Evaluation does not work for RelationNet #3
Assignees

Comments
|
To reproduce the error just add the below code in the eval(args) function of rn.py file and run the script in eval mode. model_path = os.path.join(args.save_dir, 'model.pt') |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
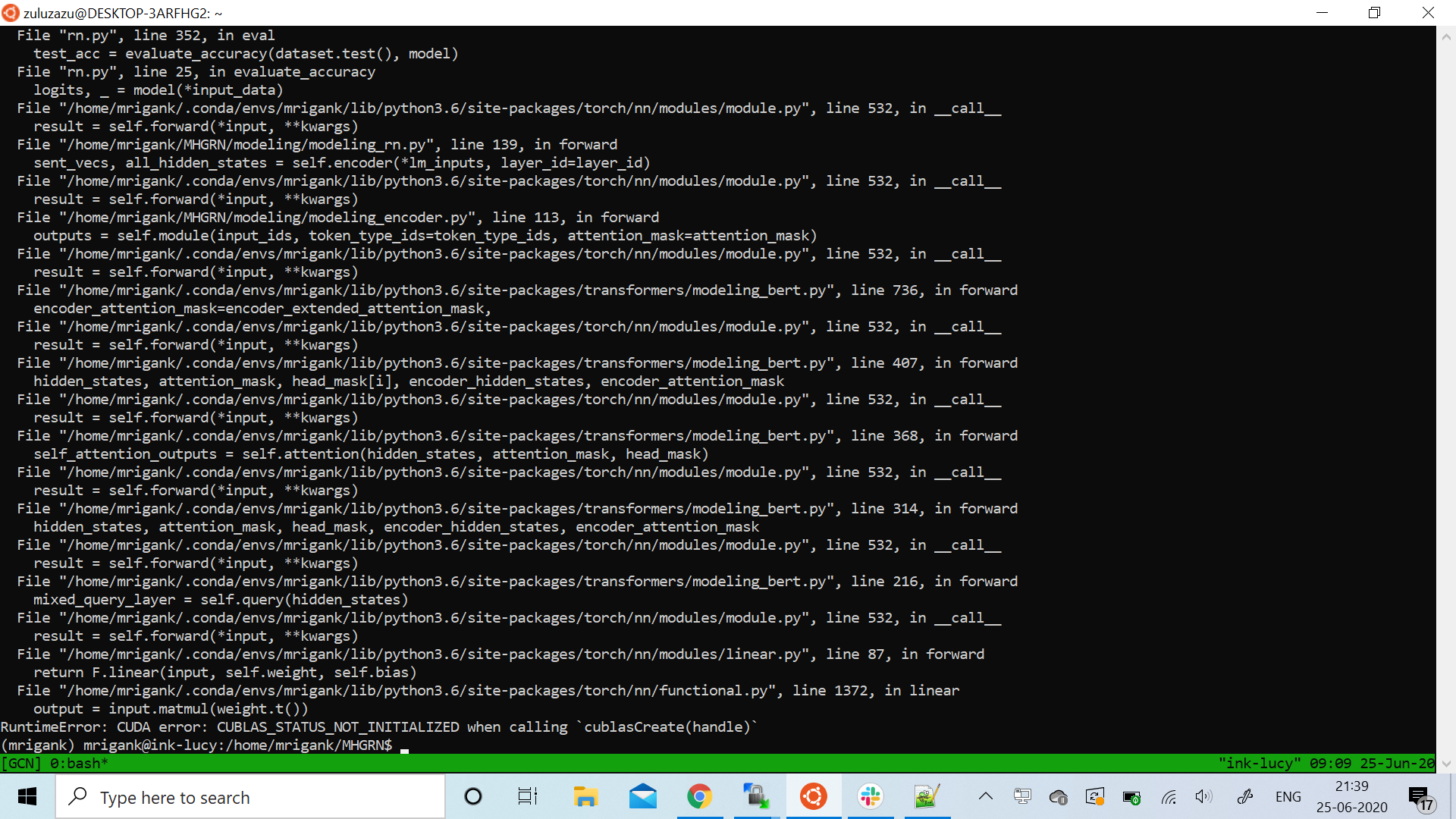
The evaluation function was not implemented in the code. So, I implemented it but I get a CUDA error which I traced back to transformers. I am hereby attaching the screenshot of the error. So for context I trained the relationNet using roberta as the encoder and then when I try to evaluate the trained model, I get this error.
The text was updated successfully, but these errors were encountered: