"
+ ]
+ },
+ "metadata": {
+ "tags": []
+ },
+ "execution_count": 39
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "57oNBLV1j0wc",
+ "colab_type": "text"
+ },
+ "source": [
+ "The only thing to explain here is the **steps** argument. This simply tells the classifier to run for 5000 steps. Try modifiying this and seeing if your results change. Keep in mind that more is not always better."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5suI1lmskE7p",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Evaluation\n",
+ "Now let's see how this trained model does!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "23rIrgbxkJUO",
+ "colab_type": "code",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 381
+ },
+ "outputId": "24767659-81cb-436f-a3c5-3fb19fcf53b2"
+ },
+ "source": [
+ "eval_result = classifier.evaluate(\n",
+ " input_fn=lambda: input_fn(test, test_y, training=False))\n",
+ "\n",
+ "print('\\nTest set accuracy: {accuracy:0.3f}\\n'.format(**eval_result))"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "INFO:tensorflow:Calling model_fn.\n",
+ "WARNING:tensorflow:Layer dnn is casting an input tensor from dtype float64 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because it's dtype defaults to floatx.\n",
+ "\n",
+ "If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2.\n",
+ "\n",
+ "To change all layers to have dtype float64 by default, call `tf.keras.backend.set_floatx('float64')`. To change just this layer, pass dtype='float64' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.\n",
+ "\n",
+ "INFO:tensorflow:Done calling model_fn.\n",
+ "INFO:tensorflow:Starting evaluation at 2020-06-19T18:22:07Z\n",
+ "INFO:tensorflow:Graph was finalized.\n",
+ "INFO:tensorflow:Restoring parameters from /tmp/tmpqaqtrlgy/model.ckpt-5000\n",
+ "INFO:tensorflow:Running local_init_op.\n",
+ "INFO:tensorflow:Done running local_init_op.\n",
+ "INFO:tensorflow:Inference Time : 0.20221s\n",
+ "INFO:tensorflow:Finished evaluation at 2020-06-19-18:22:08\n",
+ "INFO:tensorflow:Saving dict for global step 5000: accuracy = 0.93333334, average_loss = 0.41360682, global_step = 5000, loss = 0.41360682\n",
+ "INFO:tensorflow:Saving 'checkpoint_path' summary for global step 5000: /tmp/tmpqaqtrlgy/model.ckpt-5000\n",
+ "\n",
+ "Test set accuracy: 0.933\n",
+ "\n"
+ ],
+ "name": "stdout"
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4v1ZMe7jkXdp",
+ "colab_type": "text"
+ },
+ "source": [
+ "Notice this time we didn't specify the number of steps. This is because during evaluation the model will only look at the testing data one time."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "464HkZ6lknua",
+ "colab_type": "text"
+ },
+ "source": [
+ "### Predictions\n",
+ "Now that we have a trained model it's time to use it to make predictions. I've written a little script below that allows you to type the features of a flower and see a prediction for its class."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "bQRLq4M1k1jm",
+ "colab_type": "code",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 344
+ },
+ "outputId": "f720852e-66e9-448e-bddf-ce33ce98cc61"
+ },
+ "source": [
+ "def input_fn(features, batch_size=256):\n",
+ " # Convert the inputs to a Dataset without labels.\n",
+ " return tf.data.Dataset.from_tensor_slices(dict(features)).batch(batch_size)\n",
+ "\n",
+ "features = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth']\n",
+ "predict = {}\n",
+ "\n",
+ "print(\"Please type numeric values as prompted.\")\n",
+ "for feature in features:\n",
+ " valid = True\n",
+ " while valid: \n",
+ " val = input(feature + \": \")\n",
+ " if not val.isdigit(): valid = False\n",
+ "\n",
+ " predict[feature] = [float(val)]\n",
+ "\n",
+ "predictions = classifier.predict(input_fn=lambda: input_fn(predict))\n",
+ "for pred_dict in predictions:\n",
+ " class_id = pred_dict['class_ids'][0]\n",
+ " probability = pred_dict['probabilities'][class_id]\n",
+ "\n",
+ " print('Prediction is \"{}\" ({:.1f}%)'.format(\n",
+ " SPECIES[class_id], 100 * probability))\n"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "Please type numeric values as prompted.\n",
+ "SepalLength: 23\n",
+ "SepalLength: 12\n",
+ "SepalLength: 12\n",
+ "SepalLength: 3\n",
+ "SepalLength: 4\n",
+ "SepalLength: 2\n",
+ "SepalLength: 0.5\n",
+ "SepalWidth: 2\n",
+ "SepalWidth: 0.4\n",
+ "PetalLength: 0.5\n",
+ "PetalWidth: 0.3\n",
+ "INFO:tensorflow:Calling model_fn.\n",
+ "INFO:tensorflow:Done calling model_fn.\n",
+ "INFO:tensorflow:Graph was finalized.\n",
+ "INFO:tensorflow:Restoring parameters from /tmp/tmpqaqtrlgy/model.ckpt-5000\n",
+ "INFO:tensorflow:Running local_init_op.\n",
+ "INFO:tensorflow:Done running local_init_op.\n",
+ "Prediction is \"Setosa\" (38.2%)\n"
+ ],
+ "name": "stdout"
+ }
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "-tRxhpmSr1FH",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# Here is some example input and expected classes you can try above\n",
+ "expected = ['Setosa', 'Versicolor', 'Virginica']\n",
+ "predict_x = {\n",
+ " 'SepalLength': [5.1, 5.9, 6.9],\n",
+ " 'SepalWidth': [3.3, 3.0, 3.1],\n",
+ " 'PetalLength': [1.7, 4.2, 5.4],\n",
+ " 'PetalWidth': [0.5, 1.5, 2.1],\n",
+ "}"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ujwvc6ASsHID",
+ "colab_type": "text"
+ },
+ "source": [
+ "And that's pretty much it for classification! "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "d0dfaT4esRh3",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Clustering\n",
+ "Now that we've covered regression and classification it's time to talk about clustering data! \n",
+ "\n",
+ "Clustering is a Machine Learning technique that involves the grouping of data points. In theory, data points that are in the same group should have similar properties and/or features, while data points in different groups should have highly dissimilar properties and/or features. (https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68)\n",
+ "\n",
+ "Unfortunalty there are issues with the current version of TensorFlow and the implementation for KMeans. This means we cannot use KMeans without writing the algorithm from scratch. We aren't quite at that level yet, so we'll just explain the basics of clustering for now.\n",
+ "\n",
+ "####Basic Algorithm for K-Means.\n",
+ "- Step 1: Randomly pick K points to place K centroids\n",
+ "- Step 2: Assign all the data points to the centroids by distance. The closest centroid to a point is the one it is assigned to.\n",
+ "- Step 3: Average all the points belonging to each centroid to find the middle of those clusters (center of mass). Place the corresponding centroids into that position.\n",
+ "- Step 4: Reassign every point once again to the closest centroid.\n",
+ "- Step 5: Repeat steps 3-4 until no point changes which centroid it belongs to.\n",
+ "\n",
+ "*Please refer to the video for an explanation of KMeans clustering.*"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "sQ9iJrSbBTZB",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Hidden Markov Models\n",
+ "\n",
+ "\"The Hidden Markov Model is a finite set of states, each of which is associated with a (generally multidimensional) probability distribution []. Transitions among the states are governed by a set of probabilities called transition probabilities.\" (http://jedlik.phy.bme.hu/~gerjanos/HMM/node4.html)\n",
+ "\n",
+ "A hidden markov model works with probabilities to predict future events or states. In this section we will learn how to create a hidden markov model that can predict the weather.\n",
+ "\n",
+ "*This section is based on the following TensorFlow tutorial.* https://www.tensorflow.org/probability/api_docs/python/tfp/distributions/HiddenMarkovModel"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "RKJSFk4NP0eq",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Data\n",
+ "Let's start by discussing the type of data we use when we work with a hidden markov model. \n",
+ "\n",
+ "In the previous sections we worked with large datasets of 100's of different entries. For a markov model we are only interested in probability distributions that have to do with states. \n",
+ "\n",
+ "We can find these probabilities from large datasets or may already have these values. We'll run through an example in a second that should clear some things up, but let's discuss the components of a markov model.\n",
+ "\n",
+ "**States:** In each markov model we have a finite set of states. These states could be something like \"warm\" and \"cold\" or \"high\" and \"low\" or even \"red\", \"green\" and \"blue\". These states are \"hidden\" within the model, which means we do not direcly observe them.\n",
+ "\n",
+ "**Observations:** Each state has a particular outcome or observation associated with it based on a probability distribution. An example of this is the following: *On a hot day Tim has a 80% chance of being happy and a 20% chance of being sad.*\n",
+ "\n",
+ "**Transitions:** Each state will have a probability defining the likelyhood of transitioning to a different state. An example is the following: *a cold day has a 30% chance of being followed by a hot day and a 70% chance of being follwed by another cold day.*\n",
+ "\n",
+ "To create a hidden markov model we need.\n",
+ "- States\n",
+ "- Observation Distribution\n",
+ "- Transition Distribution\n",
+ "\n",
+ "For our purpose we will assume we already have this information available as we attempt to predict the weather on a given day."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "iK2QbOzr6jNJ",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Imports and Setup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Suf1v8kJ6niA",
+ "colab_type": "code",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 103
+ },
+ "outputId": "f12c7178-cc43-42cd-92c3-8084d5d61637"
+ },
+ "source": [
+ "%tensorflow_version 2.x # this line is not required unless you are in a notebook"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "`%tensorflow_version` only switches the major version: 1.x or 2.x.\n",
+ "You set: `2.x # this line is not required unless you are in a notebook`. This will be interpreted as: `2.x`.\n",
+ "\n",
+ "\n",
+ "TensorFlow is already loaded. Please restart the runtime to change versions.\n"
+ ],
+ "name": "stdout"
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GN_Fkrx30xbb",
+ "colab_type": "text"
+ },
+ "source": [
+ "Due to a version mismatch with tensorflow v2 and tensorflow_probability we need to install the most recent version of tensorflow_probability (see below)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "kawrMHKGBWyS",
+ "colab_type": "code",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 293
+ },
+ "outputId": "ad6d30ff-e53a-4776-825d-c18e2b0728cc"
+ },
+ "source": [
+ "!pip install tensorflow_probability==0.8.0rc0 --user --upgrade"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "Collecting tensorflow_probability==0.8.0rc0\n",
+ "\u001b[?25l Downloading https://files.pythonhosted.org/packages/b2/63/f54ce32063abaa682d779e44b49eb63fcf63c2422f978842fdeda794337d/tensorflow_probability-0.8.0rc0-py2.py3-none-any.whl (2.5MB)\n",
+ "\u001b[K |████████████████████████████████| 2.5MB 2.7MB/s \n",
+ "\u001b[?25hRequirement already satisfied, skipping upgrade: decorator in /usr/local/lib/python3.6/dist-packages (from tensorflow_probability==0.8.0rc0) (4.4.2)\n",
+ "Collecting cloudpickle==1.1.1\n",
+ " Downloading https://files.pythonhosted.org/packages/24/fb/4f92f8c0f40a0d728b4f3d5ec5ff84353e705d8ff5e3e447620ea98b06bd/cloudpickle-1.1.1-py2.py3-none-any.whl\n",
+ "Requirement already satisfied, skipping upgrade: six>=1.10.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_probability==0.8.0rc0) (1.12.0)\n",
+ "Requirement already satisfied, skipping upgrade: numpy>=1.13.3 in /usr/local/lib/python3.6/dist-packages (from tensorflow_probability==0.8.0rc0) (1.18.5)\n",
+ "\u001b[31mERROR: gym 0.17.2 has requirement cloudpickle<1.4.0,>=1.2.0, but you'll have cloudpickle 1.1.1 which is incompatible.\u001b[0m\n",
+ "Installing collected packages: cloudpickle, tensorflow-probability\n",
+ "Successfully installed cloudpickle-1.1.1 tensorflow-probability-0.8.0rc0\n"
+ ],
+ "name": "stdout"
+ },
+ {
+ "output_type": "display_data",
+ "data": {
+ "application/vnd.colab-display-data+json": {
+ "pip_warning": {
+ "packages": [
+ "cloudpickle"
+ ]
+ }
+ }
+ },
+ "metadata": {
+ "tags": []
+ }
+ }
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "mEIk7FYD6lcF",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "import tensorflow_probability as tfp # We are using a different module from tensorflow this time\n",
+ "import tensorflow as tf"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ssOcn-nIOCcV",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Weather Model\n",
+ "Taken direclty from the TensorFlow documentation (https://www.tensorflow.org/probability/api_docs/python/tfp/distributions/HiddenMarkovModel). \n",
+ "\n",
+ "We will model a simple weather system and try to predict the temperature on each day given the following information.\n",
+ "1. Cold days are encoded by a 0 and hot days are encoded by a 1.\n",
+ "2. The first day in our sequence has an 80% chance of being cold.\n",
+ "3. A cold day has a 30% chance of being followed by a hot day.\n",
+ "4. A hot day has a 20% chance of being followed by a cold day.\n",
+ "5. On each day the temperature is\n",
+ " normally distributed with mean and standard deviation 0 and 5 on\n",
+ " a cold day and mean and standard deviation 15 and 10 on a hot day.\n",
+ "\n",
+ "If you're unfamiliar with **standard deviation** it can be put simply as the range of expected values. \n",
+ "\n",
+ "In this example, on a hot day the average temperature is 15 and ranges from 5 to 25.\n",
+ "\n",
+ "To model this in TensorFlow we will do the following.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "4LBLEJp4YlIf",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "tfd = tfp.distributions # making a shortcut for later on\n",
+ "initial_distribution = tfd.Categorical(probs=[0.2, 0.8]) # Refer to point 2 above\n",
+ "transition_distribution = tfd.Categorical(probs=[[0.5, 0.5],\n",
+ " [0.2, 0.8]]) # refer to points 3 and 4 above\n",
+ "observation_distribution = tfd.Normal(loc=[0., 15.], scale=[5., 10.]) # refer to point 5 above\n",
+ "\n",
+ "# the loc argument represents the mean and the scale is the standard devitation"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-XtTg0l04mqc",
+ "colab_type": "text"
+ },
+ "source": [
+ "We've now created distribution variables to model our system and it's time to create the hidden markov model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "P4M6cZww4mZk",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model = tfd.HiddenMarkovModel(\n",
+ " initial_distribution=initial_distribution,\n",
+ " transition_distribution=transition_distribution,\n",
+ " observation_distribution=observation_distribution,\n",
+ " num_steps=7)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DJ0XIA2M5gqD",
+ "colab_type": "text"
+ },
+ "source": [
+ "The number of steps represents the number of days that we would like to predict information for. In this case we've chosen 7, an entire week.\n",
+ "\n",
+ "To get the **expected temperatures** on each day we can do the following."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "plVVG4fi55Jv",
+ "colab_type": "code",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 34
+ },
+ "outputId": "cef2d0a3-0edf-4226-ad65-43245933109f"
+ },
+ "source": [
+ "mean = model.mean()\n",
+ "\n",
+ "# due to the way TensorFlow works on a lower level we need to evaluate part of the graph\n",
+ "# from within a session to see the value of this tensor\n",
+ "\n",
+ "# in the new version of tensorflow we need to use tf.compat.v1.Session() rather than just tf.Session()\n",
+ "with tf.compat.v1.Session() as sess: \n",
+ " print(mean.numpy())"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "[12. 11.1 10.83 10.748999 10.724699 10.71741 10.715222]\n"
+ ],
+ "name": "stdout"
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "RzzUGR12AkiF",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Conclusion\n",
+ "So that's it for the core learning algorithms in TensorFlow. Hopefully you've learned about a few interesting tools that are easy to use! To practice I'd encourage you to try out some of these algorithms on different datasets."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEeIRxlbx0wY",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Sources\n",
+ "\n",
+ "1. Chen, James. “Line Of Best Fit.” Investopedia, Investopedia, 29 Jan. 2020, www.investopedia.com/terms/l/line-of-best-fit.asp.\n",
+ "2. “Tf.feature_column.categorical_column_with_vocabulary_list.” TensorFlow, www.tensorflow.org/api_docs/python/tf/feature_column/categorical_column_with_vocabulary_list?version=stable.\n",
+ "3. “Build a Linear Model with Estimators : TensorFlow Core.” TensorFlow, www.tensorflow.org/tutorials/estimator/linear.\n",
+ "4. Staff, EasyBib. “The Free Automatic Bibliography Composer.” EasyBib, Chegg, 1 Jan. 2020, www.easybib.com/project/style/mla8?id=1582473656_5e52a1b8c84d52.80301186.\n",
+ "5. Seif, George. “The 5 Clustering Algorithms Data Scientists Need to Know.” Medium, Towards Data Science, 14 Sept. 2019, https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68.\n",
+ "6. Definition of Hidden Markov Model, http://jedlik.phy.bme.hu/~gerjanos/HMM/node4.html.\n",
+ "7. “Tfp.distributions.HiddenMarkovModel : TensorFlow Probability.” TensorFlow, www.tensorflow.org/probability/api_docs/python/tfp/distributions/HiddenMarkovModel."
