diff --git a/README.md b/README.md
index 9229cdcd..46674769 100644
--- a/README.md
+++ b/README.md
@@ -178,19 +178,6 @@ ld.map(
## Features for transforming datasets
-
- ✅ Multi-GPU / Multi-Node Support
-
-
-
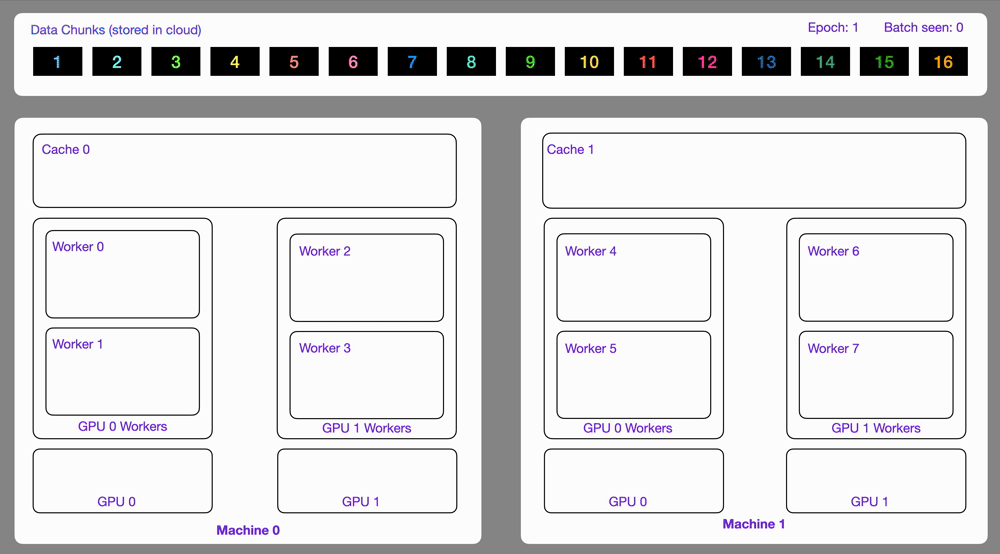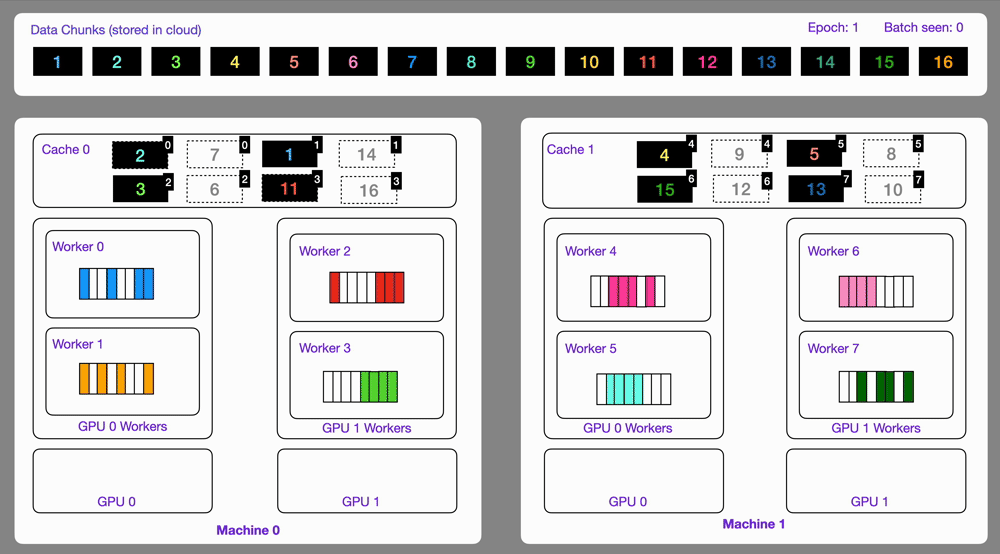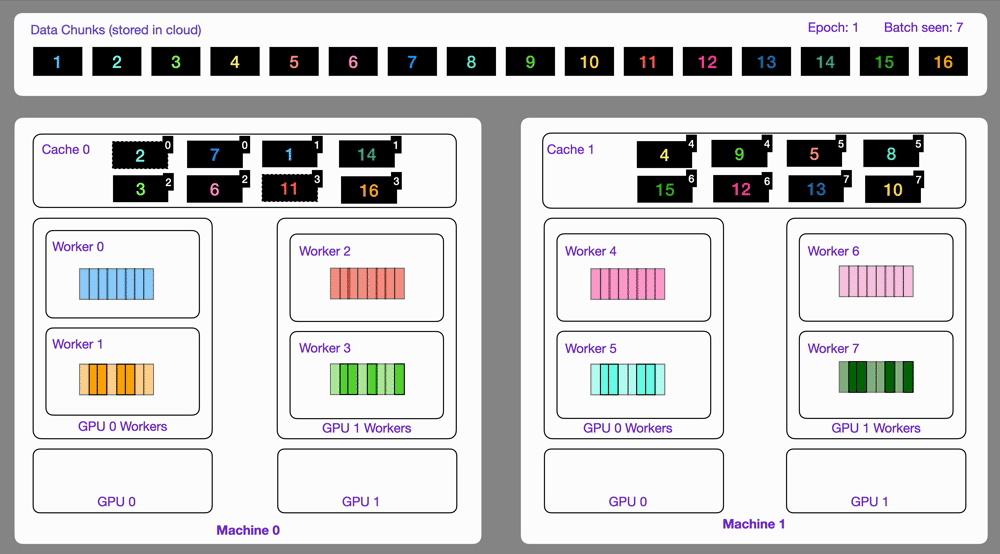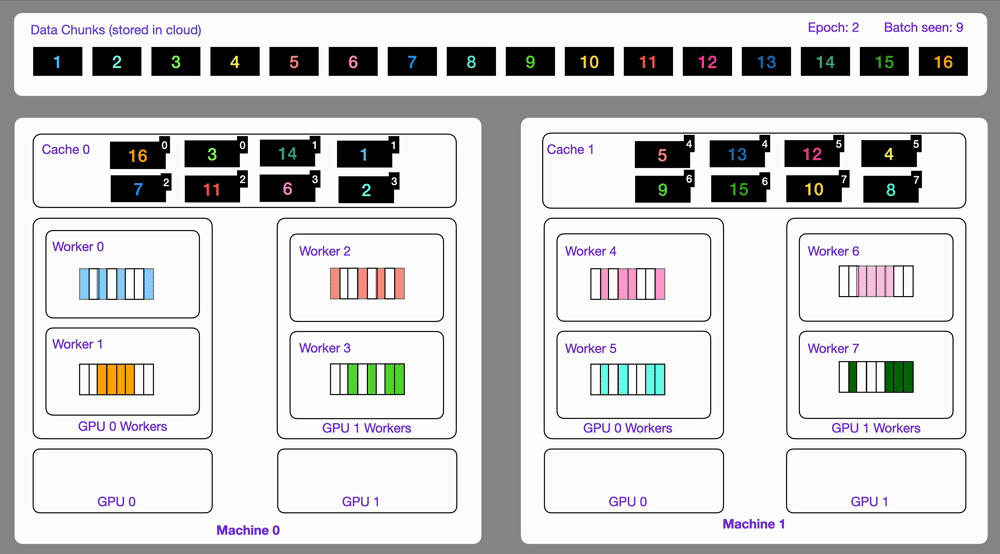
-The `StreamingDataset` and `StreamingDataLoader` automatically make sure each rank receives the same quantity of varied batches of data, so it works out of the box with your favorite frameworks ([PyTorch Lightning](https://lightning.ai/docs/pytorch/stable/), [Lightning Fabric](https://lightning.ai/docs/fabric/stable/), or [PyTorch](https://pytorch.org/docs/stable/index.html)) to do distributed training.
-
-Here you can see an illustration showing how the Streaming Dataset works with multi node / multi gpu under the hood.
-
-
-
-
-
✅ Map transformations
@@ -223,6 +210,44 @@ map(
+
+ ✅ Support S3-Compatible Object Storage
+
+
+Integrate S3-compatible object storage servers like [MinIO](https://min.io/) with litdata, ideal for on-premises infrastructure setups. Configure the endpoint and credentials using environment variables or configuration files.
+
+Set up the environment variables to connect to MinIO:
+
+```bash
+export AWS_ACCESS_KEY_ID=access_key
+export AWS_SECRET_ACCESS_KEY=secret_key
+export AWS_ENDPOINT_URL=http://localhost:9000 # MinIO endpoint
+```
+
+Alternatively, configure credentials and endpoint in `~/.aws/{credentials,config}`:
+
+```bash
+mkdir -p ~/.aws && \
+cat <> ~/.aws/credentials
+[default]
+aws_access_key_id = access_key
+aws_secret_access_key = secret_key
+EOL
+
+cat <> ~/.aws/config
+[default]
+endpoint_url = http://localhost:9000 # MinIO endpoint
+EOL
+```
+Explore an example setup of litdata with MinIO in the [LitData with MinIO](https://github.com/bhimrazy/litdata-with-minio) repository for practical implementation details.
+
+
+
+
+
+## Features for optimizing and streaming datasets for model training
+
+
✅ Stream datasets
@@ -244,51 +269,22 @@ for batch in dataloader:
- ✅ Combine datasets
-
-
-
-Easily experiment with dataset mixtures using the `CombinedStreamingDataset` class.
-
-As an example, this mixture of [Slimpajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B) & [StarCoder](https://huggingface.co/datasets/bigcode/starcoderdata) was used in the [TinyLLAMA](https://github.com/jzhang38/TinyLlama) project to pretrain a 1.1B Llama model on 3 trillion tokens.
