSERTED));\n }\n this._popper = this._createPopper(tip);\n tip.classList.add(CLASS_NAME_SHOW$2);\n\n // If this is a touch-enabled device we add extra\n // empty mouseover listeners to the body's immediate children;\n // only needed because of broken event delegation on iOS\n // https://www.quirksmode.org/blog/archives/2014/02/mouse_event_bub.html\n if ('ontouchstart' in document.documentElement) {\n for (const element of [].concat(...document.body.children)) {\n EventHandler.on(element, 'mouseover', noop);\n }\n }\n const complete = () => {\n EventHandler.trigger(this._element, this.constructor.eventName(EVENT_SHOWN$2));\n if (this._isHovered === false) {\n this._leave();\n }\n this._isHovered = false;\n };\n this._queueCallback(complete, this.tip, this._isAnimated());\n }\n hide() {\n if (!this._isShown()) {\n return;\n }\n const hideEvent = EventHandler.trigger(this._element, this.constructor.eventName(EVENT_HIDE$2));\n if (hideEvent.defaultPrevented) {\n return;\n }\n const tip = this._getTipElement();\n tip.classList.remove(CLASS_NAME_SHOW$2);\n\n // If this is a touch-enabled device we remove the extra\n // empty mouseover listeners we added for iOS support\n if ('ontouchstart' in document.documentElement) {\n for (const element of [].concat(...document.body.children)) {\n EventHandler.off(element, 'mouseover', noop);\n }\n }\n this._activeTrigger[TRIGGER_CLICK] = false;\n this._activeTrigger[TRIGGER_FOCUS] = false;\n this._activeTrigger[TRIGGER_HOVER] = false;\n this._isHovered = null; // it is a trick to support manual triggering\n\n const complete = () => {\n if (this._isWithActiveTrigger()) {\n return;\n }\n if (!this._isHovered) {\n this._disposePopper();\n }\n this._element.removeAttribute('aria-describedby');\n EventHandler.trigger(this._element, this.constructor.eventName(EVENT_HIDDEN$2));\n };\n this._queueCallback(complete, this.tip, this._isAnimated());\n }\n update() {\n if (this._popper) {\n this._popper.update();\n }\n }\n\n // Protected\n _isWithContent() {\n return Boolean(this._getTitle());\n }\n _getTipElement() {\n if (!this.tip) {\n this.tip = this._createTipElement(this._newContent || this._getContentForTemplate());\n }\n return this.tip;\n }\n _createTipElement(content) {\n const tip = this._getTemplateFactory(content).toHtml();\n\n // TODO: remove this check in v6\n if (!tip) {\n return null;\n }\n tip.classList.remove(CLASS_NAME_FADE$2, CLASS_NAME_SHOW$2);\n // TODO: v6 the following can be achieved with CSS only\n tip.classList.add(`bs-${this.constructor.NAME}-auto`);\n const tipId = getUID(this.constructor.NAME).toString();\n tip.setAttribute('id', tipId);\n if (this._isAnimated()) {\n tip.classList.add(CLASS_NAME_FADE$2);\n }\n return tip;\n }\n setContent(content) {\n this._newContent = content;\n if (this._isShown()) {\n this._disposePopper();\n this.show();\n }\n }\n _getTemplateFactory(content) {\n if (this._templateFactory) {\n this._templateFactory.changeContent(content);\n } else {\n this._templateFactory = new TemplateFactory({\n ...this._config,\n // the `content` var has to be after `this._config`\n // to override config.content in case of popover\n content,\n extraClass: this._resolvePossibleFunction(this._config.customClass)\n });\n }\n return this._templateFactory;\n }\n _getContentForTemplate() {\n return {\n [SELECTOR_TOOLTIP_INNER]: this._getTitle()\n };\n }\n _getTitle() {\n return this._resolvePossibleFunction(this._config.title) || this._element.getAttribute('data-bs-original-title');\n }\n\n // Private\n _initializeOnDelegatedTarget(event) {\n return