+ ]
+ }
+ ]
+}
\ No newline at end of file
diff --git a/Natural_Language_Processing_with_RNNs_.ipynb b/Natural_Language_Processing_with_RNNs_.ipynb
new file mode 100644
index 0000000..4d4d307
--- /dev/null
+++ b/Natural_Language_Processing_with_RNNs_.ipynb
@@ -0,0 +1,1381 @@
+{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "name": "Natural Language Processing with RNNs .ipynb",
+ "provenance": [],
+ "collapsed_sections": [],
+ "include_colab_link": true
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ },
+ "accelerator": "GPU"
+ },
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "h5cjtsHP8t5Y",
+ "colab_type": "text"
+ },
+ "source": [
+ "#Natural Language Processing \n",
+ "Natural Language Processing (or NLP for short) is a discipline in computing that deals with the communication between natural (human) languages and computer languages. A common example of NLP is something like spellcheck or autocomplete. Essentially NLP is the field that focuses on how computers can understand and/or process natural/human languages. \n",
+ "\n",
+ "###Recurrent Neural Networks\n",
+ "\n",
+ "In this tutorial we will introduce a new kind of neural network that is much more capable of processing sequential data such as text or characters called a **recurrent neural network** (RNN for short). \n",
+ "\n",
+ "We will learn how to use a reccurent neural network to do the following:\n",
+ "- Sentiment Analysis\n",
+ "- Character Generation \n",
+ "\n",
+ "RNN's are complex and come in many different forms so in this tutorial we wil focus on how they work and the kind of problems they are best suited for.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ur_FQq-Q-fxC",
+ "colab_type": "text"
+ },
+ "source": [
+ "## Sequence Data\n",
+ "In the previous tutorials we focused on data that we could represent as one static data point where the notion of time or step was irrelevant. Take for example our image data, it was simply a tensor of shape (width, height, channels). That data doesn't change or care about the notion of time. \n",
+ "\n",
+ "In this tutorial we will look at sequences of text and learn how we can encode them in a meaningful way. Unlike images, sequence data such as long chains of text, weather patterns, videos and really anything where the notion of a step or time is relevant needs to be processed and handled in a special way. \n",
+ "\n",
+ "But what do I mean by sequences and why is text data a sequence? Well that's a good question. Since textual data contains many words that follow in a very specific and meaningful order, we need to be able to keep track of each word and when it occurs in the data. Simply encoding say an entire paragraph of text into one data point wouldn't give us a very meaningful picture of the data and would be very difficult to do anything with. This is why we treat text as a sequence and process one word at a time. We will keep track of where each of these words appear and use that information to try to understand the meaning of peices of text.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8gQHK4V4e2wl",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Encoding Text\n",
+ "As we know machine learning models and neural networks don't take raw text data as an input. This means we must somehow encode our textual data to numeric values that our models can understand. There are many different ways of doing this and we will look at a few examples below. \n",
+ "\n",
+ "Before we get into the different encoding/preprocessing methods let's understand the information we can get from textual data by looking at the following two movie reviews.\n",
+ "\n",
+ "```I thought the movie was going to be bad, but it was actually amazing!```\n",
+ "\n",
+ "```I thought the movie was going to be amazing, but it was actually bad!```\n",
+ "\n",
+ "Although these two setences are very similar we know that they have very different meanings. This is because of the **ordering** of words, a very important property of textual data.\n",
+ "\n",
+ "Now keep that in mind while we consider some different ways of encoding our textual data.\n",
+ "\n",
+ "###Bag of Words\n",
+ "The first and simplest way to encode our data is to use something called **bag of words**. This is a pretty easy technique where each word in a sentence is encoded with an integer and thrown into a collection that does not maintain the order of the words but does keep track of the frequency. Have a look at the python function below that encodes a string of text into bag of words. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "5KiCCBsIkMHi",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "vocab = {} # maps word to integer representing it\n",
+ "word_encoding = 1\n",
+ "def bag_of_words(text):\n",
+ " global word_encoding\n",
+ "\n",
+ " words = text.lower().split(\" \") # create a list of all of the words in the text, well assume there is no grammar in our text for this example\n",
+ " bag = {} # stores all of the encodings and their frequency\n",
+ "\n",
+ " for word in words:\n",
+ " if word in vocab:\n",
+ " encoding = vocab[word] # get encoding from vocab\n",
+ " else:\n",
+ " vocab[word] = word_encoding\n",
+ " encoding = word_encoding\n",
+ " word_encoding += 1\n",
+ " \n",
+ " if encoding in bag:\n",
+ " bag[encoding] += 1\n",
+ " else:\n",
+ " bag[encoding] = 1\n",
+ " \n",
+ " return bag\n",
+ "\n",
+ "text = \"this is a test to see if this test will work is is test a a\"\n",
+ "bag = bag_of_words(text)\n",
+ "print(bag)\n",
+ "print(vocab)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4hEvstSBl1gy",
+ "colab_type": "text"
+ },
+ "source": [
+ "This isn't really the way we would do this in practice, but I hope it gives you an idea of how bag of words works. Notice that we've lost the order in which words appear. In fact, let's look at how this encoding works for the two sentences we showed above.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "miYshfvzmJ0H",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "positive_review = \"I thought the movie was going to be bad but it was actually amazing\"\n",
+ "negative_review = \"I thought the movie was going to be amazing but it was actually bad\"\n",
+ "\n",
+ "pos_bag = bag_of_words(positive_review)\n",
+ "neg_bag = bag_of_words(negative_review)\n",
+ "\n",
+ "print(\"Positive:\", pos_bag)\n",
+ "print(\"Negative:\", neg_bag)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pl7Fw9s3mkfK",
+ "colab_type": "text"
+ },
+ "source": [
+ "We can see that even though these sentences have a very different meaning they are encoded exaclty the same way. Obviously, this isn't going to fly. Let's look at some other methods.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DUKTycffmu1k",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Integer Encoding\n",
+ "The next technique we will look at is called **integer encoding**. This involves representing each word or character in a sentence as a unique integer and maintaining the order of these words. This should hopefully fix the problem we saw before were we lost the order of words.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "MKY4y_tjnUEW",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "vocab = {} \n",
+ "word_encoding = 1\n",
+ "def one_hot_encoding(text):\n",
+ " global word_encoding\n",
+ "\n",
+ " words = text.lower().split(\" \") \n",
+ " encoding = [] \n",
+ "\n",
+ " for word in words:\n",
+ " if word in vocab:\n",
+ " code = vocab[word] \n",
+ " encoding.append(code) \n",
+ " else:\n",
+ " vocab[word] = word_encoding\n",
+ " encoding.append(word_encoding)\n",
+ " word_encoding += 1\n",
+ " \n",
+ " return encoding\n",
+ "\n",
+ "text = \"this is a test to see if this test will work is is test a a\"\n",
+ "encoding = one_hot_encoding(text)\n",
+ "print(encoding)\n",
+ "print(vocab)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TOrLG9Bin0Zv",
+ "colab_type": "text"
+ },
+ "source": [
+ "And now let's have a look at one hot encoding on our movie reviews."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "1S-GNjotn-Br",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "positive_review = \"I thought the movie was going to be bad but it was actually amazing\"\n",
+ "negative_review = \"I thought the movie was going to be amazing but it was actually bad\"\n",
+ "\n",
+ "pos_encode = one_hot_encoding(positive_review)\n",
+ "neg_encode = one_hot_encoding(negative_review)\n",
+ "\n",
+ "print(\"Positive:\", pos_encode)\n",
+ "print(\"Negative:\", neg_encode)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jC9UYV4vpq6Y",
+ "colab_type": "text"
+ },
+ "source": [
+ "Much better, now we are keeping track of the order of words and we can tell where each occurs. But this still has a few issues with it. Ideally when we encode words, we would like similar words to have similar labels and different words to have very different labels. For example, the words happy and joyful should probably have very similar labels so we can determine that they are similar. While words like horrible and amazing should probably have very different labels. The method we looked at above won't be able to do something like this for us. This could mean that the model will have a very difficult time determing if two words are similar or not which could result in some pretty drastic performace impacts.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JRZ73YCqqiw9",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Word Embeddings\n",
+ "Luckily there is a third method that is far superior, **word embeddings**. This method keeps the order of words intact as well as encodes similar words with very similar labels. It attempts to not only encode the frequency and order of words but the meaning of those words in the sentence. It encodes each word as a dense vector that represents its context in the sentence.\n",
+ "\n",
+ "Unlike the previous techniques word embeddings are learned by looking at many different training examples. You can add what's called an *embedding layer* to the beggining of your model and while your model trains your embedding layer will learn the correct embeddings for words. You can also use pretrained embedding layers.\n",
+ "\n",
+ "This is the technique we will use for our examples and its implementation will be showed later on.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ehig3qliuUzk",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Recurrent Neural Networks (RNN's)\n",
+ "Now that we've learned a little bit about how we can encode text it's time to dive into recurrent neural networks. Up until this point we have been using something called **feed-forward** neural networks. This simply means that all our data is fed forwards (all at once) from left to right through the network. This was fine for the problems we considered before but won't work very well for processing text. After all, even we (humans) don't process text all at once. We read word by word from left to right and keep track of the current meaning of the sentence so we can understand the meaning of the next word. Well this is exaclty what a recurrent neural network is designed to do. When we say recurrent neural network all we really mean is a network that contains a loop. A RNN will process one word at a time while maintaining an internal memory of what it's already seen. This will allow it to treat words differently based on their order in a sentence and to slowly build an understanding of the entire input, one word at a time.\n",
+ "\n",
+ "This is why we are treating our text data as a sequence! So that we can pass one word at a time to the RNN.\n",
+ "\n",
+ "Let's have a look at what a recurrent layer might look like.\n",
+ "\n",
+ "\n",
+ "*Source: https://colah.github.io/posts/2015-08-Understanding-LSTMs/*\n",
+ "\n",
+ "Let's define what all these variables stand for before we get into the explination.\n",
+ "\n",
+ "**ht** output at time t\n",
+ "\n",
+ "**xt** input at time t\n",
+ "\n",
+ "**A** Recurrent Layer (loop)\n",
+ "\n",
+ "What this diagram is trying to illustrate is that a recurrent layer processes words or input one at a time in a combination with the output from the previous iteration. So, as we progress further in the input sequence, we build a more complex understanding of the text as a whole.\n",
+ "\n",
+ "What we've just looked at is called a **simple RNN layer**. It can be effective at processing shorter sequences of text for simple problems but has many downfalls associated with it. One of them being the fact that as text sequences get longer it gets increasingly difficult for the network to understand the text properly.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Fo3WY-e86zX2",
+ "colab_type": "text"
+ },
+ "source": [
+ "##LSTM\n",
+ "The layer we dicussed in depth above was called a *simpleRNN*. However, there does exist some other recurrent layers (layers that contain a loop) that work much better than a simple RNN layer. The one we will talk about here is called LSTM (Long Short-Term Memory). This layer works very similarily to the simpleRNN layer but adds a way to access inputs from any timestep in the past. Whereas in our simple RNN layer input from previous timestamps gradually disappeared as we got further through the input. With a LSTM we have a long-term memory data structure storing all the previously seen inputs as well as when we saw them. This allows for us to access any previous value we want at any point in time. This adds to the complexity of our network and allows it to discover more useful relationships between inputs and when they appear. \n",
+ "\n",
+ "For the purpose of this course we will refrain from going any further into the math or details behind how these layers work.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CRGOx6_v4eZ_",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Sentiment Analysis\n",
+ "And now time to see a recurrent neural network in action. For this example, we are going to do something called sentiment analysis.\n",
+ "\n",
+ "The formal definition of this term from Wikipedia is as follows:\n",
+ "\n",
+ "*the process of computationally identifying and categorizing opinions expressed in a piece of text, especially in order to determine whether the writer's attitude towards a particular topic, product, etc. is positive, negative, or neutral.*\n",
+ "\n",
+ "The example we’ll use here is classifying movie reviews as either postive, negative or neutral.\n",
+ "\n",
+ "*This guide is based on the following tensorflow tutorial: https://www.tensorflow.org/tutorials/text/text_classification_rnn*\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "RACGE5Ypt5u9",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Movie Review Dataset\n",
+ "Well start by loading in the IMDB movie review dataset from keras. This dataset contains 25,000 reviews from IMDB where each one is already preprocessed and has a label as either positive or negative. Each review is encoded by integers that represents how common a word is in the entire dataset. For example, a word encoded by the integer 3 means that it is the 3rd most common word in the dataset.\n",
+ " \n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "pdsus1kyXWC8",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "%tensorflow_version 2.x # this line is not required unless you are in a notebook\n",
+ "from keras.datasets import imdb\n",
+ "from keras.preprocessing import sequence\n",
+ "import keras\n",
+ "import tensorflow as tf\n",
+ "import os\n",
+ "import numpy as np\n",
+ "\n",
+ "VOCAB_SIZE = 88584\n",
+ "\n",
+ "MAXLEN = 250\n",
+ "BATCH_SIZE = 64\n",
+ "\n",
+ "(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = VOCAB_SIZE)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Wh6lOpcQ9sIZ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# Lets look at one review\n",
+ "train_data[1]"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "EAtZHE9-eQ07",
+ "colab_type": "text"
+ },
+ "source": [
+ "###More Preprocessing\n",
+ "If we have a look at some of our loaded in reviews, we'll notice that they are different lengths. This is an issue. We cannot pass different length data into our neural network. Therefore, we must make each review the same length. To do this we will follow the procedure below:\n",
+ "- if the review is greater than 250 words then trim off the extra words\n",
+ "- if the review is less than 250 words add the necessary amount of 0's to make it equal to 250.\n",
+ "\n",
+ "Luckily for us keras has a function that can do this for us:\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Z3qQ83sNeog6",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "train_data = sequence.pad_sequences(train_data, MAXLEN)\n",
+ "test_data = sequence.pad_sequences(test_data, MAXLEN)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mDm_0RTVir7I",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Creating the Model\n",
+ "Now it's time to create the model. We'll use a word embedding layer as the first layer in our model and add a LSTM layer afterwards that feeds into a dense node to get our predicted sentiment. \n",
+ "\n",
+ "32 stands for the output dimension of the vectors generated by the embedding layer. We can change this value if we'd like!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "OWGGcBIpjrMu",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model = tf.keras.Sequential([\n",
+ " tf.keras.layers.Embedding(VOCAB_SIZE, 32),\n",
+ " tf.keras.layers.LSTM(32),\n",
+ " tf.keras.layers.Dense(1, activation=\"sigmoid\")\n",
+ "])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "O8_jPL_Kkr-a",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.summary()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eyeQCk3LlK6V",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Training\n",
+ "Now it's time to compile and train the model. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "KKEMjaIulPBe",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.compile(loss=\"binary_crossentropy\",optimizer=\"rmsprop\",metrics=['acc'])\n",
+ "\n",
+ "history = model.fit(train_data, train_labels, epochs=10, validation_split=0.2)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3buYlkkhoK93",
+ "colab_type": "text"
+ },
+ "source": [
+ "And we'll evaluate the model on our training data to see how well it performs."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "KImNMWTDoJaQ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "results = model.evaluate(test_data, test_labels)\n",
+ "print(results)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "N1RRGcr9CFCW",
+ "colab_type": "text"
+ },
+ "source": [
+ "So we're scoring somewhere in the mid-high 80's. Not bad for a simple recurrent network."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "lGrBRC4YCObV",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Making Predictions\n",
+ "Now let’s use our network to make predictions on our own reviews. \n",
+ "\n",
+ "Since our reviews are encoded well need to convert any review that we write into that form so the network can understand it. To do that well load the encodings from the dataset and use them to encode our own data.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Onu8leY4Cn9z",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "word_index = imdb.get_word_index()\n",
+ "\n",
+ "def encode_text(text):\n",
+ " tokens = keras.preprocessing.text.text_to_word_sequence(text)\n",
+ " tokens = [word_index[word] if word in word_index else 0 for word in tokens]\n",
+ " return sequence.pad_sequences([tokens], MAXLEN)[0]\n",
+ "\n",
+ "text = \"that movie was just amazing, so amazing\"\n",
+ "encoded = encode_text(text)\n",
+ "print(encoded)\n"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "PKna3vxmFwrB",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# while were at it lets make a decode function\n",
+ "\n",
+ "reverse_word_index = {value: key for (key, value) in word_index.items()}\n",
+ "\n",
+ "def decode_integers(integers):\n",
+ " PAD = 0\n",
+ " text = \"\"\n",
+ " for num in integers:\n",
+ " if num != PAD:\n",
+ " text += reverse_word_index[num] + \" \"\n",
+ "\n",
+ " return text[:-1]\n",
+ " \n",
+ "print(decode_integers(encoded))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "L8nyrr00HPZF",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# now time to make a prediction\n",
+ "\n",
+ "def predict(text):\n",
+ " encoded_text = encode_text(text)\n",
+ " pred = np.zeros((1,250))\n",
+ " pred[0] = encoded_text\n",
+ " result = model.predict(pred) \n",
+ " print(result[0])\n",
+ "\n",
+ "positive_review = \"That movie was! really loved it and would great watch it again because it was amazingly great\"\n",
+ "predict(positive_review)\n",
+ "\n",
+ "negative_review = \"that movie really sucked. I hated it and wouldn't watch it again. Was one of the worst things I've ever watched\"\n",
+ "predict(negative_review)\n"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "01BJLcGb4ZqK",
+ "colab_type": "text"
+ },
+ "source": [
+ "##RNN Play Generator\n",
+ "\n",
+ "Now time for one of the coolest examples we've seen so far. We are going to use a RNN to generate a play. We will simply show the RNN an example of something we want it to recreate and it will learn how to write a version of it on its own. We'll do this using a character predictive model that will take as input a variable length sequence and predict the next character. We can use the model many times in a row with the output from the last predicition as the input for the next call to generate a sequence.\n",
+ "\n",
+ "\n",
+ "*This guide is based on the following: https://www.tensorflow.org/tutorials/text/text_generation*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "fju7i1FKrK_G",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "%tensorflow_version 2.x # this line is not required unless you are in a notebook\n",
+ "from keras.preprocessing import sequence\n",
+ "import keras\n",
+ "import tensorflow as tf\n",
+ "import os\n",
+ "import numpy as np"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "F48c-EctQ378",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Dataset\n",
+ "For this example, we only need one peice of training data. In fact, we can write our own poem or play and pass that to the network for training if we'd like. However, to make things easy we'll use an extract from a shakesphere play.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "IdRcVIhtRGlF",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NlSVGd5ACkZe",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Loading Your Own Data\n",
+ "To load your own data, you'll need to upload a file from the dialog below. Then you'll need to follow the steps from above but load in this new file instead.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "CFYFwbJOC3bP",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "from google.colab import files\n",
+ "path_to_file = list(files.upload().keys())[0]"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KtJMEqQyRhAk",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Read Contents of File\n",
+ "Let's look at the contents of the file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "-n4oovOMRnP7",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# Read, then decode for py2 compat.\n",
+ "text = open(path_to_file, 'rb').read().decode(encoding='utf-8')\n",
+ "# length of text is the number of characters in it\n",
+ "print ('Length of text: {} characters'.format(len(text)))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "KHUxQVl7Rt10",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# Take a look at the first 250 characters in text\n",
+ "print(text[:250])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5vt8Vpe0RvaJ",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Encoding\n",
+ "Since this text isn't encoded yet well need to do that ourselves. We are going to encode each unique character as a different integer.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "C7AZNI7aRz6y",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "vocab = sorted(set(text))\n",
+ "# Creating a mapping from unique characters to indices\n",
+ "char2idx = {u:i for i, u in enumerate(vocab)}\n",
+ "idx2char = np.array(vocab)\n",
+ "\n",
+ "def text_to_int(text):\n",
+ " return np.array([char2idx[c] for c in text])\n",
+ "\n",
+ "text_as_int = text_to_int(text)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "_i5kvmX_SLW4",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# lets look at how part of our text is encoded\n",