+ ✅ Multi-GPU / Multi-Node Support
-```python
-from litdata import StreamingDataset, CombinedStreamingDataset, StreamingDataLoader, TokensLoader
-from tqdm import tqdm
-import os
+
-train_datasets = [
- StreamingDataset(
- input_dir="s3://tinyllama-template/slimpajama/train/",
- item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
- shuffle=True,
- drop_last=True,
- ),
- StreamingDataset(
- input_dir="s3://tinyllama-template/starcoder/",
- item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
- shuffle=True,
- drop_last=True,
- ),
-]
+The `StreamingDataset` and `StreamingDataLoader` automatically make sure each rank receives the same quantity of varied batches of data, so it works out of the box with your favorite frameworks ([PyTorch Lightning](https://lightning.ai/docs/pytorch/stable/), [Lightning Fabric](https://lightning.ai/docs/fabric/stable/), or [PyTorch](https://pytorch.org/docs/stable/index.html)) to do distributed training.
-# Mix SlimPajama data and Starcoder data with these proportions:
-weights = (0.693584, 0.306416)
-combined_dataset = CombinedStreamingDataset(datasets=train_datasets, seed=42, weights=weights)
+Here you can see an illustration showing how the Streaming Dataset works with multi node / multi gpu under the hood.
-train_dataloader = StreamingDataLoader(combined_dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
+
-# Iterate over the combined datasets
-for batch in tqdm(train_dataloader):
- pass
-```
✅ Pause & Resume data streaming
-
LitData provides a stateful `Streaming DataLoader` e.g. you can `pause` and `resume` your training whenever you want.
Info: The `Streaming DataLoader` was used by [Lit-GPT](https://github.com/Lightning-AI/lit-gpt/blob/main/pretrain/tinyllama.py) to pretrain LLMs. Restarting from an older checkpoint was critical to get to pretrain the full model due to several failures (network, CUDA Errors, etc..).
@@ -316,49 +312,54 @@ for batch_idx, batch in enumerate(dataloader):
+
- ✅ Support S3-Compatible Object Storage
+ ✅ Combine datasets
-Integrate S3-compatible object storage servers like [MinIO](https://min.io/) with litdata, ideal for on-premises infrastructure setups. Configure the endpoint and credentials using environment variables or configuration files.
-Set up the environment variables to connect to MinIO:
-
-```bash
-export AWS_ACCESS_KEY_ID=access_key
-export AWS_SECRET_ACCESS_KEY=secret_key
-export AWS_ENDPOINT_URL=http://localhost:9000 # MinIO endpoint
-```
+Easily experiment with dataset mixtures using the `CombinedStreamingDataset` class.
-Alternatively, configure credentials and endpoint in `~/.aws/{credentials,config}`:
+As an example, this mixture of [Slimpajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B) & [StarCoder](https://huggingface.co/datasets/bigcode/starcoderdata) was used in the [TinyLLAMA](https://github.com/jzhang38/TinyLlama) project to pretrain a 1.1B Llama model on 3 trillion tokens.
-```bash
-mkdir -p ~/.aws && \
-cat <> ~/.aws/credentials
-[default]
-aws_access_key_id = access_key
-aws_secret_access_key = secret_key
-EOL
+```python
+from litdata import StreamingDataset, CombinedStreamingDataset, StreamingDataLoader, TokensLoader
+from tqdm import tqdm
+import os
-cat <> ~/.aws/config
-[default]
-endpoint_url = http://localhost:9000 # MinIO endpoint
-EOL
-```
-Explore an example setup of litdata with MinIO in the [LitData with MinIO](https://github.com/bhimrazy/litdata-with-minio) repository for practical implementation details.
+train_datasets = [
+ StreamingDataset(
+ input_dir="s3://tinyllama-template/slimpajama/train/",
+ item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
+ shuffle=True,
+ drop_last=True,
+ ),
+ StreamingDataset(
+ input_dir="s3://tinyllama-template/starcoder/",
+ item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
+ shuffle=True,
+ drop_last=True,
+ ),
+]
-
+# Mix SlimPajama data and Starcoder data with these proportions:
+weights = (0.693584, 0.306416)
+combined_dataset = CombinedStreamingDataset(datasets=train_datasets, seed=42, weights=weights)
-
+train_dataloader = StreamingDataLoader(combined_dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
-## Features for optimizing datasets
+# Iterate over the combined datasets
+for batch in tqdm(train_dataloader):
+ pass
+```
+
✅ Subsample and split datasets
-You can split your dataset with more ease with `train_test_split`.
+Split a dataset into train, val, test splits with `train_test_split`.
```python
from litdata import StreamingDataset, train_test_split
@@ -405,7 +406,7 @@ print(len(dataset)) # display the length of your data
- ✅ Append or Overwrite optimized datasets
+ ✅ Append or overwrite optimized datasets
@@ -490,7 +491,7 @@ for batch in dataloader:
- ✅ Support Profiling
+ ✅ Profile loading speed
The `StreamingDataLoader` supports profiling of your data loading process. Simply use the `profile_batches` argument to specify the number of batches you want to profile:
@@ -543,7 +544,7 @@ outputs = optimize(
- ✅ Configure Cache Size Limit
+ ✅ Reduce disk space with caching limits
Adapt the local caching limit of the `StreamingDataset`. This is useful to make sure the downloaded data chunks are deleted when used and the disk usage stays low.