lmdeploy.pytorch 是 LMDeploy 提供的推理后端之一。与着重于性能的 turbomind 相比,lmdeploy.pytorch 以较小的性能开销为代价,提供了一套更容易开发与扩展的大模型推理实现。
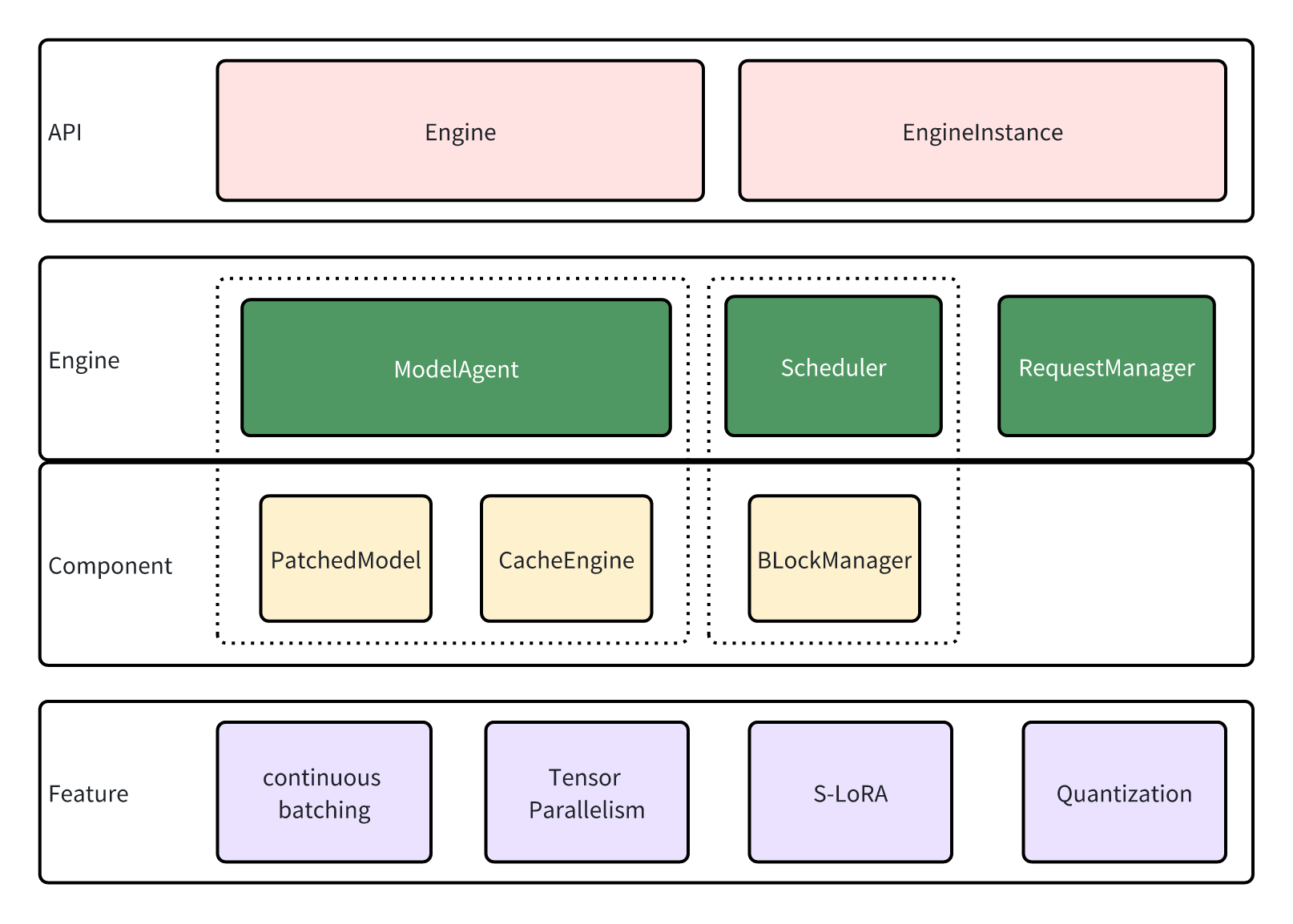
lmdeploy.pytorch 可以与 turbomind 共享同样的服务接口,这些服务接口通过 Engine 与 EngineInstance 与 lmdeploy.pytorch 进行交互。
EngineInstance 是推理请求的发起者,它会将推理请求组织成特定格式发送给 Engine,以此实现流式推理。EngineInstance 的推理接口是线程安全的,服务发起者可以在不同线程中启动各自的 EngineInstance,Engine 回根据当前资源与推理请求自动进行 batch 化处理。
Engine 是推理请求的接收与执行者。它包含如下的组件来完成这项任务:
- ModelAgent 对象负责模型的加载、缓存管理以及 tensor parallelism 的管理。
- Scheduler 对象负责 session 的管理,sequence 与 lora adapter 所需要的资源的分配。
- RequestManager 负责请求的发送与接收,可以通过它与 EngineInstance 交互。
为了应对异步推理请求,Engine 在启动后会维护一个线程,循环如下操作:
- 通过 RequestManager 读取请求,对各种请求进行分类处理。
- Scheduler 规划哪些请求可以被处理,以及它们所需的缓存和 adapters。
- ModelAgent 根据步骤 2. 得到的信息为输入分配资源,然后使用 patch 后的模型进行推理
- Scheduler 根据推理结果更新请求状态
- RequestManager 将输出返回给发送者(EngineInstance),回到步骤 1.
下面我们将介绍上述步骤中用到的几个重要组件
在进行大模型的推理时,通常会把 attention 的历史输入 key 和 value 缓存起来,以避免在未来的推理中进行重复计算。这种情况下如果要进行多 batch 的推理,由于不同数据的序列长度可能不同,kv 会进行大量的填充,浪费很多显存资源,也限制了模型的并发推理能力上限。
vLLM 提了一种 paging 策略,以 page block 为单位为 key value 分配缓存,这样就可以避免由于 padding 导致的显存浪费。 lmdeploy.pytorch 中的 Scheduler 也遵循同样的设计,根据请求的长度合理分配所需的资源,并撤出暂时不使用的资源以保证存储资源的高效利用。