+ "print(\"Text:\", text[:13])\n",
+ "print(\"Encoded:\", text_to_int(text[:13]))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mDvD5kqTWwOn",
+ "colab_type": "text"
+ },
+ "source": [
+ "And here we will make a function that can convert our numeric values to text.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Af52YChSW5hX",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "def int_to_text(ints):\n",
+ " try:\n",
+ " ints = ints.numpy()\n",
+ " except:\n",
+ " pass\n",
+ " return ''.join(idx2char[ints])\n",
+ "\n",
+ "print(int_to_text(text_as_int[:13]))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "T_49cl6uS0r-",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Creating Training Examples\n",
+ "Remember our task is to feed the model a sequence and have it return to us the next character. This means we need to split our text data from above into many shorter sequences that we can pass to the model as training examples. \n",
+ "\n",
+ "The training examples we will prepapre will use a *seq_length* sequence as input and a *seq_length* sequence as the output where that sequence is the original sequence shifted one letter to the right. For example:\n",
+ "\n",
+ "```input: Hell | output: ello```\n",
+ "\n",
+ "Our first step will be to create a stream of characters from our text data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "xBkXz9fjUQHW",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "seq_length = 100 # length of sequence for a training example\n",
+ "examples_per_epoch = len(text)//(seq_length+1)\n",
+ "\n",
+ "# Create training examples / targets\n",
+ "char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "pqmxfT7gVGlr",
+ "colab_type": "text"
+ },
+ "source": [
+ "Next we can use the batch method to turn this stream of characters into batches of desired length."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Xi0xaPB_VOJl",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "sequences = char_dataset.batch(seq_length+1, drop_remainder=True)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "fxo1Dig_VvV1",
+ "colab_type": "text"
+ },
+ "source": [
+ "Now we need to use these sequences of length 101 and split them into input and output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "03zKVHTvV0Km",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "def split_input_target(chunk): # for the example: hello\n",
+ " input_text = chunk[:-1] # hell\n",
+ " target_text = chunk[1:] # ello\n",
+ " return input_text, target_text # hell, ello\n",
+ "\n",
+ "dataset = sequences.map(split_input_target) # we use map to apply the above function to every entry"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "9p_y2YmgWbnc",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "for x, y in dataset.take(2):\n",
+ " print(\"\\n\\nEXAMPLE\\n\")\n",
+ " print(\"INPUT\")\n",
+ " print(int_to_text(x))\n",
+ " print(\"\\nOUTPUT\")\n",
+ " print(int_to_text(y))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "v6OxuFKVXpwK",
+ "colab_type": "text"
+ },
+ "source": [
+ "Finally we need to make training batches."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "cRsKcjhXXuoD",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "BATCH_SIZE = 64\n",
+ "VOCAB_SIZE = len(vocab) # vocab is number of unique characters\n",
+ "EMBEDDING_DIM = 256\n",
+ "RNN_UNITS = 1024\n",
+ "\n",
+ "# Buffer size to shuffle the dataset\n",
+ "# (TF data is designed to work with possibly infinite sequences,\n",
+ "# so it doesn't attempt to shuffle the entire sequence in memory. Instead,\n",
+ "# it maintains a buffer in which it shuffles elements).\n",
+ "BUFFER_SIZE = 10000\n",
+ "\n",
+ "data = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "E6YRmZLtX0d0",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Building the Model\n",
+ "Now it is time to build the model. We will use an embedding layer a LSTM and one dense layer that contains a node for each unique character in our training data. The dense layer will give us a probability distribution over all nodes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "5v_P2dEic4qt",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "def build_model(vocab_size, embedding_dim, rnn_units, batch_size):\n",
+ " model = tf.keras.Sequential([\n",
+ " tf.keras.layers.Embedding(vocab_size, embedding_dim,\n",
+ " batch_input_shape=[batch_size, None]),\n",
+ " tf.keras.layers.LSTM(rnn_units,\n",
+ " return_sequences=True,\n",
+ " stateful=True,\n",
+ " recurrent_initializer='glorot_uniform'),\n",
+ " tf.keras.layers.Dense(vocab_size)\n",
+ " ])\n",
+ " return model\n",
+ "\n",
+ "model = build_model(VOCAB_SIZE,EMBEDDING_DIM, RNN_UNITS, BATCH_SIZE)\n",
+ "model.summary()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8gfnHBUOvPqE",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Creating a Loss Function\n",
+ "Now we are going to create our own loss function for this problem. This is because our model will output a (64, sequence_length, 65) shaped tensor that represents the probability distribution of each character at each timestep for every sequence in the batch. \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "g_ERM4F15v_S",
+ "colab_type": "text"
+ },
+ "source": [
+ "However, before we do that let's have a look at a sample input and the output from our untrained model. This is so we can understand what the model is giving us.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "KdvEqlwc6_q0",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "for input_example_batch, target_example_batch in data.take(1):\n",
+ " example_batch_predictions = model(input_example_batch) # ask our model for a prediction on our first batch of training data (64 entries)\n",
+ " print(example_batch_predictions.shape, \"# (batch_size, sequence_length, vocab_size)\") # print out the output shape"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "RQS5KXwi7_NX",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# we can see that the predicition is an array of 64 arrays, one for each entry in the batch\n",
+ "print(len(example_batch_predictions))\n",
+ "print(example_batch_predictions)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "sA1Zhop28V9n",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# lets examine one prediction\n",
+ "pred = example_batch_predictions[0]\n",
+ "print(len(pred))\n",
+ "print(pred)\n",
+ "# notice this is a 2d array of length 100, where each interior array is the prediction for the next character at each time step"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "UbIoe7Ei8q3q",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# and finally well look at a prediction at the first timestep\n",
+ "time_pred = pred[0]\n",
+ "print(len(time_pred))\n",
+ "print(time_pred)\n",
+ "# and of course its 65 values representing the probabillity of each character occuring next"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "qlEYM1H995gR",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# If we want to determine the predicted character we need to sample the output distribution (pick a value based on probabillity)\n",
+ "sampled_indices = tf.random.categorical(pred, num_samples=1)\n",
+ "\n",
+ "# now we can reshape that array and convert all the integers to numbers to see the actual characters\n",
+ "sampled_indices = np.reshape(sampled_indices, (1, -1))[0]\n",
+ "predicted_chars = int_to_text(sampled_indices)\n",
+ "\n",
+ "predicted_chars # and this is what the model predicted for training sequence 1"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qcCBfPjN9Cnp",
+ "colab_type": "text"
+ },
+ "source": [
+ "So now we need to create a loss function that can compare that output to the expected output and give us some numeric value representing how close the two were. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "ZOw23fWq9D9O",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "def loss(labels, logits):\n",
+ " return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "kcg75GwXgW81",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Compiling the Model\n",
+ "At this point we can think of our problem as a classification problem where the model predicts the probabillity of each unique letter coming next. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "9g6o7zA_hAiS",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.compile(optimizer='adam', loss=loss)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YgDKr4yvjLPI",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Creating Checkpoints\n",
+ "Now we are going to setup and configure our model to save checkpoinst as it trains. This will allow us to load our model from a checkpoint and continue training it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "v7aMushYjSpy",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# Directory where the checkpoints will be saved\n",
+ "checkpoint_dir = './training_checkpoints'\n",
+ "# Name of the checkpoint files\n",
+ "checkpoint_prefix = os.path.join(checkpoint_dir, \"ckpt_{epoch}\")\n",
+ "\n",
+ "checkpoint_callback=tf.keras.callbacks.ModelCheckpoint(\n",
+ " filepath=checkpoint_prefix,\n",
+ " save_weights_only=True)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0p7acPvGja5c",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Training\n",
+ "Finally, we will start training the model. \n",
+ "\n",
+ "**If this is taking a while go to Runtime > Change Runtime Type and choose \"GPU\" under hardware accelerator.**\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "R4PAgrwMjZ4_",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "history = model.fit(data, epochs=50, callbacks=[checkpoint_callback])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9GhoHJVtmTsz",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Loading the Model\n",
+ "We'll rebuild the model from a checkpoint using a batch_size of 1 so that we can feed one peice of text to the model and have it make a prediction."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "TPSto3uimSKp",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model = build_model(VOCAB_SIZE, EMBEDDING_DIM, RNN_UNITS, batch_size=1)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "boEJvy_vjLJQ",
+ "colab_type": "text"
+ },
+ "source": [
+ "Once the model is finished training, we can find the **lastest checkpoint** that stores the models weights using the following line.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "PZIEZWE4mNKl",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))\n",
+ "model.build(tf.TensorShape([1, None]))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CmPPtbaTKF8d",
+ "colab_type": "text"
+ },
+ "source": [
+ "We can load **any checkpoint** we want by specifying the exact file to load."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "YQ_5p0ehKFDn",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "checkpoint_num = 10\n",
+ "model.load_weights(tf.train.load_checkpoint(\"./training_checkpoints/ckpt_\" + str(checkpoint_num)))\n",
+ "model.build(tf.TensorShape([1, None]))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KaZWalEeAxQN",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Generating Text\n",
+ "Now we can use the lovely function provided by tensorflow to generate some text using any starting string we'd like."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "oPSALdQXA3l3",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "def generate_text(model, start_string):\n",
+ " # Evaluation step (generating text using the learned model)\n",
+ "\n",
+ " # Number of characters to generate\n",
+ " num_generate = 800\n",
+ "\n",
+ " # Converting our start string to numbers (vectorizing)\n",
+ " input_eval = [char2idx[s] for s in start_string]\n",
+ " input_eval = tf.expand_dims(input_eval, 0)\n",
+ "\n",
+ " # Empty string to store our results\n",
+ " text_generated = []\n",
+ "\n",
+ " # Low temperatures results in more predictable text.\n",
+ " # Higher temperatures results in more surprising text.\n",
+ " # Experiment to find the best setting.\n",
+ " temperature = 1.0\n",
+ "\n",
+ " # Here batch size == 1\n",
+ " model.reset_states()\n",
+ " for i in range(num_generate):\n",
+ " predictions = model(input_eval)\n",
+ " # remove the batch dimension\n",
+ " \n",
+ " predictions = tf.squeeze(predictions, 0)\n",
+ "\n",
+ " # using a categorical distribution to predict the character returned by the model\n",
+ " predictions = predictions / temperature\n",
+ " predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()\n",
+ "\n",
+ " # We pass the predicted character as the next input to the model\n",
+ " # along with the previous hidden state\n",
+ " input_eval = tf.expand_dims([predicted_id], 0)\n",
+ "\n",
+ " text_generated.append(idx2char[predicted_id])\n",
+ "\n",
+ " return (start_string + ''.join(text_generated))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "cAJqhD9AA5mF",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "inp = input(\"Type a starting string: \")\n",
+ "print(generate_text(model, inp))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CBjHrzzyOBVr",
+ "colab_type": "text"
+ },
+ "source": [
+ "*And* that's pretty much it for this module! I highly reccomend messing with the model we just created and seeing what you can get it to do!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Cw-1eDE54yQo",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Sources\n",
+ "\n",
+ "1. Chollet François. Deep Learning with Python. Manning Publications Co., 2018.\n",
+ "2. “Text Classification with an RNN : TensorFlow Core.” TensorFlow, www.tensorflow.org/tutorials/text/text_classification_rnn.\n",
+ "3. “Text Generation with an RNN : TensorFlow Core.” TensorFlow, www.tensorflow.org/tutorials/text/text_generation.\n",
+ "4. “Understanding LSTM Networks.” Understanding LSTM Networks -- Colah's Blog, https://colah.github.io/posts/2015-08-Understanding-LSTMs/."
+ ]
+ }
+ ]
+}
\ No newline at end of file
diff --git a/Neural_Networks.ipynb b/Neural_Networks.ipynb
new file mode 100644
index 0000000..f0ec0cd
--- /dev/null
+++ b/Neural_Networks.ipynb
@@ -0,0 +1,826 @@
+{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "name": "Neural Networks.ipynb",
+ "provenance": [],
+ "collapsed_sections": [],
+ "include_colab_link": true
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ }
+ },
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jqVqT_Cxh4Ho",
+ "colab_type": "text"
+ },
+ "source": [
+ "#Introduction to Neural Networks\n",
+ "In this notebook you will learn how to create and use a neural network to classify articles of clothing. To achieve this, we will use a sub module of TensorFlow called *keras*.\n",
+ "\n",
+ "*This guide is based on the following TensorFlow documentation.*\n",
+ "\n",
+ "https://www.tensorflow.org/tutorials/keras/classification\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZFQqW9r-ikJb",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Keras\n",
+ "Before we dive in and start discussing neural networks, I'd like to give a breif introduction to keras.\n",
+ "\n",
+ "From the keras official documentation (https://keras.io/) keras is described as follows.\n",
+ "\n",
+ "\"Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It was developed with a focus on enabling fast experimentation. \n",
+ "\n",
+ "Use Keras if you need a deep learning library that:\n",
+ "\n",
+ "- Allows for easy and fast prototyping (through user friendliness, modularity, and extensibility).\n",
+ "- Supports both convolutional networks and recurrent networks, as well as combinations of the two.\n",
+ "- Runs seamlessly on CPU and GPU.\"\n",
+ "\n",
+ "Keras is a very powerful module that allows us to avoid having to build neural networks from scratch. It also hides a lot of mathematical complexity (that otherwise we would have to implement) inside of helpful packages, modules and methods.\n",
+ "\n",
+ "In this guide we will use keras to quickly develop neural networks.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Hivk879ZQhxU",
+ "colab_type": "text"
+ },
+ "source": [
+ "##What is a Neural Network\n",
+ "So, what are these magical things that have been beating chess grandmasters, driving cars, detecting cancer cells and winning video games? \n",
+ "\n",
+ "A deep neural network is a layered representation of data. The term \"deep\" refers to the presence of multiple layers. Recall that in our core learning algorithms (like linear regression) data was not transformed or modified within the model, it simply existed in one layer. We passed some features to our model, some math was done, an answer was returned. The data was not changed or transformed throughout this process. A neural network processes our data differently. It attempts to represent our data in different ways and in different dimensions by applying specific operations to transform our data at each layer. Another way to express this is that at each layer our data is transformed in order to learn more about it. By performing these transformations, the model can better understand our data and therefore provide a better prediction. \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GOqUCZ2klTAq",
+ "colab_type": "text"
+ },
+ "source": [
+ "##How it Works\n",
+ "Before going into too much detail I will provide a very surface level explination of how neural networks work on a mathematical level. All the terms and concepts I discuss will be defined and explained in more detail below.\n",
+ "\n",
+ "On a lower level neural networks are simply a combination of elementry math operations and some more advanced linear algebra. Each neural network consists of a sequence of layers in which data passes through. These layers are made up on neurons and the neurons of one layer are connected to the next (see below). These connections are defined by what we call a weight (some numeric value). Each layer also has something called a bias, this is simply an extra neuron that has no connections and holds a single numeric value. Data starts at the input layer and is trasnformed as it passes through subsequent layers. The data at each subsequent neuron is defined as the following.\n",
+ "\n",
+ "> $Y =(\\sum_{i=0}^n w_i x_i) + b$\n",
+ "\n",
+ "> $w$ stands for the weight of each connection to the neuron\n",
+ "\n",
+ "> $x$ stands for the value of the connected neuron from the previous value\n",
+ "\n",
+ "> $b$ stands for the bias at each layer, this is a constant\n",
+ "\n",
+ "> $n$ is the number of connections\n",
+ "\n",
+ "> $Y$ is the output of the current neuron\n",
+ "\n",
+ "> $\\sum$ stands for sum\n",
+ "\n",
+ "The equation you just read is called a weighed sum. We will take this weighted sum at each and every neuron as we pass information through the network. Then we will add what's called a bias to this sum. The bias allows us to shift the network up or down by a constant value. It is like the y-intercept of a line.\n",
+ "\n",
+ "But that equation is the not complete one! We forgot a crucial part, **the activation function**. This is a function that we apply to the equation seen above to add complexity and dimensionality to our network. Our new equation with the addition of an activation function $F(x)$ is seen below.\n",
+ "\n",
+ "> $Y =F((\\sum_{i=0}^n w_i x_i) + b)$\n",
+ "\n",
+ "Our network will start with predefined activation functions (they may be different at each layer) but random weights and biases. As we train the network by feeding it data it will learn the correct weights and biases and adjust the network accordingly using a technqiue called **backpropagation** (explained below). Once the correct weights and biases have been learned our network will hopefully be able to give us meaningful predictions. We get these predictions by observing the values at our final layer, the output layer. \n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "o-oMh18_j5kl",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Breaking Down The Neural Network!\n",
+ "\n",
+ "Before we dive into any code lets break down how a neural network works and what it does.\n",
+ "\n",
+ "\n",
+ "*Figure 1*\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-9hd-R1ulSdp",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Data\n",
+ "The type of data a neural network processes varies drastically based on the problem being solved. When we build a neural network, we define what shape and kind of data it can accept. It may sometimes be neccessary to modify our dataset so that it can be passed to our neural network. \n",
+ "\n",
+ "Some common types of data a neural network uses are listed below.\n",
+ "- Vector Data (2D)\n",
+ "- Timeseries or Sequence (3D)\n",
+ "- Image Data (4D)\n",
+ "- Video Data (5D)\n",
+ "\n",
+ "There are of course many different types or data, but these are the main categories.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Xyxxs7oMlWtz",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Layers\n",
+ "As we mentioned earlier each neural network consists of multiple layers. At each layer a different transformation of data occurs. Our initial input data is fed through the layers and eventually arrives at the output layer where we will obtain the result.\n",
+ "####Input Layer\n",
+ "The input layer is the layer that our initial data is passed to. It is the first layer in our neural network.\n",
+ "####Output Layer\n",
+ "The output layer is the layer that we will retrive our results from. Once the data has passed through all other layers it will arrive here.\n",
+ "####Hidden Layer(s)\n",
+ "All the other layers in our neural network are called \"hidden layers\". This is because they are hidden to us, we cannot observe them. Most neural networks consist of at least one hidden layer but can have an unlimited amount. Typically, the more complex the model the more hidden layers.\n",
+ "####Neurons\n",
+ "Each layer is made up of what are called neurons. Neurons have a few different properties that we will discuss later. The important aspect to understand now is that each neuron is responsible for generating/holding/passing ONE numeric value. \n",
+ "\n",
+ "This means that in the case of our input layer it will have as many neurons as we have input information. For example, say we want to pass an image that is 28x28 pixels, thats 784 pixels. We would need 784 neurons in our input layer to capture each of these pixels. \n",
+ "\n",
+ "This also means that our output layer will have as many neurons as we have output information. The output is a little more complicated to understand so I'll refrain from an example right now but hopefully you're getting the idea.\n",
+ "\n",
+ "But what about our hidden layers? Well these have as many neurons as we decide. We'll discuss how we can pick these values later but understand a hidden layer can have any number of neurons.\n",
+ "####Connected Layers\n",
+ "So how are all these layers connected? Well the neurons in one layer will be connected to neurons in the subsequent layer. However, the neurons can be connected in a variety of different ways. \n",
+ "\n",
+ "Take for example *Figure 1* (look above). Each neuron in one layer is connected to every neuron in the next layer. This is called a **dense** layer. There are many other ways of connecting layers but well discuss those as we see them. \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "a_bM6nQ-PZBY",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Weights\n",
+ "Weights are associated with each connection in our neural network. Every pair of connected nodes will have one weight that denotes the strength of the connection between them. These are vital to the inner workings of a neural network and will be tweaked as the neural network is trained. The model will try to determine what these weights should be to achieve the best result. Weights start out at a constant or random value and will change as the network sees training data."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "XwYq9doXeIl-",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Biases\n",
+ "Biases are another important part of neural networks and will also be tweaked as the model is trained. A bias is simply a constant value associated with each layer. It can be thought of as an extra neuron that has no connections. The purpose of a bias is to shift an entire activation function by a constant value. This allows a lot more flexibllity when it comes to choosing an activation and training the network. There is one bias for each layer."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "F92rhvd6PcRI",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Activation Function\n",
