Historia
Jupyter surge en 2014 como una evolución del proyecto IPython, una potente consola vitaminada para Python. Sin embargo, Jupyter es mucho más ambicioso que IPython, se pretende construir una plataforma agnóstica del lenguaje que ofrezca a los científicos un conjunto de potentes herramientas para trabajar con datos, visualizarlos y poder compartir los resultados.
El origen de su nombre es un homenaje a Galileo, al que se considera autor del primer “paper” científico de astronomía de la era moderna en 1610, en el cual describe sus observaciones astronómicas a través de un telescopio de las lunas de Júpiter. Galileo demostró que la Tierra orbita el Sol de la misma manera que las lunas de Júpiter orbitan dicho planeta.

El proyecto fue iniciado por Fernando Pérez, un científico y profesor de la Universidad de California Berkeley. Sin embargo, el proyecto es software libre y está basado en componentes libres, por lo que está apoyado, desarrollado y mantenido por una amplia comunidad.
La adopción y el éxito de Jupyter ha sido muy grande, de tal modo que se está convirtiendo en un standard para el trabajo de los científicos de datos. Hoy en día la herramienta está integrada algunas de las plataformas y entornos más importantes y extendidas como Google Cloud,Microsoft Azure, AWS, IBM Bluemix, Databricks Platform, GitHub, Rackspace, Continuum,Jetbrains.
Jupyter nos ofrece una shell interactiva vía web, a la que podemos acceder desde un navegador. La shell está organizada en pequeños bloques, cada bloque puede contener texto arbitrario formateado en Markdown, fórmulas matemáticas en LaTeX, código en multitud de lenguajes, resultados, gráficos, vídeos, widgets o cualquier elemento multimedia.
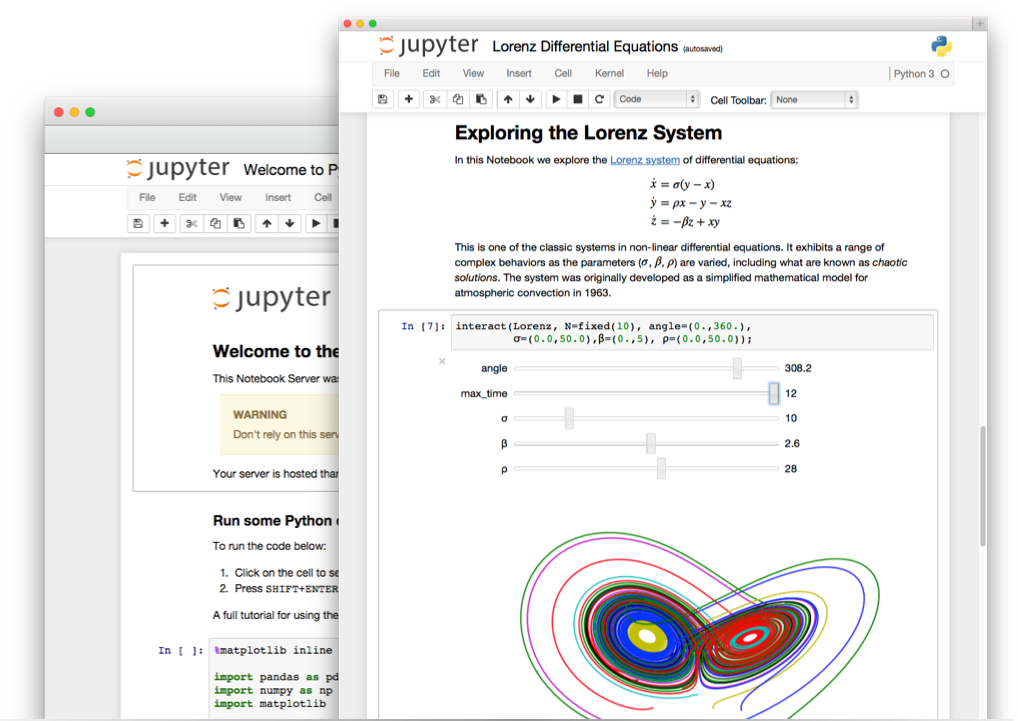
Podemos escribir código de programación en estas celdas e ir ejecutándolo paso a paso o todo de golpe, obteniendo todos los resultados parciales. También podemos usar los bloques de texto para documentar el código o añadir las explicaciones oportunas, que pueden contener enlaces, imágenes, vídeos u otros elementos.