this.constructor.getOrCreateInstance(event.delegateTarget, this._getDelegateConfig());\n }\n _isAnimated() {\n return this._config.animation || this.tip && this.tip.classList.contains(CLASS_NAME_FADE$2);\n }\n _isShown() {\n return this.tip && this.tip.classList.contains(CLASS_NAME_SHOW$2);\n }\n _createPopper(tip) {\n const placement = execute(this._config.placement, [this, tip, this._element]);\n const attachment = AttachmentMap[placement.toUpperCase()];\n return Popper.createPopper(this._element, tip, this._getPopperConfig(attachment));\n }\n _getOffset() {\n const {\n offset\n } = this._config;\n if (typeof offset === 'string') {\n return offset.split(',').map(value => Number.parseInt(value, 10));\n }\n if (typeof offset === 'function') {\n return popperData => offset(popperData, this._element);\n }\n return offset;\n }\n _resolvePossibleFunction(arg) {\n return execute(arg, [this._element]);\n }\n _getPopperConfig(attachment) {\n const defaultBsPopperConfig = {\n placement: attachment,\n modifiers: [{\n name: 'flip',\n options: {\n fallbackPlacements: this._config.fallbackPlacements\n }\n }, {\n name: 'offset',\n options: {\n offset: this._getOffset()\n }\n }, {\n name: 'preventOverflow',\n options: {\n boundary: this._config.boundary\n }\n }, {\n name: 'arrow',\n options: {\n element: `.${this.constructor.NAME}-arrow`\n }\n }, {\n name: 'preSetPlacement',\n enabled: true,\n phase: 'beforeMain',\n fn: data => {\n // Pre-set Popper's placement attribute in order to read the arrow sizes properly.\n // Otherwise, Popper mixes up the width and height dimensions since the initial arrow style is for top placement\n this._getTipElement().setAttribute('data-popper-placement', data.state.placement);\n }\n }]\n };\n return {\n ...defaultBsPopperConfig,\n ...execute(this._config.popperConfig, [defaultBsPopperConfig])\n };\n }\n _setListeners() {\n const triggers = this._config.trigger.split(' ');\n for (const trigger of triggers) {\n if (trigger === 'click') {\n EventHandler.on(this._element, this.constructor.eventName(EVENT_CLICK$1), this._config.selector, event => {\n const context = this._initializeOnDelegatedTarget(event);\n context.toggle();\n });\n } else if (trigger !== TRIGGER_MANUAL) {\n const eventIn = trigger === TRIGGER_HOVER ? this.constructor.eventName(EVENT_MOUSEENTER) : this.constructor.eventName(EVENT_FOCUSIN$1);\n const eventOut = trigger === TRIGGER_HOVER ? this.constructor.eventName(EVENT_MOUSELEAVE) : this.constructor.eventName(EVENT_FOCUSOUT$1);\n EventHandler.on(this._element, eventIn, this._config.selector, event => {\n const context = this._initializeOnDelegatedTarget(event);\n context._activeTrigger[event.type === 'focusin' ? TRIGGER_FOCUS : TRIGGER_HOVER] = true;\n context._enter();\n });\n EventHandler.on(this._element, eventOut, this._config.selector, event => {\n const context = this._initializeOnDelegatedTarget(event);\n context._activeTrigger[event.type === 'focusout' ? TRIGGER_FOCUS : TRIGGER_HOVER] = context._element.contains(event.relatedTarget);\n context._leave();\n });\n }\n }\n this._hideModalHandler = () => {\n if (this._element) {\n this.hide();\n }\n };\n EventHandler.on(this._element.closest(SELECTOR_MODAL), EVENT_MODAL_HIDE, this._hideModalHandler);\n }\n _fixTitle() {\n const title = this._element.getAttribute('title');\n if (!title) {\n return;\n }\n if (!this._element.getAttribute('aria-label') && !this._element.textContent.trim()) {\n this._element.setAttribute('aria-label', title);\n }\n this._element.setAttribute('data-bs-original-title', title); // DO NOT USE IT. Is only for backwards compatibility\n this._element.removeAttribute('title');\n }\n _enter() {\n if (this._isShown() || this._isHovered) {\n this._isHovered = true;\n return;\n }\n this._isHovered = true;\n this._setTimeout(() => {\n if (this._isHovered) {\n this.show();\n }\n }, this._config.delay.show);\n }\n _leave() {\n if (this._isWithActiveTrigger()) {\n return;\n }\n this._isHovered = false;\n this._setTimeout(() => {\n if (!this._isHovered) {\n this.hide();\n }\n }, this._config.delay.hide);\n }\n _setTimeout(handler, timeout) {\n clearTimeout(this._timeout);\n this._timeout = setTimeout(handler, timeout);\n }\n _isWithActiveTrigger() {\n return Object.values(this._activeTrigger).includes(true);\n }\n _getConfig(config) {\n const dataAttributes = Manipulator.getDataAttributes(this._element);\n for (const dataAttribute of Object.keys(dataAttributes)) {\n if (DISALLOWED_ATTRIBUTES.has(dataAttribute)) {\n delete dataAttributes[dataAttribute];\n }\n }\n config = {\n ...dataAttributes,\n ...(typeof config === 'object' && config ? config : {})\n };\n config = this._mergeConfigObj(config);\n config = this._configAfterMerge(config);\n this._typeCheckConfig(config);\n return config;\n }\n _configAfterMerge(config) {\n config.container = config.container === false ? document.body : getElement(config.container);\n if (typeof config.delay === 'number') {\n config.delay = {\n show: config.delay,\n hide: config.delay\n };\n }\n if (typeof config.title === 'number') {\n config.title = config.title.toString();\n }\n if (typeof config.content === 'number') {\n config.content = config.content.toString();\n }\n return config;\n }\n _getDelegateConfig() {\n const config = {};\n for (const [key, value] of Object.entries(this._config)) {\n if (this.constructor.Default[key] !== value) {\n config[key] = value;\n }\n }\n config.selector = false;\n config.trigger = 'manual';\n\n // In the future can be replaced with:\n // const keysWithDifferentValues = Object.entries(this._config).filter(entry => this.constructor.Default[entry[0]] !== this._config[entry[0]])\n // `Object.fromEntries(keysWithDifferentValues)`\n return config;\n }\n _disposePopper() {\n if (this._popper) {\n this._popper.destroy();\n this._popper = null;\n }\n if (this.tip) {\n this.tip.remove();\n this.tip = null;\n }\n }\n\n // Static\n static jQueryInterface(config) {\n return this.each(function () {\n const data = Tooltip.getOrCreateInstance(this, config);\n if (typeof config !== 'string') {\n return;\n }\n if (typeof data[config] === 'undefined') {\n throw new TypeError(`No method named \"${config}\"`);\n }\n data[config]();\n });\n }\n}\n\n/**\n * jQuery\n */\n\ndefineJQueryPlugin(Tooltip);\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap popover.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$3 = 'popover';\nconst SELECTOR_TITLE = '.popover-header';\nconst SELECTOR_CONTENT = '.popover-body';\nconst Default$2 = {\n ...Tooltip.Default,\n content: '',\n offset: [0, 8],\n placement: 'right',\n template: '' + '' + '' + '' + '
',\n trigger: 'click'\n};\nconst DefaultType$2 = {\n ...Tooltip.DefaultType,\n content: '(null|string|element|function)'\n};\n\n/**\n * Class definition\n */\n\nclass Popover extends Tooltip {\n // Getters\n static get Default() {\n return Default$2;\n }\n static get DefaultType() {\n return DefaultType$2;\n }\n static get NAME() {\n return NAME$3;\n }\n\n // Overrides\n _isWithContent() {\n return this._getTitle() || this._getContent();\n }\n\n // Private\n _getContentForTemplate() {\n return {\n [SELECTOR_TITLE]: this._getTitle(),\n [SELECTOR_CONTENT]: this._getContent()\n };\n }\n _getContent() {\n return this._resolvePossibleFunction(this._config.content);\n }\n\n // Static\n static jQueryInterface(config) {\n return this.each(function () {\n const data = Popover.getOrCreateInstance(this, config);\n if (typeof config !