+ "Activation functions are simply a function that is applied to the weighed sum of a neuron. They can be anything we want but are typically higher order/degree functions that aim to add a higher dimension to our data. We would want to do this to introduce more comolexity to our model. By transforming our data to a higher dimension, we can typically make better, more complex predictions.\n",
+ "\n",
+ "A list of some common activation functions and their graphs can be seen below.\n",
+ "\n",
+ "- Relu (Rectified Linear Unit)\n",
+ "\n",
+ "\n",
+ "- Tanh (Hyperbolic Tangent)\n",
+ "\n",
+ "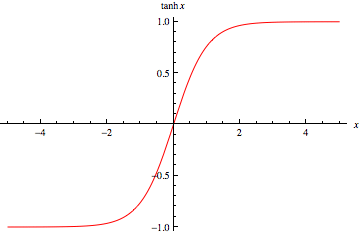\n",
+ "- Sigmoid \n",
+ "\n",
+ "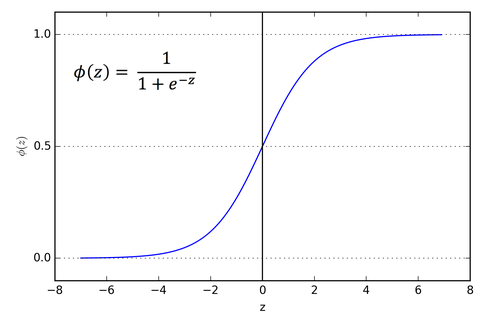\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Q2xNjpctlBUM",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Backpropagation\n",
+ "Backpropagation is the fundemental algorithm behind training neural networks. It is what changes the weights and biases of our network. To fully explain this process, we need to start by discussing something called a cost/loss function.\n",
+ "\n",
+ "####Loss/Cost Function\n",
+ "As we now know our neural network feeds information through the layers until it eventually reaches an output layer. This layer contains the results that we look at to determine the prediciton from our network. In the training phase it is likely that our network will make many mistakes and poor predicitions. In fact, at the start of training our network doesn't know anything (it has random weights and biases)! \n",
+ "\n",
+ "We need some way of evaluating if the network is doing well and how well it is doing. For our training data we have the features (input) and the labels (expected output), because of this we can compare the output from our network to the expected output. Based on the difference between these values we can determine if our network has done a good job or poor job. If the network has done a good job, we'll make minor changes to the weights and biases. If it has done a poor job our changes may be more drastic.\n",
+ "\n",
+ "So, this is where the cost/loss function comes in. This function is responsible for determining how well the network did. We pass it the output and the expected output, and it returns to us some value representing the cost/loss of the network. This effectively makes the networks job to optimize this cost function, trying to make it as low as possible. \n",
+ "\n",
+ "Some common loss/cost functions include.\n",
+ "- Mean Squared Error\n",
+ "- Mean Absolute Error\n",
+ "- Hinge Loss\n",
+ "\n",
+ "####Gradient Descent\n",
+ "Gradient descent and backpropagation are closely related. Gradient descent is the algorithm used to find the optimal paramaters (weights and biases) for our network, while backpropagation is the process of calculating the gradient that is used in the gradient descent step. \n",
+ "\n",
+ "Gradient descent requires some pretty advanced calculus and linear algebra to understand so we'll stay away from that for now. Let's just read the formal definition for now.\n",
+ "\n",
+ "\"Gradient descent is an optimization algorithm used to minimize some function by iteratively moving in the direction of steepest descent as defined by the negative of the gradient. In machine learning, we use gradient descent to update the parameters of our model.\" (https://ml-cheatsheet.readthedocs.io/en/latest/gradient_descent.html)\n",
+ "\n",
+ "And that's all we really need to know for now. I'll direct you to the video for a more in depth explination.\n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0KiTMDCKlBI7",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Optimizer\n",
+ "You may sometimes see the term optimizer or optimization function. This is simply the function that implements the backpropagation algorithm described above. Here's a list of a few common ones.\n",
+ "- Gradient Descent\n",
+ "- Stochastic Gradient Descent\n",
+ "- Mini-Batch Gradient Descent\n",
+ "- Momentum\n",
+ "- Nesterov Accelerated Gradient\n",
+ "\n",
+ "*This article explains them quite well is where I've pulled this list from.*\n",
+ "\n",
+ "(https://medium.com/@sdoshi579/optimizers-for-training-neural-network-59450d71caf6)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Kc5hFCLSiDNr",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Creating a Neural Network\n",
+ "Okay now you have reached the exciting part of this tutorial! No more math and complex explinations. Time to get hands on and train a very basic neural network.\n",
+ "\n",
+ "*As stated earlier this guide is based off of the following TensorFlow tutorial.*\n",
+ "https://www.tensorflow.org/tutorials/keras/classification\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3io6gbUrjOQY",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "y8t_EdO8jEHz",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "%tensorflow_version 2.x # this line is not required unless you are in a notebook\n",
+ "# TensorFlow and tf.keras\n",
+ "import tensorflow as tf\n",
+ "from tensorflow import keras\n",
+ "\n",
+ "# Helper libraries\n",
+ "import numpy as np\n",
+ "import matplotlib.pyplot as plt"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "p_iFN10li6V1",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Dataset\n",
+ "For this tutorial we will use the MNIST Fashion Dataset. This is a dataset that is included in keras.\n",
+ "\n",
+ "This dataset includes 60,000 images for training and 10,000 images for validation/testing."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "eQmVmgOxjCOV",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "fashion_mnist = keras.datasets.fashion_mnist # load dataset\n",
+ "\n",
+ "(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() # split into tetsing and training"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "AcIall2njfn1",
+ "colab_type": "text"
+ },
+ "source": [
+ "Let's have a look at this data to see what we are working with."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WhLXRxOdjisI",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "train_images.shape"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "D2npdFHwjsLS",
+ "colab_type": "text"
+ },
+ "source": [
+ "So we've got 60,000 images that are made up of 28x28 pixels (784 in total)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "m280zyPqj3ws",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "train_images[0,23,23] # let's have a look at one pixel"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GUciblEwkBe4",
+ "colab_type": "text"
+ },
+ "source": [
+ "Our pixel values are between 0 and 255, 0 being black and 255 being white. This means we have a grayscale image as there are no color channels."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Rn78KO7fkQPJ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "train_labels[:10] # let's have a look at the first 10 training labels"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "r90qZKsnkaW7",
+ "colab_type": "text"
+ },
+ "source": [
+ "Our labels are integers ranging from 0 - 9. Each integer represents a specific article of clothing. We'll create an array of label names to indicate which is which."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "pBiICD2tkne8",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',\n",
+ " 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4rv06eD8krMR",
+ "colab_type": "text"
+ },
+ "source": [
+ "Fianlly let's look at what some of these images look like!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Nfc8LV4Pkq0X",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "plt.figure()\n",
+ "plt.imshow(train_images[1])\n",
+ "plt.colorbar()\n",
+ "plt.grid(False)\n",
+ "plt.show()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "n_DC1b0grL1N",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Data Preprocessing\n",
+ "The last step before creating our model is to *preprocess* our data. This simply means applying some prior transformations to our data before feeding it the model. In this case we will simply scale all our greyscale pixel values (0-255) to be between 0 and 1. We can do this by dividing each value in the training and testing sets by 255.0. We do this because smaller values will make it easier for the model to process our values. \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "wHde8MYW0OQo",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "train_images = train_images / 255.0\n",
+ "\n",
+ "test_images = test_images / 255.0"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "dHOX6GqR0QuD",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Building the Model\n",
+ "Now it's time to build the model! We are going to use a keras *sequential* model with three different layers. This model represents a feed-forward neural network (one that passes values from left to right). We'll break down each layer and its architecture below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "XDxodHMv0xgG",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model = keras.Sequential([\n",
+ " keras.layers.Flatten(input_shape=(28, 28)), # input layer (1)\n",
+ " keras.layers.Dense(128, activation='relu'), # hidden layer (2)\n",
+ " keras.layers.Dense(10, activation='softmax') # output layer (3)\n",
+ "])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "c-bL-I5w0414",
+ "colab_type": "text"
+ },
+ "source": [
+ "**Layer 1:** This is our input layer and it will conist of 784 neurons. We use the flatten layer with an input shape of (28,28) to denote that our input should come in in that shape. The flatten means that our layer will reshape the shape (28,28) array into a vector of 784 neurons so that each pixel will be associated with one neuron.\n",
+ "\n",
+ "**Layer 2:** This is our first and only hidden layer. The *dense* denotes that this layer will be fully connected and each neuron from the previous layer connects to each neuron of this layer. It has 128 neurons and uses the rectify linear unit activation function.\n",
+ "\n",
+ "**Layer 3:** This is our output later and is also a dense layer. It has 10 neurons that we will look at to determine our models output. Each neuron represnts the probabillity of a given image being one of the 10 different classes. The activation function *softmax* is used on this layer to calculate a probabillity distribution for each class. This means the value of any neuron in this layer will be between 0 and 1, where 1 represents a high probabillity of the image being that class."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-j1UF9QH21Ex",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Compile the Model\n",
+ "The last step in building the model is to define the loss function, optimizer and metrics we would like to track. I won't go into detail about why we chose each of these right now."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Msigq4Ja29QX",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.compile(optimizer='adam',\n",
+ " loss='sparse_categorical_crossentropy',\n",
+ " metrics=['accuracy'])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7YYW5V_53OXV",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Training the Model\n",
+ "Now it's finally time to train the model. Since we've already done all the work on our data this step is as easy as calling a single method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "XmAtc4uI3_C7",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.fit(train_images, train_labels, epochs=10) # we pass the data, labels and epochs and watch the magic!"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "y6SRtNcF4K1O",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Evaluating the Model\n",
+ "Now it's time to test/evaluate the model. We can do this quite easily using another builtin method from keras.\n",
+ "\n",
+ "The *verbose* argument is defined from the keras documentation as:\n",
+ "\"verbose: 0 or 1. Verbosity mode. 0 = silent, 1 = progress bar.\"\n",
+ "(https://keras.io/models/sequential/)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WqI0FEO54XN1",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=1) \n",
+ "\n",
+ "print('Test accuracy:', test_acc)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nb4_EtfK5DuW",
+ "colab_type": "text"
+ },
+ "source": [
+ "You'll likely notice that the accuracy here is lower than when training the model. This difference is reffered to as **overfitting**.\n",
+ "\n",
+ "And now we have a trained model that's ready to use to predict some values!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pv0XpgwJ7GlW",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Making Predictions\n",
+ "To make predictions we simply need to pass an array of data in the form we've specified in the input layer to ```.predict()``` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "BMAkNWii7Ufj",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "predictions = model.predict(test_images)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "LmRgxuEc7Xjc",
+ "colab_type": "text"
+ },
+ "source": [
+ "This method returns to us an array of predictions for each image we passed it. Let's have a look at the predictions for image 1."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "4y2eQtCr7fnd",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "predictions[0]"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eiRNg9Yr7lCt",
+ "colab_type": "text"
+ },
+ "source": [
+ "If we wan't to get the value with the highest score we can use a useful function from numpy called ```argmax()```. This simply returns the index of the maximium value from a numpy array. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "NaagMfi671ci",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "np.argmax(predictions[0])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "aWY4SKYm8h93",
+ "colab_type": "text"
+ },
+ "source": [
+ "And we can check if this is correct by looking at the value of the cooresponding test label."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "xVNepduo8nEy",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "test_labels[0]"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Y8I1EqJu8qRl",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Verifying Predictions\n",
+ "I've written a small function here to help us verify predictions with some simple visuals."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "-HJV4JF789aC",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "COLOR = 'white'\n",
+ "plt.rcParams['text.color'] = COLOR\n",
+ "plt.rcParams['axes.labelcolor'] = COLOR\n",
+ "\n",
+ "def predict(model, image, correct_label):\n",
+ " class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',\n",
+ " 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']\n",
+ " prediction = model.predict(np.array([image]))\n",
+ " predicted_class = class_names[np.argmax(prediction)]\n",
+ "\n",
+ " show_image(image, class_names[correct_label], predicted_class)\n",
+ "\n",
+ "\n",
+ "def show_image(img, label, guess):\n",
+ " plt.figure()\n",
+ " plt.imshow(img, cmap=plt.cm.binary)\n",
+ " plt.title(\"Excpected: \" + label)\n",
+ " plt.xlabel(\"Guess: \" + guess)\n",
+ " plt.colorbar()\n",
+ " plt.grid(False)\n",
+ " plt.show()\n",
+ "\n",
+ "\n",
+ "def get_number():\n",
+ " while True:\n",
+ " num = input(\"Pick a number: \")\n",
+ " if num.isdigit():\n",
+ " num = int(num)\n",
+ " if 0 <= num <= 1000:\n",
+ " return int(num)\n",
+ " else:\n",
+ " print(\"Try again...\")\n",
+ "\n",
+ "num = get_number()\n",
+ "image = test_images[num]\n",
+ "label = test_labels[num]\n",
+ "predict(model, image, label)\n"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1HRzP5hCAijM",
+ "colab_type": "text"
+ },
+ "source": [
+ "And that's pretty much it for an introduction to neural networks!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "PmbcLZZ0lo_2",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Sources\n",
+ "\n",
+ "1. Doshi, Sanket. “Various Optimization Algorithms For Training Neural Network.” Medium, Medium, 10 Mar. 2019, www.medium.com/@sdoshi579/optimizers-for-training-neural-network-59450d71caf6.\n",
+ "\n",
+ "2. “Basic Classification: Classify Images of Clothing : TensorFlow Core.” TensorFlow, www.tensorflow.org/tutorials/keras/classification.\n",
+ "\n",
+ "3. “Gradient Descent¶.” Gradient Descent - ML Glossary Documentation, www.ml-cheatsheet.readthedocs.io/en/latest/gradient_descent.html.\n",
+ "\n",
+ "4. Chollet François. Deep Learning with Python. Manning Publications Co., 2018.\n",
+ "\n",
+ "5. “Keras: The Python Deep Learning Library.” Home - Keras Documentation, www.keras.io/."
+ ]
+ }
+ ]
+}
\ No newline at end of file
diff --git a/Reinforcement_Learning.ipynb b/Reinforcement_Learning.ipynb
new file mode 100644
index 0000000..ac9ff61
--- /dev/null
+++ b/Reinforcement_Learning.ipynb
@@ -0,0 +1,533 @@
+{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "name": "Reinforcement Learning.ipynb",
+ "provenance": [],
+ "collapsed_sections": [],
+ "include_colab_link": true
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ },
+ "accelerator": "GPU"
+ },
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-ADWvu7NKN2r",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Reinforcement Learning\n",
+ "The next and final topic in this course covers *Reinforcement Learning*. This technique is different than many of the other machine learning techniques we have seen earlier and has many applications in training agents (an AI) to interact with enviornments like games. Rather than feeding our machine learning model millions of examples we let our model come up with its own examples by exploring an enviornemt. The concept is simple. Humans learn by exploring and learning from mistakes and past experiences so let's have our computer do the same.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HGCR3JWQLaQb",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Terminology\n",
+ "Before we dive into explaining reinforcement learning we need to define a few key peices of terminology.\n",
+ "\n",
+ "**Enviornemt** In reinforcement learning tasks we have a notion of the enviornment. This is what our *agent* will explore. An example of an enviornment in the case of training an AI to play say a game of mario would be the level we are training the agent on.\n",
+ "\n",
+ "**Agent** an agent is an entity that is exploring the enviornment. Our agent will interact and take different actions within the enviornment. In our mario example the mario character within the game would be our agent. \n",
+ "\n",
+ "**State** always our agent will be in what we call a *state*. The state simply tells us about the status of the agent. The most common example of a state is the location of the agent within the enviornment. Moving locations would change the agents state.\n",
+ "\n",
+ "**Action** any interaction between the agent and enviornment would be considered an action. For example, moving to the left or jumping would be an action. An action may or may not change the current *state* of the agent. In fact, the act of doing nothing is an action as well! The action of say not pressing a key if we are using our mario example.\n",
+ "\n",
+ "**Reward** every action that our agent takes will result in a reward of some magnitude (positive or negative). The goal of our agent will be to maximize its reward in an enviornment. Sometimes the reward will be clear, for example if an agent performs an action which increases their score in the enviornment we could say they've recieved a positive reward. If the agent were to perform an action which results in them losing score or possibly dying in the enviornment then they would recieve a negative reward. \n",
+ "\n",
+ "The most important part of reinforcement learning is determing how to reward the agent. After all, the goal of the agent is to maximize its rewards. This means we should reward the agent appropiatly such that it reaches the desired goal.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "AoOJy9s4ZJJt",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Q-Learning\n",
+ "Now that we have a vague idea of how reinforcement learning works it's time to talk about a specific technique in reinforcement learning called *Q-Learning*.\n",
+ "\n",
+ "Q-Learning is a simple yet quite powerful technique in machine learning that involves learning a matrix of action-reward values. This matrix is often reffered to as a Q-Table or Q-Matrix. The matrix is in shape (number of possible states, number of possible actions) where each value at matrix[n, m] represents the agents expected reward given they are in state n and take action m. The Q-learning algorithm defines the way we update the values in the matrix and decide what action to take at each state. The idea is that after a succesful training/learning of this Q-Table/matrix we can determine the action an agent should take in any state by looking at that states row in the matrix and taking the maximium value column as the action.\n",
+ "\n",
+ "**Consider this example.**\n",
+ "\n",
+ "Let's say A1-A4 are the possible actions and we have 3 states represented by each row (state 1 - state 3).\n",
+ "\n",
+ "| A1 | A2 | A3 | A4 |\n",
+ "|:--: |:--: |:--: |:--: |\n",
+ "| 0 | 0 | 10 | 5 |\n",
+ "| 5 | 10 | 0 | 0 |\n",
+ "| 10 | 5 | 0 | 0 |\n",
+ "\n",
+ "If that was our Q-Table/matrix then the following would be the preffered actions in each state.\n",
+ "\n",
+ "> State 1: A3\n",
+ "\n",
+ "> State 2: A2\n",
+ "\n",
+ "> State 3: A1\n",
+ "\n",
+ "We can see that this is because the values in each of those columns are the highest for those states!\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "u5uLpN1yemTx",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Learning the Q-Table\n",
+ "So that's simple, right? Now how do we create this table and find those values. Well this is where we will dicuss how the Q-Learning algorithm updates the values in our Q-Table. \n",
+ "\n",
+ "I'll start by noting that our Q-Table starts of with all 0 values. This is because the agent has yet to learn anything about the enviornment. \n",
+ "\n",
+ "Our agent learns by exploring the enviornment and observing the outcome/reward from each action it takes in each state. But how does it know what action to take in each state? There are two ways that our agent can decide on which action to take.\n",
+ "1. Randomly picking a valid action\n",
+ "2. Using the current Q-Table to find the best action.\n",
+ "\n",
+ "Near the beginning of our agents learning it will mostly take random actions in order to explore the enviornment and enter many different states. As it starts to explore more of the enviornment it will start to gradually rely more on it's learned values (Q-Table) to take actions. This means that as our agent explores more of the enviornment it will develop a better understanding and start to take \"correct\" or better actions more often. It's important that the agent has a good balance of taking random actions and using learned values to ensure it does get trapped in a local maximum. \n",
+ "\n",
+ "After each new action our agent wil record the new state (if any) that it has entered and the reward that it recieved from taking that action. These values will be used to update the Q-Table. The agent will stop taking new actions only once a certain time limit is reached or it has acheived the goal or reached the end of the enviornment. \n",
+ "\n",
+ "####Updating Q-Values\n",
+ "The formula for updating the Q-Table after each action is as follows:\n",
+ "> $ Q[state, action] = Q[state, action] + \\alpha * (reward + \\gamma * max(Q[newState, :]) - Q[state, action]) $\n",
+ "\n",
+ "- $\\alpha$ stands for the **Learning Rate**\n",
+ "\n",
+ "- $\\gamma$ stands for the **Discount Factor**\n",
+ "\n",
+ "####Learning Rate $\\alpha$\n",
+ "The learning rate $\\alpha$ is a numeric constant that defines how much change is permitted on each QTable update. A high learning rate means that each update will introduce a large change to the current state-action value. A small learning rate means that each update has a more subtle change. Modifying the learning rate will change how the agent explores the enviornment and how quickly it determines the final values in the QTable.\n",
+ "\n",
+ "####Discount Factor $\\gamma$\n",