Esta serie de piezas de código, notas y resultados se guardan en un notebook, que es un fichero que contiene toda esta información. Uno de los principales objetivos de Jupyter es fomentar y simplificar la compartición de conocimiento y resultados a través de los notebooks. Plataformas como GitHub o Databricks Community Edition facilitan esta tarea. De esta manera los notebooks pueden ser fácilmente difundidos y los resultados pueden ser reproducidos y validados en diferentes entornos. Por supuesto esto es muy útil para la divulgación y la formación o en entornos educativos.
Jupyter soporta integración con más de 40 lenguajes de programación en los que podemos escribir el código de nuestro notebooks, por ejemplo Python, R, Scala, Ruby o Go. Pero también es fácilmente integrable con herramientas y plataformas de Big Data como Spark, lo que permite abstraerse de la complejidad de estas herramientas, aprovechando todo su potencial desde un entorno muy amigable.
Una forma muy sencilla de probar Jupyter es a través de Try Jupyter!, una página hospedada por Rackspace que nos ofrece una instancia de prueba donde podemos ejecutar algunos notebooks de ejemplo o escribir los nuestros propios.
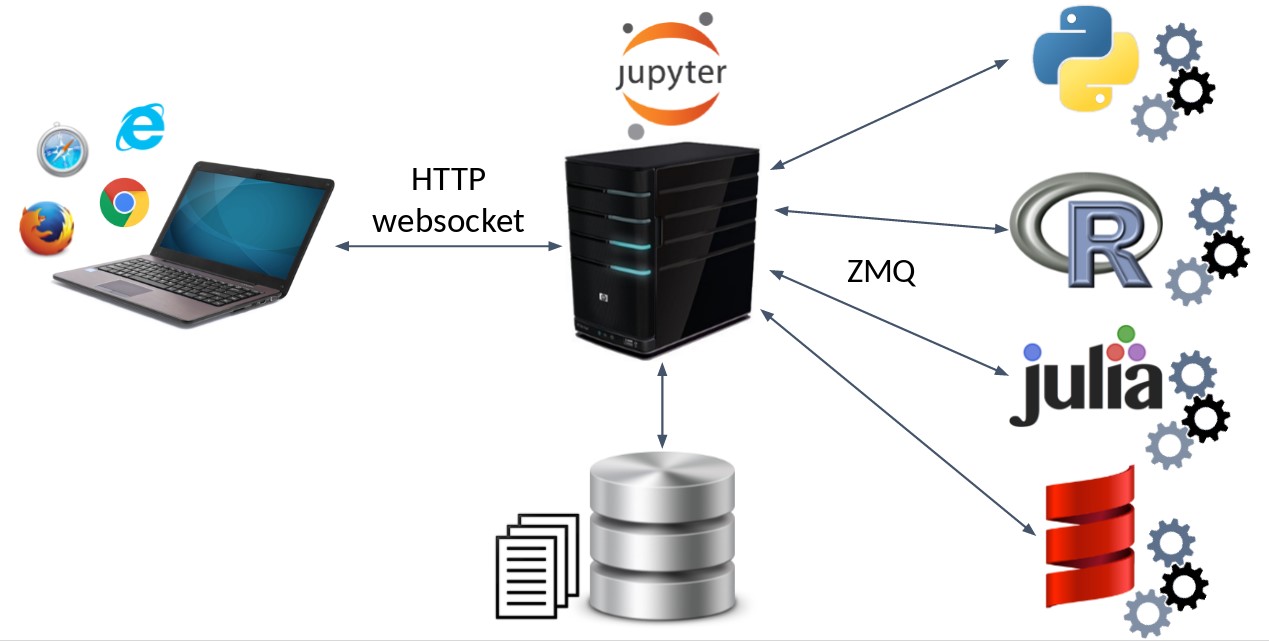
¿Cómo funciona internamente Jupyter? Usa un sistema basado en Kernel. Cada Kernel es un motor de ejecución para un lenguaje o plataforma concreta que ejecuta en el servidor. A través de un sistema de colas basado en ZMQ el código que necesita ser ejecutado es enviado al Kernel correspondiente.
Por otro lado, el navegador se comunica con el servidor a través de Websockets para optimizar el tráfico y mejorar la experiencia de usuario en el entorno de trabajo. Los notebooks son persistidos en disco para guardar todos nuestros cambios y resultados.
