$ python inference.py
Change file name in line 14 of inference.py
inference_chuncked.py lets the user analyze emotions in longer wav files.
-
The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have with each other all the time. Nowadays personalization is something that is needed in all the things we experience everyday.
-
So why not have a emotion detector that will guage your emotions and in the future recommend you different things based on your mood. This can be used by multiple industries to offer different services like marketing company suggesting you to buy products based on your emotions, automotive industry can detect the persons emotions and adjust the speed of autonomous cars as required to avoid any collisions etc.
 ©joomla_speech_prosody
©joomla_speech_prosody
Made use of two different datasets:
-
RAVDESS. This dataset includes around 1500 audio file input from 24 different actors. 12 male and 12 female where these actors record short audios in 8 different emotions i.e 1 = neutral, 2 = calm, 3 = happy, 4 = sad, 5 = angry, 6 = fearful, 7 = disgust, 8 = surprised.
Each audio file is named in such a way that the 7th character is consistent with the different emotions that they represent. -
SAVEE. This dataset contains around 500 audio files recorded by 4 different male actors. The first two characters of the file name correspond to the different emotions that the potray.
Tested out the audio files by plotting out the waveform and a spectrogram to see the sample audio files.
Waveform

Spectrogram

The next step involves extracting the features from the audio files which will help our model learn between these audio files.
For feature extraction we make use of the LibROSA library in python which is one of the libraries used for audio analysis.

- Here there are some things to note. While extracting the features, all the audio files have been timed for 3 seconds to get equal number of features.
- The sampling rate of each file is doubled keeping sampling frequency constant to get more features which will help classify the audio file when the size of dataset is small.
The extracted features looks as follows

These are array of values with lables appended to them.
Since the project is a classification problem, Convolution Neural Network seems the obivious choice. We also built Multilayer perceptrons and Long Short Term Memory models but they under-performed with very low accuracies which couldn't pass the test while predicting the right emotions.
Building and tuning a model is a very time consuming process. The idea is to always start small without adding too many layers just for the sake of making it complex. After testing out with layers, the model which gave the max validation accuracy against test data was little more than 70%
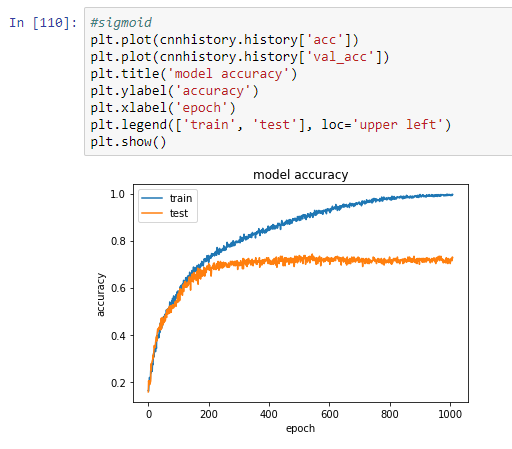
After tuning the model, tested it out by predicting the emotions for the test data. For a model with the given accuracy these are a sample of the actual vs predicted values.

In order to test out our model on voices that were completely different than what we have in our training and test data, we recorded our own voices with dfferent emotions and predicted the outcomes. You can see the results below:
The audio contained a male voice which said "This coffee sucks" in a angry tone.
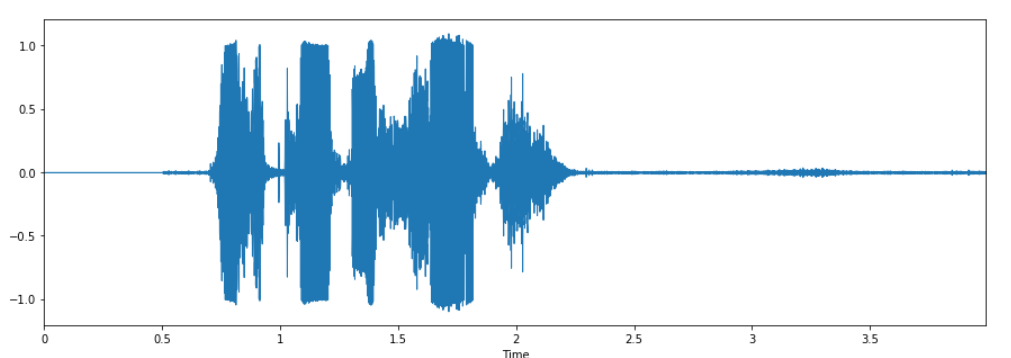
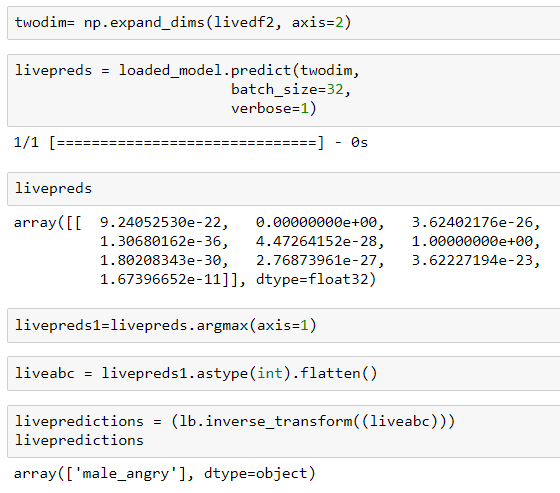
As you can see that the model has predicted the male voice and emotion very accurately in the image above.
NOTE: If you are using the model directly and want to decode the output ranging from 0 to 9 then the following list will help you.
0 - female_angry
1 - female_calm
2 - female_fearful
3 - female_happy
4 - female_sad
5 - male_angry
6 - male_calm
7 - male_fearful
8 - male_happy
9 - male_sad
Building the model was a challenging task as it involved lot of trail and error methods, tuning etc. The model is very well trained to distinguish between male and female voices and it distinguishes with 100% accuracy. The model was tuned to detect emotions with more than 70% accuracy. Accuracy can be increased by including more audio files for training.