+ "Discount factor also know as gamma ($\\gamma$) is used to balance how much focus is put on the current and future reward. A high discount factor means that future rewards will be considered more heavily.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "h5cjtsHP8t5Y",
+ "colab_type": "text"
+ },
+ "source": [
+ "#Natural Language Processing \n",
+ "Natural Language Processing (or NLP for short) is a discipline in computing that deals with the communication between natural (human) languages and computer languages. A common example of NLP is something like spellcheck or autocomplete. Essentially NLP is the field that focuses on how computers can understand and/or process natural/human languages. \n",
+ "\n",
+ "###Recurrent Neural Networks\n",
+ "\n",
+ "In this tutorial we will introduce a new kind of neural network that is much more capable of processing sequential data such as text or characters called a **recurrent neural network** (RNN for short). \n",
+ "\n",
+ "We will learn how to use a reccurent neural network to do the following:\n",
+ "- Sentiment Analysis\n",
+ "- Character Generation \n",
+ "\n",
+ "RNN's are complex and come in many different forms so in this tutorial we wil focus on how they work and the kind of problems they are best suited for.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ur_FQq-Q-fxC",
+ "colab_type": "text"
+ },
+ "source": [
+ "## Sequence Data\n",
+ "In the previous tutorials we focused on data that we could represent as one static data point where the notion of time or step was irrelevant. Take for example our image data, it was simply a tensor of shape (width, height, channels). That data doesn't change or care about the notion of time. \n",
+ "\n",
+ "In this tutorial we will look at sequences of text and learn how we can encode them in a meaningful way. Unlike images, sequence data such as long chains of text, weather patterns, videos and really anything where the notion of a step or time is relevant needs to be processed and handled in a special way. \n",
+ "\n",
+ "But what do I mean by sequences and why is text data a sequence? Well that's a good question. Since textual data contains many words that follow in a very specific and meaningful order, we need to be able to keep track of each word and when it occurs in the data. Simply encoding say an entire paragraph of text into one data point wouldn't give us a very meaningful picture of the data and would be very difficult to do anything with. This is why we treat text as a sequence and process one word at a time. We will keep track of where each of these words appear and use that information to try to understand the meaning of peices of text.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8gQHK4V4e2wl",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Encoding Text\n",
+ "As we know machine learning models and neural networks don't take raw text data as an input. This means we must somehow encode our textual data to numeric values that our models can understand. There are many different ways of doing this and we will look at a few examples below. \n",
+ "\n",
+ "Before we get into the different encoding/preprocessing methods let's understand the information we can get from textual data by looking at the following two movie reviews.\n",
+ "\n",
+ "```I thought the movie was going to be bad, but it was actually amazing!```\n",
+ "\n",
+ "```I thought the movie was going to be amazing, but it was actually bad!```\n",
+ "\n",
+ "Although these two setences are very similar we know that they have very different meanings. This is because of the **ordering** of words, a very important property of textual data.\n",
+ "\n",
+ "Now keep that in mind while we consider some different ways of encoding our textual data.\n",
+ "\n",
+ "###Bag of Words\n",
+ "The first and simplest way to encode our data is to use something called **bag of words**. This is a pretty easy technique where each word in a sentence is encoded with an integer and thrown into a collection that does not maintain the order of the words but does keep track of the frequency. Have a look at the python function below that encodes a string of text into bag of words. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "5KiCCBsIkMHi",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "vocab = {} # maps word to integer representing it\n",
+ "word_encoding = 1\n",
+ "def bag_of_words(text):\n",
+ " global word_encoding\n",
+ "\n",
+ " words = text.lower().split(\" \") # create a list of all of the words in the text, well assume there is no grammar in our text for this example\n",
+ " bag = {} # stores all of the encodings and their frequency\n",
+ "\n",
+ " for word in words:\n",
+ " if word in vocab:\n",
+ " encoding = vocab[word] # get encoding from vocab\n",
+ " else:\n",
+ " vocab[word] = word_encoding\n",
+ " encoding = word_encoding\n",
+ " word_encoding += 1\n",
+ " \n",
+ " if encoding in bag:\n",
+ " bag[encoding] += 1\n",
+ " else:\n",
+ " bag[encoding] = 1\n",
+ " \n",
+ " return bag\n",
+ "\n",
+ "text = \"this is a test to see if this test will work is is test a a\"\n",
+ "bag = bag_of_words(text)\n",
+ "print(bag)\n",
+ "print(vocab)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4hEvstSBl1gy",
+ "colab_type": "text"
+ },
+ "source": [
+ "This isn't really the way we would do this in practice, but I hope it gives you an idea of how bag of words works. Notice that we've lost the order in which words appear. In fact, let's look at how this encoding works for the two sentences we showed above.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "miYshfvzmJ0H",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "positive_review = \"I thought the movie was going to be bad but it was actually amazing\"\n",
+ "negative_review = \"I thought the movie was going to be amazing but it was actually bad\"\n",
+ "\n",
+ "pos_bag = bag_of_words(positive_review)\n",
+ "neg_bag = bag_of_words(negative_review)\n",
+ "\n",
+ "print(\"Positive:\", pos_bag)\n",
+ "print(\"Negative:\", neg_bag)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pl7Fw9s3mkfK",
+ "colab_type": "text"
+ },
+ "source": [
+ "We can see that even though these sentences have a very different meaning they are encoded exaclty the same way. Obviously, this isn't going to fly. Let's look at some other methods.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "DUKTycffmu1k",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Integer Encoding\n",
+ "The next technique we will look at is called **integer encoding**. This involves representing each word or character in a sentence as a unique integer and maintaining the order of these words. This should hopefully fix the problem we saw before were we lost the order of words.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "MKY4y_tjnUEW",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "vocab = {} \n",
+ "word_encoding = 1\n",
+ "def one_hot_encoding(text):\n",
+ " global word_encoding\n",
+ "\n",
+ " words = text.lower().split(\" \") \n",
+ " encoding = [] \n",
+ "\n",
+ " for word in words:\n",
+ " if word in vocab:\n",
+ " code = vocab[word] \n",
+ " encoding.append(code) \n",
+ " else:\n",
+ " vocab[word] = word_encoding\n",
+ " encoding.append(word_encoding)\n",
+ " word_encoding += 1\n",
+ " \n",
+ " return encoding\n",
+ "\n",
+ "text = \"this is a test to see if this test will work is is test a a\"\n",
+ "encoding = one_hot_encoding(text)\n",
+ "print(encoding)\n",
+ "print(vocab)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TOrLG9Bin0Zv",
+ "colab_type": "text"
+ },
+ "source": [
+ "And now let's have a look at one hot encoding on our movie reviews."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "1S-GNjotn-Br",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "positive_review = \"I thought the movie was going to be bad but it was actually amazing\"\n",
+ "negative_review = \"I thought the movie was going to be amazing but it was actually bad\"\n",
+ "\n",
+ "pos_encode = one_hot_encoding(positive_review)\n",
+ "neg_encode = one_hot_encoding(negative_review)\n",
+ "\n",
+ "print(\"Positive:\", pos_encode)\n",
+ "print(\"Negative:\", neg_encode)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jC9UYV4vpq6Y",
+ "colab_type": "text"
+ },
+ "source": [
+ "Much better, now we are keeping track of the order of words and we can tell where each occurs. But this still has a few issues with it. Ideally when we encode words, we would like similar words to have similar labels and different words to have very different labels. For example, the words happy and joyful should probably have very similar labels so we can determine that they are similar. While words like horrible and amazing should probably have very different labels. The method we looked at above won't be able to do something like this for us. This could mean that the model will have a very difficult time determing if two words are similar or not which could result in some pretty drastic performace impacts.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JRZ73YCqqiw9",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Word Embeddings\n",
+ "Luckily there is a third method that is far superior, **word embeddings**. This method keeps the order of words intact as well as encodes similar words with very similar labels. It attempts to not only encode the frequency and order of words but the meaning of those words in the sentence. It encodes each word as a dense vector that represents its context in the sentence.\n",
+ "\n",
+ "Unlike the previous techniques word embeddings are learned by looking at many different training examples. You can add what's called an *embedding layer* to the beggining of your model and while your model trains your embedding layer will learn the correct embeddings for words. You can also use pretrained embedding layers.\n",
+ "\n",
+ "This is the technique we will use for our examples and its implementation will be showed later on.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ehig3qliuUzk",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Recurrent Neural Networks (RNN's)\n",
+ "Now that we've learned a little bit about how we can encode text it's time to dive into recurrent neural networks. Up until this point we have been using something called **feed-forward** neural networks. This simply means that all our data is fed forwards (all at once) from left to right through the network. This was fine for the problems we considered before but won't work very well for processing text. After all, even we (humans) don't process text all at once. We read word by word from left to right and keep track of the current meaning of the sentence so we can understand the meaning of the next word. Well this is exaclty what a recurrent neural network is designed to do. When we say recurrent neural network all we really mean is a network that contains a loop. A RNN will process one word at a time while maintaining an internal memory of what it's already seen. This will allow it to treat words differently based on their order in a sentence and to slowly build an understanding of the entire input, one word at a time.\n",
+ "\n",
+ "This is why we are treating our text data as a sequence! So that we can pass one word at a time to the RNN.\n",
+ "\n",
+ "Let's have a look at what a recurrent layer might look like.\n",
+ "\n",
+ "\n",
+ "*Source: https://colah.github.io/posts/2015-08-Understanding-LSTMs/*\n",
+ "\n",
+ "Let's define what all these variables stand for before we get into the explination.\n",
+ "\n",
+ "**ht** output at time t\n",
+ "\n",
+ "**xt** input at time t\n",
+ "\n",
+ "**A** Recurrent Layer (loop)\n",
+ "\n",
+ "What this diagram is trying to illustrate is that a recurrent layer processes words or input one at a time in a combination with the output from the previous iteration. So, as we progress further in the input sequence, we build a more complex understanding of the text as a whole.\n",
+ "\n",
+ "What we've just looked at is called a **simple RNN layer**. It can be effective at processing shorter sequences of text for simple problems but has many downfalls associated with it. One of them being the fact that as text sequences get longer it gets increasingly difficult for the network to understand the text properly.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Fo3WY-e86zX2",
+ "colab_type": "text"
+ },
+ "source": [
+ "##LSTM\n",
+ "The layer we dicussed in depth above was called a *simpleRNN*. However, there does exist some other recurrent layers (layers that contain a loop) that work much better than a simple RNN layer. The one we will talk about here is called LSTM (Long Short-Term Memory). This layer works very similarily to the simpleRNN layer but adds a way to access inputs from any timestep in the past. Whereas in our simple RNN layer input from previous timestamps gradually disappeared as we got further through the input. With a LSTM we have a long-term memory data structure storing all the previously seen inputs as well as when we saw them. This allows for us to access any previous value we want at any point in time. This adds to the complexity of our network and allows it to discover more useful relationships between inputs and when they appear. \n",
+ "\n",
+ "For the purpose of this course we will refrain from going any further into the math or details behind how these layers work.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CRGOx6_v4eZ_",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Sentiment Analysis\n",
+ "And now time to see a recurrent neural network in action. For this example, we are going to do something called sentiment analysis.\n",
+ "\n",
+ "The formal definition of this term from Wikipedia is as follows:\n",
+ "\n",
+ "*the process of computationally identifying and categorizing opinions expressed in a piece of text, especially in order to determine whether the writer's attitude towards a particular topic, product, etc. is positive, negative, or neutral.*\n",
+ "\n",
+ "The example we’ll use here is classifying movie reviews as either postive, negative or neutral.\n",
+ "\n",
+ "*This guide is based on the following tensorflow tutorial: https://www.tensorflow.org/tutorials/text/text_classification_rnn*\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "RACGE5Ypt5u9",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Movie Review Dataset\n",
+ "Well start by loading in the IMDB movie review dataset from keras. This dataset contains 25,000 reviews from IMDB where each one is already preprocessed and has a label as either positive or negative. Each review is encoded by integers that represents how common a word is in the entire dataset. For example, a word encoded by the integer 3 means that it is the 3rd most common word in the dataset.\n",
+ " \n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "pdsus1kyXWC8",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "%tensorflow_version 2.x # this line is not required unless you are in a notebook\n",
+ "from keras.datasets import imdb\n",
+ "from keras.preprocessing import sequence\n",
+ "import keras\n",
+ "import tensorflow as tf\n",
+ "import os\n",
+ "import numpy as np\n",
+ "\n",
+ "VOCAB_SIZE = 88584\n",
+ "\n",
+ "MAXLEN = 250\n",
+ "BATCH_SIZE = 64\n",
+ "\n",
+ "(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = VOCAB_SIZE)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Wh6lOpcQ9sIZ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# Lets look at one review\n",
+ "train_data[1]"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "EAtZHE9-eQ07",
+ "colab_type": "text"
+ },
+ "source": [
+ "###More Preprocessing\n",
+ "If we have a look at some of our loaded in reviews, we'll notice that they are different lengths. This is an issue. We cannot pass different length data into our neural network. Therefore, we must make each review the same length. To do this we will follow the procedure below:\n",
+ "- if the review is greater than 250 words then trim off the extra words\n",
+ "- if the review is less than 250 words add the necessary amount of 0's to make it equal to 250.\n",
+ "\n",
+ "Luckily for us keras has a function that can do this for us:\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Z3qQ83sNeog6",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "train_data = sequence.pad_sequences(train_data, MAXLEN)\n",
+ "test_data = sequence.pad_sequences(test_data, MAXLEN)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mDm_0RTVir7I",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Creating the Model\n",
+ "Now it's time to create the model. We'll use a word embedding layer as the first layer in our model and add a LSTM layer afterwards that feeds into a dense node to get our predicted sentiment. \n",
+ "\n",
+ "32 stands for the output dimension of the vectors generated by the embedding layer. We can change this value if we'd like!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "OWGGcBIpjrMu",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model = tf.keras.Sequential([\n",
+ " tf.keras.layers.Embedding(VOCAB_SIZE, 32),\n",
+ " tf.keras.layers.LSTM(32),\n",
+ " tf.keras.layers.Dense(1, activation=\"sigmoid\")\n",
+ "])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "O8_jPL_Kkr-a",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.summary()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eyeQCk3LlK6V",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Training\n",
+ "Now it's time to compile and train the model. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "KKEMjaIulPBe",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.compile(loss=\"binary_crossentropy\",optimizer=\"rmsprop\",metrics=['acc'])\n",
+ "\n",
+ "history = model.fit(train_data, train_labels, epochs=10, validation_split=0.2)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3buYlkkhoK93",
+ "colab_type": "text"
+ },
+ "source": [
+ "And we'll evaluate the model on our training data to see how well it performs."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "KImNMWTDoJaQ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "results = model.evaluate(test_data, test_labels)\n",
+ "print(results)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "N1RRGcr9CFCW",
+ "colab_type": "text"
+ },
+ "source": [
+ "So we're scoring somewhere in the mid-high 80's. Not bad for a simple recurrent network."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "lGrBRC4YCObV",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Making Predictions\n",
+ "Now let’s use our network to make predictions on our own reviews. \n",
+ "\n",
+ "Since our reviews are encoded well need to convert any review that we write into that form so the network can understand it. To do that well load the encodings from the dataset and use them to encode our own data.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Onu8leY4Cn9z",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "word_index = imdb.get_word_index()\n",
+ "\n",
+ "def encode_text(text):\n",
+ " tokens = keras.preprocessing.text.text_to_word_sequence(text)\n",
+ " tokens = [word_index[word] if word in word_index else 0 for word in tokens]\n",
+ " return sequence.pad_sequences([tokens], MAXLEN)[0]\n",
+ "\n",
+ "text = \"that movie was just amazing, so amazing\"\n",
+ "encoded = encode_text(text)\n",
+ "print(encoded)\n"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "PKna3vxmFwrB",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# while were at it lets make a decode function\n",
+ "\n",
+ "reverse_word_index = {value: key for (key, value) in word_index.items()}\n",
+ "\n",
+ "def decode_integers(integers):\n",
+ " PAD = 0\n",
+ " text = \"\"\n",
+ " for num in integers:\n",
+ " if num != PAD:\n",
+ " text += reverse_word_index[num] + \" \"\n",
+ "\n",
+ " return text[:-1]\n",
+ " \n",
+ "print(decode_integers(encoded))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "L8nyrr00HPZF",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# now time to make a prediction\n",
+ "\n",
+ "def predict(text):\n",
+ " encoded_text = encode_text(text)\n",
+ " pred = np.zeros((1,250))\n",
+ " pred[0] = encoded_text\n",
+ " result = model.predict(pred) \n",
+ " print(result[0])\n",
+ "\n",
+ "positive_review = \"That movie was! really loved it and would great watch it again because it was amazingly great\"\n",
+ "predict(positive_review)\n",
+ "\n",
+ "negative_review = \"that movie really sucked. I hated it and wouldn't watch it again. Was one of the worst things I've ever watched\"\n",
+ "predict(negative_review)\n"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "01BJLcGb4ZqK",
+ "colab_type": "text"
+ },
+ "source": [
+ "##RNN Play Generator\n",
+ "\n",
+ "Now time for one of the coolest examples we've seen so far. We are going to use a RNN to generate a play. We will simply show the RNN an example of something we want it to recreate and it will learn how to write a version of it on its own. We'll do this using a character predictive model that will take as input a variable length sequence and predict the next character. We can use the model many times in a row with the output from the last predicition as the input for the next call to generate a sequence.\n",
+ "\n",
+ "\n",
+ "*This guide is based on the following: https://www.tensorflow.org/tutorials/text/text_generation*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "fju7i1FKrK_G",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "%tensorflow_version 2.x # this line is not required unless you are in a notebook\n",
+ "from keras.preprocessing import sequence\n",
+ "import keras\n",
+ "import tensorflow as tf\n",
+ "import os\n",
+ "import numpy as np"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "F48c-EctQ378",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Dataset\n",
+ "For this example, we only need one peice of training data. In fact, we can write our own poem or play and pass that to the network for training if we'd like. However, to make things easy we'll use an extract from a shakesphere play.\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "IdRcVIhtRGlF",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NlSVGd5ACkZe",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Loading Your Own Data\n",
+ "To load your own data, you'll need to upload a file from the dialog below. Then you'll need to follow the steps from above but load in this new file instead.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "CFYFwbJOC3bP",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "from google.colab import files\n",
+ "path_to_file = list(files.upload().keys())[0]"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KtJMEqQyRhAk",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Read Contents of File\n",
+ "Let's look at the contents of the file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "-n4oovOMRnP7",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# Read, then decode for py2 compat.\n",
+ "text = open(path_to_file, 'rb').read().decode(encoding='utf-8')\n",
+ "# length of text is the number of characters in it\n",
+ "print ('Length of text: {} characters'.format(len(text)))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "KHUxQVl7Rt10",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# Take a look at the first 250 characters in text\n",
+ "print(text[:250])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5vt8Vpe0RvaJ",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Encoding\n",
+ "Since this text isn't encoded yet well need to do that ourselves. We are going to encode each unique character as a different integer.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "C7AZNI7aRz6y",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "vocab = sorted(set(text))\n",
+ "# Creating a mapping from unique characters to indices\n",
+ "char2idx = {u:i for i, u in enumerate(vocab)}\n",
+ "idx2char = np.array(vocab)\n",
+ "\n",
+ "def text_to_int(text):\n",
+ " return np.array([char2idx[c] for c in text])\n",
+ "\n",
+ "text_as_int = text_to_int(text)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "_i5kvmX_SLW4",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# lets look at how part of our text is encoded\n",
+ "print(\"Text:\", text[:13])\n",
+ "print(\"Encoded:\", text_to_int(text[:13]))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "mDvD5kqTWwOn",
+ "colab_type": "text"
+ },
+ "source": [
+ "And here we will make a function that can convert our numeric values to text.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Af52YChSW5hX",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "def int_to_text(ints):\n",