Podemos ejecutar Jupyter localmente en nuestro sistema. Instalarlo es tan fácil como instalarAnaconda, la plataforma abierta para data science basada en Python, o directamente con la herramienta de instalación de paquetes de Python, Pip: $ pip3 install jupyter
También podemos usarlo remotamente conectándonos a un servidor donde esté instalado. Para simplificar este tipo de despliegues tenemos JupyterHub, una extensión orientada a entornos de trabajo compartido donde múltiples usuarios se quieran conectar al mismo servidor.
El desarrollo y la evolución de Jupyter están más vivos que nunca. En la SciPy 2016, conferencia sobre Python aplicado al mundo científico, se anunciaron algunas de las nuevas características de la siguiente generación que será conocida como JupyterLab.
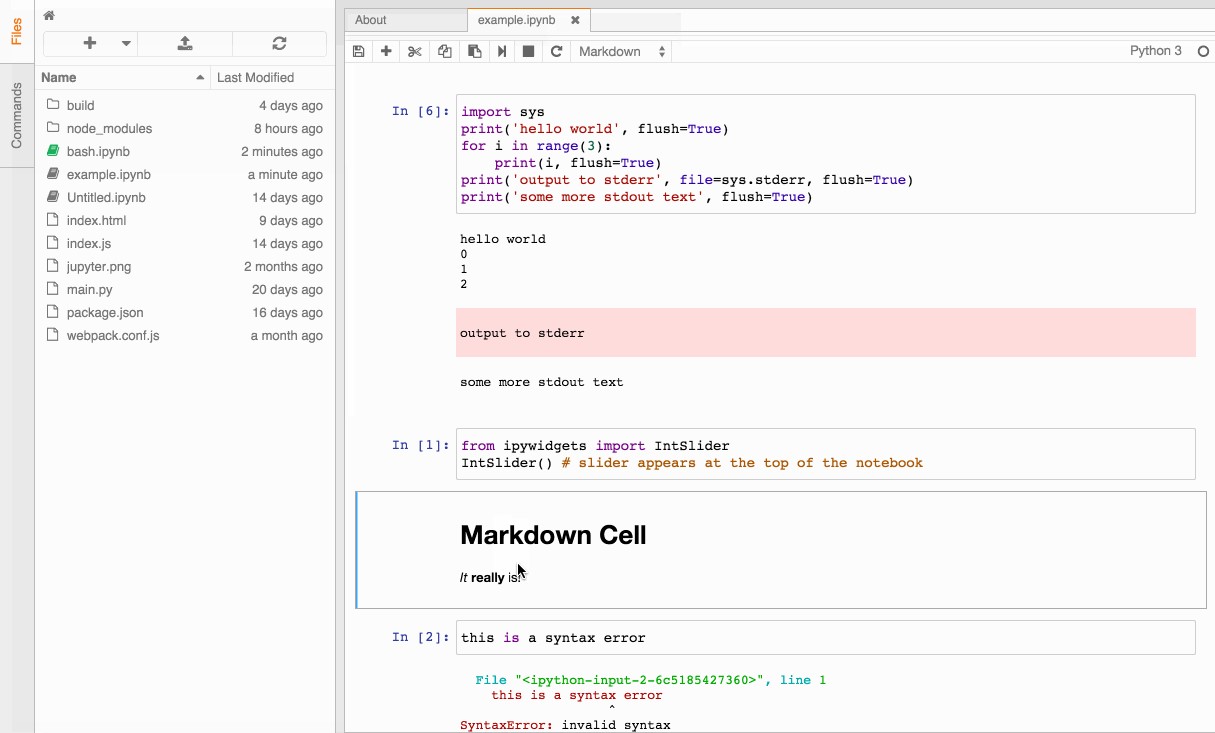
En esta versión se han incluido notables mejoras en la interfaz, ofreciéndonos un entorno más limpio, rico y flexible basado en widgets drag&drop. También nos ofrece una mejor integración con la shell del sistema, lo que nos simplifica labores como la monitorización.
Jupyter es una herramienta libre fantástica que se está convirtiendo en el standard en el mundo del análisis de datos. La comunidad que lo impulsa es muy activa y heterogénea, lo que está enriqueciendo el desarrollo y la integración con otras herramientas y plataformas.
Su impacto está siendo tan importante que hasta la prestigiosa revista científica Nature le ha dedicado un artículo que incluye una interesante demo interactiva y describe todas las ventajas de utilizar Jupyter en el mundo del análisis de datos científicos.