lmdeploy.pytorch 还对 S-LoRA 的支持,S-LoRA 是一种对单模型多 adapter 的支持方案。LoRA 在推理时通常会把 adapter 融合进模型权重当中,同时使用复数个 adapter 会导致显存使用量的激增;S-LoRA 不对 adapter 进行融合,通过使用 unified paging,在推理时动态换入需要使用的 adapter,大幅降低了使用 adapter 的显存开销。Scheduler 中也实现了相关的功能,让用户可以更方便的使用自己的 adapter.
lmdeploy.pytorch 中对 Tensor Parallelism(TP)进行了支持,不同的 TP 参数对模型的构造、权重处理、分配 cache 都存在影响。ModelAgent 对这些内容进行了封装,让 Engine 不用再关心这部分细节。
ModelAgent 有两个重要组件:
- patched_model 是更新后的 transformer 模型,更新后的模型添加了各种功能的支持,包括更高性能的子模块实现、TP、量化等等
- cache_engine 是缓存的分配与交换模块。它接收来自 scheduler 的交换请求,执行 host-device 间显存交换,adapter 加载等工作
-
Continuous Batching: 由于输入序列的长度不一样,batching 通常需要对输入进行 padding,这种 padding 会导致后续运算的计算量增加、影响速度,也会使得显存的占用大幅增加。遵循许多其他成熟框架的方案,lmdeploy.pytorch 采用了 continuous batching 的方式对输入做了连续化处理,避免了多余的资源占用。
-
Tensor Parallelism: 大模型可能会占用远超一张显卡的显存量,为了支持这样的大模型的推理,我们实现了 Tensor 并发,模型的权重会被分布在不同的设备中,每张 GPU 设备负责一部分计算,减少了单卡显存占用,也充分利用了多显卡的计算优势。
-
S-LoRA: LoRA adapter 可以帮助我们使用有限的显存来调优大模型,S-LoRA 可以帮助我们在有限的显存中同时使用复数个 LoRA 权重,扩展模型的能力。
-
Quantization: 量化可以帮助我们进一步减少显存占用,提高推理性能。lmdeploy.pytorch 分支中添加了 w8a8 模型量化的支持,可以阅读 w8a8 了解更多细节。