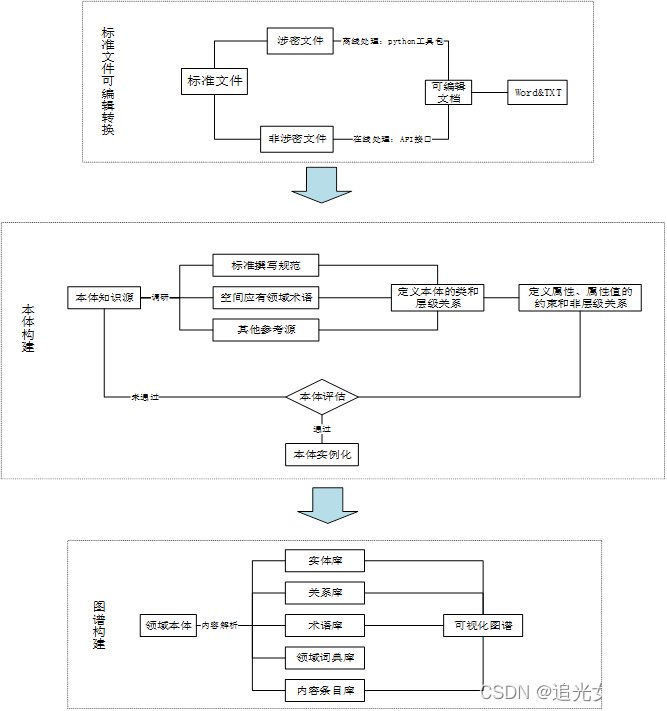
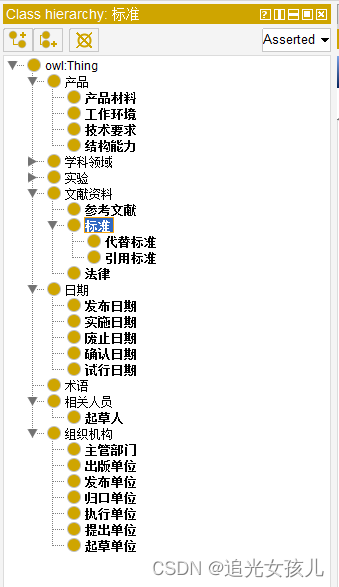
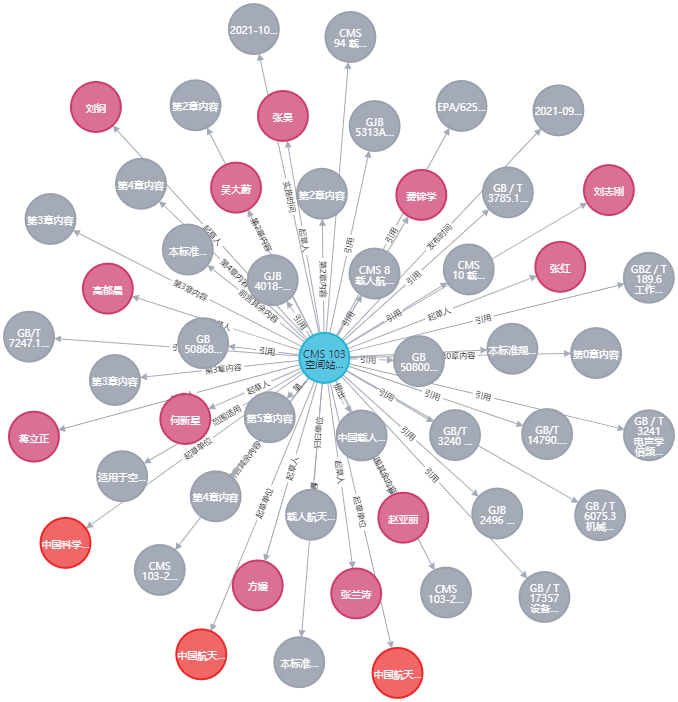
整个过程面向标准PDF文件,构建知识图谱。
整个过程大致分为3部分:一是PDF可编辑转换,二是结构化信息提取,三是图谱构建。
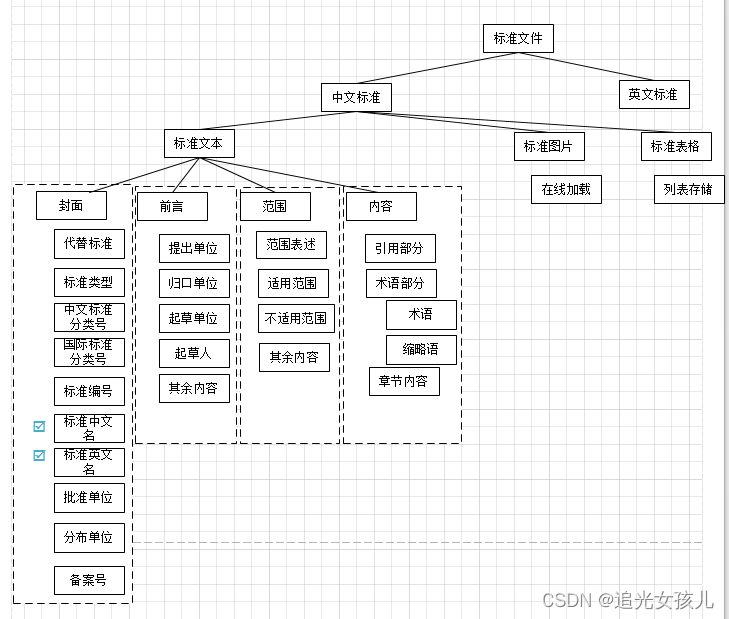
为了保证整个文件的内容无缺失性,在构造中,将文件内容分为纯文本、表格、图片三部分,分类整理。
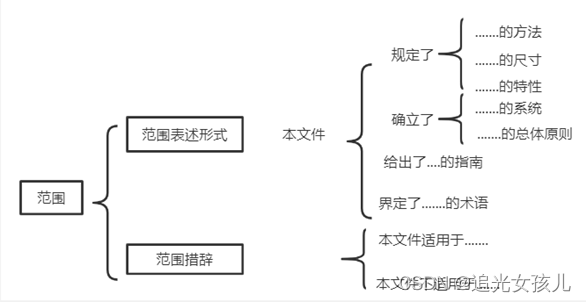
内容结构框架如下,其中,中英文名称识别,采用了bert二分类的方式(效果还可以)。
在范围内容整理时,参考了标准导则中的编写规则,如下:
GJBremove.py——移除国军标文件
pdf2word.py
文档提取图片.py
文档读取表格.py
文档内容提取.py——先word2TXT
文档语言判别.py——判断标准是中文or外文
文档内容提取.py——在extract(分章节和模块粗提取)
封面结构化信息提取.py
文档术语提取.py
标准前言信息提取.py
图片链接生成.py
parser_1.py——对上述结构化信息再整理
图谱搭建.py