+ " try:\n",
+ " ints = ints.numpy()\n",
+ " except:\n",
+ " pass\n",
+ " return ''.join(idx2char[ints])\n",
+ "\n",
+ "print(int_to_text(text_as_int[:13]))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "T_49cl6uS0r-",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Creating Training Examples\n",
+ "Remember our task is to feed the model a sequence and have it return to us the next character. This means we need to split our text data from above into many shorter sequences that we can pass to the model as training examples. \n",
+ "\n",
+ "The training examples we will prepapre will use a *seq_length* sequence as input and a *seq_length* sequence as the output where that sequence is the original sequence shifted one letter to the right. For example:\n",
+ "\n",
+ "```input: Hell | output: ello```\n",
+ "\n",
+ "Our first step will be to create a stream of characters from our text data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "xBkXz9fjUQHW",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "seq_length = 100 # length of sequence for a training example\n",
+ "examples_per_epoch = len(text)//(seq_length+1)\n",
+ "\n",
+ "# Create training examples / targets\n",
+ "char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "pqmxfT7gVGlr",
+ "colab_type": "text"
+ },
+ "source": [
+ "Next we can use the batch method to turn this stream of characters into batches of desired length."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Xi0xaPB_VOJl",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "sequences = char_dataset.batch(seq_length+1, drop_remainder=True)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "fxo1Dig_VvV1",
+ "colab_type": "text"
+ },
+ "source": [
+ "Now we need to use these sequences of length 101 and split them into input and output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "03zKVHTvV0Km",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "def split_input_target(chunk): # for the example: hello\n",
+ " input_text = chunk[:-1] # hell\n",
+ " target_text = chunk[1:] # ello\n",
+ " return input_text, target_text # hell, ello\n",
+ "\n",
+ "dataset = sequences.map(split_input_target) # we use map to apply the above function to every entry"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "9p_y2YmgWbnc",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "for x, y in dataset.take(2):\n",
+ " print(\"\\n\\nEXAMPLE\\n\")\n",
+ " print(\"INPUT\")\n",
+ " print(int_to_text(x))\n",
+ " print(\"\\nOUTPUT\")\n",
+ " print(int_to_text(y))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "v6OxuFKVXpwK",
+ "colab_type": "text"
+ },
+ "source": [
+ "Finally we need to make training batches."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "cRsKcjhXXuoD",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "BATCH_SIZE = 64\n",
+ "VOCAB_SIZE = len(vocab) # vocab is number of unique characters\n",
+ "EMBEDDING_DIM = 256\n",
+ "RNN_UNITS = 1024\n",
+ "\n",
+ "# Buffer size to shuffle the dataset\n",
+ "# (TF data is designed to work with possibly infinite sequences,\n",
+ "# so it doesn't attempt to shuffle the entire sequence in memory. Instead,\n",
+ "# it maintains a buffer in which it shuffles elements).\n",
+ "BUFFER_SIZE = 10000\n",
+ "\n",
+ "data = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "E6YRmZLtX0d0",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Building the Model\n",
+ "Now it is time to build the model. We will use an embedding layer a LSTM and one dense layer that contains a node for each unique character in our training data. The dense layer will give us a probability distribution over all nodes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "5v_P2dEic4qt",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "def build_model(vocab_size, embedding_dim, rnn_units, batch_size):\n",
+ " model = tf.keras.Sequential([\n",
+ " tf.keras.layers.Embedding(vocab_size, embedding_dim,\n",
+ " batch_input_shape=[batch_size, None]),\n",
+ " tf.keras.layers.LSTM(rnn_units,\n",
+ " return_sequences=True,\n",
+ " stateful=True,\n",
+ " recurrent_initializer='glorot_uniform'),\n",
+ " tf.keras.layers.Dense(vocab_size)\n",
+ " ])\n",
+ " return model\n",
+ "\n",
+ "model = build_model(VOCAB_SIZE,EMBEDDING_DIM, RNN_UNITS, BATCH_SIZE)\n",
+ "model.summary()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8gfnHBUOvPqE",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Creating a Loss Function\n",
+ "Now we are going to create our own loss function for this problem. This is because our model will output a (64, sequence_length, 65) shaped tensor that represents the probability distribution of each character at each timestep for every sequence in the batch. \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "g_ERM4F15v_S",
+ "colab_type": "text"
+ },
+ "source": [
+ "However, before we do that let's have a look at a sample input and the output from our untrained model. This is so we can understand what the model is giving us.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "KdvEqlwc6_q0",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "for input_example_batch, target_example_batch in data.take(1):\n",
+ " example_batch_predictions = model(input_example_batch) # ask our model for a prediction on our first batch of training data (64 entries)\n",
+ " print(example_batch_predictions.shape, \"# (batch_size, sequence_length, vocab_size)\") # print out the output shape"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "RQS5KXwi7_NX",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# we can see that the predicition is an array of 64 arrays, one for each entry in the batch\n",
+ "print(len(example_batch_predictions))\n",
+ "print(example_batch_predictions)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "sA1Zhop28V9n",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# lets examine one prediction\n",
+ "pred = example_batch_predictions[0]\n",
+ "print(len(pred))\n",
+ "print(pred)\n",
+ "# notice this is a 2d array of length 100, where each interior array is the prediction for the next character at each time step"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "UbIoe7Ei8q3q",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# and finally well look at a prediction at the first timestep\n",
+ "time_pred = pred[0]\n",
+ "print(len(time_pred))\n",
+ "print(time_pred)\n",
+ "# and of course its 65 values representing the probabillity of each character occuring next"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "qlEYM1H995gR",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# If we want to determine the predicted character we need to sample the output distribution (pick a value based on probabillity)\n",
+ "sampled_indices = tf.random.categorical(pred, num_samples=1)\n",
+ "\n",
+ "# now we can reshape that array and convert all the integers to numbers to see the actual characters\n",
+ "sampled_indices = np.reshape(sampled_indices, (1, -1))[0]\n",
+ "predicted_chars = int_to_text(sampled_indices)\n",
+ "\n",
+ "predicted_chars # and this is what the model predicted for training sequence 1"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qcCBfPjN9Cnp",
+ "colab_type": "text"
+ },
+ "source": [
+ "So now we need to create a loss function that can compare that output to the expected output and give us some numeric value representing how close the two were. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "ZOw23fWq9D9O",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "def loss(labels, logits):\n",
+ " return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "kcg75GwXgW81",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Compiling the Model\n",
+ "At this point we can think of our problem as a classification problem where the model predicts the probabillity of each unique letter coming next. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "9g6o7zA_hAiS",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.compile(optimizer='adam', loss=loss)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YgDKr4yvjLPI",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Creating Checkpoints\n",
+ "Now we are going to setup and configure our model to save checkpoinst as it trains. This will allow us to load our model from a checkpoint and continue training it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "v7aMushYjSpy",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# Directory where the checkpoints will be saved\n",
+ "checkpoint_dir = './training_checkpoints'\n",
+ "# Name of the checkpoint files\n",
+ "checkpoint_prefix = os.path.join(checkpoint_dir, \"ckpt_{epoch}\")\n",
+ "\n",
+ "checkpoint_callback=tf.keras.callbacks.ModelCheckpoint(\n",
+ " filepath=checkpoint_prefix,\n",
+ " save_weights_only=True)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0p7acPvGja5c",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Training\n",
+ "Finally, we will start training the model. \n",
+ "\n",
+ "**If this is taking a while go to Runtime > Change Runtime Type and choose \"GPU\" under hardware accelerator.**\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "R4PAgrwMjZ4_",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "history = model.fit(data, epochs=50, callbacks=[checkpoint_callback])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "9GhoHJVtmTsz",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Loading the Model\n",
+ "We'll rebuild the model from a checkpoint using a batch_size of 1 so that we can feed one peice of text to the model and have it make a prediction."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "TPSto3uimSKp",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model = build_model(VOCAB_SIZE, EMBEDDING_DIM, RNN_UNITS, batch_size=1)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "boEJvy_vjLJQ",
+ "colab_type": "text"
+ },
+ "source": [
+ "Once the model is finished training, we can find the **lastest checkpoint** that stores the models weights using the following line.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "PZIEZWE4mNKl",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))\n",
+ "model.build(tf.TensorShape([1, None]))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CmPPtbaTKF8d",
+ "colab_type": "text"
+ },
+ "source": [
+ "We can load **any checkpoint** we want by specifying the exact file to load."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "YQ_5p0ehKFDn",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "checkpoint_num = 10\n",
+ "model.load_weights(tf.train.load_checkpoint(\"./training_checkpoints/ckpt_\" + str(checkpoint_num)))\n",
+ "model.build(tf.TensorShape([1, None]))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KaZWalEeAxQN",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Generating Text\n",
+ "Now we can use the lovely function provided by tensorflow to generate some text using any starting string we'd like."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "oPSALdQXA3l3",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "def generate_text(model, start_string):\n",
+ " # Evaluation step (generating text using the learned model)\n",
+ "\n",
+ " # Number of characters to generate\n",
+ " num_generate = 800\n",
+ "\n",
+ " # Converting our start string to numbers (vectorizing)\n",
+ " input_eval = [char2idx[s] for s in start_string]\n",
+ " input_eval = tf.expand_dims(input_eval, 0)\n",
+ "\n",
+ " # Empty string to store our results\n",
+ " text_generated = []\n",
+ "\n",
+ " # Low temperatures results in more predictable text.\n",
+ " # Higher temperatures results in more surprising text.\n",
+ " # Experiment to find the best setting.\n",
+ " temperature = 1.0\n",
+ "\n",
+ " # Here batch size == 1\n",
+ " model.reset_states()\n",
+ " for i in range(num_generate):\n",
+ " predictions = model(input_eval)\n",
+ " # remove the batch dimension\n",
+ " \n",
+ " predictions = tf.squeeze(predictions, 0)\n",
+ "\n",
+ " # using a categorical distribution to predict the character returned by the model\n",
+ " predictions = predictions / temperature\n",
+ " predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()\n",
+ "\n",
+ " # We pass the predicted character as the next input to the model\n",
+ " # along with the previous hidden state\n",
+ " input_eval = tf.expand_dims([predicted_id], 0)\n",
+ "\n",
+ " text_generated.append(idx2char[predicted_id])\n",
+ "\n",
+ " return (start_string + ''.join(text_generated))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "cAJqhD9AA5mF",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "inp = input(\"Type a starting string: \")\n",
+ "print(generate_text(model, inp))"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "CBjHrzzyOBVr",
+ "colab_type": "text"
+ },
+ "source": [
+ "*And* that's pretty much it for this module! I highly reccomend messing with the model we just created and seeing what you can get it to do!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Cw-1eDE54yQo",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Sources\n",
+ "\n",
+ "1. Chollet François. Deep Learning with Python. Manning Publications Co., 2018.\n",
+ "2. “Text Classification with an RNN : TensorFlow Core.” TensorFlow, www.tensorflow.org/tutorials/text/text_classification_rnn.\n",
+ "3. “Text Generation with an RNN : TensorFlow Core.” TensorFlow, www.tensorflow.org/tutorials/text/text_generation.\n",
+ "4. “Understanding LSTM Networks.” Understanding LSTM Networks -- Colah's Blog, https://colah.github.io/posts/2015-08-Understanding-LSTMs/."
+ ]
+ }
+ ]
+}
\ No newline at end of file
diff --git a/Neural_Networks.ipynb b/Neural_Networks.ipynb
new file mode 100644
index 0000000..f0ec0cd
--- /dev/null
+++ b/Neural_Networks.ipynb
@@ -0,0 +1,826 @@
+{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "name": "Neural Networks.ipynb",
+ "provenance": [],
+ "collapsed_sections": [],
+ "include_colab_link": true
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ }
+ },
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "jqVqT_Cxh4Ho",
+ "colab_type": "text"
+ },
+ "source": [
+ "#Introduction to Neural Networks\n",
+ "In this notebook you will learn how to create and use a neural network to classify articles of clothing. To achieve this, we will use a sub module of TensorFlow called *keras*.\n",
+ "\n",
+ "*This guide is based on the following TensorFlow documentation.*\n",
+ "\n",
+ "https://www.tensorflow.org/tutorials/keras/classification\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZFQqW9r-ikJb",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Keras\n",
+ "Before we dive in and start discussing neural networks, I'd like to give a breif introduction to keras.\n",
+ "\n",
+ "From the keras official documentation (https://keras.io/) keras is described as follows.\n",
+ "\n",
+ "\"Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It was developed with a focus on enabling fast experimentation. \n",
+ "\n",
+ "Use Keras if you need a deep learning library that:\n",
+ "\n",
+ "- Allows for easy and fast prototyping (through user friendliness, modularity, and extensibility).\n",
+ "- Supports both convolutional networks and recurrent networks, as well as combinations of the two.\n",
+ "- Runs seamlessly on CPU and GPU.\"\n",
+ "\n",
+ "Keras is a very powerful module that allows us to avoid having to build neural networks from scratch. It also hides a lot of mathematical complexity (that otherwise we would have to implement) inside of helpful packages, modules and methods.\n",
+ "\n",
+ "In this guide we will use keras to quickly develop neural networks.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Hivk879ZQhxU",
+ "colab_type": "text"
+ },
+ "source": [
+ "##What is a Neural Network\n",
+ "So, what are these magical things that have been beating chess grandmasters, driving cars, detecting cancer cells and winning video games? \n",
+ "\n",
+ "A deep neural network is a layered representation of data. The term \"deep\" refers to the presence of multiple layers. Recall that in our core learning algorithms (like linear regression) data was not transformed or modified within the model, it simply existed in one layer. We passed some features to our model, some math was done, an answer was returned. The data was not changed or transformed throughout this process. A neural network processes our data differently. It attempts to represent our data in different ways and in different dimensions by applying specific operations to transform our data at each layer. Another way to express this is that at each layer our data is transformed in order to learn more about it. By performing these transformations, the model can better understand our data and therefore provide a better prediction. \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GOqUCZ2klTAq",
+ "colab_type": "text"
+ },
+ "source": [
+ "##How it Works\n",
+ "Before going into too much detail I will provide a very surface level explination of how neural networks work on a mathematical level. All the terms and concepts I discuss will be defined and explained in more detail below.\n",
+ "\n",
+ "On a lower level neural networks are simply a combination of elementry math operations and some more advanced linear algebra. Each neural network consists of a sequence of layers in which data passes through. These layers are made up on neurons and the neurons of one layer are connected to the next (see below). These connections are defined by what we call a weight (some numeric value). Each layer also has something called a bias, this is simply an extra neuron that has no connections and holds a single numeric value. Data starts at the input layer and is trasnformed as it passes through subsequent layers. The data at each subsequent neuron is defined as the following.\n",
+ "\n",
+ "> $Y =(\\sum_{i=0}^n w_i x_i) + b$\n",
+ "\n",
+ "> $w$ stands for the weight of each connection to the neuron\n",
+ "\n",
+ "> $x$ stands for the value of the connected neuron from the previous value\n",
+ "\n",
+ "> $b$ stands for the bias at each layer, this is a constant\n",
+ "\n",
+ "> $n$ is the number of connections\n",
+ "\n",
+ "> $Y$ is the output of the current neuron\n",
+ "\n",
+ "> $\\sum$ stands for sum\n",
+ "\n",
+ "The equation you just read is called a weighed sum. We will take this weighted sum at each and every neuron as we pass information through the network. Then we will add what's called a bias to this sum. The bias allows us to shift the network up or down by a constant value. It is like the y-intercept of a line.\n",
+ "\n",
+ "But that equation is the not complete one! We forgot a crucial part, **the activation function**. This is a function that we apply to the equation seen above to add complexity and dimensionality to our network. Our new equation with the addition of an activation function $F(x)$ is seen below.\n",
+ "\n",
+ "> $Y =F((\\sum_{i=0}^n w_i x_i) + b)$\n",
+ "\n",
+ "Our network will start with predefined activation functions (they may be different at each layer) but random weights and biases. As we train the network by feeding it data it will learn the correct weights and biases and adjust the network accordingly using a technqiue called **backpropagation** (explained below). Once the correct weights and biases have been learned our network will hopefully be able to give us meaningful predictions. We get these predictions by observing the values at our final layer, the output layer. \n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "o-oMh18_j5kl",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Breaking Down The Neural Network!\n",
+ "\n",
+ "Before we dive into any code lets break down how a neural network works and what it does.\n",
+ "\n",
+ "\n",
+ "*Figure 1*\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-9hd-R1ulSdp",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Data\n",
+ "The type of data a neural network processes varies drastically based on the problem being solved. When we build a neural network, we define what shape and kind of data it can accept. It may sometimes be neccessary to modify our dataset so that it can be passed to our neural network. \n",
+ "\n",
+ "Some common types of data a neural network uses are listed below.\n",
+ "- Vector Data (2D)\n",
+ "- Timeseries or Sequence (3D)\n",
+ "- Image Data (4D)\n",
+ "- Video Data (5D)\n",
+ "\n",
+ "There are of course many different types or data, but these are the main categories.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Xyxxs7oMlWtz",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Layers\n",
+ "As we mentioned earlier each neural network consists of multiple layers. At each layer a different transformation of data occurs. Our initial input data is fed through the layers and eventually arrives at the output layer where we will obtain the result.\n",
+ "####Input Layer\n",
+ "The input layer is the layer that our initial data is passed to. It is the first layer in our neural network.\n",
+ "####Output Layer\n",
+ "The output layer is the layer that we will retrive our results from. Once the data has passed through all other layers it will arrive here.\n",
+ "####Hidden Layer(s)\n",
+ "All the other layers in our neural network are called \"hidden layers\". This is because they are hidden to us, we cannot observe them. Most neural networks consist of at least one hidden layer but can have an unlimited amount. Typically, the more complex the model the more hidden layers.\n",
+ "####Neurons\n",
+ "Each layer is made up of what are called neurons. Neurons have a few different properties that we will discuss later. The important aspect to understand now is that each neuron is responsible for generating/holding/passing ONE numeric value. \n",
+ "\n",
+ "This means that in the case of our input layer it will have as many neurons as we have input information. For example, say we want to pass an image that is 28x28 pixels, thats 784 pixels. We would need 784 neurons in our input layer to capture each of these pixels. \n",
+ "\n",
+ "This also means that our output layer will have as many neurons as we have output information. The output is a little more complicated to understand so I'll refrain from an example right now but hopefully you're getting the idea.\n",
+ "\n",
+ "But what about our hidden layers? Well these have as many neurons as we decide. We'll discuss how we can pick these values later but understand a hidden layer can have any number of neurons.\n",
+ "####Connected Layers\n",
+ "So how are all these layers connected? Well the neurons in one layer will be connected to neurons in the subsequent layer. However, the neurons can be connected in a variety of different ways. \n",
+ "\n",
+ "Take for example *Figure 1* (look above). Each neuron in one layer is connected to every neuron in the next layer. This is called a **dense** layer. There are many other ways of connecting layers but well discuss those as we see them. \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "a_bM6nQ-PZBY",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Weights\n",
+ "Weights are associated with each connection in our neural network. Every pair of connected nodes will have one weight that denotes the strength of the connection between them. These are vital to the inner workings of a neural network and will be tweaked as the neural network is trained. The model will try to determine what these weights should be to achieve the best result. Weights start out at a constant or random value and will change as the network sees training data."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "XwYq9doXeIl-",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Biases\n",
+ "Biases are another important part of neural networks and will also be tweaked as the model is trained. A bias is simply a constant value associated with each layer. It can be thought of as an extra neuron that has no connections. The purpose of a bias is to shift an entire activation function by a constant value. This allows a lot more flexibllity when it comes to choosing an activation and training the network. There is one bias for each layer."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "F92rhvd6PcRI",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Activation Function\n",
+ "Activation functions are simply a function that is applied to the weighed sum of a neuron. They can be anything we want but are typically higher order/degree functions that aim to add a higher dimension to our data. We would want to do this to introduce more comolexity to our model. By transforming our data to a higher dimension, we can typically make better, more complex predictions.\n",