== 'string') {\n return;\n }\n if (typeof data[config] === 'undefined') {\n throw new TypeError(`No method named \"${config}\"`);\n }\n data[config]();\n });\n }\n}\n\n/**\n * jQuery\n */\n\ndefineJQueryPlugin(Popover);\n\n/**\n * --------------------------------------------------------------------------\n * Bootstrap scrollspy.js\n * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)\n * --------------------------------------------------------------------------\n */\n\n\n/**\n * Constants\n */\n\nconst NAME$2 = 'scrollspy';\nconst DATA_KEY$2 = 'bs.scrollspy';\nconst EVENT_KEY$2 = `.${DATA_KEY$2}`;\nconst DATA_API_KEY = '.data-api';\nconst EVENT_ACTIVATE = `activate${EVENT_KEY$2}`;\nconst EVENT_CLICK = `click${EVENT_KEY$2}`;\nconst EVENT_LOAD_DATA_API$1 = `load${EVENT_KEY$2}${DATA_API_KEY}`;\nconst CLASS_NAME_DROPDOWN_ITEM = 'dropdown-item';\nconst CLASS_NAME_ACTIVE$1 = 'active';\nconst SELECTOR_DATA_SPY = '[data-bs-spy=\"scroll\"]';\nconst SELECTOR_TARGET_LINKS = '[href]';\nconst SELECTOR_NAV_LIST_GROUP = '.nav, .list-group';\nconst SELECTOR_NAV_LINKS = '.nav-link';\nconst SELECTOR_NAV_ITEMS = '.nav-item';\nconst SELECTOR_LIST_ITEMS = '.list-group-item';\nconst SELECTOR_LINK_ITEMS = `${SELECTOR_NAV_LINKS}, ${SELECTOR_NAV_ITEMS} > ${SELECTOR_NAV_LINKS}, ${SELECTOR_LIST_ITEMS}`;\nconst SELECTOR_DROPDOWN = '.dropdown';\nconst SELECTOR_DROPDOWN_TOGGLE$1 = '.dropdown-toggle';\nconst Default$1 = {\n offset: null,\n // TODO: v6 @deprecated, keep it for backwards compatibility reasons\n rootMargin: '0px 0px -25%',\n smoothScroll: false,\n target: null,\n threshold: [0.1, 0.5, 1]\n};\nconst DefaultType$1 = {\n offset: '(number|null)',\n // TODO v6 @deprecated, keep it for backwards compatibility reasons\n rootMargin: 'string',\n smoothScroll: 'boolean',\n target: 'element',\n threshold: 'array'\n};\n\n/**\n * Class definition\n */\n\nclass ScrollSpy extends BaseComponent {\n constructor(element, config) {\n super(element, config);\n\n // this._element is the observablesContainer and config.target the menu links wrapper\n this._targetLinks = new Map();\n this._observableSections = new Map();\n this._rootElement = getComputedStyle(this._element).overflowY === 'visible' ? null : this._element;\n this._activeTarget = null;\n this._observer = null;\n this._previousScrollData = {\n visibleEntryTop: 0,\n parentScrollTop: 0\n };\n this.refresh(); // initialize\n }\n\n // Getters\n static get Default() {\n return Default$1;\n }\n static get DefaultType() {\n return DefaultType$1;\n }\n static get NAME() {\n return NAME$2;\n }\n\n // Public\n refresh() {\n this._initializeTargetsAndObservables();\n this._maybeEnableSmoothScroll();\n if (this._observer) {\n this._observer.disconnect();\n } else {\n this._observer = this._getNewObserver();\n }\n for (const section of this._observableSections.values()) {\n this._observer.observe(section);\n }\n }\n dispose() {\n this._observer.disconnect();\n super.dispose();\n }\n\n // Private\n _configAfterMerge(config) {\n // TODO: on v6 target should be given explicitly & remove the {target: 'ss-target'} case\n config.target = getElement(config.target) || document.body;\n\n // TODO: v6 Only for backwards compatibility reasons. Use rootMargin only\n config.rootMargin = config.offset ? `${config.offset}px 0px -30%` : config.rootMargin;\n if (typeof config.threshold === 'string') {\n config.threshold = config.threshold.split(',').map(value => Number.parseFloat(value));\n }\n return config;\n }\n _maybeEnableSmoothScroll() {\n if (!this._config.smoothScroll) {\n return;\n }\n\n // unregister any previous listeners\n EventHandler.off(this._config.target, EVENT_CLICK);\n EventHandler.on(this._config.target, EVENT_CLICK, SELECTOR_TARGET_LINKS, event => {\n const observableSection = this._observableSections.get(event.target.hash);\n if (observableSection) {\n event.preventDefault();\n const root = this._rootElement || window;\n const height = observableSection.offsetTop - this._element.offsetTop;\n if (root.scrollTo) {\n root.scrollTo({\n top: height,\n behavior: 'smooth'\n });\n return;\n }\n\n // Chrome 60 doesn't support `scrollTo`\n root.scrollTop = height;\n }\n });\n }\n _getNewObserver() {\n const options = {\n root: this._rootElement,\n threshold: this._config.threshold,\n rootMargin: this._config.rootMargin\n };\n return new IntersectionObserver(entries => this._observerCallback(entries), options);\n }\n\n // The logic of selection\n _observerCallback(entries) {\n const targetElement = entry => this._targetLinks.get(`#${entry.target.id}`);\n const activate = entry => {\n this._previousScrollData.visibleEntryTop = entry.target.offsetTop;\n this._process(targetElement(entry));\n };\n const parentScrollTop = (this._rootElement || document.documentElement).scrollTop;\n const userScrollsDown = parentScrollTop >= this._previousScrollData.parentScrollTop;\n this._previousScrollData.parentScrollTop = parentScrollTop;\n for (const entry of entries) {\n if (!entry.isIntersecting) {\n this._activeTarget = null;\n this._clearActiveClass(targetElement(entry));\n continue;\n }\n const entryIsLowerThanPrevious = entry.target.offsetTop >= this._previousScrollData.visibleEntryTop;\n // if we are scrolling down, pick the bigger offsetTop\n if (userScrollsDown && entryIsLowerThanPrevious) {\n activate(entry);\n // if parent isn't scrolled, let's keep the first visible item, breaking the iteration\n if (!parentScrollTop) {\n return;\n }\n continue;\n }\n\n // if we are scrolling up, pick the smallest offsetTop\n if (!userScrollsDown && !entryIsLowerThanPrevious) {\n activate(entry);\n }\n }\n }\n _initializeTargetsAndObservables() {\n this._targetLinks = new Map();\n this._observableSections = new Map();\n const targetLinks = SelectorEngine.find(SELECTOR_TARGET_LINKS, this._config.target);\n for (const anchor of targetLinks) {\n // ensure that the anchor has an id and is not disabled\n if (!anchor.hash || isDisabled(anchor)) {\n continue;\n }\n const observableSection = SelectorEngine.findOne(decodeURI(anchor.hash), this._element);\n\n // ensure that the observableSection exists & is visible\n if (isVisible(observableSection)) {\n this._targetLinks.set(decodeURI(anchor.hash), anchor);\n this._observableSections.set(anchor.hash, observableSection);\n }\n }\n }\n _process(target) {\n if (this._activeTarget === target) {\n return;\n }\n this._clearActiveClass(this._config.target);\n this._activeTarget = target;\n target.classList.add(CLASS_NAME_ACTIVE$1);\n this._activateParents(target);\n EventHandler.trigger(this._element, EVENT_ACTIVATE, {\n relatedTarget: target\n });\n }\n _activateParents(target) {\n // Activate dropdown parents\n if (target.classList.contains(CLASS_NAME_DROPDOWN_ITEM)) {\n SelectorEngine.findOne(SELECTOR_DROPDOWN_TOGGLE$1, target.closest(SELECTOR_DROPDOWN)).classList.add(CLASS_NAME_ACTIVE$1);\n return;\n }\n for (const listGroup of SelectorEngine.parents(target, SELECTOR_NAV_LIST_GROUP)) {\n // Set triggered links parents as active\n // With both - and