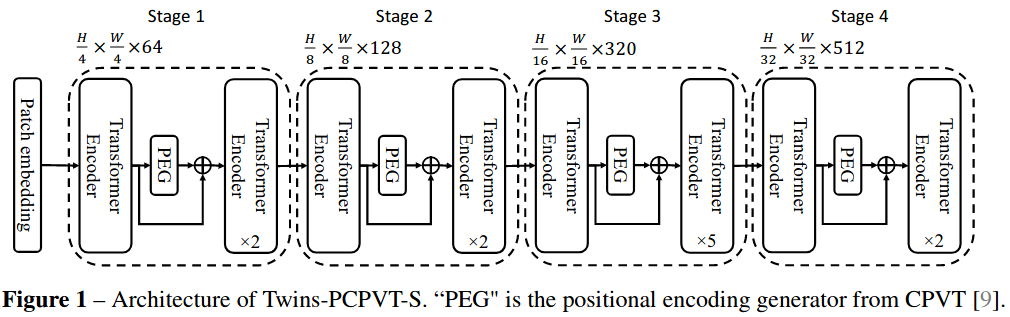
Twins: Revisiting the Design of Spatial Attention in Vision Transformers
Very recently, a variety of vision transformer architectures for dense prediction tasks have been proposed and they show that the design of spatial attention is critical to their success in these tasks. In this work, we revisit the design of the spatial attention and demonstrate that a carefully-devised yet simple spatial attention mechanism performs favourably against the state-of-the-art schemes. As a result, we propose two vision transformer architectures, namely, Twins-PCPVT and Twins-SVT. Our proposed architectures are highly-efficient and easy to implement, only involving matrix multiplications that are highly optimized in modern deep learning frameworks. More importantly, the proposed architectures achieve excellent performance on a wide range of visual tasks, including image level classification as well as dense detection and segmentation. The simplicity and strong performance suggest that our proposed architectures may serve as stronger backbones for many vision tasks. Our code is released at this https URL.
Predict image
from mmpretrain import inference_model
predict = inference_model('twins-pcpvt-small_3rdparty_8xb128_in1k', 'demo/bird.JPEG')
print(predict['pred_class'])
print(predict['pred_score'])Use the model
import torch
from mmpretrain import get_model
model = get_model('twins-pcpvt-small_3rdparty_8xb128_in1k', pretrained=True)
inputs = torch.rand(1, 3, 224, 224)
out = model(inputs)
print(type(out))
# To extract features.
feats = model.extract_feat(inputs)
print(type(feats))Test Command
Prepare your dataset according to the docs.
Test:
python tools/test.py configs/twins/twins-pcpvt-small_8xb128_in1k.py https://download.openmmlab.com/mmclassification/v0/twins/twins-pcpvt-small_3rdparty_8xb128_in1k_20220126-ef23c132.pth| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
|---|---|---|---|---|---|---|---|
twins-pcpvt-small_3rdparty_8xb128_in1k* |
From scratch | 24.11 | 3.67 | 81.14 | 95.69 | config | model |
twins-pcpvt-base_3rdparty_8xb128_in1k* |
From scratch | 43.83 | 6.45 | 82.66 | 96.26 | config | model |
twins-pcpvt-large_3rdparty_16xb64_in1k* |
From scratch | 60.99 | 9.51 | 83.09 | 96.59 | config | model |
twins-svt-small_3rdparty_8xb128_in1k* |
From scratch | 24.06 | 2.82 | 81.77 | 95.57 | config | model |
twins-svt-base_8xb128_3rdparty_in1k* |
From scratch | 56.07 | 8.35 | 83.13 | 96.29 | config | model |
twins-svt-large_3rdparty_16xb64_in1k* |
From scratch | 99.27 | 14.82 | 83.60 | 96.50 | config | model |
Models with * are converted from the timm. The config files of these models are only for inference. We haven't reproduce the training results.
@article{chu2021twins,
title={Twins: Revisiting spatial attention design in vision transformers},
author={Chu, Xiangxiang and Tian, Zhi and Wang, Yuqing and Zhang, Bo and Ren, Haibing and Wei, Xiaolin and Xia, Huaxia and Shen, Chunhua},
journal={arXiv preprint arXiv:2104.13840},
year={2021}altgvt
}