+ "\n",
+ "A list of some common activation functions and their graphs can be seen below.\n",
+ "\n",
+ "- Relu (Rectified Linear Unit)\n",
+ "\n",
+ "\n",
+ "- Tanh (Hyperbolic Tangent)\n",
+ "\n",
+ "\n",
+ "- Sigmoid \n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Q2xNjpctlBUM",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Backpropagation\n",
+ "Backpropagation is the fundemental algorithm behind training neural networks. It is what changes the weights and biases of our network. To fully explain this process, we need to start by discussing something called a cost/loss function.\n",
+ "\n",
+ "####Loss/Cost Function\n",
+ "As we now know our neural network feeds information through the layers until it eventually reaches an output layer. This layer contains the results that we look at to determine the prediciton from our network. In the training phase it is likely that our network will make many mistakes and poor predicitions. In fact, at the start of training our network doesn't know anything (it has random weights and biases)! \n",
+ "\n",
+ "We need some way of evaluating if the network is doing well and how well it is doing. For our training data we have the features (input) and the labels (expected output), because of this we can compare the output from our network to the expected output. Based on the difference between these values we can determine if our network has done a good job or poor job. If the network has done a good job, we'll make minor changes to the weights and biases. If it has done a poor job our changes may be more drastic.\n",
+ "\n",
+ "So, this is where the cost/loss function comes in. This function is responsible for determining how well the network did. We pass it the output and the expected output, and it returns to us some value representing the cost/loss of the network. This effectively makes the networks job to optimize this cost function, trying to make it as low as possible. \n",
+ "\n",
+ "Some common loss/cost functions include.\n",
+ "- Mean Squared Error\n",
+ "- Mean Absolute Error\n",
+ "- Hinge Loss\n",
+ "\n",
+ "####Gradient Descent\n",
+ "Gradient descent and backpropagation are closely related. Gradient descent is the algorithm used to find the optimal paramaters (weights and biases) for our network, while backpropagation is the process of calculating the gradient that is used in the gradient descent step. \n",
+ "\n",
+ "Gradient descent requires some pretty advanced calculus and linear algebra to understand so we'll stay away from that for now. Let's just read the formal definition for now.\n",
+ "\n",
+ "\"Gradient descent is an optimization algorithm used to minimize some function by iteratively moving in the direction of steepest descent as defined by the negative of the gradient. In machine learning, we use gradient descent to update the parameters of our model.\" (https://ml-cheatsheet.readthedocs.io/en/latest/gradient_descent.html)\n",
+ "\n",
+ "And that's all we really need to know for now. I'll direct you to the video for a more in depth explination.\n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0KiTMDCKlBI7",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Optimizer\n",
+ "You may sometimes see the term optimizer or optimization function. This is simply the function that implements the backpropagation algorithm described above. Here's a list of a few common ones.\n",
+ "- Gradient Descent\n",
+ "- Stochastic Gradient Descent\n",
+ "- Mini-Batch Gradient Descent\n",
+ "- Momentum\n",
+ "- Nesterov Accelerated Gradient\n",
+ "\n",
+ "*This article explains them quite well is where I've pulled this list from.*\n",
+ "\n",
+ "(https://medium.com/@sdoshi579/optimizers-for-training-neural-network-59450d71caf6)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Kc5hFCLSiDNr",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Creating a Neural Network\n",
+ "Okay now you have reached the exciting part of this tutorial! No more math and complex explinations. Time to get hands on and train a very basic neural network.\n",
+ "\n",
+ "*As stated earlier this guide is based off of the following TensorFlow tutorial.*\n",
+ "https://www.tensorflow.org/tutorials/keras/classification\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3io6gbUrjOQY",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Imports"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "y8t_EdO8jEHz",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "%tensorflow_version 2.x # this line is not required unless you are in a notebook\n",
+ "# TensorFlow and tf.keras\n",
+ "import tensorflow as tf\n",
+ "from tensorflow import keras\n",
+ "\n",
+ "# Helper libraries\n",
+ "import numpy as np\n",
+ "import matplotlib.pyplot as plt"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "p_iFN10li6V1",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Dataset\n",
+ "For this tutorial we will use the MNIST Fashion Dataset. This is a dataset that is included in keras.\n",
+ "\n",
+ "This dataset includes 60,000 images for training and 10,000 images for validation/testing."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "eQmVmgOxjCOV",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "fashion_mnist = keras.datasets.fashion_mnist # load dataset\n",
+ "\n",
+ "(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() # split into tetsing and training"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "AcIall2njfn1",
+ "colab_type": "text"
+ },
+ "source": [
+ "Let's have a look at this data to see what we are working with."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WhLXRxOdjisI",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "train_images.shape"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "D2npdFHwjsLS",
+ "colab_type": "text"
+ },
+ "source": [
+ "So we've got 60,000 images that are made up of 28x28 pixels (784 in total)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "m280zyPqj3ws",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "train_images[0,23,23] # let's have a look at one pixel"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GUciblEwkBe4",
+ "colab_type": "text"
+ },
+ "source": [
+ "Our pixel values are between 0 and 255, 0 being black and 255 being white. This means we have a grayscale image as there are no color channels."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Rn78KO7fkQPJ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "train_labels[:10] # let's have a look at the first 10 training labels"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "r90qZKsnkaW7",
+ "colab_type": "text"
+ },
+ "source": [
+ "Our labels are integers ranging from 0 - 9. Each integer represents a specific article of clothing. We'll create an array of label names to indicate which is which."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "pBiICD2tkne8",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',\n",
+ " 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4rv06eD8krMR",
+ "colab_type": "text"
+ },
+ "source": [
+ "Fianlly let's look at what some of these images look like!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Nfc8LV4Pkq0X",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "plt.figure()\n",
+ "plt.imshow(train_images[1])\n",
+ "plt.colorbar()\n",
+ "plt.grid(False)\n",
+ "plt.show()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "n_DC1b0grL1N",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Data Preprocessing\n",
+ "The last step before creating our model is to *preprocess* our data. This simply means applying some prior transformations to our data before feeding it the model. In this case we will simply scale all our greyscale pixel values (0-255) to be between 0 and 1. We can do this by dividing each value in the training and testing sets by 255.0. We do this because smaller values will make it easier for the model to process our values. \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "wHde8MYW0OQo",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "train_images = train_images / 255.0\n",
+ "\n",
+ "test_images = test_images / 255.0"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "dHOX6GqR0QuD",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Building the Model\n",
+ "Now it's time to build the model! We are going to use a keras *sequential* model with three different layers. This model represents a feed-forward neural network (one that passes values from left to right). We'll break down each layer and its architecture below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "XDxodHMv0xgG",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model = keras.Sequential([\n",
+ " keras.layers.Flatten(input_shape=(28, 28)), # input layer (1)\n",
+ " keras.layers.Dense(128, activation='relu'), # hidden layer (2)\n",
+ " keras.layers.Dense(10, activation='softmax') # output layer (3)\n",
+ "])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "c-bL-I5w0414",
+ "colab_type": "text"
+ },
+ "source": [
+ "**Layer 1:** This is our input layer and it will conist of 784 neurons. We use the flatten layer with an input shape of (28,28) to denote that our input should come in in that shape. The flatten means that our layer will reshape the shape (28,28) array into a vector of 784 neurons so that each pixel will be associated with one neuron.\n",
+ "\n",
+ "**Layer 2:** This is our first and only hidden layer. The *dense* denotes that this layer will be fully connected and each neuron from the previous layer connects to each neuron of this layer. It has 128 neurons and uses the rectify linear unit activation function.\n",
+ "\n",
+ "**Layer 3:** This is our output later and is also a dense layer. It has 10 neurons that we will look at to determine our models output. Each neuron represnts the probabillity of a given image being one of the 10 different classes. The activation function *softmax* is used on this layer to calculate a probabillity distribution for each class. This means the value of any neuron in this layer will be between 0 and 1, where 1 represents a high probabillity of the image being that class."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-j1UF9QH21Ex",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Compile the Model\n",
+ "The last step in building the model is to define the loss function, optimizer and metrics we would like to track. I won't go into detail about why we chose each of these right now."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Msigq4Ja29QX",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.compile(optimizer='adam',\n",
+ " loss='sparse_categorical_crossentropy',\n",
+ " metrics=['accuracy'])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7YYW5V_53OXV",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Training the Model\n",
+ "Now it's finally time to train the model. Since we've already done all the work on our data this step is as easy as calling a single method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "XmAtc4uI3_C7",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "model.fit(train_images, train_labels, epochs=10) # we pass the data, labels and epochs and watch the magic!"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "y6SRtNcF4K1O",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Evaluating the Model\n",
+ "Now it's time to test/evaluate the model. We can do this quite easily using another builtin method from keras.\n",
+ "\n",
+ "The *verbose* argument is defined from the keras documentation as:\n",
+ "\"verbose: 0 or 1. Verbosity mode. 0 = silent, 1 = progress bar.\"\n",
+ "(https://keras.io/models/sequential/)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WqI0FEO54XN1",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=1) \n",
+ "\n",
+ "print('Test accuracy:', test_acc)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nb4_EtfK5DuW",
+ "colab_type": "text"
+ },
+ "source": [
+ "You'll likely notice that the accuracy here is lower than when training the model. This difference is reffered to as **overfitting**.\n",
+ "\n",
+ "And now we have a trained model that's ready to use to predict some values!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pv0XpgwJ7GlW",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Making Predictions\n",
+ "To make predictions we simply need to pass an array of data in the form we've specified in the input layer to ```.predict()``` method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "BMAkNWii7Ufj",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "predictions = model.predict(test_images)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "LmRgxuEc7Xjc",
+ "colab_type": "text"
+ },
+ "source": [
+ "This method returns to us an array of predictions for each image we passed it. Let's have a look at the predictions for image 1."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "4y2eQtCr7fnd",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "predictions[0]"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eiRNg9Yr7lCt",
+ "colab_type": "text"
+ },
+ "source": [
+ "If we wan't to get the value with the highest score we can use a useful function from numpy called ```argmax()```. This simply returns the index of the maximium value from a numpy array. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "NaagMfi671ci",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "np.argmax(predictions[0])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "aWY4SKYm8h93",
+ "colab_type": "text"
+ },
+ "source": [
+ "And we can check if this is correct by looking at the value of the cooresponding test label."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "xVNepduo8nEy",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "test_labels[0]"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Y8I1EqJu8qRl",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Verifying Predictions\n",
+ "I've written a small function here to help us verify predictions with some simple visuals."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "-HJV4JF789aC",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "COLOR = 'white'\n",
+ "plt.rcParams['text.color'] = COLOR\n",
+ "plt.rcParams['axes.labelcolor'] = COLOR\n",
+ "\n",
+ "def predict(model, image, correct_label):\n",
+ " class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',\n",
+ " 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']\n",
+ " prediction = model.predict(np.array([image]))\n",
+ " predicted_class = class_names[np.argmax(prediction)]\n",
+ "\n",
+ " show_image(image, class_names[correct_label], predicted_class)\n",
+ "\n",
+ "\n",
+ "def show_image(img, label, guess):\n",
+ " plt.figure()\n",
+ " plt.imshow(img, cmap=plt.cm.binary)\n",
+ " plt.title(\"Excpected: \" + label)\n",
+ " plt.xlabel(\"Guess: \" + guess)\n",
+ " plt.colorbar()\n",
+ " plt.grid(False)\n",
+ " plt.show()\n",
+ "\n",
+ "\n",
+ "def get_number():\n",
+ " while True:\n",
+ " num = input(\"Pick a number: \")\n",
+ " if num.isdigit():\n",
+ " num = int(num)\n",
+ " if 0 <= num <= 1000:\n",
+ " return int(num)\n",
+ " else:\n",
+ " print(\"Try again...\")\n",
+ "\n",
+ "num = get_number()\n",
+ "image = test_images[num]\n",
+ "label = test_labels[num]\n",
+ "predict(model, image, label)\n"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1HRzP5hCAijM",
+ "colab_type": "text"
+ },
+ "source": [
+ "And that's pretty much it for an introduction to neural networks!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "PmbcLZZ0lo_2",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Sources\n",
+ "\n",
+ "1. Doshi, Sanket. “Various Optimization Algorithms For Training Neural Network.” Medium, Medium, 10 Mar. 2019, www.medium.com/@sdoshi579/optimizers-for-training-neural-network-59450d71caf6.\n",
+ "\n",
+ "2. “Basic Classification: Classify Images of Clothing : TensorFlow Core.” TensorFlow, www.tensorflow.org/tutorials/keras/classification.\n",
+ "\n",
+ "3. “Gradient Descent¶.” Gradient Descent - ML Glossary Documentation, www.ml-cheatsheet.readthedocs.io/en/latest/gradient_descent.html.\n",
+ "\n",
+ "4. Chollet François. Deep Learning with Python. Manning Publications Co., 2018.\n",
+ "\n",
+ "5. “Keras: The Python Deep Learning Library.” Home - Keras Documentation, www.keras.io/."
+ ]
+ }
+ ]
+}
\ No newline at end of file
diff --git a/Reinforcement_Learning.ipynb b/Reinforcement_Learning.ipynb
new file mode 100644
index 0000000..ac9ff61
--- /dev/null
+++ b/Reinforcement_Learning.ipynb
@@ -0,0 +1,533 @@
+{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "name": "Reinforcement Learning.ipynb",
+ "provenance": [],
+ "collapsed_sections": [],
+ "include_colab_link": true
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ },
+ "accelerator": "GPU"
+ },
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-ADWvu7NKN2r",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Reinforcement Learning\n",
+ "The next and final topic in this course covers *Reinforcement Learning*. This technique is different than many of the other machine learning techniques we have seen earlier and has many applications in training agents (an AI) to interact with enviornments like games. Rather than feeding our machine learning model millions of examples we let our model come up with its own examples by exploring an enviornemt. The concept is simple. Humans learn by exploring and learning from mistakes and past experiences so let's have our computer do the same.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "HGCR3JWQLaQb",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Terminology\n",
+ "Before we dive into explaining reinforcement learning we need to define a few key peices of terminology.\n",
+ "\n",
+ "**Enviornemt** In reinforcement learning tasks we have a notion of the enviornment. This is what our *agent* will explore. An example of an enviornment in the case of training an AI to play say a game of mario would be the level we are training the agent on.\n",
+ "\n",
+ "**Agent** an agent is an entity that is exploring the enviornment. Our agent will interact and take different actions within the enviornment. In our mario example the mario character within the game would be our agent. \n",
+ "\n",
+ "**State** always our agent will be in what we call a *state*. The state simply tells us about the status of the agent. The most common example of a state is the location of the agent within the enviornment. Moving locations would change the agents state.\n",
+ "\n",
+ "**Action** any interaction between the agent and enviornment would be considered an action. For example, moving to the left or jumping would be an action. An action may or may not change the current *state* of the agent. In fact, the act of doing nothing is an action as well! The action of say not pressing a key if we are using our mario example.\n",
+ "\n",
+ "**Reward** every action that our agent takes will result in a reward of some magnitude (positive or negative). The goal of our agent will be to maximize its reward in an enviornment. Sometimes the reward will be clear, for example if an agent performs an action which increases their score in the enviornment we could say they've recieved a positive reward. If the agent were to perform an action which results in them losing score or possibly dying in the enviornment then they would recieve a negative reward. \n",
+ "\n",
+ "The most important part of reinforcement learning is determing how to reward the agent. After all, the goal of the agent is to maximize its rewards. This means we should reward the agent appropiatly such that it reaches the desired goal.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "AoOJy9s4ZJJt",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Q-Learning\n",
+ "Now that we have a vague idea of how reinforcement learning works it's time to talk about a specific technique in reinforcement learning called *Q-Learning*.\n",
+ "\n",
+ "Q-Learning is a simple yet quite powerful technique in machine learning that involves learning a matrix of action-reward values. This matrix is often reffered to as a Q-Table or Q-Matrix. The matrix is in shape (number of possible states, number of possible actions) where each value at matrix[n, m] represents the agents expected reward given they are in state n and take action m. The Q-learning algorithm defines the way we update the values in the matrix and decide what action to take at each state. The idea is that after a succesful training/learning of this Q-Table/matrix we can determine the action an agent should take in any state by looking at that states row in the matrix and taking the maximium value column as the action.\n",
+ "\n",
+ "**Consider this example.**\n",
+ "\n",
+ "Let's say A1-A4 are the possible actions and we have 3 states represented by each row (state 1 - state 3).\n",
+ "\n",
+ "| A1 | A2 | A3 | A4 |\n",
+ "|:--: |:--: |:--: |:--: |\n",
+ "| 0 | 0 | 10 | 5 |\n",
+ "| 5 | 10 | 0 | 0 |\n",
+ "| 10 | 5 | 0 | 0 |\n",
+ "\n",
+ "If that was our Q-Table/matrix then the following would be the preffered actions in each state.\n",
+ "\n",
+ "> State 1: A3\n",
+ "\n",
+ "> State 2: A2\n",
+ "\n",
+ "> State 3: A1\n",
+ "\n",
+ "We can see that this is because the values in each of those columns are the highest for those states!\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "u5uLpN1yemTx",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Learning the Q-Table\n",
+ "So that's simple, right? Now how do we create this table and find those values. Well this is where we will dicuss how the Q-Learning algorithm updates the values in our Q-Table. \n",
+ "\n",
+ "I'll start by noting that our Q-Table starts of with all 0 values. This is because the agent has yet to learn anything about the enviornment. \n",
+ "\n",
+ "Our agent learns by exploring the enviornment and observing the outcome/reward from each action it takes in each state. But how does it know what action to take in each state? There are two ways that our agent can decide on which action to take.\n",
+ "1. Randomly picking a valid action\n",
+ "2. Using the current Q-Table to find the best action.\n",
+ "\n",
+ "Near the beginning of our agents learning it will mostly take random actions in order to explore the enviornment and enter many different states. As it starts to explore more of the enviornment it will start to gradually rely more on it's learned values (Q-Table) to take actions. This means that as our agent explores more of the enviornment it will develop a better understanding and start to take \"correct\" or better actions more often. It's important that the agent has a good balance of taking random actions and using learned values to ensure it does get trapped in a local maximum. \n",
+ "\n",
+ "After each new action our agent wil record the new state (if any) that it has entered and the reward that it recieved from taking that action. These values will be used to update the Q-Table. The agent will stop taking new actions only once a certain time limit is reached or it has acheived the goal or reached the end of the enviornment. \n",
+ "\n",
+ "####Updating Q-Values\n",
+ "The formula for updating the Q-Table after each action is as follows:\n",
+ "> $ Q[state, action] = Q[state, action] + \\alpha * (reward + \\gamma * max(Q[newState, :]) - Q[state, action]) $\n",
+ "\n",
+ "- $\\alpha$ stands for the **Learning Rate**\n",
+ "\n",
+ "- $\\gamma$ stands for the **Discount Factor**\n",
+ "\n",
+ "####Learning Rate $\\alpha$\n",
+ "The learning rate $\\alpha$ is a numeric constant that defines how much change is permitted on each QTable update. A high learning rate means that each update will introduce a large change to the current state-action value. A small learning rate means that each update has a more subtle change. Modifying the learning rate will change how the agent explores the enviornment and how quickly it determines the final values in the QTable.\n",
+ "\n",
+ "####Discount Factor $\\gamma$\n",
+ "Discount factor also know as gamma ($\\gamma$) is used to balance how much focus is put on the current and future reward. A high discount factor means that future rewards will be considered more heavily.\n",
+ "\n",
+ "
\n",
+ "To perform updates on this table we will let the agent explpore the enviornment for a certain period of time and use each of its actions to make an update. Slowly we should start to notice the agent learning and choosing better actions.
\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "rwIl0sJgmu4D",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Q-Learning Example\n",
+ "For this example we will use the Q-Learning algorithm to train an agent to navigate a popular enviornment from the [Open AI Gym](https://gym.openai.com/). The Open AI Gym was developed so programmers could practice machine learning using unique enviornments. Intersting fact, Elon Musk is one of the founders of OpenAI!\n",
+ "\n",
+ "Let's start by looking at what Open AI Gym is. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "rSETF0zqokYr",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "import gym # all you have to do to import and use open ai gym!"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "8cH3AmCzotO1",
+ "colab_type": "text"
+ },
+ "source": [
+ "Once you import gym you can load an enviornment using the line ```gym.make(\"enviornment\")```."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "UKN1ScBco3dp",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "env = gym.make('FrozenLake-v0') # we are going to use the FrozenLake enviornment"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "3SvSlmVwo8cY",
+ "colab_type": "text"
+ },
+ "source": [
+ "There are a few other commands that can be used to interact and get information about the enviornment."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "FF3icIeapFct",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "print(env.observation_space.n) # get number of states\n",
+ "print(env.action_space.n) # get number of actions"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "lc9cwp03pQVn",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "env.reset() # reset enviornment to default state"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "sngyjPDapUt7",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "action = env.action_space.sample() # get a random action "
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "HeEfi8xypXya",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "new_state, reward, done, info = env.step(action) # take action, notice it returns information about the action"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "_1W3D81ipdaS",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "env.render() # render the GUI for the enviornment "
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "vmW6HAbQp01f",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Frozen Lake Enviornment\n",
+ "Now that we have a basic understanding of how the gym enviornment works it's time to discuss the specific problem we will be solving.\n",
+ "\n",
+ "The enviornment we loaded above ```FrozenLake-v0``` is one of the simplest enviornments in Open AI Gym. The goal of the agent is to navigate a frozen lake and find the Goal without falling through the ice (render the enviornment above to see an example).\n",
+ "\n",
+ "There are:\n",
+ "- 16 states (one for each square) \n",
+ "- 4 possible actions (LEFT, RIGHT, DOWN, UP)\n",
+ "- 4 different types of blocks (F: frozen, H: hole, S: start, G: goal)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YlWoK75ZrK2b",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Building the Q-Table\n",
+ "The first thing we need to do is build an empty Q-Table that we can use to store and update our values."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "r767K4s0rR2p",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "import gym\n",
+ "import numpy as np\n",
+ "import time\n",
+ "\n",
+ "env = gym.make('FrozenLake-v0')\n",
+ "STATES = env.observation_space.n\n",
+ "ACTIONS = env.action_space.n"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "UAzMWGatrVIk",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "Q = np.zeros((STATES, ACTIONS)) # create a matrix with all 0 values \n",
+ "Q"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "vc_h8tLSrpmc",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Constants\n",
+ "As we discussed we need to define some constants that will be used to update our Q-Table and tell our agent when to stop training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "-FQapdnnr6P1",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "EPISODES = 2000 # how many times to run the enviornment from the beginning\n",
+ "MAX_STEPS = 100 # max number of steps allowed for each run of enviornment\n",
+ "\n",
+ "LEARNING_RATE = 0.81 # learning rate\n",
+ "GAMMA = 0.96"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NxrAj91rsMfm",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Picking an Action\n",
+ "Remember that we can pick an action using one of two methods:\n",
+ "1. Randomly picking a valid action\n",
+ "2. Using the current Q-Table to find the best action.\n",
+ "\n",
+ "Here we will define a new value $\\epsilon$ that will tell us the probabillity of selecting a random action. This value will start off very high and slowly decrease as the agent learns more about the enviornment."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "YUAQVyX0sWDb",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "epsilon = 0.9 # start with a 90% chance of picking a random action\n",
+ "\n",
+ "# code to pick action\n",
+ "if np.random.uniform(0, 1) < epsilon: # we will check if a randomly selected value is less than epsilon.\n",
+ " action = env.action_space.sample() # take random action\n",
+ "else:\n",
+ " action = np.argmax(Q[state, :]) # use Q table to pick best action based on current values"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5n-i0B7Atige",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Updating Q Values\n",
+ "The code below implements the formula discussed above."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "9r7R1W6Qtnh8",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "Q[state, action] = Q[state, action] + LEARNING_RATE * (reward + GAMMA * np.max(Q[new_state, :]) - Q[state, action])"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "__afaD62uh8G",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Putting it Together\n",
+ "Now that we know how to do some basic things we can combine these together to create our Q-Learning algorithm,"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "AGiYCiNuutHz",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "import gym\n",
+ "import numpy as np\n",
+ "import time\n",
+ "\n",
+ "env = gym.make('FrozenLake-v0')\n",
+ "STATES = env.observation_space.n\n",
+ "ACTIONS = env.action_space.n\n",
+ "\n",
+ "Q = np.zeros((STATES, ACTIONS))\n",
+ "\n",
+ "EPISODES = 1500 # how many times to run the enviornment from the beginning\n",
+ "MAX_STEPS = 100 # max number of steps allowed for each run of enviornment\n",
+ "\n",
+ "LEARNING_RATE = 0.81 # learning rate\n",
+ "GAMMA = 0.96\n",
+ "\n",
+ "RENDER = False # if you want to see training set to true\n",
+ "\n",
+ "epsilon = 0.9\n"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "jFRtn5dUu5ZI",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "rewards = []\n",
+ "for episode in range(EPISODES):\n",
+ "\n",
+ " state = env.reset()\n",
+ " for _ in range(MAX_STEPS):\n",
+ " \n",
+ " if RENDER:\n",
+ " env.render()\n",
+ "\n",
+ " if np.random.uniform(0, 1) < epsilon:\n",
+ " action = env.action_space.sample() \n",
+ " else:\n",
+ " action = np.argmax(Q[state, :])\n",
+ "\n",
+ " next_state, reward, done, _ = env.step(action)\n",
+ "\n",
+ " Q[state, action] = Q[state, action] + LEARNING_RATE * (reward + GAMMA * np.max(Q[next_state, :]) - Q[state, action])\n",
+ "\n",
+ " state = next_state\n",
+ "\n",
+ " if done: \n",
+ " rewards.append(reward)\n",
+ " epsilon -= 0.001\n",
+ " break # reached goal\n",
+ "\n",
+ "print(Q)\n",
+ "print(f\"Average reward: {sum(rewards)/len(rewards)}:\")\n",
+ "# and now we can see our Q values!"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Zo-tNznd65US",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# we can plot the training progress and see how the agent improved\n",
+ "import matplotlib.pyplot as plt\n",
+ "\n",
+ "def get_average(values):\n",
+ " return sum(values)/len(values)\n",
+ "\n",
+ "avg_rewards = []\n",
+ "for i in range(0, len(rewards), 100):\n",
+ " avg_rewards.append(get_average(rewards[i:i+100])) \n",
+ "\n",
+ "plt.plot(avg_rewards)\n",
+ "plt.ylabel('average reward')\n",
+ "plt.xlabel('episodes (100\\'s)')\n",
+ "plt.show()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "gy4YH2m9s1ww",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Sources\n",
+ "1. Violante, Andre. “Simple Reinforcement Learning: Q-Learning.” Medium, Towards Data Science, 1 July 2019, https://towardsdatascience.com/simple-reinforcement-learning-q-learning-fcddc4b6fe56.\n",
+ "\n",
+ "2. Openai. “Openai/Gym.” GitHub, https://github.com/openai/gym/wiki/FrozenLake-v0."
+ ]
+ }
+ ]
+}
\ No newline at end of file
diff --git a/Sounak.c b/Sounak.c
new file mode 100644
index 0000000..1296fbc
--- /dev/null
+++ b/Sounak.c
@@ -0,0 +1,5 @@
+#include
+void main()
+{
+ cout<<"Hello World";
+ }
diff --git a/TensorFlow_Introduction.ipynb b/TensorFlow_Introduction.ipynb
new file mode 100644
index 0000000..deb39b4
--- /dev/null
+++ b/TensorFlow_Introduction.ipynb
@@ -0,0 +1,481 @@
+{
+ "nbformat": 4,
+ "nbformat_minor": 0,
+ "metadata": {
+ "colab": {
+ "name": "TensorFlow-Introduction.ipynb",
+ "provenance": [],
+ "include_colab_link": true
+ },
+ "kernelspec": {
+ "name": "python3",
+ "display_name": "Python 3"
+ }
+ },
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-5u3a4csUPyn",
+ "colab_type": "text"
+ },
+ "source": [
+ "#TensorFlow 2.0 Introduction\n",
+ "In this notebook you will be given an interactive introduction to TensorFlow 2.0. We will walk through the following topics within the TensorFlow module:\n",
+ "\n",
+ "- TensorFlow Install and Setup\n",
+ "- Representing Tensors\n",
+ "- Tensor Shape and Rank\n",
+ "- Types of Tensors\n",
+ "\n",
+ "\n",
+ "If you'd like to follow along without installing TensorFlow on your machine you can use **Google Collaboratory**. Collaboratory is a free Jupyter notebook environment that requires no setup and runs entirely in the cloud."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "F7ThfbiQl96l",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Installing TensorFlow\n",
+ "To install TensorFlow on your local machine you can use pip.\n",
+ "```console\n",
+ "pip install tensorflow\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JYQWyAJ2mez6",
+ "colab_type": "text"
+ },
+ "source": [
+ "If you have a CUDA enabled GPU you can install the GPU version of TensorFlow. You will also need to install some other software which can be found here: https://www.tensorflow.org/install/gpu \n",
+ "```console\n",
+ "pip install tensorflow-gpu\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JJjNMaSClWhg",
+ "colab_type": "text"
+ },
+ "source": [
+ "## Importing TensorFlow\n",
+ "The first step here is going to be to select the correct version of TensorFlow from within collabratory!\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "vGcE8x2Gkw9K",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "%tensorflow_version 2.x # this line is not required unless you are in a notebook"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "4N7XbNDVY8P3",
+ "colab_type": "code",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 34
+ },
+ "outputId": "25d429c1-1f21-47c3-df67-74052e05f827"
+ },
+ "source": [
+ "import tensorflow as tf # now import the tensorflow module\n",
+ "print(tf.version) # make sure the version is 2.x"
+ ],
+ "execution_count": 2,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "\n"
+ ],
+ "name": "stdout"
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "duDj86TfWFof",
+ "colab_type": "text"
+ },
+ "source": [
+ "##Tensors \n",
+ "\"A tensor is a generalization of vectors and matrices to potentially higher dimensions. Internally, TensorFlow represents tensors as n-dimensional arrays of base datatypes.\" (https://www.tensorflow.org/guide/tensor)\n",
+ "\n",
+ "It should't surprise you that tensors are a fundemental apsect of TensorFlow. They are the main objects that are passed around and manipluated throughout the program. Each tensor represents a partialy defined computation that will eventually produce a value. TensorFlow programs work by building a graph of Tensor objects that details how tensors are related. Running different parts of the graph allow results to be generated.\n",
+ "\n",
+ "Each tensor has a data type and a shape. \n",
+ "\n",
+ "**Data Types Include**: float32, int32, string and others.\n",
+ "\n",
+ "**Shape**: Represents the dimension of data.\n",
+ "\n",
+ "Just like vectors and matrices tensors can have operations applied to them like addition, subtraction, dot product, cross product etc.\n",
+ "\n",
+ "In the next sections we will discuss some different properties of tensors. This is to make you more familiar with how tensorflow represnts data and how you can manipulate this data.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TAk6QhGUwQRt",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Creating Tensors\n",
+ "Below is an example of how to create some different tensors.\n",
+ "\n",
+ "You simply define the value of the tensor and the datatype and you are good to go! It's worth mentioning that usually we deal with tensors of numeric data, it is quite rare to see string tensors.\n",
+ "\n",
+ "For a full list of datatypes please refer to the following guide.\n",
+ "\n",
+ "https://www.tensorflow.org/api_docs/python/tf/dtypes/DType?version=stable"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "epGskXdjZHzu",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "string = tf.Variable(\"this is a string\", tf.string) \n",
+ "number = tf.Variable(324, tf.int16)\n",
+ "floating = tf.Variable(3.567, tf.float64)"
+ ],
+ "execution_count": 3,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "D0_H71HMaE-5",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Rank/Degree of Tensors\n",
+ "Another word for rank is degree, these terms simply mean the number of dimensions involved in the tensor. What we created above is a *tensor of rank 0*, also known as a scalar. \n",
+ "\n",
+ "Now we'll create some tensors of higher degrees/ranks."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "hX_Cc5IfjQ6-",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "rank1_tensor = tf.Variable([\"Test\"], tf.string) \n",
+ "rank2_tensor = tf.Variable([[\"test\", \"ok\"], [\"test\", \"yes\"]], tf.string)"
+ ],
+ "execution_count": 4,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "55zuGMc7nHjC",
+ "colab_type": "text"
+ },
+ "source": [
+ "**To determine the rank** of a tensor we can call the following method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Zrj0rAWLnMNv",
+ "colab_type": "code",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 34
+ },
+ "outputId": "6c51bc2d-5c13-4e4c-ed57-6e3bb755efc9"
+ },
+ "source": [
+ "tf.rank(rank2_tensor)"
+ ],
+ "execution_count": 5,
+ "outputs": [
+ {
+ "output_type": "execute_result",
+ "data": {
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {
+ "tags": []
+ },
+ "execution_count": 5
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hTv4Gz67pQbx",
+ "colab_type": "text"
+ },
+ "source": [
+ "The rank of a tensor is direclty related to the deepest level of nested lists. You can see in the first example ```[\"Test\"]``` is a rank 1 tensor as the deepest level of nesting is 1. \n",
+ "Where in the second example ```[[\"test\", \"ok\"], [\"test\", \"yes\"]]``` is a rank 2 tensor as the deepest level of nesting is 2."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "RaVrANK8q21q",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Shape of Tensors\n",
+ "Now that we've talked about the rank of tensors it's time to talk about the shape. The shape of a tensor is simply the number of elements that exist in each dimension. TensorFlow will try to determine the shape of a tensor but sometimes it may be unknown.\n",
+ "\n",
+ "To **get the shape** of a tensor we use the shape attribute.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "L_NRXsFOraYa",
+ "colab_type": "code",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 34
+ },
+ "outputId": "96bbc16c-6560-43a0-d32a-576d9ae0b824"
+ },
+ "source": [
+ "rank2_tensor.shape"
+ ],
+ "execution_count": 6,
+ "outputs": [
+ {
+ "output_type": "execute_result",
+ "data": {
+ "text/plain": [
+ "TensorShape([2, 2])"
+ ]
+ },
+ "metadata": {
+ "tags": []
+ },
+ "execution_count": 6
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "wVDmLJeFs086",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Changing Shape\n",
+ "The number of elements of a tensor is the product of the sizes of all its shapes. There are often many shapes that have the same number of elements, making it convient to be able to change the shape of a tensor.\n",
+ "\n",
+ "The example below shows how to change the shape of a tensor."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "dZ8Rbs2xtNqj",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "tensor1 = tf.ones([1,2,3]) # tf.ones() creates a shape [1,2,3] tensor full of ones\n",
+ "tensor2 = tf.reshape(tensor1, [2,3,1]) # reshape existing data to shape [2,3,1]\n",
+ "tensor3 = tf.reshape(tensor2, [3, -1]) # -1 tells the tensor to calculate the size of the dimension in that place\n",
+ " # this will reshape the tensor to [3,3]\n",
+ " \n",
+ "# The numer of elements in the reshaped tensor MUST match the number in the original"
+ ],
+ "execution_count": 7,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "M631k7UDv1Wh",
+ "colab_type": "text"
+ },
+ "source": [
+ "Now let's have a look at our different tensors."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "IFNmUxaEv6s3",
+ "colab_type": "code",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 269
+ },
+ "outputId": "a0adf3e4-0196-4e04-8762-be28264abdb5"
+ },
+ "source": [
+ "print(tensor1)\n",
+ "print(tensor2)\n",
+ "print(tensor3)\n",
+ "# Notice the changes in shape"
+ ],
+ "execution_count": 8,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "text": [
+ "tf.Tensor(\n",
+ "[[[1. 1. 1.]\n",
+ " [1. 1. 1.]]], shape=(1, 2, 3), dtype=float32)\n",
+ "tf.Tensor(\n",
+ "[[[1.]\n",
+ " [1.]\n",
+ " [1.]]\n",
+ "\n",
+ " [[1.]\n",
+ " [1.]\n",
+ " [1.]]], shape=(2, 3, 1), dtype=float32)\n",
+ "tf.Tensor(\n",
+ "[[1. 1.]\n",
+ " [1. 1.]\n",
+ " [1. 1.]], shape=(3, 2), dtype=float32)\n"
+ ],
+ "name": "stdout"
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "q88pJucBolsp",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Slicing Tensors\n",
+ "You may be familiar with the term \"slice\" in python and its use on lists, tuples etc. Well the slice operator can be used on tensors to select specific axes or elements.\n",
+ "\n",
+ "When we slice or select elements from a tensor, we can use comma seperated values inside the set of square brackets. Each subsequent value refrences a different dimension of the tensor.\n",
+ "\n",
+ "Ex: ```tensor[dim1, dim2, dim3]```\n",
+ "\n",
+ "I've included a few examples that will hopefully help illustrate how we can manipulate tensors with the slice operator."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "b0YrD-hRqD-W",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# Creating a 2D tensor\n",
+ "matrix = [[1,2,3,4,5],\n",
+ " [6,7,8,9,10],\n",
+ " [11,12,13,14,15],\n",
+ " [16,17,18,19,20]]\n",
+ "\n",
+ "tensor = tf.Variable(matrix, dtype=tf.int32) \n",
+ "print(tf.rank(tensor))\n",
+ "print(tensor.shape)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "Wd85uGI7qyfC",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "source": [
+ "# Now lets select some different rows and columns from our tensor\n",
+ "\n",
+ "three = tensor[0,2] # selects the 3rd element from the 1st row\n",
+ "print(three) # -> 3\n",
+ "\n",
+ "row1 = tensor[0] # selects the first row\n",
+ "print(row1)\n",
+ "\n",
+ "column1 = tensor[:, 0] # selects the first column\n",
+ "print(column1)\n",
+ "\n",
+ "row_2_and_4 = tensor[1::2] # selects second and fourth row\n",
+ "print(row2and4)\n",
+ "\n",
+ "column_1_in_row_2_and_3 = tensor[1:3, 0]\n",
+ "print(column_1_in_row_2_and_3)\n"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "UU4MMhB_rxvz",
+ "colab_type": "text"
+ },
+ "source": [
+ "###Types of Tensors\n",
+ "Before we go to far, I will mention that there are diffent types of tensors. These are the most used and we will talk more in depth about each as they are used.\n",
+ "- Variable\n",
+ "- Constant\n",
+ "- Placeholder\n",
+ "- SparseTensor\n",
+ "\n",
+ "With the execption of ```Variable``` all these tensors are immuttable, meaning their value may not change during execution.\n",
+ "\n",
+ "For now, it is enough to understand that we use the Variable tensor when we want to potentially change the value of our tensor.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "F2OoXbe7aSVl",
+ "colab_type": "text"
+ },
+ "source": [
+ "#Sources\n",
+ "Most of the information is taken direclty from the TensorFlow website which can be found below.\n",
+ "\n",
+ "https://www.tensorflow.org/guide/tensor"
+ ]
+ }
+ ]
+}
\ No newline at end of file